
Eigen - TuxFamily
127
Eigen a c++ linear algebra library Gaël Guennebaud [http://eigen.tuxfamily.org] CGLibs – 3 June 2013
Transcript of Eigen - TuxFamily

Eigen
a c++ linear algebra library
Gaël Guennebaud
[http://eigen.tuxfamily.org]
CGLibs – 3 June 2013

2
Outline
• 9:00 → 9:30 – Discovering Eigen– motivations– API preview
• 9:30 → 10:30 – Eigen's internals– design choices– meta-programming– expression templates
– coffee break –

3
Outline
• 11:00 → 12:30 – Use cases– Geometry & 3D algebra– RBFs (dense solvers)– (bi-)Harmonic interpolation (sparse solvers)
• 12:30 → 13:00– Roadmap– Open-source community– Open discussions

4
Presentations

5
Real-time Soft Shadows

6
Surface Reconstruction

7
Skinning & Vector Graphics

8
Computer Graphics&
Linear Algebra?

9
Computer Graphics & Linear Algebra
• points & vectors– 2D to 4D vectors (+, -, *, dot, cross, etc.)
• space transformations– 2x2 to 4x4 matrices (including non squared matrices as 3x4)
– inverse (Cramer's rule, Div. & Conq.)– polar decomposition
→ Singular Value Decomposition (SVD)
• point sets: normals, oriented bounding boxes→ Eigen-value decomposition (EVD)
small fixed size linear algebra

10
Computer Graphics & Linear Algebra
• Linear Least-square– Polynomial fit,
Curvature estimation, MLS– Radial Basis Functions
• Spectral analysis
from small to large dense linear algebra

11
Computer Graphics & Linear Algebra
• Differential equations, FEM– physical simulation– mesh processing– surface reconstruction– interpolation
large sparse linear algebra

12
Context summary
• Matrix computation are everywhere– Various applications:• simulators/simulations, video games, audio/image
processing, design, robotic, computer vision,augmented reality, etc.
– Need various tools:• numerical data manipulation, space transformations• inverse problems, PDE, spectral analysis
– Need performance:• on standard PC, smartphone, embedded systems, etc.• real-time performance

13
Matrix computation?
MatLab
+ friendly API+ large set of features- math only- extremely slow for small objects
→ Prototyping
Zoo of libs
+ highly optimized - 1 feature = 1 lib+/- tailored for advanced user / clusters - slow for small objects
→ Advanced usages
?

14
Matrix computation?
MatLab HPC libsEigen
(start: 2008)

15
Facts
• Pure C++ template library– header only– no binary to compile/install– no configuration step– no dependency (optional only)
#include <Eigen/Eigen>
using namespace Eigen;
int main() { Matrix4f A = Matrix4f::Random(); std::cout << A << std::endl;}
$ g++ -O2 example.cpp -o example

16
Facts
• Pure C++ template library– header only– no binary to compile/install– no configuration step– no dependency (optional only)
• Packaged by all Linux distributions (incl. macport)
• Opensource: MPL2
→ easy to install & distribute

17
Multi-platforms
• Supported compilers:– GCC (≥4.2), MSVC (≥2008), Intel ICC,
Clang/LLVM, old apple's compilers
• Supported systems:– x86/x86_64, ARM, PowerPC– Linux, Windows, OSX, IOS
• Supported SIMD vectorization engines:– SSE{2,3,4}– NEON (ARM)
– Altivec (PowerPC)

18
Large feature set
– Core• Matrix and array manipulation (~MatLab, 1D & 2D)• Basic linear algebra (~BLAS)
– incl. triangular & self-adjoint matrix
– LU, Cholesky, QR, SVD, Eigenvalues• Matrix decompositions and linear solvers (~Lapack)
– Geometry (transformations, …)
– Sparse• Manipulation• Solvers (LLT, LU, QR & CG, BiCGSTAB, GMRES)
– WIP modules (autodiff, non-linear opt., FFT, etc.)
→ “unified API” - “all-in-one”

19
Optimized for both small and large objects
• Small objects– means fixed sizes:
– malloc-free– meta unrolling– specialized algo
Matrix<float,4,4> Matrix<float,Dynamic,1>
• Large objects– means dynamic sizes
– cache friendly kernels– multi-threading (OpenMP)
– Vectorization (SIMD)
– Unified API → write generic code– Mixed fixed/dynamic dimensions
20
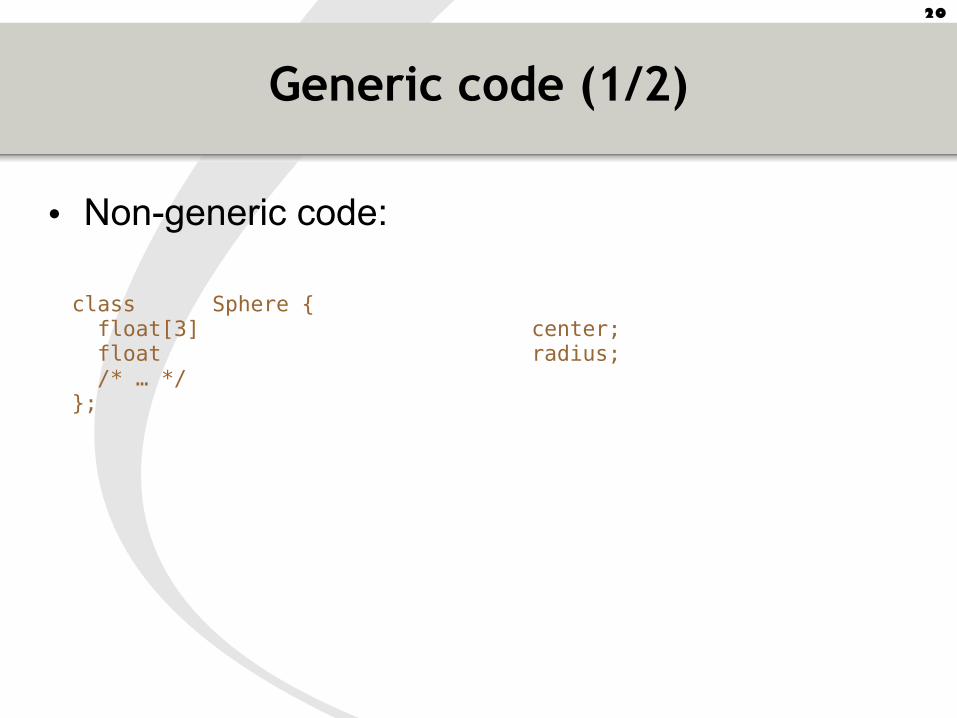
Generic code (1/2)
class Sphere { float[3] center; float radius; /* … */};
• Non-generic code:

