
Chris Dyer - 2017 - CoNLL Invited Talk: Should Neural Network Architecture Reflect Linguistic...
107
Should Neural Network Architecture Reflect Linguistic Structure? CoNLL August 3, 2017 Adhi Kuncoro (Oxford) Phil Blunsom (DeepMind) Dani Yogatama (DeepMind) Chris Dyer (DeepMind/CMU) Miguel Ballesteros (IBM) Wang Ling (DeepMind) Noah A. Smith (UW) Ed Grefenstette (DeepMind)
-
Upload
association-for-computational-linguistics -
Category
Education
-
view
100 -
download
0
Transcript of Chris Dyer - 2017 - CoNLL Invited Talk: Should Neural Network Architecture Reflect Linguistic...

Should Neural Network Architecture Reflect Linguistic Structure?
CoNLLAugust 3, 2017
Adhi Kuncoro (Oxford)
Phil Blunsom(DeepMind)
Dani Yogatama (DeepMind)
Chris Dyer (DeepMind/CMU)
Miguel Ballesteros(IBM)
Wang Ling(DeepMind)
Noah A. Smith(UW)
Ed Grefenstette (DeepMind)

Should Neural Network Architecture Reflect Linguistic Structure?
Yes.CoNLLAugust 3, 2017

But why?
And how?
CoNLLAugust 3, 2017

(1) a. The talk I gave did not appeal to anybody.
Modeling languageSentences are hierarchical
Examples adapted from Everaert et al. (TICS 2015)

(1) a. The talk I gave did not appeal to anybody.b. *The talk I gave appealed to anybody.
Modeling languageSentences are hierarchical
Examples adapted from Everaert et al. (TICS 2015)

(1) a. The talk I gave did not appeal to anybody.b. *The talk I gave appealed to anybody.
Modeling languageSentences are hierarchical
NPI
Examples adapted from Everaert et al. (TICS 2015)

(1) a. The talk I gave did not appeal to anybody.b. *The talk I gave appealed to anybody.
Generalization hypothesis: not must come before anybody
Modeling languageSentences are hierarchical
NPI
Examples adapted from Everaert et al. (TICS 2015)

(1) a. The talk I gave did not appeal to anybody.b. *The talk I gave appealed to anybody.
Generalization hypothesis: not must come before anybody
(2) *The talk I did not give appealed to anybody.
Modeling languageSentences are hierarchical
NPI
Examples adapted from Everaert et al. (TICS 2015)

Examples adapted from Everaert et al. (TICS 2015)
containing anybody. (This structural configuration is called c(onstituent)-command in thelinguistics literature [31].) When the relationship between not and anybody adheres to thisstructural configuration, the sentence is well-formed.
In sentence (3), by contrast, not sequentially precedes anybody, but the triangle dominating notin Figure 1B fails to also dominate the structure containing anybody. Consequently, the sentenceis not well-formed.
The reader may confirm that the same hierarchical constraint dictates whether the examples in(4–5) are well-formed or not, where we have depicted the hierarchical sentence structure interms of conventional labeled brackets:
(4) [S1 [NP The book [S2 I bought]S2]NP did not [VP appeal to anyone]VP]S1(5) *[S1 [NP The book [S2 I did not buy]S2]NP [VP appealed to anyone]VP]S1
Only in example (4) does the hierarchical structure containing not (corresponding to the sentenceThe book I bought did not appeal to anyone) also immediately dominate the NPI anybody. In (5)not is embedded in at least one phrase that does not also include the NPI. So (4) is well-formedand (5) is not, exactly the predicted result if the hierarchical constraint is correct.
Even more strikingly, the same constraint appears to hold across languages and in many othersyntactic contexts. Note that Japanese-type languages follow this same pattern if we assumethat these languages have hierarchically structured expressions similar to English, but linearizethese structures somewhat differently – verbs come at the end of sentences, and so forth [32].Linear order, then, should not enter into the syntactic–semantic computation [33,34]. This israther independent of possible effects of linearly intervening negation that modulate acceptabilityin NPI contexts [35].
The Syntax of SyntaxObserve an example as in (6):
(6) Guess which politician your interest in clearly appeals to.
The construction in (6) is remarkable because a single wh-phrase is associated bothwith the prepositional object gap of to and with the prepositional object gap of in, as in(7a). We talk about ‘gaps’ because a possible response to (6) might be as in (7b):
(7) a. Guess which politician your interest in GAP clearly appeals to GAP.b. response to (7a): Your interest in Donald Trump clearly appeals to Donald Trump
(A) (B)
X X
X X X X
The book X X X The book X appealed to anybodydid not
that I bought appeal to anybody that I did not buy
Figure 1. Negative Polarity. (A) Negative polarity licensed: negative element c-commands negative polarity item.(B) Negative polarity not licensed. Negative element does not c-command negative polarity item.
734 Trends in Cognitive Sciences, December 2015, Vol. 19, No. 12
- the psychological reality of structural sensitivty is not empirically controversial
- many different theories of the details of structure - more controversial hypothesis: kids learn language
easily because they don’t consider many “obvious” structural insensitive hypotheses
Language is hierarchical
The talk
I gavedid not
appeal to anybody
appealed to anybodyThe talk
I did not give

Examples adapted from Everaert et al. (TICS 2015)
containing anybody. (This structural configuration is called c(onstituent)-command in thelinguistics literature [31].) When the relationship between not and anybody adheres to thisstructural configuration, the sentence is well-formed.
In sentence (3), by contrast, not sequentially precedes anybody, but the triangle dominating notin Figure 1B fails to also dominate the structure containing anybody. Consequently, the sentenceis not well-formed.
The reader may confirm that the same hierarchical constraint dictates whether the examples in(4–5) are well-formed or not, where we have depicted the hierarchical sentence structure interms of conventional labeled brackets:
(4) [S1 [NP The book [S2 I bought]S2]NP did not [VP appeal to anyone]VP]S1(5) *[S1 [NP The book [S2 I did not buy]S2]NP [VP appealed to anyone]VP]S1
Only in example (4) does the hierarchical structure containing not (corresponding to the sentenceThe book I bought did not appeal to anyone) also immediately dominate the NPI anybody. In (5)not is embedded in at least one phrase that does not also include the NPI. So (4) is well-formedand (5) is not, exactly the predicted result if the hierarchical constraint is correct.
Even more strikingly, the same constraint appears to hold across languages and in many othersyntactic contexts. Note that Japanese-type languages follow this same pattern if we assumethat these languages have hierarchically structured expressions similar to English, but linearizethese structures somewhat differently – verbs come at the end of sentences, and so forth [32].Linear order, then, should not enter into the syntactic–semantic computation [33,34]. This israther independent of possible effects of linearly intervening negation that modulate acceptabilityin NPI contexts [35].
The Syntax of SyntaxObserve an example as in (6):
(6) Guess which politician your interest in clearly appeals to.
The construction in (6) is remarkable because a single wh-phrase is associated bothwith the prepositional object gap of to and with the prepositional object gap of in, as in(7a). We talk about ‘gaps’ because a possible response to (6) might be as in (7b):
(7) a. Guess which politician your interest in GAP clearly appeals to GAP.b. response to (7a): Your interest in Donald Trump clearly appeals to Donald Trump
(A) (B)
X X
X X X X
The book X X X The book X appealed to anybodydid not
that I bought appeal to anybody that I did not buy
Figure 1. Negative Polarity. (A) Negative polarity licensed: negative element c-commands negative polarity item.(B) Negative polarity not licensed. Negative element does not c-command negative polarity item.
734 Trends in Cognitive Sciences, December 2015, Vol. 19, No. 12
Generalization: not must “structurally precede” anybody- the psychological reality of structural sensitivty
is not empirically controversial - many different theories of the details of structure - more controversial hypothesis: kids learn language
easily because they don’t consider many “obvious” structural insensitive hypotheses
Language is hierarchical
The talk
I gavedid not
appeal to anybody
appealed to anybodyThe talk
I did not give

