
Diseño Óptimo de Experimentos en Procesos Industriales · Diseños Óptimos para la Estimación...
209
Transcript of Diseño Óptimo de Experimentos en Procesos Industriales · Diseños Óptimos para la Estimación...

Universidad de Castilla-La Mancha
E. T. S. de Ingenieros Industriales
Instituto de Matemática Aplicada a la Ciencia
y a la Ingeniería
Departamento de Matemáticas
Diseño Óptimo de Experimentos
en Procesos Industriales
Memoria que presenta para optar al grado de Doctor:
D. Licesio J. Rodríguez Aragón.Dirigida por:
Prof. Dr. Jesús López Fidalgo.
Diciembre 2007


D. Jesús López Fidalgo, Catedrático del área de Estadística e In-vestigación Operativa de la Universidad de Castilla-la Mancha.
CERTIFICA:
Que la memoria titulada Diseño Óptimo de Experimentos enProcesos Industriales presentada por el Licenciado en MatemáticasDon Licesio J. Rodríguez Aragón para optar al Grado de Doctor, hasido realizada bajo mi dirección en el Programa de doctorado Física yMatemáticas de la Universidad de Castilla-La Mancha.
Y para que así conste, expedimos y rmamos la presente certica-ción en Ciudad Real a 20 de Diciembre del 2007.
Fdo: Dr. D. Jesús López Fidalgo.


i
Agradecimientos
Este trabajo ha sido realizado bajo la dirección del Prof. Dr. Don JesúsLópez Fidalgo cuyas orientaciones, consejos y valiosas correcciones quieroagradecer. Hubiese sido imposible llegar a puerto a no ser por el tiempoque tan generosamente siempre me ha ofrecido. Quiero además agradecerlela ayuda, la conanza y la amistad que me ha brindado.
Agradecer también a mis compañeros del Departamento de Matemáti-cas de la Universidad de Castilla-La Mancha que me han ayudado en todolo que han podido. En especial a Raúl Martín Martín y Mariano Amo Salas,compañeros de fatigas.
No puedo dejar de agradecer, ni olvidar, a mis compañeros de la Univer-sidad Rey Juan Carlos de Madrid, especialmente al Dr. D. Enrique CabelloPardos, director del Face Recognition and Articial Vision group (FRAV)del que formé parte, a Cristina Conde Vilda, a Ángel Serrano Sánchez deLeón y a Jorge Pérez López, con quienes he compartido tantas horas detrabajo. Agradecer también al Departamento de Informática, Estadísticay Telemática de la URJC, a su director el Prof. Dr. D. Luis Pastor Pérezy a todos sus miembros, en especial a todos con los que compartí tareasdocentes o de investigación, sería demasiado extenso nombrarlos a todos einjusto nombrar sólo a unos pocos.
Deseo hacer extensivo este agradecimiento a los investigadores en elcampo del Diseño Óptimo de Experimentos, de cuyos trabajos tanto heaprendido y me queda por aprender. Especialmente quiero agradecer alDr. D. Juan Manuel Rodríguez Díaz cuya Tesis Doctoral me ha servido demanual en tantos momentos y a tantos otros cuyos trabajos han servido defuente y apoyo para los desarrollos llevados a cabo en éste.
Agradecer también al Prof. Dr. D. Anatoly Zhigljavsky de la Universi-dad de Cardi que me acogió durante mi estancia en el School of Mathe-matics y que tan generosamente me dedicó su tiempo.

ii
En lo personal, quiero agradecer a todos aquellos que comparten estepequeño éxito conmigo, apoyándome en el proceso de, una vez más fracasare intentarlo siempre de nuevo1, a mis padres Maria Jesús y Licesio, a mihermano Jesús y a Cristina, fuente de todas mis energías.
No puedo dejar de recordar en estos momentos de revisión del trabajo,a todos mis mayores, en especial el recuerdo siempre tan cercano de la Dra.Gonzala García Delgado, mi abuela, que pasó sus años de doctorado en elMadrid de los años treinta, tan cerca...
The simple fact is that no measurement,no experiment or observation is possible
without a relevant theoretical framework.
D. S. Kothari2.
A mi familia,a mis amigos,
a mis maestros,a mis alumnos,y a Cristina,
...de baile de disfraces cada día.
Salamanca-Madrid-Ciudad Real,Festividad de la Inmaculada Concepción, 2007.
1William Faulkner (1897-1962), Escritor estadounidense.2Daulat Singh Kothari (1905-1993), Físico indio.

Índice general
Resumen vii
Summary xiii
Introducción 1
El Experimento y su Diseño 1
Modelos 3
Etapas del Diseño Óptimo de Experimentos 4
Nota Histórica 5
Capítulo 1. Diseño Óptimo 11
1.1. Modelos de Regresión 12
1.2. Método de los Mínimos Cuadrados Generalizados 13
1.3. Contexto del Diseño Óptimo 15
1.4. Diseños Exacto y Aproximado 16
1.5. Estimadores de Funcionales Lineales 17
1.6. Matriz de Información 19
1.7. Criterios de Optimización 26
1.8. Teorema de Equivalencia 37
iii

iv Índice general
1.9. Discriminación entre Modelos: T−optimización 43
Capítulo 2. Ecuación de Arrhenius 47
2.1. Velocidad de las Reacciones Químicas 47
2.2. Dependencia de la Constante de Velocidad de la Temperatura 50
2.3. Teoría de Arrhenius 52
2.4. Otras Teorías 53
2.5. La Ecuación de Arrhenius y Fenómenos de Transporte 58
Capítulo 3. Diseños Óptimos para la Ecuación de Arrhenius 63
3.1. Necesidad de Diseños Óptimos 63
3.2. Modelo no Lineal 65
3.3. Matriz de Información y Criterios de Optimización 67
3.4. Diseño D−Óptimo 69
3.5. Método de Elfving y Diseños c−Óptimos 73
3.6. Diseños Óptimos Compuestos 79
3.7. Comparación con otros Diseños 82
Capítulo 4. Fenómenos de Adsorción 87
4.1. Generalidades 87
4.2. Método Experimental 89
4.3. Quimisorción 90
4.4. Modelo de Langmuir 91
4.5. Fisisorción 92
4.6. Modelo de Brunauer, Emmett y Teller (BET) 94
4.7. Desviaciones de la Isoterma BET: Isoterma GAB 97
Capítulo 5. Diseños Óptimos para las Isotermas de Adsorción BET y
GAB 103
5.1. Aplicaciones de los Fenómenos de Adsorción 103
5.2. Isotermas de Adsorción 106

Índice general v
5.3. Discriminación entre Modelos: BET o GAB 110
5.4. Diseños Óptimos para la Estimación de los Parámetros 115
5.5. Diseños Óptimos para el Modelo BET 117
5.6. Diseños Óptimos para el Modelo GAB 124
5.7. Comparación de los Diseños 133
Capítulo 6. Estimadores Combinados en Quimiometría 137
6.1. Ecuaciones de Velocidad 138
6.2. Caso Simplicado 142
6.3. Estimación en dos Pasos frente a la Estimación Combinada 144
Conclusiones 151
Discusión de los Resultados 154
Líneas Futuras de Investigación 157
Conclusions 159
Results Discussion 162
Issues for Further Research 164
Apéndice A. Distribución de Boltzmann 167
A.1. Aplicación a la Deducción de la Distribución de Maxwell de
las Velocidades de las Moléculas de un Gas 172
Bibliografía 175


Resumen
El trabajo que se presenta se construye sobre los fundamentos mate-
máticos de la teoría del Diseño Óptimo de Experimentos. Como se sabe,
esta disciplina trata de lograr la mejor elección posible de las observacio-
nes en las que se basará un experimento para obtener la mayor y mejor
información posible acerca de un objeto. La modelización y la inferencia
estadística son procesos en los que se obtiene información a través de ex-
perimentos, planteados para situaciones concretas y sujetos en la mayoría
de las ocasiones a restricciones y costes de diversa naturaleza.
Existen múltiples aplicaciones industriales de los fenómenos y modelos
con los que hemos trabajado. Nuestro estudio ha estado centrado en dos
tipos de fenómenos, i) la inuencia de la temperatura sobre parámetros
cinéticos (modelo de Arrhenius) y ii) fenómenos de adsorción. El mode-
lo de Arrhenius explica la dependencia de las constantes de velocidad de
reacciones químicas con la temperatura así como la de los coecientes de
otros fenómenos de transporte. Por otro lado, los modelos de adsorción son
comunes en la industria alimentaria, en procesos de ltrado y depuración,
y en la industria de materiales de construcción, entre otros.
Los diferentes capítulos de la memoria están agrupados en orden cro-
nológico según han sido abordados, aunque desde luego han sido necesarias
vii

viii Resumen
continuas revisiones de su contenido. Asimismo, se han redactado de forma
autónoma, con las ventajas e inconvenientes que ello conlleva, repitiéndose
en algunos casos ideas y conceptos, pero siempre con un especial enfoque
según la necesidad del momento.
En la Introducción se presentan las ideas generales en las que se basa
la teoría de Diseño Óptimo de Experimentos, así como la situación actual
y los antecedentes históricos de los métodos usados.
El Capítulo 1 se centra en el Diseño Óptimo de Experimentos, teoría
general en la que está basado el trabajo. Se introduce la notación y métodos
generales de estimación y regresión para, a continuación, plantear los con-
ceptos, deniciones, teoremas y propiedades que se usarán en el desarrollo
posterior. Se presentan los criterios de optimización usados y el Teorema
de Equivalencia como pilar fundamental, que proporciona un instrumento
inestimable para la comprobación de la optimalidad de un diseño.
Para el desarrollo de este trabajo ha sido necesario realizar una ta-
rea interdisciplinar con el objeto de poder aplicar las técnicas del Diseño
Óptimo a los modelos estudiados. En Capítulo 2 se resumen brevemente
algunos conceptos y propiedades resultado del estudio que ha sido necesa-
rio llevar a cabo para obtener el mayor fruto posible. Con el objetivo de
realizar una exposición equilibrada hemos incluido en un Apéndice nal
algunas propiedades relacionadas con la estadística y los fenómenos físicos
y químicos, cuyo comportamiento se corresponde con el modelo planteado
por la ecuación de Arrhenius.
El Capítulo 3 se centra en la aplicación de los criterios de optimización
a esta ecuación y en los pasos que nos han llevado a la obtención de los di-
ferentes diseños óptimos. Con el objetivo de incrementar la precisión de las
estimaciones de los parámetros de la ecuación de Arrhenius, se han calcu-
lado y comparado diferentes diseños óptimos. Basándose en el Teorema de
Equivalencia, piedra clave del Diseño Óptimo de Experimentos, se ha calcu-
lado el diseño D−óptimo y mediante el Método de Elfving se han calculado

Resumen ix
diferentes diseños c−óptimos con el objetivo de estimar combinaciones li-
neales de los parámetros. Asimismo, se han obtenido diseños compuestos
por varios criterios, que proporcionan diferentes grados de precisión a la
hora de determinar cada parámetro.
Los diseños empleados tradicionalmente han sido comparados con los
diseños óptimos calculados y, como resultado, se ha obtenido un valioso
método que permite al investigador elegir el diseño más apropiado a sus
intereses, comparando cada diseño posible con el óptimo y obteniendo así
la eciencia de su diseño.
En particular, y a modo de ejemplos, estos procedimientos se han apli-
cado a la estimación de los parámetros de la ecuación de Arrhenius en
medidas relacionadas con la Química atmosférica. Estas estimaciones son
usadas en la modelización de los procesos que se llevan a cabo en la estra-
tosfera y en capas superiores de la atmósfera que dan lugar a fenómenos
como el Efecto Invernadero y la reducción de la Capa de Ozono. Se han
elegido este tipo de procesos por sus especiales características, por las di-
cultades experimentales que presentan, por la alta incertidumbre presente
en las estimaciones existentes de estos valores y por la importancia de la
correcta modelización de estos fenómenos.
Los resultados de esta parte del trabajo han sido presentados en el 5th
Congress of Romanian Mathematicians, celebrado en Pitesti, Rumania, y
en XXX Congreso Nacional de la Sociedad Estadística Española, celebrado
en Valladolid (Rodríguez-Aragón y López-Fidalgo, 2003; 2007c) así como
publicados, en la revista Chemometrics and Intelligent Laboratory Systems
(Rodríguez-Aragón y López-Fidalgo, 2005) estando el artículo dentro del
Top25 Hottest Articles3 de la revista durante el período Abril-Junio 2005.
El desarrollo de los modelos de adsorción se realiza en el Capítulo 4,
iniciándose con una descripción genérica del fenómeno de adsorción así co-
mo del proceso experimental a seguir para poder caracterizarlo. Se han
descrito los modelos más ampliamente usados: el modelo de Langmuir para
3http://top25.sciencedirect.com

x Resumen
adsorción en monocapa y los modelos BET y GAB para la adsorción en
multicapa. La aplicación del Diseño Óptimo de Experimentos permite re-
solver la elección del modelo más adecuado para describir el fenómeno de
adsorción en multicapa, aunque deja abiertos y sin resolver otros problemas
como el diseño de experimentos en condiciones de equilibrio.
En el Capítulo 5 se obtienen los diseños óptimos para los dos modelos
de adsorción en multicapa más usados, el modelo BET y el GAB. Las dife-
rentes opiniones de la comunidad cientíca acerca de la adecuación de uno u
otro modelo al fenómeno han dado pie para el cálculo de diseños T−óptimos
mediante un procedimiento numérico y con el objetivo de discriminar entre
ambos modelos. Aunque el espacio del diseño recomendado en la literatura
es diferente según el modelo elegido, la falta de ajuste del modelo BET se
atribuye a la linealización del modelo. Por otro lado la obtención de valores
de los parámetros contradictorios con su signicado físico, justicando su
mejor ajuste al modelo, hacen de los diseños T−óptimos una herramienta
de gran interés. La aplicación del Teorema de Equivalencia nos permite ob-
tener un criterio de parada del proceso numérico mediante una cota inferior
de la eciencia.
Una vez elegido el modelo, se han calculado diseños D− y c−óptimos
para ambos modelos; de forma analítica para el modelo BET, que posee dos
parámetros desconocidos, y de forma numérica para el modelo GAB, con
tres parámetros desconocido. El empleo del Método de Elfving de forma
gráca para calcular los diseños c−óptimos para el modelo GAB presenta
numerosas dicultades, por lo que se ha sustituido por un procedimiento
algorítmico.
Existen grandes reticencias por parte de los experimentadores para lle-
var a la práctica los diseños óptimos, debido a su reducido número de puntos
de soporte, así que una vez más se han calculado las eciencias de diferentes
diseños con un mayor número de puntos en su soporte, proporcionando así
una herramienta para decidir cuál de los posibles diseños resulta más intere-
sante según las necesidades del investigador. Al mismo tiempo es posible el
cálculo de las eciencias de los diseños T−óptimos respecto a los criterios

Resumen xi
de D− y c−optimización, para conocer las ventajas e inconvenientes de los
mismos.
Los ejemplos usados para ilustrar los diseños calculados provienen de la
industria alimentaria, más en concreto de la caracterización de la adsorción
de vapor de agua, que resulta de interés a la hora de juzgar la calidad de
numerosos productos alimenticios y en la determinación de la vida útil. No
es la única aplicación interesante de los fenómenos de adsorción. Entre otras
podemos destacar el cálculo del área supercial de sólidos pulverizados o su
aplicación al estudio de la catálisis heterogénea. Es notable la actualidad
que han cobrado de los estudios de Química de supercies4, entre los que se
encuentran los fenómenos de adsorción, a raiz de la concesión del Premio
Nobel de Química 2007.
Nuestros resultados del cálculo de diseños óptimos para fenómenos
de adsorción se han presentado en el International Congress of Mathe-
maticians, celebrado en Madrid; en la International Conference on Mat-
hematical and Statistical Modelling, celebrada en Ciudad Real y en el
8th Model Oriented Design and Analysis Workshop, celebrado en Alma-
gro (Rodríguez-Aragón y López-Fidalgo, 2006a; 2006b; 2007b). El trabajo
completo ha aparecido publicado en la revista Chemometrics and Intelli-
gent Laboratory Systems (Rodríguez-Aragón y López-Fidalgo, 2007a).
Por último, se presenta, en el Capítulo 6, la consideración de uno de
los problemas surgidos durante el desarrollo de los diseños óptimos para
la ecuación de Arrhenius. Éste es uno de los muchos problemas o cuestio-
nes que han aparecido durante la realización de nuestro trabajo, cuestiones
aparentemente sencillas desde el punto de vista matemático, que se com-
plican en el momento que se profundiza en las cuestiones interdisciplinares.
La dicultad aparece cuando en lugar de considerar la constante de velo-
cidad, dependiente de la temperatura, como una magnitud directamente
medible, se considera que esta variable es el resultado de un ajuste previo
de observaciones tomadas en el tiempo. Se han recopilado los diferentes
4Gerhard Ertl (1936), Premio Nobel de Química en 2007. For his studies of chemical processeson solid surfaces.

xii Resumen
modelos según los órdenes de las reacciones químicas y se ha planteado
un caso simplicado para el que se han calculado las diferencias entre el
proceso de estimación usual en dos pasos frente al proceso de estimación
combinado, que obtiene estimadores con menor varianza.
Finalmente, se presentan las conclusiones y se realiza una discusión
de las herramientas y de los resultados obtenidos,. Se adjuntan también
posibles líneas de investigación futuras que quedan abiertas.
Acompañan al trabajo las referencias bibliográcas, tanto generales de
la teoría de Diseño Óptimo como particulares, que han sido usadas como
obras de consulta y referencia.

Summary
The work hereby presented is built on the mathematical foundations of
Optimum Experimental Design theory. As it is known, this science deals
with the election of the best observations to be carried out in an experiment
in order to obtain the highest and best information about an object. Mo-
deling and statical inference are processes in which information is obtained
through experiments. These experiments are based on precise situations
and, in most occasions, subjected to restrictions of dierent nature.
There are multiple industrial applications of the phenomena and models
we have worked with. Our study has focused on two types of phenomena:
i) the inuence of temperature upon kinetic parameters (Arrhenius model)
and ii) adsorption phenomena. Arrhenius model explains the dependence of
the rate of chemical reactions on the temperature as well as the dependence
of other coecients of transport processes. On the other hand, adsorption
models are frequent in food technology, ltering and depollution processes,
and in construction material industry, to mention just a few.
The chapters included in this report are chronologically organized as
they have been studied and developed, even though permanent revisions
of their content have been required. However, they have been structured
in an autonomous way, with the advantages and disadvantages that this
xiii

xiv Summary
presents, duplicating ideas and concepts in some cases, but always with an
special emphasis on the requirements of the moment.
The Introduction presents the general ideas on which Optimum Ex-
perimental Design theory is based, as well as the present situation and
historical background of the used methods.
Chapter 1 refers to Optimum Experimental Design, theory in which
our work is based on. Notation, inference and regression methods are rstly
introduced to later consider concepts, denitions, theorems and properties
that will be applied in further developments. Optimum criteria being used
are also presented as well as the Equivalence Theorem as a fundamental
foundation that provides a crucial tool to check the optimality of a design.
In order to apply Optimum Design techniques to the studied models, an
interdisciplinary task has been required. Chapter 2 briey summarizes some
concepts and properties merged from the necessary study to obtain the best
possible result. For the sake of showing a well balanced exposition, a nal
Appendix containing some properties related to statistics and physical and
chemical phenomena, whose behaviour is related with the model specied
by Arrhenius equation, has been included.
Chapter 3 is centered in the application of optimization criteria to the
Arrhenius equation and in the steps that have been taken to obtain the
dierent optimum designs. In order to increase the accuracy of the esti-
mations of the parameters for Arrhenius equation, dierent optimum de-
signs have been calculated and compared. With the help of the Equivalence
Theorem, milestone of Optimum Experimental Design theory, D−optimumdesigns have been obtained. Elfving method has been used to obtain dif-
ferent c−optimum designs to obtain the best possible estimations of linear
combinations of the parameters. Compound designs have also been ob-
tained allowing the experimenter to tune the required eciencies for his
estimations.
Traditional designs used have been compared to optimum designs, and
as a result, a valuable method which allows the researcher to choose the

Summary xv
most suitable design has been proposed. This comparison is carried out by
comparing each possible design to an optimum, and therefore showing its
eciency.
As examples, these procedures have been applied to the estimation of
the parameters of Arrhenius equation on measures related to atmospheric
Chemistry. These estimations are used in the modeling of stratospheric pro-
cesses on higher atmospheric layers, which are used to explain the Green-
house Eect and the reduction of the Ozone Layer. This type of processes
have been chosen due to their special characteristics, to the implied expe-
rimental diculties, to the high uncertainty of the available estimations of
the parameters and due to the importance of the correct modeling of such
phenomena.
The results have been presented in the 5th Congress of Romanian Mat-
hematicians, celebrated in Pitesti, Romania, and in the XXX Congreso
Nacional de la Sociedad Estadística Española, celebrated in Valladolid,
Spain (Rodríguez-Aragón and López-Fidalgo, 2003; 2007c) and published in
the journal Chemometrics and Intelligent Laboratory Systems (Rodríguez-
Aragón and López-Fidalgo, 2005) being the article included in the Top25
Hottest Articles5 of the journal for the period April-June 2005.
Chapter 4 includes the development of adsorption models. It starts with
a general description of adsorption phenomena as well as the experimental
procedure to follow to characterize it. The most widely used models have
been described: Langmuir model for monolayer adsorption and BET and
GAB models for multilayer adsorption. The application of Optimum Expe-
rimental Design theory solves the problem of election of the most adequate
model to describe multilayer adsorption, although it leaves unsolved the
problem of designing for observations taken at equilibrium.
Chapter 5 includes the optimum designs for the two mostly used mul-
tilayer adsorption models, BET and GAB models. The dierent criteria of
the scientic community regarding the best adequacy of one or the other
5http://top25.sciencedirect.com

xvi Summary
model have given way to the obtention of T−optimum designs through a
numerical procedure, with the purpose to discriminate between both mo-
dels. Although the recommendations in literature for the design space are
dierent for each model, the lack of t of the BET model in wider design
spaces is blamed to the linearization of the model. Besides, the obtention
of estimations of the parameters with no physical meaning, justied by its
better t of the model to the data, makes of the T−optimum designs a
tool of the greatest interest. The use of the Equivalence Theorem provides
a stopping rule for the numerical algorithm in terms of a lower bound for
the eciency.
Once the model has been chosen, D− and c−optimum designs for both
models have been computed. For the BET model, in an analytical way, with
two unknown parameters, and numerically for the GAB model, with three
unknown parameters. The use of the graphical Elfving method to obtain
c−optimum designs for the GAB model presents several diculties, which
have been avoided by using a numerical algorithm.
Experimenters are suspicious to carry measurements following optimum
designs, due to their small number of support points, so once again, e-
ciencies for dierent designs with a greater number of support points have
been calculated. The process has provided a valuable tool to decide which
of the possible designs turns to be the most interesting for the researcher's
requirements. At the same time, the obtention of D− and c−eciencies for
T−optimum designs is possible, allowing to know in advance their perfor-
mance regarding these criteria.
The samples used to illustrate the obtained designs are referred to food
industry, more precisely to characterize the moisture adsorption, which
becomes so important when judging the quality of so many food stu and
the shelf life predictions of the products. That is not the only application
of adsorption phenomena. Among others, surface area estimations of solid
materials or the application to the study of heterogenous catalysis play an

Summary xvii
important role. It must be pointed out the relevance of surface Chemistry6,
among which adsorption phenomena are included, since it has been awarded
with the Nobel Prize in Chemistry 2007.
The results obtained have been presented in the International Congress
of Mathematicians, held in Madrid, Spain; in the International Conference
on Mathematical and Statistical Modelling, held in Ciudad Real, Spain, and
in the 8th Model Oriented Design and Analysis Workshop, held in Almagro,
Spain, (Rodríguez-Aragón and López-Fidalgo, 2006a; 2006b; 2007b). The
whole work was published in the journal Chemometrics and Intelligent
Laboratory Systems (Rodríguez-Aragón and López-Fidalgo, 2007a).
Chapter 6, brings into consideration one of the problems that have ap-
peared through the development of optimum designs for Arrhenius equa-
tion. It has been one of the many problems and questions that have merged
during the undertaking of our work. The problem appears when instead of
considering the rate of a chemical reaction, temperature dependent, as a
directly measurable magnitude, this variable is considered as a parameter
obtained in a previous t of several observations versus time. Dierent mo-
dels have been gathered for several reaction rates and a simplied model
has been set to analyze the dierences between the usual two stage esti-
mation and the pooled estimation process, which obtains estimators with
lower variance.
Finally, the conclusions and a discussion of the tools and results pre-
sented is included. Future research topics are also traced.
The work includes general Optimum Design and particular bibliograp-
hic references, that have been used for the development of our work.
6Gerhard Ertl (1936), Chemistry Nobel Prize 2007. For his studies of chemical processes onsolid surfaces.


Introducción
El Experimento y su Diseño
Como denición de experimento, suciente para comprender los obje-
tivos de este trabajo, podríamos decir que es un conjunto de observaciones
o medidas llevadas a cabo con el n de alcanzar un conocimiento profun-
do acerca de un objeto. Por lo tanto, multitud de actividades cotidianas
pueden ser catalogadas como experimentos.
Normalmente un experimento requiere de un complejo grupo de accio-
nes o medidas, necesita de la preparación de muestras, de instrumentos
de medida y de un equipo de investigadores capaz de llevarlas a cabo. Sin
embargo hoy en día el procesado de los datos obtenidos juega también un
papel crucial en los resultados del experimento.
La presencia de restricciones sobre las muestras, sobre los instrumentos
de medida y sobre los equipos de investigadores, hacen que los experimen-
tos obtengan información a partir del estudio de un número limitado de
observaciones. El aumento de la complejidad de algunos fenómenos que es-
tán siendo estudiados, hacen necesaria una teoría de Diseños Óptimos que
nos permita obtener la máxima información posible a un mínimo coste,
jugando un papel crucial en este aspecto las herramientas matemáticas.
1

2 Introducción
Tres grupos de herramientas matemáticas son las que se usan en las
actividades experimentales: la Modelización Matemática, el Procesado de
Datos y el Diseño Óptimo de Experimentos. Esto es un complemento ne-
cesario para las ciencias físicas, químicas y biológicas, entre otras ciencias
experimentales, con el objetivo de maximizar la información obtenida de
un experimento.
Así pues un experimento se realiza con el objetivo de obtener informa-
ción a partir del estudio de un número limitado de observaciones. Interesa
que las observaciones analizadas proporcionen una información suciente y
representativa acerca del fenómeno. A primera vista se aprecia que dicha
abilidad crece con el aumento de casos observados, y es cierto, pero en la
práctica, este número se ve limitado por factores económicos, temporales,
de falta de recursos, etc. Además, el tratamiento estadístico de los datos se
complica con el aumento de muestras tomadas.
De lo dicho anteriormente se desprende la necesidad de optimizar los re-
sultados nales empleando para ello las observaciones experimentales opor-
tunas y estrictamente necesarias. El Diseño Óptimo de Experimentos, como
su propio nombre indica, tratará de diseñar un experimento de forma que
se alcance la inferencia estadística más precisa posible con el mínimo coste.
Ya que el objetivo es conocer el comportamiento de un sistema real,
el modelo ha de considerar las características y valores que van a ser ob-
servados, normalmente medidos, en magnitudes físicas. Cuando jamos el
modelo, es necesario expresar el objetivo del experimento, dejando claro
cuáles son las necesidades del futuro usuario del diseño.
El objetivo de maximizar la información obtenida del experimento no
es suciente para la obtención del diseño óptimo, la teoría presenta varios
criterios de optimización entre los que tendremos que elegir a la hora de
crear el diseño óptimo. Para ello es útil combinar las propiedades teóricas
del modelo junto con las experiencias prácticas del observador.

Modelos 3
Modelos
En el presente trabajo estamos principalmente interesados en expe-
rimentos donde el objetivo es conocer el comportamiento de un sistema
ajustándolo a una función o modelo. Estos modelos pueden ser polinómi-
cos o bien, como en nuestro caso, una función no lineal, que representa las
teorías de comportamiento de diferentes fenómenos o mecanismos.
La Estadística actúa como puente entre los modelos matemáticos y
los fenómenos reales, analizando las diferencias que proporcionan los datos
experimentales de los teóricos que se supondrían a partir de un modelo.
Mediante el experimento, obtenemos unas observaciones que nos van a
permitir ajustar la realidad, objeto de estudio, a un modelo. Dicho modelo
debe contener una descripción del estado del objeto observado. Los conjun-
tos de puntos observables se conocen como espacio del diseño. Los estados
de la naturaleza serán las posibles realizaciones del modelo que represen-
tarán a la realidad. Las observaciones hechas en los puntos que el diseño
haya seleccionado serán consideradas como variables aleatorias.
Cualquier teoría de experimentos ha de contar con una consideración
inicial de un modelo matemático. Existen una serie de ventajas de resumir
e interpretar los resultados de un experimento, o el comportamiento de un
fenómeno a través del ajuste a un modelo. Entre estas ventajas se encuentra
la de poder realizar una predicción de los resultados del experimento o de
las respuestas del fenómeno dentro de la region del diseño. Ahora bien,
la optimización del modelo nos puede llevar a la toma de muestras fuera
de la región experimental considerada. Estas extrapolaciones han de ser
tomadas con cautela y comprobado que las condiciones del modelo se siguen
vericando para esa nueva región experimental.
El Diseño Óptimo de Experimentos, está íntimamente ligado a los mo-
delos lineales, es decir, al análisis de la varianza, la regresión y el análisis de
la covarianza. Cuando el modelo es no lineal veremos las técnicas que nos
permiten trabajar con ellos y los inconvenientes que se nos presentan. El ob-
jetivo es lograr la mejor estimación posible de los parámetros desconocidos

4 Introducción
que aparecen en el modelo. Nuestro cometido será elegir adecuadamente los
puntos sobre los que realizar la prueba para que dichos estimadores, tengan
la menor varianza posible, tratando a la vez de minimizar las covarianzas.
La manera en que se va a hacer esto se verá más adelante.
Un estudio apropiado sobre el mejor diseño experimental mejora en
gran medida la estimación en los modelos de regresión.
La elección del modelo para la búsqueda del diseño óptimo es un pro-
blema abierto que no tiene solución general. Interesa buscar un diseño que
dé estimadores precisos para el modelo elegido y que simultáneamente pro-
porcione protección contra modelos inadecuados.
Etapas del Diseño Óptimo de Experimentos
El procedimiento recomendado para la obtención de un diseño óptimo
se puede esquematizar en tres etapas:
1. Elección del modelo para el experimento.
Deben determinarse cuales son las observaciones que pueden
ser tomadas.
Especicar las relaciones entre los parámetros desconocidos del
modelo y las variables observadas.
Determinar la precisión de las observaciones.
Plantear posibles linealizaciones, cambio de parámetros, repa-
rametrizaciones, etc. en el modelo.
Excluir a priori determinadas observaciones que aporten infor-
mación redundante.
2. Cálculo mediante técnicas analíticas o algorítmicas del diseño óp-
timo, eligiendo el criterio de optimización más adecuado.
Especicar el objetivo del experimento de la forma más clara y
precisa posible para así poder elegir o desarrollar el criterio de
optimización más adecuado.

Nota Histórica 5
Intentar calcular el diseño mediante métodos analíticos o itera-
tivos y obtener las estimaciones iniciales de los parámetros en
los casos que sean necesarias.
3. Análisis del diseño obtenido.
Calcular y comparar la eciencia del diseño respecto a los dise-
ños obtenidos mediante otros métodos y respecto a los diseños
utilizados tradicionalmente.
Considerar la posibilidad de realizar cambios en el diseño ópti-
mo con el objetivo de facilitar o hacer posible en la práctica la
obtención de las observaciones, siendo capaces de determinar
la devaluación de la eciencia del modelo y jando límites o
umbrales.
Estas etapas intentan esquematizar el proceso de creación de un diseño
óptimo para un experimento determinado junto con determinadas observa-
ciones que pueden ser tomadas en cuenta a la hora de su cálculo.
Nota Histórica
Hagamos una pequeña introducción histórica para situar el tema. El
primer trabajo en Diseño Óptimo de Experimentos fue publicado en el
año 1918 por Smith. Propuso un criterio para la regresión polinomial que,
más tarde, fue llamado G-optimización (Generalized Variance) por Kiefer
y Wolfovitz 1959. Sin embargo ha sido a partir de los años cincuenta cuan-
do se ha comenzado a trabajar en mayor medida en este tema. El punto
de arranque para el desarrollo de esta teoría fue la matriz de dispersión
o matriz de covarianzas, obtenida por el método de mínimos cuadrados,
cuya inversa es proporcional a la llamada matriz de información. El Diseño
Óptimo de Experimentos se desarrolla en dos corrientes paralelas. Por una
parte G. E. P. Box y sus seguidores (N. R. Draper, J. S. Hunter, Lucas,
Wilson y otros) basan su trabajo en la matriz de dispersión para valorar
la elección de los puntos de observación, y no emplean los llamados crite-
rios alfabéticos. Desde este punto de vista la generalización a funciones

6 Introducción
no polinómicas se hace problemática. Por otro lado, J. Kiefer propondrá
el empleo de funciones de la matriz de dispersión como posibles criterios
de optimización, desarrollando así la llamada teoría convexa de diseños
aproximados. La novedad estriba en considerar un diseño como medida de
probabilidad. Algunos de sus seguidores son Atwood, Covey-Crump, Silvey,
Fedorov, Karlin, Studden, Whittle, Wynn, etc.
En 1943 Wald establece el criterio de maximización del determinante
de la matriz de información. Más tarde Kiefer y Wolfovitz en 1960 le darán
el nombre de D-optimización (Determinant) y extenderán su utilización
al modelo de regresión más general. Es éste el más popular de todos los
criterios. En 1953, Cherno utiliza el teorema de Taylor para linealizar mo-
delos no lineales. Emplea para ello un valor inicial de los parámetros y el
criterio de la maximización de la traza de la matriz de información (A-
optimización, Average), que ya había utilizado Elfving (1952). El propio
Elfving aborda el problema de la optimización de una combinación lineal
de los parámetros introduciendo el criterio de c-optimización y proporcio-
nando incluso un método gráco para el cálculo del diseño c-óptimo. En
1955 Ehrenfeld establece un nuevo criterio de optimización que consiste
en maximizar el mínimo autovalor de la matriz de información, y que sea
llamado E-optimización (Eigenvalues). Son estos, entre otros, los llamados
criterios alfabéticos, por la denominación que se les ha ido dando.
Hoel (1958) comprueba en algunos casos, que los criterios de Smith
y de Wald dan los mismos resultados. Con esto se muestra precursor del
Teorema de Equivalencia que establecerán Kiefer y Wolfovitz en 1959.
Kiefer y Wolfovitz han contribuido en gran medida al diseño óptimo de
experimentos. A ellos se deben dos grandes resultados: la idea del diseño
como medida, como ya se ha comentado, y el Teorema de Equivalencia
entre los criterios de D y G-optimización. También proviene de ellos la
consideración del problema de optimización parcial cuando no interesa o
no es necesaria la optimización de todos los parámetros. Kiefer extiende el
Teorema de Equivalencia a esta situación.

Nota Histórica 7
Por esas fechas Box y Lucas (1959) aplicaron el criterio de D-optimi-
zación en modelos no lineales. Usando un argumento geométrico obtienen
diseños de m puntos para modelos de m parámetros. Demuestran que el
diseño D-óptimo maximiza el volumen del elipsoide de conanza de las
estimaciones de los parámetros.
De modo independiente Wynn (1970) y Fedorov (1972) son los primeros
en desarrollar un método general para la construcción del diseño D-óptimo.
Demuestran también que dicho algoritmo converge y dan un valioso proce-
dimiento para calcular la matriz de información y su inversa en cada paso
a partir de los cálculos hechos en el paso anterior. El libro de Fedorov es
publicado en ruso en 1969. Wynn (1970) publica un artículo con el desarro-
llo del algoritmo de construcción de diseños D-óptimos. Cuando en 1972 se
publica la traducción del libro de Fedorov hecha por Studden aparece en él
reejado básicamente el mismo algoritmo. Hoy día se admite la producción
independiente del algoritmo por los dos autores.
Box y Hunter en 1965 obtienen un algoritmo para la determinación
del diseño D-óptimo en el modelo no lineal. Se trata esencialmente de una
aplicación de la versión de los algoritmos sugeridos por Fedorov y Wynn a
partir del Teorema de Equivalencia. Draper y Hunter (1967), discutieron el
problema de seleccionar distribuciones de parámetros a priori con el objeto
de obtener diseños para modelos no lineales. Atkinson y Hunter (1968)
extendieron los resultados de Box y Lucas al caso en que el diseño toma
más de m puntos. Box (1968a; 1968b; 1969; 1970) da algunos resultados
adicionales para modelos no lineales.
Por su parte Silvey y Titterington en 1973 dan una interpretación geo-
métrica del diseño óptimo y plantean un algoritmo para obtener un diseño
D−óptimo en el espacio dual. El propio Titterington (1976) ahondará en
los aspectos geométricos del D-óptimo. Whittle (1973) generaliza el Teo-
rema de Equivalencia para cualquier función criterio convexa, y al mismo
tiempo White (1973) lo extiende a diseños para modelos no lineales. Kie-
fer (1974) da resultados de equivalencia para otros criterios. Wu y Wynn

8 Introducción
(1978) dan condiciones generales para la convergencia de los algoritmos
para la obtención del diseño óptimo.
Hill (1980) demostró que si un modelo no es lineal en alguno de los pará-
metros, entonces el diseñoD-óptimo no depende del valor de los parámetros
en que es lineal. Currie (1982) compara diversos diseños para estimar los
parámetros en la ecuación de Michaelis-Menten, frecuentemente utilizada
en cinética de enzimas. Abdelbasit y Placket (1983) trabajan con modelos
de regresión logística y obtienen diseños que maximizan la información so-
bre los parámetros en el modelo. Otros desarrollos interesantes se deben a
Atkinson (1982) y Pázman (1980), entre otros.
El artículo de Ash y Hedayat (1978) es una amplia recopilación de la
bibliografía sobre diseño óptimo hasta ese momento. Una buena introduc-
ción al tema la hacen John y Draper en 1975. Los libros de Fedorov (1972),
Silvey (1980), Pázman (1986) y los más recientes de Atkinson y Donev
(1992) y Pukelsheim (1993) son un buen compendio de los resultados más
importantes obtenidos hasta esos momentos. En 1985 se publicó un libro
recogiendo una colección de artículos de Kiefer sobre diseño óptimo de ex-
perimentos (Brown et al., 1985). Dicha colección es de un inestimable valor
para los investigadores en esta materia. A la memoria de Kiefer está tam-
bién dedicado el libro de Shah y Sinha (1989). Entre los de más reciente
aparición destacar el de Schwabe (1996), que se centra en modelos multi-
factoriales, y el de Fedorov y Hackl (1997), donde se introducen temas y
modelos de interés en la investigación actual en diseño óptimo. En España
resaltar la aparición del libro de Rodríguez Torreblanca y Ortíz Rodríguez
(1999), el que posiblemente sea el primer volumen en español dedicado
íntegramente a Diseño Óptimo de Experimentos.
La teoría general del diseño se ha desarrollado inicialmente para mode-
los lineales. Para modelos no lineales se complican los métodos para obtener
los diseños óptimos y hay que realizar algunas modicaciones como las ya
anteriormente citadas de Box (1968a) y las posteriores de Ford, Tittering-
ton y Kitsos (1989) y Khuri y Lee (1998).

Nota Histórica 9
Entre las monografías más recientes dedicadas al diseño cabe destacar
la aplicación de los métodos algebraicos al diseño de experimentos por
parte de Pistone, Riccomagno y Wynn (2000) y el enfoque funcional por
parte de Melas (2005) que está formado por un compendio de los trabajos
del autor durante las dos últimas décadas. Además la aplicación de esta
disciplina a ramas aplicadas de la ciencia cobra cada vez más fuerza por
el interés de reducir costes en la realización de experimentos sin renunciar
a la eciencia en los procesos de inferencia estadística. Una colección de
trabajos aplicados a los campos de la Biología, Epidemiología, Medicina,
entre otros, ha sido recogida por Berger y Wong (2005).
Destacar la celebración periódica desde el año 1987, cada tres años, de
una reunión de carácter internacional con el objetivo de reunir a investiga-
dores de todo el mundo que trabajan en el campo del diseño óptimo. Los
trabajos presentados en estas reuniones han sido publicados y forman un
resumen de los avances de los investigadores más punteros en este ámbito.
La última de estas reuniones, mODa8, se ha celebrado en el año 2007 en Al-
magro (España), bajo el auspicio de la Universidad de Castilla-la Mancha
(López-Fidalgo et al., 2007a).
El uso de la informática en los diversos campos de la estadística supone
un avance considerable. En particular, en el Diseño Óptimo de Experimen-
tos, entre los primeros que investigan sobre esto están Box y Hunter (1965)
para modelos no lineales. La ayuda del ordenador fue estimulada con el
n de conseguir diseños óptimos exactos en N pruebas. El algoritmo infor-
mático más popular es DETMAX, desarrollado por Mitchell (1974) para
la búsqueda de diseños D-óptimos. En 1980, Galil y Kiefer hacen algunas
modicaciones. Welch (1982) desarrolla un nuevo programa más completo.
Más tarde Atkinson y Donev (1992) proponen un programa en FORTRAN
para diseños exactos. Paralelamente en 1974, Snee y Marquardt desarro-
llan el programa XVERT para el diseño óptimo en mixturas de modelos.
En 1983, Nigam y Gupta proponen una nueva versión de este algoritmo.
Hardin y Sloane crean en 1994 el programa GOSSET, capaz de buscar dise-
ños óptimos respecto de algunos criterios muy utilizados para los modelos

10 Introducción
polinómicos de grados bajos, con multitud de variables de tipos distintos y
restricciones de varias clases. En 1995, Rasch y Darius realizan una revisión
de los programas que se pueden utilizar para distintos aspectos del dise-
ño, tanto creados especícamente para este objetivo como formando parte
de otros paquetes más generales. El programa SAS incluye en sus últimas
versiones un módulo dedicado al cálculo de diseños óptimos, el trabajo de
Atkinson, Donev y Tobias (2007) presenta la teoría del Diseño Óptimo de
forma paralela al desarrollo de la misma usando SAS.

