
分组密码
100
1 分分分分 分分分分分分分 《》 4 分 (1)
description
分组密码. 《 现代密码学 》 第 4 章 (1). 本章主要内容. 1 、分组密码概述 2 、数据加密标准 DES 算法 3 、分组密码的运行模式 4 、差分密码分析与线性密码分析 5 、 IDEA 算法 6 、 AES 算法 —— Rijndael. 第 1 节:分组密码概述. 在许多密码系统中,单钥分组密码是系统安全的一个重要组成部分,用分组密码易于构造伪随机数生成器、流密码、消息认证码( MAC )和杂凑函数等,还可进而成为消息认证技术、数据完整性机制、实体认证协议以及单钥数字签字体制的核心组成部分。. 1 分组密码概述. - PowerPoint PPT Presentation
Transcript of 分组密码

1
分组密码
《现代密码学》第 4章 (1)

2
本章主要内容
1 、分组密码概述 2 、数据加密标准 DES 算法 3 、分组密码的运行模式 4 、差分密码分析与线性密码分析 5 、 IDEA 算法 6 、 AES 算法——Rijndael

3
在许多密码系统中,单钥分组密码是系统安全的一个重要组成部分,用分组密码易于构造伪随机数生成器、流密码、消息认证码( MAC )和杂凑函数等,还可进而成为
消息认证技术、数据完整性机制、实体认证协议以及单钥数字签字体制的核心组成部分。
第 1 节:分组密码概述

4
实际应用中对于分组密码可能提出多方面的要求,除了安全性外,还有运行速度、存储量(程序的长度、数据分组长度、高速缓存大小)、实现平台(硬件、软件、芯片)、运行模式等限制条件。这些都需要与安全性要求之间进行适当的折中选择。
1 分组密码概述

5
是一种单钥或对称算法 通信实体双方使用相同的密钥
加密和解密 现代分组密码(由乘积密码构
成)包括 DES, Blowfish, IDEA, LOKI, RC5, Rijndael (AES) 及其它一些算法
1 分组密码概述

6
在分组密码中,消息被分成许多块,每块都要被加密
类似于许多字符被替换 - ( 64-bits or more )
许多现代分组密码具有下列形式:
1 分组密码概述

7
1 分组密码概述

8
分组密码理论基础
理想的方法是使用尽可能大的替换模块,但不实际,因为对每个 64bit 的模块,将需要 264 个实体的替换表,因此使用一些小的模块代替。
使用乘积密码的思想 这种概念由 Shannon and Feistel 提出

9
分组密码的设计原理 可变密钥长度 混合操作 依赖数据的循环移位 依赖于密钥的循环移位 依赖密钥的 S 盒子 冗长的密钥调度算法 可变的 F 函数和可变的明文 / 密文长度 可变的循环次数 在每次循环中都对两半数据进行操作

10
Shannons 保密系统理论
Claude Shannon 对现代密码的重要工作: C E Shannon, "Communication Theory of Secrecy Sy
stems", Bell System Technical Journal, Vol 28, Oct 1949, pp 656-715
C E Shannon, "Prediction and Entropy of printed English", Bell System Technical Journal, Vol 30, Jan 1951, pp 50-64
在上述文章中,提出了下列概念 : “ 熵”的概念 语言冗余度 破译密码需要多少信息量 定义了”计算安全”与”无条件安全”

11
即如果通过填加一些英语字母加密英文内容,是不安全的。
因为英语有 80% 的冗余度,英语密文如果有 60% 的冗余度,就可以破解。
Shannons 保密系统理论

12
分组密码是将明文消息编码表示后的数字序列 x0,x1,…,xi,…划分成长为 n 的组 x=(x0,x1,…,xn-1) ,各组(长为 n 的矢量)分别在密钥 k=(k0,k1,…,kt-1)控制下变换成等长的输出数字序列 y=(y0,y1,…,ym-1) (长为 m 的矢量),其加密函数 E : Vn×K→Vm , Vn 和 Vm 分别是 n维和 m维矢量空间, K 为密钥空间,如图 1所示。
1 分组密码概述

13
明文序列 x1, x2,…, xi,…
加密函数 E: Vn×KVn
这种密码实质上是字长为m的数字序列的代换密码。
解密算法加密算法
密钥 k=(k0, k1,…, kt-1 ) 密钥 k=(k0, k1,…, kt-1 )
明文x=(x0, x1,…, xm-1)
明文x=(x0, x1,…, xm-1)
密文x=(y0, y1,…, ym-1)
图 1 分组密码框图
1 分组密码概述

14
它与流密码不同之处在于输出的每一位数字不是只与相应时刻输入的明文数字有关,而是与一组长为 n 的明文数字有关。
在相同密钥下,分组密码对长为 n 的输入明文组所实施的变换是等同的,所以只需研究对任一组明文数字的变换规则。这种密码实质上是字长为 n 的数字序列的代换密码。
1 分组密码概述

15
通常取m=n 。若m>n ,则为有数据扩展的分组密码;若m<n ,则为有数据压缩的分组密码。 在二元情况下, x和 y均为二元数字序列,它们的每个分量 xi , yi∈GF(2) 。本节将主要讨论二元情况。设计的算法应满足下述要求:
1 分组密码概述

16
分组密码是许多系统安全的一个重要组成部分。可用于构造 拟随机数生成器 流密码 消息认证码 (MAC) 和杂凑函数 消息认证技术、数据完整性机构、实体认证协议以及单钥数字签字体制的核心组成部分。
分组密码概述

17
分组密码与序列密码比较,主要区别是在加密方式上:
序列密码:k
KG
k=k0k1k2
012 mmm ))()(( 001122 kmkmkm
分组密码概述