Examples adapted from Everaert et al. (TICS 2015)
containing anybody. (This structural configuration is called c(onstituent)-command in thelinguistics literature [31].) When the relationship between not and anybody adheres to thisstructural configuration, the sentence is well-formed.
In sentence (3), by contrast, not sequentially precedes anybody, but the triangle dominating notin Figure 1B fails to also dominate the structure containing anybody. Consequently, the sentenceis not well-formed.
The reader may confirm that the same hierarchical constraint dictates whether the examples in(4–5) are well-formed or not, where we have depicted the hierarchical sentence structure interms of conventional labeled brackets:
(4) [S1 [NP The book [S2 I bought]S2]NP did not [VP appeal to anyone]VP]S1(5) *[S1 [NP The book [S2 I did not buy]S2]NP [VP appealed to anyone]VP]S1
Only in example (4) does the hierarchical structure containing not (corresponding to the sentenceThe book I bought did not appeal to anyone) also immediately dominate the NPI anybody. In (5)not is embedded in at least one phrase that does not also include the NPI. So (4) is well-formedand (5) is not, exactly the predicted result if the hierarchical constraint is correct.
Even more strikingly, the same constraint appears to hold across languages and in many othersyntactic contexts. Note that Japanese-type languages follow this same pattern if we assumethat these languages have hierarchically structured expressions similar to English, but linearizethese structures somewhat differently – verbs come at the end of sentences, and so forth [32].Linear order, then, should not enter into the syntactic–semantic computation [33,34]. This israther independent of possible effects of linearly intervening negation that modulate acceptabilityin NPI contexts [35].
The Syntax of SyntaxObserve an example as in (6):
(6) Guess which politician your interest in clearly appeals to.
The construction in (6) is remarkable because a single wh-phrase is associated bothwith the prepositional object gap of to and with the prepositional object gap of in, as in(7a). We talk about ‘gaps’ because a possible response to (6) might be as in (7b):
(7) a. Guess which politician your interest in GAP clearly appeals to GAP.b. response to (7a): Your interest in Donald Trump clearly appeals to Donald Trump
(A) (B)
X X
X X X X
The book X X X The book X appealed to anybodydid not
that I bought appeal to anybody that I did not buy
Figure 1. Negative Polarity. (A) Negative polarity licensed: negative element c-commands negative polarity item.(B) Negative polarity not licensed. Negative element does not c-command negative polarity item.
734 Trends in Cognitive Sciences, December 2015, Vol. 19, No. 12
Generalization: not must “structurally precede” anybody- the psychological reality of structural sensitivty
is not empirically controversial - many different theories of the details of structure - more controversial hypothesis: kids learn language
easily because they don’t consider many “obvious” structural insensitive hypotheses
Language is hierarchical
The talk
I gavedid not
appeal to anybody
appealed to anybodyThe talk
I did not give

Examples adapted from Everaert et al. (TICS 2015)
containing anybody. (This structural configuration is called c(onstituent)-command in thelinguistics literature [31].) When the relationship between not and anybody adheres to thisstructural configuration, the sentence is well-formed.
In sentence (3), by contrast, not sequentially precedes anybody, but the triangle dominating notin Figure 1B fails to also dominate the structure containing anybody. Consequently, the sentenceis not well-formed.
The reader may confirm that the same hierarchical constraint dictates whether the examples in(4–5) are well-formed or not, where we have depicted the hierarchical sentence structure interms of conventional labeled brackets:
(4) [S1 [NP The book [S2 I bought]S2]NP did not [VP appeal to anyone]VP]S1(5) *[S1 [NP The book [S2 I did not buy]S2]NP [VP appealed to anyone]VP]S1
Only in example (4) does the hierarchical structure containing not (corresponding to the sentenceThe book I bought did not appeal to anyone) also immediately dominate the NPI anybody. In (5)not is embedded in at least one phrase that does not also include the NPI. So (4) is well-formedand (5) is not, exactly the predicted result if the hierarchical constraint is correct.
Even more strikingly, the same constraint appears to hold across languages and in many othersyntactic contexts. Note that Japanese-type languages follow this same pattern if we assumethat these languages have hierarchically structured expressions similar to English, but linearizethese structures somewhat differently – verbs come at the end of sentences, and so forth [32].Linear order, then, should not enter into the syntactic–semantic computation [33,34]. This israther independent of possible effects of linearly intervening negation that modulate acceptabilityin NPI contexts [35].
The Syntax of SyntaxObserve an example as in (6):
(6) Guess which politician your interest in clearly appeals to.
The construction in (6) is remarkable because a single wh-phrase is associated bothwith the prepositional object gap of to and with the prepositional object gap of in, as in(7a). We talk about ‘gaps’ because a possible response to (6) might be as in (7b):
(7) a. Guess which politician your interest in GAP clearly appeals to GAP.b. response to (7a): Your interest in Donald Trump clearly appeals to Donald Trump
(A) (B)
X X
X X X X
The book X X X The book X appealed to anybodydid not
that I bought appeal to anybody that I did not buy
Figure 1. Negative Polarity. (A) Negative polarity licensed: negative element c-commands negative polarity item.(B) Negative polarity not licensed. Negative element does not c-command negative polarity item.
734 Trends in Cognitive Sciences, December 2015, Vol. 19, No. 12
Generalization: not must “structurally precede” anybody- the psychological reality of structural sensitivty
is not empirically controversial - many different theories of the details of structure - more controversial hypothesis: kids learn language
easily because they don’t consider many “obvious” structural insensitive hypotheses
Language is hierarchical
The talk
I gavedid not
appeal to anybody
appealed to anybodyThe talk
I did not give

Examples adapted from Everaert et al. (TICS 2015)
containing anybody. (This structural configuration is called c(onstituent)-command in thelinguistics literature [31].) When the relationship between not and anybody adheres to thisstructural configuration, the sentence is well-formed.
In sentence (3), by contrast, not sequentially precedes anybody, but the triangle dominating notin Figure 1B fails to also dominate the structure containing anybody. Consequently, the sentenceis not well-formed.
The reader may confirm that the same hierarchical constraint dictates whether the examples in(4–5) are well-formed or not, where we have depicted the hierarchical sentence structure interms of conventional labeled brackets:
(4) [S1 [NP The book [S2 I bought]S2]NP did not [VP appeal to anyone]VP]S1(5) *[S1 [NP The book [S2 I did not buy]S2]NP [VP appealed to anyone]VP]S1
Only in example (4) does the hierarchical structure containing not (corresponding to the sentenceThe book I bought did not appeal to anyone) also immediately dominate the NPI anybody. In (5)not is embedded in at least one phrase that does not also include the NPI. So (4) is well-formedand (5) is not, exactly the predicted result if the hierarchical constraint is correct.
Even more strikingly, the same constraint appears to hold across languages and in many othersyntactic contexts. Note that Japanese-type languages follow this same pattern if we assumethat these languages have hierarchically structured expressions similar to English, but linearizethese structures somewhat differently – verbs come at the end of sentences, and so forth [32].Linear order, then, should not enter into the syntactic–semantic computation [33,34]. This israther independent of possible effects of linearly intervening negation that modulate acceptabilityin NPI contexts [35].
The Syntax of SyntaxObserve an example as in (6):
(6) Guess which politician your interest in clearly appeals to.
The construction in (6) is remarkable because a single wh-phrase is associated bothwith the prepositional object gap of to and with the prepositional object gap of in, as in(7a). We talk about ‘gaps’ because a possible response to (6) might be as in (7b):
(7) a. Guess which politician your interest in GAP clearly appeals to GAP.b. response to (7a): Your interest in Donald Trump clearly appeals to Donald Trump
(A) (B)
X X
X X X X
The book X X X The book X appealed to anybodydid not
that I bought appeal to anybody that I did not buy
Figure 1. Negative Polarity. (A) Negative polarity licensed: negative element c-commands negative polarity item.(B) Negative polarity not licensed. Negative element does not c-command negative polarity item.
734 Trends in Cognitive Sciences, December 2015, Vol. 19, No. 12
Generalization: not must “structurally precede” anybody- the psychological reality of structural sensitivty
is not empirically controversial - many different theories of the details of structure - more controversial hypothesis: kids learn language
easily because they don’t consider many “obvious” structural insensitive hypotheses
Language is hierarchical
The talk
I gavedid not
appeal to anybody
appealed to anybodyThe talk
I did not give

• Recurrent neural networks are incredibly powerful models of sequences (e.g., of words)
• In fact, RNNs are Turing complete!(Siegelmann, 1995)
• But do they make good generalizations from finite samples of data?
• What inductive biases do they have?
• Using syntactic annotations to improve inductive bias.
• Inferring better compositional structure without explicit annotation
Recurrent neural networksGood models of language?
(part 1)
(part 2)

• Recurrent neural networks are incredibly powerful models of sequences (e.g., of words)
• In fact, RNNs are Turing complete!(Siegelmann, 1995)
• But do they make good generalizations from finite samples of data?
• What inductive biases do they have?
• Using syntactic annotations to improve inductive bias.
• Inferring better compositional structure without explicit annotation
Recurrent neural networksGood models of language?
(part 1)
(part 2)

• Understanding the biases of neural networks is tricky
• We have enough trouble understanding the representations they learn in specific cases, much less general cases!
• But, there is lots of evidence RNNs prefer sequential recency
• Evidence 1: Gradients become attenuated across time
• Analysis; experiments with synthetic datasets(yes, LSTMs help but they have limits)
• Evidence 2: Training regimes like reversing sequences in seq2seq learning
• Evidence 3: Modeling enhancements to use attention (direct connections back in remote time)
• Evidence 4: Linzen et al. (2017) findings on English subject-verb agreement.
Recurrent neural networksInductive bias

