







Languages
Pages
Legal


86
Capitolul 5 – Analiza corelaţiei dintre variabile
Aşa cum am văzut la începutul acestui curs de statistică şi econometrie,
variabilele economice pot fi de mai multe tipuri, una dintre clasificări împărţindu-le
în variabile cantitative (exprimate numeric) şi variabile calitative (care surprind
anumite caracteristici ale unităţilor statistice sau apartenenţa acestora la o anumită
categorie). La rândul lor, variabilele calitative pot fi nominale sau ordinale.
Variabilele calitative nominale surprind caracteristici care nu implică existenţa unei
relaţii de ordine între valori (de exemplu, culoarea ochilor unui individ), în timp ce
variabilele calitative ordinale presupun existenţa unei ierarhii între valorile posibile
(de exemplu, nivelul studiilor unui respondent, în general exprimat prin „ultima
școală absolvită”).
După cardinalul mulţimii observaţiilor, există variabile binare (numite și
alternative, dihotomice sau booleene), pentru care spaţiul de observaţii e compus
din două valori (de exemplu, 0/1, masculin/feminin, rural/urban), variabile cu un
număr finit de valori numerice (aici se încadrează variabilele calitative şi cele
cantitative discrete) şi variabile cantitative continue, cu mulţimea specifică a valorilor
individuale reprezentată de un interval de numere reale.
În cele ce urmează vom analiza legăturile care pot avea loc între două
variabile (doi indicatori), pe care le vom nota X şi Y. O serie de date care surprinde
evoluţia concomitentă a două variabile este numită serie bivariată, în cazul nostru
seria bivariată fiind deci formată din variabilele X şi Y observate împreună. De
exemplu, informația privind X și Y poate fi colectată de la același unitate statistică
(individ sau firmă).
Trebuie subliniat faptul că, în general, metodele de analiză a corelaţiei ajută
la evidenţierea intensităţii legăturii dintre două variabile, fiind însă mai puţin utile în
ilustrarea cauzalităţii, deci pentru a arăta faptul că X îl determină pe Y sau invers.
Cauzalitatea (direcţia legăturii dintre variabile) este deseori sugerată de teoria
economică sau de succesiunea evenimentelor. De exemplu, volumul vânzărilor de
bunuri şi servicii depinde de venitul consumatorilor, productivitatea muncii depinde
de înzestrarea tehnică, complexitatea contractelor comerciale depinde de expunerea
părţilor la comportamentul oportunist al părților etc.
Una din metodele de testare şi măsurare a legăturilor de cauzalitate o
reprezintă analiza de regresie. Această metodă reprezintă unul dintre principalele
instrumente ale econometriei și va fi prezentată în capitolul următor. Ceea ce
trebuie reţinut în contextul capitolului de față este faptul că existenţa unei corelaţii
între două variabile, în general reprezentate prin variabile aleatoare (deci
caracterizate de o anumită lege de distribuție), nu implică în mod necesar și o relaţie
de tip cauză-efect între acestea.
87
5.1 Testul χ2
În cele ce urmează, ne vom referi la testul χ2 (hi pătrat) dezvoltat în anul 1900
de Karl Pearson (matematician și statistician britanic, 1857-1936), test care
evaluează legătura dintre două variabile calitative (care pot fi atât nominale, cât și
ordinale). Facem precizarea că în teoria statistică au fost dezvoltate mai multe teste
hi pătrat, noi prezentându-l aici pe cel propus de Pearson.
Întrucât toate testele χ2 sunt bazate pe distribuția cu același nume, secțiunea
de mai jos constituie o scurtă prezentare a distribuției χ2, una dintre cele mai folosite
distribuții din teoria probabilităților și statistica inferențială.
Material opțional
Dacă X1,X2,...,Xk sunt k variabile aleatoare distribuite N(0,1) şi independente,
atunci variabila Q=X12+X2
2+...+Xk
2 urmează o lege χ2 cu k grade de libertate. Spre
deosebire de distribuţia normală, care este caracterizată de doi parametri (media şi
dispersia variabilei), distribuţia χ2 are un singur parametru, un număr întreg pozitiv
ce reprezintă numărul gradelor de libertate (numărul variabilelor Xi).
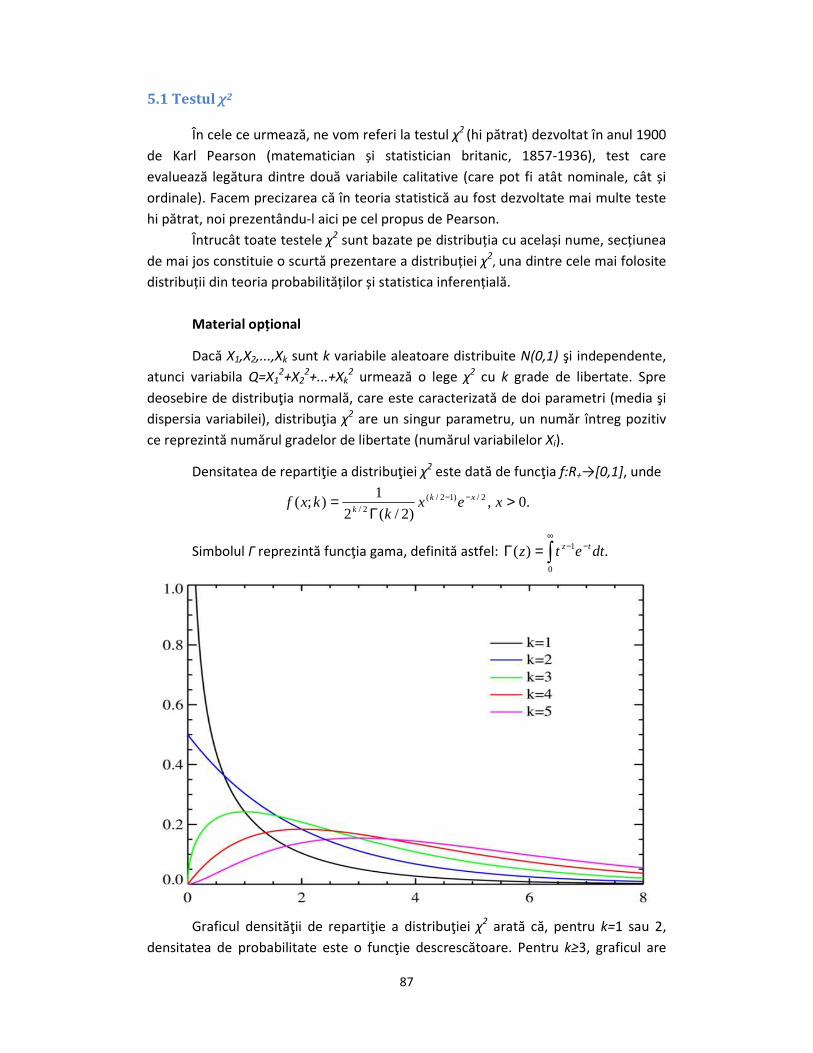
Densitatea de repartiţie a distribuţiei χ2 este dată de funcţia f:R+→[0,1], unde
.0,)2/(2
1);( 2/)12/(
2/>
Γ= −− xex
kkxf xk
k
Simbolul Г reprezintă funcţia gama, definită astfel: ∫∞
−−=Γ0
1 .)( dtetz tz
Graficul densităţii de repartiţie a distribuţiei χ2 arată că, pentru k=1 sau 2,
densitatea de probabilitate este o funcţie descrescătoare. Pentru k≥3, graficul are
88
forma unui clopot mai mult sau mai puţin simetric în funcţie de mărimea lui k. Chiar
dacă nu este reprezentat în figura de mai sus, pentru valori relativ mari ale lui k,
peste 25, graficul densităţii de repartiţie χ2 se apropie de cel al distribuţiei normale.
Caracteristicile legii χ2: Dacă Q~χ2
k, atunci E(Q)=k şi V(Q)=2k.
Pentru distribuţia χ2 au fost construite tabele care, în funcţie de valoarea lui k
şi a unei constante χ2α, arată probabilitatea ca variabila X~ χ
2k, să fie mai mare decât
χ2
α. Practic, alegând valoarea χ2
α şi cunoscând numărul gradelor de libertate k,
tabelul distribuţiei χ2 indică P(X> χ2
α). Anexa 1 conţine tabelul distribuţiei χ2 pentru
k=1 până la k=100 și șapte niveluri uzuale de semnificație statistică.
Revenind la testul χ2 dezvoltat de Pearson, pentru ușurința expunerii acesta
va fi prezentat prin intermediul unui exemplu numeric. Înaintea acestui exemplu,
trebuie să menționăm faptul că testul χ2 dă rezultate de încredere dacă:
• variabilele calitative avute în vedere înregistrează un număr redus de
categorii de răspunsuri, dar totuși nu foarte mic;
• populația din care sunt prelevate unitățile individuale analizate este de
mărimi mari;
• numărul observaţiilor (a unităților individuale analizate) este ridicat;
• observațiile sunt prelevate în mod aleatoriu din populația de referință.
Ultimele trei cerințe de mai sus permit interpretarea valorilor observate ca
probabilități de apariție a categoriilor de răspuns.
Testul χ2 se aplică în general pentru variabilele calitative nominale, care nu
implică existenţa unei relaţii de ordine între diversele categorii, dar el poate fi folosit
și pentru variabile calitative ordinale. În fine, testul hi pătrat nu este recomandat a se
aplica în cazul în care tabelul observat (detalii mai jos) conţine, în oricare dintre
celulele sale, mai puţin de 5 observaţii.
Exemplu: Într-o anumită regiune se află în jur de un milion de persoane cu drept de
vot (deci o populație de mărimi mari). Pentru a studia legătura dintre participarea la
vot şi sexul indivizilor, presupunem că am extras un eşantion aleatoriu de 10.000 de
persoane cu drept de vot (prin urmare, avem de-a face cu un număr ridicat de
observații, extrase probabilistic). Indivizii au fost întrebați dacă au votat la ultimele
alegeri, pentru fiecare fiind indicat și sexul său. Rezultatele obţinute sunt prezentate
în tabelul de mai jos, care se numeşte tabelul observat (notat O).
