
EPSRC Cross-SAT Big Data Workshop: Well Sorted Materials
11
EPSRC Cross-SAT Big Data Workshop: Well Sorted Materials 5th August 2015 Contents Introduction 1 Dendrogram 2 Tree Map 3 Heat Map 4 Raw Group Data 5 For an online, interactive version of the visualisations in this document, go here: www.well-sorted.org/output/EPSRCBigData
Transcript of EPSRC Cross-SAT Big Data Workshop: Well Sorted Materials

EPSRC Cross-SAT Big DataWorkshop:
Well Sorted Materials5th August 2015
ContentsIntroduction 1
Dendrogram 2
Tree Map 3
Heat Map 4
Raw Group Data 5
For an online, interactive version of the visualisations in this document, go here:
www.well-sorted.org/output/EPSRCBigData

Introduction
Dear participant,
Thank you for taking part in submitting and sorting your ideas.
This document contains several visualisations of your ideas, grouped by the average of your online sorts. Theyare:
Dendrogram - This tree shows each submitted idea and its similarity to the others. The lower two ideas 'join' themore people grouped those two ideas together. For example, if two ideas join at the bottom, every persongrouped those two together.
Tree Map - This visualisation presents an 'average' grouping. It is calculated by 'cutting' the Dendrogram at thedashed line so that any items which join lower than that line are placed in the same group. In addition, rectangleswhich share a side of the same length are more similar to each other than their peers.
Heat Map - This visualisation shows a similarity matrix where each idea is given a colour at the intersection withanother idea, showing how similar the two are. This is useful to see how well formed a group is. The more redthere is in a group (shown by the black lines), the more similar the ideas inside it were judged to be.
Raw Group Data - This table shows every submitted idea and its longer description. They are shown in the sameorder as the Dendrogram (so similar ideas are close to each other) and split into the coloured groups used in theTree Map. In addition, each idea has been given a unique number so they are easier to find.
EPSRC Cross-SAT Big Data Workshop - Materials Generated by Well-Sorted.Org Page 1

Dendrogram
EPSRC Cross-SAT Big Data Workshop - Materials Generated by Well-Sorted.Org Page 2
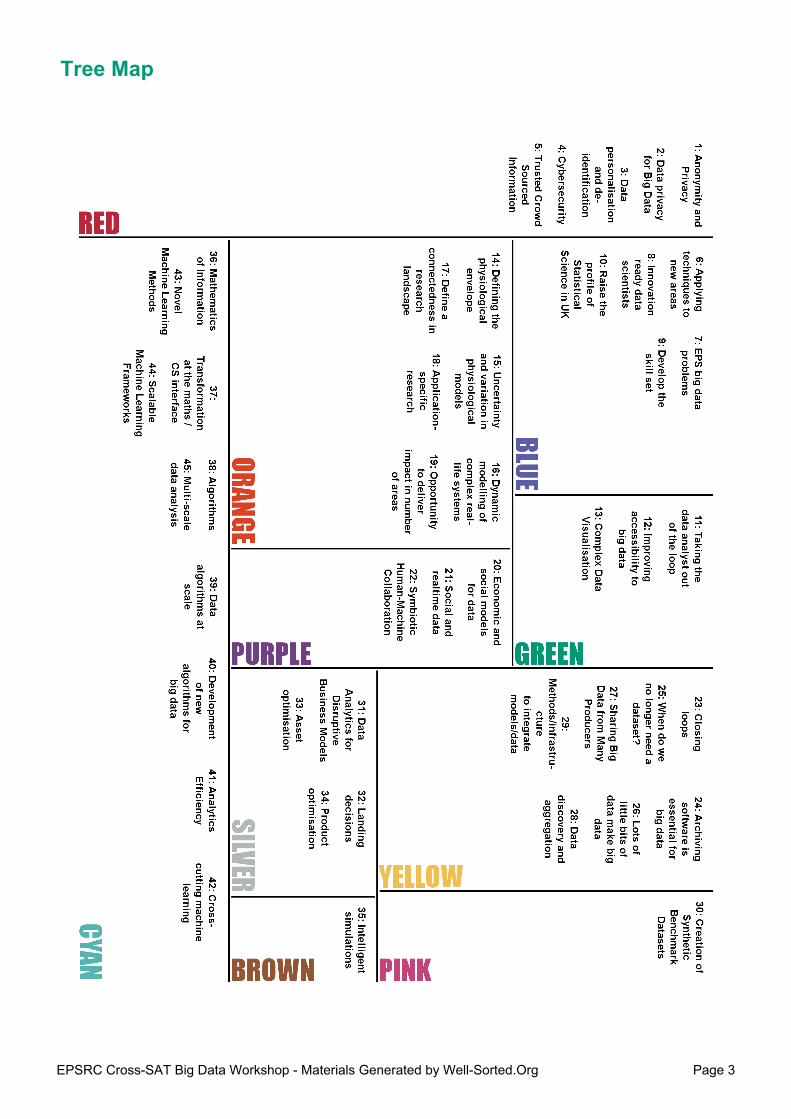
Tree Map
EPSRC Cross-SAT Big Data Workshop - Materials Generated by Well-Sorted.Org Page 3

