
Arm DynamIQ: Intelligent Solutions Using Cluster … · Intelligent Solutions Using Cluster Based...
27
© 2017 Arm Limited Peter Greenhalgh VP and GM of Central Technology and Fellow Arm DynamIQ: Intelligent Solutions Using Cluster Based Multiprocessing
Transcript of Arm DynamIQ: Intelligent Solutions Using Cluster … · Intelligent Solutions Using Cluster Based...

© 2017 Arm Limited
Peter GreenhalghVP and GM of Central Technology and Fellow
Arm DynamIQ: Intelligent Solutions Using Cluster Based
Multiprocessing

© 2017 Arm Limited 2
Drones Wearable technology Smartwatch
3D printing Voice recognition Social media
Technology innovations of 2013

© 2017 Arm Limited 3
Looking ahead from edge to cloudThe future requires a new approach to CPU design
Safe and autonomous Hyper-efficient
Secure private compute
Cortex beyond mobile Mixed reality

Confidential © Arm 2017 4
Arm DynamIQRearchitecting the compute experience
Multi-core redefined for broad market
Massive system performance uplift
More intelligent systems
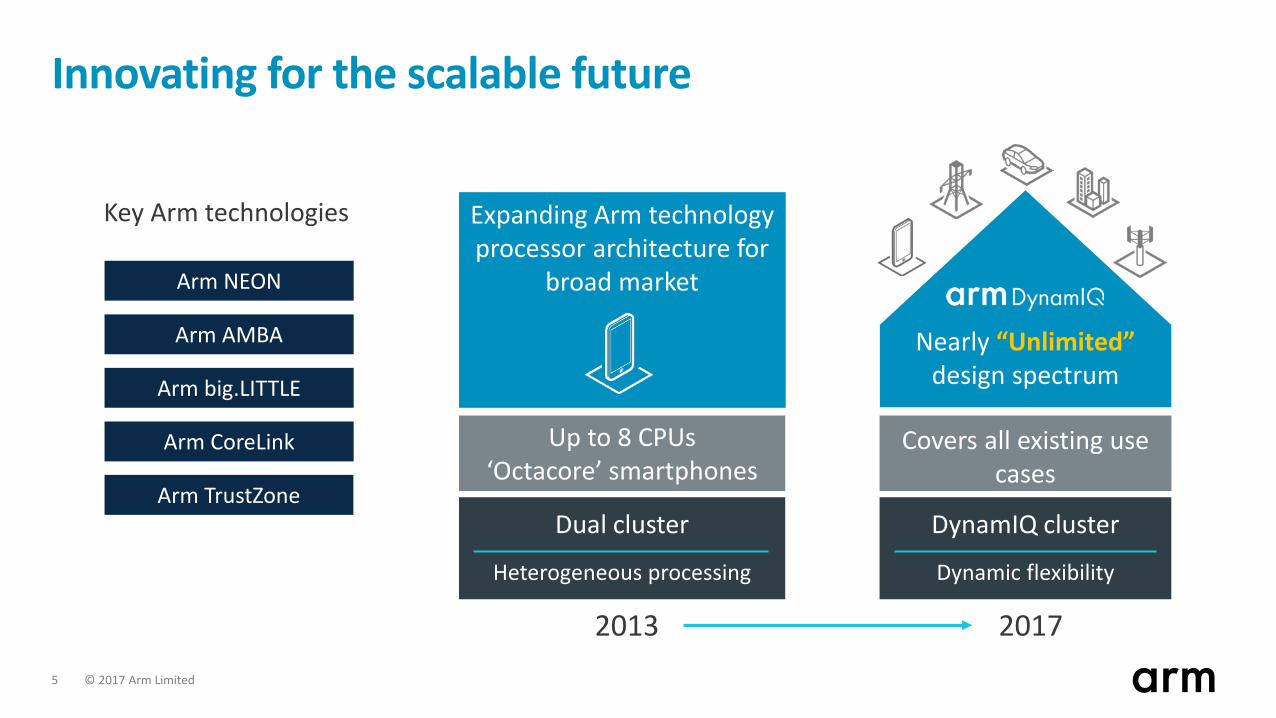
© 2017 Arm Limited 5
Innovating for the scalable future
Up to 8 CPUs‘Octacore’ smartphones
Dual cluster
Heterogeneous processing
Nearly “Unlimited” design spectrum
Covers all existing use cases
DynamIQ cluster
Dynamic flexibility
2013 2017
Expanding Arm technology processor architecture for
broad market
Arm AMBA
Arm big.LITTLE
Arm CoreLink
Arm TrustZone
Arm NEON
Key Arm technologies
© 2017 Arm Limited
DSU – Broadening the reach of technology
© 2017 Arm Limited 7
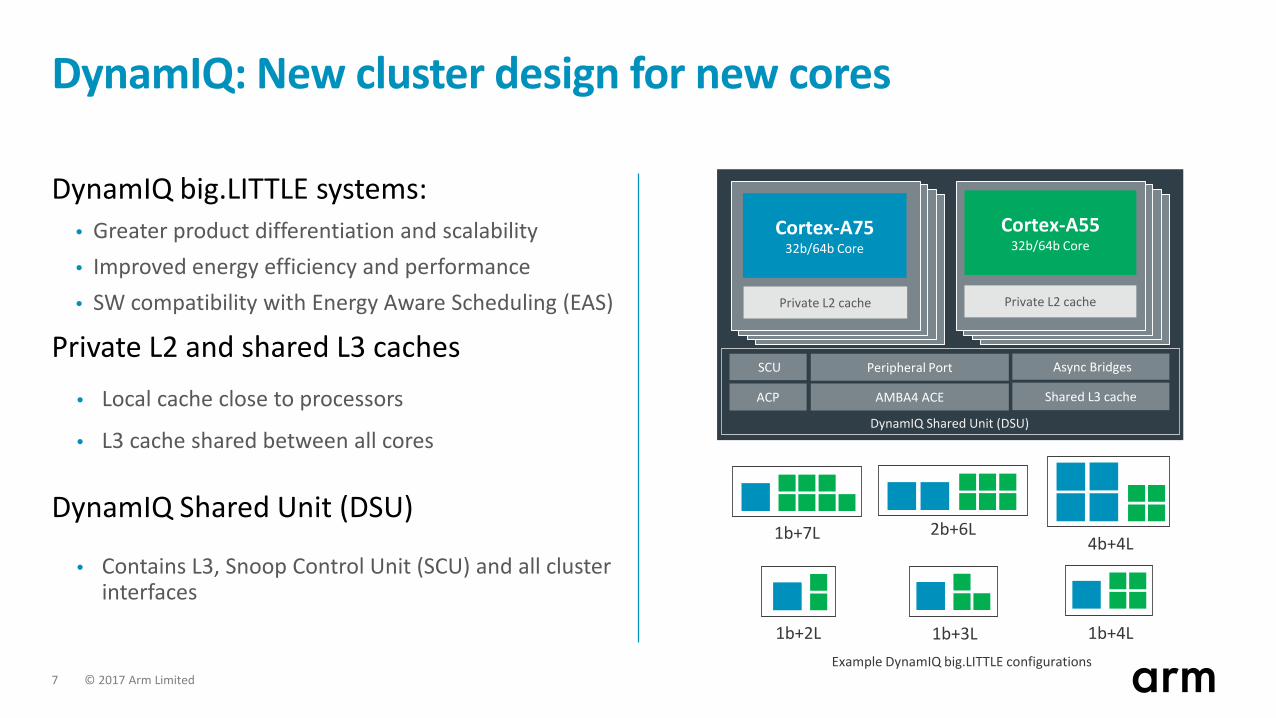
DynamIQ: New cluster design for new cores
DynamIQ big.LITTLE systems:• Greater product differentiation and scalability• Improved energy efficiency and performance• SW compatibility with Energy Aware Scheduling (EAS)
Private L2 and shared L3 caches• Local cache close to processors
• L3 cache shared between all cores
DynamIQ Shared Unit (DSU)
• Contains L3, Snoop Control Unit (SCU) and all cluster interfaces
1b+4L1b+3L1b+2L
1b+7L
Example DynamIQ big.LITTLE configurations
..