Capítulo 1
Diseño Óptimo
La Estadística actual, fruto de la unión del Cálculo de Probabilidades,
cuyo objetivo era el estudio de los juegos de azar, y de la Estadística,
centrada en la descripción de datos, actúa como puente entre los modelos
matemáticos y los fenómenos reales. Mediante ella y el uso de métodos
matemáticos, se modeliza un fenómeno natural. Para ajustar el modelo, se
lleva a cabo un experimento, se analizan los datos obtenidos y se mejora la
estrategia experimental generando un diseño óptimo.
Las ciencias experimentales (Física, Química, Biología, Medicina, So-
ciología,...) basan sus resultados nales en esta base matemática, y como
tal, su importancia no ha dejado de crecer paulatinamente hasta hacerse
casi indispensable en la mayoría de las disciplinas actuales.
En algunos problemas de Estadística se tiene cierto control sobre el
lugar y la proporción de datos experimentales que se van a recoger. Estos
problemas, en los que el experimentador puede elegir, al menos hasta cierto
punto, el experimento concreto que se va a llevar a cabo, se llaman pro-
blemas de Diseño de Experimentos. El diseño de experimentos y el análisis
estadístico de los datos están estrechamente relacionados: para diseñar ade-
cuadamente un experimento conviene tener en cuenta el análisis estadístico
que se realizará con los datos que se van a obtener, y no se debería llevar a
11

12 1. Diseño Óptimo
cabo un análisis estadístico de datos experimentales sin considerar el tipo
concreto de experimento del cual se obtienen los datos.
El Diseño Óptimo de Experimentos está íntimamente ligado a los mo-
delos lineales: al análisis de la varianza, la regresión y el análisis de la
covarianza. El objetivo es lograr la mejor estimación posible de los paráme-
tros desconocidos que aparecen en el modelo. En determinadas situaciones
es necesario el uso de modelos no lineales, preriéndose éstos a sus lineali-
zaciones, sobre todo en el caso en el que dejan de vericarse determinadas
hipótesis acerca del error (Ruppert et al., 1989).
1.1. Modelos de Regresión
En distintas ocasiones nos encontramos ante el hecho de intentar ex-
presar una variable y en función de otra u otras x1, . . . , xm. Esto se podría
escribir de la forma
y = η(x, θ) + ε,
donde θ representa un conjunto de parámetros desconocidos cuya especi-
cación determina completamente la función η, llamada supercie de res-
puesta. La hipótesis habitual es que se verica E[ε] = 0, siendo ε el error.De una manera alternativa el modelo se puede escribir
E[y] = η(x, θ).
La elección de la función η es esencial a la hora de construir el mode-
lo. Por un lado, x representa las condiciones experimentales que pueden
ser elegidas por el experimentador, a partir de un dominio experimental
X, también llamado espacio del diseño. Por otro lado, θ es un vector de
parámetros de un dominio Θ, desconocidos para el experimentador. El ex-
perimentador controla x, mientras que la naturaleza determina θ. El tér-
mino de error en el modelo puede englobar desde los errores al realizar las
medias hasta los errores debidos a la especicación del modelo. Debido a

1.2. Método de los Mínimos Cuadrados Generalizados 13
este error aleatorio, repetir experimentos nos lleva generalmente a diferen-
tes respuestas observadas incluso si las condiciones experimentales son las
mismas.
La situación más simple que podría darse es un modelo lineal
y = f t(x) θ + ε,
con f t(x) = (f1(x), . . . , fk(x)) y θt = (θ1, . . . , θk). La linealidad se reere
respecto de los parámetros θ.
Ahora bien, no todas las situaciones presentes en la naturaleza o nece-
sarias de una tarea de modelización siguen modelos lineales. Muchos fenó-
menos son modelizados mediante modelos no lineales en los que la variable
respuesta y depende de θ a través de una relación funcional del tipo
y = η(x, θ) + ε,
donde la función respuesta η es una función no lineal respecto del vector
de parámetros θ.
Una ventaja de los modelos no lineales es que acostumbran a tener
menos parámetros que modelos equivalentes de naturaleza polinómica y la
extrapolación a valores fuera del rango de valores muestreados, raramente
produce predicciones excesivamente erróneas. Como desventaja destacare-
mos la dependencia, en los diseños óptimos calculados para estos modelos,
de los propios parámetros.
1.2. Método de los Mínimos Cuadrados Generalizados
Parece ser que fue descubierto independientemente por Gauss1 y Le-
gendre2 y apareció por primera vez publicado por Legendre en 1805. Una
de sus primeras aplicaciones fue en el cálculo de órbitas de planetas.
El método, tal y como es usado hoy en día en Estadística, es el siguiente:
1Karl Friedrich Gauss (1777-1855).2Adrien Marie Legendre (1752-1833).

14 1. Diseño Óptimo
Consideremos un modelo general
y = η(x, θ) + ε,
siendo Σε la matriz de covarianzas de los errores.
La suma de cuadrados de los errores ponderada por la matriz de
covarianzas de las observaciones es entonces
εtΣ−1ε ε = [y − η(x, θ)]tΣ−1
ε [y − η(x, θ)].
El estimador mínimo cuadrático de θ es el valor θ que al ser sustituido
en la ecuación anterior minimiza εtΣ−1ε ε. Habitualmente se puede calcular
derivando la ecuación respecto de θ e igualando a cero.
En el caso lineal, detallado en el apartado anterior, y considerando el
caso de observaciones incorreladas, la solución tiene las siguientes propie-
dades:
Es un estimador de θ que minimiza la suma generalizada de cuadra-
dos de los errores, sean cuales sean las propiedades de la distribución
de éstos.
Los elementos de θ son funciones lineales de las observaciones y1,
. . . ,yN , y proporcionan estimadores centrados de θ con varianza
mínima, entre todas las funciones lineales de las observaciones que
proporcionan estimadores centrados, sea cual sea la distribución de
los errores.
Si los errores se distribuyen normalmente con media 0 y varianza
constante σ2, entonces θ es el estimador máximo verosímil de θ.
Esto es debido a que la función de verosimilitud para la muestra
sería en este caso
f(y1, . . . , yN ) =1
σn(2π)n/2exp
− 1
2σ2εtε
.
Así que para un valor jo de σ, maximizar la función de verosimi-
litud equivale a minimizar la suma generalizada de cuadrados de

1.3. Contexto del Diseño Óptimo 15
los errores. Esto es una buena justicación del empleo del procedi-
miento de mínimos cuadrados.
En los modelos no lineales suele ser necesario recurrir a algoritmos
numéricos, como el de Levenberg-Marquardt (Levenberg, 1944; Marquardt,
1963).
Si hemos utilizado el método de mínimos cuadrados para estimar θ por
θ, estén los errores distribuidos normalmente o no, tenemos los siguientes
resultados:
El vector de residuales es ε = y − y
En el caso del modelo lineal con varianza constante σ2, la ma-
triz de covarianzas de los estimadores de los parámetros es Σβ =(XtX)−1σ2. La varianza σ2 se puede estimar por máxima verosimi-
litud, y desde el punto de vista del diseño óptimo de experimentos
se puede eliminar sin más que introducirla en el modelo, incluso
aunque no sea constante.
1.3. Contexto del Diseño Óptimo
En lo que sigue utilizaremos modelos de regresión con observaciones
incorreladas. El modelo vendrá determinado por los integrantes que des-
cribimos a continuación. En primer lugar hemos de especicar el conjunto
de puntos observables, donde valoran las llamadas variables controlables.
Dicho conjunto recibe el nombre de espacio del diseño o dominio experi-
mental y será denotado por X. En la práctica el espacio X va a ser un
subconjunto compacto de un espacio euclídeo (con frecuencia un intervalo
de la recta real). Por este motivo no constituye restricción grave suponer
desde ahora en adelante que dicho conjunto es compacto.
Entenderemos por estado, ϑ, una función que asigna a cada punto de
X el promedio de las cantidades y(x) observadas en él. Estas cantidades
son variables aleatorias que dependen de la inestabilidad de las condiciones

16 1. Diseño Óptimo
siendo su varianza conocida:
σ2(x) = E(y(x)− E[y(x)]2),
mientras que la esperanza es parcialmente desconocida:
ϑ(x) = E[(y(x)] = η(x), x ∈ X.
Un buen diseño tratará de reducir al mínimo la inuencia de la inestabilidad
de las condiciones. También se podría expresar:
y(x) = η(x) + εx, x ∈ X, E(εx) = 0.
La función η se conoce como supercie respuesta o función de regresión.
Habitualmente supondremos que dicha función es parcialmente conocida,
es decir, que está dentro de un conjunto paramétrico de funciones:
η(x) = η(x, θ),
donde los parámetros θt = (θ1, . . . , θm) ∈ Rm son desconocidos y su especi-
cación determina totalmente a η. Del mismo modo, la varianza podría ser
parcialmente conocida, dependiente de estos mismos parámetros u otros,
que se introducirían en el modelo para la búsqueda del diseño óptimo.
1.4. Diseños Exacto y Aproximado
Si de antemano suponemos que el número de observaciones que pode-
mos realizar es N , llamaremos diseño de tamaño jo o diseño exacto de
tamaño N a una sucesión de N puntos de X, x1, . . . , xN , donde eventual-
mente podrían coincidir algunos de ellos. Con el objeto de no repetir puntos
denotaremos por Nx el número de observaciones realizadas en el punto x.
Podemos entonces asociar a este diseño la medida de probabilidad discreta:
ξ(x) =Nx
N, x ∈ X.
Esto sugiere una denición más general de diseño aproximado o asintó-
tico como una medida discreta de probabilidad, ξ, en X con soporte nito.

1.5. Estimadores de Funcionales Lineales 17
Cabría aún una denición más general del diseño como una medida de
probabilidad cualquiera, en cuyo caso aparecerían también diseños conti-
nuos (Atkinson y Donev, 1992). Aunque en ocasiones estos diseños podrían
ser poco viables en la práctica, son convenientes para demostrar ciertas pro-
piedades. Además eligiendoN sucientemente grande, podremos aproximar
un diseño de estas características a uno exacto, tomando un número cercano
a N · ξ(x) observaciones en el punto x. Por supuesto estas aproximaciones
proporcionan diseños tanto mejores cuanto mayor sea N , resultando peli-
grosas para tamaños pequeños. Con respecto a su eciencia véase Imhof,
López-Fidalgo y Wong (2001), que extienden los diseños exactos conocidos
en regresión polinomial y dan cotas de eciencia para diseños aproximados
redondeados con métodos tradicionales (Pukelsheim, 1993). El programa
BAZI3 permite realizar estos redondeos mediante diferentes métodos lo-
grando que el diseño exacto obtenido sea el de mayor eciencia respecto al
aproximado considerado.
El diseño concentrado en los puntos x1, ..., xN , con pesos respectivos
p1, ..., pN (0 ≤ pi ≤ 1 para i = 1, ..., N ;∑N
i=1 pi = 1) se denotará por
ξ =
(x1 ... xN
p1 ... pN
)y el peso de un punto xk, se denotará también como ξ(xk) = pk.
El soporte de un diseño ξ será:
Xξ = x ∈ X : ξ(x) > 0.
1.5. Estimadores de Funcionales Lineales
En muchas ocasiones va a resultar más interesante estimar determina-
das relaciones entre los parámetros que estimar cada uno de ellos. Esto
sugiere la denición de funcional lineal, g, como una función lineal del es-
pacio de estados en la recta real:
g : Θ −→ R.
3http://www.math.uni-augsburg.de/stochastik/bazi

18 1. Diseño Óptimo
Supondremos que la aplicación g tiene como matriz asociada en la base
f1, . . . , fm de Θ, el vector ct = (c1, . . . , cm). Es decir, dado un estado:
ϑ(x) =m∑i=1
θifi(x),
entonces g(θ) = θtc.
Buscaremos entonces una buena estimación de g(θ). Su valor será cal-
culado a partir de los datos experimentales, utilizando para ello una función
lineal de las variables respuesta:
N∑i=1
aiy(xi),
donde a1, . . . , aN son ciertos coecientes que habrá que determinar bajo
ciertas exigencias. A esta función se le llamará estimador lineal de g. Dire-
mos además que es un estimador centrado siempre que:
E
[N∑i=1
aiy(xi)
]= g(θ),
Diremos que g es estimable si existe al menos un estimador lineal cen-
trado de g. El mejor estimador lineal centrado será aquél que tenga mínima
varianza (BLUE, the Best Linear Unbiased Estimator), es decir, el estima-
dor:N∑i=1
a?i y(xi),
tal que:
V ar
[N∑i=1
a?i y(xi)
]= mın
V ar
[atY
]:a ∈ RN ,E[atY
]= g(θ), θ ∈ Θ
.
En resumen, dicho estimador vendrá dado por los coecientes a?i tales que:
N∑i=1
a?2i σ2i = mın
N∑i=1
a2iσ
2i : A ∈ RN ,
N∑i=1
aiθ(xi) = g(θ), θ ∈ Θ
.
Nos interesa obtener una expresión explícita de estos coecientes.

1.6. Matriz de Información 19
1.6. Matriz de Información
Dado un diseño de tamaño jo N , utilizaremos la siguiente notación:
Y = (y(x1), . . . , y(xN ))t,
θ = (θ1, . . . , θm)t,
X =
f1(x1) . . . fm(x1). . . . . . . . .
f1(xN ) . . . fm(xN )
.
Denición 1. La matriz de información de un diseño exacto x1, . . . , xN ,
se dene como la matriz:
M = XtΣ−1X,
donde Σ = diag(σ2(x1), . . . , σ2(xN )).
Generalizando para diseños aproximados o asintóticos.
Denición 2. Se dene la matriz de información asociada a un diseño
aproximado ξ como la matriz de orden m:
M(ξ) =∑x∈X
f(x)f t(x)σ−2(x)ξ(x)
Observación 1. La matriz de información de Fisher4, supuesta la norma-
lidad de las observaciones, coincidirá con la matriz de información denida
anteriormente:
M(ξ) = −Eξ[
∂2
∂αi∂αjlog l(y, θ, σ2)
]= Eξ
[∂ log l∂αi
∂ log l∂αj
],
donde l es la función de verosimilitud de la muestra. Esta denición será así
aplicable a modelos no lineales, pero entonces dependerá de los parámetros
que se quieran estimar.
Puede darse una denición análoga en cuanto a la matriz de información
de un diseño continuo. A partir de ahora utilizaremos solamente diseños
aproximados o asintóticos y los denominaremos simplemente diseños. Si ξ
4Ronald Aylmer Fisher (1890-1962).

20 1. Diseño Óptimo
es un diseño exacto x1, . . . , xN entonces, según esta nueva denición de
matriz de información asociada a un diseño, en general tendremos:
M(ξ) =1N
∑x∈X
fi(x)fj(x)σ−2(x)Nx =1NM
La ventaja de esta denición es que M(ξ) no depende del tamaño de la
muestra, N , sino de la proporción de observaciones en cada punto. Incluso,
si hay homocedasticidad, suele considerarse
M(ξ) =1
σ2NM,
de modo que no aparezca ningún parámetro en la matriz de información.
Denición 3. Sea A una matriz cualquiera de orden m. Se denen los
conjuntos siguientes:
M(A) = Au : u ∈ Rm
N (A) = u ∈ Rm : Au = 0,
que son los subespacios imagen y núcleo de la aplicación lineal asociada a
la matriz A.
Denotaremos por Ξ al conjunto de todos los diseños en el modelo, mien-
tras que el conjunto de todas las matrices de información será:
M = M(ξ) : ξ ∈ Ξ.
El conjunto M tiene en general una estructura más sencilla que el con-
junto Ξ. De hecho, como veremos en la siguiente proposición, M es un
subconjunto convexo de un espacio euclídeo, el de las matrices cuadradas
de orden m y simétricas. Además la varianza de un estimador será función
de la inversa generalizada de la matriz de información.
Nota: Dada una matriz cualquiera, A, diremos que A− es una inversa
generalizada (también llamada g-inversa o pseudoinversa) cuando AA−A =A. Otra denición equivalente a ésta es la siguiente: A− es una inversa
generalizada de A si A−u satisface la ecuación Ax = u para cada u de
M(A). La inversa generalizada existe siempre, pero en general no es única,

1.6. Matriz de Información 21
así A− denotará la clase de las inversas generalizadas de A. Si A es cuadrada
y regular entonces la inversa generalizada coincide con la matriz inversa.
Cuando la matriz A es simétrica, existe una g-inversa muy particular,
que se debe a Penrose, y que denotaremos por A+. Esta matriz es la única
que verica lo siguiente:
A+u =
0 si u ∈ N (A)wu si u ∈M(A)
donde wu es el único vector de M(A) tal que Awu = u. Por tanto A+
verica A+AA+ = A+ y AA+A = A, de modo que a su vez A es la g-
inversa de Penrose de A+.
Proposición 1. El conjuntoM es convexo.
Demostración: Sean ξ1, ξ2 ∈ Ξ y 0 < λ < 1, entonces:
(1− λ)M(ξ1) + λM(ξ2) = M [(1− λ)ξ1 + λξ2] ∈M.
Observación 2. En muchas ocasiones suponer, en el Diseño Óptimo de
Experimentos, que la varianza de las observaciones es uno, σ2(x) = 1, nosupone una pérdida de generalidad, sin más que sustituir σ−1(x)θ(x) y
σ−1(x)f(x) por θ(x) y f(x) respectivamente. En este caso la matriz de
información quedará:
M(ξ) =∑x∈X
f(x)f t(x)ξ(x).
En lo que sigue se supondrá siempre que σ2(x) = 1, salvo que se especiquelo contrario.
Proposición 2. Se verica que
1. La matriz de información es simétrica y semidenida positiva.
2. Si ξ tiene menos de m puntos en su soporte, entonces detM(ξ) = 0.

22 1. Diseño Óptimo
3. Se puede deducir la siguiente expresión explícita para el determi-
nante de la matriz de información:
detM(ξ) =∑
k1<...<km
ξ(xk1) · · · ξ(xkm) det[fi(xkj )]2.
Demostración:
1. La denición de la matriz de información muestra directamente
que se trata de una matriz simétrica. Además, sea u vector de Rm,
entonces:
utM(ξ)u =∑x∈X
utf(x)f t(x)uσ−2(x)ξ(x)
=∑x∈X‖ utf(x) ‖2 σ−2(x)ξ(x) ≥ 0.
Veremos más adelante que la inversa de la matriz de información
es proporcional a la matriz de covarianzas, que prueba directamente
la condición de denido positiva en el caso no singular.
2. Supongamos que ξ tiene en su soporte k < m puntos: x1, . . . , xk.
En el desarrollo del determinante aparecerán siempre al menos dos
columnas iguales y por tanto el determinante ha de ser cero.
3. Para simplicar supondremos que σ(x) = 1. En primer lugar tra-
taremos el caso en el que el soporte se reduce a m puntos, Xξ =x1, . . . , xm. Llamaremos:
mij =∑xk∈Xξ
fi(xk)fj(xk)ξ(xk),
aik = fi(xk)ξ(xk), bjk = fj(xk).
Denotando A = (aik) y B = (bjk) tendremos la siguiente expresión:
detM(ξ) = detAdetB =m∏k=1
ξ(xk) det[fi(xj)]2.

1.6. Matriz de Información 23
En el caso más general en que Xξ = x1, . . . , xr con r ≥ m ten-
dremos:
detM(ξ) = det [∑r
k=1 fi(xk)fj(xk)ξ(xk)]=
∑τ∈Sr det
[fi(xτ(j))fj(xτ(j))ξ(xτ(j))
]=
∑τ∈Sr
∏mk=1 ξ(xτ(j)) det[fi(xτ(j))]2
=∑
k1<...<kmξ(xk1) · · · ξ(xkm) det[fi(xkj )]2,
donde hemos llamado Sr al grupo simétrico de las permutaciones de
orden r. La tercera igualdad se ha obtenido a partir de la anterior.
La expresión del determinante para m puntos era bien conocida.
La fórmula más general que se proporciona aquí se debe a Ardanuy
et al. (1999).
Proposición 3. Se cumplen las siguientes propiedades:
1. g es estimable para el diseño ξ si, y sólo si c ∈M[M(ξ)]. Entoncesexiste un único vector zg ∈M[M(ξ)] de modo que c = M(ξ)zg. Lavarianza del BLUE es:
V ar(g) = N−1ztgM(ξ)zg= N−1ctM−(ξ)c
= N−1 sup (ctα)2
αtM(ξ)α : α ∈ Rm,M(ξ)α 6= 0= N−1 sup2ctα− αtM(ξ)α : α ∈ Rm.
2. Si g1 y g2 son funcionales estimables, entonces:
Cov(g1, g2) = N−1ct1M−(ξ)c2,
Observación 3. Estas expresiones no dependen de la g-inversa elegida.
En efecto, denotando A = M(ξ), si c ∈ M[M(ξ)] existe z tal que c = Az,
luego
ctA−c = ztAA−Az = ztAz,
que no depende de A−. Del mismo modo, si c1, c2 ∈M[M(ξ)] existirán z1,
z2 tales que
ct1A−c2 = zt1Az2,
que de nuevo no depende de la inversa generalizada elegida A−.

24 1. Diseño Óptimo
Observación 4. La denición general de funcional estimable hacía refe-
rencia a un diseño exacto. Así ha de entenderse la proposición anterior.
Estos resultados sugieren la siguiente denición:
Denición 4. Dado un diseño ξ y un funcional g, se dene la varianza
generalizada de g respecto del diseño ξ como:
V arξg = sup
(ctα)2αtM(ξ)α
: α ∈ Rm,M(ξ)α 6= 0,
que puede también escribirse de la forma:
V arξg =
ctM−(ξ)c si c ∈M[M(ξ)]∞ si c 6∈ M[M(ξ)]
.
Y se dene la covarianza generalizada de dos funcionales g1 y g2 respecto
de ξ como:
Covξ(g1, g2) = ct1M−(ξ)c2.
Estamos interesados en buscar ξ de manera que se hagan pequeñas
las varianzas y covarianzas de este tipo. A este n van encaminadas las
siguientes proposiciones, cuya demostración por brevedad se omite (véase
Pázman (1986) para más detalles).
Proposición 4. Si M(ξ) ≥ M(η), es decir M(ξ)−M(η) es semidenidopositiva, entonces V arξg ≤ V arηg cualquiera que sea el funcional lineal
g denido en el espacio de estados. Recíprocamente, si V arξg ≤ V arηg
entonces se cumple que:
M[M(ξ)] ⊃M[M(η)] y utM(ξ)u ≥ utM(η)u, u ∈M[M(η)].
Proposición 5. M(ξ) = M(η) si, y sólo si V arξg = V arηg, para cada
funcional lineal, g, denido en el espacio de estados.
Proposición 6. Si M(ξ) y M(η) son regulares, entonces:
M(ξ) ≥M(η)⇐⇒ V arξg ≤ V arηg, para cada funcional g.
Además:
M(ξ) > M(η)⇐⇒ V arξg < V arηg, para cada funcional g 6= 0.

1.6. Matriz de Información 25
Proposición 7. Si λ1(ξ) ≤ · · · ≤ λm(ξ) son los autovalores de M(ξ),entonces:
k∑i=1
λi(ξ) ≥k∑i=1
λi(η), k = 1, . . . ,m⇐⇒ V arξg ≤ V arηg, para cada g.
k∑i=1
λi(ξ) >k∑i=1
λi(η), k = 1, . . . ,m⇐⇒ V arξg < V arηg, para cada g 6= 0.
Teorema 1 (Caratheodory5). Sea T un subconjunto de un espacio euclídeo
de dimensión k. Todo punto del cierre convexo de T :
conv(T ) = z =n(z)∑i=1
βiti : βi ∈ [0, 1],n(z)∑i=1
βi = 1, ti ∈ T
puede ser expresado como una combinación convexa de a lo sumo k + 1puntos del conjunto T . Es decir, dado un elemento q de conv(T ), existirán
t1, . . . , tk+1 ∈ T y γ1, . . . , γk+1 ∈ [0, 1] conk+1∑i=1
γi = 1
tal que:
q =k+1∑i=1
γiti
Proposición 8. Si T es un conjunto acotado de Rk entonces conv(T ) escompacto en Rk.
Colorario 1. M es compacto.
Demostración: Denimos:
S = f(x)f t(x) : x ∈ X,
que es imagen de X por la aplicación continua:
X −→ Rm×m | x −→ f(x)f t(x),
y por tanto S es también compacto. Por la Proposición anterior M =conv(S) también lo será.
5Constantin Carathéodory (1873-1950).

26 1. Diseño Óptimo
Damos a continuación un resultado, muy interesante en cuanto a la
búsqueda del diseño óptimo más sencillo, basado en el Teorema de Carat-
heodory, y que es debido a Karlin y Studden (1966), pág. 787.
Proposición 9. Dado un diseño cualquiera ξ existe otro diseño η tal que
M(ξ) = M(η) y cuyo soporte tiene a lo sumo m(m+ 1)/2 + 1 puntos.
Demostración: Denimos el vector:
a(x) = (fi(x)fj(x) : 1 ≤ i ≤ j ≤ m)
A todo elemento de conva(x) : x ∈ X se le puede asociar una matriz de
información unívocamente. Por el Teorema de Caratheodory para el diseño
ξ existirá entonces:
γk ∈ [0, 1] y xk ∈ X, k = 1, . . . ,m(m+ 1)
2+ 1,
de modo que deniendo:
ξ =
(x1 x2 · · ·γ1 γ2 · · ·
),
se obtiene la matriz de información:
M(ξ) =
m(m+1)2
+1∑k=1
γkf(xk)f t(xk).
1.7. Criterios de Optimización
¾Qué queremos decir con diseño óptimo de un experimento? ¾Cómo
entender la expresión el mejor de los diseños posibles? Estas preguntas no
tienen una respuesta unívoca. Si bien es verdad que nos interesará el diseño
que haga mínima la varianza, también es cierto que un diseño puede hacer
mínima la varianza para un funcional lineal, y excesivamente grande para
otro.
Necesitamos por tanto elegir un criterio que sirva para buscar el me-
jor diseño en algún sentido. Su elección dependerá de los intereses que se

1.7. Criterios de Optimización 27
busquen al realizar el experimento, de la facilidad de cálculo, o de otros as-
pectos más o menos subjetivos. Vamos a dar ahora una primera denición
de lo que va a ser una función criterio.
Denición 5. Diremos que una función
Φ :M−→ R ∪ +∞
acotada inferiormente es una función criterio si se cumple lo siguiente:
M(ξ) ≥M(η) =⇒ Φ[M(ξ)] ≤ Φ[M(η)].
Diremos entonces que se trata de un criterio de Φ-optimización. Undiseño que minimice Φ[M(ξ)] se denominará diseño Φ-óptimo y lo denota-
remos por ξ?. El objeto del problema de diseño óptimo consistirá en calcular
un diseño ξ? que minimice Φ[M(ξ)].
Entre las propiedades que sería deseable que vericase una función cri-
terio podemos destacar:
1. Convexidad de la función criterio,
Φ[(1− α)M(ξ1) + αM(ξ2)] ≤ (1− α)Φ[M(ξ1)] + αΦ[M(ξ2)], α ∈ [0, 1].
Esta propiedad es necesaria para que el criterio sea sensible a los
métodos de optimización convexos y para que se verique el Teo-
rema de Equivalencia que consideraremos más adelante.
2. Positivamente homogénea en el sentido
Φ[δM(ξ)] =1δ
Φ[M(ξ)], δ ≥ 0.
Esta propiedad nos permitirá trabajar con M−1(ξ) en lugar deσ2
n M−1(ξ) que es la verdadera matriz de covarianzas de los esti-
madores de los parámetros del modelo. También permitirá dar una
medida apropiada de la eciencia de un diseño respecto de un cri-
terio, concepto que se usará mas adelante para comparar diseños.

28 1. Diseño Óptimo
Las funciones criterio que verican estas propiedades son las que más
nos interesan. A veces son precisas algunas otras condiciones para garanti-
zar la convergencia de algoritmos de cálculo.
Observación 5. Puede ocurrir que dos funciones criterio den lugar a un
mismo criterio de optimización, es decir, que produzcan los mismos diseños
óptimos. Es precisamente lo que demostrará el Teorema de Equivalencia
para algunos criterios que veremos más adelante. Desde luego, dado un
diseño óptimo, todos los diseños que tengan asociada esa misma matriz
de información serán óptimos. Pero también otras matrices de información
podrían corresponder a diseños óptimos. Algunos criterios permitirán esto,
otros no.
Por el Teorema de Caratheodory siempre existirá un diseño óptimo con
1 +m(m+ 1)/2 puntos o menos en su soporte. Para los criterios globales,
las matrices óptimas deben ser regulares, de modo que por la Proposición
2 un diseño óptimo ha de tener al menos m puntos en su soporte.
Notación 1. Llamaremos M+ = M ∈ M : detM > 0. L(M) es el
subespacio vectorial generado por el conjuntoM en el espacio vectorial de
las matrices simétricas de orden m . Si Φ es una función criterio denimos
los conjuntos:
MΦ = M ∈M : Φ(M) <∞,
Ξ?Φ = ξ ∈ Ξ : ξ es Φ-óptimo.
Proposición 10. Si Φ es una función convexa entonces el conjunto Ξ?Φ es
convexo.
Demostración: Supongamos que:
Φ[M(ξ1)] = Φ[M(ξ2)] = mınξ∈Ξ
Φ[M(ξ)],
entonces, por ser Φ convexa tendremos:
ΦM [(1− β)ξ1 + βξ2] = Φ(1− β)M(ξ1) + βM(ξ2)≤ (1− β)Φ[M(ξ1)] + βΦ[M(ξ2)]= mınξ∈Ξ Φ[M(ξ)].

1.7. Criterios de Optimización 29
Denición 6. Se dice que Φ es una función criterio estrictamente decre-
ciente cuando las condiciones M ≥ N y M 6= N implican Φ(M) < Φ(N).
Proposición 11. Si Φ es una función criterio estrictamente decreciente
entonces siempre se puede conseguir que el número de puntos del diseño
Φ-óptimo esté comprendido entre m y m(m+ 1)/2.
Demostración: La cota inferior es consecuencia inmediata de la Pro-
posición 2. En efecto, por el Teorema de Caratheodory sabemos que si ξ es
un diseño tal que M(ξ) está en la frontera deM entonces existen no más
de m(m + 1)/2 diseños unipuntuales de modo que M(ξ) se puede poner
como combinación convexa de ellos. En otras palabras, existe un diseño,
η, con soporte en no más de m(m + 1)/2 puntos tal que M(ξ) = M(η).Si demostramos que todo diseño Φ-óptimo, ξ?, tiene su matriz asociada
en la frontera de M, entonces habremos probado lo que queríamos. Su-
pongamos que no es así, y que M(ξ?) es un punto interior del conjunto
M. Existirá entonces un número positivo α tal que la matriz de informa-
ción (α + 1)M(ξ?) = M(µ) sigue estando en el conjunto M. Ahora bien
Φ[M(µ)] = Φ[(α+1)mM(ξ?)] < Φ[M(ξ?)] (ya que (α+1)mM(ξ?) ≥M(ξ?)y son distintas), que es contradictorio con el hecho de que ξ? es un diseño
Φ-óptimo.
Notación 2. En lo que sigue denotaremos indistintamente Φ[M(ξ)] ó Φ(ξ).
Denición 7. Se dene la eciencia de un diseño ξ respecto de una función
criterio positivamente homogénea Φ como
effΦ(ξ) =Φ(ξ?)Φ(ξ)
,
donde ξ? es el diseño óptimo para el criterio Φ.
Observación 6. En términos prácticos, supongamos que el diseño ξ es
ahora un diseño exacto de tamaño N . Hemos visto que NM(ξ) = M , de
modo que Φ[M(ξ)] = NΦ(M). Así, para conseguir una misma eciencia
con ambos diseños tendríamos que tomar N? observaciones con el diseño

30 1. Diseño Óptimo
ξ?, de modo que
1 =Φ(M?)Φ(M)
=NΦ(ξ?)N?Φ(ξ)
⇔ N?
N= effΦ(ξ).
Así por ejemplo, si la eciencia de un diseño es del 50% entonces bastará
tomar la mitad de observaciones con el diseño óptimo para obtener la misma
precisión que con el diseño original.
Presentamos ahora la denición de gradiente de una función criterio,
necesaria para algunas propiedades de los casos particulares que presenta-
remos a continuación.
Denición 8. Sea Φ una función denida en un entorno de la matriz A
en el espacioMm(R). Se dene el gradiente de Φ en la matriz A como la
matriz de componentes:
5Φ(A)ij =∂Φ(A)∂Aij
; i, j = 1, . . . ,m
Damos a continuación la denición de las funciones criterio utilizadas
en el desarrollo del presente trabajo. Para una relación más completa de di-
ferentes criterios, deniciones y proposiciones se pueden consultar Pázman
(1986) y Rodríguez-Díaz (2000).
1.7.1. D-optimización.
Denición 9. El criterio de D-optimización viene denido por la función
criterio siguiente:
ΦD[M(ξ)] =
log detM−1(ξ) = − log detM(ξ) si detM(ξ) 6= 0∞ si detM(ξ) = 0
Proposición 12. Se verica
1. ΦD es continua enM.
2. La función ΦD es convexa enM y estrictamente convexa enM+.

1.7. Criterios de Optimización 31
3. En las matrices en que ΦD es nita, también es diferenciable. Ade-
más su gradiente es:
5[− log detM ] = −M−1
Observación 7. La gran ventaja de esta función criterio radica en la fa-
cilidad de cálculo respecto al resto. Tiene además una sencilla e intuitiva
interpretación geométrica, ya que las longitudes de los ejes del elipsoide
de conanza de las estimaciones de los parámetros del modelo son pro-
porcionales a las raíces cuadradas de los valores propios de la matriz de
covarianzas. En otras palabras, el diseño D-óptimo, al minimizar el deter-
minante de la matriz de información, minimiza el volumen de la región de
conanza de los parámetros (véase por ejemplo Atkinson y Donev (1992),
pág. 42 y 48-53). También suele considerarse este criterio en la forma:
Φ[M(ξ)] = detM−1m (ξ).
De este modo se consigue homogeneidad, que permite el uso adecuado de la
eciencia. El logaritmo en la denición del criterio permite dar una prueba
más sencilla de la convexidad y proporciona un gradiente más simple.
1.7.2. G-optimización.
Denición 10. El criterio de G-optimización viene denido por la función
criterio siguiente:
ΦG[M(ξ)] = supx∈X
Varξgx, ξ ∈ Ξ.
Puesto que:
gx(θ) = θ(x), x ∈ X, θ ∈ Θ.
entonces:
Varξgx = f t(x)M−1(ξ)f(x),
cuando M(ξ) es regular. De modo que nuestra función puede escribirse de
la forma:
ΦG[M(ξ)] =
maxx∈X f t(x)M−1(ξ)f(x) si detM(ξ) 6= 0∞ si detM(ξ) = 0

32 1. Diseño Óptimo
Proposición 13. La función ΦG es:
1. continua enM.
2. convexa enM y estrictamente convexa enM+.
Observación 8. Para cada x, Varξgx es la varianza generalizada de la
predicción de la respuesta en x. Por tanto, este criterio busca optimizar la
predicción del modelo.
1.7.3. c-optimización.
Con este criterio el interés se centra en la estimación eciente de com-
binaciones lineales de los parámetros ctθ. De este modo se da la siguiente:
Denición 11. El criterio de c-optimización para un vector c de dimensión
m viene denido por la función criterio siguiente:
Φc[M(ξ)] = ctM−(ξ)c.
Se toma esta denición puesto que la varianza de ctθ es proporcional a
ctM−(ξ)c. La desventaja de los diseños c-óptimos es que son singulares con
cierta frecuencia. Elfving (1952) propone un método gráco para el cálculo
del diseño c-óptimo, aplicable sobre todo en el caso biparamétrico:
y = f(x)α+ g(x)β + ε(x), σ2(x) = σ2, x ∈ X.
El método es válido de forma genérica para cualquier dimensión, aunque la
dicultad para construir de forma gráca el conjunto de Elfving hace que
raramente sea usado para modelos con más de dos parámetros. López Fi-
dalgo y Rodríguez Díaz (2004) presentan un procedimiento computacional
para aplicar este método en casos de más de dos dimensiones.
Detallamos a continuación el procedimiento de Elfving para 2 paráme-
tros. Suponemos que se toma un diseño exacto cualquiera, ξ, concentra-
do en l puntos x1, . . . , xl, con pesos pi = Ni/N . Es decir, se toman Ni
observaciones en cada punto xi, siendo N el número total de observacio-
nes realizadas. Tenemos así l puntos del plano real denidos de la forma

1.7. Criterios de Optimización 33
X1 = (f(x1), g(x1)), . . . , Xl = (f(xl), g(xl)). La media de las observaciones
en cada punto xi tiene la siguiente ecuación de regresión:
yi = f(xi)α+ g(xi)β + εi
donde εi tiene varianza σ2/Ni. Denotemos ηi =√piεi, entonces Var(ηi) =
σ2/N . Por simplicidad de notación supondremos que σ2/N = 1, que no
signica ninguna merma en la generalidad de los resultados. De este modo
Var(ηi) = 1. Nos centraremos en estimadores de la forma ϕ =∑l
i=1 aiyi
(yi es el estimador lineal más eciente de f(xi)α + g(xi)β). Para que sea
centrado tiene que cumplir que
E[ϕ] =l∑
i=1
ai [f(xi)α+ g(xi)β] = c1α+ c2β, ∀α, β ∈ R,
es decir, se ha de satisfacer la ecuación vectorial:
l∑i=1
aiXi = c.
La varianza del estimador es
Var(ϕ) = σ2∑i
a2i
Ni=σ2
N
∑i
a2i
pi=∑i
a2i
pi.
Obsérvese que los pi no aparecen en la condición (1.7.3 y para minimizarla
y que se cumpla a la vez la condición∑pi = 1 utilizaremos los multiplica-
dores de Lagrange. Así habrá que hallar p1, . . . , pl, λ que minimicen∑i
a2i
pi− λ(1−
∑i
pi),
de lo que resulta
pi =| ai |∑j | aj |
=⇒ Var(ϕ) =
(l∑
i=1
| ai |
)2
.

34 1. Diseño Óptimo
Nuestro objetivo ahora es, por tanto, tomar los coecientes ai que hagan
mínima la varianza anterior bajo la condición (1.7.3), esto es,
mın
∑i
| ai |:l∑
i=1
aiXi = c
=
mın
∑i
| ai |:l∑
i=1
wi[sgn(ai)Xi] = t c
,
donde
wi =| ai |∑j | aj |
, t =1∑
j | aj |.
En consecuencia buscamos el mayor valor de t de modo que tc esté en el
cierre convexo de x1, . . . , xl. Por tanto
c? = tc =∑i
a?iXi =∑i
t ai Xi,
es una combinación convexa de los vectores ±X1, . . . ,±Xl.
La varianza alcanzará su mínimo cuando el extremo del vector c? coin-
cida con la intersección del vector c, o su prolongación, con el polígono
dado por el cierre convexo Λ de los vectores ±X1, . . . ,±Xl. La varianza es
entonces
Var(ϕ) =1t2
=‖c‖2
‖c?‖2,
y el diseño óptimo (x1 · · · xl|a1|∑j |aj |
· · · |al|∑j |aj |
).
La Figura 1.1 representa este procedimiento para el modelo biparamé-
trico. El punto de corte del vector c, o su prolongación, con la frontera de G
estará situado en el segmento que une dos de los puntos ±X1, . . . ,±Xl (en
este caso son X2 y −X1. Así c? = a?1(−X1) + a?2X2 (con a?1 + a?2 = 1). Co-mo, por otra parte, c? se podría expresar en la forma X2 +λ(−X1−X2) =λ(−X1) + (1− λ)X2, 0 ≤ λ ≤ 1 (por el hecho de estar en el segmento que
une los dos vectores), resulta inmediatamente que a?1(= λ) es proporcional

1.7. Criterios de Optimización 35
a la distancia d1 de c? a X2 sobre el segmento, y a?2 proporcional a la dis-
tancia d2 de c? a X1 sobre ese segmento, que es el método propuesto por
Elfving. \(Z
-4 -3 -2 -1 1 2 3 4
-6
-4
-2
2
4
6
X1
X2
cc*
d2
d1
] < 4 $R&YW:C @ A5 qQR: < $ & 'SP'&($R&t-T &(- 4 -t- RL P,QR/S
8_ 5 'Rd _ @ Fd 5 0 p @ _ PF$-'gDgI9 OQD&($Y-' % < /S[QR 4 4 - ?"qQR$% Dd|p]$% 4 -#QD&`/S.&MQD&(/S[QR$ 4 ' _ Fd IP$%PF$%'&(-&`-.& OQD&(.& ' & 5 0 %i$%H-c % < /S[QRp 2 0 P$%PF$%'&(-c&?-.& OQD&(.& 0 & 5 ' %i$% % % < /S[QRp 4 -c/ qQR:?P$%P 4 OQR+PF$-8 ": < C OQR S&(P-1&(i-hP'&($R& 4 &(- ( 4 $R&oP 4 [QR SPF %i- t- %P'&( - %rbC f8$QD&([QRpF6-.&YP$ &(qQR1&Sg'&(i$ &4 4 1&(- 4 -.&($9-$%$%+["|u,y _ d _ d_ %P'&(S- %rbrd 2 -.&t[QR$% % 7+-.&t$%qQD&S''&SPF$9-T"qQR$ )-.& $%[QR$R&Y?DgY$%$%(C
+ 3 #$ ' 4&# ) "! @! >! @)"! % %'-") , 8%'! !# ? ! @ .# ' # !#%'(%0 .#-?4%')@% % , ! !#%'&*%'? -@!# 4&#! .# , % %,> % @ @ )-%%'(% .# ,+ '-%'8% %! % )" )-% , ' # ! ) ,% , " (%%'(% .#-?4%')@% % %'&*%'? -@! %'-") , 8%'
# 4<4 #$# 4 #$
>qQ%QR)_ @~ NdHP$%PF 4 '&`/0&($R&h~" R&)tQR$R&MQD&($-.&( 4 ?$%#QR$%:'&( CkI7 4 [QD&0-.&( 98 $%[QR H/0& < #Q 4 9+- 9P'&($ &(/SqQR$% 9i:L%qQRH OQR/0&( Bp 4 P$%~":1&(i'&( 4 '&H/ 4,2 OQR[QD&9 4 .&- /S %/S
Figura 1.1. Método gráco debido a Elfving para calcular el diseñoc-óptimo para el modelo biparamétrico
Esto es aplicable para cualesquiera puntos posibles del espacio del di-
seño. Por tanto, en la práctica habrá que calcular el cierre convexo de
f(X) ∪−f(X) (X=espacio del diseño) y la intersección de la recta deni-
da por el vector c con la frontera de dicho cierre.
Observación 9. Este criterio proporciona en particular los mejores dise-
ños para estimar cada uno de los parámetros. Esto es una buena referencia
para estudiar la bondad (eciencia) de un diseño cualquiera para estimar
cada parámetro en particular.
1.7.4. Criterios Compuestos.
Hasta ahora hemos mostrado criterios denidos sobre el espacio de ma-
trices de información M. Existen muchos más criterios de los aquí men-
cionados, pudiéndose encontrar sus formulaciones y propiedades más ca-
racterísticas en la bibliografía existente acerca del tema, Pázman (1986),

36 1. Diseño Óptimo
Atkinson y Donev (1992), Fedorov y Hackl (1997) o Rodríguez Díaz (2000).
La elección de un criterio para el diseño de un experimento en concreto
se basa en los objetivos de dicho experimento. De los criterios presenta-
dos hasta ahora, el de D−optimización minimiza el volumen de la región
de conanza de las estimaciones de los parámetros, el de G−optimización
busca optimizar la predicción del modelo y el de c−optimización se cen-
tra en la estimación eciente de combinaciones lineales de los parámetros,
los demás criterios con los que se puede trabajar hacen especial hincapié
en determinadas características del modelo, presentándose como los más
adecuados para el diseño de determinados experimentos.
Existen también dos formas de combinar estos criterios haciendo que
el diseño calculado satisfaga las condiciones planteadas por diversos crite-
rios de optimización. Podríamos combinar dos criterios haciendo que uno
de ellos minimice su valor sujeto a una restricción del valor del otro o bien
planteando una combinación de ambos diseños mediante una media ponde-
rada de las funciones criterio. Cook y Wong (1994) plantean la equivalencia
de ambas formas, la restricción de un criterio a otro y la combinación de
varios criterios.
Si el experimento ha de satisfacer dos objetivos distintos planteados por
dos funciones criterio convexas Φ1 y Φ2, representando criterios principal
y secundario respectivamente y denidas sobre M, podríamos combinar
ambos criterios seleccionando un criterio que minimizase el valor del criterio
secundario restringido a la obtención de un valor mínimo previamente jado
para el criterio principal:
mın Φ2(ξ) sujeto a Φ1(ξ) ≤ c.
La restricción de un criterio a otro se demuestra equivalente a la ob-
tención de un único criterio compuesto a partir de los criterios primario y
secundario, considerando un diseño compuesto basado en una media pon-
derada de las funciones criterio Φ1 y Φ2,
Φ(ξ | λ) = λΦ1(ξ) + (1− λ)Φ2(ξ),

1.8. Teorema de Equivalencia 37
con 0 ≤ λ ≤ 1 una constante elegida. El valor de λ representa el peso
asignado a cada criterio, si es próximo a la unidad, hace que el criterio Φ1
tenga más peso en la determinación del diseño óptimo.
La obtención del diseño óptimo compuesto se realiza minimizando la
expresión de Φ(ξ | λ) con M(ξ) ∈M+ para λ ∈ (0, 1). Además se imponen
las siguientes condiciones:
1. Φ(ξ | λ) es considerada convexa enM y estrictamente convexa en
M+ para λ ∈ (0, 1). Con lo que las matrices de información de los
diseños óptimos son únicas para 0 ≤ λ ≤ 1 (al menos para criterios
globales).
2. Φ(ξ | λ) se supone continua sobre M, mientras que Φ1 y Φ2 se
consideran continuas sobreM+. Pázman (1986) establece las con-
diciones para asegurar la continuidad.
Como ya hemos dicho antes, se han denido en la literatura otros cri-
terios con mayor o menor grado de generalidad. Los aquí presentados son
algunos de los más utilizados y en particular los empleados en el cálculo de
diseños óptimos para la ecuación de Arrhenius.
1.8. Teorema de Equivalencia
El Teorema General de Equivalencia es una herramienta importante en
la teoría del Diseño Óptimo de Experimentos. Este teorema se utiliza para
comprobar si un diseño es el óptimo y forma la base de la mayor parte de
los procedimientos numéricos para calcular diseños óptimos aproximados
Kiefer y Wolfowitz (1960) demostraron la equivalencia de los criterios
D−óptimo y G−óptimo. Esto quiere decir que utilizando ambos criterios
siempre llegaremos al mismo diseño óptimo. En concreto:
Teorema 2. Suponiendo que σ(x) es constante para todo x de X, un diseño
ξ? es D−óptimo si, y sólo si es G−óptimo. Es decir son equivalentes:
1. detM(ξ?) = maxdetM(ξ) : ξ ∈ Ξ.
2. maxx∈X f t(x)M−1(ξ?)f(x) = mınξ∈Ξ maxx∈X f t(x)M−1(ξ)f(x).

