







Languages
Pages
Legal


National Institute of Standards and Technology
Information Technology Laboratory
2000 TREC-9
Spoken Document Retrieval Trackhttp://www.nist.gov/speech/sdr2000
John Garofolo, Jerome Lard, Ellen Voorhees

SDR 2000 - Overview
• SDR 2000 Track Overview, changes for TREC-9
• SDR Collection/Topics
• Technical Approaches
• Speech Recognition Metrics/Performance
• Retrieval Metrics/Performance
• Conclusions
• Future

• Task:– Given a text topic, retrieve ranked list of relevant
excerpts from collection of recorded speech
• Requires 2 core technologies:– Speech Recognition – Information Retrieval
Spoken Document Retrieval (SDR)
RecognizedTranscripts
Broadcast News Speech
Recognition Engine
Broadcast NewsAudio Recording
Corpus
IR SearchEngine
RankedTime
Pointer List
Topic(Query)
TemporalIndex
• First step towards • multimedia information access.• Focus is on effect of recognition accuracy on retrieval
performance• Domain: Radio and TV Broadcast News

SDR Evaluation Approach• In the TREC tradition:
– Create realish but doable application task• Increase realism (and difficulty) each year
– NIST creates: • infrastructure: test collection, queries, task definition,
relevance judgements– task includes several different control conditions:
recognizer, boundaries, etc.
– Sites submit:• speech recognizer transcripts for benchmarking and
sharing• rank-ordered retrieval lists for scoring

Past SDR Test Collections TREC-6 ‘97 TREC-7 ‘98 TREC-8 ‘99 Broadcast News Collection
43 Hours 1996-97 1,451 Stories ~276 wrds/stry
87 Hours 1996-97 2,866 Stories ~269 wrds/stry
557 Hours Jan-Jun 1998 21,754 Stories ~169 wrds/stry
Reference Transcripts
ASR Training (~2% WER)
ASR Training (~2% WER)
CCaptions (~12% WER)
Baseline ASR Transcripts
IBM (50% WER)
NIST/CMU SPHINX (33.8% / 46.6% WER)
NIST/BBN Byblos (27.5% / 26.7% WER)
Paradigm Known-Item (% at rank 1)
Ad Hoc (MAP) Ad Hoc (MAP)
Queries 50 23 49

Past SDR Evaluation Conditions
TREC-6 ‘97 TREC-7 ‘98 TREC-8 ‘99 Reference Transcripts
Yes * Yes * Yes *
Baseline ASR Transcripts
Yes * Yes *
Yes *
Speech Input Yes Yes
Yes
Cross Recognizer
No Yes (8 ASR sets)
Yes (8 ASR sets)
Unknown Story Bounds
No No Yes
* Required Test condition

SDR 2000 - Changes from 1999
2000• evaluated on whole shows
including non-news segments
• 50 ad-hoc topics in two forms: short description and keyword
• 1 baseline recognizer transcript sets (NIST/BBN B2 from 1999)
• story boundaries unknown (SU) condition is required
• recognition and use of non-lexical information
1999• evaluated on hand-segmented
news excerpts only
• 49 ad-hoc-style topics/metrics
• 2 baseline recognizer transcript sets (NIST/BBN)
• story boundaries known (SK) focus and exploratory unknown (SU) conditions

SDR 2000 - Test Collection• Based on the LDC TDT-2 Corpus
– 4 sources (TV: ABC, CNN, Radio: PRI, VOA)– February through June 1998 subset, 902 broadcasts – 557.5 hours, 21,754 stories, 6,755 filler and commercial
segments (~55 hours)– Reference transcripts
• Human-annotated story boundaries• Full broadcast word transcription
– News segments hand-transcribed (same as in ‘99)– Commercials and non-news filler transcribed via NIST ROVER
applied to 3 automatic recognizer transcript sets
• Word times provided by LIMSI forced alignment
– Automatic recognition of non-lexical information (commercials, repeats, gender, bandwidth, non-speech, signal energy, and combinations) provided by CU