AMBA4 ACE
SCU
Shared L3 cacheACP
Cortex-A5532b/64b Core
Private L2 cache
Async BridgesPeripheral Port
Cortex-A7532b/64b Core
Private L2 cache
DynamIQ Shared Unit (DSU)
2b+6L4b+4L
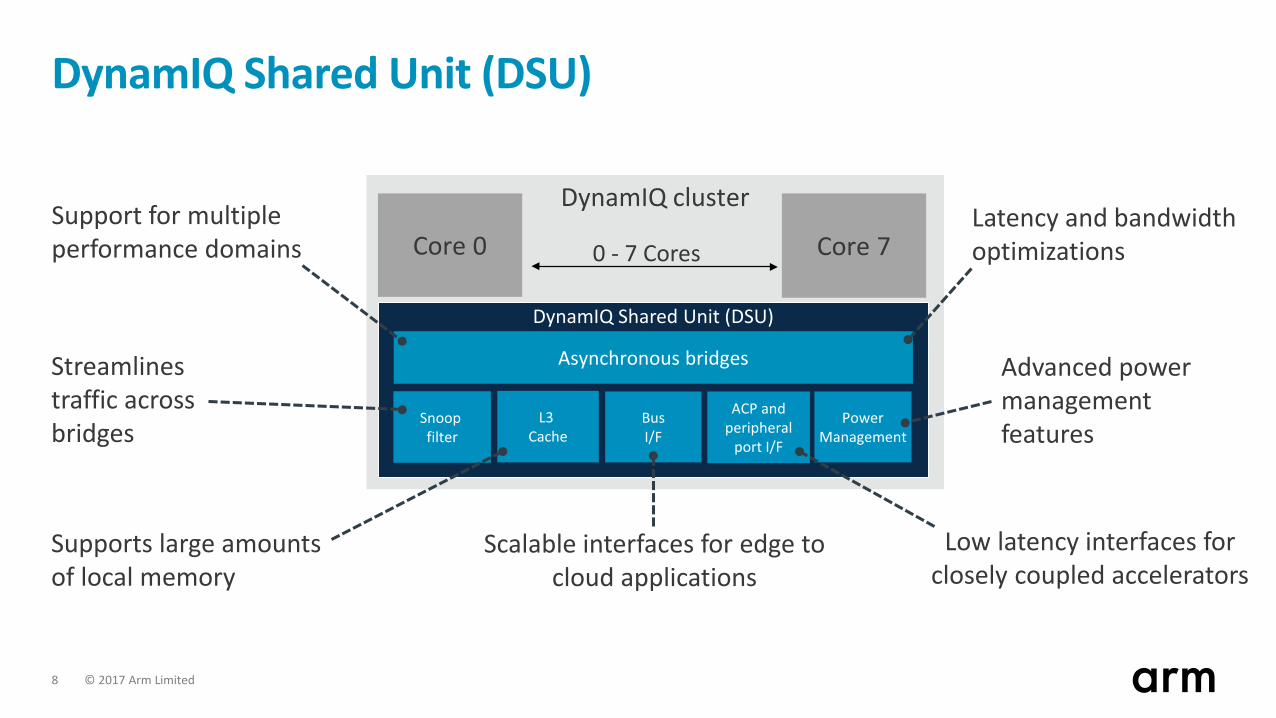
© 2017 Arm Limited 8
DynamIQ cluster
0 - 7 CoresCore 0
Snoop filter
PowerManagement
L3 Cache
BusI/F
ACP andperipheral
port I/F
Core 7
Asynchronous bridges
DynamIQ Shared Unit (DSU)
DynamIQ Shared Unit (DSU)
Streamlines traffic across bridges
Advanced power management features
Latency and bandwidth optimizations
Support for multiple performance domains
Scalable interfaces for edge to cloud applications
Supports large amounts of local memory
Low latency interfaces for closely coupled accelerators
© 2017 Arm Limited 9
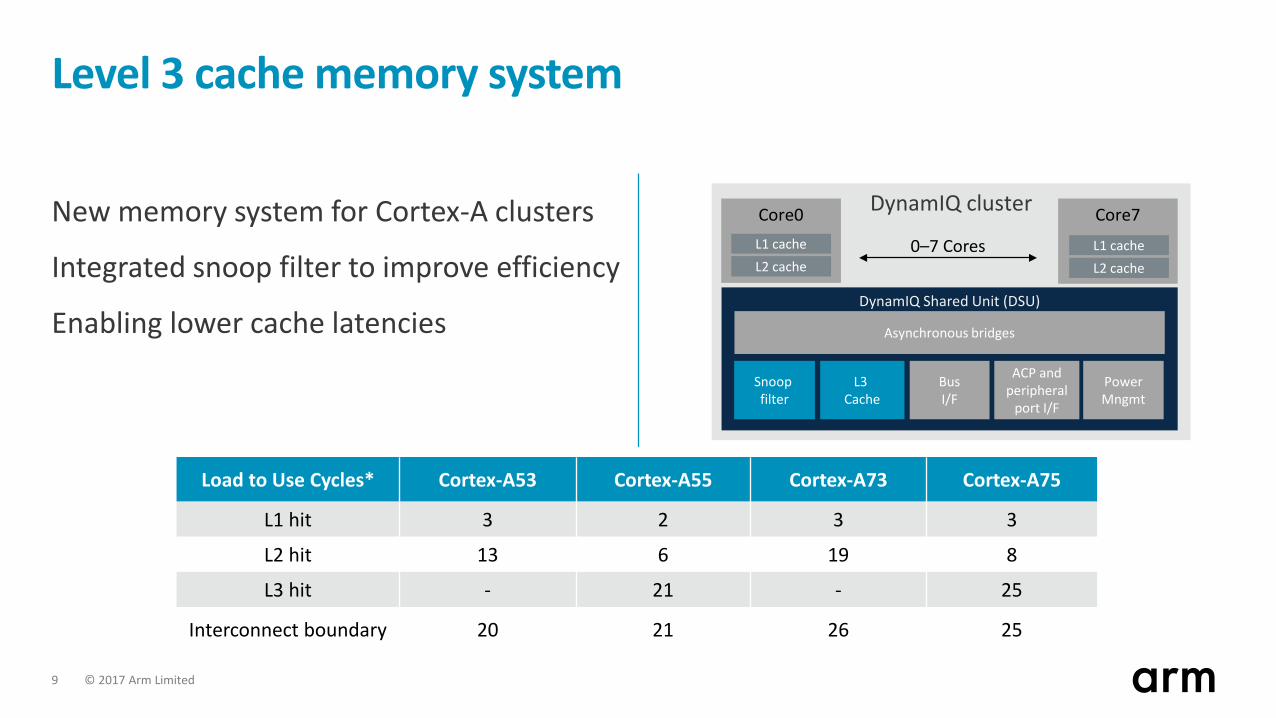
Level 3 cache memory system
New memory system for Cortex-A clusters
Integrated snoop filter to improve efficiency
Enabling lower cache latencies
DynamIQ cluster
0–7 Cores
Core0
Snoop filter
PowerMngmt
L3 Cache
BusI/F
ACP andperipheral
port I/F
Core7
Asynchronous bridges
DynamIQ Shared Unit (DSU)
L1 cacheL2 cache
Load to Use Cycles* Cortex-A53 Cortex-A55 Cortex-A73 Cortex-A75
L1 hit 3 2 3 3
L2 hit 13 6 19 8
L3 hit - 21 - 25
Interconnect boundary 20 21 26 25
L1 cacheL2 cache
© 2017 Arm Limited 10
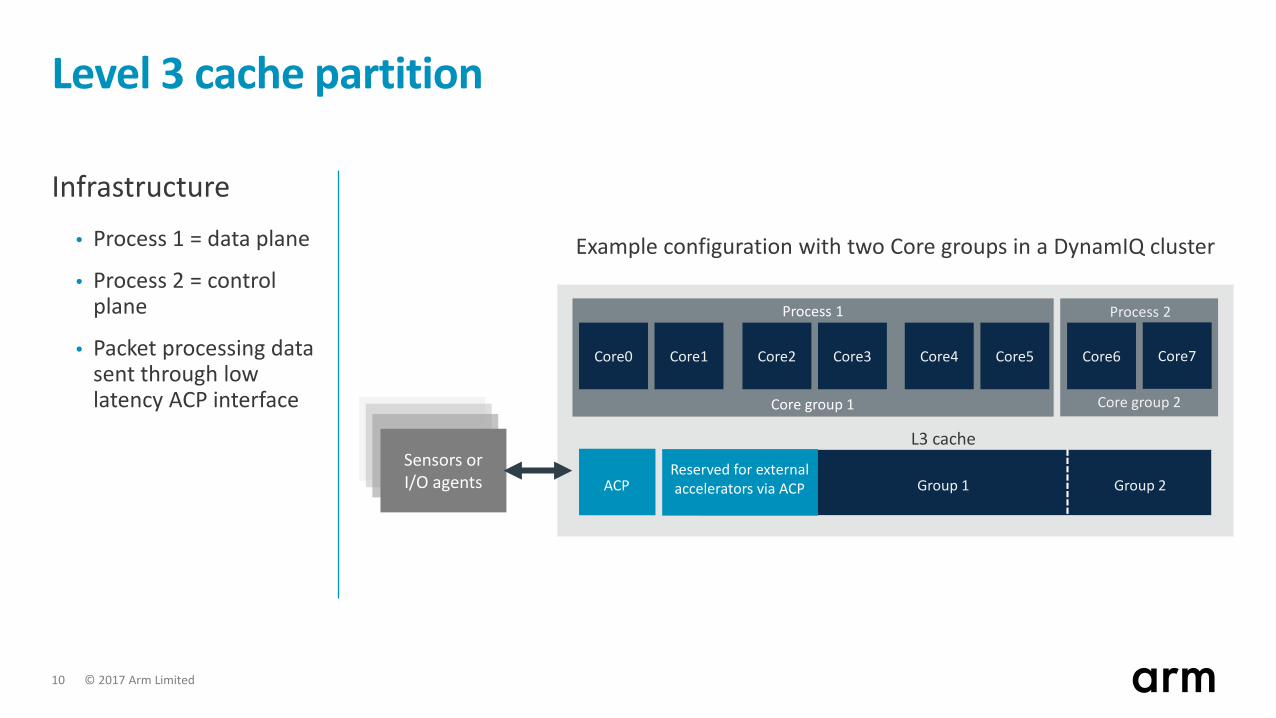
Level 3 cache partition
Infrastructure• Process 1 = data plane
