







Languages
Pages
Legal


Event storage and real-time analysis at Booking.com with Riak
Damien Krotkine
Damien Krotkine
• Software Engineer at Booking.com
• github.com/dams
• @damsieboy
• dkrotkine

• 800,000 room nights reserved per day
WE ARE HIRING

INTRODUCTION



www APImobi
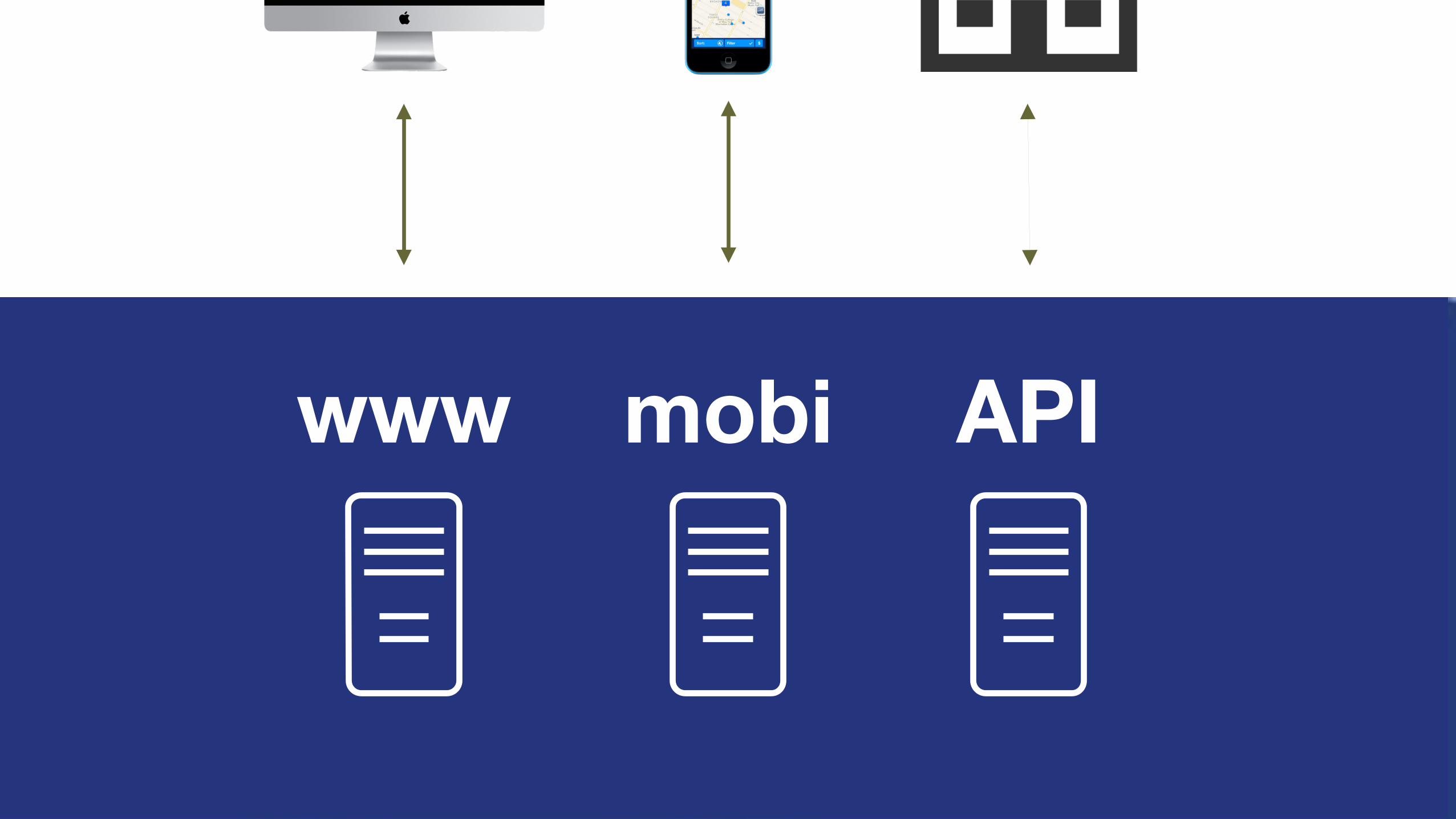
www APImobi

www APIfro
nten
dba
cken
dmobi
events storage
events: info about subsystems status
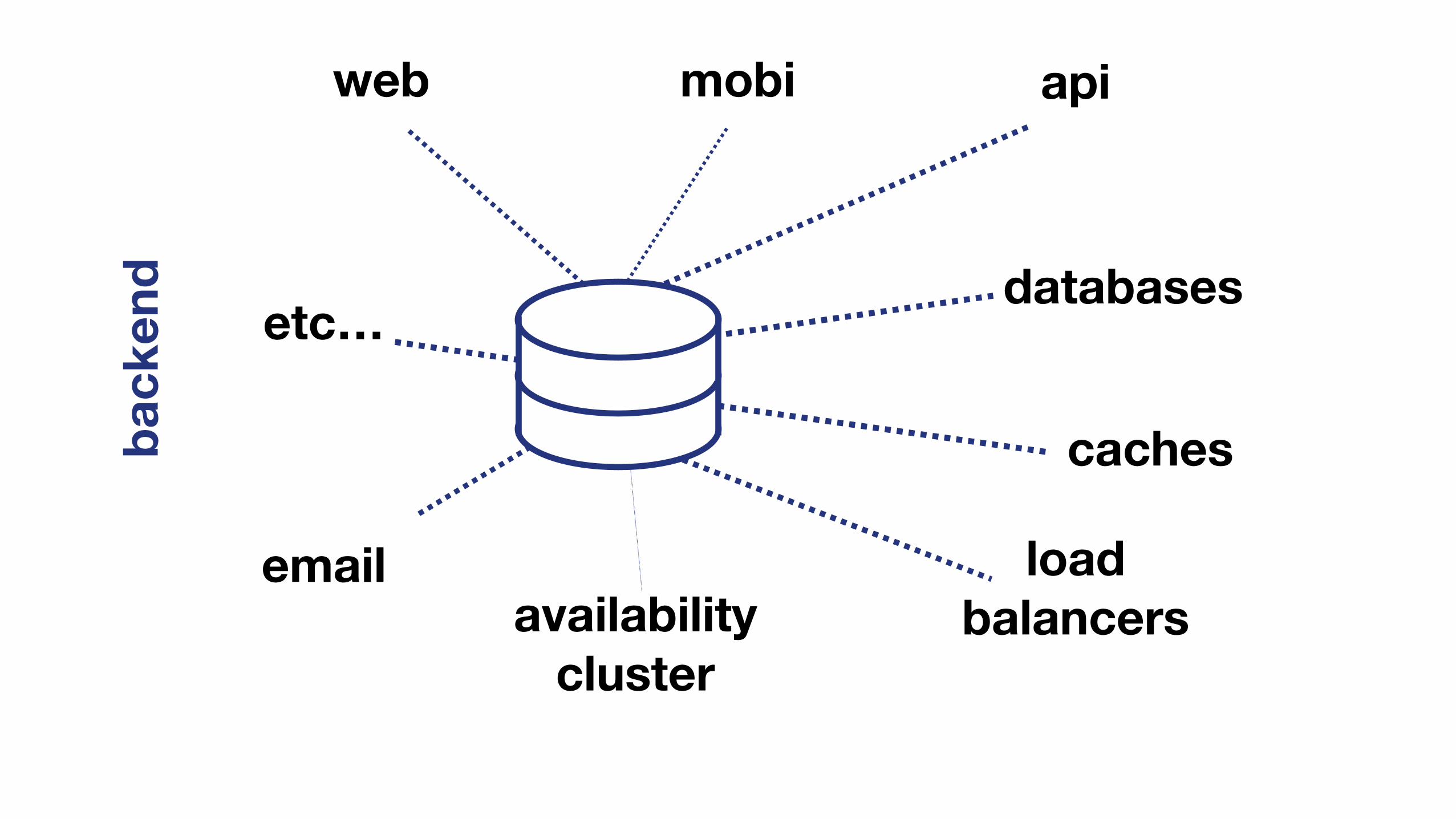
back
end
web mobi api
databases
caches
load balancersavailability
cluster
etc…

WHAT IS AN EVENT ?

EVENT STRUCTURE
• Provides info about subsystems
• Data
• Deep HashMap
• Timestamp
• Type + Subtype
• The rest: specific data
• Schema-less

EXAMPLE 1: WEB APP EVENT
• Large event
• Info about users actions
• Requests, user type
• Timings
• Warnings, errors
• Etc…

{ timestamp => 12345, type => 'WEB', subtype => 'app',
action => { is_normal_user => 1, pageview_id => '188a362744c301c2', # ... }, tuning => { the_request => 'GET /display/...' bytes_body => 35, wallclock => 111, nr_warnings => 0, # ... }, # ... }

EXAMPLE 2: AVAILABILITY CLUSTER EVENT
• Small event
• Cluster provides availability info
• Event: Info about request types and timings

{ type => 'FAV', subtype => 'fav', timestamp => 1401262979, dc => 1, tuning => { flatav => { cluster => '205', sum_latencies => 21, role => 'fav', num_queries => 7 } } }

EVENTS FLOW PROPERTIES
• Read-only
• Schema-less