Observat Bărbaţi Femei Total
Au votat 2.792 3.591 6.383
N-auvotat 1.486 2.131 3.617
Total 4.278 5.722 10.000

89
Prin acest exercițiu statistic, se dorește testarea ipotezei potrivit căreia sexul
indivizilor şi prezenţa la vot sunt variabile independente (necorelate). Această
ipoteză este deseori numită ipoteza nulă (notată H0). Alternativa acestei ipoteze este
notată H1 și reprezintă situația în care cele două variabile sunt corelate (sunt
dependente), ceea ce ar însemna că prezența la vot depinde de sexul indivizilor.
Ideea de bază a testului χ2 este aceea că, pentru două evenimente
independente A şi B, P(A∩B)=P(A)*P(B). Aceasta înseamnă că, pentru două
evenimente independente, probabilitatea de realizare concomitentă a celor două
evenimente (atât evenimentul A, cât și evenimentul B), este egală cu produsul
probabilităților celor două evenimente.
Pe baza tabelului observat se remarcă faptul că 42,78% din indivizii din
eşantion sunt bărbaţi, în timp ce 57,22% sunt femei (vezi valorile îngroșate și
subliniate de la baza tabelului anterior). Apoi, tabelul observat arată că 63,83% din
indivizii chestionaţi au votat la ultimele alegeri, în timp ce 36,17% nu au participat la
vot (valorile îngroșate și subliniate din dreapta tabelului observat). Folosind aceste
procentaje, putem calcula valorile aşteptate pentru fiecare din cele 4 categorii de
indivizi cu drept de vot: bărbaţi care au votat, bărbaţi care n-au votat, femei care au
votat și femei care n-au votat. Se poate construi astfel tabelul de mai jos, care se mai
numeşte şi tabelul aşteptat (E).
63,83%*42,78%*10.000=2.730,65≈2.731
63,83%*57,22%*10.000=3.652,35≈3.652
36,17%*42,78%*10.000=1.547,35≈1.547
36,17%*57,22%*10.000=2.069,65≈2.070
Tabelul aşteptat este construit pornind de la premisa că ipoteza H0 este
adevărată, fapt pentru care valorile așteptate ale celor 4 cazuri posibile sunt
determinate prin înmulțirea probabilităților inițiale. Altfel spus, tabelul așteptat
conţine frecvenţele absolute ce s-ar obţine în cazul în care sexul indivizilor ar fi un
factor independent de participarea acestora la vot (sexul și participarea la vot ar fi
necorelate, iar ipoteza H0 ar fi validă).
În continuare, raționamentul este următorul: dacă cele două tabele (observat
și așteptat) nu diferă în mod semnificativ, atunci vom spune că sexul şi prezenţa la
urne sunt variabile independente, pentru că tabelul așteptat a fost construit exact pe
baza acestei presupuneri. Dacă însă cele două tabele diferă în mod semnificativ unul
de celălalt, atunci vom spune că, în practică, sexul şi prezenţa la urne sunt variabile
corelate, dependente, ipoteza H0 fiind respinsă, în timp ce ipoteza H1este
considerată validă.
În exemplul de mai sus, o simplă privire asupra celor două tabele arată că
tabelul aşteptat este diferit de tabelul observat în practică. Rămâne de stabilit dacă
cele două tabele sunt diferite în mod semnificativ, sau diferențele sunt neglijabile.
Așteptat Bărbaţi Femei Total
Au votat 2.731 3.652 6.383
N-au votat 1.547 2.070 3.617
Total 4.278 5.722 10.000

90
Diferenţa dintre cele două tabele este calculată pe baza a patru componente,
fiecare dintre acestea cuantificând diferenţa dintre celulele corespunzătoare din cele
două tabele:
cij=(Oij-Eij)2/Eij, i=1,2, j=1,2,
unde Oij reprezintă valoarea observată în celula (i,j), în timp ce Eij reprezintă valoarea
aşteptată din aceeași celulă (i,j).
Astfel, c11=(2.792-2.731)2/2.731=1,3625;
c12=(3.591-3.652)2/3.652=1,0189;
c21=(1.486-1.547)2/1.547=2,4053;
c22=(2.131-2.070)2/2.070=1,7976,
Apoi, indicatorul (sau statistica) χ2 se calculează ca sumă a componentelor cij:
χ2=c11+c12+c21+c22=6,5843.
În fine, indicatorul χ2 este apoi comparat cu valoarea tabelată pentru distribuţia hi
pătrat cu k grade de libertate, unde k=(numărul rândurilor-1)*(numărul coloanelor-
1)=(numărul opțiunilor pentru X-1)*(numărul opțiunilor pentru Y-1). În cazul nostru,
k=(2-1)x(2-1)=1, întrucât tabelul observat are două rânduri și două coloane de date
(fiecare din cele două variabile calitative are doar câte două valori posibile).
Pentru comparație se folosește cel de-al doilea tabel prezentat în Anexa 1, cu
mențiunea că prima coloană a tabelului indică gradele de libertate (degrees of
freedom, prescurtat d.f.), ceea ce noi am notat prin k.
Pentru început, ne uităm în tabel la valoarea hi pătrat ce corespunde
numărului de grade de libertate și unui prag de semnificație 5% (deci nivelul uzual de
încredere în rezultate, 95%). În cazul nostru, această valoare este 3,84. Deoarece
6,5843>3,84, putem afirma că ipoteza nulă (H0) este respinsă, ceea ce înseamnă că,
cu o probabilitate de cel puțin 95% putem afirma că cele două variabile (sexul
individului şi prezenţa la urne) sunt corelate.
Mergând ceva mai departe, vedem că, pentru k=1, valoarea 5,02 corespunde
unui prag de 2,5%, iar valoarea 6,63 corespunde unuia de 1%. Întrucât valoarea
calculată anterior, χ2=6,5843, este situată între aceste două valori tabelate, spunem
că cu o probabilitate foarte ridicată, între 97,5% şi 99% (chiar mai apropiată de 99%),
în regiunea studiată, prezenţa la urne şi sexul individului sunt corelate (cele două
variabile sunt într-o relaţie de dependenţă). Mai mult, întrucât sexul respondentului
este o caracteristică exogenă, dată pentru fiecare individ, în timp ce prezența la urne
este o variabilă endogenă, ce ține de opțiunile acestuia, putem intui și direcţia
cauzalităţii: prezenţa la urne depinde de sexul persoanei cu drept de vot, şi nu invers
(datele de mai sus indică faptul că bărbaţii au fost prezenţi la vot într-o măsură mai
mare decât femeile).

91
În acest moment, trebuie făcută o precizare importantă: din punct de vedere
strict teoretic, testul χ2 nu ar trebui utilizat atunci când avem de-a face cu un singur
grad de libertate, așa cum se întâmplă atunci când testăm dependența dintre două
variabile ce iau doar câte două valori posibile (în acest caz, forma distribuției χ2 cu un
singur grad de libertate introduce o eroare de continuitate). Pentru a atenua erorile
pe care aplicarea testul χ2 le generează în acest caz, statisticianul englez Frank Yates
a sugerat corectarea termenilor cij de mai sus, formula propusă fiind următoarea:
cij=(|Oij-Eij|-0,5)2/Eij, i=1,2, j=1,2.
Prin urmare, din valoarea absolută a fiecărei diferențe (Oij-Eij) se scade 0,5,
ceea ce înseamnă că, dacă Oij-Eij=20, atunci corecția Yates conduce la |Oij-Eij|-
0,5=19,5, în timp ce pentru Oij-Eij=-20, corecția Yates conduce la |Oij-Eij|-0,5=19,5.
După această corecție, testul continuă după cum a fost indicat mai sus (se calculează
statistica χ2, care se compară apoi cu valoarea tabelată corespunzătoare și se decide
dacă ipoteza H0 este respinsă sau nu).
Utilitatea corecției propuse de Yates este pusă sub semnul întrebării de unii
statisticieni, mulți dintre aceștia considerând-o excesivă. Alți practicieni o consideră
însă utilă în ajustarea statisticii (indicatorului) χ2. Sugestia mea este să aplicați
această corecție atunci când aveți de-a face cu un singur grad de libertate.
În continuare, aplicăm corecția Yates asupra exemplului nostru:
O11-E11=2.792-2.731=61
|O11-E11|-0,5=61-0,5=60,5
c11=(|O11-E11|-0,5)2/E11=60,5
2/2.731=1,3403
O12-E12=3.591-3.652=-61
|O12-E12|-0,5=61-0,5=60,5
c12=(|O12-E12|-0,5)2/E12=60,5
2/3.652=1,0023
O21-E21=1.486-1.547=-61
|O21-E21|-0,5=61-0,5=60,5
c21=(|O21-E21|-0,5)2/E21=60,5
2/1.547=2,3660
O22-E22=2.131-2.070=61
|O22-E22|-0,5=61-0,5=60,5
c22=(|O22-E22|-0,5)2/E22=60,5
2/2.070=1,7682
χ2=c11+c12+c21+c22=6,4768.
Noua valoare a statisticii χ2 nu schimbă concluziile enunțate anterior, ipoteza
H0 este în continuare invalidată pentru pragul uzual de semnificație 5% (de fapt,
ipoteza H0 este respinsă chiar și pentru pragul de semnificație 2,5%, întrucât
6,4768>5,02).

92
Așteptat Au luat
vitamina C
Nuauluat
vitamina C
Total
Au răcit 19 18 37
Nuaurăcit 97 96 193
Total 116 114 230
Exercițiu: 230 de indivizi, aleși aleatoriu dintr-o populație mai largă, au fost
chestionați cu privire la starea lor de sănătate din această primăvară, fiind întrebați și
dacă au luat sau nu tablete de vitamina C în această perioadă. Tabelul de mai jos
reprezintă tabelul observat.
