
Patrick Glenisson Integrating Scientific Literature With Large Scale Gene Expression Analysis...
74
Genes and Microarrays Patrick Glenisson Integrating Scientific Literature With Large Scale Gene Expression Analysis December 21th 2004
-
Upload
neal-jones -
Category
Documents
-
view
214 -
download
0
Transcript of Patrick Glenisson Integrating Scientific Literature With Large Scale Gene Expression Analysis...

Genes and Microarrays
Patrick Glenisson
Integrating Scientific Literature With
Large Scale Gene Expression Analysis
December 21th 2004

Overview
Overview
Genes & microarrays
Gene expression data analysis
Text mining in biology: principles
Text mining in practice: TXTGate
Combining text and gene expression data
Conclusion

Overview M-score
Overview
Genes & microarrays
Gene expression data analysis
Text mining in biology: principles
Text mining in practice: TXTGate
Combining text and gene expression data
Conclusion
Cluster analysis

Overview
Overview
Genes & microarrays
Gene expression data analysis
Text mining in biology: principles
Text mining in practice: TXTGate
Combining text and gene expression data
Conclusion
Literature analysis

Overview
Overview
Genes & microarrays
Gene expression data analysis
Text mining in biology: principles
Text mining in practice: TXTGate
Combining text and gene expression data
Conclusion
TXTGate

Overview
Overview
Genes & microarrays
Gene expression data analysis
Text mining in biology: principles
Text mining in practice: TXTGate
Combining text and gene expression data
Conclusion
&
Integrated clustering

Overview
Overview
Genes & microarrays
Gene expression data analysis
Text mining in biology: principles
Text mining in practice: TXTGate
Combining text and gene expression data
Conclusion
&

Overview
Overview
Genes & microarrays
Gene expression data analysis
Text mining in biology: principles
Text mining in practice: TXTGate
Combining text and gene expression data
Conclusion
&

Genes and Microarrays
DNA, genes, proteins and cells

Genes and Microarrays
DNA, genes, proteins and cells
protein

Genes and Microarrays
Genes are expressed and regulated

Genes and Microarrays
Microarrays measure gene expression
Laser
excitation
Gen
es
Gene expression measurement
Conditions
G1G2G3
..
C1
C2
C3 ..
Sample annotations
Gen
e an
no
tati
on
s

Genes and Microarrays
Representing expression information
Gene expression experiments are complex : Too verbose to include in a scientific publication Too important to compromise on reproducibility Too valuable for post-genome research to have it scattered
around on various websites
Necessary level detail for reproducibility / data mining ? Hence, standard for reporting on MA experiments As a guideline for databases hosting expression
compendia
Conditions in which
expression occurs

Genes and Microarrays
Storing gene expression data

Genes and Microarrays
MIAME standard
Minimum Information About a MicroArray Experiment Internationally proposed standard Published in Dec 2001 by International consortium MGED prominent journals (Nature, Lancet, EMBO, Cell) require
MIAME-compliant submissions of data
Some hurdles: Significant overhead in filling out the questionnaire Scooping of leads (!) Proprietary information about probe sequences Query-enabled >< comparable (cfr. Affy vs cDNA)

Genes and Microarrays
Impression on MIAME’s content

Genes and Microarrays
Dissemination of gene expression data
publications
repositories

Overview
Overview
Genes & microarrays
Gene expression data analysis
Text mining in biology: principles
Text mining in practice: TXTGate
Combining text and gene expression data
Conclusion
&

Gene expression data analysis
Questions asked with microarrays
Fundamental Functional roles of genes (and transcriptional regulation) Genetic network reconstruction
Clinical Correlation of genes with a given disease Diagnosis of disease stage with patients
Pharmacological Toxicological drug response assessment

Gene expression data analysis
Microarray data analysis
Fundamental Functional roles of genes (and transcriptional regulation) Genetic network reconstruction
Clinical Correlation of genes with a given disease Diagnosis of disease stage with patients
Pharmacological Toxicological drug response assessment

Gene expression data analysis
ClusteringConditions
Gen
es
Expression data C1
C3
C2G
enes
Genes
Distance matrix
Clustering
Hierarchical clustering
k - Means

Gene expression data analysis
Data-centered statistical scores
Coherence vs separation of clusters
Stability of a cluster solution when leaving out data
Cluster validation
Define `optimal’ ?
Optimal number of clusters ?
C1
C3
C2
E.g. SILHOUETTE

Genes and Microarrays
Cluster validation – stability method

Gene expression data analysis
Data-centered statistical scores
Knowledge-based scores
Enrichment of GO annotations in clusters
Literature-based scoring
Cluster validation
Define `optimal’ ?
Optimal number of clusters ?