21
Generic code (1/2)
template < int AmbientDim=Eigen::Dynamic>class HyperSphere { Eigen::Matrix<float ,AmbientDim,1> center; float radius; /* … */};
typedef HyperSphere<2> HyperSphere2;typedef HyperSphere<3> HyperSphere3;typedef HyperSphere<3> Sphere;typedef HyperSphere<> HyperSphereX;
• Write generic code:
– Eigen takes care of the low level optimizations

22
Generic code (2/2)
template <typename Scalar, int AmbientDim=Eigen::Dynamic>class HyperSphere { Eigen::Matrix<Scalar,AmbientDim,1> center; Scalar radius; /* … */};
typedef HyperSphere<float, 2> HyperSphere2f;typedef HyperSphere<double,3> HyperSphere3d;
• Write fully generic code:

23
Custom scalar types
• Can use custom types everywhere– Exact arithmetic (rational numbers)– Multi-precision numbers (e.g., via mpfr++)– Auto-diff scalar types– Interval– Symbolic
• Example:typedef Matrix<mpreal,Dynamic,Dynamic> MatrixMP;MatrixMP A, B, X;// init A and B// solve for A.X=B using LU decompositionX = A.lu().solve(B);

24
Communication with the world
→ standard matrix representations
• to Eigen
• from Eigen
→ same for sparse matrices
float* raw_data = malloc(...);Map<MatrixXd> M(raw_data, rows, cols);// use M as a MatrixXdM = M.inverse();
MatrixXd M;float* raw_data = M.data();int stride = M.outerStride();raw_data[i+j*stride]

25
Eigen & BLAS
• Call Eigen's algorithms through a BLAS/Lapack API– Alternative to ATLAS, OpenBlas, Intel MKL• e.g., sparse solvers, Octave, Plasma, etc.
– Run the Lapack test suite on Eigen
Eigen's algorithms
Eigen'sAPI
BLAS/LapackAPI
ExistingOther libs/apps

26
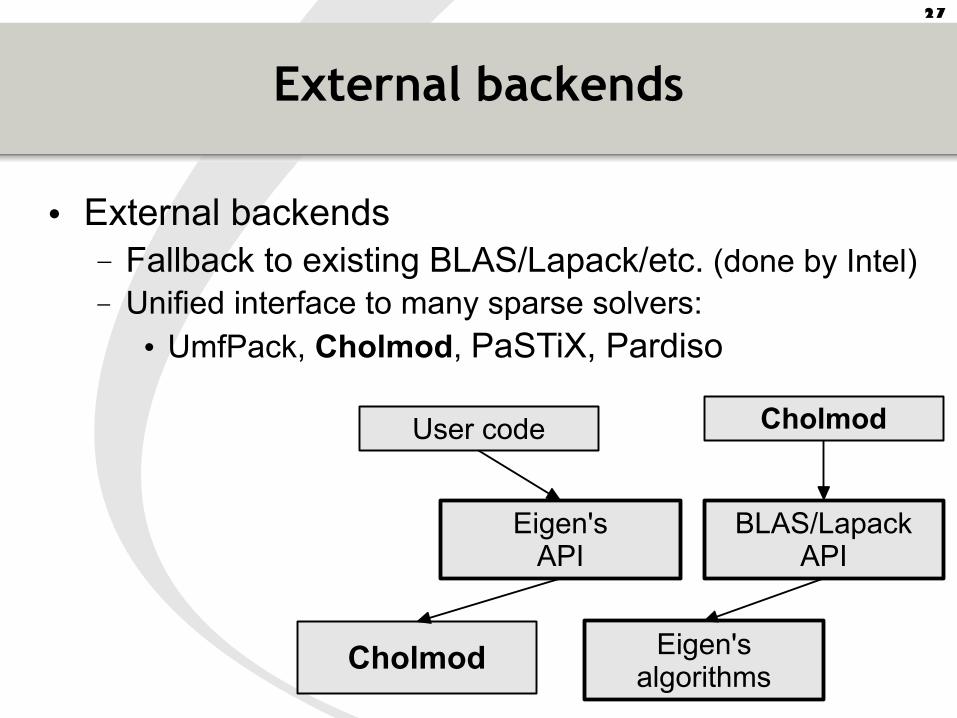
External backends
• External backends– Fallback to existing BLAS/Lapack/etc. (done by Intel)– Unified interface to many sparse solvers:
• UmfPack, Cholmod, PaSTiX, Pardiso
Eigen's algorithms
Eigen'sAPI
Other libs(BLAS, solver, ...)
BLAS/LapackAPI
ExistingOther libs
27
External backends
• External backends– Fallback to existing BLAS/Lapack/etc. (done by Intel)– Unified interface to many sparse solvers:
• UmfPack, Cholmod, PaSTiX, Pardiso
Eigen's algorithms
Eigen'sAPI
Cholmod
BLAS/LapackAPI
CholmodUser code

