Brge Svingen Chief Technology O cer, Open AdExchange
47
Genetic programming with regular expressions Børge Svingen Chief Technology Officer, Open AdExchange [email protected] 2009-03-23
Transcript of Brge Svingen Chief Technology O cer, Open AdExchange

Genetic programming with regular expressions
Børge SvingenChief Technology Officer, Open AdExchange
2009-03-23

Pattern discovery
Pattern discovery: Recognizing patterns that characterize featuresin data
Type of data Example feature
Meteorological data Bad weatherDNA Predisposition for diseaseSeismic data Presence of oilFinancial data Changes in stock prices

Purpose of this lecture
Three things:
I Practical how-to on pattern discovery
I Provide an example of using formal methods for solving apractical problem
I Demonstrate a promising topic for future work

Pattern discovery in sequences
We focus on finding patterns in sequences:
I Biological sequences (DNA, RNA, amino acids etc.)
I Time series (temperature, stock prices, etc.)
I Mathematical sequences (arithmetic, geometric etc.)

What do sequences have in common?
What do sequences that share a feature have in common?
I What do genetic sequences that give a predisposition for adisease have in common?
I What do stock price time series that lead to a crack have incommon?
I What do geometric sequences have in common?

Training sets
I Training sets: Input to the pattern discovery algorithm
I Positive training set: Contains sequences that have the feature
I Negative training set: Contains sequences that do not havethe feature
I Negative training set not always presentI One solution: Use random sequences as negative training set

Representing sequences - languages
Formal definitions:
I Alphabet: A set of characters.
I String: A finite sequence over an alphabet.
I Language: A set of strings.
We want to represent languages, i.e., the set of strings of thetraining sets

Representing sequences - types of languages
Types of languages:
I Regular languages. Can be decided by a finite automaton.
I Context-free languages. Can be decided by a push-downautomaton.
I Context-sensitive languages. Can be decided by a Turingmachine with finite memory.
I Recursive languages. Can be decided by a Turing machine.
I Recursively enumerable languages. Can be enumerated byTuring machines.
We will focus on regular languages.
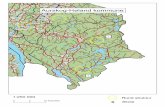
Deterministic finite automata (DFA)
s0
s1
s2
s3
0
1
1
0
0
1
Represents the languagedescribed by the strings
01001000100001...10110111011110...

DFA definition
A deterministic finite automaton is a 5-tuple (Q,Σ, δ, q0,F ) where
I A finite set of states Q.
I An alphabet Σ.
I A transition function δ : Q × Σ→ Q.
I A start state q0 ∈ Q.
I A set of accept states F ⊆ Q.
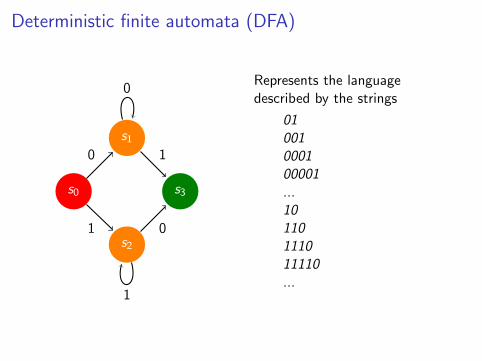
DFA example
s0
s1
s2
s3
0
1
1
0
0
1
Q = {s0, s1, s2, s3}Σ = {0, 1}q0 = s0
F = {s3}
s0 s1 s2
0 s1 s1 s31 s2 s3 s2

Nondeterministic finite automata (NFA)
s1
s2 s3
b
aa,b
εa
I NFAs have multiple choicesfor moving between states.
I Must evaluate all options.
I In multiple states ”at once”.

NFA definition
A nondeterministic finite automaton is a 5-tuple (Q,Σ, δ, q0,F )where
I A finite set of states Q.
I An alphabet Σ.
I A transition function δ : Q × Σε → P(Q).
I A start state q0 ∈ Q.
I A set of accept states F ⊆ Q.

