







Languages
Pages
Legal


PEER TO PEER AND DISTRIBUTED HASH TABLES
CS 271 1

Distributed Hash Tables
Challenge: To design and implement a robust and scalable distributed system composed of inexpensive, individually unreliable computers in unrelated administrative domains
CS 271 2Partial thanks Idit Keidar)

Searching for distributed data
• Goal: Make billions of objects available to millions of concurrent users– e.g., music files
• Need a distributed data structure to keep track of objects on different sires.– map object to locations
• Basic Operations:– Insert(key)– Lookup(key)
CS 271 3
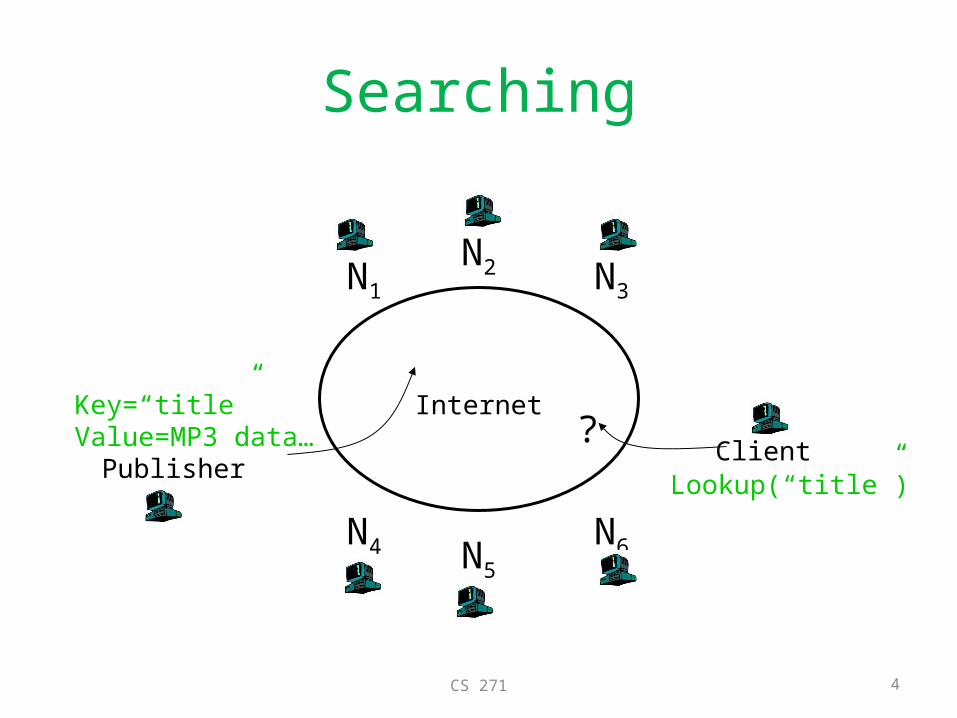
Searching
Internet
N1
N2 N3
N6N5
N4
Publisher
Key=“title”Value=MP3 data… Client
Lookup(“title”)
?
CS 271 4

