
E. Inferencial OK
155
UNIVERSIDAD NACIONAL UNIVERSIDAD NACIONAL “ “ FEDERICO VILLARREAL” FEDERICO VILLARREAL” Facultad de Ciencias Económicas Facultad de Ciencias Económicas ESTADÍSTICA INFERENCIAL ESTADÍSTICA INFERENCIAL JORGE L. PASTOR PAREDES
-
Upload
jair-alexander-serrato-huancas -
Category
Documents
-
view
217 -
download
0
description
Estadistica inferencial ejercicios
Transcript of E. Inferencial OK

UNIVERSIDAD NACIONALUNIVERSIDAD NACIONAL““FEDERICO VILLARREAL”FEDERICO VILLARREAL”Facultad de Ciencias EconómicasFacultad de Ciencias Económicas
ESTADÍSTICA INFERENCIALESTADÍSTICA INFERENCIAL
JORGE L. PASTOR PAREDES

DEFINICIÓN DE ESTADÍSTICA
Es la ciencia de recolectar, organizar, presentar, analizar e interpretar datos con el propósito de ayudar a una toma de decisión más efectiva.
Las técnicas estadísticas se usan ampliamente por personas en áreas de comercialización, contabilidad, control de calidad, consumidores, deportes, administración de hospitales, educación, política, medicina, etc.
®Jorge L. Pastor Paredes
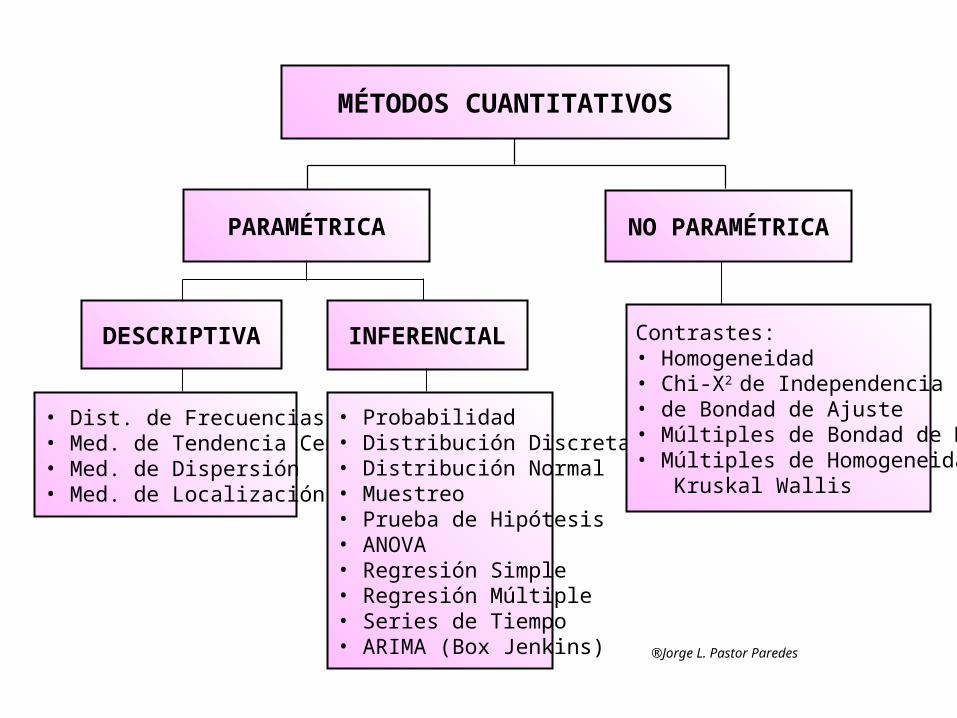
MÉTODOS CUANTITATIVOS
PARAMÉTRICA NO PARAMÉTRICA
DESCRIPTIVA INFERENCIAL
• Dist. de Frecuencias• Med. de Tendencia Central• Med. de Dispersión• Med. de Localización
• Probabilidad • Distribución Discreta• Distribución Normal• Muestreo• Prueba de Hipótesis• ANOVA• Regresión Simple• Regresión Múltiple• Series de Tiempo• ARIMA (Box Jenkins)
Contrastes: • Homogeneidad• Chi-X2 de Independencia• de Bondad de Ajuste• Múltiples de Bondad de Medias• Múltiples de Homogeneidad : Kruskal Wallis
®Jorge L. Pastor Paredes

TIPOS DE ESTADÍSTICAS
I. ESTADÍSTICA PARAMÉTRICA
Se basa en parámetros poblacionales en la que se trabaja con información obtenida con una escala de medida intervalar o de razón.
1. Estadística Descriptiva: métodos para organizar, resumir y presentar datos de manera informativa.
Ejemplo 1: Un sondeo de opinión encontró que 49% de las personas en una encuesta no sabían el nombre del primer libro de Vargas Llosa.La estadística “49” describe el número de cada 100 personas que no saben la respuesta.Ejemplo 2: Según el Consumer Reports, los dueños de lavadoras de ropa Whirlpool reportaron 9 problemas por cada 100 máquinas durante el 2012. La estadística “9” describe el número de problemas por cada 100 máquinas.
1-4
®Jorge L. Pastor Paredes

2. Estadística Inferencial: es el proceso por el cual se deducen (infieren) propiedades o características de una población a partir de una muestra significativa (estimación de parámetros estadísticos).Una población es un conjunto de todos los posibles individuos, objetos o medidas de interés.Una muestra es una porción, o parte, de la población de interés.Ejemplo 1: Las cadenas de TV monitorean la popularidad de sus programas contratando a CPI y otras organizaciones para muestrear las preferencias de televidentes.Ejemplo 2: El departamento de contabilidad de una empresa elegirá una muestra de facturas para verificar la exactitud de todas las facturas de la compañía.
1-5
®Jorge L. Pastor Paredes UBA,

II. ESTADÍSTICA NO PARAMÉTRICA
Estadística cuya información no está basada en “parámetros poblacionales” y cuya información obtenida no está referida a una escala de medida de intervalo o razón.
Se basa en propiedades nominales u ordinales, como por ejemplo, distribución libre.
Se efectúan pruebas para muestras independientes (H de Kruskal Wallis y Mediana, Chi X2) y pruebas para dos muestras relacionadas (Signos).
®Jorge L. Pastor Paredes

TIPOS DE VARIABLES
1. Variable Cualitativa o Categórica: expresa una cualidad o categoría de un determinado suceso; no es numérica. Su medición es nominal u ordinal. Son mutuamente excluyentes. Atributos o porcentajes.
Ejemplos: sexo, afiliación religiosa, tipo de automóvil que se posee, lugar de nacimiento, color de los ojos, V o F, Si o No.
2. Variable Cuantitativa: expresan cantidades numéricas de datos; la variable se puede registrar numéricamente.
Ejemplo: saldo en una cuenta de cheques, minutos que faltan para que termine la clase, número de niños en una familia.
1-7
®Jorge L. Pastor Paredes

TIPOS DE VARIABLES CUANTITATIVAS
1. Variables Discretas: representan valores numéricos. Provienen de un proceso de conteo. Son números enteros. Tienen una medición intervalar o de razón.Ejemplo: El número de alumnos en la EPG
Cantidad de autos en el estacionamiento.
2. Variables Continuas: provienen de un proceso de medición, pueden tomar cualquier valor dentro de un intervalo específico.
Ejemplo: Peso, talla, tiempo.
1-9
®Jorge L. Pastor Paredes

NIVELES DE MEDICIÓN
1. NOMINALReferidos a etiquetas o nombres que se usan para identificar un atributo del elemento. Solamente se pueden clasificar o contar datos. No existe algún orden específico entre las clases.
Empresa Beneficios
Volcan SA 1’250,000
Alicorp 1’100,000
Telefónica 800,000
Bco. Crédito 650,000
Saga 400,000
TOTAL 4’200,000
2. ORDINAL. Es cuando los datos se organizan de acuerdo a un orden. Ordena los datos por jerarquías.
Calificación Frecuencia
Excelente 6
Bueno 28
Regular 25
Malo 12
Muy malo 3
Total 74®Jorge L. Pastor Paredes

3. ESCALA DE INTERVALO o INTERVALAR Si los datos tienen la propiedad de datos ordinales y el intervalo entre observaciones se expresa en términos de una unidad fija de medida. La diferencia de valores tiene un tamaño constante.Es importante señalar que el cero (0) es un punto en la escala, no representa la ausencia de la condición.
Ejemplo: 0 grados no significa que no existe temperatura, indica que hace frío.
4. ESCALA DE RAZÓN: Si los datos tienen las propiedades de intervalo y el cociente de valores es significativa. En la práctica todos los datos cuantitativos son de nivel de razón de la medición. Es preciso mencionar que el cero (0) si tiene significado.
Ejemplo: Distancia, altura, peso y tiempo emplean la escala de medición la Razón.
®Jorge L. Pastor Paredes

1. Dato Estadístico: Son las observaciones efectuadas en un momento determinado, están asociados al estudio de una o mas variables. Son los valores que componen las variables. Ejemplo: ventas diarias de menestras efectuadas por un Supermercado.
2. Datos Transversales
Son aquellos en el cual se reúne en el mismo o aproximadamente en el mismo punto del tiempo. Ejemplo: extraer una muestra de 1.000 empresas de un sector económico al azar de esa población, identificar su volumen de ventas y calcular el porcentaje de la muestra que la clasifica como PYME. Por ejemplo, el 30% de nuestra muestra fueron clasificados como PYMEs.
3. Datos de Serie de TiempoSe recopilan a lo largo de varios periodos de tiempo. Son también longitudinales. Sigue los cambios en el transcurso del tiempo.
BASE DE DATOS
®Jorge L. Pastor Paredes

FUENTES DE DATOS ESTADÍSTICOS
Son los datos validados y procesados que se utiliza para realizar los análisis correspondientes.
La información estadística se presenta en cuadros estadísticos y en gráficos.
La información estadística se usa para la toma de decisiones. Para obtener la información estadística existen diferentes técnicas
que permiten extraer muestras representativas de una serie de sucesos.
Técnica censal, encuestas, experimentos Se pueden encontrar estadísticas relacionadas en artículos
publicados, revistas y periódicos. No todos los temas disponen de datos publicados. En esos casos, la
información deberá recolectarse y analizarse.®Jorge L. Pastor Paredes