18
大多数实用分组密码的明文信号取自于 F2 、且满足: n=n’ (即明文没有被扩展)。考察的一个分组密码体制,设 KK 为密
钥空间, n 为分组长度,那么加密变换空间为: EE={Ek|Ek: 是一一映射 ,kKK} 。
若将 中点 与其所对应的二进制数 不加区别,则每个 EEk(kKK) 可等同一个 2n- 置换。
nn FF 22
),,,( 110 nxxxX nF2
2110 )(ˆ nxxxX
分组密码概述
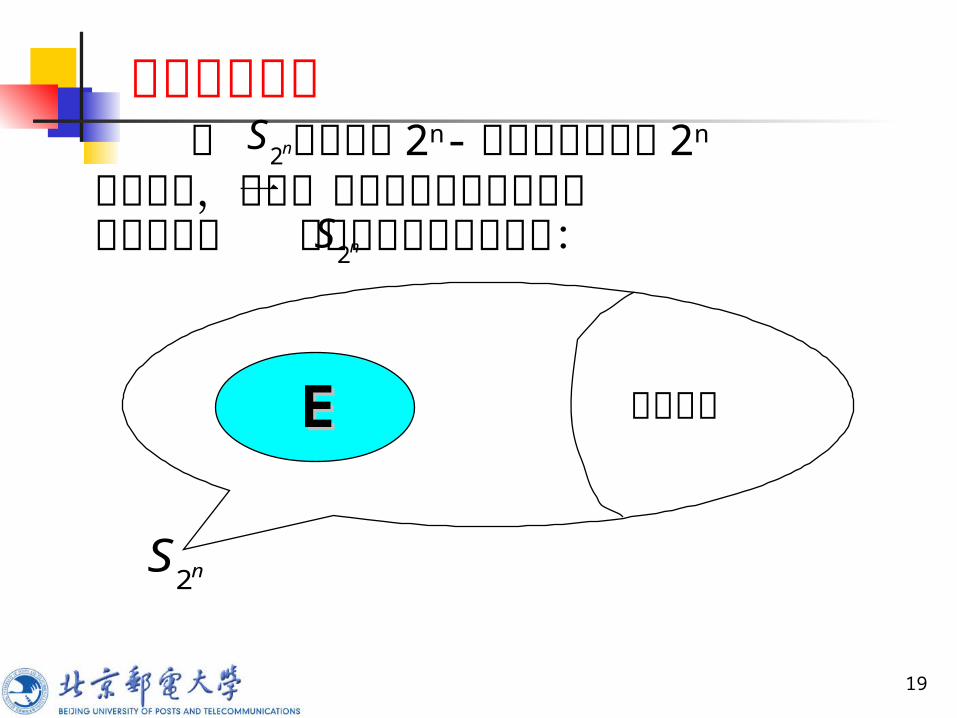
19
线性部分EE
nS2
记 为由所有 2n-置换构成的所谓 2n
次对称群,那么一个好的分组密码的加密变换空间在 中的位置应如下图所示:
nS2
nS2
分组密码概述

20
应用中对于分组码的要求 安全性 运行速度 存储量 (程序的长度、数据分组长度、高速缓存大小 )
实现平台 (硬、软件、芯片 ) 运行模式

21
分组密码设计问题
分组密码的设计问题在于找到一种算法,能在密钥控制下从一个足够大且足够好的置换子集中,简单而迅速地选出一个置换,用来对当前输入的明文的数字组进行加密变换。

22
① 分组长度 n 要足够大,使分组代换字母表中的元素个数 2n足够大,防止明文穷举攻击法奏效。 DES 、 IDEA 、 FEAL 和 LOKI等分组密码都采用 n=64 ,在生日攻击下用232 组密文成功概率为 1/2 ,同时要求 232×64b=215MB 存贮,故采用穷举攻击是不现实的。
1 分组密码算法设计要求

23
② 密钥量要足够大(即置换子集中的元素足够多),尽可能消除弱密钥并使所有密钥同等地好,以防止密钥穷举攻击奏效。但密钥又不能过长,以便于密钥的管理。 DES采用56比特密钥,看来太短了, IDEA采用 128比特密钥,据估计,在今后 30~ 40年内采用 80 比特密钥是足够安全的。
1 分组密码算法设计要求

24
③ 由密钥确定置换的算法要足够复杂,充分实现明文与密钥的扩散和混淆,没有简单的关系可循,能抗击各种已知的攻击,如差分攻击和线性攻击;有高的非线性阶数,实现复杂的密码变换;使对手破译时除了用穷举法外,无其它捷径可循。
1 分组密码算法设计要求

25
④ 加密和解密运算简单,易于软件和硬件高速实现。如将分组 n化分为子段,每段长为8 、 16 或者 32 。在以软件实现时,应选用简单的运算,使作用于子段上的密码运算易于以标准处理器的基本运算,如加、乘、移位等实现,避免用以软件难于实现的逐比特置换。
1 分组密码算法设计要求

26
为了便于硬件实现,加密和解密过程之间的差别应仅在于由秘密密钥所生成的密钥表不同而已。这样,加密和解密就可用同一器件实现。设计的算法采用规则的模块结构,如多轮迭代等,以便于软件和 VLSI快速实现。此外,差错传播和数据扩展要尽可能地小。
1 分组密码算法设计要求

27
⑤ 数据扩展。一般无数据扩展,在采用同态置换和随机化加密技术时可引入数据扩展。
⑥ 差错传播尽可能地小。
1 分组密码算法设计要求

28
软件实现的设计原则:使用子块和简单的运算。密码运算在子块上进行,要求子块的长度能自然地适应软件编程,比如 8 、 16 或 32比特等; 在软件实现中,按比特操作(如置换)是难于实现的,因此应该尽量避免它。子块上所进行的密码运算应该是一些易于软件实现的运算,最好是用一些标准处理器所具有的那些基本指令,比如加法、乘法和移位等。
1 分组密码软件设计原则

29
加密和解密应具有相似性(最好只是在密钥的使用方式上存在不同,其余皆同)以便可以用同样的器件来实现。 尽量使用规则结构,且应符合国际的统一标准,以便适合于用超大规模集成电路来实现。
值得注意的是值得注意的是:分组密码常常以乘积密码的方式来设计。由合理选择的许多子密码(相继使用)构成的乘积密码既可实现良好的混乱、又可实现良好的扩散。
1 分组密码硬件设计原则

30
要实现上述几点要求并不容易。首先,要在理论上研究有效而可靠的设计方法,而后进行严格的安全性检验,并且要易于实现。 下面介绍设计分组密码时的一些常用方法。
1 分组密码算法设计要求

31
如果明文和密文的分组长都为 n比特,则明文的每一个分组都有 2n 个可能的取值。为使加密运算可逆(使解密运算可行),明文的每一个分组都应产生惟一的一个密文分组,这样的变换是可逆的,称明文分组到密文分组的可逆变换为代换。不同可逆变换的个数有 2n!个。
( 1 )代换
1 分组密码算法设计方法

32
图 2 表示 n=4 的代换密码的一般结构,4比特输入产生 16 个可能输入状态中的一个,由代换结构将这一状态映射为 16 个可能输出状态中的一个,每一输出状态由 4 个密文比特表示。 加密映射和解密映射可由代换表来定义,如表 3.1所示。这种定义法是分组密码最常用的形式,能用于定义明文和密文之间的任何可逆映射。(见 33页表 3.1 )
( 1 )代换

