噛み砕いてKafka Streams #kafkajp
38
2016年12月15日 1 ヤフー株式会社 データ&サイエンスソリューション統括本部 データプラットフォーム本部 開発1部 パイプライン 森谷 大輔 噛み砕いてKafka Streams
-
Upload
yahoo -
Category
Technology
-
view
685 -
download
5
Transcript of 噛み砕いてKafka Streams #kafkajp

2016年12月15日
1
ヤフー株式会社 データ&サイエンスソリューション統括本部
データプラットフォーム本部 開発1部 パイプライン
森谷 大輔
噛み砕いてKafka Streams

自己紹介
• 氏名
• 森谷 大輔 @kokumutyoukan
• 業務
• 次世代データパイプラインの開発
• Kafka, Storm,Cassandra, Elasticsearch
• 好き
• 横浜ベイスターズ
• ハングリータイガー(の会会長)
2

今日のゴール
• おっ、調べてみるかなという気になってもらう
• Kafka Streamsを触った内容を噛み砕いて紹介
• 布教というわけではない
• 気になるところあれば遠慮なくツッコんでください
3

アジェンダ
• 概要
• Word Count
• Time, Window, Join
• つかってみた
• まとめ
4

アジェンダ
• 概要
• Word Count
• Time, Window, Join
• つかってみた
• まとめ
5

Kafka Streams is 何
• ストリーム処理のアプリケーションを書くためのライブラリ
• Apache Kafka に同梱されている
• 0.10.0 からアップデートの目玉として追加 (2016年5月)
6
群雄割拠勢Confluentが開発・導入促進を頑張っている

ストリーム処理アプリケーションをつくるには
• よく必要になる「難しい機能」• パーティショニング・拡張性
• 故障してもうまいこと復旧する(ステート管理)
• 遅れてやってきたデータもうまいこと処理する(時間の扱い)
• 再処理
• ウィンドウ集計
• 方法①:素のKafka Java APIを使う
• 方法②:ストリーム処理フレームワークを使う
• 方法③:Kafka Streamsを使う7

①:素の Kafka Java API を使う
• お手軽• Java ライブラリなのでアプリケーションを書いて jar にかためて java コ
マンドで起動さえすれば良い
• デプロイがシンプル
• 覚えることはAPIの使い方だけ
• ただし「難しい機能」を自分で考えて実装しなければならない
8
Consumer<byte[], byte[]> consumer = new KafkaConsumer<>(props);consumer.subscribe(topics);

②:ストリーム処理フレームワークを使う
• Stormなど群雄割拠勢
• 「難しい機能」を含めリッチな機能が使える
• ただしフレームワークの専用クラスタが必要• フレームワークならではの構成、設定、書き方
• デプロイ複雑
• 覚えることが多い
9

③:Kafka Streamsを使う
• 「Kafka Streamsはフレームワークではなく、ライブラリ」
• 「難しい機能」も抽象化されている• 大体のパターンのストリーム処理アプリケーションを書くには充分
• リアルタイム性• Spark Streamingのようなマイクロバッチではなく、Stormのような逐次処理(at least once)
• レイテンシ要求が厳しい案件でもOK
10
・サーバを分散処理モードで動かすためにセッティングし、・フレームワークのとりきめに従ったアプリケーションの実装をし、・専用のデプロイツールでデプロイしてはじめて分散処理
・ライブラリをクラスパスに含めてjarにかためてjavaコマンドうてば動く

比較
11
方法(難しい機能)実装の簡単さ
学習コスト
運用(デプロイ)
コスト
① 素のKafkaJava APIを使う ✕ ◯ ◯② ストリーム処理フレームワークを使う ◯ ✕ ✕③ Kafka Streams ◯ △ ◯
※独断と偏見
※ストリーム処理フレームワークにしかない機能もある

アジェンダ
• 概要
• Word Count
• Time, Window, Join
• つかってみた
• まとめ
12

ことはじめ
13
• ビルド設定(maven)
• APIを選ぶ• high-level DSL ←今回はこれ• low-level API
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>0.10.0.1</version>
</dependency>

プログラム
14
@Testpublic final void wordCount() {
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> queryStream= builder.stream(stringSerde, stringSerde, “search-query-topic”); // 入力トピック名は複数指定可能
KStream<String, Long> wordCounts = queryStream.flatMapValues(value -> Arrays.asList(value.split(“¥¥s+”))) // 空白区切り分割.map((key, value) -> new KeyValue<>(value, value)) // key 毎カウント下準備.countByKey(stringSerde, “Counts”) // KStream -> KTable.toStream(); // KTable -> KStream
wordCounts.to(stringSerde, longSerde, “wordcount-output”); // sink トピックに結果を書く
KafkaStreams streams = new KafkaStreams(builder, props); // props は Kafka Streams の設定streams.start(); // アプリケーション実行
}

