
Analytics with Cassandra & Spark - Big Data User Group Mannheim
Upload
planet-cassandraCategory
view
297download
2
Company Confidential 1
Sorry for the Delay• There were some technical difficulties, so we are giving folks a
few more minutes to join
• Again – sorry for the dely
© 2014 DataStax, All Rights Reserved.


All attendees
placed on muteInput questions at any time
using the online interface
Webinar Housekeeping

Big Data Analytics with Cassandra and Spark
Brian Hess
Sr. Product Manager for Analytics
DataStax

Company Confidential 5© 2014 DataStax, All Rights Reserved.

Company Confidential 6© 2014 DataStax, All Rights Reserved.
Willie SuttonBank Robber in the 1930s-1950sFBI Most Wanted List 1950 Captured in 1952

Company Confidential 7© 2014 DataStax, All Rights Reserved.
Willie Sutton
When asked “Why do you rob banks?”
“Because that’s where the money is.”

Company Confidential 8
Motivating Use CaseInternet of Things
© 2014 DataStax, All Rights Reserved.
Your Syste
m

Company Confidential 9
Motivating Use CaseInternet of Things
© 2014 DataStax, All Rights Reserved.
Your Syste
m

Company Confidential 10
Motivating Use CaseInternet of Things
© 2014 DataStax, All Rights Reserved.
Your Syste
mFAULT

Company Confidential 11© 2014 DataStax, All Rights Reserved.
Cassandra
Spark
Spark + Cassandra

Company Confidential 12
Apache Cassandra
• Distributed NoSQL database– BigTable meets Dynamo
• All nodes are equal– Always on– Linear scale out - a lot
• More data• More transactions
• Multi-Datacenter– Geographic or Workload
• Cassandra Query Language– SQL-like
© 2014 DataStax, All Rights Reserved.
200,000txns/sec
100,000txns/sec
400,000txns/sec