• Process 2 = control plane
• Packet processing data sent through low latency ACP interface
Sensors or I/O agents ACP
Process 2
Core group 2
Example configuration with two Core groups in a DynamIQ cluster
Group 1 Group 2
Core group 1
Process 1
L3 cache
Core0 Core1 Core2 Core3 Core4 Core5 Core6 Core7
Reserved for external accelerators via ACP
© 2017 Arm Limited 11
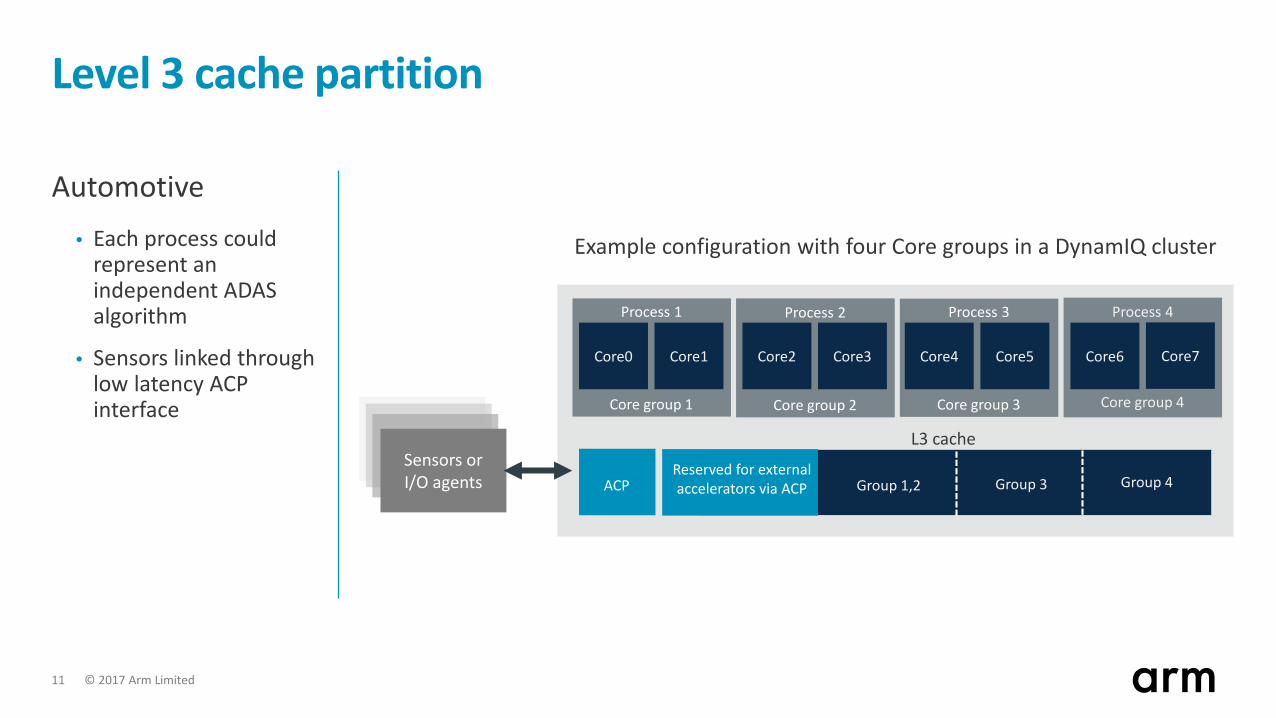
Level 3 cache partition
Automotive• Each process could
represent an independent ADAS algorithm
• Sensors linked through low latency ACP interface
Sensors or I/O agents ACP
Process 4
Core group 4
Example configuration with four Core groups in a DynamIQ cluster
Group 1,2 Group 4
Core group 1
Process 1
L3 cache
Core0 Core1 Core6 Core7
Core group 2
Process 2
Core2 Core3
Core group 3
Process 3
Core4 Core5
Group 3Reserved for external accelerators via ACP
© 2017 Arm Limited 12
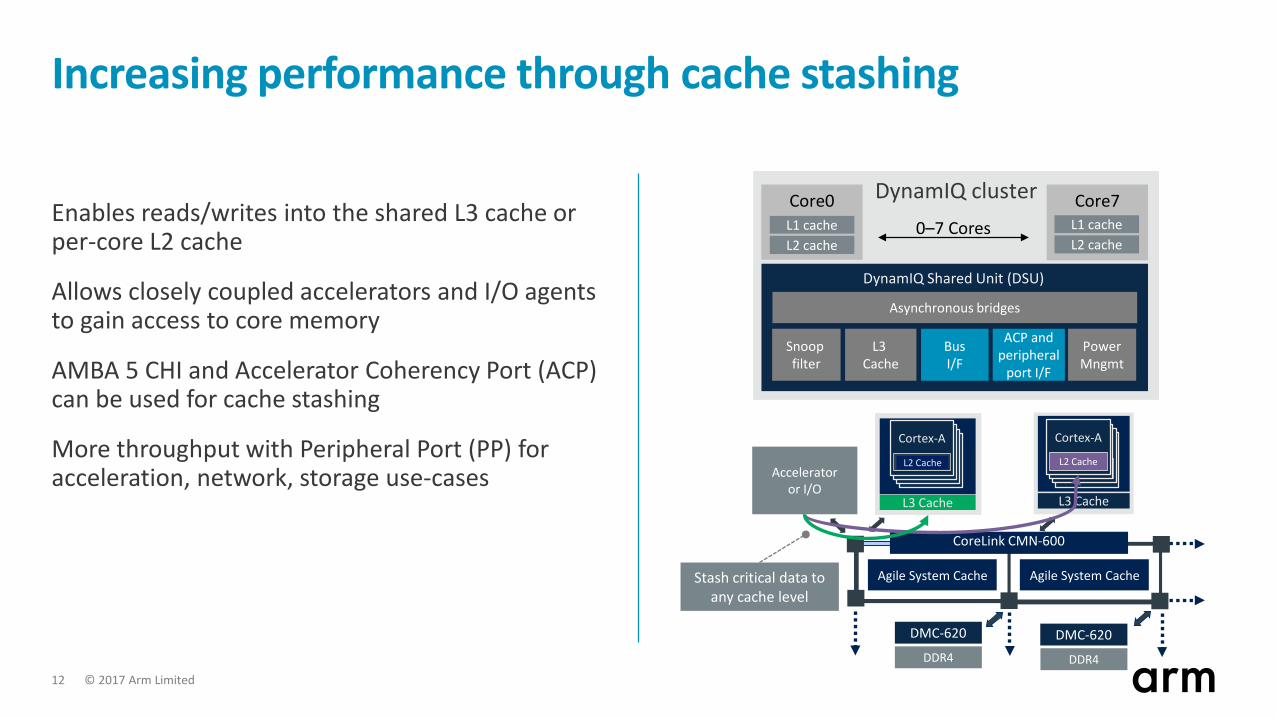
Increasing performance through cache stashing
Enables reads/writes into the shared L3 cache or per-core L2 cache
Allows closely coupled accelerators and I/O agents to gain access to core memory
AMBA 5 CHI and Accelerator Coherency Port (ACP) can be used for cache stashing
More throughput with Peripheral Port (PP) for acceleration, network, storage use-cases Accelerator
or I/O
CoreLink CMN-600
DMC-620 DMC-620
Agile System Cache
DDR4 DDR4
L3 Cache
L2 Cache