Simple Solution
• First There was Napster– Centralized server/database for lookup– Only file-sharing is peer-to-peer, lookup is not
• Launched in 1999, peaked at 1.5 million simultaneous users, and shut down in July 2001.
CS 271 5
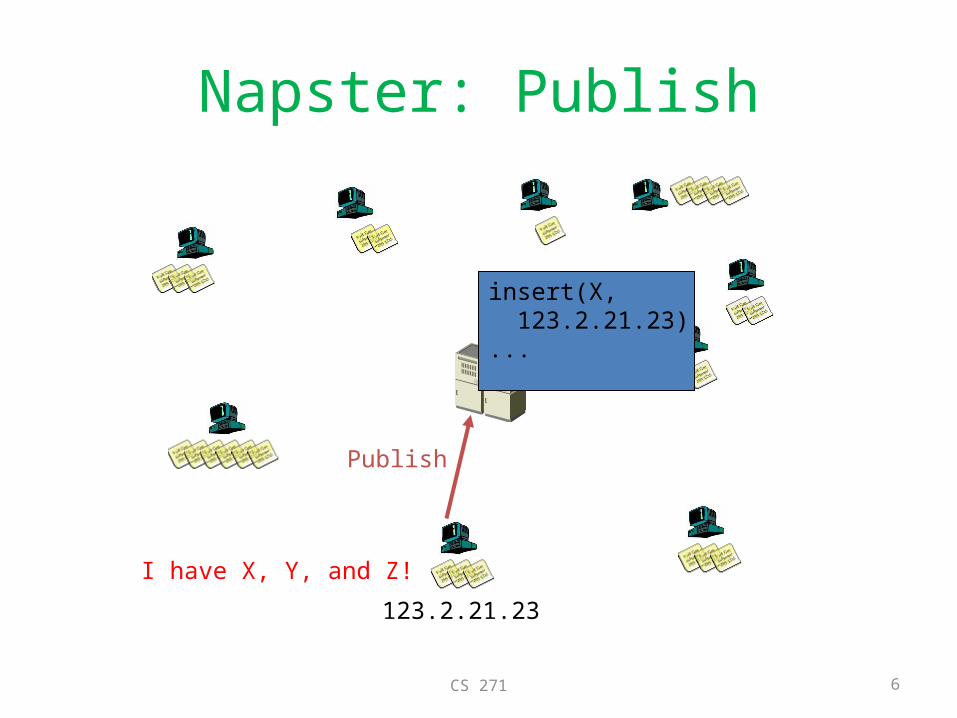
Napster: Publish
I have X, Y, and Z!
Publish
insert(X, 123.2.21.23)...
123.2.21.23
CS 271 6
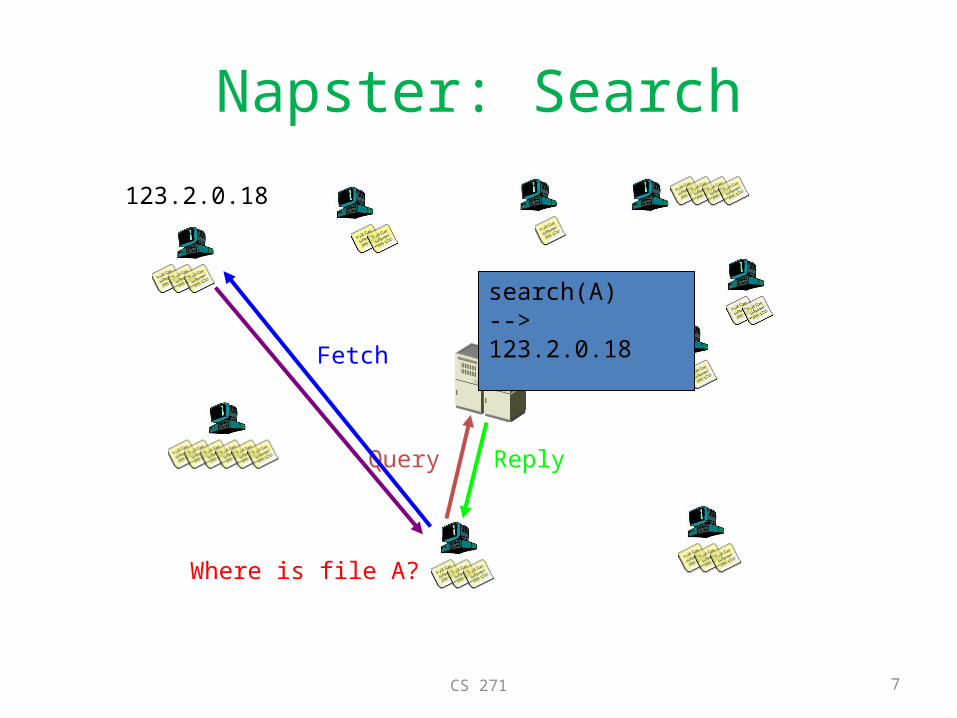
Napster: Search
Where is file A?
Query Reply
search(A)-->123.2.0.18Fetch
123.2.0.18
CS 271 7
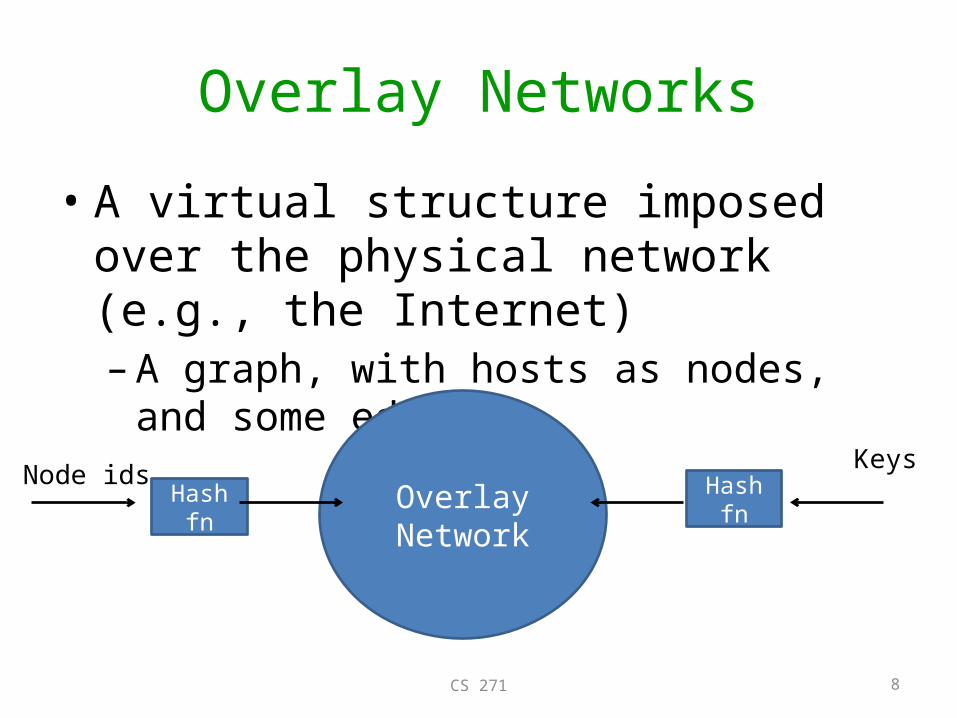
Overlay Networks
• A virtual structure imposed over the physical network (e.g., the Internet)– A graph, with hosts as nodes, and some edges
Overlay Network
Node idsHash fn Hash fn
Keys
CS 271 8

