
Spark and cassandra (Hulu Talk)
35
©2013 DataStax Confidential. Do not distribute without consent. @rustyrazorblade Jon Haddad Technical Evangelist, Datastax Getting Started with Spark & Cassandra 1
-
Upload
jon-haddad -
Category
Technology
-
view
1.521 -
download
0
Transcript of Spark and cassandra (Hulu Talk)

©2013 DataStax Confidential. Do not distribute without consent.
@rustyrazorblade
Jon HaddadTechnical Evangelist, Datastax
Getting Started with Spark & Cassandra
1

Small Data• 100's of MB to low GB, single user • sed, awk, grep are great • Python & Ruby • sqlite • Iterate quickly • Limitations: • bad for multiple concurrent users (file sharing!)

Medium Data• Fits on 1 machine •Most current web apps • Content-driven web apps (answerbag.com)
• RDBMS is fine • postgres • mysql
• Supports hundreds of concurrent users • ACID makes us feel good • Scales vertically

Can RDBMS work for big data?
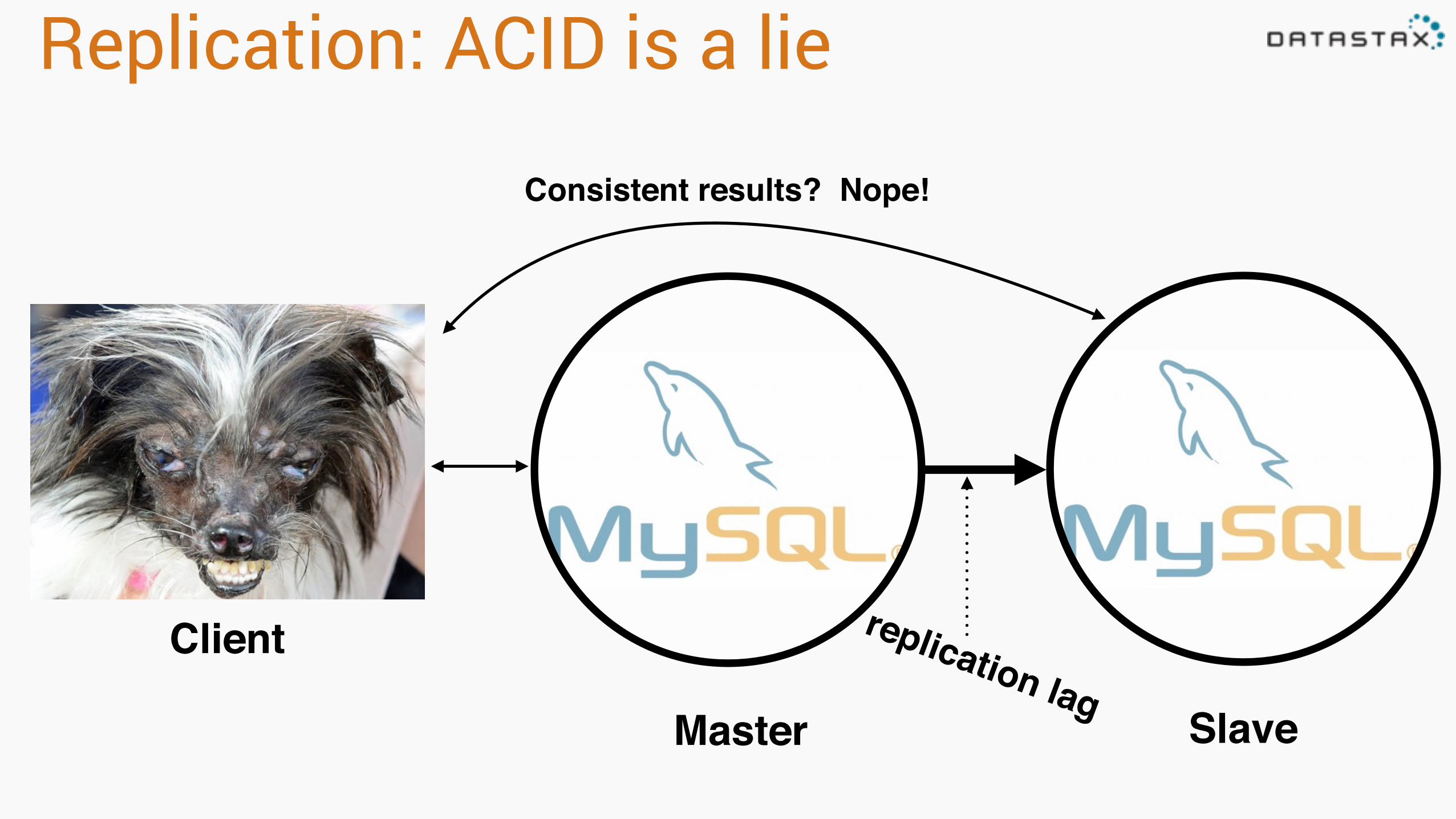
Replication: ACID is a lie
Client
Master Slave
replication lag
Consistent results? Nope!