Test Variables• Collection
– Reference (R1) - transcripts created by LDC human annotators
– Baseline (B1) - transcripts created by NIST/BBN time-adaptive automatic recognizer
– Speech (S1/S2) - transcripts created by sites’ own automatic recognizers
– Cross-Recognizer (CR) - all contributed recognizers
• Boundaries– Known (K) - Story boundaries provided by LDC annotators
– Unknown (U) - Story boundaries unknown

Test Variables (contd)• Queries
– Short (S) - 1 or 2-phrase description of information need
– Terse (T) - keyword list
• Non-Lexical Information– Default - Could make use of automatically-recognized features
– None (N) - no non-lexical information (control)
• Recognition language models– Fixed (FLM) - Fixed language model/vocabulary predating test
epoch
– Rolling (RLM) - Time-adaptive language model/vocabulary using daily newswire texts

Test ConditionsPrimary Conditions (may use non-lexical side info, but must run contrast below):
R1SU: Reference Retrieval, short topics, using human-generated "perfect" transcripts without known story boundaries R1TU: Reference Retrieval, terse topics, using human-generated "perfect" B1SU: Baseline Retrieval, short topics, using provided recognizer transcripts without known story boundaries B1TU: Baseline Retrieval, terse topics, using provided recognizer transcripts without known story boundaries S1SU: Speech Retrieval, short topics, using own recognizer without known story boundaries S1TU: Baseline Retrieval,terse topics, using provided recognizer transcripts without known story boundaries
Optional Cross-Recognizer Condition (may use non-lexical side info, but must run contrast below): CRSU-<SYS_NAME>: Cross-Recognizer Retrieval, short topics, using other participants' recognizer transcripts without known story boundaries CRTU-<SYS_NAME>: Cross-Recognizer Retrieval, terse topics, using other participants' recognizer transcripts without known story boundaries
Conditional No Non-Lexical Information Condition (required contrast if non-lexical information is used in other conditions): R1SUN: Reference Retrieval, short topics, using human-generated "perfect" transcripts without known story boundaries, no non-lexical info R1TUN: Reference Retrieval, terse topics, using human-generated "perfect" transcripts without known story boundaries, no non-lexical info B1SUN: Baseline Retrieval, short topics, using provided recognizer transcripts without known story boundaries, no non-lexical info B1TUN: Baseline Retrieval, terse topics, using provided recognizer transcripts without known story boundaries, no non-lexical info S1SUN: Speech Retrieval, short topics, using own recognizer without known story boundaries, no non-lexical info S1TUN: Speech Retrieval, terse topics, using own recognizer without known story boundaries, no non-lexical info S2SUN: Speech Retrieval, short topics, using own second recognizer without known story boundaries, no non-lexical info S2TUN: Speech Retrieval, terse topics, using own second recognizer without known story boundaries, no non-lexical info
Optional Known Story Boundaries Conditions: R1SK: Reference Retrieval, short topics, using human-generated "perfect" transcripts with known story boundaries R1TK: Reference Retrieval, terse topics, using human-generated "perfect" transcripts with known story boundaries B1SK: Baseline Retrieval, short topics, using provided recognizer transcripts with known story boundaries B1TK: Baseline Retrieval, terse topics, using provided recognizer transcripts with known story boundaries S1SK: Speech Retrieval, short topics, using own recognizer with known story boundaries S1TK: Speech Retrieval, terse topics, using own recognizer with known story boundaries
Recognition Language Models: FLM: Fixed language model/vocabulary predating test epoch RLM: Rolling language model/vocabulary using daily newswire adaptation