Unstructured Approach: Gnutella
• Build a decentralized unstructured overlay– Each node has several neighbors– Holds several keys in its local database
• When asked to find a key X– Check local database if X is known– If yes, return, if not, ask your neighbors
• Use a limiting threshold for propagation.
CS 271 9
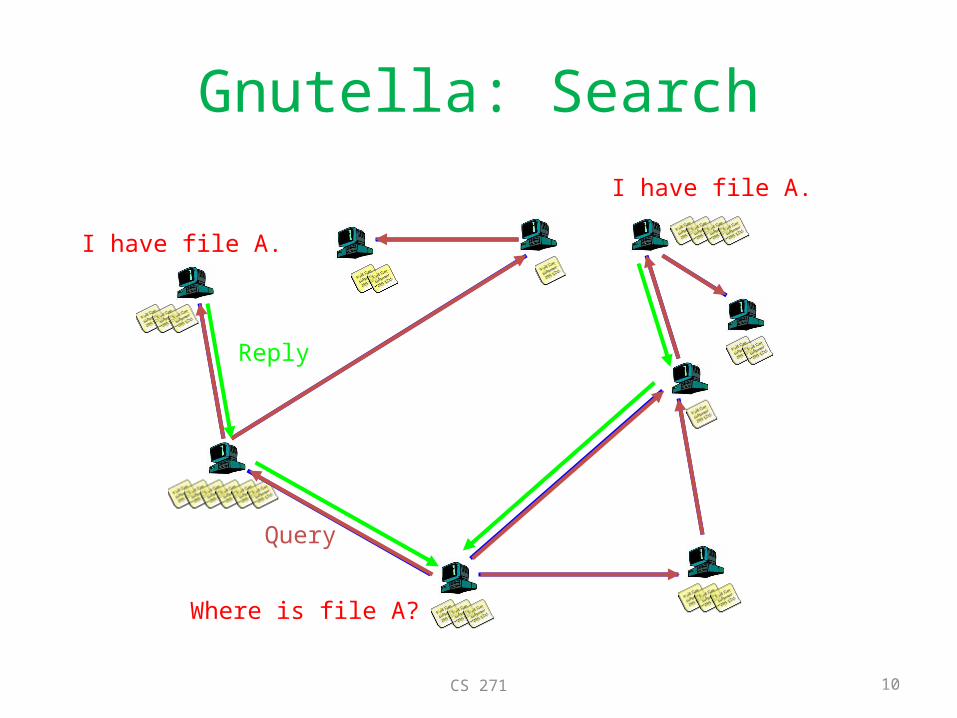
I have file A.
I have file A.
Gnutella: Search
Where is file A?
Query
Reply
CS 271 10

Structured vs. Unstructured
• The examples we described are unstructured – There is no systematic rule for how edges are
chosen,each node “knows some” other nodes
– Any node can store any data so a searched data might reside at any node
• Structured overlay:– The edges are chosen according to some rule– Data is stored at a pre-defined place– Tables define next-hop for lookup
CS 271 11

Hashing
• Data structure supporting the operations:– void insert( key, item ) – item search( key )
• Implementation uses hash function for mapping keys to array cells
• Expected search time O(1)– provided that there are few collisions
CS 271 12