Third Normal Form Doesn't Scale• Queries are unpredictable • Users are impatient • If data > memory, you = history • Disk seeks are the worst • Data must be denormalized
(SELECT CONCAT(city_name,', ',region) value, latitude, longitude, id, population, ( 3959 * acos( cos( radians($latitude) ) * cos( radians( latitude ) ) * cos( radians( longitude ) - radians($longitude) ) + sin( radians($latitude) ) * sin( radians( latitude ) ) ) ) AS distance, CASE region WHEN '$region' THEN 1 ELSE 0 END AS region_match FROM `cities` $where and foo_count > 5 ORDER BY region_match desc, foo_count desc limit 0, 11) UNION (SELECT CONCAT(city_name,', ',region) value, latitude, longitude, id, population, ( 3959 * acos( cos( radians($latitude) ) * cos( radians( latitude ) ) * cos( radians( longitude ) - radians($longitude) ) + sin( radians($latitude) ) * sin( radians( latitude ) ) ) ) AS distance,

Sharding is a Nightmare• Data is all over the place •No more joins •No more aggregations • Denormalize all the things • Querying secondary indexes
requires hitting every shard • Adding shards requires manually
moving data • Schema changes

High Availability.. not really•Master failover… who's responsible? • Another moving part… • Bolted on hack
• Downtime is frequent • Change database settings (innodb
buffer pool, etc) • Drive, power supply failures • OS updates •Multi-DC? Yeah ok buddy…

Summary of Failure• Scaling is a pain • ACID is naive at best • You aren't consistent
• Re-sharding is a manual process •We're going to denormalize for
performance •High availability is complicated,
requires additional operational overhead