Test Topics• 50 topics developed by NIST Assessors using
similar approach to TREC Ad-Hoc Task– Short and terse forms of topics were generated
Hard: Topic 125: 10 relevant stories Short: Provide information pertaining to security violations withinthe U. S. intelligence community. (.024 average MAP)Terse: U. S. intelligence violations (.019 average MAP)
Medium: Topic 143: 8 relevant stories
Short: How many Americans file for bankruptcy each year? (.505 avg MAP)Terse: Americans bankruptcy debts (.472 average MAP)
Easy: Topic 127: 11 relevant stories
Short: Name some countries which permit their citizens to commit suicide with medical assistance. (.887 average MAP)
Terse: assisted suicide (.938 average MAP)
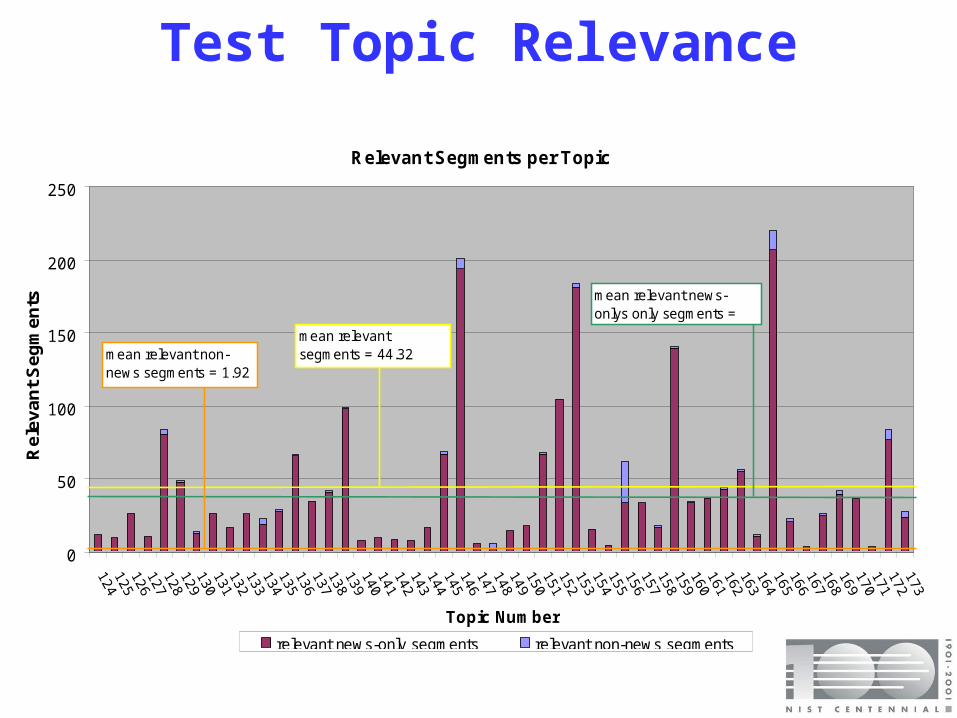
Test Topic Relevance
Relevant Segments per Topic
0
50
100
150
200
250
Topic Number
Re
lev
an
t S
eg
me
nts
relevant news-only segments relevant non-news segments
mean relevant segments = 44.32
mean relevant news-onlys only segments = 42.6
mean relevant non-news segments = 1.92
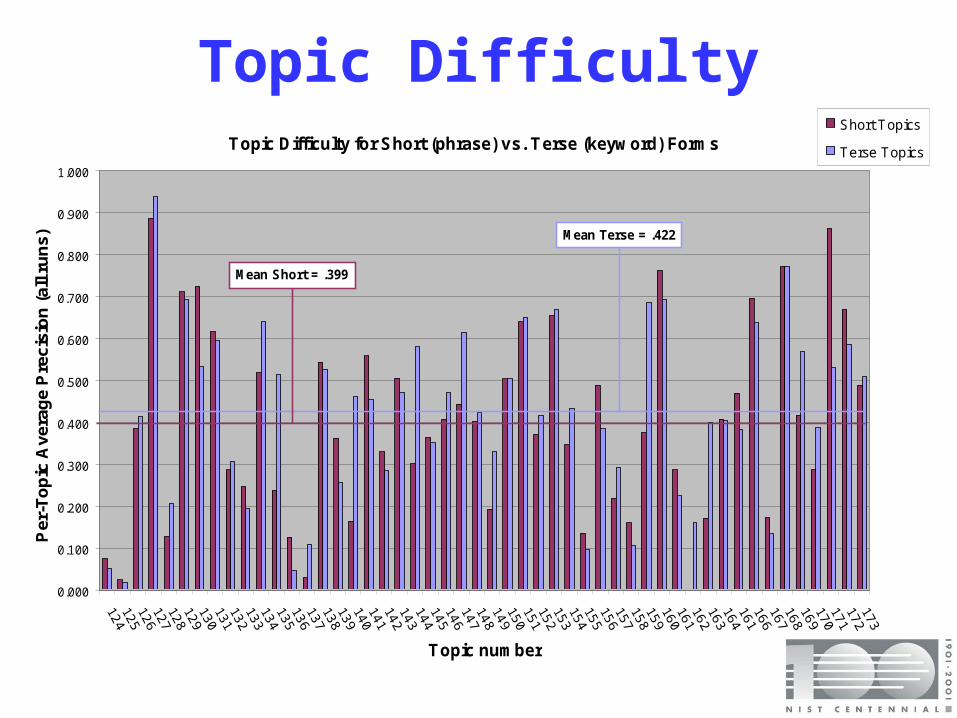
Topic DifficultyTopic Difficulty for Short (phrase) vs. Terse (keyw ord) Forms
0.000
0.100
0.200
0.300
0.400
0.500
0.600
0.700
0.800
0.900
1.000
Topic number
Per
-To
pic
Ave
rag
e P
reci
sio
n (
all r
un
s)
Short Topics
Terse Topics
Mean Terse = .422
Mean Short = .399

