







Languages
Pages
Legal


2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013
Resiliency at Scale in the Distributed Storage Cloud
Alma Riska Advanced Storage Division
EMC Corporation
In collaboration with many at Cloud Infrastructure Group

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Outline
Wide topic but this talk will focus on Architecture Resiliency Failures Redundancy schemes Policies to differentiate services
2
2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
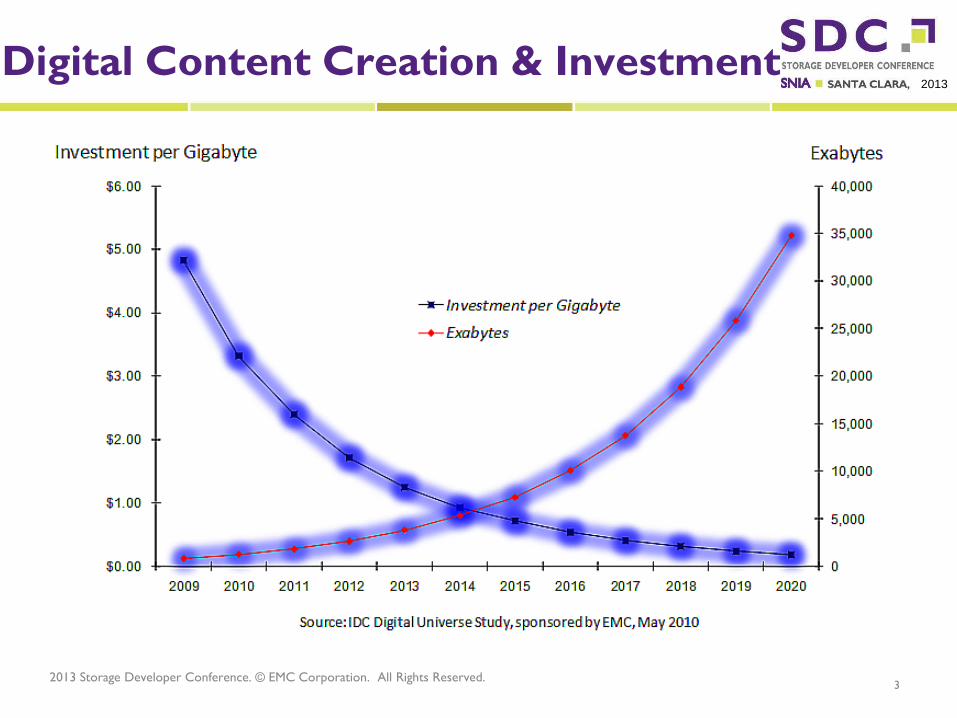
2013 Digital Content Creation & Investment
3

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Scaled-out Storage Systems
Large amount of hardware Thousands of disks Tens to hundreds of servers Significant amount of networking
Wide range of applications Internet Service Providers On-line Service Providers Private cloud
Up-to million of users 4

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Storage Requirements
Store massive amount of data (Tens) PetaBytes Direct attached high capacity nearline
HDDs Highly available Minimum down time
Reliably stored Beyond the traditional 5 nines
Ubiquitous access Cross geographical boundaries
5

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Scaled-out Storage Architecture
Hardware organized in nodes / racks / geographical sites
6
Site
Rack
Nod
e S
ervi
ces/
node
LAN / WAN
Site
Rack
Nod
e
Ser
vice
s/no
de
Site
Rack
Nod
e S
ervi
ces/
node
s ,.
Site
Rack
Nod
e
Ser
vice
s/no
de

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Scalability in Scaled-out Storage
Independence between components – no single point of failure Hardware – disks, nodes, racks, sites Software – services such as metadata
Seamlessly add/remove storage devices or nodes Isolation of failures Sustaining performance
Shared-nothing architecture Elasticity / resilience / performance
7

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 EMC Atmos Architecture
Shared nothing architecture Nodes - 15-60 large capacity SAS HDDs Racks – up to 8 nodes or 480 4TB HDDs (>1PByte) At least two sites
8
Site
Rack
Nod
e Se
rvic
es/n
ode
LAN / WAN
Site
Rack
Nod
e Se
rvic
es/n
ode