Evolutionary algorithms
Using evolution forsolving problems:
I A populationof solutions
I Selection basedon fitness (howwell thesolution solvesthe problem)
I Reproductionwith mutation
I Repeat for anumber ofgenerations
Initial generation
Evaluation
Goodenough?
SelectionNo
Reproduction
Done
Yes

Types of evolutionary algorithms
Evolutionaryalgorithms
Geneticalgorithms
Geneticprogramming
Evolutionaryprogramming
Evolutionstrategy
Learningclassifiersystems

Genetic programming - evolving programs
I In GP the individuals of thepopulation are programs
I The programs are in theform of trees (can be seenas parse trees)
I Fitness is evaluated byrunning the program
if
>
x 3
x 4
Examples of GP applications
I Designing electric circuits
I Optimization problems
I Robot control
I Pattern discovery
I Symbolic regression
+
x *
7 x

Fitness
I Fitness tells us how good a program is at solving the problem.
I Fitness is calculated by a fitness function.
I The fitness of a program decides the probability of beingselected for the next generation.
I The goal of genetic programming is to optimize the fitnessfunction.
Important: The fitness function needs to allow for gradualimprovements.

The fitness function
Different types of fitness:
I Raw fitness. Application specific context. fr (i , t) gives rawfitness for individual i in generation t.
I Standardized fitness. Standardized fitness fs(i , t) is raw fitnessadjusted so that lower values are better and 0 is best.
I Adjusted fitness. Adjusted fitness is standardized fitnessadjusted so that all fitness values fall between 0 and 1, with 1being the best. fa(i , t) = 1
1+fs(i ,t).
I Normalized fitness. Normalized fitness is adjusted fitnessnormalized so that the sum of program fitness over the wholepopulation is 1. fn(i , t) = fa(i ,t)PM
k=1 fa(k,t)where M is the
population size.

Program primitives
I Programs are built from afunction set and a terminalset.
I An important property isclosure: All functions shouldaccept all values returned byother functions or terminals.
I In this example,
F ⊆ {if , >}
andT ⊆ {x ,N}
if
>
x 3
x 4
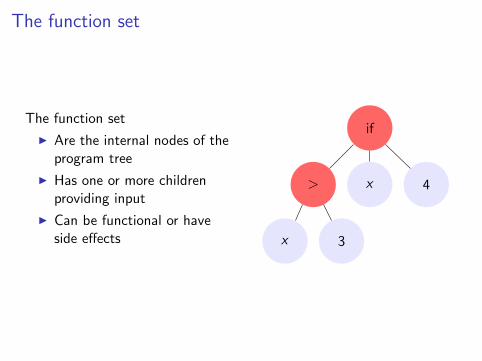
The function set
The function set
I Are the internal nodes of theprogram tree
I Has one or more childrenproviding input
I Can be functional or haveside effects
if
>
x 3
x 4
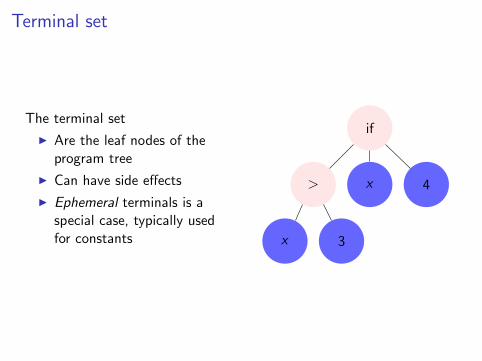
Terminal set
The terminal set
I Are the leaf nodes of theprogram tree
I Can have side effects
I Ephemeral terminals is aspecial case, typically usedfor constants
if
>
x 3
x 4

