
Analytics with Cassandra & Spark - Big Data User Group Mannheim
31
codecentric AG Matthias Niehoff Big Data Analytics with Cassandra & Spark
-
Upload
matthias-niehoff -
Category
Software
-
view
67 -
download
3
Transcript of Analytics with Cassandra & Spark - Big Data User Group Mannheim

codecentric AG
Matthias Niehoff
Big Data Analytics with Cassandra & Spark

codecentric AG
– Cassandra
– Spark Basics
– Spark & Cassandra
- Cassandra Spark Connector
- In A Cluster
- Use Cases
– Live Demo
AGENDA

codecentric AG
– Distributed database
– Highly available
– Linear scalable
– Multi datacenter support
– No singe point of failure
– CQL Querying Language
- Similar to SQL
- No joins & aggregates
– Eventual Consistency „Tunable Consistency“
CASSANDRA
15.04.2023 3

codecentric AG
DISTRIBUTED DATASTORAGE
15.04.2023 4
Node 1
Node 2
Node 3
Node 4
1-25
26-5051-75
76-0

codecentric AG
SELECT * FROM performer WHERE name = 'ACDC’
ok
SELECT * FROM performer WHERE name = 'ACDC’ and country = ’Australia’
not ok
SELECT country, COUNT(*) as quantity FROM artists GROUP BY country ORDER BY quantity DESC
not possible
CQL – QUERYING LANGUAGE WITH LIMITATIONS
15.04.2023 5
performer
name text K
style text
country text
type text

codecentric AG
– "Spark … is what you might call a Swiss Army knife of Big Data
Data analytics tools" – Reynold Xin, Berkeley Amplab
– Open Source & Apache project since 2010
– Data processing framework
- Batch processing
- Stream processing
WHAT IS APACHE SPARK?
15/04/2023 6

codecentric AG
scala> val textFile = sc.textFile("README.md")
textFile: spark.RDD[String] = spark.MappedRDD@2ee9b6e3
scala> val linesWithSpark = textFile.filter(line => line.contains("Spark"))
linesWithSpark: spark.RDD[String] = spark.FilteredRDD@7dd4af09
scala> linesWithSpark.count()
res0: Long = 126
SPARK EXAMPLE
15.04.2023 7
Transformation
Action

codecentric AG
REPRODUCE RDD USING A TREE
15.04.2023 8
Datenquelle
rdd1
rdd3
val1 rdd5
rdd2
rdd4
val2
rdd6
val3
map(..)filter(..)
union(..)
count()
count() count()
sample(..)
cache()

codecentric AG
SPARK IN A CLUSTER
15.04.2023 9
codecentric AG
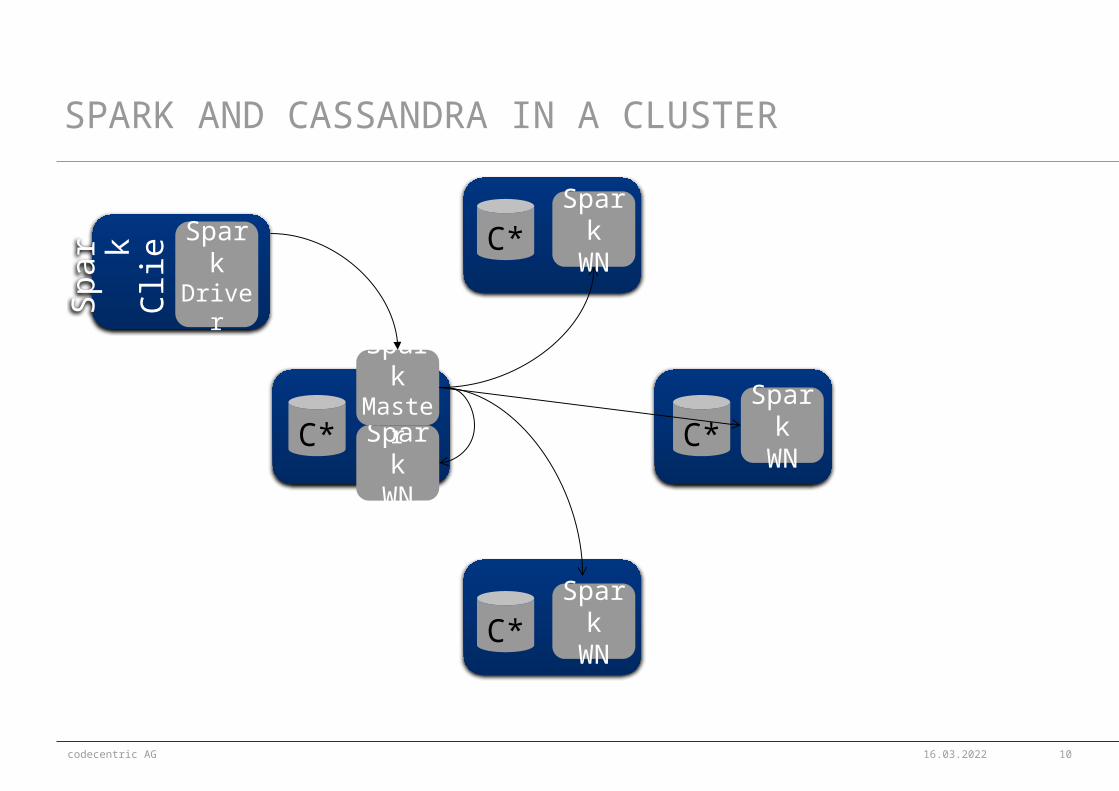
SPARK AND CASSANDRA IN A CLUSTER
15.04.2023 10
C*
C*
C*C*
SparkWN
SparkWNSpark
WN
SparkWN
SparkMaster
Spar k
Clie
n t
SparkDriver

