
CIlib 2.0: Rethinking Implementation
53
CILIB 2.0 RE-THINKING IMPLEMENTATION
-
Upload
gary-pampara -
Category
Software
-
view
25 -
download
0
Transcript of CIlib 2.0: Rethinking Implementation

CILIB 2.0RE-THINKING IMPLEMENTATION

Please feel free to ask questions at any stage

TEXT
ABOUT US
▸ Gary Pamparà, Filipe Nepomuceno and Prof. A.P Engelbrecht
▸ Members of the Computational Intelligence Research Group (CIRG) @ University of Pretoria

TEXT
AGENDA
▸ History of CIlib
▸ Problems discovered
▸ Rewrite to address major concerns
▸ Roadmap and milestones
▸ Example usage

SOME HISTORY
TEXT
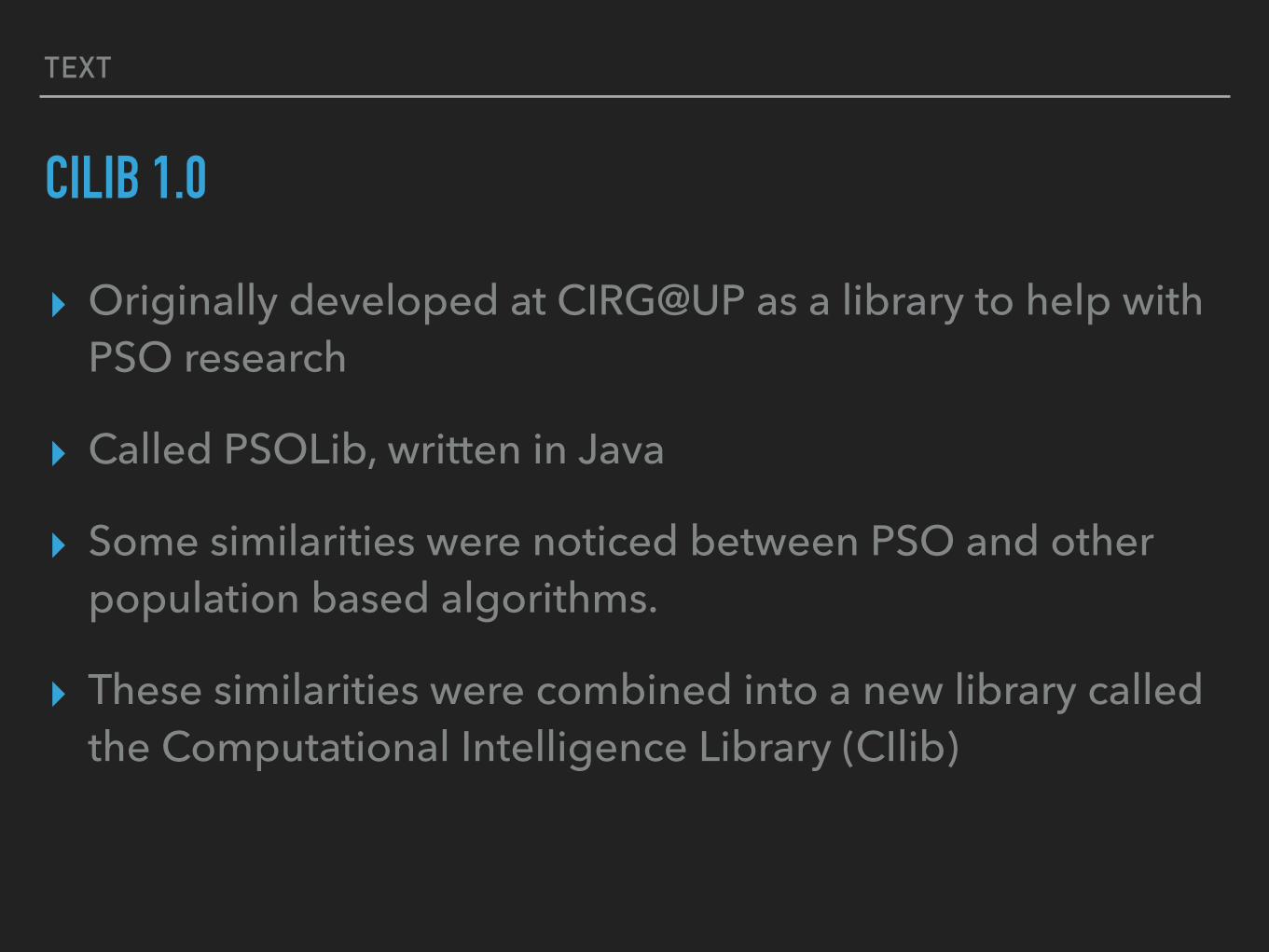
CILIB 1.0
▸ Originally developed at CIRG@UP as a library to help with PSO research
▸ Called PSOLib, written in Java
▸ Some similarities were noticed between PSO and other population based algorithms.
▸ These similarities were combined into a new library called the Computational Intelligence Library (CIlib)