Ipoteza nulă (H0) pe care o testăm acum este cea potrivit căreia starea de
sănătate nu depinde de administrarea de tablete de vitamina C (cele două variabile
calitative de mai sus sunt independente).
Rezolvare: Chiar dacă numărul total de observații (230) nu este unul impresionant,
considerăm că valorile din tabel pot fi raportate la total și interpretate ca
probabilități de apariție a fenomenelor studiate (observațiile au fost extrase
aleatoriu, numărul de observații din cele patru celule nu este mai mic de 5).
Cele 37 de persoane care au răcit, indiferent dacă au luat sau nu tablete de
vitamina C, reprezintă 16,09% din totalul celor 230 de persoane observate. Prin
urmare, cele 193 de persoane care nu au răcit, indiferent daca au luat sau nu
vitamina C, reprezintă 83,91% din total. Cele 116 persoane care au luat tablete de
vitamina C în această primăvară, atât cele care au răcit, cât și cele care nu au răcit,
reprezintă 50,43% din numărul persoanelor observate, în timp ce persoanele care nu
au luat tablete de vitamina C în această primăvară reprezintă 49,57% din totalul
observațiilor (114/230).
Tabelul așteptat se determină prin multiplicarea corespunzătoare a acestor
probabilități, ținând cont și de numărul de persoane analizate:
E11=50,43%*16,09%*230=18,66≈19
E12=49,57%*16,09%*230=37-19=18
E21=50,43%*83,91%*230=116-19=97
E22=49,57%*83,91%*230=114-18=96
Testul hi pătrat va fi aplicat cu corecția Yates, întrucât numărul gradelor de
libertate este 1.
|O11-E11|-0,5=|15-19|-0,5=3,5
c11=(|O11-E11|-0,5)2/E11=3,5
2/19=0,6447
|O12-E12|-0,5=|22-18|-0,5=3,5
c12=(|O12-E12|-0,5)2/E12=3,5
2/18=0,6806
Observat Au luat
vitamina C
Nu au luat
vitamina C
Total
Au răcit 15 22 37
Nu au răcit 101 92 193
Total 116 114 230
93
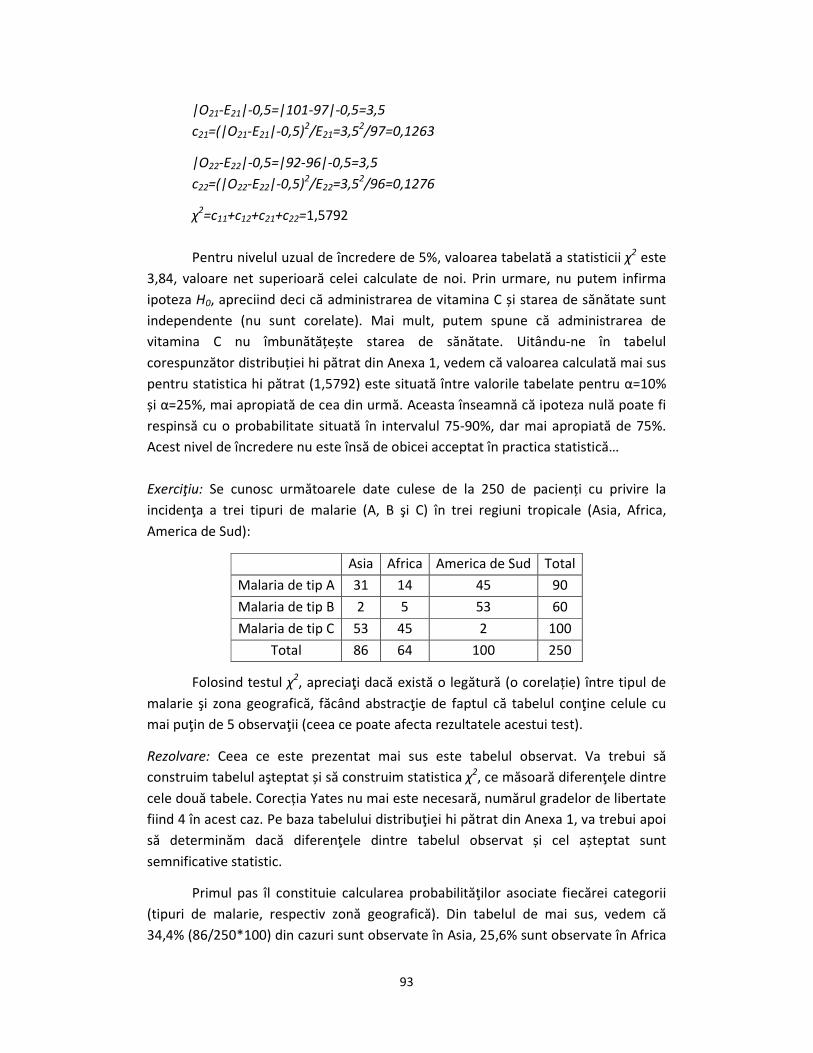
|O21-E21|-0,5=|101-97|-0,5=3,5
c21=(|O21-E21|-0,5)2/E21=3,5
2/97=0,1263
|O22-E22|-0,5=|92-96|-0,5=3,5
c22=(|O22-E22|-0,5)2/E22=3,5
2/96=0,1276
χ2=c11+c12+c21+c22=1,5792
Pentru nivelul uzual de încredere de 5%, valoarea tabelată a statisticii χ2 este
3,84, valoare net superioară celei calculate de noi. Prin urmare, nu putem infirma
ipoteza H0, apreciind deci că administrarea de vitamina C și starea de sănătate sunt
independente (nu sunt corelate). Mai mult, putem spune că administrarea de
vitamina C nu îmbunătățește starea de sănătate. Uitându-ne în tabelul
corespunzător distribuției hi pătrat din Anexa 1, vedem că valoarea calculată mai sus
pentru statistica hi pătrat (1,5792) este situată între valorile tabelate pentru α=10%
și α=25%, mai apropiată de cea din urmă. Aceasta înseamnă că ipoteza nulă poate fi
respinsă cu o probabilitate situată în intervalul 75-90%, dar mai apropiată de 75%.
Acest nivel de încredere nu este însă de obicei acceptat în practica statistică…
Exerciţiu: Se cunosc următoarele date culese de la 250 de pacienți cu privire la
incidenţa a trei tipuri de malarie (A, B şi C) în trei regiuni tropicale (Asia, Africa,
America de Sud):
Asia Africa America de Sud Total
Malaria de tip A 31 14 45 90
Malaria de tip B 2 5 53 60
Malaria de tip C 53 45 2 100
Total 86 64 100 250
Folosind testul χ2, apreciaţi dacă există o legătură (o corelație) între tipul de
malarie şi zona geografică, făcând abstracţie de faptul că tabelul conţine celule cu
mai puţin de 5 observaţii (ceea ce poate afecta rezultatele acestui test).
Rezolvare: Ceea ce este prezentat mai sus este tabelul observat. Va trebui să
construim tabelul aşteptat și să construim statistica χ2, ce măsoară diferenţele dintre
cele două tabele. Corecția Yates nu mai este necesară, numărul gradelor de libertate
fiind 4 în acest caz. Pe baza tabelului distribuţiei hi pătrat din Anexa 1, va trebui apoi
să determinăm dacă diferenţele dintre tabelul observat și cel așteptat sunt
semnificative statistic.
Primul pas îl constituie calcularea probabilităţilor asociate fiecărei categorii
(tipuri de malarie, respectiv zonă geografică). Din tabelul de mai sus, vedem că
34,4% (86/250*100) din cazuri sunt observate în Asia, 25,6% sunt observate în Africa

94
(64/250*100), iar 40% sunt observate în America de Sud (100/250*100). Apoi,
vedem că 36% (90/250*100) din cazuri sunt de malarie de tip A, 24% (60/250*100)
sunt malarie de tip B, iar 40% (100/250*100) sunt de tip C.
În contextul ipotezei nule (H0), presupunând că tipul de malarie este
independent de zona geografică, tabelul aşteptat se determină prin înmulţirea
procentelor corespunzătoare de mai sus şi a numărului total de cazuri observate,
respectiv 250. De exemplu, numărul aşteptat de cazuri de malarie de tip A în Asia
este 34,4%*36%*250=30,96≈31. Apoi, numărul aşteptat de cazuri de malarie de tipul
A în Africa este 25,6%*36%*250=23,04≈23. Tabelul aşteptat este prezentat mai jos.
Asia Africa America de Sud Total
Malaria de tip A 31 23 36 90
Malaria de tip B 21 15 24 60
Malaria de tip C 34 26 40 100
Total 86 64 100 250
Se calculează apoi valorile cij=(Oij-Eij)2/Eij, unde Oij reprezintă valoarea
observată iar Eij valoarea aşteptată.
c11=(31-31)2/31=0
c12=(14-23)2/23=3,522
c13=(45-36)2/36=2,25
...
c33=(2-40)2/40=36,1
Statistica χ2 se calculează ca sumă a valorilor cij şi reprezintă o măsură a
diferenţei dintre tabelul observat şi cel aşteptat. În cazul nostru,
χ2=c11+c12+...+c33=125,27. Această valoare este apoi comparată cu valorile tabelate
pentru distribuţia χ2 cu k grade de libertate, unde k=(3-1)*(3-1)=4.
Din tabelul distribuţiei χ2 se observă că valoarea corespunzătoare lui k=4 şi
pragului de semnificație α=5% este 9,49, valoare net inferioară celei calculate de noi.
Prin urmare, suntem în măsură să infirmăm ipoteza H0 cu probabilitate 95%, ceea ce
înseamnă că incidența diverselor tipuri de malarie este corelată cu regiunile
geografice tropicale. De fapt, întrucât valoarea statisticii hi pătrat determinată mai
sus, respectiv 125,27, este superioară chiar și valorii tabelate corespunzătoare unui
prag de semnificație 0,1% (valoarea pentru 4 grade de libertate este 18,5),
respingem ipoteza nulă cu o probabilitate de cel puţin 99,9%. De exemplu, putem
afirma acum aproape cu certitudine că malaria de tip B apare preponderent în
zonele tropicale ale Americii de Sud, incidența acesteia în Africa și Asia fiind
întâmplătoare, în timp ce malaria de tip C nu apare în America de Sud decât pur
întâmplător.