Company Confidential 13
How Cassandra Works – Writes
© 2014 DataStax, All Rights Reserved.
It’s 72°
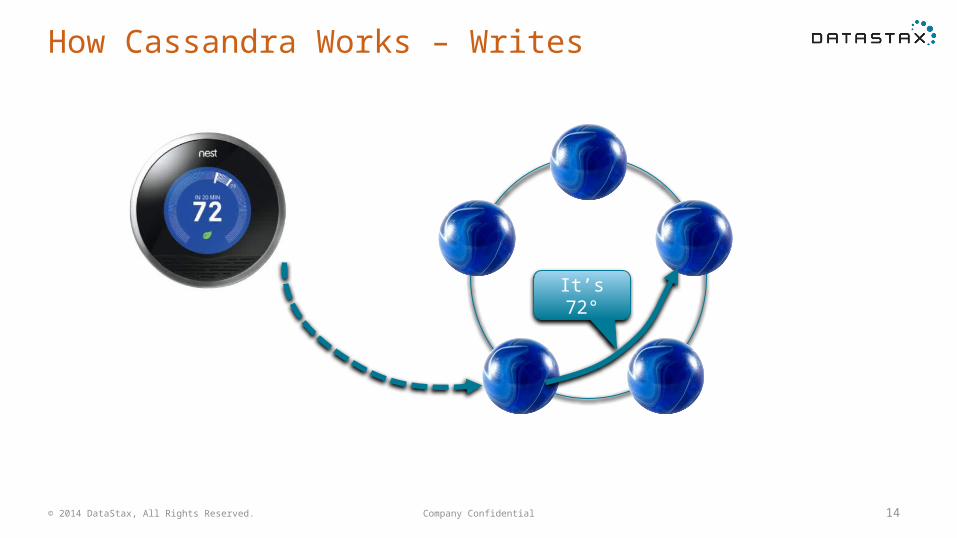
Company Confidential 14
How Cassandra Works – Writes
© 2014 DataStax, All Rights Reserved.
It’s 72°
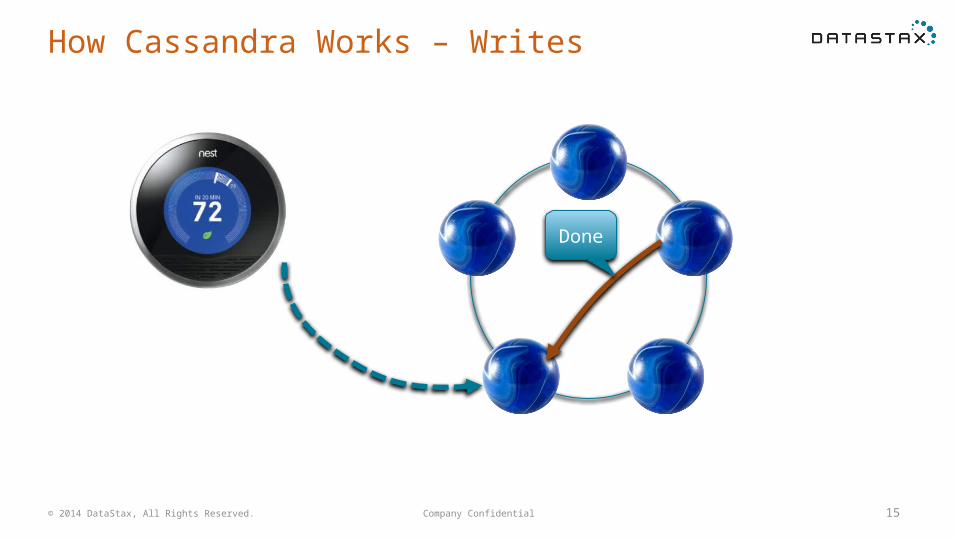
Company Confidential 15
How Cassandra Works – Writes
© 2014 DataStax, All Rights Reserved.
Done
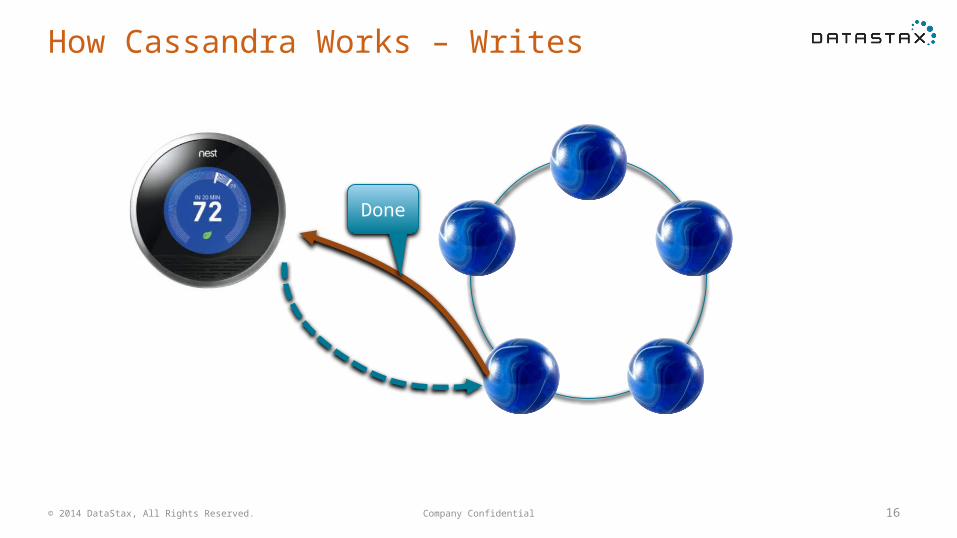
Company Confidential 16
How Cassandra Works – Writes
© 2014 DataStax, All Rights Reserved.
Done

Company Confidential 17
Tunable Consistency
• Relax the Consistency in ACID– Isn’t always needed – and isn’t guaranteed anyway (in distributed DBs)– Reads my not get the most up-to-date data – but almost always will
• All data is replicated– Set in the schema– Distributed to nodes by Token Range
• Options:– QUORUM, ONE, ALL
• Can ensure reads get most up-to-date value– E.g. – read/write at QUORUM
© 2014 DataStax, All Rights Reserved.

Company Confidential 18
How Cassandra Works – Tunable Consistency
© 2014 DataStax, All Rights Reserved.
You got it. I’ll make sure
everyone gets it.
You got it. A majority got it.
The rest will.
You got it.One guy got it.The rest will.
You got it. Everyone has it.