28
Documentation
• Documentation
• Support– Forum, IRC, Mailing-List– Bugzilla

29
API demo

Internals
31
Technical aspects
Matrix products?
Matrix factorizations?
Sparse algebra?
Expression templates
Meta-programming
Vectorization

32
Preliminaries 1/3 - C++
• Template programming & Inheritance:
• Partial template specialization:
template<typename Scalar, int N>class Vector : public SomeBaseClass { Scalar m_data[N]; /* … */};
template<typename Real, int N>class Vector<complex<Real>,N> : public AnotherBaseClass { Real m_real[N]; Real m_imag[N]; /* … */};
Vector<double,3> v1;Vector<complex<float>,3> v2;
pattern matching

33
Preliminaries 2/3 – Memory Hierarchy
regs
L1 cache
L2 cache
ALU
RAM (NUMA)
x100 bigger (90x90 floats) ; 1-4 cycles
x100 bigger (900x900 floats) ; 40-100 cycles
x1000 bigger ; ~400 cycles
small (8x8 floats) ; 1 cycle

34
Preliminaries 3/3 – Parallelism
• 4 levels of parallelism:– cluster of PCs → MPI
PC1 PC2 PCn
network
...
out of the scope of Eigen

35
Preliminaries 3/3 – Parallelism
• 4 levels of parallelism:– cluster of PCs → MPI– multi/many-cores → OpenMP
PC
shared memory
CPU1 CPU2 CPUn...

36
Preliminaries 3/3 – Parallelism
• 4 levels of parallelism:– cluster of PCs → MPI– multi/many-cores → OpenMP– SIMD → intrinsics for vector instructions (SSE, AVX, …)
4
-1
-6
2
-3
5
-2
4
* →
-12
-5
12
8
reg0 reg1 reg2

37
Preliminaries 3/3 – Parallelism
• 4 levels of parallelism:– cluster of PCs → MPI– multi/many-cores → OpenMP– SIMD → intrinsics for vector instructions (SSE, AVX, …)
– pipelining → needs non dependent instructions
1op = 4 mini ops = 4 cycles
4 ops in 7 cycles !
time
a = a * b;c = c * d;e = e * f;g = g * h;

38
Peak performance
• Example– Intel Core2 Quad CPU Q9400 @ 2.66GHz (x86_64)• pipelining → 1 mul + 1 add / cycle (ideal case)• SSE → x 4 single precision ops at once• frequency → x 2.66G• peak performance: 21,790 Mflops (for 1 core)
that's our goal!

39
Problem statement
• Example:
• Standard C++ way:
m3 = m1 + m2 + m3;
class Matrix { float m_data[M*N]; float& operator()(int i, int j) { return m_data[i+j*M]; }};
Matrix operator+(const Matrix& A, const Matrix& B) { Matrix res;
for(int j=0; j<N; ++j) for(int i=0; i<M; ++i) res(i,j) = A(i,j) + B(i,j);
return res;}

40
Problem statement
• Example:
• Standard C++ way, result:
m3 = m1 + m2 + m3;
tmp1 = m1 + m2;tmp2 = tmp1 + m3;m3 = tmp2;
→ 3 loops :(→ 2 temporaries :(→ 8*M*N memory accesses :(

41
Expression templates
• Example:
• Expression templates:– “+” returns an expression:
m3 = m1 + m2 + m3;
Sum<Matrix,Matrix>operator+(const Matrix& A, const Matrix& B) {
return Sum<Matrix,Matrix>(A,B);}
template<typename type_of_A, typename type_of_B>class Sum {
const type_of_A &A;const type_of_B &B;
};

42
Expression templates
• Example:
→ “expression tree”
m1 m2
+ Sum<Matrix,Matrix>
m3 = m1 + m2 + m3

43
Expression templates
• Example:
→ “expression tree”
m1 m2
+
+
m3 Sum< Sum<Matrix,Matrix>, Matrix >
m3 = m1 + m2 + m3

44
Expression templates
• Example:
→ “expression tree”
m1 m2
+
+
m3
Assign<Matrix, Sum< Sum<Matrix,Matrix>, Matrix > >
m3 = m1 + m2 + m3
=
m3

45
Expression templates
• Example:
→ “expression tree”
• Immediate question:– How to evaluate this?
m1 m2
+
+
m3
Assign<Matrix, Sum< Sum<Matrix,Matrix>, Matrix > >
m3 = m1 + m2 + m3;
=
m3

46
Evaluation of expressions
• Bottom-up approach:
→ simple, can specialize the implementation based on the operand types...
… but not on the whole expression :(
template<type_of_A, type_of_B>class Sum {
const type_of_A &A;const type_of_B &B;
Scalar coeff(i, j) {return A.coeff(i,j) + B.coeff(i,j);
}};

47
Evaluation of expressions
• Solution: top-down creation of an evaluator– evaluator:
– partial specialization for each operation, e.g.:
template<type_of_A, type_of_B>class Evaluator< Sum<type_of_A,type_of_B> > { Evaluator<type_of_A> evalA(A); Evaluator<type_of_B> evalB(B); Scalar coeff(i,j) { return evalA.coeff(i,j) + evalB.coeff(i,j); }};
template<ExprType> class Evaluator;