Gene expression data analysis
Cluster validation
Define `optimal’ ?
Optimal number of clusters ?
Data-centered statistical scores
Knowledge-based scores
Motif-based
DNA patterns in regulatory regions of gene groups
Regulatory DNApatterns (motifs)
Gene

Genes expression data analysis
DNA patterns in expression clusters
‘Significant’ occurrences of known motifs in cluster
Mo
tifs
Clusters
Cluster-by-Motif(motif enrichment matrix)
1 2 3 ..
A
B
C
..
-log(p-value)
M-score
Gene clusters

Genes expression data analysis
Cluster-by-motif matrix
cluster
mot
if M-Score for the entire clustering solution one-shot estimate of the `biological relevance’

Gene expression data analysis
M-score
A motif is less interesting when it (significantly) occurs in many clusters
A cluster that contains a large portion of (significant) motifs is less likely to be biologically relevant.
A `too large' number of clusters is less likely to reflect the true biological
diversity underlying the experiment.

Gene expression data analysis
M-score validation
A simplification of reality
No absolute quantification of biological relevance.
Useful tool when experimenting with
• Multiple clustering methods
• Multiple parameterizations
To economize on biological validations
Optimal k in yeast cell cycle expression data
Original studies by Tavazoie et al. used k=30
Overestimation confirmed by analyses of
• De Smet et al. (AQBC)
• Gibbons et al. (GO-based scoring)
k
M-s
core

Overview
Overview
Genes & microarrays
Gene expression data analysis
Text mining in biology: principles
Text mining in practice: TXTGate
Combining text and gene expression data
Conclusion

Text Mining: principles
Problem setting
Given a set of documents,
compute a representation, called index
to retrieve, summarize, classify or cluster them
<1 0 0 1 0 1>
<1 1 0 0 0 1>
<0 0 0 1 1 0>

Text Mining: principles
Problem setting
Given a set of genes (and their literature),
compute a representation, called gene index
to retrieve, summarize, classify or cluster them
<1 0 0 1 0 1>
<1 1 0 0 0 1>
<0 0 0 1 1 0>

Text Mining: principles
Vector space model Document processing
Remove punctuation & grammatical structure (`Bag of words’) Define a vocabulary
• Identify Multi-word terms (e.g., tumor suppressor) (phrases)• Eliminate words low content (e.g., and, thus, gene, ...) (stopwords)• Map words with same meaning (synonyms)• Strip plurals, conjugations, ... (stemming)
Define weighing scheme and/or transformations (tf-idf,svd,..)
Compute index of textual resources:
T 1
T 3
T 2
vocabulary
gene

Text Mining: principles
Validity of gene index
Genes that are functionally related should be close in text space:
Modeled wrt a background distribution of through random and permuted gene groups
Text-based coherence score

Text Mining: principles
Validity of gene index
Genes that are functionally related should be close in text space:

Text Mining: principles
Validity of gene index
Genes that are functionally related should be close in text space:

Genes and Microarrays
Validity of gene index
“Simple word vector representations are competitive also in terms of classification task with respect to more elaborate approaches ..”
..despite unaddressed issues such as phrases homonyms neglected grammatical structure
A. Seewald: Ranking for BioMinT: Investigating performance, local search and homonymy recognition.
>> www.biomint.org

Overview
Overview
Genes & microarrays
Gene expression data analysis
Text mining in biology: principles
Text mining in practice: TXTGate
Combining text and gene expression data
Conclusion
TXTGate

TXTGate - a platform to profile groups of genes
Motivation 1
“ Until now it has been largely overlooked that there is little difference between retrieving a MEDLINE abstract and downloading an
entry from a biological database ” (M. Gerstein, 2001)
12133521VEGF is associated with the development and prognosis of colorectal cancer.
12168088PTEN modulates angiogenesis in prostate cancer by regulating VEGF expression.
11866538 Vascular endothelial growth factor modulates the Tie-2:Tie-1 receptor complex
GeneRIFGO
• cell proliferation
• heparin binding
• growth factor activity

