
Entwicklung eines Datenmanagementsystems für den ... · Für stationäre Maschinen und Anlagen...
152
Abschlussbericht zum Verbundforschungsprojekt Entwicklung eines Datenmanagementsystems für den Teleservice bei mobilen Arbeitsmaschinen (DAMIT) Das diesem Bericht zugrunde liegende Vorhaben wurde mit Mitteln des Bundesministeriums für Bildung und Forschung unter dem Förderkennzeichen 0330711 gefördert. Die Verantwortung für den Inhalt dieser Veröffentlichung liegt bei den Autoren. Laufzeit: 01.05.2006 – 30.04.2009 Autoren: Brandt, V.; Dirks, M.; Ganseforth, A.; Göres, T.; Grothaus, H.-P.; Harms, H.-H.; Möller, A.; Rustemeyer, T.; Wäsch, D.
Transcript of Entwicklung eines Datenmanagementsystems für den ... · Für stationäre Maschinen und Anlagen...

Abschlussbericht zum Verbundforschungsprojekt
Entwicklung eines Datenmanagementsystems für den Teleservice bei mobilen Arbeitsmaschinen
(DAMIT)
Das diesem Bericht zugrunde liegende Vorhaben wurde mit Mitteln des Bundesministeriums
für Bildung und Forschung unter dem Förderkennzeichen 0330711 gefördert. Die
Verantwortung für den Inhalt dieser Veröffentlichung liegt bei den Autoren.
Laufzeit: 01.05.2006 – 30.04.2009
Autoren:
Brandt, V.; Dirks, M.; Ganseforth, A.; Göres, T.; Grothaus, H.-P.; Harms, H.-H.; Möller, A.;
Rustemeyer, T.; Wäsch, D.

Inhaltsverzeichnis II
Inhaltsverzeichnis
I Kurzdarstellung des Forschungsvorhabens ....................................................1
I.1 Einleitung.................................................................................................................... 1 I.2 Aufgabenstellung und Zielsetzung ............................................................................. 1 I.3 Planung und Ablauf des Vorhabens ........................................................................... 2 I.4 Stand der Wissenschaft und Technik zu Projektbeginn ............................................. 2 I.5 Zusammenarbeit mit anderen Stellen......................................................................... 8
II Eingehende Darstellung des Forschungsvorhabens.......................................9
II.1 Zustandsüberwachung exemplarischer Baugruppen ................................................. 9 II.1.1 Voraussetzungen für ein Condition Monitoring ................................................... 9
II.1.1.1 Instandhaltungsstrategien ............................................................................. 9 II.1.1.1.1 Messbarkeit des Verschleißzustandes................................................. 10 II.1.1.1.2 Interpretierbarkeit der Zustandsgröße.................................................. 11 II.1.1.1.3 Prognostizierbarkeit des Verschleißverhaltens .................................... 11
II.1.1.2 Beispielbaugruppe Walzengang ................................................................. 11 II.1.1.3 Beispielbaugruppe Hydrauliköl.................................................................... 13
II.1.2 Vorhersagbarkeit von Wartung und Instandhaltung.......................................... 16 II.1.2.1 Kettenlängung Schrägförderer .................................................................... 16
II.1.2.1.1 Einleitung ............................................................................................. 16 II.1.2.1.2 Erkenntnisse anhand Prüfstandsuntersuchungen ............................... 18 II.1.2.1.3 Abgleich mit Daten aus dem Ernteeinsatz ........................................... 19
II.1.2.2 Luftfilterverschmutzung Dieselmotor........................................................... 21 II.1.2.2.1 Einleitung ............................................................................................. 21 II.1.2.2.2 Untersuchungen am Prüfstand ............................................................ 22 II.1.2.2.3 Auswertung der Erntedaten ................................................................. 24
II.1.2.3 Zusammenfassung...................................................................................... 25 II.2 Datenmanagement ................................................................................................... 27
II.2.1 Kompressionsmethoden für verschiedene Datenarten..................................... 27 II.2.1.1 Dateneigenschaften und Anforderungen an die Kompressionsmethoden.. 27 II.2.1.2 Theoretische Betrachtungen und Voruntersuchungen................................ 32
II.2.1.2.1 Theoretische Betrachtungen................................................................ 32 II.2.1.2.2 Voruntersuchungen.............................................................................. 34
II.2.1.3 Entwicklung der Methoden.......................................................................... 43

Inhaltsverzeichnis III
II.2.1.3.1 Entwicklungsumgebung und Vorgehen................................................ 43 II.2.1.3.2 Kompressionsmethode für Messwert-Zeitreihen.................................. 44 II.2.1.3.3 Kompressionsmethode für Positionsdaten........................................... 50
II.2.1.4 Experimentelle Erprobungen....................................................................... 70 II.2.1.4.1 Versuchstraktor und Entwicklungsumgebung ...................................... 70 II.2.1.4.2 Feldversuche........................................................................................ 73 II.2.1.4.3 Erprobung der Kompressionsmethoden .............................................. 74
II.2.1.5 Hinweise für die Praxis................................................................................ 89 II.2.1.5.1 Hinweise zur Implementierung............................................................. 90 II.2.1.5.2 Hinweise zur Parametrierung............................................................... 91 II.2.1.5.3 Hinweise zu Einsatzmöglichkeiten und -grenzen................................. 94
II.2.2 Software-Architektur und Datenfluss ................................................................ 96 II.2.2.1 On-Board-Unit ............................................................................................. 96
II.2.2.1.1 Eingesetzte Hardware.......................................................................... 96 II.2.2.1.2 Programmiersprachen.......................................................................... 97
II.2.2.2 Software-Architektur.................................................................................... 97 II.2.2.2.1 Einleitung ............................................................................................. 97 II.2.2.2.2 Schichtentrennung ............................................................................... 98 II.2.2.2.3 Schichtenarchitektur............................................................................. 98
II.2.2.3 Beschreibung der Dienste........................................................................... 99 II.2.2.3.1 GSM-Treiber ........................................................................................ 99 II.2.2.3.2 WLAN-Treiber ...................................................................................... 99 II.2.2.3.3 GPS/Galileo ......................................................................................... 99 II.2.2.3.4 CAN-Bus Interface ............................................................................. 100 II.2.2.3.5 Positioning.......................................................................................... 100 II.2.2.3.6 Kommunikation .................................................................................. 100 II.2.2.3.7 Sensoren/Aktoren .............................................................................. 100 II.2.2.3.8 Datenablage....................................................................................... 100 II.2.2.3.9 Datenlogger........................................................................................ 100 II.2.2.3.10 Datenverdichter ................................................................................. 101 II.2.2.3.11 Kommunikationsmanager.................................................................. 101
II.2.2.4 Simulationsumgebung............................................................................... 101 II.2.2.5 Datenverarbeitung auf der OBU................................................................ 102
II.2.2.5.1 Sensordienste .................................................................................... 102 II.2.2.5.2 Sensortransformer ............................................................................. 103 II.2.2.5.3 Datenverdichter und Datenablage ..................................................... 104

Inhaltsverzeichnis IV
II.2.2.5.4 Alarm-Manager .................................................................................. 105 II.2.2.6 Konfiguration der OBU.............................................................................. 107 II.2.2.7 Kommunikation mit dem Backend............................................................. 108
II.2.2.7.1 Schnittstelle zwischen OBU und Backend ......................................... 108 II.2.2.7.2 Intervalle............................................................................................. 109 II.2.2.7.3 Versende-Strategien .......................................................................... 110 II.2.2.7.4 Automatische Berechnung optimaler Strategien................................ 111
II.2.2.8 XML-Dateistruktur zur internen Datenübertragung ................................... 113 II.2.2.8.1 ISO-XML ............................................................................................ 113 II.2.2.8.2 Beschreibung der Formate zur Datenübertragung............................. 115
II.2.2.9 Back-End................................................................................................... 116 II.3 Vernetzte Prozesse ................................................................................................ 119
II.3.1 Technologien und Schnittstellen im Logistikprozess ...................................... 119 II.3.1.1 Prozessmodell Logistikkette Rübe ............................................................ 119
II.3.1.1.1 Teilprozess Kampagnenplanung........................................................ 120 II.3.1.1.2 Teilprozess Roden ............................................................................. 121 II.3.1.1.3 Teilprozess Abfuhr ............................................................................. 122
II.3.1.2 Datenformate ............................................................................................ 122 II.3.1.3 Umsetzung................................................................................................ 123
II.3.2 Vorbeugende Instandhaltungsprozesse durch Teleservice ............................ 124 II.3.2.1 Einordnung des Themas „Vorbeugende Instandhaltungsprozesse durch
Teleservice“............................................................................................... 124 II.3.2.2 Was bedeutet „Instandhaltung“? ............................................................... 124 II.3.2.3 Was bedeutet „Vorbeugende Instandhaltung“? ........................................ 124 II.3.2.4 Was wird für die „Vorbeugende Instandhaltung“ benötigt? ....................... 125 II.3.2.5 Rolle der verschiedenen Forschungs-Cluster des Projektes für die
„Vorbeugende Instandhaltung“.................................................................. 125 II.3.2.5.1 „Zustandsüberwachung exemplarischer Baugruppen“ ...................... 125 II.3.2.5.2 „Datenmanagement“ .......................................................................... 125 II.3.2.5.3 „Teleservice“ ...................................................................................... 125 II.3.2.5.4 Was sind „Vorbeugende Instandhaltungsprozesse durch Teleservice“?
........................................................................................................... 126 II.4 Systembasierte Dienstleistungen ........................................................................... 129
II.4.1 Dienstleistungsangebote für mobile Arbeitsmaschinen .................................. 129 II.4.1.1 Dienstleistungsfelder und ihre aktuellen Trends ....................................... 130

Inhaltsverzeichnis V
II.4.1.1.1 Besondere Rahmenbedingungen für Instandhaltungsleistungen in der
Agrartechnik ...................................................................................... 131 II.4.1.1.2 Kundenanforderungen ....................................................................... 131
II.4.1.2 Instandhaltung als Teil der Lifecycle Kosten............................................. 132 II.4.1.2.1 Instandhaltungsbegriffe (DIN) ............................................................ 132 II.4.1.2.2 Instandhaltungsstrategien .................................................................. 132
II.4.1.3 Dienstleistungsprozess ............................................................................. 134 II.4.1.3.1 Nutzung verteilter Informationen für den Produktentstehungsprozess
........................................................................................................... 135 II.4.1.4 Dienstleistungsangebote........................................................................... 136
II.4.1.4.1 Planbare Instandhaltung als Kern wirtschaftlicher Serviceangebote . 136 II.4.1.4.2 Wirtschaftliche Serviceangebote........................................................ 137
III Zusammenfassung..........................................................................................138
IV Literaturverzeichnis ........................................................................................139
V Veröffentlichungen und Vorträge...................................................................145
V.1 Veröffentlichungen.................................................................................................. 145 V.2 Vorträge.................................................................................................................. 146

I Kurzdarstellung des Forschungsvorhabens 1
I Kurzdarstellung des Forschungsvorhabens
I.1 Einleitung
Zwei Trends haben die Entwicklungen im Segment der mobilen Arbeitsmaschinen in den
letzten Jahren nachhaltig gekennzeichnet. Neben der stetig zunehmenden Leistung und
Schlagkraft der Maschinen ist vor allem der vermehrte Einsatz von Elektronik charak-
teristisch. Insbesondere in der Landtechnik hat der Anteil elektronischer Komponenten
rapide zugenommen. Ursache hierfür waren ein gestiegener Kostendruck und der zuneh-
mende nationale und internationale Wettbewerb, dem sowohl Hersteller als auch Instand-
halter und Betreiber der Maschinen ausgesetzt sind. Neben der Reduzierung der Betriebs-
kosten zielen die Entwicklungen auf eine Erhöhung der Verfügbarkeit der Maschinen, die
häufig Schlüsselfunktionen in den Arbeitsprozessen einnehmen.
Zusätzlich zum verstärkten Elektronikeinsatz auf den Einzelmaschinen ermöglichen Tele-
matik- bzw. Teleservice-Systeme die kommunikationstechnische Verknüpfung der Maschine
mit einem zentralen Daten-Server. Eine wichtige Teilfunktion dieser Systeme stellt die Früh-
erkennung und Ferndiagnose von Maschinenzuständen dar, um Serviceprozesse optimieren
und so den Maschinennutzen für den Betreiber maximieren zu können. Auch der Zugriff auf
Maschinendaten über das Internet kann den Maschinenbetreiber unterstützen, die Einsatz-
planung seiner Maschinen zu verbessern und Prozessabläufe zu optimieren. Einem intelli-
genten Datenmanagement kommt innerhalb eines solchen Teleservice-Systems eine hohe
Bedeutung zu.
I.2 Aufgabenstellung und Zielsetzung
Das Ziel dieses Projektes bestand darin, ein Datenmanagementsystem zu entwickeln, das
es ermöglicht, den Kundennutzen beim Einsatz von Teleservice-Systemen bei mobilen
Arbeitsmaschinen zu fördern. Durch das Datenmanagement sollte eine bedarfsgerechte und
effiziente Übertragung von Maschinendaten ermöglicht werden. So sollen sich u. A. neue,
zustandsorientierte Instandhaltungsstrategien realisieren lassen, was an exemplarisch
ausgewählten Maschinenbaugruppen nachzuweisen war. Voll ausgenutzte Verschleiß-
potenziale und zustandsorientierte Instandhaltungsstrategien fördern auf der einen Seite
eine nachhaltige Produktion von qualitativ hochwertigen Lebensmitteln. Auf der anderen
Seite stellen sie eine wichtige Grundlage für attraktive Dienstleistungsangebote der Her-
steller und Instandhalter an die Maschinenbetreiber dar. Bei den internetgestützt ablaufen-

I Kurzdarstellung des Forschungsvorhabens 2
den Serviceprozessen, die im Rahmen von DAMIT entwickelt wurden, lag ein besonderer
Fokus darauf, alle Prozessbeteiligten - vom Betreiber über den Instandhalter bis zum Her-
steller - einbinden zu können. Dies trägt u. A. zur Sicherung der Arbeitsplätze in zahlreichen
kleinen Unternehmen in ländlichen Räumen bei. Auch bei der Unterstützung von komplexen
Logistikprozessen sollte das entwickelte Datenmanagementsystem nutzbringend eingesetzt
werden können, um die Wertschöpfung aller Prozessbeteiligten zu sichern.
I.3 Planung und Ablauf des Vorhabens
Zu Beginn des Projektes wurden verschiedene Maschinenbaugruppen exemplarisch
ausgewählt, für die dann systematisch zustandsabhängige Instandhaltungsstrategien ent-
wickelt wurden. Als Basis für die Entwicklung der modularen Softwarearchitektur des
Datenmanagementsystems und der zugehörigen flexiblen Kommunikationsstruktur wurden
zu Projektbeginn zwei unterschiedliche Hardwareplattformen ausgewählt, um die geforderte
Portierbarkeit der Software zu berücksichtigen. Die einzelnen Elemente des Daten-
managementsystems wurden während der Projektlaufzeit in Kooperation bzw. in enger
Abstimmung der beteiligten Projektpartner entwickelt, zum Ende des Projektes zu lauf-
fähigen Beispielanwendungen zusammengeführt und im Rahmen des Abschlussworkshops
den interessierten Besuchern demonstriert.
I.4 Stand der Wissenschaft und Technik zu Projektbeginn
In den vergangenen Jahren war die Landtechnikbranche gekennzeichnet durch einen Trend
zu leistungsfähigeren Maschinen mit erhöhten Durchsatzleistungen und hochspezialisierten
technischen Ausstattungen. Insbesondere bei Maschinen, die im Saisoneinsatz nur eine
begrenzte Zeit im Jahr betrieben werden wie Mähdrescher, Feldhäcksler, Kartoffel- oder
Rübenroder, erwarten die Kunden entsprechend hohe Maschinenlaufzeiten und Verfüg-
barkeiten sowie eine schnelle Behebung von Störfällen. Dieses erforderte eine hohe
Kompetenz in der Betreuung der Maschinen und eine schnelle Reaktionsfähigkeit des
Kundenservice, um den Service lokal verfügbar zu machen. Insbesondere Systeme und
Konzepte für Teleservice-Lösungen können diese Dienstleistungs- und Servicestrukturen
unterstützen. Die Vorteile dieser Systeme sind vielfältig:
• Fernwartung und -diagnose
• Ferninbetriebnahme und -manipulation
• Prozess- und Maschinenmodellierung
• Aufbau kundenorientierter Dienstleistungen

I Kurzdarstellung des Forschungsvorhabens 3
• Schadensfrüherkennung
• Verschleißüberwachung
• Logbuchfunktion/Crash-Recording
• Online Software Updates
Für stationäre Maschinen und Anlagen existieren bereits seit mehreren Jahren Anwen-
dungen für Teleservice-Systeme. Darauf aufbauend wurden verschiedene Projekte und
Untersuchungen durchgeführt, welche die Umsetzung der Systeme für mobile Arbeits-
maschinen zum Ziel hatten. [Lei03], [Tes00], [Mum02], [Har97], [Ven03], [Bec99], [Die97],
[Dre96], [Kau97], [Kra00], [Mat00], [Rei99], [Sch01], [Wes98]
Eines dieser Projekte war TesMa (Teleservice für mobile Maschinen und Anlagen). [Tes00]
Der Schwerpunkt lag bei diesem Projekt vor allem im Bereich der Baumaschinen. Die
Ergebnisse dieses Projektes bildeten eine Basis für Anwendungen bei Landmaschinen, es
ist jedoch nicht ohne weiteres möglich, die Ergebnisse von den Bau- zu den Landmaschinen
zu transferieren. Gründe hierfür sind unterschiedliche Elektronikkonzepte und die Tatsache,
dass Baumaschinen den Vorteil haben, dass Sie meistens quasi-stationär arbeiten, also
einen festgelegten und überschaubaren Baustellenbereich nicht verlassen. Dieses stellt eine
erhebliche Erleichterung für den Aufbau einer Kommunikation dar. Ein anderes Verbund-
projekt, an dem Hersteller mobiler Arbeitsmaschinen (Baumaschinen) beteiligt waren, war
das Projekt „mumasy“ (Multimediales Maschineninformationssystem). [Mum02] Dieses
Projekt hatte zum Ziel, ein branchenübergreifendes und konsistentes Modell für den
Datenaustausch zu entwickeln. Auch hier kam es zu dem Effekt, dass eine Anwendung, die
im stationären Anlagenbau einwandfrei funktioniert, für den echten mobilen Einsatz, vor
allem im ländlichen Bereich, nur bedingt geeignet ist.
In weiteren Projekten unter Leitung des Instituts für Landmaschinen und Fluidtechnik (ILF)
wurden die Grundlagen für Teleservice-Lösungen für Landmaschinen entwickelt. In einem
vom BMBF geförderten Verbundprojekt wurde ein „Leitfaden für eine gesamtheitliche
Teleservice(TS)-Lösung in der Landmaschinenbranche“ erstellt. [Lei03] Dieser Leitfaden gibt
Hinweise und Anregungen für die Einführung von Teleservice-Systemen und soll bestehende
Unsicherheiten und Informationsdefizite abbauen. Folgende Punkte werden in diesem
Leitfaden erläutert:
• Aufbau eines TS-Systems und Einbindung der neu geschaffenen Prozesse in die bestehenden Aufbau- und Ablauforganisationen der Unternehmen. Entwicklung der Datenmodelle, Customizing der Module und Integration der TS-Datenbanken und Strukturen in existierende ERP Systeme der Unternehmen. [Löh03a]

I Kurzdarstellung des Forschungsvorhabens 4
• Anwendungsbeispiel zur statistischen Auswertung der Informationen im After-Sales-Service. Welche Quellen müssen neben den Maschinendaten noch genutzt werden und welche Adressaten können und sollen mit den gewonnenen Informationen versorgt werden? Wie können die Informationen maschinenspezifisch und maschinenübergreifend ausgewertet und zur Verfügung gestellt werden? [Ahr03]
• Anwendungsbeispiel zur SMS-Datenerfassung. Wie kann eine Datenkommunikation zwischen einer mobilen landwirtschaftlichen Maschine und einer Service-Leitstelle unter Ausnutzung des Short Message Service (SMS) aufgebaut werden? Welche Elemente und welche Software werden benötigt und wie hoch ist die Informationsdichte? Darüber hinaus wurde untersucht, wie viel Informationen in einer SMS (160 ASCII-Zeichen) unter Ausnutzung einer optimalen Codierung übermittelt werden können. [Sch03]
• Anwendungsbeispiel zur Onlinediagnose einer mobilen Arbeitsmaschine. Am Beispiel eines selbstfahrenden Kartoffelroders wurde gezeigt, wie eine Diagnose an der Maschine über eine GSM-Verbindung durchgeführt werden kann. Mit dem entwickelten System kann eine Verbindung zur Maschine aufgebaut werden und der Servicetechniker kann von einem beliebigen Ort aus mit dem Bediener der Maschine zusammen eine Diagnose durchführen. [Möl03]
• Fehlerlokalisierung und Schadensdiagnostik an einer mobilen Arbeitsmaschine. Es wurden verschiedene Möglichkeiten der Fehlerlokalisierung an der Maschine und der Visualisierung des Zustands entwickelt. Dazu wurden klassische Verfahren genau so wie Expertensysteme verwendet. Es wurde gezeigt, dass durch geeignete Lern- und Analysemethoden eine automatisierte Zustandsbestimmung der Maschinen möglich ist. Ein entwickeltes Java-Applet ermöglicht die Visualisierung der Maschinendaten und -zustände an beliebigen Orten. [Kra03]
• Es wurden Möglichkeiten aufgezeigt, wie die Instandhaltung landtechnischer Arbeitsmittel verbessert werden kann. Welche Formen der Abnutzung und des Verschleißes liegen vor und mit welchen Maßnahmen sollten diesen in der Instandhaltung begegnet werden? [Löh03b]
• Die rechtlichen Aspekte des Teleservice. Welche gesetzlichen Auflagen existieren bei fernerbrachten Dienstleistungen? Welche juristischen Bedingungen sind zu erfüllen, um die Maschinendaten zu versenden und auszuwerten? Wer „besitzt“ die Daten und wer darf die Informationen nutzen? [Pla03]
• Gestaltungsempfehlungen für Teleservice-Systeme in der Landmaschinenbranche. Aus den untersuchten Bereichen und den Erfahrungen des Projektes wurden Empfehlungen zur Gestaltung bei Planung und Entwicklung hinsichtlich der Punkte Strategie, Organisation, Personal und Technik gegeben. [Div03]

I Kurzdarstellung des Forschungsvorhabens 5
Die Wirtschaftlichkeit von Teleservice-Systemen für mobile Arbeitsmaschinen war Gegen-
stand mehrerer Untersuchungen. Eine konkrete monetäre Bezifferung der Vorteile ist
praktisch nicht möglich, da die Entwicklung und die Einsatzfelder jeder Maschine individuell
sind. Somit ist es nicht möglich, verlässliche Beispielrechnungen zu erstellen. Generell ist
jedoch zu erwarten, dass sich durch ein Teleservice-System sowohl beim Landwirt als auch
beim Maschinenhersteller Einsparungen einstellen werden. [Har03], [Kra00] Trotz der über-
durchschnittlichen Vorteilhaftigkeit der Innovation im Gegensatz zu anderen kaufmännischen
und technischen Innovationen sind bisher relativ wenig Systeme implementiert worden.
Diese Zurückhaltung ist im stationären Maschinen- und Anlagenbau analog zu finden.
Borgmeier [Bor02] hat dieses Phänomen in einer empirischen Analyse nachgewiesen und
darauf aufbauend ein Diffusionsparadoxon entwickelt. Darüber hinaus werden Strategien
und Empfehlungen entwickelt wie diese Lücke geschlossen werden kann. Dazu gehören
u. a. Kompatibilitätsstrategien, die Entwicklung von Schnittstellen, die Förderung der Ver-
netzung, stabile Kommunikation und die Entwicklung verfeinerter Diagnoseverfahren.
Für die Instandhaltung gibt es grundsätzlich mehrere Strategien, die in der im Jahre 2003
überarbeitet erschienenen DIN 31051 aufgeführt sind. Generell gibt es die Möglichkeit,
reaktiv, zeitabhängig, zustandsorientiert oder lebensdauerorientiert zu verfahren. Die
Instandhaltung landtechnischer Arbeitsmittel war Gegenstand mehrerer Untersuchungen mit
unterschiedlichen Zielrichtungen. Beispielhaft seien hier [Bru00], [Löh03b], [Eic00a], [Eic00b]
genannt. Für die Zuordnung von Instandhaltungsstrategien zu den spezifischen Baugruppen
und Komponenten existieren jedoch noch keine Erfahrungen und Untersuchungen.
Die technische Realisierung der Datenreduktion auf der Maschine kann durch adaptive
Messungen, Expertensysteme oder statistische Diagnosemethoden erfolgen. Adaptive
Messungen (alternative Bezeichnung sind Transitional Recording oder ereignisorientierte
Messdatenerfassung) legen ein Toleranzband fest, welches zur Auslösung einer Messung
verlassen werden muss, um die Speicherung eines Datums zu verursachen. Alle Daten
innerhalb dieses Bandes werden im Falle einer späteren Analyse interpoliert. [Keh01],
[Hil98], [Wie96], [Sch95], [Sch92], [Met92], [Mic83] Die für die Anwendung an den
Baugruppen mobiler Arbeitsmaschinen individuell zulässigen Grenzen sollen im Projekt
ermittelt werden.
Expertensysteme bieten die Möglichkeit, Datensätze automatisiert in definierte Klassen
einzuordnen. Insbesondere Künstliche Neuronale Netze, Fuzzy-Logic sowie deren
Kombination in Neuro-Fuzzy-Systemen haben sich als zuverlässige Instrumente erwiesen,
die auch bei Ausreißern oder außergewöhnlichen Betriebszuständen ein robustes Verhalten

I Kurzdarstellung des Forschungsvorhabens 6
zeigen. Voraussetzung ist die vorherige Lernphase dieser Verfahren, die mit Trainingsdaten
durchgeführt werden muss. [Abe01], [Wit01], [Ali00], [Wit00], [Bot98], [Zak98], [Bro97],
[Sch97], [Nau96], [Pup96], [Bot95], [Pea95], [Pup91], [Jac87] Statistische Methoden wie das
auf dem Bayes-Theorem basierende Verfahren nach Dempster-Shafer können eine
Zuordnung/Diagnose von Datensätzen aufgrund von Wahrscheinlichkeiten durchführen. Die
Methode nach Dempster-Shafer bietet dabei den Vorteil, dass für jede Zuordnung/Diagnose
ein Sicherheitsintervall mit bestimmt wird. Dieses Intervall wird bei steigenden Datenmengen
und fundierteren Wahrscheinlichkeiten kleiner bzw. bei kleinen Datenmengen größer. Die
Güte einer Vorverarbeitung/Reduktion der Daten wird also mit angegeben wobei sich diese
Güte mit steigender Erfahrung verbessert. [Hal01], [Mah01], [Hal00], [Kla99], [Sto99],
[Var97], [Hal92], [Wal90] Auf Basis der Ergebnisse und Erfahrungen dieser Methoden
können die Abläufe der Instandhaltung ermittelt werden. Hier findet eine Kombination mit den
klassischen Verfahren der Instandhaltung statt. [Gri99], [Löh03b]
Bisher verfügbare Telematiklösungen beschränken sich häufig auf lediglich ein Kommunika-
tionsmedium, bei den Landmaschinen meist SMS-Versand oder GSM. Dem gegenüber steht
der Trend, in mobilen Geräten immer mehr drahtlose Schnittstellen mit unterschiedlicher
Bandbreite und Abdeckung zu integrieren. Die Nutzung aller verfügbaren Schnittstellen für
eine Telematiklösung stellt ungleich höhere Anforderungen an das Daten-, Verbindungs- und
Kommunikationsmanagement. [Krü00], [KTB00], [Ets00], [Aue93] Abhängig von der Wichtig-
keit der Daten muss die Maschine das passende Kommunikationsmedium auswählen. Ist
das Medium gerade nicht verfügbar, müssen die Daten zwischengespeichert und zum
nächstmöglichen Zeitpunkt übertragen werden. Ist die Bandbreite des Mediums zu gering,
kann eine gezielte Reduktion der Daten eine Übertragung über dieses Medium trotzdem
möglich machen. Tabelle I.1 gibt eine Übersicht über verfügbare drahtlose terrestrische
Kommunikationsschnittstellen.
Tabelle I.1: Vergleich verschiedener Kommunikationsschnittstellen
Medium Bandbreite Abdeckung Qualität Kosten
SMS < 1 kBit/s Sehr hoch Niedrig Hoch
Betriebsfunk/GSM 9,6 kBit/s Hoch Hoch Hoch
GPRS 56,8 kBit/s Mittel Hoch Hoch
Bluetooth 768 kBit/s 10 m Hoch Gering
WLAN 54 MBit/s Max. 300 m Hoch Gering

I Kurzdarstellung des Forschungsvorhabens 7
Durch die Nutzung der Positions- und Bewegungsinformationen (GPS) kann die
Zuverlässigkeit des Verbindungsmanagements erhöht werden. Verbindungen können
kontrolliert beendet werden, bevor sich die Maschine aus dem abgedeckten Gebiet bewegt,
ebenso wie die Maschine beispielsweise eine WLAN-Verbindung an bestimmten Orten
aufbauen kann und gesammelte Daten unter Ausnutzung der hohen Bandbreite und
geringen Kommunikationskosten automatisch übertragen kann. Voraussetzung dafür ist das
Vorhandensein der Abdeckungsdaten, die aber bei Betrieb der Maschine in festen Gebieten
auch durch die Maschine selbst ermittelt und dokumentiert werden können. Es gibt
zahlreiche Geräte, welche verschiedene Kommunikationsmedien unterstützen (z. B.
moderne Mobiltelefone), jedoch existieren keine Lösungen, die eine automatische Auswahl
treffen und das Verbindungsmanagement übernehmen.
AgroXML ist ein Datenstandard, der vom KTBL (Kuratorium für Technik und Bauwesen in
der Landwirtschaft) zusammen mit der Fachhochschule Bingen zum Datenaustausch
speziell im Agrarsektor entwickelt wird. Es soll dabei eine Datenkommunikation entlang der
Produktions- und Lieferkette gewährleistet werden, bei welcher die Daten derart
bereitgestellt werden können, dass sie jederzeit ohne zusätzliche Aufbereitung zur
Verfügung stehen und nach einmaliger Erfassung jederzeit von verschiedenen Programmen
nutzbar sind. Ein entscheidendes Merkmal ist dabei eine Plattformunabhängigkeit, die es
erlaubt, zwischen Geräten verschiedener Hersteller zu kommunizieren, wenn sie über eine
entsprechende Schnittstelle verfügen. Unterschiedlichste Software soll auf die Daten
zugreifen können, ohne dass der Nutzer sich um die Formatierung kümmern muss. Damit
bleibt es dem Landwirt erspart, die gleichen Daten in verschiedene Formulare in
unterschiedlichen Formaten einzugeben. Eine Verringerung der Datenredundanz führt somit
zu einer Zeit- und Kostenersparnis in der Verwaltung obwohl die Dokumentationspflichten
stetig zunehmen. Die Sprache AgroXML ist frei verfügbar und damit ohne Zusatzkosten für
Lizenzen implementierbar. Zur Verarbeitung dokumentationspflichtiger Lebensmittel ist eine
entsprechende Informations- und Kommunikationsstruktur notwendig, die durch den Einsatz
von AgroXML bereitgestellt werden kann. Dabei gewährleistet der Zugriff auf alle relevanten
Informationsstellen und Datenbanken die Möglichkeit einer einfachen benutzerangepassten
Dokumentation.

I Kurzdarstellung des Forschungsvorhabens 8
I.5 Zusammenarbeit mit anderen Stellen
Das dieses Verbundprojekt bearbeitende Team setzte sich aus einer Forschungseinrichtung,
einem mittelständischen Unternehmen aus dem Bereich der Informationstechnik sowie zwei
Unternehmen der Landtechnik zusammen, die ebenfalls mittelständisch organisiert sind.
Als Forschungseinrichtung war das Institut für Landmaschinen und Fluidtechnik (ILF) der
Technischen Universität Braunschweig im Wesentlichen für die Entwicklung von
Datenkompressionsmethoden sowie für die Koordination des Verbundprojektes verant-
wortlich. Zudem unterstützte das ILF die Landtechnikunternehmen Claas und Grimme bei
der Entwicklung und Umsetzung von Instandhaltungsstrategien. Claas war darüber hinaus
zuständig für die Modellierung von Serviceprozessen und Grimme für die Modellierung des
Logistikprozesses bei der Zuckerrübenernte. Die Firma eck*cellent IT (zu Projektbeginn
noch Lineas Project Services) war im Rahmen des Projektes verantwortlich für den Aufbau
einer modularen Softwarearchitektur und einer flexiblen Kommunikationsstruktur.

II.1 Zustandsüberwachung exemplarischer Baugruppen 9
II Eingehende Darstellung des Forschungsvorhabens
In den nachfolgenden Abschnitten werden verschiedene Elemente beschrieben, die
Bestandteil des entwickelten Datenmanagements sind oder eine wichtige Voraussetzung
dafür darstellen.
II.1 Zustandsüberwachung exemplarischer Baugruppen
Der folgende Abschnitt dokumentiert den Einsatz von Condition Monitoring Systemen an
selbstfahrenden Erntemaschinen. Am Beispiel ausgewählter Baugruppen wurden Konzepte
entwickelt, die Anwendung an Prüfständen und Feldversuchen erprobt und wichtige
Erkenntnisse für die zukünftige Gestaltung von Condition Monitoring Systemen abgeleitet.
II.1.1 Voraussetzungen für ein Condition Monitoring
II.1.1.1 Instandhaltungsstrategien
Die Instandhaltungsstrategie bestimmt den Zeitpunkt, an dem eine Baugruppe aufgrund von
Verschleiß ausgetauscht wird. Dazu existieren in der Praxis verschiedene Strategien.
Die reaktive Instandhaltung basiert auf dem Austausch einer Baugruppe bei Ausfall. Dadurch
wird die Baugruppen-Standzeit vollständig ausgenutzt, es werden somit keine Ressourcen
verschwendet. Da der Ausfall der Baugruppe im Regelfall nicht vorhersehbar ist, führen der
spontane Ausfall und die nachfolgende Instandhaltung zu einem Stillstand der Maschine,
was sich in einer geringen Maschinenverfügbarkeit widerspiegelt.
Die präventive Instandhaltung verfolgt den Ansatz, eine Baugruppe in festen Intervallen zu
wechseln. Dieses Intervall wird so gewählt, dass unter regulären Bedingungen kein
Verschleiß-Ausfall der Baugruppe zwischen den Wechselintervallen auftritt. Das hat zur
Folge, dass bei geringerer Belastung in einem Wechselintervall eine Baugruppe mit –zum
Teil erheblicher- Reststandzeit ausgewechselt wird. Diese Verschwendung von Ressourcen
führt zu erhöhten Instandhaltungskosten. Im Umkehrschluss steigt die Maschinenver-
fügbarkeit, weil zwischen den Wechselintervallen kein Instandhaltungsaufwand entsteht.
Gerade im Bereich selbstfahrender mobiler Arbeitsmaschinen wird heutzutage eine hohe
Maschinenverfügbarkeit gefordert, um die Erntefenster zu verkürzen. Dies führt zur
verstärkten Anwendung der präventiven Instandhaltungsstrategie, die zur Erhöhung der
Instandhaltungskosten führt.
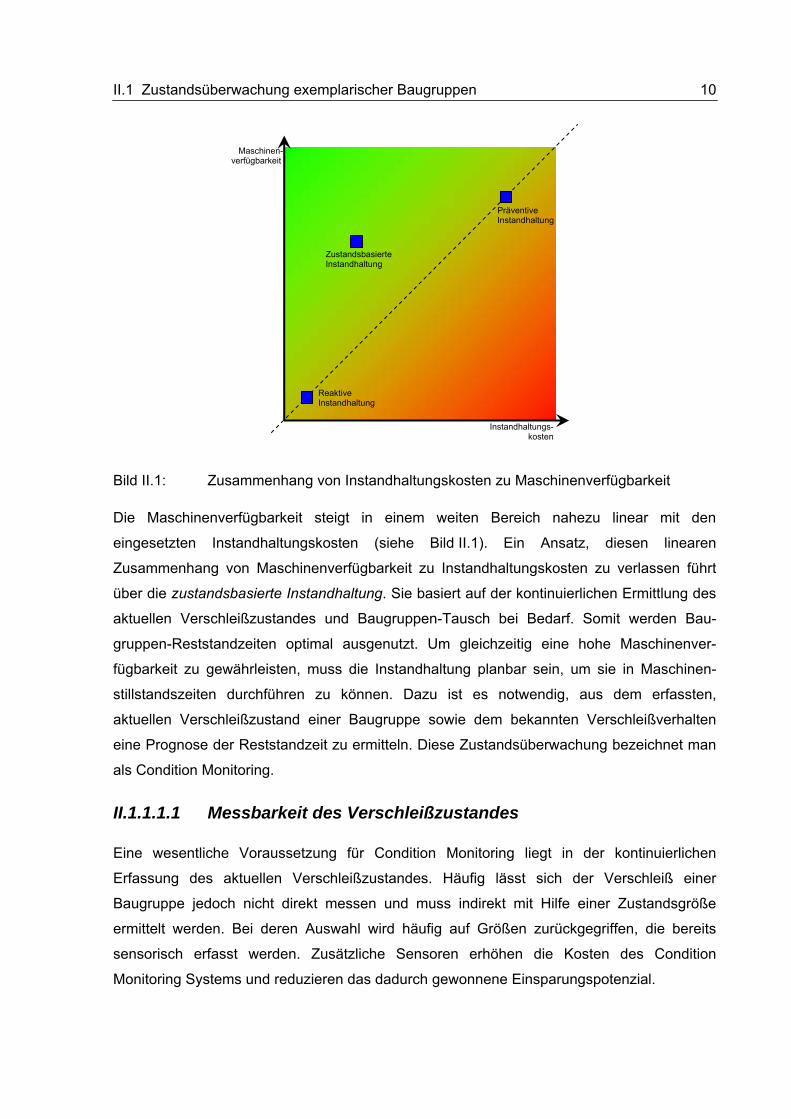
II.1 Zustandsüberwachung exemplarischer Baugruppen 10
Bild II.1: Zusammenhang von Instandhaltungskosten zu Maschinenverfügbarkeit
Die Maschinenverfügbarkeit steigt in einem weiten Bereich nahezu linear mit den
eingesetzten Instandhaltungskosten (siehe Bild II.1). Ein Ansatz, diesen linearen
Zusammenhang von Maschinenverfügbarkeit zu Instandhaltungskosten zu verlassen führt
über die zustandsbasierte Instandhaltung. Sie basiert auf der kontinuierlichen Ermittlung des
aktuellen Verschleißzustandes und Baugruppen-Tausch bei Bedarf. Somit werden Bau-
gruppen-Reststandzeiten optimal ausgenutzt. Um gleichzeitig eine hohe Maschinenver-
fügbarkeit zu gewährleisten, muss die Instandhaltung planbar sein, um sie in Maschinen-
stillstandszeiten durchführen zu können. Dazu ist es notwendig, aus dem erfassten,
aktuellen Verschleißzustand einer Baugruppe sowie dem bekannten Verschleißverhalten
eine Prognose der Reststandzeit zu ermitteln. Diese Zustandsüberwachung bezeichnet man
als Condition Monitoring.
II.1.1.1.1 Messbarkeit des Verschleißzustandes
Eine wesentliche Voraussetzung für Condition Monitoring liegt in der kontinuierlichen
Erfassung des aktuellen Verschleißzustandes. Häufig lässt sich der Verschleiß einer
Baugruppe jedoch nicht direkt messen und muss indirekt mit Hilfe einer Zustandsgröße
ermittelt werden. Bei deren Auswahl wird häufig auf Größen zurückgegriffen, die bereits
sensorisch erfasst werden. Zusätzliche Sensoren erhöhen die Kosten des Condition
Monitoring Systems und reduzieren das dadurch gewonnene Einsparungspotenzial.
Instandhaltungs- kosten
Maschinen- verfügbarkeit
Präventive Instandhaltung
Zustandsbasierte Instandhaltung
Reaktive Instandhaltung

II.1 Zustandsüberwachung exemplarischer Baugruppen 11
II.1.1.1.2 Interpretierbarkeit der Zustandsgröße
Die zweite Voraussetzung für Condition Monitoring liegt in der Interpretierbarkeit der
Zustandsgröße. Im Allgemeinen ist die gemessene Zustandsgröße nicht linear mit dem
Verschleißzustand verknüpft. Heutzutage wird der Verschleißzustand häufig rein visuell von
Experten bestimmt. Die objektive Erfassung des aktuellen Verschleißzustandes aus diesem
Expertenwissen ist damit problematisch.
II.1.1.1.3 Prognostizierbarkeit des Verschleißverhaltens
Zusätzlich zur objektiven Quantifizierung des aktuellen Verschleißzustandes muss man vom
aktuellen Verschleißzustand den Zeitpunkt des Baugruppenausfalls hochrechnen. Dazu
benötigt man Wissen über den Verschleißverlauf über der Zeit. Dieser Zusammenhang ist
jedoch häufig stark abhängig von äußeren Einflussgrößen. Die sichere Ermittlung des Ver-
schleißverhaltens ist wegen der Vielzahl der – oft nicht offensichtlichen – Randbedingungen
sowie der üblicherweise langen Baugruppenstandzeiten somit schwierig.
II.1.1.2 Beispielbaugruppe Walzengang
Als erste Beispielbaugruppe wurde der Walzengang eines Rübenroders gewählt. Dieser Teil
der Reinigungseinrichtung besteht aus Reinigungswalzen, welche die Rüben von
anhängender Erde, Steinen und Kluten befreien (siehe Bild II.2). Nachdem die Rodeschare
die Rüben ausgegraben haben, werden sie auf ein Siebband übergeben, welches die Rüben
zur Reinigungseinrichtung fördert. Starker Verschleiß an den Reinigungswalzen führt zu
schlechter Abreinigung des Erntegutes, was sich in einer verringerten Erntegutqualität
widerspiegelt.
Zur effektiveren Abreinigung arbeiten einige der hydraulisch angetriebenen Reinigungs-
walzen gegenläufig: zwei benachbarte Walzen „ziehen“ Verunreinigungen aus dem
Erntegutstrom. Gerät jedoch ein Stein in den Spalt zwischen den gegenläufigen
Reinigungswalzen, besteht die Gefahr, dass sich dieser verklemmt. Der eingeklemmte Stein
erzeugt Riefen auf den Reinigungswalzen und beschädigt die aufgebrachten
Reinigungslippen. Durch den Steinklemmer steigt der Druck in der Zuleitung des
antreibenden Hydraulikmotors. Dieser wird mit Hilfe eines Drucksensors überwacht. Bei
sprunghaftem Anstieg wird die Drehrichtung der Walzen reversiert, um den eingeklemmten
Stein auszuwerfen.

II.1 Zustandsüberwachung exemplarischer Baugruppen 12
Bild II.2: Walzengang mit Reinigungswalzen am Rübenroder
Die bisherige Instandhaltungsstrategie für die Reinigungswalzen ist bereits zustandsbasiert.
Vor Beginn jeder Erntekampagne wird der Walzengang von Servicemonteuren mit
Expertenwissen begutachtet und bewertet, ob die Walzen eine weitere Rodekampagne
überstehen oder ob die Reinigungsleistung durch die Beschädigung der Reinigungslippen zu
sehr verringert ist. Ziel ist es, die Begutachtung einzusparen und ein automatisiertes
Condition Monitoring System zu entwickeln.
Um ein kostenneutrales Condition Monitoring für den Walzengang zu realisieren, wird die
Zahl der Steinklemmer als Zustandsgröße für den Verschleißzustand gewählt.
In der ersten Kampagne zeigte die Versuchsmaschine wenig Steinklemmer, weil sie
aufgrund der guten Witterung wenig belastet war und zusätzlich in steinarmen Böden
eingesetzt wurde. Signifikanter Verschleiß am Walzengang war kaum feststellbar. In der
zweiten und dritten Kampagne war - trotz des Einsatzes der Maschine auf steinigen Böden -
der Verschleiß der Walzen auch in dieser Maschine so gering, dass kein Ausfall der
Baugruppe bis zum Projektende zu erwarten war. Zudem zeigte sich die objektive
Quantifizierung des aktuellen Verschleißzustandes trotz des Expertenwissens als schwierig.
Bei der Begutachtung des Walzenganges im Vorfeld einer Kampagne wird bisher lediglich
bewertet, ob die Rest-Standzeit der Walzen für den Einsatz in einer weiteren Erntekampagne
ausreicht. Eine Quantifizierung des Verschleißzustandes findet nicht statt.
Die Interpretierbarkeit der Zustandsgröße (die Anzahl der Steinklemmer) erschwert sich
dadurch, dass zwei Kategorien von Steinklemmern existieren. Bei einem einfachen

II.1 Zustandsüberwachung exemplarischer Baugruppen 13
Steinklemmer löst sich der Stein beim einmaligen Reversieren der Walzen. Sitzt ein Stein
nach dreimaligem Reversieren noch immer im Spalt zwischen den Reinigungswalzen, spricht
man von einem schweren Steinklemmer. Dem Fahrer wird durch eine Warnmeldung
angezeigt, dass der Stein manuell entfernt werden muss. Ein schwerer Steinklemmer
erzeugt erheblich mehr Verschleiß als drei einfache Steinklemmer, die die gleiche Zahl an
Reversiervorgängen hervorrufen. Die Ermittlung des Verschleißverlaufes über der Zeit
erschwert sich darum, da das Verhältnis von einfachen zu schweren Steinklemmern stark
schwankt.
II.1.1.3 Beispielbaugruppe Hydrauliköl
Die zweite Beispielbaugruppe für die zustandsbasierte Instandhaltung ist das Hydrauliköl. Es
ist am selbstfahrenden Rübenroder von zentraler Bedeutung, weil es zur Energieübertragung
sowohl für den hydrostatischen Fahrantrieb als auch für die Rodetechnik dient. 1/3 der
insgesamt 450 Liter Hydrauliköl befindet sich ständig im Hydrauliksystem der Maschine,
während die restlichen 300 Liter als Tankinhalt vorgehalten werden. Das komplexe
Hydrauliksystem besteht aus 17 Pumpen, ca. 40 Motoren und etwa 50 Zylindern.
Bislang wird beim Hydrauliköl die präventive Instandhaltungsstrategie angewandt. Das
Hydrauliköl wird jährlich bzw. nach 1000 Betriebsstunden gewechselt. Der Grund für das
kurze Wechselintervall ist nicht der Verschleiß des Hydrauliköls selbst, sondern die Bildung
von Kondenswasser an den Wänden des Tanks in der langen Standzeit zwischen den
Kampagnen. Eine Voraussetzung für die Ausnutzung der gesamten Ölstandzeit war der
Einbau eines Feinstfilters, der in der Lage ist, mit einem Filterelement bis zu 500 ml Wasser
aus dem Öl herauszufiltern.
Beim Verschleiß von Hydrauliköl werden die Moleküle aufgespalten und es entsteht Säure.
Bei der Neutralisation der entstandenen Säuremoleküle werden Additive abgebaut. Sind die
Additive vollständig abgebaut, steigt der Säureanteil im Öl an. Die Total Asset Number TAN
quantifiziert den Säuregehalt im Öl. Mit dem Säuregehalt steigt auch die Leitfähigkeit des
Fluids. Zusätzlich ändert sich die Kernviskosität. Als Kernviskosität bezeichnet man die
temperaturkompensierte Viskosität des Fluids.
Zur Erfassung des Hydrauliköl-Verschleißes eignet sich keiner der bisher verbauten
Sensoren. Darum wurde die Maschine mit einem zusätzlichen Ölzustandssensor
ausgestattet, der bislang in stationären Anlagen verwendet wird. Er nimmt neben der
relativen Feuchte die Öltemperatur, die relative Dielektrizitätskonstante (entspricht der
Leitfähigkeit) und die relative Kern-Viskosität auf. Die relativen Ausgangsgrößen des

II.1 Zustandsüberwachung exemplarischer Baugruppen 14
Sensors basieren auf Referenzwerten, die innerhalb der ersten 100 Betriebsstunden
aufgenommen werden. Innerhalb der ersten und zweiten Versuchskampagne wurden
zusätzlich zur Ölverschleiß-Bestimmung mit dem Ölzustandssensor Laboruntersuchungen
zur Ermittlung des Hydrauliköl-Verschleißes durchgeführt. Sowohl an der wenig belasteten
Maschine der ersten Versuchskampagne als auch in der stärker belasteten Maschine des
zweiten Versuchszeitraums zeigten die Laboruntersuchungen keinen nennenswerten
Verschleiß.
Die Kern-Viskosität wird in stationären Anlagen als hauptsächliches Verschleißkriterium
verwendet. Zu Beginn der zweiten Versuchskampagne zeigte sich jedoch, dass durch die
lange Standzeit zwischen den Kampagnen und den hohen Additivgehalt das zur
Viskositätsmessung verwendete Sensorelement verklebt und die Messwerte damit verfälscht
werden. Die Dielektrizitätskonstante ist messtechnisch gut erfassbar. Zudem kann bei
Ausschluss der relativen Kernviskosität aus dem Messverfahren die Referenzzeit von
100 Betriebsstunden auf 5 bis 10 Stunden verringert werden, weil die aufwändige Ermittlung
des Viskositäts-Temperatur-Zusammenhangs entfällt.
Die Dielektrizitätskonstante verhält sich weitestgehend proportional zur TAN. Der
Schwellwert, an dem das Hydrauliköl vollständig verschlissen ist, wird von keinem
Ölhersteller exakt beziffert. Der Hersteller des Ölzustandssensors gibt als Faustwert eine
Veränderung der Dielektrizitätskonstante von 20 % an. Mit diesem Grenzwert ist eine
Quantifizierung des aktuellen Hydraulikölverschleißes realisierbar.
Bild II.3 zeigt den theoretischen Verschleißverlauf des Hydrauliköls. Im flachen, geraden Teil
der Verschleißkurve genügt der Additivanteil im Fluid noch aus, um die frei werdenden
Säuremoleküle zu neutralisieren. Der Säuregehalt, ausgedrückt über die TAN, bleibt nahezu
konstant. Sobald die Additive jedoch abgebaut sind, steigt die TAN exponentiell an.
Für die Prognostizierbarkeit einer Reststandzeit des Hydrauliköls muss man den funktionalen
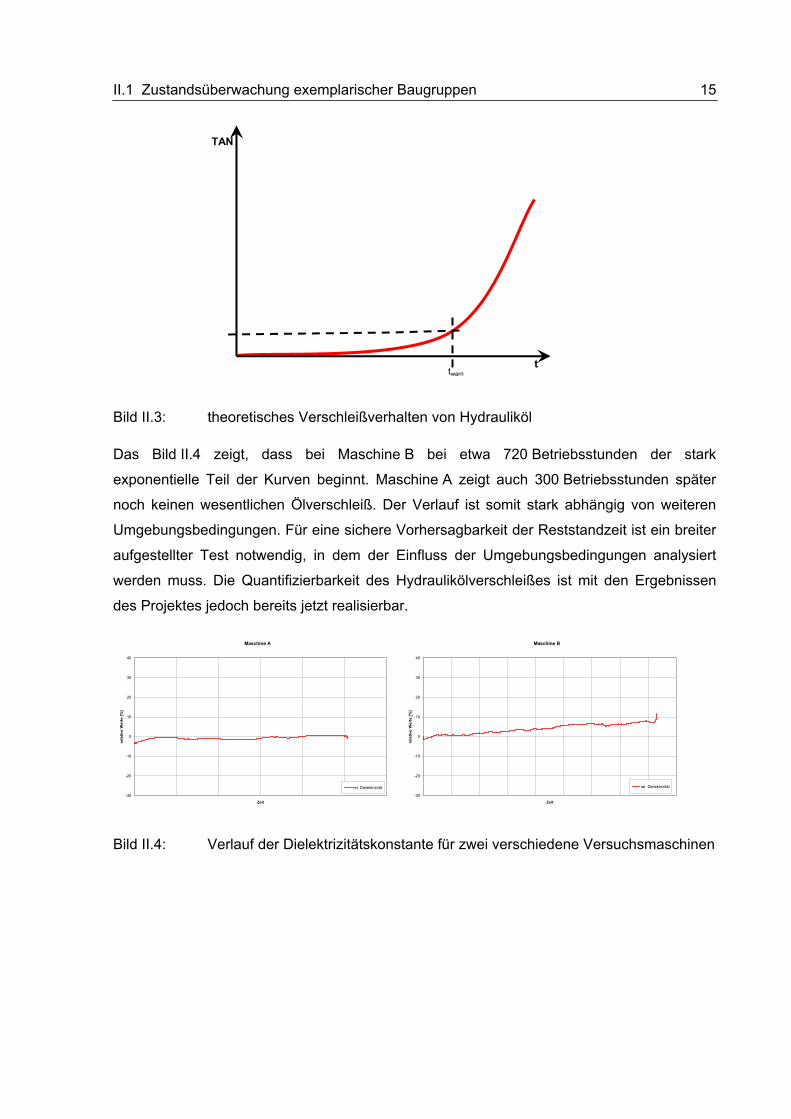
Zusammenhang des Verschleißverhaltens über der Zeit kennen. Bild II.4 zeigt den Verlauf
der Dielektrizitätskonstante über der Zeit an zwei Versuchsmaschinen aus der dritten
Versuchskampagne. Die abgebildete Maschinenlaufzeit bei Maschine A beträgt 1050 Be-
triebsstunden, die Maschine B leistete im dargestellten Zeitraum 750 Betriebsstunden.
II.1 Zustandsüberwachung exemplarischer Baugruppen 15
Bild II.3: theoretisches Verschleißverhalten von Hydrauliköl
Das Bild II.4 zeigt, dass bei Maschine B bei etwa 720 Betriebsstunden der stark
exponentielle Teil der Kurven beginnt. Maschine A zeigt auch 300 Betriebsstunden später
noch keinen wesentlichen Ölverschleiß. Der Verlauf ist somit stark abhängig von weiteren
Umgebungsbedingungen. Für eine sichere Vorhersagbarkeit der Reststandzeit ist ein breiter
aufgestellter Test notwendig, in dem der Einfluss der Umgebungsbedingungen analysiert
werden muss. Die Quantifizierbarkeit des Hydraulikölverschleißes ist mit den Ergebnissen
des Projektes jedoch bereits jetzt realisierbar.
Maschine A
-30
-20
-10
0
10
20
30
40
Zeit
rela
tive
Wer
te [%
]
rel. Dielektrizität
Maschine B
-30
-20
-10
0
10
20
30
40
Zeit
rela
tive
Wer
te [%
]
rel. Dielektrizität
Bild II.4: Verlauf der Dielektrizitätskonstante für zwei verschiedene Versuchsmaschinen
TAN
twarn t