Distributed Hash Tables (DHTs)
• Nodes store table entries• lookup( key ) returns the location of the node
currently responsible for this key• We will mainly discuss Chord, Stoica, Morris,
Karger, Kaashoek, and Balakrishnan SIGCOMM 2001
• Other examples: CAN (Berkeley), Tapestry (Berkeley), Pastry (Microsoft Cambridge), etc.
CS 271 13

CAN [Ratnasamy, et al]
• Map nodes and keys to coordinates in a multi-dimensional cartesian space
source
key
Routing through shortest Euclidean path
For d dimensions, routing takes O(dn1/d) hops
Zone
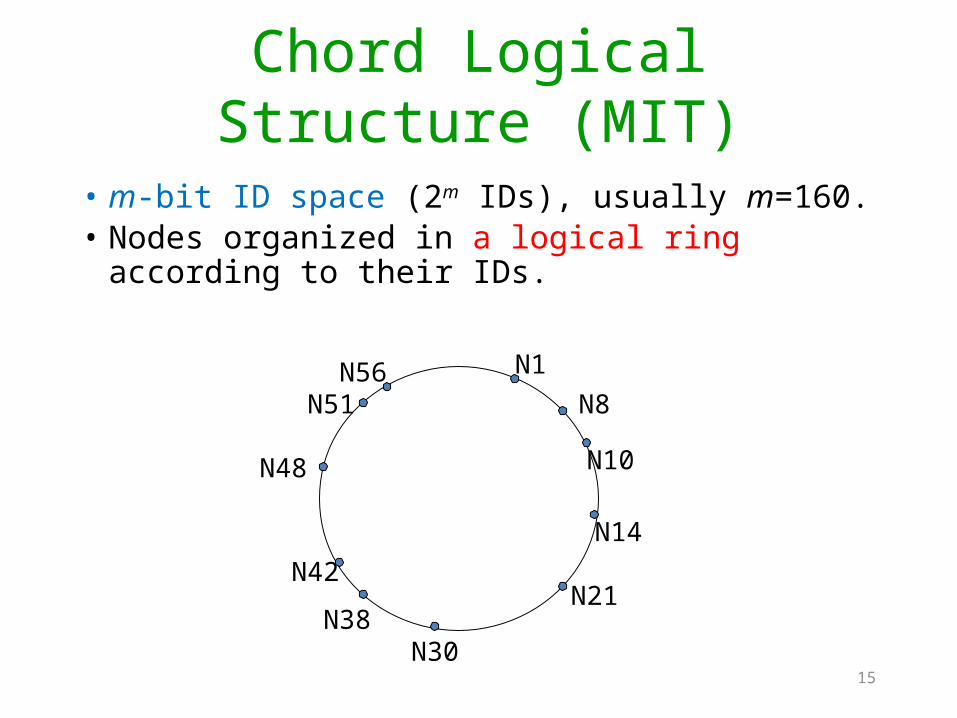
Chord Logical Structure (MIT)
• m-bit ID space (2m IDs), usually m=160.• Nodes organized in a logical ring according
to their IDs.N1
N8
N10
N14
N21
N30N38
N42
N48
N51N56
15

DHT: Consistent Hashing
N32
N90
N105
K80
K20
K5
Circular ID space
Key 5Node 105
A key is stored at its successor: node with next higher ID
CS 271 16Thanks CMU for animation

