
Serena Yeung, PHD, Stanford, at MLconf Seattle 2017
60
Towards Scaling Video Understanding Serena Yeung
-
Upload
mlconf -
Category
Technology
-
view
462 -
download
7
Transcript of Serena Yeung, PHD, Stanford, at MLconf Seattle 2017

Towards Scaling Video Understanding
Serena Yeung

YouTube TV
GoPro Smart spaces

State-of-the-art in video understanding

State-of-the-art in video understandingClassification
Abu-El-Haija et al. 2016
4,800 categories15.2 Top5 error

State-of-the-art in video understandingClassification Detection
Idrees et al. 2017, Sigurdsson et al. 2016Abu-El-Haija et al. 2016
4,800 categories15.2 Top5 error
Tens of categories~10-20 mAP at 0.5 overlap

State-of-the-art in video understandingClassification Detection
Abu-El-Haija et al. 2016
Captioning
4,800 categories15.2 Top5 error
Yu et al. 2016
Just getting started:Short clips, niche domains
Idrees et al. 2017, Sigurdsson et al. 2016
Tens of categories~10-20 mAP at 0.5 overlap

Comparing video with image understanding
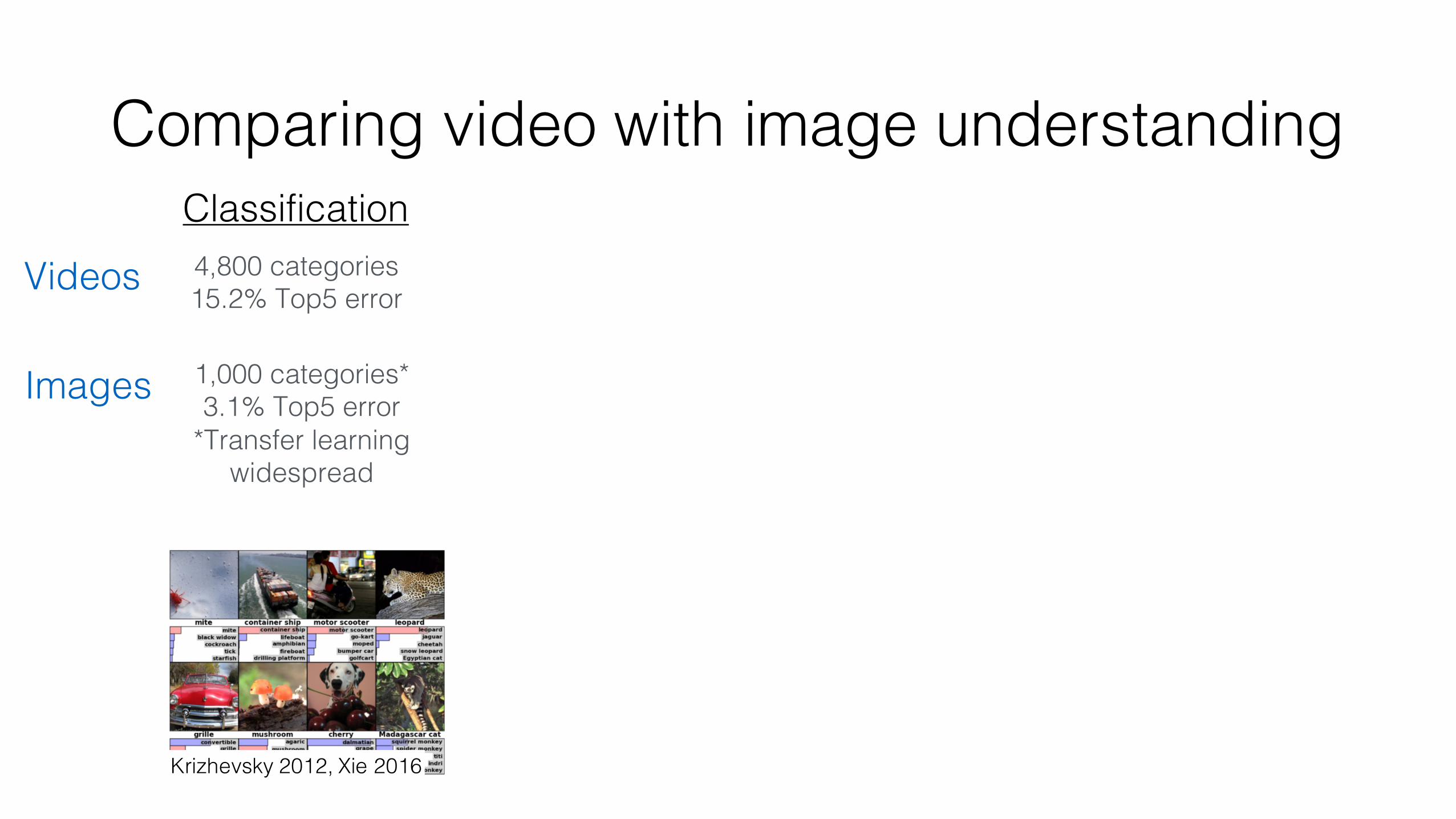
Comparing video with image understandingClassification4,800 categories15.2% Top5 errorVideos
Images 1,000 categories*3.1% Top5 error
*Transfer learning widespread
Krizhevsky 2012, Xie 2016

Comparing video with image understanding
He 2017
Classification Detection4,800 categories15.2% Top5 error
Tens of categories~10-20 mAP at 0.5 overlapVideos
Images 1,000 categories*3.1% Top5 error
*Transfer learning widespread
Hundreds of categories*~60 mAP at 0.5 overlapPixel-level segmentation
*Transfer learning widespread
Krizhevsky 2012, Xie 2016
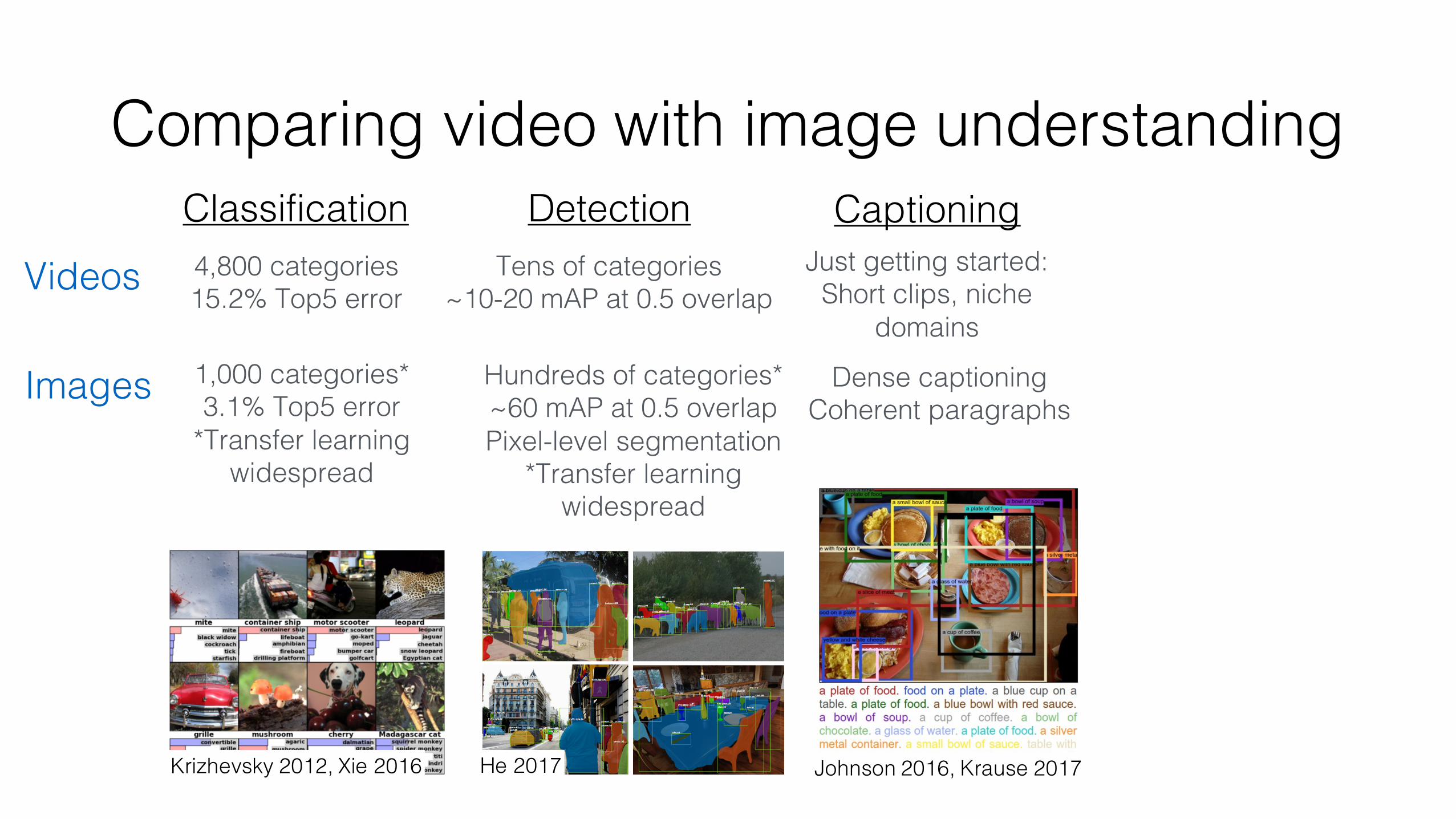
Comparing video with image understanding
He 2017 Johnson 2016, Krause 2017
Classification Detection Captioning4,800 categories15.2% Top5 error
Just getting started:Short clips, niche
domainsVideos
Images 1,000 categories*3.1% Top5 error
*Transfer learning widespread
Hundreds of categories*~60 mAP at 0.5 overlapPixel-level segmentation
*Transfer learning widespread
Dense captioningCoherent paragraphs
Krizhevsky 2012, Xie 2016
Tens of categories~10-20 mAP at 0.5 overlap
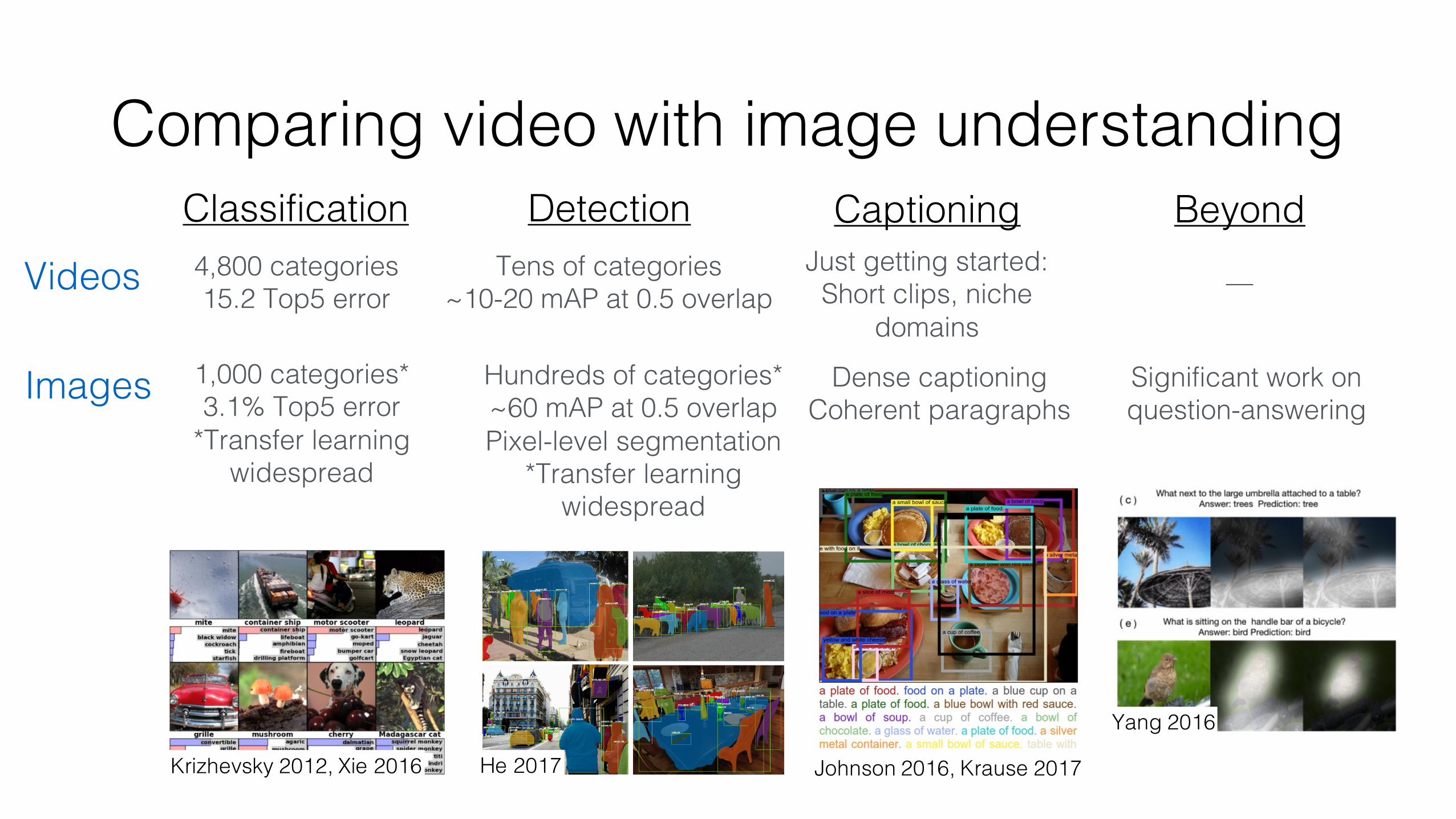
Comparing video with image understanding
He 2017 Johnson 2016, Krause 2017
Classification Detection Captioning4,800 categories15.2 Top5 error
Just getting started:Short clips, niche
domainsVideos
Beyond
Images 1,000 categories*3.1% Top5 error
*Transfer learning widespread
Hundreds of categories*~60 mAP at 0.5 overlapPixel-level segmentation
*Transfer learning widespread
Dense captioningCoherent paragraphs
Significant work on question-answering
—
Krizhevsky 2012, Xie 2016
Yang 2016
Tens of categories~10-20 mAP at 0.5 overlap