33
在 Shannon 1949 的文章中,介绍了替换 -置换网络的思想 (S-P) networks
这种思想形成了现代密码的基础 S-P network 替换 -置换乘积密码的现代形式 S-P networks 是基于下列两种最基本的密码运
算(前面介绍过): 替换( Substitution ) 置换( Permutation )
( 1 )代换
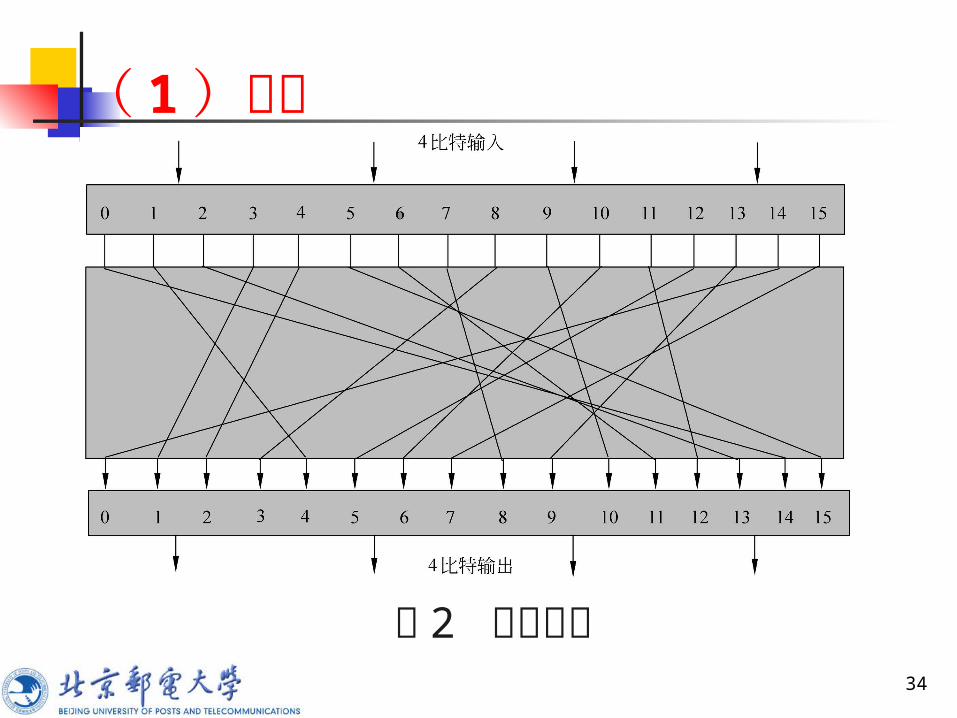
34
图 2 代换结构
( 1 )代换

35
但这种代换结构在实用中还有一些问题需考虑。如果分组长度太小,如 n=4 ,系统则等价于古典的代换密码,容易通过对明文的统计分析而被攻破。这个弱点不是代换结构固有的,只是因为分组长度太小。如果分组长度 n足够大,而且从明文到密文可有任意可逆的代换,那么明文的统计特性将被隐藏而使以上的攻击不能奏效。
( 1 )代换

36
然而,从实现的角度来看,分组长度很大的可逆代换结构是不实际的。仍以表 3.1 为例,该表定义了 n=4时从明文到密文的一个可逆映射,其中第2 列是每个明文分组对应的密文分组的值,可用来定义这个可逆映射。 因此从本质上来说,第 2 列是从所有可能映射中决定某一特定映射的密钥。这个例子中,密钥需要 64比特。一般地,对 n比特的代换结构,密钥的大小是 n×2n比特。如对 64比特的分组,密钥大小应是 64×264=270≈1021比特,因此难以处理。
( 1 )代换

37
实际中常将 n 分成较小的段,例如可选n=r·n0 ,其中 r 和 n0 都是正整数,将设计n 个变量的代换变为设计 r 个较小的子代换,而每个子代换只有 n0 个输入变量。一般 n0
都不太大,称每个子代换为代换盒,简称为S盒。例如 DES 中将输入为 48比特、输出为 32比特的代换用 8 个 S盒来实现,每个S盒的输入端数仅为 6比特,输出端数仅为4比特。
( 1 )代换

38
代换网络 代换是输入集 A 到输出 A’ 上的双射
变换: fk : AA ' 式中, k 是控制输入变量,在密码
学中则为密钥。 实现代换 fk 的网络称作代换网络。
双射条件保证在给定 k 下可从密文惟一地恢复出原明文。

39
代换 fk 的集合: S={fkkK}
K 是密钥空间。如果网络可以实现所有可能的 2n! 个代换,则称其为全代换网络。
全代换网络密钥个数必须满足条件: # {k}2n!
代换网络

40
密码设计中需要先定义代换集 S ,而后还需定义解密变换集,即逆代换网络 S-1 ,它以密文 y 作为输入矢量,其输出为恢复的明文矢量 x 。
要实现全代换网络并不容易。因此实用中常常利用一些简单的基本代换,通过组合实现较复杂的、元素个数较多的代换集。实用密码体制的集合 S 中的元素个数都远小于 2n! 。
代换网络
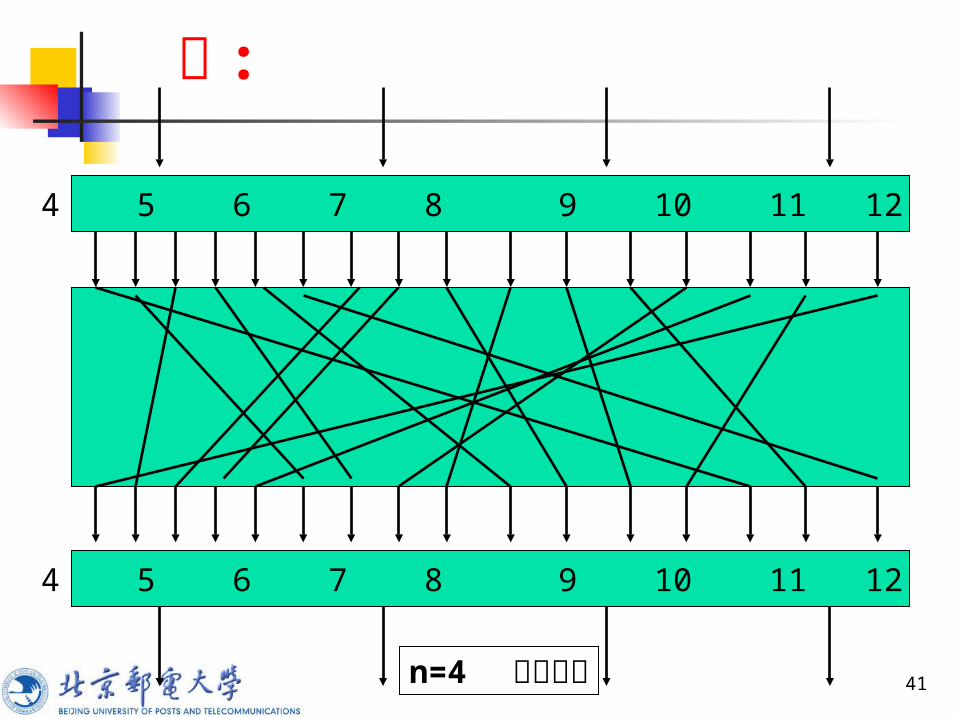
41
例 :
n=4 代换结构
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15