II.1 Zustandsüberwachung exemplarischer Baugruppen 16
II.1.2 Vorhersagbarkeit von Wartung und Instandhaltung
Wartung und Instandhaltung an selbstfahrenden Erntemaschinen wird für viele Bauteile und
Baugruppen bisher präventiv und/oder reaktiv betrieben. Das heißt entweder werden
Bauteile vor dem Ernteeinsatz aufgrund eingehender Prüfung als defekt erkannt und
ausgewechselt oder während des Einsatzes fallen Bauteile aus. Diese müssen dann
kurzfristig ersetzt werden. Wartungsarbeiten während der Hauptbetriebszeit stören den
Einsatz gleichermaßen.
Eine pauschale Wartungs- und Instandhaltungsstrategie aufgrund einfacher Bezugsgrößen,
wie z. B. geleisteter Arbeitsstunden, ist nicht immer optimal. Dies liegt auch daran, dass
verschiedene und teilweise unbekannte Einflussfaktoren mit bedeutenden Auswirkungen auf
die Nutzungsdauer der Verschleißbauteile und die Standzeit wartungsintensiver Bauteile
nicht erfasst werden. Die Zusammenhänge zwischen den Einflussgrößen und der
Nutzungsdauer bzw. der Standzeit sind teilweise qualitativ bekannt. Ein direkter quantitativer
Bezug fehlt allerdings. Unter wirtschaftlichen Gesichtspunkten erscheint es an dieser Stelle
sinnvoller, Kriterien zu ermitteln, aufgrund derer sich der Zustand der zu überwachenden
Bauteile beschreiben lässt.
Anhand zweier exemplarischer Baugruppen des Mähdreschers werden zwei verschiedene
Ansätze vorgestellt, welche aufzeigen, wie die Vorhersage von Wartung und Instandhaltung
an selbstfahrenden Erntemaschinen funktionieren kann.
II.1.2.1 Kettenlängung Schrägförderer
II.1.2.1.1 Einleitung
Die Kettenlängung im Schrägförderer des Mähdreschers ist für die Maschinenwartung und
Instandhaltung ein wichtiger und entscheidender Faktor. Bild II.5 zeigt die Einzugsketten des
Schrägförderers im eingebauten Zustand.
Die Nutzung der Ketten über die Verschleißgrenze hinweg hat einen Ausfall der Kette zur
Folge und kann große Schäden und hohe Kosten in den nachfolgenden Baugruppen wie
Dreschwerk, Rotor oder Schüttler und Strohhäcksler verursachen. Die Ausfallzeit der
Maschine ist dann entsprechend hoch. Andererseits erschwert die Anordnung von drei bis
vier parallel laufenden Ketten die Ermittlung der Verschleißlängung. Der Kontakt der Kette zu
verschiedensten Materialien wie z. B. Sand, Pflanzenteile, ölhaltige Körner, Wasser bei

II.1 Zustandsüberwachung exemplarischer Baugruppen 17
verschiedenen zu fördernden Korn-Strohgemischmengen hat weiterhin erheblichen Einfluss
auf den zeitlichen Verlauf der Längung. Dies stellt an die Ermittlung und Analyse eines
Verschleißwertes hinsichtlich Vorhersagbarkeit hohe Anforderungen.
Bild II.5: Einzugsketten am Schrägförderer
Aufgrund des mechanisch eindeutigen Verhaltens (die Kette kann immer nur länger werden)
wird der Ansatz verfolgt, den zeitlichen Verlauf der Messgröße mittels einer mathematischen
Funktion abzubilden und auf entsprechende Restlaufzeiten hin zu interpretieren. In Bild II.6
sind die qualitativen Verläufe zweier Funktionen dargestellt, die für die Beschreibung der
Kettenlängung als Ansätze dienten.
Bild II.6: Darstellung der Kettenlängung als Polynom
II.1 Zustandsüberwachung exemplarischer Baugruppen 18
II.1.2.1.2 Erkenntnisse anhand Prüfstandsuntersuchungen
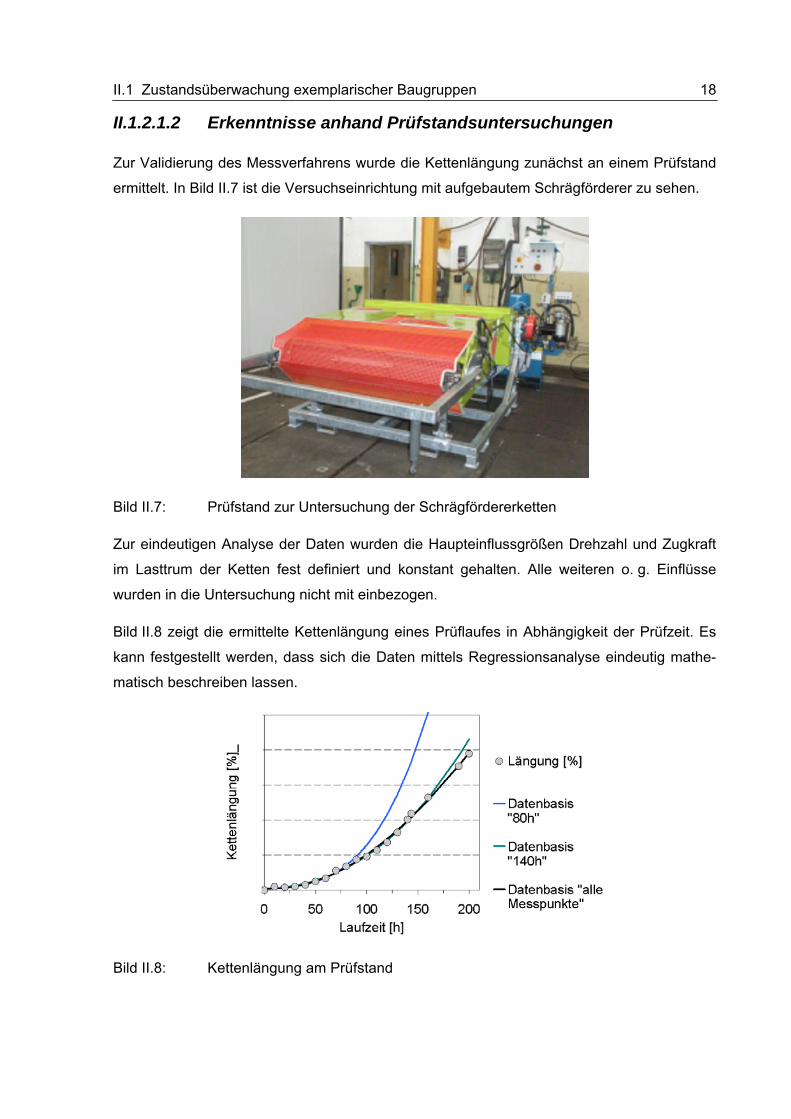
Zur Validierung des Messverfahrens wurde die Kettenlängung zunächst an einem Prüfstand
ermittelt. In Bild II.7 ist die Versuchseinrichtung mit aufgebautem Schrägförderer zu sehen.
Bild II.7: Prüfstand zur Untersuchung der Schrägfördererketten
Zur eindeutigen Analyse der Daten wurden die Haupteinflussgrößen Drehzahl und Zugkraft
im Lasttrum der Ketten fest definiert und konstant gehalten. Alle weiteren o. g. Einflüsse
wurden in die Untersuchung nicht mit einbezogen.
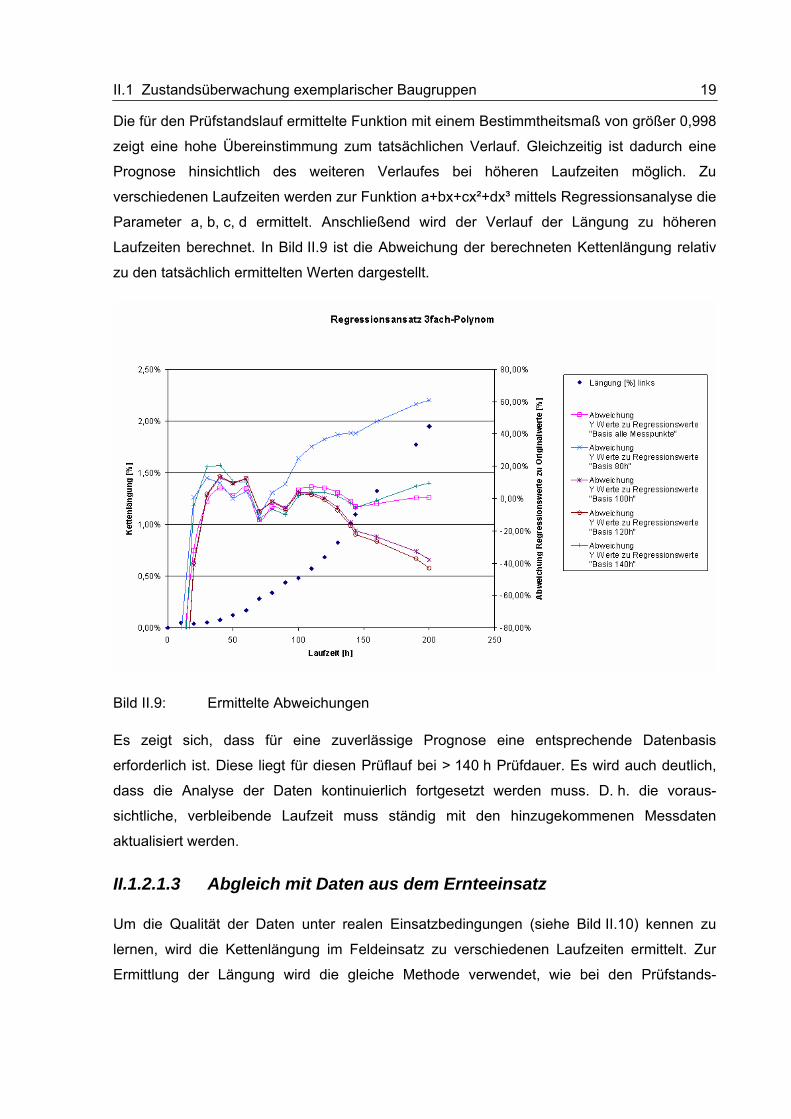
Bild II.8 zeigt die ermittelte Kettenlängung eines Prüflaufes in Abhängigkeit der Prüfzeit. Es
kann festgestellt werden, dass sich die Daten mittels Regressionsanalyse eindeutig mathe-
matisch beschreiben lassen.
Bild II.8: Kettenlängung am Prüfstand
II.1 Zustandsüberwachung exemplarischer Baugruppen 19
Die für den Prüfstandslauf ermittelte Funktion mit einem Bestimmtheitsmaß von größer 0,998
zeigt eine hohe Übereinstimmung zum tatsächlichen Verlauf. Gleichzeitig ist dadurch eine
Prognose hinsichtlich des weiteren Verlaufes bei höheren Laufzeiten möglich. Zu
verschiedenen Laufzeiten werden zur Funktion a+bx+cx²+dx³ mittels Regressionsanalyse die
Parameter a, b, c, d ermittelt. Anschließend wird der Verlauf der Längung zu höheren
Laufzeiten berechnet. In Bild II.9 ist die Abweichung der berechneten Kettenlängung relativ
zu den tatsächlich ermittelten Werten dargestellt.
Bild II.9: Ermittelte Abweichungen
Es zeigt sich, dass für eine zuverlässige Prognose eine entsprechende Datenbasis
erforderlich ist. Diese liegt für diesen Prüflauf bei > 140 h Prüfdauer. Es wird auch deutlich,
dass die Analyse der Daten kontinuierlich fortgesetzt werden muss. D. h. die voraus-
sichtliche, verbleibende Laufzeit muss ständig mit den hinzugekommenen Messdaten
aktualisiert werden.
II.1.2.1.3 Abgleich mit Daten aus dem Ernteeinsatz
Um die Qualität der Daten unter realen Einsatzbedingungen (siehe Bild II.10) kennen zu
lernen, wird die Kettenlängung im Feldeinsatz zu verschiedenen Laufzeiten ermittelt. Zur
Ermittlung der Längung wird die gleiche Methode verwendet, wie bei den Prüfstands-
II.1 Zustandsüberwachung exemplarischer Baugruppen 20
versuchen. Die Auswertung der Daten zeigt einen ähnlichen Verlauf wie die Daten vom
Prüfstandslauf.
Bild II.10: Maisernte mit einem Mähdrescher vom Typ Lexion
Wechselnde Getreidearten, Standorte und Witterungsbedingungen scheinen weniger
Einfluss auf den Verlauf zu haben als zunächst angenommen. Auch hier finden sich hohe
Bestimmtheitsmaße von 0,999 zur ermittelten Funktion (Bild II.11).
Bild II.11: Kettenlängung im Feldeinsatz
Aufgrund dieser Ergebnisse lassen sich nun Meldungen definieren, mit denen eine
vorausschauende Wartung und Instandhaltung praktiziert werden kann:
1. bei jedem Motorstart wird ein Wert abgespeichert und die aktuelle Verschleißlängung
wird errechnet
2. ab 100 Arbeitsstunden werden mittels Regressionsanalyse vorrausichtliche Lauf-
zeiten für eine Kettenlängung von 1,5 %, 2,0 %, 2,5 % und 3 % berechnet

II.1 Zustandsüberwachung exemplarischer Baugruppen 21
Folgende Meldungen lassen sich bei entsprechender Längung generieren:
a) 1,5 %: Anzeige des aktuellen Wertes & Ketten müssen in xx h gekürzt werden
b) 2,0 %: Kette muss gekürzt werden
c) 2,5 %: voraussichtliche Restlaufzeit beträgt xx h (tägliche Aktualisierung erforderlich)
d) 3,0 %: Kette muss ausgetauscht werden
Somit stehen also dem Bediener und der betreuenden Werkstatt Informationen zur
Verfügung, mit denen notwendige Wartung und Ersatz des Bauteiles vorab mitgeteilt
werden. Erforderliche Arbeiten können koordiniert werden, so dass eine möglichst hohe
Maschinenverfügbarkeit erreicht wird. Schäden durch unzulässige Nutzung mit zu hohem
Verschleiß können so vermieden werden.
II.1.2.2 Luftfilterverschmutzung Dieselmotor
II.1.2.2.1 Einleitung
Der Luftfilter zur Säuberung der Verbrennungsluft für den Dieselmotor ist ein weiteres
Bauteil, welches eine zentrale Bedeutung für eine hohe Maschinenverfügbarkeit hat.
Gleichzeitig werden hier sehr hohe Anforderungen an Funktion und Standzeit gestellt. Staub
in der Umgebungsluft der Maschine ist verfahrenstechnisch bedingt fast immer vorhanden
und gleichzeitig die begrenzende Haupteinflussgröße für die Standzeit des Filterelements.
Unter Einsatzbedingungen wie in Bild II.12 zu sehen, wird der Luftfilter u. U. extrem
beansprucht. Hier kann es sein, dass Wartungsintervalle deutlich kürzer sind als unter
weniger staubigen Verhältnissen. Eine Wartung an dieser Stelle während des Einsatzes hat
ebenfalls Ausfallzeiten zur Folge, welche bei entsprechender vorsorglicher Wartung
vermieden werden können.
Ein Indikator für den Verschmutzungszustand ist der Unterdruck im Ansaugrohr zwischen
Dieselmotor und Filterelement. Diese Messgröße wird bei näherer Betrachtung aber noch
von weiteren Einflüssen, wie z. B. der Motordrehzahl und Motorauslastung wesentlich
beeinflusst. Vibrationen können am Filterelement einen Säuberungseffekt hervorrufen. Für
die zu interpretierende Messgröße „Unterdruck“ heißt das, dass sich das Messsignal nicht
immer direkt und eindeutig in Zusammenhang zur Verschmutzung bringen lässt. Sowohl
größere als auch kleinere Werte können gemessen werden, ohne dass sich der
Verschmutzungszustand des Filters geändert hat.

II.1 Zustandsüberwachung exemplarischer Baugruppen 22
Bild II.12: Getreideernte unter sehr staubigen Bedingungen
Unter diesen Voraussetzungen ist die Analyse des zeitlichen Verlaufes des Druckes nur mit
hohem Aufwand möglich. Die Auswertung der Messgröße mittels einer Klassierung und
Analyse der Anteile mit definierten Grenzwerten (siehe Bild II.13) bietet sich hier als
Alternative an.
Bild II.13: Bsp. Klassierung als Häufigkeit
Eine bereits bekannte und einfache Variante dieser Auswertung ist die heute angewendete
Grenzwertüberwachung in Form eines Druckschalters. Anhand eines Beispieles soll also
gezeigt werden, wie eine Auswertung klassierter Daten erfolgen kann und welche Aussagen
sich für eine Prognose von Wartung und Instandhaltung ableiten lassen.
II.1.2.2.2 Untersuchungen am Prüfstand
Der direkte Zeitbezug der klassierten Daten ist bei einer Häufigkeits- oder Verweildauer-
klassierung nicht mehr herzustellen. Zur anschließenden Interpretation ist es daher wichtig,
die Qualität der Messdaten sicherzustellen.
II.1 Zustandsüberwachung exemplarischer Baugruppen 23
Hauptaufgabe für die Untersuchungen am Prüfstand ist daher die Absicherung der
Genauigkeit und des Verhaltens bei unterschiedlichen Drücken. Dazu wurde der später im
Feld eingesetzte Sensor auf dem in Bild II.14 dargestellten Prüfstand in verschiedenen
Ansaugbedingungen getestet und mit einem Referenzsensor abgeglichen.
Bild II.14: Prüfstand Drucksensor
Der absolute Verlauf bei veränderten Luftansaugbedingungen zeigt ein Signal mit geringer
Streubreite. Der in Bild II.15 dargestellte Vergleich mit dem Referenzsensor zeigt ein
schmales Band. Eine Hysterese im Bereich der geforderten Genauigkeit ist nicht festgestellt
worden.
Bild II.15: Signalverlauf Drucksensor
II.1 Zustandsüberwachung exemplarischer Baugruppen 24
II.1.2.2.3 Auswertung der Erntedaten
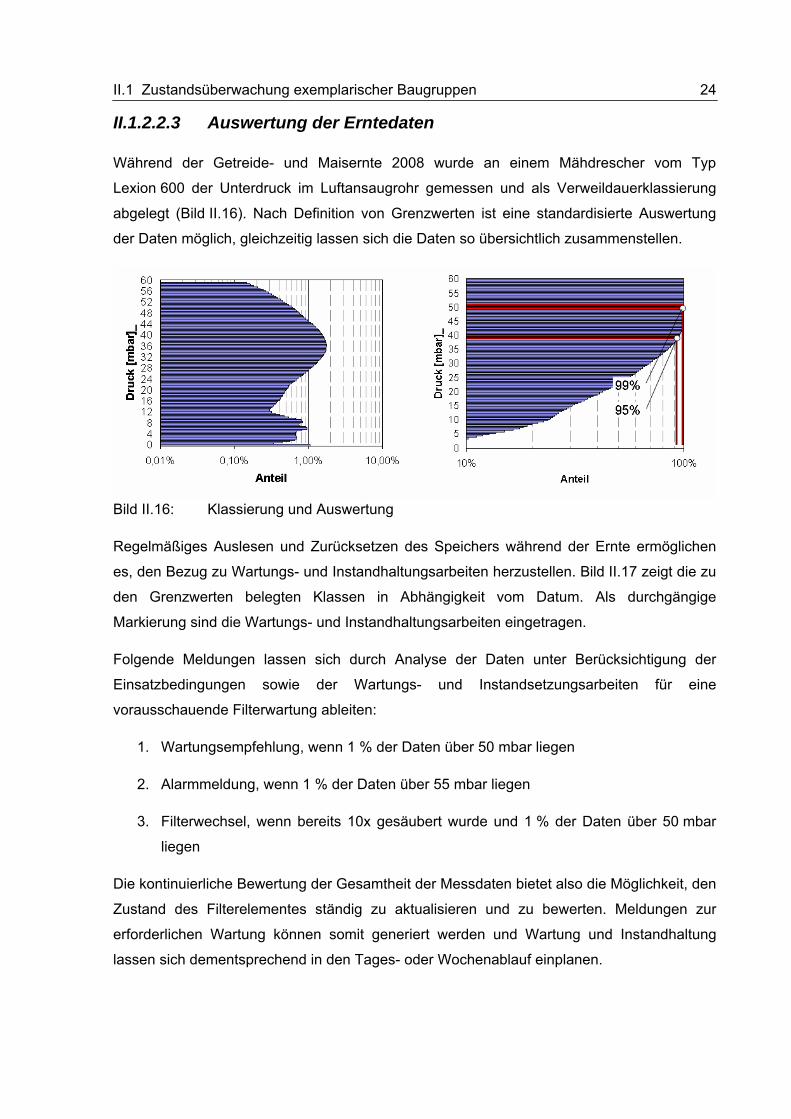
Während der Getreide- und Maisernte 2008 wurde an einem Mähdrescher vom Typ
Lexion 600 der Unterdruck im Luftansaugrohr gemessen und als Verweildauerklassierung
abgelegt (Bild II.16). Nach Definition von Grenzwerten ist eine standardisierte Auswertung
der Daten möglich, gleichzeitig lassen sich die Daten so übersichtlich zusammenstellen.
Bild II.16: Klassierung und Auswertung
Regelmäßiges Auslesen und Zurücksetzen des Speichers während der Ernte ermöglichen
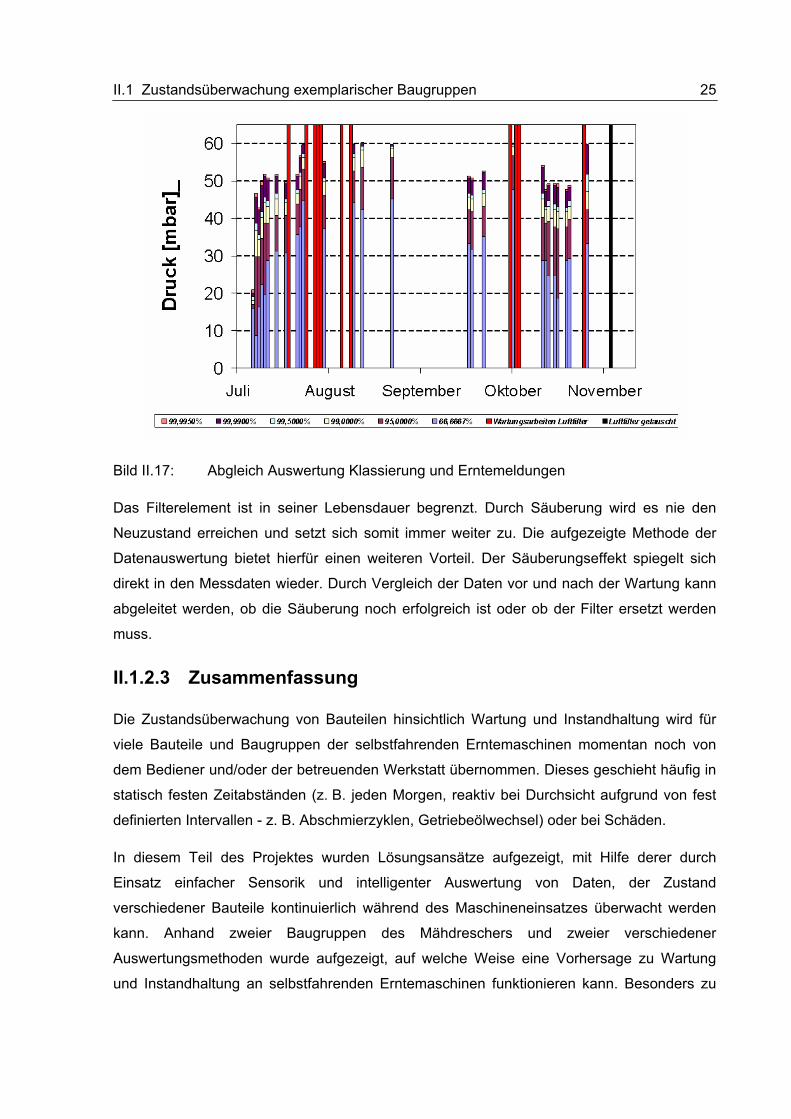
es, den Bezug zu Wartungs- und Instandhaltungsarbeiten herzustellen. Bild II.17 zeigt die zu
den Grenzwerten belegten Klassen in Abhängigkeit vom Datum. Als durchgängige
Markierung sind die Wartungs- und Instandhaltungsarbeiten eingetragen.
Folgende Meldungen lassen sich durch Analyse der Daten unter Berücksichtigung der
Einsatzbedingungen sowie der Wartungs- und Instandsetzungsarbeiten für eine
vorausschauende Filterwartung ableiten:
1. Wartungsempfehlung, wenn 1 % der Daten über 50 mbar liegen
2. Alarmmeldung, wenn 1 % der Daten über 55 mbar liegen
3. Filterwechsel, wenn bereits 10x gesäubert wurde und 1 % der Daten über 50 mbar
liegen
Die kontinuierliche Bewertung der Gesamtheit der Messdaten bietet also die Möglichkeit, den
Zustand des Filterelementes ständig zu aktualisieren und zu bewerten. Meldungen zur
erforderlichen Wartung können somit generiert werden und Wartung und Instandhaltung
lassen sich dementsprechend in den Tages- oder Wochenablauf einplanen.
II.1 Zustandsüberwachung exemplarischer Baugruppen 25
Bild II.17: Abgleich Auswertung Klassierung und Erntemeldungen
Das Filterelement ist in seiner Lebensdauer begrenzt. Durch Säuberung wird es nie den
Neuzustand erreichen und setzt sich somit immer weiter zu. Die aufgezeigte Methode der
Datenauswertung bietet hierfür einen weiteren Vorteil. Der Säuberungseffekt spiegelt sich
direkt in den Messdaten wieder. Durch Vergleich der Daten vor und nach der Wartung kann
abgeleitet werden, ob die Säuberung noch erfolgreich ist oder ob der Filter ersetzt werden
muss.
II.1.2.3 Zusammenfassung
Die Zustandsüberwachung von Bauteilen hinsichtlich Wartung und Instandhaltung wird für
viele Bauteile und Baugruppen der selbstfahrenden Erntemaschinen momentan noch von
dem Bediener und/oder der betreuenden Werkstatt übernommen. Dieses geschieht häufig in
statisch festen Zeitabständen (z. B. jeden Morgen, reaktiv bei Durchsicht aufgrund von fest
definierten Intervallen - z. B. Abschmierzyklen, Getriebeölwechsel) oder bei Schäden.
In diesem Teil des Projektes wurden Lösungsansätze aufgezeigt, mit Hilfe derer durch
Einsatz einfacher Sensorik und intelligenter Auswertung von Daten, der Zustand
verschiedener Bauteile kontinuierlich während des Maschineneinsatzes überwacht werden
kann. Anhand zweier Baugruppen des Mähdreschers und zweier verschiedener
Auswertungsmethoden wurde aufgezeigt, auf welche Weise eine Vorhersage zu Wartung
und Instandhaltung an selbstfahrenden Erntemaschinen funktionieren kann. Besonders zu

II.1 Zustandsüberwachung exemplarischer Baugruppen 26
beachten ist hierbei, dass sich für die unterschiedlichen Einsatzbedingungen und
Anwendungen kein generelles Verfahren für alle zu überwachenden Bauteile empfiehlt. Im
Einzelfall ist zu entscheiden, wie weitere Bauteile hinsichtlich Wartung und Instandhaltung
überwacht werden können.
Vorhersagbarkeit von Wartung und Instandhaltung ermöglicht dem Maschinenbediener und
der betreuenden Werkstatt durch Steigerung der Maschinenverfügbarkeit und effiziente
Einsatzplanung eine gesteigerte wirtschaftliche Nutzung der Maschine. Die technischen
Vorraussetzungen sind innerhalb dieses Projektteiles in ihrer Verfügbarkeit aufgezeigt
worden.

II.2 Datenmanagement 27
II.2 Datenmanagement
Das Datenmanagementsystem setzt sich aus unterschiedlichen Elementen zusammen, die
auf einer maschinenseitigen On-Board-Unit sowie im Back-End zum Einsatz kommen. Einige
dieser Elemente, die im Rahmen des Projektes erarbeitet wurden, sollen im Folgenden
vorgestellt werden.
II.2.1 Kompressionsmethoden für verschiedene Datenarten
Im Rahmen dieses Abschnitts soll die Entwicklung der Datenkompressionsmethoden
beschrieben werden. Dazu werden zunächst relevante Datenarten identifiziert und Anfor-
derungen gesammelt. Danach folgt die ausführliche Beschreibung des Entwicklungs-
prozesses. Abschließend werden einige beispielhafte Kompressionsergebnisse vorgestellt.
II.2.1.1 Dateneigenschaften und Anforderungen an die Kompressionsmethoden
Die zu entwickelnden Datenkompressionsmethoden sollen dazu dienen, verschiedenste
Datenarten, die auf der mobilen Arbeitsmaschine vorliegen bzw. dort erhoben, gemessen
oder errechnet werden, zu komprimieren, um so eine effiziente drahtlose Kommunikation
und ggf. eine Zwischenspeicherung zu ermöglichen.
Bei mobilen Arbeitsmaschinen müssen zur Prozessüberwachung oder zur Steuerung und
Regelung von Maschinenfunktionen häufig zeitliche Abfolgen verschiedenster Messwerte
ermittelt und übertragen werden. Druck-, Drehzahl- oder Temperaturmesswerte sind typische
Vertreter dieser Datenart. Für solche gemessenen, analogen Werte soll vorausgesetzt
werden, dass diese als abgetastetes und quantifiziertes Signal über einen maschinen-
internen Datenbus (wie z. B. einen CAN-Bus) bereitgestellt werden. Diese Bereitstellung
kann dabei, entsprechend der verschiedenen Nachrichtentypen des CAN-Protokolls,
entweder zyklisch oder in unregelmäßigen Abständen eventgesteuert erfolgen. Jedem
Messzeitpunkt ist eindeutig ein Wert der Messgröße zugeordnet. Die Abtastrate der zyklisch
einlaufenden Daten kann jedoch nicht als bekannt und konstant vorausgesetzt werden, da
diese sich beispielsweise in Abhängigkeit von der Bus-Auslastung verändern kann.
Eine weitere wichtige Datenart stellen die Positionsinformationen dar. Mit Hilfe moderner
satellitengestützter Ortungssysteme lässt sich die Position einer mobilen Maschine weltweit
mit hoher Genauigkeit bestimmen. Diese Systeme basieren bisweilen zumeist auf dem

II.2 Datenmanagement 28
amerikanischen GPS-System. Bei höheren Genauigkeitsanforderungen kommen zusätzlich
Korrektursignale zum Einsatz, die entweder satellitengestützt (DGPS) oder terrestrisch
(RTK) bereitgestellt werden. Aus der zeitlichen Abfolge dieser Positionsinformationen lässt
sich auch der zurückgelegte Weg ermitteln. Insbesondere im Bereich der Landmaschinen,
sind diese sog. Geodaten von sehr großem Interesse. Damit lassen sich in einem ersten
Schritt ortsdifferenzierte bzw. teilflächenspezifische Informationen sammeln, die in einem
zweiten Schritt genutzt werden können, die Landbewirtschaftung teilflächenspezifisch
durchzuführen. Dabei handelt es sich um das sog. Precision Farming, welches sowohl aus
ökologischen als auch aus ökonomischen Gründen zunehmend an Bedeutung gewinnt. Die
Positionsinformationen, die vom Ortungssystem i. d. R. zyklisch ausgegeben werden,
bestehen zu jedem Messzeitpunkt aus einem Wertepaar, welches die Längen- und
Breitengradinformationen enthält. Dabei sind die südlichen Breitengrade und die westlichen
Längengrade mit einem negativen Vorzeichen versehen, um auch die jeweilige Hemisphäre
der Position eindeutig anzugeben.
Einstellparameter, Statusinformationen oder Stellsignale sind weitere Daten, die auf dem
Datenbus einer mobilen Maschine häufiger vorkommen. Für eine Kompression ist diese
Datenart jedoch eher unbedeutend, da es i. d. R. nur bei einer Veränderung des Wertes oder
zur Initialisierung nach einem Maschinenneustart zu einer Übertragung kommt und die
daraus resultierende Datenmenge keinen nennenswerten Umfang hat.
Im weiteren Verlauf sollen daher vorrangig die ersten beiden Datenarten, also die Messwert-
Zeitreihen und die Positionsdaten, betrachtet werden, da die Verwendung von Daten-
kompressionsmethoden hier ein hohes Einsparpotenzial verspricht und der Bedarf für eine
Kompression bei diesen Datenarten am größten ist. Insbesondere wenn eine hohe
Genauigkeit gefordert ist, müssen diese Daten hochfrequent übertragen werden, was ohne
Kompression zwangsläufig zu sehr großen Datenmengen führt.
Damit die Entwicklung der Kompressionsmethoden zielgerichtet erfolgen kann, müssen
zunächst alle relevanten Anforderungen zusammengetragen werden. Dies geschieht im
Folgenden anhand verschiedener Kriterien.
Mobiler Einsatz
Die zu entwickelnden Kompressionsmethoden müssen für den Einsatz auf mobilen
Arbeitsmaschinen geeignet sein. Das bedeutet, dass die Kompressionsalgorithmen auf
mobiltauglichen Rechnern lauffähig implementierbar sein müssen. Dabei ist zu beachten,
dass diese Rechner, im Vergleich zu Desktop-Rechnern, bisweilen noch nur über geringe

II.2 Datenmanagement 29
Speicher- und Prozessorressourcen verfügen. Zudem sind sie vergleichsweise teuer,
weswegen eine Erhöhung der knappen Ressourcen durch die Verwendung mehrerer solcher
Rechner aus Kostengründen i. d. R. nicht darstellbar ist. Auch der nur sehr eingeschränkt
verfügbare Bauraum auf der Maschine spricht gegen den Einsatz mehrerer solcher Rechner.
Bei mobilen Arbeitsmaschinen wird die Primärenergie i. d. R. in Form von Kraftstoffen in
Tanks mitgeführt. Da diese Tanks nur über eine begrenzte Kapazität verfügen und so die
Einsatzdauer der Maschine limitieren, ist einer effizienten Energienutzung, auch bei der
Datenverarbeitung, ein hoher Stellenwert einzuräumen.
Online-Fähigkeit
Eine weitere Anforderung, die unmittelbar aus dem mobilen Einsatz resultiert ist die Online-
Fähigkeit der Kompressionsalgorithmen. Dies bedeutet, dass die einlaufenden Daten
unmittelbar verarbeitet werden können, ohne dass eine Kenntnis über zukünftige Werte
vorliegen muss. Bild II.18 macht den Begriff der Online-Fähigkeit an Hand von drei kleinen
Beispielen deutlich. Es zeigt eine zeitliche Abfolge von Daten, bestehend aus einzelnen
Messwerten, vom Zeitpunkt t0 bis zum Zeitpunkt tl. Jeder der Kästen repräsentiert dabei
einen Messwert. Die senkrechten Pfeile kennzeichnen den Zeitpunkt an dem die Kom-
pression durchgeführt werden soll und die Messwerte, die dabei vom Algorithmus verarbeitet
werden, sind grau hinterlegt. Im Fall a) müssen alle Werte zunächst zwischengespeichert
werden, bevor der Kompressionsalgorithmus zum Zeitpunkt t = tl die gesamten Daten im
Nachhinein verarbeitet. Dieser Algorithmus ist nicht online-fähig. Im Fall b) werden mehrere
zurückliegende Werte zum aktuellen Zeitpunkt t = ta verarbeitet. Hierbei handelt es sich um
einen bedingt online-fähigen Algorithmus. Im dritten Fall c) schließlich verarbeitet der online-
fähige Algorithmus jeden einzelnen Wert unmittelbar zum aktuellen Zeitpunkt.
Bild II.18: Veranschaulichung des Begriffs der Online-Fähigkeit nach [Ger07]

II.2 Datenmanagement 30
Die Online-Fähigkeit ist nicht nur wegen der begrenzten Speicherressourcen auf dem
mobilen Rechner erstrebenswert sondern insbesondere auch wegen der schwer vorher-
sehbaren Abschaltvorgänge der Maschine. Wenn der Bediener die Maschine abschaltet,
muss sichergestellt sein, dass kurze Zeit später auch die Spannungsversorgung des mobilen
Rechners unterbrochen wird. Nur so kann gewährleistet werden, dass die in der Batterie
gespeicherte Energie nicht verloren geht und für einen, ggf. mehrere Monate späteren
Neustart der Maschine im notwendigen Umfang zur Verfügung steht. Durch einen online-
fähigen Kompressionsalgorithmus kann verhindert werden, dass beim spontanen Abschalten
der mobilen Arbeitsmaschine Daten verloren gehen. Außerdem steht dadurch das
Kompressionsergebnis für eine Kommunikation oder eine Archivierung zeitnah nach dem
Einlaufen der Daten zur Verfügung.
Verlustgrad und Parametrierbarkeit
Die zu entwickelnden Kompressionsmethoden sollen verlustbehaftet arbeiten, der
Verlustgrad soll sich jedoch dem jeweiligen Bedarf und Einsatzfall entsprechend begrenzen
lassen. Wie viel Information bei der Kompression eliminiert wird, die später nicht wieder
rekonstruiert werden kann, soll bei der Kompression mit Hilfe von anschaulichen Parametern
vorgegeben werden können. Eine weitere sehr wichtige Anforderung ist, dass der
Kompressionsgewinn in einem günstigen Verhältnis zum Informationsverlust stehen soll.
Demnach sollte ein hoher Kompressionsgewinn möglichst nur einen vergleichsweise
geringen Informationsverlust bewirken. Die zu entwickelnden Methoden sollen eine zeitliche
Zuordnung der Daten nach der Kompression weiterhin ermöglichen.
Übertragbarkeit
Die zu entwickelnden Kompressionsmethoden sollen sich nach Möglichkeit zur
Komprimierung verschiedener Datenquellen nutzen lassen. Diese Übertragbarkeit soll
sicherstellen, dass nicht für jede Datenquelle eine individuelle Kompressionsmethode
entwickelt werden muss. Außerdem müssen so auf dem mobilen Fahrzeugrechner nur
wenige Kompressionsmethoden in Form von Softwarediensten implementiert werden. Diese
Softwaredienste können dann bei Bedarf, also wenn Daten aus mehreren verschiedenen
Datenquellen gleichzeitig komprimiert werden sollen, einfach mehrfach gestartet und
individuell parametriert an die verschiedenen Datenquellen angepasst werden.
Dekomprimierbarkeit
Nach Möglichkeit soll die Dekompression, also die Rückgewinnung der Information aus dem
Kompressionsergebnis, ohne großen Aufwand und ohne die Kenntnis vieler zusätzlicher

II.2 Datenmanagement 31
Informationen (Metadaten) möglich sein. Dies ist unbedingt anzustreben, da mobile
Arbeitsmaschinen nicht in einem einheitlichen, abgegrenzten Organisationsumfeld zum
Einsatz kommen. Im Gegenteil; auf Grund der großen Vielfältigkeit dieser Maschinen werden
sie in sehr unterschiedlichen Branchen und Betrieben eingesetzt. Deswegen ist auch von
sehr heterogenen Strukturen bei den Nutzern der Daten auszugehen. Vom Landwirt über
den Baubetriebsleiter bis hin zum Servicemitarbeiter in der Reparaturwerkstatt sollen alle
potenziellen Datennutzer einen möglichst einfachen Zugriff auf die komprimierten Daten
erhalten können. Dies ist am einfachsten sicherzustellen, wenn zur Decodierung keine oder
nur sehr wenige Metadaten bekannt sein müssen bzw. wenn das Kompressionsergebnis
auch ohne Decodierung lesbar und aussagekräftig ist. Für den Fall, dass keine
umfangreichen Metadaten beim Datennutzer bekannt sein müssen, ist es auch nicht
notwendig, diese zusätzlich zu den eigentlichen Daten zu übertragen. Aufgrund der
beschriebenen, sehr heterogenen Strukturen bei der Datennutzung kann nämlich nicht
davon ausgegangen werden, dass die Metadaten bei allen Datennutzern als bekannt
vorausgesetzt werden können.
Kontextsensitivität
Eine letzte und dennoch sehr wichtige Anforderung ist die Kontextsensitivität der
Kompressionsalgorithmen. Kontextinformationen sind Informationen, die sich nicht aus der
zu komprimierenden Datenmenge selbst, sondern aus der Kombination mit externen
Informationsquellen gewinnen lassen. Beispielsweise liefert eine Positionsinformation selbst
keine Aussage darüber, ob sich die Position innerhalb eines Feldes oder auf einer Straße
bzw. einem Weg befindet. Werden jedoch die Positionsinformation mit den Daten einer
digitalen Karte kombiniert, so lässt sich aus dem Kontext heraus eine solche Aussage
treffen.
Der Begriff der Kontextsensitivität beschreibt die Beeinflussbarkeit der Kompressions-
methode während ihrer Laufzeit durch Kontextinformationen. Damit wäre für das Beispiel der
Positionsinformationen denkbar, auf dem Feld aus Gründen der Genauigkeit einen niedrigen
Verlustgrad und auf der Straßen zu Gunsten der Kompressionsrate einen hohen Verlustgrad
zu wählen. Eine Anpassung des Verlustgrads einer Kompressionsmethode soll also in
Abhängigkeit von Kontextinformationen möglich sein, jedoch nicht innerhalb des
Kompressionsalgorithmus selbst, sondern nach Möglichkeit von extern durch Anpassung der
Kompressionsparameter realisiert werden können. Nur so kann die zuvor geforderte
Übertragbarkeit der Algorithmen sichergestellt werden.

II.2 Datenmanagement 32
Die Verarbeitung der Kontextinformationen muss in diesem Falle von einem speziellen
externen Softwaredienst erfolgen, der nur die Parametrierung des Kompressionsalgorithmus
in Abhängigkeit des Kontextes anpasst, nicht aber den Algorithmus selbst. Nachfolgend sind
in Tabelle II.1 alle, im vorigen Abschnitt bereits erläuterten Anforderungen in Form einer
Anforderungsliste nochmals übersichtlich zusammengestellt.
Tabelle II.1: Qualitativer Vergleich der Ergebnisse aus den Voruntersuchungen
Nr. Anforderungsmerkmal Ausprägung Anforderungsart
1 Mobiler Einsatz ermöglichen F
2 Online-Fähigleit sicherstellen F
3.1 Verlustgrad beeinflussbar gestalten und möglichst günstiges Verhältnis von
Kompressionsgewinn zu Informationsgewinn anstreben
F
3.2 Parametrierbarkeit anschauliche Parameter W
4 Übertragbarkeit sicherstellen F
5 Dekomprimierbarkeit möglichst einfach und ohne die Kenntnis von Metadaten
ermöglichen
W
6 Kontextsensitivität durch externe Maßnahmen ermöglichen
F
Neben den Anforderungsmerkmalen ist jeweils die geforderte Ausprägung aufgeführt. In der
letzten Spalte sind die Anforderungen kategorisiert. Dabei wird zwischen Festanforder-
ungen (F) und Wunschanforderungen (W) unterschieden.
II.2.1.2 Theoretische Betrachtungen und Voruntersuchungen
Auf einige theoretische Grundlagen der Datenkompression soll an dieser Stelle, mit Blick auf
die Zielsetzung der vorliegenden Arbeit, kurz eingegangen werden bevor anschließend die
Darstellung der im Rahmen des Projektes durchgeführten Vorversuche zur Daten-
kompression erfolgt.
II.2.1.2.1 Theoretische Betrachtungen
Bei der Kompression von Daten kann grundsätzlich zwischen verlustfreien und verlust-
behafteten Methoden unterschieden werden. Bei der verlustfreien Kompression werden
lediglich Redundanzen aus einer gegebenen Datenmenge entfernt, wohingegen bei den
verlustbehafteten Methoden auch Irrelevanzen aus der gegebenen Datenmenge eliminiert
werden.