Growing trees
I The initial population consists of random trees
I Functions and terminals randomly selectedI Two main ways of building random trees of a given depth:
I The full method: All leaves have the same depth.I The grow methods: Randomly choose between functions and
terminals, create leaves of different depth.
I The ”ramped half-and half” method:I Equally distributed between different depthsI For each tree of a given depth, randomly choose between the
full or grow methodI Creates tree shape diversity
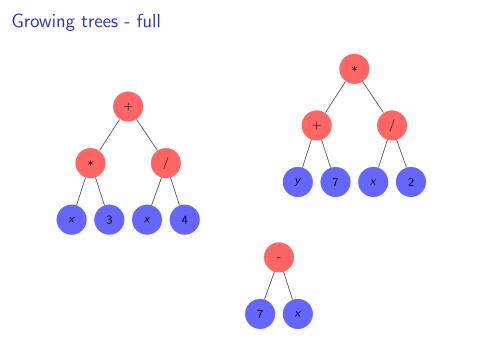
Growing trees - full
+
∗
x 3
/
x 4
-
7 x
∗
+
y 7
/
x 2
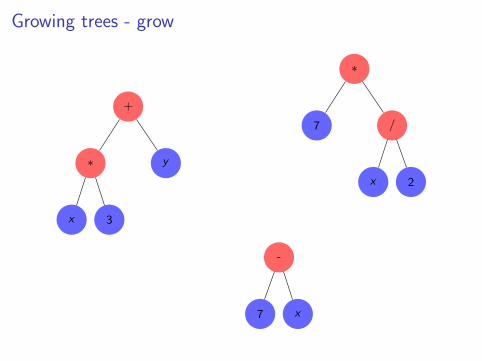
Growing trees - grow
+
∗
x 3
y
-
7 x
∗
7 /
x 2

Reproduction - crossover
+
∗
x 3
y
-
7 x
+
∗
x 3
y
-
7 x
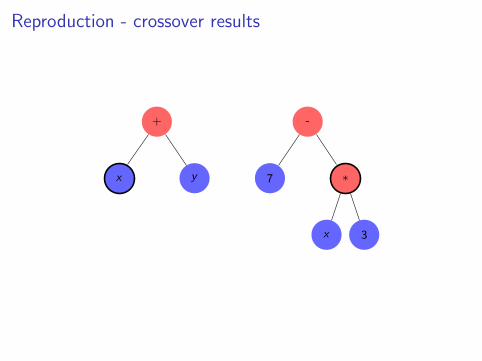
Reproduction - crossover results
+
x y
-
7 ∗
x 3
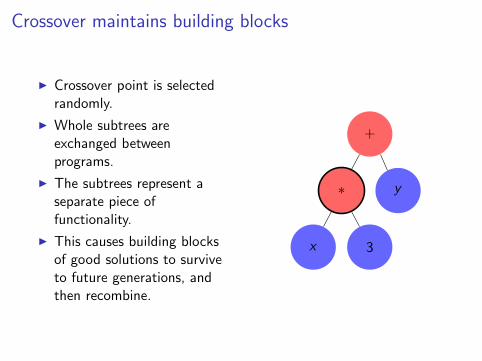
Crossover maintains building blocks
I Crossover point is selectedrandomly.
I Whole subtrees areexchanged betweenprograms.
I The subtrees represent aseparate piece offunctionality.
I This causes building blocksof good solutions to surviveto future generations, andthen recombine.
+
∗
x 3
y
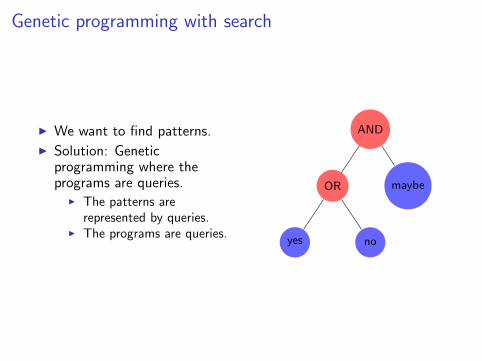
Genetic programming with search
I We want to find patterns.I Solution: Genetic
programming where theprograms are queries.
I The patterns arerepresented by queries.
I The programs are queries.
AND
OR
yes no
maybe

Evolving queries
I Every member of the population is a query.
I We evaluate each query by searching the training sets.
I The fitness function is given by how close the queries matchthe training sets.
I Trivial fitness: Count number of incorrect classifications.