42
明文 密文 明文 密文0000 11010001 01010010 00010011 01100100 10010101 11110110 00100111 0011
1000 10101001 10001010 10111011 11101100 01111101 01001110 11001111 0000
密文 明文 密文 明文0000
11110001
00100010
01100011
01110100
11010101
00010110
00110111
1100
1000 10011001 01001010 10001011 10101100 11101101 00001110 10111111 0101
正向代换 反向代换

43
在二元域上,如果明文和密文的长度都为 n 则共有多少个可逆代换?
课堂思考:

44
在密码设计中,可选 n=rn0 ,其中 r 和 n0 都为正整数,将设计 n 个变量的代换网络化为设计 r 个较小的子代换网络,而每个子代换网络只有 n0 个输入变量。称每个子代换网络为代换盒 (Substitution Box)
S盒
x5 x4 x3 x2 x1 x0
y3 y2 y1 y0
DES 的 S盒
代换盒 (S 盒 )

45
DES 的 S1- 盒的输入和输出关系
x5 x0 x5 x4 x3 x2 x1 x0
1 0 1 0 1 1 0 0
列号 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
行号 0 14 4 13 1 2 15 11 8 3 10 6 12 5 9 0 7
1 0 15 7 4 14 2 13 1 10 6 12 11 9 5 3 8
2 4 1 14 8 13 6 2 11 15 12 9 7 3 10 5 0
3 15 12 8 2 4 9 1 7 5 11 2 14 10 0 6 13
(y3 , y2, y1 , y0)=(0,0,1,0)

46
迄今为止,有关方面未曾完全公开有关 DES 的 S盒的设计准则。 Branstead 等曾披露过下述准则:
P1 S 盒的输出都不是其输入的线性或仿射函数。 P2 改变 S 盒的一个输入比特,其输出至少有两比
特产生变化,即近一半产生变化。 P3 当 S 盒的任一输入位保持不变,其它 5 位输入
变化时 ( 共有 25 =32 种情况 ) ,输出数字中的 0 和1 的总数近于相等。
这三点使 DES 的 S 盒能够实现较好的混淆。
S 盒的设计准则

47
问题 : 如何将几个 S 盒组合起来构成一个 n 值较大的组。
将几个 S盒的输入端并行,并通过坐标置换(P- 盒 ) 将各 S 盒输出比特次序打乱,再送到下一级各 S 盒的输入端,起到了 Shannon 所谓的“扩散”作用。 S盒提供非线性变换,将来自上一级不同的 S 盒的输出进行“混淆”。经过 P- 盒的扩散作用使 1均匀地分散到整个输出矢量中,从而保证了输出密文统计上的均匀性,这就是 Shannon 的乘积密码的作用。
S 盒的组合

48
扩散和混淆是由 Shannon 提出的设计密码系统的两个基本方法,目的是抗击敌手对密码系统的统计分析。如果敌手知道明文的某些统计特性,如消息中不同字母出现的频率、可能出现的特定单词或短语,而且这些统计特性以某种方式在密文中反映出来,那么敌手就有可能得出加密密钥或其一部分,或者得出包含加密密钥的一个可能的密钥集合。
( 2 )扩散和混淆

49
在 Shannon 称之为理想密码的密码系统中,密文的所有统计特性都与所使用的密钥独立。图 2讨论的代换密码就是这样的一个密码系统,然而它是不实用的。
( 2 )扩散和混淆

50
所谓扩散,就是将明文的统计特性散布到密文中去,实现方式是使得明文的每一位影响密文中多位的值,等价于说密文中每一位均受明文中多位影响。 例如对英文消息 M=m1m2m3…的加密操作
其中 ord(mi) 是求字母 mi 对应的序号,chr(i) 是求序号 i 对应的字母。
1
mod 26k
n n ii
y chr ord m
( 2 )扩散和混淆

51
这时明文的统计特性将被散布到密文中,因而每一字母在密文中出现的频率比在明文中出现的频率更接近于相等,双字母及多字母出现的频率也更接近于相等。
在二元分组密码中,可对数据重复执行某个置换,再对这一置换作用于一函数,可获得扩散。
( 2 )扩散和混淆

52
分组密码在将明文分组依靠密钥变换到密文分组时: 扩散的目的是使明文和密文之间的统计关系变得尽可能复杂,以使敌手无法得到密钥; 混淆是使密文和密钥之间的统计关系变得尽可能复杂,以使敌手无法得到密钥。
( 2 )扩散和混淆

53
因此即使敌手能得到密文的一些统计关系,由于密钥和密文之间的统计关系复杂化,敌手也无法得到密钥。使用复杂的代换算法可以得到预期的混淆效果,而简单的线性代换函数得到的混淆效果则不够理想。
扩散和混淆成功地实现了分组密码的本质属性,因而成为设计现代分组密码的基础。
( 2 )扩散和混淆