GRÁFICAS PARA LA INFORMACIÓN ESTADÍSTICA
Las tres formas de gráficas más usadas son:
Histogramas Polígonos de Frecuencia Distribuciones de Frecuencias Acumuladas (ojivas).
2-12
®Jorge L. Pastor Paredes

Histogramas: Gráfica donde las clases se marcan en el eje horizontal y las
frecuencias de clase en el eje vertical. Las frecuencias de clase se representan por las alturas de las barras y
éstas se trazan adyacentes entre sí.
Polígonos de Frecuencia: Consiste en segmentos de línea que conectan los puntos formados
por el punto medio de la clase y la frecuencia de clase.
Distribución de Frecuencia Acumulada: (ojivas) Se usa para determinar cuántos o qué proporción de los valores de
los datos es menor o mayor que cierto valor.
2-13
®Jorge L. Pastor Paredes

Histograma para las horas de estudio
0
2
4
6
8
10
12
14
10 15 20 25 30 35
Horas de estudio
Fre
cuen
cia
2-14
®Jorge L. Pastor Paredes

Histograma: Frecuencias y Marcas de Clase

Polígono de frecuencias para las horas de estudio
2-15
0
2
4
6
8
10
12
14
10 15 20 25 30 35
Horas de estudio
Fre
cuen
cia
®Jorge L. Pastor Paredes

Distribución de frecuencias acumuladaspara las horas de estudio
0
5
10
15
20
25
30
35
10 15 20 25 30
Horas de estudio
Fre
cuen
cia
2-16
®Jorge L. Pastor Paredes

Gráfica de Barras para los datos de desempleados
7300
5400
6700
89008200
8900
0
2000
4000
6000
8000
10000
1 2 3 4 5 6
Ciudades
# d
esem
ple
ado
s/10
0 00
0
AtlantaBostonChicagoLos AngelesNew YorkWashington
2-19
®Jorge L. Pastor Paredes

Gráfica Circular para tipos de zapatos
Nike
Adidas
ReebokAsics
Otros
Nike
Adidas
ReebokAsics
Otros
2-22
®Jorge L. Pastor Paredes

ESTADÍSTICA INFERENCIAL
Población
Muestra
Tamaño = N
Media = DS =
Tamaño = n
Media =
DS = s
X

Distribución de Probabilidad Conjunto de todos los posibles resultados de un experimento
asociado a la probabilidad de ocurrencia de cada uno de ellos.
Para tres tiradas de una moneda, la distribución de probabilidad que no salga cara es cero, que salga una, dos y tres caras.
Número de caras Probabilidad de los resultados
0 1/8 = 0.125
1 3/8 = 0.375
2 3/8 = 0.375
3 1/8 = 0.125
Total 8/8 = 1
0 1 2 3 Número de Caras
Px
3/8
2/8
1/8
0
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Variables Aleatorias Conjunto de variables cuyos valores dependen del azar, los cuales
pueden tomar diferentes valores, siendo posible establecer una medida de su probabilidad.
Ejemplo: considere un experimento aleatorio en el que se lanza tres veces una moneda. Sea X el número de caras. Sea C el resultado de obtener una cara y S el de obtener un sello.
El espacio muestral para este experimento será:
Entonces, los valores posibles de X (número de caras) son x = 0, 1, 2, 3.
6-3
SSC SCCSSS CSC SCS CCC CSS CCS
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Explicación: El resultado “cero caras” ocurrió una vez. El resultado “una cara” ocurrió tres veces. El resultado “dos caras” ocurrió tres veces. El resultado “tres caras” ocurrió una vez. De la definición de variable aleatoria, la X definida en este
experimento, es una variable aleatoria.
Característica de una Distribución de Probabilidad: La probabilidad de un resultado siempre debe estar entre 0 y
1. La suma de todos los resultados mutuamente excluyentes
siempre es 1.
6-5
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Variable Aleatoria Discreta
Es una variable que solo puede tomar ciertos valores claramente separados, que son el resultado de la cuenta de alguna característica de interés.
Toma únicamente un número finito o numerable de valores.
Ejemplo: sea X el número de caras obtenidas al lanzar 3 veces una moneda. Aquí los valores de X son x = 0, 1, 2, 3.Ejemplo: Si hay 40 alumnos en el aula, la cantidad de ausentes en una clase del Martes puede ser: 0, 1, 2, 3......40.
6-8
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Variable Aleatoria Continua
Es una variable que puede tomar un número infinito de valores.
Puede tomar uno de una cantidad infinitamente grande de valores, dentro de ciertas limitaciones.
Ejemplos: La altura de un jugador de básquetbol
El tiempo que dura una siesta La presión de un neumático
6-9
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Media de una Distribución Discreta
Indica la ubicación central de los datos: es el promedio.
También se conoce como el valor esperado, E(x) de una distribución de probabilidad, es un promedio ponderado.
La media se calcula con la fórmula:
donde representa la media y P(x) es la probabilidad de los diferentes resultados x.
6-10
)](*[=)(=μ xPxxE
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Varianza y Desviación Estándar
La varianza mide la cantidad de dispersión (variación) de una distribución.
La varianza de una distribución discreta se denota por la letra griega (sigma cuadrada).
La desviación estándar se obtiene sacando la raíz cuadrada de sigma.
La varianza de una distribución de probabilidad discreta se calcula a partir de la fórmula:
2
2
6-12
)]()[( 22 xPx
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Ejemplo:La siguiente distribución de
probabilidad corresponde a los autos vendidos con sus
respectivas probabilidades, encontrar la media y la varianza
de la distribución
No. AutosVendidos Prob. X P(x)
0 0.10
1 0.20
2 0.30
3 0.30
4 0.10
X P(x) XP(x) X-μ (X-μ)2 (X-μ)2 P(x) 0 0.10 0 -2.1 4.41 0.441 1 0.20 0.20 -1.1 1.21 0.242 2 0.30 0.60 -0.1 0.01 0.003 3 0.30 0.90 0.9 0.81 0.243 4 0.10 0.40 1.9 3.61 0.361
μ = 2.10 2 = 1.290

6-14
DistribuciónDiscreta
DistribuciónContinua
• Binomial• Hipergeométrica• Poisson
• Normal• Exponencial• Uniforme
®Jorge L. Pastor Paredes UBA, UNFV, UNSA
Distribuciones de Probabilidad

Distribución de Probabilidad Binomial
Es una distribución de probabilidad discreta en el que solo existe dos resultados posibles en la ejecución de un experimento.
La distribución binomial tiene las siguientes características:
1. El resultado de un experimento es mutuamente excluyente: éxito (x) o fracaso (1-x) (Bernoulli).
2. Los éxitos o fracasos son resultados de una cantidad fija de ensayos “con reemplazo”.
3. La probabilidad de éxito o fracaso es la misma para cada ensayo.
4. Los ensayos son independientes.
6-18
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Media, Varianza y Desviación Estándar
La fórmula para la distribución de probabilidad binomial es:
P xn
x n xx n x( )
!
!( )!( )
1
6-20
La media está dada por:
La varianza está dada por: Desviación estándar:
n
2 1 n ( )
®Jorge L. Pastor Paredes UBA, UNFV, UNSA
)1( n
• n el número de ensayos• x el número de éxitos observados• Л la probabilidad de éxito en cada ensayo (no es pi=3.1416)

6-21
Ejemplo:
La respuesta a una pregunta de verdadero/falso es correcta o incorrecta. Considere que 1) un examen consiste en cuatro preguntas de verdadero/falso, y 2) un estudiante no sabe nada a cerca de la materia. La probabilidad de que el alumno adivine la respuesta correcta a la primera pregunta es 0.50, Asimismo, la probabilidad de acertar en cada una de las preguntas restantes vale 0.50.
Cuál es la probabilidad de:
a) No obtener exactamente ninguna de las cuatro en forma correcta.
b) Obtener exactamente una de las cuatro.
c) Encontrar la media y la varianza.
0625.0)50.01(50.0)!04(!0
!4)0() 040
Pa
2500.0)50.01(50.0)!14(!1
!4)1() 141
Pb
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

6-22
Recuerde que = 0.50 y n = 4
Media =
Varianza = 2 = n (1 - ) = (4)(0.50)(1-0.50) =1
Desv. Estándar =
c) La media, varianza y la desviación estándar es:
®Jorge L. Pastor Paredes UBA, UNFV, UNSA
24(0.50)nπμ
11σσ 2

Distribución Hipergeométrica
Es aplicable a muestreo “sin reemplazo” de una población finita, (muestra de una población pequeña) en el cuál se da una serie de experimentos tal que el resultado de cualquiera de ellos a partir del segundo es afectado por el resultado de los anteriores.
Características:
a) Existen solo dos resultados posibles.
b) La probabilidad de un éxito no es la misma en cada ensayo.
c) La distribución resulta de un conteo del número de éxitos en una cantidad fija de ensayos.
6-27
nN
xnSNxS
C
)C)(C(P(x)
®Jorge L. Pastor Paredes UBA, UNFV, UNSA
Donde:• N es el tamaño de la población,• S es la cantidad de éxitos en la población, • x es el número de éxitos de interés, • n es el número de ensayos o muestra, y• C es una combinación.

6-28
Ejemplo:Durante la semana se fabricaron 50 juegos de PayStation (N=50). Operaron 40 sin problemas (S=40) y 10 tuvieron al menos un defecto. Se selecciona una muestra al azar de 5 (n=5). ¿Cuál es la probabilidad de que 4 (x=4) de las 5 funcionen perfectamente? Observe que el muestreo se hace sin reposición y que el tamaño de la muestra de 5 es 10% de la población (esto es mayor que la condición de 5%).
Solución:
La probabilidad de seleccionar 5 juegos al azar de 50, y descubrir que 4 de los 5 operan bien, es 0.431 o 43.1%
0.4312'118,760
0)(91,390)(1
45!5!50!
)9!1!
10!)(
36!4!40!
(P(4)
550
454050440
C
)C)(C(P(4)
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Distribución de Poisson Es aplicable a casos en los cuales se desea obtener la probabilidad de
un evento sobre algún intervalo (tiempo o espacio).
Es la forma límite de la distribución Binomial donde la probabilidad de éxito es muy pequeña y n es grande.
Ejemplo: Número de turistas que visitan el Cuzco en un mes; número de asaltos ocurridos en Lima en un año; número de computadoras que presentan fallas, etc.
6-30
( )!
x ueP x
x
®Jorge L. Pastor Paredes UBA, UNFV, UNSA
Donde: es la media aritmética del número de
ocurrencias (éxitos) en un intervalo específico de tiempo.
• e es la constante 2.71828 • x es el número de ocurrencias (éxitos).

