
Matching LBSC 708A/CMSC 828O March 8, 1999 Douglas W. Oard and Dagobert Soergel.
date post
19-Dec-2015Category
view
215download
0
A Whirlwind Tour of Search Engine Design Issues
CMSC 498W
April 4, 2006
Douglas W. Oard

Information Access Problems
Collection
Info
rmat
ion
Nee
d
Stable
Stable
DifferentEach Time
Retrieval
Filtering
DifferentEach Time

Design Strategies
• Foster human-machine synergy– Exploit complementary strengths– Accommodate shared weaknesses
• Divide-and-conquer – Divide task into stages with well-defined interfaces– Continue dividing until problems are easily solved
• Co-design related components– Iterative process of joint optimization

Human-Machine Synergy
• Machines are good at:– Doing simple things accurately and quickly– Scaling to larger collections in sublinear time
• People are better at:– Accurately recognizing what they are looking for– Evaluating intangibles such as “quality”
• Both are pretty bad at:– Mapping consistently between words and concepts

Supporting the Search Process
SourceSelection
Search
Query
Selection
Ranked List
Examination
Document
Delivery
Document
QueryFormulation
IR System
Query Reformulation and
Relevance Feedback
SourceReselection
Nominate ChoosePredict

Supporting the Search Process
SourceSelection
Search
Query
Selection
Ranked List
Examination
Document
Delivery
Document
QueryFormulation
IR System
Indexing Index
Acquisition Collection

Taylor’s Model of Question Formation
Q1 Visceral Need
Q2 Conscious Need
Q3 Formalized Need
Q4 Compromised Need (Query)
En
d-u
ser
Sea
rch
Interm
ediated
Search

Search Goal
• Choose the same documents a human would– Without human intervention (less work)– Faster than a human could (less time)– As accurately as possible (less accuracy)
• Humans start with an information need– Machines start with a query
• Humans match documents to information needs– Machines match document & query representations

Search Component Model
Comparison Function
Representation Function
Query Formulation
Human Judgment
Representation Function
Retrieval Status Value
Utility
Query
Information Need Document
Query Representation Document Representation
Que
ry P
roce
ssin
g
Doc
umen
t P
roce
ssin
g

Relevance
• Relevance relates a topic and a document– Duplicates are equally relevant, by definition
– Constant over time and across users
• Pertinence relates a task and a document– Accounts for quality, complexity, language, …
• Utility relates a user and a document– Accounts for prior knowledge
• We seek utility, but relevance is what we get!

Problems With Word Matching
• Word matching suffers from two problems– Synonymy: paper vs. article– Homonymy: bank (river) vs. bank (financial)
• Disambiguation in IR: seek to resolve homonymy– Index word senses rather than words
• Synonymy usually addressed by – Thesaurus-based query expansion– Latent semantic indexing

Stemming• Stem: in IR, a word equivalence class that
preserves the main concept.– Often obtained by affix-stripping (Porter, 1980)– {destroy, destroyed, destruction}: destr
• Inexpensive to compute• Usually helps IR performance• Can make mistakes! (over-/understemming)
– {centennial,century,center}: cent– {acquire,acquiring,acquired}: acquir {acquisition}: acquis

N-gram Indexing
• Consider a Chinese document c1 c2 c3 … cn
• Don’t segment (you could be wrong!)
• Instead, treat every character bigram as a term– _c1 c2 , c2 c3 , c3 c4 , … , cn-1 cn
• Break up queries the same way

“Bag of Terms” Representation
• Bag = a “set” that can contain duplicates “The quick brown fox jumped over the lazy dog’s back”
{back, brown, dog, fox, jump, lazy, over, quick, the, the}
• Vector = values recorded in any consistent order {back, brown, dog, fox, jump, lazy, over, quick, the, the}
[1 1 1 1 1 1 1 1 2]

Bag of Terms Example
The quick brown fox jumped over the lazy dog’s back.
Document 1
Document 2
Now is the time for all good men to come to the aid of their party.
the
quick
brown
fox
over
lazy
dog
back
now
is
time
forall
good
men
tocome
jump
aid
of
their
party
00110110110010100
11001001001101011
Term Doc
umen
t 1
Doc
umen
t 2
Stopword List