TEXT
CILIB 1.0
▸ Library evolved into a framework, providing a simulator for users
▸ XML definitions were passed to the simulator
▸ Allowed for simple experimentation
▸ Numerous example XML specifications to work from
▸ One single place to define algorithm stopping conditions, measurements and benchmark problems

TEXT
CILIB 1.0
<algorithm id="pso-lbest" class="pso.PSO">
<addStoppingCondition class="stoppingcondition.MeasuredStoppingCondition" target="100000">
<measurement class="measurement.single.FitnessEvaluations"/>
</addStoppingCondition>
</algorithm>
TEXT
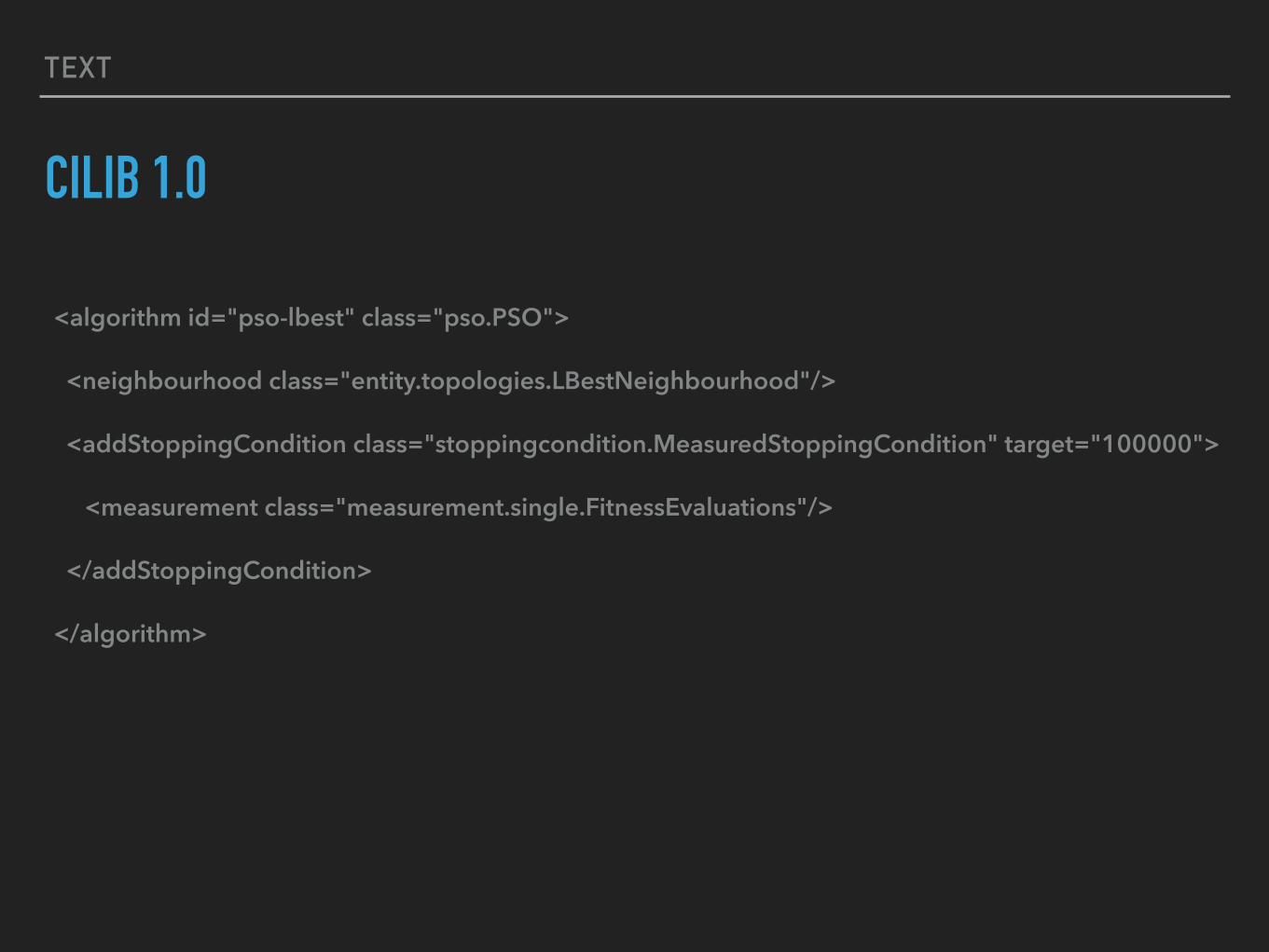
CILIB 1.0
<algorithm id="pso-lbest" class="pso.PSO">
<neighbourhood class="entity.topologies.LBestNeighbourhood"/>
<addStoppingCondition class="stoppingcondition.MeasuredStoppingCondition" target="100000">
<measurement class="measurement.single.FitnessEvaluations"/>
</addStoppingCondition>
</algorithm>