II.2 Datenmanagement 33
Redundanzreduktion
Die Informationstheorie beschäftigt sich im Wesentlichen mit der mathematischen Ermittlung
und Elimination von Redundanzen, die in einer gegebenen Datenmenge enthalten sind, um
so die erforderliche Mindest-Kanalkapazität für eine fehlerfreie Übertragung zu bestimmen.
Dazu ist die Häufigkeitsverteilung der in der Datenmenge enthaltenen Zeichen von
entscheidender Bedeutung. Methoden zur Redundanzreduktion sind meist vielseitig
verwendbar und damit auf teilweise sehr unterschiedliche Datentypen anwendbar. Diese
Tatsache ist darauf zurückzuführen, dass bei dieser Art der Kompression die zu
komprimierenden Daten nur auf ihrer Syntaxebene betrachtet und verarbeitet werden.
Semantische und pragmatische Aspekte der Daten bleiben unberücksichtigt. D. h. bei der
Kompression hat weder einen Einfluss, wofür die zu übertragenen Zeichen stehen (also
welche Bedeutung sie haben) noch, ob diese Zeichen für einen Empfänger interessant sind
oder nicht. Der Vorteil der verlustfreien Kompressionsmethoden ist, dass sich alle in der
ursprünglichen Datenmenge enthaltenen Informationen aus dem Kompressionsergebnis
fehlerfrei rekonstruieren lassen. Ein sehr großer Nachteil sind jedoch die nur vergleichsweise
niedrigen Kompressionsraten, die mit den verlustfreien Kompressionsmethoden erzielt
werden können.
Eine wesentliche Anforderung an die zu entwickelnden Kompressionsmethoden ist deren
Online-Fähigkeit. Die Häufigkeitsverteilung der zu übertragenen Zeichen bzw. Werte ist aber,
wenn überhaupt, erst im Nachhinein bekannt und steht deshalb während der Online-
Verarbeitung der einzelnen Messwerte noch nicht zur Verfügung. Außerdem handelt es sich
bei den zu komprimierenden Daten oft um digitalisierte Analogsignale. Bei hoher Auflösung
kann das Signal daher sehr viele verschiedene Werte annehmen (im Gegensatz z. B. zu
Textdaten mit einem sehr begrenzten Zeichensatz).
Für die im Rahmen dieser Arbeit verfolgten Ziele scheinen die verlustfreien
Kompressionsmethoden mit dem Ansatz der Redundanzreduktion also weniger gut geeignet
zu sein. Aus diesem Grund wird festgelegt, dass die zu entwickelnden Methoden nicht
verlustfrei sondern verlustbehaftet arbeiten sollen.
Irrelevanzreduktion
Bei den verlustbehafteten Kompressionsmethoden, die den Ansatz der Irrelevanzreduktion
verwenden, sind die erzielbaren Kompressionsraten nicht begrenzt, allerdings ist die stärkere
Kompression dabei nur auf Kosten des Informationsgehaltes möglich. Bei der Entwicklung
und Bewertung von verlustbehafteten Kompressionsmethoden muss deswegen neben der

II.2 Datenmanagement 34
Kompressionsrate (bzw. dem Kompressionsgewinn) immer auch der Informationsverlust, der
durch die verlustbehaftete Kompression hervorgerufen wurde, mit berücksichtigt werden. Die
zu entwickelnden Methoden sollen, wie bereits in Abschnitt II.2.1.1 festgelegt wurde, auf
fahrzeugseitigen Rechnern lauffähig implementiert werden können. Damit die Kompression
rechnergestützt erfolgen kann, müssen zunächst geeignete Relevanzkriterien definiert
werden. Mit Hilfe dieser Relevanzkriterien kann der Kompressionsalgorithmus irrelevante
Informationen von relevanten Informationen unterscheiden. So kann erreicht werden, dass
bei der Kompression keine relevanten sondern nur irrelevante Informationen verloren gehen.
II.2.1.2.2 Voruntersuchungen
Voruntersuchungen, die an Hand von Testdatensätzen durchgeführt wurden, sollen dazu
dienen, vorbereitend für den eigentlichen Entwicklungsprozess, eine tendenzielle
Einschätzung der Wirksamkeit verschiedener Maßnahmen zur Datenkompression zu
ermöglichen. Auf den Ablauf und die Erkenntnisse dieser Voruntersuchungen soll an dieser
Stelle etwas näher eingegangen werden.
Die Voruntersuchungen zur Entwicklung verschiedener Datenkompressionsmethoden
wurden an Hand von Testdatensätzen durchgeführt die freundlicherweise von der Firma
Claas bereitgestellt wurden. Bei den Datensätzen handelt es sich um die Verläufe der
Drehzahl des Verbrennungsmotors eines Mähdreschers. Diese wurden unter realen
Erntebedingungen mit einer Frequenz von 1/15 Hz aufgezeichnet. Die Datensätze beinhalten
die aufgezeichneten Motordrehzahlwerte über mehrere aufeinander folgende Tage, von
denen einer als repräsentativ für die ersten Voruntersuchungen ausgewählt wurde. Bild II.19
zeigt den Verlauf der Motordrehzahl über diesen ausgewählten Tag hinweg. Es ist
erkennbar, dass die Maschine an diesem Tag zwischen 10:40 Uhr und 21:20 Uhr, mit
Ausnahme von zwei längeren und einigen sehr kurzen Unterbrechungen, kontinuierlich in
Betrieb war. Weiterhin sind in diesem Messschrieb die typischen Einsatzbedingungen eines
Mähdreschermotors zu erkennen: Den überwiegenden Teil der Zeit bewegen sich die
Drehzahlwerte in einem Bereich zwischen 1900 und 2100 1/min. Nur wenige Male wurde die
Drehzahl in einen Bereich von etwa 1200 1/min abgesenkt. Diese Datensätze haben
einerseits wegen der sehr geringen zeitlichen Auflösung und außerdem durch den sehr
speziellen Drehzahlverlauf, der sich aus dem Einsatzfall „Mähdrescher" ergibt, keinen
allgemein gültigen oder gar repräsentativen Charakter für die verschiedensten zu
komprimierende Daten in Telematikanwendungen bei mobilen Arbeitsmaschinen. Dennoch
lassen sich daran einige grundlegende Kompressionsprinzipien erproben und bewerten, um
für den weiteren Verlauf des Entwicklungsprozesses wichtige Hinweise zu erlangen.
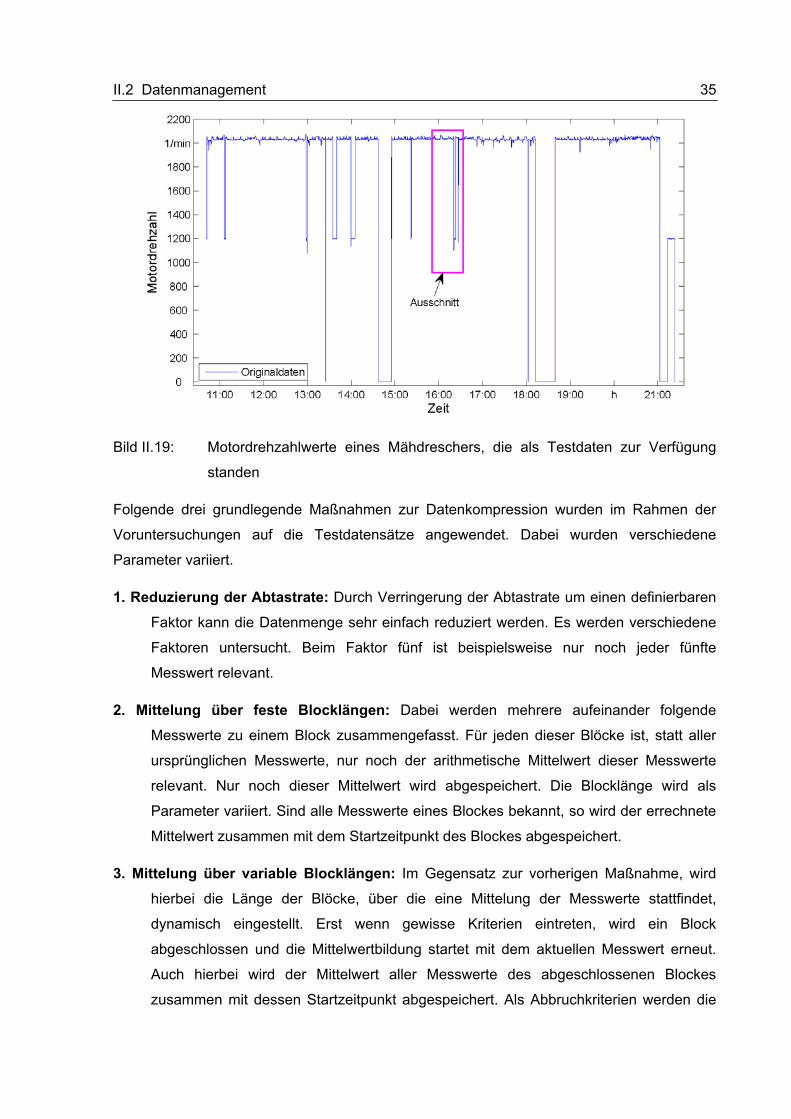
II.2 Datenmanagement 35
Bild II.19: Motordrehzahlwerte eines Mähdreschers, die als Testdaten zur Verfügung
standen
Folgende drei grundlegende Maßnahmen zur Datenkompression wurden im Rahmen der
Voruntersuchungen auf die Testdatensätze angewendet. Dabei wurden verschiedene
Parameter variiert.
1. Reduzierung der Abtastrate: Durch Verringerung der Abtastrate um einen definierbaren
Faktor kann die Datenmenge sehr einfach reduziert werden. Es werden verschiedene
Faktoren untersucht. Beim Faktor fünf ist beispielsweise nur noch jeder fünfte
Messwert relevant.
2. Mittelung über feste Blocklängen: Dabei werden mehrere aufeinander folgende
Messwerte zu einem Block zusammengefasst. Für jeden dieser Blöcke ist, statt aller
ursprünglichen Messwerte, nur noch der arithmetische Mittelwert dieser Messwerte
relevant. Nur noch dieser Mittelwert wird abgespeichert. Die Blocklänge wird als
Parameter variiert. Sind alle Messwerte eines Blockes bekannt, so wird der errechnete
Mittelwert zusammen mit dem Startzeitpunkt des Blockes abgespeichert.
3. Mittelung über variable Blocklängen: Im Gegensatz zur vorherigen Maßnahme, wird
hierbei die Länge der Blöcke, über die eine Mittelung der Messwerte stattfindet,
dynamisch eingestellt. Erst wenn gewisse Kriterien eintreten, wird ein Block
abgeschlossen und die Mittelwertbildung startet mit dem aktuellen Messwert erneut.
Auch hierbei wird der Mittelwert aller Messwerte des abgeschlossenen Blockes
zusammen mit dessen Startzeitpunkt abgespeichert. Als Abbruchkriterien werden die
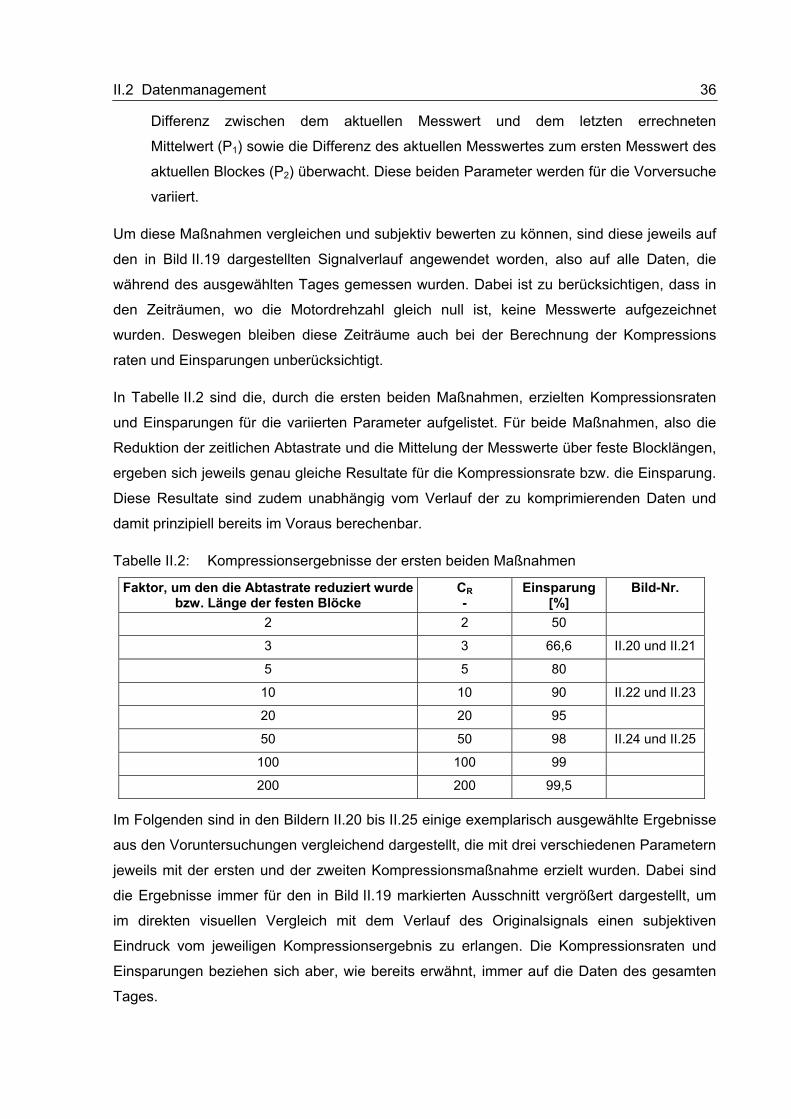
II.2 Datenmanagement 36
Differenz zwischen dem aktuellen Messwert und dem letzten errechneten
Mittelwert (P1) sowie die Differenz des aktuellen Messwertes zum ersten Messwert des
aktuellen Blockes (P2) überwacht. Diese beiden Parameter werden für die Vorversuche
variiert.
Um diese Maßnahmen vergleichen und subjektiv bewerten zu können, sind diese jeweils auf
den in Bild II.19 dargestellten Signalverlauf angewendet worden, also auf alle Daten, die
während des ausgewählten Tages gemessen wurden. Dabei ist zu berücksichtigen, dass in
den Zeiträumen, wo die Motordrehzahl gleich null ist, keine Messwerte aufgezeichnet
wurden. Deswegen bleiben diese Zeiträume auch bei der Berechnung der Kompressions
raten und Einsparungen unberücksichtigt.
In Tabelle II.2 sind die, durch die ersten beiden Maßnahmen, erzielten Kompressionsraten
und Einsparungen für die variierten Parameter aufgelistet. Für beide Maßnahmen, also die
Reduktion der zeitlichen Abtastrate und die Mittelung der Messwerte über feste Blocklängen,
ergeben sich jeweils genau gleiche Resultate für die Kompressionsrate bzw. die Einsparung.
Diese Resultate sind zudem unabhängig vom Verlauf der zu komprimierenden Daten und
damit prinzipiell bereits im Voraus berechenbar.
Tabelle II.2: Kompressionsergebnisse der ersten beiden Maßnahmen
Faktor, um den die Abtastrate reduziert wurde bzw. Länge der festen Blöcke
CR -
Einsparung [%]
Bild-Nr.
2 2 50
3 3 66,6 II.20 und II.21
5 5 80
10 10 90 II.22 und II.23
20 20 95
50 50 98 II.24 und II.25
100 100 99
200 200 99,5
Im Folgenden sind in den Bildern II.20 bis II.25 einige exemplarisch ausgewählte Ergebnisse
aus den Voruntersuchungen vergleichend dargestellt, die mit drei verschiedenen Parametern
jeweils mit der ersten und der zweiten Kompressionsmaßnahme erzielt wurden. Dabei sind
die Ergebnisse immer für den in Bild II.19 markierten Ausschnitt vergrößert dargestellt, um
im direkten visuellen Vergleich mit dem Verlauf des Originalsignals einen subjektiven
Eindruck vom jeweiligen Kompressionsergebnis zu erlangen. Die Kompressionsraten und
Einsparungen beziehen sich aber, wie bereits erwähnt, immer auf die Daten des gesamten
Tages.
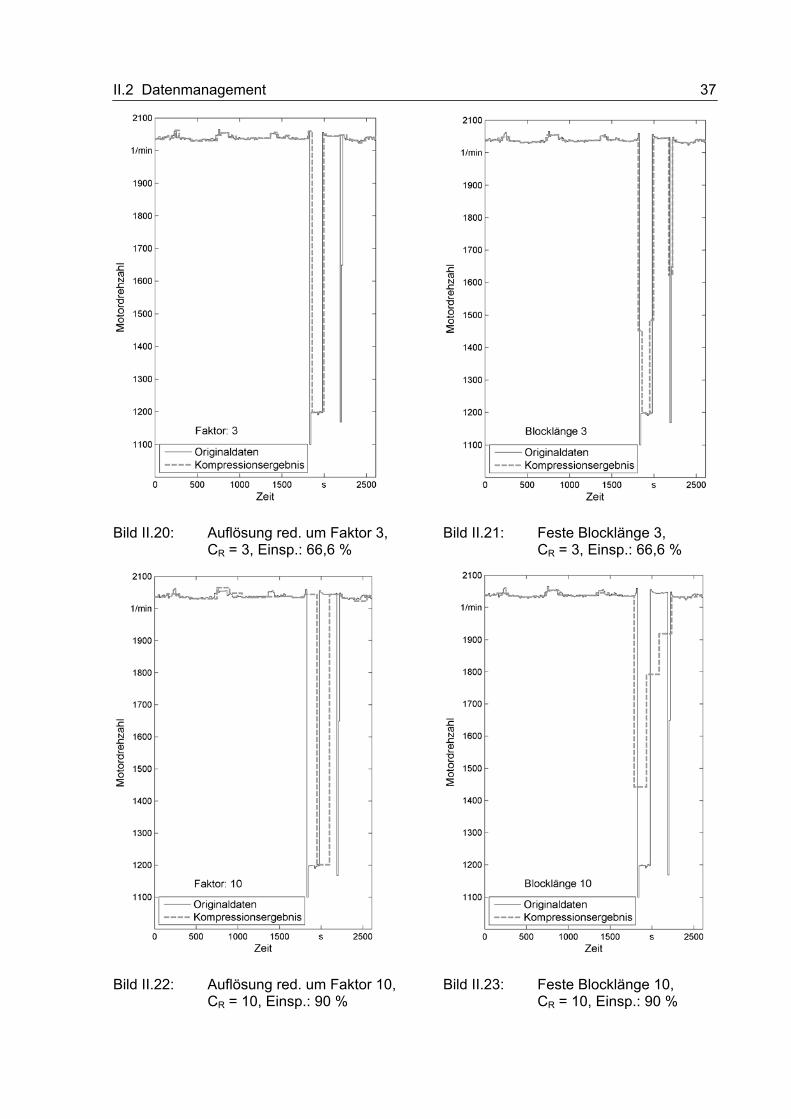
II.2 Datenmanagement 37
Bild II.20: Auflösung red. um Faktor 3, Bild II.21: Feste Blocklänge 3, CR = 3, Einsp.: 66,6 % CR = 3, Einsp.: 66,6 %
Bild II.22: Auflösung red. um Faktor 10, Bild II.23: Feste Blocklänge 10, CR = 10, Einsp.: 90 % CR = 10, Einsp.: 90 %
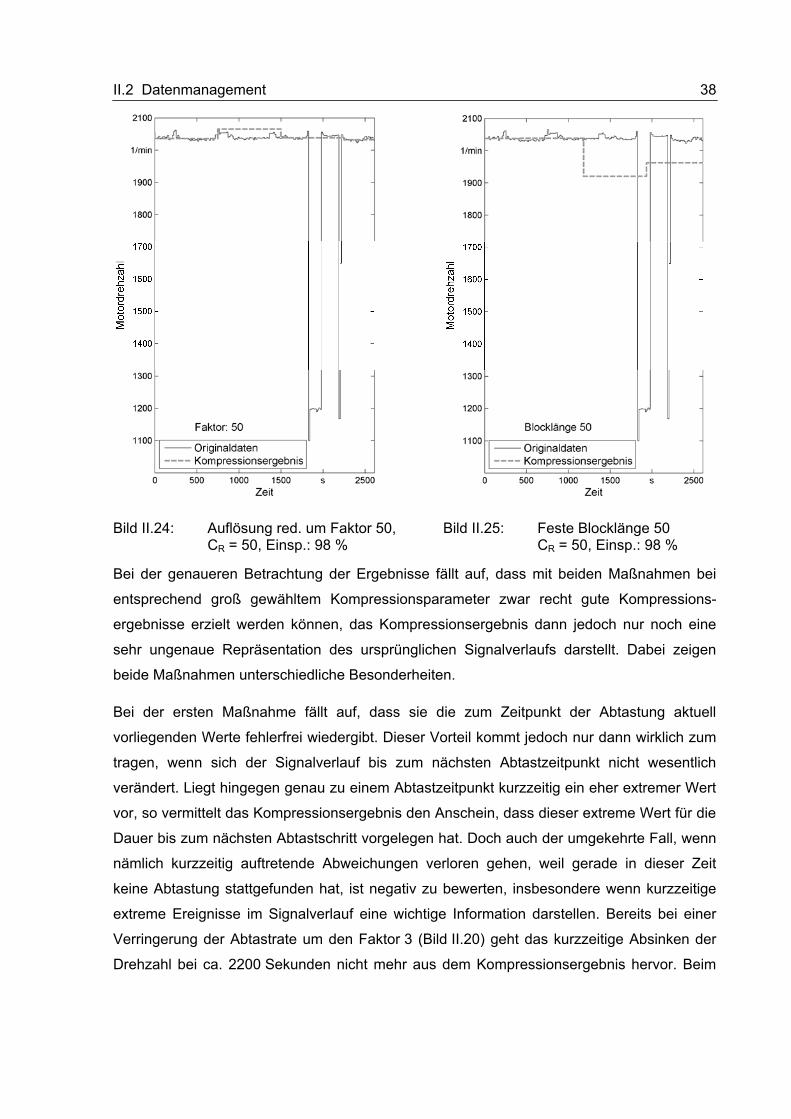
II.2 Datenmanagement 38
Bild II.24: Auflösung red. um Faktor 50, Bild II.25: Feste Blocklänge 50 CR = 50, Einsp.: 98 % CR = 50, Einsp.: 98 %
Bei der genaueren Betrachtung der Ergebnisse fällt auf, dass mit beiden Maßnahmen bei
entsprechend groß gewähltem Kompressionsparameter zwar recht gute Kompressions-
ergebnisse erzielt werden können, das Kompressionsergebnis dann jedoch nur noch eine
sehr ungenaue Repräsentation des ursprünglichen Signalverlaufs darstellt. Dabei zeigen
beide Maßnahmen unterschiedliche Besonderheiten.
Bei der ersten Maßnahme fällt auf, dass sie die zum Zeitpunkt der Abtastung aktuell
vorliegenden Werte fehlerfrei wiedergibt. Dieser Vorteil kommt jedoch nur dann wirklich zum
tragen, wenn sich der Signalverlauf bis zum nächsten Abtastzeitpunkt nicht wesentlich
verändert. Liegt hingegen genau zu einem Abtastzeitpunkt kurzzeitig ein eher extremer Wert
vor, so vermittelt das Kompressionsergebnis den Anschein, dass dieser extreme Wert für die
Dauer bis zum nächsten Abtastschritt vorgelegen hat. Doch auch der umgekehrte Fall, wenn
nämlich kurzzeitig auftretende Abweichungen verloren gehen, weil gerade in dieser Zeit
keine Abtastung stattgefunden hat, ist negativ zu bewerten, insbesondere wenn kurzzeitige
extreme Ereignisse im Signalverlauf eine wichtige Information darstellen. Bereits bei einer
Verringerung der Abtastrate um den Faktor 3 (Bild II.20) geht das kurzzeitige Absinken der
Drehzahl bei ca. 2200 Sekunden nicht mehr aus dem Kompressionsergebnis hervor. Beim

II.2 Datenmanagement 39
Faktor 50 (Bild II.24) geht durch die Kompression sogar auch die davor liegende, längere
Phase mit niedrigerer Drehzahl verloren.
Die zweite Maßnahme zeigt ihre Vorteile, wenn der Signalverlauf über der eingestellten
Blocklänge hinweg nur leichten Schwankungen unterworfen ist. Als Kompressionsergebnis
wird für die Dauer dieses Blocks der Mittelwert abgespeichert, der dann eine gute
Repräsentation des ursprünglichen Signalverlaufs darstellt. Doch, wie schon bei der ersten
Maßnahme, werden auch bei dieser Kompressionsmethode die Schwächen insbesondere
bei großen Sprüngen im Signalverlauf offensichtlich. Die Mittelwertbildung berücksichtigt
zwar diese Änderungen im Signalverlauf, die Kompressionsergebnisse zeigen jedoch auch
hierbei, insbesondere bei den größeren Blocklängen (Bild II.23 und Bild II.25), keine
grundsätzliche Übereinstimmung mit dem Ausgangssignal mehr. Durch die Mittelwertbildung
treten im Kompressionsergebnis in Bereichen, wo das Originalsignal zwischen dem hohen
und dem niedrigen Drehzahlbereich wechselt, zeitweise Signalamplituden auf, die im
Originalsignal zu keiner Zeit tatsächlich vorgelegen haben.
In Tabelle II.3 sind die Kompressionsraten und Einsparungen zusammengestellt, die im
Rahmen der Voruntersuchungen mit der dritten Maßnahme erzielt wurden. Da diese als
einzige der untersuchten Maßnahmen eventgesteuert arbeitet, sind die Kompressions-
ergebnisse individuell vom Verlauf der zu komprimierenden Daten und von den für die
beiden Abbruchkriterien eingestellten Schwellwerten abhängig. Sobald ein neu hinzu
kommender Messwert dafür sorgt, dass mindestens eines der beiden Abbruchkriterien
vorliegt, so wird der zuletzt berechnete Mittelwert abgespeichert und die Mittelwertbildung
beginnt mit dem aktuellen Messwert von neuem. Mit der Überwachung der Abbruchkriterien
wird verhindert, dass relevante Merkmale des Originalsignals bei der Kompression verloren
gehen. Die Abbruchkriterien können also auch als Relevanzkriterien bezeichnet werden. In
den Bildern II.26 bis II.28 sind ausgewählte Kompressionsergebnisse dargestellt, die mit der
dritten Kompressionsmaßnahme erzielt wurden. Um eine subjektive Vergleichbarkeit der
Ergebnisse zu erleichtern, wurden die Abbruchkriterien bei den drei dargestellten Beispielen
so gewählt, dass ähnliche Kompressionsraten erreicht wurden, wie bei den zuvor gezeigten
Ergebnissen der ersten beiden Maßnahmen.
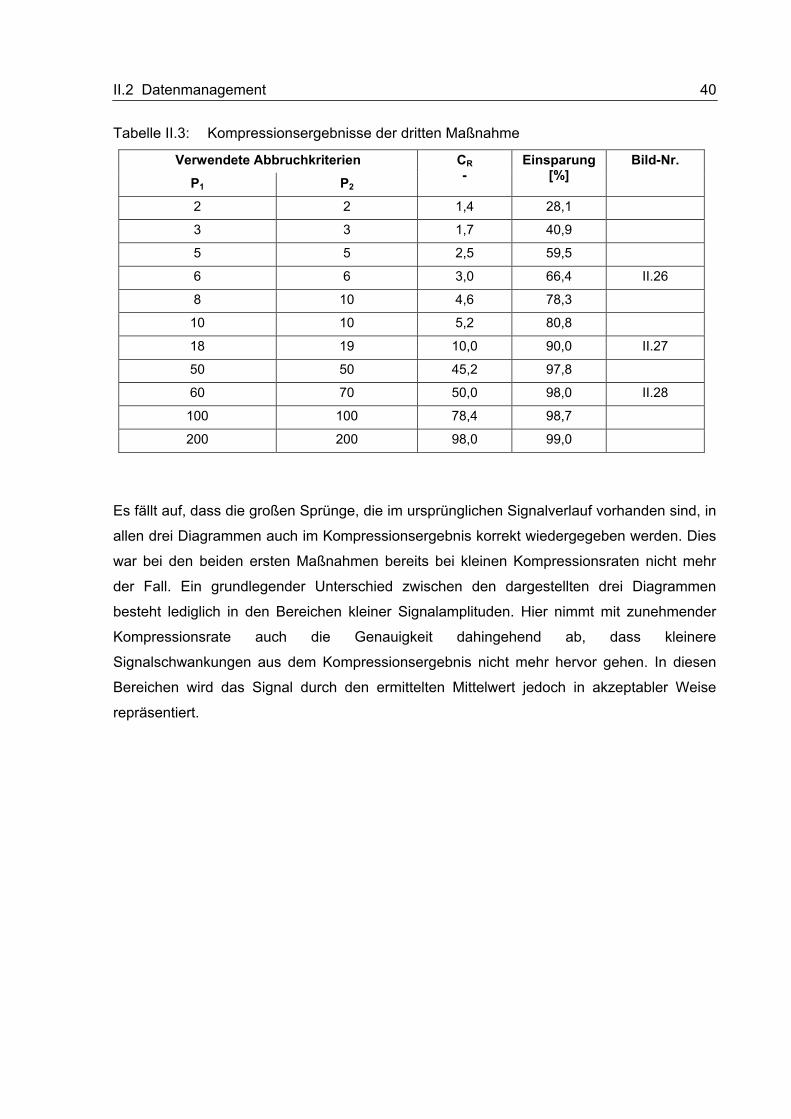
II.2 Datenmanagement 40
Tabelle II.3: Kompressionsergebnisse der dritten Maßnahme
Verwendete Abbruchkriterien
P1 P2
CR -
Einsparung [%]
Bild-Nr.
2 2 1,4 28,1
3 3 1,7 40,9
5 5 2,5 59,5
6 6 3,0 66,4 II.26
8 10 4,6 78,3
10 10 5,2 80,8
18 19 10,0 90,0 II.27
50 50 45,2 97,8
60 70 50,0 98,0 II.28
100 100 78,4 98,7
200 200 98,0 99,0
Es fällt auf, dass die großen Sprünge, die im ursprünglichen Signalverlauf vorhanden sind, in
allen drei Diagrammen auch im Kompressionsergebnis korrekt wiedergegeben werden. Dies
war bei den beiden ersten Maßnahmen bereits bei kleinen Kompressionsraten nicht mehr
der Fall. Ein grundlegender Unterschied zwischen den dargestellten drei Diagrammen
besteht lediglich in den Bereichen kleiner Signalamplituden. Hier nimmt mit zunehmender
Kompressionsrate auch die Genauigkeit dahingehend ab, dass kleinere
Signalschwankungen aus dem Kompressionsergebnis nicht mehr hervor gehen. In diesen
Bereichen wird das Signal durch den ermittelten Mittelwert jedoch in akzeptabler Weise
repräsentiert.
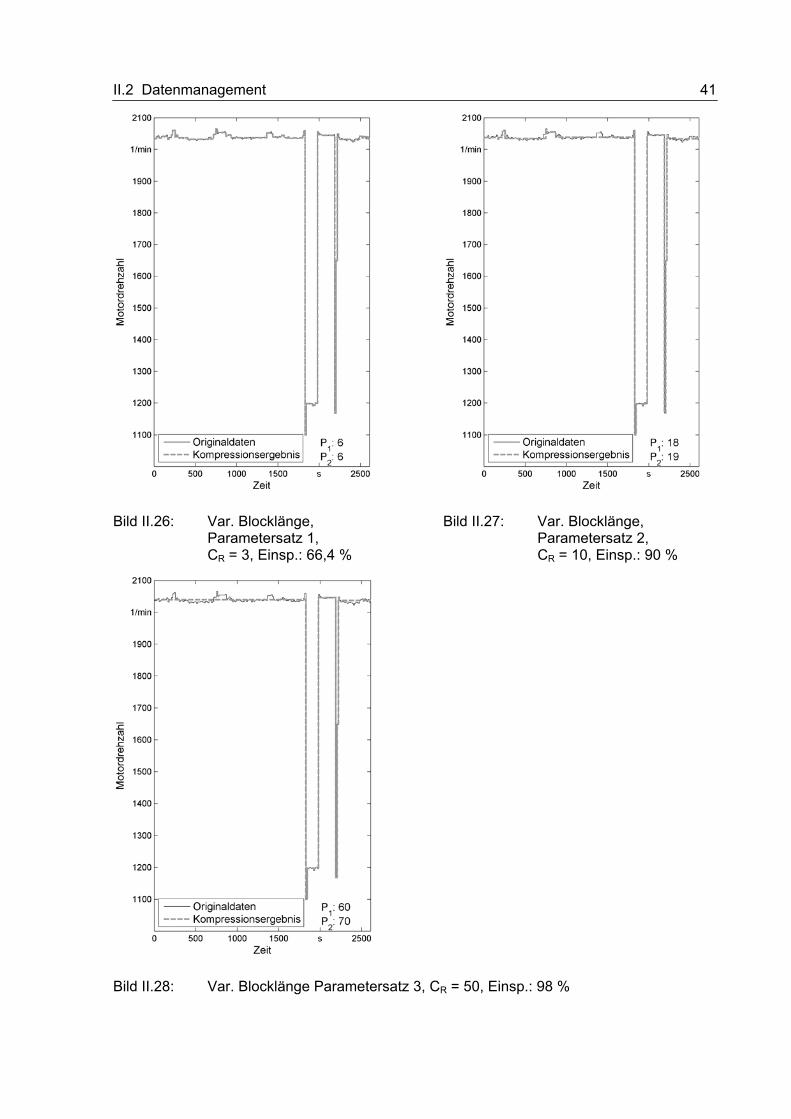
II.2 Datenmanagement 41
Bild II.26: Var. Blocklänge, Bild II.27: Var. Blocklänge, Parametersatz 1, Parametersatz 2, CR = 3, Einsp.: 66,4 % CR = 10, Einsp.: 90 %
Bild II.28: Var. Blocklänge Parametersatz 3, CR = 50, Einsp.: 98 %
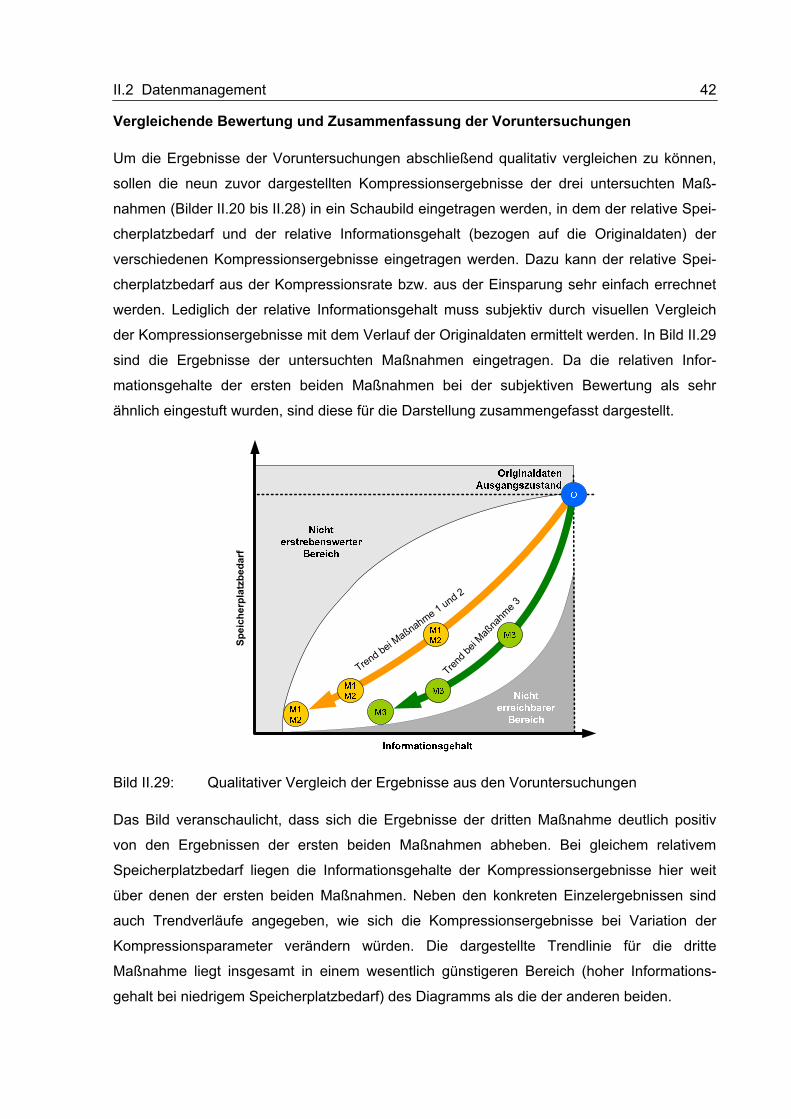
II.2 Datenmanagement 42
Vergleichende Bewertung und Zusammenfassung der Voruntersuchungen
Um die Ergebnisse der Voruntersuchungen abschließend qualitativ vergleichen zu können,
sollen die neun zuvor dargestellten Kompressionsergebnisse der drei untersuchten Maß-
nahmen (Bilder II.20 bis II.28) in ein Schaubild eingetragen werden, in dem der relative Spei-
cherplatzbedarf und der relative Informationsgehalt (bezogen auf die Originaldaten) der
verschiedenen Kompressionsergebnisse eingetragen werden. Dazu kann der relative Spei-
cherplatzbedarf aus der Kompressionsrate bzw. aus der Einsparung sehr einfach errechnet
werden. Lediglich der relative Informationsgehalt muss subjektiv durch visuellen Vergleich
der Kompressionsergebnisse mit dem Verlauf der Originaldaten ermittelt werden. In Bild II.29
sind die Ergebnisse der untersuchten Maßnahmen eingetragen. Da die relativen Infor-
mationsgehalte der ersten beiden Maßnahmen bei der subjektiven Bewertung als sehr
ähnlich eingestuft wurden, sind diese für die Darstellung zusammengefasst dargestellt.
Spei
cher
plat
zbed
arf
Trend bei Maßnahme 1 und 2
Trend b
ei Maß
nahm
e 3
Bild II.29: Qualitativer Vergleich der Ergebnisse aus den Voruntersuchungen
Das Bild veranschaulicht, dass sich die Ergebnisse der dritten Maßnahme deutlich positiv
von den Ergebnissen der ersten beiden Maßnahmen abheben. Bei gleichem relativem
Speicherplatzbedarf liegen die Informationsgehalte der Kompressionsergebnisse hier weit
über denen der ersten beiden Maßnahmen. Neben den konkreten Einzelergebnissen sind
auch Trendverläufe angegeben, wie sich die Kompressionsergebnisse bei Variation der
Kompressionsparameter verändern würden. Die dargestellte Trendlinie für die dritte
Maßnahme liegt insgesamt in einem wesentlich günstigeren Bereich (hoher Informations-
gehalt bei niedrigem Speicherplatzbedarf) des Diagramms als die der anderen beiden.

II.2 Datenmanagement 43
Die Voruntersuchungen haben gezeigt, dass sich von den drei untersuchten Maßnahmen die
dritte als am besten geeignet heraus gestellt hat. Dabei ist einschränkend anzumerken, dass
diese Aussage bislang nur auf Basis der Anwendung auf die Testdaten beruht. Diese
verfügen ihrerseits, wie bereits weiter oben dargestellt, über sehr spezielle Eigenschaften,
die nicht unbedingt als repräsentativ für viele verschiedene Datenarten betrachtet werden
dürfen. Dennoch kann festgehalten werden, dass die individuelle Beeinflussung der
Kompression durch den Verlauf des zu komprimierenden Signals durchaus einen vielver-
sprechenden Ansatz darstellt. Gegenüber den ersten beiden untersuchten Maßnahmen
ließen sich, bei vergleichbaren Kompressionsraten, wesentlich höhere Informationsgehalte
im Kompressionsergebnis erhalten. Aus diesem Grund wird an dieser Stelle das Prinzip der
dritten Maßnahme als Grundlage für die weiteren Entwicklungen ausgewählt.
II.2.1.3 Entwicklung der Methoden
Im Abschnitt II.2.1.1 wurden die grundlegenden Eigenschaften der zu komprimierenden
Daten dargestellt. Außerdem wurden dort verschiedene Anforderungen zusammengetragen,
die die zu entwickelnden Kompressionsmethoden im Idealfall erfüllen sollen. Im Rahmen von
Voruntersuchungen wurden verschiedene Maßnahmen zur Datenkompression auf ihre
prinzipielle Eignung untersucht. Die Ergebnisse dieser Voruntersuchungen wurden im
vorangegangenen Abschnitt II.2.1.2 dargestellt und diskutiert. Außerdem erfolgte eine
qualitative, vergleichende Bewertung. Auf dieser Basis wird nun im Rahmen dieses
Abschnitts die Entwicklung der Kompressionsmethoden für die vorgestellten Datenarten
beschrieben.
II.2.1.3.1 Entwicklungsumgebung und Vorgehen
Für die Entwicklungen und Untersuchungen wurde das Programmpaket Matlab von der
Firma The MathWorks® als Entwicklungsumgebung genutzt. Bei Matlab handelt es sich um
ein umfangreiches Softwarepaket für numerische Mathematik. Seine besondere Stärke liegt
in der Vektor- und Matrizenrechnung. Neben einem Basismodul, welches die obligatorischen
Ein- und Ausgabefunktionen, vielfältige zwei- und dreidimensionale Visualisierungsmöglich-
keiten, zahlreiche mathematische Funktionen sowie die Möglichkeit zur Programmierung und
Programmablaufsteuerung mitbringt, sind verschiedene Erweiterungspakete, sog. Tool-
boxen, verfügbar. Damit stellt Matlab für viele Anwendungsfälle ein geeignetes Werkzeug für
die simulative Lösung auftretender Problemstellungen dar [ABRW03]. Für die hier vorge-
stellten Untersuchungen wurde Matlab in der Programmversion R2006a (V7.2.0.232)
verwendet, die unter anderem die beiden Toolboxen Simulink und Stateflow, jeweils in der

II.2 Datenmanagement 44
Version V6.4, beinhaltet. Die im vorangegangenen Abschnitt untersuchten Maßnahmen zur
Datenkompression wurden für die Voruntersuchungen in Form von Blockschaltbildern in
Simulink prototypisch implementiert. Diese Variante bietet den Vorteil, dass die Messwerte
über ein zeitdiskretes, abgetastetes Simulationsmodell, entsprechend ihrer Messzeit,
schrittweise aus einem Speicher eingelesen und nacheinander verarbeitet werden. Damit
wurde bereits bei den Voruntersuchungen sichergestellt, dass die verwendeten Algorithmen
online-fähig sind, also nur den zurückliegenden, nicht aber den zukünftigen Signalverlauf als
bekannt voraussetzen. Ein weiterer Vorteil dieser Vorgehensweise ist die gute Portierbarkeit
der entwickelten Algorithmen auf eine Echtzeit-Hardware (RCP), was für die experimentellen
Erprobungen der Datenkompressionsmethoden von sehr großer Bedeutung ist. Für den nun
folgenden Entwicklungsprozess soll dieser Ansatz deshalb weiter verfolgt werden.
II.2.1.3.2 Kompressionsmethode für Messwert-Zeitreihen
Zur ersten Datenart, für die eine Komprimierung ermöglicht werden soll, zählen die sog.
Messwert-Zeitreihen. Auch bei den Testdaten, auf deren Basis die Voruntersuchungen
durchgeführt wurden, handelte es sich um eine solche Messwert-Zeitreihe. Aus diesem
Grund liefern die Voruntersuchungen schon sehr konkrete Ansätze zur Entwicklung einer
geeigneten Kompressionsmethode für diese Datenart.
Bei den Voruntersuchungen konnte, im Vergleich zu den anderen beiden untersuchten
Maßnahmen, mit der dritten Maßnahme zur Datenkompression (Mittelung über variable
Blocklängen) das beste Ergebnis erzielt werden. Diese Maßnahme zeichnet sich gegenüber
den anderen beiden dadurch aus, dass sie individuell auf den Verlauf der zu
komprimierenden Messwert-Zeitreihe reagieren kann, d. h. sie arbeitet signaladaptiv. Der zu
komprimierende Signalverlauf wird dabei laufend auf relevante Kriterien überprüft. Dieses
Prinzip der Irrelevanzreduktion soll im Rahmen des Entwicklungsprozesses auf Grund der
positiven Erfahrungen aus den Voruntersuchungen weiter verfolgt und verbessert werden.
Die Wahl geeigneter Relevanzkriterien übt einerseits einen entscheidenden Einfluss auf das
Kompressionsergebnis aus und außerdem hängt davon ab, ob alle Anforderungen, die zuvor
dargestellt wurden, auch erfüllt werden. Nachfolgend soll daher zunächst eine genauere
Analyse der Relevanzkriterien stattfinden, die bei den Voruntersuchungen mit der dritten
Maßnahme verwendet wurden. Ausgehend von dieser Betrachtung sollen weitere mögliche
Relevanzkriterien auf ihre Eignung hin untersucht werden, bevor abschließend eine Auswahl
geeigneter Relevanzkriterien für die algorithmische Umsetzung erfolgt.
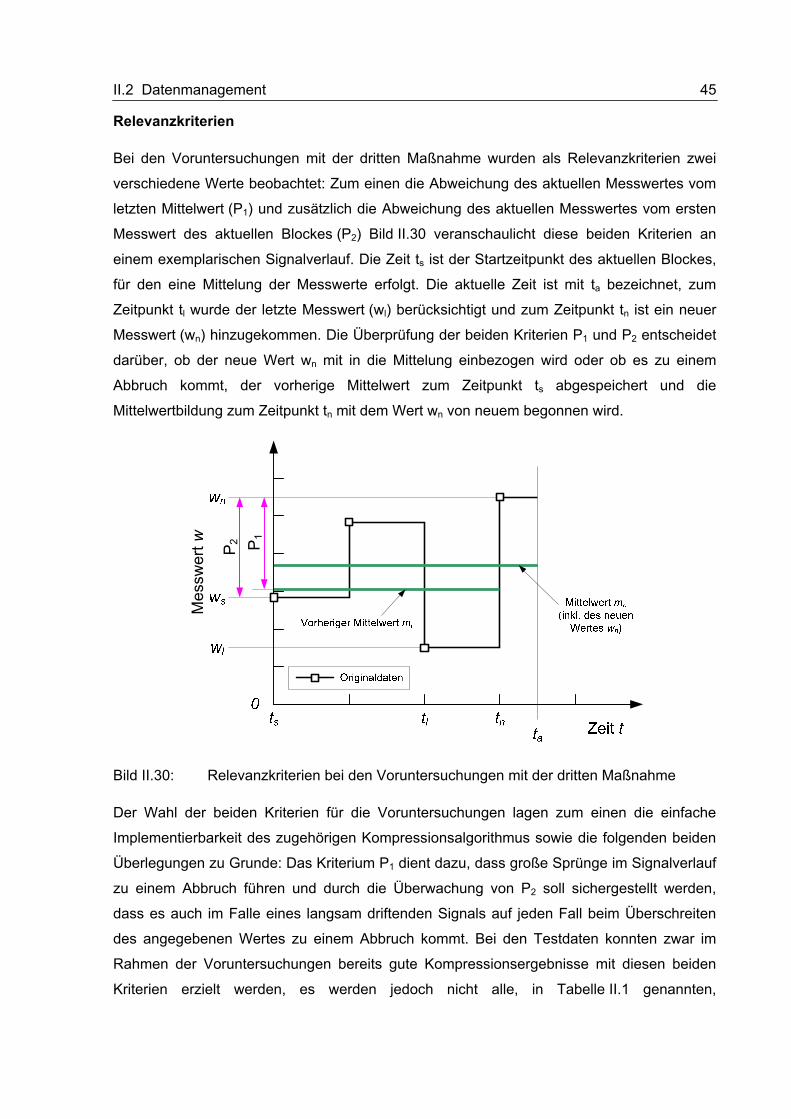
II.2 Datenmanagement 45
Relevanzkriterien
Bei den Voruntersuchungen mit der dritten Maßnahme wurden als Relevanzkriterien zwei
verschiedene Werte beobachtet: Zum einen die Abweichung des aktuellen Messwertes vom
letzten Mittelwert (P1) und zusätzlich die Abweichung des aktuellen Messwertes vom ersten
Messwert des aktuellen Blockes (P2) Bild II.30 veranschaulicht diese beiden Kriterien an
einem exemplarischen Signalverlauf. Die Zeit ts ist der Startzeitpunkt des aktuellen Blockes,
für den eine Mittelung der Messwerte erfolgt. Die aktuelle Zeit ist mit ta bezeichnet, zum
Zeitpunkt tl wurde der letzte Messwert (wl) berücksichtigt und zum Zeitpunkt tn ist ein neuer
Messwert (wn) hinzugekommen. Die Überprüfung der beiden Kriterien P1 und P2 entscheidet
darüber, ob der neue Wert wn mit in die Mittelung einbezogen wird oder ob es zu einem
Abbruch kommt, der vorherige Mittelwert zum Zeitpunkt ts abgespeichert und die
Mittelwertbildung zum Zeitpunkt tn mit dem Wert wn von neuem begonnen wird.
Mes
swer
t w P1
P 2
Bild II.30: Relevanzkriterien bei den Voruntersuchungen mit der dritten Maßnahme
Der Wahl der beiden Kriterien für die Voruntersuchungen lagen zum einen die einfache
Implementierbarkeit des zugehörigen Kompressionsalgorithmus sowie die folgenden beiden
Überlegungen zu Grunde: Das Kriterium P1 dient dazu, dass große Sprünge im Signalverlauf
zu einem Abbruch führen und durch die Überwachung von P2 soll sichergestellt werden,
dass es auch im Falle eines langsam driftenden Signals auf jeden Fall beim Überschreiten
des angegebenen Wertes zu einem Abbruch kommt. Bei den Testdaten konnten zwar im
Rahmen der Voruntersuchungen bereits gute Kompressionsergebnisse mit diesen beiden
Kriterien erzielt werden, es werden jedoch nicht alle, in Tabelle II.1 genannten,

II.2 Datenmanagement 46
Anforderungen optimal erfüllt. Insbesondere die geforderte Anschaulichkeit der beiden
Parameter ist noch verbesserungswürdig. Es kann nicht unmittelbar aus den eingestellten
Parametern abgelesen werden, welche Informationen bei der Kompression als irrelevant
eingestuft wurden.
Auch wird der neu errechnete Mittelwert bei der Relevanzprüfung bislang noch überhaupt
nicht berücksichtigt. Da dieser Wert jedoch im Kompressionsergebnis die Repräsentation der
Originaldaten darstellt, sollte dieser zukünftig bei der Relevanzprüfung mit einbezogen
werden. Auch die Abweichung des aktuellen Wertes vom Startwert (P2) erscheint nicht
unbedingt sinnvoll. Dadurch wird der Startwert gegenüber den anderen Werten, über die die
Mittelwertbildung stattfindet, stärker berücksichtigt. Auch dieser Aspekt soll zukünftig
vermieden werden, damit der Startwert nur so stark Einfluss auf die Kompression nehmen
kann, wie alle übrigen Messwerte des aktuellen Blockes auch.
Um den aufgezeigten Aspekten Rechnung zu tragen, wird ein neuer Ansatz zur
Relevanzprüfung für die Kompression von Messwert-Zeitreihen entwickelt. Dieser Ansatz
stützt sich im Wesentlichen auf die folgenden drei Punkte:
• Der aktuelle Mittelwert mn (unter Berücksichtigung des neuen, zu prüfenden
Messwertes wn) soll bei der Relevanzprüfung berücksichtigt werden.
• Bezogen auf diesen Mittelwert soll eine maximal zulässige Abweichung dzul des
ursprünglichen Signalverlaufs definierbar sein.
• Sobald diese zulässige Abweichung dzul vom Verlauf des Originalsignals an
wenigstens einer Stelle überschritten wird, soll die Mittelwertbildung nach dem letzten
gültigen Wert wl abgebrochen werden und mit dem neuen Wert wn zum Zeitpunkt tn
von neuem beginnen.
In Bild II.31 soll dieser neue Ansatz zur Relevanzprüfung veranschaulicht werden.
Bild II.31 a) zeigt den vorherigen Mittelwert ml und die zulässige Abweichung dzul. Solange
sich der Verlauf des Originalsignals innerhalb dieses Toleranzbandes befindet, liegen keine
relevanten Informationen vor. Die Mittelwertbildung als Maßnahme zur Datenkompression ist
also zulässig, weil dabei nur irrelevante Informationen eliminiert werden. In Bild II.31 b) ist
nun auch der neue Mittelwert mn eingezeichnet, der nach Hinzukommen des neuen
Wertes wn berechnet wurde. Auch die maximal zulässige Abweichung ist in Bezug auf mn
dargestellt. Die dann durchgeführte Überprüfung zeigt, dass durch Hinzukommen des neuen
Wertes wn, der Verlauf des Originalsignals nicht mehr vollständig innerhalb des
Toleranzbandes liegt.
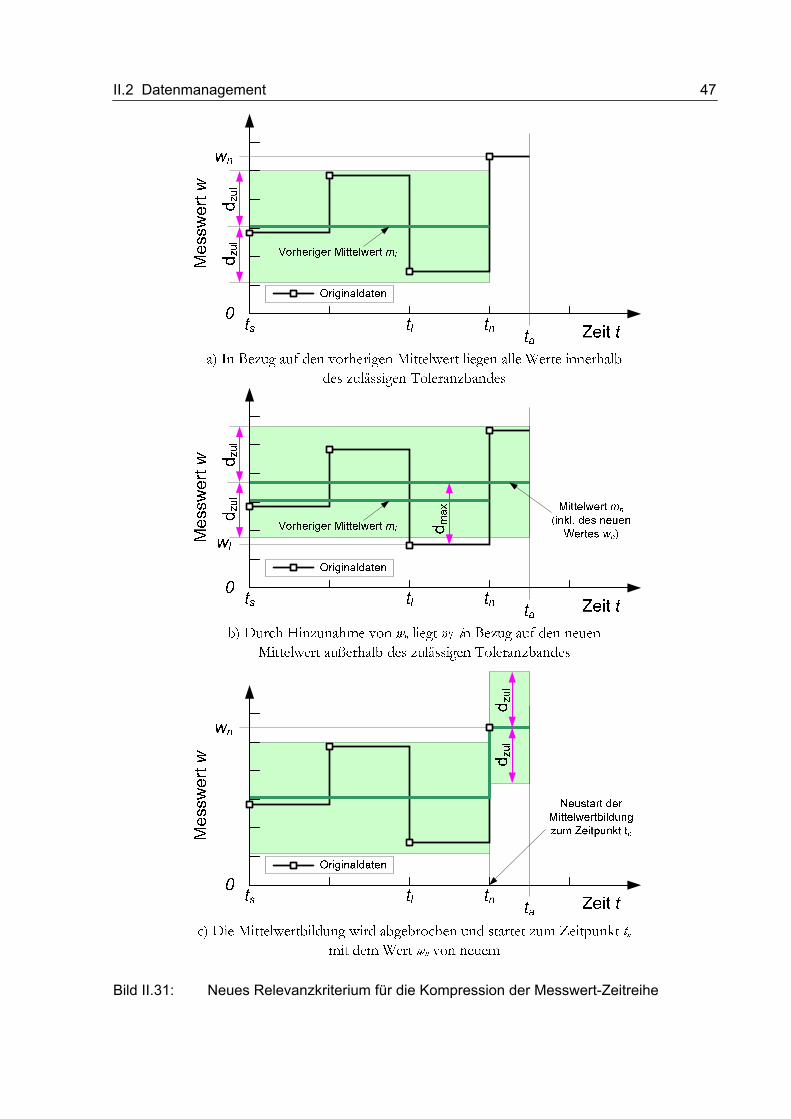
II.2 Datenmanagement 47
Bild II.31: Neues Relevanzkriterium für die Kompression der Messwert-Zeitreihe

II.2 Datenmanagement 48
Im dargestellten Beispiel liegt der Wert wl um den Betrag dmax vom neuen Mittelwert mn
entfernt. Da |dmax| größer als der zulässige Abstand dzul ist, liegt nun eine relevante
Information vor und deswegen kommt es zu einem Abbruch der Mittelwertbildung. Wie in
Bild II.31 c) gezeigt, wird beim Eintreten dieser Abbruchbedingung der vorherige
Mittelwert ml abgespeichert (zusammen mit dem Startzeitpunkt ts der bisherigen
Mittelwertbildung) und die Mittelwertbildung beginnt zum Zeitpunkt tn mit dem Wert wn von
neuem.
Algorithmische Umsetzung
Um der Anforderung nach einer Implementierbarkeit der Datenkompressionsmethode auf
einem mobiltauglichen Rechner nachzukommen, werden im Folgenden die wichtigsten
Schritte der algorithmischen Umsetzung der vorgestellten Datenkompressionsmethode
erläutert. Anschließend wird auf die prototypische, programmtechnische Umsetzung der
Methode in Form eines Stateflow-Charts eingegangen.
Die algorithmische Umsetzung der Kompressionsmethode gestaltet sich vergleichsweise
einfach: Um die Mittelwertbildung zu ermöglichen, muss nur die Summe aller Werte des
aktuellen Blockes sowie deren Anzahl bekannt sein. Das arithmetische Mittel kann dann
einfach durch Division gebildet werden. Für die Relevanzprüfung, also ob alle Punkte des
Originalsignals innerhalb der eingestellten Toleranz liegen, müssen zudem lediglich noch der
größte und der kleinste Wert des aktuellen Blocks bekannt sein. Jeder neu hinzukommende
und zu prüfende Wert wird zunächst mit den beiden bekannten Extrema des aktuellen Blocks
verglichen. Stellt der neue Wert ein neues Extremum dar, so wird eines der bisherigen
ersetzt. Danach erfolgt die Berechnung der größten Abweichung des Originalsignals
bezogen auf den neuen Mittelwert und es schließt sich ein Vergleich mit der maximal
zulässigen Abweichung an. Von diesem Vergleich hängt ab, ob durch die Hinzunahme des
neuen Wertes relevante Informationen verloren gehen würden und die Mittelwertbildung
deswegen abgebrochen wird, oder ob die Mittelwertbildung fortgesetzt werden kann, weil
keine Relevanz vorliegt.
Besonders hervorzuheben ist die Tatsache, dass, egal über welchen Zeitraum hinweg eine
Mittelung der Werte stattfindet, immer nur eine begrenzte und im Vorfeld bekannte Anzahl
von Variablen zwischengespeichert werden muss. Es ist also nicht notwendig, alle Werte des
aktuellen Blockes zwischenzuspeichern.
Bei der prototypischen, programmtechnischen Umsetzung in Form eines Stateflow-Charts,
welches in Bild II.32 dargestellt ist, wurden die o. g. Schritte konsequent umgesetzt.

II.2 Datenmanagement 49
START
(Zurück-)Setzen der Variablen
END---------START
state/
Nächste Nachricht lesen
Wert nicht einlesen solange keine neue Nachricht und somit auch kein neuer Wert vorliegt
Aktuellen Mittelwert bilden
Extremwerte aktualisieren
Überprüfen auf Abbruchbedingung
Abweichung berechnen
ODERSpeichern des aktuellen Mittel-wertes als letzten Mittelwert
ENTWEDERAusgabe des letzten Mittelwertes mit der Zeit des letzten Abbruchs
Unterfunktion zur Berechnung der Abweichung:
dev=get_deviation(Mean, Min, Max)
Allererste Nachricht lesen, ersten Wert und erste Zeit einlesen
{last_message = rx_time;new_value = value;new_time = time;reduced_mean = 0.0;reduced_time = 0.0;}
{item_number = 1;sum = new_value;mean = new_value;last_time = new_time;last_mean = new_value;min = new_value;max = new_value;}
{new_message = rx_time;new_value = value;new_time = time;}
{last_message = new_message;item_number ++;sum += new_value;mean = sum / item_number;}
[new_value < min]{min = new_value;}
[new_value > max]{max = new_value;}
[(deviation > maxDeviation)]
{deviation = get_deviation(mean, min, max);}
{last_mean = mean;}{reduced_mean = last_mean;reduced_time = last_time;}
[new_message == last_message]
123
1 2
1
2
eM
Bild II.32: Prototypische Implementierung des Kompressionsalgorithmus für Messwert- Zeitreihen in Form eines Stateflow-Charts
Dieses Stateflow-Chart ist Teil eines Simulink-Modells, welches durch Einstellen einer festen
Zykluszeit mit einer festen Sample-Rate arbeitet. Über definierte Eingangsvariablen werden
die zu komprimierenden Messwerte aus der Simulink-Umgebung an das Chart übergeben.
Zu jedem Sample-Zeitpunkt werden der jeweils aktuellste Messwert (value) sowie der
zugehörige Empfangszeitpunkt des Wertes (rx_time) an das Chart übergeben und dort
verarbeitet. Außerdem wird die Systemzeit (time) und der Kompressionsparameter dzul
(maxDeviation) übermittelt. In Klammern sind die Variablenbezeichungen in der Form
angegeben, wie sie im Chart verwendet wurden. Das Kompressionsergebnis, bestehend aus
Wert und Zeit, wird nach der internen Berechnung zu jedem Sample-Schritt über die
Variablen reduced_time und reduced_mean wieder an das Simulink-Modell ausgegeben.
Dabei handelt es sich immer um die Werte des letzten, bereits abgeschlossenen Blockes.