95
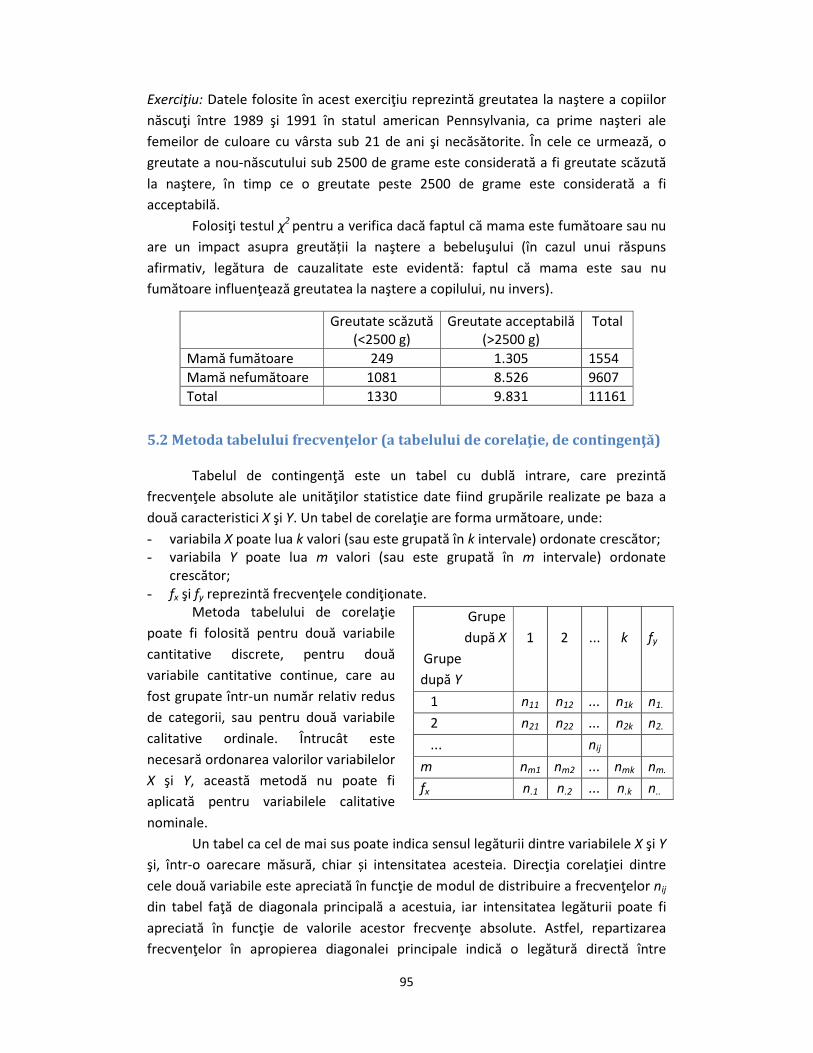
Exerciţiu: Datele folosite în acest exerciţiu reprezintă greutatea la naştere a copiilor
născuţi între 1989 şi 1991 în statul american Pennsylvania, ca prime naşteri ale
femeilor de culoare cu vârsta sub 21 de ani şi necăsătorite. În cele ce urmează, o
greutate a nou-născutului sub 2500 de grame este considerată a fi greutate scăzută
la naştere, în timp ce o greutate peste 2500 de grame este considerată a fi
acceptabilă.
Folosiţi testul χ2 pentru a verifica dacă faptul că mama este fumătoare sau nu
are un impact asupra greutății la naştere a bebeluşului (în cazul unui răspuns
afirmativ, legătura de cauzalitate este evidentă: faptul că mama este sau nu
fumătoare influenţează greutatea la naştere a copilului, nu invers).
Greutate scăzută (<2500 g)
Greutate acceptabilă (>2500 g)
Total
Mamă fumătoare 249 1.305 1554
Mamă nefumătoare 1081 8.526 9607
Total 1330 9.831 11161
5.2 Metoda tabelului frecvenţelor (a tabelului de corelaţie, de contingenţă)
Tabelul de contingenţă este un tabel cu dublă intrare, care prezintă
frecvenţele absolute ale unităţilor statistice date fiind grupările realizate pe baza a
două caracteristici X şi Y. Un tabel de corelaţie are forma următoare, unde:
- variabila X poate lua k valori (sau este grupată în k intervale) ordonate crescător; - variabila Y poate lua m valori (sau este grupată în m intervale) ordonate
crescător; - fx şi fy reprezintă frecvenţele condiţionate.
Metoda tabelului de corelaţie
poate fi folosită pentru două variabile
cantitative discrete, pentru două
variabile cantitative continue, care au
fost grupate într-un număr relativ redus
de categorii, sau pentru două variabile
calitative ordinale. Întrucât este
necesară ordonarea valorilor variabilelor
X şi Y, această metodă nu poate fi
aplicată pentru variabilele calitative
nominale.
Un tabel ca cel de mai sus poate indica sensul legăturii dintre variabilele X şi Y
şi, într-o oarecare măsură, chiar și intensitatea acesteia. Direcţia corelaţiei dintre
cele două variabile este apreciată în funcţie de modul de distribuire a frecvenţelor nij
din tabel faţă de diagonala principală a acestuia, iar intensitatea legăturii poate fi
apreciată în funcţie de valorile acestor frecvenţe absolute. Astfel, repartizarea
frecvenţelor în apropierea diagonalei principale indică o legătură directă între
Grupe
după X
Grupe
după Y
1
2
...
k
fy
1 n11 n12 ... n1k n1.
2 n21 n22 ... n2k n2.
... nij
m nm1 nm2 ... nmk nm.
fx n.1 n.2 ... n.k n..

96
variabilele X şi Y, o repartizare în jurul diagonalei secundare indică o legătură inversă
între cele două variabile, în timp ce repartizarea relativ uniformă a frecvenţelor în
tabel indică lipsa unei corelaţii între variabila X şi Y.
Exemplu: Punctul 1.5 din modelul de proiect din Statistică, autori E. Lilea, M. Vătui,
D. Boldeanu şi Z. Goschin.
5.3 Metoda grafică
Această metodă se aplică pentru acelaşi gen de variabile ca metoda tabelului
frecvenţelor, respectiv pentru variabile calitative ordinale sau pentru variabile
cantitative, care nu trebuie însă a fi neapărat grupate.
Dat fiind că luăm în considerare două serii de date, X şi Y, graficul se
construieşte pornind de la valorile (xi, yi), care se reprezintă în sistemul de axe
rectangulare. Graficul rezultat poartă numele de corelogramă sau grafic al norului de
puncte. Pentru ușurința expunerii, exemplele de grafice de mai jos sunt construite
doar pentru valori pozitive ale lui X şi Y.
În graficul din stânga, punctele par dispersate la întâmplare, în întreg
cadranul, fapt pentru care se mai poate considera că aceste puncte sunt împrăştiate
97
în jurul unei drepte paralele cu axa OX. Acest grafic arată că între cele două variabile
nu există o legătură semnificativă.
Dacă punctele se concentrează în jurul unei anumite linii, care nu este
paralelă cu axa OX, atunci apreciem că existenţă o corelaţie între cele două variabile.
Mai precis, concentrarea norului de puncte în jurul unei drepte cu pantă pozitivă, aşa
cum este cazul graficului din dreapta, indică existenţa unei legături directe (corelație
pozitivă) între variabilele X şi Y (valorile ridicate ale lui X sunt asociate valorilor
ridicate ale lui Y, și invers). Concentrarea în jurul unei drepte cu pantă negativă ar fi
fost interpretată ca indicând existența unei legături inverse (corelație negativă) între
cele două variabile.
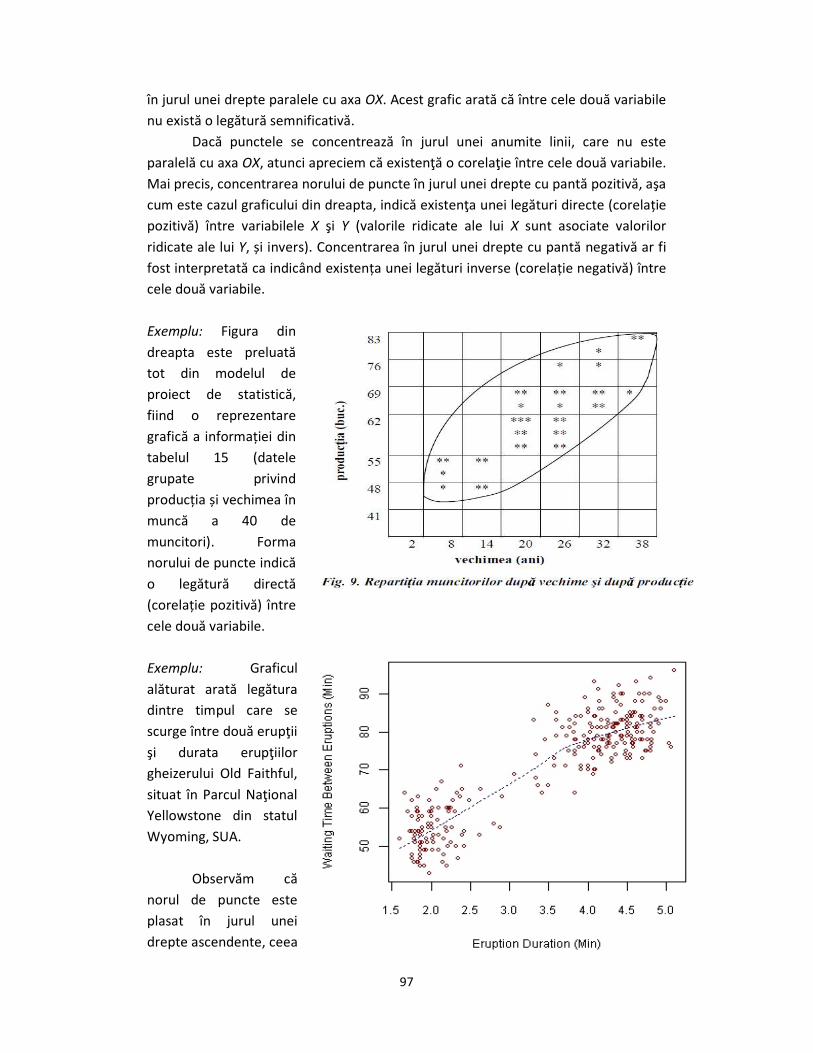
Exemplu: Figura din
dreapta este preluată
tot din modelul de
proiect de statistică,
fiind o reprezentare
grafică a informației din
tabelul 15 (datele
grupate privind
producția și vechimea în
muncă a 40 de
muncitori). Forma
norului de puncte indică
o legătură directă
(corelație pozitivă) între
cele două variabile.