• Continuous, ordered, timed
• 15 K events per sec
• 1.25 Billion events per day
• peak at 70 MB/s, min 25MB/s
• 100 GB per hour

SERIALIZATION
• JSON didn’t work for us (slow, big, lack features)
• Created Sereal in 2012
• « Sereal, a new, binary data serialization format that provides high-performance, schema-less serialization »
• Added Sereal encoder & decoder in Erlang in 2014

USAGE

ASSESS THE NEEDS
• Before thinking about storage
• Think about the usage

USAGE
1. GRAPHS 2. DECISION MAKING 3. SHORT TERM ANALYSIS 4. A/B TESTING

GRAPHS
• Graph in real-time ( few seconds lag )
• Graph as many systems as possible
• General platform health check

GRAPHS

GRAPHS

DASHBOARDS

META GRAPHS

USAGE
1. GRAPHS 2. DECISION MAKING 3. SHORT TERM ANALYSIS 4. A/B TESTING

DECISION MAKING
• Strategic decision ( use facts )
• Long term or short term
• Technical / Non technical Reporting

USAGE
1. GRAPHS 2. DECISION MAKING 3. SHORT TERM ANALYSIS 4. A/B TESTING

SHORT TERM ANALYSIS
• From 10 sec ago -> 8 days ago
• Code deployment checks and rollback
• Anomaly Detector

USAGE
1. GRAPHS 2. DECISION MAKING 3. SHORT TERM ANALYSIS 4. A/B TESTING

A/B TESTING
• Our core philosophy: use facts
• It means: do A/B testing
• Concept of Experiments
• Events provide data to compare

EVENT AGGREGATION

EVENT AGGREGATION
• Group events
• Granularity we need: second

eventeventevents storage
eventevent
even
t
eventevent
eventevent
event
even
t
event event