codecentric AG
ZWEI DATACENTER – ZWEI AUFGABEN
15.04.2023 11
C*
C*
C*C*
SparkWN
SparkWNSpark
WN
SparkWN
SparkMaster
C*
C*
C*C*
DC 1 - CASSANDRA DC 2 - ANAYLTICS

codecentric AG
– Spark Cassandra Connector by Datastax
- https://github.com/datastax/spark-cassandra-connector
– Cassandra tables as Spark RDD (read & write)
– Mapping of C* tables and rows onto Java/Scala objects
– Server-Side filtering („where“)
– Compatible with
- Spark ≥ 0.9
- Cassandra ≥ 2.0
– Clone & Compile with SBT or download at Maven Central
SPARK AUF CASSANDRA
15.04.2023 12

codecentric AG
– Start Spark Shell
bin/spark-shell --jars ~/path/to/jar/spark-cassandra-connector-assembly-1.3.0-SNAPSHOT.jar --conf spark.cassandra.connection.host=localhost
--driver-memory 2g
--executor-memory 3g
– Import Cassandra Classes
scala> import com.datastax.spark.connector._,
USE SPARK CONNECTOR
15.04.2023 13

codecentric AG
– Read complete table
val movies = sc.cassandraTable("movie", "movies")
// Return type: CassandraRDD[CassandraRow]
– Read selected columns
val movies = sc.cassandraTable("movie", "movies").select("title","year")
– Filter Rows
val movies = sc.cassandraTable("movie", "movies").where("title = 'Die Hard'")
READ TABLE
15.04.2023 14

codecentric AG
– Access columns in ResultSet
movies.collect.foreach(r => println(r.get[String]("title")))
– As Scala tuple
sc.cassandraTable[(String,Int)]("movie","movies").select("title","year")
or
sc.cassandraTable("movie","movies").select("title","year").as((_: String, _:Int))
CassandraRDD[(String,Int)]
READ TABLE
15.04.2023 15
getString, getStringOption,
getOrElse, getMap,

codecentric AG
case class Movie(name: String, year: Int)
sc.cassandraTable[Movie]("movie","movies").select("title","year")
sc.cassandraTable("movie","movies").select("title","year").as(Movie)
CassandraRDD[Movie]
READ TABLE – CASE CLASS
15.04.2023 16

codecentric AG
– Every RDD can be saved (not only CassandraRDD)
– Tuple
val tuples = sc.parallelize(Seq(("Hobbit",2012),("96 Hours",2008)))
tuples.saveToCassandra("movie","movies",SomeColumns("title","year")
- Case Class
case class Movie (title:String, year: int)
val objects = sc.parallelize(Seq( Movie("Hobbit",2012),Movie("96 Hours",2008)))
objects.saveToCassandra("movie","movies")
WRITE TABLE
15.04.2023 17

codecentric AG
( [atomic,collection,object] , [atomic,collection,object])
val fluege= List( ("Thomas", "Berlin") ,("Mark", "Paris"), ("Thomas", "Madrid") )
val pairRDD = sc.parallelize(fluege)
pairRDD.filter(_._1 == "Thomas")
.collect
.foreach(t => println(t._1 + " flog nach " + t._2))
PAIR RDD‘S
15.04.2023 18
key – not unique value

codecentric AG
– keys(), values()
– mapValues(func), flatMapValues(func)
– lookup(key), collectAsMap(), countByKey()
– reduceByKey(func), foldByKey(zeroValue)(func)
– groupByKey(), cogroup(otherDataset)
– sortByKey([ascending])
– join(otherDataset), leftOuterJoin(otherDataset), rightOuterJoin(otherDataset)
– union(otherDataset), substractByKey(otherDataset)
SPECIAL OP‘S FOR PAIR RDD‘S
15.04.2023 19