• Understanding the biases of neural networks is tricky
• We have enough trouble understanding the representations they learn in specific cases, much less general cases!
• But, there is lots of evidence RNNs have a bias for sequential recency
• Evidence 1: Gradients become attenuated across time
• Functional analysis; experiments with synthetic datasets(yes, LSTMs/GRUs help, but they also forget)
• Evidence 2: Training regimes like reversing sequences in seq2seq learning
• Evidence 3: Modeling enhancements to use attention (direct connections back in remote time)
• Evidence 4: Linzen et al. (2017) findings on English subject-verb agreement.
Recurrent neural networksInductive bias

The keys to the cabinet in the closet is/are on the table.AGREE
Linzen, Dupoux, Goldberg (2017)

• Understanding the biases of neural networks is tricky
• We have enough trouble understanding the representations they learn in specific cases, much less general cases!
• But, there is lots of evidence RNNs have a bias for sequential recency
• Evidence 1: Gradients become attenuated across time
• Functional analysis; experiments with synthetic datasets(yes, LSTMs/GRUs help, but they also forget)
• Evidence 2: Training regimes like reversing sequences in seq2seq learning
• Evidence 3: Modeling enhancements to use attention (direct connections back in remote time)
• Evidence 4: Linzen et al. (2017) findings on English subject-verb agreement.
Recurrent neural networksInductive bias
Chomsky (crudely paraphrasing 60 years of work): Sequential recency is not the right bias for modeling human language.

An alternativeRecurrent Neural Net Grammars
• Generate symbols sequentially using an RNN
• Add some control symbols to rewrite the history occasionally
• Occasionally compress a sequence into a constituent
• RNN predicts next terminal/control symbol based on the history of compressed elements and non-compressed terminals
• This is a top-down, left-to-right generation of a tree+sequence
Adhi Kuncoro

An alternativeRecurrent Neural Net Grammars
• Generate symbols sequentially using an RNN
• Add some control symbols to rewrite the history occasionally
• Occasionally compress a sequence into a constituent
• RNN predicts next terminal/control symbol based on the history of compressed elements and non-compressed terminals
• This is a top-down, left-to-right generation of a tree+sequence
Adhi Kuncoro

• Generate symbols sequentially using an RNN
• Add some control symbols to rewrite the history occasionally
• Occasionally compress a sequence into a constituent
• RNN predicts next terminal/control symbol based on the history of compressed elements and non-compressed terminals
• This is a top-down, left-to-right generation of a tree+sequence
An alternativeRecurrent Neural Net Grammars
Adhi Kuncoro

The hungry cat meows loudly
Example derivation

stack action probability

stack action probabilityNT(S) p(nt(S) | top)

stack action
(S
probabilityNT(S) p(nt(S) | top)

stack action
(S
probabilityNT(S) p(nt(S) | top)
NT(NP) p(nt(NP) | (S)

stack action
(S
(S (NP
probabilityNT(S) p(nt(S) | top)
NT(NP) p(nt(NP) | (S)

stack action
(S
(S (NP
probabilityNT(S) p(nt(S) | top)
GEN(The) p(gen(The) | (S, (NP)
NT(NP) p(nt(NP) | (S)

stack action
(S
(S (NP
(S (NP The
probabilityNT(S) p(nt(S) | top)
GEN(The) p(gen(The) | (S, (NP)
NT(NP) p(nt(NP) | (S)

stack action
(S
(S (NP
(S (NP The
probabilityNT(S) p(nt(S) | top)
GEN(The) p(gen(The) | (S, (NP)
NT(NP) p(nt(NP) | (S)
GEN(hungry) p(gen(hungry) | (S, (NP,
The)

stack action
(S
(S (NP
(S (NP The hungry
(S (NP The
probabilityNT(S) p(nt(S) | top)
GEN(The) p(gen(The) | (S, (NP)
NT(NP) p(nt(NP) | (S)
GEN(hungry) p(gen(hungry) | (S, (NP,
The)

stack action
(S
(S (NP
(S (NP The hungry
(S (NP The
probabilityNT(S) p(nt(S) | top)
GEN(The) p(gen(The) | (S, (NP)
NT(NP) p(nt(NP) | (S)
GEN(hungry) p(gen(hungry) | (S, (NP,
The)GEN(cat) p(gen(cat) | . . .)

stack action
(S
(S (NP
(S (NP The hungry cat
(S (NP The hungry
(S (NP The
probabilityNT(S) p(nt(S) | top)
GEN(The) p(gen(The) | (S, (NP)
NT(NP) p(nt(NP) | (S)
GEN(hungry) p(gen(hungry) | (S, (NP,
The)GEN(cat) p(gen(cat) | . . .)

stack action
(S
(S (NP
(S (NP The hungry cat
(S (NP The hungry
(S (NP The
probabilityNT(S) p(nt(S) | top)
GEN(The) p(gen(The) | (S, (NP)
NT(NP) p(nt(NP) | (S)
GEN(hungry) p(gen(hungry) | (S, (NP,
The)GEN(cat) p(gen(cat) | . . .)
REDUCE p(reduce | . . .)

stack action
(S
(S (NP
(S (NP The hungry cat
(S (NP The hungry
(S (NP The
(S (NP The hungry cat )
probabilityNT(S) p(nt(S) | top)
GEN(The) p(gen(The) | (S, (NP)
NT(NP) p(nt(NP) | (S)
GEN(hungry) p(gen(hungry) | (S, (NP,
The)GEN(cat) p(gen(cat) | . . .)
REDUCE p(reduce | . . .)

stack action
(S
(S (NP
(S (NP The hungry cat
(S (NP The hungry
(S (NP The
(S (NP The hungry cat )
(S (NP The hungry cat)
Compress “The hungry cat” into a single composite symbol
probabilityNT(S) p(nt(S) | top)
GEN(The) p(gen(The) | (S, (NP)
NT(NP) p(nt(NP) | (S)
GEN(hungry) p(gen(hungry) | (S, (NP,
The)GEN(cat) p(gen(cat) | . . .)
REDUCE p(reduce | . . .)

stack action
(S (NP The hungry cat)
NT(S) p(nt(S) | top)
GEN(The) p(gen(The) | (S, (NP)
NT(NP) p(nt(NP) | (S)
GEN(hungry) p(gen(hungry) | (S, (NP,
The)GEN(cat) p(gen(cat) | . . .)
REDUCE p(reduce | . . .)
(S
(S (NP
(S (NP The hungry cat
(S (NP The hungry
(S (NP The
probability

stack action
(S (NP The hungry cat)
NT(S) p(nt(S) | top)
GEN(The) p(gen(The) | (S, (NP)
NT(NP) p(nt(NP) | (S)
GEN(hungry) p(gen(hungry) | (S, (NP,
The)GEN(cat) p(gen(cat) | . . .)
REDUCE p(reduce | . . .)
(S
(S (NP
(S (NP The hungry cat
(S (NP The hungry
(S (NP The
NT(VP) p(nt(VP) | (S,(NP The hungry cat))
probability

stack action
(S (NP The hungry cat) (VP
(S (NP The hungry cat)
NT(S) p(nt(S) | top)
GEN(The) p(gen(The) | (S, (NP)
NT(NP) p(nt(NP) | (S)
GEN(hungry) p(gen(hungry) | (S, (NP,
The)GEN(cat) p(gen(cat) | . . .)
REDUCE p(reduce | . . .)
(S
(S (NP
(S (NP The hungry cat
(S (NP The hungry
(S (NP The
NT(VP) p(nt(VP) | (S,(NP The hungry cat))
probability

stack action
GEN(meows)(S (NP The hungry cat) (VP
(S (NP The hungry cat)
NT(S) p(nt(S) | top)
GEN(The) p(gen(The) | (S, (NP)
NT(NP) p(nt(NP) | (S)
GEN(hungry) p(gen(hungry) | (S, (NP,
The)GEN(cat) p(gen(cat) | . . .)
REDUCE p(reduce | . . .)
(S
(S (NP
(S (NP The hungry cat
(S (NP The hungry
(S (NP The
NT(VP) p(nt(VP) | (S,(NP The hungry cat))
probability

stack action
GEN(meows)
REDUCE
(S (NP The hungry cat) (VP meows) GEN(.)
REDUCE
(S (NP The hungry cat) (VP meows) .)
(S (NP The hungry cat) (VP meows) .
(S (NP The hungry cat) (VP meows
(S (NP The hungry cat) (VP
(S (NP The hungry cat)
NT(S) p(nt(S) | top)
GEN(The) p(gen(The) | (S, (NP)
NT(NP) p(nt(NP) | (S)
GEN(hungry) p(gen(hungry) | (S, (NP,
The)GEN(cat) p(gen(cat) | . . .)
REDUCE p(reduce | . . .)
(S
(S (NP
(S (NP The hungry cat
(S (NP The hungry
(S (NP The
NT(VP) p(nt(VP) | (S,(NP The hungry cat))
probability