Lessons Learned• Consistency is not practical • So we give it up
•Manual sharding & rebalancing is hard • So let's build in
• Every moving part makes systems more complex • So let's simplify our architecture - no more master / slave
• Scaling up is expensive • We want commodity hardware
• Scatter / gather no good • We denormalize for real time query performance • Goal is to always hit 1 partition
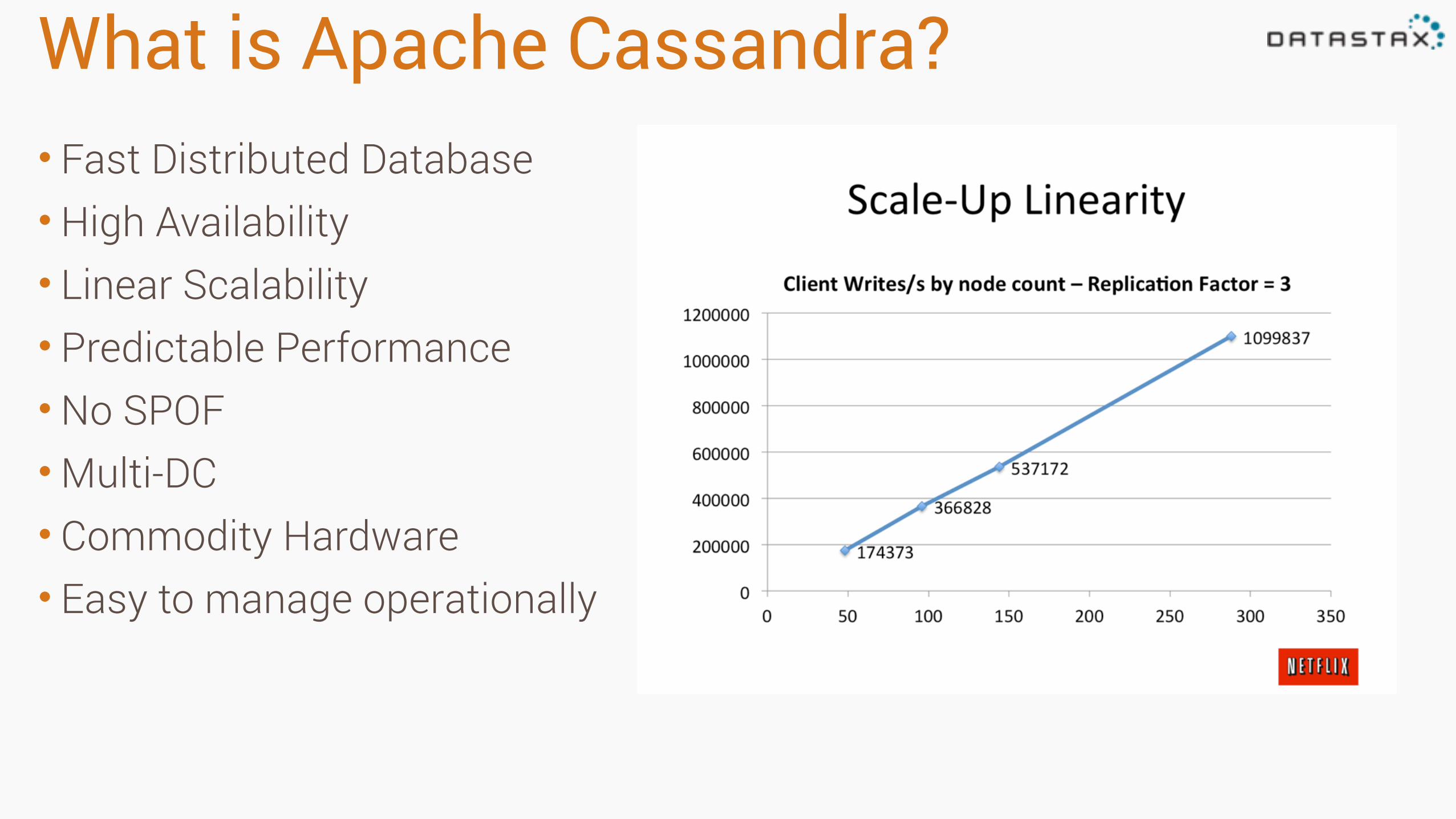
What is Apache Cassandra?• Fast Distributed Database •High Availability • Linear Scalability • Predictable Performance •No SPOF •Multi-DC • Commodity Hardware • Easy to manage operationally
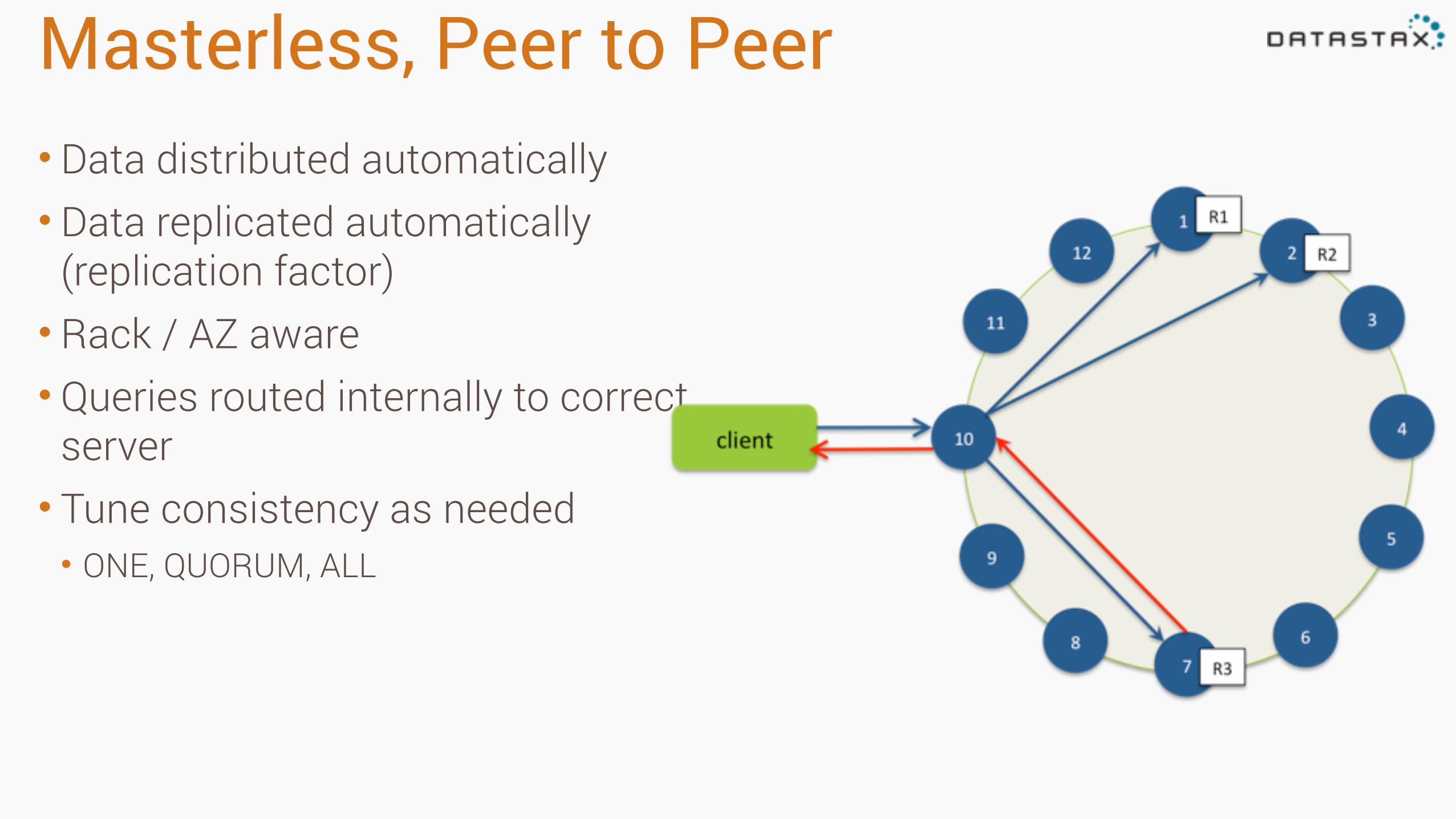
Masterless, Peer to Peer• Data distributed automatically • Data replicated automatically
(replication factor) • Rack / AZ aware • Queries routed internally to correct
server • Tune consistency as needed • ONE, QUORUM, ALL

