
Scala and spark
49
Introduction to Scala and Spark Ciao ciao Vai a fare ciao ciao Dr. Fabio Fumarola
-
Upload
fabio-fumarola -
Category
Engineering
-
view
731 -
download
3
Transcript of Scala and spark

Introduction toScala and Spark
Ciaociao
Vai a fare
ciao ciao
Dr. Fabio Fumarola

Contents
• Hadoop quick introduction• An introduction to spark• Spark – Architecture & Programming Model
2

Hadoop
• An Open-Source software for distributed storage of large dataset on commodity hardware
• Provides a programming model/framework for processing large dataset in parallel
3
Map
Map
Map
Reduce
Reduce
Input Output

Limitations of Map Reduce
• Slow due to replication, serialization, and disk IO• Inefficient for:
– Iterative algorithms (Machine Learning, Graphs & Network Analysis)– Interactive Data Mining (R, Excel, Ad hoc Reporting, Searching)
4
Input iter. 1iter. 1 iter. 2iter. 2 . . .
HDFSread
HDFSwrite
HDFSread
HDFSwrite
Map
Map
Map
Reduce
Reduce
Input Output

Solutions?
• Leverage to memory:– load Data into Memory– Replace disks with SSD
5

Apache Spark
• A big data analytics cluster-computing framework written in Scala.
• Open Sourced originally in AMPLab at UC Berkley• Provides in-memory analytics based on RDD• Highly compatible with Hadoop Storage API
– Can run on top of an Hadoop cluster
• Developer can write programs using multiple programming languages
6

Spark architecture
7
HDFS
Datanode Datanode Datanode....
Spark Worker
Spark Worker
Spark Worker
....CacheCache CacheCache CacheCache
Block Block Block
Cluster Manager
Spark Driver (Master)

Spark
8
iter. 1iter. 1 iter. 2iter. 2 . . .
Input
HDFSread
HDFSwrite
HDFSread
HDFSwrite

Spark
9
iter. 1iter. 1 iter. 2iter. 2 . . .
Input
Not tied to 2 stage Map Reduce paradigm
1. Extract a working set2. Cache it3. Query it repeatedly
Logistic regression in Hadoop and Spark
HDFSread

Spark Programming Model
10
Datanode
HDFS
Datanode…User
(Developer)
Writes
sc=new SparkContextrDD=sc.textfile(“hdfs://…”)rDD.filter(…)rDD.CacherDD.CountrDD.map
sc=new SparkContextrDD=sc.textfile(“hdfs://…”)rDD.filter(…)rDD.CacherDD.CountrDD.map
Driver Program
SparkContextSparkContext Cluster ManagerCluster
Manager
Worker Node
ExecuterExecuter CacheCache
TaskTask TaskTask
Worker Node
ExecuterExecuter CacheCache
TaskTask TaskTask

Spark Programming Model
11
User (Developer)
Writes
sc=new SparkContextrDD=sc.textfile(“hdfs://…”)rDD.filter(…)rDD.CacherDD.CountrDD.map
sc=new SparkContextrDD=sc.textfile(“hdfs://…”)rDD.filter(…)rDD.CacherDD.CountrDD.map
Driver Program
RDD(Resilient
Distributed Dataset)
RDD(Resilient
Distributed Dataset)
• Immutable Data structure• In-memory (explicitly)• Fault Tolerant• Parallel Data Structure• Controlled partitioning to
optimize data placement• Can be manipulated using
rich set of operators.
• Immutable Data structure• In-memory (explicitly)• Fault Tolerant• Parallel Data Structure• Controlled partitioning to
optimize data placement• Can be manipulated using
rich set of operators.

RDD
• Programming Interface: Programmer can perform 3 types of operations
12
Transformations
•Create a new dataset from and existing one.
•Lazy in nature. They are executed only when some action is performed.
•Example :• Map(func)• Filter(func)• Distinct()
Transformations
•Create a new dataset from and existing one.
•Lazy in nature. They are executed only when some action is performed.
•Example :• Map(func)• Filter(func)• Distinct()
Actions
•Returns to the driver program a value or exports data to a storage system after performing a computation.
•Example:• Count()• Reduce(funct)• Collect• Take()
Actions
•Returns to the driver program a value or exports data to a storage system after performing a computation.
•Example:• Count()• Reduce(funct)• Collect• Take()
Persistence
•For caching datasets in-memory for future operations.
•Option to store on disk or RAM or mixed (Storage Level).
•Example:• Persist() • Cache()
Persistence
•For caching datasets in-memory for future operations.
•Option to store on disk or RAM or mixed (Storage Level).
•Example:• Persist() • Cache()