Ejemplo:Una muestra aleatoria de 1000 viajes aéreos revela un total de 300 maletas perdidas. La media aritmética del número de maletas perdidas por vuelo es 0.3 (300/1000). Si la cantidad de maletas perdidas por viaje aéreo sigue una distribución de Poisson con μ = 0.30 Calcular la probabilidad de no perder ninguna maleta y la probabilidad de perder una maleta.
!)(
x
exP
ux
7408.0!0
3.0)0(
30.00
e
P
2222.0!1
3.0)1(
30.01
e
P
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

7-3
Distribución de Distribución de Probabilidad NormalProbabilidad Normal

Distribución de Probalidad Normal
La curva de la DPN tiene “forma de campana” con un solo pico justo en el centro de la distribución.
La media, mediana y moda (Me, Md y Mo) de la distribución son iguales y se localizan en el pico.
La mitad del área bajo la curva está a la derecha del pico, y la otra mitad está a la izquierda.
La distribución normal es simétrica respecto a su media.
La distribución normal es “asintótica” la curva se acerca cada vez más al eje x pero en realidad nunca llega a tocarlo.
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Me=Md=Mo
La curva normal essimétrica
En teoría, la curva se extiende hasta el
infinito.
Gráfico de una Distribución Normal
Cola + ∞Cola -∞
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

hi
Yi
hi
Yi
hi
Y
= 1.6 = 1.6 = 1.6
μ=283 μ=310 μ=321
μ=283 μ=310 μ=321
=41
=52 =26
Familia de Curvas de Distribución Normal
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Distribución Normal Estándar
Es aquella distribución normal que tiene media igual a 0 y desviación estándar igual a 1.
Valor Normal Z: es la distancia entre un valor seleccionado, designado como X, y la población media , dividida entre la desviación estándar de la población .
σ
μXz
7-6
-z 0 1.91 +z
0.4719
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

7-7
Ejemplo:
La media de un grupo de ingresos semanales con distribución normal para un gran conjunto de gerentes de nivel medio, es $1000 ¿cuál es el desvío normal o valor z para un ingreso x de 1100? ¿para uno de 900? DS=100
Solución:
para x = 1100 para x = 900
El desvío Z=1.00 indica que un ingreso semanal de $1100 para un gerente de nivel medio está una desviación estándar por en cima de la media; asimismo Z=-1 indica que un ingreso de $900 se encuentra una desviación estándar por debajo de la media.
El 34.13% de los ingresos semanales están entre 1100 y 1000 o existe una probabilidad de 34.13% que el ingresos específico se halle entre 1100 y 1000.
0 1 1000 1100
0.3413
1100 10001.00
100Z
900 10001.00
100Z

7-8
Áreas bajo la Curva Normal
1 2 3 1 2 3
68.26%
95.44%
99.74%
• Cerca de 68% del área bajo la curva normal está a menos de una desviación estándar respecto a la media.
• Alrededor de 95% está a menos de dos desviaciones estándar de la media.
• 99.74% está a menos de tres desviaciones estándar de la media.
1
2
3
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

1 2 3 1 2 3
-3 -2 -1 0 1 2 3 z
x
Transformación de las Mediciones a Valores Z
El área total bajo la curva normal es igual a 1.El área bajo la curva normal dentro de +/- una
DS respecto a la media es 0.6826
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

7-11
Situaciones en las que se quiere encontrar el área bajo la curva normal estándar:
1. Si se desea hallar el área entre 0 y z (o -z), puede buscarse el valor directamente en la tabla.
2. Si se quiere obtener el área más allá de z (o -z), localice la probabilidad de z en la tabla y reste ese valor de 0.50.
3. Para el área entre dos puntos en diferentes lados de la media, determine el valor z y sume las áreas correspondientes.
4. Para el área entre dos puntos en el mismo lado de la media, determine el valor z y reste al área menor de la mayor.
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Muestreo ProbabilísticoMuestreo Probabilístico

Muestreo Probabilístico Método Probabilístico:
Es una muestra seleccionada de manera que cada integrante de la población que se estudia tenga una probabilidad conocida (no igual a cero) de ser incluida en la muestra.
Característica: el azar determina los integrantes de la muestra. Método No Probabilístico:
Muestra en que no todos los integrantes de la población tienen probabilidad de ser incluidos en la muestra.
Los resultados pueden ser sesgados y no representativos de la población.
Ejemplo, muestreo por panel o por acción directa: la selección de los miembros del panel se basa en el juicio del investigacdor, y por lo tanto los resultados de la muestra pueden no ser representativos de toda la población.
8-4
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Métodos de Muestreo Aleatorio
Muestra Aleatoria Simple: Procedimiento de selección por el cuál todos y cada uno de los elementos de la población tienen la misma probabilidad de ser incluidos en la muestra.
Se utiliza la Tabla de números aleatorios Muestra Aleatoria Sistemática:
Los artículos o individuos de la población se colocan en cierto orden. Se elige un punto de partida aleatorio y después se selecciona uno cada k-ésimo elemento de la población para la muestra.
8-5
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Muestreo Aleatorio Estratificado:Se divide la población en subgrupos, llamados estratos, y se selecciona una muestra de cada estrato.
Este muestreo garantiza la representatividad de cada subgrupo.
Muestreo por Conglomeración:Primero se divide la población en subgrupos (estratos), y se selecciona un estrato.
La muestra se toma del estrato seleccionado. El error de muestreo:
Es la diferencia entre un estadístico muestral y su parámetro poblacional.
8-6
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Muestreo Aleatorio Simple. Caso Práctico:
Con reemplazo significa que se selecciona una calificación de la población y luego ésta se regresa a la misma antes de tomar la siguiente; por tanto cada calificación puede ser seleccionada más de una vez en la misma muestra.
Sin reemplazo significa que una vez seleccionada la calificación, ésta ya no se regresa a la población, y por tanto, cada calificación puede aparecer solo una vez.
Una población de 3 calificaciones: 12, 14 y 16. Se toma una muestra de tamaño n=2 con o sin reemplazo.
Con reemplazo: el número de muestras a tomar es Nn = 32 = 9 Las muestras son:
12,12 12,14 12,16
14,12 14,14 14,16
16,12 16,14 16,16
Cada una de estas muestras tiene 1/9 de probabilidad de ser escogida.

Sin reemplazo, se tiene siempre una muestra de tamaño n = 2; el número de muestras por tomar es el resultado del desarrollo combinatorio:
N N!=
n n!(N-n)!
NnC
3 3! 3 2!3
2 2!(3 2)! 2!1!
x
Las muestras son: 2,4; 2,6; 4,6 Cada de estas muestras tienen 1/3 de probabilidad de ser escogida

Distribución de Muestreo Una distribución muestral es la distribución de los valores
individuales incluidos en una muestra. Se refiere a la distribución de los diferentes valores que un
estadístico muestral o estimador, podría adoptar en muchas muestras del mismo tamaño
Como se trabaja con muestra aleatoria o subgrupos reconoce que el estadístico muestral (media o mediana) no es exactamente igual al respectivo parámetro de la población
El valor de un estadístico muestral variará de una muestra a otra, a causa de la variabilidad del muestreo aleatorio o “error aleatorio”.
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Media 1
N
jj
X
N
x = suma de todos los valoresde la población.
N = tamaño de la población.
Varianza
2
12
( )
N
j
x
N
DesviaciónEstándar
2
1 2
( )
N
j
x
N
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Distribución Muestral de Medias
Es una distribución probabilística que consta de todas las medias muestrales posibles, con o sin reemplazo, de una población y la probabilidad de ocurrencia asociada a cada media muestral.
Muestreo con Reemplazo:
Sean las siguientes calificaciones de 5 estudiantes: 14, 15, 16, 17, 18
Calcular:1. La media y la varianza de la población.2. Las medias de todas la muestra de tamaño 2.3. Transformar la serie de medias en una distribución muestral de medias.4. La media de las medias muestrales.5. El error estándar de la media (DS de la distrib. muestral de medias).6. Las probabilidades de las medias muestrales.
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

8-8
Calificaciones X X – μ (X-μ)2
14 -2 415 -1 116 0 017 1 118 2 4
= 80 0 10
165
80
25
102
4142.1
1. Media, varianza y desviación estándar de la población:
2. Medias de todas la muestras de tamaño 2, con reemplazo:
14,14 14.0 14,15 14.5 14,16 15.0 14,17 15.5 14,18 16.015,14 14.5 15,15 15.0 15,16 15.5 15,17 16.0 15,18 16.516,14 15.0 16,15 15.5 16,16 16.0 16,17 16.5 16,18 17.017,14 15.5 17,15 16.0 17,16 16.5 17,17 17.0 17,18 17.518,14 16.0 18,15 16.5 18,16 17.0 18,17 17.5 18,18 18.0
Muestra Muestra Muestra Muestra Muestra
El número de muestras de tamaño 2 que se puede obtener de una población de 5 observaciones es: Nn = 52 = 25
X X X X X

8-9
3. Transformar la serie de medias en una distribución muestral de medias: Se introduce el concepto de “frecuencia” (fi), se refiere al número de veces que ocurre un valor determinado, en término de frecuencias la media y la varianza se pueden expresar:
fX
f
2
2 ( )
f X
f
400( ) 16
25
fXE X
f
4. La serie de medias la transformamos en una distribución muestral de medias de la siguiente manera:
2( ) 251
25X
f X
f
igual a la media de la población
®Jorge L. Pastor Paredes UBA, UNFV, UNSA
5. 2 1X