e ee e
ee
e e
e ee
e eee
ee
e
LOGGER
e
e

web apieeeeee
eee
e ee e
ee
e e
e ee
e eee
ee
ee
e

web api dbseeeeeeee
eeeeeeeee
eeeeeee
e ee e
ee
e e
e ee
e eee
ee
ee
e

web api dbseeeeeeee
eeeeeeeee
eeeeeee
e ee e
ee
e e
e ee
e eee
ee
e
1 sec
e
e

web api dbseeeeeeee
eeeeeeeee
eeeeeee
e ee e
ee
e e
e ee
e eee
ee
e
1 sec
e
e
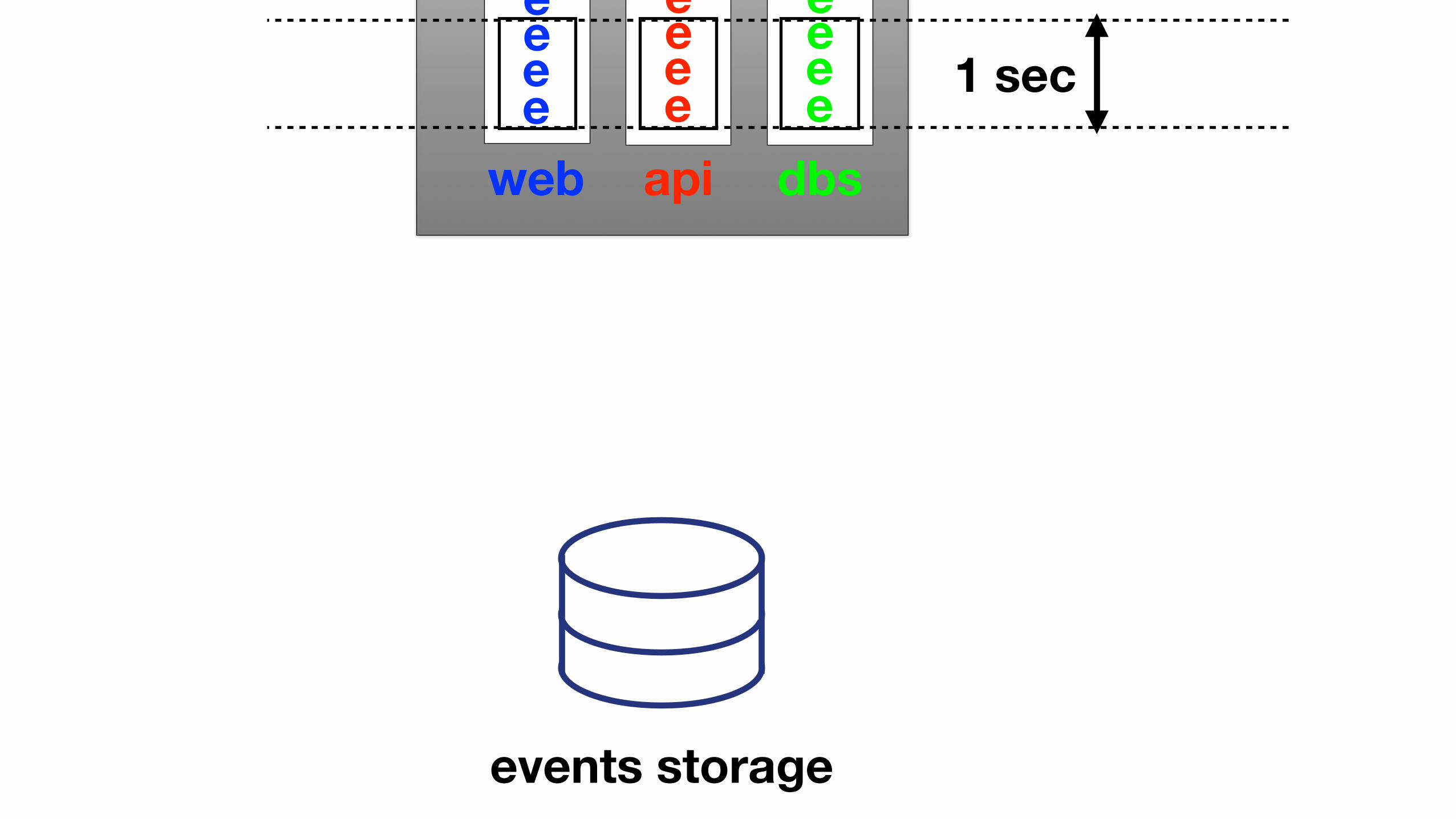
web api dbseeeee
eeeee
eeeee
1 sec
events storage

web api dbs
ee
eeeee
eeeee
1 sec
events storage
ee e reserialize + compress

events storage
LOGGER …LOGGER LOGGER

STORAGE

WHAT WE WANT
• Storage security
• Mass write performance
• Mass read performance
• Easy administration
• Very scalable

WE CHOSE RIAK
• Security: cluster, distributed, very robust
• Good and predictable read / write performance
• The easiest to setup and administrate
• Advanced features (MapReduce, triggers, 2i, CRDTs …)
• Riak Search
• Multi Datacenter Replication


CLUSTER
• Commodity hardware • All nodes serve data • Data replication
• Gossip between nodes • No master
Ring of servers

hash(key)

KEY VALUE STORE
• Namespaces: bucket
• Values: opaque or CRDTs

RIAK: ADVANCED FEATURES
• MapReduce
• Secondary indexes
• Riak Search
• Multi DataCenter Replication

MULTI-BACKEND
• Bitcask
• Eleveldb
• Memory

BACKEND: BITCASK
• Log-based storage backend
• Append-only files
• Advanced expiration
• Predictable performance
• Perfect for reading sequential data

CLUSTER CONFIGURATION

DISK SPACE NEEDED
• 8 days
• 100 GB per hour
• Replication 3
• 100 * 24 * 8 * 3
• Need 60 T

HARDWARE
• 16 nodes
• 12 CPU cores ( Xeon 2.5Ghz)
• 192 GB RAM
• network 1 Gbit/s
• 8 TB (raid 6)
• Cluster space: 128 TB