Participants
Full SDR (recognition and retrieval):Cambridge University, UKLIMSI, FranceSheffield University, UK

Approaches for 2000• Automatic Speech Recognition
– HMM, word-based - most– NN/HMM hybrid-based, Sheffield
• Retrieval– OKAPI Probabilistic Model - all– Blind Relevance Feedback and parallel corpus BRF
for query expansion - all
• Story boundary unknown retrieval– passage windowing, retrieval and merging - all
• Use of automatically-recognized non-lexical features– repeat and commercial detection - CU

ASR Metrics• Traditional ASR Metric:
– Word Error Rate (WER) and Mean Story Word Error Rate (SWER) using SCLITE and LDC ref transcripts
WER = word insertions + word deletions + word substitutionstotal words in reference
– LDC created 2 Hub-4 compliant 10-hour subsets for ASR scoring and analyses (LDC-SDR-99 and LDC-SDR-2000)
• Note that there is a 10.3% WER in the collection human (closed caption) transcripts
Note: SDR recognition is not directly comparable to Hub-4 benchmarks due to transcript quality, test set selection method, and word mapping
method used in scoring

ASR Performance
Word Error Rate Summary
0.0
5.0
10.0
15.0
20.0
25.0
30.0
35.0
Speech Recognizer
%W
ER
1999 10-hour %WER
1999 10-hour %SWER
2000 10-hour %WER
2000 10-hour %SWEROvals indicates no
significant differenceOvals indicate no
significant difference

IR Metrics• Traditional TREC ad-hoc Metric:
– Mean Average Precision (MAP) using TREC_EVAL
– Created assessment pools for each topic using top 100 of all retrieval runs
• Mean pool size: 596 (2.1% of all segments)• Min pool size: 209• Max pool size: 1309
– NIST assessors created reference relevance assessments from topic pools
– Somewhat artificial for boundary unknown conditions