• Valid (tree, string) pairs are in bijection to valid sequences of actions (specifically, the DFS, left-to-right traversal of the trees)
• Every stack configuration perfectly encodes the complete history of actions.
• Therefore, the probability decomposition is justified by the chain rule, i.e.
(chain rule)
(prop 2)
p(x,y) = p(actions(x,y))
p(actions(x,y)) =Y
i
p(ai | a<i)
=Y
i
p(ai | stack(a<i))
(prop 1)
Some things you can show

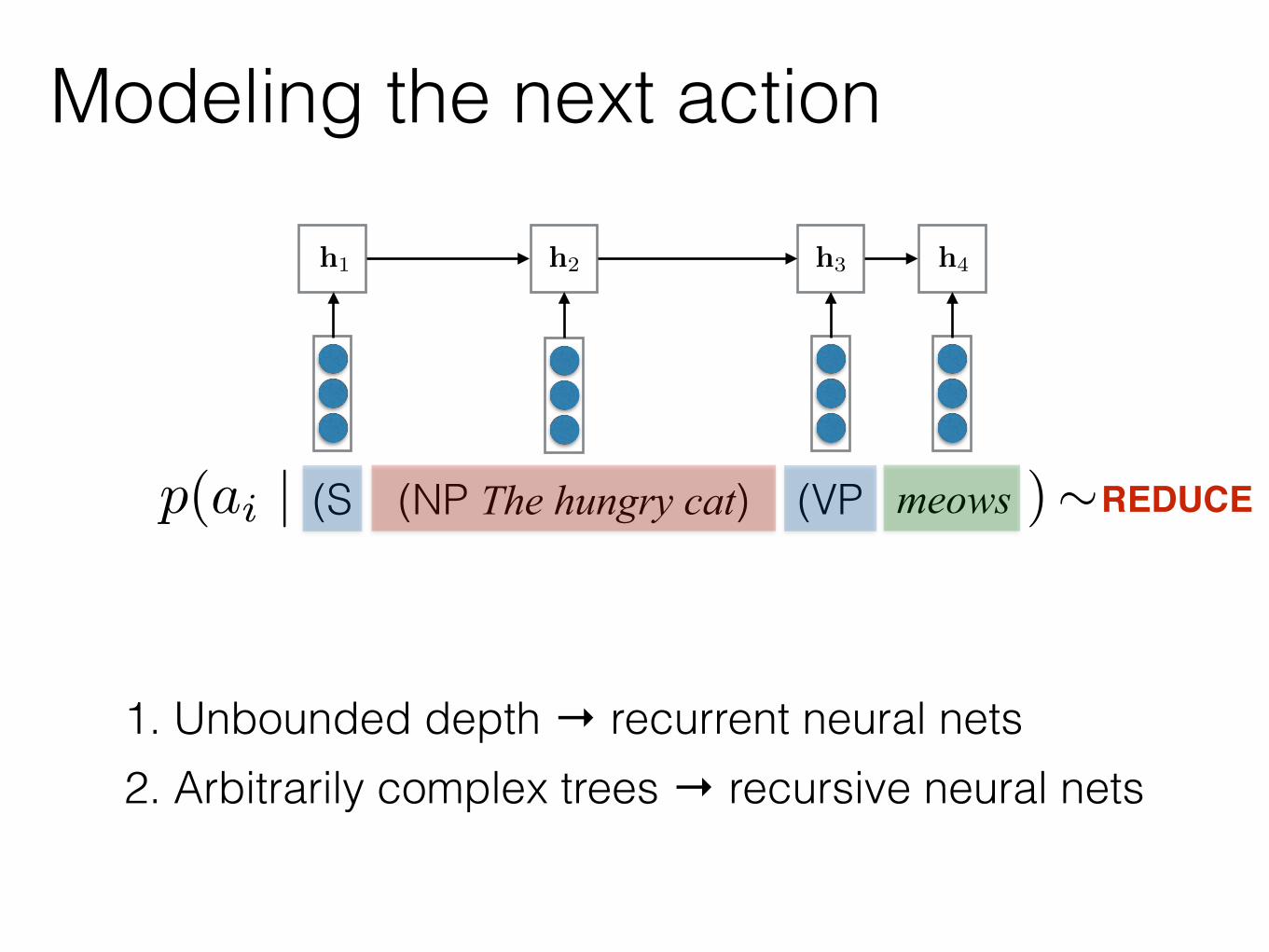
Modeling the next action
(S (NP The hungry cat) (VP meowsp(ai | )

Modeling the next action
(S (NP The hungry cat) (VP meowsp(ai | )
1. unbounded depth

Modeling the next action
(S (NP The hungry cat) (VP meowsp(ai | )
1. unbounded depth
1. Unbounded depth → recurrent neural nets
h1 h2 h3 h4

Modeling the next action
(S (NP The hungry cat) (VP meowsp(ai | )
1. Unbounded depth → recurrent neural nets
h1 h2 h3 h4

Modeling the next action
(S (NP The hungry cat) (VP meowsp(ai | )
1. Unbounded depth → recurrent neural nets
h1 h2 h3 h4
2. arbitrarily complex trees
2. Arbitrarily complex trees → recursive neural nets

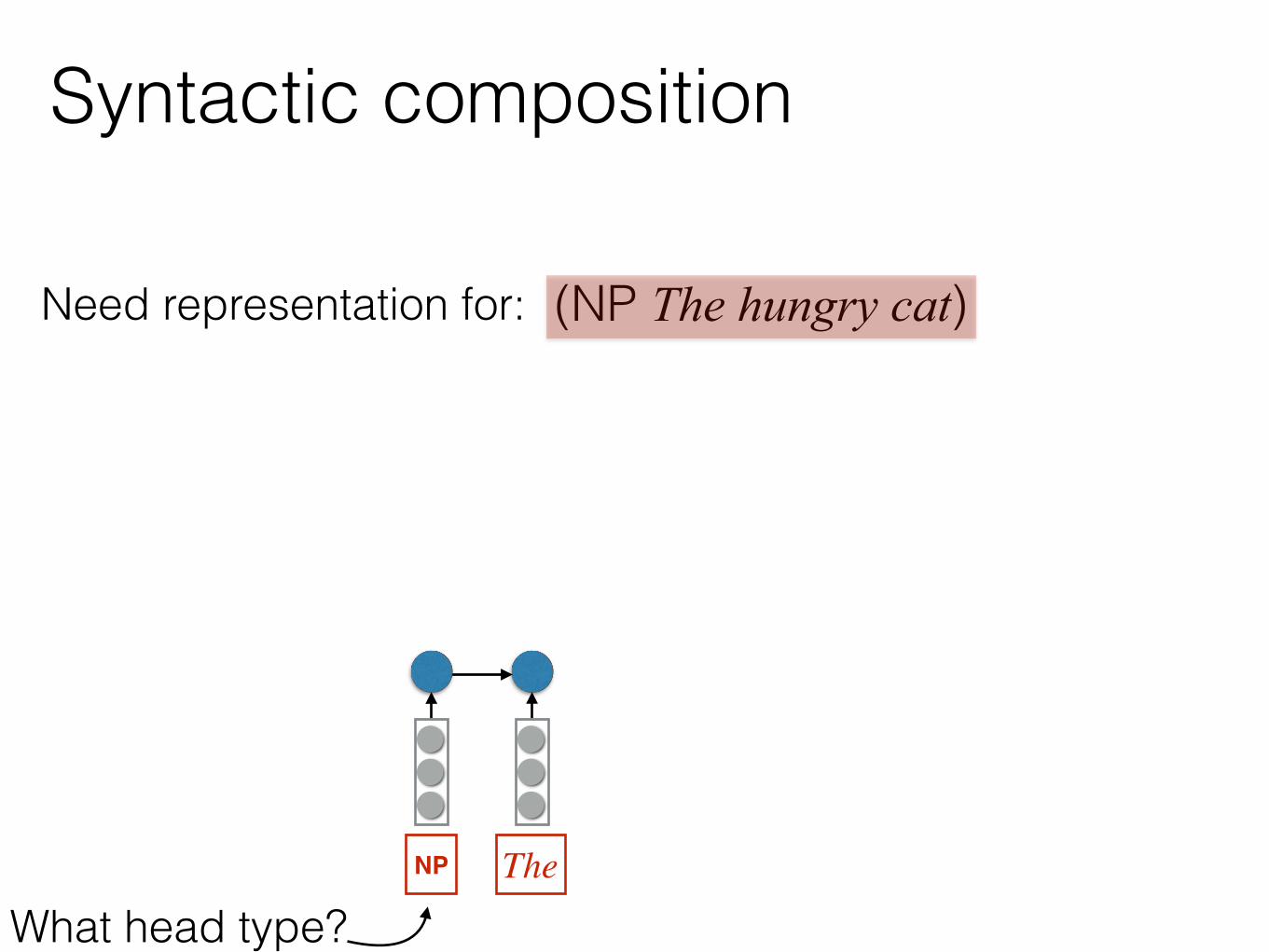
(NP The hungry cat)Need representation for:
Syntactic composition

