
“Artificial Intelligence” in Database Querying Dept. of CSE Seung-won Hwang.
30
“Artificial Intelligence” in Database Querying Dept. of CSE Seung-won Hwang
-
Upload
geraldine-barton -
Category
Documents
-
view
215 -
download
1
Transcript of “Artificial Intelligence” in Database Querying Dept. of CSE Seung-won Hwang.

“Artificial Intelligence” in Database Querying
Dept. of CSESeung-won Hwang

Why do you need to ace this class?
“producing machines to automate tasks requiring intelligent behavior” (wikipedia)
AI techniques are highly relevant to many research fields, including database

More obvious applications
But…

Crash course on DB
SQL queriesselect * from carswhere color=‘red’ and type=‘convertible’ a
nd brand=`hyundai’

Crash course on DB
Deciding the most efficient execution plan among: hyundai->red->convertible? red->convertible->hyundai? convertible->hyundai->red? …
Depends on data structures (B+-tree), data distributions, …
However, all these efforts are useless efforts, if no object qualifies

Our strength

Our strength
Internet shopping, web bulletin board, cyworld, …
You are sending SQL queries without you knowing
(at least until you see DB errors) DBMS is optimizing your query for you
without you knowing

Our weakness
But do you use DBMS for managing your word files, photos, etc..
What do you use? File system (Browsing) Google desktop (Searching)
SQL semantics is too strict No red hyundai convertible! Or too many r
ed hyundai elantra?
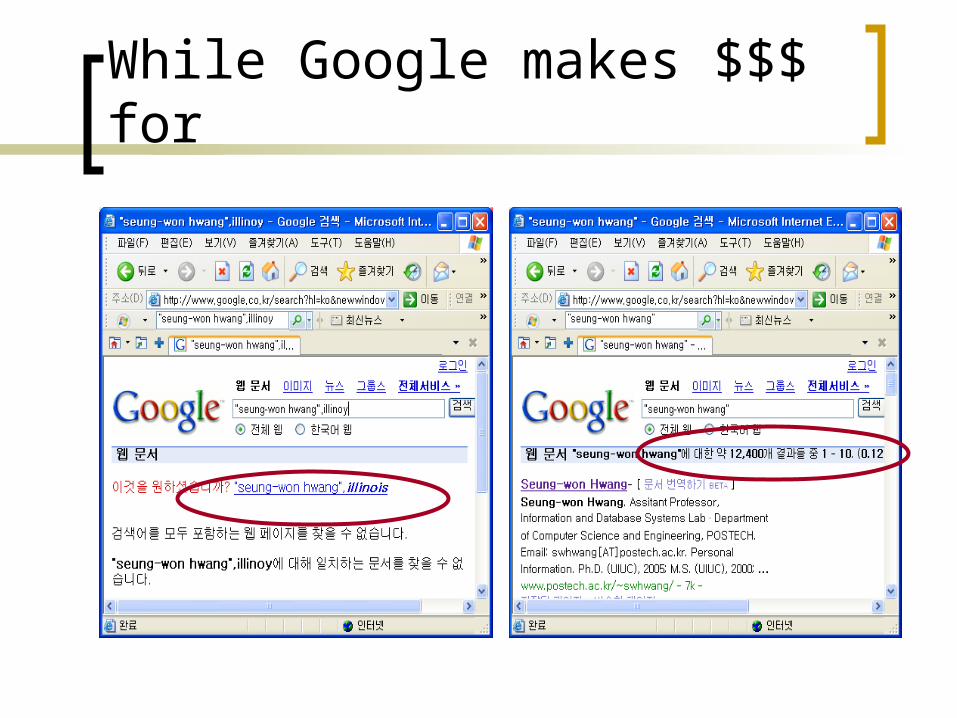
While Google makes $$$ for

Giving “Artificial Intelligence”
What are the intelligent behaviors expected? Suggesting alternatives:
Red hyundai Red convertible Orange convertible
What are the possible automation? Deciding Red hyundai < Red convertible

