
ENTROPIE, INFORMATIE EN HET MAXIMUM ENTROPIE PRINCIPE · MAXIMUM ENTROPIE PRINCIPE Een introductie...
71
ENTROPIE, INFORMATIE EN HET MAXIMUM ENTROPIE PRINCIPE Een introductie tot de actuele conceptie en toepassingen van entropie Verslag van Bachelorproject Natuur- en Sterrenkunde, omvang 12 EC, uitgevoerd tussen 01-09- 2011 en 31-05-2012 bij het Institute of Physics aan de Universiteit van Amsterdam, Faculteit der Natuurwetenschappen, Wiskunde en Informatica. Door: Rebecca Sier Studentnummer: 5893011 Inleverdatum: 25 mei 2012 Begeleider: Prof.dr.ir. F.A. Bais Tweede beoordelaar: J.P. van der Schaar, Ph.D.
Transcript of ENTROPIE, INFORMATIE EN HET MAXIMUM ENTROPIE PRINCIPE · MAXIMUM ENTROPIE PRINCIPE Een introductie...

ENTROPIE, INFORMATIE EN HET MAXIMUM ENTROPIE PRINCIPE
Een introductie tot de actuele conceptie en toepassingen van entropie
Verslag van Bachelorproject Natuur- en Sterrenkunde, omvang 12 EC, uitgevoerd tussen 01-09-2011 en 31-05-2012 bij het Institute of Physics aan de Universiteit van Amsterdam, Faculteit der
Natuurwetenschappen, Wiskunde en Informatica.
Door: Rebecca Sier
Studentnummer: 5893011
Inleverdatum: 25 mei 2012
Begeleider: Prof.dr.ir. F.A. Bais
Tweede beoordelaar: J.P. van der Schaar, Ph.D.

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
2
ABSTRACT
The concept of entropy as originally defined by physicists Boltzmann and Gibbs has been
radically changed over the past century. In the search for a quantity that measures both
the information in and uncertainty of a stochastic system, Shannon found the same
expression that Gibbs used to define the entropy of a grand canonical system. With this
new conception of entropy as a measure of information, it was Jaynes who first used the
maximum entropy principle as a starting point from which he was able to deduce all of
statististical mechanics concerning states in thermodynamic equilibrium. In this overview
we introduce this chronological development of de concept of entropy, starting as a
thermodynamical quantity, leading to being a measure for probability and information.
Finally the general utility of this new conception will be illustrated by giving examples of
the maximum entropy principle, bringing out the multidisciplinary usefulness of this
quantity, which started out having only physical meaning. Finally, an example in
linguistics is worked out in some detail.

Entropie, Informatie en het Maximum Entropie Principe
3
POPULAIR WETENSCHAPPELIJKE SAMENVATTING
Entropie is van origine een grootheid uit de warmteleer ofwel thermodynamica. Elk
thermodynamisch systeem heeft naast temperatuur, druk en volume ook een waarde voor de
hoeveelheid entropie. De tweede hoofdwet van de thermodynamica definieert een toename in
entropie als de toename in warmte gedeeld door de temperatuur van het systeem. Erg intuïtief is
deze definitie echter niet. Door de jaren heen zijn handigere definities van entropie geformuleerd.
Aan de hand van een voorbeeld met
bits kunnen we deze definities
begrijpen.
Een bit is een systeem met twee opties:
op of neer. Uit de toestand waarin een
bit zich bevindt lezen we informatie af.
Bijvoorbeeld: een magnetron kan aan
of uit staan; zit de bit in toestand , dan
staat de magnetron aan, terwijl bij
toestand de magnetron is
uitgeschakeld. Een tweede bit laten we
corresponderen met de energie-
instelling van de magnetron: toestand
staat voor een vermogen tussen de en watt; toestand voor een instelling tussen de en
watt. Met deze twee bits kunnen vier verschillende toestanden van de magnetron worden
beschreven, zoals te zien in de figuur. Laten we meer bits corresponderen met de instellingen van
de magnetron, dan hebben we meer informatie over de instellingen van het apparaat. We kunnen
daarom zeggen dat het aantal bits aangeeft hoeveel informatie over de magnetron we tot onze
beschikking hebben.
Stel nu dat bij het instellen van de magnetron geen onderscheid bestaat tussen de instelling
watt en watt – de enige instelling die je kunt doen is het aan- of uitzetten van de
magnetron. De twee bittoestanden en beschrijven nu dezelfde magnetroninstelling, aangezien
het wattage niet meer relevant is. Omdat elke bittoestand even waarschijnlijk is zal een
magnetroninstelling die correspondeert met meerdere bittoestanden waarschijnlijker zijn dan een
instelling die slechts door één bepaalde bittoestand wordt beschreven. Het aantal bittoestanden
dat correspondeert met één magnetroninstelling is daarom een maat voor de waarschijnlijkheid
van die instelling.
Zo hebben we in een paar alinea’s twee interpretaties van het bitsysteem gevonden: het aantal bits
is een maat voor de informatie in een systeem en het aantal bittoestanden is een maat voor de
waarschijnlijkheid om het systeem in een bepaalde toestand aan te treffen. Wat heeft dit met
entropie te maken? Wel, de door natuurkundigen gevonden formules voor entropie blijken exact
overeen te komen met de wiskunde die een maat voor informatie en waarschijnlijkheid uitdrukt.
Entropie, informatie en waarschijnlijkheid blijken twee kanten van dezelfde medaille te zijn.
Zo kunnen we entropie herdefiniëren als maat voor het aantal manieren waarop de toestand van
een systeem kan worden gerealiseerd. Daarnaast weten we dat het systeem met maximum
entropie het meest waarschijnlijke systeem is. Dit geeft handvatten voor een methode voor het
verkrijgen van optimale voorspellingsmodellen: het maximum entropiebeginsel. Aan de hand van
dit principe worden uiteenlopende soorten optimale modellen gecreëerd, bruikbaar voor
voorspelling van bijvoorbeeld het weer, de beurskoers en voor het maken van vertalingen. De
opvatting van entropie als maat voor informatie en waarschijnlijkheid laat zien hoe alomvattend en
verbazingwekkend alledaags het begrip is.
Magnetron aan, ingesteld op 400 – 800
watt Magnetron aan, ingesteld op 0 – 400 watt
Magnetron uit, ingesteld op 400 - 800 watt
Magnetron uit, ingesteld op 0 – 400
watt Figuur - de vier toestandsmogelijkheden van een
magnetron beschreven door twee bits

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
4
INHOUDSOPGAVE
1. EEN BIT___________________________________________________________________________________6
2. FYSISCHE ENTROPIE_____________________________________________________________________9
2.1 HOOFDWETTEN VAN DE THERMODYNAMICA_______________________________9
2.2 ENTROPIE EN STATISTIEK___________________________________________________14
2.2.1 STATISTISCHE MECHANICA, DE BASIS_____________________15
2.2.2 BOLTZMANN ENTROPIE_____________________________________16
2.2.3 GIBBS ENTROPIE_____________________________________________21
2.3 SAMENGEVAT__________________________________________________________________25
3 INFORMATIE EN ENTROPIE___________________________________________________________26
3.1 HET OPTIMALE MODEL_______________________________________________________26
3.2 SHANNON: ENTROPIE, EEN MAAT VOOR INFORMATIE___________________29
3.3 INFORMATIE EN DE TWEEDE HOOFDWET_________________________________37
3.3.1 MAXWELL’S DUIVEL_________________________________________37
3.3.2 SZILARD’S CYCLUS___________________________________________38
3.3.3 LANDAUER’S PRINCIPE______________________________________40
3.3.4 REDDING VAN DE TWEEDE HOOFDWET VAN DE
THERMODYNAMICA_________________________________________42
3.4 SAMENGEVAT__________________________________________________________________42
4 HET MAXIMUM ENTROPIEBEGINSEL_____________________________________________________44
4.1 HET EQUIPARTITIEPRINCIPE________________________________________________44
4.2 HET KANONIEK ENSEMBLE__________________________________________________46
5 ANDERE TOEPASSINGEN VAN HET MAXIMUM ENTROPIE PRINCIPE_________________49
5.1 ANT COLONY OPTIMIZATION________________________________________________49
5.2 BEELDRECONSTRUCTIE______________________________________________________52
5.3 GEOGRAFISCHE DISTRIBUTIE VAN DIERSOORTEN________________________54
6 MAXIMUM ENTROPIE IN DE TAALWETENSCHAP_______________________________________57
6.1 TAALHERKENNINGSPROGRAMMA’S_________________________________________57
6.2 KENMERKEN EN VOORWAARDEN___________________________________________58
6.3 DEFINITIE EN MAXIMALISATIE VAN DE ENTROPIE_______________________60
6.4 DE OPTIMALE GEWICHTEN VAN DE VOORWAARDEN_____________________63
7 CONCLUSIE__________________________________________________________________________________67
DANKWOORD____________________________________________________________________________________70

Entropie, Informatie en het Maximum Entropie Principe
5
GERAADPLEEGDE LITERATUUR_______________________________________________________________71

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
6
1. EEN BIT
Laat me u tot het onderwerp van deze scriptie inleiden door te beginnen met een
eenvoudig voorbeeld. Een bit is een systeem met twee opties: of , op of neer, aan of uit,
licht of donker. Uit de toestand waarin een bit zich bevindt lezen we informatie af. Een
voorbeeld: een magnetron kan aan of uit staan, twee mogelijkheden die beschreven
worden door een bit; zit de bit in toestand ‘op’, dan staat de magnetron aan, terwijl bij
toestand ‘neer’ de magnetron is uitgeschakeld. Een tweede bit kunnen we laten
corresponderen met instellingen van de magnetron, zoals het wattage waarop het
apparaat staat ingesteld: toestand ‘neer’ staat voor een vermogen tussen de en watt;
toestand ‘op’ voor een instelling tussen de en watt.
De toestand van de magnetron wordt nu beschreven door twee bits die elk twee
mogelijkheden inhouden. Twee maal twee mogelijkheden geeft vier mogelijke toestanden
waarin de magnetron zich volgens onze informatie bevinden kan. De
toestandsmogelijkheden zijn getekend in Figuur . Een bit in toestand ‘op’ wordt
aangegeven met een omhoog wijzende pijl, de toestand ‘neer’ met een naar beneden
gerichte pijl; de linker pijl geeft de bit weer die correspondeert met het aan- of uitstaan
van de magnetron, de rechtse pijl geeft informatie over het vermogen.
Laten we meer bits corresponderen met de instellingen van de magnetron, dan
hebben we meer informatie over de instellingen van het apparaat. Het ingestelde
Magnetron aan, ingesteld op 400 – 800 watt
Magnetron aan, ingesteld op 0 – 400 watt
Magnetron uit, ingesteld op 400 - 800 watt
Magnetron uit, ingesteld op 0 – 400 watt
Figuur 1 - De vier toestandsmogelijkheden van een magnetron beschreven door twee bits.

Entropie, Informatie en het Maximum Entropie Principe
7
vermogen kan bijvoorbeeld accurater worden bepaald bij gebruik van extra bits. Het
aantal afleesbare toestandsmogelijkheden van de magnetron groeit hierdoor sterk. Drie
bits kunnen verschillende toestanden beschrijven. Bits kunnen verschillende
toestanden beschrijven. Geven we het aantal toestanden weer met , dan vinden we de
volgende uitdrukking voor het aantal bits :
log .
Hoe meer bits, hoe meer toestanden mogelijk, des te meer informatie over de toestand
van de magnetron. Bovenstaande logaritmische uitdrukking is daarom een maat voor de
hoeveelheid informatie over het beschreven systeem, in termen van het aantal
toestanden waarin het systeem zich kan bevinden.
Stel nu dat meerdere bittoestanden dezelfde instelling van de magnetron beschrijven.
Dit is bijvoorbeeld het geval wanneer er bij het instellen van de magnetron geen
onderscheid bestaat tussen de instelling watt en watt – de enige
instelling die je kunt doen is het aan- of uitzetten van de magnetron. De twee
bittoestanden en beschrijven nu dezelfde magnetroninstelling, aangezien het
wattage niet meer relevant is. Omdat elke bittoestand even waarschijnlijk is zal een
magnetroninstelling die correspondeert met meerdere bittoestanden waarschijnlijker zijn
dan een instelling die slechts door één bepaalde bittoestand wordt beschreven. Het aantal
bittoestanden dat correspondeert met één magnetroninstelling is daarom een maat
voor de waarschijnlijkheid van die instelling, evenals de logaritme van .
Met de twee gevonden interpretaties van – een maat voor de hoeveelheid informatie
en de waarschijnlijkheid van een toestand – is het geen verrassing dat een logaritme in de
uitdrukking voorkomt. De logaritme vervult een handige rol omdat deze voldoet aan de
eigenschap log log log . Wordt beschouwd als maat voor informatie, dan
zorgt de logaritme ervoor dat de totale hoeveelheid informatie een optelling vormt van
afzonderlijke hoeveelheden informatie, : ∑ ∑ log . In het geval dat
wordt beschouwd als maat voor de waarschijnlijkheid van een toestand, dan moet gelden
dat wanneer deze toestand is opgebouwd uit afzonderlijke stappen , het product van de
kansen op deze stappen gelijk is aan de totale waarschijnlijkheid van de toestand:
log log log ∏ . De genoemde eigenschap van de

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
8
logaritme voldoet aan beide eigenschappen voor de twee betekenissen die gegeven zijn
aan :
∑
∑ log
log (∏
).
Uit dit simpele voorbeeld – de beschrijving van de toestand van een magnetron in
termen van bits – dient zich een interessant verband aan. De logaritme van het aantal
mogelijke toestanden is een bekende uitdrukking voor entropie – een grootheid uit de
thermodynamica – zodat met de gevonden uitdrukking een verband tussen entropie,
waarschijnlijkheid en informatie wordt gesuggereerd. Om dit verband beter te kunnen
begrijpen is kennis over entropie en informatie nodig. Aan de hand van een
chronologische beschrijving van de ontwikkeling van thermodynamica, statistische
mechanica en het begrip entropie zal in hoofdstuk 2 worden toegewerkt naar eerst
Boltzmann’s, dan Gibbs’ begrippen van en uitdrukkingen voor entropie en
waarschijnlijkheid. Shannon’s statistische interpretatie en uitwerking van het begrip
informatie geeft vervolgens in hoofdstuk 3 stevigere handvatten om informatie en
entropie aan elkaar te koppelen. Hoofdstuk 4 laat zien hoe entropie in plaats van het
eindpunt ook als beginpunt van statistische fysica kan dienen, aan de hand van hoe Jaynes
met het principe van maximum entropie gebruik maakte van Shannon’s uitwerking en
perceptie van entropie. Deze aanpak geeft aan dat de statistische mechanica één van de
vele toepassingen van het begrip entropie is, waarna in het vijfde hoofdstuk ter illustratie
een aantal voorbeelden wordt gegeven van nieuwe, geheel van natuurkunde losstaande
toepassingen van het maximum entropie principe. In hoofdstuk zes wordt een laatste
voorbeeld van het maximum entropie principe nauwkeuriger uitgewerkt.
Hoewel in historisch perspectief het entropiebegrip aanvankelijk enkel als onderdeel
van de bèta-disciplines werd beschouwd, is het inmiddels een begrip dat door zijn
interpretatie als maat voor informatie in de meest algemene zin, succesvolle toepassingen
heeft gevonden in tal van vakgebieden. Het is deze verbinding tussen entropie en
informatie die de conceptie en het gebruik van deze fundamentele grootheid veranderden.
In deze scriptie wordt daarvan een overzicht gegeven.