Boolean IR
• Strong points– Accurate, if you know the right strategies
– Efficient for the computer
• Weaknesses– Often results in too many documents, or none
– Users must learn Boolean logic
– Sometimes finds relationships that don’t exist
– Words can have many meanings
– Choosing the right words is sometimes hard

Proximity Operators
• More precise versions of AND– “NEAR n” allows at most n-1 intervening terms– “WITH” requires terms to be adjacent and in order
• Easy to implement, but less efficient– Store a list of positions for each word in each doc
• Stopwords become very important!
– Perform normal Boolean computations• Treat WITH and NEAR like AND with an extra constraint

Proximity Operator Example
• time AND come– Doc 2
• time (NEAR 2) come– Empty
• quick (NEAR 2) fox– Doc 1
• quick WITH fox– Empty
quick
brown
fox
over
lazy
dog
back
now
time
all
good
men
come
jump
aid
their
party
0 1 (9)
Term1 (13)1 (6)
1 (7)
1 (8)
1 (16)
1 (1)
1 (2)1 (15)1 (4)
0
00
0
00
0
0
0
0
0
0
00
0
0
1 (5)
1 (9)
1 (3)
1 (4)
1 (8)
1 (6)
1 (10)
Doc
1
Doc
2

Advantages of Ranked Retrieval
• Closer to the way people think– Some documents are better than others
• Enriches browsing behavior– Decide how far down the list to go as you read it
• Allows more flexible queries– Long and short queries can produce useful results

Ranked Retrieval Challenges
• “Best first” is easy to say but hard to do!– The best we can hope for is to approximate it
• Will the user understand the process?– It is hard to use a tool that you don’t understand
• Efficiency becomes a concern– Only a problem for long queries, though

Similarity-Based Queries
• Treat the query as if it were a document– Create a query bag-of-words
• Find the similarity of each document– Using the coordination measure, for example
• Rank order the documents by similarity– Most similar to the query first
• Surprisingly, this works pretty well!– Especially for very short queries

Counting Terms
• Terms tell us about documents– If “rabbit” appears a lot, it may be about rabbits
• Documents tell us about terms– “the” is in every document -- not discriminating
• Documents are most likely described well by rare terms that occur in them frequently– Higher “term frequency” is stronger evidence– Low “collection frequency” makes it stronger still

The Document Length Effect
• Humans look for documents with useful parts– But probabilities are computed for the whole
• Document lengths vary in many collections– So probability calculations could be inconsistent
• Two strategies– Adjust probability estimates for document length– Divide the documents into equal “passages”

Incorporating Term Frequency
• High term frequency is evidence of meaning– And high IDF is evidence of term importance
• Recompute the bag-of-words– Compute TF * IDF for every element
Let be the total number of documents
Let of the documents contain term
Let be the number of times term appears in document
Then
N
n N i
i j
wN
n
i j
i j i j
tf
tf log
,
, ,

TF*IDF Example
4
5
6
3
1
3
1
6
5
3
4
3
7
1
nuclear
fallout
siberia
contaminated
interesting
complicated
information
retrieval
2
1 2 3
2
3
2
4
4
0.50
0.63
0.90
0.13
0.60
0.75
1.51
0.38
0.50
2.11
0.13
1.20
1 2 3
0.60
0.38
0.50
4
0.301
0.125
0.125
0.125
0.602
0.301
0.000
0.602
idfi Unweighted query: contaminated retrievalResult: 2, 3, 1, 4
Weighted query: contaminated(3) retrieval(1)Result: 1, 3, 2, 4
IDF-weighted query: contaminated retrievalResult: 2, 3, 1, 4
tf ,i jwi j,

Document Length Normalization
• Long documents have an unfair advantage– They use a lot of terms
• So they get more matches than short documents
– And they use the same words repeatedly• So they have much higher term frequencies
• Normalization seeks to remove these effects– Related somehow to maximum term frequency– But also sensitive to the of number of terms

“Okapi” Term Weights
5.0
5.0log*
5.05.1 ,
,,
j
j
jii
jiji DF
DFN
TFLL
TFw
0.0
0.2
0.4
0.6
0.8
1.0
0 5 10 15 20 25
Raw TF
Oka
pi
TF 0.5
1.0
2.0
4.4
4.6
4.8
5.0
5.2
5.4
5.6
5.8
6.0
0 5 10 15 20 25
Raw DF
IDF Classic
Okapi
LL /
TF component IDF component

