







Languages
Pages
Legal


Real-Time Stream Processing
CMSC 491Hadoop-Based Distributed Computing
Spring 2015Adam Shook

Agenda
• Apache Storm

Traditional Data Processing
!!!ALL!!!the data
Batch Pre-Computation
(aka MapReduce)Index
Index
Index
Query
Query

Traditional Data Processing
• Slow... and views are out of date
Absorbed into batch views Not absorbed
Now
Time

Compensating for the real-time stuff
• Need some kind of stream processing system to supplement our batch views
• Applications can then merge the batch and the real time views together!

How do we do that?

APACHE STORM

Enter: Storm
• Open-source project originally built by Twitter• Now a top-level Apache project• Enables distributed, fault-tolerant, real-time,
guaranteed computation

A History Lesson on Twitter Metrics
Twitter Firehose

A History Lesson on Metrics
Twitter Firehose

Problems!
• Scaling is painful• Fault-tolerance is practically non-existent• Coding for it is awful

Wanted to Address
• Guaranteed data processing• Horizontal Scalability• Fault-tolerance• No intermediate message brokers• Higher level abstraction than message passing• “Just works”

Storm Delivers
Guaranteed data processingHorizontal ScalabilityFault-toleranceNo intermediate message brokersHigher level abstraction than message passing“Just works”

Use Cases
• Stream Processing• Distributed RPC• Continuous Computation
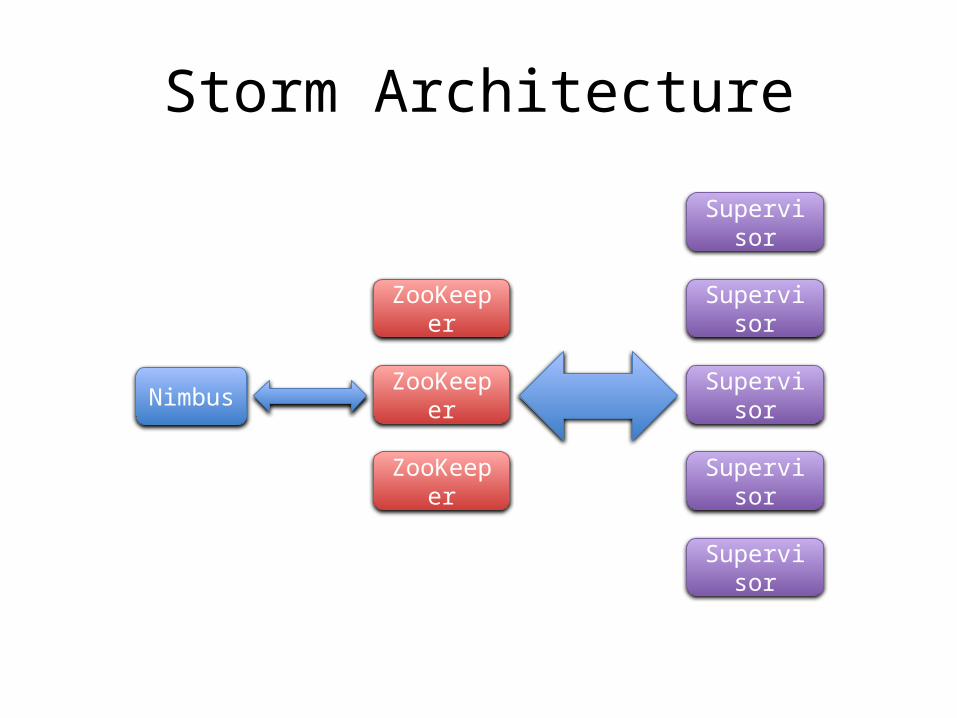
Storm Architecture
Nimbus ZooKeeper
ZooKeeper
ZooKeeper
Supervisor
Supervisor
Supervisor
Supervisor
Supervisor