II.2 Datenmanagement 50
Über den zuvor beschriebenen algorithmischen Kern der Kompressionsmethode hinaus sind
in dem Chart noch einige zusätzliche Dinge zu erkennen. Zum Start des Programms werden
zunächst einige Variablen erstmalig mit Werten belegt. Dies geschieht, beginnend in der
oberen linken Ecke des Charts, durch abarbeiten der Befehle, die in geschwungenen
Klammern an den Transitionspfeilen stehen. Während des ersten Sample-Schritts läuft das
Programm bis zum sog. state (Zustand) und verharrt dort bis zum nächsten Sample-Schritt.
Bei jedem nun folgenden Sample-Schritt durchläuft das Programm, ausgehend vom state,
eine Programmschleife, die aus verschiedenen Transitionen zusammengesetzt ist.
Entsprechend der gerade vorliegenden Bedingungen, die in eckigen Klammern an den
Transitionen angegeben sind, werden diese durchlaufen. Dabei werden ggf. die in
geschwungenen Klammern angegebenen Befehle ausgeführt.
Als erstes wird im Rahmen dieser Programmschleife geprüft, ob es sich um einen neuen
Messwert handelt, der verarbeitet werden muss. Dies wird anhand des Empfangszeitpunktes
(rx_time) festgestellt. Dieser Schritt ist der festen Sample-Rate des Simulink-Modells
geschuldet. Ist die Sample-Rate des Modells höher als die Aktualisierungsrate des
Messwertes (der z. B. von einem CAN-Bus gelesen wird) so kann es vorkommen, dass ein
zuvor bereits verarbeiteter Messwert ein weiteres Mal eingelesen wird. Für den Fall, dass es
sich um einen solchen alten Wert handelt, wird dieser sofort verworfen und die
Programmschleife abgebrochen. Handelt es sich jedoch um einen neuen Wert, so folgen
zunächst die Neuberechnung des Mittelwertes und die Aktualisierung der Extrema. Danach
wird die größte Abweichung ermittelt. Dies geschieht mit Hilfe einer sog. Embedded-Matlab-
Funktion. Dieser Funktion werden der aktuelle Mittelwert (mean) sowie der kleinste (min) und
der größte Messwert (max) des aktuellen Blockes übergeben. Abschließend erfolgt die
Relevanzprüfung, die im positiven Fall zu einem Abbruch der Mittelwertbildung, zu einer
Ausgabe des vorherigen Mittelwertes und zum Zurücksetzen der Variablen führt. Für den
Fall, dass keine Relevanz vorliegt, wird der neue Mittelwert übernommen und ohne weitere
Aktionen an den Anfang der Programmschleife gesprungen.
II.2.1.3.3 Kompressionsmethode für Positionsdaten
In Abschnitt II.2.1.1 wurden neben den Messwert-Zeitreihen auch die Positionsdaten
ausgewählt. Im Rahmen dieses Abschnitts soll nun die Entwicklung einer Methode zur
Datenkompression für diese spezielle Datenart beschrieben werden. Die Positionsdaten
beinhalten die Information über den Aufenthaltsort einer Maschine zu einem bestimmten
Zeitpunkt. Erhoben werden diese Daten fast ausschließlich mit Hilfe satellitengestützter

II.2 Datenmanagement 51
Ortungssysteme. Als geodätisches Referenzsystem wird dabei im Normalfall WGS84
[WGS00] verwendet, da dieses System einheitlich für die ganze Erde gültig ist.
Die Entwicklungen zur Kompression der Messwert-Zeitreihen lassen sich nicht unmittelbar
auf die Positionsdaten übertragen. Dies liegt vor allen Dingen daran, dass die
Positionsinformation selbst in Form von zwei verschiedenen Werten – dem Längen- und dem
Breitengrad – vorliegt. Diese Wertepaare stehen i. d. R. nicht kontinuierlich zur Verfügung,
sondern werden von den Ortungssystemen zeitdiskret ausgeben. In der zeitlichen Folge
mehrerer solcher Wertepaare stecken außerdem weitere Informationen (wie z. B.
zurückgelegte Strecke, durchschnittliche Geschwindigkeit usw.), die ggf. auch einen Einfluss
auf die Relevanz der Positionsdaten nehmen können. Eine weitere Schwierigkeit besteht
darin, dass die beiden Werte jeweils als Winkelmaß angegeben sind. Dies hat zwar den
Vorteil, dass jede Position auf der Erdoberfläche mit nur zwei Koordinaten eindeutig
beschrieben werden kann. Jedoch haben diese Winkelmaße den Nachteil, dass sie sehr
abstrakt und damit sehr viel schwerer einschätzbar sind als z. B. Streckenangaben bzw.
Abstände in Metern.
Um möglichst anschauliche Relevanzkriterien definieren zu können, muss daher zunächst
eine Transformation der zu komprimierenden Positionsinformationen in ein lokales
kartesisches Koordinatensystem mit der Einheit Meter durchgeführt werden (Bild II.33). Dazu
wird eine Position als Ursprungspunkt des lokalen Koordinatensystems definiert, von dem
aus die X-Achse in Ost-Richtung und die Y-Achse in Nord-Richtung zeigt.
Alle anderen Positionen werden in Bezug zu diesem Punkt gesetzt, indem deren Abstände
zum Ursprung in X- und Y-Richtung berechnet werden. So lassen sich alle zu
komprimierenden Positionsdaten anschaulich in einem kartesischen Koordinatensystem
darstellen und mit der Einheit Meter bemaßen. Diese Transformation stellt einen
vorbereitenden Schritt für die anschließende Relevanzprüfung dar.
Da bei dieser Transformation die Oberfläche der Erdkugel als Ebene angenähert wird,
entstehen zwangsläufig Fehler, die mit zunehmendem Abstand vom Ursprung des lokalen
Koordinatensystems größer werden. Diese sind jedoch aus verschiedenen Gründen, die
später noch genauer betrachtet werden, zu vernachlässigen.

II.2 Datenmanagement 52
Bild II.33: Einführung eines lokalen kartesischen Koordinatensystems zur anschaulichen Darstellung und Bemaßung der Positionsinformationen
Bild II.34 veranschaulicht einige Aspekte, die bei der Bestimmung des Abstandes zwischen
zwei benachbarten Positionen und somit auch bei der Transformation der
Positionsinformationen in das lokale kartesische Koordinatensystem zu berücksichtigen sind.
Durch die Definition von Längen- und Breitengradbemaßung der Erde ergibt sich die
Tatsache, dass alle benachbarten Breitengrade an der Erdoberfläche den gleichen Abstand
zueinander haben. Daher lässt sich der Abstand Δy zwischen zwei benachbarten Positionen,
die auf dem selben Längengrad liegen, aus der Breitengraddifferenz Δφ und dem
Erdradius rE, der etwa 6378137 Meter beträgt [WGS00], an Hand der nachfolgenden
Gleichung näherungsweise ermitteln:
ΔϕΔ = ⋅ π ⋅ ⋅
°E2 r360
y (II.1)
Der Breitengrad, der durch den Ursprung des lokalen Koordinatensystems läuft, soll mit φU
und der Längengrad mit λU bezeichnet werden. Ist φP der Breitengrad der zu
transformierenden Position P und wird Δφ durch (φP – φU) ersetzt, so ist Δy gleich der Y-
Koordinate yP dieser Position im lokalen Koordinatensystem.
−⋅ϕ
= ⋅ π ⋅°ϕP U
P Ey 2360
r (II.2)

II.2 Datenmanagement 53
Äquator
Nordpol
Südpol
Breitengrad φ
Äquator
Nordpol
λ
Äquator
Nordpol
Südpol
Breitengrad φ
λ
φ
Längengrad λ
Längengrad λ
Erdr
adiu
s r E
rE · cos φ
ΔλΔx1
Δx2
rE · cos φ
rE
Bild II.34: Abhängigkeit des Längengradabstandes vom Breitengrad
Die Berechnung der X-Koordinate gestaltet sich etwas komplizierter, denn benachbarte
Längengrade weisen keinen konstanten Abstand zueinander auf. Mit zunehmender
Entfernung vom Äquator nimmt deren Abstand zueinander immer weiter ab, bis schließlich
an den Polen alle Längengrade in einem Punkt zusammenlaufen. Eine Längengraddifferenz
führt auf der Erdoberfläche zu einem Abstand in Ost-West-Richtung, der zusätzlich vom
Breitengrad φ abhängt, auf dem die beiden Positionen liegen. Bei der Umrechnung einer
Längengraddifferenz Δλ in einen Abstand Δx muss daher der Kosinus des Breitengrades φ
zur Korrektur aufmultipliziert werden. Dieser Zusammenhang wird in Bild II.34 deutlich.
Vereinfachend wird festgelegt, dass bei der Transformation der Positionsdaten für alle Werte
der Kosinus des Breitengrades φU berücksichtigt wird, der durch den Ursprung des lokalen
Koordinatensystems verläuft. Dadurch wird die Rücktransformation der kartesischen

II.2 Datenmanagement 54
Koordinaten nach der Kompression wesentlich vereinfacht, weil der Korrekturfaktor cos(φU)
dann für alle Positionsdaten den gleichen Wert hat.
ΔλΔ = ⋅ π ⋅ ϕ
°⋅ ⋅E Ux 2 r cos360
(II.3)
Ist λP der Längengrad der zu transformierenden Position P so kann Δλ durch (λP – λU) ersetzt
werden und damit entspricht Δx der X-Koordinate xP der Position P.
λ − λ= ⋅ π ⋅ ϕ⋅ ⋅
°P U
P E Ux 2 r cos360
(II.4)
Damit sind alle notwendigen Rechenvorschriften für die Transformation der Positionsdaten in
ein kartesisches Koordinatensystem bekannt. Für die Rücktransformation sind die beiden
Gleichungen II.2 und II.4 lediglich nach dem gesuchten Längen- bzw. Breitengrad des
jeweiligen Punktes umzustellen. Die Fehler, die bei der Transformation entstanden sind,
wirken sich nur auf die Darstellung der Positionsdaten im kartesischen Koordinatensystem
aus und sind in mitteleuropäischen Breiten selbst für Ausdehnungen des Koordinaten-
systems über zweihundert Kilometer vernachlässigbar (< 2,5 %). Bei der Rücktransformation
werden diese Fehler wieder kompensiert, so dass sich die Transformation nicht negativ auf
die Genauigkeit der komprimierten Positionsinformationen auswirkt.
Auch für diese Datenart soll bei der Entwicklung der Kompressionsmethode der Ansatz der
Irrelevanzreduktion gewählt werden. Nachfolgend müssen dafür zunächst geeignete
Relevanzkriterien entwickelt werden, bevor anschließend die algorithmische Umsetzung
beschrieben wird.
Relevanzkriterien
Um einen geeigneten Ansatz zur rechnergestützten Relevanzprüfung entwickeln zu können,
werden auch für die Positionsdatenkompression zunächst einige grundsätzliche Punkte
definiert:
• Der Kompressionsgewinn soll erzielt werden, indem irrelevante Positionsdaten nicht
abgespeichert werden.
• Das Kompressionsergebnis besteht ausschließlich aus den verbleibenden, als
relevant eingestuften Positionen, die bereits im Originalsignal enthalten waren.
• Über die einstellbaren Kompressionsparameter soll unter anderem die Unsicherheit
bzw. Ungenauigkeit begrenzt werden können, mit der die bei der Kompression
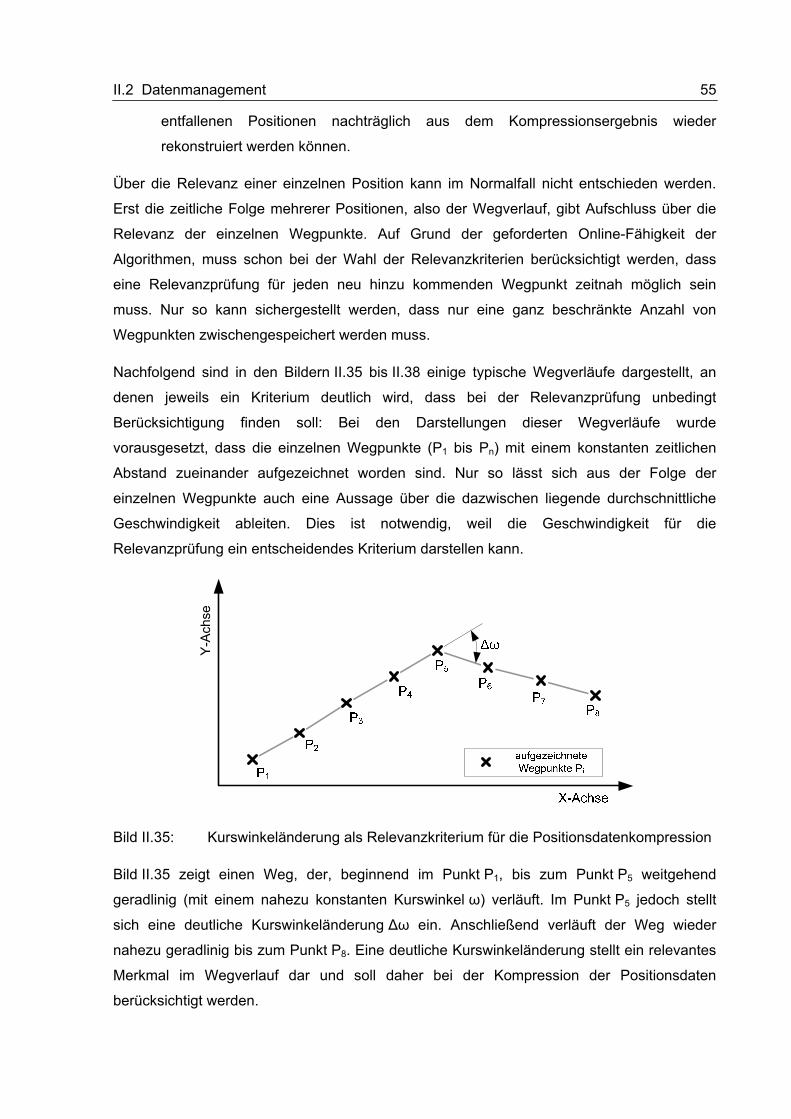
II.2 Datenmanagement 55
entfallenen Positionen nachträglich aus dem Kompressionsergebnis wieder
rekonstruiert werden können.
Über die Relevanz einer einzelnen Position kann im Normalfall nicht entschieden werden.
Erst die zeitliche Folge mehrerer Positionen, also der Wegverlauf, gibt Aufschluss über die
Relevanz der einzelnen Wegpunkte. Auf Grund der geforderten Online-Fähigkeit der
Algorithmen, muss schon bei der Wahl der Relevanzkriterien berücksichtigt werden, dass
eine Relevanzprüfung für jeden neu hinzu kommenden Wegpunkt zeitnah möglich sein
muss. Nur so kann sichergestellt werden, dass nur eine ganz beschränkte Anzahl von
Wegpunkten zwischengespeichert werden muss.
Nachfolgend sind in den Bildern II.35 bis II.38 einige typische Wegverläufe dargestellt, an
denen jeweils ein Kriterium deutlich wird, dass bei der Relevanzprüfung unbedingt
Berücksichtigung finden soll: Bei den Darstellungen dieser Wegverläufe wurde
vorausgesetzt, dass die einzelnen Wegpunkte (P1 bis Pn) mit einem konstanten zeitlichen
Abstand zueinander aufgezeichnet worden sind. Nur so lässt sich aus der Folge der
einzelnen Wegpunkte auch eine Aussage über die dazwischen liegende durchschnittliche
Geschwindigkeit ableiten. Dies ist notwendig, weil die Geschwindigkeit für die
Relevanzprüfung ein entscheidendes Kriterium darstellen kann.
Y-A
chse
Bild II.35: Kurswinkeländerung als Relevanzkriterium für die Positionsdatenkompression
Bild II.35 zeigt einen Weg, der, beginnend im Punkt P1, bis zum Punkt P5 weitgehend
geradlinig (mit einem nahezu konstanten Kurswinkel ω) verläuft. Im Punkt P5 jedoch stellt
sich eine deutliche Kurswinkeländerung Δω ein. Anschließend verläuft der Weg wieder
nahezu geradlinig bis zum Punkt P8. Eine deutliche Kurswinkeländerung stellt ein relevantes
Merkmal im Wegverlauf dar und soll daher bei der Kompression der Positionsdaten
berücksichtigt werden.
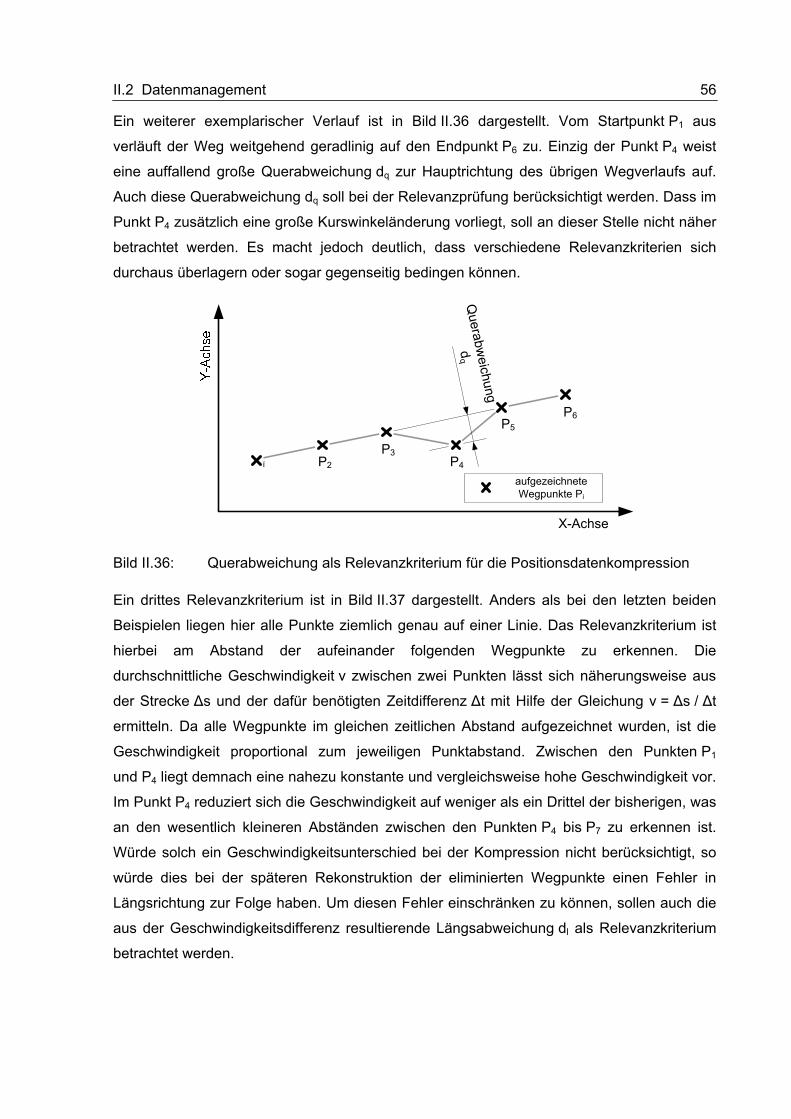
II.2 Datenmanagement 56
Ein weiterer exemplarischer Verlauf ist in Bild II.36 dargestellt. Vom Startpunkt P1 aus
verläuft der Weg weitgehend geradlinig auf den Endpunkt P6 zu. Einzig der Punkt P4 weist
eine auffallend große Querabweichung dq zur Hauptrichtung des übrigen Wegverlaufs auf.
Auch diese Querabweichung dq soll bei der Relevanzprüfung berücksichtigt werden. Dass im
Punkt P4 zusätzlich eine große Kurswinkeländerung vorliegt, soll an dieser Stelle nicht näher
betrachtet werden. Es macht jedoch deutlich, dass verschiedene Relevanzkriterien sich
durchaus überlagern oder sogar gegenseitig bedingen können.
X-Achse
P1
aufgezeichnete Wegpunkte Pi
P6P5
P4
P3P2
Querabw
eichung
dq
Bild II.36: Querabweichung als Relevanzkriterium für die Positionsdatenkompression
Ein drittes Relevanzkriterium ist in Bild II.37 dargestellt. Anders als bei den letzten beiden
Beispielen liegen hier alle Punkte ziemlich genau auf einer Linie. Das Relevanzkriterium ist
hierbei am Abstand der aufeinander folgenden Wegpunkte zu erkennen. Die
durchschnittliche Geschwindigkeit v zwischen zwei Punkten lässt sich näherungsweise aus
der Strecke Δs und der dafür benötigten Zeitdifferenz Δt mit Hilfe der Gleichung v = Δs / Δt
ermitteln. Da alle Wegpunkte im gleichen zeitlichen Abstand aufgezeichnet wurden, ist die
Geschwindigkeit proportional zum jeweiligen Punktabstand. Zwischen den Punkten P1
und P4 liegt demnach eine nahezu konstante und vergleichsweise hohe Geschwindigkeit vor.
Im Punkt P4 reduziert sich die Geschwindigkeit auf weniger als ein Drittel der bisherigen, was
an den wesentlich kleineren Abständen zwischen den Punkten P4 bis P7 zu erkennen ist.
Würde solch ein Geschwindigkeitsunterschied bei der Kompression nicht berücksichtigt, so
würde dies bei der späteren Rekonstruktion der eliminierten Wegpunkte einen Fehler in
Längsrichtung zur Folge haben. Um diesen Fehler einschränken zu können, sollen auch die
aus der Geschwindigkeitsdifferenz resultierende Längsabweichung dl als Relevanzkriterium
betrachtet werden.
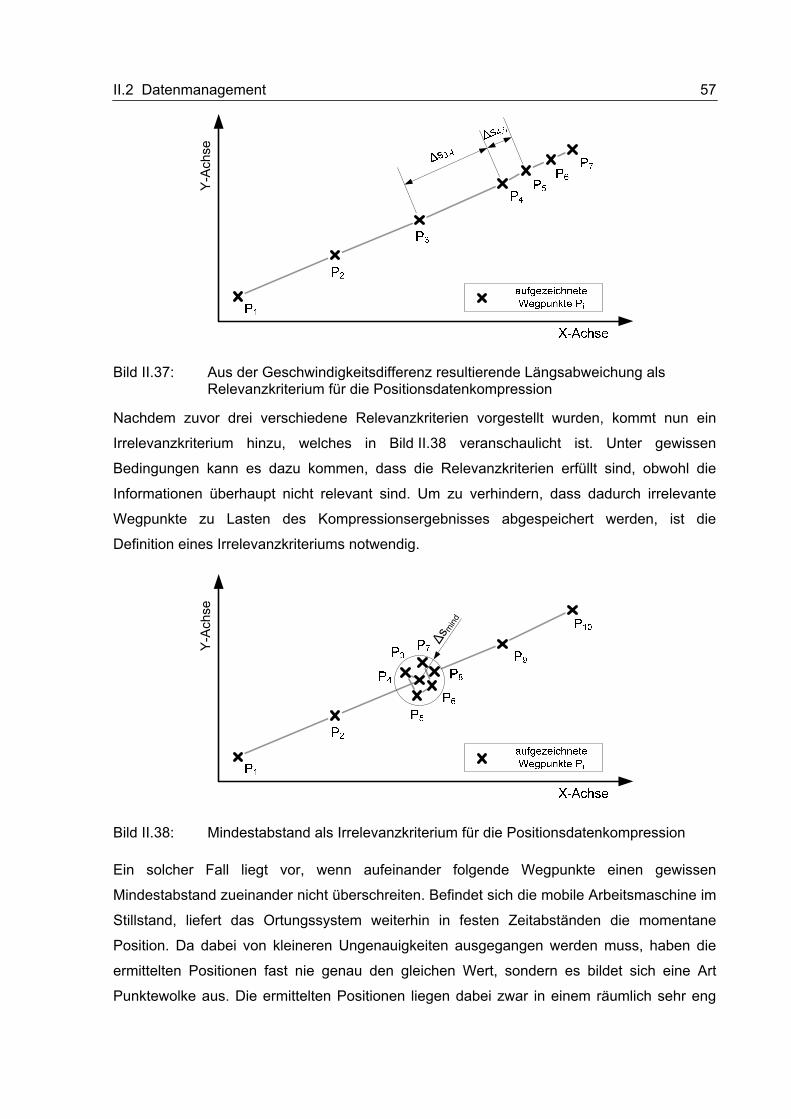
II.2 Datenmanagement 57
Y-A
chse
Bild II.37: Aus der Geschwindigkeitsdifferenz resultierende Längsabweichung als Relevanzkriterium für die Positionsdatenkompression
Nachdem zuvor drei verschiedene Relevanzkriterien vorgestellt wurden, kommt nun ein
Irrelevanzkriterium hinzu, welches in Bild II.38 veranschaulicht ist. Unter gewissen
Bedingungen kann es dazu kommen, dass die Relevanzkriterien erfüllt sind, obwohl die
Informationen überhaupt nicht relevant sind. Um zu verhindern, dass dadurch irrelevante
Wegpunkte zu Lasten des Kompressionsergebnisses abgespeichert werden, ist die
Definition eines Irrelevanzkriteriums notwendig.
Y-A
chse
Δsm
ind
Bild II.38: Mindestabstand als Irrelevanzkriterium für die Positionsdatenkompression
Ein solcher Fall liegt vor, wenn aufeinander folgende Wegpunkte einen gewissen
Mindestabstand zueinander nicht überschreiten. Befindet sich die mobile Arbeitsmaschine im
Stillstand, liefert das Ortungssystem weiterhin in festen Zeitabständen die momentane
Position. Da dabei von kleineren Ungenauigkeiten ausgegangen werden muss, haben die
ermittelten Positionen fast nie genau den gleichen Wert, sondern es bildet sich eine Art
Punktewolke aus. Die ermittelten Positionen liegen dabei zwar in einem räumlich sehr eng

II.2 Datenmanagement 58
gefassten Bereich, aber das Relevanzkriterium der Kurswinkeländerung wird fast immer
erfüllt. In Bild II.38 ist dies sehr schön erkennbar. Bis zum Punkt P3 bewegt sich die
Maschine mit einer bestimmten Geschwindigkeit. Dann stoppt die Maschine; das
Ortungssystem zeichnet die Punkte P4 bis P8 jedoch weiterhin auf. Zwischen den Punkten P8
und P10 bewegt die Maschine sich wieder mit ihrer ursprünglichen Geschwindigkeit weiter.
Bei realen Messwerten wären sicherlich Verzögerungs- und Beschleunigungsphasen
ersichtlich, die in der idealisierten Darstellung jedoch bewusst vernachlässigt worden sind.
Es ist erkennbar, dass alle Punkte, die während der Stillstandszeit aufgezeichnet wurden,
einen Mindestabstand Δsmind zum Punkt P3 nicht überschreiten, die Kurswinkeländerung Δω
jedoch immer größer als 30 Grad ist. Um nicht alle diese irrelevanten Punkte abspeichern zu
müssen, kann ein Mindestabstand Δsmind definiert werden. Liegt ein neuer Punkt zu nah am
zuletzt gültigen, so wird der neue Punkt verworfen. Liegt ein neuer Punkt weiter als Δsmind
vom letzten gültigen Wegpunkt entfernt, erfolgt eine Prüfung an Hand der Relevanzkriterien.
Demnach wären die Punkte P4 bis P8 aus Bild II.38 als irrelevant einzustufen, erst der
Punkt P9 liegt wieder weiter als Δsmind von P3 entfernt.
Für den Fall, dass sich die Maschine nicht im Stillstand befindet, sondern noch mit sehr
geringer Geschwindigkeit fortbewegt, könnte das beschriebene Irrelevanzkriterium u. U.
auch wirksam werden. Auf das Kompressionsergebnis würde sich dies dann ähnlich wie eine
Herabsetzung der Abtastrate des Ortungssystems auswirken. Für sehr niedrige
Geschwindigkeiten ist dies durchaus akzeptabel und stellt somit kein Problem dar. Ein
Abdriften der Punktewolke wird dadurch verhindert, dass der Mindestabstand Δsmind nicht
zum letzten Punkt sondern zum letzten gültigen Punkt als Irrelevanzkriterium angesetzt wird.
Für die algorithmische Umsetzung, die im folgenden Abschnitt beschrieben ist, wird die
Reihenfolge, in der die vier vorgestellten Kriterien abgeprüft werden, einen entscheidenden
Einfluss auf das Kompressionsergebnis haben.
Algorithmische Umsetzung
Da die vier vorgestellten Kriterien nicht völlig losgelöst voneinander betrachtet werden
können, muss für die algorithmische Umsetzung der Relevanzprüfung eine geeignete
Reihenfolge der einzelnen Kriterien definiert werden. Dazu werden zunächst verschiedene
Aspekte und Bedingungen formuliert, die bereits aus dem vorangegangenen Abschnitt
bekannt sind.

II.2 Datenmanagement 59
• Die Überprüfung des Kriteriums „Punktabstand“ muss möglichst früh erfolgen, damit
irrelevante Punkte als solche erkannt werden, bevor die anderen Kriterien diese als
relevant deklarieren.
• Das Kriterium „Kurswinkeländerung“ darf erst nach dem Kriterium „Punktabstand“
abgefragt werden, da, insbesondere bei sehr kleinen Punktabständen (etwa im
Stillstand), der Kurswinkel sich fast immer sehr stark ändert. Die Kurswinkeländerung
ist aber bei sehr kleinen Punktabständen vernachlässigbar.
• Kriterien, die aufwendige Rechenschritte erfordern, sollten möglichst spät überprüft
werden. Für den Fall, dass andere Kriterien vorher zutreffen, werden so die
rechenintensiven Programmteile in der Programmschleife übersprungen. Das führt zu
einer Schonung von Rechnerressourcen.
• Das Kriterium „Längsabweichung“ muss vor dem Kriterium „Punktabstand“ überprüft
werden, da sonst ggf. (etwa beim Stillstand der Maschine) die Geschwindigkeit nicht
berechnet und somit das Kriterium Längsabweichung nicht vollständig geprüft werden
kann. Da dieses Kriterium jedoch zum Beginn und zum Ende einer Stillstandsphase
aufgrund der Geschwindigkeitsänderung fast immer relevant ist, muss dieses
unbedingt vor dem Kriterium „Punktabstand“ überprüft werden.
Aus diesen Punkten ergibt sich, dass die Längsabweichung als erstes geprüft werden muss.
Danach wird der Punktabstand untersucht. Von den verbleibenden beiden Kriterien wird
zunächst die Kurswinkeländerung geprüft, da diese mit weniger Rechenaufwand verbunden
ist als die abschließende Überprüfung der Querabweichung. In Tabelle II.4 sind die vier
Kriterien noch einmal in der erarbeiteten Reihenfolge zusammengefasst.
Die algorithmische Umsetzung dieser vier Kriterien soll im Folgenden beschrieben werden,
bevor anschließend die programmtechnische Umsetzung in Form eines Stateflow-Charts
erläutert wird.
Tabelle II.4: Relevanz- und Irrelevanzkriterien für die Positionsdatenkompression
Nr. Kriterium Art Merkmal
1 Längsabweichung Relevanz dl
2 Punktabstand Irrelevanz Δsmind
3 Kurswinkeländerung Relevanz Δω
4 Querabweichung Relevanz dq
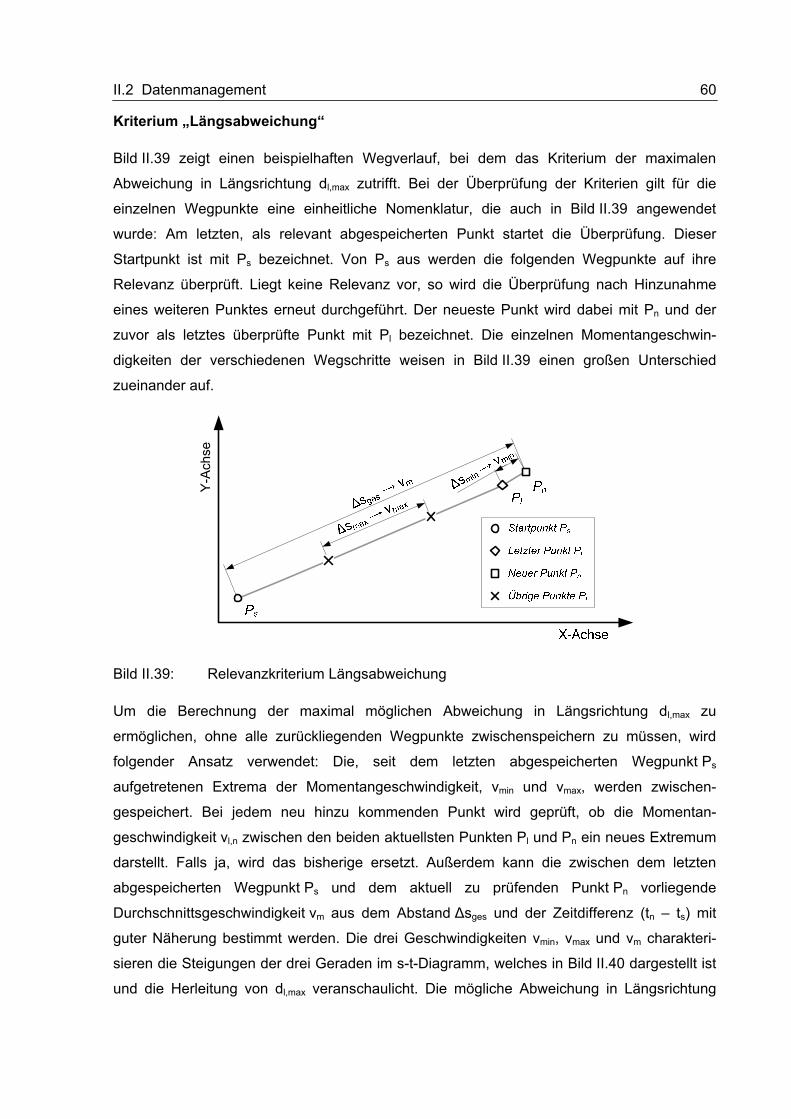
II.2 Datenmanagement 60
Kriterium „Längsabweichung“
Bild II.39 zeigt einen beispielhaften Wegverlauf, bei dem das Kriterium der maximalen
Abweichung in Längsrichtung dl,max zutrifft. Bei der Überprüfung der Kriterien gilt für die
einzelnen Wegpunkte eine einheitliche Nomenklatur, die auch in Bild II.39 angewendet
wurde: Am letzten, als relevant abgespeicherten Punkt startet die Überprüfung. Dieser
Startpunkt ist mit Ps bezeichnet. Von Ps aus werden die folgenden Wegpunkte auf ihre
Relevanz überprüft. Liegt keine Relevanz vor, so wird die Überprüfung nach Hinzunahme
eines weiteren Punktes erneut durchgeführt. Der neueste Punkt wird dabei mit Pn und der
zuvor als letztes überprüfte Punkt mit Pl bezeichnet. Die einzelnen Momentangeschwin-
digkeiten der verschiedenen Wegschritte weisen in Bild II.39 einen großen Unterschied
zueinander auf.
Y-A
chse
Bild II.39: Relevanzkriterium Längsabweichung
Um die Berechnung der maximal möglichen Abweichung in Längsrichtung dl,max zu
ermöglichen, ohne alle zurückliegenden Wegpunkte zwischenspeichern zu müssen, wird
folgender Ansatz verwendet: Die, seit dem letzten abgespeicherten Wegpunkt Ps
aufgetretenen Extrema der Momentangeschwindigkeit, vmin und vmax, werden zwischen-
gespeichert. Bei jedem neu hinzu kommenden Punkt wird geprüft, ob die Momentan-
geschwindigkeit vl,n zwischen den beiden aktuellsten Punkten Pl und Pn ein neues Extremum
darstellt. Falls ja, wird das bisherige ersetzt. Außerdem kann die zwischen dem letzten
abgespeicherten Wegpunkt Ps und dem aktuell zu prüfenden Punkt Pn vorliegende
Durchschnittsgeschwindigkeit vm aus dem Abstand Δsges und der Zeitdifferenz (tn – ts) mit
guter Näherung bestimmt werden. Die drei Geschwindigkeiten vmin, vmax und vm charakteri-
sieren die Steigungen der drei Geraden im s-t-Diagramm, welches in Bild II.40 dargestellt ist
und die Herleitung von dl,max veranschaulicht. Die mögliche Abweichung in Längsrichtung
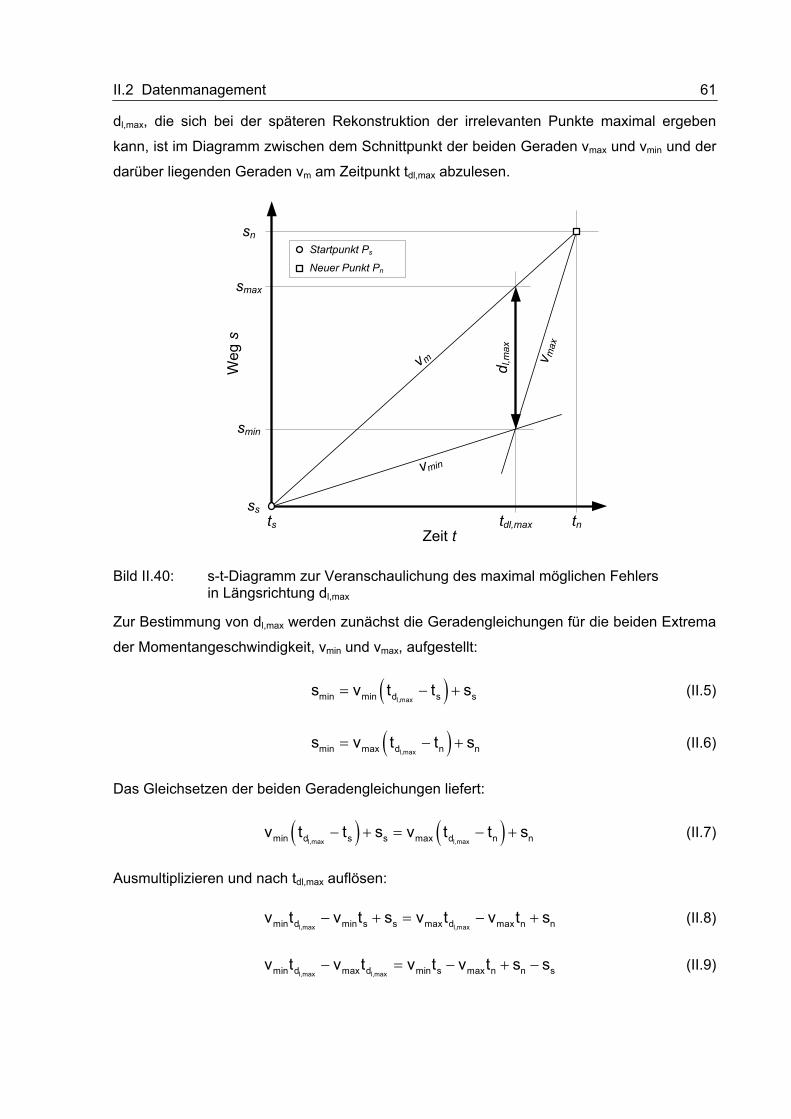
II.2 Datenmanagement 61
dl,max, die sich bei der späteren Rekonstruktion der irrelevanten Punkte maximal ergeben
kann, ist im Diagramm zwischen dem Schnittpunkt der beiden Geraden vmax und vmin und der
darüber liegenden Geraden vm am Zeitpunkt tdl,max abzulesen.
sn
ssts tn
Zeit t
Weg
s
d l,m
ax
vmin
vm v max
tdl,max
smin
smax
Startpunkt Ps
Neuer Punkt Pn
Bild II.40: s-t-Diagramm zur Veranschaulichung des maximal möglichen Fehlers in Längsrichtung dl,max
Zur Bestimmung von dl,max werden zunächst die Geradengleichungen für die beiden Extrema
der Momentangeschwindigkeit, vmin und vmax, aufgestellt:
( )= − +l,maxmin min d s ss v t t s (II.5)
( )= − +l,maxmin max d n ns v t t s (II.6)
Das Gleichsetzen der beiden Geradengleichungen liefert:
( ) ( )− + = − +l,max l,maxmin d s s max d n nv t t s v t t s (II.7)
Ausmultiplizieren und nach tdl,max auflösen:
− + = − +l,max l,maxmin d min s s max d max n nv t v t s v t v t s (II.8)
− = − + −l,max l,maxmin d max d min s max n n sv t v t v t v t s s (II.9)

II.2 Datenmanagement 62
− + −=
−l,max
min s max n n sd
min max
v t v t s stv v
(II.10)
Der Term (sn – ss) kann durch Δsges ersetzt werden.
− + Δ=
−l,max
min s max n gesd
min max
v t v t st
v v (II.11)
Damit ist tdl,max nun aus den gegebenen Größen berechenbar. Gleichung II.5 liefert einen
Ausdruck für smin und außerdem gilt für smax:
( )= − +l,maxmax m d s ss v t t s (II.12)
Für die gesuchte Größe dl,max gilt:
= −l,max max mind s s (II.13)
Das Einsetzen der Ausdrücke aus den Gleichungen II.5 und II.12 in Gleichung II.13 liefert
schließlich folgenden Ausdruck für dl,max:
( )( )= − −l,maxl,max m min d sd v v t t (II.14)
Dieser Wert für dl,max wird in der Programmschleife mit dem zulässigen
Längsabweichung dl,zul vergleichen, der als Kompressionsparameter vorgegeben ist. Ist dl,max
größer als dl,zul so liegt eine Abbruchbedingung vor: Punkt Pl wird abgespeichert und als
neuer Startwert Ps gesetzt. Liegt keine Abbruchbedingung vor, so folgt die Überprüfung des
Irrelevanzkriteriums Punktabstand.
Kriterium „Punktabstand“
Die Überprüfung des Irrelevanzkriteriums gestaltet sich vergleichsweise einfach: Bereits aus
der vorangegangenen Relevanzprüfung ist der Abstand Δsges zwischen dem Startpunkt Ps
und dem neuen Punkt Pn bekannt. Ist dieser Abstand Δsges kleiner als der notwendige
Mindestabstand Δsmind, so wird der neue Punkt als irrelevant eingestuft. Tritt dieser Fall ein,
wird einfach mit dem Einlesen des nächsten Punktes fortgefahren, ohne die übrigen
Relevanzprüfungen zu durchlaufen.
Wird der Punkt nicht als irrelevant eingestuft, d. h. wenn Δsges größer oder gleich Δsmind ist,
wird die Relevanzprüfung mit der Untersuchung der Kurswinkeländerung fortgesetzt.
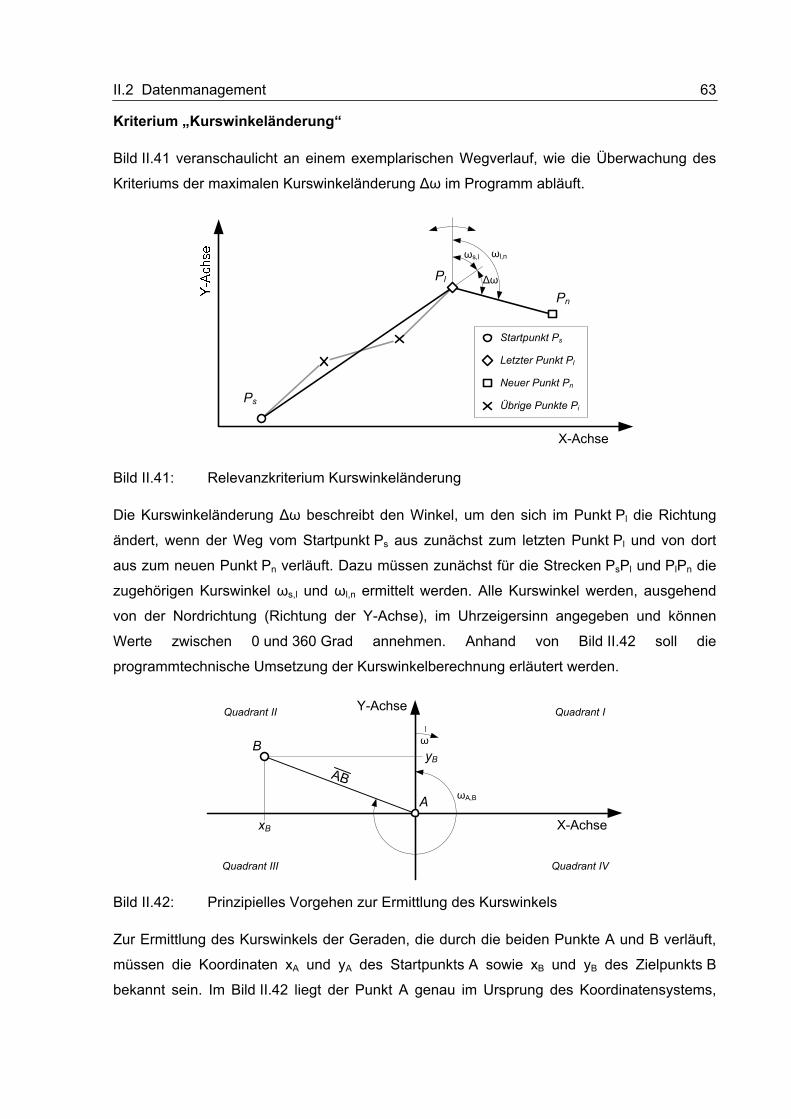
II.2 Datenmanagement 63
Kriterium „Kurswinkeländerung“
Bild II.41 veranschaulicht an einem exemplarischen Wegverlauf, wie die Überwachung des
Kriteriums der maximalen Kurswinkeländerung Δω im Programm abläuft.
ωl,n
X-Achse
Ps
Pn
Pl Δω
Startpunkt Ps
Neuer Punkt Pn
Letzter Punkt Pl
Übrige Punkte Pi
ωs,l
Bild II.41: Relevanzkriterium Kurswinkeländerung
Die Kurswinkeländerung Δω beschreibt den Winkel, um den sich im Punkt Pl die Richtung
ändert, wenn der Weg vom Startpunkt Ps aus zunächst zum letzten Punkt Pl und von dort
aus zum neuen Punkt Pn verläuft. Dazu müssen zunächst für die Strecken PsPl und PlPn die
zugehörigen Kurswinkel ωs,l und ωl,n ermittelt werden. Alle Kurswinkel werden, ausgehend
von der Nordrichtung (Richtung der Y-Achse), im Uhrzeigersinn angegeben und können
Werte zwischen 0 und 360 Grad annehmen. Anhand von Bild II.42 soll die
programmtechnische Umsetzung der Kurswinkelberechnung erläutert werden.
ωA,B
X-Achse
Y-Achse
A
ByB
xB
AB
ω
Quadrant I
Quadrant IVQuadrant III
Quadrant II
Bild II.42: Prinzipielles Vorgehen zur Ermittlung des Kurswinkels
Zur Ermittlung des Kurswinkels der Geraden, die durch die beiden Punkte A und B verläuft,
müssen die Koordinaten xA und yA des Startpunkts A sowie xB und yB des Zielpunkts B
bekannt sein. Im Bild II.42 liegt der Punkt A genau im Ursprung des Koordinatensystems,

II.2 Datenmanagement 64
daher gilt hier der Sonderfall xA = yA = 0. Liegt der Punkt B, bezogen auf A, im ersten oder
vierten Quadranten, lässt sich ωA,B sehr einfach aus der Differenz in Y-Richtung Δy und der
Länge der Strecke AB mit Hilfe der Kosinusfunktion bestimmen. Mit Δx = xB - xA, Δy = yB - yA
und AB = √(Δx² + Δy²) gilt dann:
−ω =
− + −B A
A,B 2 2B A B A
y yarccos(x x ) (y y )
(II.15)
Für den zweiten und dritten Quadranten muss der mit Gleichung II.15 ermittelte Winkel von
360 Grad subtrahiert werden, um die vereinbarte Konvention zu erfüllen. In diesem Fall gilt:
−ω = ° −
− + −B A
A,B 2 2B A B A
y y360 arccos(x x ) (y y )
(II.16)
Es ist zu beachten, dass der Abstand zwischen den Punkten A und B niemals gleich null sein
darf, da dies zu einer Division durch null führen würde. Dies lässt sich durch die vorher
durchgeführte Überprüfung des Irrelevanzkriteriums Punktabstand jedoch sehr einfach
sicherstellen. Für die Fallunterscheidung, in welchem Quadranten der Kurswinkel liegt, bietet
sich die Betrachtung des Vorzeichens der Differenz in X-Richtung Δx = xB - xA an. Für den
Fall dass Δx positive Werte annimmt, ist zur Kurswinkelberechnung die Gleichung II.15 zu
verwenden, in allen anderen Fällen hingegen Gleichung II.16.
Nachdem damit die Bestimmung der beiden Kurswinkel ωs,l und ωl,n möglich ist, soll nun auf
die programmtechnische Umsetzung zur Bestimmung der Kurswinkeländerung Δω
eingegangen werden. Dazu wird zunächst die Differenz der beiden Kurswinkel berechnet.
β = ω − ωl,n s,l (II.17)
Dabei kann β Werte zwischen -360 und +360 Grad annehmen. Für Δω sind jedoch nur
Werte aus dem Intervall [-180,180] sinnvoll. Deswegen ist auch hier wieder eine
Fallunterscheidung nötig. Für Werte von β kleiner -180 Grad gilt:
Δω = β + °360 (II.18)
Für den Fall, dass β größer als 180 Grad ist, gilt:
Δω = β − °360 (II.19)
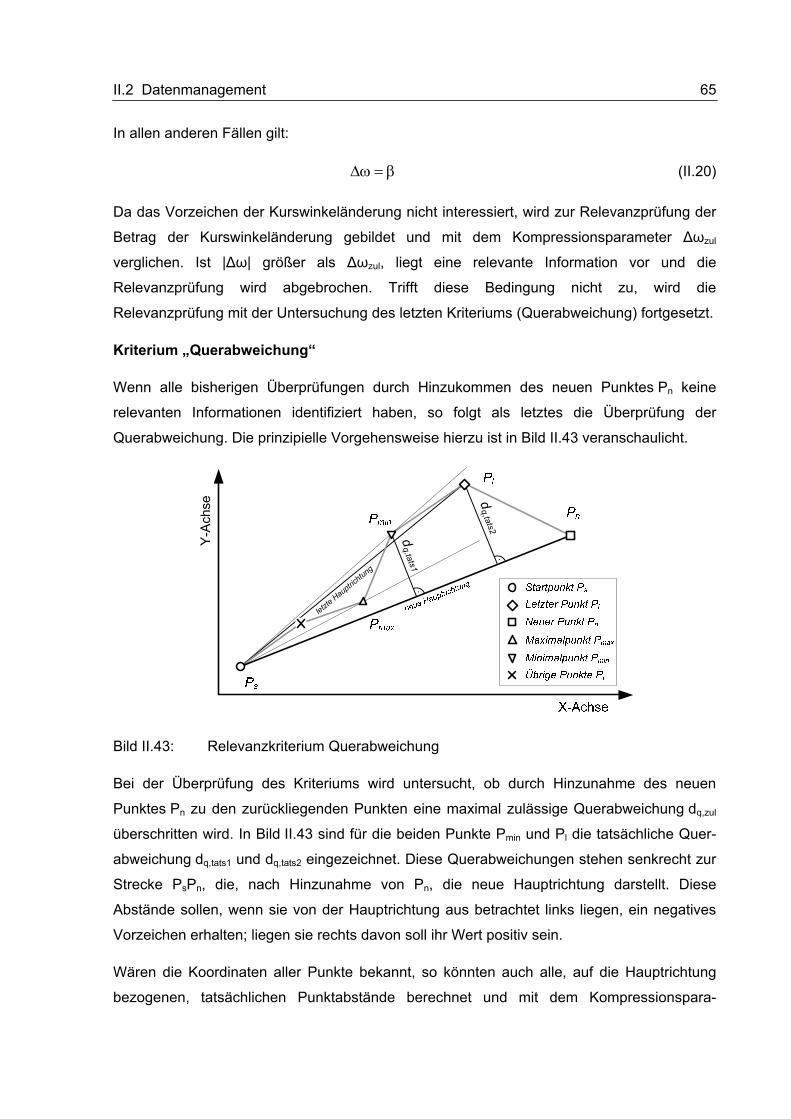
II.2 Datenmanagement 65
In allen anderen Fällen gilt:
Δω = β (II.20)
Da das Vorzeichen der Kurswinkeländerung nicht interessiert, wird zur Relevanzprüfung der
Betrag der Kurswinkeländerung gebildet und mit dem Kompressionsparameter Δωzul
verglichen. Ist |Δω| größer als Δωzul, liegt eine relevante Information vor und die
Relevanzprüfung wird abgebrochen. Trifft diese Bedingung nicht zu, wird die
Relevanzprüfung mit der Untersuchung des letzten Kriteriums (Querabweichung) fortgesetzt.
Kriterium „Querabweichung“
Wenn alle bisherigen Überprüfungen durch Hinzukommen des neuen Punktes Pn keine
relevanten Informationen identifiziert haben, so folgt als letztes die Überprüfung der
Querabweichung. Die prinzipielle Vorgehensweise hierzu ist in Bild II.43 veranschaulicht.
Y-A
chse
letzte Hauptric
htung
dq,tats2
dq,tats1
Bild II.43: Relevanzkriterium Querabweichung
Bei der Überprüfung des Kriteriums wird untersucht, ob durch Hinzunahme des neuen
Punktes Pn zu den zurückliegenden Punkten eine maximal zulässige Querabweichung dq,zul
überschritten wird. In Bild II.43 sind für die beiden Punkte Pmin und Pl die tatsächliche Quer-
abweichung dq,tats1 und dq,tats2 eingezeichnet. Diese Querabweichungen stehen senkrecht zur
Strecke PsPn, die, nach Hinzunahme von Pn, die neue Hauptrichtung darstellt. Diese
Abstände sollen, wenn sie von der Hauptrichtung aus betrachtet links liegen, ein negatives
Vorzeichen erhalten; liegen sie rechts davon soll ihr Wert positiv sein.
Wären die Koordinaten aller Punkte bekannt, so könnten auch alle, auf die Hauptrichtung
bezogenen, tatsächlichen Punktabstände berechnet und mit dem Kompressionspara-