38 1. Diseño Óptimo
Además, la última expresión es igual a m.
Observación 10. Se ha de tener en cuenta que:
1. Si σ(x) no es constante, el Teorema de Equivalencia se cumple
también haciendo una pequeña precisión. En este caso puede de-
mostrarse que ξ? es D−óptimo si, y sólo si
maxx∈X
σ−2(x)f t(x)M−1(ξ?)f(x) = mınξ∈Ξ
maxx∈X
σ−2(x)f t(x)M−1(ξ)f(x).
Siendo además la última expresión igual a m.
2. El Teorema de Equivalencia no se cumple para diseños exactos.
Atkinson y Donev (1992), pág. 98 y ss., proporcionan un ejemplo.
Observación 11. Veamos ahora con detalle la interpretación geométrica
del criterio de D-optimización. Sobre el elipsoide m-dimensional:
1. El volumen del elipsoide m-dimensional:
E = z ∈ Rm : ztM(ξ)z ≤ c2,
es igual a cmVm[detM−1(ξ)]1/2, donde Vm es el volumen de la esfera
m-dimensional de radio unidad. En efecto, por ser M(ξ) simétrica
existirá una matriz regular U tal que U tM(ξ)U = I.
Llamando w = 1cU−1z tendremos:
V ol(E) =∫Edz =
∫Scm | detU | dw = cmVm | detU |,
donde haciendo el cambio de variable anterior la región E se trans-forma en la región:
S = w : c2wtU tM(ξ)Uw ≤ c2 = w : wtw ≤ c2,
que es la esfera m-dimensional de radio unidad. Pero
(detU)2 detM(ξ) = 1,
con lo que queda probado el resultado.

1.8. Teorema de Equivalencia 39
2. Bajo la hipótesis de normalidad de las observaciones α = (α1, . . . ,
αm) se distribuye de acuerdo a una distribución normal multiva-
riante de modo que la media tiene como componentes los verdaderos
valores de los parámetros α y la matriz de covarianzas es proporcio-
nal aM−1(ξ). Supongamos sin pérdida de generalidad queM−1(ξ)es la matriz de covarianzas. Entonces la función de densidad de este
vector aleatorio será:
f(α | α) =[detM(ξ)]1/2
(2π)m/2exp
−12
(α− α)tM(ξ)(α− α)
Consideremos entonces el elipsoide siguiente:
E = α ∈ Rm : (α− α)tM(ξ)(α− α) ≤ c2,
donde c es un número jo. Además la variable v = U−1(α−α) segui-rá una distribución normal de media cero y vector de covarianzas la
identidad. De este modo vtv seguirá una distribución χ2m, es decir∫
Ef(α | α) dα =
∫vtv≤c2
(2π)−m/2 exp[−1
2vtv
]dv = P (χ2
m ≤ c2).
Se deduce, por tanto, que el elipsoide:
z ∈ Rm : (z − α)tM(ξ)(z − α) ≤ c2,
contiene la verdadera media con probabilidad P (χ2m ≤ c2), es decir,
es el elipsoide de conanza de la media α con un nivel de conanza
que lógicamente depende de c.
3. Por otro lado el elipsoide:
Eξ = z ∈ Rm : ztM−1(ξ)z ≤ m
contendrá los vectores f(x), x ∈ X, es decir, contendrá al conjunto
f(X) solamente si ξ es un diseño D−óptimo. Esto es debido al
Teorema de Equivalencia, que asegura lo siguiente:
mınξ∈Ξ
maxx∈X
f t(x)M−1(ξ)f(x) = m,

40 1. Diseño Óptimo
de modo que solamente si ξ es un diseño D−óptimo se cumple:
f t(x)M−1(ξ)f(x) ≤ m, x ∈ X.
Además como se vió más arriba el volumen de Eξ es proporcionala [detM(ξ)]1/2. De modo que el diseño D−óptimo será aquel que
haga máximo el volumen del elipsoide Eξ conteniendo el conjunto
f(X), el teorema de dualidad hace que esto sea equivalente a buscar
el elipsoide de volumen mínimo que contiene a f(X). Uno de los
inconvenientes de este criterio es que a veces el volumen del elipsoide
puede ser minimizado haciéndose estrecho y largo. Eso signica que
hay un funcional lineal de los parámetros, que es estimado con una
gran varianza. No obstante no es sencillo llevar a la práctica este
resultado para el cálculo del D-óptimo. Silvey y Titterington (1973)
proporcionan un método para su utilización.
Whittle (1973) y Kiefer (1974) amplían el Teorema de Equivalencia
para funciones criterio más generales. Con el objeto de enunciar estos re-
sultados damos una denición más restrictiva de función criterio. Para ello
nos jaremos en las propiedades que vericaban las funciones criterio vistas
anteriormente. Observamos que la mayoría de ellas son convexas y conti-
nuas. Con el objeto de salvaguardar estas propiedades daremos la siguiente
denición:
Denición 12. Diremos que una función criterio Φ en las condiciones
dadas en la sección anterior, es una función criterio convexa si cumple las
propiedades:
1. Existe UΦ abierto de L(M) tal que UΦ ⊃ M+ y Φ está denida,
es nita y convexa en UΦ.
2. Si:
Mn ∈M+, n = 1, 2, . . . y lımn→∞
Mn = M ∈M \M+
entonces:
lımn→∞
Φ(Mn) =∞,

1.8. Teorema de Equivalencia 41
lo que signicaría una especie de continuidad al pasar de M+ a
M\M+.
Observación 12. No es necesario que UΦ sea convexo. Entenderemos en-
tonces que Φ debe ser convexa en los subconjuntos convexos de UΦ.
Proposición 14. Si U es un abierto de L(M) y Φ es convexa y nita en
U , entonces Φ es continua en U .
Una demostración de este resultado puede encontrarse en Holmes (1975).
Proposición 15. Cualquier función criterio convexa, con la denición da-
da, es continua enM.
Demostración: La proposición anterior implica la continuidad en UΦ,
y por tanto en M+. Por otra parte la segunda condición de la denición
asegura la continuidad enM\M+.
Puesto que algunas de estas funciones no serán diferenciables conviene
dar la denición de derivada direccional siguiente:
Denición 13. Dada una función real Φ, convexa y denida en un subcon-junto convexo de un espacio euclídeo, y dados dos puntos de ese conjunto,
x y v, se dene la derivada direccional de Φ en el punto x y en la dirección
v como:
∂Φ(x, v) = lımβ→0+
Φ[(1− β)x+ βv]− Φ(x)β
.
Observación 13. Esta derivada direccional existe siempre gracias a la
convexidad de Φ. En efecto, demostraremos que la función:
ϕ : (0, 1) −→ R | β −→ Φ[(1− β)x+ βv]− Φ(x)β
,
es no decreciente en (0, 1). Por tanto el límite siguiente siempre existe,
siendo nito o innito negativo:
lımβ→0+
Φ[(1− β)x+ βv]− Φ(x)β
.

42 1. Diseño Óptimo
Veamos que ϕ es una función creciente. Para ello tomamos 0 < β1 < β2 < 1y calculamos:
Φ[(1− β1)x+ β1v]− Φ(x) = Φβ1
β2[(1− β2)x+ β2v] + (1− β1
β2)x − Φ(x)
≤ β1
β2Φ[(1− β2)x+ β2v] + (1− β1
β2)Φ(x)− Φ(x)
= β1
β2Φ[(1− β2)x+ β2v]− Φ(x).
Pueden darse otras deniciones de derivada direccional, pero nos interesará
la anterior debido al uso de funciones convexas. Si existe el gradiente de Φentonces por su denición, podemos escribir:
∂Φ(x, v) = tr[5Φ(x)](v − x) = 〈5Φ(x), v − x〉.
Recíprocamente, se puede denir el gradiente como aquella matriz que en-
caja en la expresión anterior.
Teorema 3 (teorema general de equivalencia). Sea Φ una función criterio
convexa y ξ? un diseño tal que:
∂Φ[M(ξ?),M(ξ)] > −∞, ξ ∈ Ξ.
Entonces son equivalentes:
1. ξ? es Φ-óptimo.
2. ξ? es Φ-óptimo local, es decir, para cada diseño ξ la función:
[0, 1) −→ R | β −→ Φ[(1− β)M(ξ?) + βM(ξ)],
tiene un mínimo local en β = 0.
3. ∂Φ[M(ξ?),M(ξ)] ≥ 0, ξ ∈ Ξ.
Obsérvese que este teorema aporta un criterio general (tercer apartado)
para contrastar si un diseño dado es o no Φ-óptimo, tanto si la función crite-
rio es diferenciable como si no lo es. Cuando la función Φ sea diferenciable,
se puede dar el siguiente teorema:
Teorema 4. Si Φ es diferenciable en un entorno de M(ξ?), entonces sonequivalentes:
1. ξ? es Φ-óptimo

1.9. Discriminación entre Modelos: T−optimización 43
2. f t(x)5 Φ[M(ξ?)]f(x) ≥ trM(ξ?)5 Φ[M(ξ?)], x ∈ X
3. mınx∈X f t(x)5Φ[M(ξ?)]f(x) =∑
x∈X ft(x)5Φ[M(ξ?)]f(x)ξ?(x)
La demostración de estos dos últimos teoremas puede encontrarse por
ejemplo en Pázman (1986), pág. 116-117. Disponemos así de un par de
condiciones para la búsqueda del soporte del óptimo. Si llamamos
ψ(x, ξ) = f t(x)5 Φ[M(ξ)]f(x)− trM(ξ)5 Φ[M(ξ)],
tenemos que ψ(x, ξ?) se anula en todos los puntos del soporte del óptimo,
y por otra parte, la segunda condición del teorema anterior nos dice que
ψ(x, ξ?) ≥ 0, ∀x ∈ X. De aquí concluimos que los puntos del soporte del
Φ-óptimo que están en el interior de X, son mínimos locales de la función
ψ(x, ξ?), y por tanto se verica
∂ψ(x, ξ?)∂x
= 0 ∀x ∈ Xξ? ∩X.
De este modo, cuando se tenga alguna sospecha de cómo puede ser el óp-
timo, estas dos condiciones podrían ayudar a encontrarlo. Posteriormente
habría que comprobar con el Teorema de Equivalencia que efectivamente
es el óptimo.
Observación 14. La función ψ(x, ξ), como ya se ha comentado, resulta
muy útil para buscar los puntos en los que tomar una observación con-
tribuye más a aproximarnos al diseño óptimo. Es decir, es una función
especialmente sensible al soporte del óptimo. Por este motivo una ligera
modicación suya es bautizada como función de sensibilidad por algunos
autores (véase por ejemplo Fedorov y Hackl (1997), pág. 33 y ss., para más
detalles en este sentido).
1.9. Discriminación entre Modelos: T−optimización
Una de las críticas más frecuentes que se le hacen a la teoría del Diseño
Óptimo de Experimentos es la necesidad de jar el modelo a la hora de
calcular diseños, aún antes de haber realizado experimento alguno. Aun-
que existen fenómenos, especialmente en procesos industriales, en los que

44 1. Diseño Óptimo
el modelo se conoce con antelación, es frecuente seleccionar el modelo ade-
cuado de entre dos ó varios modelos posibles. En estos casos es de gran
interés diseñar la mejor estrategia de discriminación entre modelos.
Un criterio óptimo para discriminar entre dos modelos de regresión
se denomina criterio T−óptimo y fue planteado por Atkinson y Fedorov
(1975a). Los mismos autores, Atkinson y Fedorov (1975b), han ampliado el
criterio para permitir la discriminación entre más de dos modelos, conside-
rando el caso homocedástico con observaciones normalmente distribuidas.
Se puede encontrar un estudio intensivo de la técnica para modelos linea-
les en Atkinson y Donev (1992). López-Fidalgo et al. (2007b) extienden
este criterio a modelos no normales basándose en la distancia de Kullback-
Leibler.
Sea el modelo general
y = η(x, θ) + ε,
cumpliéndose la hipótesis habitual, de que el error ε sea independiente y
normalmente distribuido con media cero y varianza constante σ2.
Supongamos que η(x, θ) es una de las dos funciones conocidas, η1(x, θ1)y η2(x, θ2), donde θ1 ∈ Ω1 ⊂ Rm1 y θ2 ∈ Ω2 ⊂ Rm2 son los vectores de
parámetros desconocidos. Consideremos por ejemplo que η(x, θ) = η1(x, θ1)es el modelo verdadero con sus parámetros θ1 conocidos y que η2(x, θ2) esel otro modelo rival.
Denición 14. La suma de cuadrados de los errores de ajuste para el
primer modelo respecto al modelo rival viene dada por
T21(ξ) = mınθ2∈Ω2
∑xi∈X
(η(xi, θ)− η2(xi, θ2))2ξ(xi).
Para modelos lineales T21(ξ) es proporcional al parámetro de no cen-
tralidad de la distribución X 2 de la suma de los cuadrados de los residuos
del modelo rival. Más aún, T21 es proporcional al parámetro de no centrali-
dad del contraste F para falta de ajuste del modelo rival cuando el primer
modelo es verdadero.

1.9. Discriminación entre Modelos: T−optimización 45
Entonces diremos que ξ?T es el diseño T−óptimo si maximiza T21. Esto
implica que el diseño T−óptimo maximiza la potencia del test F para la
falta de ajuste del modelo rival cuando consideramos que el primer modelo
es el verdadero.
Para el caso de modelos no lineales en los parámetros, T21 sustituye al
verdadero parámetro de no centralidad por una aproximación asintótica.
En todo caso el diseño T−óptimo dependerá de la elección del modelo
verdadero y de sus parámetros.
Denición 15. Como hemos visto llamaremos a un diseño ξ?T que maxi-
mice T21 diseño T−óptimo y diremos que un diseño T−óptimo es regular
si el siguiente problema de optimización tiene una única solución,
Ω2(ξ) =
θ2 : θ2(ξ) = arg mınθ2∈Ω2
∑xi∈X
(η(xi, θ)− η2(xi, θ2))2ξ(xi)
.
En caso contrario diremos que el diseño es singular.
Para diseños regulares se verica el Teorema de Equivalencia en la
siguiente formulación.
Teorema 5. Sea ξ?T un diseño T−óptimo regular. Entonces se satisfacen
las siguientes condiciones:
1. Una condición necesaria y suciente para que el diseño ξ?T sea
T−óptimo es que ψ(x, ξ?T ) ≤ 0, x ∈ X siendo
ψ(x, ξ) = (η(x, θ)− η2(x, θ2))2 −∑xi∈X
(η(xi, θ)− η2(xi, θ2))2ξ(xi)
y θ2 la única solución del problema de optimización previamente
propuesto.
2. En los puntos de soporte del diseño T−óptimo, Xξ?T, la función
ψ(x, ξ?T ), con x ∈ Xξ?T, alcanza máximos.

46 1. Diseño Óptimo
3. Para cualquier otro diseño ξ para el que T21(ξ) < T21(ξ?T ), se tieneque
maxx∈X
ψ(x, ξ) > T21(ξ?T )
4. El conjunto de diseños T−óptimos es convexo.

Capítulo 2
Ecuación de Arrhenius
La primera parte del trabajo se centra en el diseño de experimentos para
determinar la variación de la velocidad con la que determinados reactivos
se convierten en unos productos en función de la temperatura a la que dicha
reacción se produzca.
2.1. Velocidad de las Reacciones Químicas
El método experimental más importante para el estudio del mecanismo
de las reacciones químicas es la medida de la velocidad con la cual las
reacciones se desarrollan y la dependencia de esta velocidad de reacción con
las concentraciones de las especies reaccionantes y con la temperatura. Este
tipo de estudios recibe el nombre de Cinética de las Reacciones Químicas
y los resultados obtenidos se resumen en lo que se conoce como ecuación
de velocidad que tiene la forma general siguiente:
velocidad = k(T )(función de la concentración de los reactivos).
La magnitud k(T ) se llama constante de velocidad y, si la función que
contiene las concentraciones de los reactivos expresa de forma correcta la
dependencia entre la velocidad y estas concentraciones, k(T ) debe dependertan solo de la temperatura, T .
47

48 2. Ecuación de Arrhenius
De esta forma, la información experimental acerca del proceso de la
reacción queda plasmada en su ecuación de velocidad. Las hipótesis mo-
leculares que puedan realizarse acerca de la forma cómo una reacción se
desarrolla deben acomodarse a la información proporcionada por la ecua-
ción de velocidad. El resultado es lo que recibe el nombre de mecanismo de
la reacción.
La velocidad de una reacción se expresa de ordinario en función de la
disminución de la concentración presente de uno de los reactivos producida
en un determinado intervalo de tiempo. De forma equivalente puede utili-
zarse el incremento de la concentración de cualquiera de los productos de
la reacción.
La velocidad de una reacción se considera siempre como una cantidad
positiva. Como ejemplo intuitivo, para la reacción:
A+B → C +D,
la velocidad, que ha de ser una función de las concentraciones y de la
temperatura, se establece en función del descenso de [A] en la forma:
velocidad = −d[A]dt
,
donde [A] es la concentración del reactivo A. Por el contrario si se mide el
aumento del compuesto C, se debe escribir:
velocidad =d[C]dt
.
El mismo criterio se adopta para reacciones con otra estequiometría,
por ejemplo:
A+ 2B → productos
velocidad = −d[A]dt
= −12d[B]dt
,
ya que, por cada molécula de A se consumen 2 moléculas de B, siendo así
la velocidad de disminución de este reactivo el doble que la del primero.
Se ha encontrado en un número considerable de reacciones que, a una
temperatura determinada, la velocidad de la reacción es proporcional a la

2.1. Velocidad de las Reacciones Químicas 49
concentración de uno, dos y a veces tres de los reactivos. Si se considera
una reacción en la que A, B, C, representan posibles reactivos, la ecuación
de velocidad puede tomar la forma siguiente:
velocidad = k1[A] Primer Orden
velocidad = k2[A][B] ó Segundo Orden
= k2[A]2
velocidad = k3[A][B][C] ó Tercer Orden
= k3[A]2[B] ó
= k3[A]3
Las reacciones que evolucionan de acuerdo con estas simples ecuaciones
se llaman reacciones de primero, segundo y tercer orden. Sin embargo, no
todas las reacciones obedecen a estas leyes tan sencillas. Algunas contienen
factores de concentración elevados a exponentes fraccionarios, mientras que
hay otras que consisten en ecuaciones algebraicas de mayor complejidad.
Existe un gran número de reacciones que pueden describirse cinéticamente
con ecuaciones de orden uno, dos y en bastante menor proporción, orden
tres.
La ecuación de velocidad no está necesariamente relacionada con la es-
tequiometría de la ecuación química que describe el proceso global, ya que,
generalmente, éste transcurre a través de numerosos pasos intermedios, lla-
mados reacciones elementales, con velocidades diferentes, cuya combinación
produce la reacción nal.
Las dimensiones de las constantes de velocidad de reacciones de prime-
ro, segundo y tercer orden se deducen de sus ecuaciones de velocidad. Para
la de primer orden la constante de velocidad tiene las dimensiones de tiem-
po inverso, generalmente s−1, siendo independiente de las unidades de la
concentración. Las dimensiones de las constantes de velocidad de segundo
orden incluyen ya dimensiones de concentración, de modo que sus dimen-
siones pueden ser: dm3 ·mol−1 ·s−1, cm3 ·mol−1 ·s−1, cm3 ·molecula−1 ·s−1,

50 2. Ecuación de Arrhenius
etc. Las constantes de velocidad de tercer orden son mucho menos frecuen-
tes y sus dimensiones hay que deducirlas de la correspondiente ecuación de
velocidad.
2.2. Dependencia de la Constante de Velocidad de la
Temperatura
La ecuación de velocidad y la constante de velocidad de una reacción se
determinan a partir de los datos cinéticos a una temperatura determinada.
Si las experiencias se realizan a diferentes temperaturas se advierte, en
general, que la dependencia con la concentración de los reactivos reejada
en la ecuación de velocidad, no cambia con la temperatura, pero sí que la
constante de velocidad es mucho mayor a temperaturas más altas.
Arrhenius (1889) demostró que la constante de velocidad crece de for-
ma exponencial con la temperatura. Quizá sea más preciso armar que, por
procedimientos puramente empíricos, demostró que, al representar gráca-
mente los valores de log k en función de 1/T , resulta una variación lineal
(Figura 2.1).
Empíricamente esta relación se puede escribir del modo siguiente:
k = Ae−Ea/RT ,
donde A es el denominado factor preexponencial, Ea se conoce con el nom-
bre de energía de activación, R es la constante de los gases y T es la
temperatura absoluta. El tratamiento de los resultados experimentales se
ha llevado tradicionalmente a cabo usando la expresión anterior en la forma
logarítmica:
log(k) = log(A)− EaR· 1T.
Las constantes A y Ea son así determinables a partir de la pendiente y
ordenada en el origen de la recta que representa la variación de los valores
de log(k) con el inverso de la temperatura, 1/T .
Aunque esta expresión es una relación empírica, la forma de la ecuación
puede justicarse, en principio, a partir de la relación termodinámica que
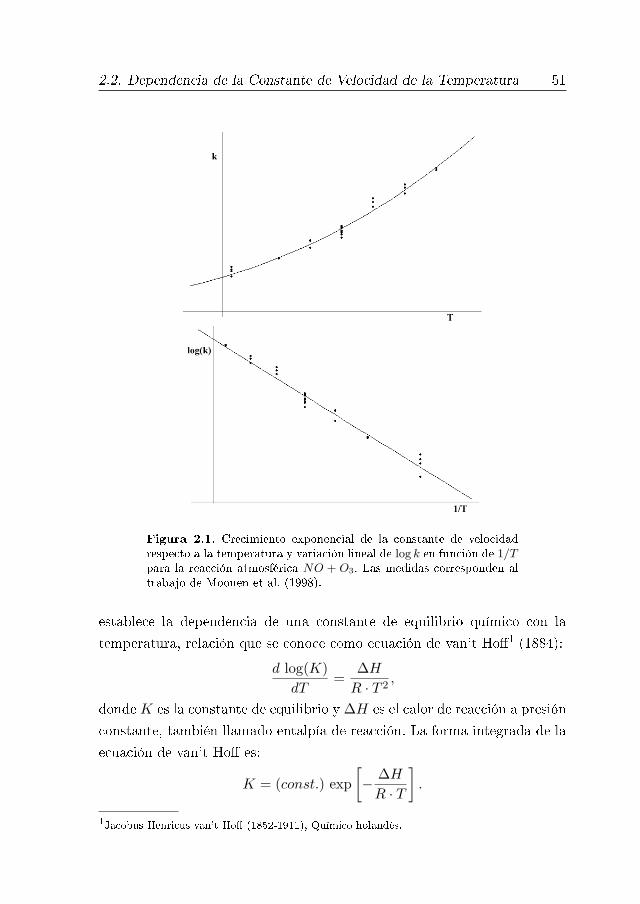
2.2. Dependencia de la Constante de Velocidad de la Temperatura 51
Figura 2.1. Crecimiento exponencial de la constante de velocidadrespecto a la temperatura y variación lineal de log k en función de 1/Tpara la reacción atmosférica NO + O3. Las medidas corresponden altrabajo de Moonen et al. (1998).
establece la dependencia de una constante de equilibrio químico con la
temperatura, relación que se conoce como ecuación de van't Ho1 (1884):
d log(K)dT
=∆HR · T 2
,
donde K es la constante de equilibrio y ∆H es el calor de reacción a presión
constante, también llamado entalpía de reacción. La forma integrada de la
ecuación de van't Ho es:
K = (const.) exp[− ∆HR · T
].
1Jacobus Henricus van't Ho (1852-1911), Químico holandés.

52 2. Ecuación de Arrhenius
Como ejemplo ilustrativo, considérese la siguiente reacción reversible:
A+B C +D,
cuya velocidad directa, v1, e inversa, v−1, son:
v1 = k1[A][B],
v−1 = k−1[C][D].
El estado de equilibrio viene determinado cuando la velocidad de ambos
procesos se iguala, es decir, v1 = v−1, en cuyo caso:
k1
k−1=
[C]eq[D]eq[A]eq[B]eq
= K.
Es posible identicar, en primera aproximación, la constante de equilibrio,
K, con el cociente de las contantes de velocidad del proceso directo e inver-
so. Ahora bien, si se expresan éstas según su dependencia de la temperatura
mediante la ecuación de Arrhenius:
k1 = A1 e−Ea1/RT , k−1 = A−1 e
−Ea−1/RT ,
se obtiene:
K =k1
k−1=
A1
A−1e−(Ea1−Ea−1 )/RT ,
ecuación que concuerda formalmente con la relación de van't Ho para una
situación de equilibrio.
2.3. Teoría de Arrhenius
Fue Arrhenius quién desarrolló el primer estudio teórico, en forma de
simple descripción cualitativa, para explicar el comportamiento molecular
que corresponde a la forma obtenida experimentalmente para la constante
de velocidad. Otras teorías posteriores, más elaboradas y de mayor carácter
cuantitativo, han apoyado estas ideas originales.
Arrhenius reconoció que en cualquier reacción puede admitirse que el
proceso tiene lugar mediante la formación de una especie química inter-
media, en la que se acumula una alta energía, conocida como complejo

2.4. Otras Teorías 53
activado, el cual se disocia con posterioridad para dar lugar a la formación
de los productos de la reacción. Si se supone que el complejo activado re-
quiere para formarse una energía, Ea, superior a la que poseen los reactivos,
el número de moléculas de complejo activo comparado con el de reactivos
puede estimarse con la ley de distribución de Boltzmann2 (Apéndice A):
Número de moléculas complejosNúmero de moléculas reactivos
= e−Ea/RT ,
y la teoría de Arrhenius expresa ahora que la velocidad de la reacción es
proporcional al número (o concentración) de complejos activos
v = A [Número ó Concentración de moléculas de complejos activos]
= A e−Ea/RT [Concentración de reactivos].
en la que A es el factor de proporcionalidad.
Mediante esta teoría lo que se viene a mostrar es que la constante
empírica Ea puede interpretarse como la energía del complejo activado
comparada con la de las moléculas del reactivo.
La hipótesis del complejo activado puede representarse esquemática-
mente en un gráco que muestra la energía del sistema en la ordenada
frente a la coordenada de reacción, que gura como abcisa, Figura 2.2. La
coordenada de reacción no es precisamente una distancia internuclear cual-
quiera, sino que más bien representa una medida de todas las distancias
internucleares que experimentan variaciones durante el transcurso de la
transformación de reactivos en productos.
2.4. Otras Teorías
La teoría de Arrhenius fue solo una descripción cualitativa que no tuvo
por objeto interpretar, desde un punto de vista molecular, la naturaleza
de la energía de activación y del factor preexponencial. Sin embargo, todas
las teorías posteriores que tratan de la determinación teórica de constantes
de velocidad de reacciones químicas contienen en germen la relación de
2Ludwig Eduard Boltzmann (1844-1906), Físico austriaco.
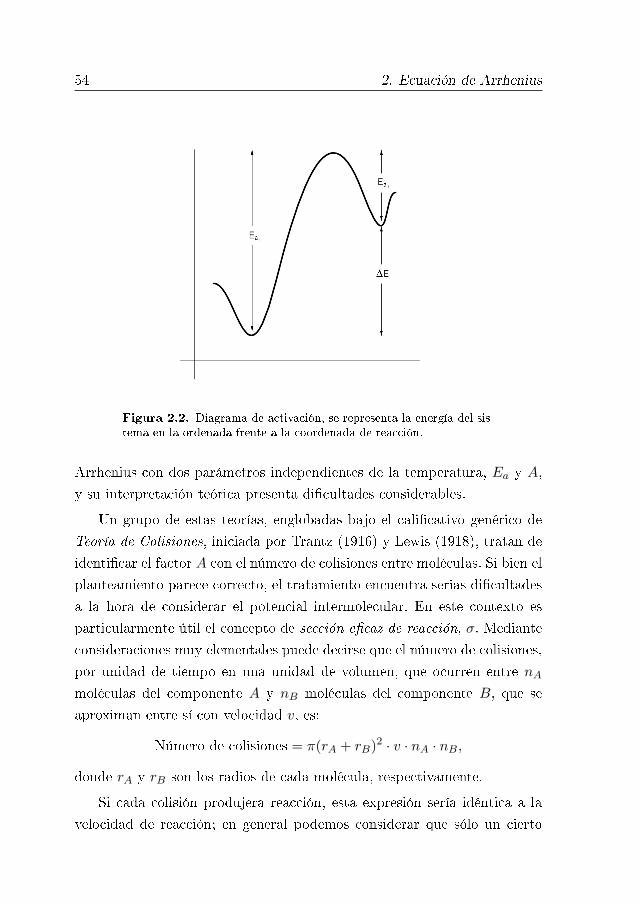
54 2. Ecuación de Arrhenius
Figura 2.2. Diagrama de activación, se representa la energía del sis-tema en la ordenada frente a la coordenada de reacción.
Arrhenius con dos parámetros independientes de la temperatura, Ea y A,
y su interpretación teórica presenta dicultades considerables.
Un grupo de estas teorías, englobadas bajo el calicativo genérico de
Teoría de Colisiones, iniciada por Trantz (1916) y Lewis (1918), tratan de
identicar el factor A con el número de colisiones entre moléculas. Si bien el
planteamiento parece correcto, el tratamiento encuentra serias dicultades
a la hora de considerar el potencial intermolecular. En este contexto es
particularmente útil el concepto de sección ecaz de reacción, σ. Mediante
consideraciones muy elementales puede decirse que el número de colisiones,
por unidad de tiempo en una unidad de volumen, que ocurren entre nAmoléculas del componente A y nB moléculas del componente B, que se
aproximan entre sí con velocidad v, es:
Número de colisiones = π(rA + rB)2 · v · nA · nB,
donde rA y rB son los radios de cada molécula, respectivamente.
Si cada colisión produjera reacción, esta expresión sería idéntica a la
velocidad de reacción; en general podemos considerar que sólo un cierto

2.4. Otras Teorías 55
número de estas colisiones son efectivas, introduciendo un factor de ecacia,
σ, que denominamos sección ecaz de reacción, de tal modo que la velocidad
de reacción entre A y B es:
velocidad = σ · v · nA · nB = k2 · nA · nB,
pudiéndose identicar la constante de velocidad de orden 2 para este pro-
ceso como:
k2 = σ · v.
Si las especies reaccionantes poseen velocidades según una distribución
de probabilidad con función de densidad f(T, v), la constante de velocidadexperimental sería un promedio según todas las velocidades de las partícu-
las:
k2(T ) =∫ ∞
0f(T, v)σ(v)v dv,
donde se ha considerado también que la sección ecaz suele ser función de
la velocidad relativa con que dos partículas colisionan.
Si se toma el sistema en equilibrio térmico, la función f(T, v) corres-
ponde a una distribución Maxwell3-Boltzmann, ver Apéndice A y Laidler
(1969), y por lo tanto la ecuación se reduce a:
k2(T ) =
[(2NA
RT
)3/2( 1µπ
)1/2 ∫ ∞0
E · σ(E) · e[(E0−E)/RT ] dE
]e−E0/RT ,
donde NA es el número de Avogadro y µ es la masa reducida del sistema
de dos partículas.
En general, las teorías de colisiones se elaboran sobre consideraciones
más o menos sustentadas por lo expresado anteriormente, en donde el ver-
dadero cuello de botella lo representa tanto la dependencia de σ con la
velocidad molecular como la función de distribución de velocidad molecu-
lar y la temperatura. En cualquier caso el resultado nal suele acomodarse
a una expresión que reproduce la relación de Arrhenius, como se ve en la
ecuación anterior.
3James Clerck Maxwell (1831-1879), Matemático y Físico escocés.

56 2. Ecuación de Arrhenius
Hay un grupo de teorías cinetoquímicas, iniciadas por Eyring (1935)
y Evans y Polanyi (1935), que efectúan el análisis del fenómeno reactivo
mediante la consideración de la especie intermedia denominada complejo
activado, como la especie que cruza la barrera de energía potencial que
debe existir entre reactivos y productos. En estas teorías, conocidas indis-
tintamente como Teoría del Complejo Activado ó del Estado de Transición,
se supone que puede determinarse la concentración de este complejo acti-
vado mediante consideraciones de Termodinámica Estadística más o menos
simplicadas.
En todas estas teorías se parte del establecimiento de las variaciones
de energía potencial de las moléculas de reactivo según distintas distancias
de aproximación y distintas geometrías moleculares. Esta función físico-
matemática, se conoce con el nombre de supercie de energía potencial
(en la mayor parte de los casos se tratará en realidad de hipersupercies).
El curso de la reacción se representa entonces como un movimiento a lo
largo de esta hipersupercie desde una zona de baja energía, determinada
por la geometría y distribución de los reactivos, hacia otras zonas de baja
energía, según la estructura de los productos. El sistema puede entonces
evolucionar según diferentes trayectorias con distinta probabilidad, según
las elevaciones energéticas que haya de superar, siendo la especie que
realiza dicho movimiento una especie intermedia entre los reactivos y los
productos, que constituye el complejo activado. Los cálculos que pueden
llevarse a cabo dentro de este contexto constituyen hoy en día una rama
muy activa dentro de la Fisico-Química conocida como Dinámica Molecular
(Hirst, 1990).
Un planteamiento elemental de este modelo, suciente para poner de
maniesto la relación entre esta teoría y la ecuación de Arrhenius, es el
siguiente.
Considérese que dos especies moleculares A y B, en su proceso reac-
cionante, establecen una especie intermedia, (AB)‡, de modo que podemos

2.4. Otras Teorías 57
considerar que básicamente ocurre:
A+B (AB)‡ → productos.
La velocidad del proceso está controlada por la descomposición de la espe-
cie intermedia que hace de complejo activado, también llamado estado de
transición.
La concentración de complejo activado, al menos formalmente, puede
establecerse en función de la condición de equilibrio:
K‡ =[AB‡][A][B]
,
[AB‡] = K‡[A][B],
donde K‡ representa una verdadera constante de equilibrio entre los reac-
tivos y el complejo AB‡. Su valor es, en principio, desconocido pero puede
estimarse sobre bases de Física Molecular. En líneas generales el resultado
que se obtiene puede alcanzarse también según las siguientes consideracio-
nes simples: la velocidad con la que el complejo se destruye puede estimarse
suponiendo que se romperá para dar la molécula de los productos cuando
una vibración apropiada, con amplitud sucientemente grande, ayude a dis-
tender el complejo hasta su ruptura. La frecuencia de esta vibración será
por lo tanto, en cierto modo similar a la velocidad con que el complejo se
disocia. El complejo activo será una substancia inestable que se mantiene
unido mediante enlaces muy débiles. Por consiguiente, las vibraciones de
estos enlaces habrán de tener frecuencias muy bajas y la energía media
por cada grado de libertad de vibración debe ser del orden de kT (donde
k = R/NA, representa la constante de Boltzmann). Por lo tanto, puede
aproximarse la energía de vibración de un enlace a su energía térmica:
hν = kT,
donde hν es la energía del cuanto de vibración y h, la constante de Planck4.
Según este simple razonamiento,que puede justicarse sobre bases teóricas
más rmes basadas en Física Molecular (Eyring et al., 1980), la velocidad
4Max Karl Ernst Ludwig Planck (1858-1947), Físico alemán.

58 2. Ecuación de Arrhenius
de reacción en el estado de transición es:
velocidad = −d[A]dt
= −d[B]dt
= K‡kT
h[A][B],
con lo que es fácil deducir que la constante de velocidad para una reacción
de este tipo es:
k2 = K‡kT
h.
Este resultado obtiene su signicado cuando la constante de equilibrio
se interpreta termodinámicamente:
∆G‡ = −RTlnK‡,
∆G‡ = ∆H‡ − T∆S‡,
donde ∆G‡, ∆H‡ y ∆S‡ son respectivamente la energía libre, entalpía y
entropía de formación del complejo activo en condiciones termodinámicas
estándar; en este contexto, se denominan parámetros de activación. Al sus-
tituir estas relaciones en la ecuación que da la constante de velocidad, se
obtiene:
k2 =(kT
h
)e∆S‡/RK‡e−∆H‡/RT ,
la cual concuerda con la ecuación de Arrhenius, si se identica:
A =kT
he∆S‡/R,
Ea = ∆H‡,
con lo que se interpreta el factor preexponencial en términos de una en-
tropía, es decir, en términos de una probabilidad asignable a las distintas
trayectorias que el complejo activado puede tomar a lo largo de la supercie
de energía potencial, mientras que la energía de activación se relaciona con
la entalpía de formación del complejo activo.
2.5. La Ecuación de Arrhenius y Fenómenos de Transporte
Existen otros fenómenos cinéticos de tipo sicoquímico que pueden in-
terpretarse a través de los mismos modelos expuestos en los apartados
anteriores y cuya base formal se apoya en la existencia de una dependencia

2.5. La Ecuación de Arrhenius y Fenómenos de Transporte 59
tipo Arrhenius respecto a las variaciones de temperatura. Algunos de estos
fenómenos son: la difusión, la viscosidad y la conductividad electrolítica de
las disoluciones iónicas.
La difusión es el fenómeno de transporte de materia impulsado por
un gradiente de concentración. Cuando el proceso tiene lugar en una sola
dirección la ecuación fenomenológica es del tipo siguiente (Ley de Fick5):
Jm =1A· dmdt
= −D∇C,
donde Jm representa el ujo de masa, m, que se transporta en la unidad de
tiempo, t, a través de una determinada área, A, transversal a la dirección del
transporte, y ∇C representa el gradiente de concentración en la dirección
del transporte de masa. El coeciente que relaciona la fuerza impulsora
o gradiente, con el efecto producido, o ujo de materia, se conoce como
coeciente de difusión, D. El coeciente de difusión es característico del
medio en el que se produce la difusión, del tipo de sustancia que se difunde,
de la temperatura y de otros factores. Cabe resaltar en este contexto que la
dependencia del coeciente de difusión de la temperatura sigue la ecuación
de Arrhenius en una gran variedad de sistemas, de modo que se puede
escribir:
D(T ) = D0e−ED/RT ,
pudiéndose hablar de una energía de activación del proceso de difusión
cuya interpretación puede hacerse formalmente con modelos similares a los
desarrollados para la constante de velocidad.
En particular, cuando la sustancia que se transporta es un electrólito,
el ujo de materia implica también un ujo de carga, es decir, una intensi-
dad de corriente, mientras que un gradiente de concentración iónica puede
relacionarse con un gradiente de potencial electroquímico. Se desprende de
estas consideraciones que entre el coeciente de difusión y el coeciente de
conducción electrolítica, o conductividad, existirá una relación directa. De
hecho los coecientes de conductividad electrolítica presentan también una
dependencia tipo Arrhenius de la temperatura (Glasstone et al., 1941).
5Adolf Eugen Fick (1829-1901), Fisiólogo alemán.

60 2. Ecuación de Arrhenius
El fenómeno de la viscosidad está relacionado con la capacidad de ujo
de gases o líquidos cuando se les aplica una fuerza deformadora.
Considerándose un uido constituido por diversas capas susceptibles
de sufrir deslizamiento unas respecto de las otras. La aplicación de una
Figura 2.3. Aplicada una fuerza de cizalla sobre la primera capa deluido, produce un gradiente de velocidad en las distintas capas a lolargo del eje z.
fuerza de cizalla, Fx, a una de las capas, provoca el deslizamiento de todas
las demás como consecuencia de la fricción que existe entre las mismas,
Figura 2.3. La fricción puede interpretarse en términos de una determinada
capacidad del sistema para intercambiar cantidad de movimiento entre las
diversas capas, lo que reduce su velocidad en la dirección x, a medida que la
capa está más distanciada de la primera, la ley de Newton, que interpreta
este fenómeno para una gran variedad de uidos, es la siguiente:
FxA
= ηdvxdz
,
es decir, se relaciona el efecto producido, gradiente de velocidades dvx/dz,
con la causa, que es la fuerza de cizalla aplicada a la primera capa por
unidad de área. El coeciente η, conocido como coeciente de viscosidad,

2.5. La Ecuación de Arrhenius y Fenómenos de Transporte 61
caracteriza la uidez de la sustancia y tiene la particularidad de depender de
la temperatura a través de una expresión similar a la ecuación de Arrhenius:
η = BeEvis/RT ,
propuesta por J. de Guzmán en 1913 y por el propio Arrhenius en 1916.
Los ejemplos anteriores ponen de maniesto que la ecuación de Arrhenius
representa un modelo muy adecuado para interpretar la evolución de nume-
rosos fenómenos físicos y sicoquímicos con la temperatura, cuya aplicación
se encuentra ampliamente extendida. Estos hechos justican cualquier es-
fuerzo de análisis que conduzca a elevar la ecacia de las interpretaciones
realizadas a través de su aplicación.