codecentric AG
val pairRDD = sc.cassandraTable("movie","director").map(r => (r.getString("country"),r))
// Directors / Country, sorted
pairRDD.mapValues(v => 1).reduceByKey(_+_).sortBy(-_._2).collect.foreach(println)
// or, unsorted
pairRDD.countByKey().foreach(println)
// All Countries
pairRDD.keys()
CASSANDRA EXAMPLE
15.04.2023 20
director
name text K
country text

codecentric AG
– Joins could be expensive
- partitions for same keys in different
tables on different nodes
- requires shuffling
val directors = sc.cassandraTable(..).map(r => (r.getString("name"),r))
val movies = sc.cassandraTable().map(r => (r.getString("director"),r))
movies.join(directors)
RDD[(String, (CassandraRow, CassandraRow))]
CASSANDRA EXAMPLE - JOINS
15.04.2023 21
director
name text K
country text
movie
title text K
director text
DirectorMovie

codecentric AG
USE CASES
15.04.2023 22
Data Loading
Validation & Normalization
Analyses (Joins, Transformations,..)
Schema Migration
Data Conversion

codecentric AG
– In particular for huge amounts of external data
– Support for CSV, TSV, XML, JSON und other
– Example:
case class User (id: java.util.UUID, name: String)
val users = sc.textFile("users.csv").repartition(2*sc.defaultParallelism).map(line => line.split(",") match { case Array(id,name) => User(java.util.UUID.fromString(id), name)})
users.saveToCassandra("keyspace","users")
DATA LOADING
15.04.2023 23

codecentric AG
– Validate consistency in a Cassandra Database
- syntactic
- Uniqueness (only relevant for columns not in the PK)
- Referential integrity
- Integrity of the duplicates
- semantic
- Business- or Application constraints
- e.g.: At least one genre per movies, a maximum of 10 tags per blog post
VALIDATION
15.04.2023 24

codecentric AG
– Modelling, Mining, Transforming, ....
– Use Cases
- Recommendation
- Fraud Detection
- Link Analysis (Social Networks, Web)
- Advertising
- Data Stream Analytics ( Spark Streaming)
- Machine Learning ( Spark ML)
ANALYSES
15.04.2023 25

codecentric AG
– Changes on existing tables
- New table required when changing primary key
- Otherwise changes could be performed in-place
– Creating new tables
- data derived from existing tables
- Support new queries
– Use the CassandraConnectors in Spark
val cc = CassandraConnector(sc.getConf)cc.withSessionDo{session => session.execute(ALTER TABLE movie.movies ADD year timestamp}
SCHEMA MIGRATION & DATA CONVERSION
15.04.2023 26

codecentric AG
– Just use the Cassandra Connector!
val csc = new CassandraSQLContext(sc)
csc.setKeyspace("musicdb")
val result = csc.sql("SELECT country, COUNT(*) as anzahl" +
"FROM artists GROUP BY country" +
"ORDER BY anzahl DESC");
result.collect.foreach(println);
WHAT ABOUT SQL, STREAMING AND MLLIB?
15.04.2023 27
performer
name text K
style text
country text
type text

codecentric AG
– Install Cassandra
- For local experiments: Cassandra Cluster Manager
https://github.com/pcmanus/ccm
- ccm create test -v binary:2.0.5 -n 3 –s
- ccm status
- ccm node1 status
- Alternative: tar ball installation
– Install Spark
- Tar Ball (Pre Built for Hadoop 2.6)
- HomeBrew
- MacPorts
CURIOUS? GETTING STARTED!
15.04.2023 28

codecentric AG
– Spark Cassandra Connector
- https://github.com/datastax/spark-cassandra-connector
- Clone, ./sbt/sbt assembly
or
- Download Jar @ Maven Central
– Start Spark shellspark-shell --jars ~/path/to/jar/spark-cassandra-connector-assembly-1.3.0-SNAPSHOT.jar --conf spark.cassandra.connection.host=localhost
– Import Cassandra classesscala> import com.datastax.spark.connector._
– For Examples: http://github.com/mniehoff/spark-cassandra-playground/
CURIOUS? GETTING STARTED!
15.04.2023 29

codecentric AG
– Production ready Cassandra
– Integrates
- Spark
- Hadoop
- Solr
– OpsCenter & DevCenter
– Bundled and ready to go
– Free for development and test
– http://www.datastax.com/download
(One time registration required)
DATASTAX ENTERPRISE EDITION
15.04.2023 30

codecentric AG 15.04.2023 31
Matthias Niehoff
codecentric AGZeppelinstraße 2
76185 Karlsruhe
tel +49 (0) 721 – 95 95 681
KONTAKT


