Heat Map
EPSRC Cross-SAT Big Data Workshop - Materials Generated by Well-Sorted.Org Page 4

Raw Group Data
Colour # Title Description
Red 1 Anonymity and Privacy Pulling together data to grain greater insights. Howeverthis has an impact on privacy. Even anonymisation or
pseudonymisation have challenges as data can beworked back to the source. Mathematic techniques to
prevent deduction of data would be useful.
2 Data privacy for Big Data Understanding how to achieve adequate levels ofprivacy given the difficulty in using traditional methods
of cleaning and delinking.
3 Data personalisation and de-identification
Finding robust, scaleable, practical ways of reconcilingthe tension between the need to identify/own personaldata (and data derived from personal data) while alsobeing able to contribute to population level analyses of
data without being identified.
4 Cybersecurity Analysis of how big data can be used to track activityin an organisation and detect possible cyber attacks,track threats and campaigns and provide context and
insight into the form of attacks. This could enable earlywarning and prevention.
5 Trusted Crowd SourcedInformation
How can we develop methods that ensure crowd-sourced information is accurate and trustworthy?
EPSRC Cross-SAT Big Data Workshop - Materials Generated by Well-Sorted.Org Page 5

Colour # Title Description
Blue 6 Applying techniques to newareas
For many big data problems there is a lack of expertisein the field to understand the correct approaches to
employ and this needs data scientists and applicationscientists to work together.
7 EPS big data problems There are a huge numbers of areas in the EPSdisciplines where big data problems exist, but the
expertise to tackle them does not. This is especiallyimportant for EPSRC engagement with industry.
8 Innovation ready data scientists How do we produce the multidisciplinary researchersand entrepreneurs who are commercially aware, cantalk/engage with people, and yet also have the data
analytic and visualisation skills?
9 Develop the skill set There is a significant lack of people with properexperience and knowledge of handling big / distributed
datasets. Those people with academic experienceoften don't have experience with the tools used in
industry
10 Raise the profile of StatisticalScience in UK
At the heart of Big Data is the statistical methodsrequired to make sane and rational inferences that
lead to actionable knowledge. SS is central to realisingpotential of Big Data and this is a good thing for
EPSRC supporting SS.
Colour # Title Description
Green 11 Taking the data analyst out ofthe loop
How do we create data exploration interfaces andassociated methodologies that enable (and guide) non-experts to explore their own data to discover and then
exploit value. Is this partly an education issue?
12 Improving accessibility to bigdata
Research to create methods & tools that non-expertscan use to explore the potential of big data - enablingwider uptake and new kinds of innovation and impact
driven by a wide range of people
13 Complex Data Visualisation How can we develop visualisations that make complexdata sets easier to understand and analyse.
EPSRC Cross-SAT Big Data Workshop - Materials Generated by Well-Sorted.Org Page 6

Colour # Title Description
Orange 14 Defining the physiologicalenvelope
Sophisticated physics-based simulations of individualpatients are performed using exquisitely accurate
anatomical data from medical images. The boundaryconditions are equally important and should be
personalised from information in the clinical record.
15 Uncertainty and variation inphysiological models
We need to learn how to characterise and to representthe uncertainty and variation in information that comes
from clinical data, and to develop methods for thepropagation into physiological models for diagnosis
and interventional planning.
16 Dynamic modelling of complexreal-life systems
Synthetic and playable data-driven models of complexinteracting systems in biology, engineering, health,
environment, transport, robotoics, manufacturing andpublic policy, unsupervised learning of emergentphenomena capable of driving decision making.
17 Define a connectedness inresearch landscape
Almost all sciences are becoming more reliant on thesensible analysis and production of Big Data. Many ofthese disparate disciplines are being tied together by
the need of common computational statistical methodsto make the advances BD promises.
18 Application-specific research Work in support of applications in the Digital Economyand PaCCS programmes. Specifically there will be
emerging "big data" challenges from the ESRCResearch and Evidence Hub and also the new EPSRC
IoT Research Hub.
19 Opportunity to deliver impact innumber of areas
There is no doubt that BD presents many opportunitiesto physical sciences - how this is to be harnessed anddeliver impact can be facilitated by EPSRC - ATI being
one example of many.
Colour # Title Description
Purple 20 Economic and social models fordata
Much of the impact from big data should come fromthe new economies and social structures that it
engenders. Can we model this in a way that givesuseful, predictive abilities for economies and societies
of the future.
21 Social and realtime data Making use of new forms of data coming from socialnetworks and sensor networks to augment curated
data from longitudinal studies.
22 Symbiotic Human-MachineCollaboration
Understand the science of how humans and machinescan work together in the most effective way that makes
the best use of their complementary data analysisskills
EPSRC Cross-SAT Big Data Workshop - Materials Generated by Well-Sorted.Org Page 7