(NP The hungry cat)Need representation for:
NP
What head type?
Syntactic composition
The
(NP The hungry cat)Need representation for:
NP
What head type?
Syntactic composition

The hungry
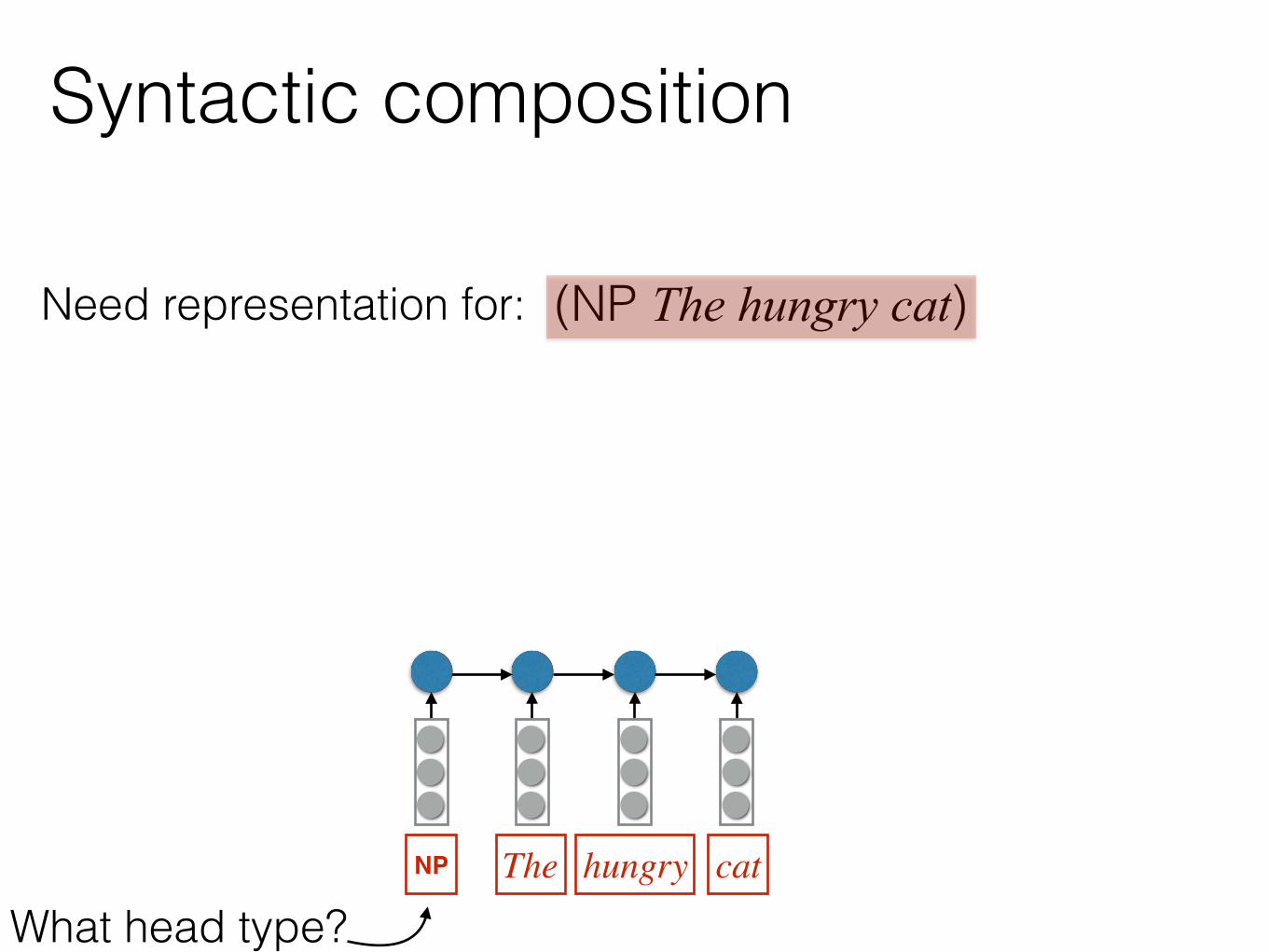
(NP The hungry cat)Need representation for:
NP
What head type?
Syntactic composition
The hungry cat
(NP The hungry cat)Need representation for:
NP
What head type?
Syntactic composition

The hungry cat )
(NP The hungry cat)Need representation for:
NP
What head type?
Syntactic composition

TheNP hungry cat )
(NP The hungry cat)Need representation for:
Syntactic composition

TheNP hungry cat ) NP
(NP The hungry cat)Need representation for:
Syntactic composition
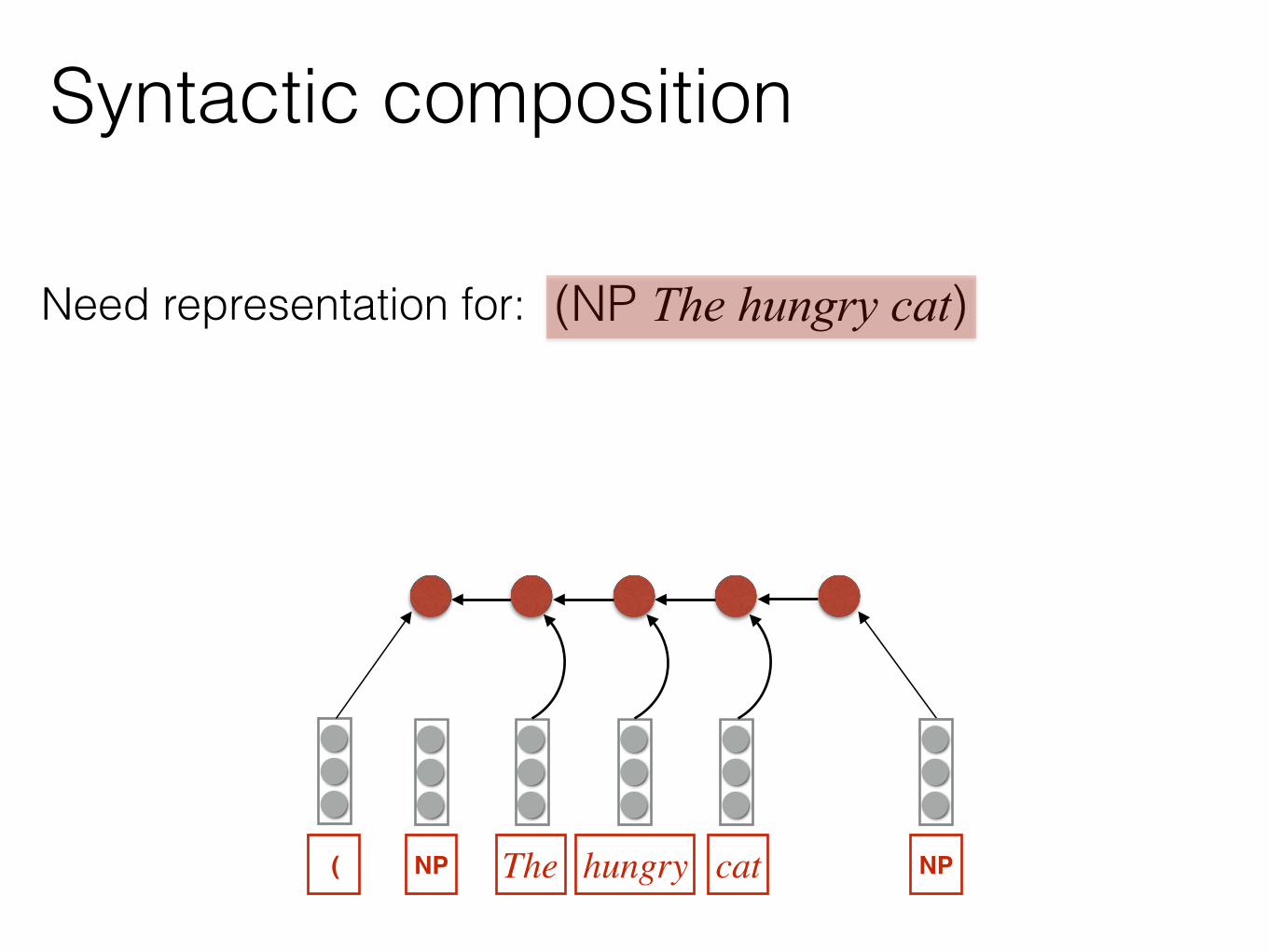
TheNP hungry cat ) NP
(NP The hungry cat)Need representation for:
(
Syntactic composition

