







Languages
Pages
Legal

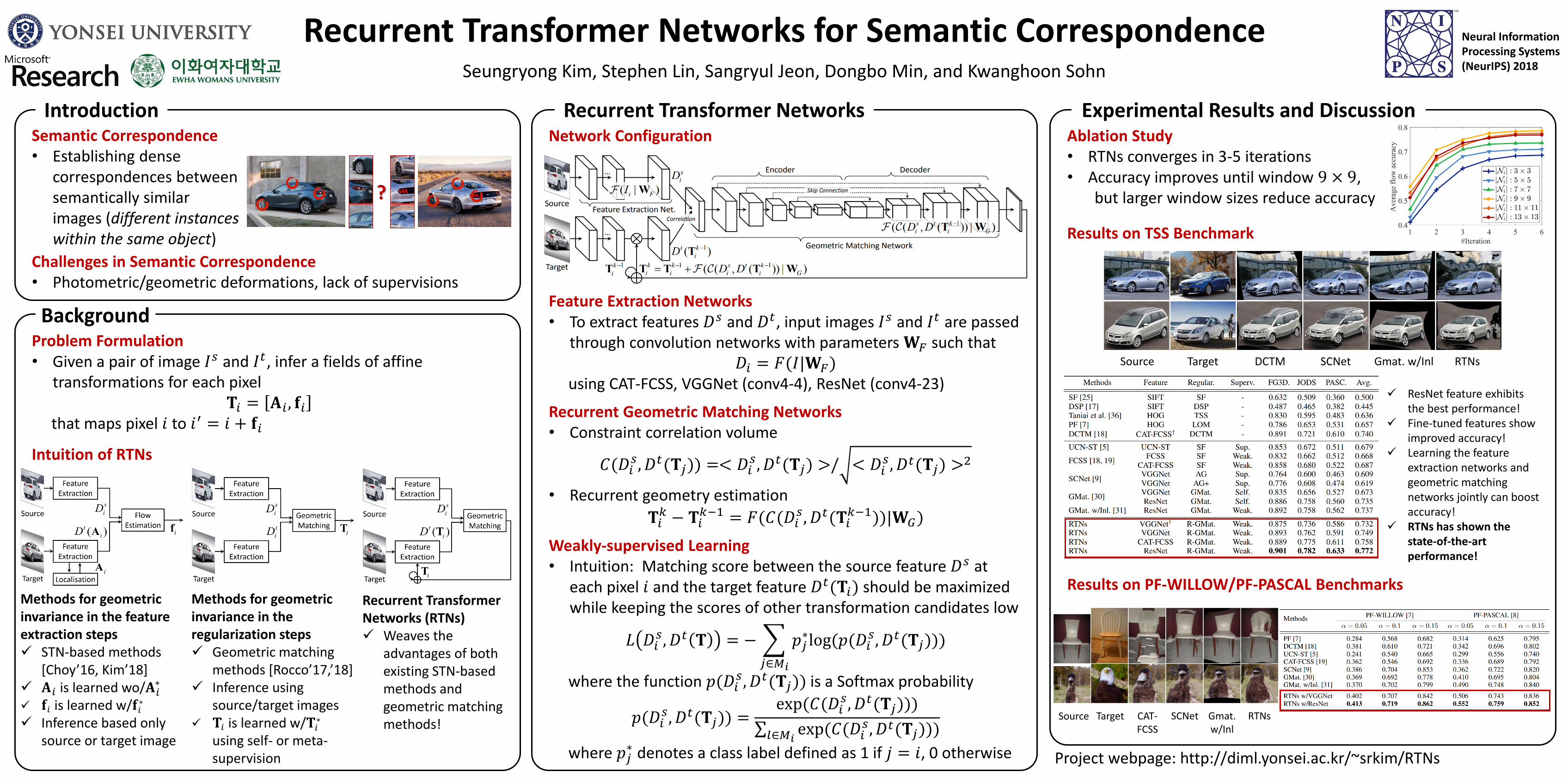
Recurrent Transformer Networks for Semantic CorrespondenceSeungryong Kim, Stephen Lin, Sangryul Jeon, Dongbo Min, and Kwanghoon Sohn
Neural Information Processing Systems (NeurIPS) 2018
Semantic Correspondence• Establishing dense
correspondences between semantically similar images (different instances within the same object)
Introduction
Background
Recurrent Transformer Networks Experimental Results and Discussion
Challenges in Semantic Correspondence• Photometric/geometric deformations, lack of supervisions
Problem Formulation• Given a pair of image 𝐼𝑠 and 𝐼𝑡, infer a fields of affine
transformations for each pixel𝐓𝑖 = 𝐀𝑖 , 𝐟𝑖
that maps pixel 𝑖 to 𝑖′ = 𝑖 + 𝐟𝑖
Intuition of RTNs
Network Configuration
Feature Extraction Networks• To extract features 𝐷𝑠 and 𝐷𝑡, input images 𝐼𝑠 and 𝐼𝑡 are passed
through convolution networks with parameters 𝐖𝐹 such that𝐷𝑖 = 𝐹(𝐼|𝐖𝐹)
using CAT-FCSS, VGGNet (conv4-4), ResNet (conv4-23)
Recurrent Geometric Matching Networks• Constraint correlation volume
𝐶(𝐷𝑖𝑠, 𝐷𝑡(𝐓𝑗)) =< 𝐷𝑖
𝑠, 𝐷𝑡(𝐓𝑗) >/ < 𝐷𝑖𝑠, 𝐷𝑡(𝐓𝑗) >
2
• Recurrent geometry estimation
𝐓𝑖𝑘 − 𝐓𝑖
𝑘−1 = 𝐹(𝐶(𝐷𝑖𝑠, 𝐷𝑡(𝐓𝑖
𝑘−1))|𝐖𝐺)
Weakly-supervised Learning• Intuition: Matching score between the source feature 𝐷𝑠 at
each pixel 𝑖 and the target feature 𝐷𝑡(𝐓𝑖) should be maximized while keeping the scores of other transformation candidates low