Capítulo 3
Diseños Óptimos para la
Ecuación de Arrhenius
3.1. Necesidad de Diseños Óptimos
Existen en la literatura trabajos en los que se proponen diseños ópti-
mos para modelos encargados de describir el equilibrio enzimático, como el
de Michaelis-Menten (Dette y Wong, 1999; López Fidalgo y Wong, 2002;
Dette et al., 2003; entre otros muchos) usados principalmente en análisis
farmacológicos y en biología (Endrenyi, 1981). Asímismo existen trabajos,
que desde la perspectiva del diseño óptimo, se acercan a la cinética de las
reacciones químicas, planteando diseños para estimar el orden de una reac-
ción (Atkinson, 1998; Atkinson y Bogacka, 1997). Como hemos visto en la
Sección 2.2, la ecuación de velocidad y la constante de velocidad se deter-
minan a temperatura constante. El objetivo es proponer diseños óptimos
para la modelización de la relación entre la constante de velocidad y la
temperatura.
Como se ha visto hasta aquí, la ecuación de Arrhenius justica la rela-
ción entre la constante de velocidad de una reacción química y la tempera-
tura a la que esta se produce, creciendo exponencialmente con el aumento
63

64 3. Diseños Óptimos para la Ecuación de Arrhenius
de la temperatura. Asímismo, se ha expuesto cómo otros fenómenos de
transporte también poseen una dependencia del tipo Arrhenius respecto
de la temperatura. Fenómenos como la difusión, la viscosidad y la conduc-
tividad electrolítica de disoluciones iónicas explican las variaciones de sus
coecientes respecto a la temperatura mediante el modelo no lineal plan-
teado en dicha ecuación. Es ésta por lo tanto una de las razones de mayor
peso que ha inuido en el desarrollo de diseños óptimos para la ecuación
de Arrhenius que se plantean.
De los múltiples fenómenos cuya dependencia con la temperatura pue-
de ser explicada mediante la ecuación planteada por Arrhenius (1889), esta
parte del trabajo se centra en la cinética de las reacciones químicas que
se producen en la estratosfera. Los diferentes gases allí presentes, activa-
dos por radiaciones procedentes tanto del sol como del espacio, reaccionan
produciendo fenómenos de un gran interés tanto desde el punto de vista
cientíco como social y económico. El Efecto Invernadero y la reducción de
la Capa de Ozono son fenómenos en cuyas raíces encontramos el estudio
cinético de las reacciones químicas producidas en la estratosfera.
Las circunstancias especiales que aprovecha y explota este trabajo son
dos. Por un lado la disciplina del Diseño Óptimo de Experimentos, cuyo
principal objetivo es lograr la mejor estimación posible de los parámetros
desconocidos que aparecen en el modelo. En segundo lugar la ecuación de
Arrhenius, cuyo objetivo es modelizar la constante de velocidad en función
de las temperaturas estratosféricas, diferentes a las de condiciones normales,
junto con la variación climática que está experimentando el planeta.
Durante la búsqueda bibliográca previa al desarrollo del trabajo, y
ante el abanico de posibles fenómenos físicos y químicos que podían ser
utilizados en los ejemplos, nos llamó la atención la existencia de un Pa-
nel de Expertos 1 que bajo la supervisión de la National Aeronautics and
Space Administration (NASA) generaba periódicamente un informe con
los valores recomendados para los parámetros de la ecuación de Arrhenius
para numerosas reacciones de carácter atmosférico. El objetivo de dichos
1Jet Propulsion Laboratory : http://jpldataeval.jpl.nasa.gov

3.2. Modelo no Lineal 65
informes aparece reejado en la introducción del informe número 13 (Jet
Propulsion Laboratory, 2000), donde se realiza un especial énfasis en la
generación de modelos para el estudio de la evolución de la capa de ozono
y sus posibles alteraciones causadas por fenómenos naturales o antropo-
génicos, para ello recalca la importancia de poseer valores contrastados y
comparados de estos parámetros. Este informe y la posterior aparición del
número 14, (Jet Propulsion Laboratory, 2003), permitieron facilitar la tarea
de búsqueda bibliográca de ejemplos y experimentos contrastados permi-
tiendo comparar los diseños propuestos con los que realmente se estaban
llevando a cabo en los laboratorios.
Así mismo los valores de referencia planteados para los parámetros
de muchas de las reacciones sufrían en el período de 2 años importantes
correcciones en sus valores. Los factores de incertidumbre que se facilitaban
para los parámetros, sobre todo en el caso del parámetro exponencial Ea/R,
oscilaban entre el 5% y el 40%, con lo que el objetivo del Diseño Óptimo de
Experimentos, reducción de la varianza de la estimación de los parámetros,
era plenamente acertado.
Por otro lado se observa en la literatura una carencia de justicación
teórica de los diseños empleados experimentalmente. Normalmente los pun-
tos donde se han venido tomado medidas experimentales se encuentran
distribuidos a lo largo del espacio de diseño sin un criterio determinado,
con la excepción de dar especial relevancia a temperaturas problemáticas
por cuestiones experimentales. La elección de una estrategia correcta en el
diseño del experimento se ha demostrado de crucial importancia de cara a
la abilidad de nuestras inferencias.
3.2. Modelo no Lineal
La primera etapa del Diseño Óptimo de Experimentos es la elección del
modelo. Para el caso de reacciones bimoleculares, como las empleadas en los
ejemplos, la ecuación de Arrhenius se adapta perfectamente y se encuentra
plenamente justicada su utilización. Tal y como se ha mencionado, el

66 3. Diseños Óptimos para la Ecuación de Arrhenius
objetivo inicial de Arrhenius (1889) fue el de explicar la variación lineal del
logaritmo de la constante de velocidad, log k, en función del inverso de la
temperatura, 1/T .
Muchos otros autores con anterioridad a Arrhenius intentaron explicar
la variación de dicha constante de velocidad a través de diferentes modelos,
Warder en 1881, Urech en 1884, Hood en 1885, Sphor en 1888, van't Ho
en 1884, Hecht y Conrad en 1989, etc. y nalmente Arrhenius de forma
acertada en 1889, vease Logan (1982) y Laidler (1984).
El modelo planteado por Arrhenius y utilizado desde entonces se ex-
presa empíricamente de la forma:
E(k) = Ae−B/T , var(k) = σ2, T ∈ X = [T1, T2], T1 ≥ 0.
Este modelo es no lineal en sus parámetros y en él no se pueden em-
plear directamente los procedimientos clásicos anteriormente descritos. Los
parámetros A y B son independientes de la temperatura, aunque para
reacciones más complejas se incluyan modicaciones en el modelo en las
que no se va a entrar. El parámetro A, es conocido como parámetro A de
Arrhenius o frecuencia y el parámetro B expresa la temperatura de activa-
ción, B = E/R, siendo E la diferencia de energías entre el estado activado
y el estado nal y R la constante universal de los gases.
Una manera de enfrentarse a estos modelos no lineales es mediante la
linealización,
log k = logA− B
T.
Esta linealización pueden incurrir en cambios importantes en la dis-
tribución de los residuos e incluye importantes problemas de heterocedas-
ticidad en los datos, Kli£ka y Kubá£ek (1997). Obviamente se obtendrán
mejores resultados empleando métodos no lineales de mínimos cuadrados.
El trabajo aquí desarrollado requiere el uso de estos métodos.
Para poder emplear entonces las herramientas anteriormente expuestas
se linealizará, expresando el modelo mediante su desarrollo de Taylor y
quedándonos con la parte lineal. El inconveniente que se presenta es que

3.3. Matriz de Información y Criterios de Optimización 67
esta matriz depende de los propios parámetros, por lo que se necesitarán
unos valores iniciales de los mismos para obtener los diseños deseados. Dicho
de otro modo, los diseños óptimos (aquellos que proporcionan una mejor
estimación de los parámetros) conseguidos mediante este procedimiento van
a depender de los propios parámetros y para cada valor inicial de éstos,
proporcionarán distintos diseños. En nuestro caso y para nuestros ejemplos
usaremos los datos proporcionados por el Jet Propulsion Laboratory (2003)
como valores iniciales.
Este caso particular de diseños se conoce como diseños localmente óp-
timos, es decir, óptimos cuando se sabe que los parámetros iniciales están
muy cercanos a ciertos valores especícos. En este sentido puede consultarse
Cherno (1953) o Frischmuth (1989).
El espacio de diseño X, donde varía la temperatura T , es acotado y ce-
rrado por las circunstancias experimentales. Se ha tomado la determinación
de expresar sus extremos como múltiplos de B, que lleva a la obtención de
resultados más claros y simplicados. Por lo tanto se ha considerado como
espacio de diseño X = [aB, bB], siendo B la mejor estimación del paráme-
tro exponencial y a y b constantes seleccionables para la especicación de
los límites inferior y superior del intervalo donde varía la temperatura.
3.3. Matriz de Información y Criterios de Optimización
Sean θt = (A,B) los parámetros a estimar del modelo, y sea f(T ) =∂E(k)/ ∂θ evaluada en unos valores concretos de los parámetros. Estos son
las mejores estimaciones disponibles a priori de los parámetros y el cálculo
de la matriz de información y de los diseños óptimos dependerán de estos
valores iniciales.
La matriz de información de Fisher para un diseño particular ξ y bajo
condiciones de normalidad de los datos, suponiendo que la varianza es uno,
σ2 = 1, es proporcional a la siguiente expresión (Observación 2),
M(ξ) =∑x∈X
f(T )f t(T )ξ(T ).

68 3. Diseños Óptimos para la Ecuación de Arrhenius
Entonces para el modelo planteado por la ecuación de Arrhenius se
tiene que
f(T ) =
(e−B/T
−Ae−B/T
T
), T ∈ X,
siendo la matriz de información de Fisher en este caso,
M(ξ, θ) =∑T∈X
(e−2B/T −Ae−2B/T
T
−Ae−2B/T
TA2e−2B/T
T 2
)ξ(T ).
La matriz de información de Fisher obtenida verica las propiedades
enunciadas con anterioridad, Proposición 2, propiedades que han sido apli-
cadas en los cálculos necesarios para la obtención de diseños óptimos.
Tal y como se ha visto en la Proposición 3, cuando N es sucientemente
grande, la covarianza de los estimadores de θ es aproximadamente σ2/N
veces la inversa de esta matriz.
A la hora de obtener Diseños Óptimos para la estimación de los pará-
metros de la ecuación de Arrhenius se han usado los criterios de D−optimi-
zación y c−optimización expuestos en la Sección 1.7. El criterio de D−opti-mización, minimiza el volumen de la región de conanza de las estimaciones
de los parámetros y es equivalente a través del Teorema de Equivalencia
con el criterio de G−optimización, que minimiza la varianza generalizada
de la predicción. El criterio de c−optimización se centra en la estimación
eciente de combinaciones lineales de los parámetros y en particular, como
se verá, proporciona los mejores diseños para estimar cada uno de los pará-
metros. A través de los criterios compuestos, se han combinado los diseños
óptimos para cada uno de los parámetros, con el objetivo de obtener un
diseño que combine al máximo la estimación de ambos parámetros.
Según lo visto, estos criterios son convexos y estrictamente decrecientes
y por lo tanto el objetivo es la obtención de diseños con valores lo más
pequeños posibles para estas funciones criterio. El diseño, de entre todos
los posibles sobre el espacio diseño X, que minimice estas funciones criterio
será el diseño, D−óptimo o c−óptimo respectivamente.

3.4. Diseño D−Óptimo 69
A la hora de medir las ventajas de cada uno de estos diseños óptimos
planteados, se ha usado la denición de eciencia (Denición 7), consi-
derando siempre que los diseños a comparar poseen el mismo número de
observaciones.
3.4. Diseño D−Óptimo
Para estimar ambos parámetros simultáneamente, se puede usar el cri-
terio de D−optimización. Como ya hemos dicho este diseño minimiza la
región de conanza de ambos parámetros, en el caso particular de 2 pa-
rámetros, m = 2, minimiza el volumen del elipsoide de conanza de las
estimaciones de los parámetros.
En nuestro caso se ha usado como criterio de D−optimización la fun-
ción ΦD[M(ξ)] = detM−1/m(ξ), donde m es el número de parámetros del
modelo (Sección 1.7.1). Utilizando el Teorema de Equivalencia (Teorema
2), tendremos que un diseño ξ?D será D−óptimo si, y sólo si es G−óptimo.
Por lo tanto los diseños obtenidos minimizando el valor de la función cri-
terio ΦD minimizarán también la varianza generalizada de la predicción de
la respuesta en T , f t(T )M(ξ)−1f(T ).
Para asegurar que el diseño propuesto es verdaderamente D−óptimo,
se ha usado nuevamente el Teorema de Equivalencia (Teorema 4). Al ser
los criterios convexos y diferenciables tendremos que un diseño ξ?Φ será
Φ-óptimo si, y sólo si:
ψ(T, ξ?Φ) = f t(T )∇Φ(ξ?Φ)f(T )− trM(ξ?Φ)∇Φ(ξ?Φ) ≥ 0, T ∈ X,
vericándose la igualdad en los puntos de soporte Xξ?Φ. Por simplicidad en
la notación, Φ(M) equivale a Φ[M(ξ)] y ∇Φ(ξ) es el gradiente de Φ(ξ).
Que aplicado a nuestra función ΦD dice que un diseño ξ?D seráD−óptimo
si, y sólo si:
f t(T )M(ξ?D)−1f(T ) ≤ m, T ∈ [aB, bB],

70 3. Diseños Óptimos para la Ecuación de Arrhenius
donde el número de parámetros esm = 2, satisfaciéndose la igualdad al me-
nos en los puntos donde se toman observaciones, también llamados puntos
de soporte del diseño (Teorema 2).
Utilizando las propiedades enumeradas en la Sección 1.7.1 y partiendo
de diseños con dos puntos en su soporte, t1B, t2B ∈ X, y pesos p y 1− prespectivamente, se obtiene que los diseños que minimicen el valor de la
función criterio serán aquellos que maximicen el valor del
detM(ξ) =p(1− p)A2e−2(t1+t2)/t1t2(t1 − t2)2
(t1t2B)2t1, t2 ∈ [a, b].
El máximo de esta expresión se alcanzará para valores de p = 1/2. Seencontrará el diseñoD−óptimo derivando respecto a t1 y t2 y comprobando
los diseños con soporte en los extremos del espacio de diseño, este diseño se
vericará como el correcto a través del Teorema de Equivalencia (Teorema
2).
El diseño propuesto como D−óptimo posee dos puntos en su soporte
con pesos iguales para cada punto en el espacio de diseño X = [aB, bB]:
Si tD = b/(1+b) ∈ [a, b], entonces ξ?D tiene como puntos de soporte
a tDB y bB.
Si tD = b/(1+b) /∈ [a, b], entonces ξ?D tiene como puntos de soporte
a aB y bB.
Se presenta a continuación un ejemplo de la aplicación de este diseño
D−óptimo a un caso real.
Ejemplo 1. Veamos que el diseño D−óptimo generado para estimar los
parámetros de la ecuación de Arrhenius para la reacción química de interés
en la modelización atmósférica: NO+O3 → NO2 +O2 satisface el Teorema
de Equivalencia.
Supongamos que se desean estimar los parámetros A y B para el rango
de temperaturas X = [aB, bB] = [212, 422], usando como aproximaciones
iniciales de los valores de los parámetros A = 3.0×10−12 y B = 1500 (±200)(Jet Propulsion Laboratory, 2003). Como puede comprobarse el factor de

3.4. Diseño D−Óptimo 71
incertidumbre presentado por el parámetro B es considerable por lo que re-
sulta acertado el planteamiento de diseños óptimos que nos lleven a reducir
la varianza de las estimaciones.
El diseño D−óptimo obtenido para este experimento tiene como puntos
de soporte los valores tDB = 329.3 y bB = 422 tomando el mismo número
de observaciones en cada punto. Este diseño expresado con la notación
clásica del diseño óptimo de experimentos tiene la siguiente forma:
ξ?D =
(tDB bB
1/2 1/2
)=
(329.3 4221/2 1/2
).
El la Figura 3.1 se representa de forma gráca los valores de la varianza
generalizada frente a la temperatura en los valores del espacio de diseño.
Con esto se demuestra que el Teorema de Equivalencia se verica y que
la desigualdad se mantiene para T ∈ [212, 422], satisfaciéndose únicamente
la igualdad para los puntos de soporte del diseño. Basándose en la deni-
aB tDB bBTemperatura
0
0.5
1
1.5
2
2.5
3
aB tDB bB
001.nb 1
Figura 3.1. Gráca de la varianza generalizada para el Ejemplo 1.
ción de eciencia de un diseño, y siempre considerando que los diseños a
comparar toman el mismo número de observaciones, se ha comparado la

72 3. Diseños Óptimos para la Ecuación de Arrhenius
eciencia de diversos diseños con el diseño D−óptimo obtenido. Los diseños
a comparar son los siguientes:
El diseño llevado a cabo por Ray y Watson (1981) en su trabajo
experimental. En él tomaron un total de 75 observaciones, (N =75), en 6 puntos distintos, con diferentes pesos para cada punto del
soporte:
ξexp =
(212 241 273 299 361 422
12/75 9/75 8/75 24/75 12/75 10/75
).
Un diseño uniformemente distribuido, de pesos iguales y con sus
puntos de soporte uniformemente distribuidos a lo largo del espacio
de diseño: este diseño tiene un valor constante d como parámetro
de espaciamiento entre los puntos de su soporte. Este parámetro es
la distancia que hay entre dos observaciones consecutivas.
Un diseño aritméticamente distribuido, de pesos iguales y con sus
puntos espaciados por un parámetro que crece en forma de progre-
sión aritmética, (id), desde el centro hasta los extremos del espacio
de diseño X, con i = 1, . . . , N/2. Sólo en el caso en el que N es
impar el centro de X es un punto de soporte de este diseño.
Un diseño geométricamente distribuido, igual que el caso aritméti-
co pero con el parámetro de espaciado creciendo en forma de una
progresión geométrica, (di),
Un diseño distribuido de forma lineal inversa: en este diseño, el
intervalo [Ae−1/a, Ae−1/b] es dividido de forma uniforme y se toman
como puntos de soporte para el diseño los puntos obtenidos a través
de la inversa de la función de regresión, ecuación de Arrhenius, en
el espacio de diseño X = [aB, bB].
Todos los diseños aquí planteados tienen el mismo número de pun-
tos en su soporte, N = 6, y salvo el primero, son simétricos respecto

3.5. Método de Elfving y Diseños c−Óptimos 73
al centro del espacio de diseño X = [212, 422]. Comparando cada di-
seño con el D−óptimo, ξ?D, calculando los valores de la función crite-
rio, ΦD(ξ) = detM−1/2(ξ), y obteniendo su eciencia respecto al óptimo,
effD(ξ) = ΦD(ξ?D)/ΦD(ξ), se obtienen los resultados que se muestran el la
Tabla 3.1.
effD(ξ)
Diseño Ray y Watson 0.55Diseño Uniforme 0.61Diseño Aritmético 0.63Diseño Geométrico 0.66Diseño Lineal Inverso 0.67
Tabla 3.1. D−eciencias del diseño experimental de Ray y Watson(1981) y de otros cuatro posibles diseños para estimar los parámetrosde la ecuación de Arrhenius.
3.5. Método de Elfving y Diseños c−Óptimos
Si el interés se centra en la estimación de una combinación lineal de
los parámetros, como por ejemplo ctθ, o bien en estimaciones individua-
les para A o B, entonces se puede usar el criterio c−óptimo. Como he-
mos visto en la Sección 1.7.3, una forma elegante de encontrar el diseño
óptimo para estimar una combinación de los parámetros fue proporcio-
nado por Elfving (1952). Para un modelo dado, con una función de re-
gresión f(T ), el método dene en primer lugar el conjunto de Elfving,
Λ = cierre convexo de (f(X) ∪ −f(X)).
El punto de intersección de la línea recta denida por el vector c con
la frontera del conjunto de Elfving, Λ, determina el diseño c−óptimo como
una combinación convexa de vértices de Λ. Estos vértices corresponden a
los puntos de soporte del diseño óptimo y los pesos de las combinaciones
convexas se corresponden con los pesos de cada punto en el diseño.

74 3. Diseños Óptimos para la Ecuación de Arrhenius
Además el valor de la función criterio para el diseño óptimo, ξ?c , es
equivalente a Φc(ξ?c ) = (‖c‖/‖c?‖)2, donde c? es el vector denido por el
punto de corte de la línea denida por el vector c con la frontera de Λ(Cherno, 1972).
El conjunto de Elfving Λ para el modelo planteado por la ecuación de
Arrhenius se muestra en la Figura 3.2. Para estimar los parámetros A y B,
se asignará a c los valores ct = (1, 0) y ct = (0, 1), siendo cada uno de los
diseños cA− y cB−óptimo respectivamente.
xb
yb
xc
yc
xa
ya
x*
y*
Figura 3.2. Conjunto de Elfving para la ecuación de Arrhenius. Lospuntos f(aB) = (xa, ya)
t y f(bB) = (xb, yb)t son los valores de f en
los extremos del espacio de diseño X. Los puntos f(tcB) = (xc, yc)t y
f(bB) = (xb, yb)t denen, en este caso, los puntos de soporte para los
diseños cA− y cB−óptimos. Los Puntos c?A = (x?, 0)t y c?B = (0, y?)t
son combinaciones convexas de (xc, yc) y (xb, yb) y los pesos de estascombinaciones son los pesos de los diseños óptimos.
Los extremos de la línea recta que unen el extremo de la curva f(X),f(bB) = (xb, yb)t, y el punto tangente sobre −f(X), −f(tcB) = (xc, yc)t, oel inicio de la curva −f(X), −f(aB) = (−xa,−ya)t, denen los puntos de
soporte para los diseños que estiman de forma óptima A y B. Los puntos de
corte de esta línea recta con ambos ejes, c?A = (x?, 0)t y c?B = (0, y?)t, de-nen los pesos para los diseños cA− y cB−óptimos respectivamente (Figura
3.2).

3.5. Método de Elfving y Diseños c−Óptimos 75
De la geometría de la Figura 3.2 junto con el método de Elfving, siendo
δ la solución principal de la ecuación δe(δ+1) = 1, δ = 0.278, se tiene queel diseño cA−óptimo puede tener una de las siguientes formas:
Si tc = b/(1 + b + δb) ∈ [a, b], entonces ξ?cA tiene como puntos de
soporte a tcB y bB, y el diseño cA−óptimo es:
ξ?cA =
(tcB bBtce1/tc
tce1/tc+be1/bbe1/b
tce1/tc+be1/b
).
Si tc = b/(1 + b + δb) /∈ [a, b], entonces ξ?cA tiene como puntos de
soporte a aB y bB, y el diseño cA−óptimo es:
ξ?cA =
(aB bBae1/a
ae1/a+be1/bbe1/b
ae1/a+be1/b
).
De la misma forma se tiene que el diseño cB−óptimo puede tener una
de las siguientes formas:
Si tc = b/(1 + b + δb) ∈ [a, b], entonces ξ?cB tiene como puntos de
soporte a tcB y bB, y el diseño cB−óptimo es:
ξ?cB =
(tcB bBe1/tc
e1/tc+e1/be1/b
e1/tc+e1/b
).
Si tc = b/(1 + b + δb) /∈ [a, b], entonces ξ?cB tiene como puntos de
soporte a aB y bB, y el diseño cB−óptimo es:
ξ?cB =
(aB bBe1/a
e1/a+e1/be1/b
e1/a+e1/b
).
Para ambas opciones, tc ∈ [a, b] y tc /∈ [a, b], los diseños cA− y cB−óptimos
tienen los mismos puntos de soporte y los pesos únicamente dependen de b
y de tc o a. Los diseños no dependen del valor inicial considerado para A,
pero sí que dependen implícitamente de B, a = T1/B y b = T2/B, siendo
T1 y T2 los límites inferior y superior del espacio de diseño X.

76 3. Diseños Óptimos para la Ecuación de Arrhenius
Los valores de la función criterio, que salvo una constante multiplicativa
son las varianzas de los estimadores, Φc(ξ) = ctM(ξ)−1c, son:
Si tc ∈ [a, b], entonces
ΦcA(ξ?cA) =
(tce
1/tc + be1/b
b− tc
)2
,
ΦcB (ξ?cB ) =
(tcbB(e1/tc + e1/b)
A(b− tc)
)2
.
Si tc /∈ [a, b], entonces
ΦcA(ξ?cA) =
(ae1/a + be1/b
b− a
)2
,
ΦcB (ξ?cB ) =
(abB(e1/a + e1/b)
A(b− a)
)2
.
Y las eciencias de cada uno de estos diseños para estimar el otro
parámetro dependen de b y de tc o a, y se corresponden con las expresiones:
Si tc ∈ [a, b], entonces
effcA(ξ?cB ) =ΦcA(ξ?cA)ΦcA(ξ?cB )
=(tce1/tc + be1/b)2
(e1/tc + e1/b)(t2ce1/tc + b2e1/b),
effcB (ξ?cA) =ΦcB (ξ?cB )ΦcB (ξ?cA)
=tcb(e1/tc + e1/b)2
(be1/tc + tce1/b)(tce1/tc + be1/b).
Si tc /∈ [a, b], entonces
effcA(ξ?cB ) =ΦcA(ξ?cA)ΦcA(ξ?cB )
=(ae1/a + be1/b)2
(e1/a + e1/b)(a2e1/a + b2e1/b),
effcB (ξ?cA) =ΦcB (ξ?cB )ΦcB (ξ?cA)
=ab(e1/a + e1/b)2
(be1/a + ae1/b)(ae1/a + be1/b).
En la Figura 3.3 se muestra el comportamiento de la eciencia del diseño
cA−óptimo para estimar B. La gráca corresponde a la representación de
la función effcA(ξ?cB ) para valores de b ∈ [0, 1.5] y a ∈ [0, b]. La eciencia esalta para valores de a cercanos al valor de b y toma el valor 1 para el caso

3.5. Método de Elfving y Diseños c−Óptimos 77
0
0.5
1 0.5
1
1.5
0.8
0.85
0.9
0.95
1
1.5 0
a
eff
b
0
0.5
1
0.8
0.85
0.9
0.95
1
Figura 3.3. Eciencia del diseño cA−óptimo para estimar B, effcA(ξ?cB).
particular en que a = b, en este caso el diseño posee un único punto en su
soporte. La eciencia disminuye según aumenta la distancia entre ambos
puntos, estando acotada inferiormente por el valor (1 + e1/a)−1 cuando b
tiende a innito.
Igualmente, en la Figura 3.4 se muestra el comportamiento de la e-
ciencia del diseño cB−óptimo para estimar el parámetro A. La gráca
corresponde a la representación de la función effcB (ξ?cA) para valores de
b ∈ [0, 1.5] y a ∈ [0, b]. Nuevamente la eciencia es alta para valores de a
cercanos a b e igual que en el caso anterior toma el valor de 1 para el diseño
con un único punto de soporte en que a = b. La eciencia disminuye tam-
bién en este caso cuando la distancia entre ambos valores aumenta pero, a
diferencia del caso anterior, ahora tiende a 0 cuando b tiende a innito.
De forma más genérica, podría interesarnos estimar ctθ, con ct = (c1, c2),y c1 6= 0. Obviamente este problema es equivalente a estimar ct = (1, c1/c2),o lo que es lo mismo (1, cA/B) siendo c arbitrario. Usando el argumento
de Elfving se prueba que:

78 3. Diseños Óptimos para la Ecuación de Arrhenius
0
0.5
1 0.5
1
1.5
0.85
0.9
0.95
1
1.5 0
a
eff
b
0
0.5
1
0.85
0.9
0.95
1
Figura 3.4. Eciencia del diseño cB−óptimo para estimar A, effcB (ξ?cA).
Si tc = b/(1 + b + δb) ∈ [a, b], y si (−1/tc) ≤ c ≤ (−1/b) entoncestendremos un diseño óptimo con un único punto en su soporte en
−B/c, tomando la función característica en ese caso el valor de
e−2c. En caso contrario ξ?c tiene como puntos de soporte a tcB y
bB, con peso en tcB igual a
ptc =tc(1 + bc)e1/tc
tc(1 + bc)e1/tc + b(1 + tcc)e1/b,
y 1 − ptc en bB. El valor de la función criterio, i.e. la varianza de
la estimación, para el diseño c−óptimo es
Φc(ξ?c ) =e2/b(1 + b+ bc+ bδ + (1 + bc)e1+δ)2
b2(1 + δ)2.
Si tc = b/(1 + b + δb) /∈ [a, b] y (−1/a) ≤ c ≤ (−1/b) entonces
nuevamente tendremos un diseño óptimo con un único punto en su
soporte en −B/c y el valor de la función característica en este caso
es e−2c. En caso contrario ξ?c tiene como puntos de su soporte a aB

3.6. Diseños Óptimos Compuestos 79
y bB, con peso en aB igual a
pa =a(1 + bc)e1/a
a(1 + bc)e1/a + b(1 + ac)e1/b
y 1− pa en bB. El valor de la función criterio, i.e. la varianza de la
estimación, para el diseño c−óptimo es
Φc(ξ?c ) =(a(1 + bc)e1/a + b(1 + ac)e1/b)2
(b− a)2.
3.6. Diseños Óptimos Compuestos
En el modelo planteado por la ecuación de Arrhenius puede resultar
de mayor interés, o requerir mayor precisión, la estimación de uno de los
dos parámetros en lugar de la estimación del otro. La eciencia de la es-
timación de uno de los parámetros ha de ser, por lo tanto, mayor que la
eciencia de la estimación del otro. Como hemos visto en la Sección 1.7.4,
es posible combinar criterios para obtener un diseño que satisfaga en de-
terminada proporción los criterios a combinar. Para este caso particular,
combinaremos los diseños cA− y cB−óptimos mediante una nueva función
criterio compuesta por ΦcA y por ΦcB :
Φλ(ξ) = λΦcA(ξ)
ΦcA(ξ?cA)+ (1− λ)
ΦcB (ξ)ΦcB (ξ?cB )
=λ
effcA(ξ)+
1− λeffcB (ξ)
.
En esta expresión, 0 ≤ λ ≤ 1 es una constante seleccionada por el
usuario que regula el peso asignado a la estimación de cada parámetro. La
nueva función criterio compuesta es una función convexa ya que resulta de
una combinación convexa de dos funciones criterio también convexas y por
lo tanto el problema de optimización es esencialmente el mismo que en el
caso de un problema de diseño óptimo con una única función criterio.
El diseño que minimice el valor de Φλ(ξ), para un λ jo, será un diseño
óptimo compuesto. El valor de λ representa el peso asignado a cada criterio
presente en la combinación de las funciones criterio. En el caso de asignar
un valor cercano a la unidad, esto sugiere que la estimación de A es más

80 3. Diseños Óptimos para la Ecuación de Arrhenius
importante y por lo tanto al diseño cA−óptimo se le asigna mayor peso en
la combinación.
Como las varianzas de las estimaciones, los valores de las funciones cri-
terio Φ(ξ?c ), pueden tomar valores muy diferentes en virtud de las diferentes
magnitudes de cada parámetro, se estandarizan dividiéndolas por sus va-
lores óptimos, dando así lugar a la formulación presentada para la función
criterio compuesta Φλ(ξ).
Para poder llevar a cabo los cálculos, es conveniente jar el valor de λ
y encontrar los diseños que minimicen Φλ(ξ) de entre todos los de la forma
ξz,p =
(zB bB
p 1− p
).
Fijando b y λ, se buscan valores para z y p que minimicen Φλ(ξ). Paradeterminar si el diseño obtenido es verdaderamente óptimo, se usa una vez
más el Teorema de Equivalencia, Teorema 4, vericándose en el caso de
optimalidad que(∂ψ
∂x
)x=zB
= 0 al mismo tiempo que ψ(zB, ξz,p) = 0.
La primera de estas condiciones puede simplicarse, López-Fidalgo y
Wong (2002), considerando que:
∇Φλ(ξz,p) = −M−1(ξz,p)
λΦcA (ξ?cA
) 0
0 1−λΦcB (ξ?cB
)
M−1(ξz,p).
Puede ser útil representar grácamente los valores de la eciencia del
diseño compuesto respecto a los diseños óptimos de cada criterio que forma
parte de la combinación, frente a los valores de λ ∈ [0, 1]. En este caso
se representaría la eciencia del diseño compuesto obtenido frente a los
diseños óptimos para calcular A y B respectivamente. Cook y Wong (1994),
muestran como, en el caso de combinaciones de dos criterios, una de las
eciencias es no decreciente mientras que la otra es no creciente frente a λ.

3.6. Diseños Óptimos Compuestos 81
La pendiente de dichas curvas expresan la pérdida que debemos sufrir en la
estimación de uno de los parámetros para mejorar en la estimación del otro.
El punto de corte de ambas curvas dará el valor de λ para el cual el diseño
compuesto resulta igual de óptimo en la estimación de ambos parámetros
del modelo. Imhof y Wong (2000) han demostrado que este tipo de diseños
óptimos se corresponden con el concepto de diseños óptimos maximin,
ya que maximizan la eciencia mínima obtenida para ambos criterios. La
representación gráca de las eciencias ayuda al investigador en la toma
de decisiones a la hora de plantear un diseño de compromiso que satisfaga
dos objetivos, en principio, contradictorios.
Ejemplo 2. A modo de ejemplo se ha calculado el diseño óptimo que
estime los parámetros de Arrhenius para la reacción entre HO2 y el ozono.
Tal y como se ha descrito anteriormente, se han representado las eciencias
del diseño compuesto frente a los diseños cA− y cB−óptimos en función del
valor de λ. Igualmente que Sinha et al. (1987) en su trabajo experimental,
se ha considerado X = [243, 413] como el espacio de diseño cubierto por
el rango de temperaturas y se han usado como aproximaciones iniciales
de los parámetros los valores A = 1.0 × 10−14 y B = 490(+160,−80)(Jet Propulsion Laboratory, 2003), que nuevamente presentan un grado
importante de incertidumbre que sugiere y justica la necesidad de un
diseño óptimo.
Como se observa en la Figura 3.5, el diseño óptimo compuesto es el que
corresponde al valor de λ = 0.48 que asigna eciencias por encima del 98 %para la estimación de ambos parámetros. Este diseño óptimo compuesto
tiene como puntos de soporte zB = aB = 243 y bB = 413 con un peso
para el punto zB = 243 correspondiente a p = 0.64.
Si se jase una eciencia mínima para la estimación de un parámetro
determinado el diseño compuesto asignaría el valor de λ correspondiente
necesario para alcanzar esta eciencia maximizando al mismo tiempo la
eciencia de la estimación del otro parámetro, sujeta a la restricción esta-
blecida. Por ejemplo, se puede observar en la Figura 3.5, que para estimar B
con una eciencia mínima del 99 %, necesitaría jarse el valor de λ = 0.37.

82 3. Diseños Óptimos para la Ecuación de Arrhenius
0 0.25 0.37 0.5 0.75 1l
0.94
0.96
0.98
0.99
1
aicneicifE
0 0.25 0.37 0.5 0.75 1
0.94
0.96
0.98
0.99
1
effcA xl effcB xl
ejemplotbab.nb 1
Figura 3.5. Representación gráca de las eciencias del diseño com-puesto para estimar A y B respectivamente
Este valor de λ aseguraría simultáneamente una eciencia en la estimación
de A del 97.5 %, máxima de entre todos los diseños sujetos a la restricción
planteada.
Se pueden encontrar justicaciones y ampliaciones del uso de esta téc-
nica en los trabajos de Huang y Wong, (1998a; 1998b) y Cook y Wong
(1994).
3.7. Comparación con otros Diseños
Los diseños óptimos obtenidos hasta aquí, y diseñados para la estima-
ción de los parámetros del modelo planteado por la ecuación de Arrhenius,
poseen como soporte uno o dos puntos distintos. Estos diseños con tan po-
cos puntos no nos permiten observar la adecuación de los puntos al modelo,
circunstancia altamente valorada por los autores de los experimentos, per-
mitiendo detectar la falta de ajuste o adecuación al modelo. Para evitar este
inconveniente, los diseños usados en la práctica tienen más de dos puntos

3.7. Comparación con otros Diseños 83
en su soporte, véanse por ejemplo los diseños usados en los experimentos
llevados a cabo por Sinha et al. (1987) o Ray y Watson (1981).
Ahora bien, una vez calculados los diferentes diseños óptimos, pueden
compararse diferentes diseños calculando sus eciencias respecto a los óp-
timos y reunir así suciente información como para elegir el más adecuado
a los intereses del experimento.
A la hora de comparar, se han calculado los valores de las funciones
criterio para estimar de forma óptima A y B de un diseño genérico con N
puntos y con pesos iguales en cada punto,
ξexp =
(t1B t2B . . . tNB
1/N 1/N . . . 1/N
),
Para este experimento genérico, los valores de las funciones criterio que
determinan los diseños cA− y cB−óptimos respectivamente son:
ΦcA(ξexp) =N∑N
i=1
(e−1/ti
ti
)2
∑Ni=1
(e−1/ti
)2∑Ni=1
(e−1/ti
ti
)2−(∑N
i=1e−2/ti
ti
)2 ,
ΦcB (ξexp) =NB2
∑Ni=1
(e−1/ti
)2A2∑N
i=1
(e−1/ti
)2∑Ni=1
(e−1/ti
ti
)2−(∑N
i=1e−2/ti
ti
)2 .
Para obtener las eciencias, se dividen los valores obtenidos en ellas por
los diseños óptimos correspondientes, ΦcA(ξ?cA) y ΦcB (ξ?cB ) calculados en
la Sección 3.5, por el valor de la función criterio correspondiente para el
experimento genérico, ξexp,
effcA(ξexp) =ΦcA(ξ?cA)ΦcA(ξexp)
, effcB (ξexp) =ΦcB (ξ?cB )ΦcB (ξexp)
,
estas expresiones resultan ser independientes de A y únicamente dependen
de B implícitamente a través de los puntos a, b, t1 . . . tN .
Para poder comparar los diseños óptimos calculados, se supone que los
diseños que se comparan toman el mismo número de observaciones en el
espacio de diseño X = [aB, bB].

84 3. Diseños Óptimos para la Ecuación de Arrhenius
Al igual que en el Ejemplo 1, se considera un parámetro de espaciado
entre puntos consecutivos del diseño y se usan diseños simétricos respecto al
centro del espacio de diseño, con pesos iguales para cada punto del soporte,
1/N , y formando parte de los puntos de soporte del diseño los extremos del
espacio de diseñoX = [aB, bB]. La comparación se realizará con los mismos
diseños enumerados en el Ejemplo 1, i.e. diseños con una distribución de
puntos Uniforme, Aritmética, Geométrica o Lineal Inversa.
Y como ejemplos ilustrativos nuevamente se usarán las reacciones de
interés en la Química atmosférica que ya se han empleado en los anteriores
ejemplos.
Ejemplo 3. Para la reacción NO+O3 → NO2 +O2, cubriendo el rango de
temperaturas del espacio de diseño los valoresX = [aB, bB] = [212, 422] taly como hacen en su trabajo experimental Ray y Watson (1981), y conside-
rando como valores iniciales, es decir mejores aproximaciones a los valores
de los parámetros, A = 3.0 × 10−12 y B = 1500(±200) (Jet Propulsion
Laboratory, 2003). Los diseños cA− y cB−óptimos obtenidos tienen como
puntos de soporte las temperaturas tcB y bB,
ξ?cA =
(310.4 4220.73 0.27
), ξ?cB =
(310.4 4220.78 0.22
).
Los resultados para las eciencias calculadas de diferentes posibles diseños
genéricos de la forma de ξexp, con los puntos de soporte distribuidos también
de diferentes formas, se presentan en la Tabla 3.2.
Como se puede observar en los resultados, se puede identicar el diseño
que aporta la mayor eciencia a la estimación de cada parámetro, en este
caso particular es el de distribución Geométrica el que nos asegura el mayor
grado de eciencia en ambos casos.
Ejemplo 4. Se puede observar una situación diferente en el siguiente ejem-
plo. Para la reacción del HO2 con el ozono, y para temperaturas cubriendo
el intervalo X = [aB, bB] = [243, 413] tal y como usan Sinha et al. (1987).
Tomando como mejores estimaciones disponibles los valores A = 1.0×10−14

3.7. Comparación con otros Diseños 85
NO +O3 effcA(ξexp) effcB
(ξexp)
ξexp N = 4 N = 6 N = 10 N = 4 N = 6 N = 10
Uniforme 0.62 0.58 0.53 0.59 0.57 0.54Aritmético 0.71 0.67 0.59 0.69 0.68 0.63Geométrico 0.77 0.77 0.64 0.74 0.80 0.71Lineal Inverso 0.51 0.52 0.51 0.50 0.52 0.51
Tabla 3.2. Eciencias de cuatro posibles diseños genéricos, con dife-rentes valores de N (puntos experimentales distintos), para la estima-ción de los parámetros A y B de la reacción NO +O3.
y B = 490(+160,−80) (Jet Propulsion Laboratory, 2003), obtenemos los
siguientes diseños cA− y cB−óptimos,
ξ?cA =
(243 4130.57 0.43
), ξ?cB =
(243 4130.70 0.30
).
Se presentan, igual que para el ejemplo anterior, los resultados para las
eciencias calculadas de diferentes posibles diseños genéricos de la forma
de ξexp, con los puntos de soporte distribuidos también de diferentes formas,
Tabla 3.3.
HO2 +O3 effcA(ξexp) effcB
(ξexp)
ξexp N = 4 N = 6 N = 10 N = 4 N = 6 N = 10
Uniforme 0.57 0.49 0.43 0.55 0.48 0.43Aritmético 0.53 0.43 0.34 0.52 0.42 0.35Geométrico 0.51 0.36 0.26 0.50 0.37 0.27Lineal Inverso 0.58 0.49 0.43 0.57 0.49 0.44
Tabla 3.3. Eciencias de cuatro posibles diseños genéricos, con dife-rentes valores de N , para la estimación de los parámetros A y B de lareacción HO2 +O3.
Nuevamente, de estos resultados podemos elegir el diseño de mayor
eciencia en la estimación de los parámetros. Para este caso, en el que los
extremos del espacio de diseño son los puntos de soporte de los diseños

86 3. Diseños Óptimos para la Ecuación de Arrhenius
cA− y cB−óptimos, el experimento genérico de mayor eciencia no resulta
ser el de distribución geométrica sino el lineal inverso o en algún caso el
uniforme, con valores de eciencia muy similares.

Capítulo 4
Fenómenos de Adsorción
La adsorción es un fenómeno supercial que consiste en la deposición
de una sustancia sobre la supercie de otra, generalmente un sólido con
supercie muy rugosa, o bien namente pulverizado, formas en las que pre-
senta una mayor área supercial por unidad de masa. La fuerza impulsora
está relacionada con el exceso de energía que poseen, por regla general, las
moléculas de la interfase en comparación con las de la fase interior de la
sustancia.
La sustancia que adsorbe se denomina adsorbente, mientras que la que
es adsorbida se denomina adsorbato. En la adsorción se alcanza un equilibrio
entre sustancia adsorbida y sustancia no adsorbida, la cual se mantiene en
contacto con el adsorbente en forma de gas (o vapor) o en forma de soluto
de una disolución.
4.1. Generalidades
Como apunte histórico puede decirse que el fenómeno de la adsorción
se conoce desde el siglo XVIII. El sueco Scheele1, en 1773, y el italiano
Fontana2, en 1777, observaron la adsorción de gases por carbón, y el ruso
1Carl Wilhelm Scheele (1742-1786).2Felice Fontana (1730-1805).
87

88 4. Fenómenos de Adsorción
Lovitz3, en 1785, registró la adsorción de sustancias orgánicas en disolución
acuosa por carbón namente pulverizado. Una de las primeras aplicaciones
del fenómeno de la adsorción de gases por carbón tuvo lugar, por ejemplo,
en la creación de la máscara antigás para la protección contra los gases
tóxicos, durante la primera guerra mundial. Indudablemente, el fenómeno
tiene una enorme importancia en el comportamiento sicoquímico de múl-
tiples procesos naturales y en general en la industria (catálisis, corrosión,
medio ambiente, alimentación, etc.; ver por ejemplo Gregg y Sing, 1982).
Convencionalmente, se habla de sisorción y quimisorción, según la
magnitud de las fuerzas que actúan: fuerzas de naturaleza física, general-
mente débiles, originadas por interacción dipolar o multipolar, o fuerzas de
tipo químico, fuerzas propiamente de enlace. Es natural que sea muy difícil
establecer con claridad una separación entre estos dos comportamientos,
por lo que existe cierto margen de casos intermedios. Además, siempre que
se presenta quimisorción aparecen también, en mayor o menor grado, fenó-
menos de sisorción, pues las fuerzas que actúan en éste último caso, son
fuerzas de tipo general.
En los procesos de adsorción, la supercie desempeña un papel funda-
mental. La supercie de un sólido no es, en modo alguno, regular, por el
contrario, presenta numerosas rugosidades, prominencias, poros, etc. que
hacen que su valor sea mucho mayor del que podría calcularse por méto-
dos geométricos (Aspectos fractales de la supercie de los sólidos: ver, por
ejemplo, Avnir (1989)). El sistema de poros puede ser muy complicado y
extenso, llegando a ser su área supercial varios órdenes de magnitud supe-
rior a la de la supercie aparente. El tamaño de los poros y, en particular,
su diámetro es muy variable; convencionalmente se habla de macroporos
(diámetro & 20nm), microporos (. 1.5nm) y mesoporos (con tamaños in-
termedios). El tamaño de los poros tiene un interés considerable, ya que
para que su supercie pueda adsorber es preciso que las moléculas de ad-
sorbato puedan penetrar a su través.
3Tobias E. Lovitz (1757-1804).