II.2 Datenmanagement 66
meter dq,zul verglichen werden. Diese Vorgehensweise hätte jedoch einige entscheidende
Nachteile: Es müssten dazu alle Wegpunkte zwischengespeichert werden, die seit dem
letzten Abbruchkriterium auf Grund von Irrelevanz verworfen wurden. Dadurch würde sich
mit jedem zusätzlichen Punkt die Rechenzeit für die Prüfung des Kriteriums erhöhen. Weil
unter bestimmten Umständen jedoch sehr viele Punkte nacheinander verworfen werden
können (was auch die Voraussetzung für eine hohe Kompressionsrate darstellt), muss nach
einem anderen Weg gesucht werden, um den Anforderungen aus Abschnitt II.2.1.1 gerecht
zu werden. Darum soll für die Überprüfung des Kriteriums ein anderer Ansatz verwendet
werden, der im Folgenden erläutert wird.
Um die Anforderungen aus Abschnitt II.2.1.1 zu erfüllen, kann nur eine begrenzte Anzahl
zusätzlicher Punkte zwischengespeichert werden, egal wie viele Punkte seit dem letzten
Abbruchkriterium bereits zurückliegen. Da die Punkte mit jeder neuen Hauptrichtung aber
auch neue Abstände zu dieser einnehmen, ist die Auswahl geeigneter relevanter Punkte
entscheidend für die Überprüfung des Kriteriums. Neben den ohnehin gespeicherten
Punkten Ps, Pl und Pn sollen dazu zwei weitere Punkte, Pmin und Pmax, zwischengespeichert
werden, die in Bild II.43 eingezeichnet sind. Dabei handelt es sich um die Punkte, die, in
Bezug auf die letzte Hauptrichtung PsPl, am weitesten links (Pmin) und am weitesten rechts
(Pmax) liegen. Dabei zählt nicht der tatsächliche Abstand, sondern die Winkeldifferenz
zwischen der Richtung PsPmin bzw. PsPmax und der letzten Hauptrichtung PsPl.
Kommt eine neuer Punkt hinzu, liegt eine neue Hauptrichtung PsPn vor. In Bezug auf diese
neue Hauptrichtung werden dann die Abweichungen der bisherigen Extrempunkte Pmin und
Pmax ermittelt und mit dem Kompressionsparameter dq,zul verglichen. Dabei ist eine
Besonderheit zu beachten, die an dem exemplarischen Wegverlauf im Bild II.43 deutlich
erkennbar ist: Weil die Strecke PsPmin eine größere, negative Winkeldifferenz in Bezug auf
die neue Hauptrichtung aufweist als die Strecke PsPl (letzte Hauptrichtung), stellt Pmin
vereinbarungsgemäß den Extrempunkt dar, der links von der neuen Hauptrichtung liegt.
Dennoch ist erkennbar, dass die tatsächliche Querabweichung dq,tats2 des Punktes Pl größer
ist als die tatsächliche Abweichung dq,tats1 des Punktes Pmin. Für die Relevanzprüfung dürfen
daher nicht die tatsächlichen Querabweichungen dq,tats, sondern die möglichen
Querabweichungen dq,min und dq,max links und rechts der Hauptrichtung betrachtet werden.
Diese möglichen Abweichungen sind in Bild II.44 eingezeichnet.
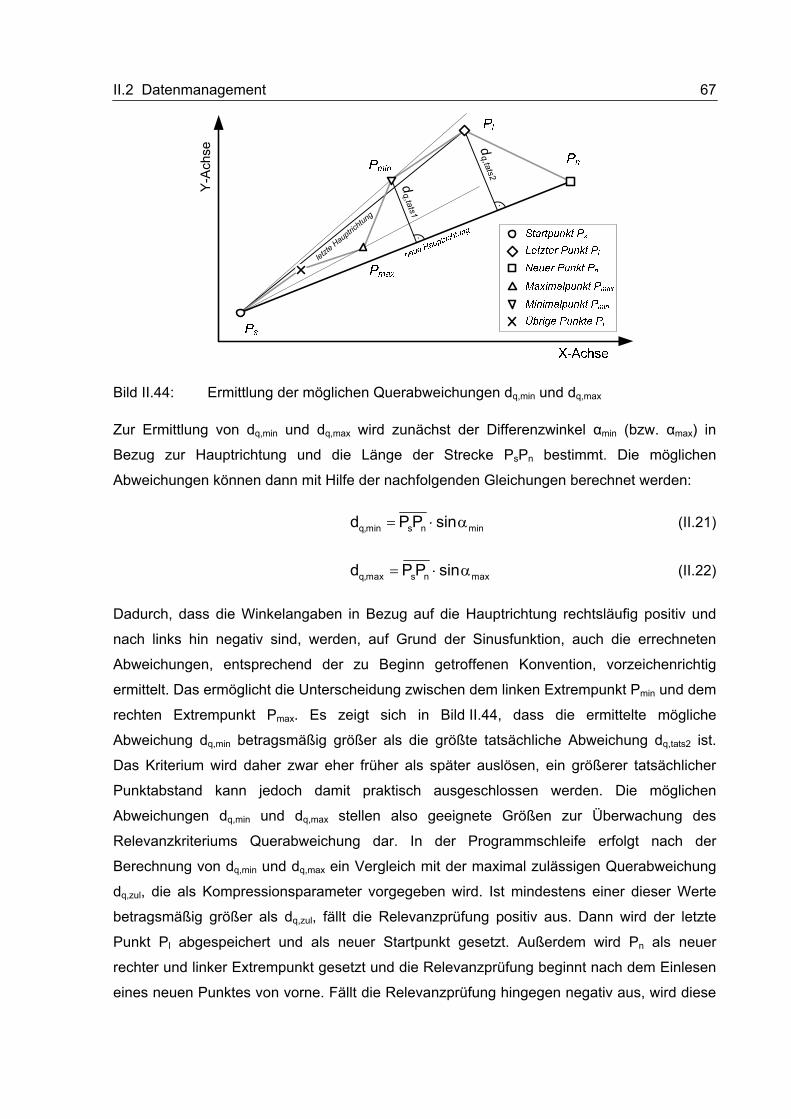
II.2 Datenmanagement 67
Y-A
chse
letzte Hauptric
htung
dq,tats2
dq,tats1
Bild II.44: Ermittlung der möglichen Querabweichungen dq,min und dq,max
Zur Ermittlung von dq,min und dq,max wird zunächst der Differenzwinkel αmin (bzw. αmax) in
Bezug zur Hauptrichtung und die Länge der Strecke PsPn bestimmt. Die möglichen
Abweichungen können dann mit Hilfe der nachfolgenden Gleichungen berechnet werden:
= ⋅ αq,min s n mind P P sin (II.21)
= ⋅ αq,max s n maxd P P sin (II.22)
Dadurch, dass die Winkelangaben in Bezug auf die Hauptrichtung rechtsläufig positiv und
nach links hin negativ sind, werden, auf Grund der Sinusfunktion, auch die errechneten
Abweichungen, entsprechend der zu Beginn getroffenen Konvention, vorzeichenrichtig
ermittelt. Das ermöglicht die Unterscheidung zwischen dem linken Extrempunkt Pmin und dem
rechten Extrempunkt Pmax. Es zeigt sich in Bild II.44, dass die ermittelte mögliche
Abweichung dq,min betragsmäßig größer als die größte tatsächliche Abweichung dq,tats2 ist.
Das Kriterium wird daher zwar eher früher als später auslösen, ein größerer tatsächlicher
Punktabstand kann jedoch damit praktisch ausgeschlossen werden. Die möglichen
Abweichungen dq,min und dq,max stellen also geeignete Größen zur Überwachung des
Relevanzkriteriums Querabweichung dar. In der Programmschleife erfolgt nach der
Berechnung von dq,min und dq,max ein Vergleich mit der maximal zulässigen Querabweichung
dq,zul, die als Kompressionsparameter vorgegeben wird. Ist mindestens einer dieser Werte
betragsmäßig größer als dq,zul, fällt die Relevanzprüfung positiv aus. Dann wird der letzte
Punkt Pl abgespeichert und als neuer Startpunkt gesetzt. Außerdem wird Pn als neuer
rechter und linker Extrempunkt gesetzt und die Relevanzprüfung beginnt nach dem Einlesen
eines neuen Punktes von vorne. Fällt die Relevanzprüfung hingegen negativ aus, wird diese

II.2 Datenmanagement 68
ohne Zurücksetzen mit einem neuen Punkt fortgesetzt. In diesem Fall wird jedoch zunächst
noch geprüft, ob die bisherigen Extrempunkte Pmin und Pmax immer noch gültig sind oder ob
einer von ihnen durch den Punkt Pn ersetzt werden muss. Dies erfolgt ganz einfach durch
Untersuchung der Vorzeichen der zuvor berechneten Werte dq,min und dq,max: Falls der Wert
für dq,max kleiner als null ist, wird der bisherige Maximalpunkt Pmax durch Pn ersetzt. Wenn
dq,min größer als null ist dann wird Pmin durch Pn ausgetauscht. Trifft keines dieser beiden
Kriterien zu, dann stellt Pn kein neues Extremum dar und die bisherigen Extrempunkte gelten
weiterhin. Für das in Bild II.44 dargestellte Beispiel ist der Wert für dq,max kleiner als null (da
er links von der Hauptrichtung liegt) und deswegen würde hier der Punkt Pn als neuer
Maximalpunkt Pmax gesetzt werden.
Programmtechnische Umsetzung
Wie bereits der Algorithmus zur Messwert-Zeitreihenkompression (Abschnitt II.2.1.3.2),
wurde auch die Positionsdatenkompression in Form eines Simulink-Modells prototypisch
implementiert, welches mit einer festen Sample-Rate arbeitet. Die Programmschleife selbst
wurde dabei wieder als Stateflow-Chart umgesetzt, welches in Bild II.45 dargestellt ist. Viele
der zuvor dargestellten Rechenoperationen wurden dabei als Funktionen (sog. Embedded-
Matlab-Funktionen) ausgelagert. Diese finden sich im unteren Bereich des Charts in den
rechteckigen Kästen. Dem Chart werden zu Beginn eines jeden Sample-Schritts über
definierte Eingangsvariablen die zu komprimierenden Messwerte aus der Simulink-
Umgebung übergeben. Dazu gehören die jeweils aktuellsten Messwerte vom Ortungssystem
– Längen- (longitude) und Breitengrad (latitude) – sowie die Systemzeit (time) und die
zugehörige Empfangszeit (rx_time}) dieser Daten vom CAN-Bus. Als Kompressions-
parameter für die Relevanzprüfung werden die zulässige Längsabweichung dl,zul
(maxDeviation_long), der Mindestabstand Δsmind (minDistance), die zulässige Querab-
weichung dq,zul (maxDeviation_lat) sowie die zulässige Kurswinkeländerung Δωzul
(maxDirectionDiff) bereitgestellt. Das Kompressionsergebnis wird über die Variablen
reduced_longitude, reduced_latitude und reduced_t an das Simulink-Modell ausgegeben.
Zusätzlich erfolgt, zur leichteren Kontrolle und Visualisierung der Kompressionsergebnisse,
eine Ausgabe der Originaldaten (new_x und new_y) und des Kompressionsergebnisses
(reduced_x und reduced_y) in kartesischen Koordinaten. Beim Kompressionsergebnis wird,
auf Grund der festen Sample-Rate, immer der jeweils letzte relevante Punkt ausgegeben.
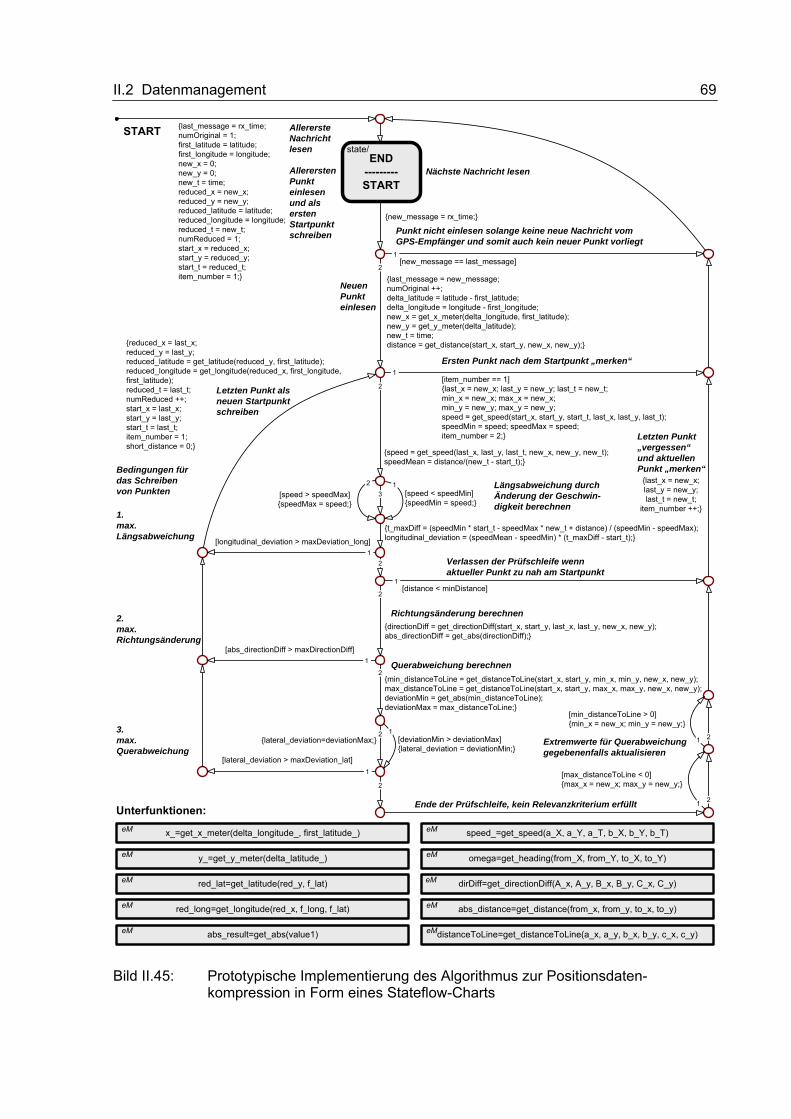
II.2 Datenmanagement 69
123
1
1 2
2
1
2
1
2
1
2
1
2
12
1
2
1
2
END---------START
state/
START Allererste Nachricht lesen
Allerersten Punkt einlesen und als ersten Startpunkt schreiben
Neuen Punkt einlesen
Letzten Punkt als neuen Startpunkt schreiben
Bedingungen für das Schreiben von Punkten
Ersten Punkt nach dem Startpunkt „merken“
Letzten Punkt „vergessen“ und aktuellen Punkt „merken“
Verlassen der Prüfschleife wenn aktueller Punkt zu nah am Startpunkt
Ende der Prüfschleife, kein Relevanzkriterium erfüllt Unterfunktionen:
Längsabweichung durch Änderung der Geschwin-digkeit berechnen
Richtungsänderung berechnen
Querabweichung berechnen
Extremwerte für Querabweichung gegebenenfalls aktualisieren
1.max.Längsabweichung
2.max.Richtungsänderung
3.max.Querabweichung
x_=get_x_meter(delta_longitude_, first_latitude_)
y_=get_y_meter(delta_latitude_)
red_lat=get_latitude(red_y, f_lat)
red_long=get_longitude(red_x, f_long, f_lat)
speed_=get_speed(a_X, a_Y, a_T, b_X, b_Y, b_T)
omega=get_heading(from_X, from_Y, to_X, to_Y)
dirDiff=get_directionDiff(A_x, A_y, B_x, B_y, C_x, C_y)
abs_distance=get_distance(from_x, from_y, to_x, to_y)
distanceToLine=get_distanceToLine(a_x, a_y, b_x, b_y, c_x, c_y)abs_result=get_abs(value1)
eM
eM
eM
eM
eM
eM
eM
eM
eM
eM
Nächste Nachricht lesen
Punkt nicht einlesen solange keine neue Nachricht vom GPS-Empfänger und somit auch kein neuer Punkt vorliegt
{lateral_deviation=deviationMax;}
[lateral_deviation > maxDeviation_lat]
[abs_directionDiff > maxDirectionDiff]
[longitudinal_deviation > maxDeviation_long]
[speed > speedMax]{speedMax = speed;}
[speed < speedMin]{speedMin = speed;}
{last_x = new_x;last_y = new_y;last_t = new_t;
item_number ++;}
[distance < minDistance]
[deviationMin > deviationMax]{lateral_deviation = deviationMin;}
[max_distanceToLine < 0]{max_x = new_x; max_y = new_y;}
[min_distanceToLine > 0]{min_x = new_x; min_y = new_y;}
{new_message = rx_time;}
[new_message == last_message]
{last_message = new_message;numOriginal ++;delta_latitude = latitude - first_latitude;delta_longitude = longitude - first_longitude;new_x = get_x_meter(delta_longitude, first_latitude);new_y = get_y_meter(delta_latitude);new_t = time;distance = get_distance(start_x, start_y, new_x, new_y);}
[item_number == 1]{last_x = new_x; last_y = new_y; last_t = new_t;min_x = new_x; max_x = new_x;min_y = new_y; max_y = new_y;speed = get_speed(start_x, start_y, start_t, last_x, last_y, last_t);speedMin = speed; speedMax = speed;item_number = 2;}
{speed = get_speed(last_x, last_y, last_t, new_x, new_y, new_t);speedMean = distance/(new_t - start_t);}
{t_maxDiff = (speedMin * start_t - speedMax * new_t + distance) / (speedMin - speedMax);longitudinal_deviation = (speedMean - speedMin) * (t_maxDiff - start_t);}
{directionDiff = get_directionDiff(start_x, start_y, last_x, last_y, new_x, new_y);abs_directionDiff = get_abs(directionDiff);}
{min_distanceToLine = get_distanceToLine(start_x, start_y, min_x, min_y, new_x, new_y);max_distanceToLine = get_distanceToLine(start_x, start_y, max_x, max_y, new_x, new_y);deviationMin = get_abs(min_distanceToLine);deviationMax = max_distanceToLine;}
{reduced_x = last_x;reduced_y = last_y;reduced_latitude = get_latitude(reduced_y, first_latitude);reduced_longitude = get_longitude(reduced_x, first_longitude, first_latitude);reduced_t = last_t;numReduced ++;start_x = last_x;start_y = last_y;start_t = last_t;item_number = 1;short_distance = 0;}
{last_message = rx_time;numOriginal = 1;first_latitude = latitude;first_longitude = longitude;new_x = 0;new_y = 0;new_t = time;reduced_x = new_x;reduced_y = new_y;reduced_latitude = latitude;reduced_longitude = longitude;reduced_t = new_t;numReduced = 1;start_x = reduced_x;start_y = reduced_y;start_t = reduced_t;item_number = 1;}
Bild II.45: Prototypische Implementierung des Algorithmus zur Positionsdaten- kompression in Form eines Stateflow-Charts

II.2 Datenmanagement 70
Zum Start des Programms werden zunächst wieder einige Variablen erstmalig mit Werten
belegt. Während des ersten Sample-Schritts läuft das Programm bis zum state. Bei jedem
nun folgenden Sample-Schritt durchläuft das Programm, ausgehend vom state, die
Programmschleife, die aus verschiedenen Transitionen zusammengesetzt ist und alle zuvor
beschriebenen Schritte der Relevanzprüfung abbildet. Zur Wahrung der Übersichtlichkeit und
zur mehrfachen Nutzbarkeit einmal implementierter Rechenschritte, wird dabei mehrmals auf
die ausgelagerten Funktionen zurückgegriffen.
Zunächst erfolgt anhand der rx_time eine Prüfung, ob es sich überhaupt um einen neue
Position handelt, die verarbeitet werden muss. Falls es sich um einen bereits verarbeitete
Position handelt, wird diese sofort verworfen und die Programmschleife abgebrochen.
Handelt es sich jedoch um einen neuen Wert, erfolgt noch die Umrechnung der Längen- und
Breitengradinformationen der jeweiligen Position in einen Punkt im lokalen kartesischen
Koordinatensystem. Daran schließen sich die vier Relevanzprüfungen in der zuvor
beschriebenen Reihenfolge an. Die Relevanzprüfungen ziehen sich entlang der Transitionen,
die senkrecht aus dem state heraus nach unten verlaufen. Die Transitionen, die von diesem
Pfad aus nach links verlaufen, haben als Bedingung das Vorliegen einer relevanten
Information. Die Transitionen auf dem Weg zurück in den state bewirken die
Rücktransformation und Ausgabe des Punktes Pn als Kompressionsergebnis sowie das
erforderliche Neusetzen verschiedener Variablen. So wird die Relevanzprüfung des
nächsten Punktes vorbereitet. Falls keine Relevanz vorliegt, wird die Programmschleife nach
rechts hin verlassen. Auf dem Weg zum state werden auch hierbei einzelne Variablen neu
gesetzt, sofern dies erforderlich ist.
II.2.1.4 Experimentelle Erprobungen
In diesem Abschnitt wird dargestellt, wie die verschiedenen Kompressionsmethoden im
Rahmen von experimentellen Erprobungen getestet wurden. Außerdem werden
verschiedene exemplarische Kompressionsergebnisse vorgestellt und subjektiv beurteilt.
II.2.1.4.1 Versuchstraktor und Entwicklungsumgebung
Die experimentellen Erprobungen wurden mit einem Traktor vom Typ Fendt 818 Vario
durchgeführt. Dieser Traktor verfügt über einen Dieselmotor mit einer Nennleistung von
132 kW, ein hydrostatisch-mechanisch-leistungsverzweigtes Stufenlos-Getriebe und ein
elektronisches Motor-Getriebe-Management (TMS). Außerdem ist der Traktor mit einem
Frontlader und mit einem elektronischen Lenk- und Rückfahrsystem der Firma Neumaier

II.2 Datenmanagement 71
ausgestattet. Bild II.46 zeigt die Maschine während der Feldversuche unter realen
Einsatzbedingungen bei der Bodenbearbeitung und beim Mähen.
Bild II.46: Versuchstraktor bei den Praxiseinsätzen zur Erprobung der Daten- kompressionsmethoden
Zur prototypischen Implementierung der Datenkompressionsalgorithmen wurde der Traktor
mit einer umfangreichen Entwicklungsumgebung ausgestattet, die im Folgenden kurz
vorgestellt werden soll. Das Hauptelement der Entwicklungsumgebung stellt eine sog. Rapid-
Control-Prototyping-Hardware der Firma dSPACE vom Typ MicroAutoBox 1401/1504 dar,
die vorne rechts in der Kabine des Traktors montiert ist. Ein Laptop, der im vorderen rechten
Bereich der Kabine in Reichweite des Fahrers mobiltauglich befestigt ist, dient als Host-PC
zur Programmierung, Steuerung und Überwachung der MicroAutoBox sowie zur
Aufzeichnung der Messdaten.
In Bild II.47 sind die einzelnen Elemente der Entwicklungsumgebung sowie deren
Montagepositionen am Versuchstraktor erkennbar. Zur Erhebung verschiedener Messwerte
kann die MicroAutoBox von drei CAN-Bussen des Traktors beliebige CAN-Botschaften
lesen. Neben einem Zugang zum sog. ISO-Bus (standardisiert nach ISO 11783), der über
die Gerätesteckdose am Traktorheck angeschlossen ist, besteht über zwei Steckdosen in
der rechten B-Säule der Kabine Zugriffsmöglichkeit auf die beiden traktorinternen Busse G-
Bus (Getriebe- und Motorinformationen) und K-Bus (u. a. Bedien- und Stellsignale). Als
Positionssensor kommt ein GPS-Ortungssystem vom Typ Trimble AgGPS 332 mit externer
Antenne zum Einsatz. Zur Steigerung der Positioniergenauigkeit wurde bei allen
durchgeführten Versuchen der kostenfreie Korrekturdatendienst EGNOS genutzt. Während
der Feldversuche bei der Bodenbearbeitung aktualisierte das System die Positionsdaten mit
einer Frequenz von 1 Hz. Für die Versuche im Mähbetrieb konnte die Aktualisierungsrate
durch eine geänderte Parametrierung auf einen Wert von 5 Hz gesteigert werden. Auch das
Ortungssystem übergibt seine Messwerte per CAN-Bus an die MicroAutoBox.

II.2 Datenmanagement 72
Bild II.47: Komponenten der Entwicklungsumgebung des Versuchstraktors
Zur übersichtlichen Verdrahtung der vier CAN-Kanäle mit der MicroAutoBox wurde eine
spezielle Anschlussbox mit mehreren D-Sub-Anschlussbuchsen aufgebaut. Hierüber besteht
auch die Möglichkeit, bis zu 24 analoge Messkanäle einzuspeisen. Die wetterfeste externe
Messtechnikbox, die vorne rechts außerhalb der Kabine montiert ist, dient zum Aufbau der
nötigen Messverstärker und der Spannungsversorgung. Im Rahmen der hier vorgestellten
Untersuchungen werden jedoch keine analogen Sensoren verwendet, da alle relevanten
Signale auf den CAN-Bussen verfügbar sind.
Zur Implementierung der Kompressionsalgorithmen auf der MicroAutoBox ist auf dem
Host-PC das Matlab-Softwarepaket in der Version R2006a (V7.2.0.232) installiert. Durch
automatische Code-Generierung wird aus den Kompressionsalgorithmen, die in Form von
Simulink-Modellen vorliegen, ein lauffähiger Programmcode für den digitalen Signal-

II.2 Datenmanagement 73
prozessor (DSP) der MicroAutoBox erzeugt und darauf übertragen. Der Programmablauf des
so erzeugten Codes kann über die Softwareanwendung ControlDesk, die von der Fa.
dSPACE bereitgestellt wird, vom Host-PC aus überwacht und beeinflusst werden. Außerdem
erfolgt darüber die Steuerung der Messwertaufzeichnung.
II.2.1.4.2 Feldversuche
Wie bereits in Bild II.46 dargestellt, wurden im Rahmen der hier vorgestellten Unter-
suchungen verschiedene Feldversuche durchgeführt. Ende August 2007 wurde der
Versuchstraktor einen Tag lang zur Bodenbearbeitung mit einem Grubber eingesetzt, der
über eine Arbeitsbreite von drei Metern verfügte. In weiteren Versuchen, die Ende Mai 2008
an zwei verschiedenen Tagen stattfanden, wurde der Traktor zusammen mit einem
Scheibenmähwerk (Arbeitsbreite 2,8 m) jeweils einige Stunden zur Grasmahd im ersten
Schnitt eingesetzt. Die im Zusammenhang mit den Feldversuchen notwendigen Straßen-
fahrten repräsentieren einen weiteren relevanten Einsatzbereich des Traktors und wurden
deshalb in die Untersuchungen eingeschlossen.
Während der ersten Feldversuche bei der Bodenbearbeitung wurde das Simulink-Modell mit
einer festen Zykluszeit von 0,1 s betrieben, was einer Frequenz von 10 Hz entspricht. Für die
Versuche im Mähbetrieb wurde die Zykluszeit auf 0,01 s reduziert und die Frequenz dadurch
auf 100 Hz gesteigert. Weil die aufgezeichneten und verarbeiteten CAN-Nachrichten über
Aktualisierungsraten von höchstens 50 Hz verfügen ist so sichergestellt, dass alle neuen
CAN-Nachrichten auch tatsächlich verarbeitet werden können und nicht zwischen den
Abtastschritten verloren gehen.
Mit den durchgeführten Feldversuchen wurden im Wesentlichen zwei Ziele verfolgt:
• Erprobung der Funktionsweise und Nachweis der Online-Fähigkeit der entwickelten
Kompressionsalgorithmen
• Erhebung verschiedener, unkomprimierter Messdaten (Originaldaten) unter
repräsentativen Einsatzbedingungen zur Weiterentwicklung und Optimierung der
Kompressionsalgorithmen im Rahmen von Simulation
Die aufgezeichneten Daten können nachträglich mehrfach in einem Offline-
Simulationsmodell unter Verwendung verschiedener Kompressionsparameter verarbeitet
werden. Bild II.48 veranschaulicht diesen Vorgang in Form eines Blockschaltbildes. Dadurch,
dass sowohl bei der Online- als auch bei der Offline-Erprobung der gleiche, in Simulink bzw.

II.2 Datenmanagement 74
Stateflow implementierte Kompressionsalgorithmus, verwendet wird, sind die erzielten
Kompressionsergebnisse direkt vergleichbar und eine subjektive Beurteilung wird möglich.
Bild II.48: Möglichkeit zur Komprimierung der Daten im Online- oder Offline-Betrieb
II.2.1.4.3 Erprobung der Kompressionsmethoden
Im Rahmen dieses Abschnittes werden einige exemplarische Ergebnisse dargestellt, die bei
der Anwendung der entwickelten Kompressionsmethoden auf verschiedene Daten erzielt
werden konnten. Neben der Variation der Datenart soll auch der Einfluss des gewählten
Kompressionsparameters an einigen Beispielen dargestellt werden.
Zunächst wird die Methode zur Kompression von Messwert-Zeitreihen auf mehrere
Datenarten angewendet. Dazu werden verschiedene Messgrößen ausgewählt, die
insbesondere mit Blick auf die Dynamik, sehr verschiedene Eigenschaften mitbringen. Durch
diese Vorgehensweise soll eine universelle Nutzbarkeit dieser Kompressionsmethode
demonstriert werden. Anschließend werden ausgewählte Ergebnisse der
Positionsdatenkompression vorgestellt. Hierbei wird zwischen dem Feldeinsatz und der
Straßenfahrt unterschieden.
Messwert-Zeitreihen
Für die Erprobung der Kompressionsmethode für Messwert-Zeitreihen wurden vier
verschiedene Messgrößen ausgewählt. Dabei handelt es sich um die Motortemperatur
(in °C), die Fahrgeschwindigkeit (in m/s), die Motordrehzahl (in 1/min) und die
Motorauslastung (in %). Diese Daten wurden bewusst gewählt, da sie verschiedene
Eigenschaften aufweisen, die für die Funktion und Arbeitsweise der Kompressionsmethode
relevant sein können. Nachfolgend soll auf die Messgrößen und die
Kompressionsergebnisse einzeln eingegangen werden. Bei den Untersuchungen wurde für
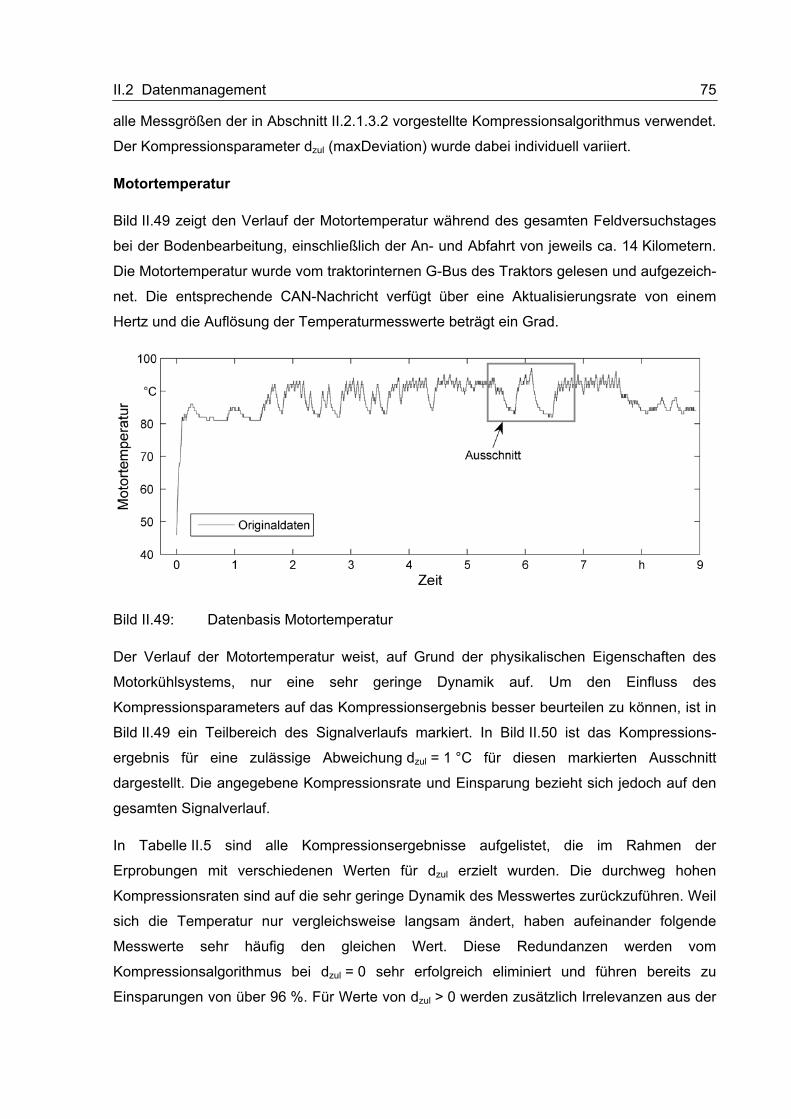
II.2 Datenmanagement 75
alle Messgrößen der in Abschnitt II.2.1.3.2 vorgestellte Kompressionsalgorithmus verwendet.
Der Kompressionsparameter dzul (maxDeviation) wurde dabei individuell variiert.
Motortemperatur
Bild II.49 zeigt den Verlauf der Motortemperatur während des gesamten Feldversuchstages
bei der Bodenbearbeitung, einschließlich der An- und Abfahrt von jeweils ca. 14 Kilometern.
Die Motortemperatur wurde vom traktorinternen G-Bus des Traktors gelesen und aufgezeich-
net. Die entsprechende CAN-Nachricht verfügt über eine Aktualisierungsrate von einem
Hertz und die Auflösung der Temperaturmesswerte beträgt ein Grad.
Bild II.49: Datenbasis Motortemperatur
Der Verlauf der Motortemperatur weist, auf Grund der physikalischen Eigenschaften des
Motorkühlsystems, nur eine sehr geringe Dynamik auf. Um den Einfluss des
Kompressionsparameters auf das Kompressionsergebnis besser beurteilen zu können, ist in
Bild II.49 ein Teilbereich des Signalverlaufs markiert. In Bild II.50 ist das Kompressions-
ergebnis für eine zulässige Abweichung dzul = 1 °C für diesen markierten Ausschnitt
dargestellt. Die angegebene Kompressionsrate und Einsparung bezieht sich jedoch auf den
gesamten Signalverlauf.
In Tabelle II.5 sind alle Kompressionsergebnisse aufgelistet, die im Rahmen der
Erprobungen mit verschiedenen Werten für dzul erzielt wurden. Die durchweg hohen
Kompressionsraten sind auf die sehr geringe Dynamik des Messwertes zurückzuführen. Weil
sich die Temperatur nur vergleichsweise langsam ändert, haben aufeinander folgende
Messwerte sehr häufig den gleichen Wert. Diese Redundanzen werden vom
Kompressionsalgorithmus bei dzul = 0 sehr erfolgreich eliminiert und führen bereits zu
Einsparungen von über 96 %. Für Werte von dzul > 0 werden zusätzlich Irrelevanzen aus der
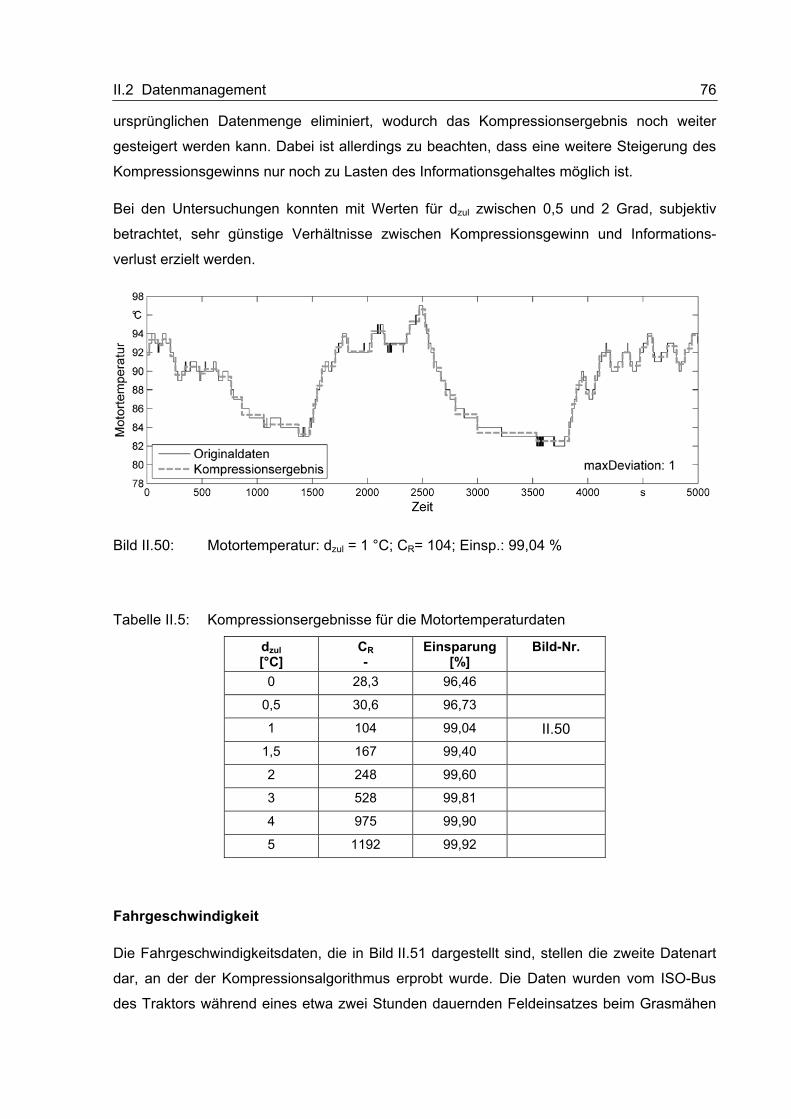
II.2 Datenmanagement 76
ursprünglichen Datenmenge eliminiert, wodurch das Kompressionsergebnis noch weiter
gesteigert werden kann. Dabei ist allerdings zu beachten, dass eine weitere Steigerung des
Kompressionsgewinns nur noch zu Lasten des Informationsgehaltes möglich ist.
Bei den Untersuchungen konnten mit Werten für dzul zwischen 0,5 und 2 Grad, subjektiv
betrachtet, sehr günstige Verhältnisse zwischen Kompressionsgewinn und Informations-
verlust erzielt werden.
Bild II.50: Motortemperatur: dzul = 1 °C; CR= 104; Einsp.: 99,04 %
Tabelle II.5: Kompressionsergebnisse für die Motortemperaturdaten
dzul [°C]
CR -
Einsparung [%]
Bild-Nr.
0 28,3 96,46
0,5 30,6 96,73
1 104 99,04 II.50 1,5 167 99,40
2 248 99,60
3 528 99,81
4 975 99,90
5 1192 99,92
Fahrgeschwindigkeit
Die Fahrgeschwindigkeitsdaten, die in Bild II.51 dargestellt sind, stellen die zweite Datenart
dar, an der der Kompressionsalgorithmus erprobt wurde. Die Daten wurden vom ISO-Bus
des Traktors während eines etwa zwei Stunden dauernden Feldeinsatzes beim Grasmähen
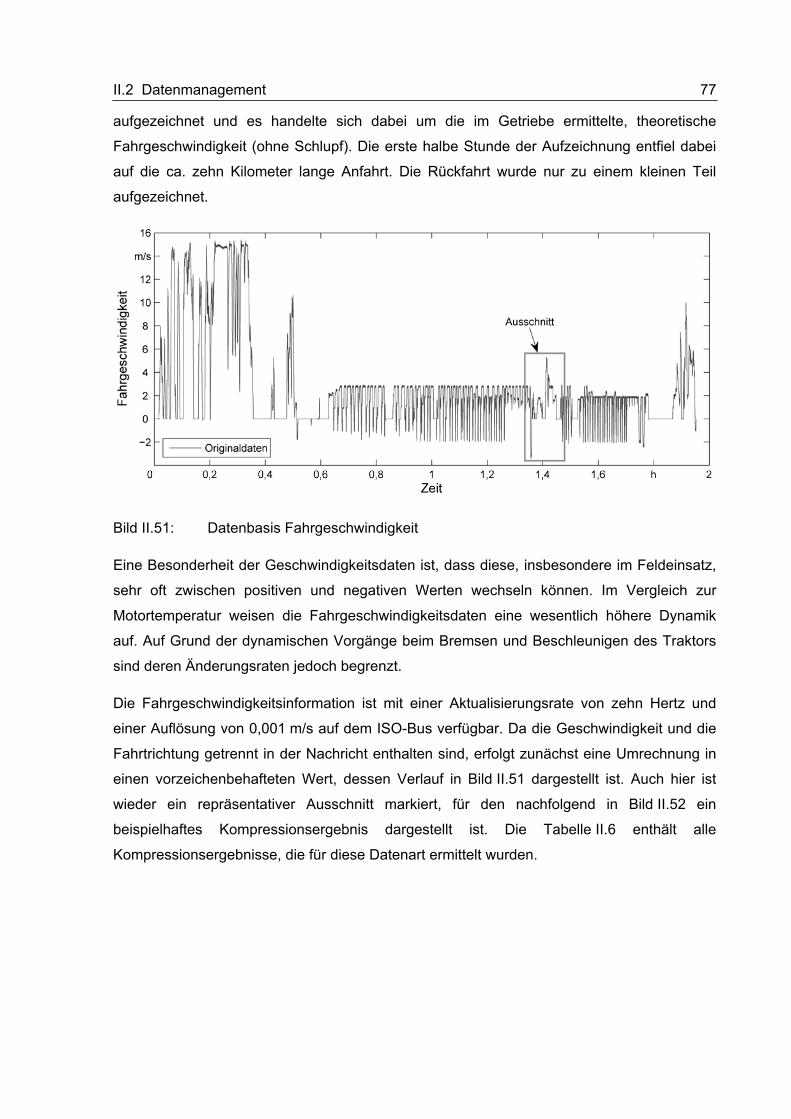
II.2 Datenmanagement 77
aufgezeichnet und es handelte sich dabei um die im Getriebe ermittelte, theoretische
Fahrgeschwindigkeit (ohne Schlupf). Die erste halbe Stunde der Aufzeichnung entfiel dabei
auf die ca. zehn Kilometer lange Anfahrt. Die Rückfahrt wurde nur zu einem kleinen Teil
aufgezeichnet.
Bild II.51: Datenbasis Fahrgeschwindigkeit
Eine Besonderheit der Geschwindigkeitsdaten ist, dass diese, insbesondere im Feldeinsatz,
sehr oft zwischen positiven und negativen Werten wechseln können. Im Vergleich zur
Motortemperatur weisen die Fahrgeschwindigkeitsdaten eine wesentlich höhere Dynamik
auf. Auf Grund der dynamischen Vorgänge beim Bremsen und Beschleunigen des Traktors
sind deren Änderungsraten jedoch begrenzt.
Die Fahrgeschwindigkeitsinformation ist mit einer Aktualisierungsrate von zehn Hertz und
einer Auflösung von 0,001 m/s auf dem ISO-Bus verfügbar. Da die Geschwindigkeit und die
Fahrtrichtung getrennt in der Nachricht enthalten sind, erfolgt zunächst eine Umrechnung in
einen vorzeichenbehafteten Wert, dessen Verlauf in Bild II.51 dargestellt ist. Auch hier ist
wieder ein repräsentativer Ausschnitt markiert, für den nachfolgend in Bild II.52 ein
beispielhaftes Kompressionsergebnis dargestellt ist. Die Tabelle II.6 enthält alle
Kompressionsergebnisse, die für diese Datenart ermittelt wurden.
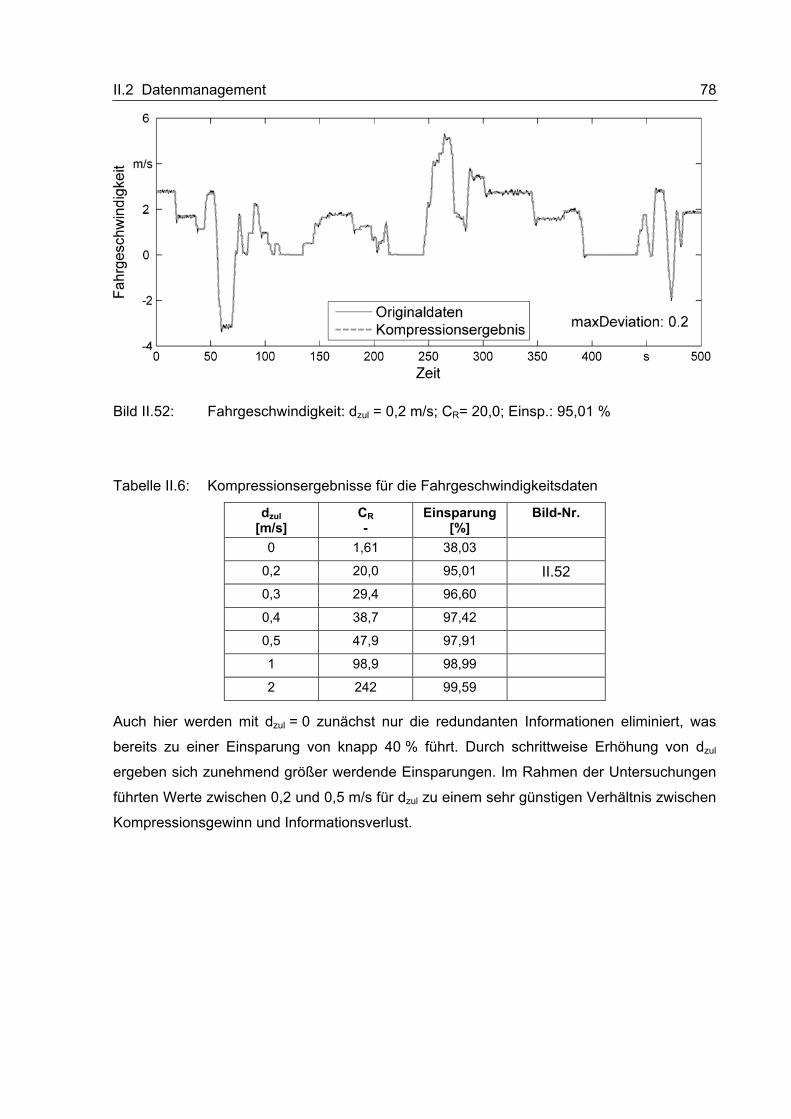
II.2 Datenmanagement 78
Bild II.52: Fahrgeschwindigkeit: dzul = 0,2 m/s; CR= 20,0; Einsp.: 95,01 %
Tabelle II.6: Kompressionsergebnisse für die Fahrgeschwindigkeitsdaten
dzul [m/s]
CR -
Einsparung [%]
Bild-Nr.
0 1,61 38,03
0,2 20,0 95,01 II.52 0,3 29,4 96,60
0,4 38,7 97,42
0,5 47,9 97,91
1 98,9 98,99
2 242 99,59
Auch hier werden mit dzul = 0 zunächst nur die redundanten Informationen eliminiert, was
bereits zu einer Einsparung von knapp 40 % führt. Durch schrittweise Erhöhung von dzul
ergeben sich zunehmend größer werdende Einsparungen. Im Rahmen der Untersuchungen
führten Werte zwischen 0,2 und 0,5 m/s für dzul zu einem sehr günstigen Verhältnis zwischen
Kompressionsgewinn und Informationsverlust.
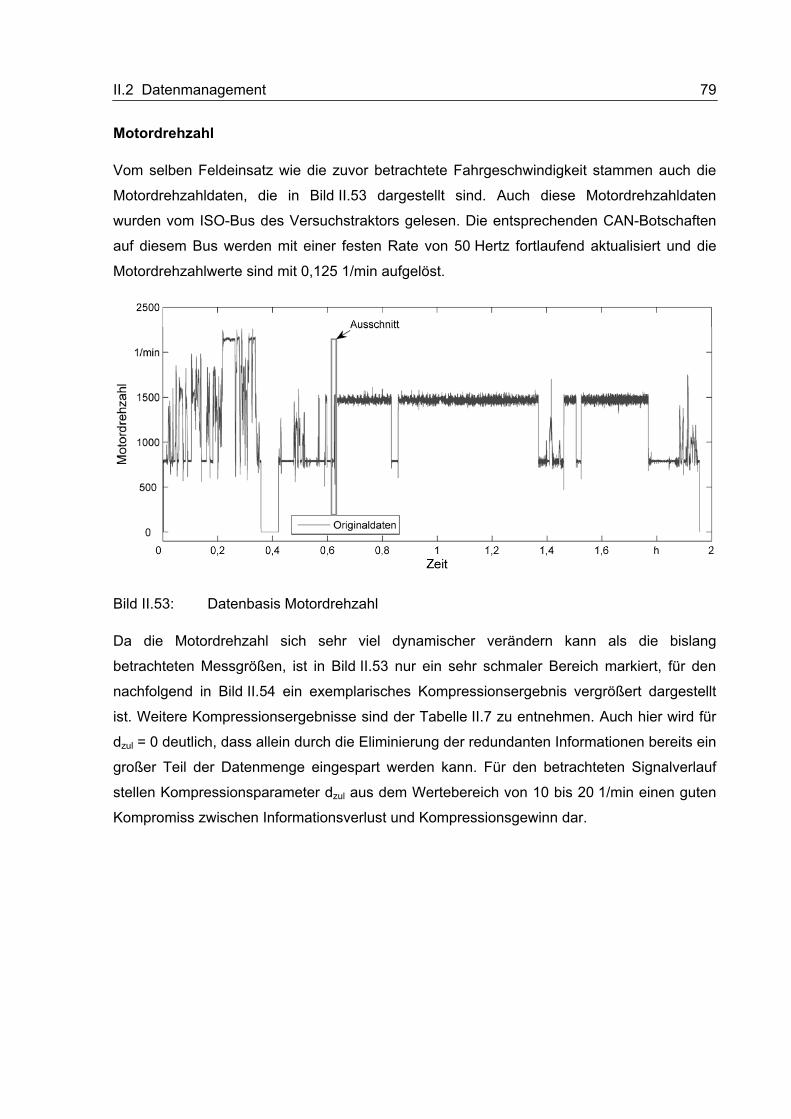
II.2 Datenmanagement 79
Motordrehzahl
Vom selben Feldeinsatz wie die zuvor betrachtete Fahrgeschwindigkeit stammen auch die
Motordrehzahldaten, die in Bild II.53 dargestellt sind. Auch diese Motordrehzahldaten
wurden vom ISO-Bus des Versuchstraktors gelesen. Die entsprechenden CAN-Botschaften
auf diesem Bus werden mit einer festen Rate von 50 Hertz fortlaufend aktualisiert und die
Motordrehzahlwerte sind mit 0,125 1/min aufgelöst.
Bild II.53: Datenbasis Motordrehzahl
Da die Motordrehzahl sich sehr viel dynamischer verändern kann als die bislang
betrachteten Messgrößen, ist in Bild II.53 nur ein sehr schmaler Bereich markiert, für den
nachfolgend in Bild II.54 ein exemplarisches Kompressionsergebnis vergrößert dargestellt
ist. Weitere Kompressionsergebnisse sind der Tabelle II.7 zu entnehmen. Auch hier wird für
dzul = 0 deutlich, dass allein durch die Eliminierung der redundanten Informationen bereits ein
großer Teil der Datenmenge eingespart werden kann. Für den betrachteten Signalverlauf
stellen Kompressionsparameter dzul aus dem Wertebereich von 10 bis 20 1/min einen guten
Kompromiss zwischen Informationsverlust und Kompressionsgewinn dar.
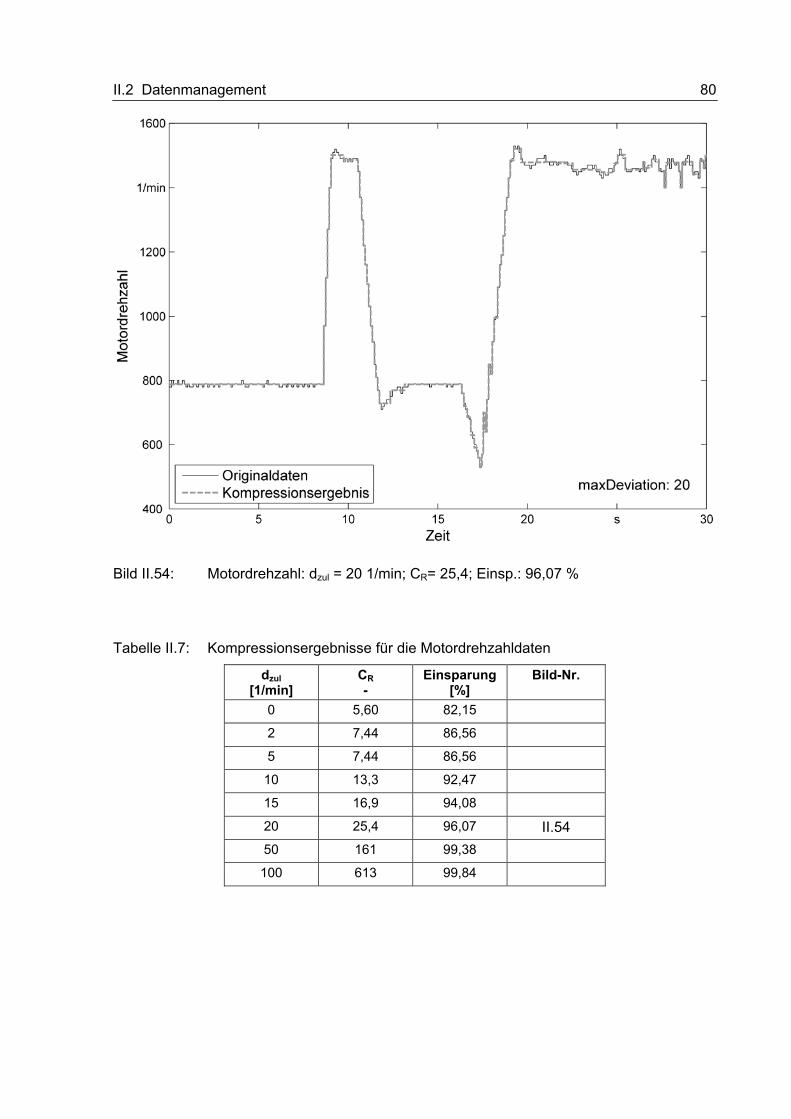
II.2 Datenmanagement 80
Bild II.54: Motordrehzahl: dzul = 20 1/min; CR= 25,4; Einsp.: 96,07 %
Tabelle II.7: Kompressionsergebnisse für die Motordrehzahldaten
dzul [1/min]
CR -
Einsparung [%]
Bild-Nr.
0 5,60 82,15
2 7,44 86,56
5 7,44 86,56
10 13,3 92,47
15 16,9 94,08
20 25,4 96,07 II.54 50 161 99,38
100 613 99,84
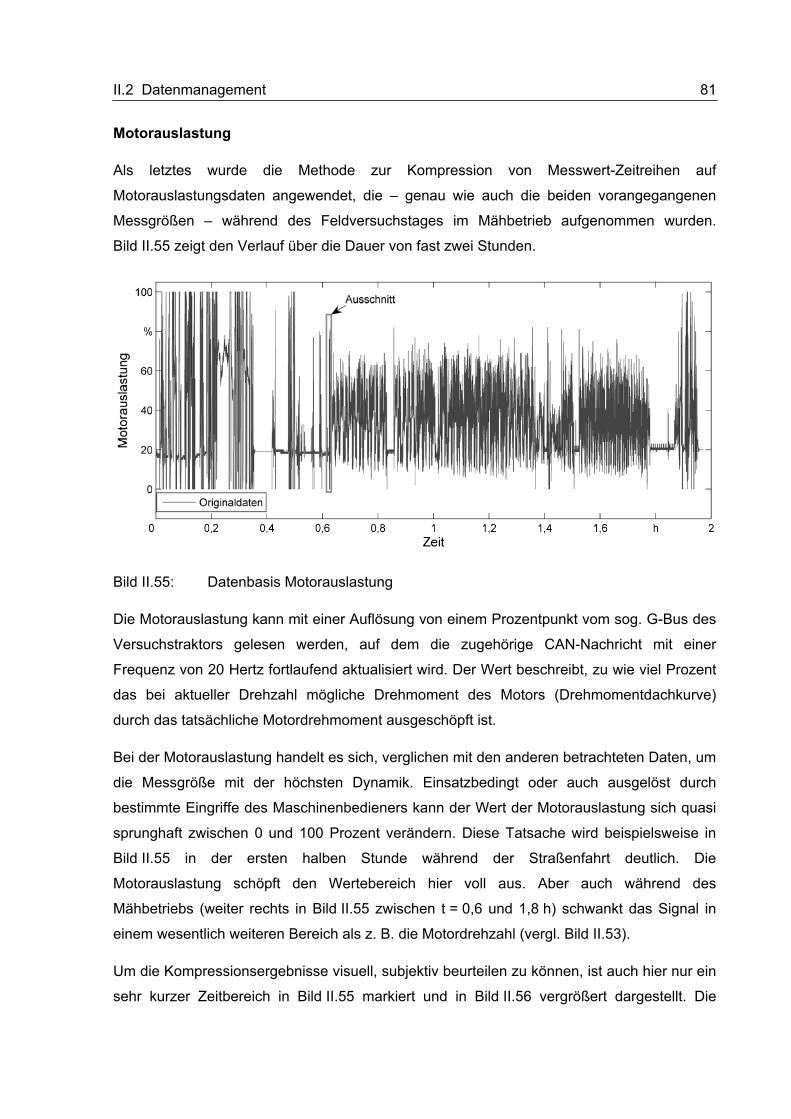
II.2 Datenmanagement 81
Motorauslastung
Als letztes wurde die Methode zur Kompression von Messwert-Zeitreihen auf
Motorauslastungsdaten angewendet, die – genau wie auch die beiden vorangegangenen
Messgrößen – während des Feldversuchstages im Mähbetrieb aufgenommen wurden.
Bild II.55 zeigt den Verlauf über die Dauer von fast zwei Stunden.
Bild II.55: Datenbasis Motorauslastung
Die Motorauslastung kann mit einer Auflösung von einem Prozentpunkt vom sog. G-Bus des
Versuchstraktors gelesen werden, auf dem die zugehörige CAN-Nachricht mit einer
Frequenz von 20 Hertz fortlaufend aktualisiert wird. Der Wert beschreibt, zu wie viel Prozent
das bei aktueller Drehzahl mögliche Drehmoment des Motors (Drehmomentdachkurve)
durch das tatsächliche Motordrehmoment ausgeschöpft ist.
Bei der Motorauslastung handelt es sich, verglichen mit den anderen betrachteten Daten, um
die Messgröße mit der höchsten Dynamik. Einsatzbedingt oder auch ausgelöst durch
bestimmte Eingriffe des Maschinenbedieners kann der Wert der Motorauslastung sich quasi
sprunghaft zwischen 0 und 100 Prozent verändern. Diese Tatsache wird beispielsweise in
Bild II.55 in der ersten halben Stunde während der Straßenfahrt deutlich. Die
Motorauslastung schöpft den Wertebereich hier voll aus. Aber auch während des
Mähbetriebs (weiter rechts in Bild II.55 zwischen t = 0,6 und 1,8 h) schwankt das Signal in
einem wesentlich weiteren Bereich als z. B. die Motordrehzahl (vergl. Bild II.53).
Um die Kompressionsergebnisse visuell, subjektiv beurteilen zu können, ist auch hier nur ein
sehr kurzer Zeitbereich in Bild II.55 markiert und in Bild II.56 vergrößert dargestellt. Die
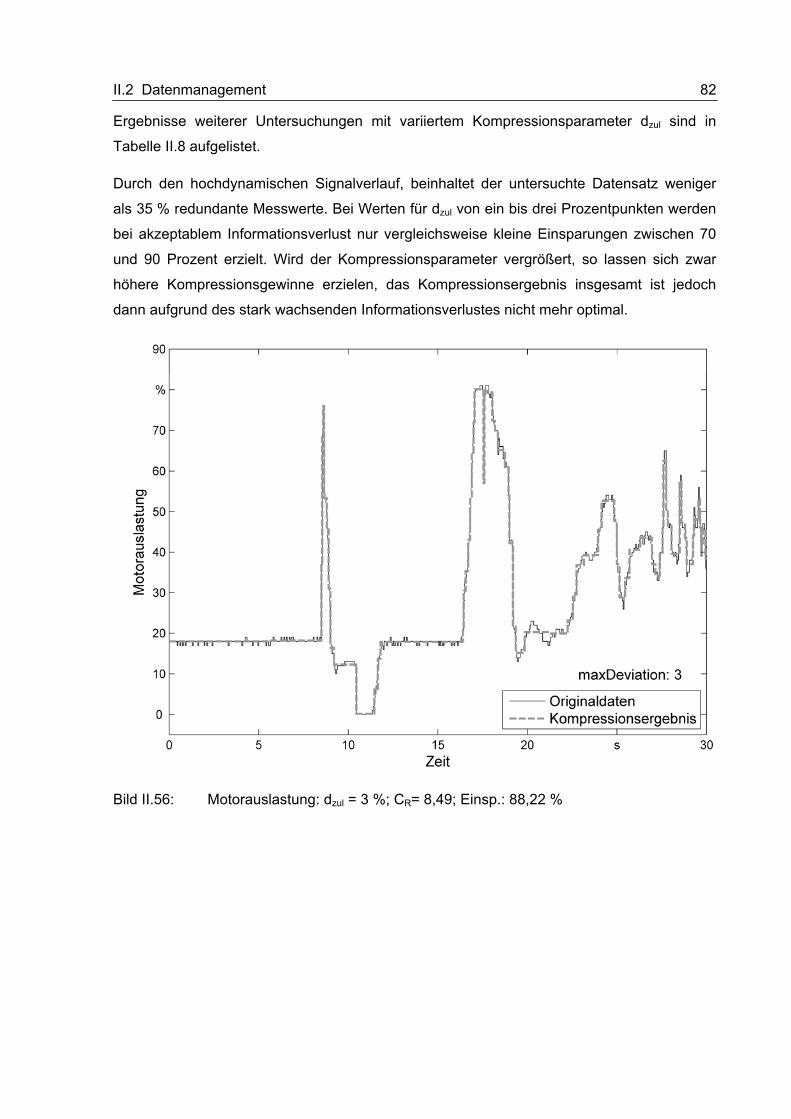
II.2 Datenmanagement 82
Ergebnisse weiterer Untersuchungen mit variiertem Kompressionsparameter dzul sind in
Tabelle II.8 aufgelistet.
Durch den hochdynamischen Signalverlauf, beinhaltet der untersuchte Datensatz weniger
als 35 % redundante Messwerte. Bei Werten für dzul von ein bis drei Prozentpunkten werden
bei akzeptablem Informationsverlust nur vergleichsweise kleine Einsparungen zwischen 70
und 90 Prozent erzielt. Wird der Kompressionsparameter vergrößert, so lassen sich zwar
höhere Kompressionsgewinne erzielen, das Kompressionsergebnis insgesamt ist jedoch
dann aufgrund des stark wachsenden Informationsverlustes nicht mehr optimal.
Bild II.56: Motorauslastung: dzul = 3 %; CR= 8,49; Einsp.: 88,22 %