Entropie, Informatie en het Maximum Entropie Principe
9
2. FYSISCHE ENTROPIE
Om inzicht te geven in het begrip entropie en haar rol in de ontwikkeling van
thermodynamica en statistische mechanica wordt allereerst de ontwikkeling zelf
beschreven. Via de hoofdwetten van de thermodynamica en haar statistische interpretatie
wordt het huidige begrip van entropie geformuleerd.
2.1 HOOFDWETTEN VAN DE THERMODYNAMICA
Thermodynamica ontstond in de 19e eeuw, toen atomen als bouwstenen van materie nog
een omstreden onderwerp waren. Omstreden juist omdat met de thermodynamica,
zonder gebruik te maken van atoomstructuur, een aantal wetten konden worden
opgesteld waarmee conclusies werden getrokken over het gedrag van macroscopische
systemen. Bij een eenvoudige formulering van de thermodynamica denken we aan een
mechanisch systeem dat energie in de vorm van warmte kan opnemen of afstaan en dat
arbeid kan verrichten.
De eerste wet van de thermodynamica luidt
en komt neer op de stelling dat energie behouden is: in een systeem is de verandering in
interne energie gelijk aan de hoeveelheid geabsorbeerde warmte minus de
hoeveelheid verrichtte arbeid . Warmte is een vorm van energie, namelijk thermische
energie – in een systeem opgenomen warmte-energie kan volgens de eerste hoofdwet
worden omgezet in interne energie en mechanische energie, ofwel arbeid. De vergelijking

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
10
staat toe dat alle opgenomen warmte bijvoorbeeld in arbeid wordt omgezet. Of en in
hoeverre dat mogelijk is wordt vastgelegd door de tweede hoofdwet.
De tweede hoofdwet van de thermodynamica luidt
,
en definieert de verandering in entropie als de ratio van de verandering in warmte
ten opzichte van de temperatuur van het systeem. Entropie wordt hier gedefinieerd als
een “toestandsgrootheid”, net zoals druk, volume of temperatuur. Elk macroscopisch
mechanisch systeem heeft een bepaalde entropie, wat van entropie een fundamentele
grootheid maakt, net zo fundamenteel als bijvoorbeeld temperatuur en even belangrijk
voor begrip van de werking van het betreffende systeem. Des te opvallender is het dat
entropie een relatief onbekende grootheid is. Tevens wordt gesteld – de eigenlijke tweede
hoofdwet – dat de hoeveelheid entropie voor een afgesloten systeem met het verstrijken
van de tijd nooit af zal nemen.
Implicaties van deze wetten blijken uit argumenten van Nicholas Léonard Sadi
Carnot (1796-1832). Hij zette de eerste stappen richting thermodynamica als nieuwe
discipline en haar hoofdwetten. Carnot onderzocht de werking van warmte en was de
eerste natuurkundige die een verband zag tussen warmte en beweging – dit inzicht leidde
tot de zojuist geformuleerde eerste hoofdwet. Afhankelijk van de temperatuur verricht
warmte arbeid, wat hij aantoonde met behulp van de cyclus die inmiddels zijn naam
draagt, weergegeven in Figuur 2. Deze tekening gebruikte Carnot zelf overigens niet, maar
werd pas later door Benoît Paul Émile Clapeyron (1799-1864) zoals in onderstaande
figuur afgebeeld.

Entropie, Informatie en het Maximum Entropie Principe
11
In de cyclus bekijkt Carnot de veranderingen in druk en volume van een in een
cilinder opgesloten gas. De cilinder is voorzien van een zuiger, zodat het volume van het
gas aan kan worden gepast. Daarnaast zijn er twee warmtereservoirs met verschillende
temperaturen waar de cilinder mee in contact kan worden gebracht als wel van kan
worden geïsoleerd. Het gas krijgt hierdoor achtereenvolgens de temperaturen en ,
waarbij geldt dat .
In vier stappen ondergaat de cilinder Carnot’s cyclus. Van punt naar punt vindt
een isotherme expansie plaats: het gas heeft in punt temperatuur en is gekoppeld aan
het warme reservoir, wat de temperatuur in de cilinder constant houdt. Er wordt een
isotherm beschreven volgens de wet van Boyle en Gay Lussac, , met voor de
hoeveelheid gas in een mol en voor de gasconstante: de druk van het gas zal de zuiger
van de cilinder doen uitschuiven onder absorptie van een hoeveelheid warmte . Met
andere woorden: onder afname van de druk van het gas neemt het volume waarin het gas
zich bewegen kan toe. Van punt naar is de cilinder van het warmtereservoir
losgekoppeld, wat zorgt voor adiabatische expansie: het gas verricht nog altijd arbeid
door de zuiger uit te schuiven, maar ontvangt niet meer de warmte om het verlies aan
energie te compenseren. Zo zal de cilinder in temperatuur dalen tot het in punt
temperatuur bereikt. Voor de stap naar punt wordt de cilinder gekoppeld aan het
koude reservoir, wat zorgt voor isotherme compressie: een hoeveelheid warmte wordt
afgegeven aan het reservoir, de omgeving van de cilinder zal arbeid verrichten om de
Figuur 2 – Carnot’s cyclus, de verandering van een gas in een cilinder afhankelijk van druk 𝑃 en volume
𝑉. Uit: Bais, F.A. & Farmer, J.D. (2008). The physics of information.

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
12
zuiger in te duwen en het volume te verkleinen. Wordt de cilinder in punt losgekoppeld
van het koude reservoir, dan blijft de omgeving arbeid verrichten, zonder daar nog
warmte van de cilinder voor te ontvangen. Deze adiabatische compressie houdt daarom
een stijging van de temperatuur in de cilinder in, tot de temperatuur is bereikt – de
cyclus is voltooid, de cilinder is terug bij haar beginpunt .
Welke implicaties van de twee hoofdwetten vinden we terug in deze cyclus? Om
dit in te zien kan de in de cyclus netto hoeveelheid verkregen arbeid berekend worden
met de volgende integraal, herschreven met behulp van de eerste hoofdwet
∮ ∮ ∮ .
De interne energie verdwijnt uit de integraal aangezien het een kringintegraal betreft
en de interne energieën op begin- en eindpunt gelijk zijn. De verandering in entropie van
de twee reservoirs kan met behulp van de tweede hoofdwet worden verkregen:
.
De gevonden uitdrukkingen gebruiken we voor berekening van het rendement van een
machine die de Carnot-cyclus ondergaat: de ratio van uitgevoerde arbeid ten opzichte
van de hoeveelheid ontvangen energie .
.
Het rendement is gelijk aan
wanneer de hoeveelheid entropie constant blijft. Dit is
het maximaal haalbare rendement, alleen afhankelijk van de ratio van de koude en warme

Entropie, Informatie en het Maximum Entropie Principe
13
temperatuurbaden. Een vergroting van entropie maakt het rendement kleiner dan
.
Omdat , geldt onder alle omstandigheden dat het rendement kleiner is dan . Dit
betekent dat in alle gevallen
;
door de cilinder ontvangen energie is altijd groter dan de hoeveelheid uitgevoerde arbeid.
Niet-gebruikte energie wordt omgezet in warmte, wat geen rendement oplevert.
De tweede hoofdwet legt zo restricties op aan de eerste hoofdwet: energie in de
vorm van arbeid kan volledig omgezet worden in warmte, maar warmte kan niet volledig
in arbeid worden omgezet. Er zijn twee verschillende warmtebronnen met verschillende
temperatuur nodig om thermische energie in arbeid om te kunnen zetten. Dit is een
belangrijke consequentie van de tweede hoofdwet: warmte kan niet zomaar van een koud
naar een warm reservoir lopen – er zal arbeid nodig zijn om warmte uit een koelkast naar
een warmere omgeving te transporteren.
Een tweede consequentie van de tweede hoofdwet is de irreversibiliteit van
processen waarbij entropie toeneemt. Zojuist bleek dat bij vergroting van entropie een
lager rendement wordt behaald dan wanneer een Carnot-cyclus wordt doorlopen, met
gelijke entropie in begin- en eindpunt. Bij vergroting van entropie zal extra warmte
verloren gaan, welke niet kan worden teruggewonnen wanneer het proces in
tegengestelde richting wordt doorlopen. Dit in tegenstelling tot de Carnot-cyclus, welke
zowel met de klok mee als tegen de klok in kan worden uitgevoerd. Dit brengt een nieuwe
eigenschap van toename van entropie aan het licht: processen waarbij de entropie
toeneemt zijn irreversibel, in tegenstelling tot processen waarbij de hoeveelheid entropie
gelijk blijft.
Het is deze laatste eigenschap van entropie die een volgende stap in het begrip
over deze grootheid mogelijk maakte. Ludwig Boltzmann zette deze stap, met behulp van
opnieuw een nieuwe tak van de fysica: statistische mechanica.

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
14
2.2 ENTROPIE EN STATISTIEK
Met de thermodynamica en haar hoofdwetten kwam ook de grootheid entropie, als
nieuwe systeemvariabele naast druk, temperatuur en volume. De nieuwe grootheid
gedefinieerd door de tweede hoofdwet is de oorzaak van thermodynamische processen,
zoals de verschijnselen reversibiliteit en irreversibiliteit, evenals het verschijnsel dat
warmte in bepaalde gevallen niet volledig in arbeid kan worden omgezet. Een veel dieper
begrip van de betekenis en werking van entropie werd echter pas verkregen met de
komst van statistische mechanica. Het doel van de statistische mechanica is om het
macroscopische gedrag van systemen zoals gassen en vloeistoffen te verklaren uit de
microscopische eigenschappen, dat wil zeggen de wetten waaraan de microscopische
bouwstenen voldoen. Anders dan bij de thermodynamica wordt in statistische mechanica
gebouwd op kennis over individuele deeltjes of atomen, met elk een eigen snelheid en
energie. We moeten ons realiseren dat macroscopische systemen een enorm aantal
microscopische vrijheidsgraden hebben, typisch van de orde van het getal van Avogadro,
. Nauwgezette kennis over de precieze toestand van al deze minuscule
deeltjes is natuurlijk onmogelijk te verkrijgen. Dat is ook niet nodig, het blijkt dat om het
macroscopische systeem in evenwicht te beschrijven in termen van de macroscopische
toestandsvariabelen, we alleen maar kennis van de gemiddelde eigenschappen van de
microscopische deeltjes variabelen hoeven te hebben. En aangezien de aantallen zeer
groot zijn, zijn de statistische voorspellingen zeer accuraat, zoals elke verzekeringsagent
je kan vertellen. Zo leveren de fysische wetten waaraan microdeeltjes onderhevig zijn, in
combinatie met de bekende wetten van de statistiek genoeg informatie om een
uitstekende beschrijving van het macroscopische systeem te geven.
Met behulp van deze statistiek kunnen thermodynamische processen van
macroscopische systemen worden begrepen door kennis van onderliggende
microscopische wetten, zonder daarbij de precieze toestand van individuele deeltjes te
hoeven kennen. Zo kon ook de macroscopische grootheid entropie begrepen worden aan
de hand van een microscopische definitie.

Entropie, Informatie en het Maximum Entropie Principe
15
2.2.1 STATISTISCHE MECHANICA, DE BASIS
Statistische mechanica doet uitspraken over hoe toestanden van grootschalige systemen
in termen van de toestanden van kleinere onderdelen samengesteld zijn, zoals
microscopisch kleine deeltjes. Dit laatste, de toestand van individuele deeltjes, wordt de
microtoestand genoemd, terwijl de grootschaliger toestanden, van een gas bijvoorbeeld,
bekend staan als macrotoestanden. Elke nieuwe toestand door een verschil in
bijvoorbeeld de positie, snelheid of energie van een atoom in een gas, geeft een nieuwe
microtoestand. Het geheel aan mogelijke microtoestanden heet de faseruimte. Eén
microtoestand correspondeert met één punt in de faseruimte. Die faseruimte is dus
gigantisch: elk deeltje wordt beschreven in termen van een positie (drie getallen) en drie
snelheidscomponenten, zodat die fase ruimte dimensies heeft.
Zoals gezegd hebben we geen nauwgezette kennis over welke van de mogelijke
microtoestanden een heersende macrotoestand veroorzaakt. Wel zijn de fysische wetten
bekend waaraan individuele deeltjes zich moeten houden. Daarnaast geeft kennis over de
macrotoestand aan van welke microtoestanden uit de faseruimte sprake zou kunnen zijn.
Deze mogelijke microtoestanden worden de accessible states of toegankelijke toestanden
genoemd. De hoeveelheid toegankelijke microtoestanden, behorend bij een bepaalde
macrotoestand, wordt de multipliciteit van die bepaalde macrotoestand genoemd.
Statistische fysica maakt gebruik van twee grondbeginselen. Het eerste beginsel
stelt dat alle toegankelijke toestanden van een gesloten systeem in evenwicht, dat wil
zeggen van een gegeven macrotoestand, even waarschijnlijk zijn. Met andere woorden, de
kans dat er sprake is van microtoestand is even groot als de kans op het geval van
microtoestand , waarbij beide microtoestanden deel uitmaken van dezelfde groep
toegankelijke microtoestanden. Dit geldt niet voor een systeem waarbij energie of deeltjes
kunnen worden uitgewisseld. In dit laatste geval zal de waarschijnlijkheid van bepaalde
microtoestanden apart moeten worden berekend.
Alvorens het tweede principe van de statistische mechanica te introduceren is
begrip over de in deze tak van de natuurkunde veelgebruikte term ‘ensemble’ vereist. Een
ensemble is een verzameling deeltjessystemen of toegankelijke microtoestanden.
Macroscopische grootheden worden beschreven door statistische kennis over
verschillende ensembles. De volgende deeltjessystemen zijn hierbij gangbaar: het
microkanoniek ensemble, een geïsoleerd systeem met constante energie en constante