RIAK CONFIGURATION
• Vnodes: 256
• Replication: n_val = 3
• Expiration: 8 days
• 4 GB files
• Compaction only when file is full
• Compact only once a day
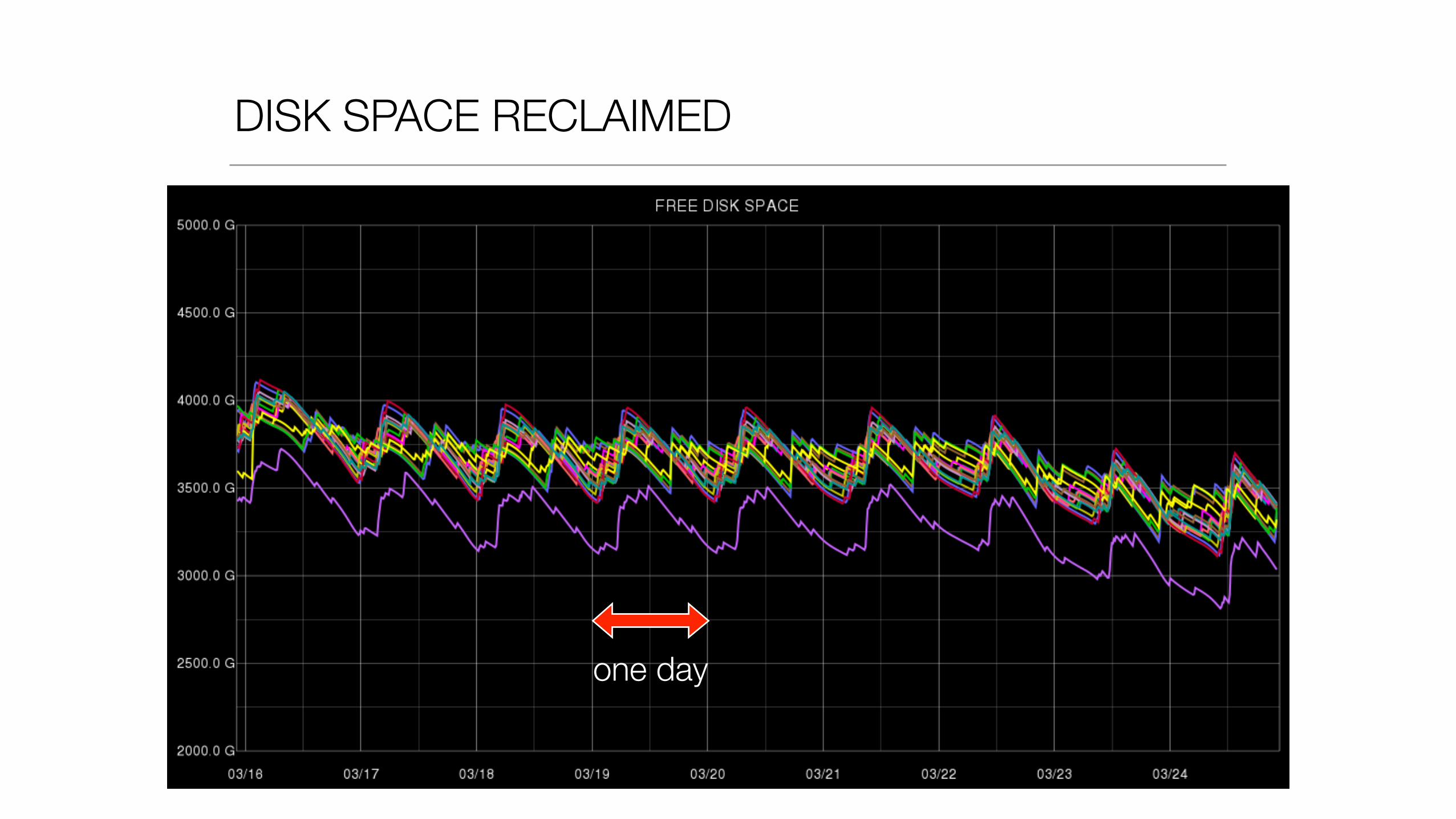
DISK SPACE RECLAIMED
one day

DATA DESIGN
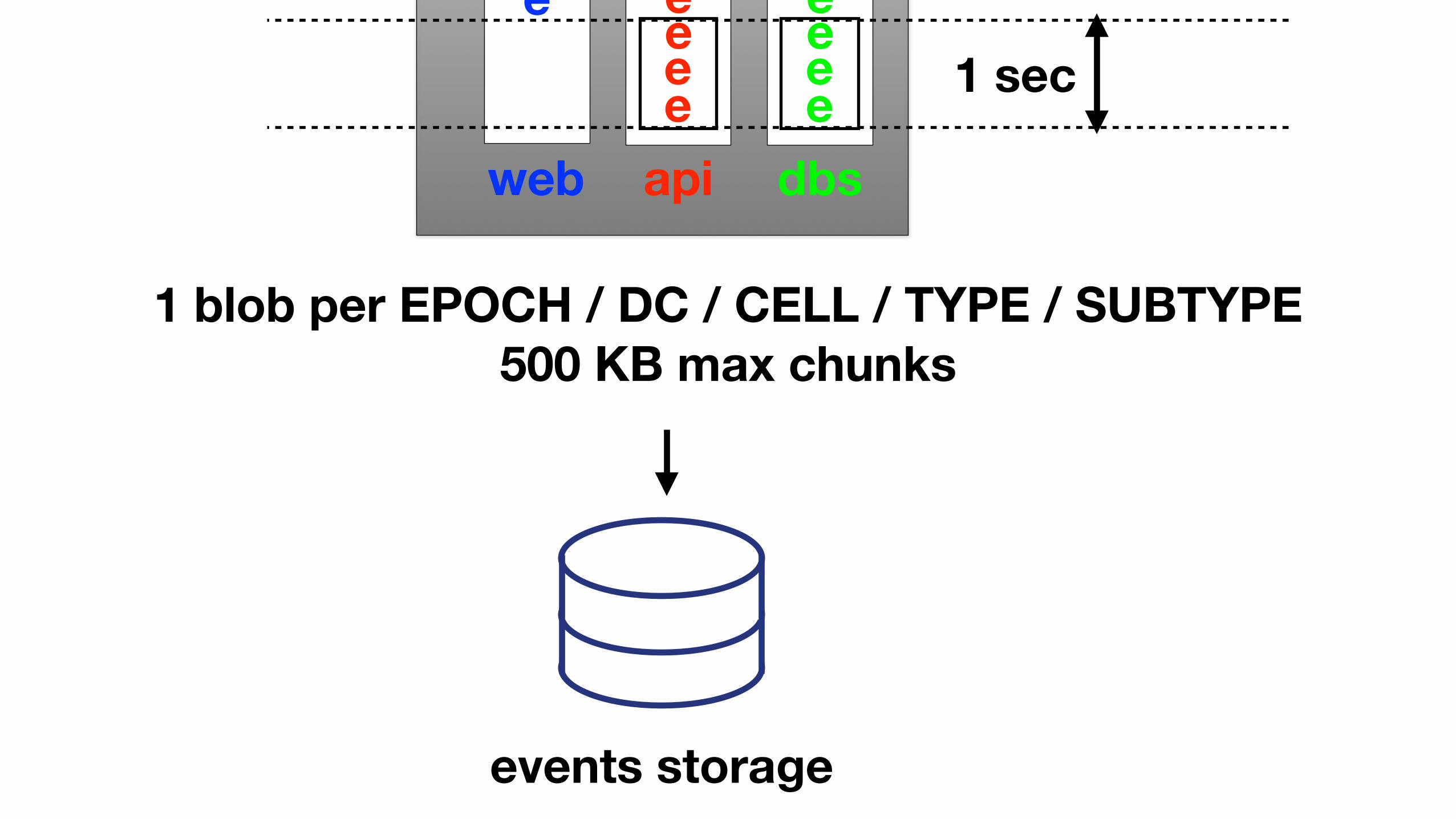
web api dbs
ee
eeeee
eeeee
1 sec
events storage
1 blob per EPOCH / DC / CELL / TYPE / SUBTYPE 500 KB max chunks