Data Structures• Like an RDBMS, Cassandra uses a Table to
store data • But there’s where the similarities end • Partitions within tables • Rows within partitions (or a single row) • CQL to create tables & query data • Partition keys determine where a partition
is found • Clustering keys determine ordering of rows
within a partition
Table
Partition
Row
Keyspace

Embrace Denormalization• Fastest way to query data is to ask
for a list of things, stored contiguously
group_name user_id name age
ninjas 1 Jon 33
ninjas 2 Luke 33
ninjas 3 Pete 103
ninjas 4 Sarah 22
partition key (grouping)clustering key (sorting)
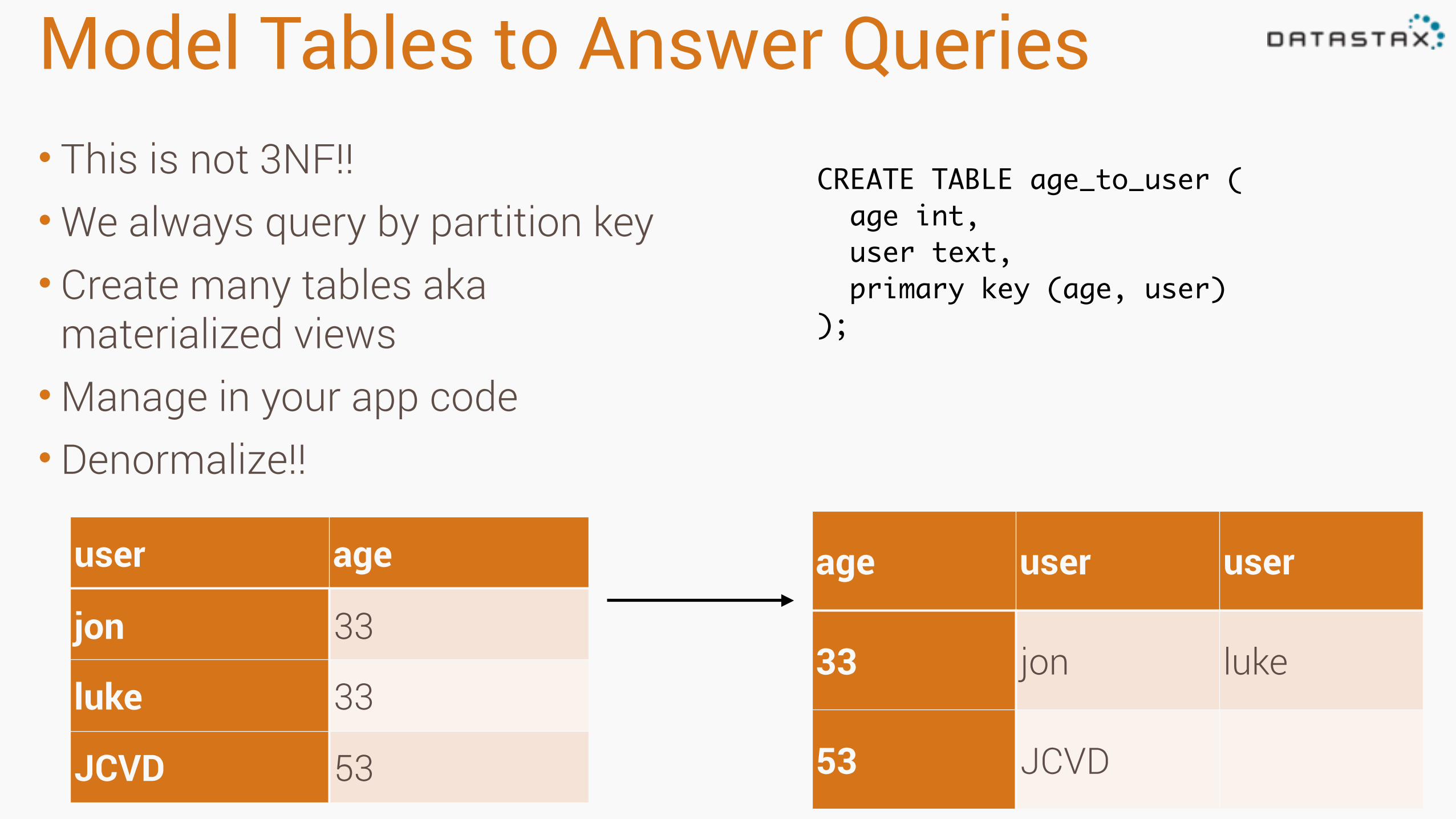
Model Tables to Answer Queries• This is not 3NF!! •We always query by partition key • Create many tables aka
materialized views •Manage in your app code • Denormalize!!
user age
jon 33
luke 33
JCVD 53
age user user
33 jon luke
53 JCVD
CREATE TABLE age_to_user ( age int, user text, primary key (age, user));