Exemplu: Graficul
alăturat arată legătura
dintre timpul care se
scurge între două erupţii
şi durata erupţiilor
gheizerului Old Faithful,
situat în Parcul Naţional
Yellowstone din statul
Wyoming, SUA.
Observăm că
norul de puncte este
plasat în jurul unei
drepte ascendente, ceea

98
ce indică existenţa unei legături directe între cele două variabile (durata erupţiilor şi
intervalul la care acestea au loc). În plus, gruparea punctelor în doi nori relativ
separați sugerează faptul că erupţiile ar putea fi de două feluri: erupţii frecvente şi
de scurtă durată şi erupţii rare, dar de lungă durată. Utilitatea graficului este relativ
redusă în a indica direcţia de cauzalitate a legăturii, cauzalitatea fiind probabil
evidentă unui geolog.
5.4 Covarianţa
Covarianţa este un indicator al corelaţiei liniare dintre două variabile
cantitative, numerice. Pentru două caracteristici X şi Y, formula de calcul a
covarianţei, deseori notată şi prin cov(x,y), este ∑=
−−=n
iiixy yyxx
ns
1
),)((1
care se
mai poate scrie ∑=
⋅−=n
iiixy yxyx
ns
1
.1
În cazul în care seria de valori pentru cele
două caracteristici este dată sub forma unui tabel de contingenţă (xi, yj, nij), cu
i,j=1,2,...,n, atunci relaţia de calcul a covarianţei devine
∑ −−=ji
ijii nyyxxn
yx,
.))((1
),cov(
Definirea covarianţei are la bază încadrarea celor n observaţii, deci a celor n
puncte (xi,yj) din cadrul unei serii bidimensionale, într-unul din cele patru cadrane
definite de mediile celor două variabile. Pentru simplitatea expunerii, graficul de mai
jos ia în considerare două variabile ce pot lua doar valori pozitive (dar discuţia este
similară şi în cazul în care valorile posibile ale variabilelor sunt şi negative).
Punctele din cadranele I şi III scot în evidenţă o legătură directă (o corelație
pozitivă) între cele două
caracteristici, în timp ce
punctele situate în cadranele II
şi IV evidenţiază o legătură
inversă. Prin urmare, dacă
majoritatea punctelor sunt
dispuse în jurul unei drepte cu
pantă pozitivă (în cadranele I şi
III), atunci covarianţa va fi un
număr pozitiv, ce va indica
existenţa unei legături liniare
directe, iar dacă punctele sunt
încadrate cu preponderenţă în
cadranele II şi IV, valoarea
calculată a covarianţei va fi negativă, indicând existenţa unei legături liniare inverse.
Dacă punctele sunt distribuite neregulat și relativ în aceeași măsură în cele patru

99
cadrane, atunci valoarea apropiată de zero a covarianţei va indica faptul că cele două
variabile sunt independente liniar. Prin urmare, covarianţa este o măsură numerică
asociată formei norului de puncte, fiind deci o extindere a metodei grafice de
determinare a corelaţiei dintre variabile, prezentată anterior.
Trebuie subliniat faptul că discutăm aici de evidenţierea unei legături liniare
între cele două variabile, covarianţa nefiind prea utilă în evaluarea legăturilor
neliniare ce pot exista între variabilele economice. De exemplu, dacă norul de puncte
are forma literei U, este posibil ca valoarea covarianţei să fie apropiată de zero.
Aceasta nu înseamnă că între cele două variabile nu există o legătură, ci că aceasta
nu este una liniară (în acest caz, Y este probabil o funcţie de gradul doi în X).
Proprietăţi ale covarianţei:
• Acest indicator nu poate fi utilizat direct pentru aprecierea intensităţii corelaţiei dintre două caracteristici, întrucât nu este un indicator normalizat, depinzând de unitatea de măsură a acestora.
• Covarianţa este o măsură simetrică: cov(x,y)=cov(y,x).
• Covarianţa a două variabile independente este egală cu zero.
• Covarianţa unei variabile numerice cu o constantă este egală cu zero.
• Covarianţa unei variabile numerice cu ea însăşi este varianţa (dispersia) acelei
variabile: .))((1
),cov(1
22∑
==−−==
n
ixiix xxxx
nsxx σ
Dată fiind formula de calcul a
covarianţei, este evident că aceasta se
calculează doar pentru o serie
bidimensională, formată din două
variabile numerice. Pentru o serie
multidimensională, care cuprinde p>2
variabile, se poate construi matricea
varianţelor şi covarianţelor, notată V. Pe
diagonala principală, această matrice
pătratică de mărime p*p va conţine
varianţa (dispersia) fiecărei dintre cele p variabile, în timp ce deasupra diagonalei
principale apar înscrise covarianţele fiecărei perechi posibile pentru cele p variabile.
Întrucât sxy=syx, valorile de deasupra diagonalei principale apar înscrise şi sub această
diagonală, fapt pentru care, de cele mai multe ori, valorile de sub diagonala
principală sunt însă omise.
=
−21
323
22322
1131221
.
..
..
..
..
p
pp
p
p
p
s
s
ss
sss
ssss
V

100
5.5 Coeficientul de corelaţie liniară
Coeficientul de corelaţie liniară este o măsură normalizată care indică
existenţa şi intensitatea corelaţiei liniare dintre două variabile numerice. Acest
coeficient se calculează pe baza relaţiei
rxy=sxy/sxsy=cov(x,y)/σxσy,
unde sxy sau cov(x,y) reprezintă covarianţa dintre variabilele X şi Y, iar sx şi sy,
respectiv σx şi σy, reprezintă abaterile standard ale celor două variabile.
Prin construcţie, rxy este un număr în intervalul [-1, 1], o valoare pozitivă
indicând existenţa unei legături directe, în timp ce o valoare negativă indică faptul că
între cele două variabile se manifestă o corelaţie liniară inversă. Cu cât valoarea rxy
este mai apropiată de limitele intervalului, cu atât legătura dintre cele două variabile
(directă sau inversă) este mai puternică. Dacă valoarea indicatorului este apropiată
de zero, atunci putem spune că cele două variabile nu sunt corelate liniar. Dacă rxy=0,
atunci variabilele X şi Y sunt perfect independente liniar. Cu toate acestea, o valoare
redusă a indicatorului nu înseamnă neapărat că cele două variabile evoluează în mod
independent, întrucât variabilele pot fi legate printr-o legătură neliniară.
Dată fiind formula de calcul a coeficientului de corelaţie liniară, rxy=ryx.
Matricea de corelaţie, notată R, se
defineşte în mod asemănător cu matricea
varianţelor-covarianţelor. Toţi termenii de pe
diagonala principală ai acestei matrice pătratice
de dimensiune p x p sunt egali cu 1,
reprezentând corelaţia fiecăreia dintre cele p
variabile cu ea însăşi. Termenii rij de deasupra
diagonalei principale reprezintă coeficienţii de
corelaţie ce măsoară dependenţa liniară dintre
variabilele Xi şi Xj. Matricea R este simetrică, la fel ca matricea V, ceea ce face ca,
deseori, elementele de sub diagonala principală să nu mai fie prezentate.
În ceea ce priveşte mărimea coeficientului de corelaţie, unii practicieni,
precum Rea şi Parker (2005)4, apreciază că |rxy|<0,1 reprezintă o legătură neglijabilă,
0,1<|rxy|<0,3 indică o legătură de intensitate scăzută, 0,3<|rxy|<0,6 este un indicator
al unei legături de intensitate medie, 0,6<|rxy|<0,75 reprezintă o legătură puternică,
în timp ce |rxy|>0,75 indică existenţa unei legături foarte puternice între cele două
serii de date. Cu toate acestea, folosirea unor astfel de criterii este relativ arbitrară,
interpretarea mărimii coeficientului de corelaţie depinzând de domeniul studiat.
4 Louis M. Rea şi Richard A. Parker – Designing and Conducting Survey Research, A Comprehensive
Guide, ediţia 3, Jossey-Bass, 2005.
=
−
1
.
..
..1
..1
..1
1
3
223
11312
pp
p
p
p
r
r
rr
rrr
R

101
Astfel, un coeficient de corelaţie de 0,8 poate fi apreciat ca foarte mic în domeniile
tehnice, când se doreşte verificarea unei legi fizice cu ajutorul unor instrumente de
înaltă calitate, în timp ce această valoare va fi considerată ca foarte ridicată în
domeniul ştiinţelor sociale.
Graficele de mai jos indică mărimea coeficientului corelaţiei liniare (r) pentru
diverse forme ale norului de puncte (pentru legături directe între două variabile).