Story Boundaries Known Condition
• Retrieval using pre-segmented news stories– systems given index of story boundaries for
recognition with IDs for retrieval• excluded non-news segments • stories are treated as documents
– systems produce rank-ordered list of Story IDs– document-based scoring:
• score as in other TREC Ad Hoc tests using TREC_EVAL
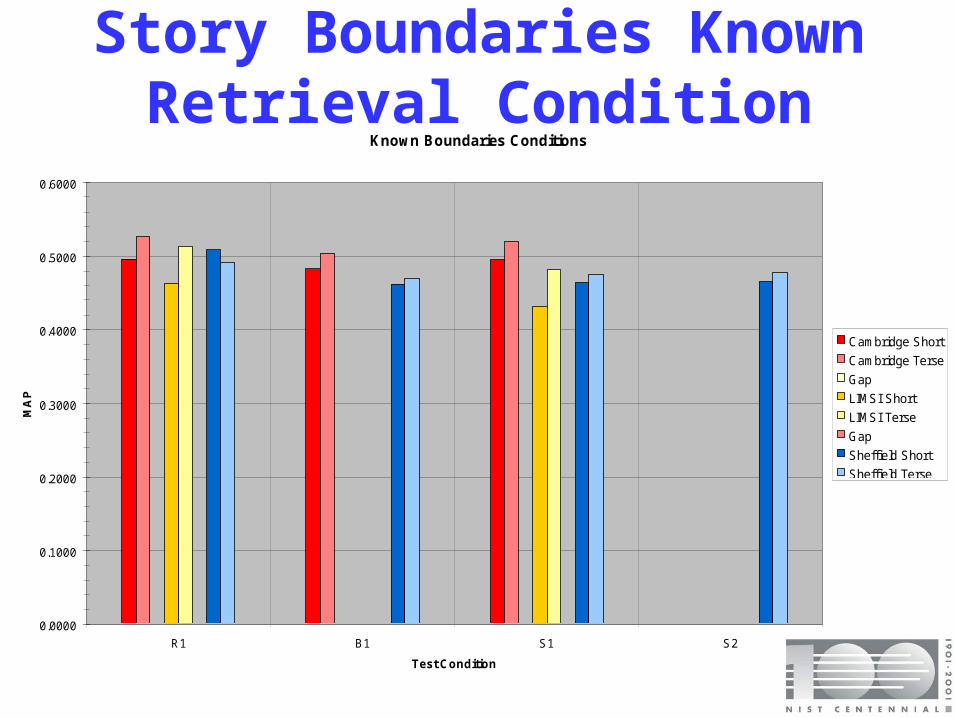
Story Boundaries Known Retrieval Condition
Known Boundaries Conditions
0.0000
0.1000
0.2000
0.3000
0.4000
0.5000
0.6000
R1 B1 S1 S2
Test Condition
MA
P
Cambridge Short
Cambridge Terse
Gap
LIMSI Short
LIMSI Terse
Gap
Sheffield Short
Sheffield Terse

Unknown Story Boundary Condition• Retrieval using continuous speech stream
– systems process entire broadcasts for ASR and retrieval with no provided segmentation
– systems output a single time marker for each relevant excerpt to indicate topical passages
• this task does NOT attempt to determine topic boundaries
– time-based scoring:• map to a story ID (“dummy” ID for retrieved non-stories
and duplicates) • score as usual using TREC_EVAL• penalizes for duplicate retrieved stories• story-based scoring somewhat artificial but
expedient