Limitations•No aggregations yet • (coming in 3.0)
•No joins • Select rows by partition key •Manage your own secondary
indexes •No arbitrary, full cluster queries

Cool… but what about the ad hoc stuff?
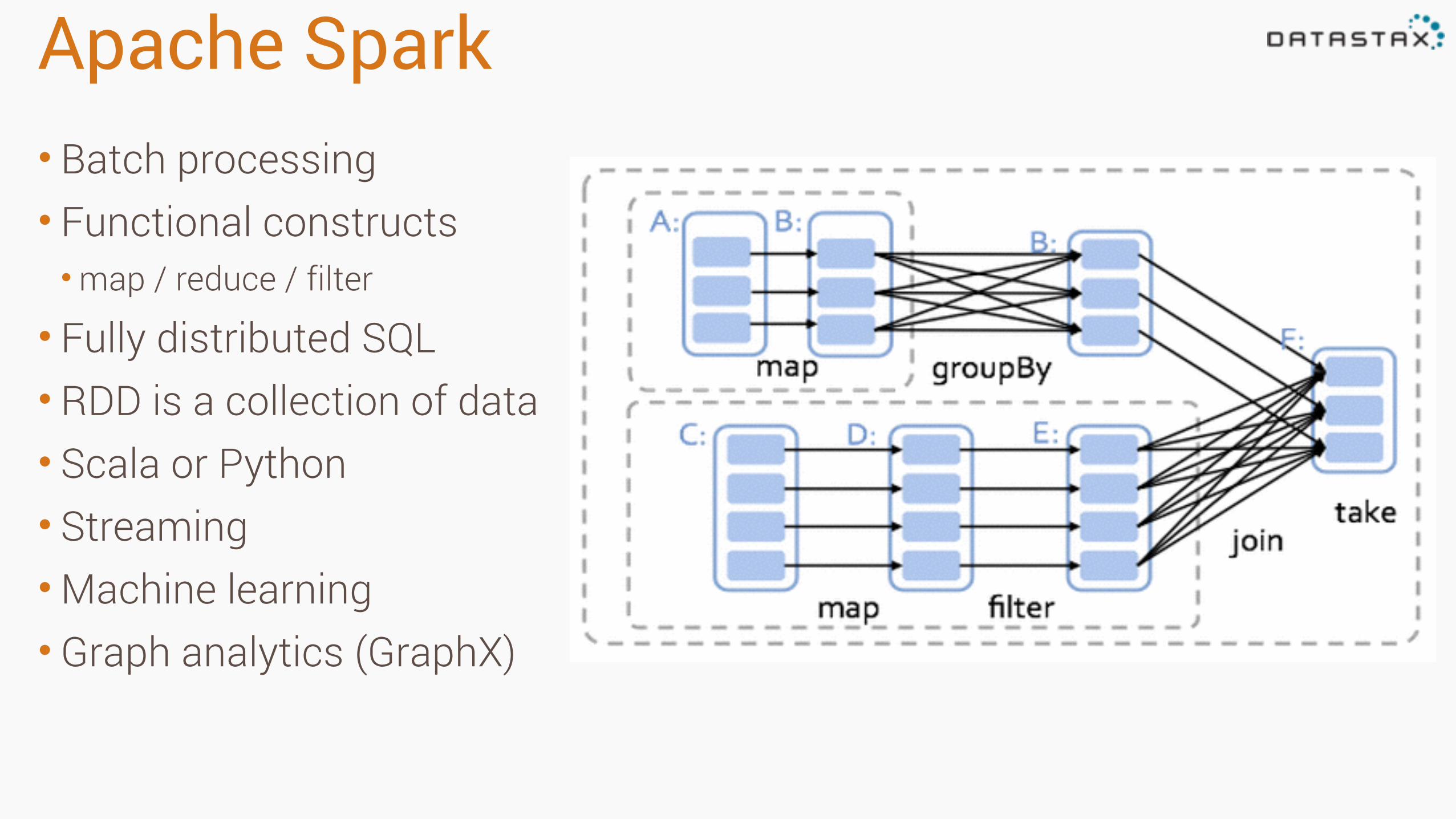
Apache Spark• Batch processing • Functional constructs •map / reduce / filter
• Fully distributed SQL • RDD is a collection of data • Scala or Python • Streaming •Machine learning • Graph analytics (GraphX)

