
Automatic Performance Modeling of HPC Applications
30
31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 1 Felix Wolf, TU Darmstadt Automatic Performance Modeling of HPC Applications
Transcript of Automatic Performance Modeling of HPC Applications
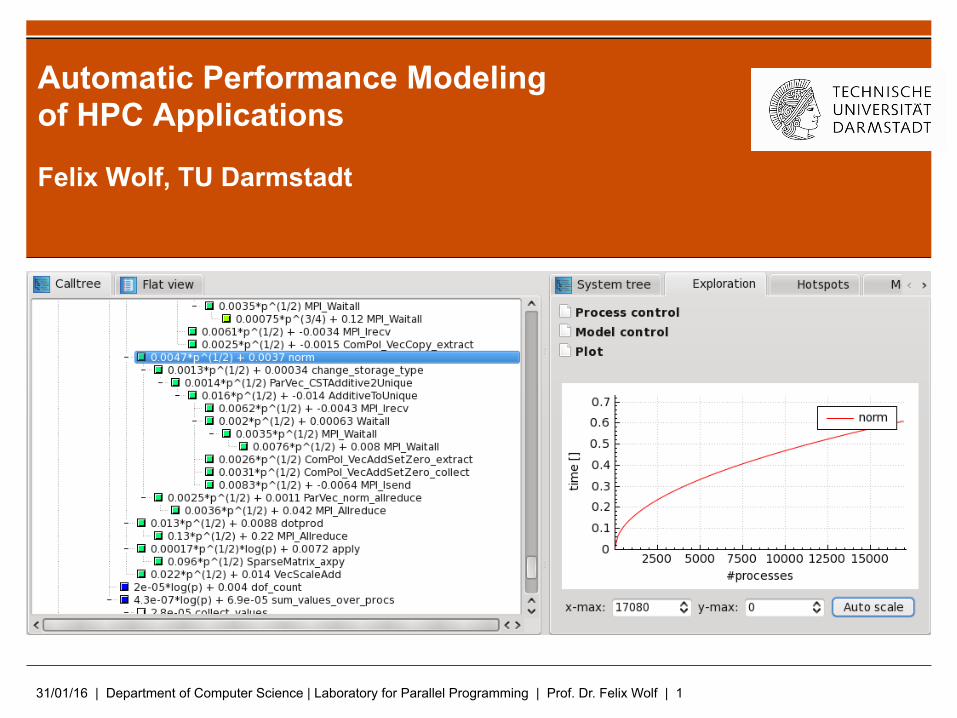
31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 1
Felix Wolf, TU Darmstadt
Automatic Performance Modeling of HPC Applications

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 2
Acknowledgement
• Christian Bischof, Alexandru Calotoiu, Christian Iwainsky, Sergei Shudler
• Torsten Hoefler, Grzegorz Kwasniewski
• Bernd Mohr, Alexandre Strube
• Andreas Vogel, Gabriel Wittum

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 3
Latent scalability bugs
System size Execution time

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 4
Latent scalability bugs
System size Execution time

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 5
Scalability model
2
92
102
112
122
130
3
6
9
12
15
18
21
3¨ 10
´4 p2
` cProcesses
Time
rss

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 6
Analytical scalability modeling
Disadvantages • Time consuming • Danger of overlooking unscalable code
Identify kernels
• Parts of the program that dominate its performance at larger scales
• Identified via small-scale tests and intuition
Create models
• Laborious process • Still confined to a small community of skilled
experts