TheNP hungry cat ) NP (
(NP The hungry cat)Need representation for:
Syntactic composition

TheNP cat ) NP (
(NP The (ADJP very hungry) cat)Need representation for: (NP The hungry cat)
hungry
Syntactic compositionRecursion

TheNP cat ) NP (
(NP The (ADJP very hungry) cat)Need representation for: (NP The hungry cat)
| {z }v
v
Syntactic compositionRecursion

Modeling the next action
(S (NP The hungry cat) (VP meowsp(ai | )
1. Unbounded depth → recurrent neural nets2. Arbitrarily complex trees → recursive neural nets
h1 h2 h3 h4
Modeling the next action
(S (NP The hungry cat) (VP meowsp(ai | )
1. Unbounded depth → recurrent neural nets2. Arbitrarily complex trees → recursive neural nets
⇠REDUCE
h1 h2 h3 h4

Modeling the next action
(S (NP The hungry cat) (VP meowsp(ai | )
1. Unbounded depth → recurrent neural nets2. Arbitrarily complex trees → recursive neural nets
⇠REDUCE
(S (NP The hungry cat) (VP meows)p(ai+1 | )

Modeling the next action
(S (NP The hungry cat) (VP meowsp(ai | )
1. Unbounded depth → recurrent neural nets2. Arbitrarily complex trees → recursive neural nets
⇠REDUCE
(S (NP The hungry cat) (VP meows)p(ai+1 | )3. limited updates
3. Limited updates to state → stack RNNs

• If we accept the following two propositions…
• Sequential RNNs have a recency bias
• Syntactic composition learns to represent trees by endocentric heads
• then we can say that they have a bias for syntactic recency rather than sequential recency
RNNGsInductive bias?

• If we accept the following two propositions…
• Sequential RNNs have a recency bias
• Syntactic composition learns to represent trees by endocentric heads
• then we can say that they have a bias for syntactic recency rather than sequential recency
RNNGsInductive bias?
(S (NP The keys (PP to the cabinet (PP in the closet))) (VP is/are

• If we accept the following two propositions…
• Sequential RNNs have a recency bias
• Syntactic composition learns to represent trees by endocentric heads
• then we can say that they have a bias for syntactic recency rather than sequential recency
RNNGsInductive bias?
(S (NP The keys (PP to the cabinet (PP in the closet))) (VP is/are
“keys”z }| {

• If we accept the following two propositions…
• Sequential RNNs have a recency bias
• Syntactic composition learns to represent trees by endocentric heads
• then we can say that they have a bias for syntactic recency rather than sequential recency
RNNGsInductive bias?
(S (NP The keys (PP to the cabinet (PP in the closet))) (VP is/are
“keys”z }| {

• If we accept the following two propositions…
• Sequential RNNs have a recency bias
• Syntactic composition learns to represent trees by endocentric heads
• then we can say that they have a bias for syntactic recency rather than sequential recency
RNNGsInductive bias?
(S (NP The keys (PP to the cabinet (PP in the closet))) (VP is/are
The keys to the cabinet in the closet is/areSequential RNN:
“keys”z }| {

• Generative models are great! We have defined a joint distribution p(x,y) over strings (x) and parse trees (y)
• We can look at two questions:
• What is p(x) for a given x? [language modeling]
• What is max p(y | x) for a given x? [parsing]
RNNGsA few empirical results

English PTB (Parsing)Type F1
Petrov and Klein (2007) Gen 90.1
Shindo et al (2012)Single model Gen 91.1
Vinyals et al (2015)PTB only Disc 90.5
Shindo et al (2012)Ensemble Gen 92.4
Vinyals et al (2015)Semisupervised
Disc+SemiSup 92.8
Discriminative PTB only Disc 91.7
Generative PTB only Gen 93.6
Choe and Charniak (2016)Semisupervised
Gen+SemiSup 93.8
Fried et al. (2017) Gen+Semi+Ensemble 94.7

English PTB (Parsing)Type F1
Petrov and Klein (2007) Gen 90.1
Shindo et al (2012)Single model Gen 91.1
Vinyals et al (2015)PTB only Disc 90.5
Shindo et al (2012)Ensemble Gen 92.4
Vinyals et al (2015)Semisupervised
Disc+SemiSup 92.8
Discriminative PTB only Disc 91.7
Generative PTB only Gen 93.6
Choe and Charniak (2016)Semisupervised
Gen+SemiSup 93.8
Fried et al. (2017) Gen+Semi+Ensemble 94.7

English PTB (Parsing)Type F1
Petrov and Klein (2007) Gen 90.1
Shindo et al (2012)Single model Gen 91.1
Vinyals et al (2015)PTB only Disc 90.5
Shindo et al (2012)Ensemble Gen 92.4
Vinyals et al (2015)Semisupervised
Disc+SemiSup 92.8
Discriminative PTB only Disc 91.7
Generative PTB only Gen 93.6
Choe and Charniak (2016)Semisupervised
Gen+SemiSup 93.8
Fried et al. (2017) Gen+Semi+Ensemble 94.7

Type F1
Petrov and Klein (2007) Gen 90.1
Shindo et al (2012)Single model Gen 91.1
Vinyals et al (2015)PTB only Disc 90.5
Shindo et al (2012)Ensemble Gen 92.4
Vinyals et al (2015)Semisupervised
Disc+SemiSup 92.8
Discriminative PTB only Disc 91.7
Generative PTB only Gen 93.6
Choe and Charniak (2016)Semisupervised
Gen+SemiSup 93.8
Fried et al. (2017) Gen+Semi+Ensemble 94.7
English PTB (Parsing)

Perplexity
5-gram IKN 169.3
LSTM + Dropout 113.4
Generative (IS) 102.4
English PTB (LM)

• RNNGs are effective for modeling language and parsing
• Finding 1: Generative parser > discriminative parser
• Better sample complexity
• No label bias in modeling action sequence
• Finding 2: RNNGs > RNNs
• PTB phrase structure is a useful inductive bias for making good linguistic generalizations!
• Open question: Do RNNGs solve the Linzen, Dupoux, and Goldberg problem?
Summary

• Recurrent neural networks are incredibly powerful models of sequences (e.g., of words)
• In fact, RNNs are Turing complete!(Siegelmann, 1995)
• But do they make good generalizations from finite samples of data?
• What inductive biases do they have?
• Using syntactic annotations to improve inductive bias.
• Inferring better compositional structure without explicit annotation
Recurrent neural networksGood models of language?
(part 1)
(part 2)

• We have compared two end points: a sequence model and a PTB-based syntactic model
• If we search for structure to obtain the best performance on down stream tasks, what will it find?
• In this part of the talk, I focus on representation learning for sentences.
Unsupervised structureDo we need syntactic annotation?
Dani Yogatama

• Advances in deep learning have led to three predominant approaches for constructing representations of sentences
Background
• Convolutional neural networks
• Recurrent neural networks
• Recursive neural networks
Kim, 2014; Kalchbrenner et al., 2014; Ma et al., 2015
Cho et al., 2014; Sutskever et al., 2014; Bahdanau et al., 2014
Socher et al., 2011; Socher et al., 2013; Tai et al., 2015; Bowman et al., 2016

• Advances in deep learning have led to three predominant approaches for constructing representations of sentences
Background
• Convolutional neural networks
• Recurrent neural networks
• Recursive neural networks
Kim, 2014; Kalchbrenner et al., 2014; Ma et al., 2015
Cho et al., 2014; Sutskever et al., 2014; Bahdanau et al., 2014
Socher et al., 2011; Socher et al., 2013; Tai et al., 2015; Bowman et al., 2016

Recurrent Encoder
A boy drags his sleds through the snow
output
input
(word embeddings)
L = � log p(y | x)

Recursive Encoder
A boy drags his sleds through the snow
output
input
(word embeddings)

Recursive Encoder
• Prior work on tree-structured neural networks assumed that the trees are either provided as input or predicted based on explicit human annotations (Socher et al., 2013; Bowman et al., 2016; Dyer et al., 2016)
• When children learn a new language, they are not given parse trees
• Infer tree structure as a latent variable that is marginalized during learning of a downstream task that depends on the composed representation.
• Hierarchical structures can also be encoded into a word embedding model to improve performance and interpretability (Yogatama et al., 2015)
L = � log p(y | x)
= � log
X
z2Z(x)
p(y, z | x)