48
Evaluation of expressions
• Matrix evaluator:class Evaluator<Matrix> { const Matrix &mat; Scalar coeff(i) { return mat.data[i]; }};

49
Evaluation of expressions
• Solution: top-down creation of an evaluator– assignment evaluator (dest ← source):
• Example: – compiles to:
for(i=0; i<m3.size(); ++i) m3[i] = “Evaluator(m1+m2+m3)”.coeff(i);
template<Dest, Source>class Evaluator< Assign<Dest,Source> > { Evaluator<Dest> evalDst(dest); Evaluator<Source> evalSrc(source); void run() { for(int i=0; i<evalDst.size(); ++i) evalDst.coeff(i) = evalSrc.coeff(i); }};
m3 = m1 + m2 + m3;

50
Template Instantiations
class Evaluator< Sum< Sum<Matrix,Matrix>, Matrix > > { Evaluator<Sum<Matrix,Matrix> > evalA(“m1+m2”); Evaluator<Matrix> evalB(“m3”); Scalar coeff(i) { return evalA.coeff(i) + evalB.coeff(i); }}; m3[i]
class Evaluator< Sum<Matrix,Matrix> > { Evaluator<Matrix> evalA(“m1”); Evaluator<Matrix> evalB(“m2”); Scalar coeff(i) { return evalA.coeff(i) + evalB.coeff(i); }}; m2[i]m1[i]
generatedby the
compiler!
for(i=0; i<m3.size(); ++i) m3[i] = “Evaluator(m1+m2+m3)”.coeff(i);

51
Template Instantiations
• After inlining:
for(i=0; i<m3.size(); ++i) m3[i] = m1[i] + m2[i] + m3[i];
→ 1 loop→ no temporaries→ /2 memory accesses
m3 = m1 + m2 + m3;

52
Expression templates
• Generalize to any coefficient-wise operations– example:
– expression type:
– compiles to:
Assign<Block<Matrix>, Difference< ScalarMultiple<Matrix>, Transpose<Matrix> > >
m3.block(1,2,rows,cols) = 2*m1 – m2.transpose();
for(int j=0; j<cols; ++j) for(int i=0; i<rows; ++i) m3(i+1,j+2) = 2*m1(i,j) – m2(j,i);

53
Expr. templates: Fused operations
• reduce temporaries, memory accesses, cache misses
L1 L2 RAM
no loop peelingfor Eigen

54
Expr. templates: Better API
• Better API– more examples:
x.col(4) = A.lu().solve(B.col(5));
x = b * A.triangularView<Lower>().inverse();

55
Combinatorial complexity
• Explosion of types and possible combinations
→ need a common base class+ polymorphism
Sum<.,.> operator+(const Matrix& A, const Matrix& B);Sum<.,.> operator+(const Sum<.,.>& A, const Matrix& B);Sum<.,.> operator+(const Sum<.,.>& A, const Sum<.,.>& B);Sum<.,.> operator+(const Sum<.,.>& A, const Transpose<.>& B);Sum<.,.> operator+(const Transpose<.>& A, const Matrix& B);...

56
Combinatorial complexity
class Matrix : MatrixBase {...};class Sum<A,B> : MatrixBase {...};
class MatrixBase {
Sum<MatrixBase,MatrixBase> operator+(const MatrixBase& other) { return Sum<MatrixBase,MatrixBase>(*this, other); }
};
cannot work this way!
• Common base class:
→ need compile-time polymorphism→ CRTP (Curiously Recurring Template Pattern)
class Evaluator<Sum<A,B> > : EvaluatorBase { /* … */ virtual Scalar coeff(i,j);};

57
CRTP
class Matrix : MatrixBase {...};class Sum<A,B> : MatrixBase {...};
class MatrixBase {
Sum<MatrixBase,MatrixBase> operator+(const MatrixBase& other) { return Sum<MatrixBase,MatrixBase>(*this, other); }
};
• base class:

58
CRTP
class Matrix : MatrixBase< Matrix > {...};class Sum<A,B> : MatrixBase< Sum<A,A> > {...};
template<typename Derived>class MatrixBase {
template<typename OtherDerived> Sum<Derived,OtherDerived> operator+(const MatrixBase<OtherDerived>& other) { return Sum<Derived,OtherDerived>(derived(), other.derived()); }
Derived& derived() { return static_cast<Derived&>(*this); } };
• base class + static polymorphism:

59
Product-like operations?
• Expression templates– very good for any coefficient-wise operations– what about matrix products?
– what's wrong?
→ OK for very very small matrices only
class Evaluator< Product<type_of_A,type_of_B> > { Scalar coeff(i,j) { return (A.row(i).cwiseProduct(B.col(i).transpose()).sum(); }};
= *

60
How to make products efficient?
→ cache-aware product algorithm• optimize L2, L1 and register reuses
– needs access the data of the result
D = C + A * B ;
needs to be evaluatedinto a temporary:Matrix tmp;gemm(A, B, tmp);D = C + tmp;

61
Performance

62
Performance

63
How to make products efficient?
• Combinatorial complexity
– one product version is very complex (lot of instructions)
→ handle only one generic version:
• op_ = nop, conjugate, transpose, adjoint• A, B, C → reference to block of memory with strides
A * B;
A.transpose() * B;
2*A * B.adjoint();
A.col(j).transpose() * B;
-A.block(i,j,r,c) * (2*B).transpose();
gemm<op1,op2>(A,B,s,C);→ C += s * op1(A) * op2(B);

