


Ensemble methods for modeling financial data
22
-
Upload
gaurav-chakravorty -
Category
Engineering
-
view
48 -
download
3
Transcript of Ensemble methods for modeling financial data

Background
● What is algorithmic trading?
● What is the relevance of machine learning?
● Where does the current topic fit in ?

Trading
Traders trade via open outcrying
Close to the conventional notion of “trading”
Slow and inefficient
Manual Algorithmic
People like you and I design algorithms to predict like human traders
Computer algorithms trade with each other
Blazingly fast with high trade volumes

Machine learning
How does an algorithm make money?

Let’s make it more interesting !

Linear regression!
(Why is the relationship linear ?)
(Any more problems ?)
Standard ML technique

How about this graph ?

Trees to the rescue !
Decision trees are very popular in classification
Can do regression as well !
Simple and efficient
Very intuitive

Walk through

Hang on
p
Phew!

Which brings us to the discussion of the day
What is an ensemble method?
How is it relevant to finance?
Two very common ( but remarkably powerful) ensemble methods

Ensemble
Wikipedia says:
“In statistics and machine learning, ensemble methods use multiple learning algorithms to obtain better predictive performance than could be obtained from any of the constituent learning algorithms”
Begin with a weak learner ( Tree in our case )
Train several of them
Combine their output ( Bagging and Boosting )


BaggingHow do you naturally expand the idea of a tree? ( Hint : think real world )

Random forest
● Training○ Sample a subset of the input
( Bootstrapping )○ Build a regression tree on top of
it○ Repeat till “convergence”
● Prediction○ Pass the input to each tree in
the forest○ Take a weighted combination


In random forests, the trees are built independently
Possibility of redundancy
Is there a way to not isolate our training subsets?
Potential issues?


Boosting
● Training○ Sample a subset of the input○ Build a tree on top of it○ Obtain an error statistic on the WHOLE
input○ Use this statistic to generate the next
input subset
Median heavy training instead of mean heavy training
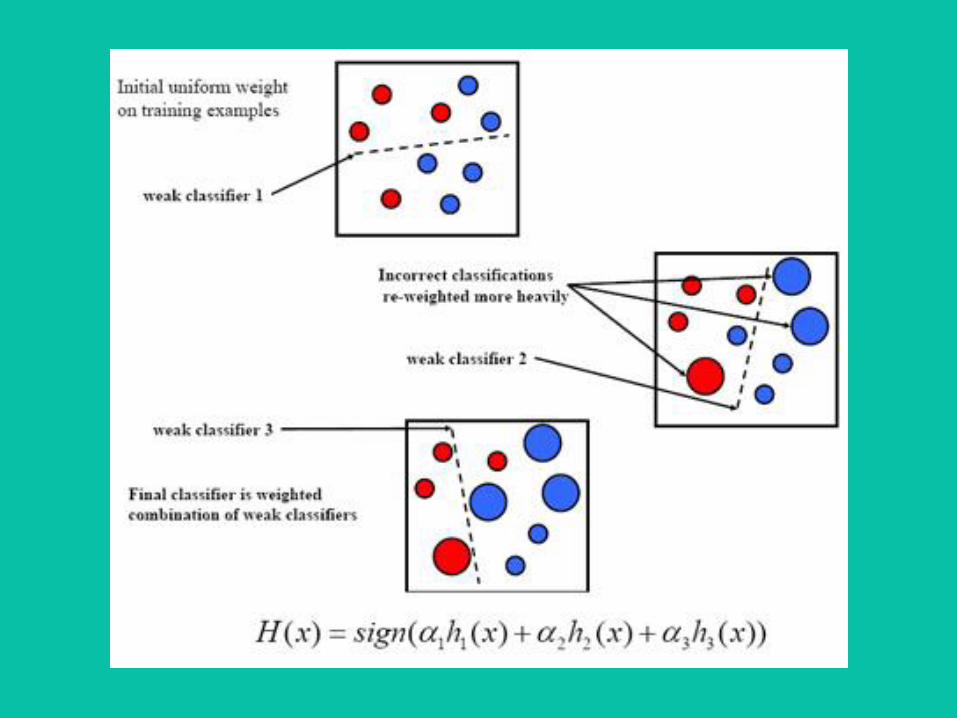

Why use this in finance ?
i.i.d assumption goes for a toss
Noise filtering is a challenge
Sophisticated methods often fail ( and are miserably slow)
We need to rely on simple methods and yet guarantee high accuracy


