II.2 Datenmanagement 83
Tabelle II.8: Kompressionsergebnisse für die Motorauslastungsdaten
dzul [%]
CR -
Einsparung [%]
Bild-Nr.
0 1,54 34,87
1 3,53 71,68
2 5,90 83,05
3 8,49 88,22 II.56 4 11,5 91,28
5 14,6 93,15
10 34,7 97,12
20 114 99,12
Positionsdaten
Die Erprobung der in Abschnitt II.2.1.3.3 entwickelten Methode zur Kompression von
Positionsdaten soll im Rahmen dieses Abschnitts an Hand von zwei Einsatzfällen durch-
geführt werden. Dabei wird zwischen dem Feldeinsatz und der Straßenfahrt des Traktors
unterschieden. Da diese beiden Fälle verschiedene Eigenschaften und Anforderungen mit
sich bringen, die für die Arbeitsweise der Kompressionsmethode und das Kompressions-
ergebnis relevant sein können, sollen beide getrennt untersucht werden.
Bei den Untersuchungen werden nur die vier Kompressionsparameter individuell variiert, um
deren Einfluss auf das Kompressionsergebnis zu veranschaulichen. Der verwendete
Kompressionsalgorithmus ist jedoch bei allen Erprobungen identisch.
Feldeinsatz
Da sich die Positionsverläufe des Traktors zwischen dem Feldeinsatz bei der Boden-
bearbeitung und beim Mähen ohnehin nur unwesentlich unterscheiden, beschränken sich
alle hier dargestellten Ergebnisse auf die Feldversuche im Mähbetrieb. Im Mähbetrieb
wurden die Positionsinformationen des Ortungssystems zudem mit einer Frequenz von fünf
Hertz und damit fünf Mal so häufig wie während der Bodenbearbeitung aktualisiert. Aus
diesem Grund enthalten diese Positionsdaten mehr Informationen und spiegeln somit den
tatsächlichen Fahrspurverlauf auch genauer wider.
Bild II.57 zeigt den Positionsverlauf des Traktors während eines Mäheinsatzes auf einem
Schlag von etwa einem Hektar Größe ca. sechs Kilometer westlich von Braunschweig. Im
Bild sind auf dem Schlag zwei Hindernisse, ein Baum und ein Baumstumpf, erkennbar, die

II.2 Datenmanagement 84
beim Mähen umfahren werden mussten. Da der Schlag bereits vor Beginn der
Messwertaufzeichnungen rundherum auf einer Breite von ca. acht Metern freigemäht worden
war, beschränken sich die Messwerte auf den verbleibenden, mittleren Teil. Der dargestellte
Positionsverlauf wurde über einen Zeitraum von 68 Minuten aufgezeichnet und setzt sich aus
der zeitlichen Abfolge von mehr als 20.000 diskreten Positionsinformationen zusammen.
Bild II.57: Positionsdatenverlauf während eines Mäheinsatzes
Nachfolgend sollen, anhand des in Bild II.57 gezeigten Positionsverlaufs, die Wirkungsweise
der Kompressionsmethode und der Einfluss der vier Kompressionsparameter untersucht
werden. Um die Arbeitsweise der Kompressionsmethode nachvollziehbar zu gestalten und
eine Beurteilung des Kompressionsergebnisses zu erleichtern, wurde eine Möglichkeit
geschaffen, die im Kompressionsergebnis kenntlich macht, welches der drei Relevanz-
kriterien (Längsabweichung, Kurswinkeländerung oder Querabweichung) zum Abspeichern
einer Position geführt hat.
In Tabelle II.9 sind alle Parametersätze aufgelistet, die im Rahmen der Erprobungen bei
Anwendung der Kompressionsmethode auf die Beispieldaten untersucht wurden. Enthalten
sind außerdem die dabei erzielten Kompressionsergebnisse; die letzte Spalte gibt die
Bildnummer an, in der das Kompressionsergebnis für die jeweilige Parameterkombination
dargestellt ist. Die Visualisierung des Kompressionsergebnisses in Bild II.58 beschränkt sich
auf den in Bild II.57 markierten Bereich am nördlichen Vorgewende des Schlages. Dieser
Bereich wurde für die visuelle Beurteilung des Ergebnisses als repräsentativ ausgewählt, da
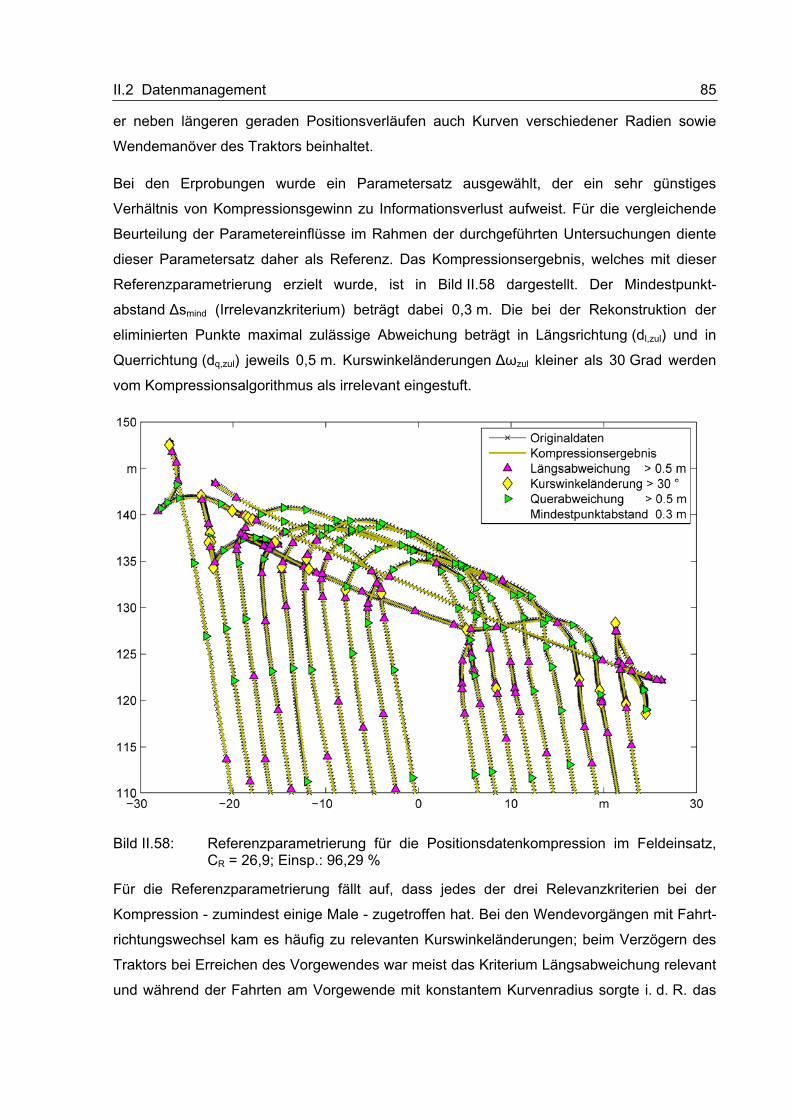
II.2 Datenmanagement 85
er neben längeren geraden Positionsverläufen auch Kurven verschiedener Radien sowie
Wendemanöver des Traktors beinhaltet.
Bei den Erprobungen wurde ein Parametersatz ausgewählt, der ein sehr günstiges
Verhältnis von Kompressionsgewinn zu Informationsverlust aufweist. Für die vergleichende
Beurteilung der Parametereinflüsse im Rahmen der durchgeführten Untersuchungen diente
dieser Parametersatz daher als Referenz. Das Kompressionsergebnis, welches mit dieser
Referenzparametrierung erzielt wurde, ist in Bild II.58 dargestellt. Der Mindestpunkt-
abstand Δsmind (Irrelevanzkriterium) beträgt dabei 0,3 m. Die bei der Rekonstruktion der
eliminierten Punkte maximal zulässige Abweichung beträgt in Längsrichtung (dl,zul) und in
Querrichtung (dq,zul) jeweils 0,5 m. Kurswinkeländerungen Δωzul kleiner als 30 Grad werden
vom Kompressionsalgorithmus als irrelevant eingestuft.
Bild II.58: Referenzparametrierung für die Positionsdatenkompression im Feldeinsatz, CR = 26,9; Einsp.: 96,29 %
Für die Referenzparametrierung fällt auf, dass jedes der drei Relevanzkriterien bei der
Kompression - zumindest einige Male - zugetroffen hat. Bei den Wendevorgängen mit Fahrt-
richtungswechsel kam es häufig zu relevanten Kurswinkeländerungen; beim Verzögern des
Traktors bei Erreichen des Vorgewendes war meist das Kriterium Längsabweichung relevant
und während der Fahrten am Vorgewende mit konstantem Kurvenradius sorgte i. d. R. das
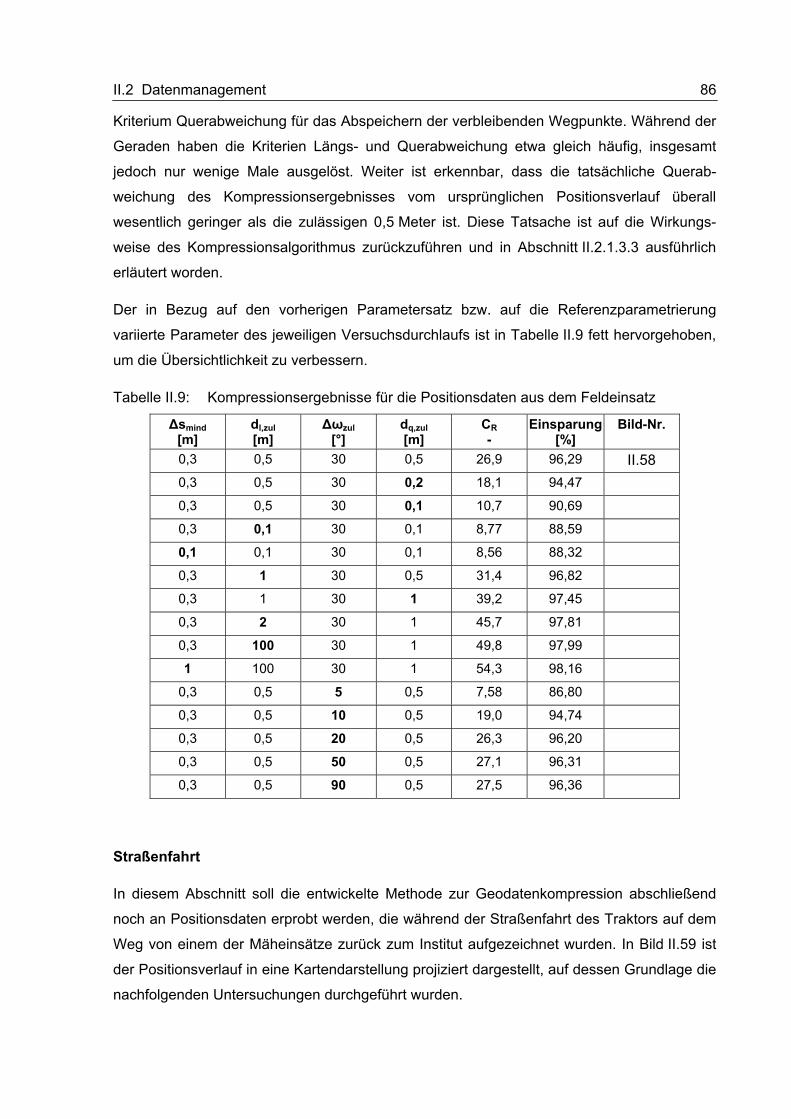
II.2 Datenmanagement 86
Kriterium Querabweichung für das Abspeichern der verbleibenden Wegpunkte. Während der
Geraden haben die Kriterien Längs- und Querabweichung etwa gleich häufig, insgesamt
jedoch nur wenige Male ausgelöst. Weiter ist erkennbar, dass die tatsächliche Querab-
weichung des Kompressionsergebnisses vom ursprünglichen Positionsverlauf überall
wesentlich geringer als die zulässigen 0,5 Meter ist. Diese Tatsache ist auf die Wirkungs-
weise des Kompressionsalgorithmus zurückzuführen und in Abschnitt II.2.1.3.3 ausführlich
erläutert worden.
Der in Bezug auf den vorherigen Parametersatz bzw. auf die Referenzparametrierung
variierte Parameter des jeweiligen Versuchsdurchlaufs ist in Tabelle II.9 fett hervorgehoben,
um die Übersichtlichkeit zu verbessern.
Tabelle II.9: Kompressionsergebnisse für die Positionsdaten aus dem Feldeinsatz
Δsmind [m]
dl,zul [m]
Δωzul [°]
dq,zul [m]
CR -
Einsparung [%]
Bild-Nr.
0,3 0,5 30 0,5 26,9 96,29 II.58 0,3 0,5 30 0,2 18,1 94,47
0,3 0,5 30 0,1 10,7 90,69
0,3 0,1 30 0,1 8,77 88,59
0,1 0,1 30 0,1 8,56 88,32
0,3 1 30 0,5 31,4 96,82
0,3 1 30 1 39,2 97,45
0,3 2 30 1 45,7 97,81
0,3 100 30 1 49,8 97,99
1 100 30 1 54,3 98,16
0,3 0,5 5 0,5 7,58 86,80
0,3 0,5 10 0,5 19,0 94,74
0,3 0,5 20 0,5 26,3 96,20
0,3 0,5 50 0,5 27,1 96,31
0,3 0,5 90 0,5 27,5 96,36
Straßenfahrt
In diesem Abschnitt soll die entwickelte Methode zur Geodatenkompression abschließend
noch an Positionsdaten erprobt werden, die während der Straßenfahrt des Traktors auf dem
Weg von einem der Mäheinsätze zurück zum Institut aufgezeichnet wurden. In Bild II.59 ist
der Positionsverlauf in eine Kartendarstellung projiziert dargestellt, auf dessen Grundlage die
nachfolgenden Untersuchungen durchgeführt wurden.
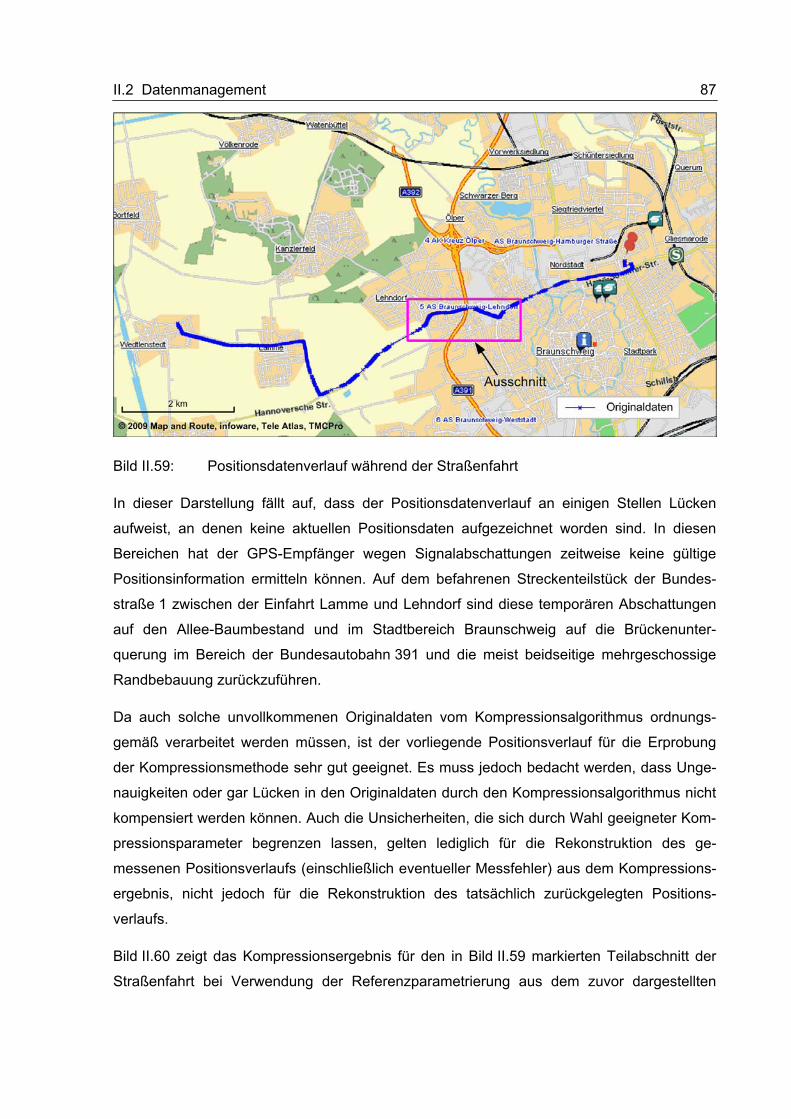
II.2 Datenmanagement 87
Bild II.59: Positionsdatenverlauf während der Straßenfahrt
In dieser Darstellung fällt auf, dass der Positionsdatenverlauf an einigen Stellen Lücken
aufweist, an denen keine aktuellen Positionsdaten aufgezeichnet worden sind. In diesen
Bereichen hat der GPS-Empfänger wegen Signalabschattungen zeitweise keine gültige
Positionsinformation ermitteln können. Auf dem befahrenen Streckenteilstück der Bundes-
straße 1 zwischen der Einfahrt Lamme und Lehndorf sind diese temporären Abschattungen
auf den Allee-Baumbestand und im Stadtbereich Braunschweig auf die Brückenunter-
querung im Bereich der Bundesautobahn 391 und die meist beidseitige mehrgeschossige
Randbebauung zurückzuführen.
Da auch solche unvollkommenen Originaldaten vom Kompressionsalgorithmus ordnungs-
gemäß verarbeitet werden müssen, ist der vorliegende Positionsverlauf für die Erprobung
der Kompressionsmethode sehr gut geeignet. Es muss jedoch bedacht werden, dass Unge-
nauigkeiten oder gar Lücken in den Originaldaten durch den Kompressionsalgorithmus nicht
kompensiert werden können. Auch die Unsicherheiten, die sich durch Wahl geeigneter Kom-
pressionsparameter begrenzen lassen, gelten lediglich für die Rekonstruktion des ge-
messenen Positionsverlaufs (einschließlich eventueller Messfehler) aus dem Kompressions-
ergebnis, nicht jedoch für die Rekonstruktion des tatsächlich zurückgelegten Positions-
verlaufs.
Bild II.60 zeigt das Kompressionsergebnis für den in Bild II.59 markierten Teilabschnitt der
Straßenfahrt bei Verwendung der Referenzparametrierung aus dem zuvor dargestellten
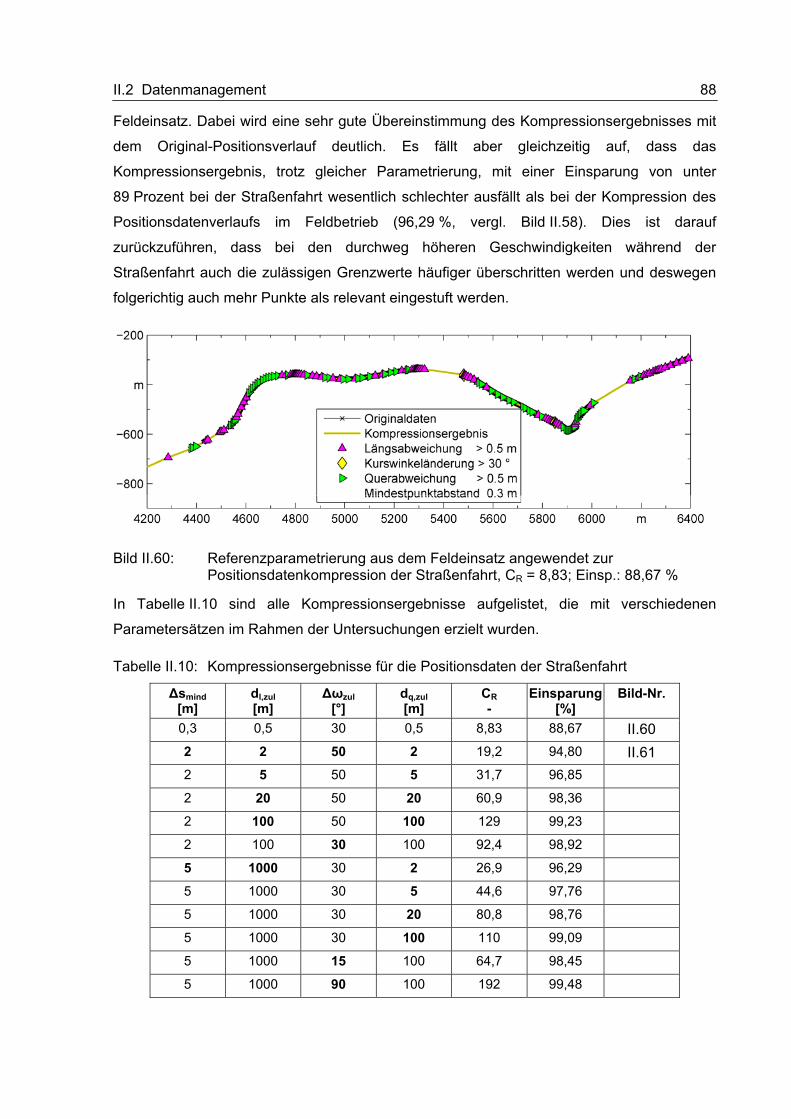
II.2 Datenmanagement 88
Feldeinsatz. Dabei wird eine sehr gute Übereinstimmung des Kompressionsergebnisses mit
dem Original-Positionsverlauf deutlich. Es fällt aber gleichzeitig auf, dass das
Kompressionsergebnis, trotz gleicher Parametrierung, mit einer Einsparung von unter
89 Prozent bei der Straßenfahrt wesentlich schlechter ausfällt als bei der Kompression des
Positionsdatenverlaufs im Feldbetrieb (96,29 %, vergl. Bild II.58). Dies ist darauf
zurückzuführen, dass bei den durchweg höheren Geschwindigkeiten während der
Straßenfahrt auch die zulässigen Grenzwerte häufiger überschritten werden und deswegen
folgerichtig auch mehr Punkte als relevant eingestuft werden.
Bild II.60: Referenzparametrierung aus dem Feldeinsatz angewendet zur Positionsdatenkompression der Straßenfahrt, CR = 8,83; Einsp.: 88,67 %
In Tabelle II.10 sind alle Kompressionsergebnisse aufgelistet, die mit verschiedenen
Parametersätzen im Rahmen der Untersuchungen erzielt wurden.
Tabelle II.10: Kompressionsergebnisse für die Positionsdaten der Straßenfahrt
Δsmind [m]
dl,zul [m]
Δωzul [°]
dq,zul [m]
CR -
Einsparung [%]
Bild-Nr.
0,3 0,5 30 0,5 8,83 88,67 II.60 2 2 50 2 19,2 94,80 II.61 2 5 50 5 31,7 96,85
2 20 50 20 60,9 98,36
2 100 50 100 129 99,23
2 100 30 100 92,4 98,92
5 1000 30 2 26,9 96,29
5 1000 30 5 44,6 97,76
5 1000 30 20 80,8 98,76
5 1000 30 100 110 99,09
5 1000 15 100 64,7 98,45
5 1000 90 100 192 99,48
II.2 Datenmanagement 89
Da bei der Straßenfahrt davon ausgegangen werden kann, dass die Genauig-
keitsanforderungen an das Kompressionsergebnis geringer sind als beim Feldeinsatz, wird
zunächst untersucht, welche Auswirkung die Vergrößerung der Kompressionsparameter dq,zul
und dl,zul auf das Kompressionsergebnis hat. Zudem wird auch der Mindestpunktabstand
Δsmind auf einen Wert von zwei Metern und die zulässige Kurswinkeländerung Δωzul auf einen
Wert von 50 Grad erhöht.
Das dabei mit Werten für dl,zul und dq,zul von jeweils zwei Metern erzielte Kompressions-
ergebnis, welches in Bild II.61 dargestellt ist, zeigt trotz einer Verdopplung der Kom-
pressionsrate noch eine sehr gute Übereinstimmung mit dem Originalverlauf und dient daher
für die Positionsdatenkompression der Straßenfahrt als neue Referenzparametrierung.
Bild II.61: Neue Referenzparametrierung für die Positionsdatenkompression im Straßeneinsatz, CR = 19,2; Einsp.: 94,8 %
Im Rahmen dieses Abschnittes konnte an Hand praktischer Erprobungen an verschiedenen
Beispielen die prinzipielle Funktionsweise der entwickelten Methoden deutlich gemacht
werden. Außerdem wurde veranschaulicht, wie sich die Qualität der Kompressionsergeb-
nisse durch gezielte Variation des bzw. der Kompressionsparameter nachvollziehbar
beeinflussen lässt.
II.2.1.5 Hinweise für die Praxis
Im Rahmen der vorangegangenen Abschnitte wurde die Entwicklung verschiedener
Datenkompressionsmethoden zur Verwendung in Telematiksystemen bei mobilen
Arbeitsmaschinen dargelegt. Vom Zusammenstellen der Anforderungen über die
durchgeführten Vorversuche und den eigentlichen Entwicklungsprozess bis hin zur
praktischen Erprobung wurden dabei alle Schritte umfassend beschrieben.

II.2 Datenmanagement 90
In diesem Abschnitt sollen nun noch einige Hinweise zusammengestellt werden, die bei der
praktischen Umsetzung der entwickelten Datenkompressionsmethoden in einem Telematik-
system besonders zu beachten sind. Diese lassen sich drei verschiedenen Kategorien
zuordnen. Neben Hinweisen, die die Implementierung der Kompressionsalgorithmen auf
einer mobiltauglichen Rechnerplattform betreffen, werden wichtige Aspekte aufgeführt, die
für die Parametrierung der Algorithmen von Bedeutung sind. Im dritten Punkt werden
schließlich noch Hinweise zu den Einsatzmöglichkeiten und den Einsatzgrenzen der
entwickelten Kompressionsmethoden gegeben.
II.2.1.5.1 Hinweise zur Implementierung
Für eine produkttaugliche Implementierung der Kompressionsalgorithmen müssen einige
Punkte beachtet werden, die bei der vorgestellten prototypischen Implementierung
vernachlässigbar waren.
Serienimplementierung
Für die produkttaugliche Serienimplementierung ist zunächst eine geeignete Rechner-
hardware auszuwählen, die einerseits die notwendigen Schnittstellen (u. a. CAN) sowie
darüber hinaus die nötigen Speicherressourcen mitbringt und über eine ausreichende
Rechenleistung verfügt. Entsprechend des nutzbaren Betriebssystems bzw. der nutzbaren
Laufzeitumgebung für die ausgewählte Rechnerhardware, ist eine geeignete Programmier-
sprache auszuwählen, in der die Kompressionsalgorithmen implementiert werden können.
Aus heutiger Sicht scheinen sog. dienstebasierte Software-Architekturen besonders gut
geeignet für die Implementierung der Datenkompressionsalgorithmen [GGRM07]. In einer
solchen Architektur können die beiden entwickelten Kompressionsalgorithmen als sog.
Anwendungsdienste eingebunden werden, die dann während der Laufzeit bedarfsgesteuert
(zur Kompression verschiedener Messgrößen ggf. auch mehrfach mit unterschiedlichen
Parametersätzen) gestartet werden können.
Abschaltvorgänge
Ein weiterer Punkt, der unbedingt beachtet werden muss ist, dass die Rechnerhardware, die
auf der mobilen Arbeitsmaschine zum Einsatz kommt und auf der die Kompressions-
algorithmen laufen, nicht permanent mit Betriebsspannung versorgt werden kann. In der
Regel wird beim Abstellen des Verbrennungsmotors der mobilen Arbeitsmaschine nach einer
kurzen Verzögerungsphase die Spannungsversorgung der auf der Maschine installierten
Systeme unterbrochen. Da zwischen dem Abstellen der Maschine und einer anschließenden

II.2 Datenmanagement 91
Wiederinbetriebnahme unter Umständen mehrere Monate liegen können, muss diesen
Abschaltvorgängen auch bei der Implementierung der Kompressionsalgorithmen besondere
Beachtung geschenkt werden, damit keine Daten verloren gehen.
Beide entwickelten Algorithmen schließen den zurückliegenden Signalverlauf immer erst
dann ab, wenn eine relevante Information detektiert wird. Um keine Daten zu verlieren, muss
beim Abschalten der Maschine ein Relevanzkriterium bewusst ausgelöst werden, um den
aktuellen Datensatz abzuschließen und abzuspeichern. Dieses Vorgehen bietet sich auch
an, wenn alle zurückliegenden Daten zu einem bestimmten Zeitpunkt von der Maschine aus
übertragen werden sollen.
II.2.1.5.2 Hinweise zur Parametrierung
Im Rahmen der experimentellen Erprobungen wurden verschiedene Erfahrungen hinsichtlich
der Parametrierung der beiden Kompressionsalgorithmen gemacht, die an dieser Stelle noch
einmal kurz zusammengefasst werden sollen.
Messwert-Zeitreihen
Für die Wahl des richtigen Wertes für den Kompressionsparameter dzul ist zunächst immer
entscheidend, wozu die Daten anschließend – also nach der Kompression – verwendet
werden sollen und wie viel Informationsverlust dabei akzeptiert werden kann. Außerdem
hängt der zu wählende, absolute Wert für dzul natürlich auch sehr stark von der Einheit und
dem Wertebereich der zu komprimierenden Größe ab. Deswegen lassen sich hierzu an
dieser Stelle keine pauschalen, absoluten Zahlenwerte als Empfehlung formulieren.
Es kann jedoch festgehalten werden, dass sich bei allen vier untersuchten Messgrößen gute
bis sehr gute Übereinstimmungen des Kompressionsergebnisses mit dem Originalsignal
ergeben haben, solange für dzul Werte eingesetzt wurden, die nicht mehr als zwei Prozent
des zu erwartenden maximalen Wertes der Messgröße betrugen. Eine relative
Parametervorgabe, bezogen auf den maximal zu erwartenden Betrag der Messgröße, kann
demnach für die hier untersuchten Messgrößen prinzipiell als Richtwert empfohlen werden.
Für andere Signale ist diese Empfehlung jedoch im Einzelfall zu überprüfen.
Eine weitere Möglichkeit zur Parametervorgabe bestünde darin, diesen relativ, in Bezug auf
den jeweils aktuellen Mittelwert, anzugeben. Damit wäre die Parametervorgabe völlig
unabhängig vom zu erwartenden Wertebereich der zu komprimierenden Messgröße möglich.
Dies hätte jedoch zur Folge, dass im Bereich nahe Null bereits viel geringere absolute
Abweichungen als relevant eingestuft würden als wenn das Signal deutlich von Null

II.2 Datenmanagement 92
verschieden ist. Aus diesem Grund wurden im Rahmen der hier vorgestellten
Untersuchungen nur Erprobungen mit absoluter Parametervorgabe durchgeführt.
Bei den experimentellen Erprobungen konnte außerdem festgestellt werden, dass sich diese
Kompressionsmethode unter gewissen Bedingungen auch zur verlustfreien Kompression
eignet. Dazu muss für den Kompressionsparameter dzul der Wert Null gewählt werden. Für
den Fall, dass das Originalsignal mehrere aufeinander folgende, gleiche Werte enthält,
können diese im Kompressionsergebnis eingespart werden, ohne dabei Informationen zu
verlieren. Die damit erzielbaren Einsparungen sind umso größer, je geringer die zu
komprimierenden Werte aufgelöst sind, je weniger dynamisch sich das Originalsignal ändert
und je höher die Abtastrate beim Einlesen der Daten ist.
Positionsdaten
Auch die zu wählenden Parameter für die Positionsdatenkompression hängen zunächst
maßgeblich von den Genauigkeitsanforderungen ab, die an das Kompressionsergebnis
gestellt werden. Da die Methode zur Kompression von Positionsdaten ausschließlich für eine
Datenart eingesetzt wird, fällt es hier etwas leichter, einige allgemein gültige Hinweise zur
Parameterwahl zu formulieren. Da sich die Parameter in Ihrer Wirkungsweise teilweise
gegenseitig beeinflussen, dürfen die vier Parameter nicht völlig losgelöst voneinander
betrachtet werden. Wird beispielsweise nur der Parameter dl,zul verändert, so führt dies nicht
nur dazu, dass weniger Werte auf Grund des Kriteriums Längsabweichung abgespeichert
werden, sondern in der Regel nimmt dadurch auch die Summe der Punkte zu, die auf Grund
zu großer Querabweichung als relevant gelten.
Um keine relevanten Positionsinformationen zu verlieren, sollte der Parameter Δsmind i. d. R.
immer kleiner sein, als der kleinste der beiden Parameter dl,zul und dq,zul.
Für das Kriterium Kurswinkeländerung wurden im Rahmen der durchgeführten Untersuch-
ungen durchweg gute Ergebnisse erzielt, wenn für den Parameter Δωzul Werte größer als
20 Grad gewählt wurden. Um Reversiervorgänge sicher erfassen und den Wendepunkt als
relevant einstufen zu können, sollte der Wert für Δωzul jedoch nicht größer als 90 Grad sein.
Falls an das Kriterium Längsabweichung im Kompressionsergebnis keinerlei Anforderungen
gestellt werden, so kann für dl,zul einfach ein sehr großer Wert (z. B. 1000 m) eingesetzt
werden. Durch diese Maßnahme lässt sich das Kriterium zu Gunsten einer höheren
Kompressionsrate sehr einfach außer Kraft setzen.

II.2 Datenmanagement 93
Für den Fall, dass bei der Rekonstruktion der zurückgelegten Strecke sowohl die
Genauigkeit der Längs- als auch der Querabweichung von Bedeutung ist, so sollten die
Werte für dl,zul und dq,zul sich nicht zu sehr unterscheiden. Bei der Definition dieser
Kompressionsparameter wurde sehr auf ein hohes Maß an Anschaulichkeit geachtet. Beide
Werte geben an, wie weit eine aus dem Kompressionsergebnis für einen bestimmten
Zeitpunkt rekonstruierte Position maximal von der tatsächlich zu diesem Zeitraum ermittelten
Originalposition abweichen kann. In Abschnitt II.2.1.3.3 wurde bei der Beschreibung der
zugehörigen Kompressionsalgorithmen bereits erläutert, dass es meist schon vor Erreichen
einer tatsächlichen Abweichung in Höhe dieser Grenzwerte zum Auslösen der Kriterien
kommt. Deswegen sind die tatsächlichen Abweichungen der Punkte in Längs- und
Querrichtung in der Praxis meist nur etwa halb so groß wie die eingestellten Grenzwerte.
Eine Garantie für diese Unterschreitung der Grenzwerte gibt es zwar nicht, jedoch kann der
Umstand bei der Festlegung der Parameter durchaus berücksichtigt werden.
Wie bereits in Abschnitt II.2.1.4.3 angedeutet, soll an dieser Stelle nochmals darauf
hingewiesen werden, dass Ungenauigkeiten, die schon in den Originaldaten vorhanden sind,
durch den Kompressionsalgorithmus nicht kompensiert werden können. Auch die
Unsicherheiten, die sich durch die Wahl geeigneter Kompressionsparameter begrenzen
lassen, gelten lediglich für die Rekonstruktion des gemessenen Positionsverlaufs
(einschließlich eventueller Messfehler) aus dem Kompressionsergebnis, nicht jedoch für die
Rekonstruktion des tatsächlich zurückgelegten Positionsverlaufs.
Allgemeiner Hinweis zur Parametrierung
Bei der Entwicklung der Kompressionsmethoden wurde entsprechend der Anforderungen
aus Abschnitt II.2.1.1 darauf geachtet, dass die Parameter den Kompressionsalgorithmen
extern bereitgestellt werden können. In Kombination mit dienstebasierten Software-
Architekturen lassen sich die Kompressionsalgorithmen so kontextsensitiv, also in
Abhängigkeit weiterer Umstände, parametrieren. Die Parametrierung muss also nicht
einmalig mit festen Parametern erfolgen, sondern kann den Erfordernissen sehr flexibel
angepasst werden. In diesem Fall muss ein separater Softwaredienst die Aufgabe
übernehmen, auf Basis der Kontextinformationen die passenden Kompressionsparameter
auszuwählen und diese den Kompressionsdiensten bereitzustellen.

II.2 Datenmanagement 94
II.2.1.5.3 Hinweise zu Einsatzmöglichkeiten und -grenzen
Abschließend soll noch kurz auf einige Fälle eingegangen werden, bei denen ein Einsatz der
entwickelten Kompressionsmethoden möglich und sinnvoll erscheint. Zudem werden auch
die Einsatzgrenzen der entwickelten Methoden zur Datenkompression aufgezeigt.
Einsatzmöglichkeiten
Zu den klassischen Anwendungsfällen von Telematiksystemen bei mobilen Arbeitsmaschi-
nen zählen die Dokumentation, die Datenerhebung zur Entscheidungsunterstützung (z. B.
Flottenmanagement) sowie die Prozess- und Zustandsüberwachung. Die entwickelten
Datenkompressionsmethoden sind für einen Einsatz im Rahmen all dieser Anwendungsfälle
prädestiniert, da sie es ermöglichen, in einer bestimmten Datenmenge wesentlich mehr
relevante Informationen zu übertragen als wenn die Übertragung ohne vorherige
Kompression erfolgen würde.
Die entwickelten Methoden eignen sich aber nicht ausschließlich für die Kompression der
Daten vor einer drahtlosen Übertragung. Sie können ebenso für eine nachträgliche Kompres-
sion der Daten vor der Archivierung (z. B. auf einem stationären Datenserver) dienen. Dabei
steht nicht primär die Einsparung von Speicherplatz, der sich bei stationären Systemen
relativ kostengünstig und nahezu unbegrenzt erweitern lässt, im Vordergrund, sondern der
Fokus liegt dabei auf den vereinfachten Zugriffs- und Darstellungsmöglichkeiten, die die klei-
neren Datenmengen gegenüber den unkomprimierten Daten bieten. Da die komprimierten
Daten ihren zeitlichen Bezug behalten und auch die komprimierten Messgrößen weiterhin in
ihrer ursprünglichen Skalierung vorliegen, ist keine Dekomprimierung erforderlich. Das
begünstigt den Zugriff auf die komprimiert vorliegenden Informationen sehr.
Auf Grund der beschriebenen Eigenschaften und der universellen Verwendbarkeit können
die entwickelten Methoden, über den Bereich der mobilen Arbeitsmaschinen hinaus,
prinzipiell auch für Anwendungen auf anderen Gebieten interessant sein.
Einsatzgrenzen
Bedingt durch die Arbeitsweise der Kompressionsmethoden ergeben sich jedoch auch
Einsatzgrenzen. Zwar sind beide Methoden prinzipiell online-fähig, d. h. Daten können
unmittelbar so vom jeweiligen Algorithmus verarbeitet werden, wie sie vom CAN-Bus
einlaufen. Das Kompressionsergebnis steht als Ausgangssignal jedoch erst mit einem mehr
oder weniger langen zeitlichen Verzug zur Verfügung, dessen Dauer vom Messgrößen-
verlauf und den gewählten Kompressionsparametern abhängt. Erst wenn ein Messwert oder

II.2 Datenmanagement 95
eine Position als relevant eingestuft wird, ist der davor liegende Signalverlauf seit dem
vorherigen relevanten Ereignis im Kompressionsergebnis bekannt. Für die Dauer seit dem
letzten relevanten Ereignis im Originalsignal bis zum aktuell betrachteten Zeitpunkt enthält
das Kompressionsergebnis noch keine Informationen. Diese variablen Verzugszeiten sind
der Grund dafür, dass die entwickelten Methoden sich nicht für den Einsatz in
Zusammenhang mit laufzeitkritischen Anwendungen wie beispielsweise Regelungen eignen.
Unerwünschtes Systemverhalten oder Fehlfunktionen könnten hier die Folge sein,
weswegen für diesen Einsatzfall von einer Verwendung der Kompressionsverfahren
unbedingt abzusehen ist.

II.2 Datenmanagement 96
II.2.2 Software-Architektur und Datenfluss
Ein wichtiges Ziel während des Projektes war es, eine offene, flexible und portable Software-
Architektur für die On-Board-Unit zu entwickeln. Im Rahmen des Projektes sollten zwei
unterschiedliche Systeme mit unterschiedlicher Ausstattung eingesetzt werden und der
Portierungsaufwand für die Software so gering wie möglich gehalten werden.
Gerade auch die Bestandteile des Systems für die Steuerung der Kommunikation sollten
möglichst ohne Anpassungen übernommen werden können
II.2.2.1 On-Board-Unit
Die On-Board-Unit übernimmt verschiedene Aufgaben, die hier kurz aufgeführt werden
sollen:
• Sammlung der Sensordaten und Aktorstellungen über den CAN-Bus der
Erntemaschine. Wobei mehrere CAN-Busse auf der Maschine vorhanden sein
können, die alle gleichzeitig überwacht werden müssen.
• Bestimmung der Position über den integrierten GPS-Empfänger
• Steuerung der Kommunikation über die zur Verfügung stehenden
Kommunikationswege
• Kompression der Daten
II.2.2.1.1 Eingesetzte Hardware
In dem Projekt wurden zwei unterschiedliche On-Board-Units aus dem Automotive-Bereich
eingesetzt:
• CarMediaLab The Flea
• T-Systems/gedas gComet
Die eingesetzte Hardware unterscheidet sich in den verfügbaren Ressourcen deutlich.
Während der Flea ein 32-bit Microcontroller-basiertes System ist (Infineon TriCore), nutzt der
gComet einen x86-kompatiblen Prozessor (AMD Geode). Auch die Speicherausstattung
unterscheidet sich. Beiden Plattformen gemeinsam ist die Nutzung von Linux als
Betriebssystem. Durch die unterschiedlichen Prozessor-Architekturen ergeben sich aber

II.2 Datenmanagement 97
trotz des gleichen Betriebssystems deutliche Unterschiede. Auch die Anbindungen der
zusätzlichen Hardware auf Treiber-Ebene (GPS, CAN, GPRS) ist zwischen den beiden
Systemen nicht kompatibel.
II.2.2.1.2 Programmiersprachen
Auf beiden Plattformen ist eine Java-Laufzeitumgebung (JRE) verfügbar. Während die x86-
Plattform offiziell von Sun unterstützt wird, ist auf dem Flea nur eine Kaffe VM verfügbar, die
zudem nur Java 1.3 unterstützt.
Für die Entwicklung der Treiber zum direkten Zugriff auf die Hardware wurde C in
Verbindung mit dem Java Native Interface eingesetzt. So kann direkt aus Java heraus auf
die Schnittstellen zugegriffen werden, wenn die entsprechenden Funktionen in C umgesetzt
wurden.
II.2.2.2 Software-Architektur
II.2.2.2.1 Einleitung
Aus Gründen der Portabilität wurde Java als Programmiersprache gewählt, da diese
aufgrund der Java Virtual Machine (JVM) Plattform-unabhängig ist. Die Plattform-
abhhängigen Teile wie Treiber wurden über JNI eingebunden.
Außerdem ist Java eine objekt-orientierte Programmiersprache, die für viele Plattformen
verfügbar ist. Aufgrund der virtuellen Maschine ist außerdem das Nachladen von
Programmteilen zur Laufzeit möglich, die auf mehreren Plattformen gleichzeitig Laufen.
Dieses wäre beispielsweise in C++ nicht möglich gewesen. Über dynamisch gelinkte
Bibliotheken lassen sich zwar Module dynamisch Nachladen und auch zur Laufzeit
austauschen, aber diese Bibliotheken müssen in kompilierter Form für jede Plattform einzeln
bereitgestellt werden.
Für das dynamische Nachladen und Austauschen von Programmteilen gibt es in Java
bereits ein standardisiertes Framework – OSGi. OSGi steht für Open Services Gateway
initiative. Dabei handelt es sich um hardware-unabhängige, dynamische Software-Plattform,
die es erleichtert, Anwendungen und ihre Dienste per Komponentenmodell zu modularisieren
und zu verwalten.