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 7
Objective
MakeperformancemodelingaccessibletoawideraudienceofHPCapplica9ondevelopersthroughautoma9on
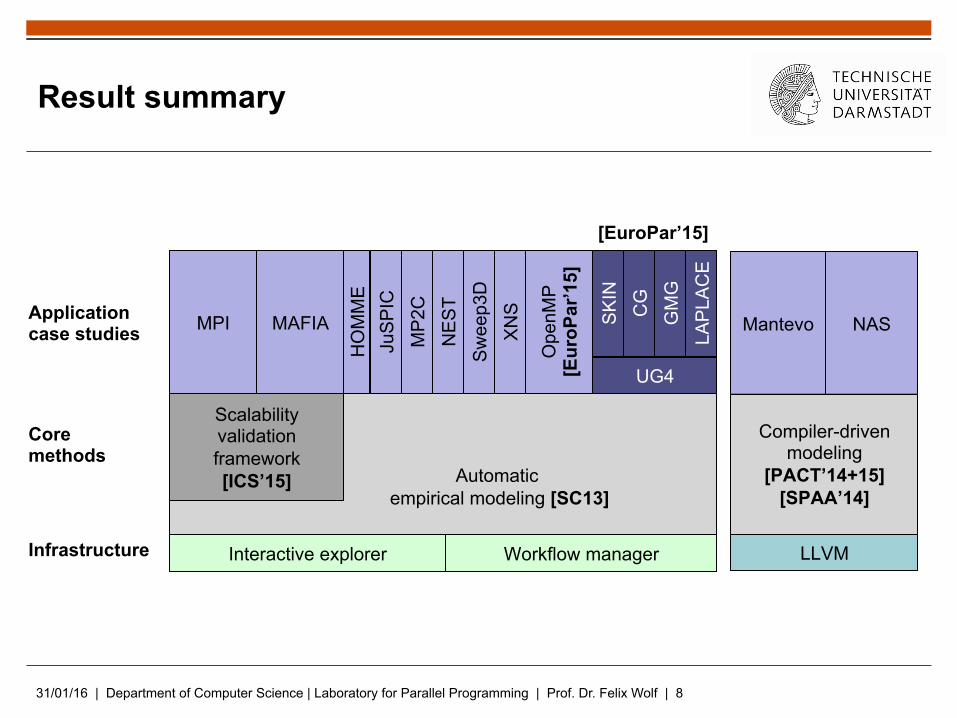
31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 8
Result summary
Compiler-driven modeling
[PACT’14+15] [SPAA’14]
LLVM
Mantevo NAS Application case studies
Core methods
Infrastructure
Automatic empirical modeling [SC13]
Interactive explorer Workflow manager
Scalability validation framework [ICS’15]
MPI MAFIA
HO
MM
E
JuS
PIC
MP
2C
NE
ST
Sw
eep3
D
XN
S
Ope
nMP
[E
uroP
ar’1
5]
SK
IN
CG
GM
G
LAP
LAC
E
UG4
[EuroPar’15]

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 9
Automated empirical modeling
f (p) = ck ⋅ pik ⋅ log2
jk (p)k=1
n
∑
Performance model normal form (PMNF)
Generation of candidate models and selection of best fit
c1 + c2 ⋅ p
c1 + c2 ⋅ p2
c1 + c2 ⋅ log(p)c1 + c2 ⋅ p ⋅ log(p)
c1 + c2 ⋅ p2 ⋅ log(p)
c1 ⋅ log(p)+ c2 ⋅ pc1 ⋅ log(p)+ c2 ⋅ p ⋅ log(p)c1 ⋅ log(p)+ c2 ⋅ p
2
c1 ⋅ log(p)+ c2 ⋅ p2 ⋅ log(p)
c1 ⋅ p+ c2 ⋅ p ⋅ log(p)c1 ⋅ p+ c2 ⋅ p
2
c1 ⋅ p+ c2 ⋅ p2 ⋅ log(p)
c1 ⋅ p ⋅ log(p)+ c2 ⋅ p2
c1 ⋅ p ⋅ log(p)+ c2 ⋅ p2 ⋅ log(p)
c1 ⋅ p2 + c2 ⋅ p
2 ⋅ log(p)
Model output
Small-scale measurements
Kernel [2 of 40]
Model [s] t = f(p)
sweep → MPI_Recv
sweep
4.03 p
582.19

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 10
Model refinement
Hypothesis generation; hypothesis size n
Scaling model
Input data
Hypothesis evaluation via cross-validation
Computation of for best hypothesis
No
Yes
n =1;R02= −∞
Rn2
n++Rn−12> Rn
2∨
n = nmax

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 11
Modeling operations vs. time
Program
Computation Communication
FLOPS Load Store #Msgs #Bytes …
Time
Disagreement may be indicative of wait states

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 12
Case studies
Sweep3d Lulesh Milc HOMME JUSPIC
XNS NEST UG4 MP2C BLAST

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 13
Sweep3D - Neutron transport simulation
• LogGP model for communication developed by Hoisie et al.
Kernel [2 of 40]
Model [s] t = f(p)
Predictive error [%] pt=262k
sweep → MPI_Recv
sweep
5.100.01
4.03 p
582.19 #bytes = const. #msg = const.
pi ≤ 8k
tcomm = [2(px + py − 2)+ 4(nsweep −1)]⋅ tmsgtcomm = c ⋅ p