64
Top-down expression analysis
• Products– detect & evaluate product sub expressions• e.g.:
→ ... 3*m1 + (2*m2).adjoint() * m3 + ...
gemm<Adj,Nop>(m2, m3, -2, tmp);
Evaluator<Product<type_of_A,type_of_B> > : Evaluator<Matrix> { Evaluator(A,B) : Evaluator<Matrix>(tmp) {
EvaluatorForProduct<type_of_A> evalA(A); EvaluatorForProduct<type_of_B> evalB(B);
gemm<evalA.op,evalB.op>( evalA.data, evalB.data,evalA.scale*evalB.scale,tmp);
} Matrix tmp; };

65
Top-down expression analysis
• Products– avoid temporary when possible• e.g.:
→ m4 -= (2 * m2).adjoint() * m3;
gemm<Adj,Nop>(m2, m3, -2, m4);
Evaluator<Assign<type_of_C,Product<type_of_A,type_of_B> > { Evaluator(C,P) {
EvaluatorForProduct<type_of_A> evalA(P.A()); EvaluatorForProduct<type_of_B> evalB(P.B());
gemm<evalA.op,evalB.op>( evalA.data, evalB.data,evalA.scale*evalB.scale,C);
}};

66
Top-down expression analysis (cont.)
• More complex example:
– so far:
– better:
tmp = m2 * m3;m4 -= m1 + tmp;
m4 -= m1 + m2 * m3;
m4 -= m1;m4 -= m2 * m3;
// catch R = A + B * CEvaluator<Assign<R,Sum<A,Product<B,C> > > { … };

67
Tree optimizer
• Even more complex example:
– Tree optimizer→
– yields:
– Need only two rules:
res -= m1 + m2 + m3*m4 + 2*m5 + m6*m7;
// catch A * B + Y and builds Y' + A' * B'TreeOpt<Sum<Product<A,B>,Y> > { … };
// catch X + A * B + Y and builds (X' + Y') + (A' * B')TreeOpt<Sum<Sum<X,Product<A,B> >,Y> > { … };
res -= ((m1 + m2 + 2*m5) + m3*m4) + m6*m7;
res -= m1 + m2 + 2*m5;res -= m3*m4;res -= m6*m7;
→ demo

68
Tree optimizer
• Last example:
– Tree optimizer→
– Rule:
res += m1 * m2 * v;
TreeOpt<Product<Product<A,B>,C> > { … };
res += m1 * (m2 * v);

69
Vectorization
• How to exploit SIMD instructions?– Evaluator:
class Evaluator< Sum<type_of_A,type_of_B> > { Scalar coeff(i,j) { return evalA.coeff(i,j) + evalB.coeff(i,j); } Packet packet(i,j) { return padd(evalA.packet(i,j), evalB.packet(i,j)); }};
unified wrapper to intrinsics(SSE, NEON, AVX)

70
Vectorization
• How to exploit SIMD instructions?– Assignment:
class Evaluator< Assign<Dest,Source> > { void run() { for(int i=0; i<evalDst.size(); ++i) evalDst.coeff(i,j) = evalSrc.coeff(i,j); }
void run_simd() { for(int i=0; i<evalDst.size(); i+=PacketSize) evalDst.writePacket(i,j, evalSrc.packet(i,j)); }};

71
Vectorization: result
#include<Eigen/Core>using namespace Eigen;
void foo(Matrix2f& u, float a, const Matrix2f& v, float b, const Matrix2f& w){ u = a*v + b*w - u;}
movl 8(%ebp), %edxmovss 20(%ebp), %xmm0movl 24(%ebp), %eaxmovaps %xmm0, %xmm2shufps $0, %xmm2, %xmm2movss 12(%ebp), %xmm0movaps %xmm2, %xmm1mulps (%eax), %xmm1shufps $0, %xmm0, %xmm0movl 16(%ebp), %eaxmulps (%eax), %xmm0addps %xmm1, %xmm0subps (%edx), %xmm0movaps %xmm0, (%edx)

72
Unrolling
• Small sizes→ cost dominated by loop logic → remove the loop... yourself!
(don't overestimate compiler's abilities)
for(int i=n-1; i>=0; --i) foo(i,args);
void foo_impl(int i,args) { foo(i,args); if(i>0) foo_impl(i-1,args);} foo_impl(n-1,args);
template<int I> struct foo_impl { static void run(args) { foo(I,args); foo_impl<I-1>::run(args); }};
template<> struct foo_impl<-1> { static void run(args) {}}; foo_impl<N-1>::run(args);
functional approach

73
Controls
• Still many questions:– which loops have to be unrolled?– which sub-expressions have to be evaluated?– is vectorization worth it?
• Depend on many parameters:– scalar type– expression complexity– kind of operations– architecture
→ need an evaluation cost model

74
Cost model
• Cost Model– Track an approximation of the cost to evaluate one
coefficient• each scalar type defines: ReadCost, AddCost, MulCost
• combined for each expression by the evaluator, e.g.:
class Evaluator< Sum<A,B> > { enum { Cost = NumTraits<Scalar>::AddCost + Evaluator<A>::Cost + Evaluator<B>::Cost; }; …};