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
16
hoeveelheid deeltjes; het kanoniek ensemble, een systeem met constante hoeveelheid
deeltjes en in thermisch evenwicht, in staat tot uitwisseling van energie met de omgeving;
en het groot kanoniek ensemble, waarin zowel energie als deeltjes met de omgeving
worden uitgewisseld.
Het tweede principe, noodzakelijk voor het trekken van conclusies zoals de
statistische fysica dat doet, is die van ergodiciteit. Volgens deze stelling is de
evenwichtstoestand van een ensemble van deeltjessystemen, gemiddeld over de tijd,
gelijk aan de gemiddelde toestand van dat gehele ensemble op één ogenblik. Dit betekent
dat het niet nodig is om de precieze beweging van alle deeltjes in een ensemble te kennen
– gemiddeld over de tijd is dit namelijk gelijk aan de waarschijnlijkheidsverdeling over de
microscopische toestanden van de systemen in het ensemble op één ogenblik. Omdat het
vrijwel onmogelijk is om de exacte heersende microtoestanden te kennen en gedurende
de tijd bij te houden biedt de stelling van ergodiciteit een belangrijk gereedschap van
waaruit de statistische fysica kon ontstaan: door de mogelijke microtoestanden en hun
waarschijnlijkheden horend bij een macrotoestand te berekenen kunnen uitspraken
worden gedaan over de verandering van microtoestanden alsmede bijbehorende
macrotoestanden in de tijd. Zo kan ondanks een gebrek aan kennis over de heersende
microtoestand toch aan de hand van microscopische systemen een precieze verklaring en
uitdrukking worden gegeven voor de toestandsvariabelen van een macrotoestand en
vervolgens ook van de wetten van de thermodynamica.
2.2.2 BOLTZMANN ENTROPIE
Het was Ludwig Boltzmann (1844-1906) die een verbinding tussen de tweede hoofdwet
en statistiek legde (Cercignani, 1998). Boltzmann stelde dat entropie een maat is voor de
kans op een macrotoestand. De tweede hoofdwet die zegt dat entropie groter of gelijk
blijft stelt daarmee dat er altijd een beweging naar de toestand met een grotere
waarschijnlijkheid zal plaatsvinden.
Hoe Boltzmann tot deze conclusie kwam kan het best worden ingezien aan de
hand van een versimpeld voorbeeld van een fysisch systeem. Boltzmann zelf gebruikte het
meest simpele model van een gas, opgesloten in een vat met perfect reflecterende wanden.

Entropie, Informatie en het Maximum Entropie Principe
17
Daarnaast nam Boltzmann aan dat het gas uit deeltjes met discrete energieën
, , , , , bestaat. In deze wordt een soortgelijk model gebruikt, met het verschil
dat niet de toestand van gasdeeltjes, maar de toestand van bits wordt beschreven. Een
microtoestand van vier bits bepaalt de energie van de macrotoestand. Een bit in
toestand ‘op’ draagt bij aan de totale energie, een bit in toestand ‘neer’ draagt bij.
Het aantal manieren waarop de vier bits kunnen worden gerangschikt is .
Elk van deze 16 microtoestanden geeft een macroscopische energie . In Figuur 3 staan
de 16 mogelijke microtoestanden weergegeven. Verschillende microtoestanden blijken
dezelfde energie te leveren – dit zijn de toegankelijke microtoestanden van één
macrotoestand.
Het aantal toegankelijke microtoestanden ofwel de multipliciteit van een
macrotoestand wordt volgens de regels van de combinatoriek berekend:
,
𝐸
Ω
𝐸
Ω
𝐸
Ω
𝐸
Ω
𝐸
Ω
Figuur 3 – De 16 mogelijkheden waarop vier bits kunnen worden gerangschikt met bijbehorende
macroscopische energie 𝐸.

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
18
met voor het totaal aantal bits, het aantal bits in toestand ‘op’ en het aantal bits in
toestand ‘neer’. Een voorbeeld: voor de macrotoestand met geldt , en
, zodat
.
We hebben te maken met een gesloten systeem, zodat het eerstgenoemde
grondbeginsel van de statistische fysica geldt: alle microtoestanden van het systeem zijn
even waarschijnlijk. De macrotoestand met grootste multipliciteit is daarom de meest
waarschijnlijke macrotoestand. Sterker, de multipliciteit behorend bij een macrotoestand
is een maat voor de kans op die bepaalde macrotoestand.
In werkelijkheid hebben we te maken met een groot aantal bits of deeltjes.
Volgens het getal van Avogadro bevat een mol gas , atomen (Schroeder,
2000), zodat we kunnen spreken over een hoeveelheid deeltjes in de orde van .
Vanwege dit grote aantal kan bij berekening van multipliciteit gebruik worden gemaakt
van de formule van Stirling: , waarbij vergeleken met de overige
variabelen uit de formule langzaam verandert, zodat deze als een constante kan worden
beschouwd. Invullen geeft
.
Door de logaritme van te nemen krijgen we een uitdrukking die net als de in het
voorbeeld van een bit uit het eerste hoofdstuk voldoet aan de handige eigenschap
log log log :
log (log log log
) log
log log log log
log log log log ,
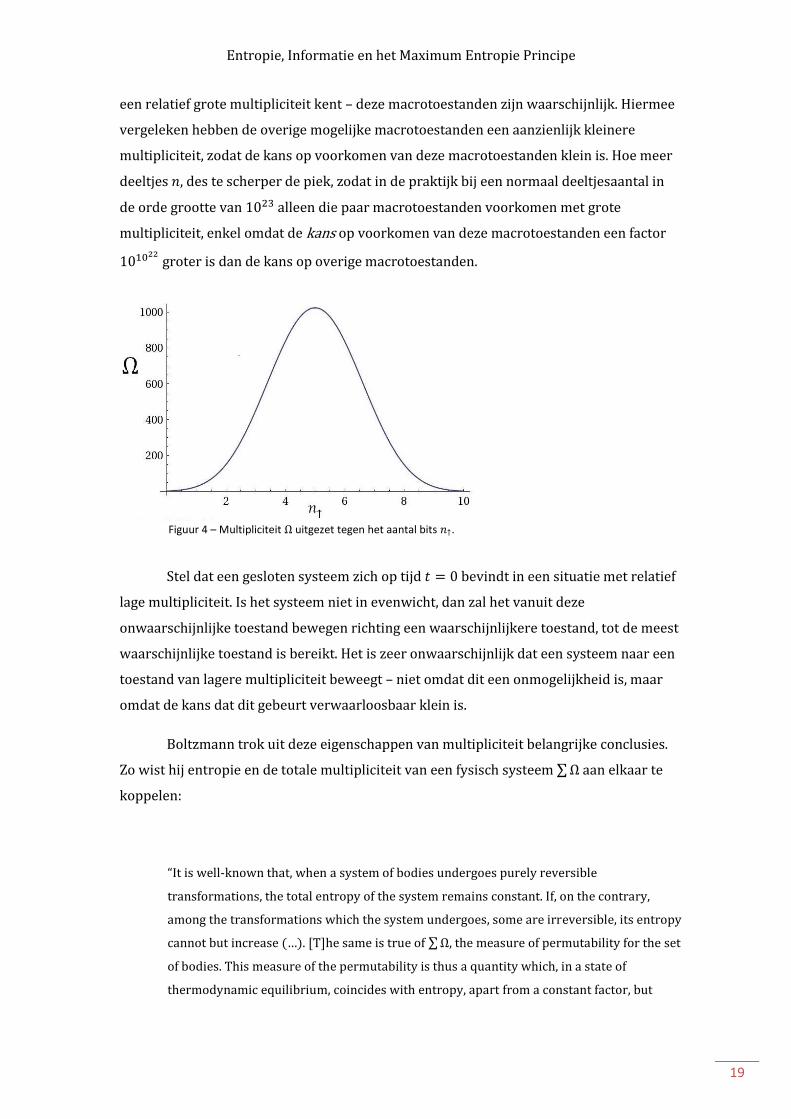
waarbij gebruik wordt gemaakt van . In Figuur 4 zien we de gevolgen van deze
uitdrukking in het geval : de piek geeft aan dat een klein aantal macrotoestanden
Entropie, Informatie en het Maximum Entropie Principe
19
een relatief grote multipliciteit kent – deze macrotoestanden zijn waarschijnlijk. Hiermee
vergeleken hebben de overige mogelijke macrotoestanden een aanzienlijk kleinere
multipliciteit, zodat de kans op voorkomen van deze macrotoestanden klein is. Hoe meer
deeltjes , des te scherper de piek, zodat in de praktijk bij een normaal deeltjesaantal in
de orde grootte van alleen die paar macrotoestanden voorkomen met grote
multipliciteit, enkel omdat de kans op voorkomen van deze macrotoestanden een factor
groter is dan de kans op overige macrotoestanden.
Stel dat een gesloten systeem zich op tijd bevindt in een situatie met relatief
lage multipliciteit. Is het systeem niet in evenwicht, dan zal het vanuit deze
onwaarschijnlijke toestand bewegen richting een waarschijnlijkere toestand, tot de meest
waarschijnlijke toestand is bereikt. Het is zeer onwaarschijnlijk dat een systeem naar een
toestand van lagere multipliciteit beweegt – niet omdat dit een onmogelijkheid is, maar
omdat de kans dat dit gebeurt verwaarloosbaar klein is.
Boltzmann trok uit deze eigenschappen van multipliciteit belangrijke conclusies.
Zo wist hij entropie en de totale multipliciteit van een fysisch systeem ∑ aan elkaar te
koppelen:
“It is well-known that, when a system of bodies undergoes purely reversible
transformations, the total entropy of the system remains constant. If, on the contrary,
among the transformations which the system undergoes, some are irreversible, its entropy
cannot but increase . [T]he same is true of ∑ , the measure of permutability for the set
of bodies. This measure of the permutability is thus a quantity which, in a state of
thermodynamic equilibrium, coincides with entropy, apart from a constant factor, but
Figuur 4 – Multipliciteit Ω uitgezet tegen het aantal bits 𝑛 .

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
20
which has a meaning even during each irreversible process, when it increases
continuously” Boltzmann, 77 .
Bij vergroting van multipliciteit, gepaard gaande met een vergroting van
waarschijnlijkheid, vindt een irreversibel proces plaats: de multipliciteit zal niet meer
verlagen aangezien daar een verwaarloosbaar kleine kans toe bestaat. Blijft de
multipliciteit tijdens een verandering van het systeem gelijk, dan is deze verandering
reversibel: begin- en eindtoestand van het systeem zijn even waarschijnlijk, zodat er een
goede kans bestaat dat het proces wordt teruggedraaid. Deze eigenschappen zijn gelijk –
zoals het citaat van Boltzmann aangeeft – aan die van entropie, zoals gezien aan de hand
van Carnot’s cyclus: bij een vergroting van entropie vindt een irreversibel proces plaats,
terwijl een toestandsverandering zonder invloed op de hoeveelheid entropie reversibel is.
Aan de hand van simpele telvoorbeelden en statistiek is een verband gelegd tussen
entropie en multipliciteit , zoals Boltzmann stelde en zoals te lezen op zijn graftombe:
log ,
met de constante van Boltzmann .
Entropie blijkt in Boltzmann’s definitie een maat voor de waarschijnlijkheid van
een toestand. De tweede hoofdwet van de thermodynamica is zo niet meer dan de stelling
dat een systeem van minder naar meer waarschijnlijke toestanden zal bewegen – een
tegengestelde beweging is niet onmogelijk maar zo onwaarschijnlijk dat we haar in de
natuur niet tegenkomen.
2.2.3 GIBBS ENTROPIE
De in de vorige sectie verkregen uitdrukking voor entropie, zoals gevonden door
Boltzmann, geldt voor het microkanoniek ensemble waarbij geen energie- en

Entropie, Informatie en het Maximum Entropie Principe
21
deeltjesuitwisseling mogelijk is. Josiah Willard Gibbs (1839-1903) vond een algemenere
uitdrukking entropie, geldend voor het groot kanoniek ensemble.
Een uitdrukking voor entropie in het geval zowel energie als deeltjes in een
systeem uitwisselbaar zijn houdt een verbinding tussen een macroscopische en een
microscopische grootheid in. Het verbindt thermodynamica met statistische mechanica.
Om een uitdrukking te vinden die beide niveaus bevat dient een aantal nieuwe
grootheden te worden geïntroduceerd.
Allereerst de Helmholtz vrije energie, . Deze macroscopische grootheid geeft de
hoeveelheid energie, beschikbaar voor het verrichten van arbeid en is als volgt
gedefinieerd:
.
De vrije energie is een grootheid uit de thermodynamica, welke een cruciale stap vormde
richting de ontwikkeling van statistische mechanica. Deze stap omvatte de combinatie van
macroscopische met microscopische grootheden, zoals in de volgende alinea’s zal worden
getoond.
Een tweede uitdrukking van belang is de kansverdeling van de toestand van een
systeem in thermisch evenwicht, ofwel een situatie van constante temperatuur . James
Clerk Maxwell (1831–1879) was de eerste die een dergelijke verdeling opstelde aan de
hand van een aantal vooraf opgestelde relaties en aannames (Bais & Farmer, 2008):
1. Een kansverdeling van de toestand van een systeem in thermisch
evenwicht, niet beïnvloed door externe krachten, hangt niet af van plaats
of tijd. De kansverdeling is daarom enkel afhankelijk van de snelheden van
individuele deeltjes.
2. Omdat de kans dat drie of meer deeltjes tegelijkertijd op elkaar inwerken
veel kleiner is dan de kans dat slechts twee deeltjes wisselwerken kan de
versimpelende aanname worden gedaan dat alleen wisselwerking van
twee deeltjes voorkomt.
3. Aangenomen dat de snelheden van twee deeltjes en vóór interactie
onafhankelijk zijn van elkaar kan de samengestelde waarschijnlijkheid
, worden weergegeven als het product van de onafhankelijke
waarschijnlijkheden: , .
4. In (thermisch) evenwicht dient de kansverdeling vóór een interactie gelijk
te zijn aan de kansverdeling na afloop: , ,
. Gevolg

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
22
hiervan is dat de kansverdeling enkel afhankelijk kan zijn van grootheden
die behouden blijven gedurende de interactie. In het huidige geval van
thermisch evenwicht gebruikte Maxwell het behoud van de kinetische
energie van de deeltjes in het systeem.
Uit deze relaties leidde Maxwell zijn kansverdeling voor een systeem in thermisch
evenwicht af:
(
)
e p (
).
Boltzmann vond een meer algemene kansverdeling door de gevolgen van een
externe kracht werkend op het systeem mee te nemen. Dit is een verdeling voor het
kanoniek ensemble en betekende een vervanging van de kinetische energie in Ma well’s
uitdrukking door de totale behouden energie, welke naast kinetische energie ook
potentiële energie meeneemt. Boltzmann’s kansverdeling werd met deze nieuwe
aanname
⁄ ,
waarbij de totale energie van toestand is. De partitiefunctie dient als
normalisatiefactor, zodat
∑
⁄
⁄
.
Met de Helmholtz vrije energie en Boltzmann’s distributiefunctie in handen kan de
verbinding tussen een macroscopische en een microscopische grootheid worden gemaakt.
Tussen de Helmholtz vrije energie en de partitiefunctie bestaat de volgende relatie:

Entropie, Informatie en het Maximum Entropie Principe
23
ln .
Met de definitie voor Helmholtz vrije energie wordt gevonden dat
.
Vullen we de uitdrukking voor in in die van , dan volgt
ln
ln .
Hieruit blijkt opnieuw dat een macroscopische grootheid wordt gekoppeld aan een
uitdrukking op microscopisch niveau, aangezien de linkerzijde van de uitdrukking niet
zoals de rechterzijde afhangt van . Tevens wordt gebruik gemaakt van een uitdrukking
voor de interne energie, gedefinieerd als de gewogen som van alle mogelijke
energietoestanden van het systeem
∑
.
Omdat ∑ kan de volgende toevoeging aan de uitdrukking voor worden gedaan:
(∑ ∑ ln
).