Passage Retrieval
• Another approach to long-document problem– Break it up into coherent units
• Recognizing topic boundaries is hard– But overlapping 300 word passages work fine
• Document rank is best passage rank– And passage information can help guide browsing

Summary
• Goal: find documents most similar to the query
• Compute normalized document term weights– Some combination of TF, DF, and Length
• Optionally, get query term weights from the user– Estimate of term importance
• Compute inner product of query and doc vectors– Multiply corresponding elements and then add

Another Perspective
• We ask “is this document relevant?”– Vector space: we answer “somewhat”– Probabilistic: we answer “probably”

Probability Ranking Principle• Assume binary relevance/document independence
– Each document is either relevant or it is not– Relevance of one doc reveals nothing about another
• Assume the searcher works down a ranked list– Seeking some number of relevant documents
• Theorem (provable from assumptions):– Documents should be ranked in order of decreasing
probability of relevance to the query,
P(d relevant-to q)

Some Questions for Indexing• How long will it take to find a document?
– Is there any work we can do in advance?• If so, how long will that take?
• How big a computer will I need?– How much disk space? How much RAM?
• What if more documents arrive?– How much of the advance work must be repeated?
– Will searching become slower?
– How much more disk space will be needed?

The Indexing Process
quick
brown
fox
over
lazy
dog
back
now
time
all
good
men
come
jump
aid
their
party
00110000010010110
01001001001100001
Term Doc
1
Doc
2
00110110110010100
11001001001000001
Doc
3D
oc 4
00010110010010010
01001001000101001
Doc
5D
oc 6
00110010010010010
10001001001111000
Doc
7D
oc 8
A
B
C
FD
GJLMNOPQ
T
AIALBABR
THTI
4, 82, 4, 61, 3, 7
1, 3, 5, 72, 4, 6, 8
3, 53, 5, 7
2, 4, 6, 83
1, 3, 5, 72, 4, 82, 6, 8
1, 3, 5, 7, 86, 81, 3
1, 5, 72, 4, 6
PostingsInverted File

The Finished Product
quick
brown
fox
over
lazy
dog
back
now
time
all
good
men
come
jump
aid
their
party
Term
A
B
C
FD
GJLMNOPQ
T
AIALBABR
THTI
4, 82, 4, 61, 3, 7
1, 3, 5, 72, 4, 6, 8
3, 53, 5, 7
2, 4, 6, 83
1, 3, 5, 72, 4, 82, 6, 8
1, 3, 5, 7, 86, 81, 3
1, 5, 72, 4, 6
PostingsInverted File

How Big Is the Postings File?
• Very compact for Boolean retrieval– About 10% of the size of the documents
• If an aggressive stopword list is used!
• Not much larger for ranked retrieval– Perhaps 20%
• Enormous for proximity operators– Sometimes larger than the documents!

Building an Inverted Index• Simplest solution is a single sorted array
– Fast lookup using binary search– But sorting large files on disk is very slow– And adding one document means starting over
• Tree structures allow easy insertion– But the worst case lookup time is linear
• Balanced trees provide the best of both– Fast lookup and easy insertion– But they require 45% more disk space

How Big is the Inverted Index?
• Typically smaller than the postings file– Depends on number of terms, not documents
• Eventually, most terms will already be indexed– But the postings file will continue to grow
• Postings dominate asymptotic space complexity– Linear in the number of documents

Index Compression
• CPU’s are much faster than disks– A disk can transfer 1,000 bytes in ~20 ms– The CPU can do ~10 million instructions in that time
• Compressing the postings file is a big win– Trade decompression time for fewer disk reads
• Key idea: reduce redundancy– Trick 1: store relative offsets (some will be the same)– Trick 2: use an optimal coding scheme

Summary
• Slow indexing yields fast query processing– Key fact: most terms don’t appear in most documents
• We use extra disk space to save query time– Index space is in addition to document space– Time and space complexity must be balanced
• Disk block reads are the critical resource– This makes index compression a big win