Consistent Hashing Guarantees
• For any set of N nodes and K keys:– A node is responsible for at most (1 + )K/N keys– When an (N + 1)st node joins or leaves,
responsibility for O(K/N) keys changes hands
CS 271 17
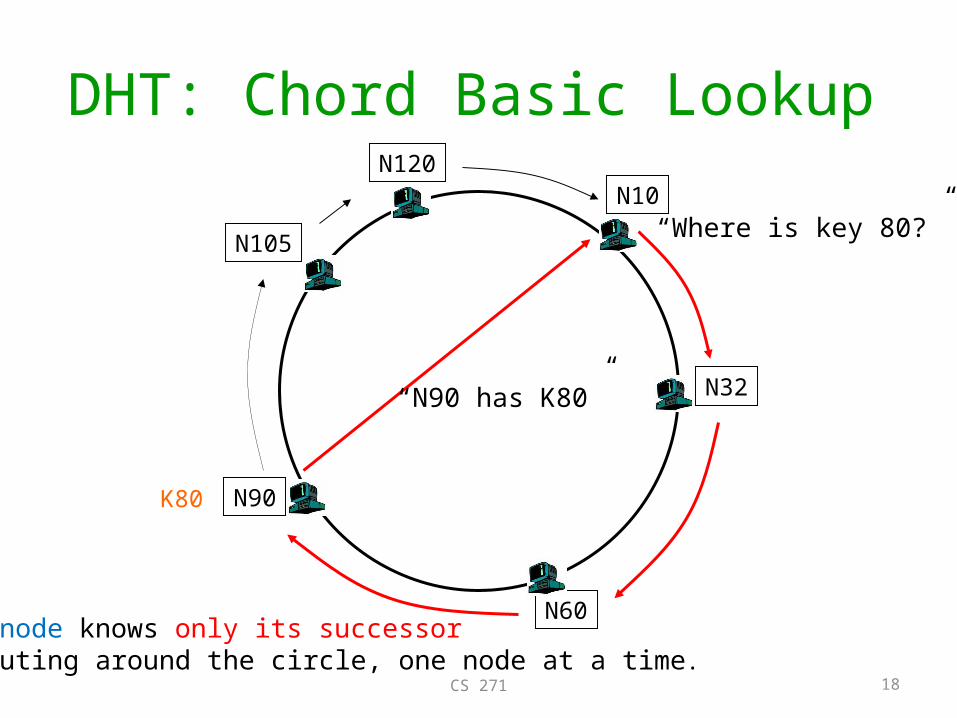
DHT: Chord Basic Lookup
N32
N90
N105
N60
N10N120
K80
“Where is key 80?”
“N90 has K80”
Each node knows only its successor • Routing around the circle, one node at a time.
CS 271 18
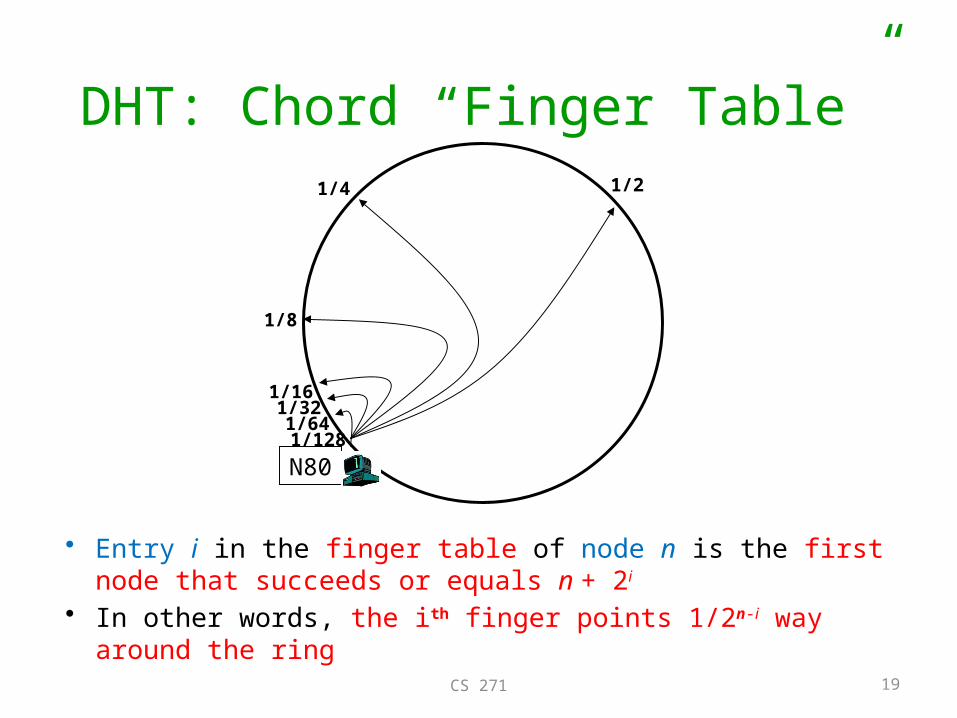
DHT: Chord “Finger Table”
N80
1/21/4
1/8
1/161/321/641/128