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
24
Invullen geeft de uitdrukking voor entropie waar naar gezocht wordt:
( ∑ ∑ ∑ ln )
∑ ln
∑ ln
.
Deze laatste uitdrukking is die van de bekende Gibbs entropie.
Dat Gibbs entropie algemener is dan de uitdrukking die Boltzmann voor entropie
vond kan worden ingezien door Gibbs’ uitdrukking te bekijken voor het specifieke geval
waarin Boltzmann’s entropie geldt; het microkanoniek ensemble. Omdat er geen energie-
en deeltjesuitwisseling plaatsvindt in dit ensemble zal de kans op voorkomen van de
verschillende microtoestanden gelijk zijn aan
. Invullen in de uitdrukking voor
Gibbs entropie geeft Boltzmann’s entropie
∑
ln
∑
ln ln .
2.3 SAMENGEVAT
De grootheid entropie werd gedefinieerd als
en voldoet aan de tweede hoofdwet
van de thermodynamica:
.

Entropie, Informatie en het Maximum Entropie Principe
25
De hierin inbegrepen stelling dat de hoeveelheid entropie in een gesloten systeem met het
verstrijken van de tijd nooit af zal nemen heeft verschillende consequenties. Een proces
dat een toename in entropie veroorzaakt is irreversibel. Tevens kan warmte niet volledig
worden omgezet in arbeid, terwijl arbeid wel in zijn geheel kan worden omgezet in
warmte.
Met de opkomst van statistische mechanica werd entropie beter begrepen in
termen van het gedrag van individuele deeltjes. Boltzmann zag in dat entropie een maat
voor het aantal mogelijke toestanden en stelde
log
Voor het microkanoniek ensemble. Gibbs gaf een algemenere uitdrukking voor entropie in
termen van kansverdelingen, geldend voor het groot kanoniek ensemble.
∑ ln
,
waarbij de kansverdeling voor toestand aangeeft.

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
26
3. INFORMATIE EN ENTROPIE
In de inleiding is een verband tussen entropie, waarschijnlijkheid en informatie
gesuggereerd. In het voorgaande hoofdstuk zagen we hoe Boltzmann inderdaad liet zien
hoe entropie begrepen kan worden in termen van kans ofwel waarschijnlijkheid. Het was
Claude Shannon die entropie definieerde als uitdrukking voor de hoeveelheid informatie
in een systeem. Shannon legde hiermee de basis voor de informatietheorie.
De hier volgende secties geven aan hoe Shannon tot het verband tussen entropie
en informatie kwam en hoe hij en fysici met hem deze ontdekking interpreteerden.
Allereerst een korte introductie tot het optimale model, aanleiding gevend tot Shannon’s
werk.
3.1 HET OPTIMALE MODEL
De complexiteit van fenomenen is vaak te ingewikkeld om er met absolute zekerheid
precieze toekomstvoorspellingen over te doen. Neem de beweging van de beurskoers, het
aantal studenten dat cum laude zal slagen in komend schooljaar of de beweging van
individuele moleculen in een gas – het zijn complexe macroscopische fenomenen, want
afhankelijk van een groot aantal al dan niet meetbare microscopische factoren. Exacte
toekomstvoorspellingen aan de hand van al die factoren vereist daarom een zeer
tijdrovende en ingewikkelde berekening.
Statistiek biedt uitkomst. Ze biedt geen zekerheden over toekomstige beweging
van de beurskoers, maar kan aan de hand van resultaten uit het verleden kansen op
specifieke uitkomsten geven. Met andere woorden: geeft de waarschijnlijkheid
van de uitkomst . Resultaten uit het verleden geven voorwaarden waar een
voorspellingsmodel , bestaande uit de set van waarschijnlijkheden ,
aan dient te voldoen. Verschillende voorspellingsmodellen zullen aan deze
voorwaarden voldoen – de vraag is welk model uit deze set de

Entropie, Informatie en het Maximum Entropie Principe
27
kansverdeling van mogelijke uitkomsten het beste voorspelt. Om de kansverdeling te
vinden die de toekomstige uitkomst het best voorspelt wordt gezocht naar de optimale
verdeling .
Laten we het voorbeeld van de veranderende beurskoers gebruiken om een
versimpelde voorstelling te geven van de mogelijke voorspellingsmodellen .
Stel dat resultaten uit het verleden vijf reële, mogelijke uitkomsten voor verwachte
stijging of daling van de beurskoers geven: , , , , .
Omdat de kansen van alle mogelijke uitkomsten bij elkaar opgeteld gelijk aan 1
horen te zijn geeft dit een eerste voorwaarde waar het voorspellingsmodel aan
behoort te voldoen:
∑
,
.
Oneindig veel modellen voldoen aan deze voorwaarde. Een voorbeeld is
, wat betekent dat de beurskoers zonder twijfel een stijging van zal
doormaken. Ook het model waarbij
,
en de rest van de kansen
gelijk is aan voldoet. Beide modellen nemen echter meer aan dan bekend is – bekend is
alleen de gegeven normalisatievoorwaarde, niet de individuele kansen op bepaalde
toekomstscenario’s.
Intuïtief is het model dat zo min mogelijk aanneemt en derhalve de grootst
mogelijke onzekerheid over de toekomst laat het aantrekkelijkst: het optimale model
. In het huidige geval is dit het model waarbij alle kansen gelijk zijn:

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
28
{
De kansverdeling van het optimale voorspellingsmodel is zo uniform
mogelijk zodat de uitkomst van de verandering van de beurskoers zo onzeker mogelijk is.
Dit om niet meer aan te nemen dan in de gegeven voorwaarden besloten zit. Het is in lijn
met Ockhams scheermes: ‘Entia non sunt multiplicanda preater neccessitatem’, ofwel
‘Men moet de zijnden niet zonder noodzaak verveelvoudigen’. Geen object binnen een
hypothese behoort te worden bevoordeeld boven andere objecten zolang daar geen reden
toe is in de vorm van voorwaarden.
Een extra voorwaarde gevonden in de data uit koersbewegingen in het verleden
zal een nieuw, zo onzeker mogelijk toekomstmodel geven. Stel bijvoorbeeld dat de kans
op óf een stijging van , óf geen stijging of daling gelijk is aan
. De nieuwe
voorwaarde luidt
.
Het optimale voorspellingsmodel, behorend bij de twee gegeven voorwaarden met
een zo uniform en onzeker mogelijke kansverdeling is eenvoudig na te rekenen:

Entropie, Informatie en het Maximum Entropie Principe
29
{
Volgt uit de data een derde voorwaarde, dan wordt het vinden van het optimale
model, kloppend met de gegeven voorwaarden maar niets anders aannemend, complex.
Een wiskundige maat voor uniformiteit of onzekerheid is hierom waardevol:
maximalisatie van onzekerheid zou het unieke, meest uniforme model aanwijzen; het
model dat de optimale waarschijnlijkheidsverdeling voor de mogelijke toekomstige
uitkomsten geeft. Shannon vond deze maat.
3.2 SHANNON: ENTROPIE, EEN MAAT VOOR INFORMATIE
Claude Elwood Shannon (1916- schreef in 9 zijn baanbrekende artikel ‘A
mathematical theory of communication’, waarin hij een maat voor de hoeveelheid
informatie in een bericht vond. Zoals in het eerste hoofdstuk begon Shannon met een
uitdrukking voor de hoeveelheid informatie, gelijk aan het aantal bits welke een bericht
(de toestand van de magnetron uit hoofdstuk 1) uitdrukken:
log ,
met voor het aantal toestanden die de bits kunnen beschrijven en waarbij elke
mogelijke toestand even waarschijnlijk is.
Ook zag Shannon in dat deze uitdrukking voor informatie kan worden
geïnterpreteerd als een uitdrukking voor de waarschijnlijkheid van het voorkomen van
een specifieke toestand, zoals aangegeven in hoofdstuk 1. In de vorige paragraaf zagen we

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
30
dat een grotere waarschijnlijkheid van een voorspellingsmodel gepaard gaat met een
grotere onzekerheid over de uitkomst.
De twee interpretaties van , die van een hoeveelheid informatie en die van een zo
groot mogelijke onzekerheid, leidden Shannon tot de overtuiging dat er één algemene
maat bestaat voor zowel een hoeveelheid aan informatie als voor onzekerheid. Gegeven
een set kansen, zoals de hierboven gevonden modellen voor het beursverloop, zocht hij
een maat die aangeeft hoeveel keuzevrijheid de kansverdeling openlaat of hoe onzeker de
uitkomst van het model is.
Shannon’s maat , , , hoort volgens hem aan een aantal condities te
voldoen (1948). Hij toonde aan dat er slechts één functie voldoet aan deze
voorwaarden:
1. hoort continu the zijn in , want een continu stijgende kans dient een continue
stijging in waarschijnlijkheid te leveren.
2. Als alle gelijk zijn,
, dan is een monotoon stijgende functie van . Hoe
meer mogelijke uitkomsten met dezelfde kans, hoe groter immers de
keuzevrijheid of onzekerheid.
3. Als een uitkomst wordt verdeeld onder twee elkaar opvolgende keuzes, dan is
de gewogen som van de individuele waarden van .
Deze laatste voorwaarde licht Shannon toe met Figuur 5. De drie mogelijke uitkomsten
van de linkse boom zijn gelijk aan die van de rechtse boom, met het verschil dat de rechtse
meer stappen laat zetten om tot hetzelfde resultaat te komen. De onzekerheid van de
linkerboom moet gelijk zijn aan die van de rechterboom:
(
,
,
) (
,
)
(
,
).

Entropie, Informatie en het Maximum Entropie Principe
31
De coëfficient
is hierbij de weging van de tweede onzekerheidsmaat in de boom – deze
tweede stap komt slechts in de helft van de gevallen voor.
Aan de hand van de gegeven drie voorwaarden leidt Shannon (1948) als volgt een
uitdrukking voor af.
Laat (
,
, ,
) . Uit conditie (3) volgt dat de onzekerheid over even
waarschijnlijke mogelijkheden gelijk is aan de onzekerheid over achtereenvolgende
stappen van even waarschijnlijke mogelijkheden:
.
In Figuur 6 wordt dit opnieuw geïllustreerd met kansbomen, waarbij en . De
acht mogelijke uitkomsten van de linkerboom zijn gelijk aan die van de rechterboom, met
het verschil dat de rechterboom uit verschillende stappen bestaat.
Figuur 5 – Decompositie van drie mogelijke uitkomsten (Uit: Shannon, 1948).

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
32
De takken van de linkerboom vormen de mogelijke, even waarschijnlijke uitkomsten met
kansen
. De rechterboom bestaat uit elkaar opvolgende even
waarschijnlijke stappen met kansen
. Uit dit voorbeeld blijkt dat
(
,
,
,
,
,
,
,
) (
,
).
In het algemeen geldt daarom dat
.
En evenzo geldt
.
Shannon stelt dat een en gevonden kunnen worden waarvoor geldt dat
Figuur 6 – 𝐴 𝑠𝑚 𝑚𝐴 𝑠 met 𝑚 en 𝑠 .
1/8
1/8
1/8
1/8
1/8
1/8
1/8
1/8
1/2
1/2
1/2
1/2
1/2
1/2
1/2
1/2 1/2
1/2
1/2
1/2
1/2
1/2
1/8
1/8
1/8
1/8
1/8
1/8
1/8
1/8

Entropie, Informatie en het Maximum Entropie Principe
33
.
Van deze uitdrukking de logaritme genomen en vervolgens gedeeld door log geeft
log
log
log
log
log
log
log
log
log
log
log
log
log
log
,
zodat,
log
log
,
of
|
log
log |
voor een willekeurig kleine . Uit de tweede conditie volgt voor op soortgelijke wijze
dat

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
34
en uit een deling door volgt
,
of
|
| .
De twee verkregen ongelijkheden worden als volgt omgeschreven
log
log
.
Vermenigvuldigen we deze laatste uitdrukking met dan krijgen we
.
Dit opgeteld bij de eerste, nog onveranderde ongelijkheid geeft
log
log

Entropie, Informatie en het Maximum Entropie Principe
35
|
log
log | .
Het getal kan willekeurig klein worden gekozen, zodat deze gelijk aan kan worden
gesteld:
log
log
log
log
log
log .
Omdat de twee zijden van deze laatste vergelijking onafhankelijk zijn van elkaar kunnen
we ze gelijk stellen aan een constante :
log
log .
Shannon’s derde conditie geeft opnieuw een volgende stap. Aangenomen wordt dat een
keuze wordt gemaakt uit ∑ mogelijkheden met waarschijnlijkheden
∑ , zodat
(∑
) log (∑
) , , ∑
, , ∑ log
.
Nu kan een uitdrukking voor worden gevonden, waarbij gebruik wordt gemaakt van de
definitie ∑ ,

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
36
, , (∑
) log(∑
) (∑ log
)
[(∑
) log(∑
) (∑ log
)] ∑
[log
∑ ]
∑
log .
We hebben Shannon’s maat voor onzekerheid en informatie gevonden, de unieke
oplossing van die voldoet aan de drie gegeven voorwaarden:
∑ log .
Gegeven een aantal mogelijke voorspellingsmodellen wordt het unieke, meest
onbevooroordeelde model gekenmerkt door de grootste onzekerheid . Het
voorspellingsmodel met de maximale waarde voor is daarom het meest uniforme
model, als beste bruikbaar voor toekomstvoorspellingen aan de hand van beperkte data
uit het verleden.
Met Shannon’s maat voor informatie in handen zien we iets bijzonders: de
uitdrukking voor is identiek aan de uitdrukking voor Gibbs’ entropie, aangenomen dat
gelijk is aan Boltzmann’s constante . Dit leidde Shannon tot de conclusie dat de door
Boltzmann en Gibbs gevonden uitdrukkingen voor entropie in termen van statistische
mechanica veel verregaandere toepassingen en betekenis hebben dan enkel de fysische.
Shannon generaliseerde entropie van een thermodynamisch naar een
informatietheoretisch concept, inzicht gevend in de hoeveelheid informatie in elke
denkbare kansverdeling. De Gibbs-entropie geeft de Shannon-informatie van een
kansverdeling.