Problems with “Free Text” Search
• Homonymy– Terms may have many unrelated meanings– Polysemy (related meanings) is less of a problem
• Synonymy– Many ways of saying (nearly) the same thing
• Anaphora– Alternate ways of referring to the same thing
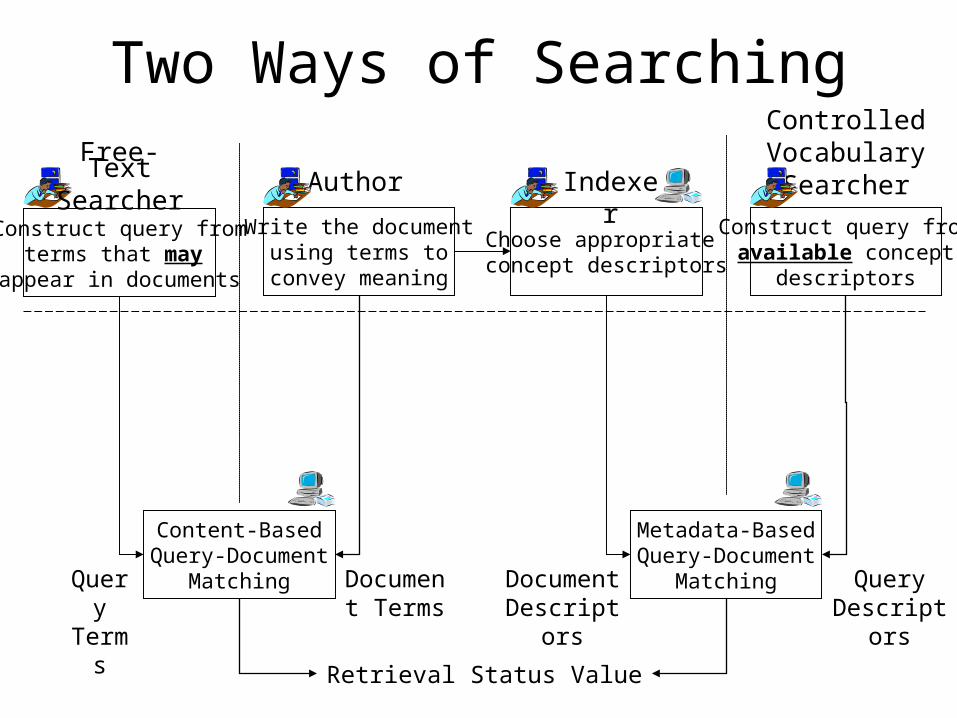
Two Ways of Searching
Write the documentusing terms to
convey meaning
Author
Content-BasedQuery-Document
Matching Document Terms
Query Terms
Construct query fromterms that may
appear in documents
Free-TextSearcher
Retrieval Status Value
Construct query fromavailable concept
descriptors
ControlledVocabulary
Searcher
Choose appropriate concept descriptors
Indexer
Metadata-BasedQuery-Document
Matching Query Descriptors
Document Descriptors

Applications
• When implied concepts must be captured– Political action, volunteerism, …
• When terminology selection is impractical– Searching foreign language materials
• When no words are present– Photos w/o captions, videos w/o transcripts, …
• When user needs are easily anticipated– Weather reports, yellow pages, …

Supervised Learningf1 f2 f3 f4 … fN
v1 v2 v3 v4 … vN Cv
w1 w2 w3 w4 … wN Cw
Learner
Classifier
New example
x1 x2 x3 x4 … xNCx
Labelled training examples
Cw

