
Dcpl cloud computing amazon fail
8
AMAZON FAIL DC Public Library’s Lessons Learned from the Amazon Cloud Outage Friday, June 24, 2011
-
Upload
chris-tonjes -
Category
Technology
-
view
492 -
download
1
Transcript of Dcpl cloud computing amazon fail

AMAZON FAILDC Public Library’s Lessons Learned from the Amazon Cloud Outage
Friday, June 24, 2011

BACKGROUND
• DClibrary.org was first major DC Government website to use cloud-based hosting beginning circa June 2009
• Initial architecture designed to leverage low cost of large instances Amazon Web Services (AWS) servers for database operations and lower cost small and mid servers for WWW services
• DClibrary.org Content Management System is Drupal 6
• Bonus: Experimental Drupal 7 amazon machine instance available on our website; currently undergoing user testing
Friday, June 24, 2011

• Background: AWS de-couples the physical hard disk space (called Elastic Block Storage or EBS) from the CPUs (called “compute instances”)
• late April 2011: an AWS engineer mistakenly routed “backplane” (internal server traffic) which connects EBS to the CPUS through a system that could not handle the load
• This triggered an alarm; since everything in AWS is redundant, the systems thought the backup EBS drives had all failed simultaneously, causing an overload as the system tried to compensate
• In a nutshell, it’s almost as if the CPUs no longer had hard drives
WHAT WENT WRONG
Friday, June 24, 2011
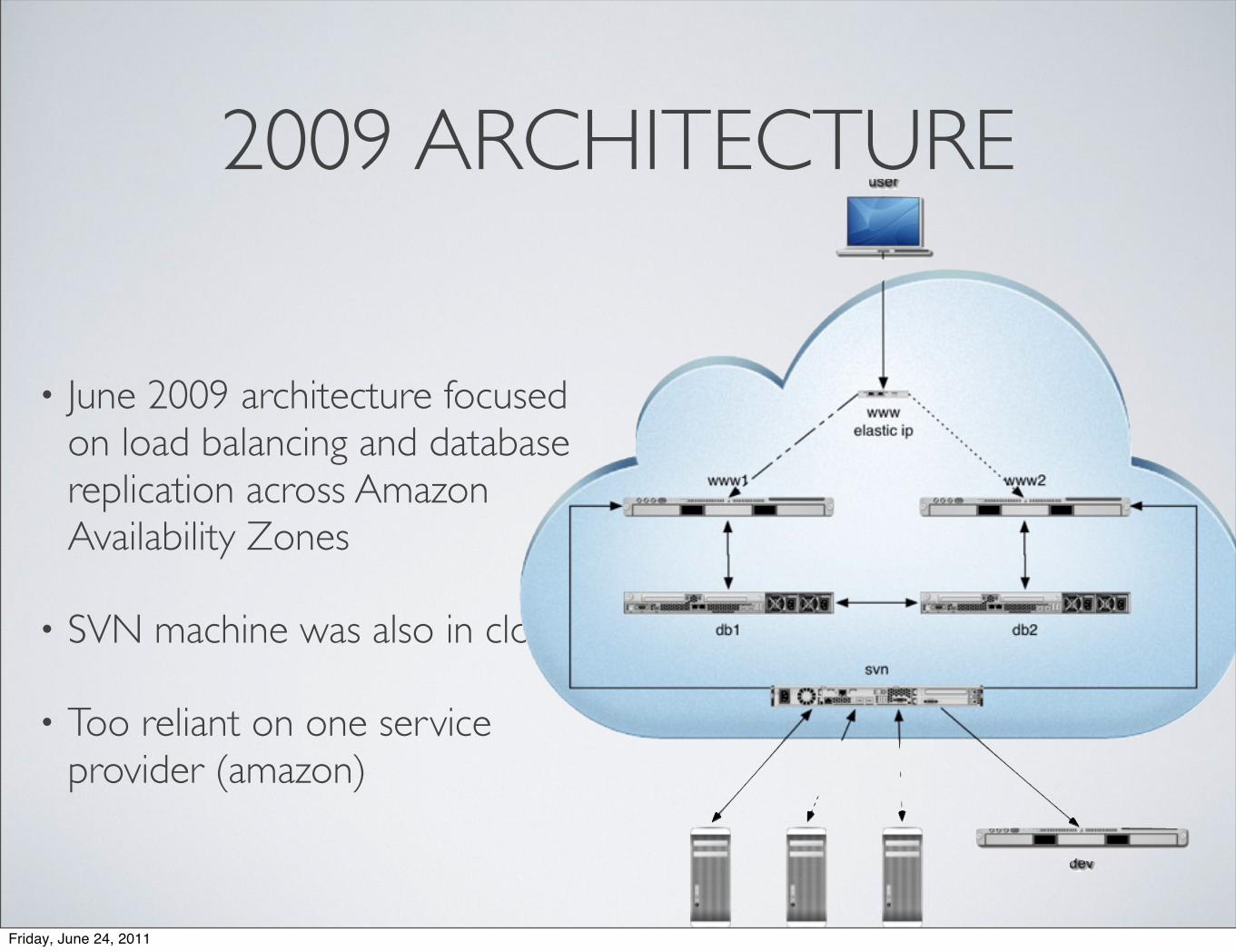
2009 ARCHITECTURE
• June 2009 architecture focused on load balancing and database replication across Amazon Availability Zones
• SVN machine was also in cloud
• Too reliant on one service provider (amazon)
Friday, June 24, 2011

PRE-OUTAGE ARCHITECTURE
• AWS began a new service called “RDS” for Relational Data Service in 2010. This was a managed database service -- mySQL -- that was more powerful and simpler to administer than us doing so ourselves on large servers
• We migrated to RDS in 2010
• The remaining architecture, with the mid-instance front ends and load balancers, remained the same
Friday, June 24, 2011

KEY LESSONS LEARNED
• Amazon’s multiple availability zones failover are not reliable
• Does not imply separate physical or logical facilities!
• Amazon’s poor communication during the outage compounded this problem
• Due to Amazon’s poor initial incidence response communications, we on the spot decided to
create new machine instances (AMIs) in a different geographic zone (US-West vs. US-East) and
copy over the “offsite” one-day-old SVN and DB backups
• Downtime minimized to 1.5 hours; many websites (Reddit, Quora, Foursquare) were down for
days
• Future Worst Case: Amazon goes completely offline. Means we need a very recent full backup of
both WWW and DB instances in a physically and logically separate facility + ability to load balance/
change DNS quickly
• Solution was to scale up Rackspace instances and make daily copies to those servers
Friday, June 24, 2011

2011 ARCHITECTURE
Friday, June 24, 2011

WHAT WE RECOMMEND• get physically and logically separate backup servers
• do nightly full copy backups to the above servers
• have a clear, written process in place for the following things:
• communicating with superiors about what’s happening
• what steps need to be taken to failover
• when the “worst-case” failover plan is implemented (can be time-based or circumstance-based
or both)
• either implement automatic load balancing or (not as good) have complete control over your DNS
• use a very good alerts monitoring service; some of the best ones are cheap/free. We use
binarycanary.com.
Friday, June 24, 2011


