DATA
• Bucket name: “data“
• Key: “12345:1:cell0:WEB:app:chunk0“
• Value: serialized compressed data
• About 120 keys per seconds

METADATA
• Bucket name: “metadata“
• Key: epoch-dc “12345-2“
• Value: list of data keys:[ “12345:1:cell0:WEB:app:chunk0“, “12345:1:cell0:WEB:app:chunk1“ … “12345:4:cell0:EMK::chunk3“ ]
• As pipe separated value

PUSH DATA IN

PUSH DATA IN
• In each DC, in each cell, Loggers push to Riak
• 2 protocols: REST or ProtoBuf
• Every seconds:
• Push data values to Riak, async
• Wait for success
• Push metadata

JAVA
Bucket DataBucket = riakClient.fetchBucket("data").execute(); DataBucket.store("12345:1:cell0:WEB:app:chunk0", Data1).execute(); DataBucket.store("12345:1:cell0:WEB:app:chunk1", Data2).execute(); DataBucket.store("12345:1:cell0:WEB:app:chunk2", Data3).execute();
Bucket MetaDataBucket = riakClient.fetchBucket("metadata").execute(); MetaDataBucket.store("12345-1", metaData).execute(); riakClient.shutdown();

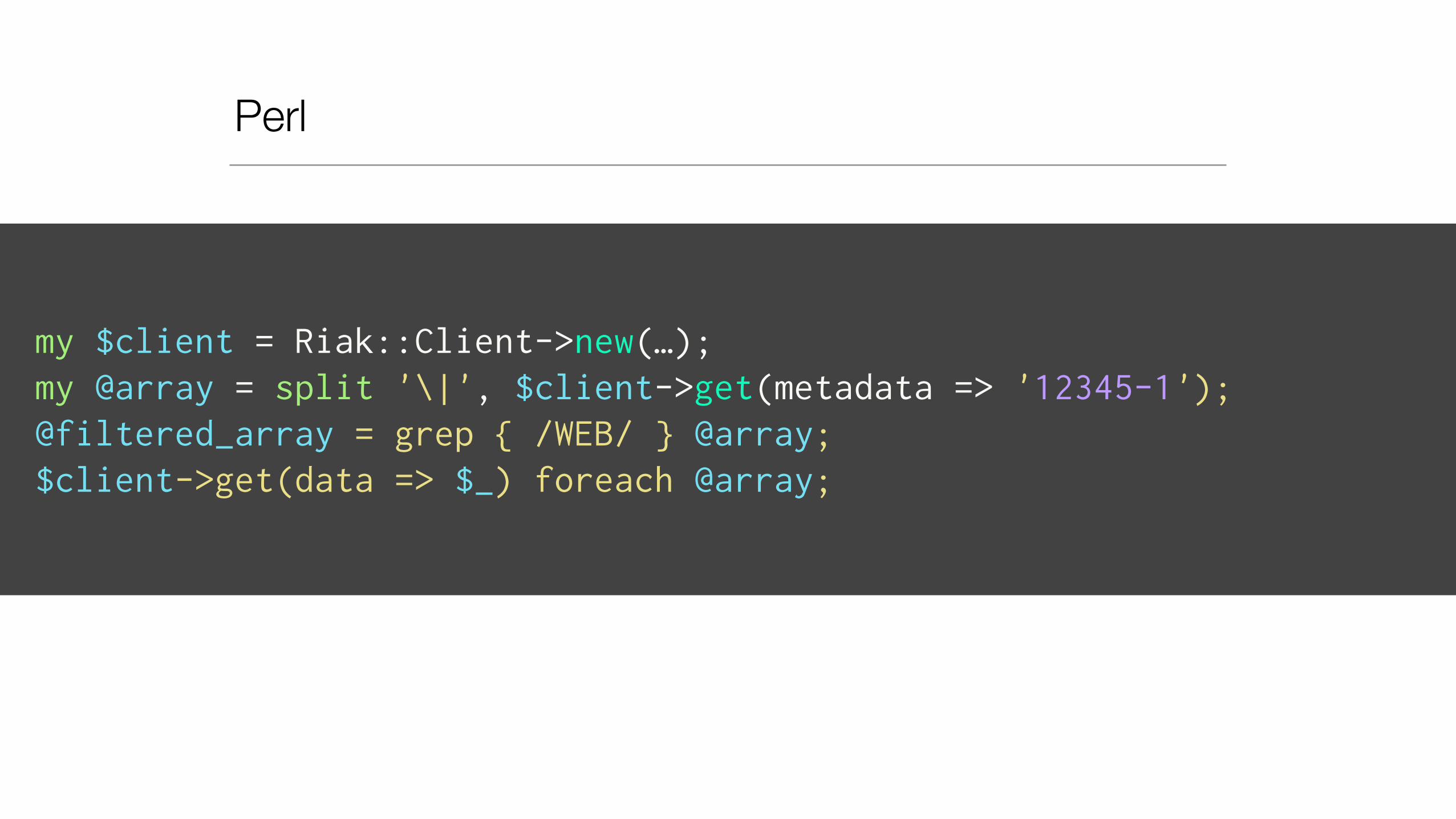
Perl
my $client = Riak::Client->new(…);
$client->put(data => '12345:1:cell0:WEB:app:chunk0', $data1); $client->put(data => '12345:1:cell0:WEB:app:chunk1', $data2); $client->put(data => '12345:1:cell0:WEB:app:chunk2', $data3);
$client->put(metadata => '12345-1', $metadata, 'text/plain' );

