

Apache Spark - Santa Barbara Scala Meetup Dec 18th 2014
46
CONFIDENTIAL - RESTRICTED Introduction to Spark Scala SB Meetup December 18 th 2014 Maxime Dumas Systems Engineer, Cloudera
-
Upload
cdmaxime -
Category
Technology
-
view
205 -
download
1
Transcript of Apache Spark - Santa Barbara Scala Meetup Dec 18th 2014

CONFIDENTIAL - RESTRICTED
Introduction to SparkScala SB Meetup
December 18th 2014
Maxime Dumas
Systems Engineer, Cloudera

Thirty Seconds About Max
• Systems Engineer
• aka Sales Engineer
• SoCal, AZ, NV
• former coder of PHP
• teaches meditation + yoga
• from Montreal, Canada
2

What Does Cloudera Do?
• product
• distribution of Hadoop components, Apache licensed
• enterprise tooling
• support
• training
• services (aka consulting)
• community
3

4
Quick and dirty, for context.
The Apache Hadoop Ecosystem

©2014 Cloudera, Inc. All rights
reserved.
• Scalability• Simply scales just by adding nodes• Local processing to avoid network bottlenecks
• Efficiency• Cost efficiency (<$1k/TB) on commodity hardware• Unified storage, metadata, security (no duplication or
synchronization)
• Flexibility• All kinds of data (blobs, documents, records, etc)• In all forms (structured, semi-structured, unstructured)• Store anything then later analyze what you need
Why Hadoop?

Why “Ecosystem?”
• In the beginning, just Hadoop
• HDFS
• MapReduce
• Today, dozens of interrelated components
• I/O
• Processing
• Specialty Applications
• Configuration
• Workflow
6

HDFS
• Distributed, highly fault-tolerant filesystem
• Optimized for large streaming access to data
• Based on Google File System
• http://research.google.com/archive/gfs.html
7

Lots of Commodity Machines
8
Image:Yahoo! Hadoop cluster [ OSCON ’07 ]

MapReduce (MR)
• Programming paradigm
• Batch oriented, not realtime
• Works well with distributed computing
• Lots of Java, but other languages supported
• Based on Google’s paper
• http://research.google.com/archive/mapreduce.html
9

Apache Hive
• Abstraction of Hadoop’s Java API
• HiveQL “compiles” down to MR
• a “SQL-like” language
• Eases analysis using MapReduce
10

Apache Hive Metastore
• Maps HDFS files to DB-like resources
• Databases
• Tables
• Column/field names, data types
• Roles/users
• InputFormat/OutputFormat
11
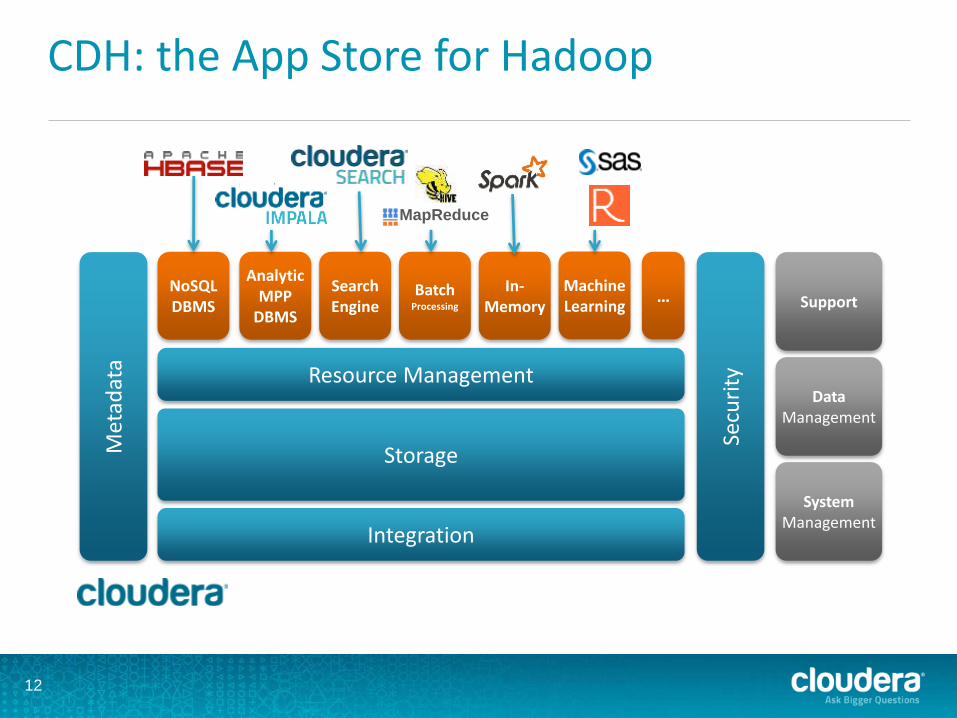
CDH: the App Store for Hadoop
12
Integration
Storage
Resource Management
Met
adat
a
NoSQLDBMS
…Analytic
MPPDBMS
SearchEngine
In-Memory
Batch Processing
System Management
Data Management
Support
Secu
rity
Machine Learning
MapReduce

13
Introduction to Apache Spark
Credits:
• Ben White
• Todd Lipcon
• Ted Malaska
• Jairam Ranganathan
• Jayant Shekhar
• Sandy Ryza

Can we improve on MR?
• Problems with MR:
• Very low-level: requires a lot of code to do simple things
• Very constrained: everything must be described as “map” and “reduce”. Powerful but sometimes difficult to think in these terms.
14