Entropie, Informatie en het Maximum Entropie Principe
37
3.3 INFORMATIE EN DE TWEEDE HOOFDWET
Shannon’s generalisatie van entropie wordt inzichtelijk gemaakt door het verband tussen
entropie en informatie. Om dit verband beter aan het licht te brengen volgt een schets van
een bekend fysisch probleem – Ma well’s duivel – welke opgelost werd door toepassing
van het verband tussen entropie en informatie.
3.3.1 MAXWELL’S DUIVEL
Maxwell bedacht in 1871 een probleem waar veel van zijn collega’s zich over zouden
buigen. Een klein wezen, ‘Ma well’s duivel’ genoemd, zou in staat zijn de tweede hoofdwet
van de thermodynamica te omzeilen.
Maxwell beschreef het wezen als klein genoeg om individuele moleculen te
kunnen onderscheiden. We weten dat moleculen in een gas met uniforme temperatuur
zich niet uniform gedragen – de individuele moleculen hebben bijvoorbeeld verschillende
snelheden. Stel nu dat Ma well’s duivel zich in een ruimte bevindt, door een schot
verdeeld in twee compartimenten, A en B. In het schot zit een door de duivel afsluitbaar
gat, klein genoeg om er één molecuul door te laten passeren. De kleine duivel besluit er
met het openen en sluiten van het gat voor te zorgen dat alleen de snellere moleculen van
deel A naar deel B worden doorgelaten, terwijl de meer langzame moleculen van deel B
naar deel A worden gesluisd. Zonder extra energie in de ruimte te stoppen heeft de duivel
zo van een uniforme, ordelijke temperatuurverdeling een onevenwichtige, wanordelijke
verdeling gemaakt – in tegenstelling tot wat de tweede hoofdwet oplegt is de entropie in
de ruimte gedaald, zonder extra toevoeging van energie.
Charles H. Bennett (1987) beschreef hoe fysici vaak tevergeefs geprobeerd
hebben de tweede hoofdwet te beschermen door een onjuiste werking van Ma well’s
duivel aan te tonen. Zo werd onterecht geopperd dat quantum-onzekerheid of Brownse
beweging beperkingen oplegde aan het handelen van het duiveltje. De juiste redding van
de tweede hoofdwet bleek later echter in het gevonden verband tussen entropie en
informatie te zitten.

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
38
3.3.2 SZILARD’S CYCLUS
Laten we de handelingen van het duiveltje met de vergelijkbare cyclus in Figuur 7
verduidelijken, zoals bedacht door en vernoemd naar Szilard (1929) en zoals ook door
Bennett (1987) gebruikt. De cyclus vormt een eerste stap in de oplossing van Ma well’s
probleem. Bennett stelde zich een cilinder voor met aan beide uiteinden een zuiger. Het
apparaat staat in contact met een warmtebad en in de cilinder zit één deeltje dat
onwillekeurig door het apparaat beweegt. Ma well’s duivel weet in eerste instantie niet
waar in de cilinder het deeltje zich bevindt – zijn kennis over de plaats van het deeltje in
de cilinder is ‘blanco’, in situatie a van de figuur aangegeven met toestand ⟩.
Stel nu dat een schot in het apparaat wordt aangebracht, zoals te zien in stap (b),
zodat het deeltje in één van de twee ontstane compartimenten zit. Nog altijd weet de
duivel niet waar het deeltje zich bevindt, tot hij een meting doet. Na een meting in stap (c)
zal zijn kennis over de plaats van het deeltje veranderen van ‘blanco’ naar ‘links’ of ‘rechts’,
aangegeven met respectievelijk ⟩ of ⟩, afhankelijk van waar hij het deeltje aantreft.
Zoals te zien in stap (d) kan de duivel de zuiger, die zich aan de andere kant bevindt dan
die waar het deeltje zit, induwen tot het schot wordt bereikt. Wordt het schot vervolgens
verwijderd in stap (e), dan zal het deeltje in de cilinder door haar willekeurige
bewegingen tegen dezelfde zuiger botsen en hem daarmee terugduwen naar zijn
begintoestand in stap (f). Rest er nog één stap om daadwerkelijk terug te komen bij de
begintoestand van het proces: de kennis van de duivel over de plaats van het deeltje moet
worden uitgewist. De gemeten toestand ⟩ of ⟩ wordt in stap (g) teruggezet naar de

Entropie, Informatie en het Maximum Entropie Principe
39
blanco toestand ⟩.
Laten we de invloed van de individuele stappen op de entropie van het gesloten
systeem, namelijk die van het gas in de cilinder, onderzoeken om te begrijpen welk
thermodynamisch effect de beschreven cyclus heeft. Door het plaatsen van een schot in
stap (b) wordt de ruimte waarin het deeltje bewegen kan gehalveerd, wat een
entropieafname van het gas veroorzaakt van ln . Het doen van een
meting in stap (c) kost geen energie en brengt geen verandering teweeg in de entropie
van het systeem. Ook het induwen van de zuiger in stap (d) kost geen energie, aangezien
de zuiger in een vacuüm wordt geduwd. Tijdens stap (e) zal het deeltje door verwijdering
van het schot tegen de zuiger duwen tot de zuiger weer de oorspronkelijke, uitgeschoven
toestand bereikt. De beweegruimte is nu weer gelijk aan de oorspronkelijke
beweegruimte, wat resulteert in een entropietoename gelijk aan de afname in stap (b):
. Warmte uit de omgeving van de cilinder wordt gebruikt als energiebron voor
𝐵⟩ 𝐵⟩
𝐿⟩ 𝑅⟩
𝐿⟩ 𝑅⟩
𝐿⟩ 𝑅⟩
𝐵⟩
Figuur 7 – Het mechanisme van Maxwell’s duivel en het
ééndeeltjesapparaat zoals voorgesteld door Bennett (1987).
(a)
(b)
(c)
(d)
(e)
(f)
𝐿⟩ 𝑅⟩
(g)
𝐵⟩

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
40
het deeltje om de zuiger uit te schuiven: ln . Dit resulteert in een
entropieafname van het gas van
.
Aangekomen bij stap (f) heeft er een netto entropieafname plaatsgevonden van
ln , terwijl het gas in de cilinder in stap (f) terug is bij haar begintoestand, met
hetzelfde volume en dezelfde temperatuur als in stap (a). De entropie van het gas lijkt
afgenomen terwijl er arbeid is verricht – een onmogelijkheid volgens de tweede hoofdwet
die stelt dat de entropie nooit zal afnemen!
3.3.3 LANDAUER’S PRINCIPE
Het was Bennett die met behulp van Landauer’s principe de tweede hoofdwet redde. De
laatste stap van Szilard’s cyclus blijkt cruciaal voor begrip over hoe ook een wezen als
Ma well’s duivel geen uitzondering op de tweede hoofdwet van de thermodynamica kan
veroorzaken. Met de cilinder in stap (f) in haar oorspronkelijke toestand is de cyclus nog
niet voltooid: Ma well’s duivel verkeert in stap f nog altijd in de veronderstelling dat het
deeltje zich in één van de twee compartimenten van stap (c) bevindt. Wat gebeurt er als
de duivel zijn kennis over de positie van het deeltje vergeet?
Rolf Landauer, werkzaam bij IBM, onderzocht de thermodynamica van
dataverwerking, zo schreef Bennett (1987). Hij vond dat het doen van metingen geen
energie hoeft te kosten en derhalve geen bijdrage hoeft te leveren aan de entropie, terwijl
het vergeten ofwel uitwissen van kennis wel degelijk een thermodynamisch effect heeft.
Sleutel tot Landauer’s ontdekking was zijn conceptie van kennis: informatie
beschouwde hij als een puur fysieke toestand, voor te stellen als opnieuw een deeltje in
een cilinder bestaande uit twee compartimenten. De cilinder werkt als een bit: het deeltje
zit ofwel links, ofwel rechts, zoals hoe een bit zich in de toestanden ⟩ of ⟩ kan bevinden.
Het wissen van informatie stelde Landauer zich voor zoals te zien in Figuur 8.
In de eerste stap van het wisproces zit het deeltje in het linker- of
rechtercompartiment van de cilinder, maar onbekend is in welke van de twee. Zodra het
schot wordt verwijderd kan het deeltje door de gehele cilinder bewegen. Vervolgens
wordt de zuiger van rechts naar het midden geduwd, het schot teruggeplaatst en de zuiger

Entropie, Informatie en het Maximum Entropie Principe
41
uitgeschoven naar de oorspronkelijke toestand. Het deeltje zal in het linker compartiment
van de cilinder eindigen, onafhankelijk van waar ze begon. Tevens kan niet meer
achterhaald worden waar in de cilinder het deeltje begon, want de positie van het deeltje
was aan het begin onbekend, zodat die informatie verloren is gegaan: de informatie is
vergeten.
Met dit mechanisme in handen kan worden onderzocht wat het
thermodynamische effect is van het wissen van informatie (Plenio & Vitelli, 2001).
1. Aan het begin van het proces kan het deeltje zich in beide compartimenten
bevinden, aangezien niet gemeten is in welke van de twee het deeltje
daadwerkelijk zit.
2. Na verwijdering van het schot is de ruimte verdubbeld, wat een vergroting van de
entropie van het gas veroorzaakt van ln .
3. Bij het naar inschuiven van de zuiger wordt de ruimte gehalveerd, wat een
verkleining van de entropie van het gas veroorzaakt van ln . Tevens is
voor de compressie een minimale hoeveelheid arbeid ln nodig, welke de
entropie van het gas vergroot met ln .
Figuur 8 – Het wissen van informatie volgens Landauer’s principe.
𝐵⟩
𝐵⟩
𝐵⟩
𝐵⟩ → 𝐿⟩ 𝐿⟩ 𝐿⟩

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
42
Netto heeft aan het eind van het proces een vergroting van entropie van ln
plaatsgevonden. Het thermodynamische effect van het wissen van een bit aan informatie
blijkt een vergroting van entropie van ln .
3.3.4 REDDING VAN DE TWEEDE HOOFDWET VAN DE THERMODYNAMICA
Terug naar Szilard’s cyclus en het geheugen van Ma well’s duivel. We zagen dat
aangekomen in stap (f) van Figuur 7 een netto entropieafname van het gas in de cilinder
van ln heeft plaatsgevonden. In het licht van Landauer’s principe is dit echter
slechts een deel van het verhaal: niet alleen het gas maakt een verandering in entropie
door, maar ook de entropie van het geheugen van Ma well’s duivel dient te worden
meegerekend voor een complete beschrijving van Szilard’s cyclus. Het te beschouwen,
gesloten systeem in Szilard’s cyclus blijkt daarom zowel het gas als de informatie die
Ma well’s duivel over de cilinder heeft te omvatten.
De netto entropieverandering in het gas bleek een afname van minimaal
ln te zijn. De netto entropieverandering van het geheugen van Ma well’s duivel is
gelijk aan de entropietoename bij het wissen van één bit aan informatie: ln . Deze
twee waarden leveren het inzicht dat het doorlopen van Szilard’s cyclus, het gesloten
systeem van gas en geheugen, geen entropieafname teweeg kan brengen. Er vindt ofwel
geen verandering, ofwel een vergroting van entropie plaats.
Hiermee is het probleem van Ma well’s duivel opgelost en de tweede hoofdwet
van de thermodynamica gered: de netto entropieafname in stap f van Szilard’s cyclus
wordt gecompenseerd door een entropietoename veroorzaakt door het vergeten van
eerder opgeslagen informatie.
3.4 SAMENGEVAT

Entropie, Informatie en het Maximum Entropie Principe
43
Samenvattend kan worden gesteld dat informatie en entropie onlosmakelijk met elkaar
verbonden blijken te zijn. Rolf Landauer zag dit in door informatie te beschouwen als
puur fysisch concept, zoals een deeltje in een cilinder met twee kamers: het vergeten van
informatie brengt een vergroting van entropie teweeg. Deze ontdekking maakt de
gevonden gelijkenis van Shannon’s maat voor onzekerheid en Boltzmann’s en Gibbs’
uitdrukkingen voor entropie inzichtelijk. Hoe groter de onzekerheid in een
voorspellingsmodel, des te groter de keuzevrijheid en aan het systeem inherente
informatie, des te waarschijnlijker de juistheid van het voorspellingsmodel. Plaatsen we
dit in het licht van Landauer’s principe, dan zal het betreffende voorspellingsmodel met zo
min mogelijk aannamen de grootste hoeveelheid informatie en entropie bevatten.

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
44
4 HET MAXIMUM ENTROPIEBEGINSEL
Met ma imalisatie van Shannon’s entropie wordt het optimale voorspellingsmodel
gevonden. Dit is het model dat een zo uniform mogelijke kansverdeling geeft die beschrijft
wat de mogelijke uitkomsten of toekomstscenario’s zijn. Hierbij houdt uniformiteit in dat
alleen bekende data worden gebruikt en geen aannamen worden gedaan over
ontbrekende informatie met betrekking tot de uitkomst. De bekende data worden
vertaald in voorwaarden waar de optimale kansverdeling aan dient te voldoen.
Statistische fysica blijkt een voorbeeld van de toepassing van
entropiemaximalisatie. Edwin Thompson Jaynes (1922–1998) liet in 1957 zien hoe
maximalisatie van entropie, gebruik makend van de juiste voorwaarden, leidt tot de
partitiefunctie. Daarmee keerde Jaynes de uitwerking van statistische fysica
binnenstebuiten: in plaats van te beginnen met de bekende postulaten zoals de
partitiefunctie, leidend tot de functie voor entropie, wordt nu entropie als beginpunt
gebruikt, van waaruit de gehele statistische fysica – waar het evenwichtsverdelingen
betreft – kan worden afgeleid. Het toont aan dat statistische mechanica slechts één van de
vele toepassingen is van het maximum entropiebeginsel. Entropie heeft zo niet een puur
fysische betekenis, zoals deze in eerste instantie werd afgeleid in de thermodynamica,
maar blijkt toepasbaar in alle optimalisatieproblemen die afhangen van
verdelingsfuncties.
4.1 HET EQUIPARTITIEPRINCIPE
Zoals gezegd wordt de gezochte evenwichtssituatie gekenmerkt door een maximale
hoeveelheid entropie. Het vinden van de evenwichtsverdeling is daarom slechts het
vinden van de kansverdeling behorend bij de gemaximaliseerde entropie-uitdrukking van
Shannon, onderhevig aan de bekende constraints ofwel beperkende voorwaarden van
betreffende macroscopische situatie.