4.2. Método Experimental 89
Las áreas suelen expresarse como área especíca, s, que es el área que
presenta 1 g de sólido, y suelen medirse en m2 g−1. La mayor parte de
los sólidos implicados en procesos de adsorción de cierto interés suelen
tener áreas especícas muy grandes, de hasta un orden de magnitud de
1000 m2 g−1.
4.2. Método Experimental
Puede resultar de interés en este punto una somera descripción del
método experimental habitualmente utilizado en la obtención de datos de
adsorción. Una descripción detallada de estos procedimientos puede encon-
trarse en la correspondiente monografía de la IUPAC (1985).
Desde un punto de vista fenomenológico hay dos magnitudes experi-
mentales de importancia. Una es la cantidad de adsorbato por unidad de
adsorbente, magnitud que designaremos por n, y la otra es el calor de ad-
sorción. Según el método de medida que se utilice será más conveniente
expresar n en unas u otras unidades. Las más corrientes son gramos, moles
o centímetros cúbicos (en condiciones normales de presión, p, y tempera-
tura, T : 1 atm y 0C) de adsorbato por gramo de adsorbente.
La cantidad adsorbida, n, depende de la temperatura, la presión o la
concentración de adsorbato, y la naturaleza sicoquímica del sistema. Si
n se expresa por gramo de adsorbente, depende también de la supercie
especíca de éste:
n = f(T, p, s, naturaleza del sistema).
Hay dos métodos generales para determinar n en sistemas sólido-gas:
el volumétrico y el gravimétrico (Adamson y Gast, 1997). En el método
volumétrico el adsorbente se coloca en un bulbo termostatizado (T = cte.),
conectado a un sistema manométrico que facilita la medida de la presión en
su interior. Se permite al adsorbato, en fase gaseosa, ponerse en contacto
con el sólido adsorbente. A medida que se produce la adsorción la presión
del gas disminuye hasta que se alcanza el equilibrio. De la diferencia de

90 4. Fenómenos de Adsorción
la presión de equilibrio respecto de la presión inicial se puede deducir el
volumen de gas adsorbido.
En el método gravimétrico se procede de forma muy parecida, excepto
que la cantidad de gas adorbido se deduce por pesada del sólido adorben-
te, antes y después de alcanzarse el equilibrio de adsorción. Los equipos
utilizados en este menester son especialmente sensibles.
Generalmente, las experiencias se llevan a cabo a temperatura constan-
te, obteniéndose la isoterma de adsorción.
La otra magnitud experimental de importancia la constituye el calor de
adsorción. La medida del calor desarrollado durante el proceso de adsorción
de un gas puede determinarse con ayuda de un calorímetro convencional. En
los fenómenos de adsorción, y muy especialmente en los de sisorción, el ca-
lor desarrollado es muy pequeño, por lo que se necesita una alta sensibilidad
en la determinación calorimétrica. Experimentalmente se ha comprobado
que, al igual que ocurre en los fenómenos de condensación y solidicación,
el calor de adsorción es siempre negativo, es un calor liberado por el sis-
tema, es decir, el fenómeno de adsorción es un fenómeno exotérmico. Esto
explica que la capacidad adsorbente de un sólido disminuya al aumentar la
temperatura.
4.3. Quimisorción
La quimisorción es debida a la formación de un verdadero enlace quí-
mico entre el adsorbente y el adsorbato. Es, pues, un verdadero proceso
de reacción química, y de ello se derivan sus características: las moléculas
quimisorbidas son nuevas especies químicas; el calor de adsorción suele ser
grande, mayor que el de condensación; la velocidad de reacción es general-
mente pequeña, como corresponde a un proceso con energía de activación
más o menos notable, etc.
El enlace químico es de corto alcance y solo lo pueden formar las molé-
culas en contacto directo con la supercie, situadas a la distancia de enlace.

4.4. Modelo de Langmuir 91
Por lo tanto, se formará una monocapa quimisorbida. Además, las inter-
acciones adsorbente/adsorbato son intensas, por lo que la heterogeneidad
de la supercie juega un papel determinante. La quimisorción no destruye
la red cristalina del sólido adsorbente, limitándose a añadir encima de ella
la capa de moléculas adsorbidas. Solamente si la reacción química es muy
favorable, el ataque continúa hacia el interior del sólido rompiéndose su red
y formando nuevos productos.
4.4. Modelo de Langmuir
La isoterma para describir los procesos de quimisorción deberá tomar
en cuenta estas dos características principales: la formación de la monocapa
y la heterogeneidad de la supercie. No existe ningún modelo plenamente
satisfactorio, aunque alguno, en determinados casos, resulta aceptable.
El modelo de Langmuir4 es el más simple y el más antiguo. La deducción
que se sigue a continuación es básicamente la proporcionada por Langmuir
(1918), en la que se utilizan argumentos relacionados con las velocidades
de condensación y de evaporación. En principio, se supone que la supercie
se encuentra constituída por un determinado número de centros activos,
S, en los que S1 se encuentran ocupados y S0 = S - S1 están libres. Si
la velocidad de condensación se toma como proporcional a S1, k1S1, y la
de condensación como proporcional al número total de centros, S0 y a la
presión, p, del gas, k2pS0, en el equilibrio se cumplirá:
k1S1 = k2pS0 = k2p(S − S1).
Según esto, la fracción de centros ocupados (supercie cubierta), θ =S1/S, puede expresarse:
θ =bp
1 + bp,
donde:
b =k2
k1.
4Irving Langmuir (1881-1957), Químico y Físico norteamericano.

92 4. Fenómenos de Adsorción
De forma alternativa, la fracción de supercie cubierta puede represen-
tarse como, θ = n/nm, donde n representa el número de moles de sustancia
adsorbida, por gramo de adsorbente, en unas determinadas condiciones y
nm es el número de moles necesario para cubir totalmente la supercie de
esta misma cantidad de adsorbente, formando una monocapa. Así:
n =nmbp
1 + bp.
Como se ve en la Figura 4.1, a baja presión la cantidad de sustancia
adsorbida, n ' nmbp, puede tomarse proporcional a la presión, p, mientras
que a valores altos tiende al valor de saturación, nm.
p
nnm
nm
langmuir.nb 1
Figura 4.1. Perl de la isoterma de Langmuir para dos valores dife-rentes del parámetro b.
4.5. Fisisorción
Cuando las fuerzas que actúan entre adsorbato y adsorbente son de tipo
físico, similares a las que existen entre moléculas en estado líquido o gaseo-
so, el fenómeno se cataloga como sisorción, siendo el calor desarrollado del
mismo orden de magnitud que el calor latente de vaporización del adsorbato
(1 - 5 kJ/mol). Además, los procesos de sisorción son considerablemente

4.5. Fisisorción 93
más rápidos que los de quimisorción, al ser su energía de activación no-
tablemente inferior, e incluso nula. Las características diferenciales entre
ambos tipos de adsorción se resumen en considerar que en quimisorción
se forman verdaderos enlaces químicos con el adsorbente, mientras que en
sisorción el comportamiento es similar a una condensación.
En sisorción se obtienen isotermas que presentan formas diferentes
según la naturaleza del sistema del que se trata. Aunque existe una amplia
variedad y no siempre es posible clasicar todos los comportamientos en
unos pocos tipos, la mayor parte de ellos corresponden a algunos de los cinco
tipos de la clasicación llevada a cabo por Brunauer, Deming, Deming y
Teller (BDDT) que se presenta en la Figura 4.2.
p0 p
n
I
isotermas.nb 1
p0 p
n
II
nm
isotermas.nb 1
p0 p
n
III
isotermas.nb 1
p0 p
n
IV
isotermas.nb 1
p0 p
n
V
isotermas.nb 1
Figura 4.2. Cinco tipos de isotermas, según la clasicación BDDTdada por Brunauer et al. (1940).
De los cinco tipos, Brunauer et al. (1940), el tipo I representa claramen-
te el comportamiento establecido por el modelo de Langmuir, si bien hay
que resaltar que no existen estudios experimentales en los que se observe de

94 4. Fenómenos de Adsorción
forma continuada este comportamiento hasta valores de presión próximos
a la presión de vapor del adsorbato, p0 (la presión de vapor representa la
presión de equilibrio entre las fases de vapor y de líquido del adsorbato).
En las isotermas de los tipos II y III, la curva de adsorción crece asintóti-
camente en p0. Este comportamiento se observa en fenómenos de adsorción
de gases en sólidos pulverizados. El crecimiento aparentemente ilimitado
de la capa adsorbida parece ser debido a la condensación en los intersticios
existentes entre las pequeñas partículas. Las isotermas de los tipos IV y V
representan comportamientos de adsorción de gases sobre sólidos porosos.
Todos estos comportamientos se pueden explicar satisfactoriamente a
partir de la teoría de Brunauer, Emmett y Teller, que constituye el modelo
básico de sisorción y que se expone a continuación.
4.6. Modelo de Brunauer, Emmett y Teller (BET)
Este modelo fue principalmente desarrollado con el objetivo de pro-
porcionar una interpretación del comportamiento de adsorción de gases en
sólidos pulverizados, de importancia práctica considerable al ser el fenó-
meno que se encuentra con mayor frecuencia (Brunauer et al., 1938). Se
basa en dos suposiciones principales:
La supercie del adsorbente se supone uniforme.
Las moléculas del gas se adsorben sobre la supercie en capas su-
cesivas, completas o no, en equilibrio dinámico entre sí y con el gas
no adsorbido.
Se supone, así mismo, que el modelo de adsorción de Langmuir es aplicable
a cada capa, con la diferencia de que para la primera capa, la energía libre
de adsorción, ∆G1, puede tomar un valor determinado según la interacción
entre el adsorbato y el adsorbente, pero para las capas sucesivas este pará-
metro es igual a ∆Gv, energía libre de vaporización del adsorbato en fase
líquida. Una suposición adicional es que la condensación/evaporación sólo
tiene lugar sobre la supercie de trabajo.

4.6. Modelo de Brunauer, Emmett y Teller (BET) 95
Figura 4.3. Adsorción en multicapas
La Figura 4.3 muestra esquemáticamente esta situación, en donde S0
representa la fracción de supercie libre de adsorbato, S1, la fracción de
supercie cubierta con una única capa de moléculas (monocapa), S2, la
fracción de supercie cubierta con doble capa, etc. La condición de que se
alcanza el equilibrio entre cada capa impone las relaciones siguientes. Para
la primera capa5:
pS0 = S1 exp[−∆G1/RT ],
y para las capas sucesivas:
pSi−1 = Si exp[−∆Gv/RT ],
lo cual puede escribirse de forma más simple:
S1 = yS0 S2 = xS1,
y
Si = xi−1S1 = yxi−1S0 = cxiS0,
donde:
y = p exp[∆G1/RT ] x = p exp[∆Gv/RT ],
y
c =y
x= exp[(∆G1 −∆Gv)/RT ] ' exp[(∆H1 −∆Hv )/RT ].
5∆G = ∆H − T∆S, representa la energía libre de Gibbs de equilibrio, siendo ∆H, laentalpía, es decir el calor desarrollado a presión constante, y ∆S, la entropía. Mientras quela entalpía es diferente para la interacción del adsorbente con la primera capa de adsorbato ycon las capas sucesivas, la entropía del proceso de adsorción se toma como aproximadamente lamisma para todas las capas.

96 4. Fenómenos de Adsorción
Con estas consideraciones, puede determinarse la fracción de supercie
cubierta:n
nm=∑∞
i=1 iSi∑∞i=1 Si
= cS0
∑∞i=1 ix
i
S0 + cS0∑∞
i=1 xi.
La sustitución del resultado algebraico en las correspondientes sumas da:
n
nm=
cx(1−x)2
1 + cx1−x
,
que puede reordenarse como:
θ =n
nm=
cx
(1− x)[1 + (c− 1)x]=
11− x
− 11 + (c− 1)x
,
donde x = p/p0, V es el volumen de gas adsorbido y p0 = exp[−∆Gv/RT ],es su presión de vapor.
0.2 0.4 0.6 0.8 1x
n
c=20050 10 3 1 0.1
isotermas.nb 1
Figura 4.4. Isoterma BET según diferentes valores del parámetro c
A la ecuación anterior se la conoce como isoterma BET y en la Figura
4.4 se presenta la forma de la curva prevista por esta ecuación. Se puede
comprobar que, según los valores del parámetro c, la forma de la isoterma
es distinta; la ecuación puede expresarse como la diferencia de dos hipér-
bolas en las que el parámetro c gura solamente en el sustraendo. Además,

4.7. Desviaciones de la Isoterma BET: Isoterma GAB 97
a valores grandes de c aparece un punto de inexión cuyas coordenadas
pueden determinarse:
xinex. =(c− 1)2/3 − 1
(c− 1) + (c− 1)2/3,(
n
nm
)inex.
=1c
[(c− 1)1/3 + 1][(c− 1)2/3 − 1].
Puesto que sólo los valores reales y positivos de x tiene sentido físico,
el punto de inexión aparecerá únicamente para c > 2. Para valores supe-
riores, la curva presenta un comportamiento similar a la isoterma Tipo II,
y el hombro es tanto más pronunciado cuanto mayor es el valor de c. Por el
contrario, para c < 2 el punto de inexión aparece a valores de x negativos
(2 > c > 1) o imaginarios (c < 1), es decir, sin interés físico. Para estos
casos la curva se asemeja a una isoterma del Tipo III.
Según las ecuaciones previas, se ve que el valor de c representa una
constante de equilibrio. Como magnitud termodinámica, su logaritmo está
en relación directa con el calor desarrollado en el proceso de adsorción, que
puede expresarse como diferencia del calor de adsorción de la primera ca-
pa, ∆H1 y el de las demás (calor de condensación), ∆Hv . Cuando ambos
valores son parecidos (c < 2) el comportamiento es del Tipo III. Por el
contrario, cuando los valores dieren bastante y c es grande, la adsorción
es fuerte y aparece un punto de inexión característico del Tipo II; es como
si se produjera la adsorción preferente en la primera capa, seguida de la
adsorción más débil en las restantes. En particular, cuando c es grande y el
margen de valores de x no es muy amplio, el comportamiento se asemeja a
la isoterma Tipo I, o isoterma de Langmuir (se obtiene de la fracción de su-
percie cubierta, n/nm, considerando que solamente se forma la monocapa,
es decir, i = 1).
4.7. Desviaciones de la Isoterma BET: Isoterma GAB
La mayor utilidad del modelo BET aplicado a procesos de adsorción
descritos por isotermas del Tipo II y III estriba en la determinación de

98 4. Fenómenos de Adsorción
la capacidad de la monocapa, nm, a partir de la cual se puede estimar la
supercie especíca del sólido adsorbente, de la misma forma que en los
casos de adsorción Tipo I. Una vez sabido cuántas moléculas cubren com-
pletamente la unidad de supercie, basta multiplicar por el área que ocupa
cada molécula para obtener la supercie. Este dato es de de gran relevan-
cia, por ejemplo, en catálisis heterogénea, pues es el factor determinante de
la velocidad de reacción.
Cuando la supercie del sólido adsorbente contiene mesoporos, cuyo
tamaño permite la inclusión de moléculas de adsorbato, el efecto que se
produce es la creación de capas de adsorción internas sobre las que, con-
trariamente a lo que ocurre en las externas, la cantidad de sustancia que
puede adsorberse tiene un límite: hasta que el poro se llena completamente.
Como consecuencia, las isotermas presentan dos características principales:
saturación de la adsorción a presiones altas y aparición de histéresis en el
supuesto proceso de desorción (la histéresis aparece cuando el proceso de
desorción no se corresponde con el inverso de adsorción).
Las formas de las isotermas Tipos IV y V corresponden a este compor-
tamiento. Estas isotermas caracterizan, además, procesos de adsorción en
los que la interacción gas-sólido es muy débil y, en este contexto, el agua
constituye un adsorbato de gran interés. La adsorción de humedad durante
las etapas de fabricación, almacenamiento y distribución de alimentos, pro-
ductos farmacéuticos, y otras sustancias de gran aplicación, en estado de
pulverización, es de vital importancia a la hora de controlar sus propieda-
des sicoquímicas a lo largo del tiempo. Cuando el adsorbato es vapor de
agua, la magnitud x = p/p0 se denomina actividad del agua y se designa
como a o aw.
El tratamiento completo cuantitativo de estos fenómenos de adsorción
es complicado y no existe ningún modelo completamente satisfactorio. No
obstante, debido, en parte, al considerable éxito del modelo BET, se han
introducido una serie de modicaciones que proporcionan una aceptable

4.7. Desviaciones de la Isoterma BET: Isoterma GAB 99
descripción de los procesos de adsorción cuando ocurre en un número li-
mitado de capas. De entre las numerosas correcciones habitualmente uti-
lizadas cabe destacar la denominada ecuación GAB (Guggenheim, 1966;
Anderson, 1946; de Boer, 1953), que goza de gran aceptación en el campo
de las Ciencias de los Alimentos (van den Berg, 1984), a cuya descripción
dedicaremos el resto de esta sección. Con esta ecuación pueden ajustarse
datos de adsorción de agua hasta un valor de aw = 0, 90, mientras que con
la ecuación del modelo BET, el margen de aplicación queda restringido a
valores de aw entre 0,05 y 0,35.
Si en la deducción de la isoterma BET se considera que el número de
capas está limitado a N , las sumas de la ecuación que determina la fracción
de supercie cubierta deben efectuarse entre i = 1 e i = N . El resultado
nal es, entonces (Brunauer et al., 1938):
n
nm=
cx
1− x
[1− (N + 1)xN +NxN+1
1 + (c− 1)x− cxN+1
].
La ecuación anterior y la denominada como isoterma BET interpretan
las isotermas I, II y III, para sólidos no porosos y porosos. La forma de
las isotermas IV y V son similares a la II y III excepto en el comporta-
miento de saturación que presentan a altas presiones, justo por debajo de
la presión de vapor, p0. Este hecho fue interpretado por Brunauer et al.
(1940) en el sentido de que a medida que la presión se acerca al valor de
saturación, la energía de interacción entre las capas se hace mayor que el
calor de condensación, lo que hace que el proceso de adsorción deje de ser
termodinámicamente favorable a partir de una determinada capa. Con esta
suposición adicional y siguiendo un procedimiento similar a los casos an-
teriores, puede deducirse la ecuación que describe el comportamiento de la
adsorción para las isotermas Tipos IV y V:
n
nm=
cx
1− x
[1 + (Ng/2−N)xN−1 − (Ng −N + 1)xN +NgxN+1/2
1 + (c− 1)x+ (cg/2− c)xN − cgxN+1/2
].
Esta ecuación se conoce habitualmente como isoterma BDDT. El pará-
metro g = exp(q/RT ) y q es el calor de adsorción en exceso que se supone

100 4. Fenómenos de Adsorción
se desarrolla en la deposición de la N-esima capa, la última capa. El resto
de los símbolos mantienen su signicado.
Si se expresa g/2 = k, la isoterma BDDT, para N = 1, se reduce a la
siguiente forma (Caurie, 2006):
n
nm=
ckx
1 + ckx,
donde el parámetro k se toma como un coeciente de corrección sobre x.
Cuando este parámetro es k = 1, la ecuación anterior se reduce a la isoterma
Langmuir (N = 1):n
nm=
cx
1 + cx.
Si, de modo equivalente, se introduce k, como coeciente corrector de
x, en la isoterma BET limitada a N capas, se obtiene:
n
nm=
ckx
1− kx
[1− (N + 1)(kx)N +N(kx)N+1
1 + (c− 1)kx− c(kx)N+1
],
que puede reorganizarse del modo siguiente:
n
nm=ckx[(1− (kx)N )/(1− kx)] + [(n/nm)−N ]c(kx)N+1
1 + (c− 1)kx.
Tanto en el modelo BET como en el BDDT, n/nm = N (número de
capas adsorbidas) y, por lo tanto, en la ecuación anterior, n/nm −N = 0,con lo que se reduce a:
n
nm=
ckx[1− (kx)N ](1− kx)[1 + (c− 1)kx]
.
Si k 1 y N , entonces (kx)N puede ser despreciable, en cuyo caso la
ecuación anterior toma la forma simplicada:
n
nm=
ckx
(1− kx)[1 + (c− 1)kx],
que se conoce como ecuación o isoterma GAB (Guggenheim, 1966; Ander-
son, 1946; de Boer, 1953).

4.7. Desviaciones de la Isoterma BET: Isoterma GAB 101
Por otra parte, sin considerar (kx)N despreciable y suponiendo k = 1se obtiene la ecuación de Pickett (Pickett, 1945):
n
nm=
cx(1− xN )(1− x)[1 + (c− 1)x]
,
que representa otra de las numerosas correcciones aplicadas a la isoterma
BET, si bien de menor alcance e importancia que la ecuación GAB.
La utilización de las isotermas de adsorción es muy amplia en numerosos
fenómenos de naturaleza sicoquímica y su aplicación está muy extendi-
da. Resulta por tanto de gran interés cualquier esfuerzo que contribuya
a aumentar la abilidad de las conclusiones que puedan obtenerse de la
aplicación de estos modelos.


Capítulo 5
Diseños Óptimos para
las Isotermas de
Adsorción BET y GAB
5.1. Aplicaciones de los Fenómenos de Adsorción
A lo largo del Capítulo 4 se han desarrollado las nociones teóricas que
permiten plantear los modelos que se han venido usando de forma clásica
en la literatura para explicar los fenómenos superciales de adsorción de
gases sobre sólidos (Adamson y Gast, 1997). La correcta modelización de
los fenómenos de adsorción es fundamental en numerosos procesos indus-
triales de naturaleza química. Cabe destacar como etapas claves la correcta
elección del modelo (isoterma) así como la correcta estimación de los pa-
rámetros. El objetivo del trabajo es facilitar estas tareas mediante diseños
óptimos que permitan el ahorro de tiempo y dinero aumentando a la vez
la calidad de las estimaciones y por lo tanto la calidad de las decisiones
tomadas a la vista de los datos.
De entre los fenómenos físicoquimicos en los que las medidas de adsor-
ción de gases y vapores sobre sólidos resultan de interés, podemos destacar
103

104 5. Diseño Óptimo: Isotermas BET y GAB
la captación de sustancias químicas por los suelos (Shonnard et al., 1993),
la adsorción de agua por alimentos lo cual controla su estabilidad durante
el tiempo de almacenamiento (esta magnitud es una variable de suma im-
portancia en la determinación de periodos de caducidad de los productos
alimenticios) (Arslan y Togrul, 2005), en procesos de teñido de bras tex-
tiles, en la descontaminación de residuos líquidos industriales (Avom et al.,
2001), etc. En todos estos procesos uno de los parámetros fundamentales es
el área supercial del sólido adsorbente así como la distribución y tamaño
del poro. Estos parámetros resultan de interés en adsorbentes industria-
les, catalizadores, pigmentos, cerámicas, materiales de construcción, entre
otros.
Como ya se ha mencionado, el fenómeno de la adsorción consiste en la
deposición de uno o más componentes gaseosos sobre la supercie de un
sólido. El fenómeno tiene lugar cuando un gas susceptible de ser adsorbido
(adsorbato) entra en contacto con la supercie del sólido (adsorbente). La
distribución del adsorbato sobre el adsorbente puede ser en forma una única
capa, monocapa, o en forma de multicapa.
Fenomenológicamente, la adsorción se describe en términos de una fun-
ción de desarrollo empírico o teórico, n = f(P, T ) donde n es la cantidad
adsorbida, P = p/p0, donde p es la presión parcial de equilibrio del gas
sobre el adsorbente y p0 es la presión de saturación o presión de vapor,
y T es la temperatura. Cuando la temperatura se mantiene constante, la
relación anterior se denomina isoterma de adsorción.
La cantidad de adsorbato necesario para cubrir la supercie del adsor-
bente con una única capa de moléculas se denomina capacidad de la mo-
nocapa, nm, pudiéndose calcular el área supercial del adsorbente a partir
de dicho valor, sabiendo el área efectiva ocupada por cada molécula de ad-
sorbato. Este tipo de medidas tiene gran interés en la determinación del
tamaño del poro en sólidos porosos, en el cálculo del tamaño de partícula
en sólidos pulverizados y en la determinación de la ecacia de catalizadores
en catálisis heterogénea entre otras aplicaciones.

5.1. Aplicaciones de los Fenómenos de Adsorción 105
Existe una amplia variedad de modelos usados en la literatura para
describir los fenómenos de adsorción. De entre los desarrollados de forma
teórica y sobre los que nos hemos centrado en el Capítulo 4 es de destacar
el modelo de Langmuir (1918) para adsorción en monocapa. La obtención
de diseños óptimos para el modelo de Langmuir ya ha sido abordada con
anterioridad, ya que dicho modelo es formalmente equivalente al modelo
de catálisis enzimática de Michaelis-Menten para el que se han calculado
diseños óptimos en múltiples trabajos (Currie, 1982; López-Fidalgo yWong,
2002; Dette et al., 2003).
De entre los modelos más utilizados para describir los fenómenos de
adsorción multicapa es de destacar el modelo BET (Brunauer et al., 1938) y
su extensión, el modelo GAB (Guggenheim, 1966; Anderson, 1946; de Boer,
1953), cuya justicación teórica ha sido desarrollada en el Capítulo 4. El
modelo BET tiene la ventaja de su simplicidad y cuenta con la aprobación
de la International Union of Pure and Applied Chemistry (IUPAC, 1985).
Por otro lado el modelo GAB se utiliza cuando el margen de presiones es
mayor, y ha sido recomendado para la caracterización de la adsorción de
vapor de agua en alimentos por el European Project Group COST 90 (Wolf
et al., 1985).
Es asimismo destacable la existencia de multitud de modelos semi-
empíricos y modelos modicados que se utilizan principalmente en la indus-
tria alimenticia para la caracterización de la adsorción de vapor de agua.
Como se ha mencionado anteriormente el contenido de vapor de agua es una
variable crucial en la determinación de la calidad de determinados produc-
tos alimenticios. De entre la multitud de modelos semi-empíricos existentes
en la literatura podemos citar Oswin (1946), Hailwood y Horrobin (1946),
Halsey (1948), Chirife y Iglesias (1978), Ferro Fontan et al. (1982) , entre
otros muchos
Como hemos dicho, existe un amplio interés en la modelización de los
fenómenos de adsorción en procesos industriales de naturaleza química.
En este sentido, el objetivo de este trabajo se centra en la elaboración de
diseños óptimos que permitan a los investigadores discriminar entre posibles

106 5. Diseño Óptimo: Isotermas BET y GAB
isotermas, asunto que presumimos es de un alto interés para la comunidad
cientíca internacional (Timmermann et al., 2001; Timmermann, 2003).
Una vez elegida la isoterma, la aplicación de diseños D− y c−óptimos
(Secciones 1.7.1 y 1.7.3) permiten al experimentador una mejor estimación
de los parámetros de interés, al mismo tiempo que son capaces de medir la
eciencia de los diseños experimentales utilizados mediante su comparación
con los óptimos.
Nuestro trabajo se ha centrado en la adsorción de vapor de agua por
productos alimenticios, sobre todo a la hora de mostrar ejemplos y aplica-
ciones del trabajo. Como ya se ha dicho, la cantidad de humedad presente
en los alimentos es una variable crítica para juzgar la calidad de determi-
nados productos alimenticios y la caracterización del proceso de adsorción
por parte de estos es necesaria para realizar estimaciones de vida útil del
producto al mismo tiempo que durante procesos de secado, almacenado y
en el diseño de contenedores y sistemas de embalaje. Hasta tal punto es
importante el seguimiento de el proceso de adsorción que son frecuentes
los controles sobre cereales y hortalizas (Al-Muhtaseb et al., 2004), frutas
(Moraga et al., 2006) y especias (Cepeda et al., 1999) así como la monito-
rización de la estabilidad de los alimentos en procesos de preservado como
el congelado o el secado (Jouppila y Roos, 1997) que aseguren una máxima
calidad del producto nal.
El interés en estos ejemplos de adsorción de vapor de agua sobre pro-
ductos alimenticios, maniestado por la cantidad de bibliografía hallada,
se debe al alto interés práctico de estos procesos. La extensión de los re-
sultados presentados es inmediata a cualquier otro fenómeno de adsorción
como los ya mencionados.
5.2. Isotermas de Adsorción
De las diferentes teorías y modelos de adsorción presentes en la litera-
tura la obtención y representación de los datos a temperatura constante

5.2. Isotermas de Adsorción 107
(isoterma) es no sólo la mas conveniente sino también la forma más ade-
cuada para obtener conclusiones teóricas.
Al tratar de adsorción de vapor de agua utilizaremos la notación más
frecuentemente usada en este campo: la cantidad de agua adsorbida we = n
se expresa en términos de cantidad de agua adsorbida por cantidad de
adsorbente, y la actividad del agua aw = p/p0, donde p es la presión de
vapor del agua contenida en el producto y p0 es la presión de vapor de agua
pura a la temperatura a la que se lleve a cabo el experimento. La actividad
del agua puede variar en el intervalo [0, 1], siendo 0 la ausencia total de
agua y 1 un 100 % de humedad.
De las isotermas planteadas en el Capítulo 4 la isoterma Langmuir coin-
cide formalmente con el modelo de Michaelis-Menten (Perso y Thomas,
1988).
La isoterma de adsorción BET (Brunauer et al., 1938) es uno de los
modelos más utilizados para explicar la adsorción multicapa. Representa
la cantidad de gas o agua adsorbida, we, en términos de la presión de
equilibrio o actividad del agua aw, siguiendo una distribución normal de
media y varianza:
E(we) =wmBcBaw
(1− aw)(1 + (cB − 1)aw), var(we) = σ2.
En este modelo no lineal en los parámetros, el parámetro wmB es la
capacidad de la monocapa mientras que cB está relacionado exponencial-
mente con la entalpía de adsorción como ya se ha comentado durante el
desarrollo teórico del modelo. Ambos parámetros son necesarios para la
caracterización del fenómeno de adsorción mientras que la capacidad de
la monocapa, nm, se emplea para determinar el área supercial del ad-
sorbente. Cuanto mejor sean las estimaciones de estos parámetros mejores
conclusiones y resultados se obtendrán.

108 5. Diseño Óptimo: Isotermas BET y GAB
Tradicionalmente el modo de enfrentarse a estos modelos no lineales es
mediante linealizaciones,
F (BET ) ≡ aw(1− aw)we(aw)
=1
cBwmB+cB − 1cBwmB
aw,
representando la relación lineal existente entre F (BET ) y aw (Adamson y
Gast, 1997).
El informe de la IUPAC, Commission on Colloid and Surface Che-
mistry of the International Union of Pure and Applied Chemistry (1985),
recomienda el modelo BET como un método estándar en la evaluación de
capacidad de la monocapa en actividades del adsorbato no superiores a
p/p0 = 0.3, aunque en adsorción de vapor de agua sobre alimentos este
límite superior suele extenderse hasta 0.5. Las razones para este límite se
justican en la pérdida de la relación lineal entre F (BET ) y aw para valores
fuera de ese rango. Ahora bien, son numerosos los trabajos en los que sus
autores muestran su preocupación por las alteraciones que pueden incluir
las linealizaciones y someten a métodos de regresión no lineales los datos
obteniendo resultados muy satisfactorios para rangos mucho más amplios
(Belarbi et al., 2000; Saevels et al., 2004). Otros autores, aún observan-
do estos problemas, continúan despreciando las medidas por encima de un
cierto límite (Moraga et al., 2006).
Por otro lado, la isoterma de adsorción GAB (Guggenheim, 1966; An-
derson, 1946; de Boer, 1953), ha sido usada de forma extensiva a la hora
de describir el fenómeno de adsorción por parte de productos alimenticios.
Este modelo como modicación de la isoterma BET introduce la idea de
que después de la primera capa adsorbida las capas subsiguientes presen-
tan las mismas propiedades entre sí aunque distintas a las propiedades del
vapor o gas condensado. Esta nueva interpretación exige la introducción
de un nuevo parámetro que explica la relación entre las capas consecutivas
de vapor adsorbido. La cantidad de gas o agua adsorbida we sigue una
distribución normal de media y varianza:
E(we) =wmGcGkaw
(1− kaw)(1 + (cG − 1)kaw), var(we) = σ2.

5.2. Isotermas de Adsorción 109
Nuevamente el modelo resulta ser no lineal en los parámetros, siendo los
parámetros wmG y cG análogos en signicado a los del modelo BET, esto
es capacidad de la monocapa y constante energética; el nuevo parámetro
introducido, k, es una medida de la entalpía libre de las moléculas del
adsorbato entre las capas más allá de la primera.
Al igual que para la isoterma BET, el modelo no lineal se ha venido
linealizando a la hora de realizar el ajuste,
F (GAB) ≡ aw(1− kaw)we(aw)
=1
cGkwmG+cG − 1cGwmG
aw,
representando nuevamente la relación lineal existente entre F (GAB) y aw(Adamson y Gast, 1997).
El uso de la isoterma GAB se extiende hasta valores de actividad de
agua aw = 0.8−0.9 y debido a su mejor adaptabilidad en la linealización a
los datos de adsorción de vapor de agua sobre alimentos (Wolf et al., 1985).
La utilización de las linealizaciones pueden incurrir en cambios impor-
tantes en la distribución de los residuos, por lo que la utilización de métodos
no lineales de mínimos cuadrados es mucho más recomendable. Presenta-
mos las versiones linealizadas por su tratamiento clásico en textos e incluso
en recientes artículos de investigación aunque el trabajo aquí desarrollado
requiere la utilización de los métodos no lineales.
El cálculo de diseños óptimos para estos modelos no lineales se basa
en la utilización de la matriz de información de Fisher como herramienta
en la estimación de los parámetros y requiere suponer la normalidad en las
observaciones. La dependencia de dicha matriz de los propios parámetros
hace necesario la existencia de unas estimaciones iniciales de los valores
que estos tomarán. En el campo de la adsorción de vapor de agua por
parte de alimentos existen multitud de referencias de las que poder obtener
dichos valores así como el carácter de control dichas medias que hace que
se repitan cíclicamente en el tiempo.

110 5. Diseño Óptimo: Isotermas BET y GAB
El espacio de diseño X donde varía la actividad del agua, aw = p/p0
está jado teóricamente en el intervalo X = [0, 1] aunque existe una impo-
sibilidad muy alta de tomar observaciones en valores extremos. Usualmente
el espacio de diseño estará delimitado por 0.05 como extremo inferior y se-
gún la naturaleza de las observaciones el extremo superior podrá oscilar
entre 0.3 y 0.9.
5.3. Discriminación entre Modelos: BET o GAB
Como se ha dicho hasta ahora, el proceso de adsorción viene carac-
terizado por una isoterma. Dentro de la adsorción multicapa existen dos
modelos diferentes que pueden explicar el proceso de adsorción, especial-
mente sobre productos alimenticios. La primera decisión que ha de tomarse
a la hora de caracterizar un proceso de adsorción es la elección de la isoter-
ma que mejor ajustará a los datos experimentales y que por lo tanto mejor
ayudará a entender el fenómeno.
De las dos isotermas más usadas que mejor explican el fenómeno de
adsorción multicapa, modelos BET y GAB, la principal diferencia que los
experimentadores encuentran en su aplicación es el rango de actividad del
agua recomendado para cada una de ellas: mientras que para la isoterma
BET el espacio de diseño recomendado en la literatura es XB = [0.05, 0.3−0.5], para la isoterma GAB el espacio del diseño recomendado es mayor
XG = [0.05, 0.8−0.9]. El modelo BET fuera del rango de valores XB parece
no ajustarse de forma adecuada a los datos experimentales (Timmermann,
2003), aunque de acuerdo con la literatura esta falta de ajuste es causada
por la utilización de la versión linealizada del modelo en lugar de aplicar
los métodos adecuados de regresión no lineal. La simplicidad del modelo
BET es en muchos casos preferida a la modicación incluida en el modelo
GAB (Belarbi et al., 2000; Saevels et al., 2004).
Como ya hemos mencionado antes el modelo GAB es una modicación
del modelo BET en el que se incluye un nuevo parámetro k, siendo am-
bos modelos equivalentes para el valor de k = 1. Se puede observar cómo

5.3. Discriminación entre Modelos: BET o GAB 111
frecuentemente en la literatura, el modelo GAB es tratado como un mode-
lo puramente empírico con valores de k > 1 que no guardan relación con
el signicado físico del parámetro, como es resaltado por Lewicki (1997).
Este hecho lleva a muchos investigadores a preferir la simplicidad del mo-
delo BET y extender el rango de actividad del agua hasta 0.8 o incluso
valores más altos, mientras que en otros, aún preriendo el modelo BET,
mantienen las medidas en rangos de actividad del agua reducidos.
5.3.1. T−optimización.
El objetivo es obtener diseños que nos permitan discriminar entre am-
bos modelos posibles, respondiendo así a una necesidad real que permita a
los investigadores decidir si es adecuada la elección del modelo modicado
GAB o bien si por el contrario el modelo BET puede ser utilizado para
explicar el fenómeno de adsorción en márgenes de actividad del agua en
principio no recomendables.
El criterio óptimo más usado para encontrar diseños que permitan una
discriminación entre modelos es T−optimización, propuesto por Atkinson y
Fedorov (1975a) y que ha sido recientemente extendido mediante un criterio
de parada para el algoritmo a través de una cota inferior de la eciencia
del diseño (López-Fidalgo et al., 2007b).
Un diseño apropiado para la discriminación de modelos es aquel que
proporciona un alto valor para la suma de cuadrados de los errores del
modelo incorrecto; por lo tanto dados dos modelos entre los que elegir,
podremos plantear dos funciones criterio de T−optimización dependiendo
del modelo que consideremos verdadero en cada caso. En nuestro caso el
objetivo es comprobar cuando en valores de actividad del agua amplios,
XG, el modelo GAB puede ser sustituido por el modelo BET, más sencillo.
El diseño T−óptimo proporcionará el contraste F de mayor potencia para
la falta de ajuste del modelo BET suponiendo que el modelo GAB es el
adecuado (Atkinson et al., 1998).