Primul grafic arată că, dacă legătura dintre cele două variabile este directă şi
perfect liniară, atunci coeficientul de corelaţie liniară va fi egal cu 1. Apoi, celelalte
grafice de pe primul rând arată că, cu cât cele două variabile sunt mai puţin corelate,
cu atât valoarea coeficientului calculat va fi mai redusă. Al doilea rând de grafice
arată faptul că coeficientul corelaţiei liniare indică doar intensitatea legăturii (forma
norului de puncte), fără a oferi informaţii cu privire la panta dreptei care
aproximează legătura dintre cele două variabile. Se observă deci că rxy=1 pentru
primele trei grafice din rândul doi, cu toate că legătura dintre variabile are o pantă
diferită. Pentru ultimul grafic, unde Y este o constantă, rxy este indicat a fi egal cu
zero, ceea ce nu este tocmai corect: întrucât covarianţa unei variabile aleatoare cu o
constantă este zero (cov(x,y)=0 pentru y constant), iar abaterea standard a unei
constante este tot zero (σy=0), coeficientul de corelaţie rxy=cov(x,y)/σxσy este de fapt
nedefinit.
De multe ori, ceea ce se raportează este pătratul coeficientului de corelaţie,
r2, numit coeficient de determinare. Acesta poate fi mai util pentru că are o
interpretare practică mai facilă, r2 x 100 reprezentând procentul variaţiei lui Y care
este explicat de variaţia lui X. În plus, r2 are o valoare mai mică decât r, ceea ce poate
ajuta la evitarea situaţiei în care o valoare relativ redusă a lui r poate fi considerată
ca fiind semnificativă (de exemplu, pătratul lui r=0,2, valoare pe care cineva ar putea
fi tentat a o considera semnificativă, este r2=0,04, valoare foarte apropiată de zero).
102
Evident, 0≤r2≤1, acest indicator fiind încă o măsură a intensităţii relaţiei
liniare dintre cele două variabile. După cum vom vedea în secţiunea destinată
regresiei liniare, coeficientul de determinare este şi un indicator al apropierii dreptei
de regresie de datele observate.
La fel ca în cazul covarianței, pe baza căreia se și calculează, coeficientul de
corelație este util pentru evaluarea unei legături liniare între două serii de date,
rezultatele aplicării sale fiind denaturate în cazul existenței unei legături neliniare.
Un alt aspect ce trebuie reținut este acela că ar trebui evitată evaluarea corelației
prin intermediul coeficientului de corelație liniară (sau a covarianței) atunci când
datele par a fi grupate într-un anumit mod.
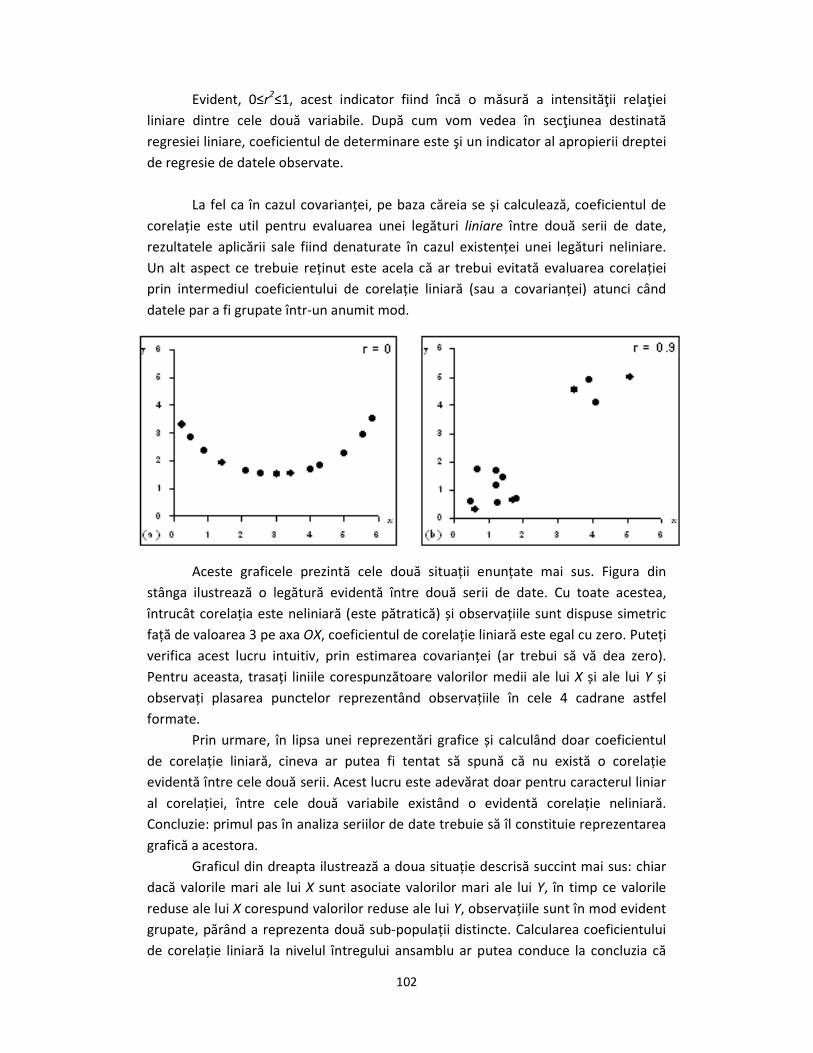
Aceste graficele prezintă cele două situații enunțate mai sus. Figura din
stânga ilustrează o legătură evidentă între două serii de date. Cu toate acestea,
întrucât corelația este neliniară (este pătratică) și observațiile sunt dispuse simetric
față de valoarea 3 pe axa OX, coeficientul de corelație liniară este egal cu zero. Puteți
verifica acest lucru intuitiv, prin estimarea covarianței (ar trebui să vă dea zero).
Pentru aceasta, trasați liniile corespunzătoare valorilor medii ale lui X și ale lui Y și
observați plasarea punctelor reprezentând observațiile în cele 4 cadrane astfel
formate.
Prin urmare, în lipsa unei reprezentări grafice și calculând doar coeficientul
de corelație liniară, cineva ar putea fi tentat să spună că nu există o corelație
evidentă între cele două serii. Acest lucru este adevărat doar pentru caracterul liniar
al corelației, între cele două variabile existând o evidentă corelație neliniară.
Concluzie: primul pas în analiza seriilor de date trebuie să îl constituie reprezentarea
grafică a acestora.
Graficul din dreapta ilustrează a doua situație descrisă succint mai sus: chiar
dacă valorile mari ale lui X sunt asociate valorilor mari ale lui Y, în timp ce valorile
reduse ale lui X corespund valorilor reduse ale lui Y, observațiile sunt în mod evident
grupate, părând a reprezenta două sub-populații distincte. Calcularea coeficientului
de corelație liniară la nivelul întregului ansamblu ar putea conduce la concluzia că
103
datele sunt puternic corelate (în acest caz, r=0,9). Dacă însă aceste date chiar provin
de la două sub-populații distincte, atunci analiza ar trebui făcută la nivelul fiecărui
grup, caz în care corelația este extrem de slabă (niciunul din cele două grupuri de
puncte nu pare a prezenta o anumită tendință). Prin urmare, avem de-a face cu o
corelație aparentă, nu una reală (în engleză, spurious correlation – cei interesați pot
căuta exemple de astfel de corelații pe internet, unele sunt chiar amuzante).
În clasă am dat un exemplu similar, dar dus chiar la extrem, în care cele două
grupuri distincte de puncte prezentau, fiecare, o tendință de corelare inversă. În
acest caz, analizând întregul set de date prin intermediul covarianței sau al
coeficientului de corelație liniară, am fi induși complet în eroare și am aprecia că
avem de-a face cu o corelație pozitivă (poate chiar puternică). Concluzie: primul pas
în analiza seriilor de date trebuie să îl constituie reprezentarea grafică a acestora.
Analiza corelației dintre variabile prin intermediul covarianței și coeficientului
de corelație liniară mai prezintă o limitare, care afectează interpretarea în cazul
seriilor de date cronologice (de timp): cei doi indicatori indică corelația instantanee
dintre două fenomene și nu surprind eventualele efecte întârziate (lag-uri) ale unei
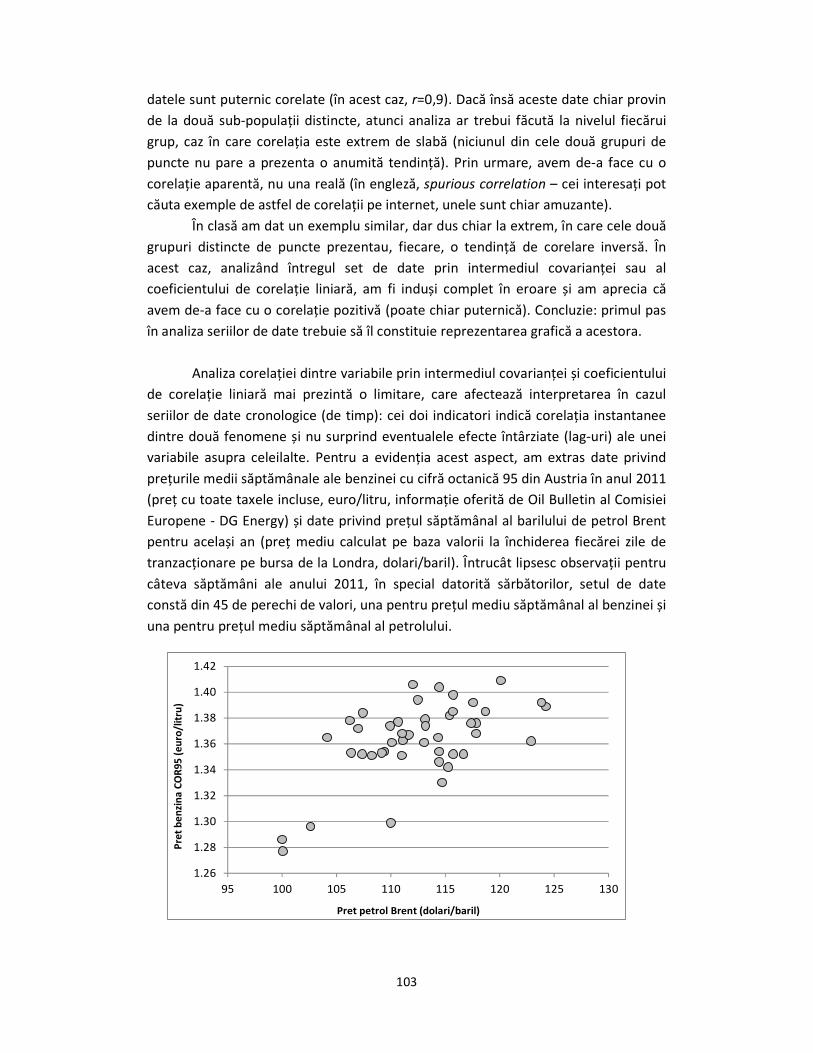
variabile asupra celeilalte. Pentru a evidenția acest aspect, am extras date privind
prețurile medii săptămânale ale benzinei cu cifră octanică 95 din Austria în anul 2011
(preț cu toate taxele incluse, euro/litru, informație oferită de Oil Bulletin al Comisiei
Europene - DG Energy) și date privind prețul săptămânal al barilului de petrol Brent
pentru același an (preț mediu calculat pe baza valorii la închiderea fiecărei zile de
tranzacționare pe bursa de la Londra, dolari/baril). Întrucât lipsesc observații pentru
câteva săptămâni ale anului 2011, în special datorită sărbătorilor, setul de date
constă din 45 de perechi de valori, una pentru prețul mediu săptămânal al benzinei și
una pentru prețul mediu săptămânal al petrolului.