• Entry i in the finger table of node n is the first node that succeeds or equals n + 2i
• In other words, the ith finger points 1/2n-i way around the ring
CS 271 19
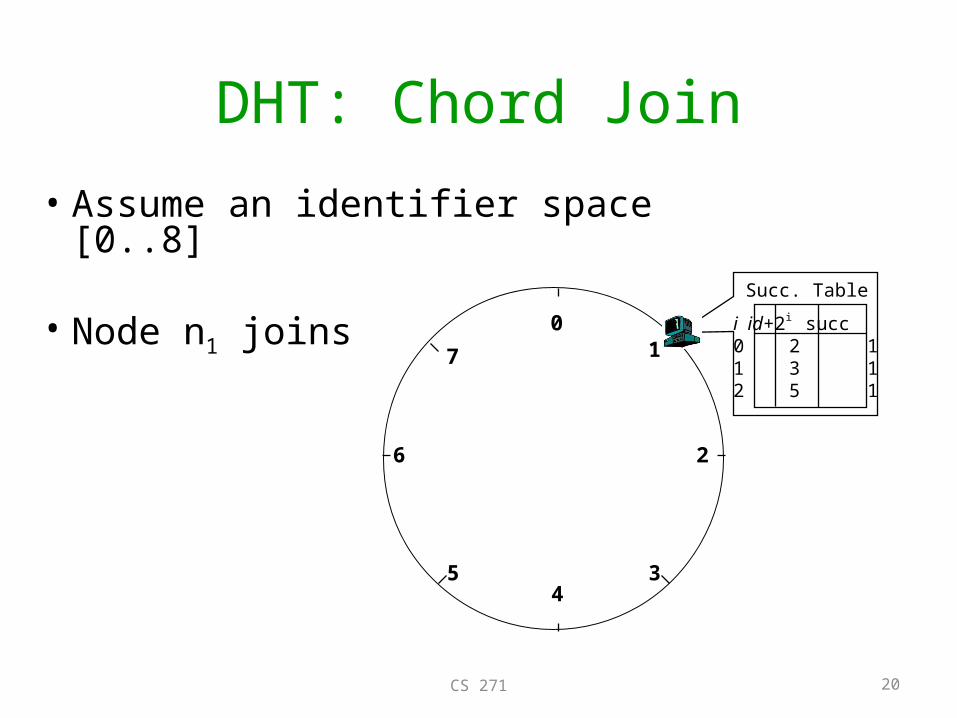
DHT: Chord Join
• Assume an identifier space [0..8]
• Node n1 joins0
1
2
34
5
6
7
i id+2i succ0 2 11 3 12 5 1
Succ. Table
CS 271 20
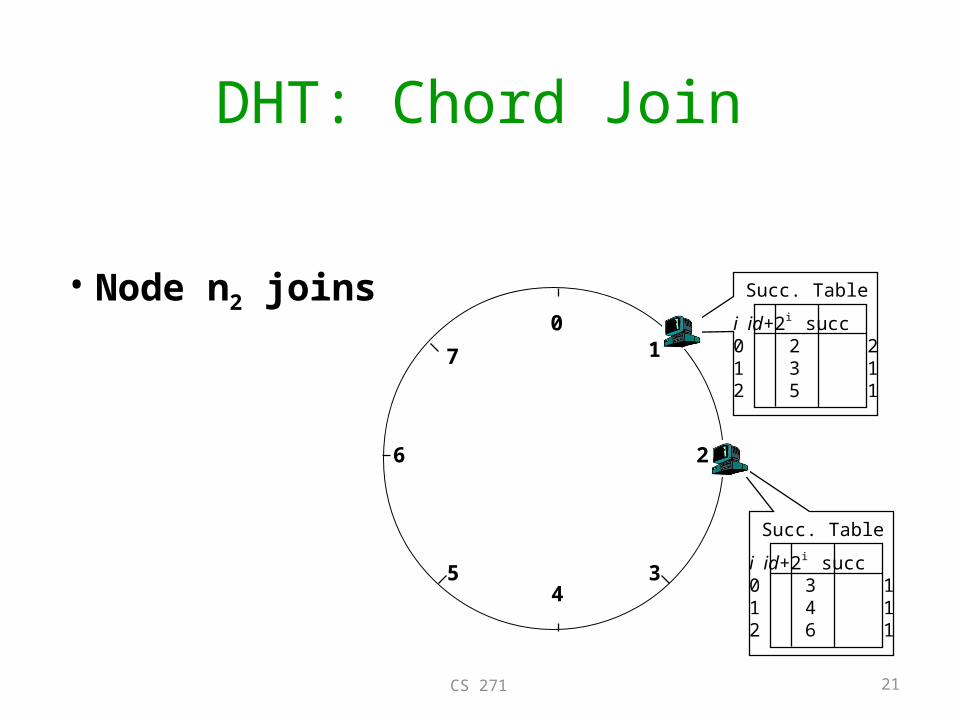
DHT: Chord Join
• Node n2 joins0
1
2
34
5
6
7
i id+2i succ0 2 21 3 12 5 1
Succ. Table
i id+2i succ0 3 11 4 12 6 1
Succ. Table
CS 271 21
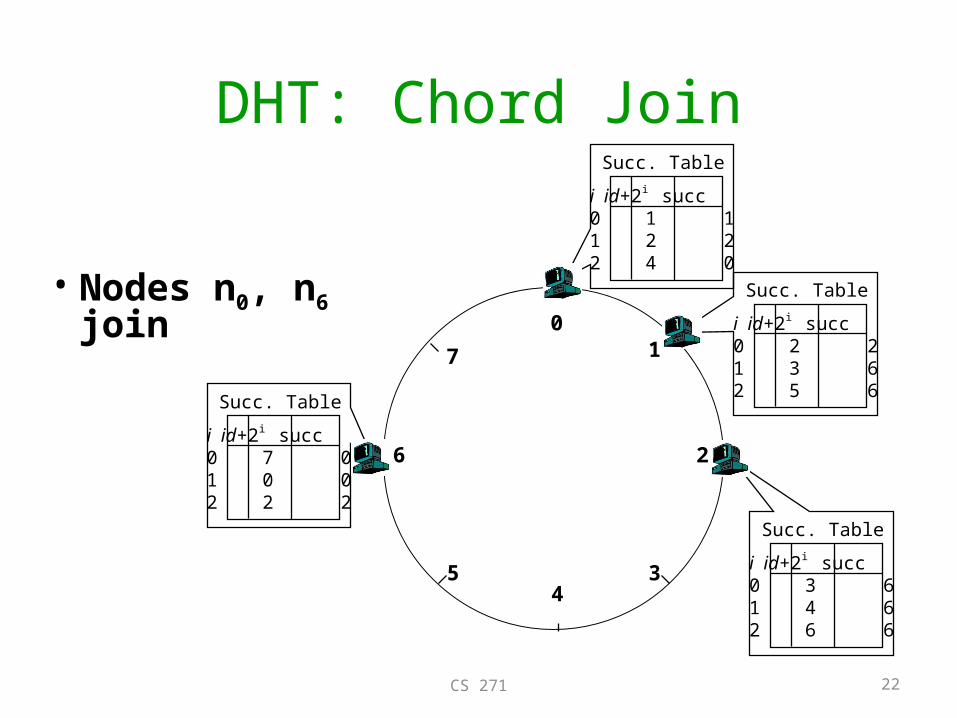