112 5. Diseño Óptimo: Isotermas BET y GAB
Consideremos un modelo genérico no lineal
we = η(aw) + ε, aw ∈ X,
siendo la variable aleatoria ε independiente y normalmente distribuida
con media cero y varianza constante σ2. La función η(aw) será o bien
el modelo GAB, ηG(aw, θG), o el modelo BET, ηB(aw, θB), siendo θtG =(wmG, cG, k) ∈ ΩB ⊂ R3 y θtB = (wmB, cB) ∈ ΩG ⊂ R2 los vectores
de parámetros. Tal y como hemos especicado antes, supondremos que
η(aw) = ηG(aw, θG) será el modelo verdadero con sus parámetros θG co-
nocidos.
La función criterio de T−optimización resulta ser en este caso la si-
guiente
TBG(ξ) = mınθB∈ΩB
∑i
(η(awi)− ηB(awi, θB))2ξ(awi).
Y llamaremos a un diseño que maximice la función TBG(ξ), diseño T−óptimo,
ξ?T .
Para diseños regulares y tal y como hemos visto en la Sección 1.9 el
Teorema de Equivalencia (Teorema 5) nos proporciona una herramienta
para comprobar el diseño: un diseño ξ?T is T−óptimo si y sólo si
ψ(aw, ξ?T ) = (η(aw)−ηB(aw, θB))2−∑i
(η(awi)−ηB(awi, θB))2ξ(awi) ≤ 0,
con aw ∈ X, vericándose la igualdad en los puntos de soporte del diseño
T−óptimo, Xξ?T.
Sea ξ un diseño cualquiera, entonces la proporción dada por effBG(ξ) =TBG(ξ)/TBG(ξ?T ) es una medida de la eciencia de ξ respecto al diseño
T−óptimo ξ?T . Esta eciencia se considera como una medida de la bondad
o adecuación del diseño respecto al criterio de T−optimización, aunque
no tiene la interpretación directa en ahorro de observaciones como en los
criterios homogéneos.
La construcción de diseños T−óptimos requiere la utilización de un
algoritmo numérico debido a la necesidad de estimar θB para el modelo

5.3. Discriminación entre Modelos: BET o GAB 113
rival. La función criterio TBG(ξ) tiene como argumento a θB y esta esti-
mación cambiará de valores en cada paso del algoritmo. En la práctica se
ha usado un algoritmo de primer orden para encontrar el diseño T−óptimo
(Atkinson y Fedorov, 1975a). El procedimiento es iterativo y se desarrolla
de la siguiente manera:
Paso 1: Para un diseño inicial dado ξs con los siguientes puntos en
su soporte aw1, aw2, . . . , aws, consideremos
θB,s(ξs) = arg mınθB∈ΩB
∑i
(η(awi)− ηB(awi, θB))2ξs(awi).
Paso 2: Encontrar el punto aws+1 tal que,
aws+1 = arg maxaw∈X
(η(aw)− ηB(aw, θB,s))2.
Paso 3: Sea ξaws+1un diseño unipuntual en aws+1. Se construye un
nuevo diseño de la siguiente forma:
ξs+1 = (1− αs+1)ξs + αs+1ξaws+1.
Siendo αs una secuencia de valores que, por lo general, veriquenlas siguientes condiciones,
lıms→∞
αs = 0,∞∑s=0
αs =∞,∞∑s=0
α2s <∞.
Paso 4: Para concluir el algoritmo se plantea una condición de
parada a través de una cota inferior de la eciencia effBG(ξ)[1 +
maxaw∈X ψ(aw, ξs)TBG(ξs)
]−1
> δ,
con 0 < δ < 1 un valor prejado, e.g. δ = 0.998 (López-Fidalgo et
al., 2007b).
5.3.2. Ejemplos. Con el objetivo de ilustrar la aplicación del cálculo
de diseños T−óptimos, se presentan a continuación dos ejemplos. El es-
pacio de muestreo en ambos es el de mayor margen XG = [0.05, 0.8], quesupuestamente sólo es aceptable para el modelo GAB. Por lo tanto se ha

114 5. Diseño Óptimo: Isotermas BET y GAB
considerado el modelo GAB como el modelo verdadero y el modelo BET
como el modelo rival. Para calcular los diseños con máxima capacidad de
discriminación, se necesitan estimaciones iniciales para θtG = (wmG, cG, k)que han sido obtenidas de trabajos experimentales reales.
Ejemplo 5. En el trabajo de Cepeda et al. (1999) se estudia la adsorción
de vapor de agua por parte de café con el objetivo de poder predecir sus
propiedades higroscópicas y diseñar recipientes para su conservación ópti-
ma durante el período de almacenaje. En este trabajo se recalca la ausencia
de estudios de adsorción en la literatura para el café torrefacto (café tos-
tado con azucar). Los resultados que se dan a una temperatura de 25C,son las siguientes estimaciones de los parámetros para la isoterma GAB
wmG = 0.03445 g de H2O adsorbida / g de café, cG = 11.70 y k = 0.994.Recordemos que para k = 1 las isotermas GAB y BET son equivalentes,
por lo que parece que el uso del modelo más complicado podría evitar-
se. Para comparar ambos modelos se ha obtenido el diseño T−óptimo que
permitirá el contraste F para la falta de ajuste del modelo BET.
Después de 182 iteraciones del algoritmo de primer orden descrito pre-
viamente (menos de 2 segundos de tiempo de cálculo), con αs = 1/(s+ 1)el algoritmo converge y la condición de parada se satisface obteniéndose un
diseño concentrado en tres puntos experimentales, con sus respectivos pe-
sos indicando la proporción de medidas que han de tomarse en cada punto.
El diseño se ha calculado jando una cota inferior de la eciencia mayor
que δ = 0.998.
ξ?T =
(0.056 0.62 0.8
27182
47
51182
)=
(0.056 0.62 0.80.15 0.57 0.28
).
Para comprobar el diseño propuesto se utilizará el Teorema de Equi-
valencia (Teorema 5) que ha de vericarse. La función de sensibilidad de
dicho teorema se ha representado grácamente en la Figura 5.1 comprobán-
dose que ψ(aw, ξ?T ) ≤ 0 y que en los puntos de soporte se alcanzan sendos
máximos.
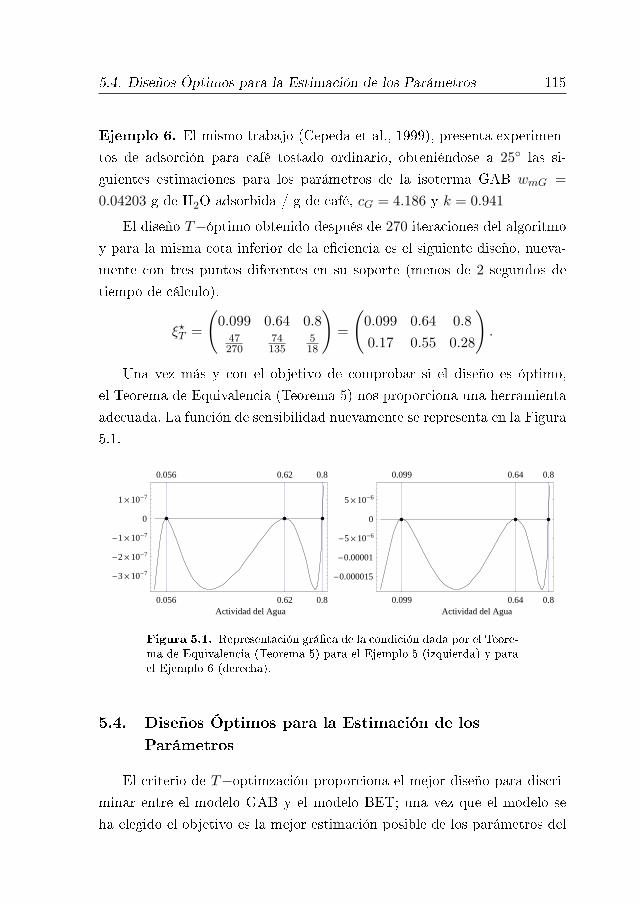
5.4. Diseños Óptimos para la Estimación de los Parámetros 115
Ejemplo 6. El mismo trabajo (Cepeda et al., 1999), presenta experimen-
tos de adsorción para café tostado ordinario, obteniéndose a 25 las si-
guientes estimaciones para los parámetros de la isoterma GAB wmG =0.04203 g de H2O adsorbida / g de café, cG = 4.186 y k = 0.941
El diseño T−óptimo obtenido después de 270 iteraciones del algoritmo
y para la misma cota inferior de la eciencia es el siguiente diseño, nueva-
mente con tres puntos diferentes en su soporte (menos de 2 segundos de
tiempo de cálculo).
ξ?T =
(0.099 0.64 0.8
47270
74135
518
)=
(0.099 0.64 0.80.17 0.55 0.28
).
Una vez más y con el objetivo de comprobar si el diseño es óptimo,
el Teorema de Equivalencia (Teorema 5) nos proporciona una herramienta
adecuada. La función de sensibilidad nuevamente se representa en la Figura
5.1.
0.056 0.62 0.8Actividad del Agua
-3´10-7
-2´10-7
-1´10-7
0
1´10-7
0.056 0.62 0.8
0.099 0.64 0.8Actividad del Agua Agua
-0.000015
-0.00001
-5´10-6
0
5´10-6
0.099 0.64 0.8
Figura 5.1. Representación gráca de la condición dada por el Teore-ma de Equivalencia (Teorema 5) para el Ejemplo 5 (izquierda) y parael Ejemplo 6 (derecha).
5.4. Diseños Óptimos para la Estimación de los
Parámetros
El criterio de T−optimzación proporciona el mejor diseño para discri-
minar entre el modelo GAB y el modelo BET; una vez que el modelo se
ha elegido el objetivo es la mejor estimación posible de los parámetros del

116 5. Diseño Óptimo: Isotermas BET y GAB
mismo. Los criterios que se han usado son los de D− y c−optimación. El
criterio de D−optimización obtendrá el diseño que minimize el volumen
del elipsoide de conanza de los parámetros (Sección 1.7.1), mientras que
el criterio de c−optimización se usará para estimar combinaciones lineales
de los parámetros, en particular para obtener estimaciones individuales de
cada parámetro (Sección 1.7.3).
Sea entonces θ el vector de parámetros a estimar y sea f(aw) = ∂E(we)/∂θ evaluada en unas estimaciones iniciales de los parámetros. Estos valores
serían las mejores estimaciones de los parámetros antes del comienzo del
experimento. Bajo las condiciones de normalidad, la matriz de información
de Fisher para un diseño ξ es,
M(ξ, θ) =∑aw∈X
f(aw)f t(aw)ξ(aw).
Cuando el número de observaciones N es lo sucientemente grande la
matriz de covarianzas de los estimadores es aproximadamente σ2/N veces
la inversa de esta matriz (Proposición 3).
Los criterios usados para obtener los mejores estimadores de los pa-
rámetros vienen dados por las funciones criterio respectivas: la función
criterio de D−optimación, ΦD[M(ξ, θ)] = detM(ξ, θ)−1/m, siendo m el
número de parámetros del modelo, y la función criterio de c−optimización,
Φc[M(ξ, θ)] = ctM(ξ, θ)−1c, siendo ctθ la combinación lineal de los pará-
metros que se desea estimar.
Ambas funciones criterio, según ya hemos visto, son convexas y estric-
tamente decrecientes y por lo tanto buscaremos diseños con valores lo más
pequeños posibles para las funciones criterio. Un diseño que minimice las
funciones criterio anteriores de entre todos los posibles diseños en X se
llamará diseño D− o c−óptimo respectivamente.
La ventaja de trabajar con diseños aproximados es que la optimali-
dad de un diseño puede comprobarse mediante el Teorema de Equivalencia
(Teorema 4) que al mismo tiempo puede proporcionarnos métodos para la
construcción de diseños óptimos (Atkinson y Donev, 1992; Fedorov y Hackl,

5.5. Diseños Óptimos para el Modelo BET 117
1997). La condición de optimalidad para una función criterio Φ genérica,
convexa, estrictamente decreciente y diferenciable, es que un diseño ξ?Φ será
Φ−óptimo si y sólo si,
ψ(aw, ξ?Φ) = f t(aw)∇Φ(ξ?Φ)f(aw)− trM(ξ?Φ, θ)∇Φ(ξ?Φ) ≥ 0, aw ∈ X,
vericándose la igualdad en los puntos de soporte Xξ?Φ. Por simplicidad en
la notación, Φ(M) equivale a Φ[M(ξ, θ)] y ∇Φ(ξ) es el gradiente de Φ(ξ).
A la hora de medir las diferencias entre un diseño propuesto y el óptimo
se ha usado la denición de eciencia (Denición 7).
Es importante resaltar que ambos modelos, BET y GAB, son parcial-
mente no lineales, es decir, que los modelos son lineales para el parámetro
de la capacidad de la monocapa, wm, y no lineales para el resto de los
parámetros. Esto signica que los diseños D− y c−óptimos serán indepen-
dientes de las estimaciones iniciales del parámetro wm y sólo dependerán
de los verdaderos parámetros no lineales.
5.5. Diseños Óptimos para el Modelo BET
Para el modelo de adsorción BET, siendo el vector de parámetros θtB =(wmB, cB) y f(aw) = ∂E(we)/∂θB evaluada en las estimaciones iniciales
de los parámetros θB,
f(aw) =
(cBaw
(1−aw)(1+(cB−1)aw)wmBaw
(1+(cB−1)aw)2
), aw ∈ XB = [aw0, awF ],
siendo la matriz de información de Fisher en este caso,
M(ξ, θB) =∑
aw∈XB
( cBaw(1−aw)(1+(cB−1)aw)
)2wmBcBa
2w
(1−aw)(1+(cB−1)aw)3
wmBcBa2w
(1−aw)(1+(cB−1)aw)3(wmBaw)2
(1+(cB−1)aw)4
ξ(aw).
5.5.1. Diseños D−óptimos.
Para estimar simultáneamente los dos parámetros del modelo BET se
puede usar el criterio deD−optimización, obteniéndose el diseñoD−óptimo

118 5. Diseño Óptimo: Isotermas BET y GAB
concentrado en 2 puntos, tal que maximiza el determinate de la matriz de
información, lo que equivale a minimizar el volumen del elipsoide de con-
anza de los parámetros.
Para el modelo BET, el diseño D−óptimo ξ?D está igualmente concen-
trado sobre dos puntos experimentales en XB:
Si awD ∈ XB, entonces ξ?D está concentrado en awD y awF .
Si awD /∈ XB, entonces ξ?D está concentrado en aw0 y awF .
Siendo awD la única solución en XB de la ecuación:
a3wD − a2
wD
(2awF +
1cB − 1
)+ awD
(awF +
2cB − 1
)− awFcB − 1
= 0.
Se puede comprobar numéricamente que es la única solución en dicho in-
tervalo utilizando el Teorema de Sturm. Que el diseño ξ?D sea igualmente
concentrado signica que la mitad de las observaciones se toman en cada
uno de los dos puntos del soporte.
El Teorema de Equivalencia proporciona la condición que permite com-
probar la D−optimización del diseño ξ?D. Por lo tanto, el diseño ξ?D será
D−óptimo si y sólo si:
f t(aw)M(ξ?D)−1f(aw) ≤ m, aw ∈ XB,
dondem = 2 el número de parámetros del modelo, vericándose la igualdad
de la expresión anterior en los puntos de soporte del diseño. Los valores de
awD en función del parámetro no lineal del modelo cB ∈ [1, 30] se han
representado grácamente en la Figura 5.2.
Ejemplo 7. En la mayoría de las ocasiones, el diseño D−óptimo puede
que no satisfaga las necesidades de un experimentador debido a su forma
extrema, con únicamente dos puntos en su soporte e incluso, en algunos
casos, los dos extremos del espacio de diseño. En experimentos reales suele
ser frecuente la toma de medidas en un número mayor de puntos de sopor-
te. Normalmente los puntos se distribuyen a lo largo del espacio de diseño

5.5. Diseños Óptimos para el Modelo BET 119
5 10 15 20 25 30cB
0.1
0.2
0.3
0.4
0.5
awD
[email protected],0.8D
[email protected],0.5D
Figura 5.2. Valores de awD en función de cB para el espacio de diseñoXB y para el espacio de diseño extendido XG. En ambos casos paravalores cB > 20, awD = aw0 = 0.05.
sin ningún tipo de criterio. En la mayor parte de los casos el equipamien-
to cientíco o la intuición del experimentador hacen que los puntos sigan
determinados patrones.
El diseño D−óptimo proporciona una herramienta al experimentador
de tal forma que puede medir la eciencia de cualquier diseño experimental
ξ. El contraste de cualquier diseño con el D−óptimo puede llevarse a cabo
comparando el valor de la función criterio ΦD(ξ) = detM(ξ, θB)−1/2 de am-
bos diseños mediante el cálculo de la eciencia effD(ξ) = ΦD(ξ?D)/ΦD(ξ).
En el ejemplo que se discute, se han medido las eciencias de diferen-
tes tipos de diseños en comparación con el D−óptimo. Todos los diseños
comparados se han supuesto con 6 puntos en su soporte e igualmente dis-
tribuidos, esto signica que en cada punto del soporte se han tomado N/6observaciones. El número total de observaciones N será constante en todos
los diseños y ha de ser prejado por el experimentador atendiendo a las
restricciones y costes del experimento. Los diseños que se han comparado
son los siguientes:
Un diseño uniforme, en el que los puntos del soporte del diseño
se encuentran uniformemente distribuidos a lo largo del espacio de

120 5. Diseño Óptimo: Isotermas BET y GAB
diseño con un parámetro de espaciamiento constante, d, que es la
distancia entre dos observaciones consecutivas.
Un diseño aritmético, en el que el parámetro de espaciamiento crece
siguiendo una progresión aritmética (id) de izquierda a derecha delespacio de diseño, con i = 0, . . . , 5.
Un diseño geométrico (izquierda), en el que el parámetro de espa-
ciamiento crece siguiendo una progresión geométrica di de izquierda
a derecha del espacio de diseño.
Un diseño geométrico (derecha), en el que la progresión geométrica
va de derecha a izquierda del espacio de diseño.
Un diseño lineal inverso, en el que el intervalo [ηB(aw0), ηB(awF )] esuniformemente dividido y esos puntos proyectados sobre el espacio
de diseño XB a través de la inversa de la función de regresión.
En todos estos casos el parámetro d se ha jado de forma que los puntos
inicial y nal del espacio de diseño siempre formen parte del soporte del
diseño resultante.
Las eciencias de estos cinco diseños experimentales se presentan en
la Figura 5.3 frente a estimaciones iniciales del parámetro no lineal del
modelo, cB. Estos grácos pueden ser usados por el experimentados para
seleccionar o rechazar unos u otros diseños según las estimaciones iniciales
del parámetro cB.
5.5.2. Diseños c-óptimos.
Para estimar combinaciones lineales de los parámetros, ctθB, usaremos
el criterio de c−optimización. Este criterio es especialmente útil cuando
deseamos obtener estimaciones individuales de cada uno de los paráme-
tros. En el caso de desear estimar únicamente el parámetro que indica la
capacidad de la monocapa, wmB, bastará con obtener el diseño c−óptimo
con ct = (1, 0) y dicho diseño se denominará wmB−óptimo.

5.5. Diseños Óptimos para el Modelo BET 121
5 10 15 20 25 30cB
0.4
0.5
0.6
0.7
eff
lineal inversogeométrico izq.geométrico dcha.aritméticouniforme
[email protected],0.5D
5 10 15 20 25 30cB
0.4
0.5
0.6
0.7
eff
lineal inversogeométrico izq.geométrico dcha.aritméticouniforme
[email protected],0.8D
Figura 5.3. Eciencias de los dinco diseños experimentales en com-paración con el diseño D−óptimo. La eciencia permite al experimen-tador escoger la distribución de los puntos experimentales más apro-
piada.
Elfving (1952) propuso un método gráco para el cálculo de diseños
c−óptimos. El método dene el conjunto de Elfving como Λ = cierre con-
vexo de (f(XB) ∪ −f(XB)). El diseño c−óptimo, ξ?c , vendrá dado por c?,
denido por la intersección de la recta denida por el vector c y la frontera
del conjunto de Elfving Λ. Este punto de intersección podrá denirse como
una combinación convexa de los vértices de Λ, siendo los vértices de Λ los
puntos de soporte del diseño y siendo los coecientes de dicha combinación
convexa los pesos de cada punto del diseño. Además el valor de la función
criterio es equivalente a Φc(ξ?c ) = (||c||/||c?||)2.
El conjunto de Elfving Λ para el modelo BET se muestra en la Figura
5.4. Los vértices de la frontera de dicho conjunto son los siguientes puntos
junto con sus simétricos por el origen:
1. El punto nal de la curva f(XB), f(awF ) = (xF , yF ).
2. El punto tangencial f(aws) = (xs, ys) de la recta con extremo
f(awF ),
aws =1√
awF (1− cB).
3. O bien el punto inicial de la curva f(XB), f(aw0) = (x0, y0), oel punto tangencial f(awt) = (xt, yt) de la recta con extremo en

122 5. Diseño Óptimo: Isotermas BET y GAB
- xF
- yF
- x0
- y0
xt
yt
xs
ys
x*
y*
Figura 5.4. Conjunto de Elfving para el modelo BET. Los pun-tos f(aw0) = (x0, y0)
t y f(awF ) = (xF , yF )t son los valores de fpara los extremos del espacio de diseño XB . En este caso particu-lar los diseños c−óptimos están denidos por f(awt) = (xt, yt)
t yf(awF ) = (xF , yF )t. Los puntos (x?, 0)t y (0, y?)t son combinacionesconvexas de estos dos puntos f(awt), f(awF ) y los coecientes de estascombinaciones son los pesos de cada uno de ellos en los diseños óptimos
f(awF ). Donde awt es la solución real en XB de la ecuación
−a4wtawF (1−cB)2+2a3
wta2wF (1−cB)2+a2
wt(a3wF (cB−1)2−2cBa2
wF (cB−1)
+ 6a2wF (cB − 1)− awF (4cB − 6)− 1)− 2awtawF + a2
wF = 0.
4. Los puntos de la curva f(XB) entre los puntos 2. y 3.
El punto de corte x? de Λ con el vector ct = (1, 0) puede expresarse
como una combinación lineal de f(awF ) y de −f(awt) o −f(aw0). Estospuntos son los puntos de soporte del diseño wmB−óptimo y los pesos vie-
nen dados por los coecientes de la combinación convexa. Equivalentemen-
te, el punto de corte y? de Λ con el vector ct = (0, 1) puede expresarse
como una combinación convexa de −f(awF ) y o bien f(awt) o f(aw0). Estacombinación convexa nos da los puntos de soporte y los pesos del diseño
cB−óptimo.
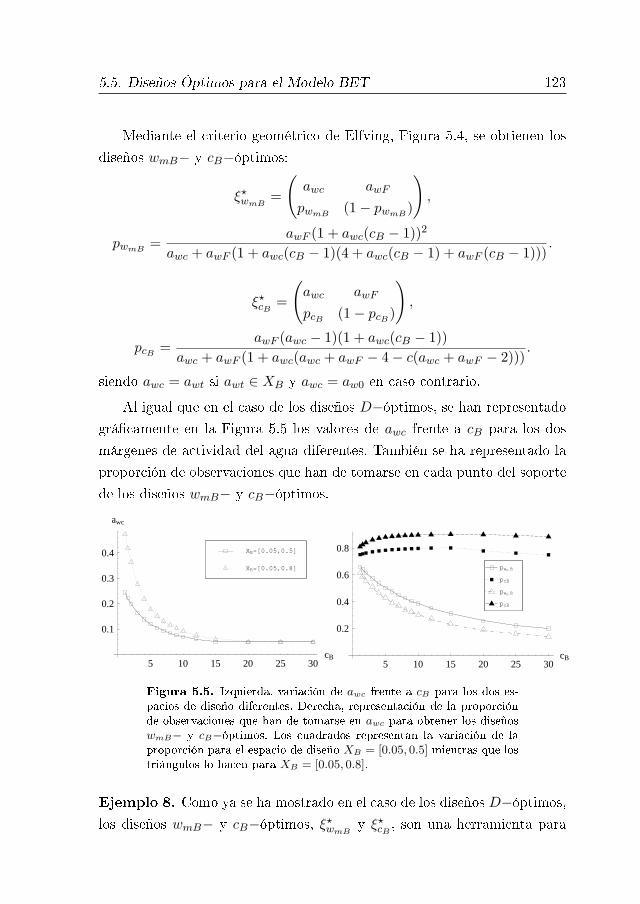
5.5. Diseños Óptimos para el Modelo BET 123
Mediante el criterio geométrico de Elfving, Figura 5.4, se obtienen los
diseños wmB− y cB−óptimos:
ξ?wmB =
(awc awF
pwmB (1− pwmB )
),
pwmB =awF (1 + awc(cB − 1))2
awc + awF (1 + awc(cB − 1)(4 + awc(cB − 1) + awF (cB − 1))).
ξ?cB =
(awc awF
pcB (1− pcB )
),
pcB =awF (awc − 1)(1 + awc(cB − 1))
awc + awF (1 + awc(awc + awF − 4− c(awc + awF − 2))).
siendo awc = awt si awt ∈ XB y awc = aw0 en caso contrario.
Al igual que en el caso de los diseños D−óptimos, se han representado
grácamente en la Figura 5.5 los valores de awc frente a cB para los dos
márgenes de actividad del agua diferentes. También se ha representado la
proporción de observaciones que han de tomarse en cada punto del soporte
de los diseños wmB− y cB−óptimos.
5 10 15 20 25 30cB
0.1
0.2
0.3
0.4
awc
[email protected],0.8D
[email protected],0.5D
5 10 15 20 25 30cB
0.2
0.4
0.6
0.8
pcB
pwm B
pcB
pwm B
Figura 5.5. Izquierda, variación de awc frente a cB para los dos es-pacios de diseño diferentes. Derecha, representación de la proporciónde observaciones que han de tomarse en awc para obtener los diseñoswmB− y cB−óptimos. Los cuadrados representan la variación de laproporción para el espacio de diseño XB = [0.05, 0.5] mientras que lostriángulos lo hacen para XB = [0.05, 0.8].
Ejemplo 8. Como ya se ha mostrado en el caso de los diseños D−óptimos,
los diseños wmB− y cB−óptimos, ξ?wmB y ξ?cB , son una herramienta para

124 5. Diseño Óptimo: Isotermas BET y GAB
el experimentador que permite medir la eciencia de cualquier diseño ex-
perimental propuesto, ξ, en el caso de necesitar únicamente la estimación
de uno de los parámetros del modelo. Cualquier diseño se puede comparar
al correspondiente c−óptimo mediante la evaluación de la función criterio
Φc(ξ) = ctM(ξ, θB)−1c, siendo ct = (1, 0) para el diseño wmB−óptimo o
ct = (0, 1) para el diseño cB−óptimo. Entonces la eciencia en comparación
con cada diseño c−óptimo será, effc(ξ) = Φc(ξ?c )/Φc(ξ).
Al igual que en el Ejemplo 7, se ha calculado la eciencia de los cinco di-
seños experimentales antes propuestos con 6 puntos de soporte e igualmente
distribuidos, tomando en cada punto N/6 de la observaciones, respecto a
ambos diseños c−óptimos.
Las eciencias para estos cinco diseños y para los dos espacios de diseño
se han representado grácamente en la Figura 5.6 frente a diferentes valores
del parámetro no lineal cB.
Se pueden resaltar una serie de diferencias entre las eciencias para la
estimación de wmB o de cB. Por ejemplo, para estimar wmB con estimacion
inicial del valor de cB > 10, el mejor diseño experimental de los cinco
propuestos, resulta ser el que sigue una progresión geométrica de derecha a
izquierda de XB, mientras que el de menor eciencia de los cinco resulta ser
el geométrico (izquierda). Por el contrario, para estimar cB en las mismas
condiciones los resultados con completamente opuestos.
5.6. Diseños Óptimos para el Modelo GAB
Al igual que para el modelo BET, también se pueden obtener los diseños
D− y c−óptimos para la isoterma GAB, siendo θtG = (wmG, cG, k) el vectorde parámetros desconocidos que se desean estimar y tomando f(aw) =∂E(we)/∂θG, evaluada en unos valores nominales, mejores estimaciones
iniciales disponibles de los parámetros θG,
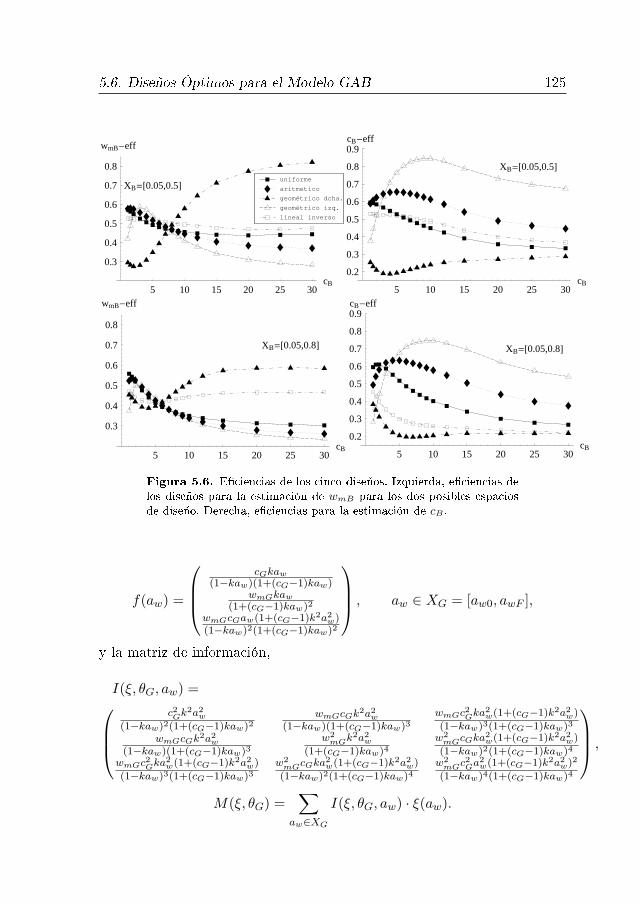
5.6. Diseños Óptimos para el Modelo GAB 125
5 10 15 20 25 30cB
0.3
0.4
0.5
0.6
0.7
0.8
wmB-eff
[email protected],0.5D
lineal inverso
geométrico izq.
geométrico dcha.
aritmetico
uniforme
5 10 15 20 25 30cB
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9cB-eff
[email protected],0.5D
5 10 15 20 25 30cB
0.3
0.4
0.5
0.6
0.7
0.8
wmB-eff
[email protected],0.8D
5 10 15 20 25 30cB
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9cB-eff
[email protected],0.8D
Figura 5.6. Eciencias de los cinco diseños. Izquierda, eciencias delos diseños para la estimación de wmB para los dos posibles espaciosde diseño. Derecha, eciencias para la estimación de cB .
f(aw) =
cGkaw
(1−kaw)(1+(cG−1)kaw)wmGkaw
(1+(cG−1)kaw)2
wmGcGaw(1+(cG−1)k2a2w)
(1−kaw)2(1+(cG−1)kaw)2
, aw ∈ XG = [aw0, awF ],
y la matriz de información,
I(ξ, θG, aw) =c2Gk
2a2w
(1−kaw)2(1+(cG−1)kaw)2wmGcGk
2a2w
(1−kaw)(1+(cG−1)kaw)3
wmGc2Gka
2w(1+(cG−1)k2a2
w)
(1−kaw)3(1+(cG−1)kaw)3
wmGcGk2a2w
(1−kaw)(1+(cG−1)kaw)3
w2mGk
2a2w
(1+(cG−1)kaw)4
w2mGcGka
2w(1+(cG−1)k2a2
w)
(1−kaw)2(1+(cG−1)kaw)4
wmGc2Gka
2w(1+(cG−1)k2a2
w)
(1−kaw)3(1+(cG−1)kaw)3
w2mGcGka
2w(1+(cG−1)k2a2
w)
(1−kaw)2(1+(cG−1)kaw)4
w2mGc
2Ga
2w(1+(cG−1)k2a2
w)2
(1−kaw)4(1+(cG−1)kaw)4
,
M(ξ, θG) =∑
aw∈XG
I(ξ, θG, aw) · ξ(aw).

126 5. Diseño Óptimo: Isotermas BET y GAB
5.6.1. Diseños D−óptimos.
Con el objetivo de estimar simultáneamente los tres parámetros del
modelo GAB, θG, se han calculado los diseños D−óptimos. En este caso,
a diferencia de la isoterma BET, la obtención de una expresión analítica
que nos especique los diseños no es posible. De todas formas el procedi-
miento se realiza de manera análoga. El objetivo es encontrar un diseño
que minimize la expresión ΦD[M(ξ, θG)] = detM(ξ, θG)−1/m, m = 3, quees equivalente a encontrar un diseño que maximice log(detM(ξ, θG)).
Los diseños D−óptimos serán igualmente distribuidos y concentrado
en tres puntos,
ξ?D =
(aw1 aw2 awF
1/3 1/3 1/3
),
siendo awF el extremo superior del espacio de diseño XG, aw2 ∈ XG y
siendo aw1 un punto del interior de XG o el extremo inferior de XG, aw0.
Los diseños D−óptimos para el modelo GAB en el espacio de diseño
XG = [0.05, 0.8] se han calculado numéricamente para diferentes estima-
ciones iniciales de los parámetros no lineales. Los puntos de soporte aw1
y aw2 de estos diseños se han representado grácamente en la Figura 5.7.
Como el modelo es parcialmente no lineal los diseños D−óptimos dependen
únicamente de los parámetros cG, k y del espacio de diseño que se elija. Los
diseños siempre tienen entre sus puntos de soporte el extremo superior de
XG, awF ; los otros dos puntos del soporte, aw1 y aw2 se han obtenido para
diferentes valores del parámetro cG ∈ (1, 30] y para dos valores diferentes
del parámetro k = 0.5, 0.8.
Nuevamente el Teorema de Equivalencia, nos proporciona una herra-
mienta para comprobar la optimalidad de los diseños obtenidos,
f t(aw)M(ξ?D)−1f(aw) ≤ m, aw ∈ XG.
Ejemplo 9. Como se ha hecho en el Ejemplo 7, se han calculado las e-
ciencias de cinco diseños experimentales diferentes con 6 puntos de soporte
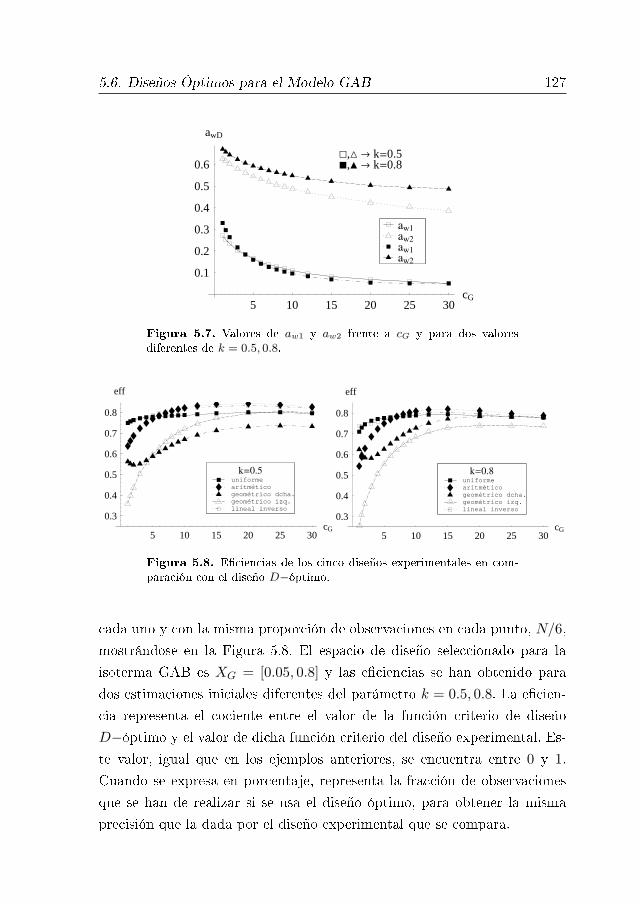
5.6. Diseños Óptimos para el Modelo GAB 127
5 10 15 20 25 30cG
0.1
0.2
0.3
0.4
0.5
0.6
awD
á,ó ® k=0.5à,ò ® k=0.8
aw2
aw1
aw2
aw1
Figura 5.7. Valores de aw1 y aw2 frente a cG y para dos valoresdiferentes de k = 0.5, 0.8.
5 10 15 20 25 30cG
0.3
0.4
0.5
0.6
0.7
0.8
eff
lineal inversogeométrico izq.geométrico dcha.aritméticouniforme
k=0.5
5 10 15 20 25 30cG
0.3
0.4
0.5
0.6
0.7
0.8
eff
lineal inversogeométrico izq.geométrico dcha.aritméticouniforme
k=0.8
Figura 5.8. Eciencias de los cinco diseños experimentales en com-paración con el diseño D−óptimo.
cada uno y con la misma proporción de observaciones en cada punto, N/6,mostrándose en la Figura 5.8. El espacio de diseño seleccionado para la
isoterma GAB es XG = [0.05, 0.8] y las eciencias se han obtenido para
dos estimaciones iniciales diferentes del parámetro k = 0.5, 0.8. La ecien-
cia representa el cociente entre el valor de la función criterio de diseño
D−óptimo y el valor de dicha función criterio del diseño experimental. Es-
te valor, igual que en los ejemplos anteriores, se encuentra entre 0 y 1.Cuando se expresa en porcentaje, representa la fracción de observaciones
que se han de realizar si se usa el diseño óptimo, para obtener la misma
precisión que la dada por el diseño experimental que se compara.

128 5. Diseño Óptimo: Isotermas BET y GAB
En este caso, el diseño aritmético es el que proporciona valores de e-
ciencia más elevados para valores de cG altos, mientras que para valores
pequeños del parámetro el mejor diseño es el uniforme. Como en los ejem-
plos anteriores, resulta difícil dar un consejo general al experimentador para
una elección correcta del diseño. Ahora bien, el diseño óptimo nos permite
medir la eciencia de cualquier diseño en particular y por lo tanto nos pro-
porciona la suciente información como para elegir el diseño menos malo
posible.
5.6.2. Diseños c−óptimos.
Los diseños c−óptimos para el modelo GAB presentan la dicultad
añadida de la dimensión del vector de parámetros θG, en este caso tres,
representándose el conjunto de Elfving en R3. La obtención de las com-
binaciones convexas es por lo tanto más complicada que la obtención de
las mismas para el modelo BET. El método propuesto por Elfving (1952)
es válido para cualquier dimensión del vector de parámetros, aunque su
uso geométrico es muy complicado para más de dos parámetros y por lo
tanto muy raramente usado. López-Fidalgo y Rodríguez-Díaz (2004) han
propuesto un procedimiento por el que se obtienen los diseños c−óptimos
basándose en el procedimiento de Elfving, pero evitando las necesidades
geométricas del método.
Para obtener los diseños c−óptimos, es necesario determinar el punto
de intersección u? de la recta dada por el vector c y el conjunto de Elfving
Λ = cierre convexo de (f(XG)⋃−f(XG)). Este punto de corte se podrá
entonces expresar como combinación convexa de los vértices de Λ. El teo-rema de Caratheodory nos dice que para cada punto de la frontera de Λexiste una combinación convexa de como mucho m puntos, siendo m = 3el número de parámetros del modelo para el modelo GAB. En general, el
punto de corte u? vendrá dado por,
u? = p1ε1f(aw1) + p2ε2f(aw2) + p3ε3f(aw3),

5.6. Diseños Óptimos para el Modelo GAB 129
siendo (aw1, aw2, aw3) los puntos de soporte, εi = ±1, el signo de cada
término de la combinación convexa y (p1, p2, p3), los pesos, tales que 0 <pi < 1 y p1 + p2 + p3 = 1. Sea entonces c = (1, c2, c3) el vector no nulo quedetermina la combinación lineal de los parámetros que se desea estimar.
Para c2 = c3 = 0, el diseño c−óptimo que se obtendrá será el diseño
wmG-óptimo que nos permitirá obtener la mejor estimación posible de la
capacidad de la monocapa. El punto de corte u? = (u?1, u?2, u
?3) no sólo se
encontrará en Λ sino que además se encontrará en la recta denida por el
vector c, y por lo tanto vericará las siguientes ecuaciones,u?2 = c2u?1,
u?3 = c3u?1.
Considerando ambas condiciones, u? ∈ Λ y u? en la recta denida por
c, el sistema a resolver se transforma en el siguiente,(d2(aw2) d2(aw3)d3(aw2) d3(aw3)
)(p2
p3
)= −ε1
(h2(aw1)h3(aw1)
),
D(aw1, aw2, aw3)p = −ε1H(aw1),
siendo di(awj) = εjhi(awj)− ε1hi(aw1) y hi(aw) = fi(aw)− cif1(aw).
La solución, según la ecuación anterior, p estará en función de (aw1, aw2, aw3),
p = p(aw1, aw2, aw3) = −ε1D(aw1, aw2, aw3)−1H(aw1),
siendo p1 = 1− p2 − p3.
La combinación lineal de los parámetros dada por c = (1, c2, c3) se haconsiderado no nula en su primera componente. Por lo tanto, maximizar el
módulo del vector en ambas posibles direcciones de la recta determinada
por c, sujeto a las condiciones de estar en Λ, es equivalente a maximizar el
cuadrado de la primera componente de u,

130 5. Diseño Óptimo: Isotermas BET y GAB
u21(aw1, aw2, aw3) = ((1− p2 − p3)ε1f1(aw1) + p2ε2f1(aw2) + p3ε3f1(aw3))2
sujeto a:
pi ≥ 0, i = 2, 3
p2 + p3 ≤ 1
Este es un problema de programación matemática que depende de
(aw1, aw2, aw3).
Este problema ha de resolverse para todas las posibles combinaciones
del vector de signo ε no simétricas entre sí.
El procedimiento se puede resumir algorítmicamente de la forma si-
guiente:
Paso 1: Elegir un vector de signo ε.
Paso 2: Calcular el valor de p = −ε1D(aw1, aw2, aw3)−1H(aw1).
Paso 3: Resolver el problema de programación planteado anterior-
mente encontrando un máximo de u21(aw1, aw1, aw1).
Paso 4: Elegir un nuevo vector de signo ε y repetir desde el Paso
2.
Paso 5: Cuando se han elegido todos los vectores de signo posibles,
los puntos de soporte de nuestro diseño serán (aw1, aw2, aw3) talesque u2
1(aw1, aw2, aw3) es el mayor de todos los obtenidos.
Este algoritmo permite el cálculo de los diseños c−óptimos ξ?wmG , ξ?cG
y
ξ?k, que permiten la obtención de las mejores estimaciones posibles para cada
uno de los parámetros de θG de forma individual. Los vectores c que pro-
porcionan estos diseños son (1, 0, 0), (0, 1, 0) y (0, 0, 1) respectivamente. El
valor de la función criterio que se ha de minimizar es Φc(ξ) = ctM(ξ, θG)−1c
y el Teorema de Equivalencia (Teorema 4) proporciona una herramienta
para comprobar la optimalidad del diseño obtenido. Además el mismo teo-
rema proporciona una cota inferior de la eciencia que puede utilizarse

5.6. Diseños Óptimos para el Modelo GAB 131
como condición de parada en el procedimiento numérico de resolución del
problema de programación.
1 +ınfaw∈XG ψ(aw, ξ)
Φc(ξ)=
1+ınfaw∈XG [−f t(aw)M(ξ, θG)−1cctM(ξ, θG)−1f(aw) + tr(ctM(ξ, θG)−1c)]
ctM(ξ, θG)−1c> δ,
siendo 0 < δ < 1 un valor apropiado para la eciencia deseada.
Los diseños c−óptimos están concentrados en 3 o menos puntos expe-
rimentales (Teorema de Caratheodory), que son los vértices del conjunto
de Elfving Λ en R3. Para cada combinación lineal de los parámetros dada
por c, el diseño c−óptimo proporcionará el mejor diseño para estimarla.
En particular, y como ya hemos mencionado, pueden resultar de interés los
diseños wmG−, cG− y k−óptimos. La forma general de un diseño c−óptimo
será la siguiente:
ξ?c =
(aw1 aw2 awF
pc qc rc
),
siendo awF el extremo superior del espacio de diseño XG, aw2 ∈ XG y aw1
se encuentra o bien el el interior de XG o coincide con el extremo inferior
de XG, aw0.
Los puntos de soporte de los diseños c−óptimos en el espacio de diseño
XG = [0.05, 0.8] se han calculado de forma numérica y la no linealidad
parcial del modelo hace que los diseños sólo dependan de los parámetros
no lineales cG, k y del espacio de diseño. Los puntos de soporte aw1 y
aw2 se representan grácamente en la Figura 5.9 para diferentes valores
de cG ∈ (1, 30] y para dos estimaciones iniciales diferentes del parámetro
k = 0.5, 0.8.
La estimación de la capacidad de la monocapa es, como ya hemos visto,
de especial interés ya que se usa para medir el area supercial efectiva y
es un método usado de forma exhaustiva en muchos procesos industriales.
Como ejemplo ilustrativo se muestran los pesos (pwmG , qwmG , rwmG) para el
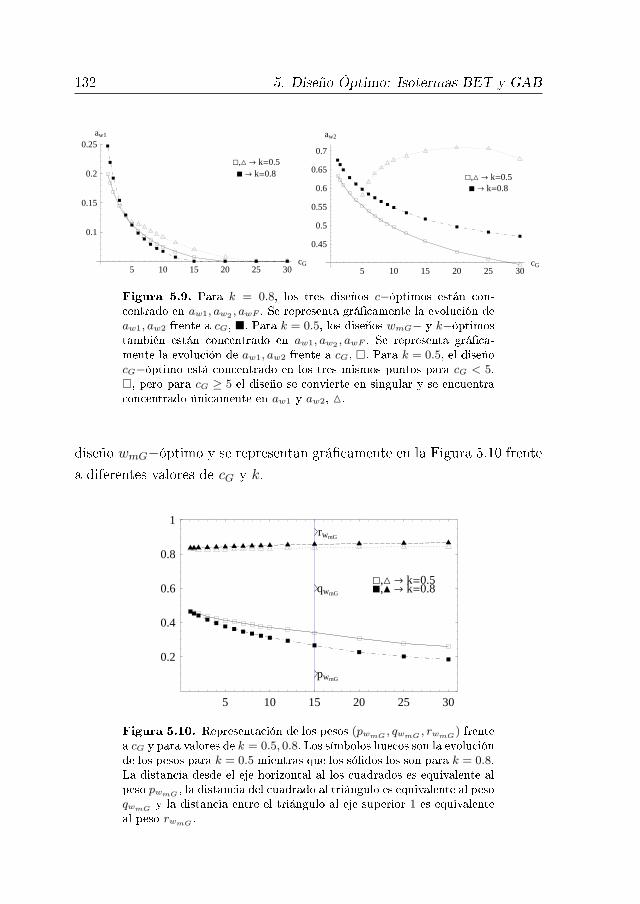
132 5. Diseño Óptimo: Isotermas BET y GAB
5 10 15 20 25 30cG
0.1
0.15
0.2
0.25aw1
á,ó ® k=0.5à ® k=0.8
5 10 15 20 25 30cG
0.45
0.5
0.55
0.6
0.65
0.7
aw2
á,ó ® k=0.5à ® k=0.8
Figura 5.9. Para k = 0.8, los tres diseños c−óptimos están con-centrado en aw1, aw2 , awF . Se representa grácamente la evolución deaw1, aw2 frente a cG, . Para k = 0.5, los diseños wmG− y k−óptimostambién están concentrado en aw1, aw2 , awF . Se representa gráca-mente la evolución de aw1, aw2 frente a cG, . Para k = 0.5, el diseñocG−óptimo está concentrado en los tres mismos puntos para cG < 5,, pero para cG ≥ 5 el diseño se convierte en singular y se encuentraconcentrado únicamente en aw1 y aw2, M.
diseño wmG−óptimo y se representan grácamente en la Figura 5.10 frente
a diferentes valores de cG y k.
5 10 15 20 25 30
0.2
0.4
0.6
0.8
1
pwmG
qwmG
rwmG
á,ó® k=0.5à,ò® k=0.8
Figura 5.10. Representación de los pesos (pwmG , qwmG , rwmG) frentea cG y para valores de k = 0.5, 0.8. Los símbolos huecos son la evoluciónde los pesos para k = 0.5 mientras que los sólidos los son para k = 0.8.La distancia desde el eje horizontal al los cuadrados es equivalente alpeso pwmG , la distancia del cuadrado al triángulo es equivalente al pesoqwmG y la distancia entre el triángulo al eje superior 1 es equivalenteal peso rwmG .