TXTGate - a platform to profile groups of genes
Motivation 2
Controlled vocabularies are of great value when constructing interoperable and computer-parsable systems.
A number of structured vocabularies have already arisen:• Gene Ontology (GO)• MeSH• eVOC
Standards are systematically being adopted to store biological concepts or annotations: • HUGO• GOA@EBI

TXTGate - a platform to profile groups of genes
Motivation 3
(Figure courtesy: S. Van Vooren)

Genes and Microarrays
Development of text mining platform
a platform that offers multiple ‘views’ on vast amounts of (gene-based) free-text information available in selected curated database entries & linked scientific publications.
incorporates term-based indices ..
.. and use them as a starting point to explore the text through the eyes of different domain vocabularies to link out to other resources by query building, or to sub-cluster genes based on text.

Genes and Microarrays

Genes and Microarrays

Genes and Microarrays

Genes and Microarrays
Illustration: sub-clustering Eisen et al. (1998)

Genes and Microarrays
Illustration: profiling Chaussabel et al. (2003)

TXTGate - a platform to profile groups of genes
TXTGate: towards closing the KD loop
Profile
Distance matrix &Clustering
Other vocabulary

TXTGate - a platform to profile groups of genes
TXTGate – a case study Gene modules over various expression data sets
Reported two sub modules of TCA cycle
Two ‘new’ genes ACN9 & CAT8 in module 2
Visualize with BioLayout / LGL

Overview
Overview
Genes & microarrays
Gene expression data analysis
Text mining in biology: principles
Text mining in practice: TXTGate
Combining text and gene expression data
Conclusion
&

Fusion of text and expression data
Problem setting
“How can we analyze data in an integrated fashion to extract more information than solely from
expression data ? ”

Fusion of text and expression data
Various ways to integrate data

Fusion of text and expression data
In each information space
Appropriate preprocessing Choice of distance measures
Integration of text and data

Fusion of text and expression data
Integration of text and data
Combine data:
confidence attributed to either of the two data types
in case of distance, we can see it as a scaling constant between the norms of the data- and text representations.

Fusion of text and expression data
Integration of text and data
However, distribution of distances invoke a bias Scaling problem
Therefore, use technique from statistical meta-analysis (so-called omnibus procedure)
Expression Distance
histogram Text Distance
histogram

Fusion of text and expression data
Overview meta-clustering
M-score
Clustering

Fusion of text and expression data
Integration improves M-score
M-score expression data only
M-s
core
int e
gra t
ed c
lust
e rin
gVarious cutoffs k of the cluster tree
Optimal k ?

Fusion of text and expression data
A look inside the integration

Fusion of text and expression data
A look inside the integration
Expression Profile Text Profile
Strongre-enforcement

Overview
Overview
Genes & microarrays
Gene expression data analysis
Text mining in biology: principles
Text mining in practice: TXTGate
Combining text and gene expression data
Conclusion
&

Conclusion
Contributions
Representation of a gene expression experiment MIAME Laboratory Information Management System v. at the VIB
MicroArray Facility Gene expression analysis
Iterative clustering to determine optimal k M-score
Text-based gene representation To represent functional information about genes To score gene groups based on literature To cluster genes based on literature
TXTGate text mining application To profile, in an flexible and interactive manner, gene groups from
different ‘views’ Integration of text and expression data in clustering

Conclusion
Semantically-oriented text mining representations Algorithm-based: ( cfr Bioinformatics)
• Improved phrases (word co-locations)• Latent Semantic Indexing• concept clustering, bi-clustering
Knowledge based: ( cfr. PSB 2005 conference)• Gene Ontology distance in a taxonomy• Basic natural language processing + statistics = Shallow Parsing
Advanced ways of integrating data Combine link information with term information Ways to determine
Future work

Conclusion
References
http://www.esat.kuleuven.ac.be/~sistawww/cgi-bin/pub.pl
http://www.esat.kuleuven.ac.be/~dna/BioI/
PapersTechnical ReportsPhD thesis (references to datasets, tools,..)

Questions
??