1.26
1.28
1.30
1.32
1.34
1.36
1.38
1.40
1.42
95 100 105 110 115 120 125 130
Pre
t b
en
zin
a C
OR
95
(e
uro
/lit
ru)
Pret petrol Brent (dolari/baril)
104
Calcularea coeficientului de corelație liniară pentru acest set de date conduce
la valoarea r=0,588, ceea ce indică o legătură directă între prețul barilului de petrol și
prețul benzinei COR95. Cu toate acestea, valoarea coeficientului de corelație liniară
nu este atât de mare pe cât ne-am fi așteptat, ceea ce poate să însemne că există
mulți alți factori, importanți, care afectează prețul benzinei, în afara prețului
petrolului Brent. Valoarea 0,588 pentru coeficientul de corelație liniară implică o
valoare de 0,346 pentru r2, coeficientul de determinare.
Graficul de mai sus ilustrează forma norului de puncte reprezentând cele 45
de observații săptămânale. Concluzia enunțată deja de două ori se aplică și aici:
primul pas în analiza seriilor de date trebuie să îl constituie reprezentarea grafică a
acestora. Întrucât avem de-a face cu serii de timp, graficul potrivit va fi unul de tip
linie, prezentând evoluția simultană a celor două variabile pe parcursul anului 2011.
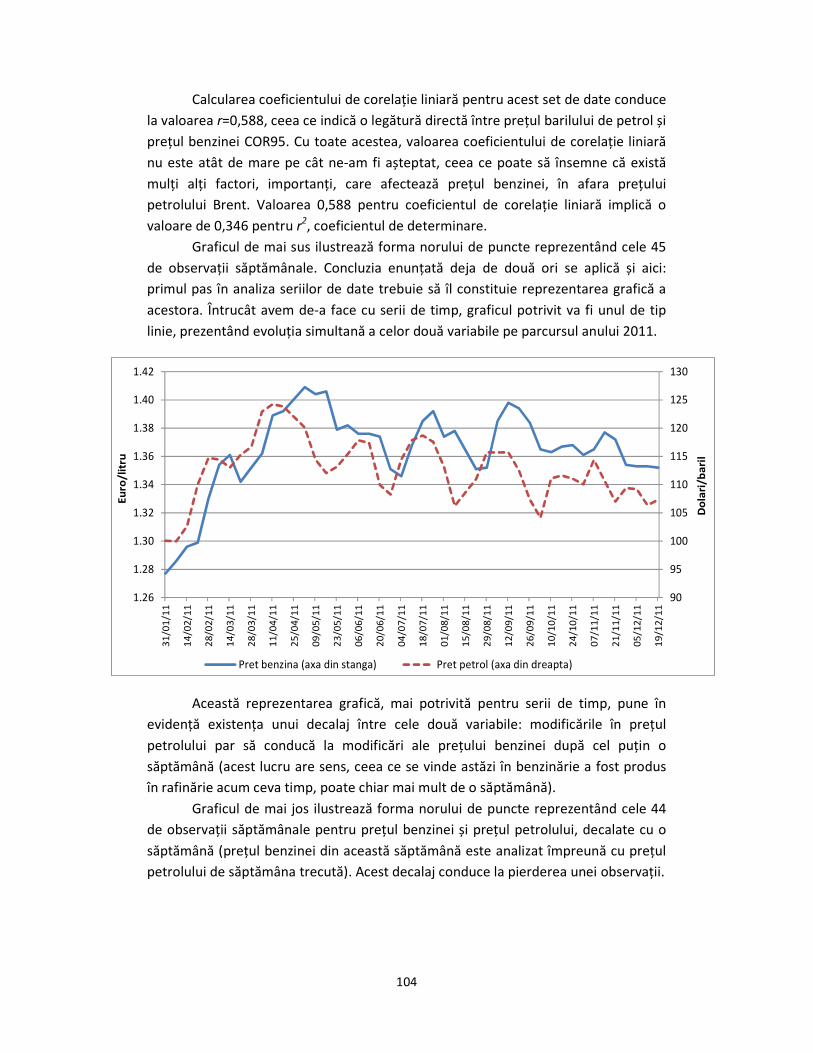
Această reprezentarea grafică, mai potrivită pentru serii de timp, pune în
evidență existența unui decalaj între cele două variabile: modificările în prețul
petrolului par să conducă la modificări ale prețului benzinei după cel puțin o
săptămână (acest lucru are sens, ceea ce se vinde astăzi în benzinărie a fost produs
în rafinărie acum ceva timp, poate chiar mai mult de o săptămână).
Graficul de mai jos ilustrează forma norului de puncte reprezentând cele 44
de observații săptămânale pentru prețul benzinei și prețul petrolului, decalate cu o
săptămână (prețul benzinei din această săptămână este analizat împreună cu prețul
petrolului de săptămâna trecută). Acest decalaj conduce la pierderea unei observații.
90
95
100
105
110
115
120
125
130
1.26
1.28
1.30
1.32
1.34
1.36
1.38
1.40
1.42
31/01/11
14/02/11
28/02/11
14/03/11
28/03/11
11/04/11
25/04/11
09/05/11
23/05/11
06/06/11
20/06/11
04/07/11
18/07/11
01/08/11
15/08/11
29/08/11
12/09/11
26/09/11
10/10/11
24/10/11
07/11/11
21/11/11
05/12/11
19/12/11
Dolari/baril
Euro/litru
Pret benzina (axa din stanga) Pret petrol (axa din dreapta)
105
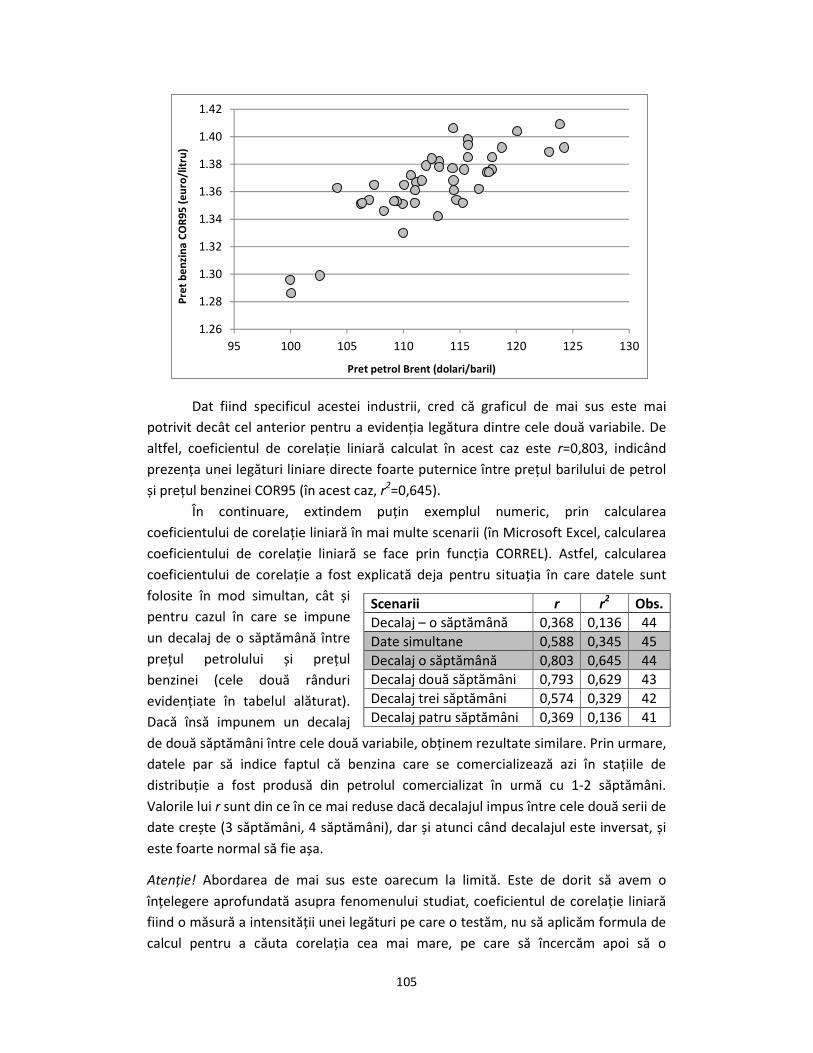
Dat fiind specificul acestei industrii, cred că graficul de mai sus este mai
potrivit decât cel anterior pentru a evidenția legătura dintre cele două variabile. De
altfel, coeficientul de corelație liniară calculat în acest caz este r=0,803, indicând
prezența unei legături liniare directe foarte puternice între prețul barilului de petrol
și prețul benzinei COR95 (în acest caz, r2=0,645).