Can we improve on MR?
• Two approaches to improve on MapReduce:
1. Special purpose systems to solve one problem domain well.• Giraph / Graphlab (graph processing)• Storm (stream processing)• Impala (real-time SQL)
2. Generalize the capabilities of MapReduce to provide a richer foundation to solve problems.• Tez, MPI, Hama/Pregel (BSP), Dryad (arbitrary DAGs)
Both are viable strategies depending on the problem!
15

What is Apache Spark?
Spark is a general purpose computational framework
Retains the advantages of MapReduce:• Linear scalability• Fault-tolerance• Data Locality based computations
…but offers so much more:• Leverages distributed memory for better performance• Supports iterative algorithms that are not feasible in MR• Improved developer experience• Full Directed Graph expressions for data parallel computations• Comes with libraries for machine learning, graph analysis, etc.
16

What is Apache Spark?
Run programs up to 100x faster than HadoopMapReduce in memory, or 10x faster on disk.
One of the largest open source projects in big data:
• 170+ developers contributing
• 30+ companies contributing
• 400+ discussions per month on the mailing list
17

Popular project
18

Getting started with Spark
• Java API
• Interactive shells:
• Scala (spark-shell)
• Python (pyspark)
19

Execution modes
20

Execution modes
• Standalone Mode
• Dedicated master and worker daemons
• YARN Client Mode
• Launches a YARN application with the driver program running locally
• YARN Cluster Mode
• Launches a YARN application with the driver program running in the YARN ApplicationMaster
21
Dynamic resource management between Spark, MR, Impala…
Dedicated Spark runtime with static resource limits

Spark Concepts
22

RDD – Resilient Distributed Dataset
• Collections of objects partitioned across a cluster
• Stored in RAM or on Disk
• You can control persistence and partitioning
• Created by:
• Distributing local collection objects
• Transformation of data in storage
• Transformation of RDDs
• Automatically rebuilt on failure (resilient)
• Contains lineage to compute from storage
• Lazy materialization
23

RDD transformations
24

Operations on RDDs
Transformations lazily transform a RDD to a new RDD
• map
• flatMap
• filter
• sample
• join
• sort
• reduceByKey
• …
Actions run computation to return a value
• collect
• reduce(func)
• foreach(func)
• count
• first, take(n)
• saveAs
• …
25

Fault Tolerance
• RDDs contain lineage.
• Lineage – source location and list of transformations
• Lost partitions can be re-computed from source data
26
msgs = textFile.filter(lambda s: s.startsWith(“ERROR”)).map(lambda s: s.split(“\t”)[2])
HDFS File Filtered RDD Mapped RDDfilter
(func = startsWith(…))map
(func = split(...))

27
Examples

Word Count in MapReduce
28
package org.myorg;
import java.io.IOException;import java.util.*;
import org.apache.hadoop.fs.Path;import org.apache.hadoop.conf.*;import org.apache.hadoop.io.*;import org.apache.hadoop.mapreduce.*;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();StringTokenizer tokenizer = new StringTokenizer(line);while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());context.write(word, one);
}}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {
sum += val.get();}context.write(key, new IntWritable(sum));
}}
public static void main(String[] args) throws Exception {Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);}
}

Word Count in Spark
sc.textFile(“words”)
.flatMap(line => line.split(" "))
.map(word=>(word,1))
.reduceByKey(_+_).collect()
29

Logistic Regression
• Read two sets of points
• Looks for a plane W that separates them
• Perform gradient descent:
• Start with random W
• On each iteration, sum a function of W over the data
• Move W in a direction that improves it
30

Intuition
31

Logistic Regression
32

Logistic Regression Performance
33

34
Spark and Hadoop:a Framework within a Framework

35

36
Integration
Storage
Resource Management
Met
adat
a
HBase …Impala Solr SparkMap
Reduce
System Management
Data Management
Support
Secu
rity

Spark Streaming
• Takes the concept of RDDs and extends it to DStreams• Fault-tolerant like RDDs
• Transformable like RDDs
• Adds new “rolling window” operations• Rolling averages, etc.
• But keeps everything else!• Regular Spark code works in Spark Streaming
• Can still access HDFS data, etc.
• Example use cases: • “On-the-fly” ETL as data is ingested into Hadoop/HDFS.
• Detecting anomalous behavior and triggering alerts.
• Continuous reporting of summary metrics for incoming data.
37

Micro-batching for on the fly ETL
38

What about SQL?
39
http://databricks.com/blog/2014/07/01/shark-spark-sql-hive-on-spark-and-the-future-of-sql-on-spark.htmlhttp://blog.cloudera.com/blog/2014/07/apache-hive-on-apache-spark-motivations-and-design-principles/

Fault Recovery Recap
• RDDs store dependency graph
• Because RDDs are deterministic:Missing RDDs are rebuilt in parallel on other nodes
• Stateful RDDs can have infinite lineage
• Periodic checkpoints to disk clears lineage
• Faster recovery times
• Better handling of stragglers vs row-by-row streaming
40

Why Spark?
• Flexible like MapReduce
• High performance
• Machine learning, iterative algorithms
• Interactive data explorations
• Concise, easy API for developer productivity
41

42
Demo Time!
• Log file Analysis
• Machine Learning
• Spark Streaming

What’s Next?
• Download Hadoop!
• CDH available at www.cloudera.com
• Try it online: Cloudera Live
• Cloudera provides pre-loaded VMs
• http://tiny.cloudera.com/quickstartvm
43

44
Preferably related to the talk… or not.
Questions?

46











![[Spark meetup] Spark Streaming Overview](https://static.fdocuments.net/doc/165x107/55a457161a28ab057e8b45fd/spark-meetup-spark-streaming-overview.jpg)