How Spark works
• RDD: Parallel collection with partitions• User application create RDDs, transform them, and
run actions.• This results in a DAG (Directed Acyclic Graph) of
operators.• DAG is compiled into stages• Each stage is executed as a series of Task (one Task
for each Partition).
13

Example
14
sc.textFile(“/wiki/pagecounts”) RDD[String]
textFile

Example
15
sc.textFile(“/wiki/pagecounts”).map(line => line.split(“\t”))
RDD[String]
textFile map
RDD[List[String]]

Example
16
sc.textFile(“/wiki/pagecounts”).map(line => line.split(“\t”)).map(R => (R[0], int(R[1])))
RDD[String]
textFile map
RDD[List[String]]
RDD[(String, Int)]
map
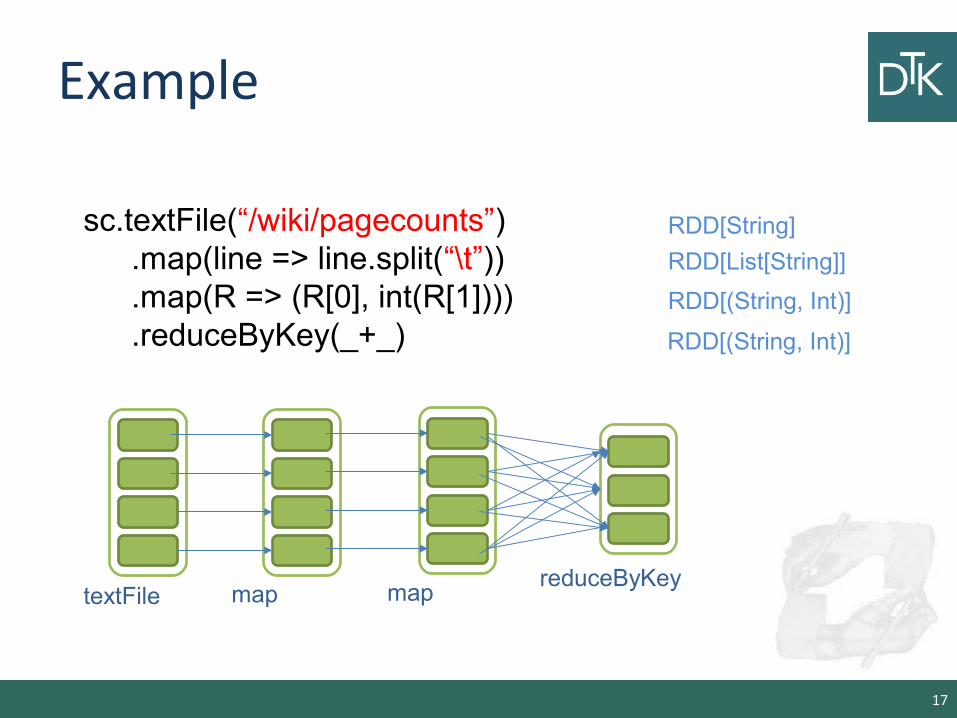
Example
17
sc.textFile(“/wiki/pagecounts”).map(line => line.split(“\t”)).map(R => (R[0], int(R[1]))).reduceByKey(_+_)
RDD[String]
textFile map
RDD[List[String]]
RDD[(String, Int)]
map
RDD[(String, Int)]
reduceByKey

Example
18
sc.textFile(“/wiki/pagecounts”).map(line => line.split(“\t”)).map(R => (R[0], int(R[1]))).reduceByKey(_+_, 3).collect()
RDD[String]
RDD[List[String]]
RDD[(String, Int)]
RDD[(String, Int)]
reduceByKey
Array[(String, Int)]
collect

Execution Plan
Stages are sequences of RDDs, that don’t have a Shuffle in between
19
textFile map mapreduceByKey
collect
Stage 1 Stage 2

Execution Plan
20
textFile map mapreduceByKey
collect
Stage 1
Stage 2
Stage 1
Stage 2
1. Read HDFS split2. Apply both the maps3. Start Partial reduce4. Write shuffle data
1. Read shuffle data2. Final reduce3. Send result to driver
program