The challenge of scale
Training labels Inference
Models
Video processing is computationally expensive
Video annotation is labor-intensive
Temporal dimension adds complexity

The challenge of scale
Training labels InferenceVideo processing is
computationally expensiveVideo annotation is
labor-intensive
ModelsTemporal dimension adds
complexity
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame
Glimpses in Videos. CVPR 2016.

Input Output
t = 0 t = TRunning
Task: Temporal action detection
Talking
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
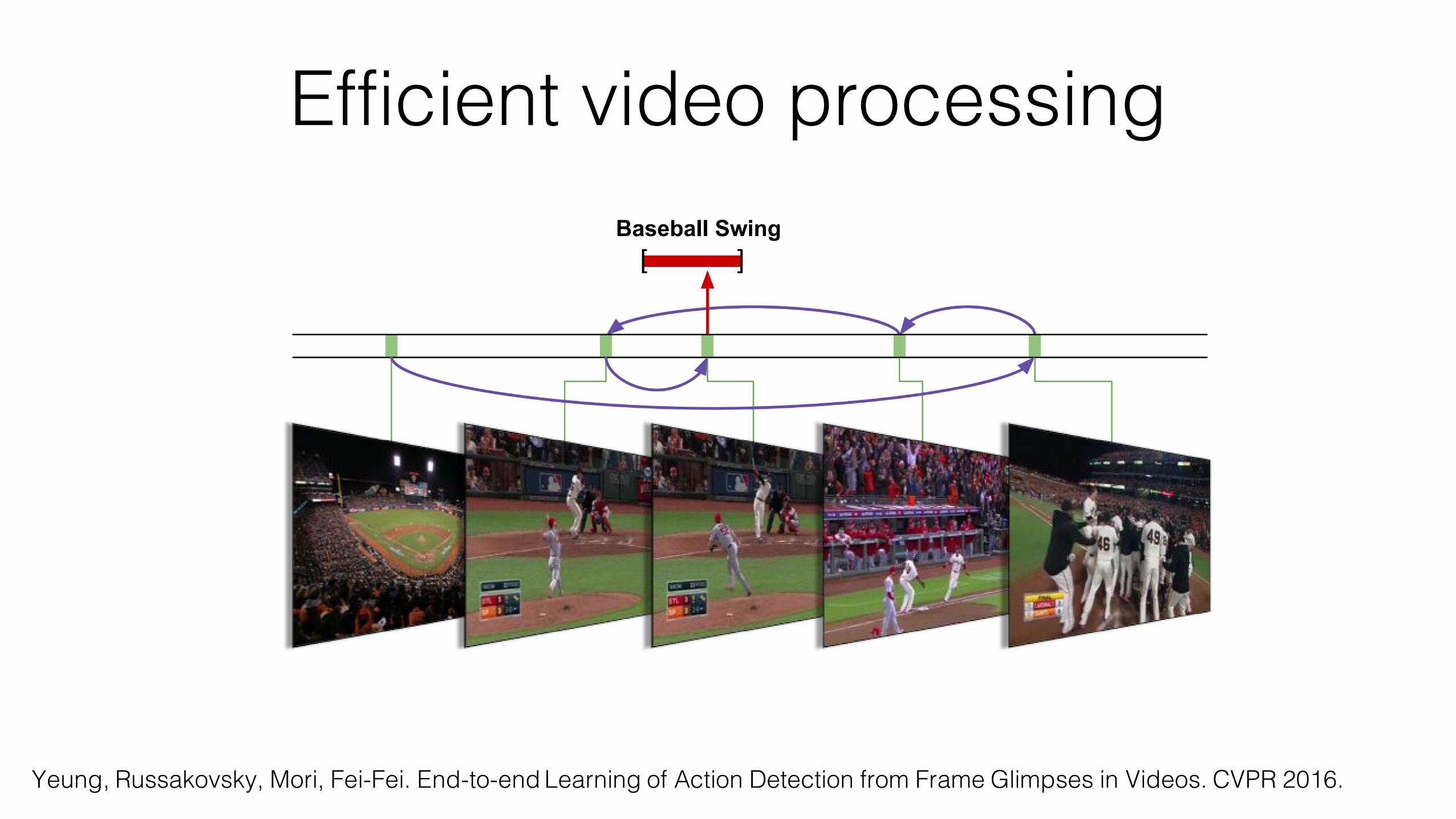
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
Efficient video processing
t = 0 t = T
Output
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
Frame modelInput: a frame
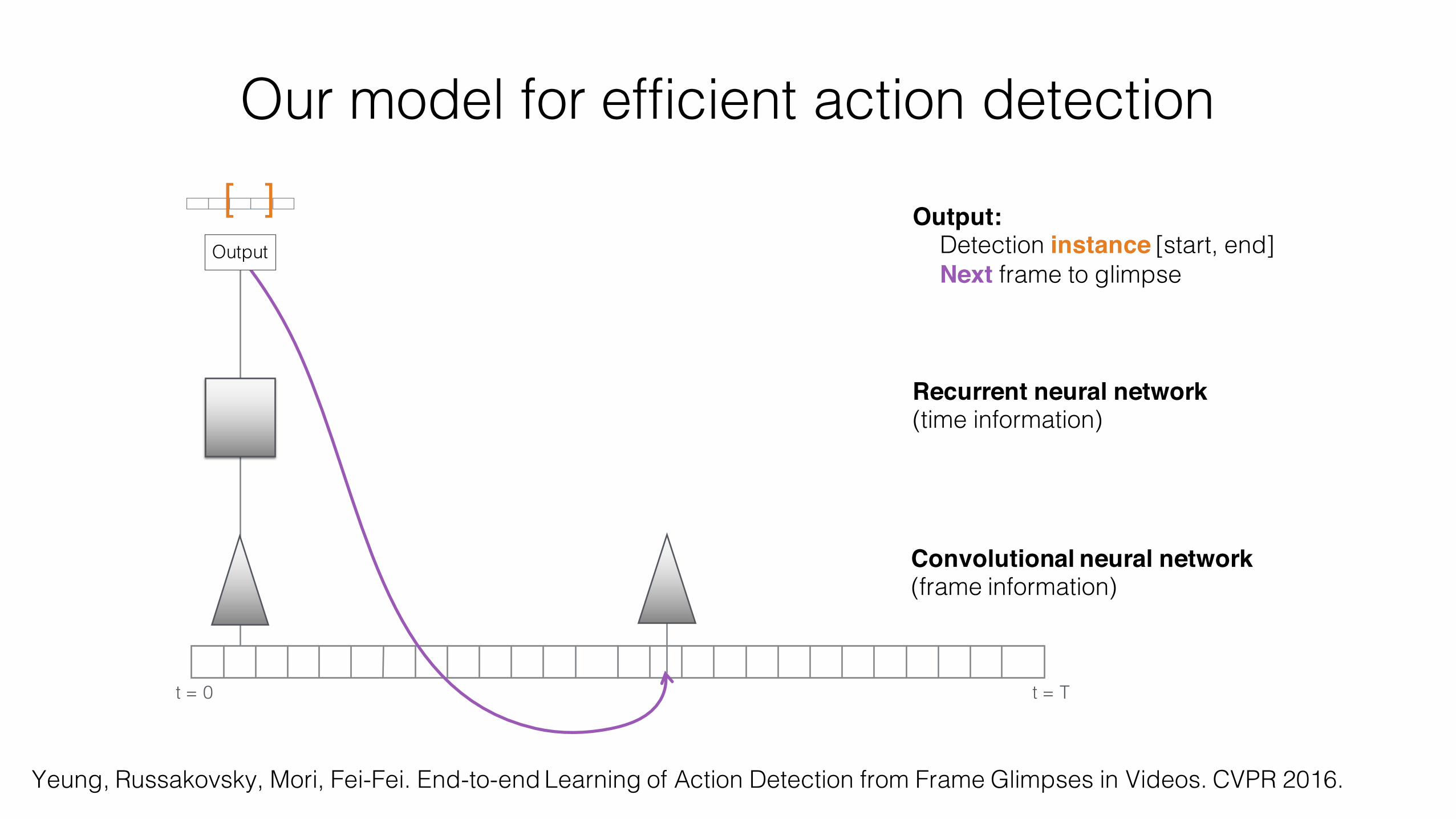
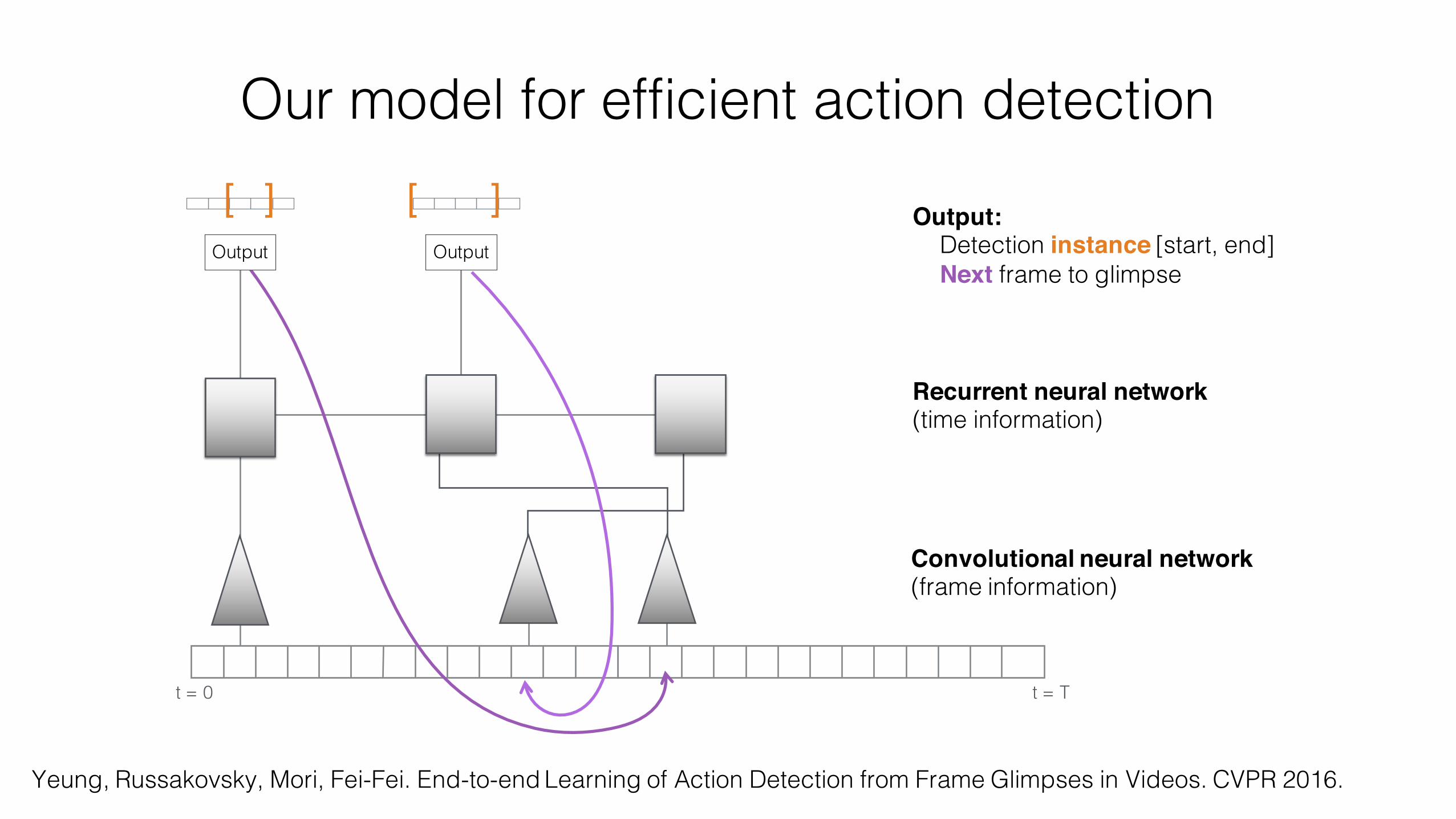
Our model for efficient action detection
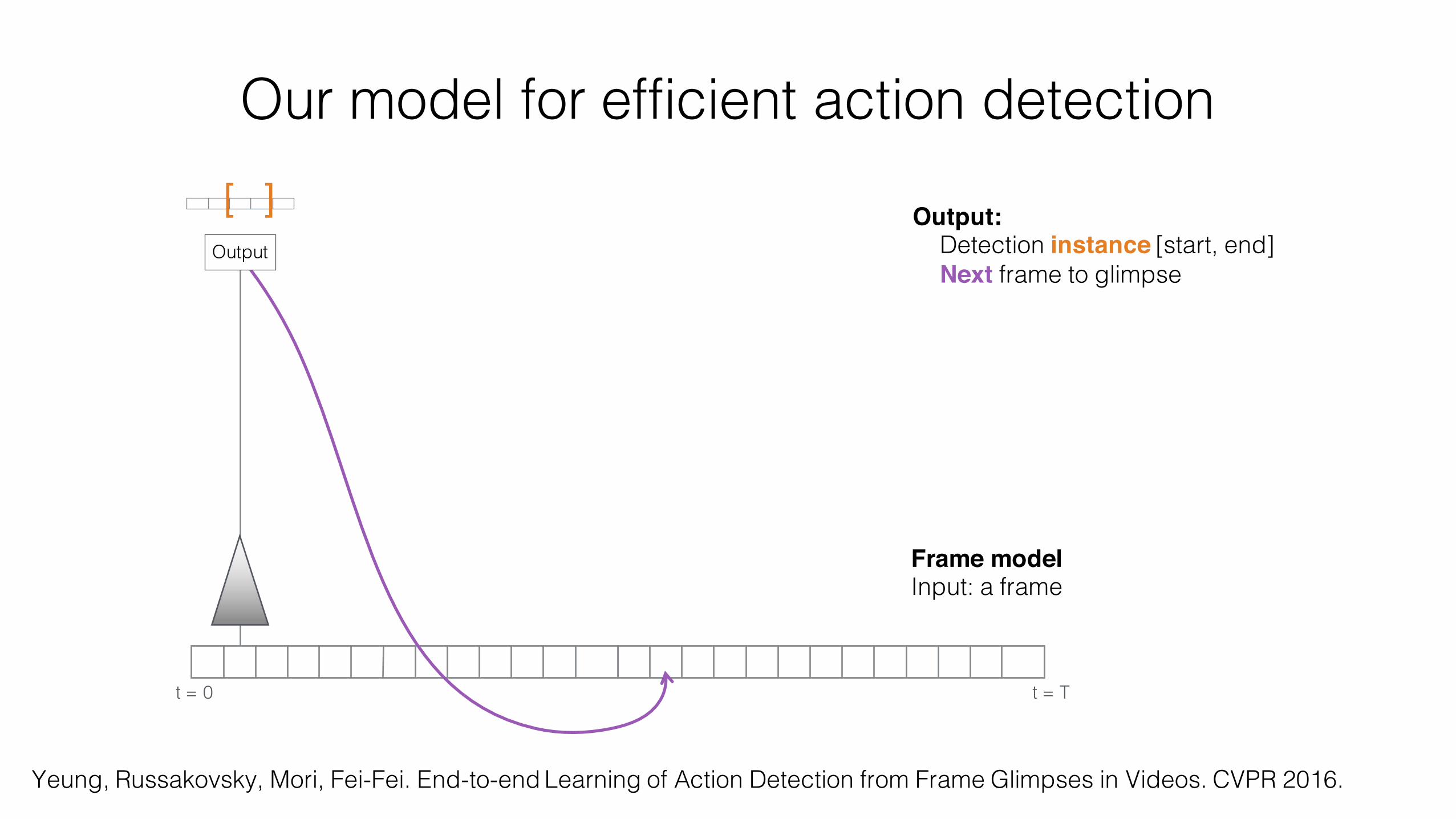
t = 0 t = T
[ ]Output
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
Output:Detection instance [start, end]Next frame to glimpse
Frame modelInput: a frame
Our model for efficient action detection
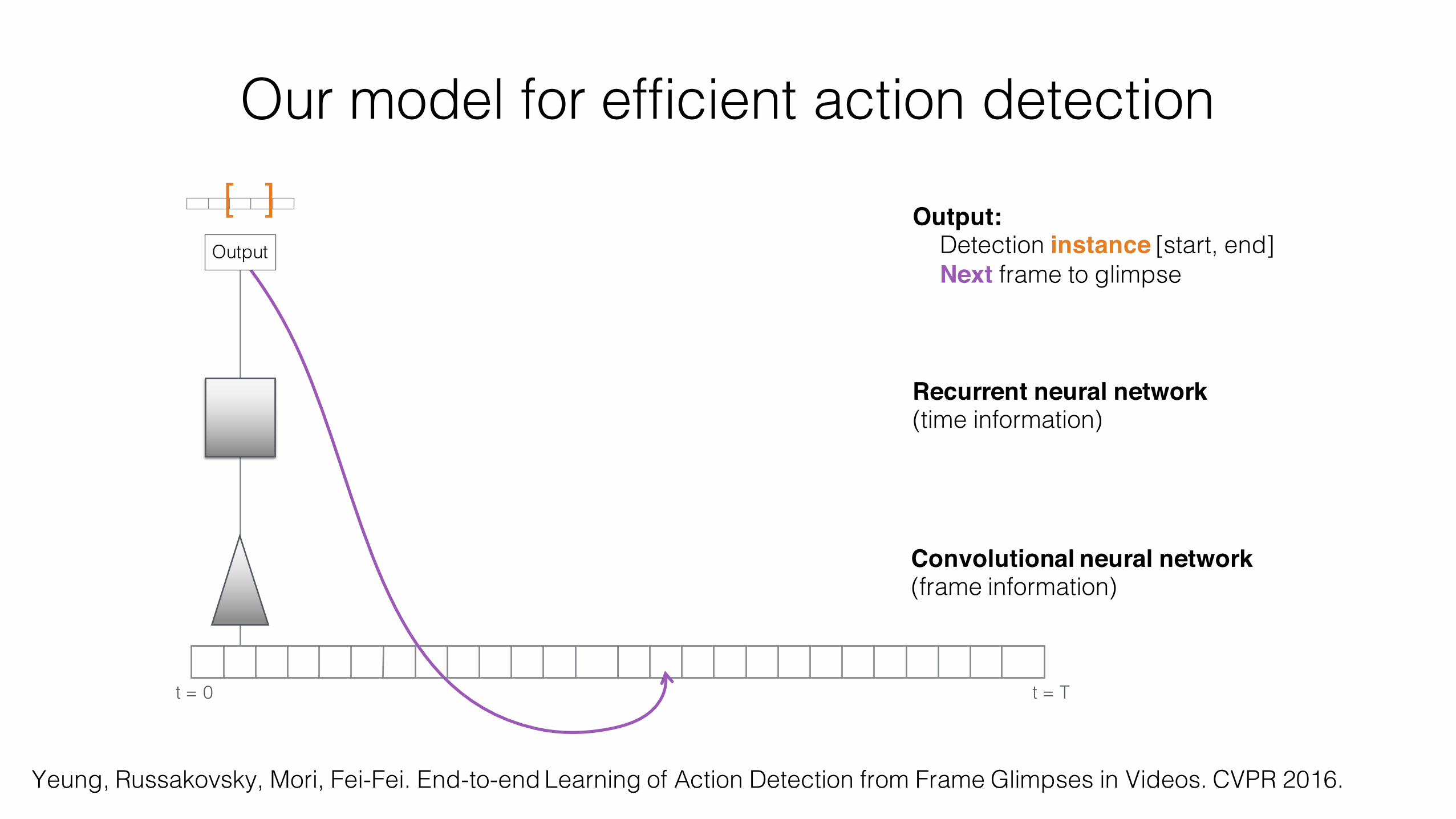
t = 0 t = T
Recurrent neural network(time information)
[ ] Output:Detection instance [start, end]Next frame to glimpse
Output