Entropie, Informatie en het Maximum Entropie Principe
45
Is van een macroscopisch systeem alleen de normalisatievoorwaarde ∑
bekend, dan dient de functie , , afhankelijk van Shannon’s entropie, de
normalisatievoorwaarde en Lagrange multiplicator , te worden gemaximaliseerd:
, ∑ ln
(∑
).
De extrema, dat wil zeggen de minima en maxima van de functie worden verkregen door
de partiële afgeleiden van , gelijk te stellen aan . In de gevallen die wij
beschouwen blijkt dit inderdaad een maximum te zijn omdat de functie voor entropie een
convexe kromme beschrijft, waarbij enkel een maximum bestaat.
ln
(∑
) .
Dit geeft dat en het levert opnieuw de normalisatievoorwaarde ∑ .
Is dus een constante die niet afhangt van , zodat geldt dat
∑ ∑
.
De unieke oplossing voor wordt daarom gegeven door
,

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
46
met voor het totale aantal toestanden. Dit resultaat klopt met de stelling dat
entropiemaximalisatie het meest uniforme model levert. Geldt alleen de
normalisatievoorwaarde, dan volgt de uniforme kansverdeling zoals gegeven door het
equipartitieprincipe.
4.2 HET KANONIEK ENSEMBLE
Wordt naast de normalisatievoorwaarde de voorwaarde gesteld dat de gemiddelde
energie van het systeem gelijk is aan de interne energie, dan resulteert dat in de
Boltzmann distributie, geldig in het kanoniek ensemble.
Gemiddelde energie wordt met de volgende voorwaarde uitgedrukt:
∑ ,
Met de energie in toestand , en de kans op voorkomen van toestand . De functie
, , hangt ditmaal af van twee constraints:
, , ∑ ln
(∑
) (∑
).
Opnieuw worden de partiële afgeleiden van , , gelijkgesteld aan :
ln

Entropie, Informatie en het Maximum Entropie Principe
47
(∑
)
(∑
) .
Uit de eerste van de afgeleiden volgt dat . Invullen in de
normalisatievoorwaarde geeft ∑ , zodat
∑
.
De gevonden uitdrukking ingevuld in Shannon’s uitdrukking voor entropie (met
), gebruik makend van de tweede constraint, levert
∑ ln( )
(∑
) ln ,
met de constante die ln geeft.
Door gebruik te maken van de thermodynamische definitie van ,
, blijkt
evenwel dat
.
Zo vinden we dat de inverse van de partitiefunctie is,
∑
,
en tot slot de uitdrukking voor de kansverdeling onder de twee gegeven voorwaarden,

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
48
.
Zoals verwacht is de gevonden kansverdeling gelijk aan de Boltzmann distributie.
Uitwerking van overige begrippen uit de statistische fysica zoals vrije energie is mogelijk
aan de hand van de gevonden distributie. Zo is aangetoond dat het maximalisatiebeginsel
van entropie, onder de bekende beperkende voorwaarden zoals de waarde van de
gemiddelde totale energie, voldoende is om de statistische mechanica voor
evenwichtssituaties uit te werken.
Wat we aan de hier gegeven afleiding zien is dat de Boltzmann verdeling een
voorbeeld is van een heel algemene klasse van gevallen. Statistische mechanica is slechts
één van de vele toepassingen van entropiemaximalisatie. Entropiemaximalisatie blijkt een
beginsel dat toepasbaar is op talloze verdelingsproblemen waar een beperkende
voorwaarde wordt gelegd met betrekking tot de gemiddelde waarde die een bepaalde
grootheid aanneemt. In de volgende sectie zal een introductie worden gegeven tot een
aantal andere toepassingen van het maximum entropie principe. Een toepassing in de
taalwetenschap zal ten slotte in hoofdstuk 6 worden toegelicht en uitgewerkt, waaruit
duidelijk wordt dat gebruikmaking van het maximum entropie principe met een geheel
ander doel dan die van de statistische mechanica toch eenzelfde wiskundige uitwerking
heeft.

Entropie, Informatie en het Maximum Entropie Principe
49
5 ANDERE TOEPASSINGEN VAN HET
MAXIMUM ENTROPIEBEGINSEL
Op de webpagina Edge beschreef psycholoog Stephen M. Kosslyn (2012) constraint
satisfaction als de wijze waarop men keuzes maakt. Bij het oplossen van een probleem of
het maken van een keuze dient te worden voldaan aan een aantal vooraf opgestelde
voorwaarden. Kosslyn illustreert dit in een aardig voorbeeld over het besluitproces bij de
inrichting van zijn huis: de grootte en vorm van het meubilair legt voorwaarden op de
wijze waarop de meubels geplaatst kunnen worden, welke op hun beurt de plaatsing van
overige meubels bepalen. Zonder deze voorwaarden zou het huis op een oneindig aantal
manieren kunnen worden ingericht. De beperkingen die de voorwaarden oplegden
zorgden er echter voor dat slechts een aantal inrichtingsmogelijkheden overbleef.
Constraint satisfaction is het proces waarin de uitkomsten worden geselecteerd die zo
veel mogelijk voldoen aan de gestelde voorwaarden.
Worden de uitkomsten die na constraint satisfaction overblijven beschreven in
termen van kansverdelingen, dan is het mogelijk de hoeveelheid entropie van die
uitkomsten te berekenen. De optimale keuze uit de verschillende overgebleven
mogelijkheden is die met maximum entropie.
Zo beschouwd en zoals gezien in voorgaande secties heeft het principe van
maximum entropie een breed scala aan toepassingen. Elk denkbaar
optimaliseringsprobleem beperkt door voorwaarden en uitgedrukt in termen van
kansverdelingen kan een optimale uitkomst vinden aan de hand van het maximum
entropiebeginsel. Een aantal uiteenlopende optimaliseringsproblemen waarin het
beginsel kan worden toegepast zal kort worden uitgelicht.
5.1 ANT COLONY OPTIMIZATION

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
50
Ant colony optimization (ACO) is een optimaliseringstechniek geïnspireerd op gedrag van
sommige mierensoorten. Deze mieren laten een feromoon achter op het pad dat ze
bewandelen, als aanwijzing voor andere mieren wat de beste weg naar voedsel is. Met
andere woorden: feromonensporen geven een kansverdeling voor de verschillende
mogelijke paden naar voedsel, waarmee de mieren in staat zijn het optimale pad te vinden.
De door de mieren gebruikte optimalisatiemethode wordt in ACO nagebootst met
kunstmatige mieren, onderdeel van een algoritme voor oplossing van
optimaliseringsproblemen. Laten we allereerst de inspiratiebron van het algoritme nader
bekijken: hoe vinden mieren het optimale pad?
Stel dat een mier uit twee wegen kan kiezen, beide leidend tot voedsel. Dit was de
opzet van het double bridge experiment, zoals uitgevoerd door Deneubourg et al. (1990).
In Figuur 9 is de schematische opstelling van een variant van het experiment afgebeeld,
waarbij één van de twee wegen de optimale want de kortste weg naar het voedsel is.
In eerste instantie weten de mieren niet welk pad te kiezen, omdat nog geen van
de wegen eerder werd bewandeld. De insecten kiezen willekeurig één van de twee
mogelijkheden en laten daarbij eerste lagen feromoon achter. Omdat beide wegen
willekeurig worden gekozen zullen beide paden even vaak worden gekozen, zodat op
beide paden een feromonenspoor achterblijft. Bij het lange pad duurt het gemiddeld
langer voordat een mier die via deze weg het voedsel vond terugloopt naar het nest. Deze
extra tijd doet het feromoon op het lange pad meer verdampen dan op het korte pad. De
netto grotere hoeveelheid feromoon op het korte pad levert zo een voorkeur voor het
Figuur 9 – Het double bridge experiment met vertakkingen van verschillende lengte. (Uit: Dorigo,
Birattari, & Stützle (2006)).
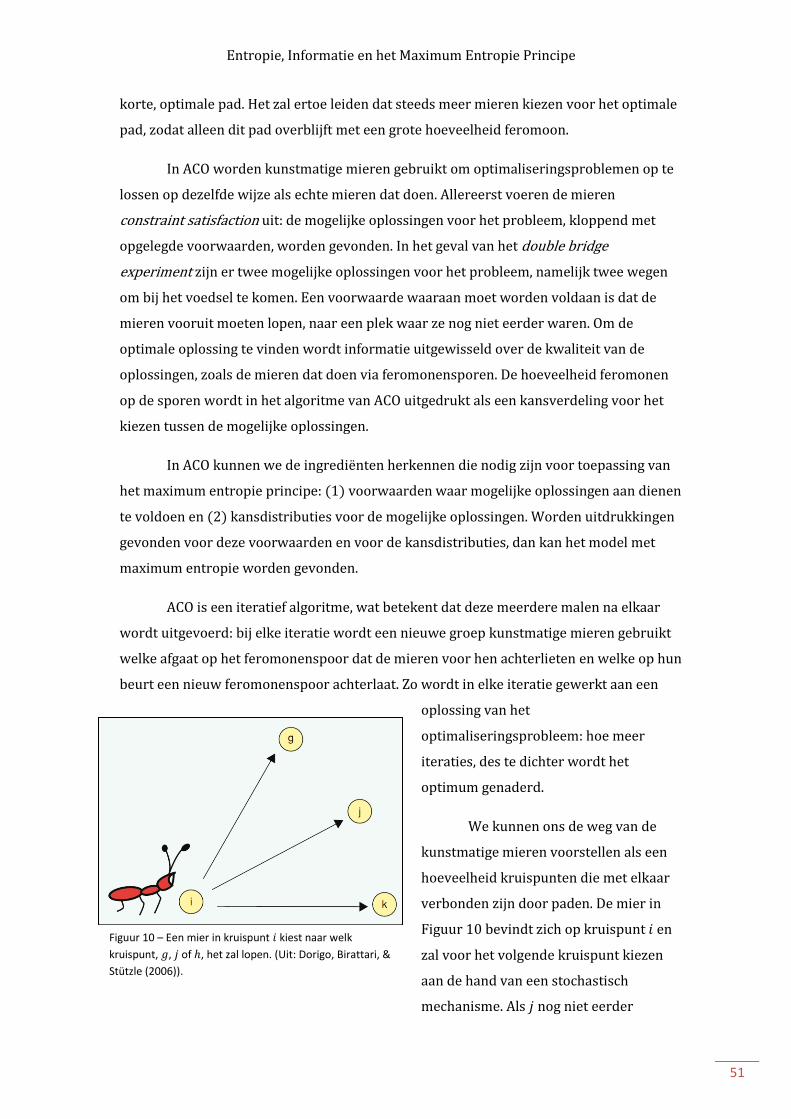
Entropie, Informatie en het Maximum Entropie Principe
51
korte, optimale pad. Het zal ertoe leiden dat steeds meer mieren kiezen voor het optimale
pad, zodat alleen dit pad overblijft met een grote hoeveelheid feromoon.
In ACO worden kunstmatige mieren gebruikt om optimaliseringsproblemen op te
lossen op dezelfde wijze als echte mieren dat doen. Allereerst voeren de mieren
constraint satisfaction uit: de mogelijke oplossingen voor het probleem, kloppend met
opgelegde voorwaarden, worden gevonden. In het geval van het double bridge
experiment zijn er twee mogelijke oplossingen voor het probleem, namelijk twee wegen
om bij het voedsel te komen. Een voorwaarde waaraan moet worden voldaan is dat de
mieren vooruit moeten lopen, naar een plek waar ze nog niet eerder waren. Om de
optimale oplossing te vinden wordt informatie uitgewisseld over de kwaliteit van de
oplossingen, zoals de mieren dat doen via feromonensporen. De hoeveelheid feromonen
op de sporen wordt in het algoritme van ACO uitgedrukt als een kansverdeling voor het
kiezen tussen de mogelijke oplossingen.
In ACO kunnen we de ingrediënten herkennen die nodig zijn voor toepassing van
het maximum entropie principe: (1) voorwaarden waar mogelijke oplossingen aan dienen
te voldoen en (2) kansdistributies voor de mogelijke oplossingen. Worden uitdrukkingen
gevonden voor deze voorwaarden en voor de kansdistributies, dan kan het model met
maximum entropie worden gevonden.
ACO is een iteratief algoritme, wat betekent dat deze meerdere malen na elkaar
wordt uitgevoerd: bij elke iteratie wordt een nieuwe groep kunstmatige mieren gebruikt
welke afgaat op het feromonenspoor dat de mieren voor hen achterlieten en welke op hun
beurt een nieuw feromonenspoor achterlaat. Zo wordt in elke iteratie gewerkt aan een
oplossing van het
optimaliseringsprobleem: hoe meer
iteraties, des te dichter wordt het
optimum genaderd.
We kunnen ons de weg van de
kunstmatige mieren voorstellen als een
hoeveelheid kruispunten die met elkaar
verbonden zijn door paden. De mier in
Figuur 10 bevindt zich op kruispunt en
zal voor het volgende kruispunt kiezen
aan de hand van een stochastisch
mechanisme. Als nog niet eerder
Figuur 10 – Een mier in kruispunt 𝑖 kiest naar welk
kruispunt, 𝑔, 𝑗 of ℎ, het zal lopen. (Uit: Dorigo, Birattari, &
Stützle (2006)).