Unknown Boundaries Test Conditions
0.0000
0.1000
0.2000
0.3000
0.4000
0.5000
0.6000
Human Reference (R1) Baseline ASR (B1) Own ASR (S1) Own 2nd ASR (S2)
Speech Recognizer Used
MA
P
Cambridge Short
Cambridge Terse
Gap
LIMSI Short
LIMSI Terse
Gap
Sheffield Short
Sheffield Terse
Story Boundaries Unknown Retrieval Condition
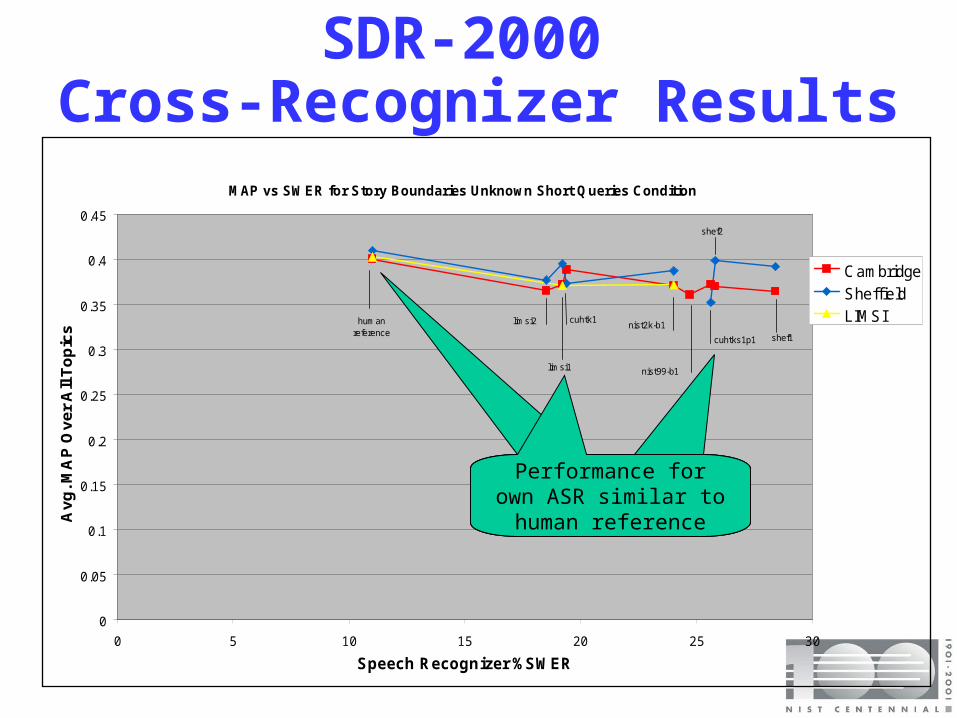
SDR-2000 Cross-Recognizer Results
MAP vs SWER for Story Boundaries Unknown Short Queries Condition
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0 5 10 15 20 25 30
Speech Recognizer %SWER
Av
g. M
AP
Ov
er
All
To
pic
s
CambridgeSheffieldLIMSIhuman
referencelimsi2
limsi1
cuhtk1nist2k-b1
nist99-b1
cuhtks1p1
shef2
shef1
Performance for own ASR similar to human
reference
Performance for own ASR similar to human
reference
Performance for own ASR similar to human
reference

Conclusions• ad hoc retrieval in broadcast news domain
appears to be a “solved problem”– systems perform well at finding relevant passages
in transcripts produced by a variety of recognizers on full unsegmented news broadcasts
• performance on own recognizer comparable to human reference
• just beginning to investigate use of non-lexical information
– Caveat Emptor• ASR may still pose serious problems for Question
Answering domain where content errors are fatal