But how?
Any idea?
Underspecified/Overspecified Queries
GAP
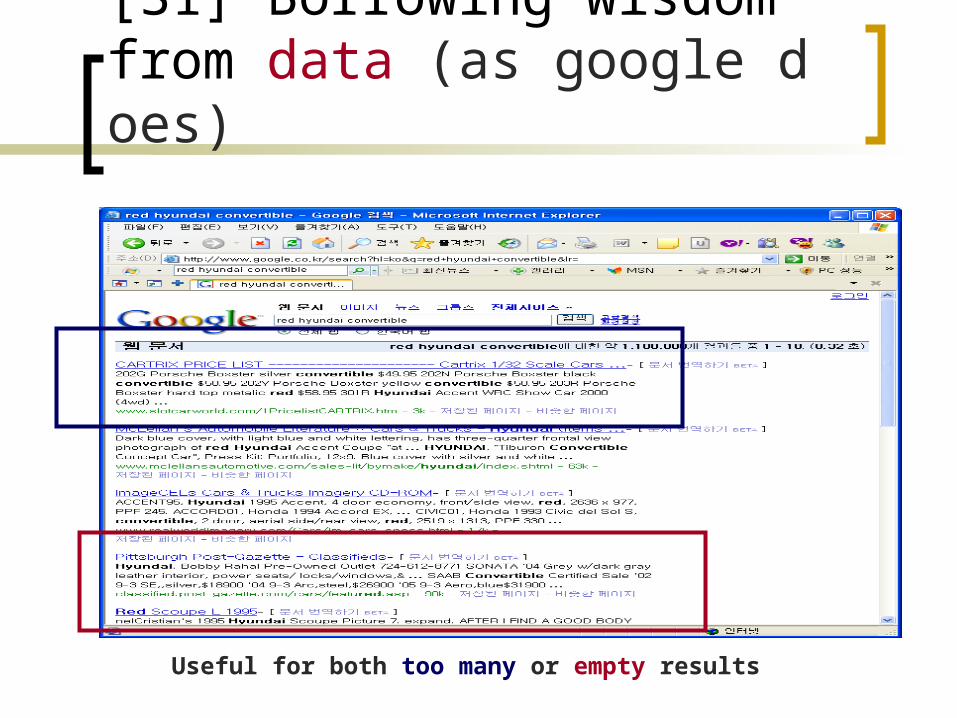
[S1] Borrowing wisdom from data (as google does)
Useful for both too many or empty results
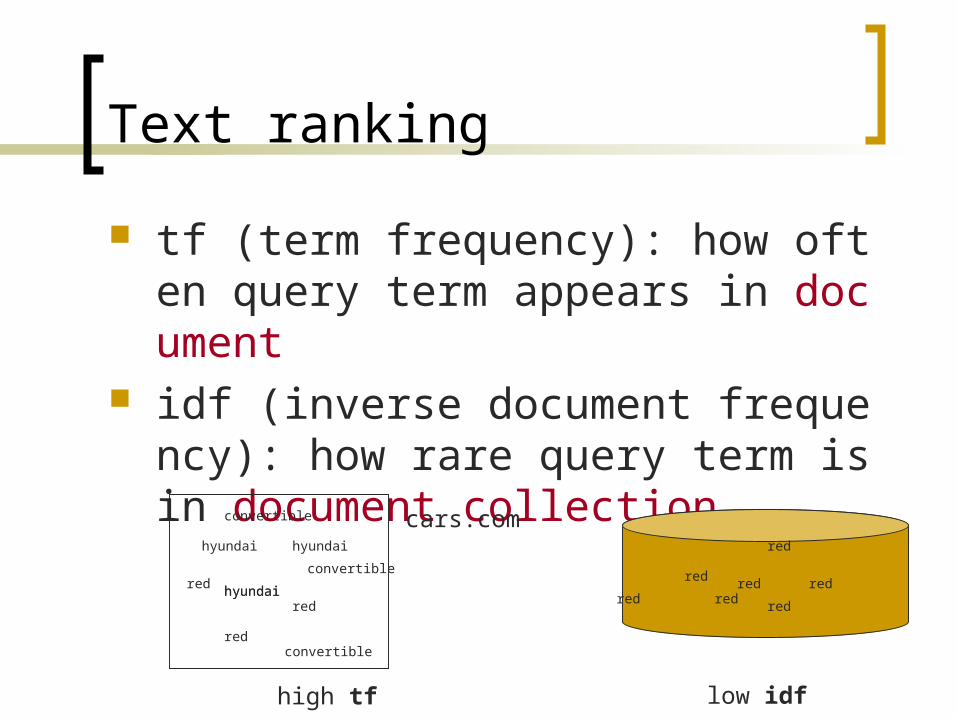
Text ranking
tf (term frequency): how often query term appears in document
idf (inverse document frequency): how rare query term is in document collection
hyundai
hyundaihyundai
hyundai
red
redconvertible
red
convertible
convertible
high tf
cars.com
low idf
red redred
red
red
red
red