TEXT
CILIB 1.0 CURRENT FEATURES
▸ Single population algorithms
▸ Multi-population based algorithms
▸ Multi-Objective Optimisation
▸ Niching algorithms
▸ Cooperative algorithms
▸ Neural Networks
▸ Very large collection of established benchmark functions
▸ Unified control parameter usage and representation

TEXT
CILIB 1.0 CURRENT FEATURES
▸ Simulator Application
▸ Selection of Stopping Conditions
▸ Selection of Measurements
▸ Output results automatically to a file based persistence
▸ Allows for use of custom code, provided it is accessible on classpath

PROBLEMS DISCOVERED

TEXT
CILIB 1.0 PROBLEMS
▸ As helpful as the simulator is, several problems developed as a result of it
▸ Random number generator (PRNG)
▸ Java bean style instance creation (very verbose declaration files and java source code)
▸ Complex object interactions, concurrency and mutable state
▸ Additions resulted in a large amount of additional work

TEXT
CILIB 1.0 PROBLEMS
▸ Java beans style, together with inheritance, is a massive problem. Reflection schemes translated to property names.
/** * Get the current strategy to perform personal best updates. * @return The current {@link PersonalBestUpdateStrategy}. */ PersonalBestUpdateStrategy getPersonalBestUpdateStrategy();
/** * Set the strategy to perform personal best updates. * @param personalBestUpdateStrategy The instance to set. */ void setPersonalBestUpdateStrategy(PersonalBestUpdateStrategy personalBestUpdateStrategy);

TEXT
CILIB 1.0 PROBLEMS
▸ Data output - having the data output to text files as a default is very, very restrictive
▸ Concurrency for executing experiments could result in very strange behaviour
▸ Did not effectively use the underlying hardware (CPUs etc)
▸ Scripting the simulator was difficult and cumbersome
▸ Many configuration errors only manifested during runtime

TEXT
CILIB 1.0 PROBLEMS
▸ Fundamental problems needing attention
▸ Replicating experiments, given an XML definition, is not simple. PRNG seed values etc
▸ Possible to create an experiment with the wrong usage of object instances, by accident
▸ Difficult to verify correct ahead of time
▸ Tests can only be defined for specific use cases / examples