8-10
14.0 1 14 -2.0 4.00 4.0 1/2514.5 2 29 -1.5 2.25 4.5 2/2515.0 3 45 -1.0 1.00 3.0 3/2515.5 4 62 -0.5 0.25 1.0 4/2516.0 5 80 0.0 0.00 0.0 5/2516.5 4 66 0.5 0.25 1.0 4/2517.0 3 51 1.0 1.00 3.0 3/2517.5 2 35 1.5 2.25 4.5 2/2518.0 1 18 2.0 4.00 4.0 1/25 25 400 0 25.0 25/25
f Prob.
Se ha obtenido relacionando este valor con el de 2 se deduce que: x2 = 1
2 22 22 2
;2 2X X Xn n n
Distribución Muestral de Medias, n=2
Error Muestral dela distribución de Probabilidad.
®Jorge L. Pastor Paredes UBA, UNFV, UNSA
f XX (X- ) 2(X- ) 2f(X- )

8-11
La relación anterior indica que la desviación estándar de la distribución muestral de medias, es directamente proporcional a la desviación estándar poblacional e inversamente proporcional a la raíz cuadrada del tamaño de la muestra.
Esta fórmula es de gran utilidad para la inferencia estadística la cual concuerda con el “error estándar” de la distribución muestral de medias encontrada en el caso anterior:
Las probabilidades de 25 medias muestrales se presentan en la última columna de la tabla anterior. Cuando las 25 muestras se seleccionan al azar, cada muestra tendrá la probabilidad de 1/25 de ser seleccionada. Puesto que hay cuatro muestras con 15.5, por ejemplo, y el total de medias es 25, la probabilidad de que una muestra seleccionada tenga media de 15.5 será 4/25.
1.41421
2X n
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Muestreo Sin Reemplazo:Con las mismas calificaciones de los 5 estudiantes, responder las
mismas preguntas.
1. La media poblacional μ=16, la varianza 2=2 y la desviación estándar = 1.4142
2. El número de muestras de tamaño 2 sin reemplazo, resulta del desarrollo combinatorio:
!!!
nNnNN
n
N
nC
10
!25!2
!55
2
C
N
n
14,15 14.5 15,17 16.014,16 15.0 15,18 16.514,17 15.5 16,17 16.514,18 16.0 16,18 17.015,16 15.5 17,18 17.5
Muestra Muestra
Tabla de muestras de tamaño 2y sus respectivas medias.
®Jorge L. Pastor Paredes UBA, UNFV, UNSA
X X

14.5 1 14.5 -1.5 2.25 2.25 1/1015.0 1 15.0 -1.0 1.00 1.00 1/1015.5 2 31.0 -0.5 0.25 0.50 2/1016.0 2 32.0 0.0 0.00 0.00 2/1016.5 2 33.0 0.5 0.25 0.50 2/1017.0 1 17.0 1.0 1.00 1.00 1/1017.5 1 17.5 1.5 2.25 2.25 1/10 10 160 0 7.50 10/10
3. Distribución Muestral de Medias, n=2
16016
10
fX
f
2( ) 7.50.866
10
f X
X f
4.
5.
®Jorge L. Pastor Paredes UBA, UNFV, UNSA
f Prob.f XX (X- ) 2(X- ) 2f(X- )

El mustreo sin reemplazo genera poblaciones finitas, de tal manera que para calcular la desviación estándar de la distribución muestral de medias, es decir el “error estándar” de las medias, en muestreo sin reemplazo, se tiene que introducir el factor de corrección finita:
La fórmula del error estándar quedará:1
N
nN
1
X
N nx
Nn
1.4141 5 20.866
1.4141 5 1
X x
6. Las probabilidades de las 10 medias muestrales figuran en la tabla anterior. Cuando las 10 muestras se seleccionan al azar, cada muestra tendrá la probabilidad de 1/10 de ser seleccionada. Puesto que hay dos muestras con medias 15.5, 16.0 y 16.5 la probabilidad de ser seleccionada cada una de ellas es 2/10, la probabilidad del resto de las medias 1/10 para cada una.
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Teorema del Límite Central
Para muestras grandes, se puede obtener una aproximación cercana de la distribución muestral de la media con una distribución normal.
Para muestras aleatorias de poblaciones finitas, si es la media de una muestra aleatoria de tamaño n de una población finita con la media μ y la desviación estándar y n es grande, entonces:
yX X n
8-12
Xz
n
Es el valor Z de una variable aleatoria que tiene aproximadamente la distribución normal estándar, cuando se conoce su DS poblacional.
®Jorge L. Pastor Paredes UBA, UNFV, UNSA
X
ERROR ESTÁNDAR DE LA MEDIA
X error muestral
Xz
sn
Es el valor Z de una variable aleatoria que tiene aproximadamente la distribución normal estándar, cuando se conoce su DS muestral.
n 30

Ejemplo:¿Cuál es la probabilidad de que el error sea menor que 5, cuando se usa una muestra aleatoria de tamaño n= 64 para estimar la media de una población infinita con =20? Solución:
2
6420
5
z
2
6420
5z
μ -5 μ +5z=-2 z=2
0.4772 0.4772
0.4772 + 0.4772= 0.9544
La probabilidad es aproximadamente 0.95 (95%) de que la media de una muestra aleatoria de tamaño n=64 de la población de referencia difiera de la población por menos de 5.

Estimación e Intervalos de Confianza
Una estimación es un valor específico observado de una estadística. Se hace una estimación cuando se toma una muestra y se calcula el valor que toma el “estimador” de esa muestra.
El estimador es una estadística de muestra utilizada para estimar un parámetro de la población.
Por ejemplo, la media de la muestra puede ser estimado de la media de la población , y la porción de la muestra (p) se puede utilizar como estimador de la porción de la población ().
Tipos de Estimación:
1. Estimación puntual
2. Estimación por intervalos
3. Estimador Insesgado o Sesgado
X

La Estimación Puntual: es solo un estadístico que se utiliza para estimar un parámetro de una población desconocida. Solo tiene dos opciones: correcta o incorrecta.
La Estimación de Intervalo: es un intervalo de valores que se utiliza para estimar un parámetro de la población. Esta estimación indica el error de dos maneras: por la extensión del intervalo o por la probabilidad de obtener el verdadero parámetro de la población que se encuentra dentro del intervalo.
El Estimador Insesgado: es un estadístico muestral cuyo valor esperado es igual al parámetro por estimar. El “valor esperado” es el promedio a largo plazo del estadístico muestral.
La eliminación de todo “sesgo” está asegurada cuando el estadístico muestral corresponde a una muestra aleatoria tomada de una población.

PARÁMETRO DE LA POBLACIÓN ESTIMADOR
Madia:
Diferencias de medias de dos poblaciones: 1 - 2
Proporción:
Diferencias de proporciones de dos poblaciones: 1 - 2
Varianza: 2
Desviación Estándar:
p
p1-p2
s2
s
X
1 2X -X

Estimadores Puntuales
Error Estándar de la Media:Cuando se conoce la desviación
estándar de la población:X n
X
ss
n
Error Estándar de la Media:Con base en la desviación estándar
de la muestra, por que en la mayoría de los casos se desconoce la
desviación estándar de la población:
Intervalo de Confianza para una Media Poblacional (n30):
sX z
n
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Intervalos de confianza de 95% y 99% para µ
Los intervalos de confianza (IC) de 95% y 99% para cuando n 30 se forman como sigue:1. IC de 95% para la media poblacional está dado por:
2. IC de 99% para la media poblacional está dado por:
Los valores 1.96 y 2.58 son los valores Z correspondientes al 95% y 99%.
1.96s
Xn
2.58s
Xn
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Caso Práctico:
Una empresa multinacional desea conocer el ingreso promedio de sus gerentes de mando medio, con un nivel de confianza del 95%. En una muestra aleatoria de 256 gerentes, la media es $45,420 y la DS es $2,050. Se pregunta:
a)Cuál es la media poblacional?
b)Cuál es un intervalo razonable para la media poblacional?
c)Cómo se interpretan los resultados?
Solución:
a)No se conoce. En este caso la media muestral puede considerarse como “estimador puntual” de la media poblacional.
b)Al 95% de nivel de confianza:
2,05045,4201.96 45,420 251
25645,420 251 45,169
45,420 251 45,671
sX z
n
Nivel de Confianza = 95%Intervalo de Confianza:45,169-45,671

Intervalo de Confianza para una Proporción de la Población
Se obtiene dividiendo el número de éxitos en la muestra, entre el número total muestrado.
Intervalo de Confianzapara una Proporción dela Población:
Error Estándarde la ProporciónMuestral:
Intervalo de Confianzapara una ProporciónMuestral:
pzp
n
ppp
)1(
n
ppzp
)1(
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Factor de Corrección para Población Finita
Error Estándar de la Media Muestral, con un Factor deCorrección:
Error Estándar de la Proporción Muestral, con un Factor deCorrección:
1.
N
nN
nx
1
)1(
N
nN
n
ppp
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

Selección de un Tamaño de Muestra Adecuado
Tamaño de la Muestra parauna Media:
Tamaño de la Muestra parauna Proporción:
2.
E
szn
2
)1(
E
zppn
Donde: n = tamaño de la muestraz = valor normal estándar según el NC deseados = estimador de la DS de la poblaciónE = máximo error permisiblep = proporción muestral
®Jorge L. Pastor Paredes UBA, UNFV, UNSA

La Prueba de HipótesisLa Prueba de Hipótesis

¿Qué es una Hipótesis?
Es un proposición afirmativa acerca de una población elaborada con el fin de ponerse a prueba.
Ejemplos: El crecimiento de la economía permitirá reducir la
morosidad bancaria en 20%. El precio del kg. de limones bajará de 2.00 a 1.50 si las
áreas de cultivo se incrementara en 20%. El mercado de valores en el Perú podrá ser más
profundo si se creara una mayor cantidad de instrumentos de inversión.
La tasa de rentabilidad del mercado de capitales peruano ha originado un mayor ingresos de dólares ocasionando una mayor apreciación del nuevo sol.
9-3
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Métodos para la Prueba de Hipótesis
1. Método del Valor Crítico:Se determinan los valores críticos de los estadísticos de prueba que ameritarían el rechazo o aceptación de una hipótesis, tras lo cual el estadístico calculado se compara con los valores críticos.
2. Método del valor P:Se basa en la determinación de la probabilidad condicional de que el valor observado de un estadístico muestral pueda ocurrir al azar, dado que en un supuesto particular sobre el valor del parámetro poblacional asociado sea correcto.
3. Método del Intervalo de Confianza:Se basa en la observación de si el valor supuesto de un parámetro poblacional está incluido en el rango de valores que define a un intervalo de confianza para ese parámetro.