Future for Multi-Media Retrieval?• SDR Track will be sunset
• Other opportunities– TREC
• Question Answering Track• New Video Retrieval Track
– CLEF • Cross-language SDR
– TDT Project
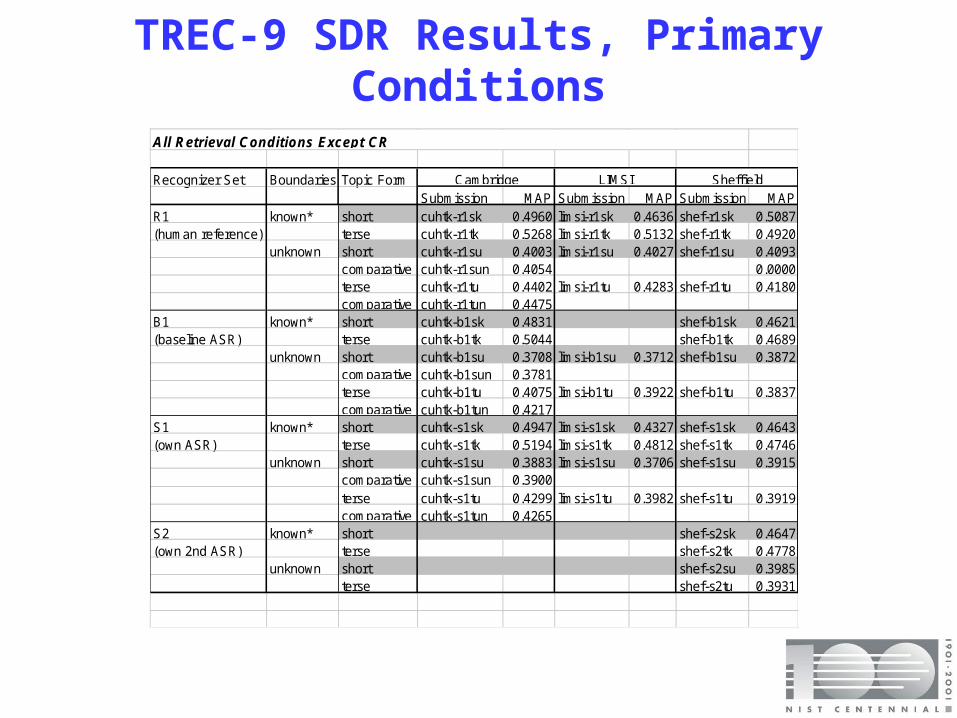
TREC-9 SDR Results, Primary Conditions
Recognizer Set Boundaries Topic FormSubmission MAP Submission MAP Submission MAP
R1 known* short cuhtk-r1sk 0.4960 limsi-r1sk 0.4636 shef-r1sk 0.5087(human reference) terse cuhtk-r1tk 0.5268 limsi-r1tk 0.5132 shef-r1tk 0.4920
unknown short cuhtk-r1su 0.4003 limsi-r1su 0.4027 shef-r1su 0.4093comparative no non-lexicalcuhtk-r1sun 0.4054 0.0000terse cuhtk-r1tu 0.4402 limsi-r1tu 0.4283 shef-r1tu 0.4180comparative no non-lexicalcuhtk-r1tun 0.4475
B1 known* short cuhtk-b1sk 0.4831 shef-b1sk 0.4621(baseline ASR) terse cuhtk-b1tk 0.5044 shef-b1tk 0.4689
unknown short cuhtk-b1su 0.3708 limsi-b1su 0.3712 shef-b1su 0.3872comparative no non-lexicalcuhtk-b1sun 0.3781terse cuhtk-b1tu 0.4075 limsi-b1tu 0.3922 shef-b1tu 0.3837comparative no non-lexicalcuhtk-b1tun 0.4217
S1 known* short cuhtk-s1sk 0.4947 limsi-s1sk 0.4327 shef-s1sk 0.4643(own ASR) terse cuhtk-s1tk 0.5194 limsi-s1tk 0.4812 shef-s1tk 0.4746
unknown short cuhtk-s1su 0.3883 limsi-s1su 0.3706 shef-s1su 0.3915comparative no non-lexicalcuhtk-s1sun 0.3900terse cuhtk-s1tu 0.4299 limsi-s1tu 0.3982 shef-s1tu 0.3919comparative no non-lexicalcuhtk-s1tun 0.4265
S2 known* short shef-s2sk 0.4647(own 2nd ASR) terse shef-s2tk 0.4778
unknown short shef-s2su 0.3985terse shef-s2tu 0.3931
All Retrieval Conditions Except CR
Cambridge LIMSI Sheffield