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 14
HOMME – Climate
Core of the Community Atmospheric Model (CAM)
§ Spectral element dynamical core on a cubed sphere grid
Kernel [3 of 194]
Model [s] t = f(p)
Predictive error [%] pt = 130k
box_rearrange → MPI_Reduce
vlaplace_sphere_vk
compute_and_apply_rhs
3.63⋅10-6p ⋅ p+ 7.21⋅10-13p3
pi ≤ 43k
30.34
4.280.83
24.44+2.26 ⋅10-7p2
49.09

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 15
HOMME – Climate (2)
Table 4: Models of the kernels of HOMME derived from smaller and larger-scale input configurations. The predictive errorrefers to the target scale of pt = 130k.
KernelP4(pi ⇥ 15, 000) P5(pi ⇥ 43, 350)
Model [s] Predictive Model [s] Predictivet = f(p) error [%] t = f(p) error [%]
box_rearrange ⇤ MPI_Reduce 0.026 + 2.53 · 10�6 · p⌅p + 1.24 · 10�12 · p3 57.02 3.63 · 10�6 · p⌅p + 7.21 · 10�13 · p3 30.34vlaplace_sphere_wk 49.53 99.32 24.44 + 2.26 · 10�7 · p2 4.28laplace_sphere_wk 44.08 99.32 21.84 + 1.96 · 10�7 · p2 2.34biharmonic_wk 34.40 99.33 17.92 + 1.57 · 10�7 · p2 3.43divergence_sphere_wk 16.88 99.31 8.02 + 7.56 · 10�8 · p2 4.25vorticity_sphere 9.74 99.55 6.51 + 7.09 · 10�8 · p2 8.66divergence_sphere 15.36 99.33 7.74 + 6.91 · 10�8 · p2 0.95gradient_sphere 14.77 99.33 6.33 + 6.88 · 10�8 · p2 5.17advance_hypervis 9.76 99.25 5.5 + 3.91 · 10�8 · p2 1.47compute_and_apply_rhs 48.68 1.65 49.09 0.83euler_step 28.08 0.51 28.13 0.33
kernels. Obviously, the enlarged set exposes a phenomenonnot visible in the smaller set. With the number of processeschosen large enough, both the quadratic and the cubic termswill turn into serious bottlenecks, contradicting our initialexpectation the code would scale well. The table also showsthe predictive error, which characterizes the deviation of theprediction from measurement at the taget scale pt = 130k,highlighting the benefits of including the extra data points.
After looking at the number of times any of the quadratickernels was visited at runtime, a metric we measure andmodel as well, the quadratic growth was found to be theconsequence of an increasing number of iterations inside aparticular subroutine. Interestingly, the formula by whichthe number of iterations is computed contained a ceilingterm that limits the number of iterations to one for up to andincluding 15k processes. Beyond this threshold, a term de-pending quadratically on the process count causes the num-ber of iterations being executed to grow rapidly, causing asignificant drop in performance. It turned out, the devel-opers were aware of this issue and had already developed atemporary solution, involving manual adjustments of theirproduction code configurations. Specifically, they fix thenumber of iterations and carefully tune other configurationparameters to ensure numerical stability. Nevertheless, theissue was correctly detected by our tool. Given the tuningnecessary to ensure numerical stability, a weak scaling anal-ysis of the workaround is beyond the scope of this paper.
In contrast to the previous problem, the cubic growth of thetime spent in the reduce function was previously unknown.The reduce is needed to funnel data to dedicated I/O pro-cesses. The coe⇤cient of the dominant term at scale is verysmall (i.e., in the order of 10�13). While not being visibleat smaller scales, it will have an explosive e�ect on perfor-mance at larger scales, becoming significant even if executedjust once. The reason why this phenomenon remained un-noticed until today is that it belongs to the initializationphase of the code that was not assumed to be performancerelevant in larger production runs. While still not yet crip-pling in terms of the overall runtime, which is in the order ofdays for production runs, the issue costed already more thanone hour in the large-scale experiments we conducted. Theproblem was reported back to the developers at NCAR, whoare currently working on a solution. The example demon-
strates the advantage of modeling the entire application vs.only selected candidate kernels expected to be time inten-sive. Some problems simply might escape attention becausenon-linear relationships make our intuition less reliable atlarger scales.
Figure 4 summarizes our two findings and compares our pre-dictions with actual measurements. While the growing iter-ation count seems to be more urgent now, the reduce mightbecome the more serious issue in the future.
5. RELATED WORKAnalytic performance modeling techniques have been usedto model the performance of numerous important applica-tions manually [21, 25]. It is well understood that analyticmodels have the potential of providing important insightsinto complex behaviors [29]. Performance models also o�erinsight into di�erent parts of the system. For example, Boydet al. used performance models to assess the quality of a toolchain, such as a compiler or runtime system [6]. In general,there is consensus that performance modeling is a powerful
210 212 214 216 218 220 222
0.01
1
102
104
106
108
Processes
Tim
e(s)
MPI_Reduce
vlaplace_sphere_wk
compute_and_apply_rhs
Training
Prediction
Figure 4: Runtime of selected kernels in HOMME as a func-tion of the number of processes. The graph compares predic-tions (dashed or contiguous lines) to measurements (smalltriangles, squares, and circles).