Glossary
• Streams– Constant pump of data as Tuples
• Spouts– Source of streams
• Bolts– Process input streams and
produce new streams– Functions, Filters, Aggregation,
Joins, Talk to databases, etc.• Topologies
– Network of spouts and bolts
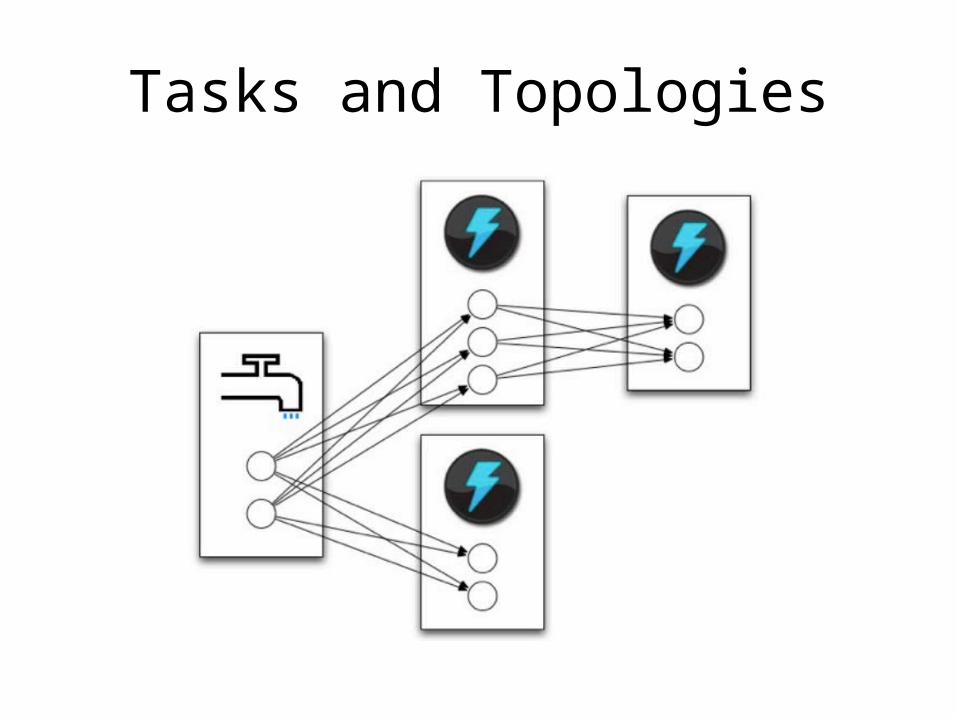
Tasks and Topologies

Grouping
• When a Tuple is emitted from a Spout or Bolt, where does it go?
• Shuffle Grouping– Pick a random task
• Fields Grouping– Consistent hashing on a subset of tuple fields
• All Grouping– Send to all tasks
• Global Grouping– Pick task with lowest ID

Topology
shuffle
[“url”]
shuffle
shuffle [“id1”, “id2”]
all

Guaranteed Message Processing
• A tuple has not been fully processed until it all tuples in the “tuple tree” have been completed
• If the tree is not completed within a timeout, it is replayed
• Programmers need to use the API to ‘ack’ a tuple as completed

Stream Processing ExampleWord Count
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(1, new SentenceSpout(true), 5);builder.setBolt(2, new SplitSentence(), 8).shuffleGrouping(1);builder.setBolt(3, new WordCount(), 12).fieldsGrouping(2, new Fields(“word”));
Map conf = new HashMap();conf.put(Config.TOPOLOGY_WORKERS, 5);
StormSubmitter.submitTopology(“word-count”, conf, builder.createTopology());

public static class SplitSentence extends ShellBolt implements IRichBolt {
public SplitSentence() {super(“python”, “splitsentence.py”);
}public void declareOutputFields(OutputFieldsDeclaraer
declarer) {declarer.declare(new Fields(“word”));
}}
#!/usr/bin/python
import storm
class SplitSentenceBolt(storm.BasicBolt):def process(Self, tup):
words = tup.values[0].split(“ “)for word in words:
storm.emit([word])

public static class WordCount implements IBasicBolt {Map<String, Integer> counts = new HashMap<String, Integer>();
public void prepare(Map conf, TopologyContext context) {}
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);Integer count = counts.get(word);if (count == null) {
count = 0;}++count;counts.put(Word, count);collector.emit(new Values(word, count));
}
public void cleanup () {}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields(“word”, “count”));}
}