TXTGate - a platform to profile groups of genes
TXTGate – final considerations
Flexible tool for analyzing gene groups (~200 genes) due to various term- and gene-centric vocabularies
… that allow some level of interoperability with external annotation databases
Sub-clustering gene groups useful to detect biological sub-patterns, or, shortcomings of the text representation.
Reasonably robust to corrupted groups
Gene index normalizes for unbalanced references and handles multiple gene function by ‘overruling’

Genes and Microarrays
Representing expression information
Rationale: Gene expression experiments are a chain of biotechnological
operations, protocols and data processing steps Too verbose to include in a scientific publication Too important to compromise on reproducibility Too valuable for post-genome research to have it scattered
around on various websites
Standards for reporting on MA experiments MIAME-compliant databases hosting expression
compendia
Conditions in which
expression occurs
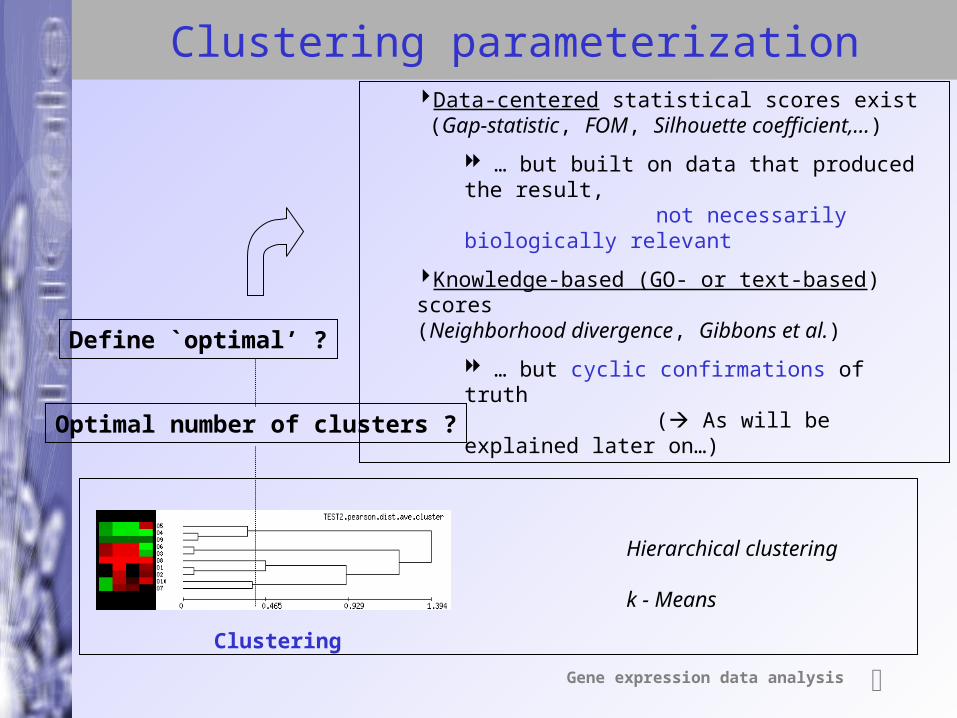
Gene expression data analysis
Clustering parameterization
Clustering
Hierarchical clustering
k - Means
Optimal number of clusters ?
Define `optimal’ ?
Data-centered statistical scores exist (Gap-statistic, FOM, Silhouette coefficient,…)
… but built on data that produced the result, not necessarily biologically
relevant
Knowledge-based (GO- or text-based) scores (Neighborhood divergence, Gibbons et al.)
… but cyclic confirmations of truth ( As will be explained later
on…)

Genes expression data analysis
Optimal k by looking at DNA patterns
Evaluation : we constructed a motif-based heuristic
in terms of upstream regulatory sequence patterns in clusters,
To have a one-shot estimate of the `biological relevance’ ofa clustering result.

TXTGate - a platform to profile groups of genes
TXTGate
multiple ‘views’ (through use of different vocabularies) on vast amounts of (gene-based) free-text information available in selected curated
database entries & linked scientific publications.

TXTGate - a platform to profile groups of genes
TXTGate
incorporates term-based indices ..(cfr before)
.. and use them as a starting point
to explore terms generated through different domain vocabularies to link out to other resources by query building, or to sub-cluster genes based on text.

TXTGate - a platform to profile groups of genes
TXTGate – case 2

Text Mining: principles
How to construct a gene index
Gene index
Documentindex
Gene-literature
associations

TXTGate - a platform to profile groups of genes
TXTGate – case 1
Gene clusters from microarray experiment on human immune response
Comparative study with Chaussabel et al.
TXTGate’s disease vocabulary

Fusion of text and expression data
Various ways to integrate data


