5.7. Comparación de los Diseños 133
5 10 15 20 25 30cG
0.1
0.2
0.3
0.4
0.5
0.6
wmG-eff
lineal inversogeométrico izq.geométrico dcha.aritméticouniforme
k=0.5
5 10 15 20 25 30cG
0.1
0.2
0.3
0.4
0.5
0.6
wmG-eff
lineal inversogeométrico izq.geométrico dcha.aritméticouniforme
k=0.8
Figura 5.11. Eciencias de los cinco diseños experimentales en com-paración con el diseño wmG−óptimo.
Cabe destacar, como se observa en la Figura 5.9, que el diseño cG−óptimo
para la estimación inicial del parámetro k = 0.5 resulta ser singular, estan-
do concentrado únicamente en dos puntos, en lugar de tres,
ξ?cG =
(aw1 aw2
pcG qcG
).
Ejemplo 10. Como se ha dicho, los diseños óptimos son herramientas
útiles para medir la eciencia de cualquier diseño que se desee llevar a
cabo. La eciencia se obtiene mediante la comparación de los valores de la
función criterio del diseño óptimo con el del diseño experimental,effc =Φc(ξ?c )/Φc(ξ).
Como en los ejemplos anteriores se comparan los cinco diseños propues-
tos con 6 puntos experimentales en su soporte e idénticamente distribuidos.
Estos diseños se han comparado con el diseño wmG−óptimo y se muestran
en la Figura 5.11 para diferentes valores de cG y k.
En este caso los valores de eciencia más altos se obtienen para la
estimación de k = 0.5 con los diseños uniforme y aritmético mientras que
para k = 0.8 el diseño con mayor eciencia es el diseño uniforme.
5.7. Comparación de los Diseños
Según se ha planteado el trabajo, la elección del modelo parece inde-
pendiente de la estimación de los parámetros de interés. En algunos casos

134 5. Diseño Óptimo: Isotermas BET y GAB
effΦ(ξ?T ) GAB BET
ξ?T D− wmG− cG− k− D− wmB− cB−
Example 5 0.84 0.88 0.25 0.99 0.52 0.44 0.19Example 6 0.81 0.69 0.28 0.88 0.59 0.40 0.27Tabla 5.1. D− y c− eciencias de los diseños T−optimum obtenidosen los Ejemplos 5 y 6.
el experimentador podrá permitirse realizar dos tandas de experimentos.
La primera para vericar si es o no adecuada la elección del modelo más
complejo, GAB, frente al modelo más sencillo, BET y una vez elegido el
modelo diseñar de acuerdo a sus intereses utilizando los criterios de D−o c−optimización. En el caso que esto sea posible, podemos utilizar las
medidas tomadas en el primer experimento de discriminación para obtener
unas nuevas estimaciones iniciales de los parámetros no lineales, resultando
de interés conocer la eciencia del diseño T−óptimo para estimar paráme-
tros individuales. En otros casos puede que no haga falta la segunda tanda
de experimentos porque la eciencia del diseño T−óptimo puede resultar
suciente para la caracterización de fenómeno.
El cálculo de las D− y c−eciencias de los diseños T−óptimos cal-
culados puede entonces resultar muy interesante proporcionando al expe-
rimentador información acerca de la conveniencia de una segunda tanda
de experimentos destinados especícamente a la estimación de los pará-
metros después de la fase de discriminación de los modelos. En la Tabla
5.1 se muestran las eciencias de los diseños T−óptimos obtenidos para
los Ejemplos 5 y 6 respecto al diseño D−óptimo y a los diferentes diseños
c−óptimos, para ambos resultados posibles del proceso de discriminación.
Cabe destacar que las eciencias de los diseños óptimos destinados a
estimar los parámetros del modelo GAB resultan más altas que para el
modelo BET, debiéndose a que el criterio de T−optimización considera
el modelo GAB como el adecuado para caracterizar el fenómeno mientras
que el modelo BET será el modelo alternativo. También destacar la alta

5.7. Comparación de los Diseños 135
eciencia del diseño T−óptimo para la estimación del parámetro k del
modelo GAB. Recordemos una vez más que ambos modelos se diferencian
en la inclusión de este nuevo parámetro y que para valores de k = 1 ambos
modelos coinciden. En el Ejemplo 5 la estimación inicial del parámetro
k = 0.994 es muy cercana a 1 y por lo tanto el diseño que nos permita
estimar con mayor eciencia k será un diseño que también nos permita
discriminar entre ambos modelos.


Capítulo 6
Estimadores Combinados
en Quimiometría
En el Capítulo 3 se trató de la estimación de los parámetros A y B de
la ecuación de Arrhenius considerando que la magnitud que actúa como
variable dependiente, k(T ), es directamente medible. Esta consideración
no es estrictamente cierta, puesto que en realidad su determinación se lleva
a cabo mediante medidas de concentración frente al tiempo utilizando un
modelo cinético previo que relaciona estas dos magnitudes. En vista de esto
nos proponemos analizar las particularidades del proceso de estimación
en dos pasos frente a estimadores combinados y desarrollar una primera
aproximación al problema en estos casos (Borjas, 1982).
En un primer lugar y de forma muy descriptiva, vamos a desarrollar
algunos casos en los que se presentarían modelos consecutivos en dos o más
pasos en relación con medidas relacionadas con la ecuación de Arrhenius,
posteriormente presentaremos un caso simplicado sobre el que analizare-
mos la estimación en dos pasos frente a la estimación combinada.
137

138 6. Estimadores Combinados en Quimiometría
6.1. Ecuaciones de Velocidad
La constante de velocidad k(T ) que gura como variable dependiente
en la ecuación de Arrhenius corresponde a un parámetro cinético que se
determina mediante diferentes modelos según la ecuación de velocidad del
proceso cinético al que corresponde. Se entiende por ecuación de veloci-
dad la ecuación diferencial que relaciona la velocidad con que evolucionan
reactivos y productos en función de sus concentraciones (Moore y Pearson,
1981; House, 2007). En términos genéricos, como ya se ha expuesto en la
Sección 2.1, las ecuaciones de velocidad pueden ser de orden cero, de orden
uno o de orden dos. A una somera descripción de estas ecuaciones cinéticas
dedicaremos el siguiente apartado.
6.1.1. Procesos Cinéticos de Orden Cero.
El caso más sencillo que puede encontrarse es un proceso cinético de or-
den cero (Tokunaga et al., 2006), que se podría describir esquemáticamente
de la siguiente forma,
Sk0(T )
GGGGGGGGGGAP,
donde S representa el sustrato que se transforma en el producto P a lo
largo del tiempo. En el momento inicial la cantidad de sustrato vendrá
dada por [S](0) mientras que en un instante de tiempo t la cantidad inicial
de sustrato se habrá reducido y se habrá convertido en una cantidad de
producto [P ](t), de tal forma que [S](t) = [S](0) − [P ](t). Si el procesoocurre según un modelo de orden cero la velocidad será constante y vendrá
dada por
v = −d[S](t)dt
=d[P ](t)dt
= k0(T ),
cuya integración, a temperatura constante, da la evolución temporal del
sustratro que reacciona:
[S](t) = [S](0)− k0(T )t,

6.1. Ecuaciones de Velocidad 139
o bien la cantidad de producto que se forma:
[P ](t) = [S](0)− [S](t) = k0(T )t.
Esta constante de velocidad de orden cero depende de la temperatura
según la relación de Arrhenius,
k0(T ) = A0 exp(−B0/T ),
siendo A0 y B0 constantes frente a la temperatura.
El proceso experimental se cifra en la determinación de la concentración
[P] o [S] a distintos tiempos bajo condiciones de temperatura constante, ob-
teniéndose el valor k0 como la pendiente de cualquiera de los dos modelos
lineales. Repitiéndose estas mediciones a distintas temperaturas y poste-
riormente realizando una nueva regresión, se obtendrán los parámetros A0
y B0 de la ecuación de Arrhenius.
6.1.2. Procesos Cinéticos de Orden Uno.
En una reacción de orden uno, el esquema inicial puede ser el mismo
que en el caso anterior:
Sk1(T )
GGGGGGGGGGAP,
habiendo reaccionado en un instante t de tiempo una cantidad de sustrato
equivalente a la cantidad de producto formado. La diferencia con las reac-
ciones de orden cero está en que la velocidad, en lugar de ser constante,
disminuye de forma proporcional con la concentración de sustrato (Chou y
Chang, 2007), tomando la siguiente forma,
v = −d[S](t)dt
=d[P ](t)dt
= k1(T )[S](t) = k1(T )([S](0)− [P ](t)),
cuya integración, a temperatura constante, da lugar a la evolución frente
al tiempo de la concentración de sustrato,
[S](t) = [S](0)− [P ](t) = [S](0) exp(−k1(T )t),

140 6. Estimadores Combinados en Quimiometría
o de la concentración del producto,
[P ](t) = [S](0)[1− exp(−k1(T )t)].
Nuevamente la constante de velocidad de orden uno, k1(T ), dependede la temperatura según la relación de Arrhenius:
k1(T ) = A1 exp(−B1/T ),
siendo A1 y B1 constantes frente a la temperatura. El proceso experimental
a seguir resulta equivalente al caso de orden cero, con la salvedad de la no
linealidad de ambos modelos que se encadenan.
6.1.3. Procesos Cinéticos de Orden Dos.
Los procesos de orden dos pueden presentarse, al menos, de dos formas
diferentes. Consideremos en primer lugar la reacción entre dos sustratos S1
y S2:
S1 + S2
k2(T )GGGGGGGGGGAP.
Si en el instante inicial las cantidades de sustratos son [S1](0) y [S2](0),en un instante cualquiera t de tiempo se habrá formado una cantidad de
producto [P ](t), de forma que, suponiendo una estequiometría 1:1 en la
reacción (es decir una molécula de S1 reacciona con una molécula de S2),
al tiempo t, se tiene: [S1](t) = [S1](0)− [P ](t) y [S2](t) = [S2](0)− [P ](t),y la velocidad de la reacción vendrá dada por,
−d[S1](t)dt
= −d[S2](t)dt
=d[P ](t)dt
= k2(T )[S1](t)[S2](t)
= k2(T )([S1](0)− [P ](t))([S2](0)− [P ](t)).
Separando las variables de le ecuación diferencial anterior, e integrando
a temperatura constante se obtiene la ecuación integrada,
1[S1](0)− [S2](0)
log[S2](0)([S1](0)− [P ](t))[S1](0)([S2](0)− [P ](t))
= k2(T )t,

6.1. Ecuaciones de Velocidad 141
que puede expresarse de forma explícita según las ecuaciones siguientes,
[S1](t)[S2](t)
=[S1](0)[S2](0)
exp (k2(T )([S1](0)− [S2](0)))t
o bien,
[P ](t) =[S1](0)[S2](0)(1− exp(([S1](0)− [S2](0))k2(T )t))[S2](0)− [S1](0) exp(([S1](0)− [S2](0))k2(T )t)
que resulta ser una ecuación también de forma exponencial y donde la cons-
tante de velocidad también depende de la temperatura según una relación
de Arrhenius,
k2(T ) = A2 exp(−B2/T )
en la que A2 y B2 son constantes frente a la temperatura.
Resulta de interés considerar el caso particular en el que la concentra-
ción inicial de uno de los reactivos es mucho mayor que la del otro (Karakaya
et al., 2005). Por ejemplo, considérese que [S2](0) [S1](0) y que, por lo
tanto, [S2](0) [P ](t) en cualquier instante de tiempo. Puede entonces to-
marse como aproximación considerar [S2](t) ' [S2](0) constante a lo largo
del tiempo. En estas circunstancias, tanto la ecuación de velocidad:
−d[S1](t)dt
=d[P ](t)dt
= k2(T )[S1](t)[S2](0) = k2(T )[S2](0)([S1](0)−[P ](t)),
como la forma integrada:
log([S1](0)− [P ](t))
[S1](0)= −k2(T )[S2](0)t,
o bien
[P ](t) = [S1](0)(1− exp(−k2(T )[S2](0)t)),
se reducen a expresiones cinéticas similares a las de un proceso de pseudo
orden uno, en el que la constante de velocidad, denominada en este caso
constante de experimental, kexp, es
kexp([S2];T ) = k2(T )[S2].
En la práctica resulta muy corriente recurrir a estas condiciones de
trabajo, por lo que la determinación de los parámetros de activación de

142 6. Estimadores Combinados en Quimiometría
la ecuación de Arrhenius para k2, contiene una estimación en tres pasos
sucesivos. En primer lugar a temperatura constante se realizan diferentes
determinaciones de kexp([S2];T ) variando la concentración del sustrato [S2]que se considera permanece constante frente al tiempo, a continuación se
obtiene k2(T ) y por último se obtienen A2 y B2 parámetros de la ecuación
de Arrhenius.
La segunda reacción de orden dos que consideraremos es el caso parti-
cular de que se trate de una reacción del tipo:
2Sk2(T )
GGGGGGGGGGAP,
en la que se trata de que un mismo sustrato se dimeriza (Mata-Segreda,
2002), el planteamiento cinético es en este caso,
−d[S](t)dt
= +d[P ](t)dt
= k2(T )[S](t)2 = k2(T )([S](0)− [P ](t))2,
donde [P ](t) = [S](0)− [S](t) es la cantidad de sustrato que ha reaccionado
hasta el instante t de tiempo. La ecuación integrada una vez separadas las
variables resulta ser,
[P ](t) =k2(T )[S2](0)2t
1 + k2(T )[S2](0)2t,
o bien,
[S](t) =[S2](0)
1 + k2(T )t[S2](0).
En este caso el modelo resulta ser una hipérbola. La constante de velo-
cidad k2 depende asimismo de la temperatura a través de la ecuación de
Arrhenius.
6.2. Caso Simplicado
Con el objetivo de analizar la eciencia de la estimación en dos pasos
y de cara a comparar dicha estimación con un estimador combinado como
veremos más adelante, hemos simplicado un caso particular de estimación
de los parámetros de la ecuación de velocidad de un proceso cinético de

6.2. Caso Simplicado 143
orden cero seguido de la estimación de los parámetros de la ecuación de
Arrehnius.
En primer lugar el proceso cinético de orden cero que consideraríamos,
Sk(T )
GGGGGGGGGAP,
sería tal que pudiésemos medir la concentración de productos generados en
un instante de tiempo dado, siendo dicha concentración en el instante inicial
cero. Al ser el proceso cinético de orden cero, a temperatura constante, la
concentración de productos será proporcional al instante de tiempo y la
constante de proporcionalidad será la velocidad de la reacción.
[P ](t) = kt.
La constante k será la constate de velocidad de la reacción y dependerá
de la temperatura siguiendo la ecuación de Arrhenius,
k(T ) = A exp(−B/T ),
siendo A y B los parámetros ya descritos en el Capítulo 2.
El carácter no lineal de la ecuación de Arrhenius presenta dicultades
a la hora de plantear la estimación combinada. Dicha ecuación se podría
desarrollar de la siguiente forma,
k(T ) ≈ A exp(−B/T0) +B(A exp(−B/T0))
T 20
(T − T0),
donde T0 es una temperatura de control, por ejemplo 25C, es decir 298K.
Esta simplicación del modelo no lineal de Arrhenius por su desarrollo de
Taylor alrededor de la temperatura de control puede ser aceptable en inter-
valos pequeños de temperatura, aproximándose la variación de la constante
de velocidad con la temperatura mediante una recta. Resulta además que
el valor A exp(−B/T0) es la constante k a temperatura T0, k(T0), y por lo
tanto la expresión podría aproximarse,
k(T ) ≈ k(T0) +Bk(T0)T 2
0
(T − T0) = k(T0)(1− B
T0) +
Bk(T0)T 2
0
T.

144 6. Estimadores Combinados en Quimiometría
De esta forma el problema queda reducido a dos modelos lineales conse-
cutivos con parámetros de interés k(T0) y B, con los que la determinación
de A es inmediata.
6.3. Estimación en dos Pasos frente a la Estimación
Combinada
De forma práctica el caso simplicado conllevaría la realización sucesiva
de varios experimentos para lograr las estimaciones de los parámetros de
la ecuación de Arrhenius. En primer lugar habría que diseñar y jar los ex-
perimentos a realizar tomando medidas de la evolución de la concentración
de los productos a lo largo del tiempo t1, . . . , tn y en condiciones de tem-
peratura constante, estableciendo un conjunto de temperaturas T1, . . . , Tm
para las que se llevaría a cabo los experimentos.
En la práctica este tipo de estimaciones se realizan en dos pasos de la
siguiente manera. Una vez jada una temperatura T y al ser la cinética de
la reacción de orden cero tendremos que,
z(t) = yt+ ε,
donde t es la variable independiente, z la variable dependiente e y el pa-
rámetro desconocido. Una vez realizados los experimentos planteados a las
diferentes temperaturas y estimados los diferentes parámetros y tendremos,
y(T ) = α+ βT + ε.
Donde T es la variable independiente y cuyos valores hemos jado, y es en
este caso la variable dependiente, no observable directamente sino que ha
sido obtenida como un parámetro de la ecuación cinética de orden cero y
por último α y β los parámetros de interés.
La estimación combinada por el contrario realiza una única estimación
de los parámetros de interés, α y β, con las mismas observaciones,
z(t, T ) = αt+ βtT + ε

6.3. Estimación en dos Pasos frente a la Estimación Combinada 145
siendo t y T variables independientes y z la variable dependiente y física-
mente medible.
La comparación de ambos métodos de estimación se realizará mediante
el cálculo de las matrices de covarianzas de los parámetros α y β, prerién-
dose el método de menor covarianza ya que no existen diferencias experi-
mentales en el modo de realizar los experimentos sino que las diferencias
radican en el tratamiento de los datos.
De los dos métodos a comparar, la estimación en dos pasos es el que
se lleva a cabo en la práctica mientras que la estimación combinada se
evita, tal vez por su aparente mayor complejidad y por las dicultades que
conlleva presentar resultados de forma diferente, aún pudiendo ser mejores.
6.3.1. Estimación en dos Pasos: I.
A efectos de notación consideraremos zij = z(ti, Tj), y consideraremos
que la variable aleatoria zij condicionada al verdadero y desconocido valor
de yj = y(Tj) seguirá la distribución normal,
zij |yj ≡ N(yjti, σ2),
siguiendo la variable aleatoria yj una distribución normal,
yj ≡ N(α+ βTj , τ2).
Entonces el estimador yj condicionado al verdadero valor de yj seguirá una
distribución,
yj |yj ≡ N(yj , σ2(XttXt)−1),
donde Xt es el vector formado por los tiempos Xt = (t1, . . . , tn)t en los que
se toman observaciones.
Por lo tanto el proceso de estimación en dos pasos consistirá primero
en la obtención de yj para las diferentes temperaturas jadas T1, . . . , Tn de
tal forma que,
yj ≡ N(α+ βTj , σ2(Xt
tXt)−1 + τ2),

146 6. Estimadores Combinados en Quimiometría
siendo las estimaciones de los diferentes yj con j = 1, . . . ,m las dadas por,
Y = ((XttXt)−1Xt
tZ)t = ZtXt(XttXt)−1,
con Z la matriz de las observaciones, de dimensiones n ×m, y siendo las
estimaciones de las yj independientes.
Los estimadores de los parámetros de interés α y β, serán,(α
β
)= (Xt
TXT )−1XtT Y = (Xt
TXT )−1XtT (Xt
tXt)−1XttZ,
siendo
XT =
1 T1
......
1 Tm
.
Resultando ser la matriz de covarianzas de los estimadores de los pa-
rámetros de interés,
ΣI(α,β)t
= (XtTXT )−1(σ2(Xt
tXt)−1 + τ2).
6.3.2. Estimación en un Paso o Combinada: II.
Respecto a la estimación combinada podemos considerar la estimación
mediante un único paso. Considerando que la variable aleatoria yj sigue
una distribución normal,
yj ≡ N(α+ βTj , τ2),
y que la variable aleatoria zij condicionada al verdadero y desconocido valor
de y sigue una distribución normal,
zij |yj ≡ N(yjti, σ2),
tendremos que la variable aleatoria zij seguira la siguiente distribución
normal,
zij ≡ N(αti + βtiTj , τ2t2j + σ2)

6.3. Estimación en dos Pasos frente a la Estimación Combinada 147
Entonces tendremos que una vez tomadas las observaciones zij como
resultado de los experimentos llevados a cabo a temperaturas constantes
Tj , j = 1, . . . ,m, y para cada una de estas en los instantes de tiempo ti,
i = 1, . . . , n, podemos obtener las estimaciones de los parámetros de interés
α y β, (α
β
)= (Xt
tTΣ−1z XtT )−1Xt
tTΣ−1z Z,
siendo
XtT =
t1 t1T1
......
tn tnT1
......
t1 t1Tm...
...
tn tnTm
=
Xt XtT1
......
Xt XtTm
,
con Σz la matriz de las covarianzas de las observaciones, formada por m
cajas diagonales idénticas,
Σz =
Σ
. . .
Σ
,
teniendo cada una de estas cajas Σ la forma,
Σ =
τ2t21 + σ2
. . .
τ2t2n + σ2
,
y por último formando, en este caso, las observaciones zij un vector,
Z = (z11, . . . , zn1, . . . , z1m, . . . , znm)t.

148 6. Estimadores Combinados en Quimiometría
Operando algebraicamente podemos expresar los estimadores de α y β
como, (α
β
)= (Xt
tΣ−1Xt)−1(Xt
TXT )−1XtTZ
tΣ−1Xt,
siendo Z la matriz n×m de las observaciones.
Resultando ser la matriz de covarianzas de los estimadores de los pa-
rámetros de interés,
ΣII(α,β)t
= (XtTXT )−1(Xt
tΣ−1Xt)−1.
6.3.3. Comparación de ambos Métodos.
Ambas estrategias, obtienen estimadores de los parámetros de interés
α y β que es el objetivo nal de los experimentos, pero las matrices de
covarianzas de los mismos poseen estructuras diferentes,
ΣI(α,β)t
= (XtTXT )−1(σ2(Xt
tXt)−1 + τ2),
ΣII(α,β)t
= (XtTXT )−1(Xt
tΣ−1Xt)−1.
Las matrices se diferencian en los factores escalares que las multiplican.
Llamaremos a estos factores KI y KII respectivamente, cuyos valores son,
KI = (σ2(XttXt)−1 + τ2) = τ2 +
σ2∑ni=1 t
2i
,
KII = (XttΣ−1Xt)−1 =
(n∑i=1
t2iτ2t2i + σ2
)−1
.
Para comparar los dos métodos considerados analizaremos la diferencia
entre las matrices de covarianzas de los estimadores. El cociente de ambos
factores KI y KII nos permitirá saber cual de los dos métodos proporciona

6.3. Estimación en dos Pasos frente a la Estimación Combinada 149
estimadores con menor covarianza que es lo deseado,
KI
KII=
(τ2 +
σ2∑ni=1 t
2i
)( n∑i=1
t2iτ2t2i + σ2
)
=n∑i=1
(τ/σ)2t2i + t2i /∑n
i=1 t2i
(τ/σ)2t2i + 1
Si calculamos los límites del cociente KI/KII cuando τ y σ tienden a cero,
lımτ→0
KI
KII= 1, lım
σ→0
KI
KII= n.
Mientras que si calculamos los límites de la expresión cuando τ y σ tienden
a innito,
lımτ→∞
KI
KII= n, lım
σ→∞
KI
KII= 1.
Además ambas constantes son iguales en el caso en el que sólo se tome una
observación en el tiempo, es decir en el caso en que n = 1. Resaltar tam-
bién que el cociente de ambas constantes posee una singularidad cuando
σ = τ = 0, lo que no presenta interés alguno desde el punto de vista esta-
dístico ya que en ausencia de varianzas las medidas a tomar se ajustarían
perfectamente a un único juego de parámetros.
Podemos comprobar además que para valores positivos de las respecti-
vas desviaciones típicas se cumplirá,
KI > KII .
Considerando los límites anteriores bastará con vericar que el cociente
resulta monótonamente decreciente al aumentar σ para valores jos de τ y
que resulta monónotonamente creciente al aumentar τ para valores jos de
σ. Esto se puede comprobar realizando el cambio de variable (τ/σ)2 = x
y considerando que x ∈ (0,∞) corresponde a todas las posibles parejas de
desviaciones típicas (τ, σ).
KI
KII=
n∑i=1
xt2i + t2i /∑n
i=1 t2i
xt2i + 1,

150 6. Estimadores Combinados en Quimiometría
vericándose que el límite cuando x → 0 es 1 mientras que cuando x →∞ es n. El cociente de ambas constantes resulta ser suma de funciones
monónotonas crecientes y mayores que uno para x ∈ (0,∞) y por lo tanto
podemos asegurar que se verica la desigualdad KI > KII .
Este resultado teórico justica las diferencias observadas en las simu-
laciones que llevamos a cabo en la etapa inicial del trabajo. Presentándose
la estructura de covarianzas de los parámetros diferente según el método
utilizado, obteniéndose eso si estimadores correctos en ambos casos.
Como conclusión podríamos decir que el método combinado, sin pre-
sentar diferencias en el desarrollo de la experimentación obtiene unos esti-
madores más precisos que el método en dos pasos. Este resultado contrasta
con la preferencia en el caso real por el método en dos pasos, pudiéndose
observar como la totalidad de los ejemplos citados utilizan este método.
Para el caso simplicado con el que hemos trabajado, el cálculo de diseños
D−óptimos da lugar a diseños concentrados en los extremos de los espacios
del diseño al ser ambos modelos lineales en los factores.
Hemos querido presentar aquí este resultado para llamar la atención
sobre este problema que ha surgido, como algunos otros, en el desarrollo
de los trabajos expuestos en los capítulos anteriores. Quedando abierta la
linea del análisis de los estimadores y el cálculo de los diseños óptimos para
los problemas reales, con modelos no lineales, que podemos encontrar en la
estimación de ecuaciones de velocidad y de los parámetros de la ecuación
de Arrhenius.

Conclusiones
El objetivo principal de este trabajo ha sido proponer diseños óptimos
que permitan una discriminación entre modelos o una estimación más e-
ciente de los parámetros estadísticos que se obtienen. Los modelos con los
que se ha trabajado son la ecuación de Arrhenius y los modelos de adsorción
BET y GAB. Se ha presentado una variedad de diseños óptimos de diferen-
tes características, que se han comparado a través del cálculo de eciencias
con diseños utilizados en casos experimentales. Como resultado se ha obte-
nido una herramienta que permite al experimentador la elección del diseño
más adecuado en términos de eciencia, o lo que es lo mismo, en términos
de ahorro de observaciones. Durante el trabajo se han utilizado los criterios
de D−, c− y T−optimización junto con el cálculo de diseños compuestos y
se han analizado las necesidades reales de los experimentadores buscando
dar respuesta a problemas que aparecen durante los experimentos y que
preocupan a la comunidad cientíca.
Durante el estudio de los procedimientos experimentales que se realizan
para caracterizar procesos cinéticos, apareció la necesidad de llevar a cabo
experimentos de cinética de reacciones en dos pasos. Se ha analizado la
diferencia entre estimadores en dos pasos y estimadores combinados cuan-
do el experimento consta de dos procesos de regresión, estimándose en el
151

152 Conclusiones
primero de ellos la variable dependiente del segundo modelo. El análisis de
un modelo simplicado ha permitido demostrar la menor varianza de los
estimadores combinados frente a los estimadores en dos pasos.
A continuación enumeramos las principales conclusiones del trabajo
para permitir una consideración global del mismo:
a) Respecto a los diseños D−óptimos calculados para la ecuación de
Arrhenius, con dos puntos en su soporte, el extremo superior del espacio del
diseño siempre forma parte del diseño, mientras que el segundo punto puede
ser o bien un punto interior o el extremo inferior. Este diseño no reduce
las dicultades de las observaciones extremas, pero facilita el desarrollo del
experimento, al reducir el número de condiciones experimentales diferentes.
b) Destacar que de los experimentos con N = 6 puntos de soporte,
cuya eciencia ha sido calculada, el de menor eciencia resulta ser el que
ha sido obtenido de un trabajo experimental real (Ray y Watson, 1981). El
de mayor eciencia resulta ser el diseño linear inverso, que depende para
su construcción de las estimaciones iniciales de los parámetros.
c) Los cálculos de los diseños c−óptimos han permitido obtener las e-
ciencias analíticas para diseños genéricos con N puntos en su soporte y
con la misma proporción de observaciones asignadas a cada punto. De los
ejemplos planteados destacar que en muy pocas ocasiones el aumento del
número de puntos del diseño conlleva un aumento en la eciencia. La re-
comendación de un diseño en particular se hace especialmente complicada,
dependiendo del número de puntos y de la estimación inicial del parámetro
B, por ello resulta interesante la obtención de las expresiones analíticas.
d) Se ha observado en la bibliografía, la alta incertidumbre del paráme-
tro B. Los diseños compuestos calculados permiten estimar ambos paráme-
tros jado una eciencia mínima para la estimación de dicho parámetro.
e) Respecto al cálculo de diseños T−óptimos para la discriminación
entre los modelos BET y GAB, dichos diseños han de ser calculados numé-
ricamente jando unas estimaciones iniciales de los parámetros del modelo
GAB. En los ejemplos obtenidos los diseños poseen tres puntos, el extremo

Conclusiones 153
superior, el extremo inferior o un punto muy cercano a él y un punto inter-
medio, para el que se han de realizar más de la mitad de las observaciones.
f) Los diseños D−óptimos calculados para el modelo BET, poseen dos
puntos, incluyendo el extremo superior del espacio del diseño y, o bien un
punto interior o el extremo inferior. Respecto a las eciencias de los 5 dise-
ños experimentales comparados, con N = 6 puntos, sus valores dependen
del espacio del diseño considerado y del valor del parámetro no lineal cB.
Los grácos de la Figura 5.3 permiten la elección del más adecuado para
los dos espacios del diseño considerados y valores de c ∈ [1, 30].
g) Se han obtenido los diseños c−óptimos que permiten estimaciones
individuales de los parámetros del modelo BET. La comparación de las
eciencias de los 5 diseños experimentales propuestos, presenta la particu-
laridad de que los mejores diseños para la estimación del parámetro wmBresultan ser los menos adecuados para la estimación de cB y viceversa.
h) Los diseños tanto D− como c−óptimos para el modelo GAB han
de ser calculados de forma numérica. Destacar que el extremo superior del
espacio del diseño, forma parte de los diseños óptimos salvo para el diseño
cG−óptimo que resulta ser singular para estimaciones iniciales de k = 0.5y valores de cG > 5. De los cálculos de eciencias, cabe destacar el buen
comportamiento del diseño uniforme.
i) Del cálculo de las eciencias de los diseños T−óptimos, cabe des-
tacar la obtención de eciencias más altas cuando son comparados con
los diseños óptimos obtenidos para el modelo GAB, ya que el criterio de
T−optimización empleado considera el modelo GAB como el verdadero.
Para valores iniciales de k cercanos a 1 (recordemos que cuando k = 1 am-
bos modelos son el mismo) el modelo que permite la discriminación, posee
una altísima eciencia para la estimación del parámetro k.
j) La comparación del proceso de estimación en dos pasos, frente a la es-
timación combinada, que se ha tratado en el Capítulo 6, da como resultado
la menor varianza de los estimadores combinados frente a los estimadores
en dos pasos, que tradicionalmente son utilizados en estos métodos.

154 Conclusiones
Discusión de los Resultados
Rodríguez Díaz (2000), en su tesis doctoral, realiza una crítica a la
teoría del Diseño Óptimo de Experimentos. En ella enumera seis inconve-
nientes de la teoría del Diseño que nos pueden permitir realizar un balance
del trabajo desarrollado.
i) En primer lugar se observa que la teoría del Diseño Óptimo requiere la
elección previa del modelo, sin contar con las observaciones, siendo incapaz
por tanto de descubrir la falta de ajuste al modelo planteado. En los casos
prácticos presentados, este problema es menor ya que, tanto el modelo
planteado por Arrhenius como las isotermas de adsorción desarrolladas por
Brunauer-Emmett-Teller y Guggenheim-Anderson-de Boer, se encuentran
fuertemente justicados teóricamente (Capítulos 2 y 4) y se vienen usando
ampliamente en el estudio de los fenómenos ya citados en este trabajo. Por
lo tanto el hecho de elegir con anterioridad el modelo no es, en este caso,
un inconveniente que pueda inuir de forma negativa en las estimaciones
obtenidas de los experimentos. Ahora bien, el criterio de T−optimización
da respuesta a discriminación entre modelos rivales, como hemos visto en
el Capítulo 4, permitiendo elegir el modelo que mejor explique los datos.
El mejor ajuste de los datos experimentales a un modelo, no debe justicar
la obtención de valores de los mismos sin signicado físico, tratando en ese
caso el modelo de forma puramente empírica (Lewicki, 1997).
ii) Para el caso de modelos no lineales se plantea la dicultad de elección
de los valores iniciales. Durante el desarrollo de este trabajo se decidió apli-
car los diseños óptimos obtenidos a casos de Química atmosférica (ecuación
de Arrhenius) y de adsorción de vapor de agua en alimentos (isotermas BET
y GAB). Esta decisión no fue fruto de un capricho ni de una casualidad.
Para el primer caso, la existencia de los informes generados por el Panel
de Expertos, (Jet Propulsion Laboratory, 2000, 2003), permiten disponer
de un amplio repositorio de parámetros contrastados que pueden usarse
como valores iniciales amparados por la reputación de la NASA. Además

Discusión de los Resultados 155
los altos márgenes de los límites de conanza de los parámetros sirven pa-
ra incentivar la búsqueda de diseños que permitan aumentar la eciencia
de los diseños utilizados y reducir así la incertidumbre de los parámetros.
La importancia de disponer de parámetros lo más ajustados posibles en la
modelización de fenómenos como el Efecto Invernadero y la evolución de la
Capa de Ozono, son cuestiones de un amplio interés cientíco, económico y
social, que han sido determinantes a la hora de profundizar en el tema. En
el segundo caso el carácter aplicado de las medidas de adsorción de vapor
de agua en alimentos es muy amplio. La bibliografía relacionada con este
fenómeno es muy elevada existiendo numerosas publicaciones relacionadas
con la Tecnología de los Alimentos, donde se caracterizan los procesos de
adsorción en frutas, verduras, cereales, productos lácteos, etc. Es de sumo
interés conocer estimaciones precisas de la adsorción en alimentos para po-
der llevar a cabo procesos de congelado, desecado, envasado o exportación
pudiéndose garantizar la calidad nal del producto.
iii) A la hora de seleccionar el criterio de optimización, esta elección se
realiza de nuevo sin antes haber observado los datos. Así, un diseño pue-
de ser óptimo para un criterio de interés pero desafortunado desde otro
punto de vista. Para ello, se ha hecho hincapié en el desarrollo de diseños
compuestos, que permiten combinar varios criterios a la hora de plantear
diseños óptimos, permitiendo jar los grados de satisfacción de cada criterio
en el nuevo diseño. Así mismo, se ha intentado relacionar los diseños plan-
teados, calculando la eciencia de los diferentes diseños óptimos respecto
a demás criterios. Hay que resaltar también que la variedad de criterios
puede ser una ventaja para el investigador ya, que le permite elegir la más
conveniente de entre las diversas opciones.
iv) La evolución de la teoría de diseño óptimo en dos corrientes parale-
las e irreconciliables, diseños exactos frente a diseños aproximados. Acerca
de esta división, conviene decir que, en nuestro caso y sobretodo en el caso
particular de la Química atmosférica y de la adsorción de vapor de agua,
de donde proceden los ejemplos utilizados, el tamaño de los diseños es alto,
por lo que es fácilmente aplicable la idea del diseño aproximado y de la

156 Conclusiones
probabilidad discreta, ξ(x) con x ∈ X. Además, la posibilidad de usar el
Teorema de Equivalencia, que no se verica en el caso de diseños exactos,
permite la realización de los cálculos de optimización y proporciona una
herramienta fundamental para comprobar que verdaderamente los diseños
propuestos son los que minimizan los valores de las funciones criterio.
v) Los diseños óptimos, muy frecuentemente obligan a tomar observa-
ciones en condiciones extremas. En el caso de la ecuación de Arrhenius,
los principales problemas de la obtención de buenas estimaciones de los
parámetros provienen de las dicultades experimentales a altas y bajas
temperaturas. Los espacios de diseño planteados en los ejemplos presenta-
dos, se han obtenido de trabajos experimentales reales y en algunos casos,
los puntos del diseño óptimo son más asequibles y menos costosos de obte-
ner que los extremos del espacio de diseño. Además, la concentración de las
observaciones en los puntos de soporte frente a la dispersion tradicional de
éstas, tiene clarísimas e importantes ventajas experimentales para los in-
vestigadores, simplicando las dicultades técnicas, como la estabilización
de la temperatura deseada y los cambios en el instrumental que surgen al
tener que tomar medidas en muchos y diferentes puntos. En el caso de los
fenómenos de adsorción, los razonamientos aplicados para la ecuación de
Arrhenius son igualmente válidos. La repetición de experimentos a presio-
nes dadas se puede llevar a cabo de forma mucho más económica, e incluso
de forma simultánea, usando las mismas condiciones de presión y tempe-
ratura de la cámara donde se lleva a cabo el experimento para replicarlo.
vi) La no invariancia de algunos criterios por cambios de escala, aunque
no se ha abordado en profundidad en este trabajo, quedando para futuros
desarrollos del mismo, sí se ha tenido en cuenta a la hora de plantear diseños
compuestos, en los que se estandariza la función criterio dividiendo cada
sumando por el valor de la función criterio para el diseño óptimo en cada
caso. Así se evita la inuencia que las diferencias entre las magnitudes de
cada parámetro puedan tener en la obtención del diseño óptimo.

Líneas Futuras de Investigación 157
Líneas Futuras de Investigación
Este trabajo ha servido para establecer un primer contacto y sentar las
bases del cálculo de diseños óptimos para diferentes modelos no lineales,
quedando abiertos diferentes caminos por donde es posible continuar.
Puede plantearse el cálculo y el estudio de las eciencias de diseños
óptimos bajo diferentes criterios a los aquí considerados, A−, E−, L−,Φp−optimización (Rodríguez-Díaz, 2000), analizándose las posibles venta-
jas y desventajas de cada criterio entre sí y frente a los diseños ya calculados.
Así mismo, queda abierta la posibilidad de generar código o programas
informáticos especícos, no sólo para calcular los diseños, sino para sugerir
diseños de eciencia máxima para un número de puntos experimentales
jados por el experimentador así como obtener el ajuste de los modelos.
El estudio de sensibilidad, analizando las uctuaciones de los valores de
la eciencia frente a las variaciones en las estimaciones iniciales de los pará-
metros, no ha sido considerado y queda pendiente para futuros desarrollos
del trabajo, así como la consideración de condiciones de heterocedasticidad.
La inclusión de modicaciones en el modelo de Arrhenius, también pue-
de ser considerada. Rodríguez-Díaz y Santos-Martín (2007) ya han consi-
derado el diseño óptimo de experimentos para la modicación propuesta
por Laidler (1984), para rangos de temperaturas muy amplios, que permite
que el factor preexponencial A sea proporcional a la temperatura T ele-
vada a una cierta potencia m, siendo la nueva expresión para el modelo:
k = ATme−B/T . Queda pendiente el cálculo de diseños T−óptimos que
facilite la discriminación entre ambos modelos.
Con relación a los modelos de fenómenos de adsorción se ha mencio-
nado la existencia de isotermas modicadas y de modelos semi-empíricos,
Oswin (1946), Hailwood y Horrobin (1946), Halsey (1948), Chirife y Igle-
sias (1978), Ferro Fontan et al. (1982), para los que cabe la posibilidad de
determinar diseños óptimos.
En otro campo diferente hay destacar la modicación de la ecuación
de Arrhenius en la caracterización de la uencia plástica de materiales

158 Conclusiones
metálicos sometidos a fuerzas de torsión a altas temperaturas. Este com-
portamiento viene caracterizando mediante la ecuación de Garofalo y =Ae−B/T sinh(ασ)n, siendo los parámetros θ = (A,B, α, n) (Garofalo, 1965).La ecuación tiene aplicación directa en la Tecnología de Materiales, y la
realización de experimentos a altas temperaturas, difíciles de alcanzar y
controlar, hacen del cálculo de diseño de experimentos una herramienta
muy interesante.
También queda pendiente la obtención de diseños óptimos para medi-
das en equilibrio, que surgen cuando, en fenómenos de adsorción y debido al
equipo disponible, no es posible controlar la presión del adsorbato, hacién-
dola permanecer constante a lo largo del tiempo. En estos casos el experi-
mento transcurre hasta que la cantidad de adsorbato que se ha depositado
sobre la supercie de adsorbente no varía, midiéndose en ese instante, la
presión del gas en el equilibrio, y la cantidad del mismo que se ha depo-
sitado sobre la supercie. Ambas variables, tanto la dependiente como la
independiente, son en este caso observadas y medidas en el equilibrio.
El estudio de las propiedades de los estimadores combinados frente a
la estimación en dos pasos, para los diferentes modelos no lineales men-
cionados en el Capítulo 6, queda también pendiente. El cálculo de diseños
de experimentos que permitan responder a las necesidades experimentales
en estos casos, se presenta también como una interesante línea futura de
trabajo.

Conclusions
The main purpose of this work has been to obtain optimum designs to
discriminate between competing models or to obtain an ecient estimation
of the unknown parameters. The models used are the Arrhenius equation
and the BET and GAB adsorption models. A variety of optimum designs
with dierent characteristics has been presented, and have been compared
to designs used in real experiments through the obtention of eciency
measures. As a result, a tool helping the experimenter with the election of
the most adequate design in terms of eciency has been obtained, being the
eciency concept equivalent to a reduction of the number of observations.
The optimality criteria that have been used are D−, c− and T−optimality
and real experimental needs have been analyzed to answer real problems
that appear throughout the experiments.
While studying the experimental procedures to characterize kinetic pro-
cesses, the need to perform kinetic experiments in two stages appeared.
Dierences between two stage and pooled estimators have been analyzed.
This appears when the experiment includes two regression steps, estima-
ting in the rst regression the dependent variable of the second model. A
159

160 Conclusions
simplied sample has been analyzed and its results have shown the advan-
tages of the pooled estimation strategy that obtains estimators with lower
variances.
In the following paragraphs, a sequence of conclusion is presented for
the shake of a clearer global view:
a) Regarding D−optimum designs obtained for Arrhenius equation,
supported at two dierent points, the upper limit of the design space al-
ways belongs to the design, while the second point is either an interior
point or the lower extreme. This design does not reduce the diculty of
obtaining observations for extreme points but makes the development of
the experiment easier, by reducing the number of dierent experimental
conditions.
b) From the comparison of the experimental designs with N = 6 sup-
port points, for which the eciency has been obtained, we can state that
the one with the lowest eciency is the obtained from a real experimental
work (Ray y Watson, 1981). The one with highest eciency happened to be
the linear inverse design, which needs initial best guesses of the parameters
for its construction.
c) The c−optimal designs have given way to the obtention of analytical
expressions of the eciencies for generic designs with N support points,
and equally weighted. From the examples obtained it can be pointed out
that in very few occasions, the increase of the number of support points
in a design leads to an eciency increase. It is quite dicult to give a
general recommendation for practitioners. Eciencies depend on the num-
ber of points and on the initial best guess of B. Therefore the analytical
expressions of the eciencies result of a great interest.
d) The high uncertainty of the parameter B is made clear along litera-
ture. Compound designs face the estimation of all parameters with a xed
minimum eciency for the estimation of this parameter.