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 16
Which problem? Where in the program?
Which process?
www.scalasca.org

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 17
Download and training
• Tuning workshop in Garching, April 18-22, 2016
• Past tutorials
http://www.scalasca.org/software/extra-p/
Extra-P

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 18
OpenMP
• How scalable are OpenMP runtimes in terms of the number of threads?
• Challenges
• Simultaneous entry of construct to be measured
• Different behavioral classes
• Noise
0.00E+00
5.00E-05
1.00E-04
1.50E-04
2.00E-04
2.50E-04
3.00E-04
3.50E-04
4.00E-04
0 8 16 24 32 40 48 56 64 72 80 88 96 104 112 120 128
GNUIntelPGI

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 19
OpenMP
25.01.2016 | FB Computer Science | Scientific Computing | Christian Iwainsky | 1
All Models
Parallel Barrier Dynamic 16
Static 16
Guided 16
First Private
GNU Po2 𝑡 . 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡
ODD 𝑡 . 𝑡 . 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡
Intel Po2 log 𝑡 𝑡 . 𝑡 log 𝑡 𝑡 log 𝑡
PGI Po2 𝑡 . log 𝑡 log 𝑡 𝑡 . log 𝑡 log 𝑡 𝑡 . 𝑡 .
ODD 𝑡 log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . 𝑡 . 𝑡 . log 𝑡
Intel (Phi)
Po2 𝑡 . 𝑡 . 𝑡 . 𝑡 . 𝑡 𝑡 .
Linear 𝑡 . 𝑡 . log 𝑡 𝑡 . 𝑡 𝑡 .
8X log 𝑡 log 𝑡 𝑡 . 𝑡 . log 𝑡 𝑡 log 𝑡
IBM Po2 𝑡 . 𝑡 . log 𝑡 𝑡 . 𝑡 . 𝑡 𝑡 .

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 20
OpenMP
25.01.2016 | FB Computer Science | Scientific Computing | Christian Iwainsky | 2
All Models
Parallel Barrier Dynamic 16
Static 16
Guided 16
First Private
GNU Po2 𝑡 . 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡
ODD 𝑡 . 𝑡 . 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡
Intel Po2 log 𝑡 𝑡 . 𝑡 log 𝑡 𝑡 log 𝑡
PGI Po2 𝑡 . log 𝑡 log 𝑡 𝑡 . log 𝑡 log 𝑡 𝑡 . 𝑡 .
ODD 𝑡 log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . 𝑡 . 𝑡 . log 𝑡
Intel (Phi)
Po2 𝑡 . 𝑡 . 𝑡 . 𝑡 . 𝑡 𝑡 .
Linear 𝑡 . 𝑡 . log 𝑡 𝑡 . 𝑡 𝑡 .
8X log 𝑡 log 𝑡 𝑡 . 𝑡 . log 𝑡 𝑡 log 𝑡
IBM Po2 𝑡 . 𝑡 . log 𝑡 𝑡 . 𝑡 . 𝑡 𝑡 .

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 21
OpenMP
25.01.2016 | FB Computer Science | Scientific Computing | Christian Iwainsky | 3
All Models
Parallel Barrier Dynamic 16
Static 16
Guided 16
First Private
GNU Po2 𝑡 . 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡
ODD 𝑡 . 𝑡 . 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡
Intel Po2 log 𝑡 𝑡 . 𝑡 log 𝑡 𝑡 log 𝑡
PGI Po2 𝑡 . log 𝑡 log 𝑡 𝑡 . log 𝑡 log 𝑡 𝑡 . 𝑡 .
ODD 𝑡 log 𝑡 𝑡 . log 𝑡 𝑡 . log 𝑡 𝑡 . 𝑡 . 𝑡 . log 𝑡
Intel (Phi)
Po2 𝑡 . 𝑡 . 𝑡 . 𝑡 . 𝑡 𝑡 .
Linear 𝑡 . 𝑡 . log 𝑡 𝑡 . 𝑡 𝑡 .
8X log 𝑡 log 𝑡 𝑡 . 𝑡 . log 𝑡 𝑡 log 𝑡
IBM Po2 𝑡 . 𝑡 . log 𝑡 𝑡 . 𝑡 . 𝑡 𝑡 .