75
Cost model
• Examples:– loop unrolling (partial)
– evaluation of sub expressions• (a+b) * c → (a+b) is evaluated into a temporary• enable vectorization of sub expressions
// somewhere in Evaluator<Assign>:assign_impl< (Evaluator<Src>::Cost*N > threshold)
? NoUnrolling : Unrolling >::run(dst,src);
(2*A+B).log() + C.abs()/4
1 loop, butno vectorization
t1 = 2*A+B; // vec ont1 = t1.log(); // no vect1 + C.abs()/4; // vec on
?
76
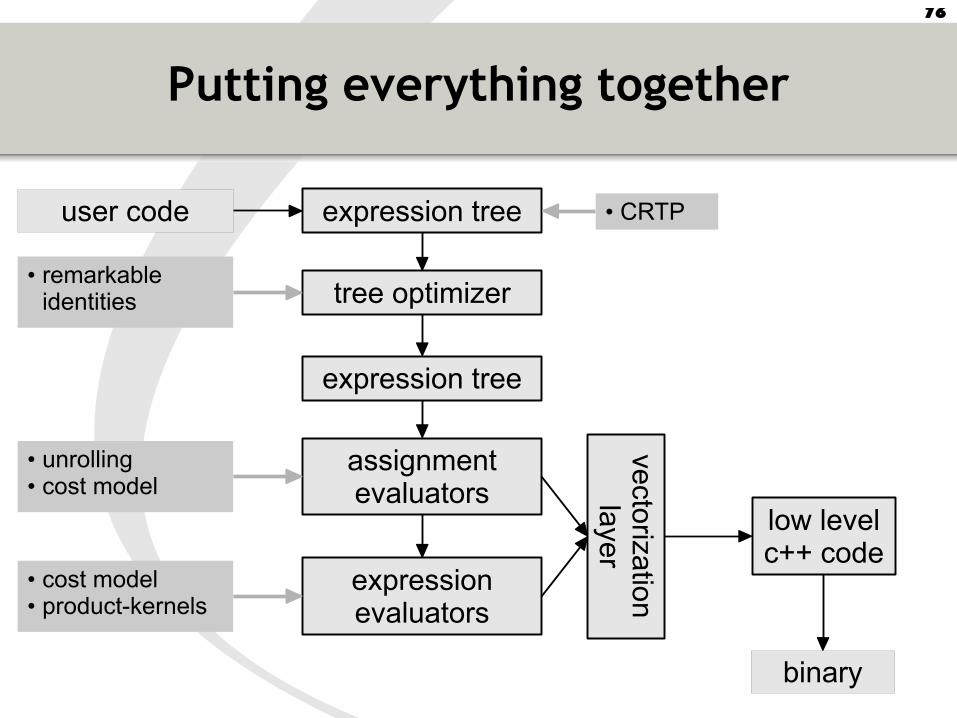
Putting everything together
expression tree
tree optimizer
expressionevaluators
assignmentevaluators
user code
• unrolling• cost model
• cost model• product-kernels
expression tree
vector izatio
nlaye
r
low levelc++ code
binary
• remarkable identities
• CRTP

77
Putting everything together
Eigen = CODE
GENERATOR
user code
low levelc++ code
binary

78
Reductions
• Example:
• Naive way:
dot = (v1.array() * v2.array()).sum();
class MatrixBase { … Scalar sum() const { Evaluator<Derived> eval(this->derived()); Scalar acc = 0; for(int i=0; i<size(); ++i) acc = acc + eval.coeff(i); return acc; } …}; cannot exploit
instruction level parallelism (:

79
Reductions
→ divide & conquer:
• Exercise: write a generic D&C meta-unroller!– solution in Eigen/src/Core/Redux.h
a0
+
a1 a2 a3 a4 a5
+ +
+
a4 a5
+
+
+
→ demo

Eigen tutorial
– coffee break –

Eigen tutorial
Use cases

82
Space Transformation & OpenGL

83
Space Transformations
• Needs– Translations, Scaling, Rotations,– Isometry, Affine/Projective transformation– … in arbitrary dimensions
• Many different approaches

84
TransformationsOwn cooking
Matrix<float,3,4> T;T.leftCols<3>() = 2*rot;T.col(3) = p – rot * p;
• Low level math:
• Directly manipulate a D+1 matrix:– form the matrix:
– apply the transformation:
Matrix3f rot = ???;v' = rot * (2*v-p) + p;
Vector4f v1;v1 << v, 1;v' = T * v1;
v' = 2*rot*v + (p-rot*p)
v' = T.leftCols<3>() * v + T.col(3);
v' = T * v.homogeneous();

85
TransformationsThe procedural approach
Transform<float,3,Affine> T; // wrap a Matrix4f
T.setIdentity();T.translate(p);T.rotate(angle,axis);T.translate(-p);T.scale(2);
v' = T * v;
• OpenGL1 inspired
– cons:• hide the concatenation logic
– how to concatenate on the left?– error prone, does help to understand transformations– far away to what people write on paper
T.setIdentity();T.preScale(2);T.preTranslate(-p);T.preRotate(angle,axis);T.preTranslate(p);

86
TransformationsThe “natural” approach
• Example:
• Unified concatenate/apply → “*”
Transform<float,3,Affine> T;
T = Translation3f(p) * rot * Translation3f(-p) * Scaling(2);
v' = T * v;
Translation3f(p) * v; // compiles to “p+v”Isometry3f T1;T1 * Scaling(-1,2,2); // returns an Affine3f

87
TransformationsThe “natural” approach
• 3D rotations:– AngleAxis, Unit quaternion, Unitary matrix
• Unified conversions → “=”
• Unified inversion → .inverse()
… * AngleAxis3f(M_PI/2, Vector3f::UnitZ()) * …
Translation3f(p).inverse() // → Translation3f(-p)Isometry3f T1;T1.inverse() // → T1.linear().transpose()
* Translation3f(-T1.translation())
Quaternionf q; q = AngleAxis3f(...);

