
CS 61C: Great Ideas in Computer Architecture Pipelining...
35
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards 1 Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.Berkeley.edu/~cs61c/sp16
Transcript of CS 61C: Great Ideas in Computer Architecture Pipelining...

CS61C:GreatIdeasinComputerArchitecture
PipeliningandHazards
1
Instructors:VladimirStojanovicandNicholasWeaverhttp://inst.eecs.Berkeley.edu/~cs61c/sp16

PipelinedExecutionRepresentation
• Everyinstructionmusttakesamenumberofsteps,sosomestageswillidle– e.g.MEMstageforanyarithmeticinstruction
IF ID EX MEM WBIF ID EX MEM WB
IF ID EX MEM WBIF ID EX MEM WB
IF ID EX MEM WBIF ID EX MEM WB
Time
2

GraphicalPipelineDiagrams
• Usedatapath figurebelowtorepresentpipeline:IF ID EX Mem WB
ALUI$ Reg D$ Reg
1.InstructionFetch
2.Decode/RegisterRead
3.Execute 4.Memory 5.WriteBack
PC
inst
ruct
ion
mem
ory
+4
RegisterFilert
rsrd
ALU
Dat
am
emor
y
imm
MU
X
3

Instr
Order
Load
Add
Store
Sub
Or
I$
Time (clock cycles)
I$
ALU
Reg
Reg
I$
D$
ALU
ALU
Reg
D$
Reg
I$
D$
Reg
ALU
Reg Reg
Reg
D$
Reg
D$
ALU
• RegFile: left half is write, right half is read
Reg
I$
GraphicalPipelineRepresentation
4

PipeliningPerformance(1/3)• UseTc (“timebetweencompletionofinstructions”)tomeasurespeedup–– Equalityonlyachievedifstagesarebalanced(i.e.takethesameamountoftime)
• Ifnotbalanced,speedupisreduced• Speedupduetoincreasedthroughput
– Latency foreachinstructiondoesnotdecrease– Infact,latency mustincreaseasthepipelineregistersthemselvesadddelay(whyNick'sPh.D.thesishasa"thiswasastupididea"chapter)
5

PipeliningPerformance(2/3)
• Assumetimeforstagesis– 100psforregisterreadorwrite– 200psforotherstages
• Whatispipelinedclockrate?– Comparepipelineddatapath withsingle-cycledatapath
Instr Instrfetch
Register read
ALU op Memory access
Register write
Total time
lw 200ps 100 ps 200ps 200ps 100 ps 800ps
sw 200ps 100 ps 200ps 200ps 700ps
R-format 200ps 100 ps 200ps 100 ps 600ps
beq 200ps 100 ps 200ps 500ps
6

PipeliningPerformance(3/3)
Single-cycleTc = 800 psf = 1.25GHz
PipelinedTc = 200 ps
f = 5GHz
7

Clicker/PeerInstructionLogicinsomestagestakes200psandinsome100ps.Clk-Qdelayis30psandsetup-timeis20ps.Whatisthemaximumclockfrequencyatwhichapipelineddesigncanoperate?• A:10GHz• B:5GHz• C:6.7GHz• D:4.35GHz• E:4GHz
8

Administrivia…
• StartonProject3-1now– Logisim canbeabit,well,tedious:Theprojectisn'tnecessarilyhardbutitwilltakeafairamountoftime• Alternativewouldbetohaveyoulearnyetanotherprogramminglanguageinthisclass!
– Forreference,ittookNickaboutanhouroftediouslydrawinglinesforhissolutiontopart1• 5minutestoknowwhathewantedtodo…• And55minutestoactuallydoit.L
9

PipeliningHazards
Ahazard isasituationthatpreventsstartingthenextinstructioninthenext clockcycle
1) Structuralhazard– Arequiredresourceisbusy(e.g.neededinmultiplestages)
2) Datahazard– Datadependencybetweeninstructions– Needtowaitforpreviousinstructiontocomplete
itsdataread/write3) Controlhazard
– Flowofexecutiondependsonpreviousinstruction10