54
代换运算
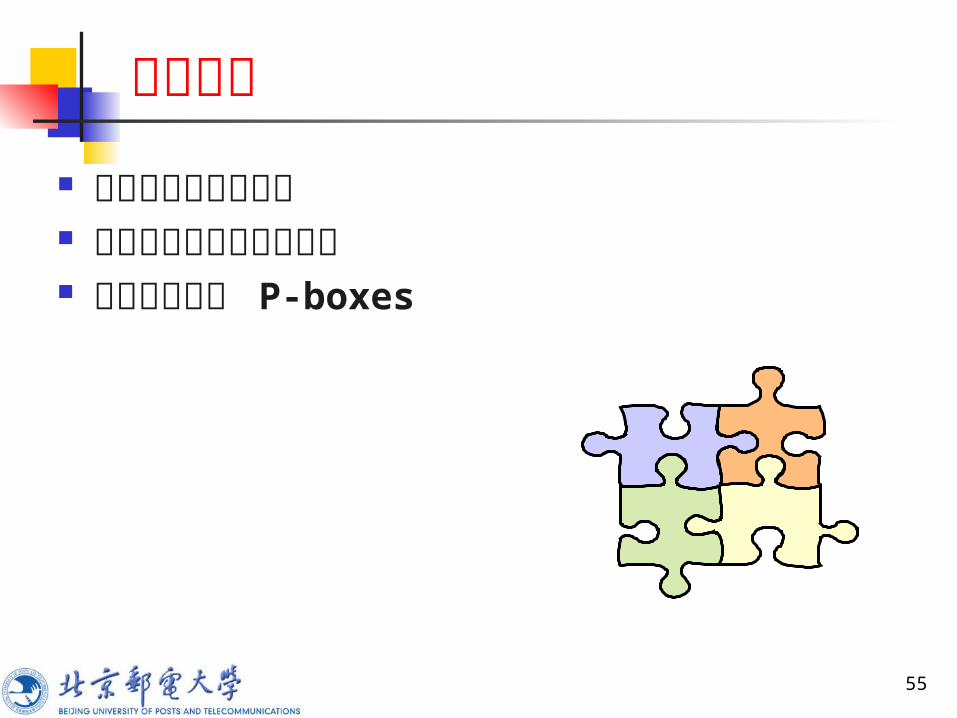
55
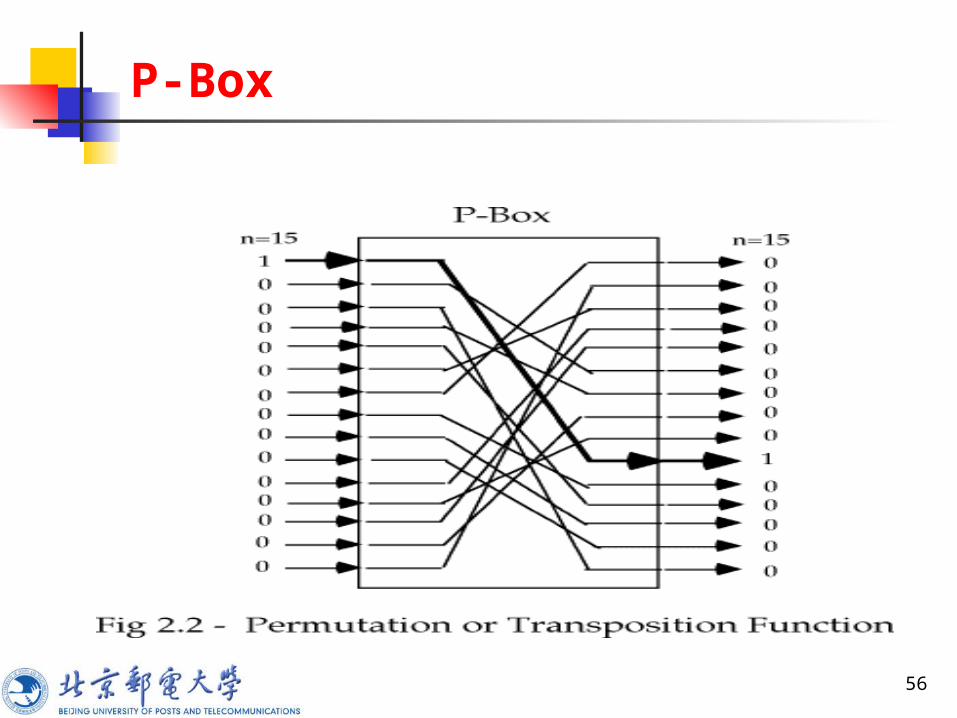
二进制字次序被打乱 重新排序的方法构成密钥 叫这种变换为 P-boxes
代换运算
56
P-Box

57
Substitution-Permutation Network
Shannon 把这两种运算组合在一起 一些 S-boxes 由 P-box 连接 这种变换叫做混合变换 ( mixing transformations )

58
替换 - 置换网络

59
实际使用的替换 - 置换网络
实际中,我们需要加密,也需要解密 因此,有两种方法: 1.定义每个替换、置换的逆,这样增加
了复杂度2. 定义一种结构,容易求逆,这样可以使
用基本的相同编码或硬件用于加密和解密

60
Horst Feistel, ( working at IBM Thomas J Watson Research Labs ) 70‘s初,设计了这样的结构,我们现在叫做 feistel cipher
思想是把输入块分成左右两部分 L(i-1) 和 R(i-1), 变换是在密码的第 I轮只使用 R(i-1)
函数 g incorporates one stage of the S-P network的每个阶段有 g 工作,由第 i 个密钥控制(叫子密钥)。
Feistel 密码结构

61
很多分组密码的结构从本质上说都是基于一个称为 Feistel网络的结构。 Feistel 提出利用乘积密码可获得简单的代换密码,乘积密码指顺序地执行两个或多个基本密码系统,使得最后结果的密码强度高于每个基本密码系统产生的结果, Feistel还提出了实现代换和置换的方法。其思想实际上是 Shannon 提出的利用乘积密码实现混淆和扩散思想的具体应用。
Feistel 密码结构

62
图 3 是 Feistel网络示意图,加密算法的输入是分组长为 2w 的明文和一个密钥 K 。将每组明文分成左右两半 L0 和 R0 ,在进行完 n轮迭代后,左右两半再合并到一起以产生密文分组。其第 i轮迭代的输入为前一轮输出的函数:
其中 Ki 是第 i轮用的子密钥,由加密密钥 K得到。一般地,各轮子密钥彼此不同而且与 K也不同。
1
1 1,i i
i i i i
L R
R L F R K
1.Feistel 加密结构

63图 3 Feistel网络示意图

64
Feistel网络中每轮结构都相同,每轮中右半数据被作用于轮函数 F后,再与左半数据进行异或运算,这一过程就是上面介绍的代换。每轮的轮函数的结构都相同,但以不同的子密钥 Ki 作为参数。 代换过程完成后,再交换左、右两半数据,这一过程称为置换。这种结构是 Shannon 提出的代换——置换网络( substitution-permutation network, SPN)的特有形式。
1.Feistel 加密结构