Spark on Cassandra• Use the DataStax Spark connector (OSS) • Data locality - run spark locally on each
node • Dedicated DC - different workload • Jobs write results back to Cassandra

Data Migrationsname favorite_foodjon bacondave baconluke cheesepatrick eggs
favorite_food user
bacon jon
bacon dave
cheese luke
eggs patrick

Data Migrations 1 import org.apache.spark.{SparkContext,SparkConf} 2 import com.datastax.spark.connector._ 3 4 object DataMigration { 5 def main(args: Array[String]): Unit = { 6 7 val conf = new SparkConf(true) 8 .set("spark.cassandra.connection.host", "127.0.0.1") 9 10 val sc = new SparkContext("local", "test", conf) 11 12 case class FoodToUserIndex(food: String, user: String) 13 14 val user_table = sc.cassandraTable("tutorial", "user") 15 16 val food_index = user_table.map(r => 17 new FoodToUserIndex(r.getString("favorite_food"), 18 r.getString("name"))) 19 20 food_index.saveToCassandra("tutorial", "food_to_user_index") 21 22 } 23 }

SparkSQL• Register an RDD as a table • Query as if it was RDBMS • Joins, aggregations, etc • Join across data sources (Postgres to Cassandra) • Supports JDBC & ODBC
1 case class Person(name: String, age: Int) 2 sc.cassandraTable[Person]("test", "persons").registerAsTable("persons") 3 val adults = sql("SELECT * FROM persons WHERE age > 17") 4

Spark Streaming

Overview• Read data from a streaming source • ZeroMQ, Kafka, Raw Socket
• Data is read in batches • Streaming is at best an approximation • val ssc = new StreamingContext(sc, Seconds(1))
Time 1.1 1.5 1.7 2.1 2.4 2.8 3.4
Data (1,2) (4,2) (6,2) (9,1) (3,5) (7,1) (3,10)

What is Apache Kafka?• Distributed, partitioned pub/sub •Messages are sent to “topics” (sort of
like a queue) •Multiple subscribers can read from
same partition • Each subscriber maintains it's own • position • Scales massively •We can use this to message both
ways

Streaming Snippet 1 2 val rawEvents: ReceiverInputDStream[(String, String)] = 3 KafkaUtils.createStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, Map(topic -> 1), 4 StorageLevel.MEMORY_ONLY) 5 6 val parsed: DStream[PageView] = rawEvents.map{ case (_,v) => 7 parse(v).extract[PageView] 8 } // return parsed json as RDD 9 10 case class PageViewsPerSite(site_id:String, ts:UUID, pageviews:Int) 11 12 val pairs = parsed.map(event => (event.site_id, 1)) 13 14 val hits_per_site: DStream[PageViewsPerSite] = pairs.reduceByKey(_+ _).map( 15 x => { 16 val (site_id, hits) = x 17 PageViewsPerSite(site_id, UUIDs.timeBased(), hits) 18 19 } 20 ) 21 22 hits_per_site.saveToCassandra("killranalytics", "real_time_data")
Full source: https://github.com/rustyrazorblade/killranalytics/blob/master/spark/src/main/scala/RawEventProcessing.scala

Things to keep in mind….• Streaming aggregations are an
approximation • Best practice is to come up w/ a
rough number in streaming • You’ll need to reaggregate original
data if you want precision • If it's time series, use
DateTieredCompaction with consistent TTLs