GET DATA OUT

GET DATA OUT
• Request metadata for epoch-DC
• Parse value
• Filter out unwanted types / subtypes
• Fetch the data keys
Perl
my $client = Riak::Client->new(…); my @array = split '\|', $client->get(metadata => '12345-1'); @filtered_array = grep { /WEB/ } @array; $client->get(data => $_) foreach @array;

REAL TIME PROCESSING OUTSIDE OF RIAK

STREAMING
• Fetch 1 second every second
• Or a range ( last 10 min )
• Client generates all the epochs for the range
• Fetch all epochs from Riak

EXAMPLES
• Continuous fetch => Graphite ( every sec )
• Continuous fetch => Anomaly Detector ( last 2 min )
• Continuous fetch => Experiment analysis ( last day )
• Continuous fetch => Hadoop
• Manual request => test, debug, investigate
• Batch fetch => ad hoc analysis
• => Huge numbers of fetches

events storage
graphite cluster
Anomaly detector
experimentcluster
hadoop cluster
mysql analysis
manual requests
50 MB/s
50 MB/s
50 M
B/s 50 MB/s
50 MB/s50 MB/s

REALTIME
• 1 second of data
• Stored in < 1 sec
• Available after < 1 sec
• Issue : network saturation

REAL TIME PROCESSING INSIDE RIAK

THE IDEA
• Instead of
• Fetching data, crunch data, small result
• Do
• Bring code to data

WHAT TAKES TIME
• Takes a lot of time
• Fetching data out
• Decompressing
• Takes almost no time
• Crunching data

MAPREDUCE
• Send code to be executed
• Works fine for 1 job
• Takes < 1s to process 1s of data
• Doesn’t work for multiple jobs
• Has to be written in Erlang

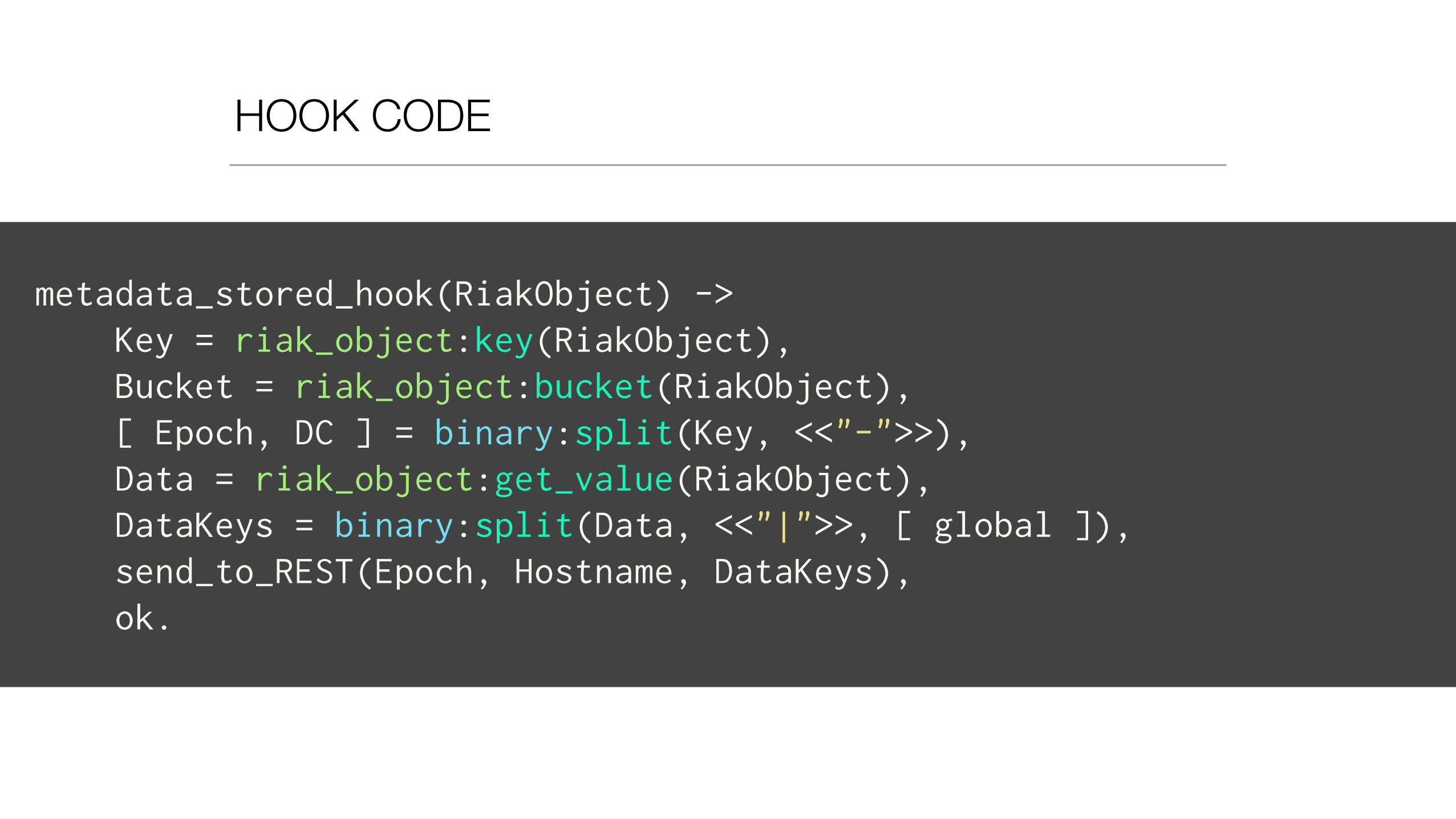
HOOKS
• Every time metadata is written
• Post-Commit hook triggered
• Crunch data on the nodes