Convolutional neural network (frame information)
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
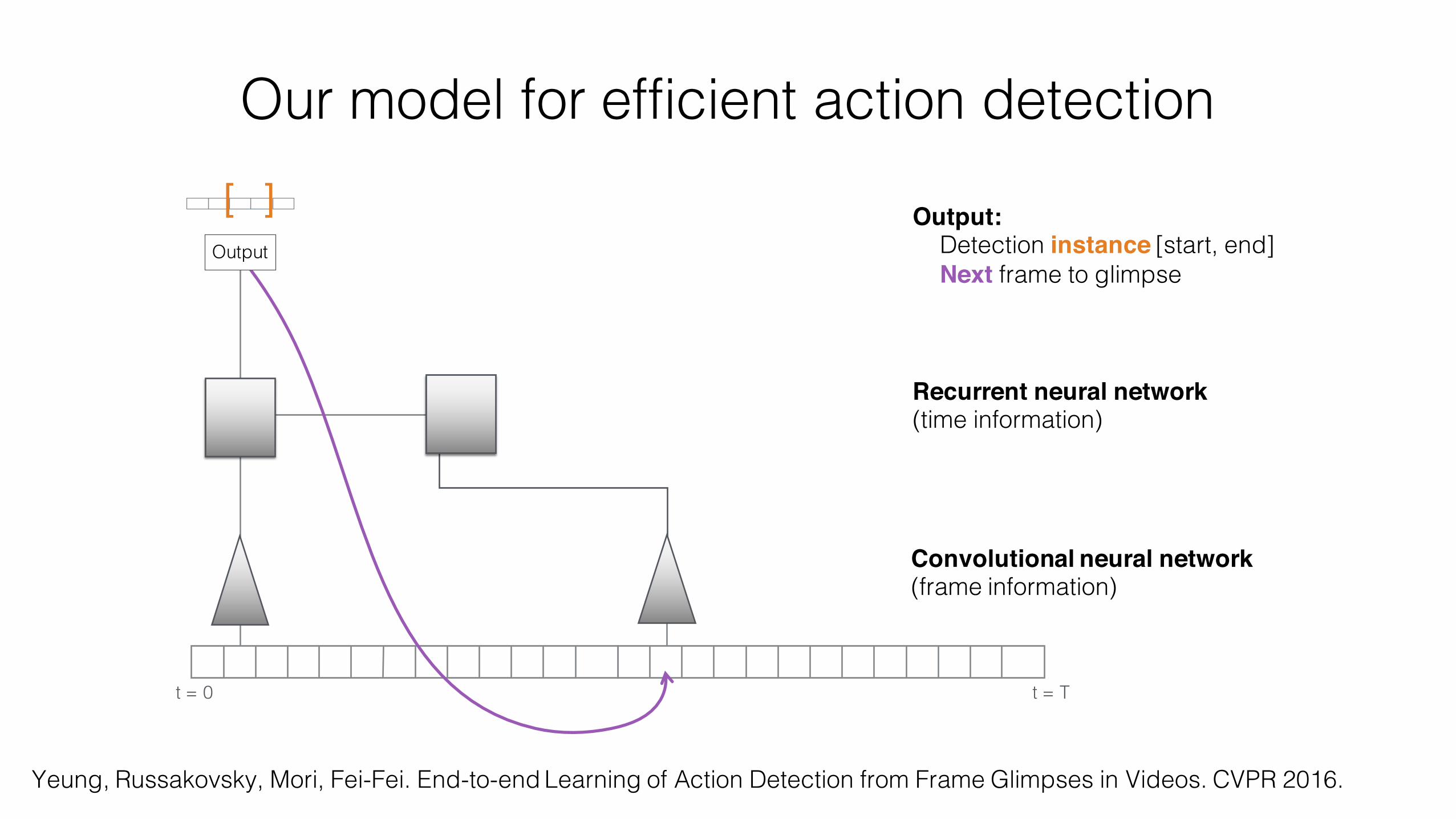
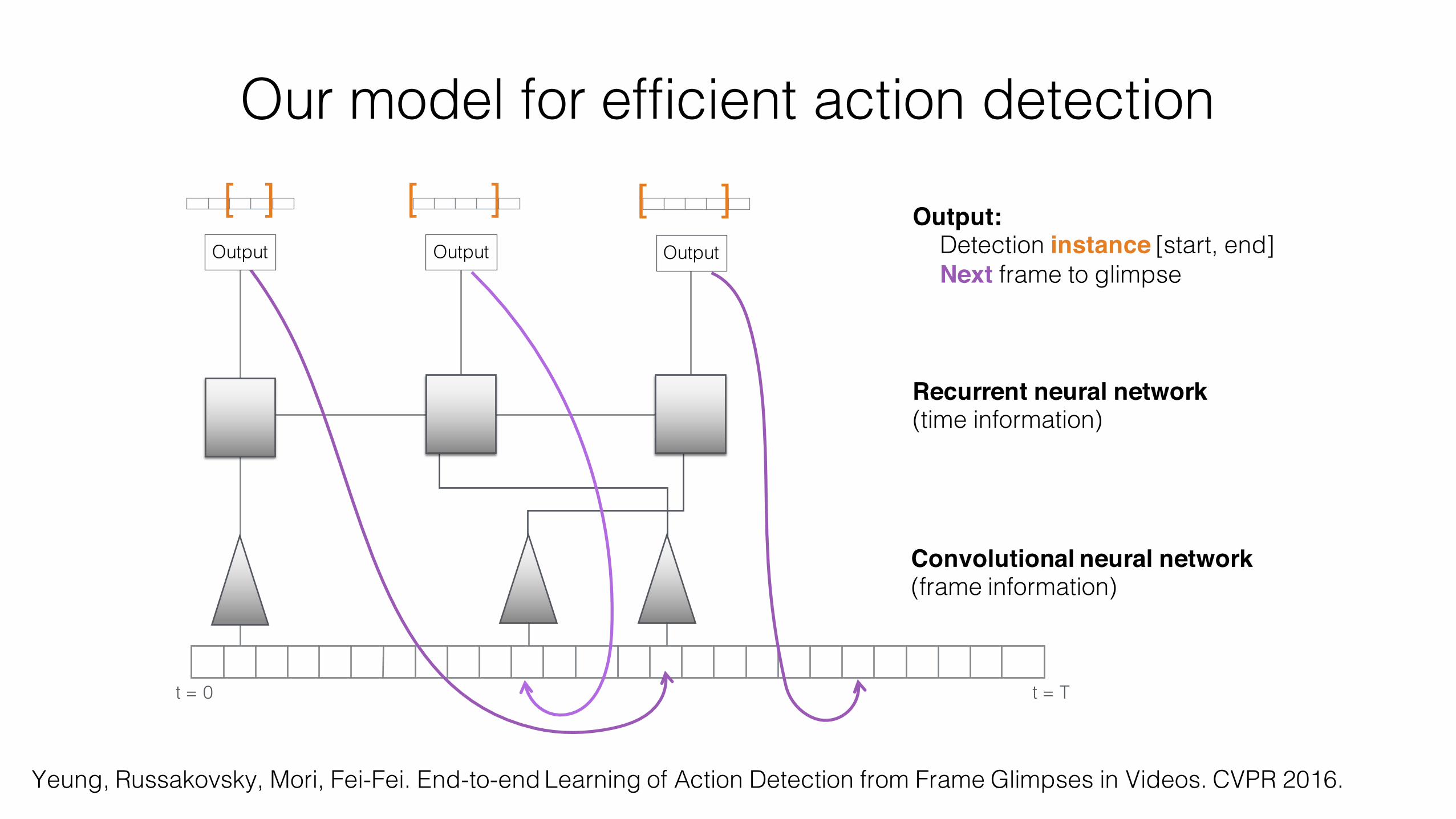
Our model for efficient action detection
t = 0 t = T
Recurrent neural network(time information)
[ ] Output:Detection instance [start, end]Next frame to glimpse
Output
Convolutional neural network (frame information)
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
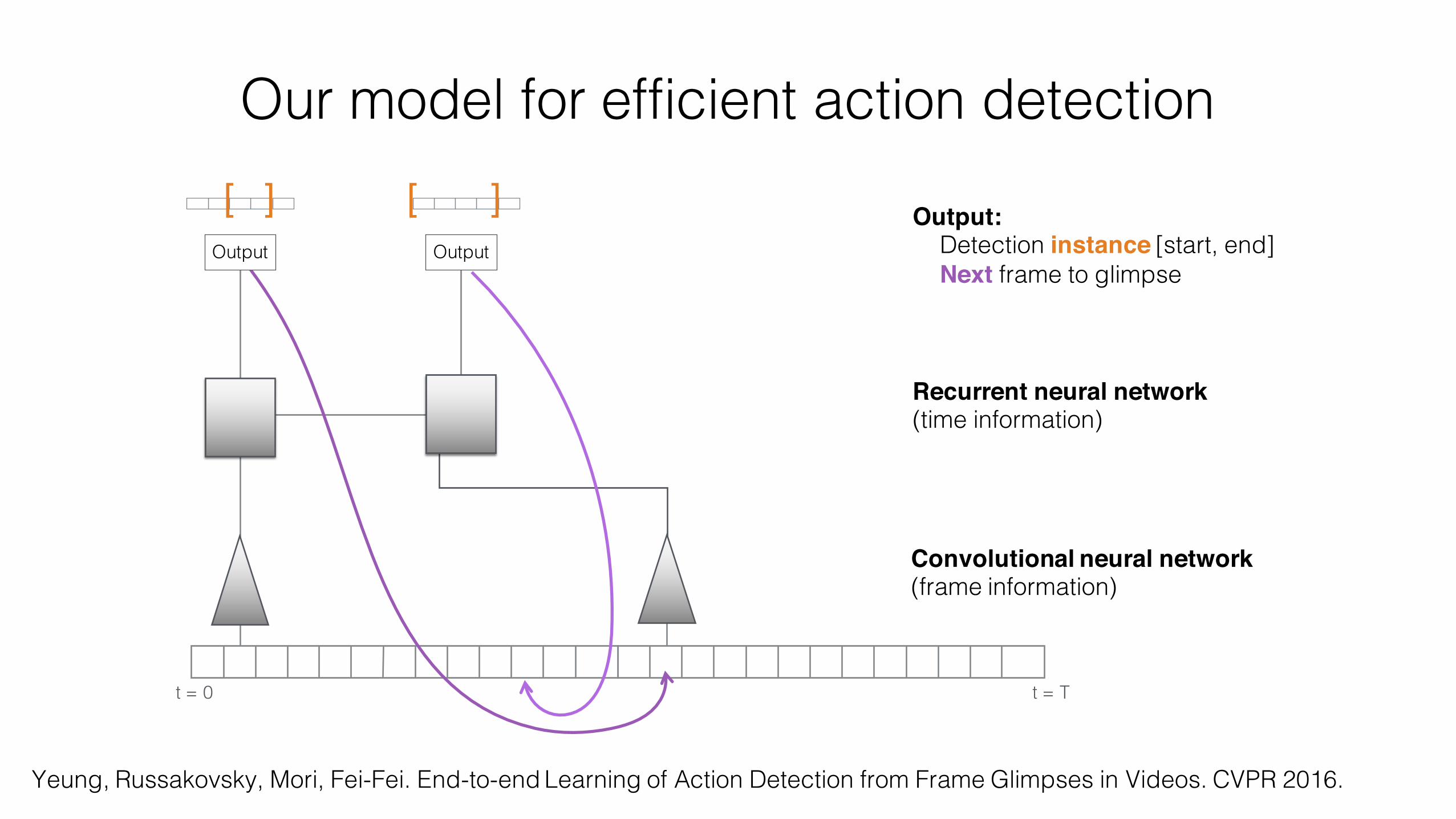
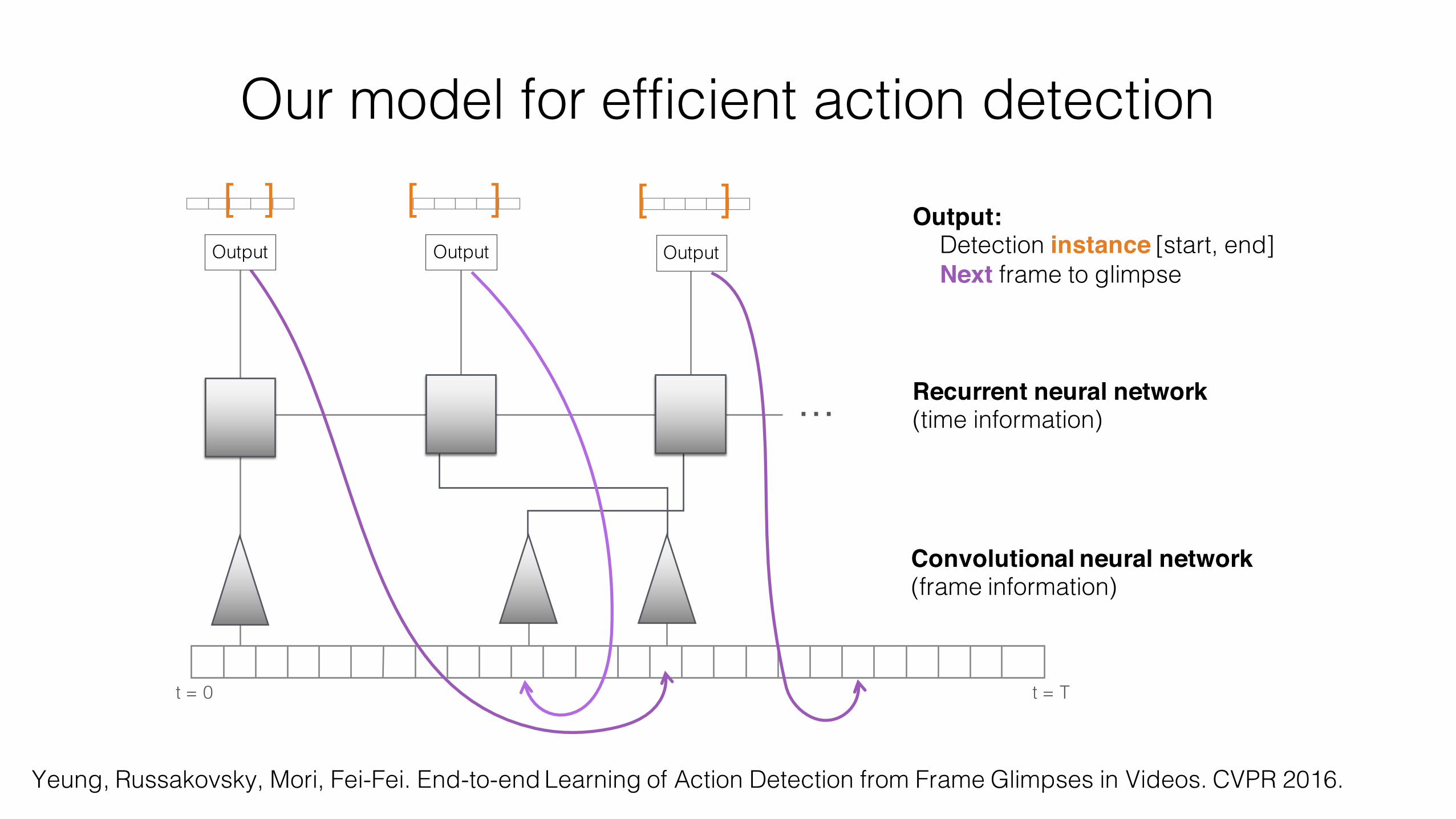
Our model for efficient action detection
t = 0 t = T
Recurrent neural network(time information)
[ ] Output:Detection instance [start, end]Next frame to glimpse
Output
Convolutional neural network (frame information)
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
Our model for efficient action detection
t = 0 t = T
Output
Our model for efficient action detection
Recurrent neural network(time information)
[ ] [ ] Output:Detection instance [start, end]Next frame to glimpse
Output
Convolutional neural network (frame information)
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
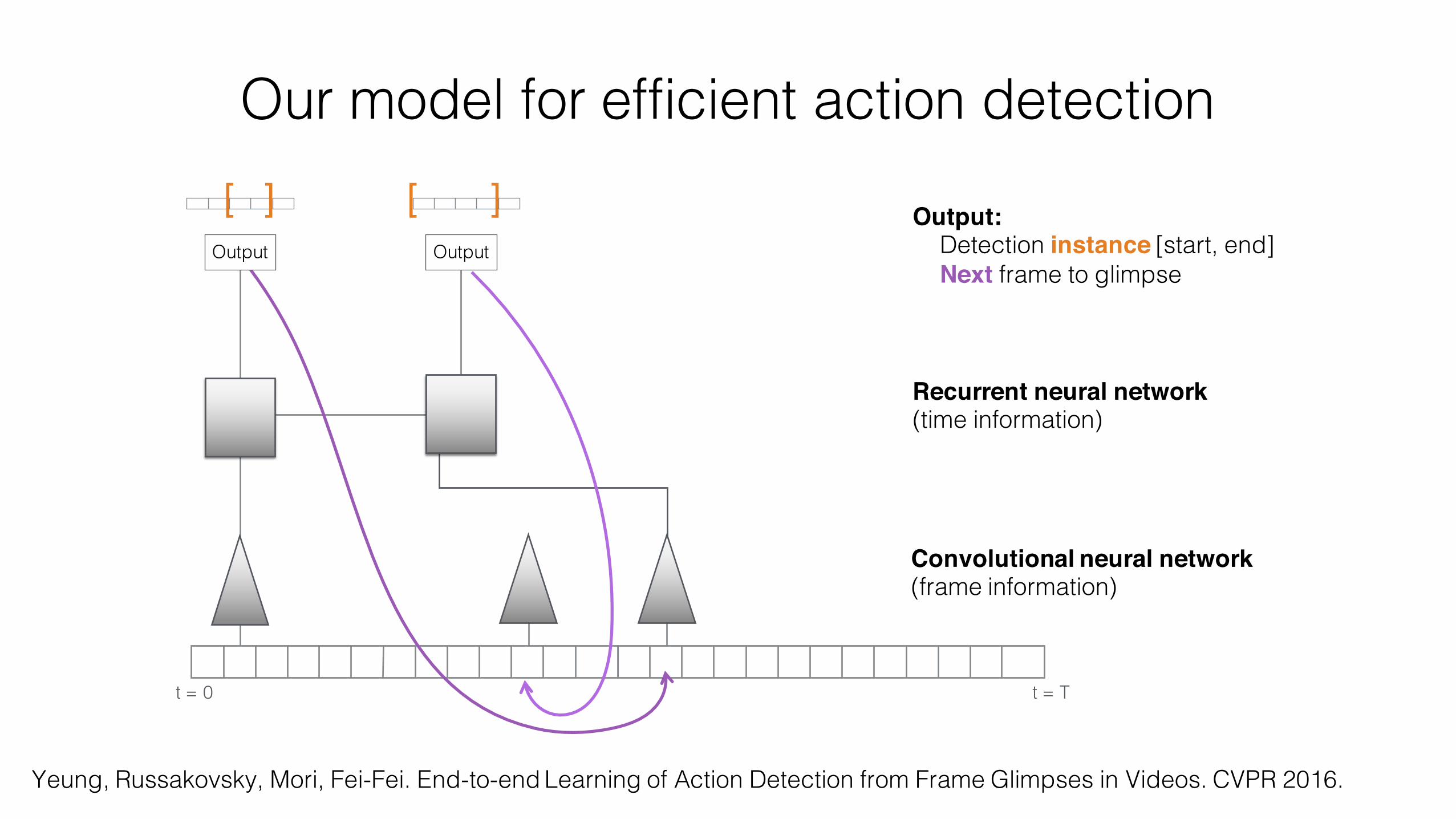
t = 0 t = T
Output
Our model for efficient action detection
Recurrent neural network(time information)
[ ] [ ] Output:Detection instance [start, end]Next frame to glimpse