Machine Learning (mllib)
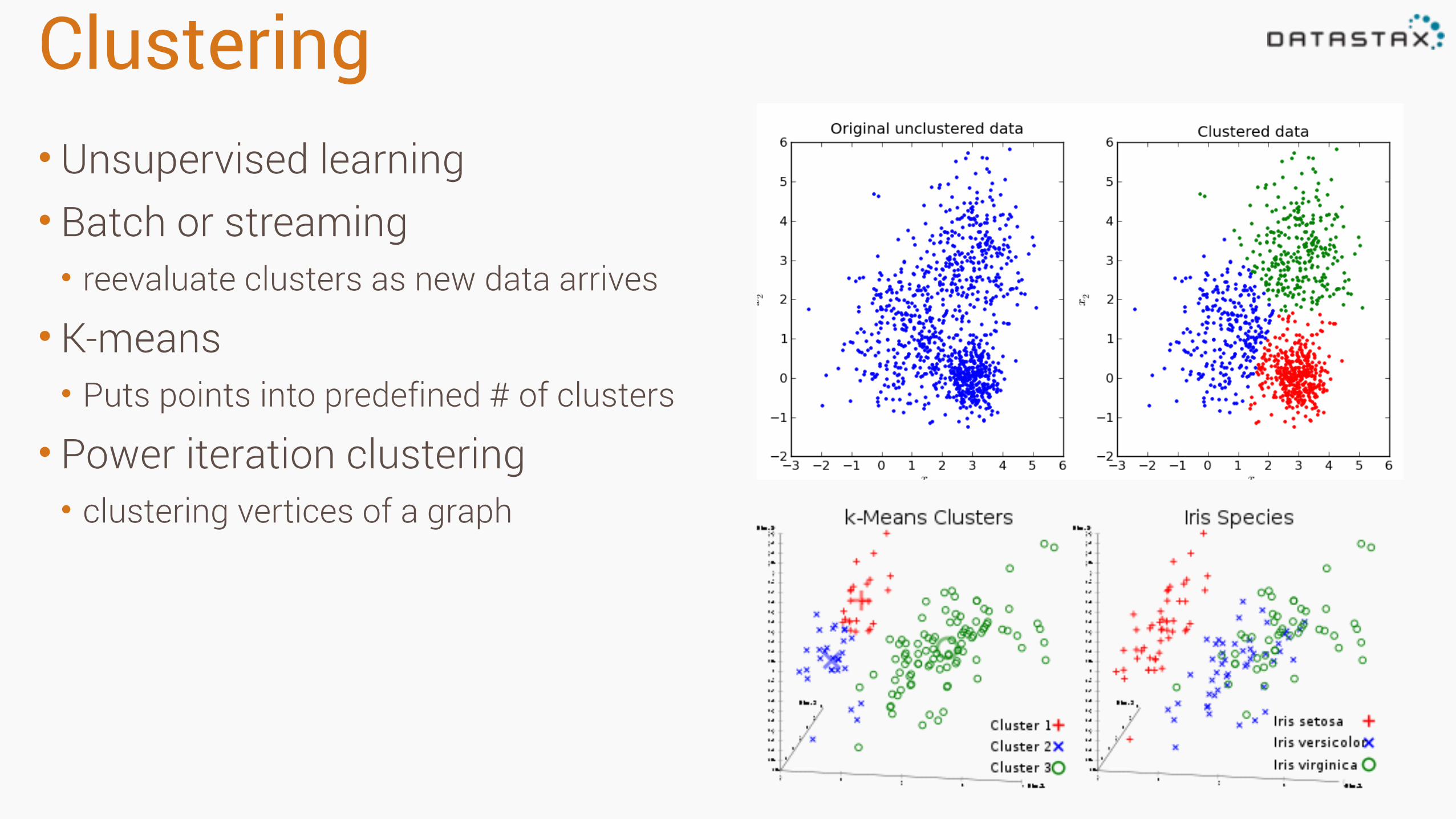
Clustering• Unsupervised learning • Batch or streaming • reevaluate clusters as new data arrives
• K-means • Puts points into predefined # of clusters
• Power iteration clustering • clustering vertices of a graph

Logistic Regression• Predict binary response • Example: predict political election
result • Available in streaming