Stage Execution
• Create a task for each Partition in the new RDD• Serialize the Task• Schedule and ship Tasks to Slaves
And all this happens internally (you need to do anything)
21
Task 1
Task 2
Task 2
Task 2

Spark Executor (Slaves)
22
Fetch Input
Execute Task
Write Output
Fetch Input
Execute Task
Write Output
Fetch Input
Execute Task
Write Output
Fetch Input
Execute Task
Write Output
Fetch Input
Execute Task
Write Output
Fetch Input
Execute Task
Write Output
Fetch Input
Execute Task
Write Output
Core 1
Core 2
Core 3

Summary of Components
• Task: The fundamental unit of execution in Spark
• Stage : Set of Tasks that run parallel
• DAG: Logical Graph of RDD operations
• RDD: Parallel dataset with partitions
23

Start the docker container
From•https://github.com/sequenceiq/docker-spark
docker run -i -t -h sandbox sequenceiq/spark:1.1.1-ubuntu /etc/ bootstrap.sh –bash
•Run the spark shell using yarn or localspark-shell --master yarn-client --driver-memory 1g --executor-memory 1g --executor-cores 2
24

Running the example and Shell
• To Run the examples– $ run-example SparkPi 10
• We can start a spark shell via– spark-shell -- master local n
• The -- master specifies the master URL for a distributed cluster
• Example applications are also provided in Python– spark-submit example/src/main/python/pi.py 10
25

Collections and External Datasets
• A Collection can be parallelized using the SparkContext – val data = Array(1, 2, 3, 4, 5)– val distData = sc.parallelize(data)
• Spark can create distributed dataset from HDFS, Cassandra, Hbase, Amazon S3, etc.
• Spark supports text files, Sequence Files and any other Hadoop input format
• Files can be read from an URI local or remote (hdfs://, s3n://)– scala> val distFile = sc.textFile("data.txt")– distFile: RDD[String] = MappedRDD@1d4cee08– distFile.map(s => s.length).reduce((a,b) => a + b)
26

RDD operations
• Count the length of the words in the file– val lines = sc.textFile("data.txt")– val lineLengths = lines.map(s => s.length)– val totalLength = lineLengths.reduce((a, b) => a + b)
• If we want to use lineLengths later we can run– lineLengths.persist()
• This will save in the memory the value of lineLengths before reducing
27

Passing a function to Spark
• Spark is based on Anonymous function syntax– (x: Int) => x *x
• Which is a shorthand fornew Function1[Int,Int] {
def apply(x: Int) = x * x
}
• We can define functions with more parameters and without– (x: Int, y: Int) => "(" + x + ", " + y + ")”– () => { System.getProperty("user.dir") }
• The syntax is a shorthand for– Funtion1[T,+E] … Function22[…]
28

Passing a function to Spark
object MyFunctions {
def func1(s: String): String = s + s
}
file.map(MyFunctions.func1)
class MyClass {
def func1(s: String): String = { ... }
def doStuff(rdd: RDD[String]): RDD[String] = { rdd.map(func1) }
}
29

Working with Key-Value Pairs
• We can setup RDD with key-value pairs that are caster to Tuple2 type– val lines = sc.textFile("data.txt")– val pairs = lines.map(s => (s, 1))– val counts = pairs.reduceByKey((a, b) => a + b)
• We can use counts.sortByKey() to sort• And finally counts.collect() to bring them back• NOTE: when using custom objects as key-value we
should be sure that they have the method equals() with hashcode() http://docs.oracle.com/javase/7/docs/api/java/lang/Object.html#hashCode() 30

Transformations
• There are several transformations supported by Spark– Map– Filter– flatMap– mapPartitions– ….– http://spark.apache.org/docs/latest/programming-
guide.html
• When they are executed?
31

Actions
• The following table lists some of the common actions supported:– Reduce– Collect– Count– First– Take– takeSample
32

RDD Persistence
• One of the most important capabilities in Spark is persisting (or caching) a dataset in memory across operations
• Caching is a key tool for iterative algorithms and fast interactive use
• You can mark an RDD to be persisted using the persist() or cache() methods on it
• The first time it is computed in an action, it will be kept in memory on the nodes. Spark’s cache is fault-tolerant – if any partition of an RDD is lost, it will automatically be recomputed using the transformations that originally created it.
33