CPUL2 Cache
CPUL2 Cache
CPU
L2 Cache
Cortex-A
Agile System Cache
L3 Cache
L2 Cache
CPUL2 Cache
CPUL2 Cache
CPU
L2 Cache
Cortex-A
Stash critical data to any cache level
DynamIQ cluster0–7 Cores
Core0
Snoop filter
PowerMngmt
L3 Cache
BusI/F
ACP andperipheral
port I/F
Core7
Asynchronous bridges
DynamIQ Shared Unit (DSU)
L1 cacheL2 cache
L1 cacheL2 cache
© 2017 Arm Limited 13
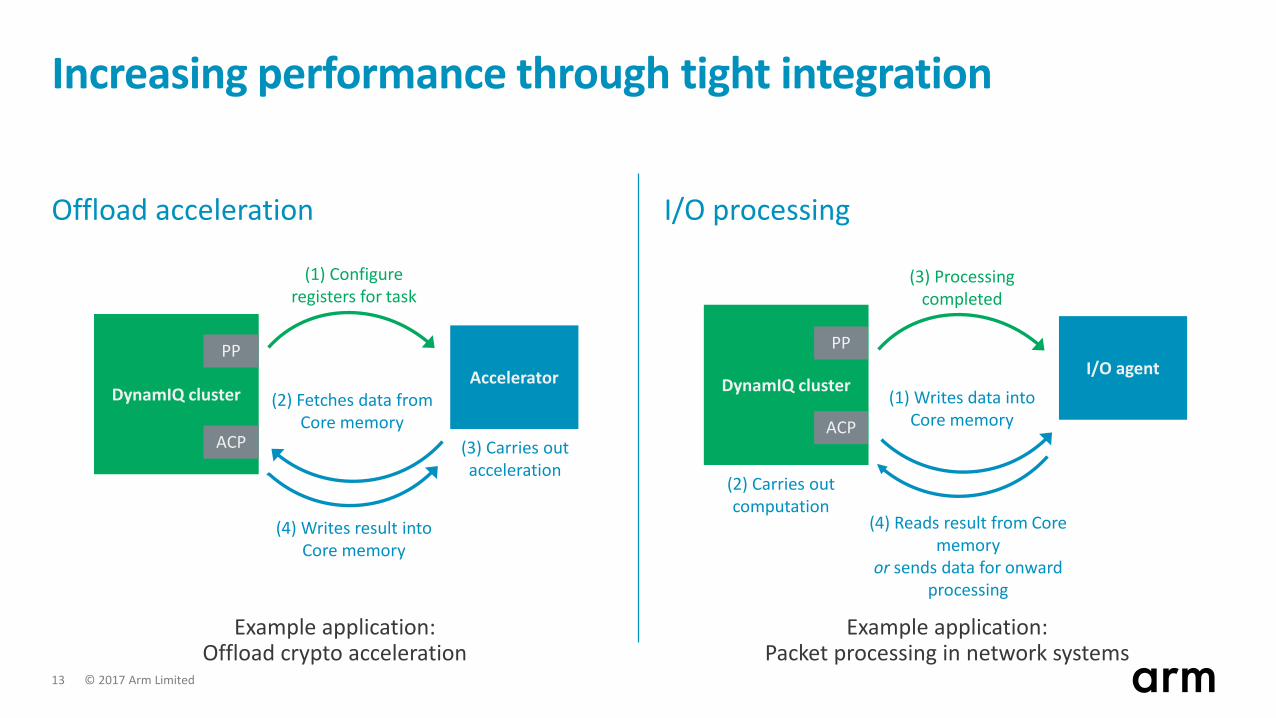
Increasing performance through tight integration
Offload acceleration
Example application: Offload crypto acceleration
I/O processing
Example application: Packet processing in network systems
DynamIQ clusterAccelerator
(4) Writes result into Core memory
(1) Configure registers for task
(2) Fetches data from Core memory
(3) Carries out acceleration
ACP
PP
DynamIQ clusterI/O agent
(4) Reads result from Core memory
or sends data for onward processing
(3) Processing completed
(1) Writes data into Core memory
(2) Carries out computation
ACP
PP
© 2017 Arm Limited 14
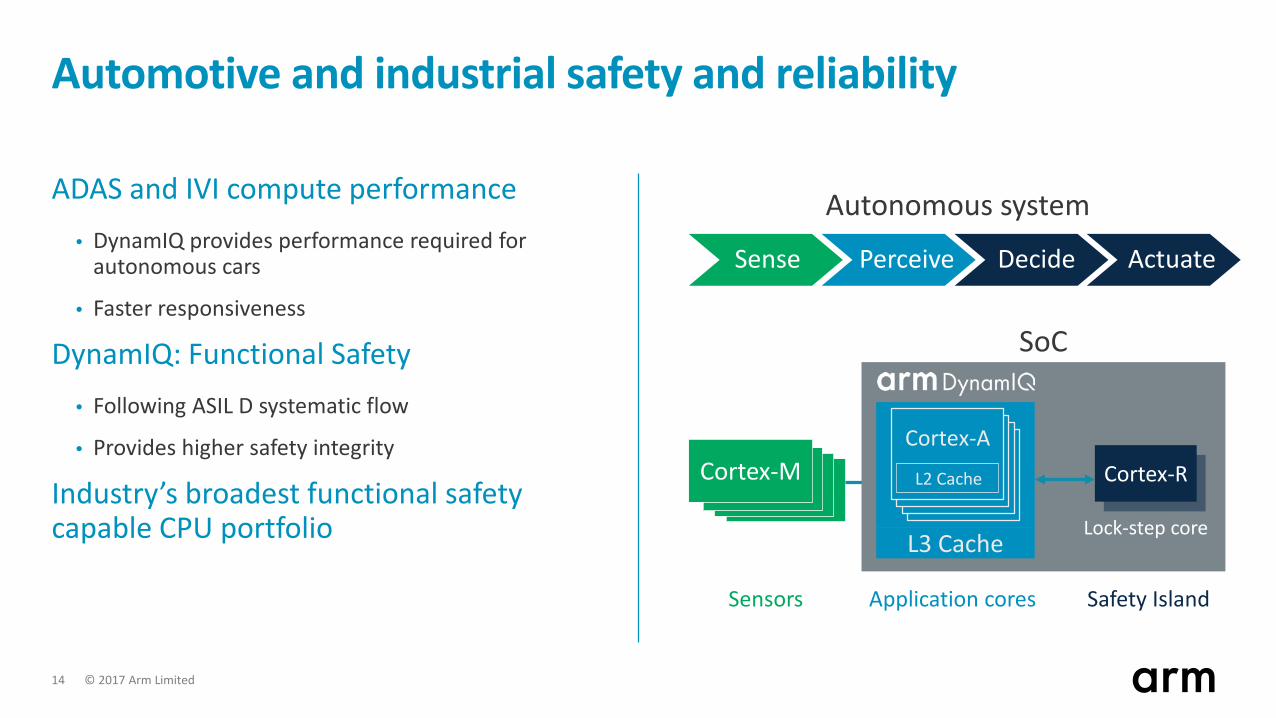
Automotive and industrial safety and reliability
ADAS and IVI compute performance• DynamIQ provides performance required for
autonomous cars
• Faster responsiveness
DynamIQ: Functional Safety• Following ASIL D systematic flow
• Provides higher safety integrity
Industry’s broadest functional safety capable CPU portfolio
Autonomous system
Sense Perceive Decide Actuate