入力・結果例
15
// 入力producer.send(new ProducerRecord<>(“search-query-topic”, “ぬこ 飼い方”));producer.send(new ProducerRecord<>(“search-query-topic”, “犬 飼い方”));producer.send(new ProducerRecord<>(“search-query-topic”, “本当すこ ぬこ"));
consumer.subscribe(Arrays.asList("wordcount-output"));while (true) {
ConsumerRecords<String, Long> records = consumer.poll(100);for (ConsumerRecord<String, Long> record : records) {
System.out.println("record = " + record.key() + ", " + record.value());}
}// 出力record = ぬこ, 1record = 飼い方, 1record = 犬, 1record = 飼い方, 2record = 本当すこ, 1record = ぬこ, 2
アプリケーションの動作確認はKafka Unit Testを使うと便利※Kafka 公式 FAQ 参照

KStream? KTable?
• KStream
• record streamを扱う場合はKStreamクラスを使う
• 自己完結のデータストリーム
• 例えばPVログ、サーバログ、ツイート
• KTable
• changelog streamを扱う場合はKTableクラスを使う
• 状態を持つ、keyで値が更新されるデータのストリーム
• 例えばこの単語が今までに何件出現したか、のようなデータ
• Stateとしてローカルに保持される
16

アジェンダ
• 概要
• Word Count
• Time, Window, Join
• つかってみた
• まとめ
17

Time• ストリームであるイベントが流れてきた時、そのイベントのタイムスタンプとしてどんな情
報を使うべきか
• 例えばイベントがツイートだとして、一時間毎のツイート数を計算したいといった場合、なんのタイムスタンプ毎に計算する?
1. ユーザがツイートした瞬間
2. ツイートをAPIからバックエンドサーバが受け取ってKafkaに投げた瞬間
3. Kafkaに入った瞬間
4. Kafka Streamsがそのイベントを処理した瞬間
18
Tweet!
TwitterAPI
my BEserver
Kafka Streams
① ② ③ ④

Time• ストリームであるイベントが流れてきた時、そのイベントのタイムスタンプとしてどんな情
報を使うべきか
• 例えばイベントがツイートだとして、一時間毎のツイート数を計算したいといった場合、なんのタイムスタンプ毎に計算する?
1. ユーザがツイートした瞬間
2. ツイートをAPIからバックエンドサーバが受け取ってKafkaに投げた瞬間
3. Kafkaに入った瞬間
4. Kafka Streamsがそのイベントを処理した瞬間
• 多くは1だと思うが、アプリケーションの仕様によって異なる
• Kafka Streamsでは設定項目 timestamp.extractor でどれを選択するか簡単に決められる
19

Kafka Streams的分類• event-time
• ログ内の独自タイムスタンプの場合• 「ユーザがツイートした瞬間」
• Kafka messageに付与されているタイムスタンプを使う場合• 「ツイートをAPIからバックエンドサーバが受け取ってKafkaに投げた瞬間」
• broker設定 log.message.timestamp.type=CreateTime (デフォルト)
• このタイムスタンプはKafka0.10からMessageに付与される• 0.9以前のproducerから投げると -1
• ingestion-time• 「Kafkaに入った瞬間」
• log.message.timestamp.type=LogAppendTime だった場合
• そのイベントがKafka Brokerに入ったときの時刻がmessageタイムスタンプに付与
• processing-time• 「Kafka Streamsがそのイベントを処理した瞬間」
20

timestamp.extractor
21
Time分類 timestamp.extractor
event-time(独自) 自分で実装する
event-time(message) ConsumerRecordTimestampExtractor
ingestion-time ConsumerRecordTimestampExtractor
processing-time WallclockTimestampExtractor
import java.util.Properties;import org.apache.kafka.streams.StreamsConfig;
Properties props = new Properties();props.put(StreamsConfig.TIMESTAMP_EXTRACTOR_CLASS_CONFIG,
WallclockTimestampExtractor.class.getName());
設定例