88
TransformationsGeneric programming
• Write generic optimized functions:
template<typename TransformationType>void foo(const TransformationType& T) { T * v T.inverse() * v Projective3f(...) * T * Translation3f(...) * T.inverse() …}
89
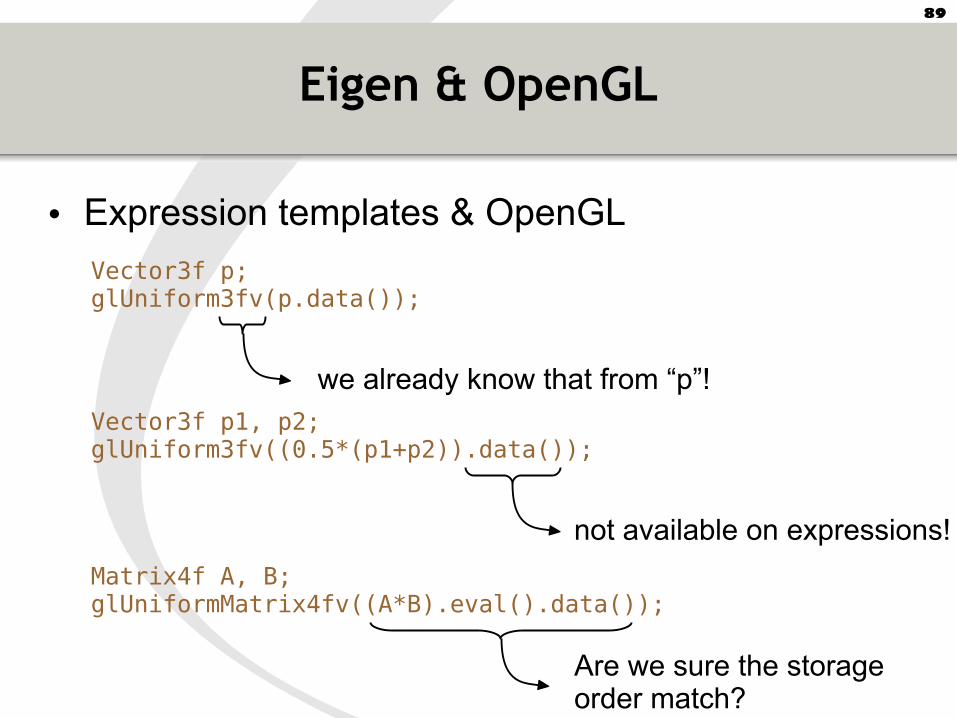
Eigen & OpenGL
• Expression templates & OpenGL
Vector3f p;glUniform3fv(p.data());
we already know that from “p”!
Vector3f p1, p2;glUniform3fv((0.5*(p1+p2)).data());
not available on expressions!
Matrix4f A, B;glUniformMatrix4fv((A*B).eval().data());
Are we sure the storageorder match?

90
Eigen & OpenGL
• <Eigen/OpenGLSupport>
#include <Eigen/OpenGLSupport>using Eigen::glUniform;
Vector3f p1, p1;Matrix3f A;glUniform(p1+p2);glUniform(A*p1);glUniform(A.topRows<2>().transpose());…

91
Vectorization of 3D vectors

92
Vectorization: difficulties?
instruction
ALU
Challenge:put 4 balls in frontof each player!

93
Vectorization: difficulties?
memory
fast(aligned)
slower(not aligned) don't be silly!

94
AoS versus SoA
• Array of Structure
• Structure of Array
• Example: compute the mean
std::vector<Vector3f> points_aos;
struct SoA { VectorXf x, y, z;};
SoA points_soa;
for(int i, …) mean_aos += points_aos[i];
mean_soa << points_soa.x.mean(), points_soa.y.mean(),
points_soa.z.mean();

95
AoS versus SoA
• Eigen's way
– Highly flexible:
Matrix<float,3,Dynamic,ColMajor> points_aos;Matrix<float,3,Dynamic,RowMajor> points_soa;
points_xxx.col(i) = Vector3f(...);
Affine3f T;point_xxx = T * points_xxx;
mean = points_xxx.rowwise().mean();
→ demo

96
Covariance Analysis

97
Covariance Analysis
• Example on 3D point cloudsMatrix3Xf points = …;Matrix3xf c_points = points.colwise() - points.rowwise().mean();Matrix3f cov = c_points * c_points.transpose();SelfAdjointEigenSolver<Matrix3f> eig(cov);

98
Covariance Analysis
• Example on 3D point clouds
– normal estimations
– local planar parameterization
– compute (cheap) oriented bounding boxes
Matrix3Xf points = …;Matrix3xf c_points = points.colwise() - points.rowwise().mean();Matrix3f cov = c_points * c_points.transpose();SelfAdjointEigenSolver<Matrix3f> eig(cov);
Matrix3Xf l_points = eig.eigenvectors().transpose() * points;
AlignedBox3f bbox;for(int i=0; i<points.cols(); ++i) bbox.extend(l_points.col(i));Quaternionf q(eig.eigenvectors().transpose());
Vector3f normal = eig.eigenvectors().col(0);

99
Covariance Analysis
• Tips for 2D and 3D matrices– default iterative algorithm:
– closed form algorithms:(fast but lack a few bits of precision)
SelfAdjointEigenSolver<Matrix3f> eig;eig.compute(cov);
SelfAdjointEigenSolver<Matrix3f> eig;eig.computeDirect(cov);

100
Linear Regression(Dense Solvers)

Scattered Data Approximation
• Example in the functional settings
input:• sample positions • with associated values
output:• a smooth scalar field s.t.,
pi
f i
f :ℝd →ℝf (pi)≈f i