Cortex-M Cortex-R
Safety IslandApplication cores
L3 Cache
L2 Cache
CPUL2 Cache
CPUL2 Cache
CPUL2 Cache
Cortex-A
Sensors
SoC
Lock-step core
© 2017 Arm Limited
Cortex-A75 – Increasing PerformanceCortex-A55 – Improving Efficiency

© 2017 Arm Limited 16
New levels of performance for smart solutions
Cortex-A75 Cortex-A55
All comparisons at ISO process and frequency
Baseline to Cortex-A73 Baseline to Cortex-A53
1.21x
1.42x
1.97x
1.14x
1.22x
SPECINT2006
SPECFP2006
LMBench memcpy
Octane 2.0
Geekbench v4
1.22x
1.33x
1.16x
1.48x
1.34x
SPECINT2006
SPECFP2006
LMBench memcpy
Octane 2.0
Geekbench v4
All comparisons at ISO process and frequency
© 2017 Arm Limited 17
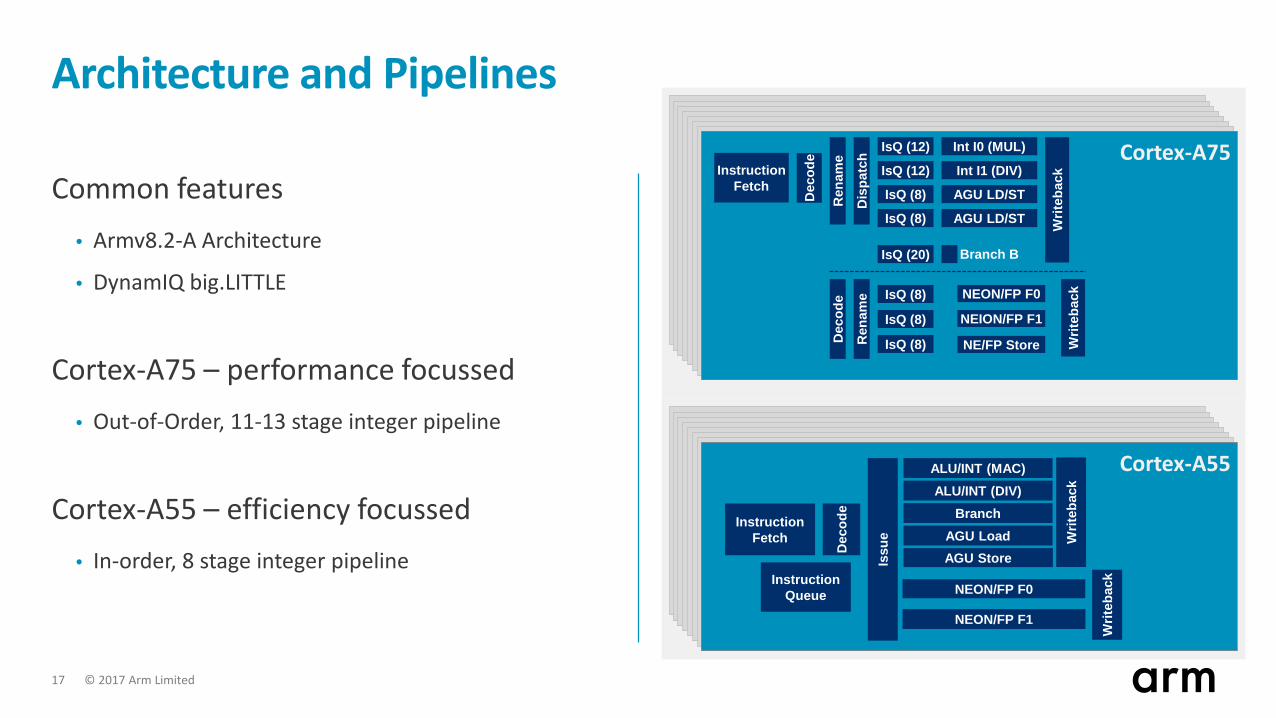
Architecture and Pipelines
Common features• Armv8.2-A Architecture
• DynamIQ big.LITTLE
Cortex-A75 – performance focussed• Out-of-Order, 11-13 stage integer pipeline
Cortex-A55 – efficiency focussed• In-order, 8 stage integer pipeline
ALU/INT (MAC)
NEON/FP F0
Dec
ode
NEON/FP F1
InstructionFetch W
riteb
ack
Issu
e
ALU/INT (DIV)Branch
AGU LoadAGU Store
Cortex-A55
Int I0 (MUL)
Dec
ode
InstructionFetch
Writ
ebac
kInt I1 (DIV)
AGU LD/ST
AGU LD/ST
Branch B
Cortex-A75
InstructionQueue
Writ
ebac
k
Ren
ame
Dis
patc
h
IsQ (12)
IsQ (12)
IsQ (8)
IsQ (8)
IsQ (20)
Dec
ode
Ren
ame IsQ (8)
IsQ (8)
IsQ (8)
NEION/FP F1
NE/FP Store
NEON/FP F0
Writ
ebac
k
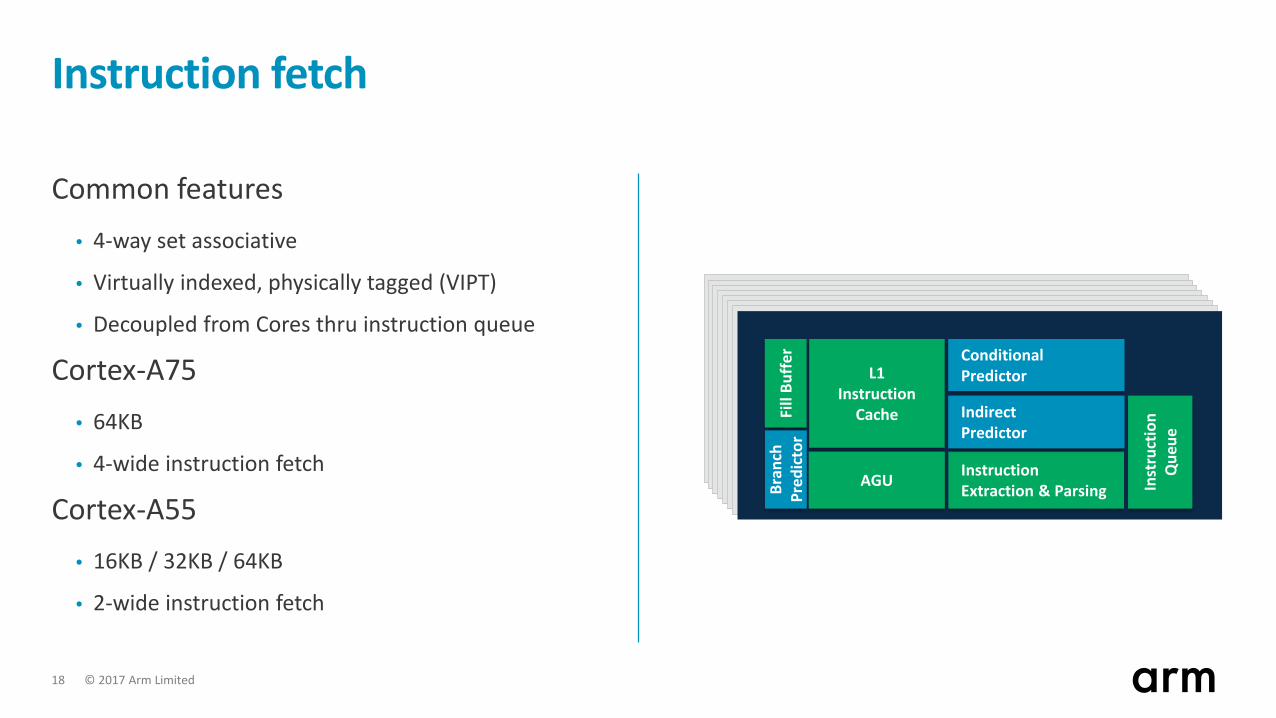