Colour # Title Description
Yellow 23 Closing loops Creating new and automated ways of collecting in-use,through and end of life data and feeding it back to earlystages of product development processes - to improveexisting products and inform the development of new
ones.
24 Archiving software is essentialfor big data
Software often generates big data. If this is the case, itis not necessary to always keep the big data but isimportant to make sure the software generating thedata is archived in a sustainable and recoverable
manner.
25 When do we no longer need adataset?
The increase in speed of software can mean it is betterto reproduce data than store it. A life expectancy of thisdata might therefore be four times as long as it takes to
generate it. Understanding this life cycle is key to aneffective big data policy.
26 Lots of little bits of data makebig data
Alot, if not most, of big data is made up of many bits ofsmall data. Engendering a culture of sustainablydocumenting and archiving small data is a critical
component of many scientific areas where EPSRC cancontribute by promoting best practice.
27 Sharing Big Data from ManyProducers
Understanding how to move big data where the modelis not simply having one large instrument, but is
instead many producers of large amounts of data whoneed to share and combine subsets places different
stresses on the infrastructure we have in place.
28 Data discovery and aggregation Within large organisations data is often distributed inseparate IT systems many using commercial
enterprise software. How do we apply map-reducetype operations at a meta-level? How do we securelyaggregate data that may be commercially sensitive?
29 Methods/infrastructure tointegrate models/data
The model-based interpretation of Big Data requireseffective and efficient integration of the data with themodelling and simulation tools. We need to develop
the whole area of physics-based Reduced-OrderModelling, and the infrastructure to integrate.
Colour # Title Description
Pink 30 Creation of SyntheticBenchmark Datasets
Based on an understanding of application areas, thecreation of large scale, realistic data sets that can be
used to benchmark potential solutions.
EPSRC Cross-SAT Big Data Workshop - Materials Generated by Well-Sorted.Org Page 8

Colour # Title Description
Silver 31 Data Analytics for DisruptiveBusiness Models
New ways of collecting, analysing, visualisingheterogeneous data (especially that of new double-
sided markets and platforms). What are the best waysto encourage the two sides to provide value?
32 Landing decisions Businesses don't need more data or insights, theyneed better decisions based on data. how to translatebig data into business changes and impact (beyond
good sounding case studies) is difficult.
33 Asset optimisation How do we organise assets to provide optimisedservice offerings? E.g. real-time asset tracking andhealth monitoring; portfolio management; predicting
customer behaviour and usage patterns.
34 Product optimisation How do we optimise products using all relevantproduct data? E.g. physics based design simulations;manufacturing process data; service data from current
products in the field; knowledge of the market placeand competitor products.
Colour # Title Description
Brown 35 Intelligent simulations Big data could be used to inform the design, validationand verification of computational simulations - bringing
process simulations closer to real-world processes,akin to CAD for 3D products.
EPSRC Cross-SAT Big Data Workshop - Materials Generated by Well-Sorted.Org Page 9

Colour # Title Description
Cyan 36 Mathematics of Information Mathematics is the language of information and data.Some mathematical areas (harmonic analysis,
optimization, computation, topology) are alreadyengaged in Big Data research, the challenge is tocreate intellectual space for further developments.
37 Transformation at the maths /CS interface
Using problems of challenging data (big,heterogeneous, streaming, soft, uncertain, partial,
garbled) to generate novel research at the interfacebetween mathematics and computer science,
especially in algorithms, complexity, computability andreasoning.
38 Algorithms Theoretical Computer Sciences are fairly weak in UK,the challenge is expanding capacity in general area of
Algorithms: deterministic, random, combinatorial,mixed..., their design, analysis and complexity.
39 Data algorithms at scale Developing robust algorithms to give good enoughdecisions/predictions in situations of very high datavolumes/velocities and/or at very low levels of dataintegrity (through heterogeneity or measurement
uncertainty).
40 Development of new algorithmsfor big data
Given the size and complexity of some big dataproblems new approaches are needed that combined
statistics, computer science and high performancecomputing to tackle the analysis.
41 Analytics Efficiency As data grows exponentially although advances inprocessing it are also speeding up there comes a point
when the cost of analysing it exceeds the valuegained. Research into efficient analytic techniques will
help to continue getting the benefit from this
42 Cross-cutting machine learning Machine learning is the machine room of Big Data. Itspans themes in Statistics, Functional Analysis,Approximation Theory, Optimization, Computer
Science and Engineering. The challenge is to planresearch there as truly inter-disciplinary.
43 Novel Machine LearningMethods
New algorithms to support real-time analysis ofuncertain, incomplete, inconsistent and possibly
corrupted data.
44 Scalable Machine LearningFrameworks
Interactive programming notebooks could be the newexcel. If these get linked to distributed computing andeasy to use programming frameworks, business canget faster access to insights without specialised staff.
45 Multi-scale data analysis Applications involving very large data sets and streamsbeing mined for structure, pattern and communitydetection on a variety of scales simultaneously.
Examples: social, economic, behavioural as well assystems biology, gen- and proteomics, cosmology.
Powered by TCPDF (www.tcpdf.org)
EPSRC Cross-SAT Big Data Workshop - Materials Generated by Well-Sorted.Org Page 10


