DHT: Chord Join
• Nodes n0, n6 join 0
1
2
34
5
6
7
i id+2i succ0 2 21 3 62 5 6
Succ. Table
i id+2i succ0 3 61 4 62 6 6
Succ. Table
i id+2i succ0 1 11 2 22 4 0
Succ. Table
i id+2i succ0 7 01 0 02 2 2
Succ. Table
CS 271 22
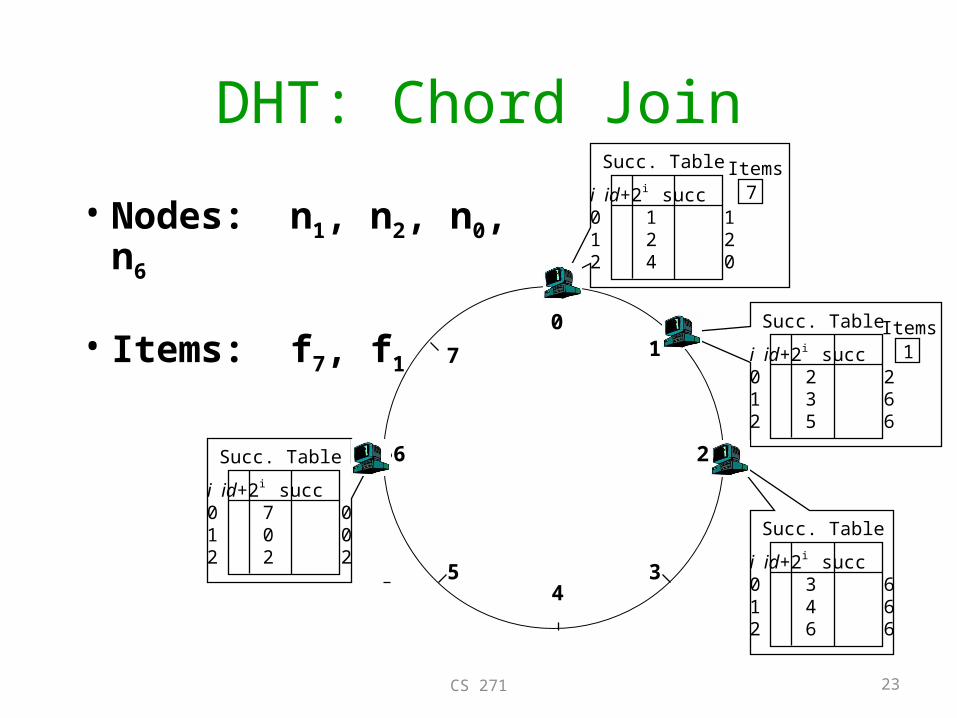
DHT: Chord Join
• Nodes: n1, n2, n0, n6
• Items: f7, f1 01
2
34
5
6
7 i id+2i succ0 2 21 3 62 5 6
Succ. Table
i id+2i succ0 3 61 4 62 6 6
Succ. Table
i id+2i succ0 1 11 2 22 4 0
Succ. Table
7
Items 1
Items
i id+2i succ0 7 01 0 02 2 2
Succ. Table
CS 271 23