I$
Load
Instr 1
Instr 2
Instr 3
Instr 4
ALUI$ Reg D$ Reg
ALUI$ Reg D$ Reg
ALUI$ Reg D$ Reg
ALUReg D$ Reg
ALUI$ Reg D$ Reg
Instr
Order
Time (clock cycles)
StructuralHazard#1:SingleMemory
Trying to read same memory twice in same clock cycle
11

SolvingStructuralHazard#1withCaches
12

StructuralHazard#2:Registers(1/2)
I$
Load
Instr 1
Instr 2
Instr 3
Instr 4
ALUI$ Reg D$ Reg
ALUI$ Reg D$ Reg
ALUI$ Reg D$ Reg
ALUReg D$ Reg
ALUI$ Reg D$ Reg
Instr
Order
Time (clock cycles)
Can we read and write to registers simultaneously?
13

StructuralHazard#2:Registers(2/2)
• Twodifferentsolutionshavebeenused:1) SplitRegFile accessintwo:Writeduring1st halfand
Readduring2nd halfofeachclockcycle• PossiblebecauseRegFile accessisVERY fast
(takeslessthanhalfthetimeofALUstage)2) BuildRegFile withindependentreadandwriteports
(E.g.foryourproject)
• Conclusion:ReadandWritetoregistersduringsameclockcycleisokay
Structuralhazardscan(almost)alwaysberemovedbyaddinghardware resources
14

DataHazards(1/2)
• Considerthefollowingsequenceofinstructions:
add $t0, $t1, $t2sub $t4, $t0, $t3and $t5, $t0, $t6or $t7, $t0, $t8xor $t9, $t0, $t10
15

2.DataHazards(2/2)• Data-flowbackwards intimearehazards
sub $t4,$t0,$t3ALUI$ Reg D$ Reg
and $t5,$t0,$t6
ALUI$ Reg D$ Reg
or $t7,$t0,$t8 I$
ALUReg D$ Reg
xor $t9,$t0,$t10
ALUI$ Reg D$ Reg
add $t0,$t1,$t2IF ID/RF EX MEM WBA
LUI$ Reg D$ RegInstr
Order
Time (clock cycles)
16

DataHazardSolution:Forwarding• Forwardresultassoonasitisavailable
– OKthatit’snotstoredinRegFile yet
sub $t4,$t0,$t3ALUI$ Reg D$ Reg
and $t5,$t0,$t6
ALUI$ Reg D$ Reg
or $t7,$t0,$t8 I$
ALUReg D$ Reg
xor $t9,$t0,$t10
ALUI$ Reg D$ Reg
add $t0,$t1,$t2IF ID/RF EX MEM WBA
LUI$ Reg D$ Reg
17