65
Feistel网络的实现与以下参数和特性有关: ① 分组大小分组越大则安全性越高,但加密速度就越慢。分组密码设计中最为普遍使用的分组大小是 64比特。② 密钥大小密钥越长则安全性越高,但加密速度就越慢。现在普遍认为 64比特或更短的密钥长度是不安全的,通常使用 128比特的密钥长度。
1.Feistel 网络的实现

66
③ 轮数单轮结构远不足以保证安全性,但多轮结构可提供足够的安全性。典型地,轮数取为 16 。
④ 子密钥产生算法该算法的复杂性越大,则密码分析的困难性就越大。
⑤ 轮函数轮函数的复杂性越大,密码分析的困难性也越大。
1.Feistel 网络的实现

67
在设计 Feistel网络时,还有以下两个方面需要考虑: ① 快速的软件实现在很多情况中,算法是被镶嵌在应用程序中,因而无法用硬件实现。此时算法的执行速度是考虑的关键。② 算法容易分析如果算法能被无疑义地解释清楚,就可容易地分析算法抵抗攻击的能力,有助于设计高强度的算法。
1.Feistel 网络的设计

68
Feistel 解密过程本质上和加密过程是一样的,算法使用密文作为输入,但使用子密钥 Ki 的次序与加密过程相反,即第 1轮使用Kn ,第 2轮使用 Kn-1 ,……,最后一轮使用K1 。这一特性保证了解密和加密可采用同一算法。
2.Feistel 解密结构

69
图 4 的左边表示 16轮 Feistel网络的加密过程,右边表示解密过程,加密过程由上而下,解密过程由下而上。为清楚起见,加密算法每轮的左右两半用 LEi 和 REi 表示,解密算法每轮的左右两半用 LDi 和 RDi 表示。 图中右边标出了解密过程中每一轮的中间值与左边加密过程中间值的对应关系,即加密过程第 i轮的输出是 LEi‖REi (‖表示链接),解密过程第 16-i轮相应的输入是 RDi‖LDi 。
2.Feistel 解密结构

70
明文 (2w比特 )
F
1L 1R
0L 0RW比特 W比特第 1轮
F
nL nR
1nL 1nR第 n轮
1K
nK
密文 (2w比特 )
1nL1nR

71
2 Feistel 网络解密结构
输入(明文)
F1K
F1K
0LE 0RE
1RE1LE
2RE
2LE
F15K
14RE14LE
F16K 15LE
15RE
16RE16LE
输出(密文) 输入(密文)
F16K
160 RELD 160 LERD
F15K
F
2K
F1K
输出(明文)
151 LERD
151 RELD
142 RELD 142 LERD
214 RELD 214 LERD
115 LERD 115 RELD
016 RELD 016 LERD
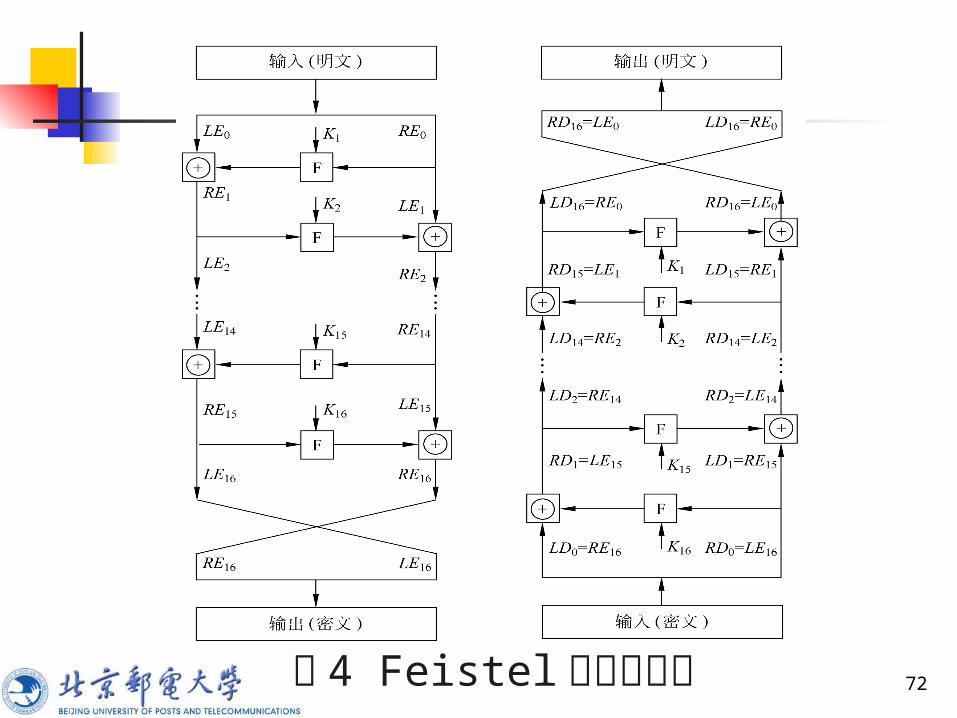
72图 4 Feistel 加解密过程

73
加密过程的最后一轮执行完后,两半输出再经交换,因此密文是 RE16‖LE16 。解密过程取以上密文作为同一算法的输入,即第 1轮输入是 RE16‖LE16 ,等于加密过程第 16轮两半输出交换后的结果。下面证明解密过程第 1轮的输出等于加密过程第 16轮输入左右两半的交换值。
2.Feistel 解密结构

74
在加密过程中:
在解密过程中
16 15
16 15 15 16,
LE RE
RE LE F RE K
1 0 16 15
1 0 0 16 16 15 16
15 15 16 15 16
15
, ,
, ,
LD RD LE RE
RD LD F RD K RE F RE K
LE F RE K F RE K
LE
2.Feistel 解密结构

75
所以解密过程第 1轮的输出为 LE15‖RE15 ,等于加密过程第 16轮输入左右两半交换后的结果。容易证明这种对应关系在 16轮中每轮都成立。一般地,加密过程的第 i轮有
因此
1
1 1,i i
i i i i
LE RE
RE LE F RE K
1
1 1, ,i i
i i i i i i i
RE LE
LE RE F RE K RE F LE K
2.Feistel 解密结构

76
以上两式描述了加密过程中第 i轮的输入与第 i轮输出的函数关系,由此关系可得图 4右边显示的 LDi 和 RDi 的取值关系。 最后可以看到,解密过程第 16轮的输出是 RE0‖LE0 ,左右两半再经一次交换后即得最初的明文。
2.Feistel 解密结构