DHT: Chord Routing• Upon receiving a query for
item id, a node:• Checks whether stores the
item locally?• If not, forwards the query to
the largest node in its successor table that does not exceed id
01
2
34
5
6
7 i id+2i succ0 2 21 3 62 5 6
Succ. Table
i id+2i succ0 3 61 4 62 6 6
Succ. Table
i id+2i succ0 1 11 2 22 4 0
Succ. Table
7
Items 1
Items
i id+2i succ0 7 01 0 02 2 2
Succ. Table
query(7)
CS 271 24

Chord Data Structures
• Finger table• First finger is successor• Predecessor
• What if each node knows all other nodes– O(1) routing– Expensive updates
CS 271 25
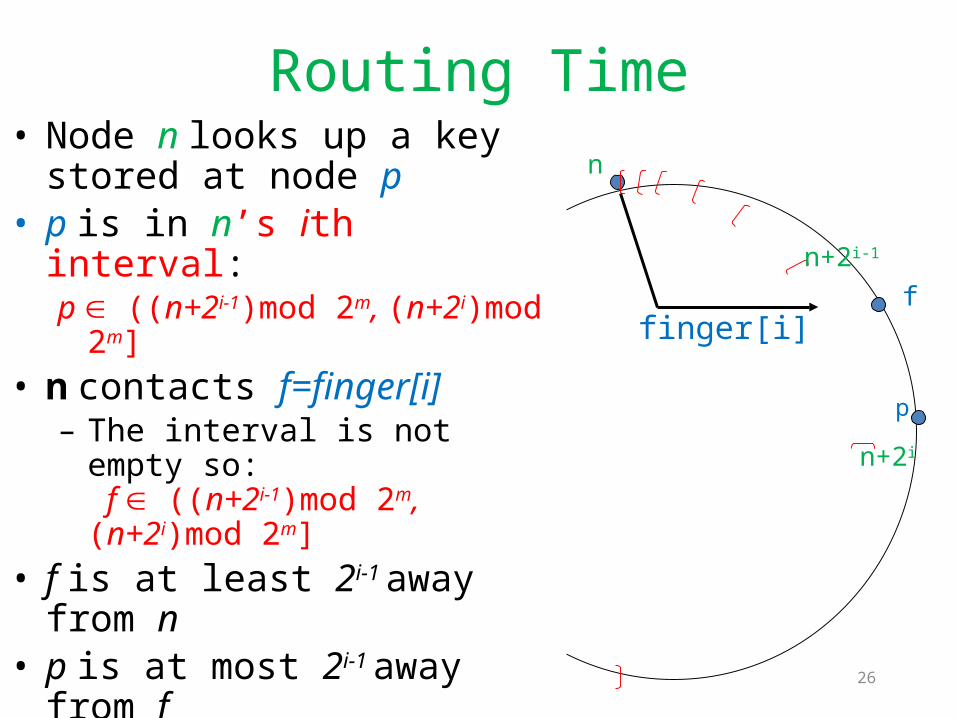
Routing Timen
f
p
finger[i]
• Node n looks up a key stored at node p
• p is in n’s ith interval: p ((n+2i-1)mod 2m, (n+2i)mod 2m]
• n contacts f=finger[i]– The interval is not empty so:
f ((n+2i-1)mod 2m, (n+2i)mod 2m] • f is at least 2i-1 away from n• p is at most 2i-1 away from f• The distance is halved at each
hop.
n+2i-1
n+2i
26

Routing Time
• Assuming uniform node distribution around the circle, the number of nodes in the search space is halved at each step: – Expected number of steps: log N
• Note that:– m = 160 – For 1,000,000 nodes, log N = 20
CS 271 27

P2P Lessons
• Decentralized architecture.• Avoid centralization• Flooding can work.• Logical overlay structures provide strong
performance guarantees.• Churn a problem.• Useful in many distributed contexts.
CS 271 28
Top Related