Datapath for Forwarding(1/2)
• What changes need to be made here?
18

Datapath forForwarding(2/2)
• Handledbyforwardingunit
19

Datapath andControl
• Thecontrolsignalsarepipelined,too20
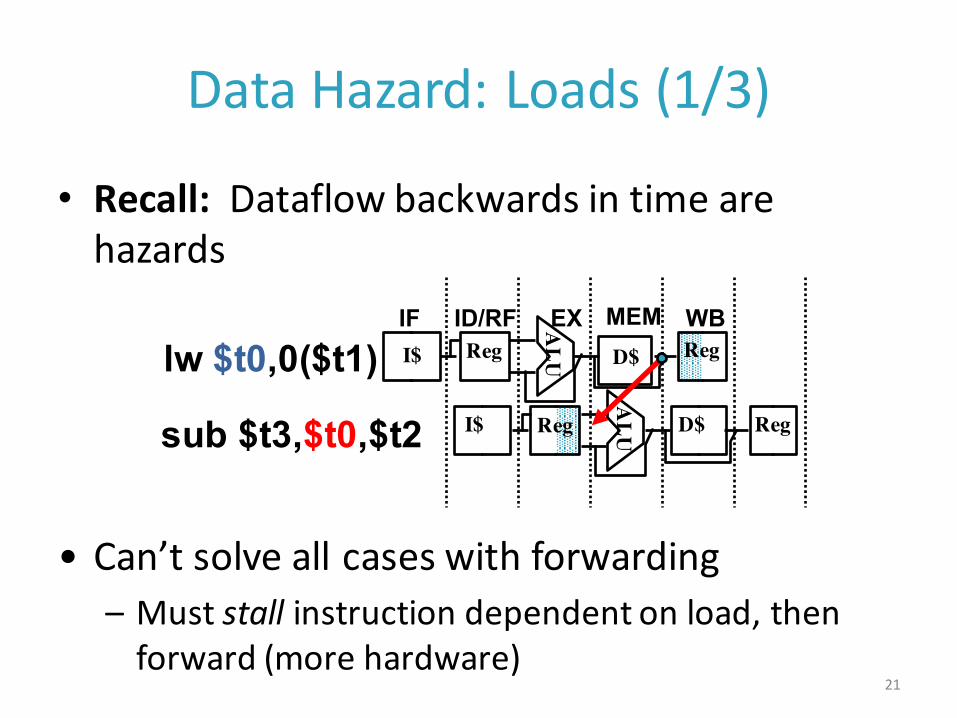
DataHazard:Loads(1/3)
• Recall: Dataflowbackwardsintimearehazards
• Can’tsolveallcaseswithforwarding– Muststall instructiondependentonload,thenforward(morehardware)
sub $t3,$t0,$t2
ALUI$ Reg D$ Reg
lw $t0,0($t1)IF ID/RF EX MEM WBA
LUI$ Reg D$ Reg
21

DataHazard:Loads(2/3)• Stalledinstructionconvertedto“bubble”,actslikenop
sub $t3,$t0,$t2
and $t5,$t0,$t4
or $t7,$t0,$t6 I$
ALUReg D$
lw $t0, 0($t1) ALUI$ Reg D$ Reg
bubble
bubble
bubble
ALUI$ Reg D$ Reg
ALUI$ Reg D$ Reg
sub $t3,$t0,$t2
22
I$ Reg
First two pipe stages stall by repeating stage one cycle later

DataHazard:Loads(4/4)
• Slotafteraloadiscalledaloaddelayslot– Ifthatinstructionusestheresultoftheload,thenthehardwareinterlockwillstallitforonecycle
– Lettingthehardwarestalltheinstructioninthedelayslotisequivalenttoputtinganexplicitnopintheslot(exceptthelatterusesmorecodespace)
• Idea: Letthecompilerputanunrelatedinstructioninthatslotà nostall!
23

ClickerQuestionHowmanycycles(pipelinefill+process+drain)doesittaketoexecutethefollowingcode?
lw$t1, 0($t0)lw$t2, 4($t0)add $t3, $t1, $t2sw$t3, 12($t0)lw$t4, 8($t0)add $t5, $t1, $t4sw$t5, 16($t0)
24
A. 7B. 9C. 11D. 13E. 14

CodeSchedulingtoAvoidStalls
• Reordercodetoavoiduseofloadresultinthenextinstruction!
• MIPScodeforD=A+B; E=A+C;# Method 1:lw $t1, 0($t0)
lw $t2, 4($t0)
add $t3, $t1, $t2
sw $t3, 12($t0)
lw $t4, 8($t0)add $t5, $t1, $t4
sw $t5, 16($t0)
# Method 2:lw $t1, 0($t0)
lw $t2, 4($t0)
lw $t4, 8($t0)
add $t3, $t1, $t2
sw $t3, 12($t0)add $t5, $t1, $t4
sw $t5, 16($t0)
Stall!
Stall!
13 cycles 11 cycles25

3.ControlHazards
• Branchdeterminesflowofcontrol– Fetchingnextinstructiondependsonbranchoutcome
– Pipelinecan’talwaysfetchcorrectinstruction• StillworkingonIDstageofbranch
• BEQ,BNEinMIPSpipeline• SimplesolutionOption1:Stalloneverybranchuntilbranchconditionresolved– Wouldadd2bubbles/clockcyclesforeveryBranch!(~20%ofinstructionsexecuted)
26