Riak post-commit hook
REST serviceRIAK service
key keysocket
new data sent for storage
fetch, decompressand process all tasks
NODE HOST
HOOK CODE
metadata_stored_hook(RiakObject) -> Key = riak_object:key(RiakObject), Bucket = riak_object:bucket(RiakObject), [ Epoch, DC ] = binary:split(Key, <<"-">>), Data = riak_object:get_value(RiakObject), DataKeys = binary:split(Data, <<"|">>, [ global ]), send_to_REST(Epoch, Hostname, DataKeys), ok.

send_to_REST(Epoch, Hostname, DataKeys) -> Method = post, URL = "http://" ++ binary_to_list(Hostname) ++ ":5000?epoch=" ++ binary_to_list(Epoch), HTTPOptions = [ { timeout, 4000 } ], Options = [ { body_format, string }, { sync, false }, { receiver, fun(ReplyInfo) -> ok end } ], Body = iolist_to_binary(mochijson2:encode( DataKeys )), httpc:request(Method, {URL, [], "application/json", Body}, HTTPOptions, Options), ok.

REST SERVICE
• In Perl, using PSGI, Starman, preforks
• Allow to write data cruncher in Perl
• Also supports loading code on demand

ADVANTAGES
• CPU usage and execution time can be capped
• Data is local to processing
• Two systems are decoupled
• REST service written in any language
• Data processing done all at once
• Data is decompressed only once

DISADVANTAGES
• Only for incoming data (streaming), not old data
• Can’t easily use cross-second data
• What if the companion service goes down ?

FUTURE
• Use this companion to generate optional small values
• Use Riak Search to index and search those

THE BANDWIDTH PROBLEM

• PUT - bad case
• n_val = 3
• inside usage = 3 x outside usage

• PUT - good case
• n_val = 3
• inside usage = 2 x outside usage

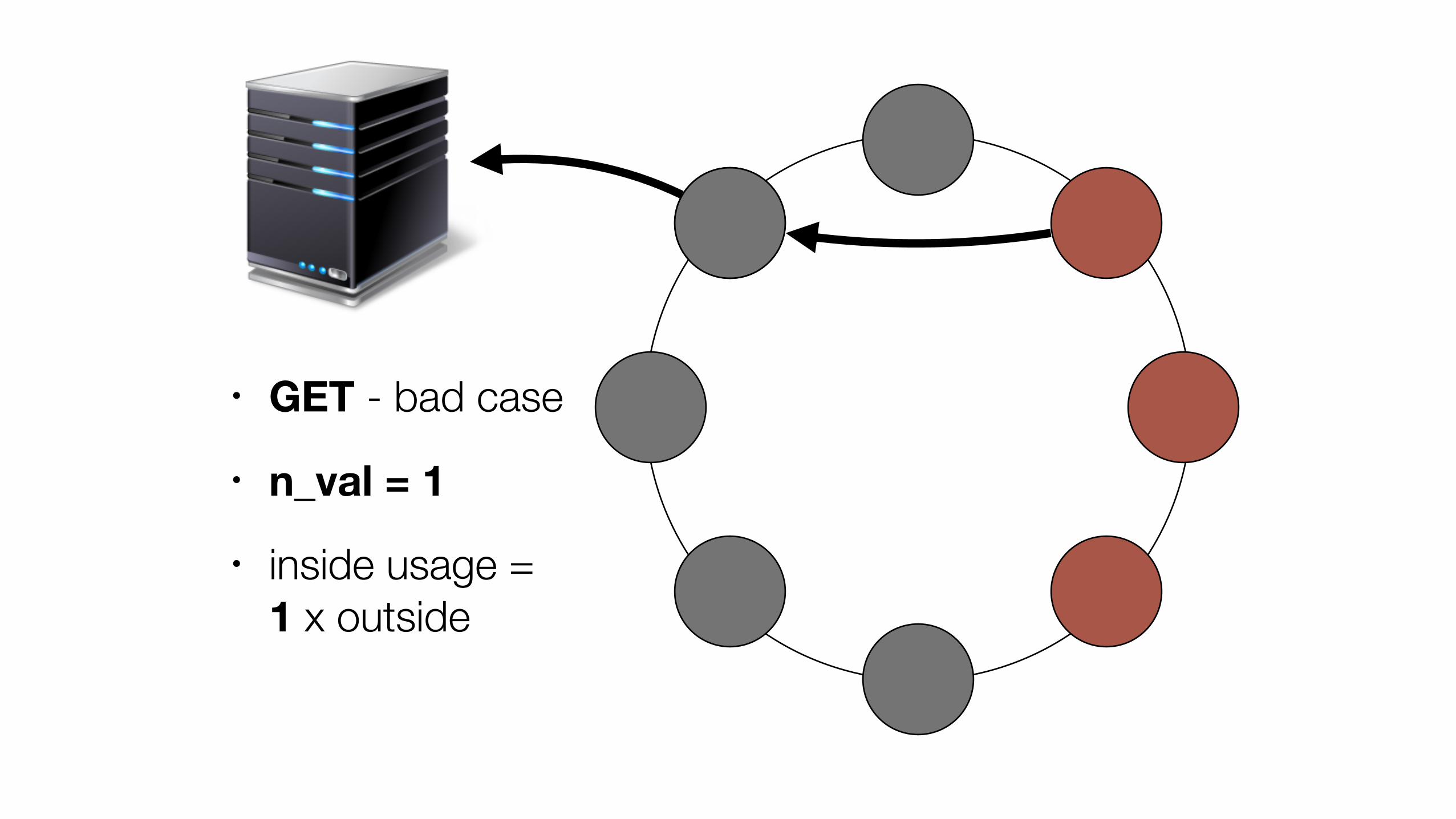
• GET - bad case
• inside usage = 3 x outside usage

