






Languages
Pages
Legal


Hadoopw poszukiwaniu złotego młotka
Kamil Chmielewski Jacek Juraszek

Źródło: IDC's Digital Universe Study, sponsored by EMC, June 2011

• Facebook – 30 PB (2011)• 2000 serwerów• 22 400 rdzeni• 64 TB RAM
• Yahoo – 14 PB (2010)• 4000 serwerów
• Ebay – 5,3 PB• 532 serwery• 4256 rdzeni
• Google – 24 PB ???

Wzrost mocy obliczeniowej
Źródło: The Free Lunch Is Over, Herb Sutter


Architektura HDFS

HDFS File System Shell
• hadoop fs -cat file:///file3 /user/hadoop/file4
• hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
• hadoop fs -du /user/hadoop/dir1
• hadoop fs -get hdfs://nn.example.com/user/hadoop/file localfile
• hadoop fs -ls /user/hadoop/file1
• hadoop fs -mkdir hdfs://nn1.example.com/user/hadoop/dir
• hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
• hadoop fs -put localfile hdfs://nn.example.com/hadoop/hadoopfile
• hadoop fs -rm hdfs://nn.example.com/file
• hadoop fs -tail pathname

Rozproszony klient?

NameNode HA

Zrównoleglenie – MapReduce
function map(String name, String document): // name: document name // document: document contents for each word w in document: emit (w, 1)
function reduce(String word, Iterator partialCounts): // word: a word // partialCounts: a list of aggregated partial counts sum = 0 for each pc in partialCounts: sum += pc emit (word, sum)
http://en.wikipedia.org/wiki/MapReduce

MapReduce – Hadoop JAVA
http://wiki.apache.org/hadoop/WordCount
63 linie !!!

MapReduce – Apache PIG
http://en.wikipedia.org/wiki/Pig_(programming_tool)
input_lines = LOAD '/tmp/my-copy-of-all-pages-on-internet' AS (line:chararray);
-- Extract words from each line and put them into a pig bag-- datatype, then flatten the bag to get one word on each rowwords = FOREACH input_lines GENERATE FLATTEN(TOKENIZE(line)) AS word; -- filter out any words that are just white spacesfiltered_words = FILTER words BY word MATCHES '\\w+'; -- create a group for each wordword_groups = GROUP filtered_words BY word; -- count the entries in each groupword_count = FOREACH word_groups
GENERATE COUNT(filtered_words) AS count, group AS word; -- order the records by countordered_word_count = ORDER word_count BY count DESC;STORE ordered_word_count INTO '/tmp/number-of-words-on-internet';
7 linii dobrze,63 źle