Local Mode!TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(1, new SentenceSpout(true), 5);builder.setBolt(2, new SplitSentence(), 8).shuffleGrouping(1);builder.setBolt(3, new WordCount(), 12).fieldsGrouping(2, new Fields(“word”));
Map conf = new HashMap();conf.put(Config.TOPOLOGY_WORKERS, 5);
LocalCluster cluster = new LocalCluster();cluster.submitTopology(“word-count”, conf, builder.createTopology());Thread.sleep(10000);cluster.shutdown();

Command Line Interface
• Starting a topology
storm jar mycode.jar twitter.storm.MyTopology demo
• Stopping a topology
storm kill demo

Distributed RPC
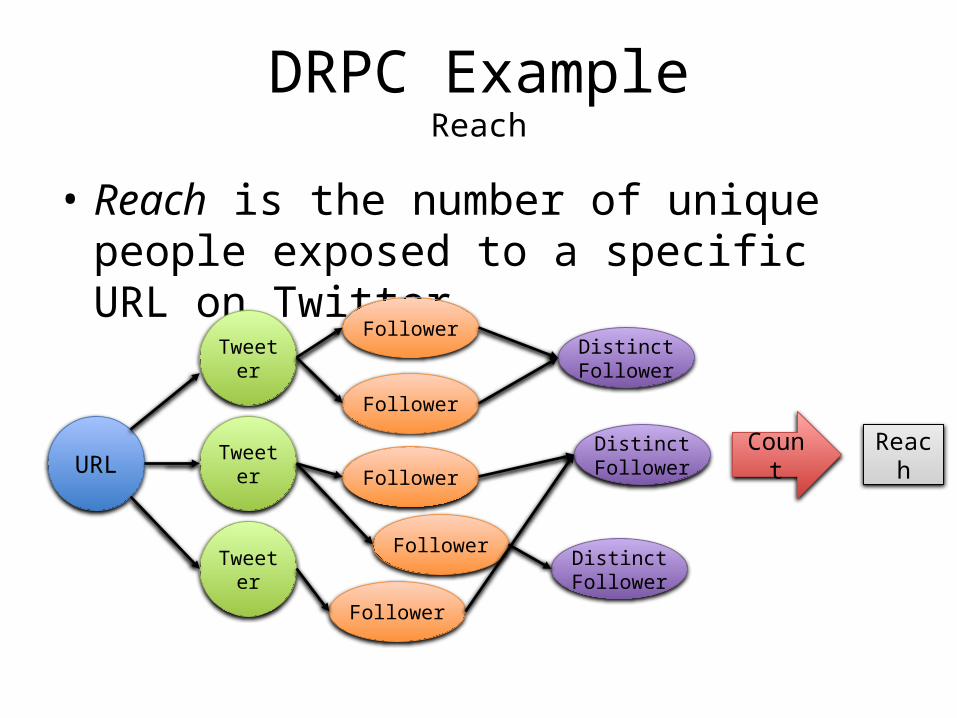
DRPC ExampleReach
• Reach is the number of unique people exposed to a specific URL on Twitter
URL
Tweeter
Tweeter
Tweeter
Follower
Follower
Follower
Follower
Follower
Distinct Follower
Distinct Follower
Distinct Follower
Count Reach

Reach Topology
Spout GetTweeters
CountAggregator
GetFollowers
Distinct
shuffleshuffle
[“follower-id”]
global

Storm Review
• Distributed code and configurations• Robust process management• Monitors topologies and reassigns failed tasks• Provides reliability by tracking tuple trees• Routing and partitioning of streams• Serialization• Fine-grained performance stats of topologies

APACHE SPARK

Concern!
• Say I have an application that involves many iterations...– Graph Algorithms– K-Means Clustering– Six Degrees of Bieber Fever
• What's wrong with Hadoop MapReduce?

References
• http://storm.incubator.apache.org/• http://
www.slideshare.net/nathanmarz/storm-distributed-and-faulttolerant-realtime-computation
• http://www.slideshare.net/Hadoop_Summit/realtime-analytics-with-storm
• http://spark.apache.org• http://www.cs.berkeley.edu/~matei/papers/201
2/nsdi_spark.pdf
Top Related