Output
Convolutional neural network (frame information)
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
t = 0 t = T
Output
Our model for efficient action detection
Recurrent neural network(time information)
[ ] [ ] Output:Detection instance [start, end]Next frame to glimpse
Output
Convolutional neural network (frame information)
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
t = 0 t = T
Output
Our model for efficient action detection
Recurrent neural network(time information)
[ ] [ ] Output:Detection instance [start, end]Next frame to glimpse
Output
Convolutional neural network (frame information)
Output
[ ]
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
t = 0 t = T
Output
Our model for efficient action detection
Recurrent neural network(time information)
[ ] [ ] Output:Detection instance [start, end]Next frame to glimpse
Output
Convolutional neural network (frame information)
Output
[ ]
…
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
t = 0 t = T
Output
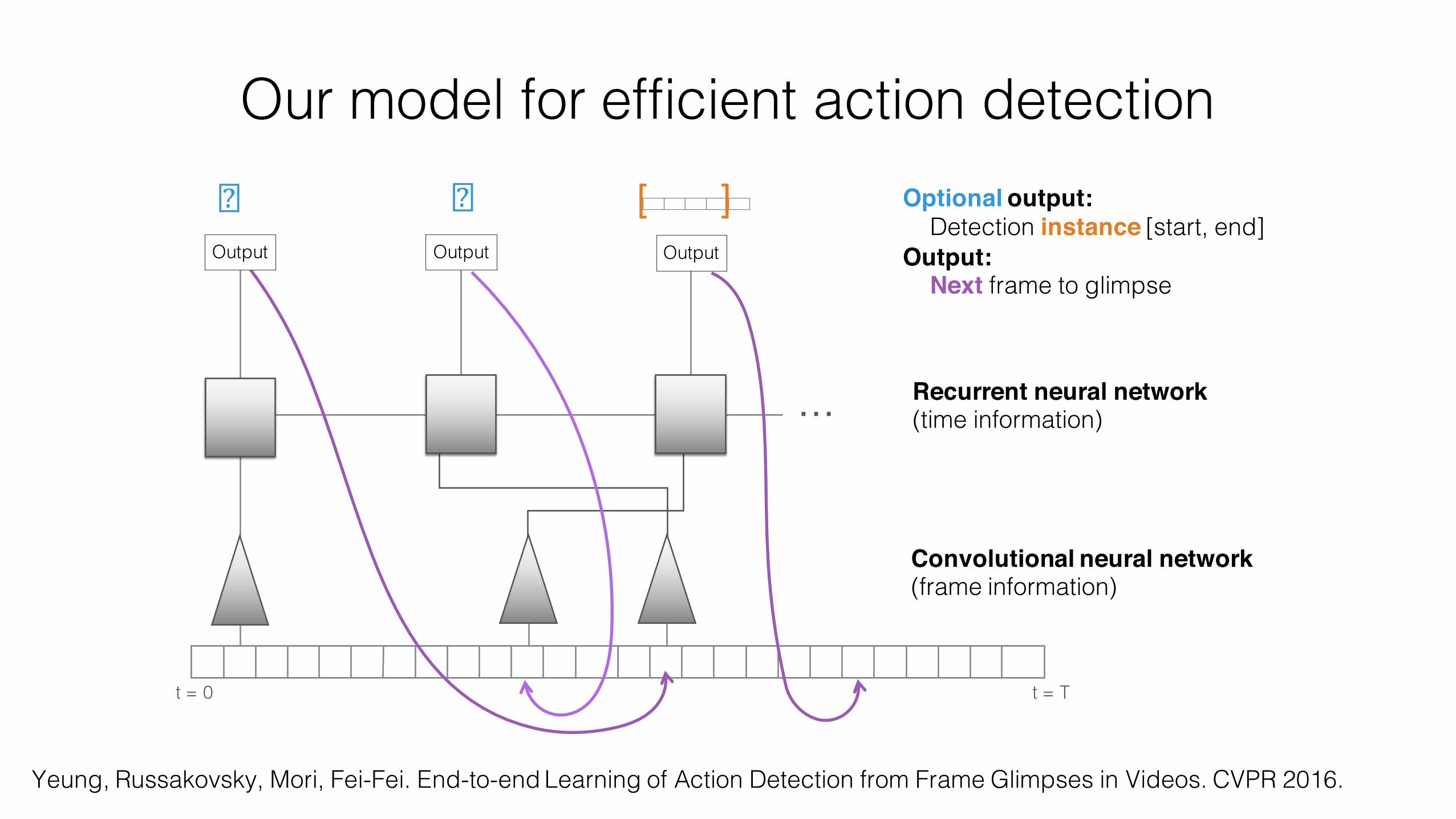
Our model for efficient action detection
Recurrent neural network(time information)
Output
Convolutional neural network (frame information)
Output
[ ]
…
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
�� Optional output:Detection instance [start, end]
Output:Next frame to glimpse

Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
Our model for efficient action detection• Train differentiable outputs (detection output class and bounds) using
standard backpropagation
• Train non-differentiable outputs (where to look next, when to emit a prediction) using reinforcement learning (REINFORCE algorithm)
• Achieves detection performance on par with dense sliding window-based approaches, while observing only 2% of frames

Learned policy in action
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.

Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame Glimpses in Videos. CVPR 2016.
Learned policy in action

The challenge of scale
Training labels InferenceVideo processing is
computationally expensiveVideo annotation is
labor-intensive
ModelsTemporal dimension adds
complexity
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame
Glimpses in Videos. CVPR 2016.
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling
of Actions in Complex Videos. IJCV 2017.
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling
of Actions in Complex Videos. IJCV 2017.
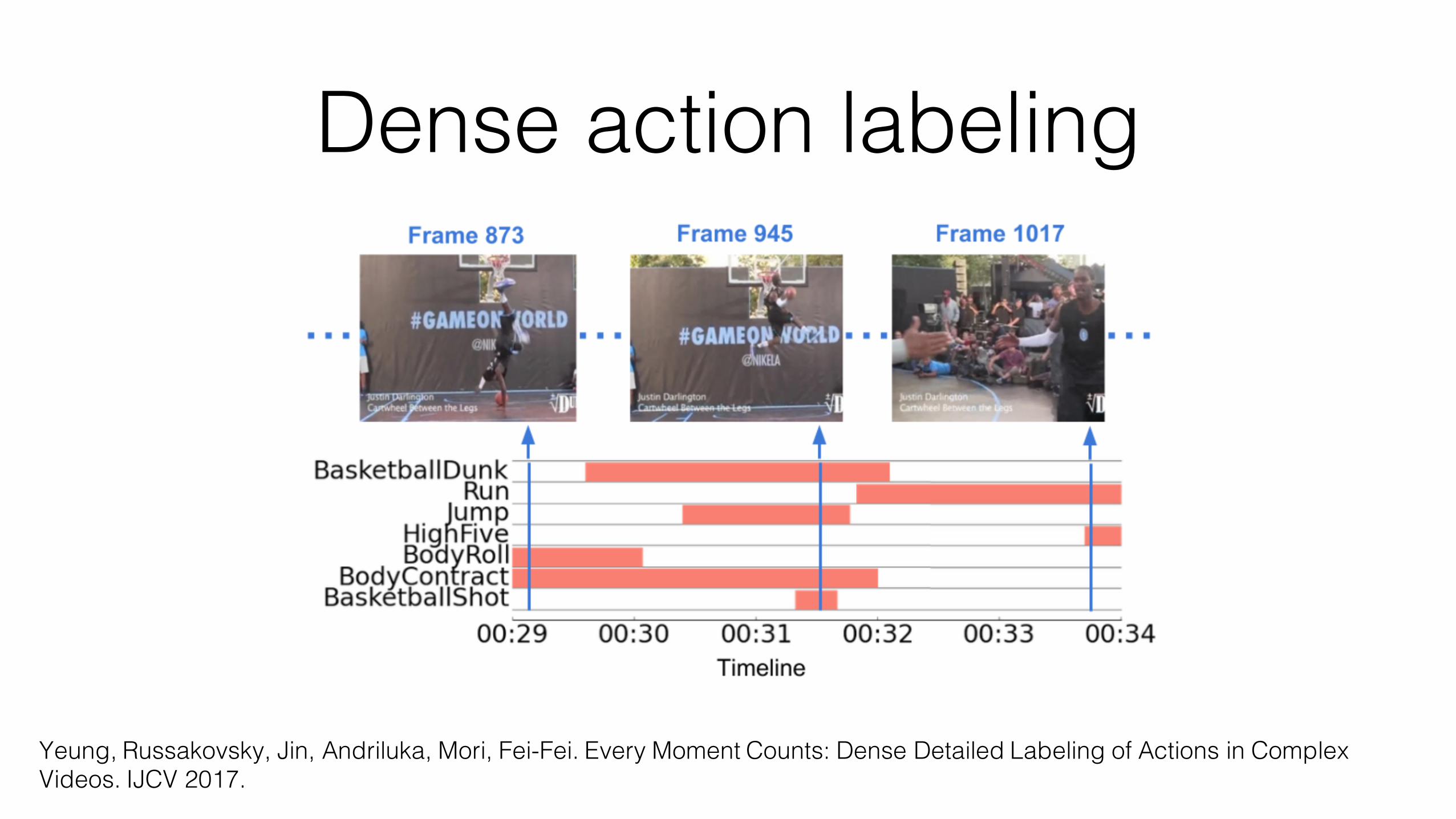
Dense action labeling
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos. IJCV 2017.