Example: kNN Classifier

Challenges• Changing concept inventories
– Literary warrant and user needs are hard to predict
• Accurate concept indexing is expensive– Machines are inaccurate, humans are inconsistent
• Users and indexers may think differently– Diverse user populations add to the complexity
• Using thesauri effectively requires training– Meta-knowledge and thesaurus-specific expertise
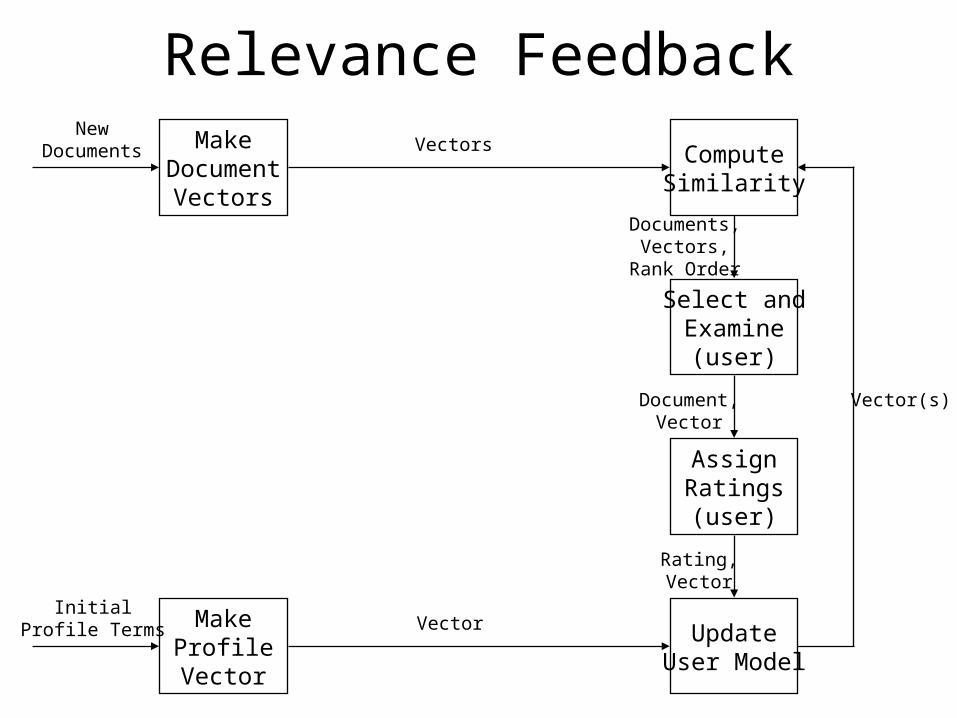
Relevance Feedback
MakeProfileVector
ComputeSimilarity
Select andExamine
(user)
AssignRatings(user)
UpdateUser Model
NewDocuments
Vector
Documents,Vectors,
Rank Order
Document,Vector
Rating,Vector
Vector(s)
MakeDocument
Vectors
InitialProfile Terms
Vectors

Rocchio Formula
ectorfeedback v negative
ectorfeedback v positive
vectorprofile original vectorprofile
0 4 0 8 0 0
1 2 4 0 0 1
2 0 1 1 0 4
-1 6 3 7 0 -3
0 4 0 8 0 0
2 4 8 0 0 2
8 0 4 4 0 16
Original profile
Positive Feedback
Negative feedback
0.1
5.0
25.0
(+)
(-)
New profile

Implicit Feedback
• Observe user behavior to infer a set of ratings– Examine (reading time, scrolling behavior, …)– Retain (bookmark, save, save & annotate, print, …)– Refer to (reply, forward, include link, cut & paste, …)
• Some measurements are directly useful– e.g., use reading time to predict reading time
• Others require some inference– Should you treat cut & paste as an endorsement?

View Listen
Select
Print Bookmark Save Purchase Delete
Subscribe
Copy / paste Quote
Forward Reply Link Cite
Mark up Rate Publish
Organize
Some Observable Behaviors

Examine View Listen
Select
Retain Print Bookmark Save Purchase Delete
Subscribe
Reference Copy / paste Quote
Forward Reply Link Cite
Annotate Mark up Rate Publish
Organize
Beh
avio
r C
ateg
ory
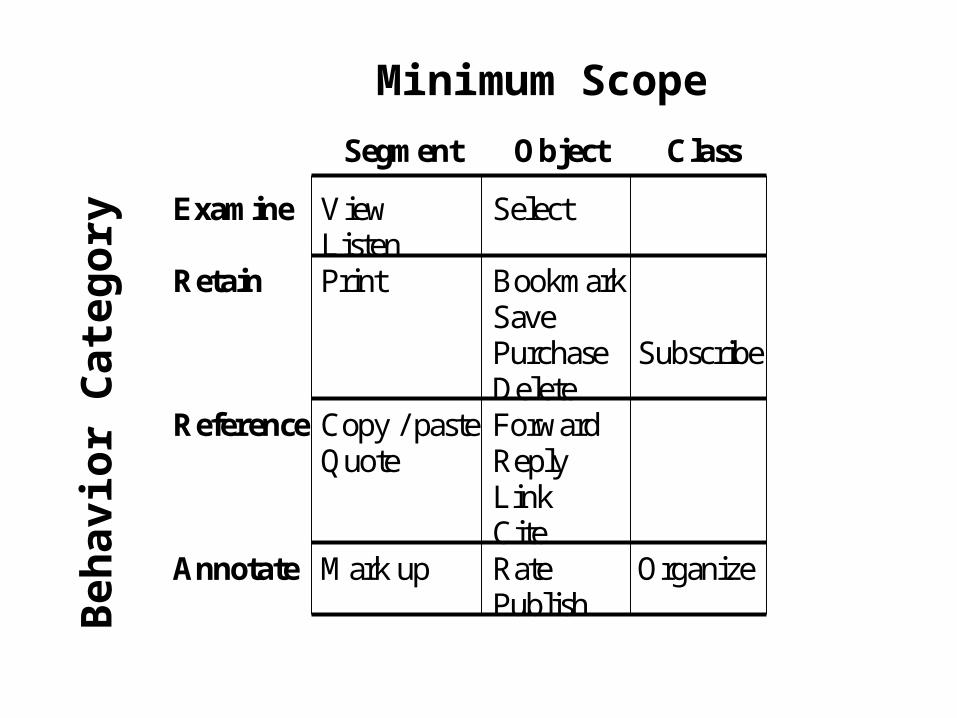
Segment Object Class
Examine View Listen
Select
Retain Print Bookmark Save Purchase Delete
Subscribe
Reference Copy / paste Quote
Forward Reply Link Cite
Annotate Mark up Rate Publish
Organize
Beh
avio
r C
ateg
ory
Minimum Scope