Company Confidential 19
How Cassandra Works – Query
© 2014 DataStax, All Rights Reserved.
SELECT user_idFROM usersWHERE name =‘PBCupFan’;

Company Confidential 20
How Cassandra Works – Query
© 2014 DataStax, All Rights Reserved.
Sure Thing, Let me get that for you.
SELECT user_idFROM usersWHERE name =‘PBCupFan’;
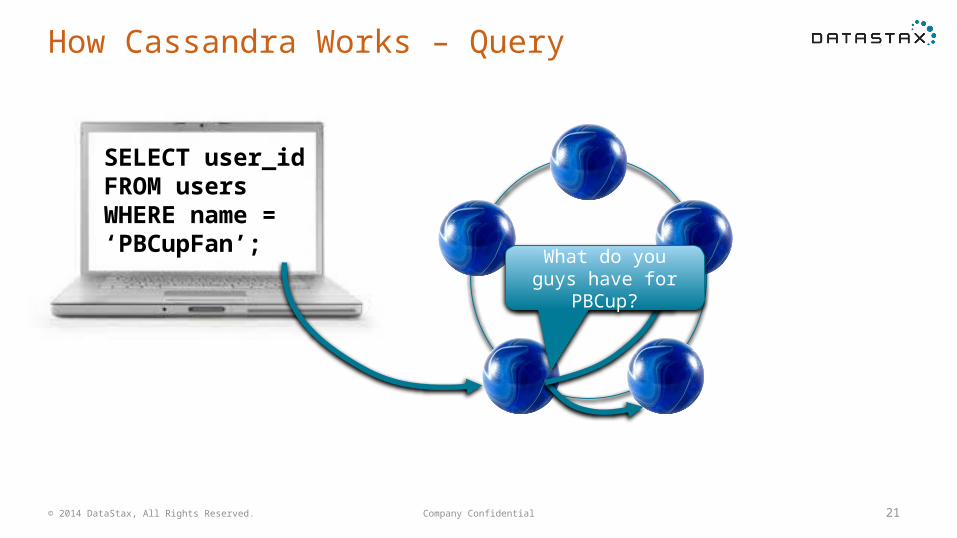
Company Confidential 21
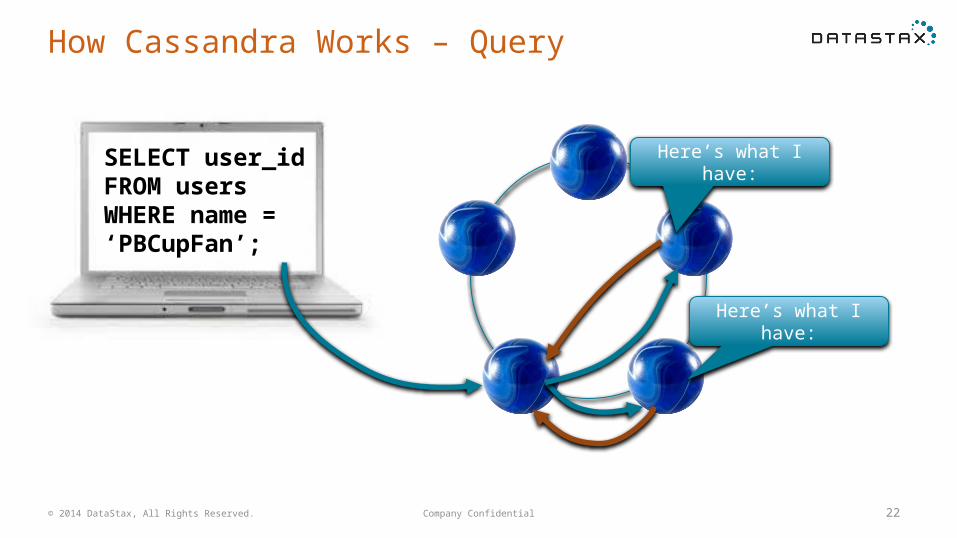
How Cassandra Works – Query
© 2014 DataStax, All Rights Reserved.
What do you guys have for PBCup?
SELECT user_idFROM usersWHERE name =‘PBCupFan’;
Company Confidential 22
How Cassandra Works – Query
© 2014 DataStax, All Rights Reserved.
Here’s what I have:
Here’s what I have:
SELECT user_idFROM usersWHERE name =‘PBCupFan’;