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 22
Algorithm engineering
Courtesy of Peter Sanders, KIT

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 23
How to validate scalability in practice?
Small text book example
Real application
Verifiable analytical
expression
Asymptotic complexity
Program
Expectation
#FLOPS = n2(2n − 1) #FLOPS = O(n2.8074)

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 24
HPC libraries
• Focus on algorithms rather than applications
• Theoretical expectations more common
• Reuse factor makes scalability even more important
Example: MPI communication library Network

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 25
Search space generation
Model generation Benchmark
Performance measurements
Scaling model Expectation
+ optional deviation limit
Divergence model
Initial validation Comparing alternatives
Regression testing
Scalability evaluation framework

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 26
Customized search space
• Constructed around expectation
• Supports wider range of model functions than original PMNF
E(x) E 2 (x)1 E(x)*D(x)E(x) D(x)
Search space boundaries
Deviation limits
Approx. match No match Approx. match No match

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 27
Platform Juqueen Juropa Piz Daint
MPI memory [MB] Expectation: O (log p)
Model O (log p) O (p) O (log p)
R2 0.72 1 0.23
Divergence O (1) O (p / log p) O (1)
Match ✔ ✘ ✔
Comm_create [B] Expectation: O (p)
Model O (p) O (p) O (p)
R2 1 1 0.99
Divergence O (1) O (1) O (1)
Match ✔ ✔ ✔
Win_create [B] Expectation: O (p)
Model O (p) O (p) O (p)
R2 1 1 0.99
Divergence O (1) O (1) O (1)
Match ✔ ✔ ✔
MPI
Platform Juqueen Juropa Piz Daint
Barrier [s] Expectation: O (log p)
Model O (log p) O (p0.67 log p) O (p0.33)
R2 0.99 0.99 0.99
Divergence O (1) O (p0.67) O (p0.33/log p)
Match ✔ ✘ ~
Bcast [s] Expectation: O (log p)
Model O (log p) O (p0.5) O (p0.5)
R2 0.86 0.98 0.94
Divergence O (1) O (p0.5/log p) O (p0.5/log p)
Match ✔ ~ ~
Reduce [s] Expectation: O (log p)
Model O (log p) O (p0.5 log p) O (p0.5 log p)
R2 0.93 0.99 0.94
Divergence O (1) O (p0.5) O (p0.5)
Match ✔ ~ ~
Platform Juqueen Juropa Piz Daint Allreduce [s] Expectation: O (log p) Model O (log p) O (p0.5) O (p0.67 log p)
R2 0.87 0.99 0.99 Divergence 0 O (p0.5/log p) O (p0.67)
Match ✔ ~ ✘! Comm_dup [B] Expectation: O (1) Model 2.2e5 256 3770 + 18p
R2 1 1 0.99 Divergence O (1) O (1) O (p)
Match ✔ ✔ ✘

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 28
Mass-producing performance models
• Is feasible • Offers insight • Requires low effort • Improves code coverage

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 29
References
• Arnamoy Bhattacharyya, Grzegorz Kwasniewski, Torsten Hoefler: Using Compiler Techniques to Improve Automatic Performance Modeling. PACT'15
• Andreas Vogel, Alexandru Calotoiu, Alexandre Strube, Sebastian Reiter, Arne Nägel, Felix Wolf, Gabriel Wittum: 10,000 Performance Models per Minute - Scalability of the UG4 Simulation Framework. Euro-Par’15
• Christian Iwainsky, Sergei Shudler, Alexandru Calotoiu, Alexandre Strube, Michael Knobloch, Christian Bischof, Felix Wolf: How Many Threads will be too Many? On the Scalability of OpenMP Implementations. Euro-Par’15
• Sergei Shudler, Alexandru Calotoiu, Torsten Hoefler, Alexandre Strube, Felix Wolf: Exascaling Your Library: Will Your Implementation Meet Your Expectations?, ICS’15
• Torsten Hoefler, Grzegorz Kwasniewski: Automatic Complexity Analysis of Explicitly Parallel Programs. SPAA’14
• Alexandru Calotoiu, Torsten Hoefler, Marius Poke, Felix Wolf: Using Automated Performance Modeling to Find Scalability Bugs in Complex Codes. SC13

31/01/16 | Department of Computer Science | Laboratory for Parallel Programming | Prof. Dr. Felix Wolf | 30
Thank you!


