Some Examples
• Read/Ignored, Saved/Deleted, Replied to
(Stevens, 1993)
• Reading time
(Morita & Shinoda, 1994; Konstan et al., 1997)
• Hypertext Link
(Brin & Page, 1998)

Estimating Authority from Links
Authority
Authority
Hub

Collecting Click Streams
• Browsing histories are easily captured– Make all links initially point to a central site
• Encode the desired URL as a parameter
– Build a time-annotated transition graph for each user• Cookies identify users (when they use the same machine)
– Redirect the browser to the desired page
• Reading time is correlated with interest– Can be used to build individual profiles– Used to target advertising by doubleclick.com

0
20
40
60
80
100
120
140
160
180
NoInterest
LowInterest
ModerateInterest
HighInterest Rating
Rea
din
g T
ime
(sec
on
ds)
Full Text Articles (Telecommunications)
50
32
5843

Critical Issues
• Protecting privacy– What absolute assurances can we provide?– How can we make remaining risks understood?
• Scalable rating servers– Is a fully distributed architecture practical?
• Non-cooperative users– How can the effect of spamming be limited?

Gaining Access to Observations
• Observe public behavior– Hypertext linking, publication, citing, …
• Policy protection– EU: Privacy laws– US: Privacy policies + FTC enforcement
• Architectural assurance of privacy– Distributed architecture– Model and mitigate privacy risks

Adversarial IR
• Search is user-controlled suppression– Everything is known to the search system– Goal: avoid showing things the user doesn’t want
• Other stakeholders have different goals– Authors risk little by wasting your time– Marketers hope for serendipitous interest
• Metadata from trusted sources is more reliable

Index Spam
• Goal: Manipulate rankings of an IR system
• Multiple strategies:– Create bogus user-assigned metadata– Add invisible text (font in background color, …)– Alter your text to include desired query terms– “Link exchanges” create links to your page

Putting It All Together
Free Text Behavior Metadata
Topicality
Quality
Reliability
Cost
Flexibility

Evaluation Criteria
• Effectiveness– System-only, human+system
• Efficiency– Retrieval time, indexing time, index size
• Usability– Learnability, novice use, expert use

IR Effectiveness Evaluation
• User-centered strategy– Given several users, and at least 2 retrieval systems
– Have each user try the same task on both systems
– Measure which system works the “best”
• System-centered strategy– Given documents, queries, and relevance judgments
– Try several variations on the retrieval system
– Measure which ranks more good docs near the top

Good Measures of Effectiveness
• Capture some aspect of what the user wants
• Have predictive value for other situations– Different queries, different document collection
• Easily replicated by other researchers
• Easily compared– Optimally, expressed as a single number

Comparing Alternative Approaches
• Achieve a meaningful improvement– An application-specific judgment call
• Achieve reliable improvement in unseen cases– Can be verified using statistical tests