Conclusions 161
e) The T−optimum designs obtained for the discrimination between
BET and GAB adsorption models, have to be numerically computed, set-
ting initial estimations for the parameters of the GAB model. In the propo-
sed examples the designs are supported at three support points, the upper
bound of the space design, either the lower bound or a very closed point,
and a middle point that retains more than half of the observations.
f) D−optimum designs obtained for the BET model, are supported
at two dierent points, including the upper bound of the design space and
either a interior point or the lower bound. Regarding the eciencies of the 5compared experimental designs , with N = 6 points, their values depend on
the space design and on the initial best guesses on the non linear parameter
cB. Figure 5.3 allows the election of the most convenient design for both
space designs considered and for values of c ∈ [1, 30].
g) c−optimum designs for obtaining individual estimations of the pa-
rameters of the BET model have been computed. The comparison of the
eciencies of the 5 proposed experimental designs concludes that the best
designs to estimate the parameter wmB turns to be the less adequate for
the estimation of cB, and viceversa.
h) Both D− and c−optimum designs for GAB model have been nu-
merically computed. Emphasize that the upper limit of the design space
is present in all the possible designs, except for the cG−óptimum design,
which happens to be singular for the initial best guesses of k = 0.5 and
values of cG > 5. From the eciencies obtained the good performance of
the uniform design should be noticed.
i) Eciencies for the T−optimum designs have been obtained, getting
higher eciencies while comparing to optimum designs obtained for the
GAB model, probably because T−optimality criterion uses GAB model as
the true one. For initial best guesses of parameter k close to 1 (for k = 1both models are equivalent), the discriminating design has a very high
eciency for estimating parameter k.

162 Conclusions
j) Comparison of the two stages estimation versus pooled estimation,
analyzed in Chapter 6, gives as result the obtention of estimators with
lower variance for the pooled estimation strategy, against the two stages
estimators that are traditionally used in these methods.
Results Discussion
Rodríguez Díaz (2000), in his PhD report, carries out possible criticisms
to Optimum Experimental Designs. His six dierent mentioned drawbacks
can help us to perform a critical analysis of our work.
i) Optimum Design theory is blamed to be strongly model dependent.
The model has to be chosen even before considering the observations, there-
fore it may be imposible to detect the lack of t in the model. In the practical
samples here presented this initial model assumption is a minor problem.
The models proposed by Arrhenius as well as the adsorption isotherms de-
veloped by Brunauer-Emmett-Teller and Guggenheim-Anderson-de Boer
are strongly theoretically justied (Chapters 2 and 4) and are widely used
in the modeling of the phenomena mentioned along our work. Therefore,
the prior election of the model is not an strong inconvenience in our deve-
lopments as it does not to produce wrong estimations of the parameters.
However, T−optimality criteria helps to answer the discrimination problem
between rival models, as those seen in Chapter 4, allowing the election of
the model that would best explain the behaviour of the phenomena. It
must be pointed out that the best possible t will never justify the obten-
tion of parameters with values unwanted by the physics behind the model,
considering in these cases the model as an empirical one (Lewicki, 1997).
ii) For the case of non linear models, the election of prior estimations of
the unknown parameters turns out to be also a problem. In the development
of our work the application of optimum designs to atmospheric processes
(Arrhenius equation) and to moisture adsorption on food stu (BET and
GAB isotherms) was considered. For the rst case, the existence of a co-
llection of reports from the Panel of Experts, (Jet Propulsion Laboratory,

Results Discussion 163
2000, 2003), facilitates the use of a wide estimations repository with the
reputation provided by NASA. It was also interesting to obtain optimum
designs because the high uncertainty of the published parameters. It could
be reduced by the use of optimum experiments that would lead to increase
the eciency of the experiments, and therefore to reduce their uncertainty.
Correct estimations of the parameters are crucial for the correct modeling
of phenomena such as the Greenhouse Eect and the depletion of the Ozo-
ne Layer. These are topics of great interest from the scientic, social and
economic point of view. For the second case, the applied character of the
measurements for the characterization of moisture adsorption on food stu
is of great interest. There are several bibliographic references related to
Food Technology where the characterization of the adsorption processes on
fruits, vegetables, grain, dairy products, etc. are carried out. It is of the
highest interest to know precise estimations of the parameters to proceed
with freezing, drying, storing or exporting in the best conditions and to
assure the nal quality of the products.
iii) In order to select the optimization criterion, the election is made
once again without prior knowledge of the observations. Therefore, a design
can be optimum for a certain criterion but unfortunate from other points of
view. Compound designs have been considered to combine several criteria
while obtaining optimum designs, allowing the establishment of levels for
each considered criterion in a new design. On the other hand, the optimum
designs obtained have been compared through the eciency of each design
with respect to other criteria. It should be pointed out that the wide variety
of optimization criteria is an advantage for the researcher, because it allows
the election of the most adequate option for each circumstance.
iv) Optimum experimental designs have evolved in two parallel lines,
exact versus approximate designs. In our samples, especially in atmosp-
heric Chemistry and in moisture adsorption phenomena, the number of
observations of each experiment is higher enough as to apply the idea of
approximate designs and the concept of discrete measure, ξ(x) with x ∈ X.
Besides, the possibility of applying the Equivalence theorem, which is not

164 Conclusions
veried for exact designs, provides a fundamental tool to obtain and check
the optimality of a design, and so minimizing the value of the criterion
function.
v) Diculties appear due to extreme observations, frequently requested
by optimum designs. This is not new. For the Arrhenius equation the pro-
blems of obtaining accurate estimations of the parameters are related to
the diculties of taking observations at extreme temperatures. The design
spaces have been obtained from the examples used, which correspond to
real experimental works. In some cases the support points of the optimal
designs are more aordable and less costly to obtain than the extremes
of the design space. The observations gathered at the support point ver-
sus the traditional spacing, have very important experimental advantages
for the researchers, simplifying some technical diculties, such as tempe-
rature stabilization and the changes in the equipment that appear, when
dierent observations have to be carried out at dierent support points.
These reasons also apply to the adsorption phenomena. The replication of
an experiment at a given pressure is much more economic, being possible
to carry out several experiments under the same conditions of pressure and
temperature at the same time.
vi) The no invariance of some criteria with respect to scale changes.
Although it has not been deeply considered in this work, it has been ta-
ken partially into account when obtaining the compound designs. In these
designs the criterion function is standardized by its value for the opti-
mum design in each case. Future developments of this work remain open to
coming studies. Thus, the inuence of the dierences between parameter
quantities can be avoided during the obtention of the optimum design.
Issues for Further Research
This work has established a rst contact with, and set the foundations
for, the obtention of optimum designs for dierent non linear models, lea-
ving dierent open topics for further research.

Issues for Further Research 165
The obtention and study of dierent optimum designs under dierent
criteria (A−, E−, L−, Φp−optimality, Rodríguez-Díaz, 2000), from the he-
reby used, can be approached analyzing the advantages and disadvantages
of each of them in terms of eciency.
The option to develop specic code or computer programs, not only
to obtain optimum designs, but also to suggest maximum ecient designs
with a xed number of support points, as required by the required by the
researcher, as well as to t the model and to obtain parameter estimators,
can be committed.
The study of sensibility, analyzing the variations of the eciency versus
the initial best guesses of the parameters, has not been considered and
remains as an open issue for future research developments. Neither the
heteroscedastic assumptions have been included.
The inclusion of possible changes in the Arrhenius model, could also be
considered. Rodríguez-Díaz and Santos-Martín 2007, have already conside-
red the variation proposed by Laidler (1984), adequate for wide tempera-
ture ranges. It allows that the preexponential factor A be proportional to
temperature Tm, so the new expression is k = ATme−B/T . The obtention
of T−optimum designs to discriminate between both models is still open.
Regarding the adsorption models, the existence of modied isotherms
and semi-empirical models, Oswin (1946), Hailwood and Horrobin (1946),
Halsey (1948), Chirife and Iglesias (1978),Ferro Fontan et al. (1982), has
already been mentioned, and there are still possibilities to determine opti-
mum designs for them.
In a dierent eld, the correction of Arrhenius equation for characte-
rizing plastic uency of metallic materials, subjected to torsion tensions
at high temperatures, may be an issue for future studies. The behaviour
is characterized by the Garofalo equation y = Ae−B/T sinh(ασ)n, beingthe unknown parameters θ = (A,B, α, n) (Garofalo, 1965). The equation
has a direct application in Material Technology, and the experiments at

166 Conclusions
high temperatures, hard to reach and to control, make the obtention of
experimental designs an interesting and useful aim.
It is also open for study the obtention of optimum experimental designs
for measurement taken at equilibrium. This is found in adsorption pheno-
mena, that due to the technical equipment, make uncontrollable the adsor-
bate pressure. In these cases, the experiment proceeds until the amount of
adsorbate laid on the surface of the adsorbent does not change with time.
The pressure of the gas at equilibrium, and the amount of it laid on the
surface, are then measured. Both variables are then observed and measured
at the equilibrium.
The study of the properties of pooled estimators versus the two stage
estimations, for dierent non linear models mentioned in Chapter 6, is
also an open issue. The obtention of optimum experimental designs that
may give answer to experimental needs in those cases, also appears as an
interesting and prospective further research.

Apéndice A
Distribución de
Boltzmann
En la década de 1860, Clausius1 propuso una denición de Entropía,
S, como función termodinámica que en sistemas aislados solamente puede
aumentar, siendo el valor máximo el que caracteriza el estado de equilibrio.
En la década siguiente, Ludwig Boltzmann indagó acerca del signicado
de esta función misteriosa. En aquellos momentos, hablar en términos mo-
leculares era algo más que una proeza, puesto que entidades tales como
átomos, moléculas, etc. eran considerados como meras cciones intelectua-
les, hipótesis más o menos plausibles todavía sin pruebas experimentales.
Algunas ideas de la mecánica son aplicables tanto a moléculas y áto-
mos individuales como a sistemas de muchas partículas. Este es el caso
de conceptos como el de masa, velocidad, energía, por ejemplo. En cam-
bio, conceptos como temperatura, entropía, no son asociables más que a
grandes colectivos de partículas.
Como ejemplo simple para ilustrar estos hechos consideraremos lo que
ocurre en la expansión de un gas que pasa de ocupar un pequeño volumen
1Rudolf Clausius (1822-1888), Físico alemán.
167

168 A. Distribución de Boltzmann
a llenar totalmente el volumen de un recipiente mayor. El sistema evo-
luciona hacia una distribución homogénea en la que las partículas ocupan
todo el volumen, es decir, evoluciona desde un estado poco probable -la acu-
mulación de partículas en un volumen relativamente pequeño- hacia una
conguración más probable -todas las moléculas repartidas en el volumen
total de modo homogéneo, uniforme-. Parece de esta forma que puede aso-
ciarse el concepto de evolución hacia el equilibrio (entropía) con el concepto
de probabilidad. Los distintos estados que ha adoptado un sistema desde
un estado de no equilibrio hasta alcanzar el equilibrio son cada vez más
probables. El sistema evoluciona de modo que la probabilidad de su estado
no puede más que crecer, tal como ocurre con la entropía.
Para tratar de relacionar la probabilidad con la entropía, introduci-
mos el concepto de microestados -conguraciones moleculares posibles- en
contraposición de macroestados -estados macroscópicos reales del sistema-
La idea intuitiva de probabilidad nos conduce a la regla de Laplace del
cociente de los casos favorables respecto de los casos totales. La probabili-
dad es, así, proporcional al número de posibles microestados, W .
La probabilidad es una función multiplicativa, es decir, que si un siste-
ma se puede encontrar en W1 microestados posibles y otro puede hallarse
en W2 microestados posibles, el sistema resultante de la unión de ambos
podrá encontrarse en W1 ·W2 microestados posibles. Sin embargo, la en-
tropía, como función termodinámica, está denida como aditiva. La forma
más simple de relacionar ambas es a través de la función logarítmica. Bol-
tzmann, concretamente propuso la relación siguiente:
S = k logW,
donde k es una constante que permite generalizar la relación y que deno-
minaremos constante de Boltzmann. Su signicación habrá que buscarla en
consideraciones físicas.
Esta relación es la clave de la conexión entre el mundo microscópico y
el macroscópico y constituye la base de la Mecánica Estadística.

A. Distribución de Boltzmann 169
Para la determinación del número de microestados, la idea fundamen-
tal es que, en un sistema aislado, todos los microestados son igualmente
probables. Esta es la hipótesis más simple que puede formularse para cuya
aclaración se propone un ejemplo sencillo.
Supongamos un sistema con cuatro partículas subdividido en dos partes
por una pared dotada de un oricio a través del cual pueden pasar estas
partículas. Consideramos como un macroestado el número de moléculas en
cada lado de la pared, de modo que un macroestado vendrá caracterizado
por dos números, nA y nB, correspondientes al número de moléculas en la
división A y en la división B, respectivamente. De esta forma se comprueba
que puede haber cinco posibles macroestados:
nA nB
0 41 32 23 14 0
Tomando como microestados las posibles distribuciones de las partí-
culas concretas, compatibles con las condiciones de cada macroestado, los
microestados serán aquellas disposiciones que especiquen con detalle qué
moléculas se hallan en cada subsistema, en lugar de limitarse a decir cuán-
tas hay en cada uno de ellos. Naturalmente, la especicación de cuántas
(macroestado) es mucho menos detallada que la especicación de cuáles
(microestados). En la tabla siguiente se presentan de modo explícito los
microestados y el número de ellos, W , compatibles con cada macroestado:
Con este ejemplo se muestra, también de modo explícito el principio
de evolución del sistema del estado menos probable (0, 4) al más probable
(2, 2). En la práctica, efectivamente, si un gas se encuentra en un recipiente
de pequeño volumen y éste se destapa , el gas se expande espontáneamente
hasta ocupar homogéneamente todo el volumen que le es accesible.

170 A. Distribución de Boltzmann
Macrtoestados Microestados
nA nB Partículas en A y en B W
0 4 ∅ | 1, 2, 3, 4 11 3 1 | 2, 3, 4 2 | 1, 3, 4 3 | 1, 2, 4 4 | 1, 2, 3 42 2 1, 2 | 3, 4 1, 3 | 2, 4 1, 4 | 2, 3 2, 3 | 1, 4 2, 4 | 1, 3 3, 4 | 1, 2 63 1 1, 2, 3 | 4 1, 2, 4 | 3 2, 3, 4 | 1 1, 3, 4 | 2 44 0 1, 2, 3, 4 | ∅ 1
Si en lugar de cuatro moléculas o partículas se tiene un número n,
de modo que la distribución es de nA y de nB = n − nA, el número de
microestados posibles para un determinado macroestado puede determi-
narse fácilmente, según la combinatoria elemental, mediante la expresión
siguiente:
W =(nA + nB)!nA! nB!
En la práctica, la mayor parte de los sistemas naturales no son sistemas
aislados, sino que se habla de sistemas en los que el parámetro constante
es la temperatura. En este caso los microestados correspondientes a un
macroestado ya no son igualmente probables sino que su probabilidad de-
pende tanto de la energía como de la temperatura. Aquí la distribución
de probabilidades es de gran interés práctico y se conoce como función de
distribución canónica.
Para pasar de la situación anterior -sistema aislado con microestados
de la misma probabilidad- al caso presente, se supondrá que el sistema se
encuentra en contacto con una fuente térmica exterior que hace las veces
de termostato manteniendo constante su temperatura. Además, se consi-
derará que el conjunto de nuestro sistema y la fuente térmica constituyen
un sistema aislado del exterior.
Si consideramos el conjunto aislado de nuestro sistema más la fuente
térmica, cada microestado de este conjunto será la combinación de un mi-
croestado del sistema y de un microestado de la fuente térmica, de modo
que el número total de microestados del conjunto, W , será el producto del
número de microestados del sistema, W1, y del número de microestados de

A. Distribución de Boltzmann 171
la fuente térmica, W2:
W = W1 ·W2
Todos estos microestados compuestos tienen la misma probabilidad ya que
corresponden a un sistema aislado. Nuestro problema estriba, sin embargo,
en conocer la probabilidad de cada microestado concreto del sistema 1,nuestro sistema. La respuesta a esta cuestión es simple: un microestado
del sistema 1 será tanto más probable cuanto mayor sea el número de
microestados del sistema 2 fuente térmica con los que pueda combinarse
para formar microestados del conjunto aislado, 1 + 2.
Supóngase que un micro estado del sistema 1 tenga una energía E mien-
tras que el sistema conjunto 1+2 tenga la energía Etot. Los microestados de
2 combinables con el microestado de 1 para dar microestados del conjunto
con energía Etot serán aquellos microestados de 2 con energía Etot − E.
Para conocer cuánto vale el número de estos microestados, W2, se recurrirá
a la relación de Boltzmann según la cual S2 = k logW2, o bien:
W2(Etot − E) = exp[S2
k
]Sin embargo, dado que Etot E, puesto que la fuente térmica es mucho
mayor que el sistema 1, se puede escribir el siguiente desarrollo en serie:
S2(Etot − E) = S2(Etot)−(∂S2
∂E
)E +
12
(∂2S2
∂2E
)E2 − . . .
Mediante consideraciones termodinámicas simples, que evitamos abordar
por motivos de espacio, puede demostrarse que:(∂S2
∂E
)=
1T(
∂2S2
∂2E
)=
1C2T 2
donde T es la temperatura del sistema y de la fuente térmica, y C2 es la ca-
pacidad caloríca de la fuente. Como la fuente puede tomarse muy grande
en comparación a la del sistema, este término se hace prácticamente des-
preciable (ya que C2T2 tomaría valores comparativamente muy elevados).

172 A. Distribución de Boltzmann
En consecuencia, el desarrollo puede truncarse del modo siguiente:
S2(Etot − E) ' S2(Etot)−E
T
siendo S2(Etot) una constante que no depende de E.
De esta forma, el número de microestados W2 toma el siguiente valor:
W2(Etot − E) = exp[S2(Etot)
k
]· exp
[− E
kT
]y puesto que el primer término exponencial es constante y la probabilidad
del microestado es proporcional aW2(Etot−E) puede nalmente escribirse
que la probabilidad es:
Pr(E) ∝ exp[− E
kT
]expresión que se conoce como distribución de Boltzmann y que es la base de
la interpretación estadística de numerosos fenómenos sicoquímicos sobre
bases moleculares.
A.1. Aplicación a la Deducción de la Distribución de
Maxwell de las Velocidades de las Moléculas de un
Gas
Un ejemplo sencillo de la aplicación de la distribución de Boltzmann lo
constituye la deducción de la distribución de las velocidades de las molé-
culas de un gas ideal monoatómico.
En este caso, la energía que corresponde a una molécula de masa m,
con velocidad v, es simplemente su energía cinética, es decir:
E =12mv2.
Según lo deducido anteriormente, la probabilidad de que una molécula ten-
ga velocidad v es:
Pr(v) ∝ exp[−mv
2
2kT
],

A.1. Aplicación a la distribución de Maxwell 173
por otra parte, el número de microestados con velocidad | v | es:
g(v) = 4πv2dv,
puesto que éste representa el volumen de la capa esférica de radio v y
espesor dv en donde pueden encontrarse los vectores v con módulos com-
prendidos entre | v | y | v + dv |. Así, se tiene que la probabilidad de que
la componente vx, por ejemplo, se encuentre entre | vx | y | vx + dvx | es:
Pr(vx)dvx =( m
2πkT
)1/2exp
[−mv
2x
2kT
]dvx
donde (m/2πkT )1/2 representa un factor de normalización de tal forma que∫ +∞
−∞Pr(vx)dvx = 1.
Esta función de distribución toma la forma de una campana de Gauss.
Por otra parte, la función de distribución del módulo de la velocidad
| v |, denido como | v2 |= v2x + v2
y + v2z viene dada por la expresión:
Pr(v)dv = f(T, v)dv =( m
2πkT
)3/24πv2 exp
[−mv
2
2kT
]dv.
Que representa la denominada distribución de Maxwell-Boltzmann.


Bibliografía
K. M. Abdelbasit y R. L. Plackett. Experimental design for binary data.
J. Amer. Statist. Assoc., 78(381):9098, 1983.
A. W. Adamson y A. P. Gast. Physical Chemistry of Surfaces. Wiley, New
York, 1997.
A. H. Al-Muhtaseb, W. A. M. McMinn, y T. R. A. Magee. Water sor-
ption isotherm of starch powders. Part 1: Mathematical description of
experimental data. J. Food Eng., 61:297307, 2004.
R. B. Anderson. Modications on the Brunnauer, Emmet and Teller equa-
tion. J. Am. Chem. Soc., 68:686691, 1946.
R. Ardanuy, J. López-Fidalgo, P. J. Laycock, y W. K. Wong. When is
an equally-weighted design D-optimal? Ann. Inst. Statist. Math., 51(3):
531540, 1999.
S. Arrhenius. Ober die reacktionsgeschwindigkeit bei der inversion von
rohrzucker durch saüren. Z. Physik. Chem., 4:226248, 1889.
N. Arslan y H. Togrul. Modelling of water sorption isotherms of macaro-
ni stored in a chamber under controlled humidity and thermodynamic
approach. J. Food Eng., 69:133145, 2005.
175

176 Bibliografía
A. Ash y A. Hedayat. An introduction to design optimality with an over-
view of the literature. Comm. Statist. ATheory Methods, 7(14):1295
1325, 1978.
A. C. Atkinson. Developments in the design of experiments. Internat.
Statist. Rev., 50:161177, 1982.
A. C. Atkinson. New developments and applications in experimental design,
volume 34 of IMS Lecture Notes - Monograph Series, capítulo Optimum
experimental designs for chemical kinetics and clinical trials, páginas
3649. 1998.
A. C. Atkinson y B. Bogacka. Compound, D- and Da-optimum designs for
determining the order of a chemical reaction. Technometrics, 39:347356,
1997.
A. C. Atkinson y A. Donev. Optimum Experimental Designs. Oxford
University Press, New York, 1992.
A. C. Atkinson y V. V. Fedorov. The design of experiments for discrimi-
nating between two rival models. Biometrika, 62:5770, 1975a.
A. C. Atkinson y V. V. Fedorov. Optimal design: Experiments for discri-
minating between several models. Biometrika, 62:289303, 1975b.
A. C. Atkinson y W. G. Hunter. The design of experiments for parameter
estimation. Technometrics, 10(2):271289, 1968.
A. C. Atkinson, B. Bogacka, y M. B. Bogacki. D− and T−optimum designs
for the kinetics of a reversible chemical reaction. Chemom. Intell. Lab.
Syst., 43:185198, 1998.
A. C. Atkinson, A. Donev, y R. Tobias. Optimum Experimental Designs,
with SAS. Oxford University Press, 2007.
D. Avnir, editor. The Fractal Approach to Heterogeneous Chemistry. Wiley,
New York, 1989.
J. Avom, J. Ketcha Mabdcam, M. R. L. Matip, y P. Germain. Adsorption
isotherme del lácide acétique par des charbons dórigine vegétale. Afr. J.
Sci. Techol., 2:17, 2001.

Bibliografía 177
A. Belarbi, Ch. Aymard, J. M. Meot, A. Themelin, y M. Reynes. Water
desorption isotherms for eleven varieties of dates. J. Food Eng., 43:103
107, 2000.
M. P. F. Berger y W.-K. Wong, editores. Applied Optimal Designs. Wiley,
2005.
G. J. Borjas. On regressing regresion coecients. JSPI, 7:131137, 1982.
G. E. P. Box y W. G. Hunter. Sequential design of experiments for non-
linear models, IBM Scientic Computing Synposium in Statistics, pági-
nas 111137. 1965.
G. E. P. Box y H. L. Lucas. Design of experiments in non-linear situations.
Biometrika, 46:7790, 1959.
M. J. Box. The use of designed experiments in non linear model building,
The future of Statistics, páginas 241268. 1968a.
M. J. Box. The ocurrence of replications in optimal designs of experiments
to estimate parameters in nonlinear models. J. Roy. Statist. Soc. Ser.
B, 30:290302, 1968b.
M. J. Box. The design of experiments and non linear model-building under
a variety of error structures. PhD thesis, University of London, 1969.
M. J. Box. Some experiences with a nonlinear experimental design criterion.
Technometrics, 12:569589, 1970.
L. D. Brown, I. Olkin, J. Sacks, y H. P. Wynn. Jack Carl Kiefer Collected
papers III. Springer Verlag, New York, 1985.
S. Brunauer, P. H. Emmett, y E. Teller. Adsorption of gases in multimole-
cular layers. J. Am. Chem. Soc., 60:309319, 1938.
S. Brunauer, L. S. Deming, W. E. Deming, y E. Teller. On a theory of the
van der Waals adsorption of gases. J. Am. Chem. Soc., 62:17231732,
1940.
M. Caurie. The derivation of the GAB adsorption equation from the BDDT
adsorption theory. Int. J. Food Sci. Technol., 41:173179, 2006.

178 Bibliografía
E. Cepeda, R. Ortíz de Latierro, M. J. San José, y M. Olazar. Water
sorption isotherms of roasted coee and coee roasted with sugar. Int.
J. Food Sci. Technol., 34, 1999.
H. Cherno. Locally optimal designs for estimating parameters. Ann.
Math. Stat., 24:586602, 1953.
H. Cherno. Sequential Analysis and Optimal Design. PA:SIAM. CBMS-
NSF, Philadelphia, 1972.
J. Chirife y H. A. Iglesias. Equations for tting water sorption isotherms
of foods: Part 1 A review. J. Food Technol., 13:159174, 1978.
M.-S. Chou y K.-L. Chang. UV/ozone degradation of gaseous hexamethyl-
disilazane (HMDS). Chemosphere, 69:697704, 2007.
R. D. Cook y W. K. Wong. On the equivalence of constrained and com-
pound optimal designs. J. Amer. Statist. Assoc., 89:687692, 1994.
D. J. Currie. Estimating Michaelis-Menten parameters: bias, variance and
experimental design. Biometrics, 38:8292, 1982.
J. H. de Boer. The dynamic character of adsorption. Oxford: Clarendon
Press, 1953.
J. de Guzmán. Relación entre la uidez y el calor de fusión. Anales de la
Sociedad Española de Física y Qímica, 11:353362, 1913.
H. Dette y W. K. Wong. Optimal desings when the variance is a function
of its mean. Biometrics, 55:925929, 1999.
H. Dette, V. B. Melas, y A. Pepelyshev. Standarized maximin E−optimal
designs for the Michaelis-Menten model. Statist. Sinica, 13(4):11471163,
2003.
N. R. Draper y W. G. Hunter. The use of prior information in the design
of experiments for parameter estimation in non-linear situation: Multi-
response case. Biometrika, 54:662665, 1967.
S. Ehrenfeld. On the eciency of the experimental designs. Ann. Math.
Stat., 26:247255, 1955.

Bibliografía 179
G. Elfving. Optimum allocation in linear regression theory. Ann. Math.
Stat., 23:255262, 1952.
L. Endrenyi. Design of Experiments for Estimating Enzyme and Pharma-
cokinetic Parameters. Plenum Press, 1981.
M. G. Evans y M. Polanyi. Application of the transition-state method
to the calculation of reactions velocities, especially in solution. Trans.
Faraday Soc., 31:875894, 1935.
H. Eyring. Activated complex in chemical reactions. J. Chem. Phys., 3:
107115, 1935.
H. Eyring, S. H. Lin, y S. M. Lin. Basic Chemical Kinetics. J. Wiley, New
York, 1980.
V. V. Fedorov. Theory of optimal experiments. Technical report, Depar-
tament of Statistics, Purdue University, 1972.
V. V. Fedorov y P. Hackl. Model-Oriented Design of Experiments. Lecture
Notes in Statistics. Spinger, New York, 1997.
C. Ferro Fontan, J. Chirife, E. Sancho, y H. A. Iglesias. Analysis of a model
for water sorption phenomena in foods. J. Food Sci., 47:15901594, 1982.
I. Ford, D. M. Tittterington, y C. P. Kitsos. Recent advances in nonlinear
experimental design. Technometrics, 31(1):4960, 1989.
K. Frischmuth. On locally D-optimal experimental design. Rostock. Math.
Kolloq., 36:5164, 1989.
Z. Galil y J. Kiefer. Time -and space- saving computer methods, related
to Mitchell's DETMAX, for nding D-optimum designs. Technometrics,
22(3):301313, 1980.
F. Garofalo. Fundamentals of Creep and Creep Rupture in Metals. McMi-
llan, 1965.
S. Glasstone, K. J. Laidler, y H. Eyring. The Theory of Rate Processes.
McGraw-Hill, New York, 1941.
S. J. Gregg y K. S. W. Sing. Adsorption, surface area and porosity. Aca-
demic Press, London, 1982.

180 Bibliografía
E. A. Guggenheim. Application of statistical mechanics. Oxford: Clarendon
Press, 1966.
A. J. Hailwood y S. Horrobin. Absorption of water by polymers: Analysis
in terms of a simple model. J. Chem. Soc., Faraday Trans. B, 42:8489,
1946.
G. Halsey. Pysical adsorption of non-uniform surfaces. J. Chem. Phys., 16:
931937, 1948.
R. H. Hardin y N. J. A. Sloane. Operating manual for GOSSET: A general-
purpose program for constructing experimental designs. Technical re-
port, Mathematical Sciences Research Center, AT&T Bell Laboratories,
Murray Hill, New Jersey, 1994.
D. H. Hill. D-optimal designs for partially nonlinear regression models.
Technometrics, 22(2):275276, 1980.
D. M. Hirst. A Computational Approach to Chemistry. Blackwell Sci. Pub.,
Oxford, 1990.
P. G. Hoel. Eciency problems in polynomial estimation. Ann. Math.
Stat., 29:307316, 1958.
R. B. Holmes. Geometric Functional Analysis and its Applications. Sprin-
ger, New york, 1975.
J. E. House. Principies of Chemical Kinetics. Elsevier, 2007.
Y. C. Huang y W. K. Wong. Sequential construction of multiple-objective
designs. Biometrics, 54:188197, 1998a.
Y. C. Huang y W. K. Wong. Multiple-objective designs for biomedical
studies. J. Biopharm. Stat., 8:635643, 1998b.
L. Imhof y W. K. Wong. A graphical method for nding maximin designs.
Biometrics, 56:113117, 2000.
M. Imhof, J. López-Fidalgo, y W. K. Wong. Eciences of optimal aproxi-
mate designs for small samples. Statist. Neerlandica, 55:301315, 2001.
IUPAC, Commission on Colloid and Surface Chemistry of the International
Union of Pure and Applied Chemistry. Reporting physisorption data for

Bibliografía 181
gas/solid systems - with special references to the determination of surface
area and porosity. Pure Appl. Chem., 57:603619, 1985.
Jet Propulsion Laboratory. Chemical kinetics and photochemical data for
use in stratospheric modelling, suplement to evaluation 12: Update of key
reactions. Technical Report Evaluation Number 13, California Institute
of Technology, NASA, Pasadena, California, March 2000.
Jet Propulsion Laboratory. Chemical kinetics and photochemical data for
use in atmospheric studies. Technical Report Evaluation Number 14, Ca-
lifornia Institute of Technology, NASA, Pasadena, California, February
2003.
R. C. St. John y N. R. Draper. D-optimality for regression design: A review.
Technometrics, 17(1):1523, 1975.
K. Jouppila y Y. H. Roos. Water soprtion isotherms of freeze-dried milk
products: applicability of linear and non-linear regression analysis in mo-
delling. Int. J. Food Sci. Technol., 32:459471, 1997.
P. Karakaya, M. Sidhoum, C. Christodoulatos, S. Nicolich, y W. Balas.
Aqueous solubility and alkaline hydrolysis of the novel high explosive
hexanitrohexaazaisowurtzitane (CL-20). J. Hazard. Mater., B120:183
191, 2005.
S. Karlin y W. Studden. Optimal experimental designs. Ann. Math. Stat.,
37:783810, 1966.
A. I. Khuri y J. Lee. A graphical approach for evaluating and comparing
designs for nonlinear models. Comput. Statist. Data Anal., 27(4):433
443, 1998.
J. Kiefer. General equivalence theory for optimum designs (Aproximate
theory). Ann. Statist., 2(5):848879, 1974.
J. Kiefer y J. Wolfowitz. Optimum design in regresion problems. Ann.
Math. Stat., 30:271294, 1959.
J. Kiefer y J. Wolfowitz. The equivalence of two extremum problems.
Canad. J. Math., 12:363366, 1960.

182 Bibliografía
R. Kli£ka y L. Kubá£ek. Statistical properties of linearization of the
Arrhenius equation via the logarithmic transformation. Chemom. In-
tell. Lab. Syst., 39:6975, 1997.
K. J. Laidler. Theories of Chemical Reaction Rates. McGraw-Hill Book
Co, New York, 1969.
K. J. Laidler. The development of the Arrhenius equation. J. Chem. Ed.,
61(6):494498, 1984.
I. Langmuir. The adsorption of gases on plane surfaces of glass, mica and
platinum. J. Am. Chem. Soc., 40(9):13611403, 1918.
K. Levenberg. A method for the solution of certain problems in least
squares. Quart. Appl. Math., 2:164168, 1944.
P. P. Lewicki. The applicability of the GAB model to food water sorption
isotherms. Int. J. Food Sci. Technol., 32:553557, 1997.
W. C. McC. Lewis. Studies in catalysts. IX. The calculation in absolu-
te measure of velocity constants and equilibrium constants in gaseous
systems. J. Chem. Soc., Abstracts, 113:471492, 1918.
S. R. Logan. The origin and status of the Arrhenius equation. J. Chem.
Ed., 59(4):279281, 1982.
J. López-Fidalgo y W. K. Wong. Design for the Michaelis-Menten model.
J. Theoret. Biol., 215:111, 2002.
J. López-Fidalgo y J. M. Rodríguez-Díaz. Elfving's method for m-
dimensional models. Metrika, 59(3), 2004.
J. López-Fidalgo, J. M. Rodríguez-Díaz, y B. Torsney, editores. mODa8-
Advances in Model-Oriented Design and Analysis. Springer, 2007a.
J. López-Fidalgo, C. Trandar, y Ch. Tommasi. An optimal experimental
design criterion for discriminating between non-normal models. J. Roy.
Statist. Soc. Ser. B, 69(2):112, 2007b.
D. Marquardt. An algorithm for least-squares estimation of nonlinear pa-
rameters. SIAM J. Appl. Math., 11:431441, 1963.

Bibliografía 183
J. F. Mata-Segreda. Hydroxide as general base in the saponication of
ethyl acetate. J. Am. Chem. Soc., 124:22592262, 2002.
V. B. Melas. Functional Approach to Optimal Experimental Design. Lecture
Notes in Statistics. Springer, 2005.
T. J. Mitchell. An algorithm for the construction of D-optimal experimental
designs. Technometrics, 16(2):203210, 1974.
P. C. Moonen, J. N. Cape, R. L. Storeton-West, y R. McColm. Measure-
ment of the NO+O3 reaction rate at atmospheric pressure using realistic
mixing ratios. J. Atmos. Chem., 29:299314, 1998.
J. W. Moore y R. G. Pearson. Kinetics and Mechanism. A study of homo-
geneous Chemical reactions. Wiley, 1981.
G. Moraga, N. Martínez Navarrete, y A. Chiralt. Water sorption isotherms
and phase transitions in kiwifruit. J. Food Eng., 72:147156, 2006.
A. K. Nigam, S. C. Gupta, y S. Gupta. A new algorithm for extreme vertices
designs for linear mixture models. Technometrics, 25(4):367371, 1983.
C. R. Oswin. The kinetics of package life. III. The isotherm. Chem. Ind.
(London), 65:419423, 1946.
A. Pázman. Singular experimental designs (Standard and Hilbert-space
approaches). Math. Operationsforsch. Statist. Ser. Statist., 11(1):137
149, 1980.
A. Pázman. Foundations of Optimum Experimental Design. D. Reidel
publishing company, Dordrecht, 1986.
P. Perso y J. F. Thomas. Estimating Michaelis-Menten or Langmuir isot-
herm constants by weighted nonlinear least squares. Soil Sci. Soc. Am.
J., 52:886889, 1988.
G. Pickett. Modication of the Brunauer-Emmet-Teller theory of multi-
molecular adsorption. J. Am. Chem. Soc., 67:19581962, 1945.
G. Pistone, E. Riccomagno, y H. P. Wynn. Algebraic Statistics: Compu-
tational Commutative Algebra in Statistics. Chapman & Hall, 2000.

184 Bibliografía
F. Pukelsheim. Optimal Design of Experiments. John Wiley and Sons, New
York, 1993.
D. Rasch y P. Darius. Computer Aided Design of Experiments. Compu-
tational Statistics. Physica-Verlag, Heidelberg, 1995.
G. W. Ray y R. T. Watson. Kinetics of the reaction NO+O3 → NO2 +O2
from 212 to 422. J. Phys. Chem., 85:16731676, 1981.
L. J. Rodríguez-Aragón y J. López-Fidalgo. Optimal designs for the
Arrhenius model. En 5th Congress of Romanian Mathematicians, pá-
ginas 7576, 2003.
L. J. Rodríguez-Aragón y J. López-Fidalgo. Optimal designs for the
Arrhenius equation. Chemom. Intell. Lab. Syst., 77:131138, 2005.
L. J. Rodríguez-Aragón y J. López-Fidalgo. Optimum designs for the des-
cription of sorption data using isotherm equations. En International
Congress of Mathematicians, página 62, 2006a.
L. J. Rodríguez-Aragón y J. López-Fidalgo. Optimum designs for adsor-
ption models. En International Conference on Mathematical and Statis-
tical Modelling, página 93, 2006b.
L. J. Rodríguez-Aragón y J. López-Fidalgo. T−, D− and c− optimum
designs for BET and GAB adsorption isotherms. Chemom. Intell. Lab.
Syst., 89:3644, 2007a.
L. J. Rodríguez-Aragón y J. López-Fidalgo. Application of optimum de-
signs to the characterization of adsorption isotherms. En 8th Model
Oriented Design and Analysis Workshop, página 62, 2007b.
L. J. Rodríguez-Aragón y J. López-Fidalgo. Diseño óptimo de experimentos
en quimiometría. En XXX Congreso Nacional de la Sociedad Estadística
Española, página 147, 2007c.
J. M. Rodríguez-Díaz. Criterios Característicos en Diseño Óptimo de Ex-
perimentos. PhD thesis, Universidad de Salamanca, 2000.
J. M. Rodríguez-Díaz y M. T. Santos-Martín. Optimal designs for a mo-
died exponential model. En 8th Model Oriented Design and Analysis

Bibliografía 185
Workshop, páginas 6263, 2007.
C. Rodríguez Torreblanca y I. M. Ortíz Rodríguez. Diseño Óptimo de Ex-
perimentos para Modelos de Regresión. Universidad de Almería, Sevicio
de Publicaciones, Almería, 1999.
D. Ruppert, N. Cressie, y R. J. Carroll. A transformation/weighting model
for estimating Michaelis-Menten parameters. Biometrics, 45:637656,
1989.
S. Saevels, A. Z. Berna, J. Lammertyn, C. di Natale, y B. M. Nicolaï. Cha-
racterisation of QMB sensors by means of the BET adsorption isotherm.
Sens. Actuators, B, 101:242251, 2004.
R. Schwabe. Optimum Designs for Multi-Factor Models. Springer, New
York, 1996.
K. R. Shah y B. K. Sinha. Theory of Optimal Design. Lecture Notes in
Statistics. Springer Verlag, New York, 1989.
D. R. Shonnard, R. L. Bell, y A. P. Jackman. Eects of nonlinear sorption
on the diusion of benzene and dichloromethane from two air-dry soils.
Environ. Sci. Technol., 27:457466, 1993.
S. D. Silvey. Optimal Design. Chapman & Hall, London, 1980.
S. D. Silvey y D. M. Titterington. A geometric aproach to optimal design
theory. Biometrika, 60(1):2132, 1973.
A. Sinha, E. R. Lovejoy, y C. J. Howard. Kinetic study of the reaction of
HO2 with ozone. J. Chem. Phys., 87(4):21222128, 1987.
K. Smith. On the standard deviations of adjusted and interpolates values
of an observed polynomial functions and its constants and the guidance
they give towards a proper choice of the distribution of observations.
Biometrika, 12:185, 1918.
R. D. Snee y W. Marquardt. Extreme vertices designs for linear mixture
models. Technometrics, 16(3):399408, 1974.
E. O. Timmermann. Multilayer sorption parameters: BET or GAB values?
Colloids Surf., A, 220:235260, 2003.

186 Bibliografía
E. O. Timmermann, J. Chirife, y H. A. Iglesias. Water sorption isotherms
of foods and foodstus: BET or GAB parameters? J. Food Eng., 48:
1931, 2001.
D. M. Titterington. Optimal designs: Some geometrical aspects of D-
optimality. Biometrika, 2(313320), 1976.
M. Tokunaga, J. Kiyosu, Y. Obora, y Y. Tsuji. Kinetic resolution displaying
zeroth order dependence on substrate consumption: Copper-catalyzed
asymmetric alcoholysis of azlactones. J. Am. Chem. Soc., 128:4481
4486, 2006.
M. Trautz. The law of reaction velocity and of equilibrium in gases. the
additivity of Cv-3/2R. new determinations of the integration constants
and of the molecular diameter. Z. Anorg. Allgem. Chem., 96:128, 1916.
C. van den Berg. Engineering and Food: Engineering Sciences in the Food
Industry, volume 1, capítulo Description of water activity of foods for
Engineering purposes by means of the GAB model of sorption, páginas
311321. Elsevier, London, 1984.
J. H. van't Ho. Etudes de Dynamique Chimique. F. Muller & Co., Ams-
terdam, 1884.
A. Wald. On the ecient design of statistical investigations. Ann. Math.
Stat., 14:134140, 1943.
W. J. Welch. Branch-and-bound search for experimental design based on
D-optimality and other criteria. Technometrics, 24(1):4148, 1982.
L. V. White. An extension of the general equivalence theorem to nonlinear
models. Biometrika, 60(2):354348, 1973.
P. Whittle. Some general points in the theory of optimal experimental
design. J. Roy. Statist. Soc. Ser. B, (1):123130, 1973.
W. Wolf, W. E. L. Spiess, y G. Jung. Standardization of isotherm measu-
rements (COST-project 90 and 90 bis). En D. Simatos y J. L. Multon,
editores, Properties of water in foods, páginas 661679. Martinum Nij-
ho, Dordrecht, 1985.

Bibliografía 187
Ch-F. Wu y H. P. Wynn. The convergence of general step-length algorithms
for regular optimum design criteria. Ann. Statist., 6(6):12731285, 1978.
H. P. Wynn. The sequiential generation of D-Optimum experimental de-
signs. Ann. Math. Stat., 41(5):16551664, 1970.


