Stall=>2Bubbles/Clocks
Where do we do the compare for the branch?
I$
beq
Instr 1
Instr 2
Instr 3
Instr 4ALUI$ Reg D$ Reg
ALUI$ Reg D$ Reg
ALUI$ Reg D$ Reg
ALUReg D$ Reg
ALUI$ Reg D$ Reg
Instr.
Order
Time (clock cycles)
27

ControlHazard:Branching
• Optimization#1:– InsertspecialbranchcomparatorinStage2– Assoonasinstructionisdecoded(Opcodeidentifiesitasabranch),immediatelymakeadecisionandsetthenewvalueofthePC
– Benefit:sincebranchiscompleteinStage2,onlyoneunnecessaryinstructionisfetched,soonlyoneno-opisneeded
– SideNote:meansthatbranchesareidleinStages3,4and5
28

OneClockCycleStall
Branch comparator moved to Decode stage.
I$
beq
Instr 1
Instr 2
Instr 3
Instr 4ALUI$ Reg D$ Reg
ALUI$ Reg D$ Reg
ALUI$ Reg D$ Reg
ALUReg D$ Reg
ALUI$ Reg D$ Reg
Instr.
Order
Time (clock cycles)
29

ControlHazards:Branching
• Option2:Predictoutcomeofabranch,fixupifguesswrong– Mustcancelallinstructionsinpipelinethatdependedonguessthatwaswrong
– Thisiscalled“flushing”thepipeline• SimplesthardwareifwepredictthatallbranchesareNOTtaken– Why?
30

ControlHazards:Branching
• Option#3:Redefinebranches– Olddefinition:ifwetakethebranch,noneoftheinstructionsafterthebranchgetexecutedbyaccident
– Newdefinition:whetherornotwetakethebranch,thesingleinstructionimmediatelyfollowingthebranchgetsexecuted(thebranch-delayslot)
• DelayedBranchmeanswealwaysexecuteinstafterbranch
• ThisoptimizationisusedwithMIPS
31

Example:Nondelayed vs.DelayedBranch
add $1, $2, $3
sub $4, $5, $6
beq $1, $4, Exit
or $8, $9, $10
xor $10, $1, $11
Nondelayed Branchadd $1, $2,$3
sub $4, $5, $6
beq $1, $4, Exit
or $8, $9, $10
xor $10, $1, $11
Delayed Branch
Exit: Exit:32

ControlHazards:Branching
• NotesonBranch-DelaySlot– Worst-CaseScenario:putanop inthebranch-delayslot
– BetterCase:placesomeinstructionprecedingthebranchinthebranch-delayslot—aslongasthechangeddoesn’taffectthelogicofprogram• Re-orderinginstructionsiscommonwaytospeedupprograms
• Compilerusuallyfindssuchaninstruction50%oftime• Jumpsalsohaveadelayslot…
33

GreaterInstruction-LevelParallelism(ILP)
• Deeperpipeline(5=>10=>15stages)– Lessworkperstage⇒ shorterclockcycle
• Multipleissue“superscalar”– Replicatepipelinestages⇒multiplepipelines– Startmultipleinstructionsperclockcycle– CPI<1,souseInstructionsPerCycle(IPC)– E.g.,4GHz4-waymultiple-issue
• 16BIPS,peakCPI=0.25,peakIPC=4– Butdependenciesreducethisinpractice
• “Out-of-Order”execution– Reorderinstructionsdynamicallyinhardwaretoreduceimpactof
hazards• "Multithreading"
– Sharefunctionalunitsbetweenindependentthreadsofexecution• TakeCS152nexttolearnaboutthesetechniques!
34

InConclusion
• Pipeliningincreasesthroughputbyoverlappingexecutionofmultipleinstructionsindifferentpipestages
• Pipestages shouldbebalancedforhighestclockrate• Threetypesofpipelinehazardlimitperformance
– Structural(alwaysfixablewithmorehardware)– Data(useinterlocksorbypassingtoresolve)– Control(reduceimpactwithbranchpredictionorbranchdelayslots)
35


