77
Shannons 混合变换形成一种特殊的乘积密码,组成部分一起工作 :
S-Boxes ( S-盒 ) :提供输入 bits混合作用 (confusion)
其目的在于使作用于明文的密钥和密文之间的关系复杂化,使明文和密文之间、密文和密钥之间的统计相关特性极小化,从而使统计分析攻击不能奏效。通常的方法是“替换( Substitution)” (回忆恺撒密码)。
2.Feistel 结构设计原理

78
P-Boxes
P-Boxes :提供扩散作用 (diffusion) 将明文及密钥的影响尽可能迅速地散布到较多个输出的密文中(将明文冗余度分散到密文中)。产生扩散的最简单方法是通过“换位 (Permutation)” (比如:重新排列字符)
这种效果进一步解释为”雪崩”与”完全性” (Avalanche and Completeness )by Webster & Tavares
"On the Design of S-boxes", in Advances in Cryptology - Crypto 85, Lecture Notes in Computer Science, No 218, Springer-Verlag, 1985, pp 523-534

79
雪崩效应 (Avalanche effect )
输入改变 1bit, 导致近一般的比特发生变化
一个函数 F 具有好的雪崩特性是指 : 对 2^m 个明文 向量 , 分为 2^m-1 个向量对 xi 和 xi’,
每对向量只有一个 bit 不同 , 定义 Vi = f(X) XOR f(Xi) ,则近一半的 Vi 为 1.

80
完备性效应 (Completeness effect )
每个输出比特是所有输入比特的复杂函数的输出,
F 具有好的完备性是指 : 对密文输出向量的每一比特 j, 0<j<m, 至
少存在一个明文对 (xi,xi’), 此明文对只在第 i比特不同 ,且 F(xi) 与 F(xi’) 的第 j比特不同 .

81
分组密码设计 (Block Cipher Design) 这些设计原理是设计好的分组密码的准
则。 “雪崩”保证小的输入变化导致大的输
出变化; 完全性保证每个输出比特依赖于所有的
输入比特; 我们可以看到 , 古典密码没有这些性质。

82
Feistel Cipher 设计 设计密码时 , 下列参数需要考虑 : 分组大小 (block size)
增加分组长度会提高安全性 , 但降低了密码运算速度
密钥大小 (key size) 增加密钥长度 , 可以提高安全性 ( 使得穷搜索困难 ), 同样 ,降低了密码速度 .

83
轮数 增加轮数可以提高安全性 , 但降低速度
子密钥生成 子密钥生成越复杂 , 就越安全 , 但降低速度
轮函数 复杂的轮函数能够使的密码分析困难 ,但降低速度
(所有问题就是平衡问题 ) 设计”安全”的密码算法并不难 ,只要使用足够多的轮数就可以 , 但降低速度
得到一个快速 \安全的算法是困难的
Feistel Cipher 设计

84
密码设计 评价 “好的”密码设计具有 : 雪崩特性 , 完备性 ,
不可预料性 (avalanche, completeness, unpredictability )
差的密码设计缺乏随机性 , 具有太大的可预料性
许多密码都被攻破 (incl. commercial products like Wordperfect, pkzip, all current mobile phone ciphers)
即使密码学专家也会犯这样的错误 最好的办法是测试 , 通过实际检验证明它的安
全性

85
若以一个简单函数 f ,进行多次迭代,就称其为迭代密码。 每次迭代称作一轮 (Round) 。相应函数 f 称作轮函数。 每一轮输出都是前一轮输出的函数,即 y(i)=f[y(i-1), k(i)] ,其
中 k(i) 是第 i 轮迭代用的子密钥,由秘密密钥 k 通过密钥生成算法产生。
子 密 钥 产 生 器k
k(1) k(2) k(r)
y(0) = x y(1) y(2) y(r-1) y(r)=y
迭代分组密码

86
加密函数 f(x, k) ,实现 F2n× F2
t F2n 的映射。
其中, n 是分组长, t 是密钥长。若对每个密钥取值都有 f[f(x, k) , k]=x ,即
f(x, k)2 =I ( 恒等置换 )
则称其为对合密码,以 fI表示。
对合密码 (Involution Cipher)

87
I 型迭代分组密码
以对合密码函数构造的多轮迭代分组密码。E[x, k]=fI[fI [ fI [fI[x, k(1)] , k(2)] , k(r-1)] , k(r)]
D[y, k] =fI [fI[ fI[fI[y, k(r)] , k(r-1)] , k(2)] , k(1)]
缺点:对任意偶数轮变换,若对所有 i 选择 k(2i-1) =k(2i) ,则加密的变换等价于恒等变换,在实用中需要避免这类密钥选择。

88
对合置换 令 P 是对 x 的置换,即 P : F2
n F2n ,若对所
有 xGF(2n) ,有 P[P[x]]=x ,即 PP=I( 恒等置换 ) ,以 PI表示。
II 型迭代分组密码 每轮采用对合密码函数和对合置换级连,即
F[x, k] = PI [fI [x, k]]
并选解密子密钥与加密子密钥逆序,则加密解密可用同一器件完成。
DES 、 FEAL 和 LOKI 等都属此类。
对合置换和 II 型迭代分组密码

89
群密码:若密钥与明文、密文取自同一空间GF(2 n) ,且 y=xk ,式中,是群运算,则称其
为群密码。 显然 x 可通过 k 的逆元求得 x=yk-1
令 xk 为一群密码,令 fI(x, kB) 为一对合密码,以 F[x, k] = fI (xkA, kB) 为迭代函数,可以III 型多轮迭代分组密码。在最后一轮中,另外加了一次群密码运算,用以保证整个加、解密的对合性。
III 型迭代分组密码

90
轮函数F F y(1) y(r-1) (a) 加密 x fI ··· fI y kA
(1) kB(1) kA
(r) kB(r) kA
(r+1)
F F
y fI ··· fI x
(b) 解密 kA
(r+1)) -1 kB(r) (kA
(r))-1 kB(1) (kA)-1
III 型迭代分组密码