La Prueba de Hipótesis
Procedimiento basado en la evidencia muestral y en la teoría de proba-bilidad.
Se emplea para deter-minar si la hipótesis es un enunciado razonable y debe aceptarse o si no es razonable y debe ser rechazado.
9-4
N o rech azar lah ip ó tes is n u la
R ech azar la h ip ó tes is n u lay acep ta r la a lte rn a
P aso 5 : tom ar u n a m u es tra , lleg ar a u n a d ec is ió n
P aso 4 : fo rm u la r u n a reg la d e d ec is ió n
P aso 3 : id en tifica r e l va lo r es tad ís tico d e p ru eb a
P aso 2 : se lecc ion ar u n n ive l d e s ig n ifican c ia
P aso 1 : p lan tear las h ip ó tes is n u la y a lte rn a
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Definiciones
1.Hipótesis Nula H0:
Afirmación acerca del valor de un parámetro poblacional.Hipótesis Alterna H1:
Afirmación que se aceptará si los datos muestrales proporcionan evidencia de que la hipótesis nula es falsa.
2.Nivel de Significancia: Probabilidad de rechazar la hipótesis nula cuando es verdadera.Error Tipo I: Rechazar la hipótesis nula cuando en realidad es verdadera.
9-6
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Error Tipo II: Aceptar la hipótesis nula cuando en realidad es falsa.
3. Calcular el valor del Estadístico de Prueba:Valor obtenido a partir de la información muestral, se utiliza para determinar si se rechaza o no la hipótesis.
4. Valor Crítico: El punto que divide la región de aceptación y la región de rechazo de la hipótesis nula.
9-7
zX
/ n
0 1.65 escala de Z
Zona deRechazo
No se rechazaSe acepta
H0
Prob. 0.95 Prob. 0.05
Estadístico deprueba para lamedia poblacional.
Hipótesis Se acepta Se rechaza Nula H0 H0
H0 verdadera Decisión Error correcta Tipo I
H0 falsa Error Decisión Tipo II correcta
Valor Crítico
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Prueba de Significancia de una Cola
Una prueba es de una cola cuando la hipótesis alterna, H1, establece una dirección, como: H0 : el ingreso medio de las mujeres es menor
que o igual al ingreso medio de los hombres. H1 : el ingreso medio de los hombre es mayor
que el ingreso medio de las mujeres.
9-8
-1.65 0 escala de Z
Zona deRechazo
AceptaciónH0
Valor Crítico
®Dr.Jorge L. Pastor Paredes-UBA,Nivel de Significancia 0,05

Prueba de Significancia de Dos Colas
Una prueba es de dos colas cuando no se establece una dirección específica de la hipótesis alterna H1, como: H0 : No hay diferencia entre el ingreso medio de
los hombres y el ingreso medio de las mujeres. H1 : Hay una diferencia entre el ingreso medio
de los hombres y el ingreso medio de las mujeres.
9-10
-1.96 0 1.96 escala de Z
Zona deRechazo
0.025Aceptación H0
Valor Crítico
Zona deRechazo
0.025
Valor Crítico
0.95
Ver TablaApéndice D
0.50 – 0.025 = 0.4750 = 1.96
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Prueba para la Media Poblacional con
Cuando se hace una prueba para la media poblacional de una muestra grande y se conoce la desviación estándar, el estadístico de prueba está dado por:
zX
/ n
9-12
Donde:X = media muestralμ = media poblacional = desviación de la poblaciónn = número en la muestra
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Solución:Paso 1: Se establece la hipótesis nula y alterna: no se
visualiza una dirección, es una hipótesis de dos colas:
Paso 2: Se establece la regla de decisión para un nivel de significancia de 0.01.
200: 200: 10 HH
9-14
Caso:Una empresa fabrica y ensambla escritorios para oficina. La producción semanal de escritorios modelo A325 en la planta del Cuzco, se distribuye normalmente con una media de 200 y una desviación estándar de 16. Recientemente, debido a la expansión del mercado, se han introducido nuevos métodos de producción y se han contratado nuevos empleados. El gerente quiere saber si ha habido un cambio total en la producción semanal del citado mueble, es decir si el número medio de escritorios producidos en la planta del Cuzco es diferente de 200 para un nivel de significancia de 0.01 (n=50 semanas y media de escritorios producidos en el último año es 203.5)
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

55.150/16
2005.203
z
Paso 3: Se calcula el valor del estadístico de prueba:
H0 se rechaza si z < - 2.58 o z > 2.58
Paso 4: Decisión sobre H0: se acepta H0 porque 1.55 es menor que el valor crítico 2.58 por consiguiente se concluye que la media de la población no es diferente de 200.
-2.58 -1.55 0 1.55 2.58 escala de Z
Zona deRechazo
0.01/2=0.005
Aceptación H0
Valor Crítico
Zona deRechazo
0.01/2=0.005
Valor Crítico
Ver TablaApéndice D
0.50
0.4950 0.4950
La evidencia muestral no refleja que la tasa productiva de la planta haya cambiado de 200 por semana. La diferencia de 3.5 unidades se debe al azar.
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Prueba para la Media Poblacional con “s”
Aquí es desconocida, así que se estimará con la desviación estándar de la muestra s.Siempre que el tamaño de muestra sea grande n 30, z puede aproximarse con:
ns/
μXz
9-17
Caso:La cadena de tiendas EL emite su propia “credit card”. El gerente de crédito, quiere determinar si la media mensual de saldos no pagados es mayor que $400. El nivel de significancia es de 0.05. Una revisión al azar de 172 saldos reveló que la media muestral es $407 y la desviación estándar muestral es $38. ¿Debe el gerente concluir que la población media es mayor que $400, o es razonable suponer que la diferencia de $7 ($407-$400) se debe al azar?
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

9-18
Paso 1:Paso 2: H0 se rechaza si z > 1.65
Paso 3:
Paso 4: H0 se rechaza. Debido a que el valor estadístico de prueba 2.42 es mayor que el valor crítico 1.65. El gerente puede concluir que la media de saldos no pagados es mayor que $400.
H H0 1400 400: :
Solución:
42.2172/38
400407
z
0 1.65 2.42 escala de Z
Zona deRechazo
0.05
Valor Crítico
Valor p
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Comparación de dos Medias Muestrales
9-20
Suponga que los parámetros para dos poblaciones son:
Para muestras grandes el estadístico de prueba es:
2121 y , ,
zX X
s
n
s
n
1 2
12
1
22
2
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Caso:Una compañía realizó un estudio para comparar los años promedio de servicio de las personas que se jubilaron en 1979 con los que se jubilaron el año anterior. Con un nivel de significancia de 0.01 ¿Podría concluirse que los trabajadores que se retiraron el año anterior trabajaron más años según la siguiente muestra?
Característica 1979 Año anterior
Media de la muestra 25.6 30.4Desviación estándar
de la muestra2.9 3.6
Tamaño de la muestra 40 45
9-22
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Paso 1: Establecer la Ho y la H1 alternativa
Paso 2: Elegir el nivel de significancia.
Rechace H0 si z > 2.33 (0.50-0.01=0.4900) tabla=2.33
Paso 3:
Paso 4: Como z = 6.80 > 2.33, H0 se rechaza.
Los que se jubilaron el año anterior tenían más años de servicio.
H H0 2 1 2 1: : 1
z
30 4 256
3645
2 940
6802 2
. .
. ..
9-23
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Distribución “ Distribución “ t ”t ” Student Student

Distribución “ t ” de Student Estadístico que valúa la incidencia de cada uno de los coeficientes
de regresión individuales en el modelo, permite estimar la media poblacional a partir de una muestra pequeña: n<30.
Se toman todas las muestras posibles de tamaño n<30 de una determinada población con distribución normal, y se calcula el estadístico de prueba t.
Para construir un polígono de frecuencias con valores calculados y “s” de cada una de estas muestras, es necesario aplicar la prueba t:
Xt
s
n
donde:X = media muestralμ = media poblacionals = desviación estándar muestraln = número de datos
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA
X

Se utiliza para la estimación y prueba de hipótesis. Tiene forma de campana y perfectamente simétrica con respecto a
t=0 pero con una dispersión mayor, la cual aumenta a medida que disminuye el tamaño de la muestra.
No existe solo una distribución t, sino varias distribuciones t. Cada una de ellas está asociada a “grados de libertad” (gl).
-3 -2.58 -2 -1 0 1 2 2.58 3 z
-5.84 0 5.84 t
Distribución normalDistribución t con gl=29Distribución t con gl=3Nivel de confianza 0.99 (t0.005=0.01/2=0.005)
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Los “grados de libertad” (gl), se define como el número de observaciones menos uno: gl=n-1, la forma de la distribución dependerá del tamaño de la muestra.
En la gráfica se han marcado valores críticos de Z y t. Para un nivel de confianza de 0.99 el valor crítico de z es 2.58 y el valor t para 3 gl es 5.84
El valor crítico de t para 3 gl (t0.005) es 5.84. Indica que el 0.5% del área bajo la curva t está a la derecha de +5.84 o a la izquierda -5.84; en consecuencia, el 99% del área bajo t está incluida en el intervalo 5.84; es decir hay una probabilidad de 99% de que la variable t esté en el intervalo [-5.84, 5.84]
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