Genetic programming with search - an example
An example of geneticprogramming with search([3, 2, 5]):
I Genetic programming doneon the genetic programmingmailing list.
I Simple single word basedsearch.
I Trying to classify articlesabout GP selection methods.
I GP done on positive andnegative training sets.
I Results tested on separatetest set.
ADF1 (IF (OR P0 (PRESENT candidate))(IF (+
(PRESENT tournament)(PRESENT demes)
)1P0
)(IF (PRESENT tournaments)
8607(IF (PRESENT tournament)
1(PRESENT (- (PRESENT scant) 1))
))
)ADF2 (+ 3980 (NOT P0))ADF3 (IF (PRESENT tournament)
1(- (ADF1 P0))
)RPB0 (IF (ADF2 1 1)
(-(- (PRESENT deme))(ADF3 (PRESENT pet))
)(ADF3 0))
RPB1 (IF (PRESENT galapagos)5976(PRESENT deme)
)RPB2 1
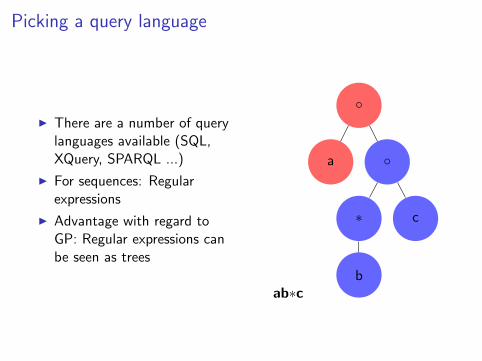
Picking a query language
I There are a number of querylanguages available (SQL,XQuery, SPARQL ...)
I For sequences: Regularexpressions
I Advantage with regard toGP: Regular expressions canbe seen as trees
ab∗c
◦
a ◦
∗
b
c

Regular expressions
Regular expressions can be defined by the following grammar:
R → a, for some a ∈ Σ (1)
R → ε (2)
R → ∅ (3)
R → (R ∪ R) (4)
R → (R ◦ R) (5)
R → (R∗) (6)
Σ is here the alphabet used, (R1 ∪ R2) matches either R1 or R2,and (R1 ◦ R2) matches R1 followed by R2. (R1∗) matches anynumber of occurrences of R1.
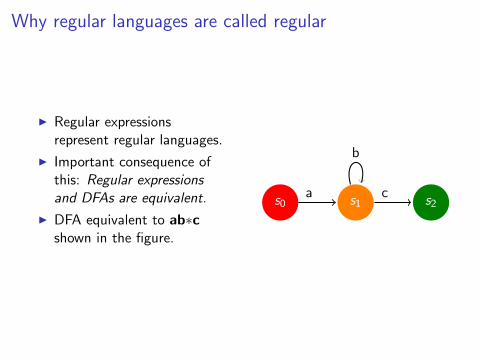
Why regular languages are called regular
I Regular expressionsrepresent regular languages.
I Important consequence ofthis: Regular expressionsand DFAs are equivalent.
I DFA equivalent to ab∗cshown in the figure.
s0 s1 s2a
b
c

Equivalence proof for DFA and regular expressions
Proof outline:
I DFAs and NFAs are equivalentI DFA → NFA is trivial, DFA ⊆ NFA.I NFA → DFA: Create DFA with ”collective” states.
Regular expression → DFA
1. Build NFA recursively for regular expression2. Convert NFA to DFA
DFA → regular expressionI More complex ... The main idea is to use GNFAs, NFAs where
the edges may contain regular expressions, and convert theGNFA to a regular expression

Pattern evolution
An algorithm for evolving DFAs:
1. Use GP to find regular expressions.
2. Convert the regular expressions to DFA.

A practical example
I Used the Tomita benchmark languages, a set of seven regularlanguages.
I For each language, used positive and negative training sets of500 strings, the latter randomly created.
I Each GP individual was a regular expression tree.
I Each regular expression tree was evaluated on the trainingsets by creating a DFA.
I Population size of 10000 over 100 generations.
[4]

The Tomita benchmark languages
Language Description
TL1 1*TL2 (10)*TL3 no odd 0 strings after odd 1 stringsTL4 no 000 substringsTL5 an even number of 01’s and 10’sTL6 number of 1’s - number of 0’s is multiple
of 3TL7 0*1*0*1*

Function set
Function Arity Explanation
+ 2 Builds an automaton that ac-cepts any string accepted by oneof the two argument automata.
. 2 Builds an automaton that ac-cepts any string that is the con-catenation of two strings thatare accepted by the two argu-ment automata, respectively.
* 1 Builds an automaton that ac-cepts any string that is theconcatenation of any numberof strings where each string isaccepted by the argument au-tomaton.