Model• Shift reduce parsing
A boy drags his sleds
(Aho and Ullman, 1972)
Stack Queue

Model• Shift reduce parsing
A boy drags his sleds
(Aho and Ullman, 1972)
Stack Queue

Model• Shift reduce parsing
boy drags his sleds
(Aho and Ullman, 1972)
Stack Queue
SHIFT
A
A
Tree

Model• Shift reduce parsing
boy drags his sleds
(Aho and Ullman, 1972)
Stack Queue
A
A
Tree

Model• Shift reduce parsing
drags his sleds
(Aho and Ullman, 1972)
Stack Queue
SHIFT
A
boy
A
Tree
boy

Model• Shift reduce parsing
drags his sleds
(Aho and Ullman, 1972)
Stack Queue
A
boy
A
Tree
boy

Model• Shift reduce parsing
drags his sleds
(Aho and Ullman, 1972)
Stack Queue
A
boy
REDUCEA
Tree
boy

Model• Shift reduce parsing
drags his sleds
(Aho and Ullman, 1972)
Stack Queue
REDUCE
i = �(WI [hi,hj ] + bI)
o = �(WO[hi,hj ] + bI)
fL = �(WFL [hi,hj ] + bFL)
fR = �(WFR [hi,hj ] + bFR)
g = tanh(WG[hi,hj ] + bG)
c = fL � ci + fR � cj + i� g
h = o� c
• Compose top two elements of the stack with Tree LSTM (Tai et al., 2015 Zhu et al., 2015)
A
boy

Model• Shift reduce parsing
drags his sleds
(Aho and Ullman, 1972)
Stack Queue
REDUCE
• Compose top two elements of the stack with Tree LSTM (Tai et al., 2015 Zhu et al., 2015)
Tree-LSTM(a, boy)
• Push the result back onto the stack
A
Tree
boy

Model• Shift reduce parsing
drags his sleds
(Aho and Ullman, 1972)
Stack Queue
Tree-LSTM(a, boy)
A
Tree
boy
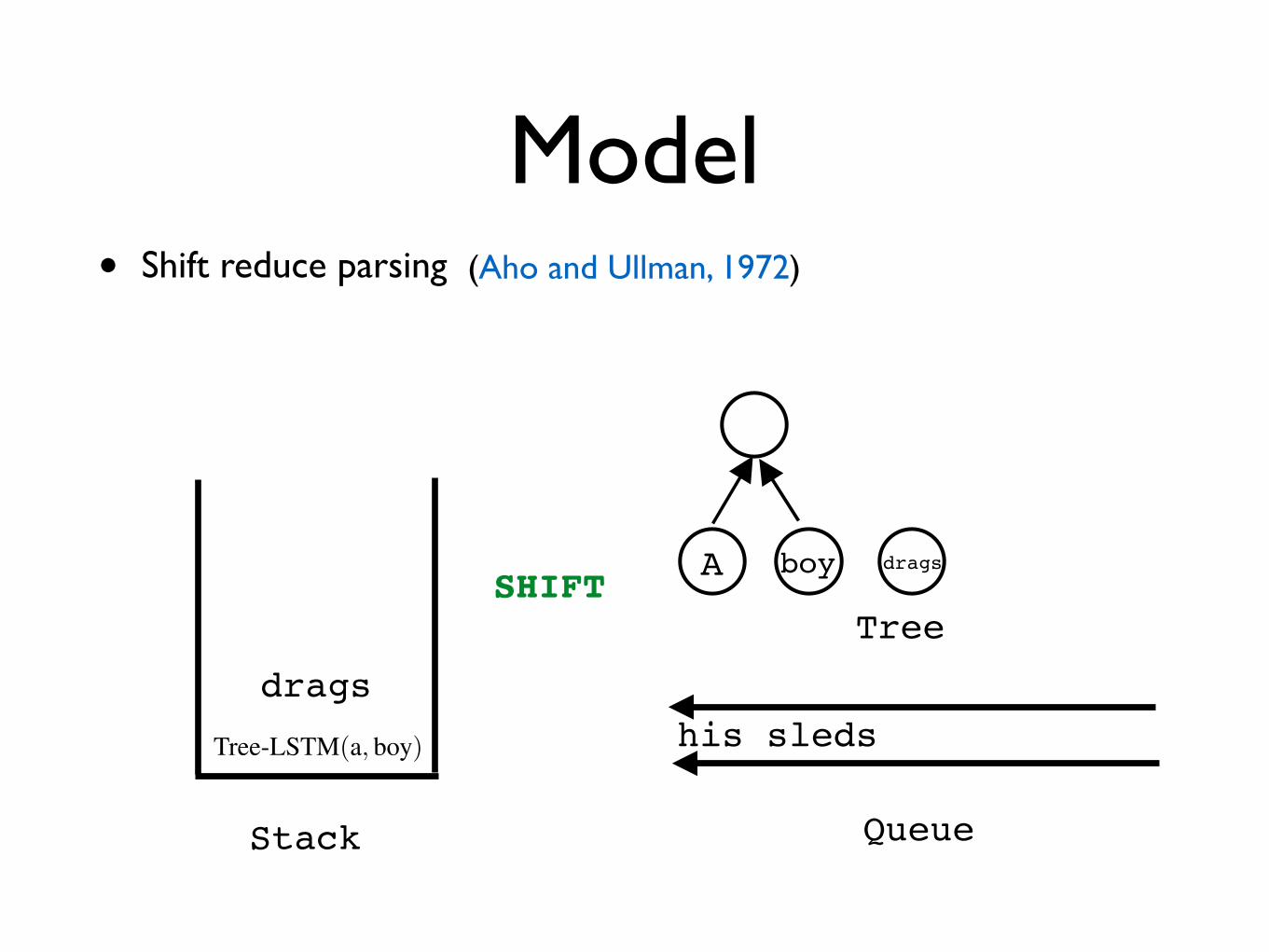
Model• Shift reduce parsing
his sleds
(Aho and Ullman, 1972)
Stack Queue
Tree-LSTM(a, boy)
SHIFT
drags
A
Tree
boy drags
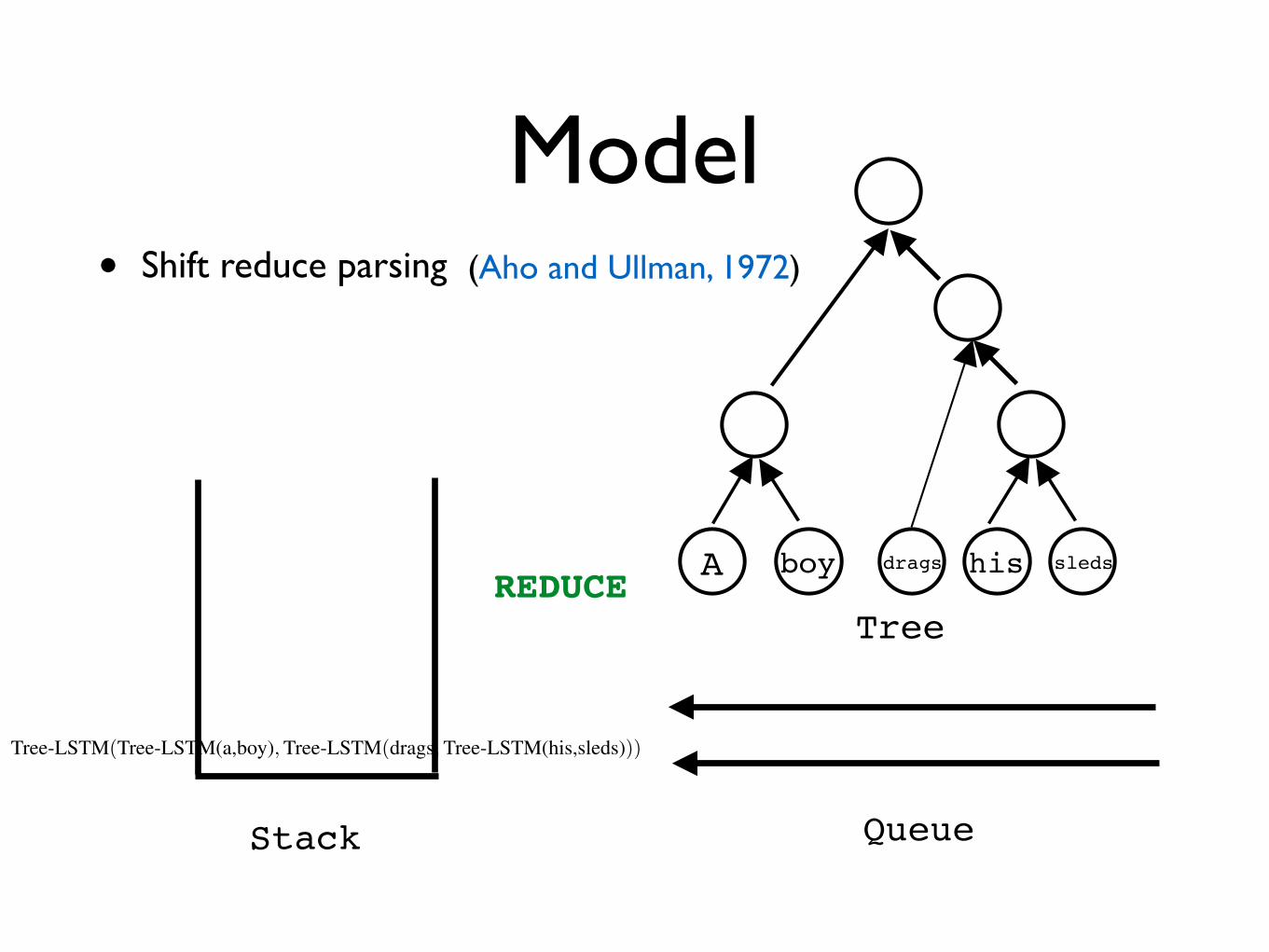
Model• Shift reduce parsing (Aho and Ullman, 1972)
Stack Queue
REDUCE
Tree-LSTM(Tree-LSTM(a,boy),Tree-LSTM(drags,Tree-LSTM(his,sleds)))
A
Tree
boy drags his sleds