El valor de 2.76 corresponde al valor crítico de la distribución t para 29 gl, indica que el 0.5% del área bajo la curva está a la derecha de 2.76 o a la izquierda -2.76, indica que el 99% del área bajo la curva t está incluida en el intervalo 2.76, es decir, existe una probabilidad de 99% de que la variable t esté en el intervalo [-2.76, 2.76]
Se observa que el valor de t ha disminuido al crecer el número de gl. Si el tamaño de la muestra hubiese aumentado en forma infinita, el valor de t tomaría el valor de 2.58, que es igual al valor de Z para la curva normal.
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Caso:
La experiencia en la investigación de demandas por accidente en una institución aseguradora revela que en promedio cuesta $60 la realización de todos los trámites. Este costo se consideró exorbitante comparado con el de otras compañías aseguradoras y se instauraron medidas para reducir los costos. A fin de evaluar el impacto de estas nuevas medidas se seleccionó aleatoriamente una muestra de 26 demandas recientes y se realizó un estudio de costos. Se encontró que la media muestral X y la desviacion estándar s, de la muestra fueron $57 y $10, respectivamente. En el nivel 0.01 de significacion, ¿hay una reducción en el costo promedio, o la diferencia de $3(57-60) puede atribuirse al azar?
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Solución:Paso1: Plantear la hipótesis nula y la hipótesis alternativa. La hipótesis nula, H0, es que la media poblacional vale $60. Esto se expresa como sigue:
H0: µ = $60
H1: µ < $60
Paso 2: Selección del nivel de significación: Se usará el nivel 0.01Paso 3: Identificar el estadístico de prueba. Tal estadístico es la distribución t estudent, ya que 1) no se conoce la desviación estándar de la población, y 2) el tamaño de muestra es pequeño (n<30). Paso 4: Los valores críticos de t se encuentran en la tabla. La columna del extremo izquierdo de la tabla se titula “grados de libertad, gl”. Para esta prueba hay (n-1) grados de libertad. Se recorre hacia abajo esa columna hasta 25( n-1, o sea 26-1=25). El valor critico para gl=25, una prueba de una cola, y el nivel 0.01 es 2.485
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Parte de la distribución tValores críticos de t
Grados de libertad g.l
Nivel de significación para una prueba de cola
0.10 0.5 0.025 0.01 0.005 0.0005
Nivel de significación para una prueba de dos colas
0.20 0.10 0.05 0.02 0.01 0.001
21 1.323 1.721 2.080 2.518 2.831 3.819
22 1.321 1.717 2.074 2.508 2.819 3.792
23 1.319 1.714 2.069 2.500 2.807 3.767
24 1.318 1.711 2.064 2.492 2.797 3.745
25 1.316 1.708 2.060 2.485 2.787 3.725
26 1.315 1.706 2.056 2.479 2.779 3.707
27 1.314 1.703 2.052 2.473 2.771 3.690
28 1.313 1.701 2.048 2.467 2.763 3.674
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Paso 5: calcular t: 1.53
26
106057
n
sμX
t
Puesto que -1.53 se encuentra en la región de aceptación (a la derecha de -2.485), la hipótesis nula de que µ=$60 no se rechaza al nivel de 0.01. Esto indica que no hay una reducción en el costo promedio en la investigación de una demanda por accidente. La media sigue siendo $60.
-2.485 -1.53Valor crítico t calculado
NC = 0.01gl = 26-1=25
H0 : μ = 60H0 : μ 60
ZonaAceptación
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Caso:
La tasa actual para producir fusibles de 5 amp. en GE Co. es 250 por hora. Se compró e instaló una máquina nueva que, según el proveedor, aumentará la tasa de producción. Una muestra de 10 horas seleccionadas al azar el mes pasado, indica que la producción media por hora en la nueva máquina es 256, con desviación estándar muestral de 6 por hora. Con 0.05 de nivel de significancia, ¿Puede la empresa concluir que la nueva máquina es más rápida?
Solución:
Paso 1:
Paso 2: H0 se rechaza si t >1.833, gl = 9
Paso 3:
Paso 4: H0 se rechaza. La nueva máquina es más rápida.
H H0 1250 250: :
t [ ] / [ / ] .256 250 6 10 316
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

1.83 3.16Valor crítico t calculado
NC = 0.05gl = 9
En los ejemplos anteriores se proporcionan la media y la desviación estándar de la muestra. En los siguientes ejemplos se necesita calcular estas medias a partir de observaciones muestrales.
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Caso:
La longitud promedio de un tornillo es 43mm. Se cree que los ajustes en la máquina, que producen los tornillos, hayan cambiando la longitud. La hipótesis nula, que se probará al nivel 0.02, es que no hay cambios en la longitud media µ=43. La hipótesis alternativa es que ha ocurrido un cambio µ ≠43.
Se seleccionaron aleatoriamente doce tornillos (n=12) y se registró su longitud. Las medidas son (en milimetros) 42, 39, 42, 45, 43, 40, 39, 41, 40, 42, 43 y 42. ¿Ha habido un cambio estadísticamente significativo en la longitud media de los tornillos?
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Solución:
Las hipótesis nula y alternativa son:
H0 : µ = 43
H1 : µ ≠ 43
La hipótesis alternativa no indica una dirección, por lo que se trata de una prueba de dos colas. Hay gl=11, que se obtienen por n-1=12-1=11. Por lo que, consultando el Apendice F para una prueba de dos colas en el nivel 0.02, el valor crítico es 2.718. Los valores críticos para el nivel 0.02 se muestran en el diagrama. Por tanto, la regla de decisión es rechazar la hipótesis nula si el valor t no se encuentra entre +2.718 y -2.718. De otra manera se acepta H0, que expresa que la longitud media de los tornillos es 43mm.
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

La desviación estándar de la muestra puede determinarse elevando al cuadrado las desviaciones con respecto a la media, o mediante una formula de equivalencia que utiliza los cuadrados de los valores reales.
Con las desviaciones cuadráticas respecto a la media
1
2
2
n
n
XX
s
Con los cuadros de los valores reales
1
2
n
XXs
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Los cálculos necesarios para estos dos métodos se muestran en la tabla. La media es 41.5mm, y la desviación estándar (s) vale 1.78mm. Ahora es fácil calcular t
92.2
12
78.10.435.41
n
sX
t
La hipótesis nula de que la media poblacional es 43mm se rechaza al nivel de significación 0.02(ya que el valor t calculado de -2.92 se encuentra en el área de la cola mas allá del valor critico de -2.718).
La hipótesis alternativa de que la media no es 43mm se acepta. Aparentemente la maquina esta desajustada y esto debe informarse al ingeniero de control de calidad
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

mmX 5.4112
498
78.1
112
35
1
2
n
XXs
X(mm)
(X-X) (X-X)2
X2
42 0.5 0.25 1764
39 -2.5 6.25 1521
42 0.5 0.25 1764
45 3.5 12.25 2025
43 1.5 2.25 1849
40 -1.5 2.25 1600
39 -2.5 6.25 1521
41 -0.5 0.25 1681
40 -1.5 2.25 1600
42 0.5 0.25 1764
43 1.5 2.25 1849
42 0.5 0.25 1764
498 0 35 20702
Cálculos necesarios para la desviación estándar de la muestra:
Método de los cuadrados de desviaciones
Cuadrados de valores reales:
78.1
11212
49820702
1
222
n
n
XX
s
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

2.718 Valor
crítico
H0: u = 43H1: u = 43gl = 11
-2.718 Valor
crítico
H1 se acepta
H0 se rechazaH0 se rechaza
0
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Comparación de dos Medias Poblacionales
Para realizar esta prueba se requieren tres suposiciones: las poblaciones deben tener una distribución normal o
normal aproximada las poblaciones deben ser independientes las varianzas de las poblaciones deben ser iguales
sn s n s
n np2 1 1
22 2
2
1 2
1 1
2
( ) ( )
10-10
tX X
sn np
1 2
2
1 2
1 1
Varianza MuestralCombinada
Prueba de dos Muestrasde las Medias
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Un estudio reciente compara el ahorro de combustible en carretera de los automóviles nacionales e importados. Una muestra de 15 autos nacionales reveló una media de 33.7 km.pg con desviación estándar de 2.4 km.pg. Una muestra de 12 autos importados indicó una media de 35.7 km.pg con desviación estándar de 3.9. Para 0.05 de nivel de significancia, ¿Se puede concluir que el consumo de km.pg para los autos importados es mayor? (Asocie el subíndice 1 a los autos nacionales.)
Solución:
10-12
Paso 1:
Paso 2: H0 se rechaza si t < 1.708, gl=25
Paso 3: t = -1.64 (verifique)
Paso 4: H0 no se rechaza.
La evidencia muestral es insuficiente para asegurar que el consumo de km.pg es más alto en los autos importados.
H H0 2 1 1 2 1: :
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

11-3
Análisis de Varianza-Análisis de Varianza-ANOVAANOVA

El Análisis de Varianza-ANOVA
Se utiliza para probar si dos muestras proceden de poblaciones con varianzas iguales y también cuando se desea comparar simultáneamente varias medias poblacionales.
La distribución probabilística F, es el estadístico que se utiliza para contrastar la hipótesis de que varias medias son iguales. Es una extensión de la prueba t para dos muestras.
Además de determinar que existen diferencias entre las medias es posible saber también que medias difieren.

ANOVA requiere las siguientes condiciones: La población que se muestrea tiene una
distribución normal. Las poblaciones tienen desviaciones estándar
iguales. Las muestras se seleccionan al azar y son
independientes. La distribución F (Fisher) permite determinar la
validez o significancia del modelo de regresión múltiple, es decir, validar si las variables independientes, incluidas en el modelo en conjunto, son significativamente explicativas de la variable dependiente.

Características de la Distribución F
Existe una “familia” de distribuciones F. Cada miembro de la familia está determinado
por dos parámetros: los grados de libertad (gl) en el numerador y los grados de libertad en el denominador.
El valor de F no puede ser negativo y es una distribución continua.
La distribución F tiene sesgo positivo. Sus valores varían de 0 a . Conforme F la curva se aproxima al eje X.

Prueba para Varianzas Iguales
11-4
Para prueba de dos colas, el estadístico de prueba está dado por:
son las varianzas muestrales para las dos muestras.
La hipótesis nula se rechaza si el cálculo del estadístico de prueba es mayor que el valor crítico (de tablas) con nivel de confianza y grados de libertad para el numerador y el denominador.
FS
S 1
2
22
/ 2
22
21 y SS

Procedimiento para el Análisis de Varianza
Hipótesis Nula: H0: Las medias de las poblaciones son iguales.
Hipótesis Alterna: H1:Al menos una de las medias es diferente.
Estadístico de prueba:
F=(varianza entre muestras)/(varianza dentro de muestras) Regla de decisión:
“Para un nivel de significancia , la hipótesis nula se rechaza si F (calculada) es mayor que F (en tablas) con grados de libertad en el numerador y en el denominador”.