Company Confidential 23
How Cassandra Works – Query
© 2014 DataStax, All Rights Reserved.
Let me resolve any conflicts
SELECT user_idFROM usersWHERE name =‘PBCupFan’;

Company Confidential 24
How Cassandra Works – Query
© 2014 DataStax, All Rights Reserved.
Here ya go!
user_id--------- 1234
(1 rows)

Company Confidential 25
Cassandra for Internet of Things
It’s all about scaling
© 2014 DataStax, All Rights Reserved.

Company Confidential 26
Cassandra for Internet of Things
It’s all about scaling
© 2014 DataStax, All Rights Reserved.

Company Confidential 27
Cassandra for Internet of Things
It’s all about scaling
© 2014 DataStax, All Rights Reserved.

Company Confidential 28
Cassandra
• Always On– No down time
• Linear Scalability– For writes or reads– For data size
© 2014 DataStax, All Rights Reserved.
• Terrific choice for Internet of Things, Web, Mobile, etc. – British Gas, Nike, etc – Thermostats, Manufacturing, Oil/Gas, etc
It’s where the data is!

Company Confidential 29
Cassandra Limitations
• No aggregations– Optimized for lookups & writes– No GROUP BYs– No Windowed Aggregates
• No Joins– Data model to avoid
• Must select by partition key– There are secondary indexes
• But they are an antipattern
• Not optimized for full-table scans
© 2014 DataStax, All Rights Reserved.
It actually can’t do everything

Company Confidential 30
Apache Spark
• Distributed computing framework• Generalized DAG execution• Easy Abstraction for Datasets• Integrated SQL Queries• Streaming• Machine Learning Library
© 2014 DataStax, All Rights Reserved.
All In One Package!

Company Confidential 31
Spark Components
© 2014 DataStax, All Rights Reserved.
Spark Core Engine
Spark SQL SparkStreaming
MLlib GraphX Spark R

Company Confidential 32
Spark Components
© 2014 DataStax, All Rights Reserved.
TRANSFORMS
SQLStreaming Machine
LearningGraph
Analytics R

Spark Provides a Simple and Efficient framework for Distributed ComputationsNode Roles 2
In Memory Caching Yes!
Generic DAG Execution Yes!
Great Abstraction For Datasets? Dataframe!(previously Resilient Distributed Dataset (RDD))
SparkMaster
SparkWorker
SparkWorker
SparkWorkerSpark Executor
Spark Partition
Dataframe(or RDD)

Spark Provides a Simple and Efficient framework for Distributed Computations
Spark Master: Assigns cluster resources to applicationsSpark Worker: Manages executors running on a machineSpark Executor: Started by Worker - Workhorse of the spark application
SparkMaster
SparkWorker
SparkWorker
SparkWorkerSpark Executor
Spark Partition
Dataframe(or RDD)

Spark Provides a Simple and Efficient framework for Distributed Computations
Spark Master: Assigns cluster resources to applicationsSpark Worker: Manages executors running on a machineSpark Executor: Started by Worker - Workhorse of the spark application
SparkMaster
SparkWorker
SparkWorker
SparkWorkerSpark Executor
Spark Partition
Dataframe(or RDD)

Spark Provides a Simple and Efficient framework for Distributed Computations
Spark Master: Assigns cluster resources to applicationsSpark Worker: Manages executors running on a machineSpark Executor: Started by Worker - Workhorse of the spark application
SparkMaster
SparkWorker
SparkWorker
SparkWorkerSpark Executor
Spark Partition
Dataframe(or RDD)

RDDs Can be Generated from a Variety of Sources
Textfiles
Parallelized Collections

RDDs Can be Generated from a Variety of Sources
Textfiles
Parallelized Collections


Company Confidential 40
Spark on Cassandra
© 2014 DataStax, All Rights Reserved.
Spark Core Engine
Spark SQL SparkStreaming
MLlib GraphX Spark R
Cassandra
DataStax Spark-Cassandra Connector

Spark Cassandra Connector uses the DataStax Java Driver to Read from and Write to Cassandra
Each Executor Maintains a connection to the C* Cluster
Spark Executor
DataStax Java Driver
Tokens 1-1000
Tokens 1001 -2000
Tokens …
RDD’s read into different splits based on sets of tokens
C*
Full TokenRange

Company Confidential 42© 2014 DataStax, All Rights Reserved.