© 2017 Arm Limited 18
Instruction Extraction & Parsing In
stru
ctio
nQ
ueue
Fill
Buffe
r ConditionalPredictorL1
InstructionCache
AGU
IndirectPredictor
Bran
chPr
edic
tor
Instruction fetch
Common features• 4-way set associative
• Virtually indexed, physically tagged (VIPT)
• Decoupled from Cores thru instruction queue
Cortex-A75• 64KB
• 4-wide instruction fetch
Cortex-A55• 16KB / 32KB / 64KB
• 2-wide instruction fetch
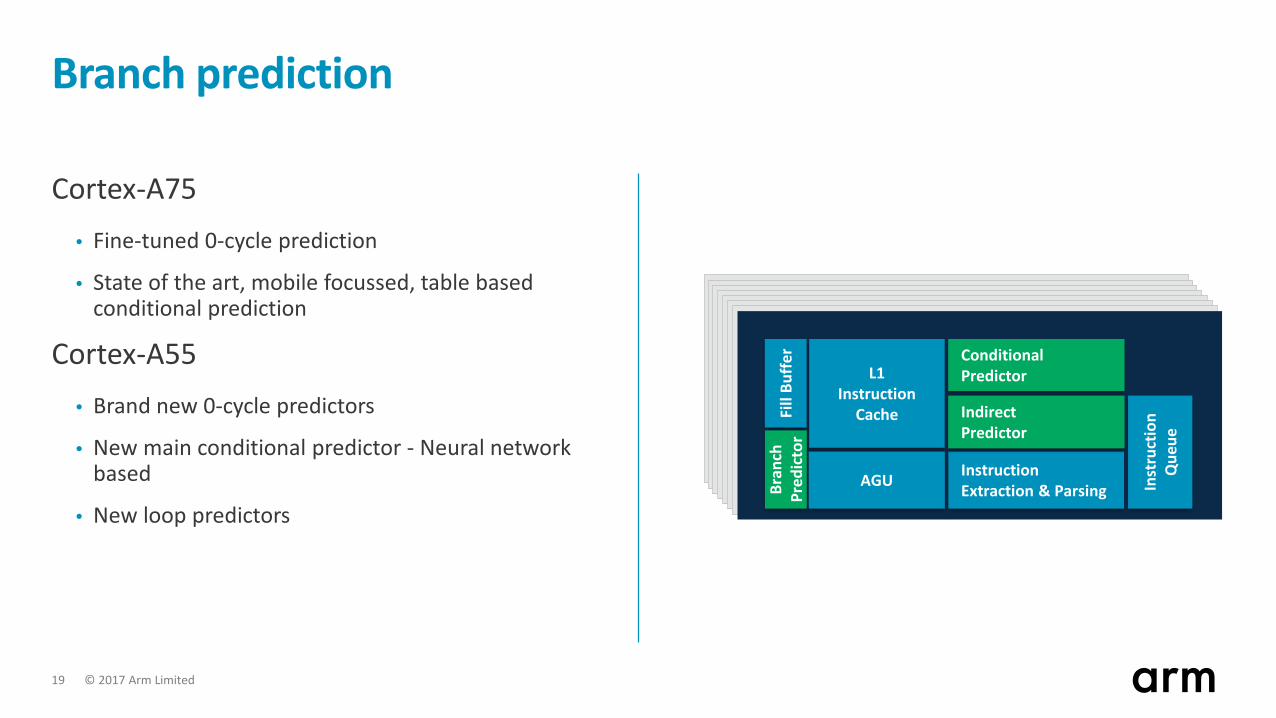
© 2017 Arm Limited 19
Instruction Extraction & Parsing In
stru
ctio
nQ
ueue
Fill
Buffe
r ConditionalPredictorL1
InstructionCache
AGU
IndirectPredictor
Bran
chPr
edic
tor
Branch prediction
Cortex-A75• Fine-tuned 0-cycle prediction
• State of the art, mobile focussed, table based conditional prediction
Cortex-A55• Brand new 0-cycle predictors
• New main conditional predictor - Neural network based
• New loop predictors
© 2017 Arm Limited 20
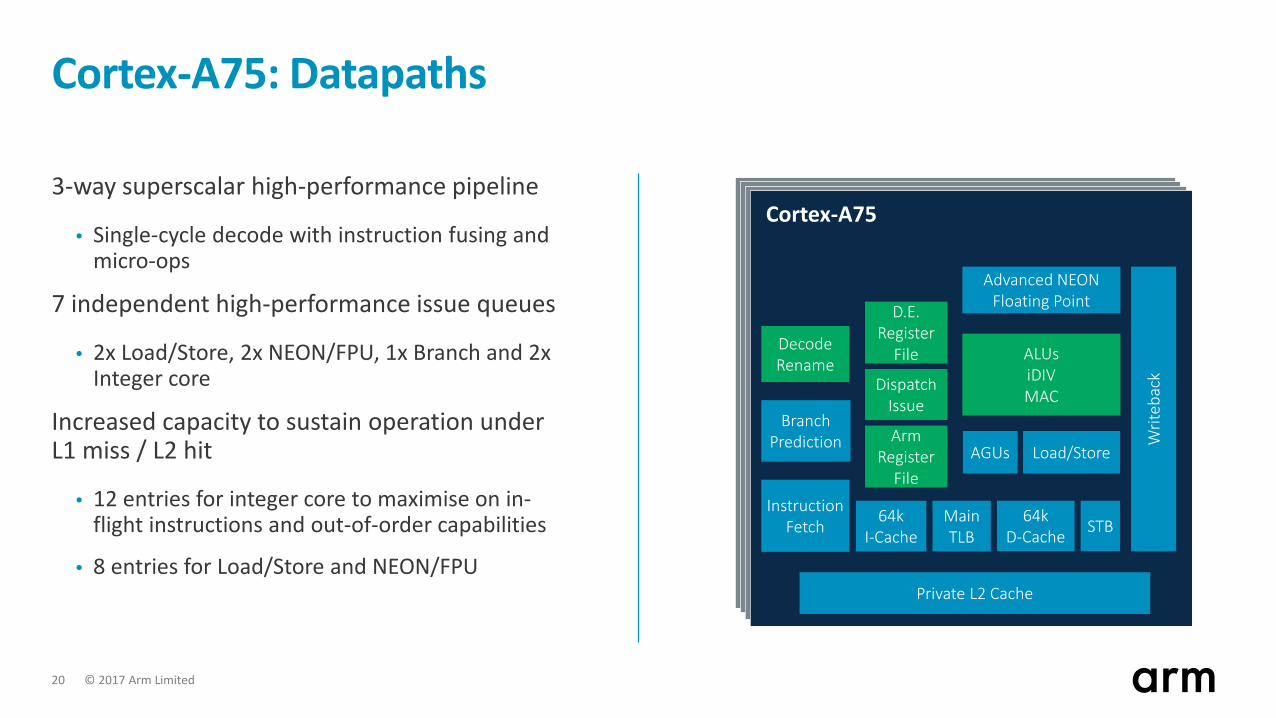
Cortex-A75: Datapaths
3-way superscalar high-performance pipeline
• Single-cycle decode with instruction fusing and micro-ops
7 independent high-performance issue queues
• 2x Load/Store, 2x NEON/FPU, 1x Branch and 2x Integer core
Increased capacity to sustain operation under L1 miss / L2 hit
• 12 entries for integer core to maximise on in-flight instructions and out-of-order capabilities
• 8 entries for Load/Store and NEON/FPU