Collaborative Filtering• Recommendation engine • Algo: Alternating least squares •Movies, music, etc • Perfect match for Cassandra • Source of truth •Hot, live data • Spark generates recommendations
(store in cassandra) • Feedback loops generates better
recommendations over time
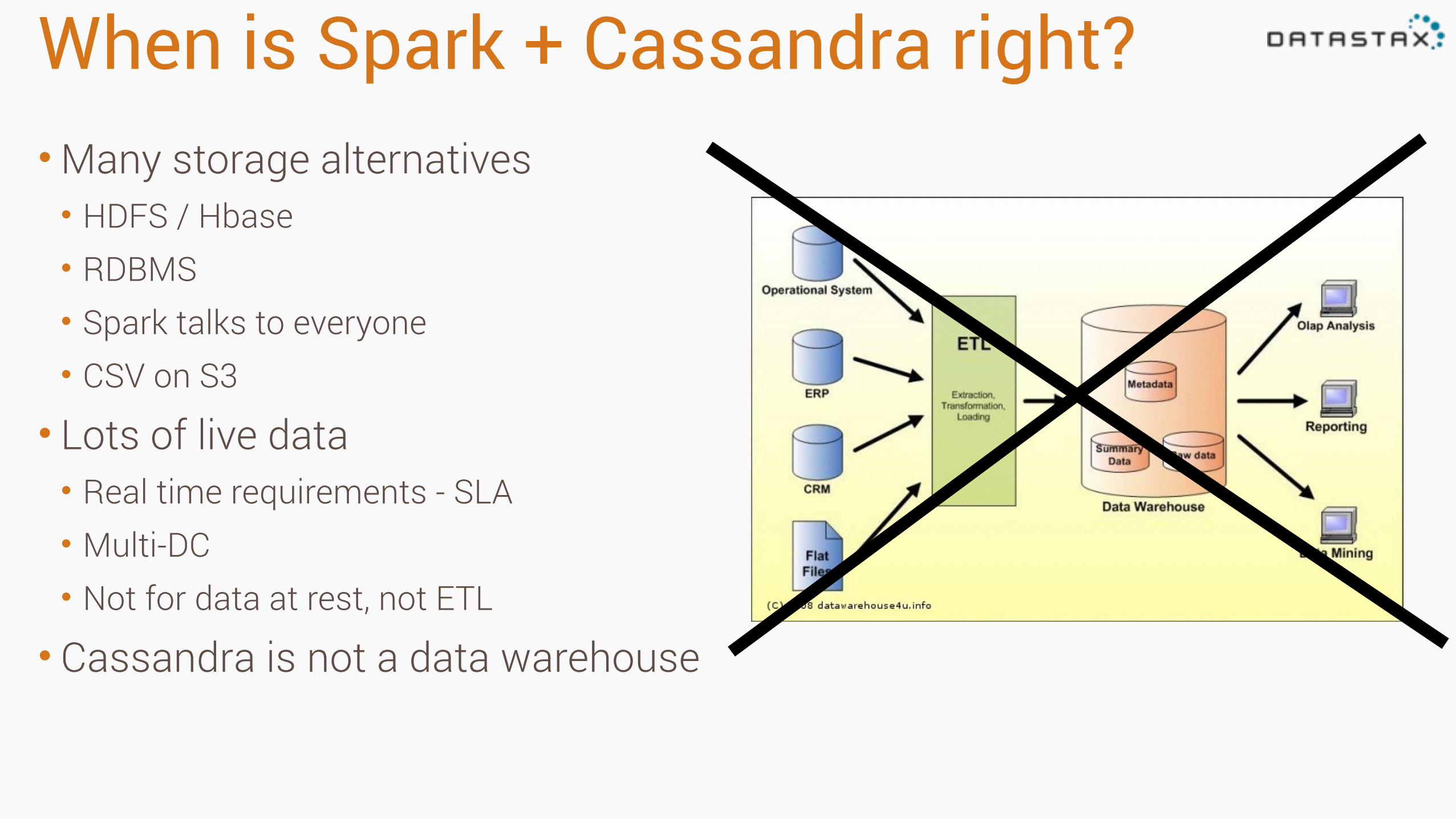
When is Spark + Cassandra right?•Many storage alternatives • HDFS / Hbase • RDBMS • Spark talks to everyone • CSV on S3
• Lots of live data • Real time requirements - SLA • Multi-DC • Not for data at rest, not ETL
• Cassandra is not a data warehouse

Open Source• Latest, bleeding edge features • File JIRAs • Support via mailing list & IRC • Fix bugs • cassandra.apache.org • Perfect for hacking
DataStax Enterprise• Integrated Multi-DC Solr • Integrated Spark • Free Startup Program • <3MM rev & <$30M funding
• Extended support • Additional QA • Focused on stable releases for enterprise • Included on USB drive

©2013 DataStax Confidential. Do not distribute without consent. 35


