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
52
bezocht is voldoet het aan de eerder gestelde voorwaarde en vormt de weg tussen en
een oplossing. De kans dat voor de weg tussen beide knooppunten , wordt gekozen is
evenredig met de hoeveelheid feromoon op dit pad.
Dorigo, Birattari en Stützle (2006) lichtten het model van ACO toe door het te
presenteren als variant op het combinatoriële optimalisatieprobleem. Dit is het type
optimalisatieprobleem waarvan de optimale oplossing een discrete variabele is,
onderdeel van een eindige set mogelijke oplossingen. Om ACO als variant van het
combinatoriële optimalisatieprobleem aan te geven is een model S, , van dat
optimalisatieprobleem nodig. Hierbij hoort:
- Een ruimte S waarin wordt gezocht naar oplossingen, gedefinieerd over een
eindige set van discrete beslissingsvariabelen , waarbij , ;
- Een set van voorwaarden onder de variabelen;
- Een te minimaliseren objectieve functie : S → . Een maximalisatieprobleem
kan immers worden omgevormd tot een minimalisatieprobleem door .
Een mogelijke oplossing van het optimalisatieprobleem is S, waarbij de
beslissingsvariabelen voldoen aan alle voorwaarden . Voor de optimale oplossing , dus
de oplossing met maximum entropie, geldt S.
Het model wordt in ACO geïnterpreteerd als model voor de hoeveelheid feromonen.
Bij elke oplossing hoort een feromoonwaarde, waarbij de oplossing is met de hoogste
feromoonwaarde: de optimale oplossing.
5.2 BEELDRECONSTRUCTIE
In onder andere astronomie, hoge-energie fysica, biologie en de medische wetenschappen
wordt het maximum entropiebeginsel gebruikt voor image reconstruction, ofwel
beeldreconstructie: ruis wordt uit te onderzoeken beelden gefilterd, zodat een beeld kan
worden geconstrueerd dat zo veel mogelijk klopt met het originele object. Het principe
van maximum entropie dient dit doel uitstekend vanwege de eigenschap dat het model

Entropie, Informatie en het Maximum Entropie Principe
53
met maximum entropie de unieke oplossing is die zo veel mogelijk klopt met en niets
anders aanneemt dan de gegeven data. Het betekent dat elk beetje aan informatie in het
resulterende gereconstrueerde beeld terug te vinden moet zijn in de originele data. De
techniek wordt toegepast bij beelden die het gehele elektromagnetische spectrum beslaan,
waaronder beelden uit de astronomie die de eclips van accretieschijven in kaart brengen
en beelden van tomografie uit de medische fysica.
Skilling en Bryan (1984) geven een overzicht van het gebruik van het maximum
entropie principe bij beeldreconstructie. Een beeld wordt uitgedrukt in een set nader te
bepalen positieve getallen , , , . Een kansdistributie voor het voorkomen van deze
getallen is ∑ . Zo kan de entropie van het beeld – voor nu nog zonder extra
termen die voorwaarden uitdrukken – worden gevonden aan de hand van de Shannon
entropie:
∑ log
.
Ook in deze kan de Shannon entropie worden begrepen in termen van informatie.
In dat geval geeft het intensiteitspatroon van het gereconstrueerde beeld aan,
afhankelijk van de positie van elk afzonderlijk uitgestraalde foton. De kans is de kans
op uitgestraalde fotonen op positie , zodat de entropie in dit geval een maat is voor het
aantal bits aan informatie dat nodig is voor het bepalen van de positie van een
uitgestraald foton. De kansverdeling behorend bij het model met maximum entropie, is
de optimale verdeling die voorspelt waar een volgend foton uit het beeld vandaan zal
komen. Met deze informatie kan ruis uit het beeldmateriaal worden gefilterd en een
reconstructie worden gemaakt.
Voorwaarden voor de reconstructie worden opgesteld met behulp van data ,
gegeven voor elke informatie-eenheid . is op bekende wijze gerelateerd aan het te
reconstrueren beeld. Deze data bevatten optelbare ruis, wat betekent dat het een
optelling is van de ruisloze data en de bijgekomen ruis :
,

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
54
waarbij de standaard fout in is en een willekeurige variabele met een gemiddelde
van en een variantie .
De voorwaarde waar reconstructies aan dienen te voldoen luidt dat de
daadwerkelijk gevonden data binnen de foutmarge kloppen met de gesimuleerde data
zonder ruis, . Deze gesimuleerde data geven aan hoe de gevonden data eruit
zouden hebben gezien zonder ruis in het geval de data worden weergegeven met de
reconstructies . Vallen de reconstructies binnen de gestelde voorwaarde, dan kloppen
de gesimuleerde data met de gevonden data binnen de grenzen van de foutmarge.
Met deze methode wordt opnieuw duidelijk dat geen aannamen worden gedaan, anders
dan de daadwerkelijk gemeten datapunten.
Van de gevonden reconstructies die voldoen aan de gestelde voorwaarde
is de reconstructie met maximum entropie de optimale oplossing voor
reconstructie van het beeld. Hierbij dient de entropiefunctie, nu met de gestelde
voorwaarde maal een Lagrange multiplicator inbegrepen, te worden gemaximaliseerd:
, ∑ log
.
5.3 GEOGRAFISCHE DISTRIBUTIE VAN DIERSOORTEN
Een derde toepassing van het maximum entropie principe vinden we in de modellering
van de geografische distributies van diersoorten. Deze modellen voorspellen in hoeverre
een gebied geschikt is voor een bepaalde diersoort, als functie van gegeven
omgevingsvariabelen. Deze variabelen zijn bijvoorbeeld de aanwezigheid van
voedselbronnen, veiligheid met betrekking tot predatie door andere diersoorten en het
klimaat van het onderzochte gebied. De modellen spelen een belangrijke rol in de

Entropie, Informatie en het Maximum Entropie Principe
55
analytische biologie, waarbij ze worden ingezet bij bijvoorbeeld de bescherming van
diersoorten, ecologie, evolutieleer en epidemiologie.
Geografische distributies van diersoorten kunnen worden opgesteld door middel
van algemene statistische methoden wanneer alle benodigde informatie over zowel de
hoeveelheid aanwezige als de aantallen afwezige dieren in het onderzochte leefgebied
bekend is. Data over de afwezigheid van soorten in met name tropische gebieden is echter
zeldzaam of betwijfelbaar, wat betekent dat een deel van de gewenste informatie mist.
Tegelijkertijd is juist in deze gebieden de modellering van geografische distributies
gewenst vanwege de toepassing in de conservatie van de daar levende diersoorten. Een
methode die de distributie van diersoorten voorspelt aan de hand van alleen de
informatie over de aanwezigheid van soorten is daarom waardevol. Phillips, Anderson en
Schapire (2006) laten zien hoe het principe van maximum entropie deze methode levert.
Het maximum entropiebeginsel dient het doel de kansdistributie te vinden
die zo goed mogelijk klopt met de daadwerkelijke kansdistributie , de exacte
verdeling behorend bij de betreffende situatie. Dit betekent dat dient te kloppen met
bekende informatie (over de aanwezigheid van een diersoort en de onderzochte
omgeving) maar niets aanneemt over onbekende gegevens (de afwezigheid van een
diersoort en onbekende omgevingsvariabelen). Hierbij geldt dat , , , waarbij
de verzameling is van bekende data over het voorkomen van de diersoort in het
onderzochte gebied.
Gemiddelde waarden van bekende data over omgevingsvariabelen als het klimaat,
grond- of vegetatietype worden vertaald in een set reële variabelen die “features”
of “kenmerken” worden genoemd. Nu kunnen de voorwaarden voor worden
gedefinieerd: de verwachtingswaarden van de kenmerken zoals gegeven door horen
gelijk te zijn aan de verwachtingswaarden (gemiddelden) van de empirisch gevonden
waarden die kloppen met de eigenlijke distributie . Deze laatste
verwachtingswaarden van de kenmerken onder worden gedefinieerd als
[ ] ∑
,

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
56
waarbij een benadering van wordt gegeven door de relatieve frequentie van het
voor komen van volgens de empirisch vergaarde data:
het aantal keer dat voorkomt.
Met het maximum entropie principe wordt kortom gezocht naar de kansverdeling
met maximum entropie, welke voldoet aan de voorwaarde dat elk kenmerk
dezelfde verwachtingswaarde [ ] onder heeft als onder de empirisch
geobserveerde distributie :
[ ] [ ].
Natuurlijk wordt ook in dit geval de distributie met maximum entropie gevonden
door maximalisatie van de Shannon entropie, waaraan met Lagrange multiplicatoren de
voorwaarden worden toegevoegd:
, ∑ ln
∑ [ ] [ ]
.
Zo blijkt het maximum entropie principe opnieuw een methode om het optimale
voorspellingsmodel te vinden, kloppend onder uit de bekende data gevonden
voorwaarden.

Entropie, Informatie en het Maximum Entropie Principe
57
6 MAXIMUM ENTROPIE IN DE TAALWETENSCHAP
Zoals we in de afgelopen hoofdstukken hebben laten zien blijkt het entropiebegrip,
hoewel oorspronkelijk afkomstig uit de statistische thermodynamica, een veel algemenere
relevantie en breder toepassingsgebied te hebben. Het maximale entropie principe is
bruikbaar om de evenwichtssituatie van een statistische verdeling te bepalen, onder
zekere beperkende voorwaarden bijvoorbeeld leidend tot statistische mechanica. In het
vorige hoofdstuk is een aantal voorbeelden gegeven van andere vakgebieden waarbij dit
principe wordt gebruikt als een wiskundig instrument om optimaliseringsproblemen mee
aan te pakken. In dit hoofdstuk zal tenslotte een laatste toepassing worden uitgelicht en in
meer detail besproken. Het gaat hierbij om een toepassing in de taalwetenschap.
Taalwetenschappers als Berger, Della Pietra en Della Pietra (1996) en Hayes en
Wilson (2008) gebruikten het maximale entropie principe in navolging van Shannon en
Jaynes. Het bracht ze tot een beste model voor respectievelijk een Engels-Frans
vertaalsysteem en voor het aanleren van grammatica zoals dat gedaan wordt door native
speakers.
Aan de hand van het werk van genoemde wetenschappers volgt een algemene
wiskundige uitleg over het vinden van de voorwaarden en bijbehorende optimale
verdelingen met behulp van het maximale entropiebeginsel. Voorbeelden worden
gegeven in het gebied van taalkunde, waarbij een model dient te worden gecreëerd dat
klopt met gegeven trainingsdata. De onderliggende vraag is: Hoe kan een computer
herkennen uit welke taal een woord afkomstig is?
6.1 TAALHERKENNINGSPROGRAMMA’S
Computerprogramma’s zijn in staat om de taal te herkennen waar een gegeven woord in
geschreven staat. Een bekend voorbeeld is Google’s vertaalsite, welke de instructie kan
worden gegeven de taal van te vertalen woorden te herkennen.

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
58
Taalherkenningsprogrammatuur als deze is, net als die voor het maken van
vertalingen, gebaseerd op eerder ingevoerde ‘trainingsdata’. Deze woorden zijn door een
op dit gebied bekwame persoon verbonden met bijbehorende taal. Het programma
bestaat in de creatie van modellen die de gegeven trainingsdata zo goed mogelijk
beschrijven – voor elke taal één model. Een nieuw woord waarvan de taal moet worden
herkend wordt door het programma vergeleken met de verschillende ontwikkelde
modellen. Het programma zal de taal van het best passende model aanwijzen als de taal
van het gegeven woord.
Het principe van maximale entropie is het instrument waarmee het model dat het
best past bij de trainingsdata kan worden aangewezen. Het is namelijk het meest
uniforme model met inachtneming van de beperkende voorwaarden, anders gezegd, het
onder de gegeven of gevonden voorwaarden minst bevooroordeelde model dat daardoor
ook de beste pasvorm aan de trainingsdata heeft. Nog weer anders verwoord: van een
oneindige hoeveelheid modellen, die kloppen met uit de trainingsdata gedestilleerde
voorwaarden, is het beste model dat met grootste entropie.
6.2 KENMERKEN EN VOORWAARDEN
Net als in het geval van statistische mechanica is het zaak allereerst de voorwaarden te
vinden waar het model van een taal aan dient te voldoen. Wordt in de trainingsdata een
veelvoorkomend patroon gevonden, zoals de wijze waarop klinkers en medeklinkers of
bepaalde letters elkaar opvolgen, dan kan dit patroon tot een ‘feature’ of ‘kenmerk’
worden benoemd (Berger, Della Pietra en Della Pietra, 1996). De stelling dat het te
construeren model kloppen moet met het gedrag van dit kenmerk in de trainingsdata is
een ‘voorwaarde’. Zo wordt het belang van het kenmerk meegenomen in het volgens de
trainingsdata te construeren model.
Neem een kenmerk dat aangeeft dat in een Spaans woord de letter volgt op de
letter . Dit kenmerk kan als volgt worden weergegeven, in lijn met de wiskunde uit
Berger, Della Pietra en Della Pietra (1996):

Entropie, Informatie en het Maximum Entropie Principe
59
, { als en volgt op in overige gevallen.
Hierbij geeft de taal en een eigenschap van het betreffende woord aan, tezamen een
kenmerk , vormend. De kans op een woord met het gedefinieerde kenmerk
wordt gevonden in de trainingsdata:
∑ , ,
.
.
Hierbij is de kansverdeling , de relatieve frequentie van het tegelijkertijd
voorkomen van en in de trainingsdata, gedefinieerd als
,
het aantal keer dat , voorkomt in de trainingsdata,
met voor de totale hoeveelheid bekeken trainingsdata. In dit geval is de in de
trainingsdata totale hoeveelheid letters volgend op de letter .
We willen een model vinden dat dezelfde uitkomsten geeft wat betreft het
gevonden kenmerk . Het “model” is dan de conditionele waarschijnlijkheid die de
waarschijnlijkheid van het voorkomen van voorspelt, gegeven dat het geval is. Dit
geeft voor de verwachte waarde van kenmerk volgens het model
∑ ,
,
.
Hierbij is de kans dat voorkomt volgens de trainingsdata.

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
60
Aan de met het model bepaalde wordt de voorwaarde gesteld te kloppen met
de verwachtingswaarde zoals gevonden in de trainingsdata :
,
ofwel
∑ ,
,
∑ , ,
.
.
Zo worden aan de hand van een set kenmerken de voorwaarden gevonden waar een
model aan dient te voldoen. Hiermee kan een volgende stap worden gezet: maximalisatie
van entropie met de methode van Lagrange-multiplicatoren.
6.3 DEFINITIE EN MAXIMALISATIE VAN DE ENTROPIE
De informatie-inhoud of de entropie van het model wordt beschreven door
Shannon’s formule. Hierbij moeten we wel al vermenigvuldigen met een factor ,
aangezien we een maat willen voor onzekerheid op het (volgens het model) voorkomen
van in het geval van . Dit geeft
∑ log
,
.