RDD persistence
• In addition, each persisted RDD can be stored using a different storage level,
• for example we can persist – the dataset on disk, – in memory but as serialized Java objects (to save space), replicate it
across nodes, – off-heap in Tachyon
• Note: In Python, stored objects will always be serialized with the Pickle library, so it does not matter whether you choose a serialized level.
• Spark also automatically persists some intermediate data in shuffle operations (e.g. reduceByKey), even without users calling persist
34

Which Storage Level to Choose?
• Memory only if that fit in the main memory• If not, try using MEMORY_ONLY_SER and selecting a fast
serialization library to make the objects much more space-efficient, but still reasonably fast to access.
• Don’t spill to disk unless the functions that computed your datasets are expensive, or they filter a large amount of the data. Otherwise, recomputing a partition may be as fast as reading it from disk.
• Use the replicated storage levels if you want fast fault recovery
• Use OFF_HEAP in environments with hig amounts of memory used or multiple applications
35

Shared Variables
• Normally when functions are executed on a remote node it works on immutable copies
• However, Sparks does provide two types of shared variables for two usages:– Broadcast variables– Accumulators
36

Broadcast Variables
• Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks.
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)
37

Accumulators
• Accumulators are variables that are only “added” to through an associative operation and can therefore be efficiently supported in parallel
• Spark natively supports accumulators of numeric types, and programmers can add support for new types
• Note: not yet supported on Python
scala> val accum = sc.accumulator(0, "My Accumulator")
accum: spark.Accumulator[Int] = 0
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
scala> accum.value
res7: Int = 10
38

Accumulators
object VectorAccumulatorParam extends AccumulatorParam[Vector] {
def zero(initialValue: Vector): Vector = {
Vector.zeros(initialValue.size)
}
def addInPlace(v1: Vector, v2: Vector): Vector = {
v1 += v2
}
}
// Then, create an Accumulator of this type:
val vecAccum = sc.accumulator(new Vector(...))(VectorAccumulatorParam)
39

Spark Examples
• Let’s walk through http://spark.apache.org/examples.html
• Other examples are on • Basic Sample
=>https://github.com/apache/spark/tree/master/examples/src/main/scala/org/apache/spark/examples
• Streaming Samples => https://github.com/apache/spark/tree/master/examples/src/main/scala/org/apache/spark/examples/streaming
40

Create a Self Contained App in Scala/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "YOUR_SPARK_HOME/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
41

Create a Self Contained App in ScalaCreate a build.sbt filename := "Simple Project"
version := "1.0"
scalaVersion := "2.10.4"
libraryDependencies += "org.apache.spark" %% "spark-core" % "1.2.0"
42

Project folder
• That how the project directory should look$ find .
.
./simple.sbt
./src
./src/main
./src/main/scala
./src/main/scala/SimpleApp.scala
• With sbt package we can create the jar• To submit the job$ YOUR_SPARK_HOME/bin/spark-submit \
--class "SimpleApp" \
--master local[4] \
target/scala-2.10/simple-project_2.10-1.0.jar43

Gradle Project
• https://github.com/fabiofumarola/spark-demo
44

Spark Streaming
45

A simple example
• We create a local StreamingContext with two execution threads, and batch interval of 1 second.
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
// Create a local StreamingContext with two working thread and batch interval of 1 second.
// The master requires 2 cores to prevent from a starvation scenario.
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
46

A sample example
• Using this context, we can create a DStream that represents streaming data from a TCP sourceval lines = ssc.socketTextStream("localhost", 9999)
• Split each line into wordsval words = lines.flatMap(_.split(" "))
• Count each word in the batchimport org.apache.spark.streaming.StreamingContext._
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
47

A sample example
• Note that when these lines are executed, Spark Streaming only sets up the computation it will perform when it is started, and no real processing has started yet
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
• Start netcat as data server by using– Nc –lk 9999
48

A sample example
• If you have already downloaded and built Spark, you can run this example as follows. You will first need to run Netcat (a small utility found in most Unix-like systems) as a data server by using– nc -lk 9999
• Run the example by– run-example streaming.NetworkWordCount localhost
9999
• http://spark.apache.org/docs/latest/streaming-programming-guide.html
49


