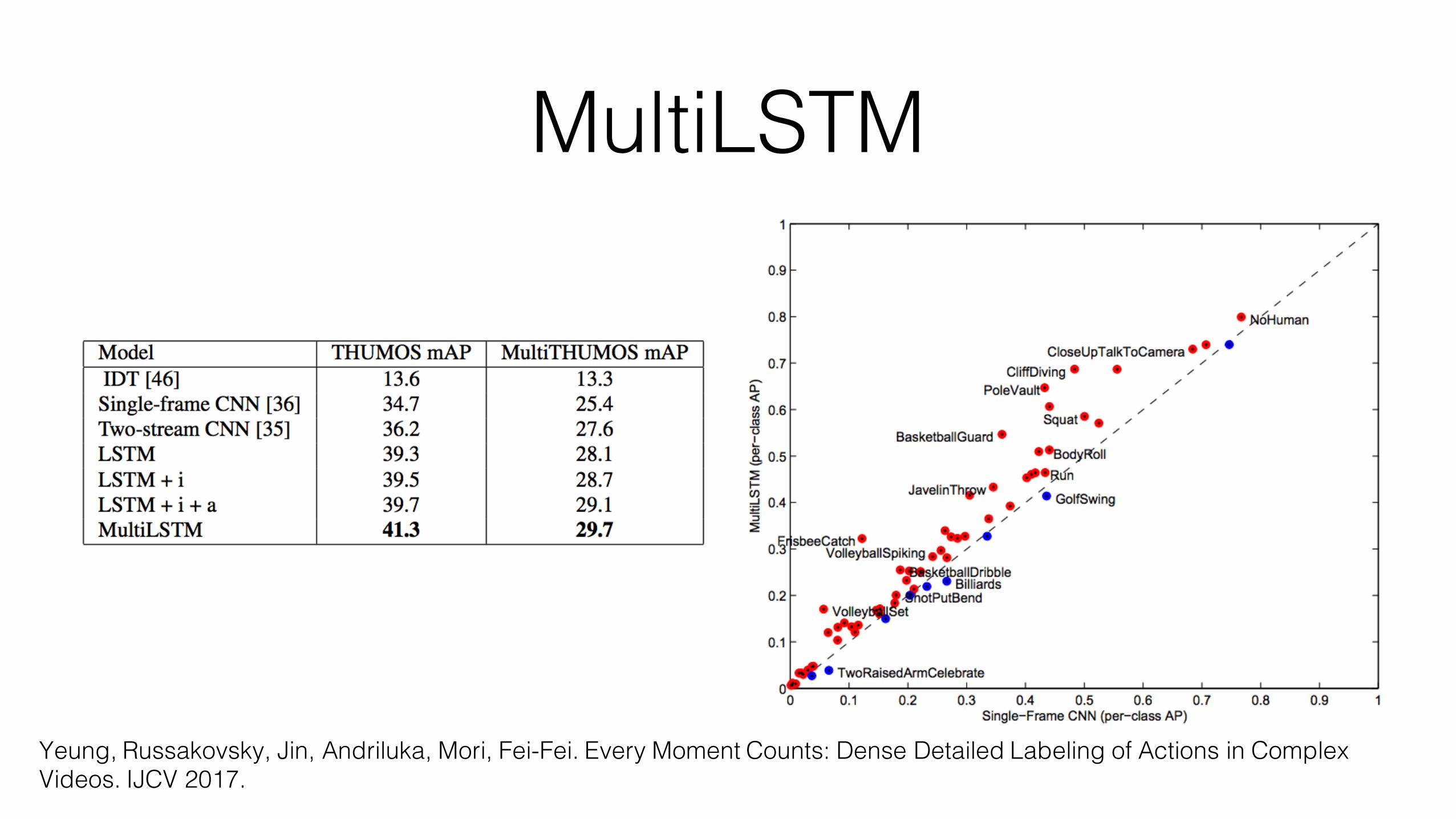
MultiTHUMOS• Extends the THUMOS’14 action detection dataset with dense, multilevel,
frame-level action annotations for 30 hours across 400 videos
THUMOS MultiTHUMOSAnnotations 6,365 38,690
Classes 20 65Density (labels / frame) 0.3 1.5
Classes per video 1.1 10.5Max actions per frame 2 9Max actions per video 3 25
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos. IJCV 2017.

Modeling dense, multilabel actions• Need to reason about multiple potential actions simultaneously
• High degree of temporal dependency
• In standard recurrent models for action recognition, all state is in hidden layer representation
• At each time step, makes prediction of current frame based on the current frame and previous hidden representation
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos. IJCV 2017.

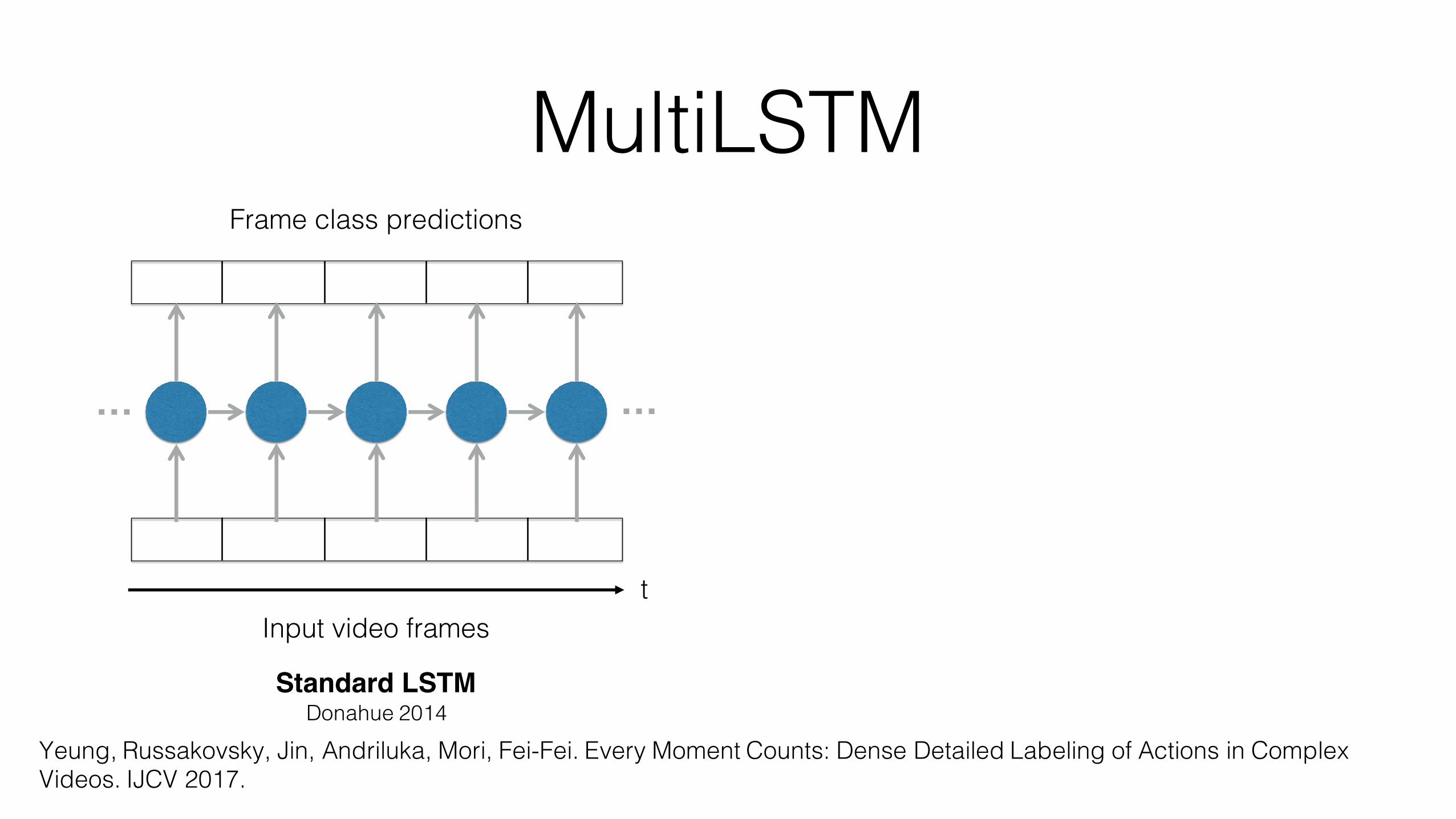
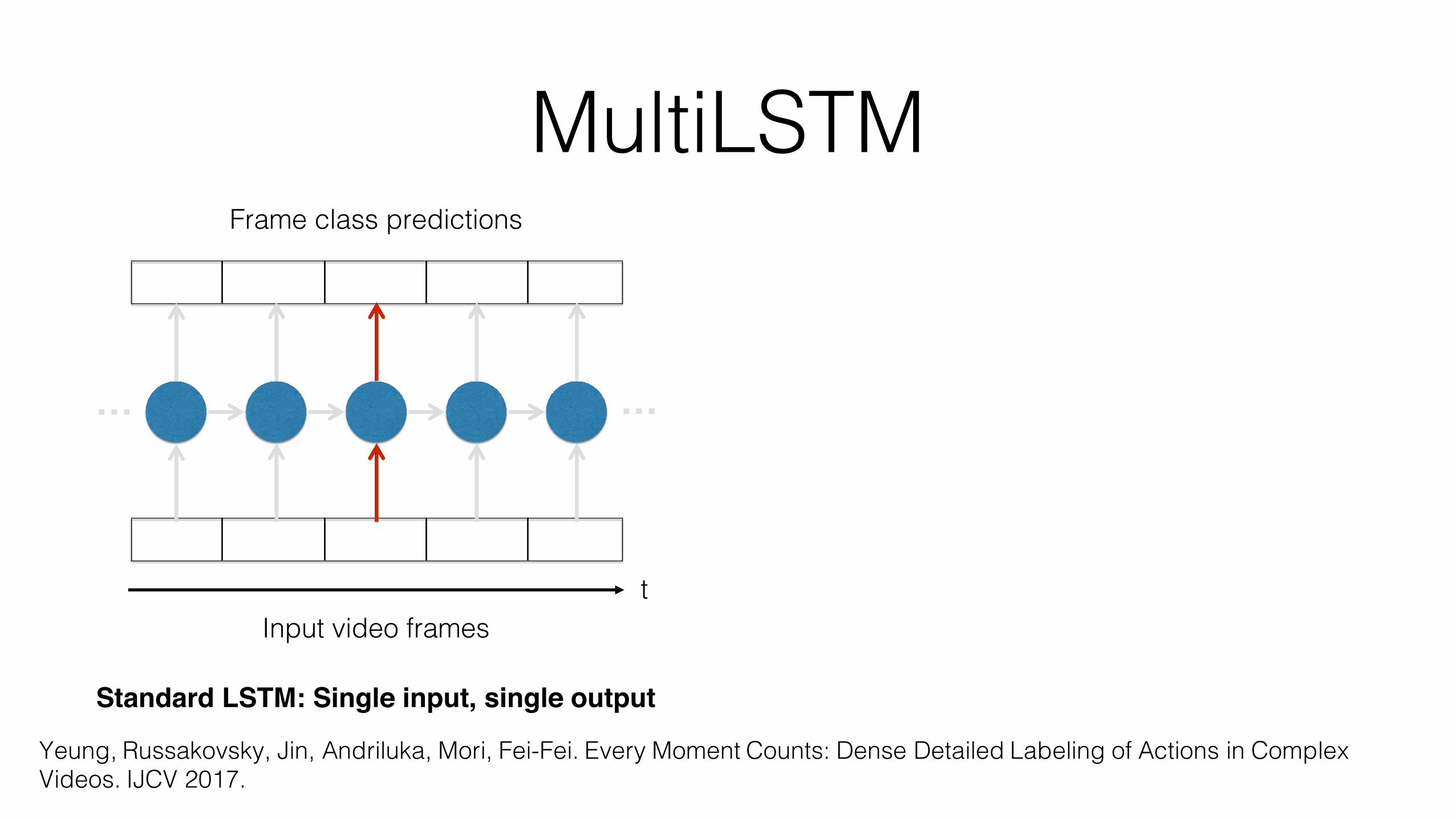
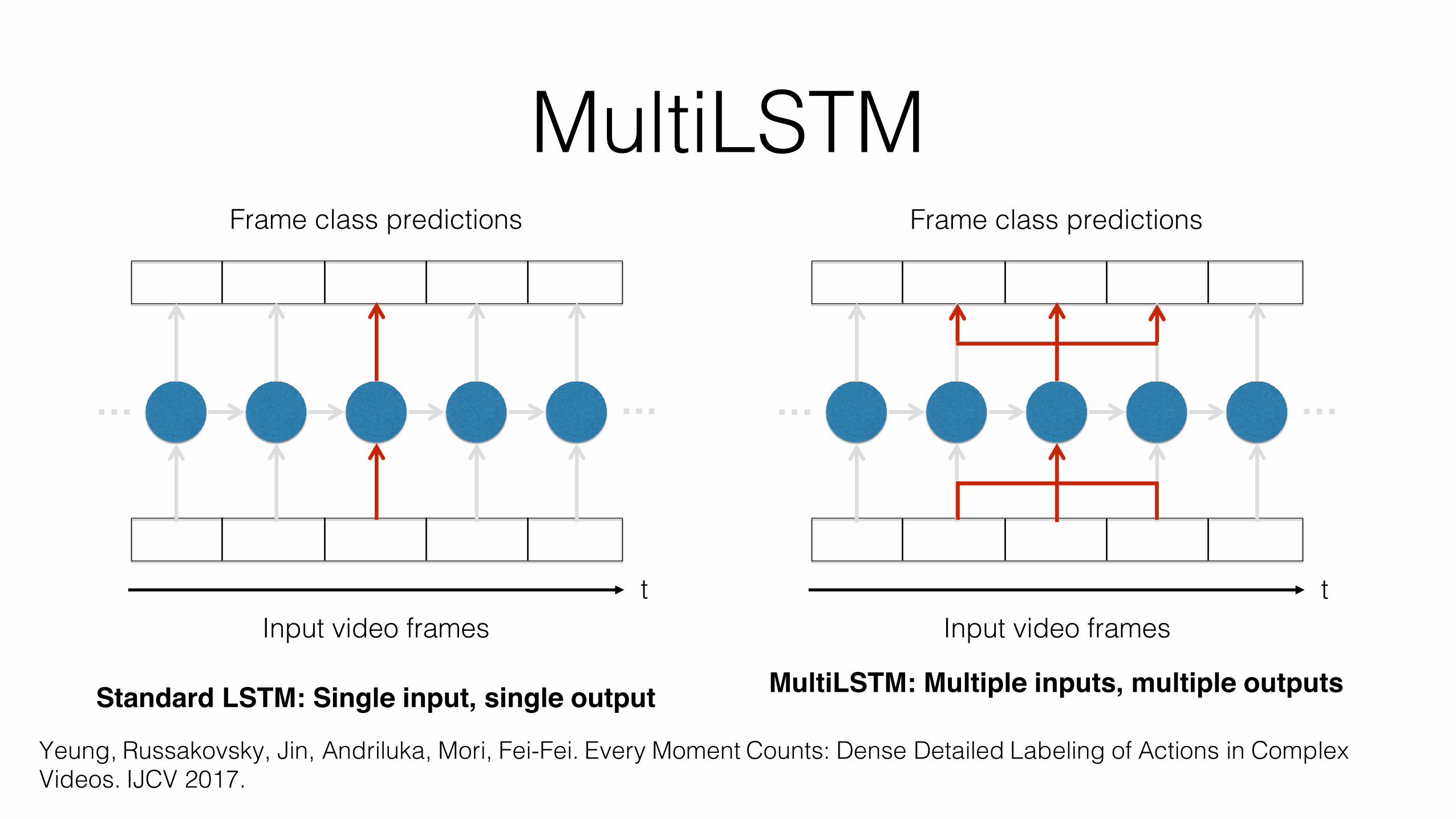
MultiLSTM• Extension of LSTM that expands the temporal receptive field of input
and output connections
• Key idea: providing the model with more freedom in both reading input and writing output reduces the burden placed on the hidden layer representation
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos. IJCV 2017.
MultiLSTM
Input video frames
Frame class predictions
t
Standard LSTM
……
Donahue 2014
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos. IJCV 2017.
MultiLSTMFrame class predictions
t
……
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos. IJCV 2017.
Standard LSTM: Single input, single output
Input video frames
MultiLSTMFrame class predictions
t
……
Frame class predictions
t
MultiLSTM: Multiple inputs, multiple outputs
……
Standard LSTM: Single input, single output
Input video frames Input video frames
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos. IJCV 2017.