5744699.8 6 957450.0 65.736 .000a
1281720.9 88 14565.010
7026420.7 94
Regresión
Residual
Total
Modelo1
Suma decuadrados gl
Mediacuadrática F Sig.
ANOVAb
Variables predictoras: (Constante), LAGS(DF,1), D, MS, SS, XS, LSa.
Variable dependiente: DFb.

Caso:Credibolsa SAB en el mercado de valores, reportó que la tasa media de rentabilidad de una muestra de 10 acciones del ISBVL fue 12.6% con una desviación estándar de 3.9%. La tasa media de retorno en otra muestra de 8 acciones de compañías de servicios fue 10.9% con desviación estándar de 3.5%. Para un 0.05 de nivel de significancia, ¿puede la sociedad agente de bolsa concluir que hay mayor variación en las acciones del ISBVL? Solución:
11-6
Paso 1:
Paso 2: H0 se rechaza si F > 3.68,
gl = (9, 7), = 0.05
Paso 3:
Paso 4: H0 no se rechaza. No hay evidencia suficiente para asegurar que hay mayor variación en las acciones de servicio.
H Hs u s u0 1: :
F ( . ) / ( . ) .39 35 124162 2

NOTA
Si se muestrean k poblaciones, entonces los gl (numerador) = k - 1
Si hay un total de N puntos en la muestra, entonces los gl (denominador) = N - k
El estadístico de prueba se calcula con:F = [(SST) /(k - 1)] /[(SSE) /(N - k)].
SST es la suma de cuadrados de los tratamientos. SSE es la suma de cuadrados del error. Sea TC el total de la columna, nc el número de
observaciones en cada columna, y X la suma de todas las observaciones.
11-10

Correlación Múltiple

Coeficiente de Correlación
Mide el grado en el cual dos variables se relacionan entre sí en forma lineal y está directamente relacionado con el concepto de regresión, que expresa la estructura funcional de la relación existente entre las variables.
Su valor fluctúa en un intervalo de +1 a -1 Si el coeficiente es negativo, indicará que existe una relación lineal
inversa entre las variables dependientes e independientes, significa que al aumentar el valor de una variable disminuye el valor de la otra.
Mientras más fuerte sea la correlación entre las variables mayor será el poder predictivo entre ellas.
La covarianza permite señalar el sentido de la variación conjunta de las variables que se está considerando. ®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Coeficiente de Correlación (R)
Para una población
N
ZZρ XY
2222 Y)(YNX)(XN
Y)X)((XYNρ
Para una muestra 2222 Y)(YnX)(Xn
Y)X)((XYn r
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Coeficiente deCorrelación
AB = +1 perfectamente positivaAB = 0 no existe correlaciónAB = -1 perfectamente negativa
W2A . 2
A
W2B . 2
B WB.WA. BA B A
WA.WB. AB A B
W2C . 2
C
WA.WC. AC A C
WB.WC. BC B C
WC.WA. CA C A WC.WB. CB C B
Matriz de Varianzas y Covarianzas
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Coeficientes de Correlación
AB = 0 no existecorrelación
AB = -1 perfectamente negativa
RA RARA
RB RB RB
·
·
·
· · ·
·· ··
· · ··
····
AB = +1 perfectamente positiva
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Correlación por Rangos de Spearman Mide el grado de correlación entre las variables ordinales, cuyos
valores indican rangos en cada una de ellas.
Coeficiente de Correlación de Pearson
Coeficiente de mayor utilidad en el análisis de la información cuantitativa. Se aplica cuando se trata de averiguar la correlación de dos variables en escala de intervalo.
NN
di
3
261
2222 Y)()Yn(X)()Xn(
Y)X)((XY)n(
R
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Es el cuadrado del coeficiente correlación (R2) mide la bondad de ajuste de la ecuación de regresión, es decir, cuantifica el porcentaje de la variación total en la variable dependiente Y que es explicada por la variable independiente X.
El valor del coeficiente de determinación de la muestra se define como :
En la practica, R2 ( coeficiente de determinación de
la muestra) se puede calcular mediante la siguiente fórmula equivalente :
2_
22
)(
)(1
YY
YYR
2_2
2_
2 0
YnY
YnXYbYbR
Coeficiente de Determinación R2
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

.904a .818 .805 120.6856 2.206Modelo1
RR
cuadrado
Rcuadradocorregida
Error típ.de la
estimación Durbin-Watson
Resumen del modelob
Variables predictoras: (Constante), LAGS(DF,1), D, MS, SS, XS, LSa.
Variable dependiente: DFb.

Correlaciones Bivariadas
Correlaciones Parciales
Calcula el coeficiente de correlación que describe la relación lineal existente entre dos variables mientras se controlan los efectos de una o más variables adicionales.
Dos variables pueden estar perfectamente relacionadas, pero si la relación no es lineal, el coeficiente de correlación no es un estadístico adecuado para medir su asociación.
Calcula el coeficiente de correlación de Pearson, la de Spearman y la tau-b de Kendall, con sus niveles de significación.
Los coeficientes miden cómo están relacionadas las variables o los órdenes de los rangos.
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Matriz de Correlación• La matriz de correlación se usa para mostrar todos los
posibles coeficientes de correlación simple entre todas las variables. La matriz también se útil para localizar la correlación
de las variables independientes. En la matriz se muestra qué tan fuerte está
correlacionada la variable independiente con la variable dependiente.1.000 -.108 .808 -.154 -.558 .486 .886
-.108 1.000 -.203 .117 .204 -.324 -.074
.808 -.203 1.000 -.216 -.748 .593 .799
-.154 .117 -.216 1.000 -.040 .010 -.171
-.558 .204 -.748 -.040 1.000 -.546 -.550
.486 -.324 .593 .010 -.546 1.000 .547
.886 -.074 .799 -.171 -.550 .547 1.000
. .148 .000 .068 .000 .000 .000
.148 . .024 .130 .023 .001 .239
.000 .024 . .018 .000 .000 .000
.068 .130 .018 . .351 .460 .048
.000 .023 .000 .351 . .000 .000
.000 .001 .000 .460 .000 . .000
.000 .239 .000 .048 .000 .000 .
95 95 95 95 95 95 95
95 95 95 95 95 95 95
95 95 95 95 95 95 95
95 95 95 95 95 95 95
95 95 95 95 95 95 95
95 95 95 95 95 95 95
95 95 95 95 95 95 95
DF
D
LS
MS
SS
XS
LAGS(DF,1)
DF
D
LS
MS
SS
XS
LAGS(DF,1)
DF
D
LS
MS
SS
XS
LAGS(DF,1)
Correlaciónde Pearson
Sig.(unilateral)
N
DF D LS MS SS XS LAGS(DF,1)
Correlaciones

13-3
Regresión Multivariable

Análisis de Regresión Multivariable La ecuación general de regresión múltivariable con k variables
independientes es:
El criterio de mínimos cuadrados se usa para el desarrollo de esta ecuación.
X1 , X2 , X3 son las variables independientes.
b0 es la intercepción en Y.
b1 , b2, b3 es el cambio neto en Y por cada cambio unitario en X1, manteniendo X2 , X3 constante. Se denomina coeficiente de regresión.
Como estimar b1, b2, etc. es muy tedioso, existen muchos programas de cómputo que pueden utilizarse para estimarlos.
13-4
iXbXbXbbY 3322110ˆ
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

13-5
El coeficiente de regresión mide el promedio de cambio en la variable dependiente por unidad de cambio en la variable independiente relevante, manteniendo constantes las demás variables independientes.
Las variables independientes y dependientes tienen una relación lineal.
La variable dependiente debe ser continua y al menos con escala de intervalo.
La variación en (Y - Ŷ) o residuo debe ser la misma para todos los valores de Y. Cuando éste es el caso, se dice que la diferencia presenta homoscedasticidad.
Los residuos deben tener distribución normal con media igual a 0.
Las observaciones sucesivas de la variable dependiente no deben estar correlacionadas.
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Supuestos del Modelo
1. Existe una relación lineal entre la variable dependiente y las variables independientes.
2. La variable dependiente tiene escalización de intervalo o de razón.
3. Las observaciones sucesivas de la variable dependiente no están correlacionadas.
4. Las diferencias entre los valores reales y los valores estimados (residuos) están distribuidos en forma normal.
5. La variación en los residuos es la misma para todos los valores ajustados de Ŷ es decir la distribución (Y-Ŷ) es la misma para todos los valores de Ŷ.
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Error Estándar de la Estimación
El error estándar múltiple de la estimación es la medida de la eficiencia de la ecuación de regresión.
Está medida en las mismas unidades que la variable dependiente.
Es difícil determinar cuál es un valor grande y cuál es uno pequeño para el error estándar.
La fórmula es:
donde n es el número de observaciones y k es el número de variables independientes.
)1(
)( 2
12
kn
YYS kY
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

13-12
Validación del Modelo.
1. Cuando el tamaño de la fuente es lo suficientemente grande (30-más elementos), el teorema del límite central proporciona un razonamiento para usar estas pruebas estadísticas sin la suposición de normalidad.
2. Si en una situación dada no hay una varianza constante, existe heteroscedasticidad.
3. Implica una muestra aleatoria de puntos dados X-Y. A lo que se llama correlación en serie.
4. Indica una relación lineal; ésta es una importante suposición de que el modelo está correctamente especificado.
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