• GET - good case
• inside usage = 2 x outside usage

• network usage ( PUT and GET ): • 3 x 13/16+ 2 x 3/16= 2.81 • plus gossip • inside network > 3 x outside network

• Usually it’s not a problem • But in our case: • big values, constant PUTs, lots of GETs • sadly, only 1 Gbit/s
• => network bandwidth issue

THE BANDWIDTH SOLUTIONS

THE BANDWIDTH SOLUTIONS
1. Optimize GET for network usage, not speed 2. Don’t choose a node at random
• GET - bad case
• n_val = 1
• inside usage = 1 x outside

• GET - good case
• n_val = 1
• inside usage = 0 x outside

WARNING
• Possible only because data is read-only
• Data has internal checksum
• No conflict possible
• Corruption detected

RESULT
• practical network usage reduced by 2 !

THE BANDWIDTH SOLUTIONS
1. Optimize GET for network usage, not speed 2. Don’t choose a node at random
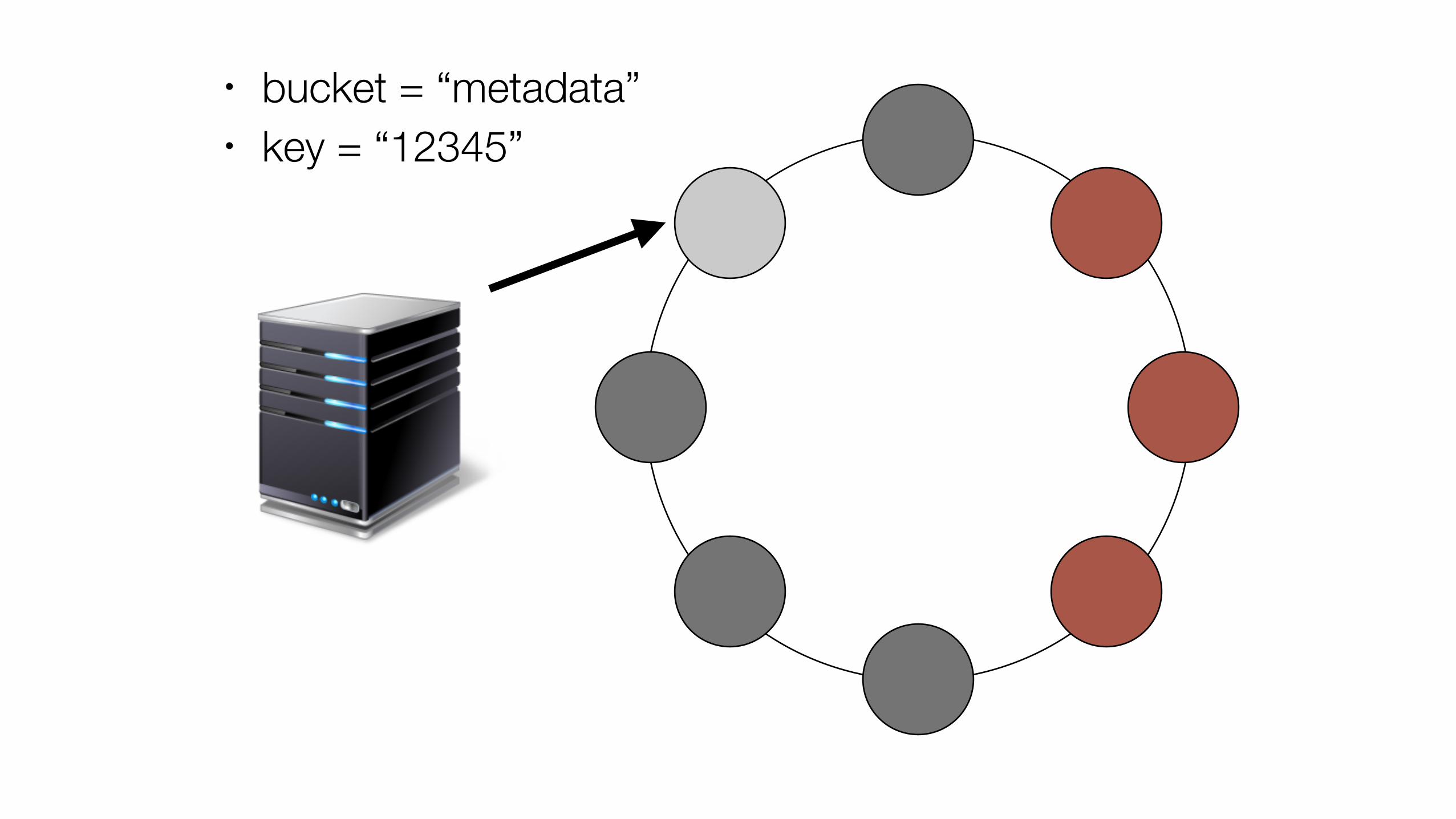
• bucket = “metadata” • key = “12345”

• bucket = “metadata”
• key = “12345”
Hash = hashFunction(bucket + key)
RingStatus = getRingStatus
PrimaryNodes = Fun(Hash, RingStatus)

hashFunction()
getRingStatus()

hashFunction()
getRingStatus()

WARNING
• Possible only if • Nodes list is monitored • In case of failed node, default to random • Data is requested in an uniform way

RESULT
• Network usage even more reduced ! • Especially for GETs

CONCLUSION

CONCLUSION
• We used only Riak Open Source
• No training, self-taught, small team
• Riak is a great solution
• Robust, fast, scalable, easy
• Very flexible and hackable
• Helps us continue scaling

Q&A@damsieboy