ADDRESSING THE PROBLEMS
TEXT
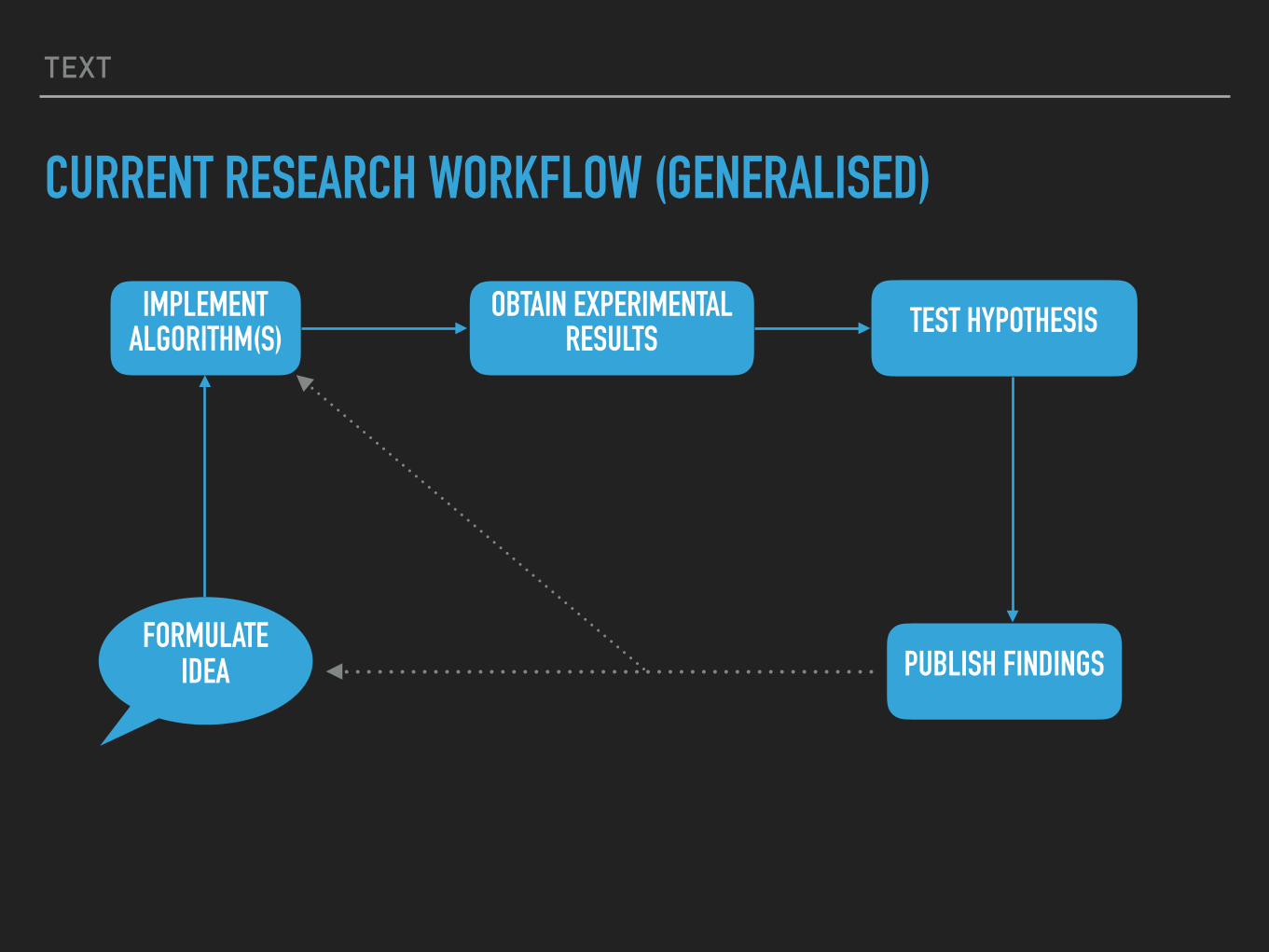
CURRENT RESEARCH WORKFLOW (GENERALISED)
IMPLEMENT ALGORITHM(S)
OBTAIN EXPERIMENTAL RESULTS
FORMULATE IDEA PUBLISH FINDINGS
TEST HYPOTHESIS