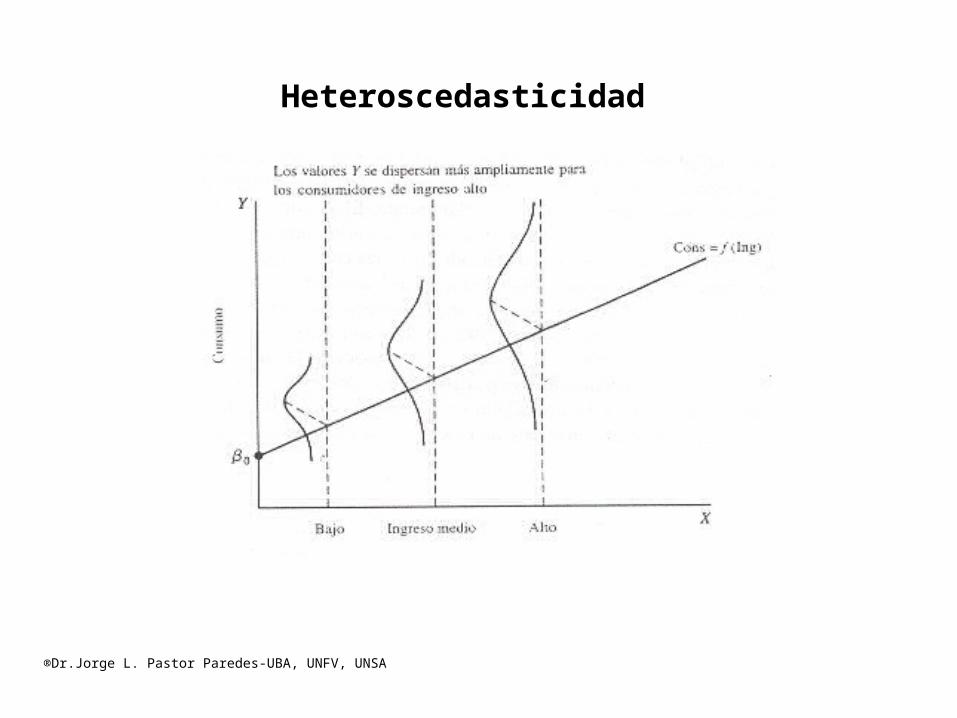
Existe heteroscedasticidad cuando los errores o residuos no tienen una varianza constante a través de un nivel completo de valores.
Y Y
Ŷ Ŷ
X X Homoscedasticidad Heteroscedásticidad
Heteroscedasticidad.
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Homoscedasticidad
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA
Heteroscedasticidad
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Colinealidad La colinealidad es la situación en que las variables
independientes de una ecuación de regresión múltiple están altamente inter-correlacionadas.
En un análisis, la colinealidad causa problemas en los siguientes aspectos:
1. Un coeficiente de regresión que tiene signo positivo en una ecuación de regresión de dos variables, pudiera cambiar a signo negativo en una ecuación de regresión múltiple que contenga otras variables con las que está altamente relacionado y viceversa.
2. La estimación de los coeficientes de regresión fluctúa marcadamente entre una muestra y otra.
3. Cuando las variables de predicción están interrelacionadas, éstas explican la misma varianza en la estimación de la variable dependiente, lo que dificulta separar las variables individuales de cada una de las variables independientes.
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Autocorrelación-DW
Ocurre cuando los términos de error no son independientes. La prueba Durbin-Watson-DW permite detectar autocorrelación, es
decir está correlacionada con sí misma. Se acepta la H0 si el DW se encuentra alrededor de 2.
2
2)( 1
te
eed
tt
.904a .818 .805 120.6856 2.206Modelo1
RR
cuadrado
Rcuadradocorregida
Error típ.de la
estimación Durbin-Watson
Resumen del modelob
Variables predictoras: (Constante), LAGS(DF,1), D, MS, SS, XS, LSa.
Variable dependiente: DFb.
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Los problemas de análisis de regresión se resuelven utilizando programas de cómputo de regresión.
El paquete recomendado es el SPSS (Statistical Package for the Social Sciences) produce una salida que es típica en comparación con las generadas por otros programas como ejemplo: E-view, Minitab, etc.
No existe un formato estándar para presenta los resultados de un análisis de regresión.
Objetivos de la Regresión Multivariable
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

1. El coeficiente de correlación múltiple R, permite evaluar el grado de asociación entre la variable dependiente y el conjunto de variables independientes.
2. El coeficiente de determinación R2, evalúa la proporción (porcentaje) de la variación total de la variable dependiente Y que es explicada por el modelo de regresión utilizado.
3. La prueba F (Fisher), determina la validez o significancia del modelo de regresión múltiple.
4. La prueba del Durbin-Watson, permite detectar falta de independencia o autocorrelación entre las variables independientes.
5. La prueba “t” de Student, evaluar los coeficientes de regresión individuales para cada variable independiente.
Determinar:
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

6. Para detectar posibles casos de multicolinealidad se estudió la matriz de correlaciones elaborada por el programa SPSS.
7. El análisis de varianza ANOVA para comparación de medias.
8. Para contrastar la normalidad o simetría de la distribución de los residuos se analizó los gráficos probabilísticos de normalidad, el histograma de frecuencia y el gráfico de simetría, para cada variable independiente.
9. Para detectar problemas de heteroscedasticidad (varianzas no constantes), error en el análisis, inadecuación del modelo por falta de linealidad y existencia de observaciones atípicas se analizó el gráfico de residuos ei frente a las predicciones . )ˆ( iy
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

-346.192 333.217 -1.039 .302 -1008.391 316.007
3.275E-02 .010 .338 3.308 .001 .013 .052
57.970 114.581 .037 .506 .614 -169.735 285.675
-10.382 12.894 -.040 -.805 .423 -36.005 15.242
.177 .201 .044 .880 .381 -.222 .576
-.267 .199 -.083 -1.338 .184 -.663 .129
.689 .080 .686 8.657 .000 .531 .847
(Constante)
LS
SS
D
MS
XS
LAGS(DF,1)
Modelo1
B Error típ.
Coeficientes noestandarizados
Beta
Coeficientes
estandarizados
t Sig.Límiteinferior
Límitesuperior
Intervalo de confianzapara B al 95%
Coeficientesa
Variable dependiente: DFa.
Coeficientes de Regresión Multivariable
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

18-3
Regresión de Series de TiempoLa Correlación Serial

Una serie de tiempo es una colección de datos obtenidos en un periodo, como semanas, meses o trimestres.
Se refiere a la relación lineal entre dos o más variables. Se emplea el conocimiento de la variable independiente (X)
para predecir la variable dependiente (Y).
Ŷ = b0 + bX La variable independiente es el tiempo (X). La variable bajo estudio (Y) toma diferentes valores a través
del tiempo. Las series de tiempo se utilizan para descubrir patrones pasados
de variabilidad, que puedan emplearse para predecir valores futuros.
Conceptualización
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

En regresión de series de tiempo el valor de cada período comprende o está relacionado con el período anterior, en vez de que sea independiente de él, por ejemplo, un precio dado de un año ejerce influencia sobre el precio del año siguiente.
Correlación Serial Existe, cuando las observaciones sucesivas a través del tiempo se
encuentran relacionadas entre sí. Puede ser causado por dos motivos: sea por omisión de una variable
importante, o por que los términos independientes de error están interrelacionados en la ecuación.
La solución consiste en encontrar las variables claves, denominado como técnica de la especificación del modelo, pero este modelo no siempre es confiable.
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Las mediciones de series de tiempo no pueden considerarse muestras probabilísticas por lo que en vez de ello, están sujetas a:
1. Tendencias:
Componente a largo plazo que constituye la base del crecimiento (o declinación) de una serie histórica, se ve afectada por cambios en la población, inflación, cambio tecnológico e incremento en la productividad.
2. Variación Cíclica:
Conjunto de fluctuaciones en forma de ondas o ciclos, producidos por cambios en las condiciones económicas, representa la diferencia entre los valores esperados de una variable (tendencia) y los valores reales.
Características Importantes
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

3. Variación Estacional:
Se refiere a un patrón de cambio regularmente recurrente a través del tiempo. Se encuentran típicamente en los datos clasificados por trimestre, mes o semana; el movimiento se completa dentro de la duración de un año y se repite a sí mismo año tras año.
4. Fluctuación Irregular:
Compuesto por fluctuaciones causadas por sucesos impredecibles o no periódicos, como un clima poco usual, huelgas, guerras, elecciones y cambios en las leyes.
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Tendencia lineal
La ecuación de la tendencia a largo plazo (lineal) se estima con la ecuación de mínimos cuadrados para el tiempo t:
n
tb
n
Ya
ntt
ntYtYb
btaY
/)(
/))((22
18-5
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Método del Promedio Móvil (MA)
El método del promedio móvil se usa para alisar (suavizar) una serie de tiempo. Se logra “moviendo” la media aritmética a lo largo de la serie de tiempo.
El promedio móvil es el método básico usado para medir la fluctuación estacional.
Para aplicar este método a una serie de tiempo, los datos deben seguir una tendencia bastante lineal y tener un patrón de fluctuación rítmico definido.
18-8
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Tendencias No Lineales
Si la tendencia es no lineal pero los incrementos tienden a ser un porcentaje constante, los valores de Y se convierten en logaritmos y la ecuación de mínimos cuadrados se determina con ellos.
tbaY )][log()][log()log(
18-9
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Variación Estacional
El método de mayor uso para calcular el patrón estacional típico se llama “método de razón a promedio móvil”
1. Elimina las componentes de tendencia, cíclica e irregular de los datos originales (Y).
2. Los números que resultan se denominan índices estacionales típicos.
18-10
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Determinación del Indice Estacional
Paso 1: establecer el total móvil para la serie de tiempo.
Paso 2: determinar el promedio móvil para la serie de tiempo.
Paso 3: centrar los promedios móviles.Paso 4: calcular el índice estacional específico
para cada periodo dividiendo los valores de Y entre los promedios móviles centrados.
Paso 5: organizar los índices estacionales específicos en una tabla.
Paso 6: Aplicar el factor de corrección.
18-11
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Desestacionalización de Datos
Un conjunto común de índices es útil al ajustar una serie (por ejemplo, ventas)
La serie resultante (ventas) se llama ventas desestacionalizadas o ventas con ajuste estacional.
La razón para desestacionalizar una serie (ventas) es eliminar la fluctuación estacional para poder estudiar la tendencia y el ciclo.
18-12
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA

Pronósticos Econométricos.
Cuando la variable dependiente se encuentra en una serie histórica, el análisis de regresión se conoce con el nombre de modelo econométrico.
La construcción de un modelo econométrico mediante el análisis de regresión consiste en la identificación y especificación de factores de causa, a utilizar en una ecuación de regresión.
Los modelos econométricos comprender un gran número de ecuaciones de regresión lineal múltiple simultáneas, por ello son sistemas de ecuaciones simultáneas que comprenden gran cantidad de variables independientes.
®Dr.Jorge L. Pastor Paredes-UBA, UNFV, UNSA


