MultiLSTMMultiple Inputs (soft attention)
Multiple Outputs (weighted average)
Multilabel Loss
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos. IJCV 2017.
MultiLSTM
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos. IJCV 2017.

Retrieving sequential actions
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos. IJCV 2017.

Retrieving co-occurring actions
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos. IJCV 2017.

The challenge of scale
Training labels InferenceVideo processing is
computationally expensiveVideo annotation is
labor-intensive
ModelsTemporal dimension adds
complexity
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame
Glimpses in Videos. CVPR 2016.
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling
of Actions in Complex Videos. IJCV 2017.
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling
of Actions in Complex Videos. IJCV 2017.
Yeung, Ramanathan, Russakovsky, Shen, Mori, Fei-Fei. Learning to learn from noisy web videos.
CVPR 2017.

Labeling videos is expensive• Takes significantly longer to
label a video than an image
• If spatial or temporal bounds desired, even worse
• How can we practically learn about new concepts in video?
Web queries are a source of noisy video labels

Image search is much cleaner!

Can we effectively learn from the noisy web queries?
• Our approach: learn how to selective positive training examples from noisy queries in order to train classifiers for new classes
• Use a reinforcement learning-based formulation to learn a data labeling policy that achieves strong performance on a small, manually-labeled dataset of classes
• Then use this policy to automatically label noisy web data for new classes
Yeung, Ramanathan, Russakovsky, Shen, Mori, Fei-Fei. Learning to learn from noisy web videos. CVPR 2017.

Balancing diversity vs. semantic drift• Want diverse training examples to improve classifier
• But too much diversity can also lead to semantic drift
• Our approach: balance diversity and drift by training labeling policies using an annotated reward set which the policy must successfully classify
Yeung, Ramanathan, Russakovsky, Shen, Mori, Fei-Fei. Learning to learn from noisy web videos. CVPR 2017.
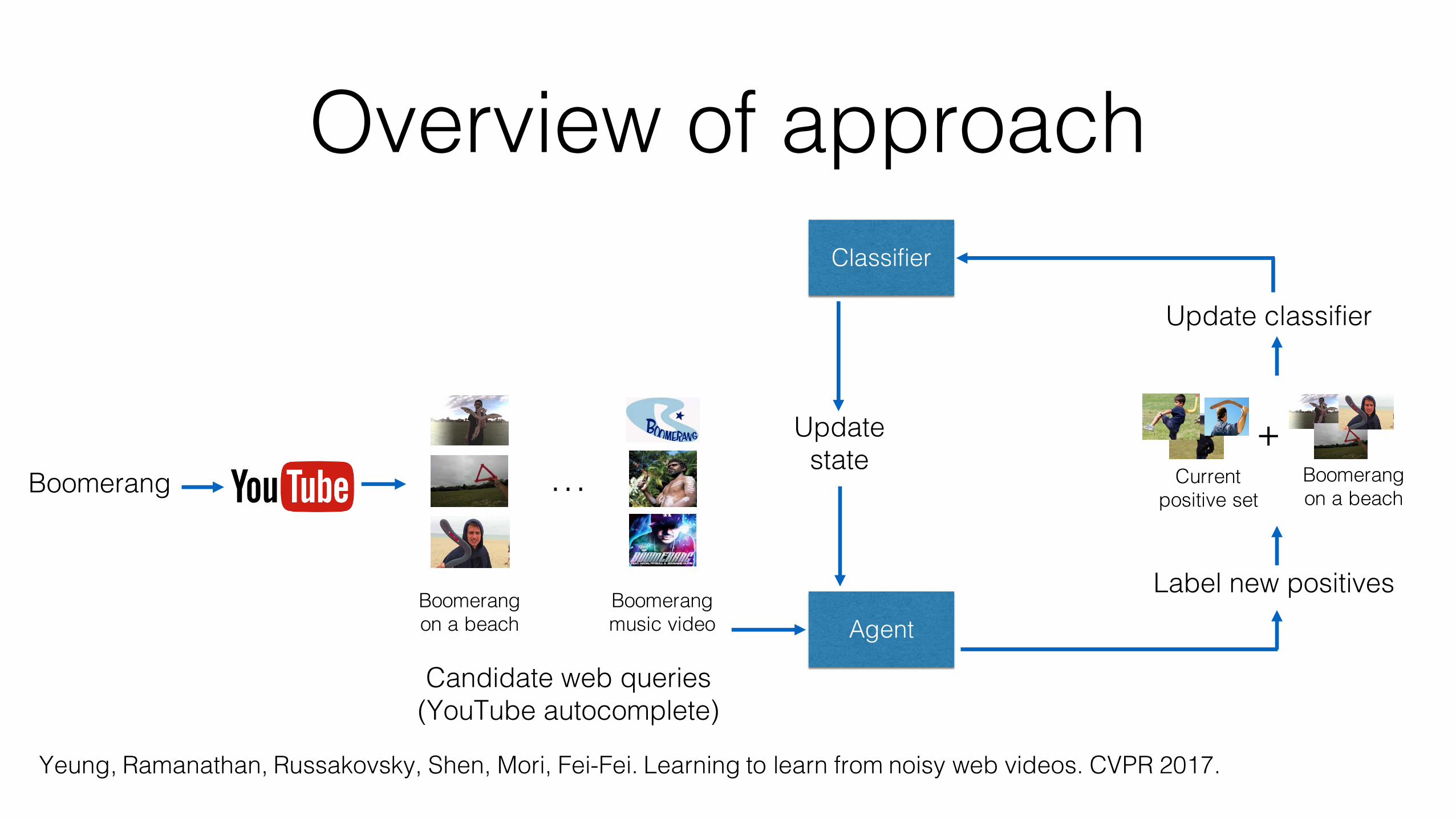
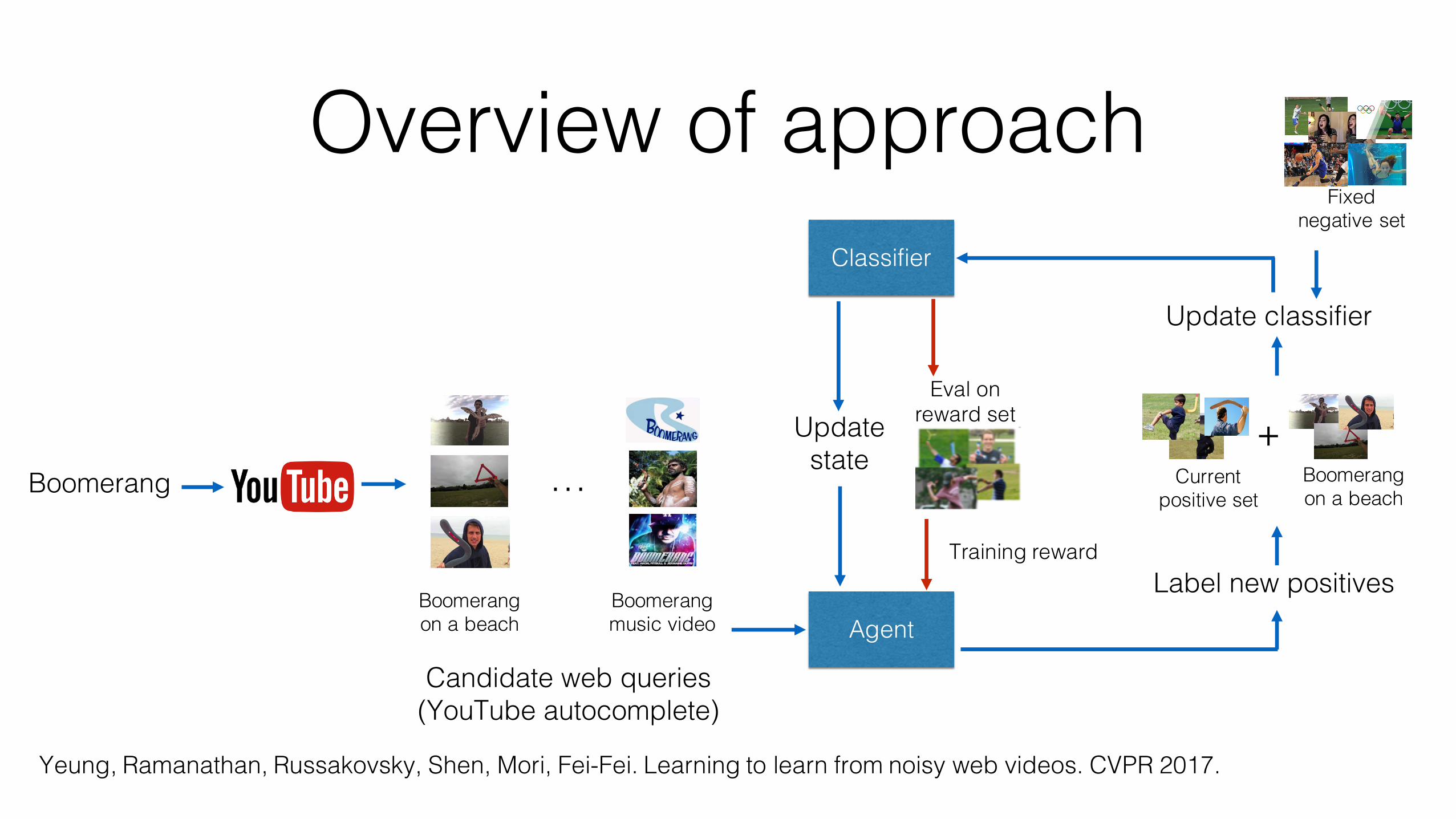
Overview of approach
Boomerang …
Boomerang on a beach
Boomerang music video
Classifier
Candidate web queries (YouTube autocomplete)
Agent
Label new positives
+Boomerang on a beach
Current positive set
Update classifier
Yeung, Ramanathan, Russakovsky, Shen, Mori, Fei-Fei. Learning to learn from noisy web videos. CVPR 2017.
Update state
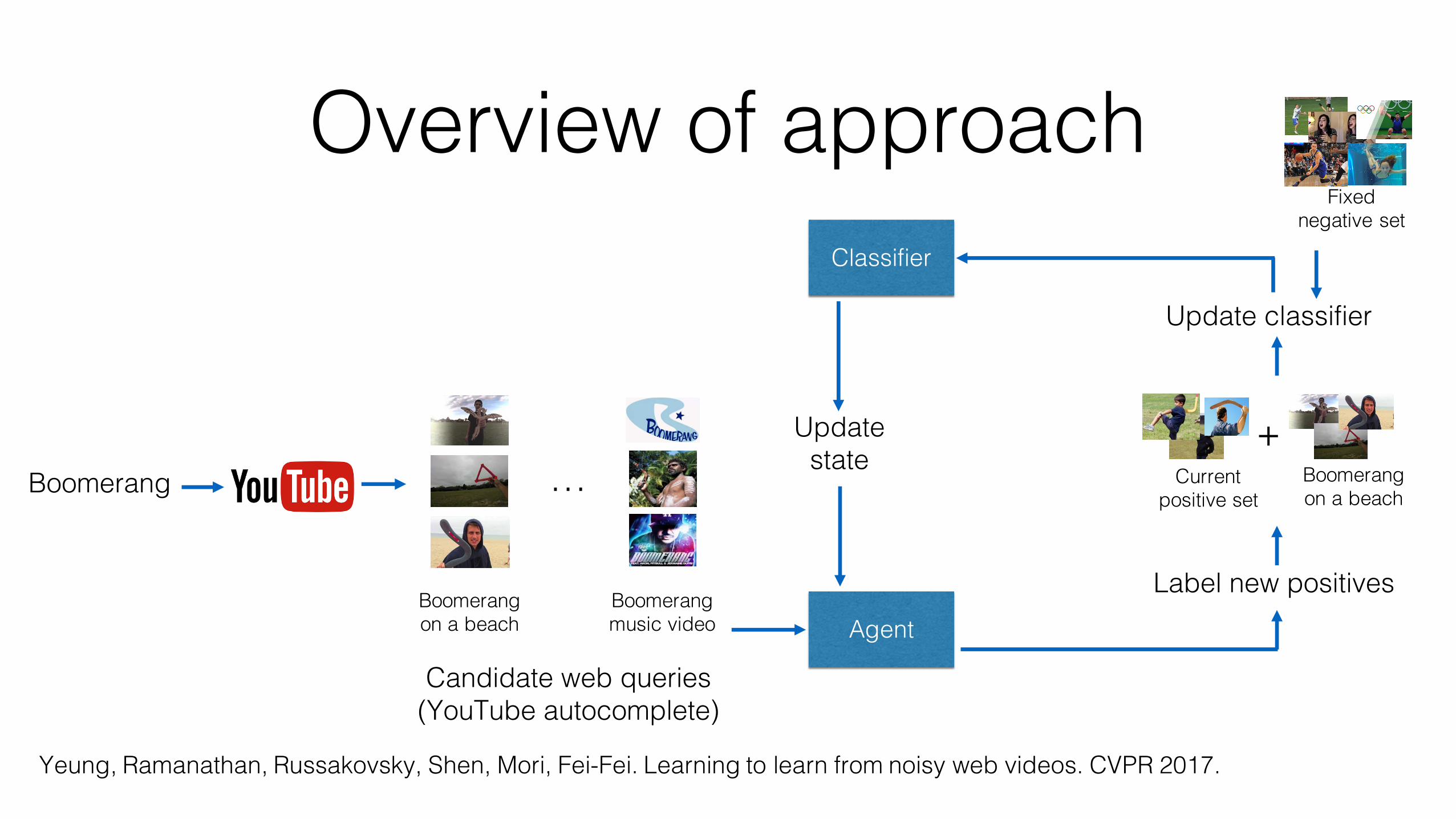
Overview of approach
Boomerang …
Boomerang on a beach
Boomerang music video
Classifier
Candidate web queries (YouTube autocomplete)
Agent
Label new positives
+Boomerang on a beach
Current positive set
Update classifier
Fixed negative set
Yeung, Ramanathan, Russakovsky, Shen, Mori, Fei-Fei. Learning to learn from noisy web videos. CVPR 2017.
Update state
Overview of approach
Boomerang …
Boomerang on a beach
Boomerang music video
Classifier
Candidate web queries (YouTube autocomplete)
Agent
Label new positives
+Boomerang on a beach
Current positive set
Update classifier
Update state
Fixed negative set
Yeung, Ramanathan, Russakovsky, Shen, Mori, Fei-Fei. Learning to learn from noisy web videos. CVPR 2017.
Training reward
Eval on reward set