Evolution of Evaluation
• Evaluation by inspection of examples
• Evaluation by demonstration
• Evaluation by improvised demonstration
• Evaluation on data using a figure of merit
• Evaluation on test data
• Evaluation on common test data
• Evaluation on common, unseen test data

Which is the Best Rank Order?
R
R
R
R
R
R
R
R
R
R
RRRRRR
RR
R
R
R
RRR
R
R
R
R
R
RRRRR
R
RRRR
R
R
a b c d e f g h

IR Test Collection Design
• Representative document collection– Size, sources, genre, topics, …
• “Random” sample of representative queries– Built somehow from “formalized” topic statements
• Known binary relevance– For each topic-document pair (topic, not query!)– Assessed by humans, used only for evaluation
• Measure of effectiveness– Used to compare alternate systems

Set-Based Effectiveness Measures
• Precision– How much of what was found is relevant?
• Often of interest, particularly for interactive searching
• Recall– How much of what is relevant was found?
• Particularly important for law, patents, and medicine
• Fallout– How much of what was irrelevant was rejected?
• Useful when different size collections are compared

Effectiveness Measures
Relevant Retrieved
False Alarm Irrelevant Rejected
MissRelevant
Not relevant
Retrieved Not RetrievedDocAction
FA
Miss
1RelevantNot
Rejected IrrelevantFallout
1Relevant
RetrievedRelevant Recall
Retrieved
RetrievedRelevant Precision
User-Oriented
System-Oriented

Single-Figure Set-Based Measures
• Balanced F-measure– Harmonic mean of recall and precision
– Weakness: What if no relevant documents exist?
• Cost function– Reward relevant retrieved, Penalize non-relevant
• For example, 3R+ - 2N+
– Weakness: Hard to normalize, so hard to average
RP
F5.05.0
1

RankedRetrieval
Query
Ranked List
Documents
Abstract Evaluation Model
Evaluation
Measure of Effectiveness
Relevance Judgments

Uninterpolated MAP
R
R
1/3=0.33
2/7=0.29
AP=0.31
RR
R
R
1/1=1.002/2=1.00
3/5=0.60
4/9=0.44
AP=0.76
R
R
R
1/2=0.50
3/5=0.60
4/8=0.50
AP=0.53
MAP=0.53

Why Mean Average Precision?
• It is easy to trade between recall and precision– Adding related query terms improves recall
• But naive query expansion techniques kill precision
– Limiting matches by part-of-speech helps precision• But it almost always hurts recall
• Comparisons should give some weight to both– Average precision is a principled way to do this– More “central” than other available measures

What MAP Hides
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Recall
Prec
isio
n
Adapted from a presentation by Ellen Voorhees at the University of Maryland, March 29, 1999

Hypothesis Testing Paradigm
• Choose some experimental variable X
• Establish a null hypothesis H0
• Identify distribution of X, assuming H0 is true
• Do experiment to get an empirical value x
• Ask: “What’s the probability I would have gotten this value of x if H0 were true?”
• If this probability p is low, reject H0
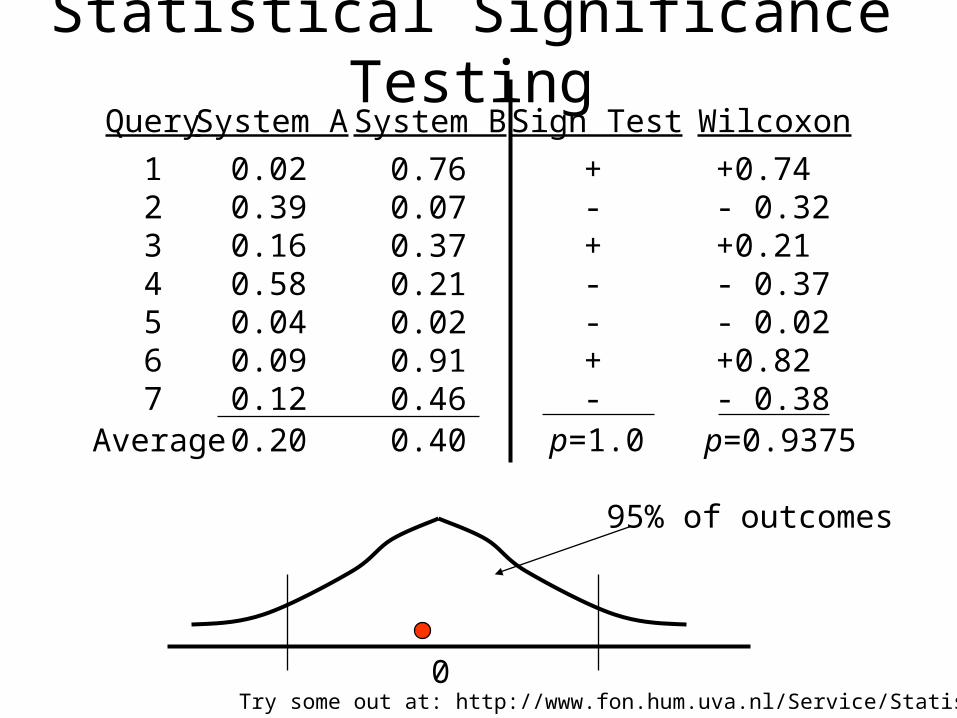
Statistical Significance TestingSystem A
0.020.390.160.580.040.090.12
System B
0.760.070.370.210.020.910.46
Query
1234567
Average 0.20 0.40
Sign Test
+-+--+-
p=1.0
Wilcoxon
+0.74- 0.32+0.21- 0.37- 0.02+0.82- 0.38
p=0.9375
0
95% of outcomes
Try some out at: http://www.fon.hum.uva.nl/Service/Statistics.html

