
Advisor-advisee Relationship Mining from Research Publication Network Chi Wang 1, Jiawei Han 1,...
13
Advisor-advisee Relationship Mining from Research Publication Network Chi Wang 1 , Jiawei Han 1 , Yuntao Jia 1 , Jie Tang 2 , Duo Zhang 1 , Yintao Yu 1 , Jingyi Guo 2 1 University of Illinois at Urbana-Champaign {chiwang1, hanj, yjia3, dzhang22, yintao}@illinois.edu 2 Tsinghua University {jietang, guojy07@mails}.tsinghua.edu.cn
-
Upload
cory-oliver -
Category
Documents
-
view
216 -
download
1
Transcript of Advisor-advisee Relationship Mining from Research Publication Network Chi Wang 1, Jiawei Han 1,...

Advisor-advisee Relationship Mining from Research Publication Network
Chi Wang1, Jiawei Han1, Yuntao Jia1, Jie Tang2, Duo Zhang1, Yintao Yu1, Jingyi Guo2
1 University of Illinois at Urbana-Champaign{chiwang1, hanj, yjia3, dzhang22, yintao}@illinois.edu
2 Tsinghua University {jietang, guojy07@mails}.tsinghua.edu.cn

Motivation
• Latent knowledge in information network: – Relationships:
friends/relatives/colleagues/enemies?• If they can be mined by links, it will benefit our
study in– Community structure clustering & classification– Exerting Searching search & ranking– Evolution patterns prediction &
recommendation
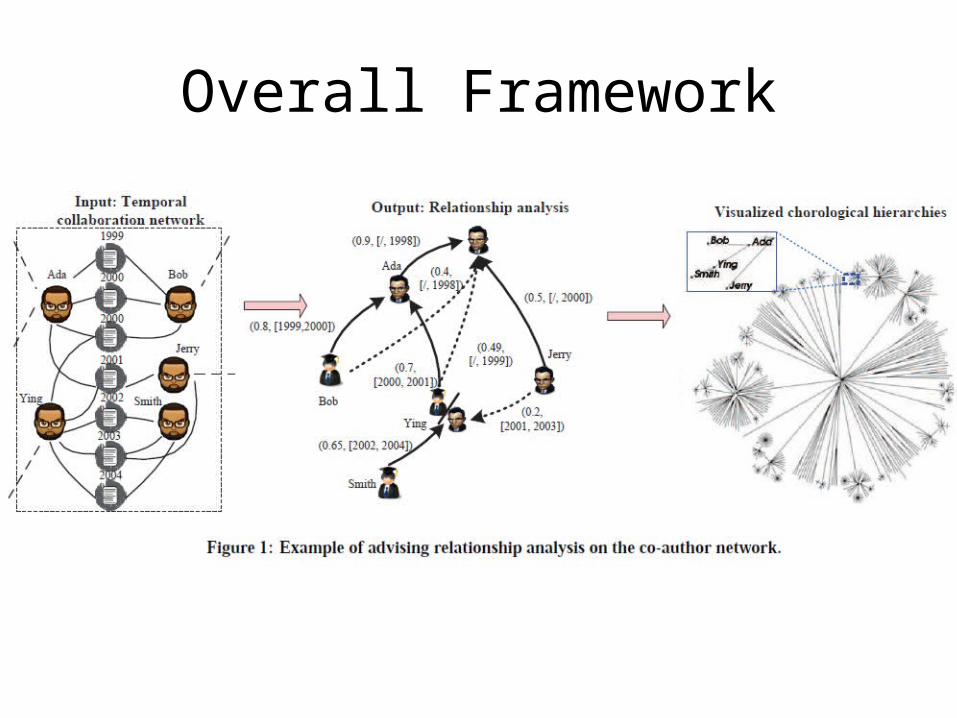
Overall Framework

Overall Framework• ai: author i
• pj: paper j• py: paper year• pn: paper#• sti,yi: starting
time• edi,yi: ending
time• ri,yi: ranking
score

Heuristics
• ASSUMPTION 1: at each time t during the publication history of a node x, x is either being advised or not being advised. Once x starts to advise another node, it will never be advised again.
• ASSUMPTION 2: for a given pair of advisor and advisee, the advisor always has a longer publication history than the advisee.

Stage 1: Preprocessing
• From author-paper bipartite network to authorship collaboration homogenous network.
• Then a filtering process is performed to remove unlikely relations of advisor-advisee.