𝐿 𝐷𝑖𝑠, 𝐷𝑡 𝐓 = −
𝑗∈𝑀𝑖
𝑝𝑗∗log(𝑝(𝐷𝑖
𝑠, 𝐷𝑡(𝐓𝑗)))
where the function 𝑝(𝐷𝑖𝑠, 𝐷𝑡(𝐓𝑗)) is a Softmax probability
𝑝(𝐷𝑖𝑠, 𝐷𝑡(𝐓𝑗)) =
exp(𝐶(𝐷𝑖𝑠, 𝐷𝑡(𝐓𝑗)))
𝑙∈𝑀𝑖 exp(𝐶(𝐷𝑖𝑠, 𝐷𝑡(𝐓𝑗)))
where 𝑝𝑗∗ denotes a class label defined as 1 if 𝑗 = 𝑖, 0 otherwise
Ablation Study• RTNs converges in 3-5 iterations• Accuracy improves until window 9 × 9,
but larger window sizes reduce accuracy
Results on TSS Benchmark
Results on PF-WILLOW/PF-PASCAL BenchmarksMethods for geometric invariance in the regularization steps Geometric matching
methods [Rocco’17,’18] Inference using
source/target images 𝐓𝑖 is learned w/𝐓𝑖
∗
using self- or meta-supervision
Methods for geometric invariance in the feature extraction steps STN-based methods
[Choy’16, Kim’18] 𝐀𝑖 is learned wo/𝐀𝑖
∗
𝐟𝑖 is learned w/𝐟𝑖∗
Inference based only source or target image
Recurrent Transformer Networks (RTNs) Weaves the
advantages of both existing STN-based methods and geometric matching methods!
Source Target DCTM SCNet Gmat. w/Inl RTNs
Source Target CAT-FCSS
SCNet Gmat.w/Inl
RTNs
ResNet feature exhibits the best performance!
Fine-tuned features show improved accuracy!
Learning the feature extraction networks and geometric matching networks jointly can boost accuracy!
RTNs has shown the state-of-the-art performance!
Project webpage: http://diml.yonsei.ac.kr/~srkim/RTNs
Top Related