独自クラス実装例
22
import org.apache.kafka.clients.consumer.ConsumerRecord;import org.apache.kafka.streams.processor.TimestampExtractor;
// TimestampExtractorインタフェースを実装するpublic class MyEventTimeExtractor implements TimestampExtractor {@Override public long extract(ConsumerRecord<Object, Object> record) {
// ログをパースしてtimestampを取り出すFoo myPojo = (Foo) record.value();if (myPojo != null) {
return myPojo.getTimestampInMillis();} else {// valueがnullだったらとりあえず現在時刻をいれておくreturn System.currentTimeMillis();}
}}
http://docs.confluent.io/3.0.0/streams/developer-guide.html#timestamp-extractor (コメント以外引用)

Window
23
• Tumbling time window• 5分毎のユーザ毎のPV数とか
• Hopping time window• 1つのイベントが複数のウィンドウにまたがる
KStream<String, String> viewsByUser = ユーザIDがkeyのPVログStreamなど;KTable<Windowed<String>, Long> userCounts =
viewsByUser.countByKey(TimeWindows.of(”WindowName", 5 * 60 * 1000L));
TimeWindows.of(”WindowName", 5 * 60 * 1000L).advanceBy(60 * 1000L);

Join
24
• ストリーム処理でよくやるストリームとテーブルのJoinができる
• KTableはローカルにあり、常に最新である• メッセージ処理毎にネットワークを超えてKVSを叩く必要も、鮮度を諦めて定期的にRDBを
メモリにロードする必要もない
KStream<String, String> voteRegionStream = ...(“vote-topic”)KTable<String, String> partyTable = ...("party-topic");
KStream<String, String> voteParty= voteRegionStream.leftJoin(
partyTable, (region, party) -> region + ”," + party);
k: Hillary v: California k: candidate v: party
Hillary Democratic
Trump Republican
k: Hillary v: California, Democratic

アジェンダ
• 概要
• Word Count
• Time, Window, Join
• つかってみた
• まとめ
25

Kafka Streamsで開発してみた
• Kafkaクラスタから引いた全メッセージをグルーピング、ウィンドウ集計して指標をsinkに書くシンプルなアプリ
• ローカルでテストは通った、本番デプロイいこう
• バグを踏む:Kafka-4160 (´・ω・`)
• Kafka Streamsのフォアグラウンドスレッドとバッググラウンドハートビートスレッドの間に単一のロックがある
• タスク生成中にハートビートをブロックするのでタスク生成が長いとセッションタイムアウトを超える
• consumerがグループから追い出されて再度タスク生成を始める
• 永遠に繰り返してデッドロックみたくなる
• 入力パーティション数が少ないと問題にならないのだが本番では1topicあたり最大60あったため本番で初めて発覚した
26

続き
• バグは Kafka 0.10.1.0 で解消されたよ!(今client, server共に 0.10.0.1)
• Kafka Streams をバージョンアップすれば解決しそう
• > Apps built with Kafka Streams 0.10.1 only work against Kafka clusters running 0.10.1+.• 古いサーバに対しても互換性なんとかしたいとは書いてあった
• 0.10.0.1のKafkaにバグフィックスだけパッチ当ててアプリに入れるか・・・
• 対象コードが 0.10.1 で大きく変わってて厳しい
• やっぱりサーバあげよう ← イマココ
27
___________/|:: ┌──────┐ ::|
/. |:: | Exception | ::| / ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄|.... |:: | Use 0.10.1 !| ::| | マイナーバージョンアップなら…アレ?|.... |:: | .| ::| \_ ______|.... |:: └──────┘ ::| ∨\_| ┌────┐ .| ∧∧
 ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ( _)/ ̄ ̄ ̄ ̄ ̄旦 ̄(_, )
/ \| ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄|、_) ̄| ̄| ̄ ̄ ̄ ̄ ̄ ̄|

思ったこと
• 向くユースケースなら向く• Kafka Streamsのコンセプトがわかってきてからシステム設計した方がいいかも
• 既にカッチリ決まった要件にKafka Streamsを合わせようとするとハックするはめになるかも
• ライブラリならアプリケーション開発を楽にしてくれなくちゃいけない• Kafkaの素のハイレベルAPIがそもそもかなりちょうどいい抽象化
• Kafka Streams APIの利点が活かせるかどうか
• インターナルトピックをかなり大量に作ることを想定している(アプリのバージョンアップごとにトピックは増える)• 小さめのサービス専用クラスタとかならいいが、マルチテナント向けのクラスタだとちょっと気持ち悪
いかも
• 現在は1 Kafkaクラスタしか指定できないが将来的には複数可能になるかも
28