TEXT
NEED TO DEFINE GOALS
▸ We should be able to talk about algorithms and implementations without necessarily considering the complications
▸ Worry about how to run them later
▸ Very important aspects to get right:
▸ CorrectnessPrincipled design to promote intuitive usage
▸ Experimental reproducibilityNot being able to reproduce experimental results is utterly useless
▸ Type safetyThe ability to exploit types to prevent errors by making the construction of error states impossible

TEXT
ADDRESSING PROBLEMS
▸ Library first. Not a framework - users should be able to replace parts they don’t like easily
▸ Library should be highly modular. Only include what is required
▸ Other community projects that can provide missing pieces should be used - good open source attitude
▸ The library should be as expressive as possible
TEXT
ADDRESSING PROBLEMS
▸ Restructure the CIRG@UP organisation on GitHub to more correctly reflect ideas
▸ http://github.com/cirg-up
▸ Several independent projects that are benefiting from each other

HTTP://GITHUB.COM/CIRG-UP
BENCHMARKSCILIBCORE
PSO
GA
DE
NN
MOO
STATIC ENV
DYNAMIC ENV
…

TEXT
ADDRESSING PROBLEMS
▸ Object inheritance results in large amounts of complexity and composition is much more flexible (the expression problem)
▸ We decided to instead focus on data structures that encourage correctness and consistency
▸ First class functions were therefore a requirement, but Java does not fully address this (even in JDK8). The only statically compiled language that matched our needs at the time is Scala, which supports higher-kinded types

TEXT
ADDRESSING PROBLEMS
▸ Mutable state is a gigantic concern in programming
▸ The best way to minimise state in a program is to simply not use it!
▸ Scala is a language that merges object orientated and functional programming. We focus on functional programming as it can provide better guarantees for us
▸ Functional programming has strong foundations in mathematics, which is really nothing more than a boon to productivity and correctness

TEXT
ADDRESSING PROBLEMS
▸ Functional programming allows for clear declarations of computation, using rich data structures, governed by laws formalised in mathematics
▸ The standard Scala libraries are, however, hopelessly insufficient - we rely on some fantastic open source libraries to bridge the gap
▸ Complexities should be hidden within the library code, making user usage simpler
▸ Testing should be done by using property based testing, where the test is a specification of invariants and the test system generates test data for us, identifying many, many more edge and invalid cases

TEXT
SIMPLER EXPERIMENTATION WITH A REPL

DATA STRUCTURESSOME SPECIFICS

TEXT
A QUICK DETOUR: LENSES
▸ A data structure that abstracts the concept of getters and setters
▸ Allows the ability to “zoom” into a nested data structure
▸ Any changes in to the zoomed data will result in an updated nested data structure
▸ We use lenses to emulate row-polymorphism

TEXT
CORE STRUCTURE: POSITION
▸ We abstract over candidate solutions using a Position
▸ A Position can only be one of two possible cases
▸ Point - A single point in a hyper-dimensional search space
▸ Solution - A point in the hyper-dimensional space that has been quantified. It includes a fitness and a list of violated constraints

TEXT
CORE STRUCTURE: ENTITY
▸ All nature inspired algorithms apply some kind of metaphor to a candidate solution
▸ This extends to:
▸ Bees
▸ Particles
▸ Individuals
▸ etc

TEXT
CORE STRUCTURE: ENTITY
▸ There is a general structure, which is a combination of the candidate solution together with some “state”
▸ The state should contain all the additional data that the Entity is tracking for the given algorithm. Eg: velocity, memory, etc
▸ Individual pieces of state are manipulated with Lenses
▸ Having the state accessed by lenses also means we can restrict the type of Entity instance used in a given function
case class Entity[S,A](state: S, pos: Position[A])