Basis Functions Decomposition
• Express the solution as:
• Radial Basis Functions
– example:•• ? → evenly distributed
f (x)=∑ jα jϕ j(x )
q j
f (x)=∑ jα jϕ(∥x−q j∥)
ϕ(t )=t3

Matrix formulation
• Least square minimization:
• Matrix form:
– as many unknowns as constraints:→ interpolation
α=argminα
∑i ( f (pi)−f i )2
[ ⋮⋯ ϕ(∥pi−q j∥) ⋯
⋮ ]⋅α=[⋮f i
⋮ ] → α=argminα
∥Aα−b∥2
⇔ Aα=b
→ demo

Dense Solvers
HouseholderQR
PartialPivLU
LDLT
LLT
ColPivHouseholderQR
JacobiSVD
robu
s tness
spee
d
LS
squareproblem
normalequation

105
(bi-)Harmonic interpolation(Sparse Solvers)

106
Laplacian equation
• Many applications– interpolation– smoothing– regularization– deformations– parametrization– etc.
Δ f =0
Δ f =▽⋅▽ f =∂2 f x
∂ x2 +∂2 f y
∂ y2 +⋯
[courtesy of A. Jacobson et al.]

107
Laplacian equation
Δ f =0
[courtesy of A. Jacobson et al.]

108
Discretization
• Example on a 2D grid:
– Matrix form:
Δ f (i , j)=( f (i−1, j)+f (i+1, j)+f (i , j−1)+f (i , j+1))
4−f (i , j) = 0
Δ ⇔ [0 1 01 −4 10 1 0 ] f (i , j)
Lf=0

109
Discretization
• On a 3D mesh:
Δ f (vi)= ∑v j∈N 1(vi)
Li , j(f (v j)−f (vi))
Li , j=cotαij+cotβij
A i+A j
Li ,i=− ∑v j∈N 1(vi)
Li , j
→ demo
[courtesy of M. Botsch and O. Sorkine]

110
Sparse Representation
• Naive way:
• Eigen::SparseMatrix– Matrix:
– Compressed Column-major Storage:
std::map<pair<int,int>, double>

111
Constraints
• Dirichlet boundary conditions– fix a few (or many) values:
– updated problem:
f (vi)=f̄ i , vi∈Γ
[L00 L01
L10 L11]⋅[ f̂f̄ ]= [00 ] ⇒L00⋅̂f=−L01⋅̄f
→ demo

112
Bi-harmonic interpolation
• Continuous formulation:
• Discrete form:
Δ⋅Δ f =0
L⋅L⋅f=0
→ demo

113
Solver Choice
• Questions:– Solve multiple times with the same matrix?• yes → direct methods
– Dimension of the support mesh• 2D → direct methods• 3D → iterative methods
– Can I trade the performance? Good initial solution?• yes → iterative methods
– Hill conditioned?
• Still lost? → sparse benchmark→ demo

What next?

115
Coming soon: 3.2
• Already in 3.2-beta1– SparseLU– SparseQR– GeneralEigenSolver (Ax=lBx)– Ref<>• write generic but non-template function!

116
WIP: AVX
• AVX– SIMD on 256bits register (8 floats, 4 doubles)– … or 128bits (4 floats, 2 doubles)
• Challenge– select the best register-width

117
WIP: CUDA
• Why only now?– CUDA 5 made it possible
• Roadmap– call Eigen from CUDA kernel• useful for small fixed size algebra
– add a CudaMatrix class• coefficient-wise ops
– special assignment evaluator
• products & solvers– wrap optimized CUDA libraries
(ViennaCL, CuBlas, Magma, etc.)

118
WIP: SparseMatrixBlock
• SparseMatrixBlock→ “SparseMatrix<Matrix4f>”
– useful with high-order elements– classic with iterative methods (→ ViennaCL)– would be a first with direct methods!• huge speed-up expected!

119
WIP: Non-Linear Optimization
• Non-linear least square– Generic Levenberg-Marquart• Dense & Sparse
• Quadratic Programming– linear least-square + inequalities

120
WIP: utility modules
• Auto-diff
• Polynomials– differentiation & integration

Concluding remarks

122
License
• Initially:– LGPL3+
→ default choice→ not as liberal as it might look...
• Now:– MPL2 (Mozilla Public License 2.0)• same spirit but with tons of advantages:
– accepted by industries– do work with header only libraries– versatile (apply to anything)– a lot simpler– good reputation

123
Developer Community
• Jan 2008: start of Eigen2– part of KDE• packaged by all Linux distributions
– open repository– open discussions on mailing/IRC• 300 members, 300 messages/month
→ good quality API
• Today– most development @ Inria (Gaël + full-time engineer)
• Future→ consortium... ??

124
User community
• Active project with many users– Website:
~30k uniquevisitors/months
• Major domains– Geometry processing, Robotics,
Computer vision, Graphics
01/01/08 11/01/08 09/01/09 07/01/10 05/01/11 03/01/12 01/01/130
5
10
15
20
25
30
35
40
Visitors/month

125
Summary
• Many unique features:– C++ friendly API– Easy to use, install, distribute, etc.– Versatile• small, large, sparse• custom scalar types• large set of tools
– No compromise on performance• static allocation, temporary removal, unrolling,
auto vectorization, cache-aware algorithms,multi-threading, etc.
– Multi-platforms

126
Acknowledgements
• Main contributors– Benoit Jacob,– Jitse Niesen,– Hauke Heibel,– Désiré Nuentsa,– Christoph Hertzberg,– Thomas Capricelli
+ 100 others
• You're welcome to join!– documentation– bug report/patches– write unit tests– discuss the future on ML– ...
– don't be shy!

127


