Cortex-A75
Private L2 Cache
Instruction Fetch
MainTLB
ArmRegister
File
D.E.Register
File
DispatchIssue
64kD-Cache STB64k
I-Cache
BranchPrediction
Decode Rename
Load/Store
Advanced NEONFloating Point
ALUs iDIVMAC
AGUs
Writ
ebac
k
© 2017 Arm Limited 21
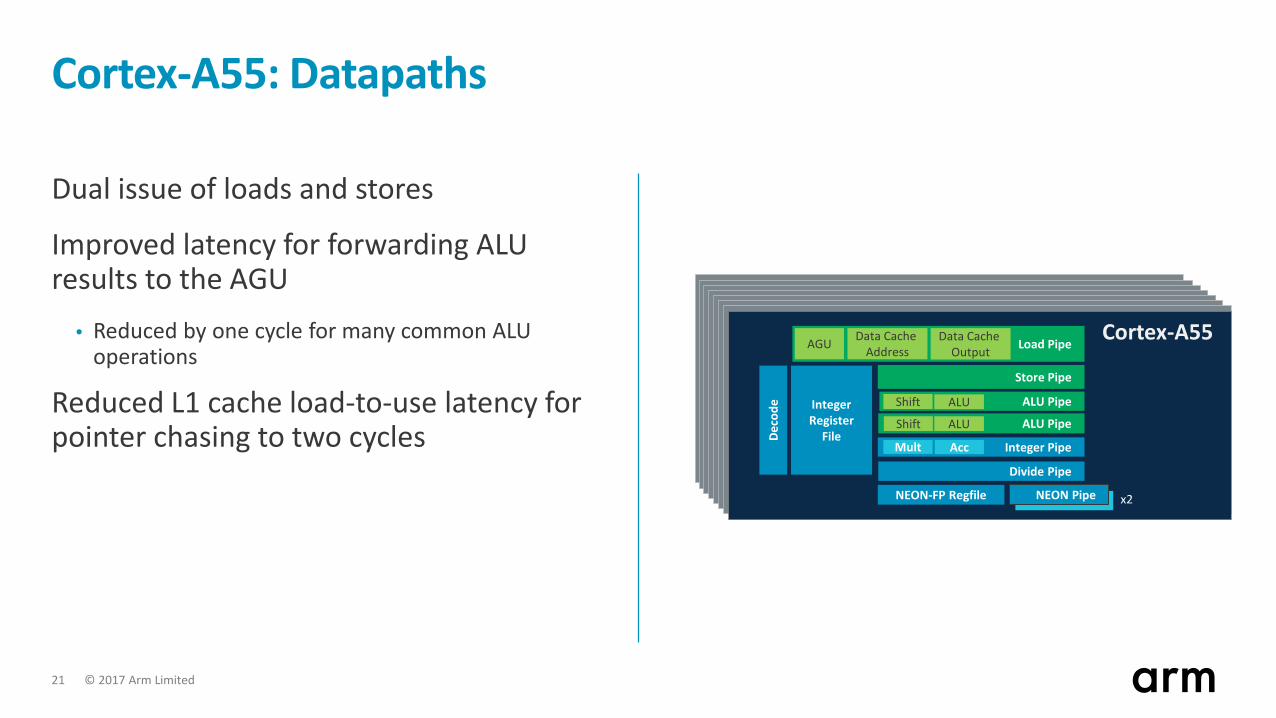
Cortex-A55: Datapaths
Dual issue of loads and stores
Improved latency for forwarding ALU results to the AGU
• Reduced by one cycle for many common ALU operations
Reduced L1 cache load-to-use latency for pointer chasing to two cycles
IntegerRegister
File
NEON-FP Regfile NEON Pipe
Deco
de
Store Pipe
x2
Cortex-A55
ALU Pipe
ALU Pipe
Integer Pipe
Divide Pipe
Mult Acc
Shift ALU
Shift ALU
Load PipeAGU Data Cache Output
Data Cache Address

© 2017 Arm Limited 22
L1 memory system
Common features• 4-way set associative• VIPT with PIPT programmer’s view• Improved prefetchers
Cortex-A75• 64KB• Wider load-store than Cortex-A73• Support Read-after-Write OoO with filtering
Cortex-A55• 16KB / 32KB / 64KB• Improved store buffer bandwidth to L1• Larger 16-entry L1-TLB
Store BufferL1
DataCache
Prefetcher
L1 TLB
L2 TLB
L2 Cache

© 2017 Arm Limited 23
Store BufferL1
DataCache
Prefetcher
L1 TLB
L2 TLB
L2 Cache
L2 memory system
Common features• Private L2 cache in each Core
• Running at Core speed
• Exclusive data cache
• Cache stashing into the L2
• Non-blocking 1024-entry TLB for hit-under-miss