91
在 III 型密码的轮函数基础上,再增加一个对合置换 PI ,构成 IV 型迭代分组密码的轮函数
F[x, k] = PI[fI [xkA, kB]]
IV 型迭代分组密码
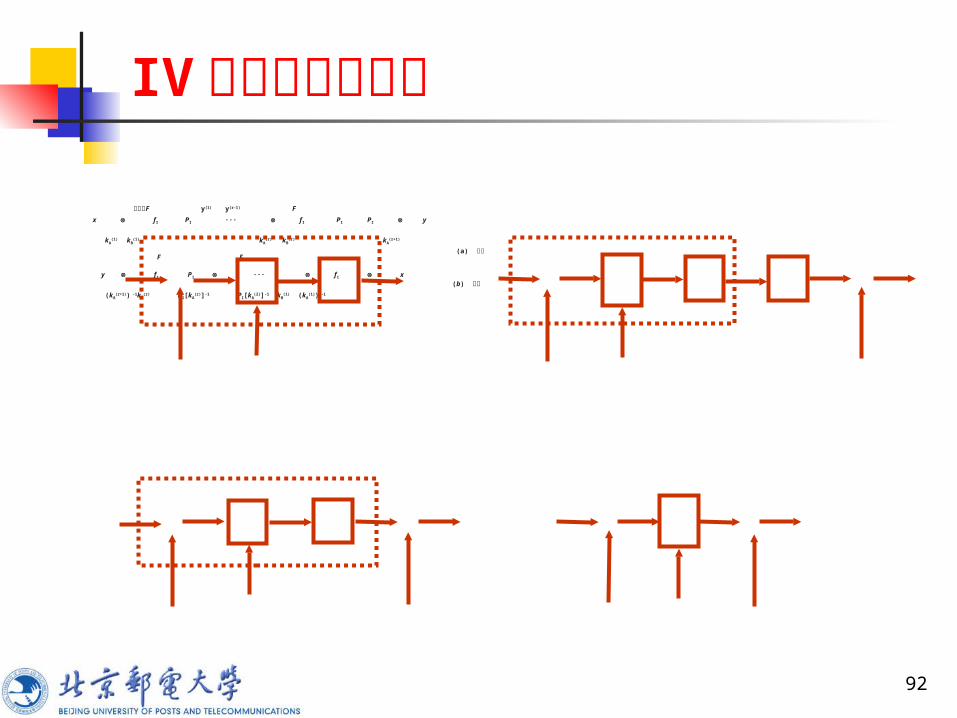
92
轮函数F y(1) y(r-1) F
x fI PI ··· fI PI PI y
kA(1) kB
(1) kA(r) kB
(r) kA(r+1)
(a) 加密 F F
y fI PI ··· fI x (b) 解密 (kA
(r+1)) -1kB(r) PI[kA
(r)]-1 PI[kA(2)]-1 kB
(1) (kA(1)) -1
IV 型迭代分组密码

93
Lucifer 密码 第一个可用的替换 -置换密码 (by Horst Feistel at
IBM labs ) Horst Feistel, "Cryptography and Computer Privacy", Scientific American, Vol 228(5), May 1973, pp 15-23.
提供了这项工作的框架 , 但没有 Lucifer 的细节 详细的介绍 : Arthur Sorkin, "Lucifer, A Cryptogr
aphic Algorithm", Cryptologia, Vol 8(1), Jan 1984, pp 22-41, with addenda in Vol 8(3) pp260-261
包括算法的详细描述 \实现
94
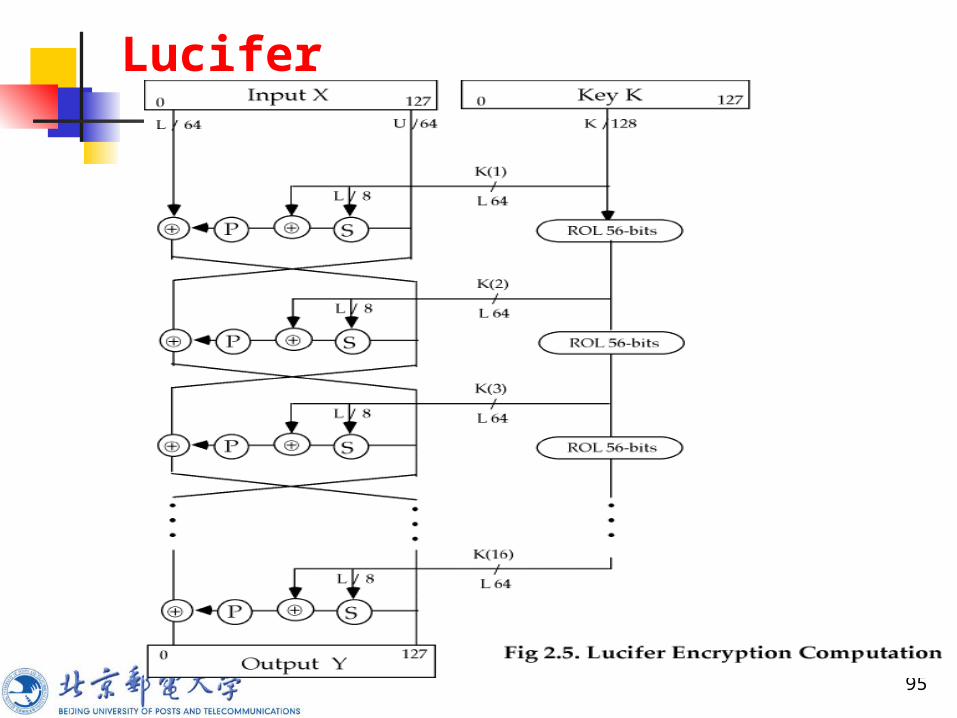
Lucifer 浏览
原始描述没有给出细节
以下列形式描述 :
95
Lucifer

96
Lucifer 密钥编排
Lucifer IS Feistel cipher, 分组长度是 128-bit , 密钥长度是 128-bit
每轮使用的子密钥是密钥的左半部分 密钥每次要向左旋转 56-bits, 所以 , 密
钥的每部分都参加运算

97
Lucifer 数据计算
16轮数据计算 ( 使用子密钥 ) 输出的右半部分作为下轮的输入 RH side as inputs to the round function
交换位置前 , 与左半异或 S-P function for Lucifer 有下列结构 : substitution 使用 8 个 4-bit S-boxes (S0 & S1)
( 对 ) 每个对的交替使用方法依赖与密钥 (order (S0|S1) o
r (S1|S0) depending on the key ) subkey 替换输出相加 (modulo 2) 在通过几个 8bit 置换组成 128 的简单置换

98
Lucifer Function f

99
Lucifer Security
Lucifer 没有经过很强的分析 现在认为是理论可破的 ( 通过差分分析 )
现在不被使用 是 DES 的前生

100
THE END !


