TEXT
CORE STRUCTURE: RVAR
▸ The most important abstraction within CIlib
▸ It tracks the effect of randomness, but doesn’t describe how the randomness is applied, nor which PRNG to use
▸ RVar provides some guarantees
▸ It is stack safe to prevent problems with stack overflow
▸ Providing the same seeded PRNG will provide the same result when executed

TEXT
CORE STRUCTURE: RVAR
▸ RVar is so important, that it forms the base computation within CIlib
▸ As an argument, it accepts a PRNG in order to execute
▸ Has several useful functions that are commonly used:
▸ choose
▸ shuffle
▸ sample
▸ etc

TEXT
CORE STRUCTURE: DIST
▸ Building on RVar, a Dist is a generator to produce values from a given probability distribution
▸ Gaussian / Cauchy / Uniform / Gamma / Exponential / Lognormal / etc
▸ Standard versions exist with predefined parameters

TEXT
CORE STRUCTURE: STEP
▸ Step is a layer above RVar. Step is defined to be a single operations within an algorithm definition
▸ Step adds two parameters to a computation
▸ The optimisation scheme to use: Min / Max
▸ The Eval instance that quantifies the quality of a Position

TEXT
CORE STRUCTURE: STEPdef gbest[S](w: Double, c1: Double, c2: Double, cognitive: Guide[S,Double], social: Guide[S,Double])(implicit M: Memory[S,Double], V: Velocity[S,Double], MO: Module[Position[Double],Double]): List[Particle[S,Double]] => Particle[S,Double] => Step[Double,Particle[S,Double]] = collection => x => for { cog <- cognitive(collection, x) // Step soc <- social(collection, x) // Step v <- stdVelocity(x, soc, cog, w, c1, c2) // Step p <- stdPosition(x, v) // Step p2 <- evalParticle(p) // Step p3 <- updateVelocity(p2, v) // Step updated <- updatePBest(p3) // Step } yield updated

TEXT
CORE STRUCTURE: ALGORITHM
List[Particle[S,Double]] => Particle[S,Double] => Step[Double,Particle[S,Double]]

TEXT
CORE STRUCTURE: ALGORITHM
List[A] => A => Step[Double,A]

TEXT
CORE STRUCTURE: STEP WITH STATE
▸ Some algorithms require additional state that is managed during the execution of the algorithm
▸ It’s simple to extend Step to contain some additional state
▸ This is known as StepS
▸ It is important to note that this state is localised to the computation

TEXT
CORE STRUCTURE: ITERATION
▸ Iterations are the repetition scheme for algorithms
▸ Iterations may either be “synchronous” or “asynchronous”
▸ Important to note that synchronous iteration may be fully parallelised, whereas asynchronous iteration cannot be as asynchronous iteration uses the current collection of entities in the computation

TEXT
CORE STRUCTURE: ITERATION
▸ An Iteration is created by passing an algorithm to one of the several functions that create an Iteration
▸ The Iteration converts the signature of an algorithm to:
▸ M in the above is a computational context, which generally is a Step, StepS or RVar, but any valid context is possible
List[A] => M[List[A]]

ROADMAP AND MILESTONES

TEXT
ROADMAP AND MILESTONES
▸ Currently several areas being worked on
▸ Co-operative algorithms
▸ Neural networks
▸ Niching and multi-swarm
▸ Benchmark problems (implementing current standard functions and allowing for benchmark function composition)
▸ There is currently a released version, 2.0.0-M1, which is available for use. New versions are currently scheduled for publication