Cortex-A75• 256KB / 512 KB
Cortex-A55• 0KB / 64KB / 128KB / 256KB

© 2017 Arm Limited 24
Next-generation features
Dot product and half-precision float for AI/ML processing
Virtualized Host Extensions (VHE) offering Type-2 hypervisor (KVM) performance improvements
Cache stashing and atomic operations improves multicore networking performance and improves latencyCache clean to persistence to support storage class memoryInfrastructure class RAS enhancement including data poisoning and improved error management

© 2017 Arm Limited 25
Innovating for the scalable future
2013-2017: The nature of compute is changing the landscape
Expanding Arm technologies for broad market applicability
New cluster design with new DynamIQ cores: • Cortex-A75: Breakthrough performance
• Cortex-A55: Efficiency redefined
Functional safety for industrial and automotive applications
New features expanding microarchitecture capabilities:• DynamIQ Shared Unit , new cache features, new branch prediction

2626
Thank You!Danke!Merci!谢谢!ありがとう!Gracias!Kiitos!
© 2017 Arm Limited

2727 © 2017 Arm Limited
The Arm trademarks featured in this presentation are registered trademarks or trademarks of Arm Limited (or its subsidiaries) in the US and/or elsewhere. All rights reserved. All other marks featured may be trademarks of their respective owners.
www.arm.com/company/policies/trademarks


