Entropie, Informatie en het Maximum Entropie Principe
61
Maximalisatie van entropie wordt verkregen door opstelling van een te maximaliseren
Lagrangiaan. We moeten dan de termen met de Lagrange-multiplicatoren ,
vermenigvuldigd met de in de voorgaande sectie verkregen voorwaarden, toevoegen.
, ∑ ( )
∑ log
,
∑
(∑ ,
,
∑ , ,
,
) .
Maximalisatie van , gebeurt door op te leggen dat alle partiële afgeleiden gelijk aan
zijn. Allereerst kijken we naar de partiële afgeleide naar , om daarmee een uitdrukking
te vinden voor , de waarvoor , haar maximum bereikt:
∑
,
log ∑
,
∑
(∑ ,
,
)
Uitwerking van deze conditie geeft,
log ∑ ,
,
ofwel
log ∑ ,
Deze vergelijking heeft als algemene oplossing de exponentiële uitdrukking

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
62
e p(∑ ,
).
Hierin is een constante, vergelijkbaar met de uit de statistische mechanica bekende
partitiesom, welke gevonden kan worden met de normalisatievoorwaarde dat alle kansen
bij elkaar opgeteld leveren:
∑
∑
e p (∑ ,
)
,
zodat,
∑e p(∑ ,
)
.
Hiermee is de algemene uitdrukking verkregen voor het optimale model, passend bij
desbetreffende taal, . Volgende stap is het vinden van de optimale waarden van de
Lagrange-multiplicatoren .
6.4 DE OPTIMALE GEWICHTEN VAN DE VOORWAARDEN
De Lagrange multiplicatoren kun je interpreteren als het belang of gewicht van
bijbehorende voorwaarden . Inderdaad, als heel groot gekozen wordt zal

Entropie, Informatie en het Maximum Entropie Principe
63
deze term, wanneer niet aan deze voorwaarde is voldaan, een grote negatieve bijdrage
aan de energie leveren. De maximalisatieperiode zal er dan voor zorgen dat aan die
conditie zo goed mogelijk wordt voldaan. Berekening van de gewichten van voorwaarden,
is een volgende stap in het maximalisatieprobleem. Eerst vullen we de verkregen
algemene oplossing van in in de formule voor , , leidend tot een functie van
multipliers die Berger, Della Pietra en Della Pietra (1996) noemen. Hierbij wordt
gebruik gemaakt van de eerder gevonden uitdrukking voor .
∑ ( )
∑
,
e p(∑ ,
) log(
e p(∑ ,
))
∑ ∑
e p(∑ ,
)
,
,
∑
∑ , ,
,
.
De eerste term in de som kan worden herschreven, gebruikmakend van log
log
log en de definitie voor :
∑
log ∑
,
e p(∑ ,
) log
∑ ∑
e p(∑ ,
)
,
,
∑
.
Herschikken levert

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
64
∑
log ∑
(∑log
,
∑
∑ ,
,
)∑
e p(∑ ,
)
,
.
Omdat ∑ log ∑ ∑ , , , geldt vervolgens
∑
log ∑
( ∑∑ ,
,
)∑
e p (∑ ,
)
,
,
zodat we in de laatste stap met opnieuw de definities voor en de gewenste
uitdrukking vinden:
∑
log ∑
∑
∑
log( ) ∑
.
Het is nu zaak de optimale set waarden te vinden, door te maximaliseren.
Een analytische oplossing door bijvoorbeeld af te leiden en gelijk te stellen aan lijkt
in dit geval niet mogelijk. Gelukkig is er een rijk scala aan numerieke methoden
beschikbaar om zulke problemen op te lossen, dat wil zeggen de extrema te bepalen van
een functie van meerdere variabelen. Berger, Della Pietra, Della Pietra (1996) noemen
bijvoorbeeld coordinate-wise ascent, iterative scaling en (steepest) gradient ascent. Deze
laatste methode, ook wel de “methode van de steilste helling” genoemd, wordt toegelicht
door Hayes en Wilson (2008). Ik zal hem kort bespreken.
De methode van de steilste helling is een iteratieve methode waarbij je in een
aantal stappen naar de maximale waarde van de functie toe klimt. Als nulde iteratie zetten

Entropie, Informatie en het Maximum Entropie Principe
65
we alle gelijk aan . Verandering van de gewichten levert ofwel een vergroting, ofwel
een verkleining van de waarschijnlijkheid van de trainingsdata volgens het model .
Wordt in elk punt de optie gekozen die maximaal vergroot, dan wordt een
stijgend pad bewandeld dat leidt tot de maximaal haalbare waarde . Zo verkrijgen
we bij zeer goede benadering de optimale waarden van de gewichten , en dus ook van
de waarschijnlijkheid en de maximale entropie of . Bijbehorend model is de
oplossing die de trainingsdata optimaal genereert. Het model met maximale entropie is
uniek. Dit is te zien aan de convexe vorm van , met slechts één maximum, zonder
lokale maxima waar de beschreven maximalisatiemethode vast zou kunnen lopen.
Bij deze methode is het niet nodig steeds opnieuw de waarde van te
berekenen. Het is voldoende de lokale gradiënt te berekenen, welke aangeeft wat de
steilste weg omhoog is. Deze gradiënt is de vector van partiële afgeleiden van naar
alle afzondelijke . Hoe groter
, des te steiler het bijbehorende pad langs het
oppervlak van , des te sneller het optimale model wordt bereikt.
De betekenis en tevens berekening van dit proces van opklimmen kan
inzichtelijker worden gemaakt: door langs het oppervlak van het model te klimmen
wordt steeds beter de werkelijke, te modelleren taal benaderd. De partiële afgeleiden
geven aan hoe steil het pad naar het optimale punt is, wat tevens een maat is voor de
afstand tot dat punt, aangezien de convexe kromming van minder steil wordt
naarmate het optimum dichter wordt genaderd. Daarom kan de gradiënt worden
beschouwd als indicatie voor de mate waarin het model afwijkt van de trainingsdata: het
verschil tussen het voorkomen van de onderzochte kenmerken in de trainingsdata en de
verwachtingswaarde van dezelfde kenmerken volgens het model,
∑∑ , ,
,
∑∑ ,
,
,
waarbij voor het optimale model geldt
∑∑ , ,
,
∑∑ ,
,

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
66
, .
In plaats van berekening van de gradiënt kan worden berekend, in alle
richtingen vanuit het betreffende punt. De richting met de kleinste waarde voor
is de richting die dient te worden uitgegaan, om uit te komen bij het model
met optimale gewichten .
Met behulp van het principe van maximale entropie is het model bepaald
dat de trainingsdata het best benadert:
e p(∑
,
),
waarbij voldaan wordt aan de voorwaarde dat
, .
We hebben in dit hoofdstuk een interessante toepassing behandeld van het maximale
entropiebeginsel in de taalwetenschap om te illustreren hoe algemeen dit beginsel in feite
is. Het is dan ook niet verbazingwekkend dat dit beginsel in veel vakgebieden waar het
gaat om het construeren van optimale modellen voor problemen waarin beperkende
voorwaarden een belangrijke rol spelen.

Entropie, Informatie en het Maximum Entropie Principe
67
7. CONCLUSIE
We hebben in deze tekst onderzocht wat de actuele conceptie van entropie is en hoe deze
tot stand is gekomen. Resultaten en bevindingen in deze scriptie zijn verkregen uit een
literatuuronderzoek, met behulp van de literatuur waarnaar is verwezen in de tekst. Een
eigen onderzoek is derhalve niet uitgevoerd, resultaten van bijvoorbeeld het optimale
model voor de vertaling en herkenning van teksten zijn niet geverifieerd aan de hand van
computersimulatie. Wel zijn dergelijke uitgevoerde simulaties – en bijbehorende discussie
– te vinden in de geciteerde werken.
Al uit een eenvoudig voorbeeld waarbij de configuratie van een aantal bits een
systeemtoestand voorstellen bleek een verband tussen entropie, waarschijnlijkheid en
informatie te bestaan. Een chronologisch overzicht van de wijze waarop entropie
begrepen en geformuleerd werd leidde tot een groter inzicht in de betekenis en de
mogelijke toepassingen van deze grootheid. Met een korte samenvatting gaan we nog
eenmaal langs de hoofdpunten in de ontwikkeling van ons begrip over en gebruik van
entropie.
De eerste definitie van entropie is te vinden in de tweede hoofdwet van de
thermodynamica: de verandering van entropie is de ratio van de verandering in warmte
ten opzichte van de temperatuur en entropie neemt in de praktijk niet af in een gesloten
systeem,
,
.
Entropie is in deze conceptie een toestandsgrootheid, net zoals druk, volume of
temperatuur. De gevolgen van entropie voor de thermodynamica zijn groot: warmte kan
niet volledig in arbeid worden omgezet en processen die gepaard gaan met een toename
van entropie zijn irreversibel. Deze irreversibiliteit bracht Ludwig Boltzmann op het
spoor van statistische mechanica en een nieuwe conceptie van entropie
De statistische mechanica maakte het mogelijk entropie te begrijpen in termen
van het gedrag van individuele deeltjes. Boltzmann stelde dat entropie een maat is voor

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
68
het aantal mogelijke toestanden van een deeltjessysteem en definieerde entropie voor het
microkanoniek ensemble:
log .
Omdat elke toestand in een microkanoniek ensemble even waarschijnlijk is zal een
macrotoestand waarmee meer microtoestanden corresponderen waarschijnlijker zijn. Dit
bracht Boltzmann tot een nieuw begrip van entropie: entropie is een maat voor de
waarschijnljkheid van een toestand. De tweede hoofdwet van de thermodynamica vertaalt
dan in de stelling dat een systeem gemiddeld altijd van een minder naar een meer
waarschijnlijke toestand zal bewegen – een tegengestelde beweging is niet onmogelijk
maar zo onwaarschijnlijk dat we haar in de natuur niet tegenkomen.
Gibbs stelde vervolgens met behulp van de Boltzmann distributie en Helmholtz
vrije energie een derde, algemenere uitdrukking van entropie op, afhangend van de
kansverdeling die hoort bij de beschreven toestand:
∑ ln
.
Het was precies deze uitdrukking die Shannon vond bij de uitwerking van een
maat voor zowel informatie als onzekerheid, met het verschil dat de constante van
Boltzmann nu een willekeurige constante is. Zo werd het verband tussen entropie,
informatie en onzekerheid gelegd. Hoe groter de entropie in een bericht, des te groter de
hoeveelheid informatie in en de onzekerheid over dat bericht. Shannon generaliseerde
entropie van een thermodynamisch naar een informatietheoretisch concept, inzicht
gevend in de hoeveelheid informatie in elke denkbare kansverdeling.
In het modelleren van de mogelijke uitkomsten van een proces blijkt entropie in
de betekenis van Shannon zeer bruikbaar. Gegeven een aantal mogelijke
voorspellingsmodellen wordt het unieke, meest onbevooroordeelde en daarom optimale
model gekenmerkt door de grootste onzekerheid, ofwel de grootste entropie. Het
optimale model dient alleen bekende informatie aan te nemen, terwijl verder een zo groot

Entropie, Informatie en het Maximum Entropie Principe
69
mogelijke onzekerheid over de uitkomst wordt gelaten. Dit principe van het zoeken naar
het optimale model aan de hand van de maximalisatie van entropie heet het maximum
entropiebeginsel.
De algemene betekenis en bruikbaarheid die door Shannon aan entropie is
toegekend lichtte Jaynes verder toe, door te laten zien hoe statistische mechanica – waar
entropie eerder uit werd afgeleid – één van de vele mogelijke toepassingen van het
maximum entropie principe is. Entropiemaximalisatie blijkt een beginsel dat toepasbaar
is in talloze verdelingsproblemen waar een beperkende voorwaarde wordt gelegd met
betrekking tot de gemiddelde waarde die een bepaalde grootheid aanneemt. In het geval
van statistische mechanica is deze beperkende voorwaarde de stelling dat de interne
energie gelijk is aan het gemiddelde energie van het systeem.
Elke evenwichtssituatie wordt gekenmerkt door een maximale hoeveelheid
entropie. Het vinden van de optimale evenwichtsverdeling ofwel het optimale model is
daarom gereduceerd tot (1) het uitvoeren van constraint satisfaction, waarbij voldaan
wordt aan de beperkende voorwaarden om zo tot een aantal mogelijke modellen te
komen, (2) het vinden van het model met de grootste hoeveelheid entropie. We hebben
gezien hoe niet alleen de statistische mechanica, maar ook ant colony optimization,
beeldreconstructie, de geografische distributie van diersoorten en taalherkenning
optimaal gemodelleerd kunnen worden aan de hand van het maximum entropiebeginsel.
Als afsluitende conclusie kan worden gezegd dat entropie door de jaren heen een
veel algemenere betekenis heeft gekregen dan de betekenis die aanvankelijk werd
gegeven door de thermodynamica. Entropie blijkt als maat voor waarschijnlijkheid,
onzekerheid en informatie toepasbaar in talloze disciplines waarin optimalisatie van
kansverdelingen voor de modellering van nog onbekende uitkomsten of resultaten een rol
speelt.

Rebecca Sier – Bachelorscriptie natuur- en sterrenkunde
70
DANKWOORD
Veel dank aan mijn begeleider bij de uitvoering van dit bachelorproject, Prof.dr.ir. F.A.
Bais. Dank voor de interessante suggesties die leidden tot dit onderzoek, dank voor alle
inzichten, het geduld en steeds weer uitgebreide commentaar op tussentijdse versies van
de tekst, wat maakte dat het verslag de vorm heeft gekregen die het nu heeft.

Entropie, Informatie en het Maximum Entropie Principe
71
GERAADPLEEGDE LITERATUUR
Bais, F. A., & Farmer, J. D. (2008). The physics of information. In D. M. Gabbay, P. Thagard,
& J. Woods, Handbook of the philosophy of science. Volume 8: Philosophy of
information (pp. 617-691). Elsevier.
Bennett, C. H. (1987). Demons, Engines and the Second Law. Scientific American, 108-116.
Berger, A. L., Della Pietra, S. A., & Della Pietra, V. J. (1996). A maximum entropy approach
to natural language processing. Association for computational linguistics, 1-36.
Boltzmann, L. (1877). Über die Beziehung zwischen dem zweiten Hauptsatze der
mechanischen Wärmetheorie und der Warscheinlichkeitsrechnung respektive den
Sätzen über das Wärmegleichgewicht. Wiener Berichte(76), 373-435.
Cercignani, C. (1998). Ludwig Boltzmann: the man who trusted atoms. Oxford: Oxford
University Press.
Deneubourg, J. -L., Aron, S., Goss, S., & Pasteels, J. M. (1990). The self-organizing
exploratory pattern of the Argentine ant. Journal of Insect Behavior, 159-168.
Dorigo, M., Birattari, M., & Stützle, T. (2006). Ant colony optimization: artificial ants as a
computational intelligence technique. IEEE Computational Intelligence Magazine,
28-39.
Hayes, B., & Wilson, C. (2008). A maximum entropy model of phonotactics and
phonotactic learning. Linguistic Inquiry, 379-440.
Jaynes, E. T. (1957). Information theory and statistical mechanics. Physical review, 620-
630.
Kosslyn, S. M. (2012, April 29). Constraint Satisfation. Opgeroepen op April 29, 2012, van
Edge: http://www.edge.org/print/res-detail.php?rid=924
Phillips, S. J., Anderson, R. P., & Schapire, R. E. (2006). Maxmimum entropy modeling of
species geographic distributions. Ecological Modelling, 231-259.
Plenio, M. B., & Vitelli, V. (2001). The physics of forgetting: Landauer's erasure principle
and information theory. Contemporary Physics, 25-60.
Schroeder, D. V. (2000). An introduction to thermal physics. United States: Addison
Wesley Longman.
Shannon, C. E. (1948). A Mathematical Theory of Communication. Mobile Computing and
Communications Review, 3-55.
Skilling, J., & Bryan, R. K. (1984). Maximum entropy image reconstruction: general
algorithm. Monthly Notices of the Royal Astronomical Society, 111-124.


