How Much is Enough?
• Measuring improvement– Achieve a meaningful improvement
• Guideline: 0.05 is noticeable, 0.1 makes a difference
– Achieve reliable improvement on “typical” queries• Wilcoxon signed rank test for paired samples
• Know when to stop!– Inter-assessor agreement limits max precision
• Using one judge to assess the other yields about 0.8

Pooled Assessment Methodology
• Systems submit top 1000 documents per topic
• Top 100 documents for each are judged– Single pool, without duplicates, arbitrary order– Judged by the person that wrote the query
• Treat unevaluated documents as not relevant
• Compute MAP down to 1000 documents– Treat precision for complete misses as 0.0

Alternative Ways to Get Judgments• Exhaustive assessment is usually impractical
– Topics * documents = a large number!
• Pooled assessment leverages cooperative evaluation– Requires a diverse set of IR systems
• Search-guided assessment is sometimes viable– Iterate between topic research/search/assessment– Augment with review, adjudication, reassessment
• Known-item judgments have the lowest cost– Tailor queries to retrieve a single known document– Useful as a first cut to see if a new technique is viable

Ten Commandments of Evaluation
• Thou shalt define insightful evaluation metrics• Thou shalt define replicable evaluation metrics• Thou shalt report all relevant system parameters• Thou shalt establish upper bounds on performance• Thou shalt establish lower bounds on performance• Thou shalt test differences for statistical significance• Thou shalt say whether differences are meaningful• Thou shalt not mingle training data with test data• Thou shalt not mingle training data with test data• Thou shalt not mingle training data with test data

Automatic Evaluation
Search
Query
Ranked List

User Studies
Search
Query
Selection
Ranked List
Examination
Document
Document
QueryFormulation
Query Reformulation and
Relevance Feedback

User Studies
• Goal is to account for interface issues– By studying the interface component– By studying the complete system
• Formative evaluation– Provide a basis for system development
• Summative evaluation– Designed to assess performance

Quantitative User Studies• Select independent variable(s)
– e.g., what info to display in selection interface
• Select dependent variable(s)– e.g., time to find a known relevant document
• Run subjects in different orders– Average out learning and fatigue effects
• Compute statistical significance– Null hypothesis: independent variable has no effect– Rejected if p<0.05

Qualitative User Studies• Observe user behavior
– Instrumented software, eye trackers, etc.– Face and keyboard cameras– Think-aloud protocols– Interviews and focus groups
• Organize the data– For example, group it into overlapping categories
• Look for patterns and themes
• Develop a “grounded theory”

Questionnaires
• Demographic data– For example, computer experience– Basis for interpreting results
• Subjective self-assessment– Which did they think was more effective?– Often at variance with objective results!
• Preference– Which interface did they prefer? Why?

Summary
• Qualitative user studies suggest what to build
• Design decomposes task into components
• Automated evaluation helps to refine components
• Quantitative user studies show how well it works

Source: Global Reach
EnglishEnglish
2000 2005
Global Internet User Population
Chinese


