Applying to database
brand idf color idf
hyundai 0.5 black 0.1
BMW 0.8 red 0.4
kia 0.3 purple
0.9
Red hyundai = 0.9
Red honda = 0.4
Black hyundai = 0.8

What is the assumption?
Rare items are preferred Can you think of exceptions?
‘purple pony’ vs. ‘purple lexus’ How can we handle this problem?
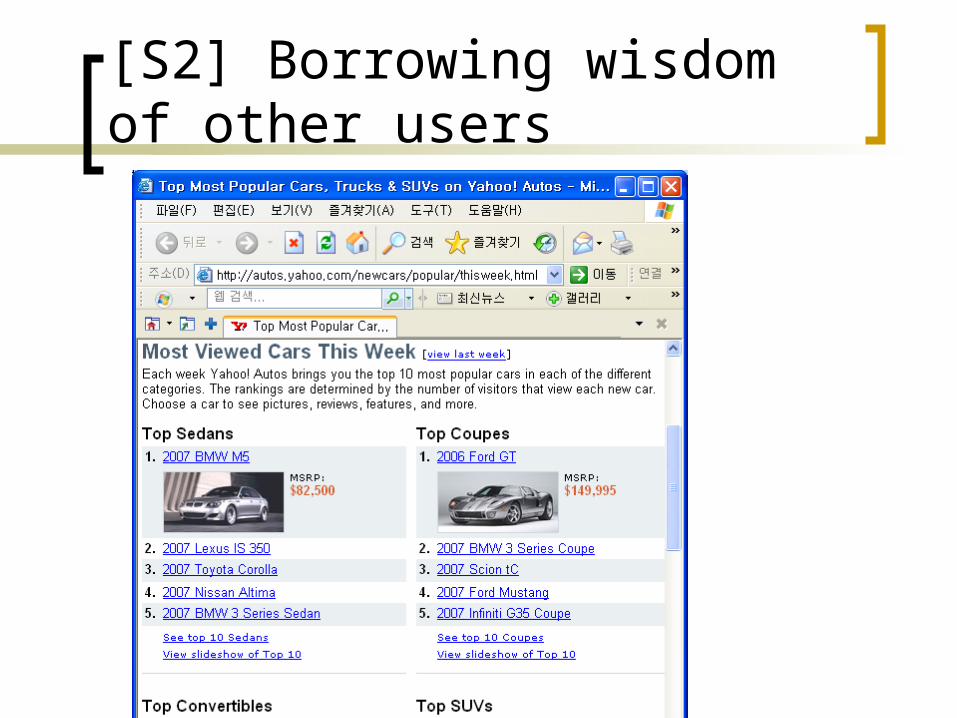
[S2] Borrowing wisdom of other users