Stage 1: Preprocessing• Author aj is not considered to be ai’s advisor if
one of the following conditions holds:

Stage 1: Preprocessing
• In addition, estimate:– the starting time stij is estimated as the time they
started to collaborate;– the ending time edij can be estimated as either the
time point when the Kulczynski measure starts to decrease;
– the local likelihood of aj being ai’s advisor lij

Stage 2: Graph Factor Model
• For each node ai, there are three variables to decide: yi, sti, and edi. Suppose we have already had a local feature function g(yi, sti, edi) defined on the three variables of any given node.
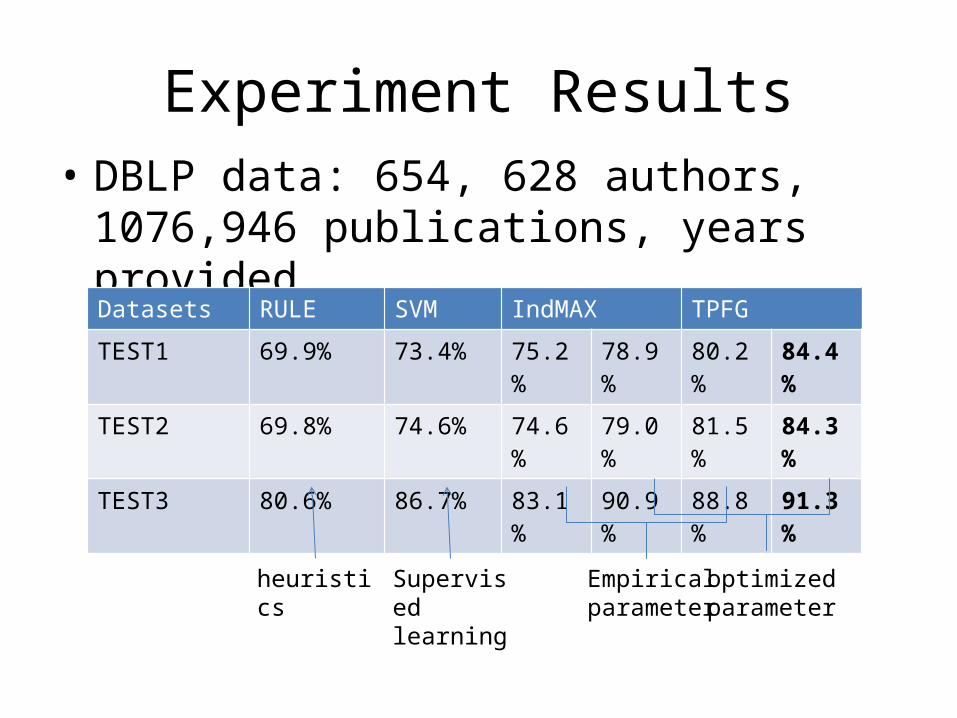
Experiment Results• DBLP data: 654, 628 authors, 1076,946
publications, years provided.
Datasets RULE SVM IndMAX TPFG
TEST1 69.9% 73.4% 75.2% 78.9% 80.2% 84.4%
TEST2 69.8% 74.6% 74.6% 79.0% 81.5% 84.3%
TEST3 80.6% 86.7% 83.1% 90.9% 88.8% 91.3%
Empiricalparameter
optimizedparameter
heuristics Supervised learning

Case StudyAdvisee Top Ranked Advisor Time Note
David M. Blei
1. Michael I. Jordan 01-03 PhD advisor, 2004 grad2. John D. Lafferty 05-06 Postdoc, 2006
Hong Cheng
1. Qiang Yang 02-03 MS advisor, 20032. Jiawei Han 04-08 PhD advisor, 2008
Sergey Brin 1. Rajeev Motawani 97-98 “Unofficial advisor”

Effect of rules - ROC curve
• Filtering rules in TPFG
12

THANK YOU

















![1 1 1 1 1 1 1 ¢ 1 , ¢ 1 1 1 , 1 1 1 1 ¡ 1 1 1 1 · 1 1 1 1 1 ] ð 1 1 w ï 1 x v w ^ 1 1 x w [ ^ \ w _ [ 1. 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ð 1 ] û w ü](https://static.fdocuments.net/doc/165x107/5f40ff1754b8c6159c151d05/1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-w-1-x-v.jpg)