Terminal set
Terminal Explanation
0 Returns an automaton accept-ing the single character ’0’.
1 Returns an automaton accept-ing the single character ’1’.

Results 1-4
Language Solution Simplified Solution
TL1 (* (* 1)) 1*TL2 (* (* (. 1 0))) (10)*TL3 (. (* (+ (. 1 (+ (+ 1
1) (. 1 0))) (* 0))) (. (*(+ (. 1 (+ (+ 1 (. 0 0))(. 1 0))) (* (. 0 0)))) (*1)))
(11 | 110 | 0)*(11 | 100 |110 | 00)*1*
TL4 (+ 0 (. (+ (* (+ 1 (. 0(+ 1 (. 0 1))))) 1) (+(+ (. (. 0 0) (* 1)) 0)(* (+ 1 (. (+ (. 1 0) 1)0))))))
((1 | 01 | 001)*|001*|0)(1 | 100 | 10)*

Results 5-7
Language Solution Simplified Solution
TL5 (+ (* (+ 0 (. (. 0 (* (*(. (* 0) 1)))) 0))) (* (.(. 1 (* (. (* 0) 1))) (*1))))
(0 | 0(0*1)*0)* |(1(0*1)*1*)*
TL6 (* (+ (* (+ (. 1 (. (* (.1 0)) 0)) (. (. 0 (* (* (.0 1)))) 1))) (+ (* (+ (.1 (. 1 1)) (. (. (. 1 1) (*(. 0 1))) 1))) (. (. (. 0(* (* (. 0 1)))) 0) 0))))
(1(10)*0 | 0(01)*1 |11(01)*1 | 0(01)*00)*
TL7 (. (. (. (* (* 0)) (* 1))(* 0)) (* (+ 1 1)))
0*1*0*1*

Pattern Matching Chip (PMC)

The end.

Bibliography I
Arne Halaas, Børge Svingen, Magnar Nedland, Pal Sætrom,Ola Snøve, and Olaf Birkeland.A recursive MISD architecture for pattern matching.IEEE Transactions on Very large Scale Integration (VLSI)Systems, 12(7):727–734, July 2004.
Børge Svingen.GP++ an introduction.In John R. Koza, editor, Late Breaking Papers at the 1997Genetic Programming Conference, pages 231–239, StanfordUniversity, CA, USA, 13–16 July 1997. Stanford Bookstore.
Børge Svingen.Using genetic programming for document classification.In John R. Koza, editor, Late Breaking Papers at the 1997Genetic Programming Conference, pages 240–245, StanfordUniversity, CA, USA, 13–16 July 1997. Stanford Bookstore.

Bibliography II
Børge Svingen.Learning regular languages using genetic programming.In John R. Koza, Wolfgang Banzhaf, Kumar Chellapilla,Kalyanmoy Deb, Marco Dorigo, David B. Fogel, Max H.Garzon, David E. Goldberg, Hitoshi Iba, and Rick Riolo,editors, Genetic Programming 1998: Proceedings of the ThirdAnnual Conference, pages 374–376, University of Wisconsin,Madison, Wisconsin, USA, 22-25 July 1998. MorganKaufmann.
Børge Svingen.Using genetic programming for document classification.In Diane J. Cook, editor, Proceedings of the EleventhInterational Florida Artificial Intelligence Research SymposiumConference. AAAI Press, 1998.

Bibliography III
Michael Sipser.Introduction to the Theory of Computation.PWS Publishing Company, 1997.
M. Tomita.Dynamic construction of finite-state automata from examplesusing hill climbing.In Proceedings of the Fourth Annual Cognitive ScienceConference, pages 105–108, Ann Arbor, MI, 1982.