II.2 Datenmanagement 98
II.2.2.2.2 Schichtentrennung
Neben OSGi als Komponentenmodell für die einzelnen Anwendungsmodule wurde
zusätzlich ein Schichtenmodell für die OBU spezifiziert. Dabei werden drei Schichten
unterschieden.
Die erste Schichte – der Hardware Abstraction Layer (HAL) – stellt die nicht portablen
Bestandteile der Anwendung dar. Diese müssen für jede Plattform angepasst und
bereitgestellt werden. Diese Schicht wurde so klein und schlank wie möglich gehalten, um
den Portierungsaufwand zu minimieren.
Die zweite Schicht – die Basisdienste – stellen grundlegende Funktionalitäten bereit. Dabei
handelt es sich bereits um anwendungsrelevante Funktionen, wie das Ermitteln der aktuellen
Position, das Lesen von Sensor- und Aktor-Informationen, die Ablage von Daten und das
Übertragen von Daten. Diese stellen eine anwendungsorientierte Schnittstelle für den Zugriff
auf die Hardware-Ressourcen bereit. Die Basisdienste dürfen keine Abhängigkeiten zur
Hardware haben, sondern nur die fest definierten Schnittstellen des HAL nutzen. Dadurch
sind die Basisdienste zwischen verschiedenen Plattformen portabel.
Die dritte und letzte Schicht – die Anwendungsdienste – setzen schließlich die
Anwendungsfälle für den Einsatz der OBU um. Dabei handelt es sich unter anderem um die
Kommunikationssteuerung, Fahrspurverfolgung, Datenlogging und Datenkompression. Die
Anwendungsdienste sollten nur auf die Basisdienste oder andere Anwendungsdienste
zurückgreifen. Ein direkter Zugriff auf den HAL ist zwar möglich, sollte aber vermieden
werden. Wenn hier Funktionen fehlen, so sollten sie bei den Basisdiensten ergänzt oder ein
neuer Basisdienst geschaffen werden.
II.2.2.2.3 Schichtenarchitektur
Das nachfolgende Bild II.62 stellt das im vorigen Abschnitt beschriebene Schichtenmodell
mit den einzelnen Diensten dar. Nicht alle dargestellten Dienste wurden im Rahmen des
Projektes auch umgesetzt. Lediglich die für die Ziele des Projektes wichtigen wurden auch
tatsächlich umgesetzt. Die weiteren Dienste wurden zur Einordnung der Funktionen in die
Architektur exemplarisch mit aufgeführt, da sie für Telematik- und Teleserviceanwendungen
allgemein von Bedeutung sind.

II.2 Datenmanagement 99
Bild II.62: Schichtenarchitektur der On-Board-Unit
II.2.2.3 Beschreibung der Dienste
Im Folgenden werden die umgesetzten Dienste beschrieben.
II.2.2.3.1 GSM-Treiber
Der GSM-Treiber ist für die Kommunikation über das GSM-Mobilfunknetz zuständig. Über
ihn kann eine Internet-Verbindung aufgebaut werden, können eingehende Telefonanrufe
erkannt werden und können SMS verschickt und empfangen werden.
II.2.2.3.2 WLAN-Treiber
Der WLAN-Treiber ist für das Überwachen und Steuern der WLAN-Kommunikation
zuständig. Über ihn werden bekannte WLAN-Netze bei Verfügbarkeit erkannt und
Verbindungen auf- und abgebaut.
II.2.2.3.3 GPS/Galileo
Die Aufgabe des GPS-Treibers ist es, aktuelle Positionsinformationen zu liefern. Zusätzlich
werden Status-Informationen geliefert, wie die Anzahl der empfangenen Satelliten,
Geschwindigkeit und Genauigkeit.

II.2 Datenmanagement 100
II.2.2.3.4 CAN-Bus Interface
Das CAN-Bus-Interface liest Informationen von einem oder mehreren CAN-Bussen der
Maschine. Über den CAN-Bus sind üblicherweise die Sensorinformationen verfügbar.
II.2.2.3.5 Positioning
Der Positioning-Dienst stellt interpretierte Ortsinformationen bereit. Dabei ist die Darstellung
der Ortsinformation unabhängig vom Satellitensystem. Dadurch können sowohl transparent
die Satellitensysteme zwischen GPS, Galileo und GLONASS gewechselt werden, aber auch
mehrere parallel betrieben werden, um die Genauigkeit und Verfügbarkeit zu steigern.
II.2.2.3.6 Kommunikation
Der Kommunikationsdienst ist für das Übertragen von Informationen zuständig. Er bündelt
die Kommunikation über SMS, GSM, GPRS, WLAN und Bluetooth zu einem einheitlichen
Dienst.
II.2.2.3.7 Sensoren/Aktoren
Der Sensor- und Aktordienst liefert Sensor- und Aktorinformationen der Maschine, die vom
CAN-Bus gelesen werden. Dieser Dienst ist außerdem für eine einheitliche Darstellung der
Informationen zuständig. So abstrahiert er von den rein technischen Darstellungsformen in
Bits und Bytes der CAN-Botschaften und liefert semantisch aufbereitete Informationen, wie
beispielsweise eine Motordrehzahl in U/min.
II.2.2.3.8 Datenablage
Der Datenablage-Dienst dient der Speicherung von Daten auf dem System. Dabei
abstrahiert er von der tatsächlichen Speicherung und legt die Daten unabhängig vom
tatsächlichen Speichermedium ab (RAM, Festplatte, Flash-Speicher).
II.2.2.3.9 Datenlogger
Der Datenlogger ist der einfachste Anwendungsdienst. Seine Aufgabe ist es, eine vorher
festgelegte Zahl von Sensor-Informationen zusammen mit der Position in regelmäßigen
Abständen zu protokollieren und in regelmäßigen Abständen auch zu übertragen.

II.2 Datenmanagement 101
II.2.2.3.10 Datenverdichter
Der Datenverdichter ist eine erweiterte und verbesserte Form des Datenloggers. Neben dem
reinen Protokollieren der Informationen kann er sie zusätzlich verdichten, so dass sie
weniger Speicherplatz auf dem System benötigen und weniger Bandbreite bei der
Übertragung. Die in diesem Dienst umgesetzten Verfahren sind ein wichtiger Bestandteil des
Projektes.
II.2.2.3.11 Kommunikationsmanager
Der Kommunikationsmanager entscheidet, wann und wie Daten übertragen werden. Dazu
überwacht er die verfügbaren Kommunikationswege, die zu übertragenden Datenmengen
und die für die Kommunikation vorgegebenen Parameter, die über die Wichtigkeit der
einzelnen Informationen entscheiden.
Im Kommunikationsmanager wurde die variable Kommunikationsstruktur erfolgreich
umgesetzt, die eines der primären Ziele des Projektes waren.
II.2.2.4 Simulationsumgebung
Durch die modulare Architektur und die Nutzung von Java und OSGi mit fest definierten
Schnittstellen lässt sich für die Entwicklung und den Test von Modulen/Diensten leicht eine
Simulationsumgebung schaffen, was im Rahmen des Projektes auch gemacht wurde.
Einzelne Dienste können simuliert werden, so kann beispielsweise der Positionierungsdienst
Daten einer vorher aufgezeichneten Fahrt liefern, ebenso wie auch der Sensor- und
Aktorwert. So lassen sich darauf basierende Module wie der Datenverdichter während der
Entwicklung gezielt testen, ohne dass zeitraubende Feldversuche unternommen werden
müssen.
Durch die fest definierten Schnittstellen im Rahmen der OSGi-Architektur ist sichergestellt,
dass die so getesteten Dienste auch in der Zielumgebung ohne Anpassungen funktionieren.
Im Rahmen des Projektes wurden Simulationsdienste für die Positionierung und Sensor-
/Aktorwerte entwickelt und für den Test der Datenverdichtung genutzt.

II.2 Datenmanagement 102
II.2.2.5 Datenverarbeitung auf der OBU
Sensordienste sorgen auf der OBU dafür, dass Daten vom CAN-Bus ins System gelangen
und weiterverarbeitet werden. Diese Weiterverarbeitung geschieht durch Sensortransformer,
Datenverdichter und AlarmManager.
II.2.2.5.1 Sensordienste
Sensordienste sind, wie bereits angedeutet, tatsächlich keine Sensoren im eigentlichen
Sinne. Vielmehr dienen Sensordienste dazu, Sensordaten aus dem CAN-Bus-System der
Landmaschine aufzunehmen und an weiterverarbeitende Dienste weiterzuleiten.
Sensoren gehören zu den Basisdiensten und greifen auf das CAN-Bus-Interface im
Hardware Abstraction Layer zu, um an die benötigten Daten zu gelangen.
Das CAN-Bus-Interface besteht aus einer Programmbibliothek, die in der
Programmiersprache C geschrieben ist und die Rohdaten vom CAN-Bus aufnimmt. Mit Hilfe
eines Java Native Interfaces (JNI) gelangen sie zum OSGi-Bundle CanBridge. Dieses
Bundle stellt lediglich die OSGi-seitige Schnittstelle zu den nativen Bibliotheken dar. Die
erste Weiterverarbeitung geschieht dann im CanService: Hier werden Methoden zum Lesen
und Schreiben von CAN-Daten mit bestimmten IDs angeboten.
Erst im Sensor-Basisdienst, dem Bundle SensorActor, werden aus den CAN-Daten Integer-
oder Double-Zahlenwerte extrahiert. Dazu wird für jede ID, die ausgelesen werden soll, ein
Thread gestartet. Jeder dieser Sensordienste hat folgende Einstellungsmöglichkeiten:
• CAN-Bus: Die Nummer des CAN-Busses, von dem die Daten ausgelesen werden
sollen
• Message ID: Die Message-ID, auf die der Sensordienst lauschen soll. Hier sind
sowohl normale als auch extended Message-IDs möglich. Message-IDs, bei denen
die Inhalte von bestimmten Bits in der Nachricht abhängen, werden derzeit nicht
unterstützt.
• Update Interval: Das Intervall, mit denen die Daten ausgelesen werden. Die Angabe
erfolgt in Millisekunden.
• Start Bit: Die Bitnummer, bei der die auszulesende Zahl beginnt. Das erste Bit hat
hierbei die Nummer 0.

II.2 Datenmanagement 103
• Data Length: Die Länge der Zahl in Bit. Besteht die Zahl aus mehr als einem Byte, so
werden die Zahlen low-byte-first verarbeitet.
• Factor, Offset: Die Rohdaten können mit einem Faktor a und einem Offset b affin
verzerrt werden. Ist x die vom CAN-Bus gelesene Zahl, so wird bax +⋅ )( als
gelesener Wert bereit gehalten.
• Unit: Die Einheit, in der der Wert gemessen wird.
Ein Sensordienst implementiert sowohl das DataProvider-Interface als auch das
DataListenerRegistry-Interface. Darüber können andere Dienste entweder die gelesenen
Daten selbsttätig beim Sensordienst abholen, oder sie können sich als Listener registrieren
und so bei neuen Werten automatisch benachrichtigt werden.
II.2.2.5.2 Sensortransformer
Die Sensortransformer-Dienste gehören, wie die Sensoren, zu den Basisdiensten. Sie
dienen dazu, aus dem Werteverlauf eines Sensors einen neuen Wert zu berechnen.
Typischerweise werden Sensortransformer dazu benutzt, um Werte für Alarm-Manager
bereit zu halten. Dazu kann beispielsweise der aktuelle Gradient berechnet, Fraktile
bestimmt oder Korrelationsfunktionen durch die bisherigen Messwerte gelegt werden.
Sensortransformer melden sich bei einem Sensor als Listener an und halten, wie Sensoren
auch, die Werte sowohl über das DataProvider-Inerface, wie auch das DataListenerRegistry-
Interface bereit. So können sie von anderen Diensten genau wie Sensoren angesprochen
werden. Insbesondere können Daten der Sensortransformer damit auch über
Datenverdichter komprimiert werden und als Messwerte zum Backend gesendet werden.
Im Rahmen der Projektlaufzeit wurden beispielhaft zwei Sensortransformer vorgesehen:
• FraktilTransformer. Diese dienen dazu, einen Sensorwert über eine einstellbare
Anzahl von Werten zu beobachten und zu ermitteln, wo der kleinste Messwert der
oberen x Prozent der Werte liegt. Dies kann dazu benutzt werden, um aus dem
Differenzdruck am Luftfilter den Verschmutzungsgrad abzuleiten. Dieser Transformer
ist implementiert worden.
• RegressionTransformer. Dieser Transformer ist in der Lage, eine Regression n-ten
Grades durch die letzten Messwerte zu legen und aus deren Verlauf zu ermitteln,
wann die Messwerte voraussichtlich einen bestimmten Grenzwert überschreiten

II.2 Datenmanagement 104
werden. Dies kann mit einer kubischen Regression beispielsweise dazu benutzt
werden, die Kettenlängung vom Schrägförderer vorherzusagen.
II.2.2.5.3 Datenverdichter und Datenablage
Datenverdichter werden im OSGi-Bundle DataCompressor implementiert. Diese Dienste
gehören zu den Anwendungsdiensten. Jeder Datenverdichter ist dafür zuständig, einen
Sensorwert zu komprimieren und die Daten mit Hilfe des Basisdienstes Datenablage zu
speichern.
Ein Null-Verdichter kann dabei zum Loggen der Daten benutzt werden, so dass über die
Datenverdichter auch der Logging-Dienst realisiert werden kann.
Die Datenablage ist im OSGi-Bundle Persistence realisiert. Über das Interface Persistence
können neue Ablageplätze (Storages) angelegt, gesucht oder gelöscht werden. Beim
Anlegen kann über einen zusätzlichen Parameter die Art der Komprimierung eingestellt
werden: Keine Komprimierung, GZIP oder 7Z.
Um Daten in einem Storage abzulegen oder sie auszulesen, muss man sich einen
StorageHandle geben lassen. Darüber sind Funktionen zum Laden und Speichern von
Strings und Byte-Arrays realisiert. Darüberhinaus kann man sich einen DataOutput geben
lassen, um die primitiven Java-Datentypen als Binärdatei zu speichern.
Der Basisdienst Datenablage greift dabei nicht auf einen Dienst aus dem Hardware-
Abstraction-Layer zurück, da das Öffnen und Schließen von Dateien und die Verknüpfung
von Dateien mit Streams bereits von der Java-Virtual-Machine gekapselt wird.
Jeder Datenverdichter fordert bei der Datenablage einen eigenen Ablageplatz an und legt die
Daten in einem eigenen XML-Format (siehe Abschnitt II.2.2.8, XML-Dateistruktur) ab. Damit
die Daten das Backend erreichen können, implementieren sie das Interface
SendingDataProvider. Über dieses Interface können Datenkomprimierer aufgefordert
werden, die alte Datenablage abzuschließen und eine neue zu beginnen. Zudem kann über
dieses Interface der Kommunikations-Manager die Dateien, die zum Versand bereit stehen,
abfragen.
Bild II.63 zeigt eine Übersicht der beteiligten Module: Ein Datum liegt am CAN-Bus vor und
wird über den Sensordienst und das CAN-Bus-Interface vom Datenverdichter geholt. Hier
werden die Daten wie beschrieben komprimiert und an die Datenablage weitergereicht. Der
Kommunikationsmanager prüft, wie in Abschnitt II.2.2.7.2, Kommunikation mit dem Backend-
II.2 Datenmanagement 105
Intervalle beschrieben, regelmäßig die Größe der gespeicherten Dateien. Bei Bedarf wird
dann über den Kommunikationsdienst und den GSM-Treiber (oder einen anderen
Treiberdienst aus dem HAL) eine Internetverbindung zum Backend-Server aufgebaut und die
Daten versandt.
Bild II.63: Datenfluss und Beteiligte Module bei der Sammlung von Daten
II.2.2.5.4 Alarm-Manager
Alarm-Manager haben Ähnlichkeiten zu Datenverdichtern. Der wesentliche Unterschied ist,
dass sie die Daten nur beobachten und im richtigen Augenblick Alarm schlagen, statt Daten
zu sammeln und abzuspeichern.
Alarm-Manager melden sich als Listener bei einem Sensortransformer (oder auch direkt an
einem Sensor) an und bekommen von diesem dann die aktuellen Werte geliefert. Dieser
Sensorwert wird mit zwei (verschiedenen) Schwellwerten s1 und s2 verglichen.
Nun gibt es zwei Möglichkeiten für das Verhältnis zwischen s1 und s2:
1. s1<s2 oder
2. s1>s2.

II.2 Datenmanagement 106
In beiden Fällen wird ein gelber Alarm ausgelöst, wenn der neue Wert zwischen den beiden
Schwellen liegt. Ist der Wert echt größer als s2 (Fall 1) bzw. echt kleiner als s2 (Fall 2), so
wird ein roter Alarm ausgelöst. Ansonsten wird kein Alarm ausgelöst. Deswegen heißt s1 das
grüne Limit, s2 heißt das gelbe Limit.
Im Falle eines Alarms soll natürlich der Fahrer benachrichtig werden. Da im Rahmen des
DAMIT-Projektes kein Terminal- oder Displaydienst realisiert wurde, wird der Fahrer auch
nicht benachrichtig. Parallel dazu wird der Messwert zusammen mit einer Alarm-ID an das
Backend verschickt. Dieses stößt dann gegebenenfalls Teilautomatisierte
Geschäftsprozesse an – beispielsweise zur Wartung und Instandhaltung der Landmaschine.
Eine Übersicht zu diesem Vorgang bietet Bild II.64. Ein Datum liegt am CAN-Bus an, wird
durch den Sensordienst gelesen und (meist) an einen Werteanalyse-Dienst weitergereicht.
Dort wird aus dem bisherigen Datenfluss eine Kennzahl berechnet und an den Alarm-
Manager kommuniziert. Der Alarm-Manager entscheidet, ob und welcher Alarm ausgelöst
wird. Ein eventueller Alarm wird dann an den Kommunikationsmanager gemeldet, der dann
über den Kommunikationsdienst und einen geeigneten Treiber die Verbindung zum Internet
herstellt. Dann wird der Alarm ans Backend versandt.
Bild II.64: Datenfluss und Beteiligte Module für das Alarm-Management

II.2 Datenmanagement 107
II.2.2.6 Konfiguration der OBU
Die OBU kann über das Backend konfiguriert werden. Da auf Seiten des Backends nicht
sichergestellt werden kann, dass die OBU eingeschaltet oder empfangsbereit ist, wird die
Kommunikation von Seiten des mobilen Gerätes aus etabliert. Über einen HTTP-GET
übermittelt die OBU ihre Identifikation und bekommt dafür die für sie gültige Konfiguration
geliefert.
Eine Konfiguration besteht aus einer Datei im Properties-Format, d.h. in jeder Zeile steht ein
Key-Value-Paar, getrennt durch ein Gleichheitszeichen.
Bild II.65: Ausschnitt einer Properties-Datei
Die Keys beginnen alle mit einem Schlüsselwort für den Namensraum. Darüber wird die
Zuordnung der Properties zu den einzelnen Programmteilen realisiert. Der Namensraum wird
durch einen Punkt von dem restlichen Key abgetrennt. In Bild II.65 sind die Namensräume
Sensors_CAN und Sensors_Transformer zu erkennen. Sensors_CAN ist der Namensraum
für den Sensordienst, Sensors_Transformer der für die Werteanalyse. Zeilen, die mit einer
Raute (#) eingeleitet werden, sind Kommentarzeilen und dienen lediglich der besseren
Lesbarkeit für den Menschen.

II.2 Datenmanagement 108
Auf der OBU selbst melden sich alle Programmteile, die konfigurierbar sind, über die
Methode void appendConfigurable(Configurable) des Interfaces ConfManager beim
Konfigurations-Manager an. Wenn der Konfigurationsmanager dann mit einer neuen
Konfiguration versorgt wird, spaltet er diese zunächst in die verschiedenen Namensräume
auf und verteilt dann an alle konfigurierbaren Programmteile nur die Key-Value-Paare, die
dem Namensraum genügen.
Für eine initiale Konfiguration stehen auf der OBU üblicherweise zwei Konfigurationsdateien
zur Verfügung, die beide geladen werden:
1. Die Basis-Konfiguration, die insbesondere eine erste Konfiguration des
Kommunikations-Managers bereit stellen muss. Hierüber wird sichergestellt, dass die
mobile Einheit eine Verbindung zum Backend aufbaut, um sich von dort die gerade
gültige Konfiguration zu holen.
2. Die zuletzt vom Server geladene Konfiguration. Dies dient dazu, dass auch dann
Daten aufgezeichnet und Alarme verarbeitet werden, wenn vielleicht gerade keine
Verbindung hergestellt werden kann.
Der genaue Ablauf der Kommunikation wird im Abschnitt II.2.2.7, Kommunikation mit dem
Backend, beschrieben.
II.2.2.7 Kommunikation mit dem Backend
Da die OBU nicht ständig mit dem Internet verbunden ist, kann von außen nicht so leicht
eine Verbindung aufgebaut werden. Die Initiative hierzu geht immer von der OBU aus; sie
wählt sich auf einem geeigneten Weg ins Internet ein und sucht dann die Verbindung zum
Backend.
II.2.2.7.1 Schnittstelle zwischen OBU und Backend
Die Kommunikationsschnittstelle zum Backend erfolgt ausschließlich über das HTTP-
Protokoll. Wie bereits erwähnt, geht dabei die Initiative immer vom mobilen Gerät aus. Dazu
stehen für alle Kommandos, die vom mobilen Gerät an das Backend gerichtet werden,
Webseiten mit Formularen zur Verfügung, die über HTTP-GET bzw. HTTP-POST ausgefüllt
werden können.
Derzeit sind folgende Schnittstellen realisiert:

II.2 Datenmanagement 109
• Kommandos herunterladen. Hiermit kann der Server die OBU veranlassen, eine neue
Konfiguration zu laden oder Software-Pakete zu updaten.
• Konfiguration herunterladen. Auf diese Weise wird eine neue Konfiguration auf die
OBU geladen, wie in Abschnitt II.2.2.6, Konfiguration der OBU, beschrieben.
• Daten hochladen. Hier werden die gesammelten Daten zum Backend übertragen. Es
kann immer nur eine Datei übertragen werden; wenn mehrere Dateien übertragen
werden müssen, muss diese Seite mehrfach aufgerufen werden. Damit das Backend
die einzelnen Dateien auch versteht, muss als erstes ein Inhaltsverzeichnis über die
kommenden Dateien verschickt werden. Die Struktur der Dateien wird in Abschnitt
II.2.2.8, XML-Dateistruktur, beschrieben.
• Datei herunterladen. Hier können Binärdateien heruntergeladen werden. Dies dient
dazu, Software-Updates aufspielen zu können. Dazu wurde das OSGi-Paket
BundleManager implementiert, das in der Lage ist, während der Laufzeit Pakete
durch neue Dateien zu ersetzen.
• Alarm melden. Hierüber können Alarm-Manager ihren aktuellen Messwert an das
Backend übertragen. Die Entscheidung, was mit dem übertragenen Wert passieren
soll, wird im Backend gefällt.
Die einzige Möglichkeit, der OBU eine Mitteilung zu schicken, ist eine SMS, die über die
GSM-Anbindung der Digibox empfangen wird. Daraufhin stellt die mobile Einheit eine
Internet-Verbindung zum Backend her, um von dort die aktuellen Kommandos
herunterzuladen. Auf diese Weise wird auch verhindert, dass eine versehentliche SMS zu
einem größeren Schaden führt, weil die tatsächlichen Kommandos nicht über die SMS,
sondern über die Backend-Schnittstelle übertragen werden.
II.2.2.7.2 Intervalle
In der Konfiguration des Kommunikationsmanagers sind drei Intervalle wichtig:
1. Fehler-Intervall für das Empfangen einer Server-Konfiguration. Die OBU versucht,
möglichst schnell die Konfiguration zu empfangen. Gelingt dies nicht, wartet sie eine
Zeit lang, um dann einen neuen Versuch zu machen. Diese Schleife wird
unterbrochen, wenn das Herunterladen der Konfiguration gelungen ist und erst
wieder aufgenommen, wenn die OBU durch Kommandos dazu aufgefordert wird.

II.2 Datenmanagement 110
2. Intervall für das Empfangen von SMS. Die OBU schaut in regelmäßigen Abständen,
ob eine SMS empfangen wurde. Aufgrund von technischen Einschränkungen ist es
auf der Digibox derzeit nicht möglich, den SMS-Speicher zu prüfen, während eine
Internet-Verbindung über GPRS steht. Daher wird der SMS-Speicher nur geprüft,
wenn keine Verbindung zum Internet hergestellt ist.
3. Intervall für das Prüfen der Datenmenge für den besten derzeit verfügbaren
Kommunikationsweg. Hier wird in regelmäßigen Abständen geprüft, worüber die
derzeit beste Internet-Verbindung hergestellt werden könnte. Zu jeder Verbindungsart
gibt es eine Datenschwelle, ab der die Daten zum Backend versendet werden
müssen. Ist diese Datenschwelle überschritten, wird allen Datenverdichtern mitgeteilt,
dass sie neue Dateien beginnen sollen. Dann wird die Verbindung zum Internet
hergestellt und die Dateien werden versendet.
II.2.2.7.3 Versende-Strategien
Je nachdem, welche Hardware zur Verfügung steht, können unterschiedliche Wege benutzt
werden, um die OBU mit dem Internet zu verbinden. Auf der Digibox sind das das W-LAN
und GPRS, aber auch Bluetooth oder UMTS sind grundsätzlich denkbar.
Tabelle II.11: Einige mögliche Kommunikationsnetze mit Übertragungsgeschwindigkeit,
anfallende Kosten und Netzabdeckung
Netz Geschwindigkeit Kosten Abdeckung/Reichweite
WLAN Sehr schnell Niedrig Geringe Reichweite
Bluetooth Schnell Niedrig Sehr geringe Reichweite
UMTS Schnell Mittel Geringe Abdeckung
EDGE Mittel Hoch Mittlere Abdeckung
GPRS Langsam Hoch Große Abdeckung
SMS Sehr langsam Sehr hoch Sehr große Abdeckung
Wie Tabelle II.11 zeigt, können die unterschiedlichen Verbindungswege leicht in eine
Qualitäts/Kosten-Reihenfolge gebracht werden, da eine hohe Geschwindigkeit auch mit
geringen Kosten einhergeht. Leider läuft dem die Verfügbarkeit entgegen, d.h. die schnellen,
günstigen Verbindungen sind nur schlecht verfügbar.

II.2 Datenmanagement 111
Um einen Überlauf zu verhindern und unnötige Verbindungskosten zu vermeiden, wird
jedem möglichen Übertragungsweg n ein Datenschwellwert s(n) zugeordnet. Diese
Zuordnung heißt Versende-Strategie. Langsamen, teuren Verbindungen wird im Normalfall
ein höherer Schwellwert zugeordnet werden. Damit soll vermieden werden, Daten über eine
ungünstige Verbindung zu verschicken. Im Notfall jedoch muss auch eine langsame
Verbindung benutzt werden, um Datenverluste zu vermeiden.
Eine solche Versende-Strategie kann natürlich von Hand erstellt werden. Alternativ kann
man auch über einen Algorithmus aus der stochastischen dynamischen Optimierung eine
optimale Strategie automatisch bestimmen lassen.
II.2.2.7.4 Automatische Berechnung optimaler Strategien
Da die Fahrtwege, Datenmengen und die Übertragungswege nicht von vorne herein bekannt
sind, handelt es sich hierbei um eine stochastische Fragestellung. Als Kosten fallen dabei die
tatsächlichen Übertragungskosten an plus die Kosten, die durch Datenverluste entstehen. Je
nachdem wie wichtig die Daten sind, können Datenverluste hingenommen werden; daher
müssen sie als Kosten mit eingehen.
Eine Versende-Strategie heißt dann optimal, wenn die erwarteten Kosten minimal sind. Das
bedeutet, dass man eventuell im Nachhinein für eine konkrete Fahrt eine bessere Strategie
finden kann. Da die konkreten Daten aber erst im Nachhinein vorliegen, ist die optimale
Versende-Strategie die Beste, für die man sich entscheiden kann.
Zur Bestimmung der optimalen Strategie liegt folgendes mathematische Modell aus der
stochastischen dynamische Optimierung (siehe z. B. [KW03]) zugrunde:
Der Zustandsraum Z besteht aus allen möglichen Zuständen z mit
z = (n,d)
Dabei ist n das Beste der möglichen Netze (also W-LAN, Bluetooth, GPRS usw.) und d die
Größe der Daten in Byte. Wichtig ist, dass die Menge der Netze geordnet ist, d.h. wenn zwei
Netze verfügbar sind, kann man eindeutig das bessere Netz auswählen. So bedeutet also
beispielsweise z=(W-LAN,8192), dass das beste verfügbare Netz W-LAN ist und dass 8 kiB
Daten versendet werden müssen.
Die Menge der Aktionen hat zwei Elemente: versenden und lagern. Versenden bedeutet,
dass alle momentan vorhandenen Daten zum Backend-Server versendet werden und diese
von der OBU gelöscht werden. Lagern heißt, dass kein Versandt stattfindet. Wie bereits

II.2 Datenmanagement 112
oben angedeutet, entscheidet sich die OBU in festen Zeitintervallen für eine dieser beiden
Aktionen.
Je nach gewählter Aktion fallen Kosten c(z,a), abhängig vom Zustand z=(n,d) und der
gewählten Aktion a, an. Vorausgesetzt ist hier:
a) Die Lagerkosten sind unabhängig vom gewählten Netz, d.h.
c(lagern,n1,d) = c(lagern,n2,d)
b) Die Kosten müssen in d monoton wachsen
c) Es muss für jedes Netz n eine Größe dn geben, so dass für alle d>dn:
c(lagern,n,d) > c(versenden,n,d)
Die Kosten müssen nicht genau den realen Kosten entsprechen. Insbesondere sind die
Lagerkosten rein virtuelle Kosten, die einen möglichen Datenverlust und die Verzögerung,
mit der die Daten am Backend zur Verfügung stehen, repräsentieren.
Der Übergang von einem Zustand z1=(n,d1) zu einem Nachfolgezustand z2=(m,d2) ist
natürlich von der gewählten Aktion abhängig, da die Datenmenge zunächst entweder gleich
bleibt (bei der Aktion lagern) oder auf 0 fällt (bei der Aktion versenden). Trotzdem lässt sich
der Übergang nur durch eine Wahrscheinlichkeit beschreiben, da die im nächsten
Zeitintervall verfügbaren Netze und die hinzugekommenen Daten nicht vorhersehbar sind.
Zur Vereinfachung wird angenommen, dass eine konstante Datenmenge δd pro Zeitintervall
hinzukommt; die Menge hat sich in Experimenten als nicht sehr veränderlich herausgestellt.
Für die Netze allerdings benötigt man sogenannte Übergangswahrscheinlichkeiten: Die
Wahrscheinlichkeit pnm beschreibt die Wahrscheinlichkeit, dass man in einem Zustand als
bestes Netz n sieht und im Nachfolgezustand Netz m.
Damit ergeben sich, ausgehend von z1 für z2=(m,d2) und eine Aktion a, folgende
Wahrscheinlichkeiten:
P(d2=δd) = pnm, falls a=versenden
P(d2=d1+ δd) = pnm und falls a=lagern
Um eine optimale Strategie zu ermitteln, müssten jetzt die erwarteten Kosten, die sich aus
einer Entscheidung ergeben, aufaddiert werden. Dadurch ergeben sich aber automatisch

II.2 Datenmanagement 113
unendliche Kosten, weswegen auf die diskontierte Kostensumme zurückgegriffen wird. Die
Kosten die im k-ten Schritt entstehen, werden also mit βk multipliziert, mit 0<β<1.
Aufgrund der Struktur des Problems kann der Wert der diskontierten Folgekosten durch eine
ereignisgesteuerte Simulation (siehe z. B. [Kol08]) geschätzt werden, wobei die Anzahl der
Schritte der Simulation groß genug sein muss, damit jedes Netz hinreichend oft besucht
werden muss.
Um jetzt die optimale Strategie zu bestimmen, wird folgender Algorithmus verwendet:
1. Beginne mit einer zufälligen Strategie s.
2. Berechne für einen Zustand z die Ein-Schritt-Kosten der Aktionen versenden und
lagern.
3. Berechne die diskontierten Folgekosten für die Aktionen unter der Strategie s und
vergleiche die Gesamtkosten der Aktionen. Ist die billigere Aktion so, wie Strategie s
vorgibt, ist alles in Ordnung. Ist die billigere Aktion aber gerade anders, als Strategie
s vorgibt, so muss die Strategie s so geändert werden, dass die Wahl für Zustand
z=(n,d) korrigiert wird (indem s(n)=d oder s(n)=d-1 gesetzt wird, je nachdem, was
billiger ist).
4. Auf diese Art und Weise werden so lange Zustände ausgewertet, bis sich s nicht
mehr verändert. Dann weiß man aber, dass s optimal sein muss.
II.2.2.8 XML-Dateistruktur zur internen Datenübertragung
Zur Übertragung der Daten zwischen mobilem Arbeitsgerät und Backend-Server werden
Dateien im XML-Format übertragen. XML hat zwar gegenüber Binär-Formaten den Nachteil,
dass es einen relativ großen Overhead an Strukturinformationen hat. Durch einfache ZIP-
Komprimierung wird dieser Nachteil aber im Wesentlichen kompensiert, so dass die Vorteile,
z.B. robuste Parser, automatische Überprüfung der Korrektheit, mit nur geringen Nachteilen
einhergehen.
II.2.2.8.1 ISO-XML
Zum Datenaustausch zwischen mobilem Arbeitsgerät und Backend-Server wurde zunächst
das ISO-XML ins Auge gefasst [ISO09].Dabei handelt es sich um eine XML-Sprache, die
entwickelt wurde, um den Datenaustausch zwischen Programmen verschiedener Hersteller
zu vereinfachen.

II.2 Datenmanagement 114
Um Daten zu versenden, werden in ISO-XML die Daten nicht direkt im XML abgelegt,
sondern in einer Extra-Datei im Binär-Format übertragen. Die Daten werden dabei immer in
einer Tabelle mit fester Spaltenzahl und festen Zeitabständen abgelegt. Die Bedeutung der
Spalten und ein Hinweis auf den Dateinamen werden wiederum im XML-Format
beschrieben, so dass einem allgemeinen Verständnis nichts im Wege steht.
Tabelle II.12: Aufbau der Daten-Binär-Datei im ISO-XML
Zeitstempel 1 Datum 1.1 Datum 2.1 …
Zeitstempel 2 Datum 1.2 Datum 2.2 …
… … …
Leider ist das Format nicht dazu geeignet, komprimierte Daten zu versenden, denn das
Wesen unserer Datenverdichtung ist es ja gerade, Daten von möglichst vielen Zeiten
wegzulassen. Hier ist es aber so, dass die obige Tabelle keine Lücken aufweisen darf, d.h.
es müssen alle Daten zumindest als Nullwerte existieren. Daher ist es – gerade bei guter
Kompression – besser, die Datenreihen einzeln jeweils mit ihren Zeiten abzuspeichern,
obwohl man so für jeden Messwert einen Zeitstempel speichern muss und nicht nur pro Zeile
einen.
Ein weiteres Problem mit dem Tabellenformat ist die Tatsache, dass alle Daten in nur einer
Datei liegen. Das bedeutet, dass entweder alle Datenkomprimierer in der richtigen
Reihenfolge gemeinsam schreibend auf eine Datei zugreifen müssen, um die Zeilen korrekt
zu füllen, dass jeder Messwert in einer eigenen Zeile stehen muss oder dass die Daten
zunächst nur zwischengespeichert werden, um sie dann zum Versand in das ISO-XML-
Format umzukopieren. Das erhöht den Platzbedarf auf der On-Board-Unit auf das Doppelte
und führt zu erheblichem CPU- und Zugriffsaufwand.
Um jedoch den Datenaustausch mit anderen Programmen zu ermöglichen, können in der
Konfiguration im Backend bereits ISO-XML-spezifische Daten wie z.B. das DDI eingetragen
werden. So wird ein ISO-XML-Export aus dem Backend leicht und verlustfrei ermöglicht;
beispielsweise kann ein Programm zur teilautomatisierten Ausführung von Geschäftspro-
zessen Daten im ISO-XML-Format entgegennehmen und an Werkstattsysteme weiterleiten,
die mit ISO XML arbeiten.

II.2 Datenmanagement 115
II.2.2.8.2 Beschreibung der Formate zur Datenübertragung
Für jede einzelne Messreihe wird eine eigene XML-Datei angelegt, die je nach Kompres-
sionsverfahren unterschiedlich formatiert ist. Die Dateinamen setzen sich aus dem
Zeitstempel der Erstellung, dem Namen des Sensors und einer Zufallszahl zusammen. Dies
verhindert, dass Dateien von unterschiedlichen mobilen Geräten gleiche Dateinamen
besitzen, was zu Verwechselungen auf dem Server führen kann.
Die einzelnen Dateien für die Datenreihen sind sehr ähnlich aufgebaut. Durch das Root-
Element wird beschrieben, um welche Kompressionsart es sich handelt. Neben den üblichen
Angaben zum verwendeten XML-Schema wird in einem Attribut die Start-Zeit der Messung
festgehalten.
Im Rahmen des Projektes wurden folgende drei Formate realisiert:
1. CompressedDataGPS. Solche Daten dienen dazu, GPS-Positionen zu bescheiben.
Zum Kompressions-Algorithmus siehe Abschnitt II.2.1.3.3. Innerhalb dieses Elemen-
tes können nur Elemente vom Typ GPSItem benutzt werden. Als Attribute werden ein
Zeitstempel, die geographische Länge und die geographische Breite (in Grad)
angegeben.
2. CompressedDataMeans. In diesen Dateien werden komprimierte Zeitschriebe
gespeichert. Der Kompressionsalgorithmus wird in Abschnitt II.2.1.3.2 beschrieben.
Die Daten selbst werden in Elementen vom Typ MeansItem beschrieben: Als
Attribute wird ein Zeitstempel und der (mittlere) Sensorwert gespeichert.
3. CompressedDataCategorization. Diese XML-Dateien werden benutzt, um Tabellen
von klassierten Daten zu speichern. Die Daten werden in Elementen vom Type
CategorizationItem gehalten; dieses hat als Attribut einen Zeitstempel. Darin werden
in Category-Elementen im Attribut Frequency die absoluten Häufigkeiten der einzel-
nen Kategorien gespeichert. In Elementen vom Typ SuccessiveCategory wird gespei-
chert, wie viele Wechsel es von einer Kategorie in eine andere gegeben hat. Als Kon-
vention wird vereinbart, dass alle Werte, die nicht in der Datei aufgefürt sind, als 0
gelten.
Zum Versand der Dateien wird zunächst eine Inhaltsverzeichnis-Datei erstellt, an der der
Backend-Server erkennen kann, mit welchen Dateien er zu rechnen hat und was ihr Inhalt
ist. Das Root-Element DamitData enthält Attribute zur OBU-ID und zur Mess-ID, damit die
Messdaten eindeutig einem Gespann und einer Messung zugeordnet werden können.

II.2 Datenmanagement 116
Außerdem enthält die Datei einen Zeitstempel der internen Zeit (nach der alle Zeitstempel
genommen werden) und der GPS-Zeit, damit im Backend Fehler der internen Zeit
ausgeglichen werden können. Danach folgen SeriesOfMeasurement-Elemente, die die
Zuordnung Messreihe–Dateiname ermöglichen. Diese Datei wird als erstes zum Backend
übertragen; so können die nachfolgenden Dateien korrekt zugeordnet werden, auch wenn
sie durch einen eventuellen Verbindungsabbruch eventuell erst sehr viel später versendet
werden können.
II.2.2.9 Back-End
Das entwickelte Back-End ist für die Speicherung, Visualisierung und Konfiguration der
OBUs zuständig. Dabei handelt es sich um eine Web-Anwendung, die über einen Web-
Browser aufgerufen und bedient werden kann. Zur Datenablage werden alle Daten in einer
relationalen Datenbank gespeichert.
Die Architektur des Back-Ends orientiert sich an den klassischen, modernen Web-
Architekturen im Java-Enterprise-Bereich und ist in Bild II.66 dargestellt. Zum Zugriff auf die
Datenbank wird eine Persistenzschicht genutzt, in diesem Fall Hibernate, während die
Oberfläche selbst auf dem ZK-Framework basiert, was die Erstellung von hoch-interaktiven
Web-Anwendungen ermöglicht, die in der Benutzbarkeit kaum von klassischen Desktop-
Anwendungen zu unterscheiden sind.
Bild II.66: Architektur Back-End

II.2 Datenmanagement 117
Die wichtigsten Aufgaben des Back-Ends liegen in der Konfiguration, der Datenspeicherung
und der Visualisierung. Neben den Maschinen ist auch die Verwaltung von Gespannen, also
der Zusammenschluss von mehreren Geräten, im Back-End abbildbar.
Der nachfolgende Screenshot in Bild II.67 gibt einen groben Überblick über den Aufbau und
die Funktionsweise des Back-Ends.
Bild II.67: Screenshot der Bedienoberfläche des Back-Ends
Auf der linken Seite findet sich die Hauptnavigation, in der die einzelnen Bereiche aufgelistet
sind und ausgewählt werden können. Im Hauptbereich rechts werden dann die Informationen
angezeigt. In diesem Fall eine Übersicht über die vorhandenen Gespanne im System, das
für die Abschlusspräsentation nur den ILF Versuchstraktor umfasst.
Die gesammelten Daten werden dann zu den einzelnen Maschinen und Zeitpunkten
abgespeichert und können unter den Messaufträgen eingesehen werden. Die nachfolgenden
Screenshots zeigen exemplarisch die Darstellung der Motordrehzahl (Bild II.68) und die
Aufzeichnung der GPS-Fahrspur während der Abschlusspräsentation (Bild II.69).
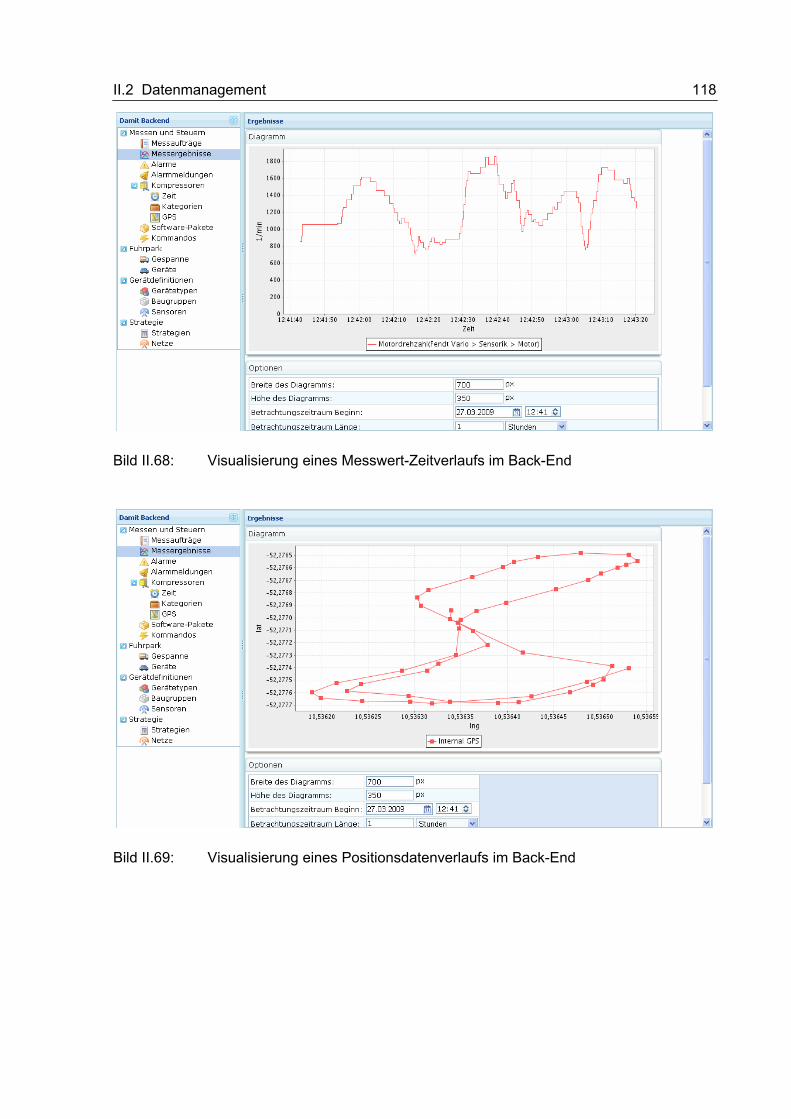
II.2 Datenmanagement 118
Bild II.68: Visualisierung eines Messwert-Zeitverlaufs im Back-End
Bild II.69: Visualisierung eines Positionsdatenverlaufs im Back-End

II.3 Vernetzte Prozesse 119
II.3 Vernetzte Prozesse
Neben den mehr technischen Aspekten des Projektes bei der „Zustandsüberwachung
exemplarischer Baugruppen“ und beim „Datenmanagement“ wird unter dem Topic „Vernetzte
Prozesse“ die Verknüpfung der Technik mit den darüber liegenden Geschäftsprozessen
verdeutlicht. Beispielhaft sind Prozessmodelle für die Logistikkette Rübe und für den Service-
Ablauf einer Landtechnikwerkstatt dargestellt.
II.3.1 Technologien und Schnittstellen im Logistikprozess
Ein effizienter Informationsaustausch innerhalb der Logistikkette Rübe ist die Basis für den
wirtschaftlichen Anbau und die ökonomische Verwertung der Zuckerrübe. Derzeitige
Probleme im Logistikprozess entstehen durch
• Inkompatible „Insellösungen“ bei der Datenerfassung
• Schlechte Bedienbarkeit der Systeme durch geringe Integration in die Maschinen
• Regionale Spezialitäten in Abhängigkeit der beteiligten Partner
• Geringe Aktualität des Datenbestandes
Im Projekt wird ein Prozessmodell einer beispielhaften Logistikkette Rübe erarbeitet. Die
reale Ausprägung kann aufgrund der bereits genannten regionalen Spezialitäten leicht von
diesem Modell abweichen. Auf diesem Modell basierend wird eine in die Maschine integrierte
Datenerfassung am Rübenroder implementiert und mit einer standardisierten Schnittstelle
versehen, die den Anforderungen der Logistikkette genügt.
II.3.1.1 Prozessmodell Logistikkette Rübe
Bild II.70 zeigt die Beteiligten der Logistikkette Rübe. Die komplexe Logistikkette Rübe wird
weitgehend zentral von der Zuckerfabrik gesteuert (links unten). Weitere Prozessbeteiligte
sind der Anbauer (oben links), der Rodedienstleister (oben rechts) sowie die Abfuhrgemein-
schaft (unten rechts).

II.3 Vernetzte Prozesse 120
Bild II.70: Beteiligte im Logistikprozess Rübe
Der Gesamtprozess der Rübenlogistik wird in die Teile Kampagnenplanung, Roden und
Abfuhr unterteilt. Die Kampagnenplanung beginnt im Frühjahr vor der Aussaat der Rübe. Im
Herbst schließt sich der Teilprozess Roden an, dem die Abfuhr der Rüben folgt. Die
folgenden Sequenzdiagramme (Bild II.71 bis II.73) zeigen, welche Informationen zwischen
den Prozessbeteiligten zu welchem Zeitpunkt ausgetauscht werden.
II.3.1.1.1 Teilprozess Kampagnenplanung
Roder ZuckerfabrikAnbauer
Festlegung Liefermenge
Abfuhr
Festlegung der Anbaufläche
Kampagnenplanung, Abfuhrplan Kampagnenplanung, Abfuhrplan
Kampagnenplanung
Festlegung der Mietenposition
Festlegung der Schläge
Festlegung der Schläge
Bild II.71: Informationsfluss im Teilprozess Kampagnenplanung

II.3 Vernetzte Prozesse 121
Die Kampagnenplanung beginnt im Frühjahr mit der Festlegung der Gesamtliefermenge in
der folgenden Kampagne durch die Zuckerfabrik. Den Anbauern wird basierend auf ihrer
Lieferquote die geforderte Liefermenge mitgeteilt. Hat jeder Anbauer die Anbaufläche an die
Zuckerfabrik bekannt gegeben, erfolgt bereits eine erste grobe Kampagnen- und
Abfuhrplanung durch die Zuckerfabrik, die den ungefähren Rodetermin festlegt und damit
Einfluss auf den Aussaat-Termin hat. Daraufhin legt der Anbauer die Schläge fest, auf denen
im aktuellen Wirtschaftsjahr Rüben angebaut werden. Diese Daten fließen wiederum in eine
detailliertere Kampagnenplanung durch die Zuckerfabrik ein. Als letzter Schritt in der
Kampagnenplanung wird - häufig sogar vor Ort - die Mietenposition auf dem Schlag anhand
der geografischen Gegebenheiten (Straßen, Zufahrten, Untergrundgegebenheit) festgelegt.
II.3.1.1.2 Teilprozess Roden
Bild II.72: Informationsfluss im Teilprozess Roden
Während des Teilprozesses Roden findet die eigentliche Ernte der Zuckerrübe statt. Vom
Anbauer wird dazu der Termin, die Fläche mit der Mietenposition und der Ort an den
ausführenden Rodedienstleister, meistens ein Lohnunternehmer oder eine
Maschinengemeinschaft, übermittelt. Dieser bestätigt den Auftrag und meldet nach
Ausführung des Rodeauftrags manuell oder durch das integrierte Datenerfassungsprogramm
des Roders die Erntemenge, die Position der Miete und Informationen über die Qualität des
Erntegutes an das Datenmanagementsystem der Zuckerfabrik und den Anbauer.

II.3 Vernetzte Prozesse 122
II.3.1.1.3 Teilprozess Abfuhr
Roder ZuckerfabrikAnbauer
Liefernachricht: Liefermenge, Verschmutzung, Zuckergehalt, Qualität
Abfuhr der Rüben
Abfuhr
Liefertermin, Lademenge, Mietenposition
Bild II.73: Informationsfluss im Teilprozess Abfuhr
Vor der Abfuhr wird von der Zuckerfabrik der Liefertermin, die Lademenge und die Mieten-
position an die Lademaus übermittelt. Diese verlädt das Erntegut. Mit den Daten sowie den
bei der Anlieferung ermittelten Werten generiert die Zuckerfabrik eine Liefernachricht, die
dem Anbauer zugestellt beziehungsweise über das Datenmanagementsystem zugänglich
gemacht wird.
II.3.1.2 Datenformate
Das bestehende Prozessmodell der Logistikkette wurde verwendet, um darauf basierend
eine maschinenintegrierte Datenerfassung auf dem Rübenroder zu entwickeln. Aus dem
Prozessmodell der Logistikkette ergibt sich dabei, welche Daten während des Rode-
prozesses erhoben und exportiert werden müssen und welche Daten im Vorfeld des
Rodeauftrags zur Verfügung stehen und importiert werden müssen. Nahezu alle großen
westeuropäischen Zuckerkonzerne betreiben mittlerweile Datenmanagementsysteme, an die
weitere Prozessbeteiligte angeschlossen sind. Jedes dieser Datenmanagementsysteme
besitzt proprietäre Daten-Schnittstellen zum Im- und Export der Daten an die Prozess-
beteiligten. Derzeit ist meistens spezielle zusätzliche Hardware für die Datenerfassung
notwendig. Auch die Daten, die bereits im Elektroniksystem der Maschine erfasst sind
(beispielsweise Flächen oder Erträge), müssen manuell in das System übernommen werden.
Für eine Integration der Datenerfassung in die Maschine und die Online-Anbindung der
Maschine an die Datenmanagementsysteme ist eine Standardisierung der Im- und Export-
Schnittstelle unabdingbar, da das Vorhalten sämtlicher proprietärer Schnittstellen nicht reali-

II.3 Vernetzte Prozesse 123
sierbar ist. Der internationale Standard ISOBUS [ISO09] definiert in der Norm Teil 10 der
ISO 11783 ein XML-basiertes Datenformat für den Austausch von Auftrags- und Prozess-
daten zwischen einer Maschine und einem Hof-PC. Im Projektverlauf wurde gezeigt, dass
die ISOBUS-XML Schnittstelle geeignet ist, alle notwendigen Daten, die an der Schnittstelle
zwischen Datenmanagementsystem der Logistikkette Rübe und dem Rübenroder anfallen,
aufzunehmen.
II.3.1.3 Umsetzung
Basierend auf den gesammelten Anforderungen wurde im Verlauf des Projektes eine
Anwendung zur Datenerfassung entwickelt, die auf dem maschinenintegrierten Terminal
parallel zur Maschinenbedienung abläuft (siehe Bild II.74).
Bild II.74: Hauptbildschirm des maschinenintegrierten Datenerfassungsprogramms
Sämtliche, ohnehin auf der Maschine verfügbaren Daten wie z. B. die GPS-Position können
damit automatisch sehr komfortabel in das System einfließen. Das System verfügt über eine
ISOBUS XML Schnittstelle, über die im Vorfeld der Kampagne per USB-Stick die Stamm-
daten bestehend aus Betrieben, Schlägen und Fahrern sowie die vorgeplanten Rodeaufträge
an der Maschine importiert werden. Nach Abarbeitung der Aufträge erfolgt der Export
ebenfalls per ISOBUS XML auf dem USB-Stick, um die Daten für Dokumentations- und
Fakturierungszwecke am Hof-PC wieder einzulesen. Zusätzlich wurde eine Online-Über-
tragung des standardisierten Austauschformates zu einer beispielhaften Implementation
eines Onlineportals realisiert. Sobald in den bestehenden Datenmanagementsystemen damit
eine standardisierte ISOBUS-XML Schnittstelle zur Verfügung steht, können die erfassten
Daten des Rübenroders in Echtzeit drahtlos übertragen werden.