EXAMPLE USAGE

TEXT
GBEST PARTICLE SWARM OPTIMISATION

TEXT
LBEST PARTICLE SWARM OPTIMISATION

TEXT
GENETIC ALGORITHM
TEXT
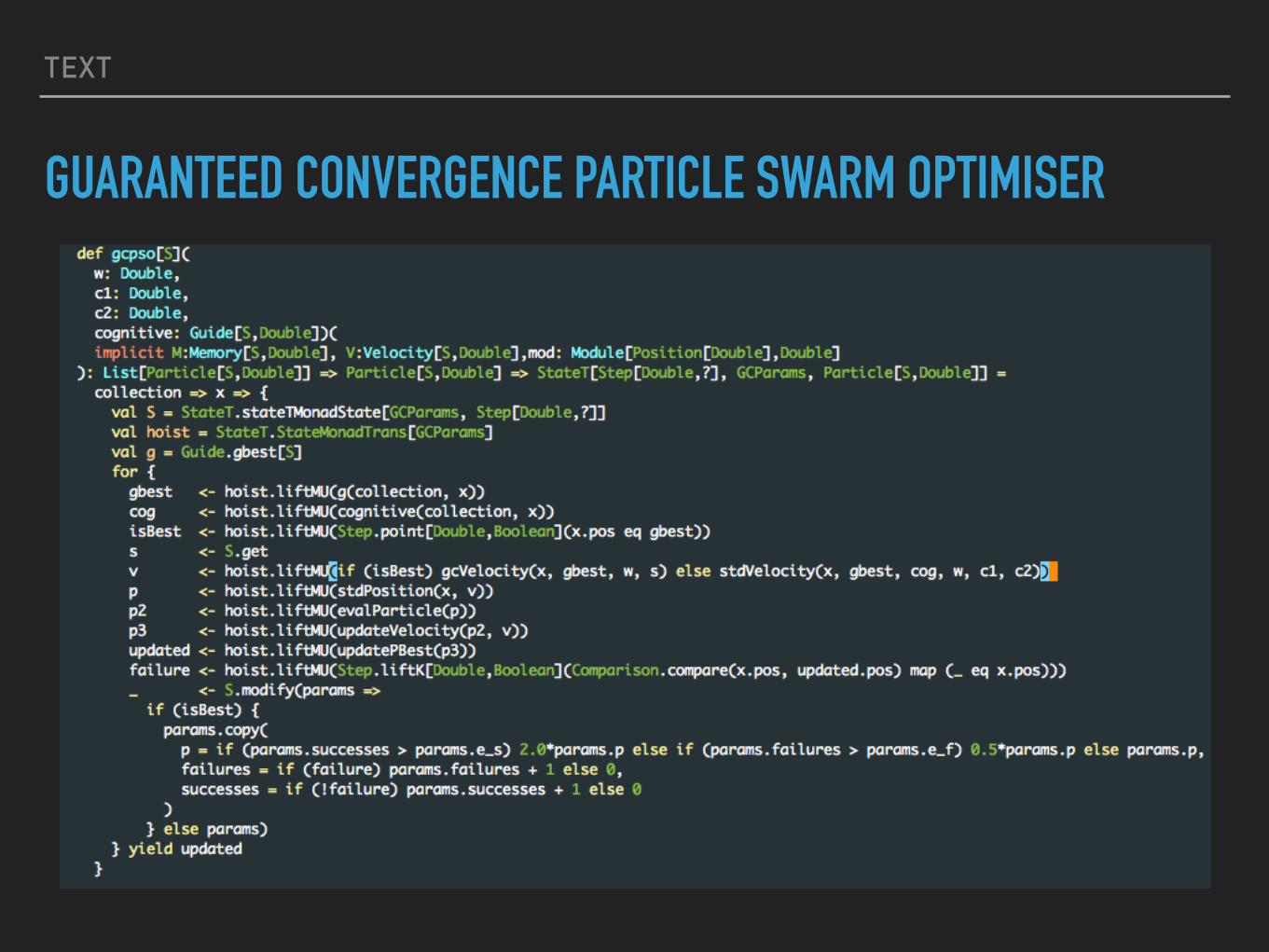
GUARANTEED CONVERGENCE PARTICLE SWARM OPTIMISER

TEXT
TIME VARYING CONTROL PARAMETERS▸ We simply use function composition and partial function
application to enable this functionality
APPLY PARAMETERS TO ALGORITHM FUNCTION EXECUTE ITERATION