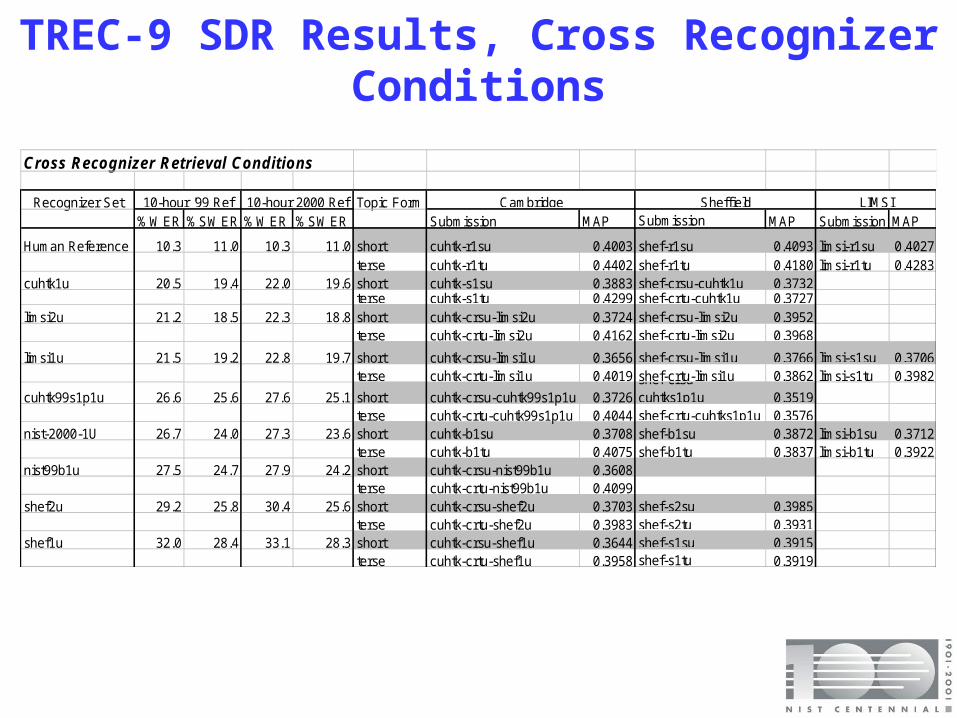
TREC-9 SDR Results, Cross Recognizer Conditions
Cross Recognizer Retrieval Conditions
Recognizer Set Topic Form%WER %SWER %WER %SWER Submission MAP Submission MAP Submission MAP
Human Reference 10.3 11.0 10.3 11.0 short cuhtk-r1su 0.4003 shef-r1su 0.4093 limsi-r1su 0.4027terse cuhtk-r1tu 0.4402 shef-r1tu 0.4180 limsi-r1tu 0.4283
cuhtk1u 20.5 19.4 22.0 19.6 short cuhtk-s1su 0.3883 shef-crsu-cuhtk1u 0.3732terse cuhtk-s1tu 0.4299 shef-crtu-cuhtk1u 0.3727
limsi2u 21.2 18.5 22.3 18.8 short cuhtk-crsu-limsi2u 0.3724 shef-crsu-limsi2u 0.3952terse cuhtk-crtu-limsi2u 0.4162 shef-crtu-limsi2u 0.3968
limsi1u 21.5 19.2 22.8 19.7 short cuhtk-crsu-limsi1u 0.3656 shef-crsu-limsi1u 0.3766 limsi-s1su 0.3706terse cuhtk-crtu-limsi1u 0.4019 shef-crtu-limsi1u 0.3862 limsi-s1tu 0.3982
cuhtk99s1p1u 26.6 25.6 27.6 25.1 short cuhtk-crsu-cuhtk99s1p1u 0.3726shef-crsu-cuhtks1p1u 0.3519
terse cuhtk-crtu-cuhtk99s1p1u 0.4044 shef-crtu-cuhtks1p1u 0.3576nist-2000-1U 26.7 24.0 27.3 23.6 short cuhtk-b1su 0.3708 shef-b1su 0.3872 limsi-b1su 0.3712
terse cuhtk-b1tu 0.4075 shef-b1tu 0.3837 limsi-b1tu 0.3922nist99b1u 27.5 24.7 27.9 24.2 short cuhtk-crsu-nist99b1u 0.3608
terse cuhtk-crtu-nist99b1u 0.4099shef2u 29.2 25.8 30.4 25.6 short cuhtk-crsu-shef2u 0.3703 shef-s2su 0.3985
terse cuhtk-crtu-shef2u 0.3983 shef-s2tu 0.3931shef1u 32.0 28.4 33.1 28.3 short cuhtk-crsu-shef1u 0.3644 shef-s1su 0.3915
terse cuhtk-crtu-shef1u 0.3958 shef-s1tu 0.3919
LIMSI10-hour '99 Ref 10-hour 2000 Ref Cambridge Sheffield
Top Related