Company Confidential 43
Co-locate Spark and C* for Best Performance
• Run Cassandra and Spark on same nodes
• Local reads/writes
• Increased performance
© 2014 DataStax, All Rights Reserved.

Company Confidential 44
Things you can’t do in Cassandra– Using SparkSQL
• JOINssc.sql("SELECT t.sensor_id, t.temp, m.location
FROM ks.temperatures t JOIN ks.metadata mON t.sensor_id = m.sensor_idWHERE t.sensor_id = 12345");
• Aggregatessc.sql("SELECT sensor_id, year, month, MAX(temp) mtemp
FROM ks.temperaturesGROUP BY sensor_id, year, month");
© 2014 DataStax, All Rights Reserved.

Company Confidential 45
Things you can’t do in Cassandra– External Data
• JOIN with HDFS data
val temp2014 = sc.textFile("webhdfs://myhadoop/data/temp2014.csv").map(x=>x.split(",")).map(x=>((x(0).toInt, x(1).toInt, x(2).toInt),
x(3).toDouble))val temp2015 = sc.cassandraTable("ks", "temperatures").
map(x=>((x.getInt("sensor_id"), x.getInt("year"), x.getInt("month")),
x.getDouble("avgTemp")))val hotter = temp2015.join(temp2014).filter(x => x._2._1._1 > x._2._2._1)
• Non-Partition Key Predicates
csc.sql("SELECT * FROM ks.temperatures WHERE temp > 100")© 2014 DataStax, All Rights Reserved.

Company Confidential 46
Tools
• ODBC and JDBC tools via SparkSQL– Tableau, Pentaho, R, etc
• Apache Zeppelin (incubating)A web-based notebook
that enables interactive data
analytics.
© 2014 DataStax, All Rights Reserved.

Company Confidential 47
Quick word on Spark Streaming and Cassandra• Very good combination
– Simple, powerful, useful, scalable, etc, etc, etc.
© 2014 DataStax, All Rights Reserved.
Rec
eive
r

Company Confidential 48
Quick word on Spark Streaming and Cassandra
© 2014 DataStax, All Rights Reserved.
import com.datastax.spark.connector.streaming._
// Spark connection optionsval conf = new SparkConf(true)...
// streaming with 1 second batch windowval ssc = new StreamingContext(conf, Seconds(1))
// stream inputval lines = ssc.socketTextStream(serverIP, serverPort)
// count wordsval wordCounts = lines.flatMap(_.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
// stream outputwordCounts.saveToCassandra("test", "words")
// start processingssc.start() ssc.awaitTermination()

Company Confidential 49
DataStax Enterprise
© 2014 DataStax, All Rights Reserved.
Combines Cassandra,Spark, and Solr (and more!)
- Fault Tolerance- Management- Visual Monitoring- Security- ETC!

Company Confidential 50
Motivating Use CaseInternet of Things
© 2014 DataStax, All Rights Reserved.

Company Confidential 51
Cassandra + Spark
• Unleash the power of analytics• On your operational data
– IoT, Web, Mobile, etc
© 2014 DataStax, All Rights Reserved.
“Because that’s where the Data is.”
Company Confidential 52
Contacts and Links
• Links– Cassandra Summit: http://cassandrasummit-datastax.com/ – DataStax Academy: https://academy.datastax.com/
• Contacts– Kevin Pardue, Regional Channel Manager: [email protected] – Brian Hess, Sr Product Manager for Analytics: [email protected] – Devin Saxon, Marketing Specialist: [email protected]
© 2014 DataStax, All Rights Reserved.

Company Confidential 53© 2014 DataStax, All Rights Reserved.


