În continuare, extindem puțin exemplul numeric, prin calcularea
coeficientului de corelație liniară în mai multe scenarii (în Microsoft Excel, calcularea
coeficientului de corelație liniară se face prin funcția CORREL). Astfel, calcularea
coeficientului de corelație a fost explicată deja pentru situația în care datele sunt
folosite în mod simultan, cât și
pentru cazul în care se impune
un decalaj de o săptămână între
prețul petrolului și prețul
benzinei (cele două rânduri
evidențiate în tabelul alăturat).
Dacă însă impunem un decalaj
de două săptămâni între cele două variabile, obținem rezultate similare. Prin urmare,
datele par să indice faptul că benzina care se comercializează azi în stațiile de
distribuție a fost produsă din petrolul comercializat în urmă cu 1-2 săptămâni.
Valorile lui r sunt din ce în ce mai reduse dacă decalajul impus între cele două serii de
date crește (3 săptămâni, 4 săptămâni), dar și atunci când decalajul este inversat, și
este foarte normal să fie așa.
Atenție! Abordarea de mai sus este oarecum la limită. Este de dorit să avem o
înțelegere aprofundată asupra fenomenului studiat, coeficientul de corelație liniară
fiind o măsură a intensității unei legături pe care o testăm, nu să aplicăm formula de
calcul pentru a căuta corelația cea mai mare, pe care să încercăm apoi să o
1.26
1.28
1.30
1.32
1.34
1.36
1.38
1.40
1.42
95 100 105 110 115 120 125 130
Pre
t b
en
zin
a C
OR
95
(e
uro
/lit
ru)
Pret petrol Brent (dolari/baril)
Scenarii r r2 Obs.
Decalaj – o săptămână 0,368 0,136 44
Date simultane 0,588 0,345 45
Decalaj o săptămână 0,803 0,645 44
Decalaj două săptămâni 0,793 0,629 43
Decalaj trei săptămâni 0,574 0,329 42
Decalaj patru săptămâni 0,369 0,136 41

106
justificăm. În acest caz simplu, ar trebui să știm dinainte cam care este orizontul de
timp al reacției prețului benzinei la modificările prețului petrolului, orizont de timp
ce este apoi testat numeric, nu să construim coeficienții de corelație și apoi să-l
alegem pe cel mai mare, justificându-l ulterior prin scenarii mai mult sau mai puțin
fanteziste.
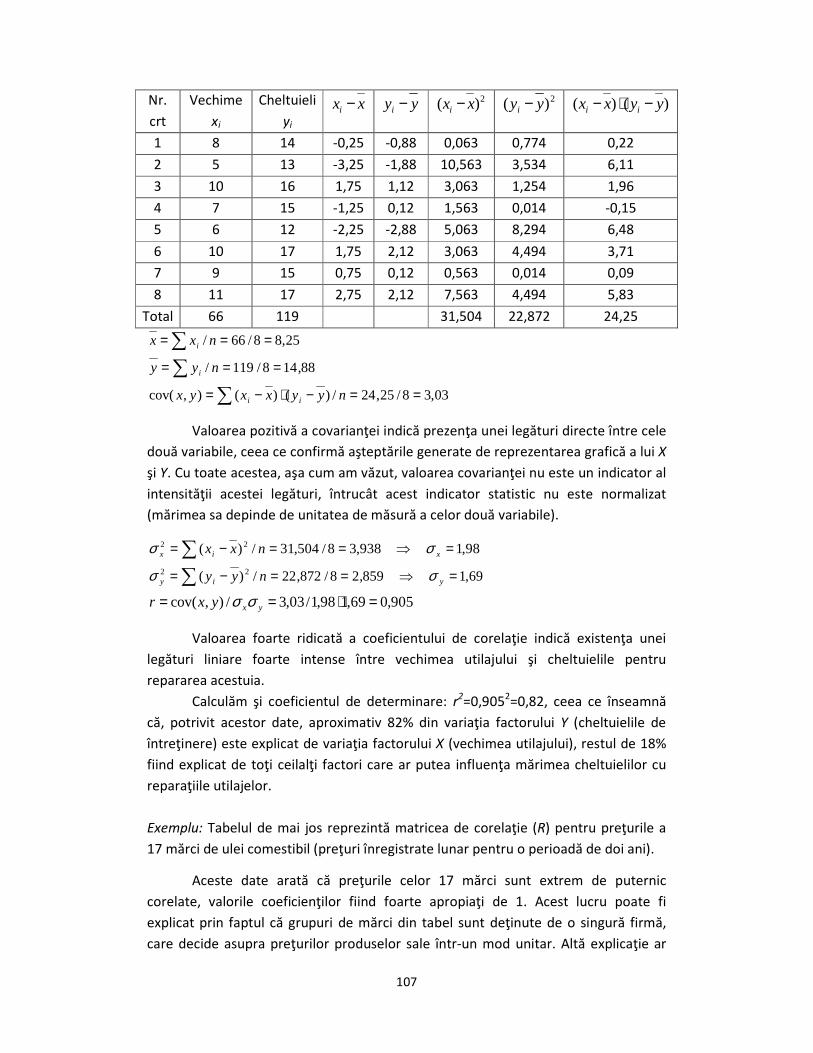
Exerciţiu: Se cunosc următoarele date cu privire la vechimea (în ani) şi cheltuielile cu
reparaţiile (în mii lei) pentru 8 utilaje.
Utilaj 1 2 3 4 5 6 7 8
Vechime (X) 8 5 10 7 6 10 9 11
Cheltuieli (Y) 14 13 16 15 12 17 15 17
Analizaţi corelaţia dintre aceste variabile folosind metoda grafică şi apoi
metode numerice (calculând covarianţa şi coeficientul de corelaţie).
Rezolvare: Reprezentarea grafică a acestor două variabile indică existenţa unei
legături directe între X şi Y, întrucât norul de (doar 8) puncte pare a fi distribuit în
jurul unei drepte cu pantă pozitivă. Deoarece vechimea utilajului este o caracteristică
predeterminată, putem intui şi direcţia dependenţei: o vechime mai mare a unui
utilaj implică costuri sporite de reparaţii a acestuia.
În vederea calculării covarianţei şi a coeficientului corelaţiei liniare, construim
tabelul de mai jos.
10
11
12
13
14
15
16
17
18
4 5 6 7 8 9 10 11 12
Y
X
107
Nr.
crt
Vechime
xi
Cheltuieli
yi
xxi − yyi − 2)( xxi − 2)( yyi − )()( yyxx ii −⋅−
1 8 14 -0,25 -0,88 0,063 0,774 0,22
2 5 13 -3,25 -1,88 10,563 3,534 6,11
3 10 16 1,75 1,12 3,063 1,254 1,96
4 7 15 -1,25 0,12 1,563 0,014 -0,15
5 6 12 -2,25 -2,88 5,063 8,294 6,48
6 10 17 1,75 2,12 3,063 4,494 3,71
7 9 15 0,75 0,12 0,563 0,014 0,09
8 11 17 2,75 2,12 7,563 4,494 5,83
Total 66 119 31,504 22,872 24,25
25,88/66/ ===∑ nxx i
88,148/119/ ===∑ nyy i
∑ ==−⋅−= 03,38/25,24/)()(),cov( nyyxxyx ii
Valoarea pozitivă a covarianţei indică prezenţa unei legături directe între cele
două variabile, ceea ce confirmă aşteptările generate de reprezentarea grafică a lui X
şi Y. Cu toate acestea, aşa cum am văzut, valoarea covarianţei nu este un indicator al
intensităţii acestei legături, întrucât acest indicator statistic nu este normalizat
(mărimea sa depinde de unitatea de măsură a celor două variabile).
98,1938,38/504,31/)( 22 =⇒==−=∑ xix nxx σσ
69,1859,28/872,22/)( 22 =⇒==−=∑ yiy nyy σσ
905,069,198,1/03,3/),cov( =⋅== yxyxr σσ
Valoarea foarte ridicată a coeficientului de corelaţie indică existenţa unei
legături liniare foarte intense între vechimea utilajului şi cheltuielile pentru
repararea acestuia.
Calculăm şi coeficientul de determinare: r2=0,9052=0,82, ceea ce înseamnă
că, potrivit acestor date, aproximativ 82% din variaţia factorului Y (cheltuielile de
întreţinere) este explicat de variaţia factorului X (vechimea utilajului), restul de 18%
fiind explicat de toţi ceilalţi factori care ar putea influenţa mărimea cheltuielilor cu
reparaţiile utilajelor.
Exemplu: Tabelul de mai jos reprezintă matricea de corelaţie (R) pentru preţurile a
17 mărci de ulei comestibil (preţuri înregistrate lunar pentru o perioadă de doi ani).
Aceste date arată că preţurile celor 17 mărci sunt extrem de puternic
corelate, valorile coeficienţilor fiind foarte apropiaţi de 1. Acest lucru poate fi
explicat prin faptul că grupuri de mărci din tabel sunt deţinute de o singură firmă,
care decide asupra preţurilor produselor sale într-un mod unitar. Altă explicaţie ar

108
putea fi dată de existenţa unei materii prime cu o influenţă covârşitoare asupra
preţului produsului finit. În cazul de faţă este vorba de floarea soarelui, preţul acestei
materii prime influenţând probabil preţul tuturor mărcilor de ulei în acelaşi sens şi în
acelaşi timp.
Tabelul mai arată că, din cele 17 mărci de ulei, două par a avea trăsături
oarecum diferite de restul, şi apropiate între ele. Este vorba de mărcile 2 şi 14, între
care coeficientul de corelaţie este foarte ridicat, 0,955, dar care prezintă coeficienţi
de corelaţie uşor reduşi cu celelalte 15 mărci de ulei.
Top Related