
Copyright 2008 Digital Enterprise Research Institute. All rights reserved. Digital Enterprise...
11
Copyright 2008 Digital Enterprise Research Institute. All rights reserved. Digital Enterprise Research Institute www.deri.i e Anatomy of a Semantic Virus Nature inspired Reasoning for the Semantic Web (NatuReS) 7th International Semantic Web Conference (ISWC 2008) Karlsruhe, Germany 27th October 2008 Peyman Nasirifard [email protected]
-
Upload
johnathan-williams -
Category
Documents
-
view
214 -
download
2
Transcript of Copyright 2008 Digital Enterprise Research Institute. All rights reserved. Digital Enterprise...

Copyright 2008 Digital Enterprise Research Institute. All rights reserved.
Digital Enterprise Research Institute www.deri.ie
Anatomy of a Semantic Virus
Nature inspired Reasoning for the Semantic Web (NatuReS)7th International Semantic Web Conference (ISWC 2008)
Karlsruhe, Germany
27th October 2008
Peyman [email protected]

Digital Enterprise Research Institute www.deri.ie
What Do We Have Now?
We have currently Semantic-Web-Oriented applications and APIs Semantic digital libraries SIOC-enabled shared workspaces Semantic URL shorten tools Semantic Wiki Semantic blog Lots more...
The applications „talk“ in RDF Importing and exporting RDF
These applications provide partially „food“ for Semantic Search engines

Digital Enterprise Research Institute www.deri.ie
What Do We Have Now? (2)
Semantic-Web-Oriented researchers (including me :-) encourage others Use RDF, Publish RDF, Talk RDF!
Sematnic search engines Finding RDF-related materials from the Web Indexing them Querying and reasoning over data
Sematnic search engines are RDF-hungry „Submit RDF to us“
– Crawl deep Web
„Tell us where you saw an RDF document“ They monitor services like „pingthesemanticweb.com“
Digital Enterprise Research Institute www.deri.ie
What Do We Have Now? (3)
Users can submit their RDF data using services like Ping The Semantic Web (PTSW)
Feeds of the PTSW are further used Search engines follow the links and index RDF data
We have services like DBpedia DBpedia is a community effort to extract structured
information from Wikipedia and to make this information available on the Web (source: http://dbpedia.org/About)
Can be used for reasoning

Digital Enterprise Research Institute www.deri.ie
Common Sense facts Milk is white Lions eat meat
Web (e.g. Wikipedia) is for humans, whereas Semantic Web (e.g. DBpedia) aims to be for machines. Humans have wisdom and can distinguish ridiculous common
sense facts, but machines can not detect them and will use them in reasoning.
Do you trust Wikipedia articles? How much? Why is not Wikipedia cited in scientific articles?
What about DBpedia? Can we really benefit from the generated RDF? If we can not trust Wikipedia articles, how can we use DBpedia for
further reasoning?
Real World
Digital Enterprise Research Institute www.deri.ie
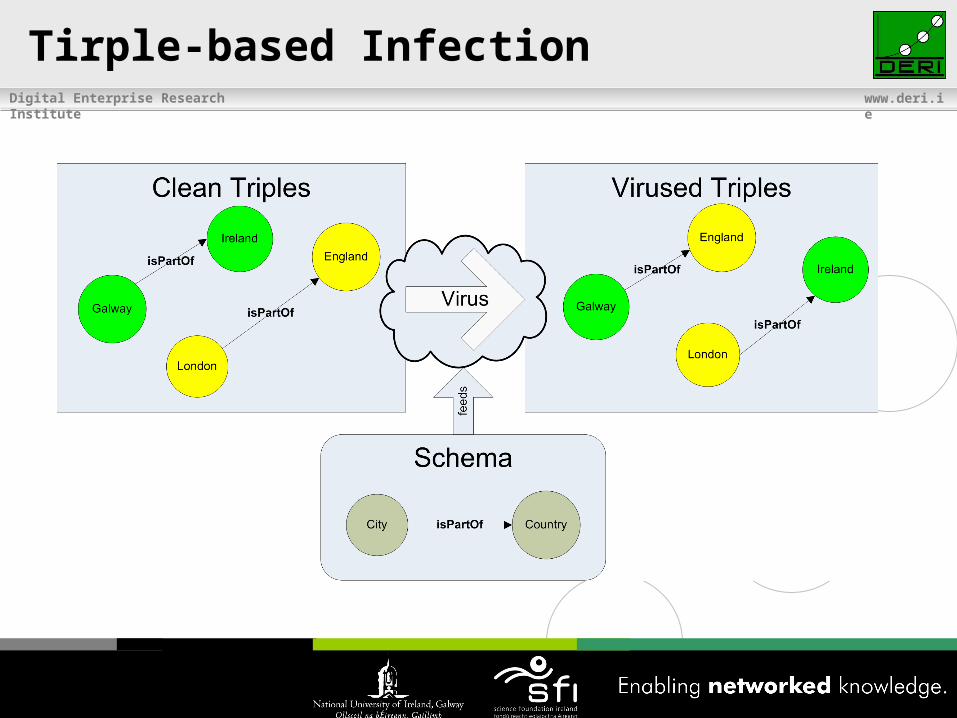
Tirple-based Infection

Digital Enterprise Research Institute www.deri.ie
Possible Attack

Digital Enterprise Research Institute www.deri.ie
Some Facts and Discussions
Fake knowledge can exist on the Semantic Web Maliciously: Semantic Virus Non maliciously: Human faults (machines will not have
faults) Semantic Web is NOT just FOAF and FOAF-based
computing Semantic Web does not grow as fast as the Web
Google has indexed one Trillion pages (source: Google official blog)
Such attacks are not feasible on the Web Because We as humans can understand some common
sense facts, but machines do not have the common sense facts that we have

Digital Enterprise Research Institute www.deri.ie
Trust and Proof (and perhaps logic) are the layers that the possible virus target
Digital Signature can not address such issues. Information quality issues (e.g. validity)
Trusting on RDF sources? We trust mostly on sources (e.g. We trust on LiveJournal
RDF files, because Livejournal is a trusted party) We trust SIOC plugins that generate SIOC But can we limit knowledge providers to just some
sources?– Internet does not do it, so we need
to accetp RDF from everyone!
Some Facts and Discussions (2)

Digital Enterprise Research Institute www.deri.ie
Conclusions
Future works based on developing the virus is not really recommended!
The paper opens some research areas in the trust layer of the Semantic Web tower How much do you trust DBpedia?
How can we ensure that RDF is not fake? Should we revise all RDF statements using some
references?– Where do we get the references?
Do we need a global, peer-reviewed and always up-to-date common sense facts repository?
– Sounds very difficult or even impossible Can we benefit from nature-inspired reasoning?
– Can we use statistical approaches?

Copyright 2008 Digital Enterprise Research Institute. All rights reserved.
Digital Enterprise Research Institute www.deri.ie
Thank you for your attention!
11 of 4
Questions? Comments?
Please contact Peyman: [email protected]


