II.3 Vernetzte Prozesse 124
II.3.2 Vorbeugende Instandhaltungsprozesse durch Teleservice
Die Erhöhung der Betriebsbereitschaft bzw. die Erhaltung der Verfügbarkeit von mobilen
Arbeitsmaschinen u. a. im landwirtschaftlichen Umfeld nimmt einen immer größeren Raum
und damit eine zunehmende Gewichtigkeit ein. Vorbeugende Instandhaltungsprozesse sind
ein Baustein zur Erhaltung der Maschinenverfügbarkeit. Eine unmittelbare Reaktion auf
Veränderungen von Betriebsparametern muss gewährleistet werden. Dazu sind geeignete
Schlüssel-Indikatoren zu überwachen. Das wiederum bedingt eine geeignete Sensorik. Die
sensierten Schlüssel-Indikatoren müssen dann geeignete Methoden zur Behandlung von
Triggerereignissen durchlaufen. Um die zeitnahe bzw. unmittelbare Veranlassung von
Maßnahmen nach Eintreffen von auslösenden Triggerereignissen sicherzustellen, kommen
die Techniken des „Teleservice“ zum Einsatz.
II.3.2.1 Einordnung des Themas „Vorbeugende Instandhaltungsprozesse durch Teleservice“
Vorbeugende Instandhaltung erfordert die Planung von Maßnahmen zur Bewahrung und
Wiederherstellung des Sollzustandes sowie die Feststellung und Beurteilung des
Istzustandes von technischen Mitteln eines Systems, hier der mobilen Arbeitsmaschine.
Techniken des Teleservice ermöglichen die Feststellung und Beurteilung des Istzustandes
einer mobilen Arbeitsmaschine mit minimalem Zeitverzug, also quasi Online.
II.3.2.2 Was bedeutet „Instandhaltung“?
Gemäß Definition nach DIN 31051 (Instandhaltung – Begriffe und Maßnahmen) bedeutet
Instandhaltung der Einsatz von „Maßnahmen zur Bewahrung und Wiederherstellung des
Sollzustandes sowie zur Feststellung und Beurteilung des Istzustandes von technischen
Mitteln eines Systems“.
II.3.2.3 Was bedeutet „Vorbeugende Instandhaltung“?
Durch die Planung von Maßnahmen, die der Bewahrung des Sollzustandes sowie zur
Feststellung und Beurteilung des Istzustandes von Mitteln eines Systems dienen, erweitert
sich Instandhaltung zu der vorbeugenden Instandhaltung.

II.3 Vernetzte Prozesse 125
II.3.2.4 Was wird für die „Vorbeugende Instandhaltung“ benötigt?
Eine vorbeugende Instandhaltung erfordert die Identifikation von Schlüssel-Indikatoren, die
eine verlässliche Basis für die Auslösung der notwendigen Maßnahmen einer vorbeugenden
Instandhaltung zur Verfügung stellen. Um diese Schlüssel-Indikatoren praktisch - also
technisch - auszugestalten ist eine geeignete Sensorik vorzusehen. Die Sensorik in
Kombination mit den Algorithmen zur Extrahierung der Schlüssel-Indikatoren liefert dann
Methoden, um die geforderten Triggerereignisse zu behandeln. Die Triggerereignisse
werden zum Auslösen von Prozessketten verwendet.
II.3.2.5 Rolle der verschiedenen Forschungs-Cluster des Projektes für die „Vorbeugende Instandhaltung“
Wie bereits angeklungen, werden die Ergebnisse der Forschungs-Cluster „Zustands-
überwachung exemplarischer Baugruppen“ und „Datenmanagement“ mit den in Vorprojekten
gewonnenen Erkenntnissen des „Teleservice“ in einer geeigneten Art und Weise kombiniert,
um eine vorbeugende Instandhaltung zu realisieren.
II.3.2.5.1 „Zustandsüberwachung exemplarischer Baugruppen“
Die mittels einer systematischen Versuchmethodik erhobenen Daten und die daraus
gewonnenen mathematischen Modelle liefern die notwendigen und geeigneten Schlüssel-
Indikatoren.
II.3.2.5.2 „Datenmanagement“
Der Forschungs-Cluster „Datenmanagement“ setzt die mathematischen Modelle in Algorith-
men um, die informationstechnisch abgebildet werden. Die implementierten Algorithmen sind
auf der On-Board-Unit (OBU) der mobilen Arbeitsmaschine oder auf einem zentralen Infor-
mationssystem ablauffähig. Das Datenmanagement bereitet Sensordaten auf und liefert
vorverarbeitete Daten für den dargestellten Prozessablauf der vorbeugenden Instandhaltung.
II.3.2.5.3 „Teleservice“
Teleservice wird in diesem Zusammenhang als Vehikel für den Transport von Daten
zwischen einer mobilen Arbeitsmaschine und einem zentralen Informationssystem genutzt.
Teleservice ist gemäß Definition „… der Datenaustausch mit entfernt stehenden technischen

II.3 Vernetzte Prozesse 126
Anlagen (z. B: mobilen Arbeitsmaschinen) zum Zweck der Fehlererkennung, Diagnose,
Wartung, Datenanalyse oder Optimierung“.
II.3.2.5.4 Was sind „Vorbeugende Instandhaltungsprozesse durch
Teleservice“?
Vorbeugende Instandhaltungsprozesse durch Teleservice ist nun die konsequente „Um-
setzung der Planung von Maßnahmen zur Bewahrung des Sollzustandes, sowie die Fest-
stellung und Beurteilung des Istzustandes einer mobilen Arbeitsmaschine“ unter Zuhilfe-
nahme der Techniken des Teleservice.
Die Bewahrung des Sollzustandes, und damit die Aufrechterhaltung der Betriebsfähigkeit der
mobilen Arbeitsmaschine, wird exemplarisch durch die Überwachung eines Motorluftfilters
gezeigt. Es wird die Druckdifferenz zwischen Ein- und Ausgang des Luftfilters gemessen.
Nach Über- bzw. Unterschreitung vordefinierter Differenzdrücke wird ein Trigger ausgelöst.
Dieser Trigger löst den relevanten Instandhaltungsprozess aus.
Der Ablauf des Instandhaltungsprozesses ist schematisch in Bild II.75 und Bild II.76 skizziert.

II.3 Vernetzte Prozesse 127
Bild II.75: Condition Monitoring am Beispiel der Luftfilterüberwachung
Teil 1: Prozessschritte 1 bis 5

II.3 Vernetzte Prozesse 128
Bild II.76: Condition Monitoring am Beispiel der Luftfilterüberwachung
Teil 2: Prozessschritte 6 bis 11

II.4 Systembasierte Dienstleistungen 129
II.4 Systembasierte Dienstleistungen
Neben dem Verkauf landtechnischer Produkte hat der Service bei CLAAS eine hohe
Bedeutung. Eine hohe Betriebsbereitschaft und Verfügbarkeit der CLAAS Maschinen, die
Erbringung wertschöpfender Dienstleistungen und der Erhalt der Kundenzufriedenheit
motivieren zum Ausbau des Dienstleistungsgeschäftes. Ziel des Unternehmens ist es, für die
komplette Bandbreite der Produkte Dienstleistungen anzubieten. Diese Dienstleistungen
über den Lebenszyklus der Maschinen richten sich auf individuelle Bedingungen der
Kunden. Durch Verknüpfung technischer Produkte mit „intelligenten“ Dienstleistungen
werden integrierte/hybride Leistungsangebote geschaffen. Diese Leistungssysteme stützen
sich auf moderne Informations- und Kommunikationstechnologien.
II.4.1 Dienstleistungsangebote für mobile Arbeitsmaschinen
Bild II.77: Entwicklung der Dienstleistungsangebote für mobile Arbeitsmaschinen
Der Wandel vom Produktanbieter zum Anbieter von Leistungssystemen aus Produkten und
Dienstleistungen (Bild II.77) erfordert eine entsprechende Dienstleistungsstrategie, eine
angepasste Gestaltung des Dienstleistungsportfolios. Claas hat die drei Dienstleistungsfelder
Agrartechnik und Produktionsmittel, (Agrar-) Produktion und Unternehmensmanagement
definiert (Bild II.78). Daneben existieren noch Claas-interne und vertriebspartnergerichtete
Dienste.

II.4 Systembasierte Dienstleistungen 130
CLAAS interneDienste
Vertriebspartner - gerichtete Dienste
Unternehmens- management• Marktorientierung/
Differenzierung• Betriebswirtschaftl.
gemanagte Gro ß betriebe, neue Kooperationsformen
• Vernetzung mit Kompetenzpartnern ( - zentren)
(Agrar) Produktion• Arbeitserledigung als
Komplettangebot• Dokumentation von
Prozessdaten• Prozess- /Stückkosten-
optimierung
Agrartechnik undProduktionsmittel• Nutzung statt
Investment• H ö chste Effizienz• Hohe Sicherheit/
Verfü gbarkeit
Maschinen
Bild II.78: Dienstleistungsfelder und ihre aktuellen Trends
II.4.1.1 Dienstleistungsfelder und ihre aktuellen Trends
Die drei Dienstleistungsfelder (Bild II.78) werden im Folgenden näher beschrieben:
Im Dienstleistungsfeld Agrartechnik und Produktionsmittel rückt die langfristige Nutzung
der Maschine gegenüber dem Anfangsinvestment in den Vordergrund. Wichtig ist hier die
Sicherstellung der Maschinenbetriebsbereitschaft und -verfügbarkeit.
Das Dienstleistungsfeld (Agrar-)Produktion geht darüber hinaus und fokussiert die
Arbeitserledigung. Das heißt die Maschine ist betriebsbereit sowie verfügbar und soll nun
effizient eingesetzt werden. Dazu gehören sowohl die Dokumentation von Prozessdaten als
auch die Prozess- bzw. Stückkostenoptimierung als Dienstleistung für den Kunden.
Das umfassendste Dienstleistungsfeld ist das Unternehmensmanagement. Hier werden
Fragen des gesamten Unternehmensmanagements im Agrarbereich betrachtet. Angeboten
werden beispielsweise Optimierung im Prozessmanagement, Managementsysteme für
Lohnunternehmer und überbetriebliche Maschinenverwendung oder Fuhrparkmanagement.

II.4 Systembasierte Dienstleistungen 131
II.4.1.1.1 Besondere Rahmenbedingungen für Instandhaltungsleistungen in der Agrartechnik
Die Landtechnikbranche ist im Vergleich zur Kfz- und Nutzfahrzeugbranche durch geringe
Stückzahlen bei gleichzeitig hoher Variantenvielfalt gekennzeichnet. Das führt dazu, dass
bekannte und ausgereifte Methoden der Instandhaltung, wie sie insbesondere im
Automobilbereich verbreitet sind, für die Landtechnik nur sehr eingeschränkt angewandt
werden können. Je nach Nutzung der Maschinen – insbesondere unter den regional stark
variierenden Umweltbedingungen – gibt es große Abweichungen in den Wartungs- und
Instandhaltungsaufwendungen. Außerdem erschwert die unterschiedliche Ausstattung der
Werkstätten (teilweise ländliche, handwerkliche Prägung, wenig IT-Unterstützung, teilweise
unvollständige Arbeitsplanung) die Vorplanung.
II.4.1.1.2 Kundenanforderungen
Die Anforderungen des Maschinenbetreibers (Landwirt, Lohnunternehmer) gegenüber dem
Dienstleistungsanbieter sind:
a) niedrige Kosten der Betriebsbereitschaft
b) geringe Ausfallzeiten der Maschinen
c) hohe Zuverlässigkeit und Verfügbarkeit.
Zudem soll der Maschinenbetreiber unterstützt werden, die Maschinen effizient zu betreiben.
Aus einer von CLAAS durchgeführten Umfrage geht hervor (Bild II.79), dass die Forderung
der Kunden höherer Maschinenverfügbarkeit stetig zunimmt. Dies ist die Folge der
fortschreitenden Weiterentwicklung zu immer leistungsfähigeren Maschinen. Folglich werden
für die gleiche Arbeitsleistung immer weniger Maschinen benötigt. Somit steigt das Risiko bei
einem Maschinenausfall, einen Verfügbarkeitsengpass nicht ausgleichen zu können. Durch
stetige Verbesserung der Maschinenqualität durch kontinuierliche Verbesserungsmaß-
nahmen der Hersteller sinken die Instandhaltungskosten im Verhältnis zum ursprünglichen
Maschineninvest.
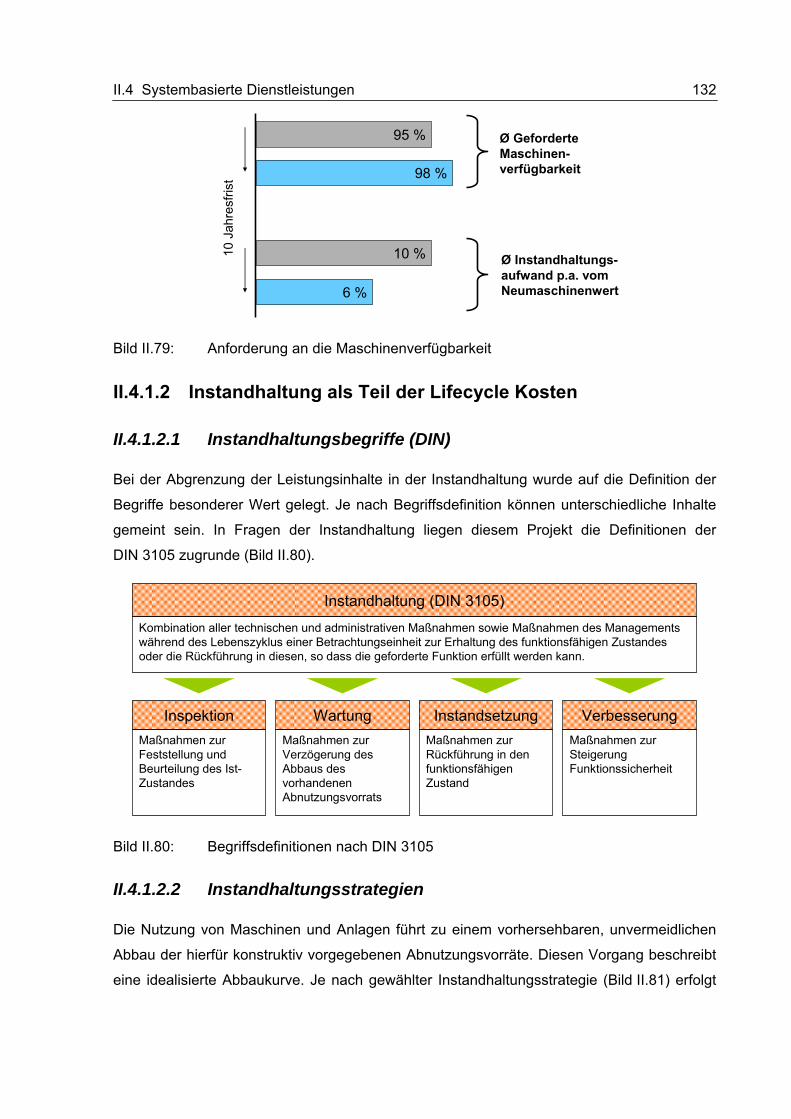
II.4 Systembasierte Dienstleistungen 132
95 %
98 %
10 %
6 %
Ø GeforderteMaschinen-verfügbarkeit
Ø Instandhaltungs-aufwand p.a. vom Neumaschinenwert
10 J
ahre
sfris
t
Bild II.79: Anforderung an die Maschinenverfügbarkeit
II.4.1.2 Instandhaltung als Teil der Lifecycle Kosten
II.4.1.2.1 Instandhaltungsbegriffe (DIN)
Bei der Abgrenzung der Leistungsinhalte in der Instandhaltung wurde auf die Definition der
Begriffe besonderer Wert gelegt. Je nach Begriffsdefinition können unterschiedliche Inhalte
gemeint sein. In Fragen der Instandhaltung liegen diesem Projekt die Definitionen der
DIN 3105 zugrunde (Bild II.80).
Kombination aller technischen und administrativen Maßnahmen sowie Maßnahmen des Managements während des Lebenszyklus einer Betrachtungseinheit zur Erhaltung des funktionsfähigen Zustandes oder die Rückführung in diesen, so dass die geforderte Funktion erfüllt werden kann.
Maßnahmen zur Feststellung und Beurteilung des Ist-Zustandes
Maßnahmen zur Verzögerung des Abbaus des vorhandenen Abnutzungsvorrats
Maßnahmen zur Rückführung in den funktionsfähigen Zustand
Maßnahmen zur Steigerung Funktionssicherheit
Inspektion Wartung Instandsetzung Verbesserung
Instandhaltung (DIN 3105)
Bild II.80: Begriffsdefinitionen nach DIN 3105
II.4.1.2.2 Instandhaltungsstrategien
Die Nutzung von Maschinen und Anlagen führt zu einem vorhersehbaren, unvermeidlichen
Abbau der hierfür konstruktiv vorgegebenen Abnutzungsvorräte. Diesen Vorgang beschreibt
eine idealisierte Abbaukurve. Je nach gewählter Instandhaltungsstrategie (Bild II.81) erfolgt

II.4 Systembasierte Dienstleistungen 133
die Instandsetzung zu unterschiedlichen Zeitpunkten im Verlauf der Abbaukurve einer
Maschine oder Anlage.
Ausfall
Sollzustand(nach Instandsetzung)
Schadensgrenze
Zeit Δ t
AusfallbedingteInstandhaltung (Feuerwehr)
Sollzustand(nach Instandsetzung)
Schadensgrenze
Zeit
Δ t
Sollzustand(nach Instand-setzung)
Schadens-grenze
Zeit Δ tΔ t
InspektionRest-Nutzungs-
vorrat
Soll-Ist-Differenz
VorbeugendeInstandhaltung (periodisch wiederkehrend)
Zustands-abhängigeInstandhaltung Zeit Dauerfest!
Bild II.81: Instandhaltungsstrategien
Traditionell wird die ausfallbedingte Instandhaltung verfolgt. Hier ist es wichtig, dass bei
Eintreten eines Schadensereignisses, eine rasche Instandhaltung sichergestellt wird. Eine
andere Strategie kommt insbesondere bei kritischen Bauteilen und Baugruppen zur
Anwendung. Diese Teile werden dauerfest konstruiert, um einen Schadensfall während des
Maschinenlebenszyklus mit hoher Wahrscheinlichkeit auszuschließen. Diese Strategie ist bei
Betrachtung der Maschinenlebenszykluskosten selten wirtschaftlich. Alternativ findet man die
vorbeugende Instandhaltung. Diese kommt häufig auch im Zusammenhang mit der
Inspektion und Wartung zum Tragen. Im Rahmen von definierten Zeitintervallen werden
ausgewählte Teile untersucht (Feststellung eines definierten Abnutzungsgrades) und
Verbrauchsmaterialien (Öle, Filter) ausgetauscht. Als vierte und auch im Projekt an
ausgewählten Baugruppen (Einzugskette, Luftfilter) sowie am Hydrauliköl untersuchte
Strategie kommt die zustandsabhängige Instandhaltung (Condition Monitoring), insbe-
sondere bei kritischen Bauteilen und Komponenten (hohe Folgekosten bei Ausfall), zum
Tragen. Wichtig ist eine eingehende Beurteilung aller Bauteile, Baugruppen und Kompo-
nenten zur Auswahl geeigneter Instandhaltungsstrategien.
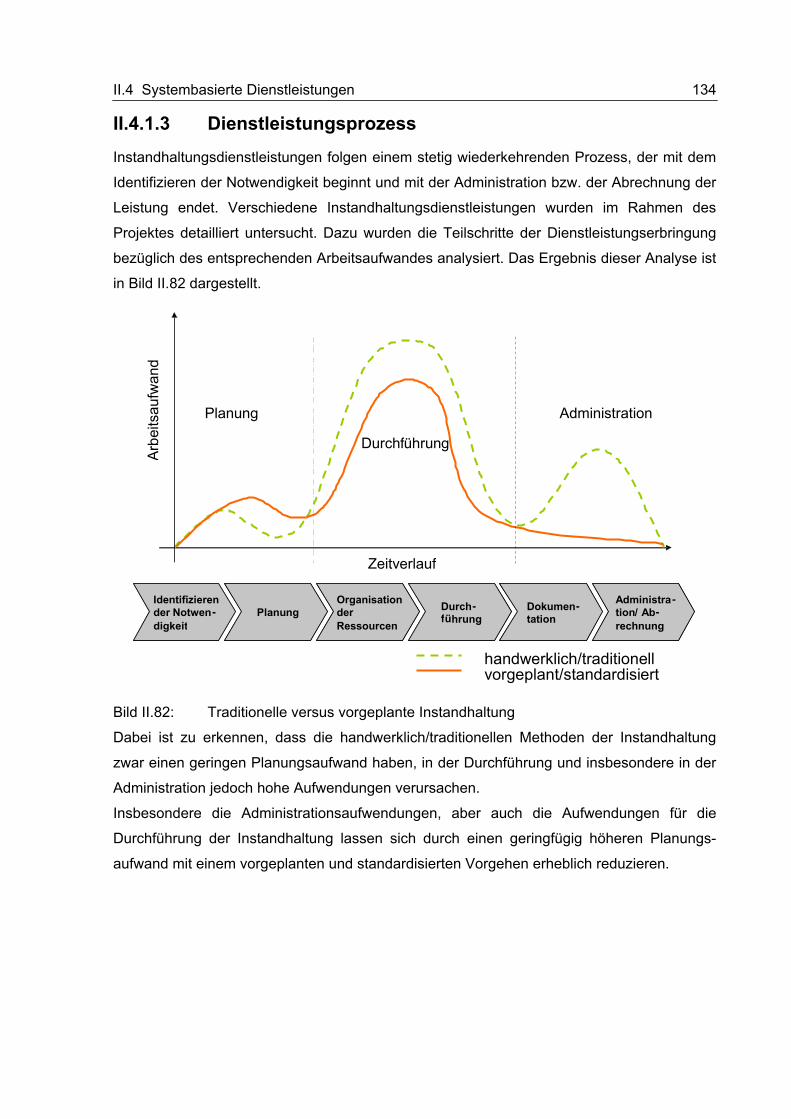
II.4 Systembasierte Dienstleistungen 134
II.4.1.3 Dienstleistungsprozess
Instandhaltungsdienstleistungen folgen einem stetig wiederkehrenden Prozess, der mit dem
Identifizieren der Notwendigkeit beginnt und mit der Administration bzw. der Abrechnung der
Leistung endet. Verschiedene Instandhaltungsdienstleistungen wurden im Rahmen des
Projektes detailliert untersucht. Dazu wurden die Teilschritte der Dienstleistungserbringung
bezüglich des entsprechenden Arbeitsaufwandes analysiert. Das Ergebnis dieser Analyse ist
in Bild II.82 dargestellt.
Identifizierender Notwen- digkeit
PlanungOrganisation der Ressourcen
Durch-führung
Dokumen- tation
Administra-tion/ Ab-rechnung
Identifizierender Notwen- digkeit
PlanungOrganisation der Ressourcen
Durch-führung
Dokumen- tation
Administra-tion/ Ab-rechnung
Arbe
itsau
fwan
d
Zeitverlauf
Durchführung
Planung Administration
handwerklich/traditionellvorgeplant/standardisiert
Bild II.82: Traditionelle versus vorgeplante Instandhaltung
Dabei ist zu erkennen, dass die handwerklich/traditionellen Methoden der Instandhaltung
zwar einen geringen Planungsaufwand haben, in der Durchführung und insbesondere in der
Administration jedoch hohe Aufwendungen verursachen.
Insbesondere die Administrationsaufwendungen, aber auch die Aufwendungen für die
Durchführung der Instandhaltung lassen sich durch einen geringfügig höheren Planungs-
aufwand mit einem vorgeplanten und standardisierten Vorgehen erheblich reduzieren.

II.4 Systembasierte Dienstleistungen 135
II.4.1.3.1 Nutzung verteilter Informationen für den Produktentstehungsprozess
Produktentstehungsprozess
KundenFeedback
SchadenStatistik
MaschinenCAN-BusVersuch ET-
Umsätze
Telematik
Serviceverträge
Informationsquellen
Bild II.83: Verteilte Informationen verbessern den Produktentstehungsprozess
Ein Landtechnikhersteller, der wirtschaftliche Instandhaltungsangebote über den kompletten
Maschinenlebenszyklus anbieten will, muss möglichst umfassende Informationen zu Maschi-
neneinsatz und -nutzung zusammentragen. Dafür stehen ihm verschiedene Informations-
quellen zur Verfügung (Bild II.83). Traditionell werden in den Versuchsabteilungen der Her-
steller vielfältige Untersuchungen zu Funktion und Festigkeit angestellt. Darüber hinaus
bietet die Sensorausstattung der Maschinen die Möglichkeit, Maschinendaten zu generieren
und anschließend auszuwerten. Zu den im Markt befindlichen Maschinen erhält der
Hersteller über Kundendienstmitarbeiter und Schulungszentren ein umfangreiches Feed-
back, das informationstechnisch erfasst und strukturiert aufbereitet wird. Zusätzlich können
aus Ersatzteilumsätzen und Schadensstatistiken Instandhaltungsinformationen abgeleitet
werden. Sind Versuchsmaschinen in eine Telematikinfrastruktur eingebunden, so erlaubt
dies ein Monitoring von Sensorwerten zur Maschinennutzung und zum Auftreten von
Alarmen und Störungen. Eingebunden in Serviceverträge wird der komplette Instandhal-
tungsprozess professionell begleitet und zu Abrechnungs- und Dokumentationszwecken
einzelmaschinenbezogen informationstechnisch festgehalten. Die Bündelung und intelligente
Auswertung dieser Informationen geht in die frühen Phasen der Produktentstehung neuer
Maschinen ein. Dies verbessert die Qualität der Maschinen und der Instandhaltungsprozesse
über den gesamten Lebenszyklus.

II.4 Systembasierte Dienstleistungen 136
II.4.1.4 Dienstleistungsangebote
II.4.1.4.1 Planbare Instandhaltung als Kern
wirtschaftlicher Serviceangebote
FuE Methoden
PI (Planbare Instandhaltung)
Vernetzte Systembasis
Product-Lifecycle ManagementWer
ksta
ttman
agem
ent
DL-Entwicklung(Service Engineering)
und -Erbringung FuE M
anagement
Dienstleistungsstandards
Dienstleistungsmarkteting/-vertrieb
Dienstleistungskompetenz (HR)
Dienstleistungscontrolling
Service-Engineering Methoden
Bild II.84: Planbare Instandhaltung als Teil der Dienstleistungsorganisation
Die zuvor beschriebenen Werkzeuge zur Schaffung einer planbaren Instandhaltung sind Teil
der gesamten Dienstleistungsorganisation (Bild II.84). Wichtig sind FuE Methoden, um die
planbare Instandhaltung in den Produktentstehungsprozess zu integrieren. Weiterhin sind
durchgängige und vernetzte Systeme über alle Leistungsebenen erforderlich. Eingebettet ist
dieser Methoden- und Systemkern in das Product-Lifecycle-Management, das Werkstatt-
management der verteilten Händlerwerkstätten und das FuE Management des Unter-
nehmens. Ein steuernder Bestandteil im Gesamtprozess ist die systematische Dienst-
leistungsentwicklung und -erbringung basierend auf den Methoden des „Service
Engineering“.

II.4 Systembasierte Dienstleistungen 137
II.4.1.4.2 Wirtschaftliche Serviceangebote
Bild II.85: Standardisierte Bereitschaftsangebote
Die definitorische Klarheit aus der Instandhaltungsnorm (Bild II.80) sowie eindeutig beschrie-
bene, in der Leistungstiefe klar abgegrenzte, modellierte Instandhaltungsprozesse erlauben
die Beschreibung und Implementierung standardisierter Betriebsbereitschaftsangebote
(Bild II.85). Voraussetzung ist eine durchgängig vernetzte Systembasis von den Maschinen
über Händlersysteme bis hin zum Maschinenhersteller. Wirtschaftlich erfolgreich sind
Dienstleistungsangebote zur Maschinenbetriebsbereitschaft und -verfügbarkeit insbesondere
dann, wenn die beschriebenen Prozesse der systematischen Dienstleistungsentwicklung
zum Tragen kommen.

III Zusammenfassung 138
III Zusammenfassung
Zu den wichtigsten Entwicklungen im Segment der mobilen Arbeitsmaschinen der
vergangenen Jahre zählen die Teleservice-Systeme. Eine wichtige Teilfunktion dieser
Systeme stellt die Früherkennung und Ferndiagnose von Maschinenzuständen dar, um
Serviceprozesse optimieren und so den Maschinennutzen für den Betreiber maximieren zu
können. Auch der Zugriff auf Maschinendaten über das Internet kann den
Maschinenbetreiber unterstützen, die Einsatzplanung seiner Maschinen zu verbessern und
Prozessabläufe zu optimieren. Einem intelligenten Datenmanagement kommt innerhalb
eines Teleservice-Systems eine hohe Bedeutung zu.
Im Rahmen des Verbundprojektes ist es als Gesamtergebnis gelungen, ein umfassendes
Datenmanagementsystem für den Teleservice bei mobilen Arbeitsmaschinen zu entwickeln
sowie komplexe Logistik- und Instandhaltungsprozesse zu modellieren, um diese durch das
Datenmanagementsystem zu unterstützen.
In einem Teilprojekt wurde dazu eine modulare, dienstebasierte Softwarearchitektur
geschaffen. Parallel dazu wurde eine flexible Kommunikationsstruktur entwickelt, die eine
situationsabhängige Auswahl eines geeigneten Übertragungsmediums für die
Datenübertragung von der Maschine zum Backend-Server sowie die dortige Archivierung
ermöglicht. Zur Reduzierung der zu übertragenden Datenmengen wurden in einem weiteren
Teilprojekt leistungsfähige Kompressionsalgorithmen entwickelt und in praktischen
Versuchen erfolgreich erprobt. Es erfolgte weiterhin die Entwicklung und Erprobung von
Methoden zur automatisierten Zustandsüberwachung exemplarischer Baugruppen mit dem
Ziel einer Reststandzeitprognose, die dann als Grundlage zur Ableitung zustandsbasierter
Instandhaltungsstrategien für diese Baugruppen genutzt wurden. Die Entwicklung von
Prozessmodellen für die Logistikkette Rübe und einen Instandhaltungsprozess fand im
Rahmen eines weiteren Teilprojektes statt.
In verschiedenen praktischen Umsetzungen des Systems, sowohl auf einem stationären
Versuchstand als auch auf mehreren verschiedenen mobilen Arbeitsmaschinen, konnte die
Funktionsfähigkeit des Systems nachgewiesen werden.

IV Literaturverzeichnis 139
IV Literaturverzeichnis
[Abe01] Abe, S. Pattern Classification – Neuro-Fuzzy Methods and Their Comparison. Springer, London et al., 2001, ISBN 1-85233-352-9
[ABRW03] Angermann, A.; Beuschel, M.; Rau, M.; Wolfarth, U.
Matlab – Simulink – Stateflow. 2. Auflage. Oldenbourg Verlag München Wien, 2003
[Ahr03] Ahrends, O. Anwendungsbeispiel 1: Das Serviceformular – Ganzheitliche Umsetzung im Unternehmen. In [Lei03]
[Ali00] Aliev, R.; Bonfig, K. W.; Aliew, F.
Soft Computing. Verlag Technik, Berlin, 2000, ISBN 3-341-01238-9
[Aue93] Auernhammer, H.; Frisch, J.
Landwirtschaftliches Bus-System LBS. LAV, Frankfurt/Main, 1993
[Bec99] Becker, E. Teleservice in der Antriebstechnik auf Basis von Schwingungen. VDI-Berichte, Nr. 1416, VDI-Verlag, Düsseldorf, 1998, S. 90-93
[Bor02] Borgmeier, A. Teleservice im Maschinen- und Anlagenbau. Dissertation, TU Darmstadt, Deutscher Universitäts-Verlag, Wiesbaden, 2002, ISBN 3-8244-0658-6
[Bot95] Bothe, H.-H. Fuzzy Logic. 2. Aufl. Springer, Berlin, Heidelberg et. al., 1995, ISBN 3-540-56967-7
[Bot98] Bothe, H.-H. Neuro-Fuzzy-Methoden. Springer, Berlin, Heidelberg et. al., 1998, ISBN 3-540-57966-4
[Bro97] Brooks, R. R.; Iyengar, S. S.
Multi-Sensor Fusion: Fundamentals and Applications with Software. Prentice Hall PTR, Upper Saddle River – New Jersey, 1997, ISBN 0-13-901653-8,
[Bru00] Bruhn, I. Erhebung zu den Reparaturkosten von Maschinen auf Großbetrieben, dargestellt für Traktoren und Mähdrescher. Dissertation, Forschungsbericht Agrartechnik des VDI/MEG 357, Kiel, 2000, ISSN 0931-6264
[Die97] Diekhans, N.; Kausch, C.; Meyer, H. J.
Teleservicesysteme – Einsatzpotential bei Landmaschinen, Landtechnik, Ausgabe 02/1998, S. 104-105
[Div03] -, -. Autorenkollektiv des Leitfadens: Empfehlungen zur Gestaltung von Teleservice-Systemen in der Landmaschinenbranche. In [Lei03]

IV Literaturverzeichnis 140
[Dre96] Drews, P.; van de Venn, H. W.
Teleservice. BMT – Baumaschine + Technik, H. 11/12, 1996, S. 16-18
[Eic00a] Eichler, C. Instandhaltungstechnik, 5. Auflage, Verlag Technik GmbH, Berlin, 2000, ISBN 3444100667-2
[Eic00b] Eichler, C. Zu Entwicklungstendenz der Instandhaltung landtechnischer Arbeitsmittel. Agartechnik, 40 (1990), H. 9, S. 416-418
[Ets00] Etschberger, K. Controller Area-Network. 2. Aufl., Carl Hanser Verlag, München, Wien, 2000, ISBN 3-446-19431-2
[Ger07] Gericke, C. Entwicklung von Datenreduktionsverfahren mit dem Ziel der Fehlerfrüherkennung zur Verwendung in Teleservice Systemen, Technische Universität Braunschweig, Institut für Landmaschinen und Fluidtechnik, Studienarbeit, 2007
[GGRM07] Göres, T.; Grothaus, H.-P.; Rustemeyer, T.; Möller, A.
Development of a Data Management System for Teleservice Applications on Mobile Working Machines – DAMIT. In: Proceedings “Engineering Solutions for Energy and Food Production" of the 65th International Conference on Agricultural Engineering (Landtechnik AgEng), 2007, S. 265 - 270
[Gri99] Grimmelius, H. T.; Meiler, P. P.; Maas, H.L.M.M.; Bonnier, B.; Grevink, J. S.; van Kuilenburg, R. F.
Three State-of-the-Art Methods for Condition Monitoring. IEEE Transactions on Industrial Electronics, 46 (1999), No. 2, pp. 407-416
[Hal00] Hall, D. L. Lectures in Multisensor Data Fusion and Target Tracking. Tech Reach Inc. Artech House, Boston, CD-ROM, 2000, ISBN 1-580-53140-7
[Hal01] Hall, D. L.; Llinas, J.
Handbook of Multisensor Data Fusion. CRC Press. Boca Raton, London, New York, 2001, ISBN 0-8493-2379-7
[Hal92] Hall, D. L. Mathematical Techniques in Multisensor Data Fusion. Artech House, Boston, London, 1992, ISBN 0-89006-558-6
[Har03] Harms, H.-H.; Krallmann, J.
Teleservice von morgen – Entwicklungen und Trends, Tagung Landtechnik für Profis, VDI/MEG am 29.01.2003, Magdeburg, Tagungsband S.97-111
[Har97] Harnischfeger, M.; Hudetz, W.
Leitfaden: Teleservice einführen und nutzen. Maschinenbau-Verlag, Frankfurt/Main, 1997

IV Literaturverzeichnis 141
[Hil98] Hillenbrand, F. Transitional Recording für analoge Daten. etz Elektrotechnik und Automation, 119 (1998), H. 12, S. 42-43
[ISO09] -, -. ISO 11783, Tractors and machinery for agriculture and forestry - Serial control and communications data network
[Jac87] Jackson, P. Expertensysteme – eine Einführung. Addison Wesley, Bonn, 1987, ISBN 3-925118-4
[Kau97] Kausch, C. Einsatzpotential von Teleservice bei Landmaschinen. Unveröffentlichte Diplomarbeit am Institut für Landmaschinen und Fluidtechnik der TU Braunschweig, 1997
[Keh01] Kehrer, R. Konzentriert Messen. Computer und Automation. 2001, H. 11, S. 74-78
[Kla99] Klaus, F. Einführung in Techniken und Methoden der Multisensor-Datenfusion. Habilitation, Universität Siegen, 1999, Elektronische Ressource, urn:nbn:de:hbz:467-575
[Kol08] Kolonko, M. Stochastische Simulation, Vieweg+Teubner, 1. Auflage (2008), ISBN 978-3835102170
[Kra00] Krallmann, J. Analyse des Einspar- und Nutzenpotentials eines Teleservicesystems in der Landwirtschaft unter technischen und wirtschaftlichen Gesichtspunkten. Unveröffentlichte Diplomarbeit am Institut für Landmaschinen und Fluidtechnik der TU Braunschweig, 2000
[Kra03] Krallmann, J.; Fölster, N.
Fehlerlokalisierung und Schadensdiagnostik. In [Lei03]
[Krü00] Krüger, G.; Reschke, D.
Lehr- und Übungsbuch Telematik. Fachbuchverlag Leipzig, München, Wien, 2000, ISBN3-446-21053-9
[KTB00] -, -. Kuratorium für Technik und Bauwesen in der Landwirtschaft (KTBL): Elektronikeinsatz in der Landwirtschaft. KTBL-Schrift 390, 2000, ISBN 3-7843-2114-3
[KW03] Kall, P.; Wallace, S. W.
Stochastic Programming, Second Edition (2003), http://home.himolde.no/~wallace/manujw.pdf siehe auch: Stochastic Programming, Jogn Wiley & Sons, Chichester (1994)

IV Literaturverzeichnis 142
[Lei03] -, -. Leitfaden für eine gesamtheitliche Teleservice-Lösung in der Landmaschinenbranche. Abschlussbericht des Projektes „eine gesamtheitliche Teleservice-Lösung für die Landmaschinenbranche, CD-ROM, Braunschweig, 2003, ISBN 3-00-011832-2
[Löh03a] Löhner, L. Leitfaden für die Einführung von Teleservice. In [Lei03]
[Löh03b] Löhner, L. Verbesserte Instandhaltung landtechnischer Arbeitsmaschinen. In [Lei03]
[Luo95] Luo, R. C.; Kay, M. G.
Multisensor Intergration and Fusion for Intelligent Machines and Systems. Balex Publishin Corporation, Norwood, 1995, ISBN 0-89391-863-6
[Mah01] Mahler, R. Random Set Theory for Target Tracking and Identification. In [Hal01], pp. 14/1-14/33, 2001
[Mat00] Mattfeld, R. Systematische Grundlagenermittlung für ein Teleservice-System zur Betreuung eines selbstfahrenden Kartoffelroders während der Erntekampagne. Unveröffentlichte Diplomarbeit am Institut für Landmaschinen und Fluidtechnik der TU Braunschweig, 2000
[Met92] Metzger, K. Exakte Erfassung veränderlicher Meßgrößen – Transitional Recording für analoge Meßsignale. Markt und Technik, 1992, H. 37, S. 74-78
[Mic83] Michaelis, B. Einführung zusammengesetzter Messgrößen – ein Konzept zur Datenreduktion. Messen, Steuern, Regeln, 26 (1983), H. 6, S. 302-304
[Möl03] Möller, A. Anwendungsbeispiel 3: Onlinediagnose am Kartoffelvollernter. In [Lei03]
[Mum02] -, -. Mumasy (Multimediales Maschineninformationssystem). Abschlusspräsentation, 23.04.2002, VDMA, Frankfurt/Main
[Nau96] Nauck, D.; Klawonn, F.; Kruse, R.
Neuronale Netze und Fuzzy-Systeme – Grundlagen des Konnektionismus, neuronaler Fuzzy-Systeme und der Kopplung mit wissensbasierten Methoden, 2. Aufl. Vieweg, Braunschweig, Wiesbaden, 1996, ISBN 3-528-15265-6
[Pea95] Pearson, J. C.; Gelfand, J. J.; Sullivan, W. E.; Peterson, R. M.; Spence, C. D.
Neural Network Approach to Sensory Fusion. In [Luo95], pp. 111-120
[Pla03] Platon, G. Rechtliche Aspekte des Teleservice. In [Lei03]

IV Literaturverzeichnis 143
[Pup91] Puppe, F. Einführung in Expertensysteme. 2.Aufl. Springer, Berlin, Heidelberg et. al., 1991, ISBN 3-540-54023-7
[Pup96] Puppe, F.; Gappa, U.; Poeck, K., Bamberger, S.
Wissensbasierte Diagnose- und Informationssysteme. Springer-Verlag, Berlin, 1996, ISBN 3-540-61369-2
[Rei99] Reininghaus, F. Systematische Grundlagenermittlung für ein Teleservice-System zur Betreuung eines selbstfahrenden Bunkerköpfroders während der Zuckerrübenernte. Unveröffentlichte Diplomarbeit am Institut für Landmaschinen und Fluidtechnik der TU Braunschweig, 1999
[Sch01] Schlichting, M. Erarbeitung eines Konzepts zur Implementierung eines Teleservicemoduls in eine Großballenpresse. Unveröffentlichte Diplomarbeit am Institut für Landmaschinen und Fluidtechnik der TU Braunschweig, 2001
[Sch03] Schlichting, M. Anwendungsbeispiel 2: SMS-Datenerfassung. In [Lei03]
[Sch92] Scholz, P.; Metzger, K.
Transitional Recording. Ein neues Verfahren zur Online-Datenreduktion bei der PC-gestützten, vielkanaligen Langzeitdatenaufnahme. Konferenz-Einzelbericht, MessComp ´92, Tagungsband, S. 95-98, ISBN 3-924651-33-7
[Sch95] Scholz, P. Methoden der ereignisgesteuerten Datenaufnahme. Konferenz-Einzelbericht, MessComp ´95, Tagungsband, S. 283-286, ISBN 3-924651-48-5
[Sch97] Scherer, A. Neuronale Netze: Grundlagen und Anwendungen. Vieweg, Braunschweig, Wiesbaden, 1997, ISBN 3-528-05465-4
[Sto99] Stone, L. D.; Barlow, C. A.; Corwin, Th., L.
Bayesian Multiple Target Tracking. Artech House, Bosten, London, 1999, ISBN 1-58053-024-9
[Tes00] -, -. Teleservice für mobile Maschinen und Anlagen – Abschlussbericht. VDMA-Verlag, Frankfurt/Main, 2000, ISBN 3-8163-0395-1
[Var97] Varshney, P. K. Distributed Detection and Data Fusion. Springer, Berlin et al., 1997, ISBN 0-387-94712-4
[Ven03] van de Venn, H. W.
Internetbasierter Teleservice für mobile Maschinen und Anlagen. Dissertation, RWTH Aachen, Berichte aus der Automatisierungstechnik, Shaker, Aachen, 2003, ISBN 3-8322-2123-9

IV Literaturverzeichnis 144
[Wal90] Waltz, E.; Llinas, J.
Multisensor Data Fusion. Artech House, Boston/London, 1990, ISBN 0-89006-277-3
[Wes98] Westkämper, E.; Wieland, J.
Neue Chancen durch Teleservice. Werkstatt und Betrieb, H. 6, 1998, S. 598-601
[WGS00] -, -. Department of Defense World Geodetic System 1984: Its Denition and Relationships with Local Geodetic Systems. 2000
[Wie96] Wiesbauer, A. Langzeit-Meßsignalaufzeichnung mit Datenkompression. Technischen Messen, 63 (1996), H. 1, S. 30-33
[Wit00] Wittmann, Th.; Hunscher, M.; Kischka, P.; Ruhland, J.
Data Mining. Peter Lang Verlag, Frankfurt/Main et. al., 2000, ISBN 3-631-36680-9
[Wit01] Witten, I. H.; Frank, E.
Data Mining. Carl Hanser Verlag, München, Wien, 2001, ISBN 3-446-21533-6
[Zak98] Zakharian, S.; Ladewig-Riebler, P.; Thoer, S.
Neuronale Netze für Ingenieure. Vieweg, Braunschweig, Wiesbaden, 1998, ISBN 3-528-05578-2

Veröffentlichungen und Vorträge 145
V Veröffentlichungen und Vorträge
Folgende Veröffentlichungen und Vorträge sind im Lauf des Verbundprojektes von den
Projektpartnern, teilweise in Kooperation, getätigt worden.
V.1 Veröffentlichungen
Göres, T.; Harms, H.-H.
Datenmanagementsystem für den Teleservice bei mobilen Arbeitsmaschinen, Landtechnik 62 (2007), Heft 5, S. 328-329, ISSN 0023-8082
Göres, T.; Harms, H.-H.
Data Management System for Teleservice in Mobile Machines, Beitrag Nr. 328 in der Online-Ausgabe der Zeitschrift Landtechnik, www.landtechnik-net.com,
Göres, T.; Grothaus, H.-P.; Rustemeyer, T.; Möller, A.
Development of a Data Management System for Teleservice Applications on Mobile Working Machines – DAMIT, 65th International Conference on Agricultural Engineering (Landtechnik AgEng) 09.-10.11.2007, Hannover Tagungsband “Engineering Solutions for Energy and Food Production” S. 265-270, ISBN: 978-3-18-092001-6
Göres, T. Daten für den Teleservice managen, Eilbote, Heft 18, 2008, Seite 9
Göres, T. Datenmanagement in der Landtechnik - Verschleiß messen und dem Fahrer melden, Lohnunternehmen 63 (2008), Heft 6, Seite 44-46
Göres, T.; Harms, H.-H.; Lang, T.
Methoden zur Datenkompression für Telematikanwendungen bei Landmaschinen, 66th International Conference Agricultural Engineering (LAND.TECHNIK 2008) 25.-26.09.2008, Stuttgart-Hohenheim Tagungsband “Landtechnik regional und international” S. 397-403, ISBN: 978-3-18-092045-0
Göres, T.; Harms, H.-H.; Lang, T.; Oetker, J. T.
Modellgestützte Zustandsdiagnose eines Luftfilters, Landtechnik 63 (2008), Heft 6, S. 346-347, ISSN 0023-8082
Göres, T.; Harms, H.-H.; Lang, T.; Oetker, J. T.
Model-based condition diagnosis of an air filter, Beitrag Nr. 346 in der Online-Ausgabe der Zeitschrift Landtechnik, www.landtechnik-net.com,
Göres, T. Datenmanagement für den Teleservice – Maschinenzustände automatisch überwachen, Neue Landwirtschaft 19 (2008), Heft 12, S. 62, ISSN 0863-2847

Veröffentlichungen und Vorträge 146
Göres, T.; Lang, T.; Harms, H.-H.
Datenkompressionsmethoden für Telematikanwendungen bei mobilen Maschinen, Landtechnik 64 (2009), Heft 1, S. 40 - 42, ISSN 0023-8082
Göres, T.; Lang, T.; Harms, H.-H.
Methods for data compression in telematics applications on mobile machines, S. 40-42 in der Online-Ausgabe 1/2009 der Zeitschrift Landtechnik, www.landtechnik-online.eu
V.2 Vorträge
Harms, H.-H.; Göres, T.
Entwicklung eines Datenmanagementsystems für den Teleservice bei mobilen Arbeitsmaschinen, Vortrag anlässlich der Veranstaltung „Industrielle Anwendungen als Herausforderung für Hochleistungs-Bioschmierstoffe“ der AG Bioöl des TAT am 16.10.2007 in Duisburg
Göres, T.; Grothaus, H.-P.; Rustemeyer, T.; Möller, A.
Development of a Data Management System for Teleservice Applications on Mobile Working Machines – DAMIT, 65th International Conference on Agricultural Engineering (Landtechnik AgEng) 09.-10.11.2007, Hannover
Göres, T.; Datenmanagement für den Teleservice - Aktueller Stand des Forschungsprojektes DAMIT, Vortrag vor dem Arbeitskreis Teleservice des VDMA am 27.02.2008 in Damme
Göres, T. Methoden zur Datenkompression bei Telematikanwendungen, Vortrag beim Kolloquium „Datenmanagement für den Teleservice bei Mobilen Arbeitsmaschinen“ am 04.04.2008 in Braunschweig
Bergmann-Eggers, S.; Wäsch, D.
Architektur und Kommunikation in Telematikanwendungen, Vortrag beim Kolloquium „Datenmanagement für den Teleservice bei Mobilen Arbeitsmaschinen“ am 04.04.2008 in Braunschweig
Ganseforth, A.; Möller, A.
OPTIPLAN – Datenmanagement in der Zuckerrüben-Logistikkette, Vortrag beim Kolloquium „Datenmanagement für den Teleservice bei Mobilen Arbeitsmaschinen“ am 04.04.2008 in Braunschweig
Grothaus, H.-P.. Planbare Instandhaltung über die Maschinenlebensdauer als Basis für innovatives Werkstattmanagement, Vortrag beim Kolloquium „Datenmanagement für den Teleservice bei Mobilen Arbeitsmaschinen“ am 04.04.2008 in Braunschweig
Göres, T.; Harms, H.-H.; Lang, T.
Methoden zur Datenkompression für Telematikanwendungen bei Landmaschinen, 66th International Conference Agricultural Engineering (LAND.TECHNIK 2008) 25.-26.09.2008, Stuttgart-Hohenheim

Veröffentlichungen und Vorträge 147
Ganseforth, A. Voraussetzungen für ein Condition Monitoring, Vortrag beim Abschlussworkshop im Verbundforschungsprojekt DAMIT „Datenmanagement für den Teleservice bei mobilen Arbeitsmaschinen“ am 27.03.2009 in Braunschweig
Dirks, M. Vorhersagbarkeit von Wartung und Instandhaltung, Vortrag beim Abschlussworkshop im Verbundforschungsprojekt DAMIT „Datenmanagement für den Teleservice bei mobilen Arbeitsmaschinen“ am 27.03.2009 in Braunschweig
Göres, T. Kompressionsmethoden für verschiedene Datenarten, Vortrag beim Abschlussworkshop im Verbundforschungsprojekt DAMIT „Datenmanagement für den Teleservice bei mobilen Arbeitsmaschinen“ am 27.03.2009 in Braunschweig
Wäsch, D. Software-Architektur und Datenfluss, Vortrag beim Abschlussworkshop im Verbundforschungsprojekt DAMIT „Datenmanagement für den Teleservice bei mobilen Arbeitsmaschinen“ am 27.03.2009 in Braunschweig
Möller, A. Technologien und Schnittstellen im Logistikprozess, Vortrag beim Abschlussworkshop im Verbundforschungsprojekt DAMIT „Datenmanagement für den Teleservice bei mobilen Arbeitsmaschinen“ am 27.03.2009 in Braunschweig
Brandt, V. Vorbeugende Instandhaltungsprozesse durch Teleservice, Vortrag beim Abschlussworkshop im Verbundforschungsprojekt DAMIT „Datenmanagement für den Teleservice bei mobilen Arbeitsmaschinen“ am 27.03.2009 in Braunschweig
Grothaus, H.-P.. Dienstleistungsangebote für mobile Arbeitsmaschinen, Vortrag beim Abschlussworkshop im Verbundforschungsprojekt DAMIT „Datenmanagement für den Teleservice bei mobilen Arbeitsmaschinen“ am 27.03.2009 in Braunschweig


