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Storage Resiliency
Data Reliability Data is stored persistently in device(s) like HDDs
Data Availability Data is available independently of the failures of
hardware
Data Consistency and Accuracy Returned data is what the user has stored in the
system
9

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Failures
Data devices (HDDs) Other components Hardware
Network Power outages Cooling outages
Software Drivers Services (metadata)
10
Site
Rack
No
de
Ser
vice
s/n
ode
LAN / WAN
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Transient Failures
Many failures are transient Temporary interruption of
operation of a component Variability in component
response time can be seen as a transient failure Particularly network delays
System load causes transient failures
Transient failures occur much more often than hardware component failures
11
Site
Rack
No
de
Ser
vice
s/n
ode
LAN / WAN
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Impact of Failures
Reliability Disk failures directly But all other failures too
Availability Directly impacted by any
failure, particularly transient Consistency Service failures
Metadata
Transient failures
12
Site
Rack
No
de
Ser
vice
s/n
ode
LAN / WAN
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Criticality of Failures in the Cloud
Large scale, e.g., node failure Make unavailable large amount of data and other
components simultaneously Since there are more components in the system,
failures happen more often System needs to be design with high component
unavailability in mind Even if the unavailability is transient
13

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Challenges of Handling Failures
Correct identification of failures Many failures have similar symptoms
Disk unreachable (disk failure, controller failure, power failure, network failure)
Effective isolation of failures Limit the cases when a single component failure
becomes a node or site failure Timely detection of failures In a large system failures may go undetected Particularly transient failures and their impact
14

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Example of System Alerts
15
HDD events are overwhelming
Event do not necessarily indicate disk failures
Rather temporary unreachable HDDs Various reasons Majority,
transient

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013
Site
Rack
No
de
Ser
vice
s/n
ode
LAN / WAN
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode
Fault Tolerance in Cloud Storage
Transparency toward failures Disks / Nodes / Racks Services Even entire sites
Transparency varies by system Goal or targets
16
x
X
X x

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Fault Tolerance in Cloud Storage
17
Site
Rack
No
de
Ser
vice
s/n
ode
LAN / WAN
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode Transparency toward failures
Disks / Nodes / Racks Services Even entire sites
Transparency varies by system Goal or targets
Resilience goals determine fault domains

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Fault Domains
The hierarchy of the set of resources whose failure can be tolerated in a system
Example: Tolerate a site failure Two racks or 16 nodes or 240 disks
Determines distribution Data Services
18
Site
Rack
No
de
Ser
vice
s/n
ode
LAN / WAN
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Fault Tolerance and Redundancy
Fault tolerance is primarily achieved via redundancy More hardware and software than needed
Achieving a fault tolerant goal depends Amount of redundancy (storage capacity)
Traditionally parity (RAID) Often in the cloud is replication Erasure coding
Pro-active measures Monitoring/analysis/prediction of system’s health Background detection of failures
19

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Fault Tolerance and Data Replication
Replicate data (including metadata) up to 4 times Pros High reliability High availability Good performance and accessibility Easy to implement
Cons High capacity overhead
Up to 300% in a 4-way replication
20

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Replication in Scale-Out Cloud Storage
Average case in a cloud storage system Several tens (up to hundred) of raw PBytes
capacity Multiple tens of user PBytes capacity
Does not scale well with regard to Cost Resilience
With only 3 replicas it is not always possible to tolerate multi-node and site failure
21

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Erasure Coding
Generalization of parity-based fault tolerance RAID schemes Replication is a special case
Out of n fragments of information m are actual data k are additional codes (n=m+k) k missing fragments of data can be tolerated Code is referred to as m/n code
22

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Erasure Coding
Capacity overhead k/n Overhead reduces as n increases
Same protection
Complexity – computational and management Increases as n increases As network delays dominate performance erasure
coding becomes feasible approach Trade-off between protection, complexity, overhead Common EMC Atmos codes are 9/12, 10/16
23

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 EC vs. Other redundancy schemes
24

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Erasure Coding at Scale
Data fragments distributed based on the system fault domains
Placement of these fragments is crucial Round-robin placement ensures uniform
distribution of fragments Assumed in previous calculations
Placement of data fragments depends on User requirements with regard to
Performance Priorities
25