• Shift reduce parsing
Model
1 2 4 5
3 6
7
1 2 4 6
3
7
5
1 2 3 4
7
5
6
1 2 3 6
4
5
7
S, S,R, S, S,R,R S, S, S,R,R, S,R S, S,R, S,R, S,R S, S, S, S,R,R,R
Different Shift/Reduce sequences lead to different tree structures
(Aho and Ullman, 1972)

Learning• How do we learn the policy for the shift reduce sequence?
• Supervised learning! Imitation learning!
• But we need a treebank.
• What if we don’t have labels?

Reinforcement Learning• Given a state, and a set of possible actions, an agent needs to
decide what is the best possible action to take
• There is no supervision, only rewards which can be not observed until after several actions are taken

Reinforcement Learning• Given a state, and a set of possible actions, an agent needs to
decide what is the best possible action to take
• There is no supervision, only rewards which can be not observed until after several actions are taken
• State
• Action
• A Shift-Reduce “agent”
• Reward
embeddings of top two elements of the stack, embedding of head of the queue
shift, reduce
log likelihood on a downstream task given the produced representation

Reinforcement Learning
• We use a simple policy gradient method, REINFORCE (Williams, 1992)
R(W) = E⇡(a,s;WR)
"TX
t=1
rtat
#⇡(a | s;WR)• The goal of training is to train a policy network
to maximize rewards
• Other techniques for approximating the marginal likelihood are available (Guu et al., 2017)

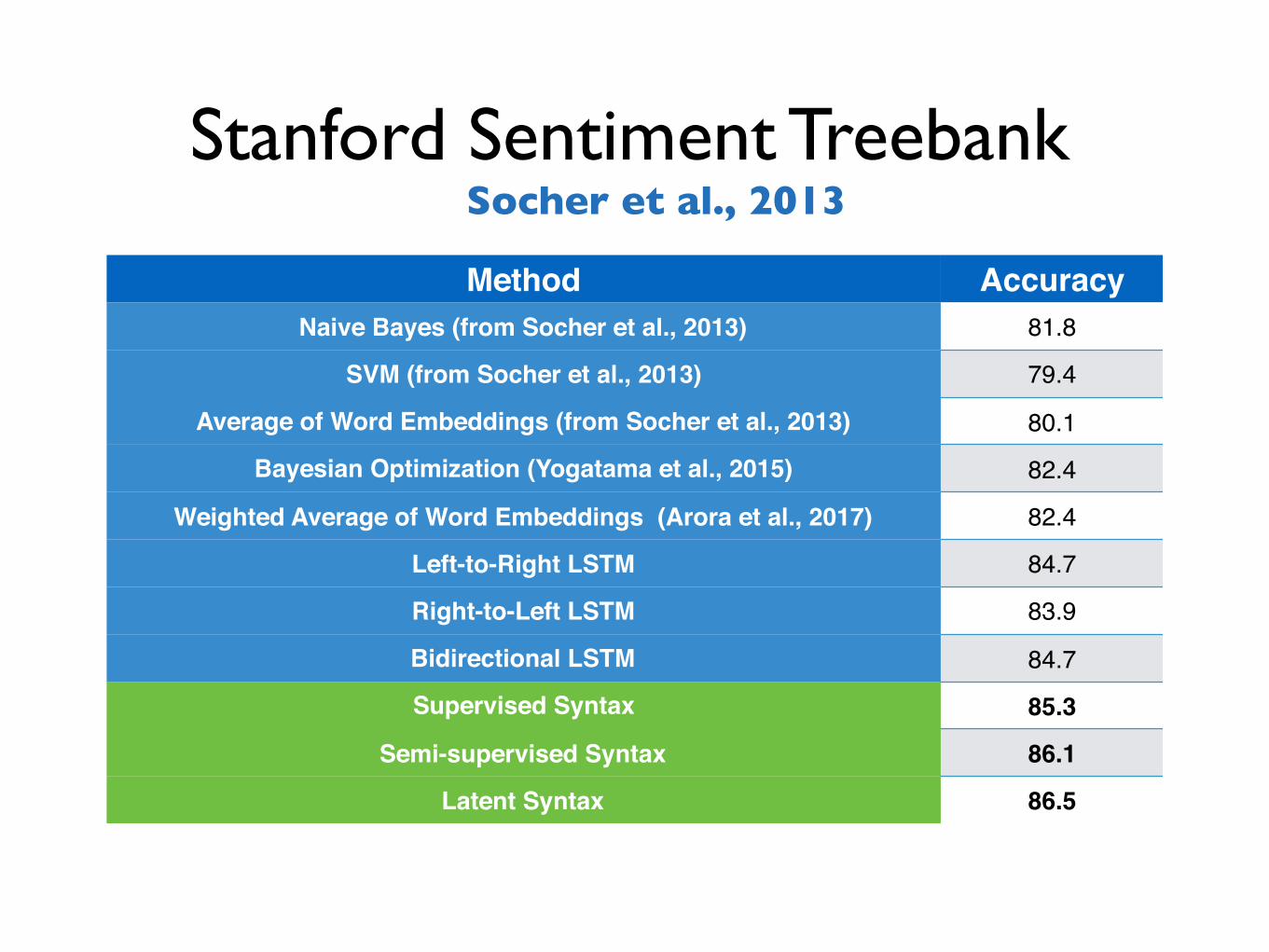
Stanford Sentiment Treebank
Method AccuracyNaive Bayes (from Socher et al., 2013) 81.8
SVM (from Socher et al., 2013) 79.4
Average of Word Embeddings (from Socher et al., 2013) 80.1
Bayesian Optimization (Yogatama et al., 2015) 82.4
Weighted Average of Word Embeddings (Arora et al., 2017) 82.4
Left-to-Right LSTM 84.7
Right-to-Left LSTM 83.9
Bidirectional LSTM 84.7
Supervised Syntax 85.3
Semi-supervised Syntax 86.1
Latent Syntax 86.5
Socher et al., 2013
Stanford Sentiment Treebank
Method AccuracyNaive Bayes (from Socher et al., 2013) 81.8
SVM (from Socher et al., 2013) 79.4
Average of Word Embeddings (from Socher et al., 2013) 80.1
Bayesian Optimization (Yogatama et al., 2015) 82.4
Weighted Average of Word Embeddings (Arora et al., 2017) 82.4
Left-to-Right LSTM 84.7
Right-to-Left LSTM 83.9
Bidirectional LSTM 84.7
Supervised Syntax 85.3
Semi-supervised Syntax 86.1
Latent Syntax 86.5
Socher et al., 2013

Examples of Learned Structures
intuitive structures

non-intuitive structures
Examples of Learned Structures

• Trees look “non linguistic”
• But downstream performance is great!
• Ignore the generation of the sentence in favor of optimal structures for interpretation
• Natural languages must balance both.
Grammar Induction Summary

• Do we need better bias in our models?
• Yes! They are making the wrong generalizations, even from large data.
• Do we have to have the perfect model?
• No! Small steps in the right direction can pay big dividends.
Linguistic Structure Summary

Thanks!
Questions?


