Sports1M
Greedy classifier Ours
Yeung, Ramanathan, Russakovsky, Shen, Mori, Fei-Fei. Learning to learn from noisy web videos. CVPR 2017.

Sports1M
Greedy classifier Ours
Yeung, Ramanathan, Russakovsky, Shen, Mori, Fei-Fei. Learning to learn from noisy web videos. CVPR 2017.

Novel classes
Greedy classifier Ours
Yeung, Ramanathan, Russakovsky, Shen, Mori, Fei-Fei. Learning to learn from noisy web videos. CVPR 2017.

The challenge of scale
Training labels InferenceVideo processing is
computationally expensiveVideo annotation is
labor-intensive
ModelsTemporal dimension adds
complexity
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame
Glimpses in Videos. CVPR 2016.
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling
of Actions in Complex Videos. IJCV 2017.
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling
of Actions in Complex Videos. IJCV 2017.
Yeung, Ramanathan, Russakovsky, Shen, Mori, Fei-Fei. Learning to learn from noisy web videos.
CVPR 2017.

The challenge of scale
Training labels InferenceVideo processing is
computationally expensiveVideo annotation is
labor-intensive
ModelsTemporal dimension adds
complexity
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame
Glimpses in Videos. CVPR 2016.
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling
of Actions in Complex Videos. IJCV 2017.
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling
of Actions in Complex Videos. IJCV 2017.
Yeung, Ramanathan, Russakovsky, Shen, Mori, Fei-Fei. Learning to learn from noisy web videos.
CVPR 2017.
Learning to learn

The challenge of scale
Training labels InferenceVideo processing is
computationally expensiveVideo annotation is
labor-intensive
ModelsTemporal dimension adds
complexity
Yeung, Russakovsky, Mori, Fei-Fei. End-to-end Learning of Action Detection from Frame
Glimpses in Videos. CVPR 2016.
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling
of Actions in Complex Videos. IJCV 2017.
Yeung, Russakovsky, Jin, Andriluka, Mori, Fei-Fei. Every Moment Counts: Dense Detailed Labeling
of Actions in Complex Videos. IJCV 2017.
Yeung, Ramanathan, Russakovsky, Shen, Mori, Fei-Fei. Learning to learn from noisy web videos.
CVPR 2017.
Learning to learnUnsupervised learning
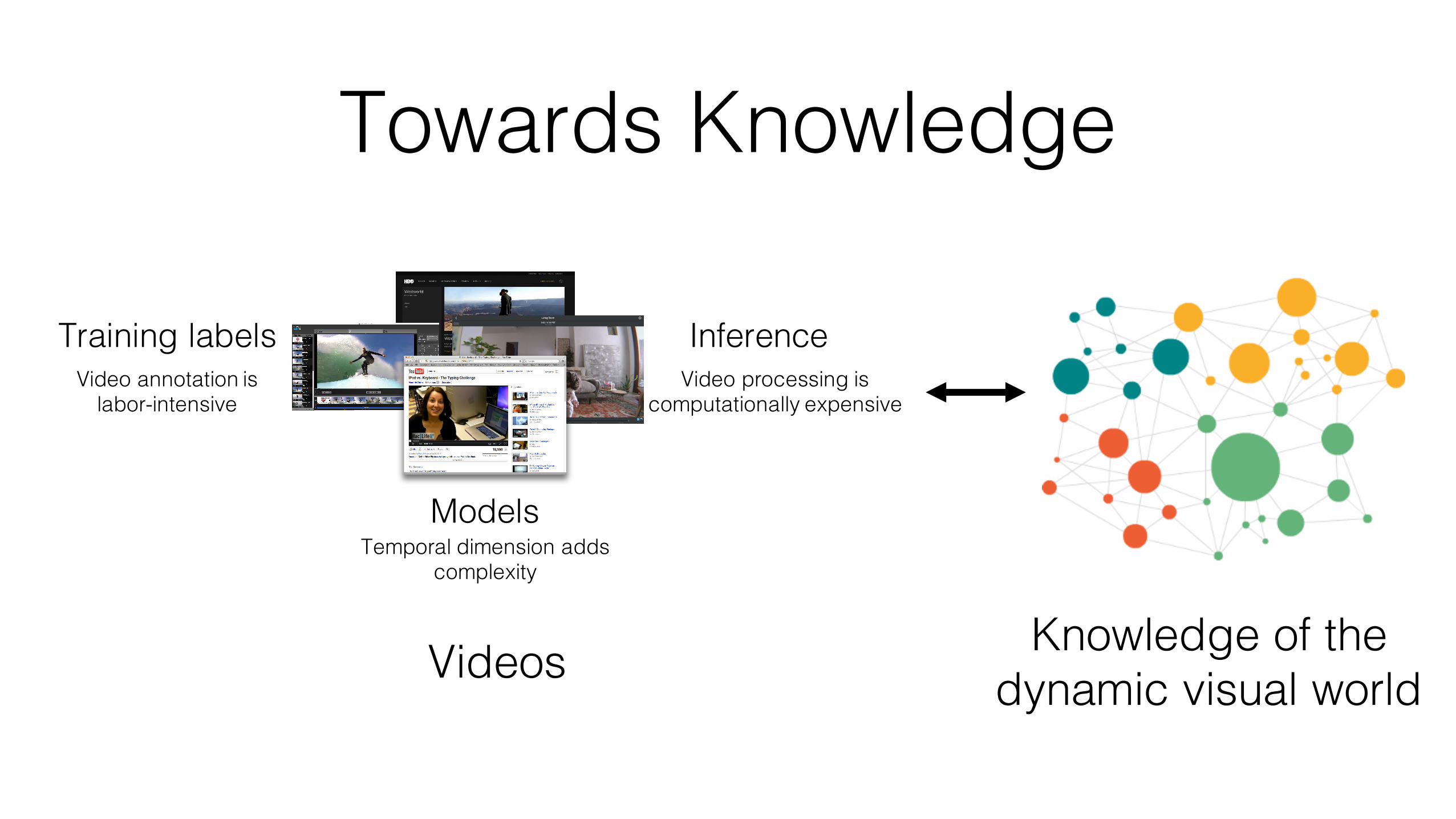
Towards Knowledge
Training labels InferenceVideo processing is
computationally expensiveVideo annotation is
labor-intensive
ModelsTemporal dimension adds
complexity
Videos Knowledge of the dynamic visual world

Collaborators
Olga Russakovsky Mykhaylo Andriluka Ning Jin Vignesh Ramanathan Liyue Shen
Greg Mori Fei-Fei Li

Thank You


