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 EC data placement in the Cloud
We develop a model to see dependencies between EC fragment placement and system size/architecture
Determine Tolerance toward site failures as a function of
Number of sites m/n erasure code parameters
Additional node failure tolerance

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 EC data placement in the Cloud
Assumptions: Homogeneous geographically distributed sites Equal number of nodes and disks Equal network delays between any pair of sites Equal data priority
Round robin distribution of the fragments across Sites / nodes / disks
Failures on disks / nodes / sites (power, network)

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Failure Tolerance in 2 Site System
In a two site system there is only one site failure tolerance Each site has 6 nodes available The numbers inside each (x,y) tuple are the number of nodes tolerated in addition to the sites tolerated

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Failure Tolerance in 4 Site System
In a four site system there are one, two and three site failure tolerance Each site has 6 nodes available The numbers inside each (x,y) tuple are the number of nodes tolerated in addition to the sites tolerated

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Heterogeneous Protection Policies
As system evolve their resources become heterogeneous Different node or site sizes Different network bandwidth Different data priority
location origin
In such a case Uniformity of data distribution not a requirement The above factors (including performance) should
determine data fragment placement
30

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013
Abstraction of Heterogeneous Cloud Storage
Group components based on affinity criteria Network bandwidth
Create homogeneous sub-cluster
Determine redundancy for each sub-cluster
Handle each sub-cluster independently
Combine outcome for system-wide placement
Site
Rack
No
de
Ser
vice
s/n
ode
LAN / WAN
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013
Abstraction of Heterogeneous Cloud Storage - Example
Two sites are close (e.g. on the same US coast) Fast network connection
Data can be placed in any of the nodes in both sites and retrieving it will not suffer extra network delay
If an 6/12 redundancy scheme is used If data primary location is the upper
two-site subcluster then 6 data fragments can be placed in its two sites and the 6 codes in the other remote sites Accessing the data is not affected
by network bandwidth One site failure is tolerated
Site
Rack
No
de
Ser
vice
s/n
ode
LAN / WAN
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode
Site
Rack
No
de
Ser
vice
s/n
ode

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Differentiate Protection via Policy
Flexible policy settings for grouping resources and isolating applications /tenants
Easily managing a large heterogeneous system Hybrid protection schemes that combine multiple
replication schemes E.g., a two replications policy where
First replica is the original data (stored in the closest site to tenant)
Second replica is a 9/12 EC scheme that distributes the data in the rest of the sites for resilience
33

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Protection Policies in the Field
34
Tenants Sites 2 replicas >= 3 replicas 1 EC replica >= 2 EC replica Mix regular/EC
1 1 10/2; 9/3 4 1 sync; async 2 2 sync; async async 3 2 sync async
4 2 sync; async 9/3 9/3; 10/6; sync; async 2 2 sync; async sync; async 2 2 9/3; sync; async
2 sync; async sync 3 2 sync 9:3; sync; async 2 4 sync; async async 10/6; 9/3 9/3; sync; async 9:/3; async 1 2 10:2 2 2 sync 9:3; sync; async 9/3 async 2 1 sync 9:3 2 2 sync async 9/3 async 1 6 9:3 async 2 2 async 2 2 sync 9:3 9:3 async 3 2 sync async 3 3 sync async 2 1 sync

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Proactive Failure Detection
Monitoring the health of devices and services Logging events
Taking corrective measures before failures happen Strengthen the resilience Address without the redundancy affected by
failure Example Use of SMART logs to determine health of drives
Replace HDDs that are about to fail rather than failed
35

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Proactive Failure Detection
Verify in the background the validity of data, services and health of hardware Critical aspect of resiliency in the cloud
System are large and some portions maybe idle for extended periods of time Failures and issues may go undetected
Ensure timely failure detection Improve resilience for a given amount of redundancy
36

2013 Storage Developer Conference. © EMC Corporation. All Rights Reserved.
2013 Conclusions
Resilience at scale = reliability+availability+consistency Wide range of large scale failures Redundancy aids resiliency at scale Erasure coding – efficient scaling of resiliency Proactive measures to ensure resiliency at scale
37
Top Related