Query frequency
Keyword frequency in prior queries Eg., car=‘BMW’ appearing in 50% of prior
queries Summing up, we can highly rank cars t
hat are heavily queried beforeand rare in stocks

[S3] Borrowing wisdom from domain knowledge

Example 1: color
(a) (b) (c) (d) (e)

Example 2: shape=‘retro’

[S4] Borrowing wisdom from specific user
Notion of similarity significantly differs across users
Shape?
AB
C

You cannot expect users to describe
(or machine to understand) explicit explanation like
I want a photo of a building similar to eiffel tower in terms of shape, but not in terms of the overall shape, but in terms of the shape of the steel material…………..
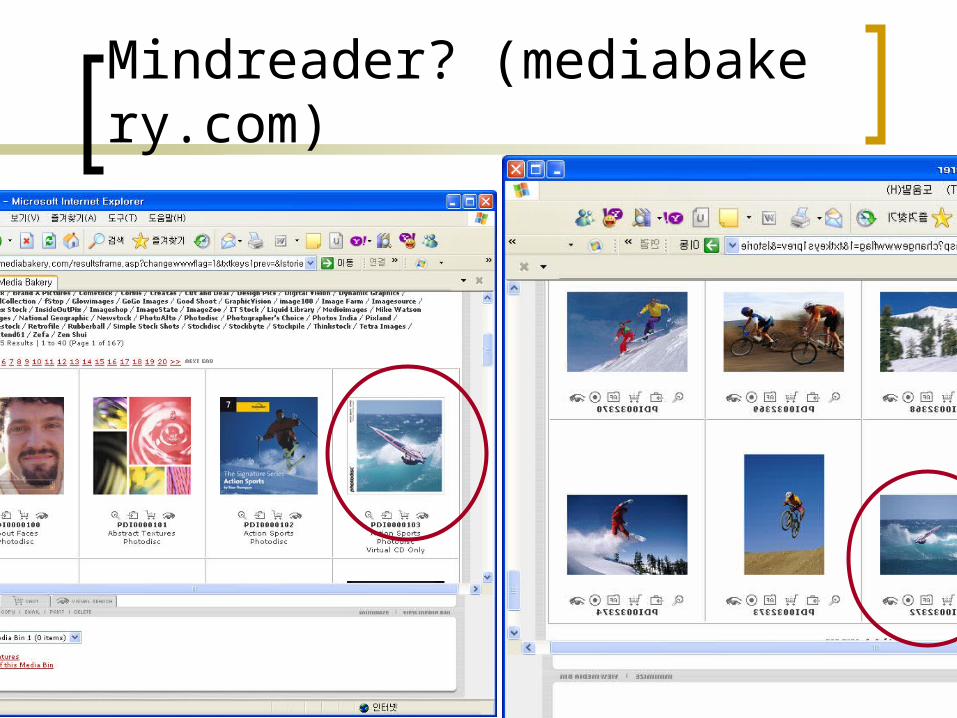
Mindreader? (mediabakery.com)

In our car search example
You can show ‘red bmw’ and ‘hyundai sedan’
Based on user response (or clicks), you can figure out which is more important factors, e.g., color
Then you can show more red cars to figure out further on preference on brands

Summing up
You need to bridge the gap between SQL and ideal results, by collecting/analyzing as much as information available from data, prior users, user himself/herself, …
Implicitly and automatically

Another implicit info to think about
Tagging frequency ranking/ automatic classification?

Summary
Networks enables access to a large amount of user created contents/info “Web 2.0” http://youtube.com/watch?v=6gmP4nk0EOE (interesting
web 2.0 video) Intelligent retrieval techniques is the key in new era
Ranking Classification
I will then show how AI techniques (that you already know!) got me a PhD in intelligent retrieval research Rank Formulation: machine learning Rank/Classification Processing : best first search, hill
climbing

Q&A



