TEXT
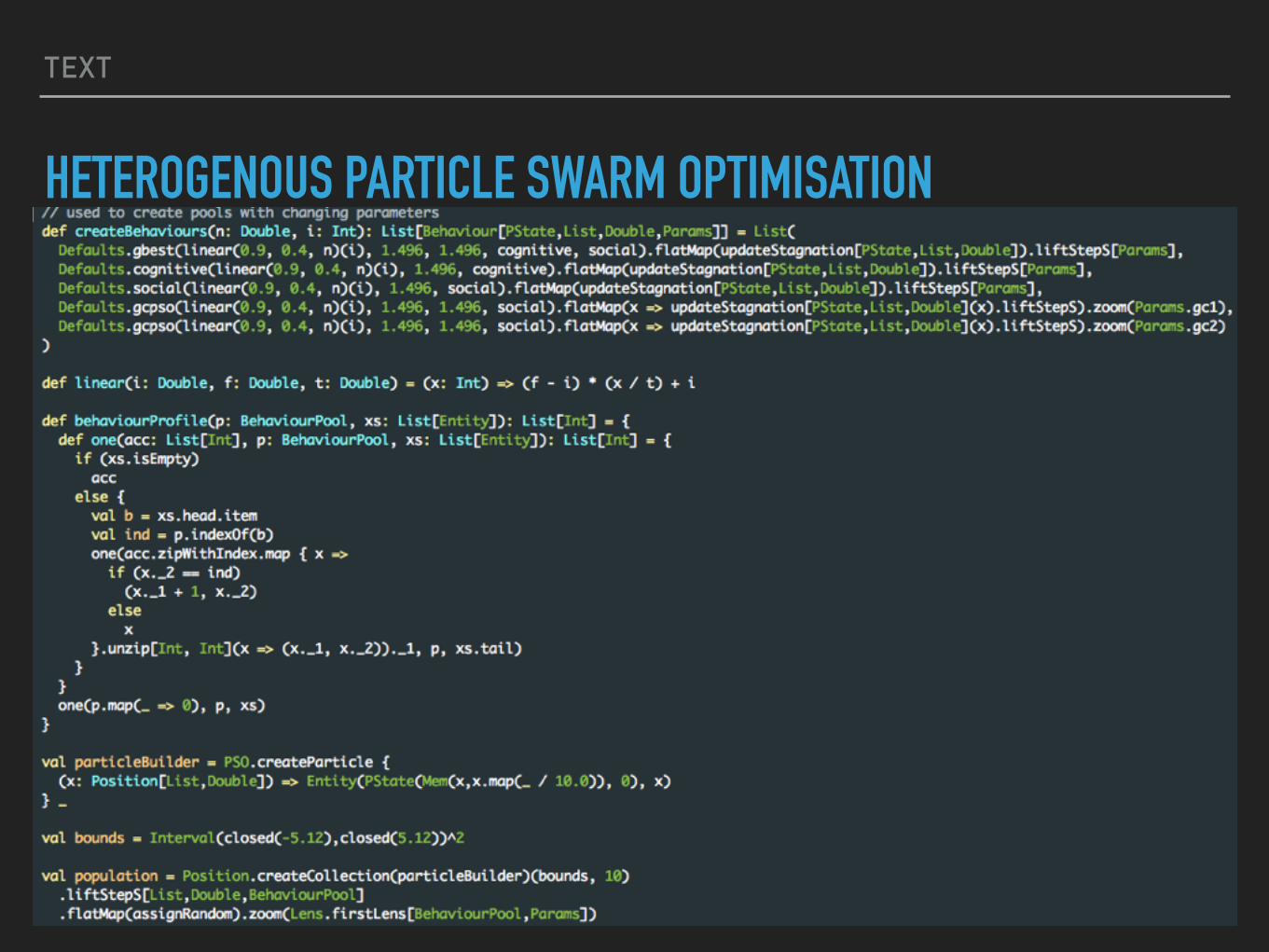
HETEROGENOUS PARTICLE SWARM OPTIMISATION
TEXT
HETEROGENOUS PARTICLE SWARM OPTIMISATION

TEXT
HETEROGENOUS PARTICLE SWARM OPTIMISATION

THANK YOU


