アジェンダ
• 概要
• Word Count
• Time, Window, Join
• つかってみた
• まとめ
29

まとめ
• Kafka Streamsはストリーム処理のアプリケーションを実装するためのライブラリ
• シンプルながらストリーム処理でよく必要になる、自分で実装するには難しい機能を実現する
• 時間軸に何を使うか開発者が選択できる
• Kafka Streamsが便利に使えるようにシステム設計をすると吉
30

Appendix
31

Kafka Streamsはどこで動くの?
32
• consumerアプリケーション
• 普通はKafkaクラスタの(物理的に)近くのアプリケーション専用サーバ上でJavaプロセスとして動かすと思う
• ライブラリなので何でもできるが、Kafkaとしか接続しないように全体設計すると楽そう
Kafkaクラスタ
source topic
internal topic
sink topic
Kafka
Streams
Kafka
Connect 等
Kafka
Connect 等

Configuration
33
import java.util.Properties;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ConsumerConfig;
Properties settings = new Properties();
settings.put(StreamsConfig.APPLICATION_ID_CONFIG, “my-app”); // StreamConfigのこの3つは必須settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, ”localhost:9092");
settings.put(StreamsConfig.ZOOKEEPER_CONNECT_CONFIG, ”localhost:2181");
settings.put(ProducerConfig...., “”); // 必須でないsettings.put(ConsumerConfig...., “”); // 必須でない
application.id アプリケーション認識名. consumer group名やinternal topic名等に利用される.
bootstrap.servers 接続するKafkaクラスタのhost/portペアのリスト.
zookeeper.connect 接続するZooKeeperのコネクション文字列(host:port/chroot).
num.stream.threads ストリーム処理のために使うスレッド数.
replication.factor internal topicを作るときのレプリケーションファクタ
state.dir State Storeのディレクトリパス
timestamp.extractor 後述

フォールトトレラント• 故障時にStateを復旧させるため、Kafkaクラスタにchangelog topicという内部topicが作ら
れる
34
Node
Task
source part-1
changelog part-1
Node
Task
source part-0
changelog part-0

フォールトトレラント• 故障時にStateを復旧させるため、Kafkaクラスタにchangelog topicという内部topicが作ら
れる
35
Node
Task
source part-1
changelog part-1
Node
Tasksource part-0
changelog part-0Task

changelog topic(おまけ)• topicはKafka Streamsアプリケーションの実行時に自動で作成される
• 手動でtopicを作るときと同じような感じで、Kafka設定auto.create.topics.enable=falseでも作成される
• topic設定はcompact• 同じkeyで頻繁にvalueが変わるはずだから
• タスク数分パーティションが作られる
36

プログラム(full)
37
@Testpublic final void wordCount() {
final Serde<String> stringSerde = Serdes.String(); // Serde is Serializer/Deserializerの略、Kafka共通のクラスfinal Serde<Long> longSerde = Serdes.Long(); // 基本的なビルトインをSerdesから呼べる、もちろん自作可能
KStreamBuilder builder = new KStreamBuilder();// 入力名からKStreamを作る. 1: key Serde, 2: value Serde, 3: 入力トピック名(複数指定可能)KStream<String, String> queryStream = builder.stream(stringSerde, stringSerde, “search-query-topic”);
KStream<String, Long> wordCounts = queryStream// valueに対して空白区切りで文字列を分割して次に送る処理.flatMapValues(value -> Arrays.asList(value.split(“¥¥s+”)))// key毎カウントしたいからkeyにvalueを入れる.map((key, value) -> new KeyValue<>(value, value)).countByKey(stringSerde, “Counts”) // KStream -> KTable、第二引数はKTable名.toStream(); // KTable -> KStreamwordCounts.to(stringSerde, longSerde, “wordcount-output”); // sinkトピックに結果を書く
KafkaStreams streams = new KafkaStreams(builder, props); // propsはKafka StreamsやClientの設定Propertiesstreams.start(); // アプリケーション実行
}

比較(full)
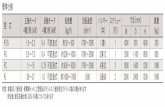
38
方法(難しい機能)実装の簡単さ
学習コスト
運用(デプロイ)
コスト実績
ドキュメント充実度
① 素のKafkaJava APIを使う ✕ ◯ ◯ ◯ ◯② ストリーム処理フレームワークを使う ◯ ✕ ✕ △
(差異が大きい)△?
③ Kafka Streams ◯ △ ◯ ✕ △
※独断と偏見