Przykład z życia wziętypublic static class MetricsMapper extends TableMapper<Text, IntWritable> { private final static Logger log = LoggerFactory.getLogger(MetricsMapper.class);
protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, Text, IntWritable>.Context context) throws IOException, InterruptedException { String query = Bytes.toString(value.getValue(RawDataFamily.CF_B, RawDataFamily.QUERY.getColumn())); Map<String, String> infoTags = getValuesFromQuery(query, KEYS); for (String key : KEYS) {
long eventTime = toLong(value.getValue(EvalDataFamily.CF_B, EvalDataFamily.CREATE_TIME.getColumn()));
long eventTruncatedToDay = timestampToDay(eventTime);
String tagValue = resolveTagValue(key, value, infoTags); int visitCount = toInt(value.getValue(EvalDataFamily.CF_B, EvalDataFamily.VISIT_COUNT.getColumn())); context.write(new Text(eventTruncatedToDay + KEY_DELIMITER + infoKey(key) + KEY_DELIMITER + tagValue), new IntWritable( visitCount)); } }; private String resolveTagValue(String attr, Result result, Map<String, String> allTags) { String tagValue = allTags.get(attr); tagValue = StringUtils.isBlank(tagValue) ? UNDEFINED : tagValue; if (SOURCE.equals(attr)) { if (!UNDEFINED.equals(tagValue)) { return tagValue; } String direct = Bytes.toString(result.getValue(RawDataFamily.CF_B, RawDataFamily.DIRECT.getColumn())); if (StringUtils.isNotBlank(direct)) { return retrieveOrigin(direct); } return DIRECT; } else if (MEDIUM.equals(attr)) { String source = resolveTagValue(SOURCE, result, allTags); return source + VALUE_DELIMITER + tagValue; } return tagValue; }
private String retrieveHost(String url) { if (StringUtils.isNotBlank(url)) { try { return (new URL(url)).getHost().replaceFirst("www.", ""); } catch (MalformedURLException e) { log.warn("Malformed URL '{}'. Could not retrieve host value.", url); } } return null; }
DEFINE extractor pl.allegro.cm.pig.udf.specific.Extractor();DEFINE isNotBlank pl.allegro.cm.pig.udf.IsNotBlank();DEFINE concat pl.allegro.cm.pig.udf.Concat();
in = LOAD 'events.$account' USING org.apache.pig.backend.hadoop.hbase.HBaseStorage('r:userId e:processId e:createTime r:query r:direct e:newprocess', '-caster HBaseBinaryConverter') AS (userId:chararray, processId:chararray, createTime:chararray, query:chararray, direct:chararray, newprocess:chararray);
rows = FILTER in BY (userId IS NOT NULL) AND (processId IS NOT NULL) AND (createTime IS NOT NULL);rows = FOREACH rows GENERATE SUBSTRING(createTime,0,10) AS createTime, userId, processId, query, direct, newprocess;rows = FILTER rows BY '$lower' <= createTime AND '$upper' >= createTime;
processs = GROUP rows BY (userId,processId);processs = FOREACH processs GENERATE concat(group.$0,'|',group.$1) AS countId, COUNT($1) AS count;
firstEvFromEachprocess = FILTER rows BY (newprocess IS NOT NULL);firstEvFromEachprocess = FOREACH firstEvFromEachprocess GENERATE createTime AS ct, concat(userId,'|',processId) AS campId, extractor(query,direct) AS params;
joinedData = JOIN firstEvFromEachprocess BY procId, processs BY countId;unpackParams = FOREACH joinedData GENERATE ct AS t, FLATTEN(params), count AS c, (count==1 ? 1 : 0) AS b;dataForWrite = GROUP unpackParams BY (t,$1,$2);dataForWrite = FOREACH dataForWrite GENERATE group.t, group.$1, group.$2, SUM(unpackParams.b),SUM(unpackParams.c), COUNT(unpackParams);
STORE dataForWrite INTO 'metrics' USING org.apache.pig.piggybank.storage.DBStorage('$driver','$url','$usr','$pass','INSERT INTO metrics (account, date, key,value, cripled, events, processs) VALUES ("$account", ?, ?, ?, ?, ?, ?) ON DUPLICATE KEY UPDATE cripled=VALUES(cripled), events=VALUES(events), processs=VALUES(processs)');
private Map<String, String> getValuesFromQueryString(String query, Set<String> keys) { String[] keyVal = split(query, '&'); Map<String, String> result = new HashMap<String, String>(); for (String s : keyVal) { String[] kv = split(s, '='); if (keys.contains(kv[0]) && kv.length > 1) { result.put(kv[0], kv[1]); } } return result; } private String key(String key) { if (SOURCE.equals(key)) { return SOURCE; } else if (MEDIUM.equals(key)) { return MEDIUM; } return key; } } public static class MetricsReducer extends TableReducer<Text, IntWritable, Writable> { protected void reduce(Text key, Iterable<IntWritable> visitCounts, Reducer<Text, IntWritable, Writable, Writable>.Context context) throws IOException, InterruptedException { long visits = 0; long pv = 0; long bounces = 0; for (IntWritable vc : visitCounts) { visits++; pv += vc.get(); bounces += vc.get() == 1 ? 1 : 0; } context.write( null, new Put(Bytes.toBytes(key.toString())) .add(Constants.CF_B, Constants.VISITS.getColumn(), toBytes(visits)) .add(Constants.CF_B, Constants.PV.getColumn(), toBytes(pv)) .add(Constants.CF_B, Constants.BOUNCES.getColumn(), toBytes(bounces))); }; }
A to jest PIG…

Hadoop + MongoDB
MongoDB
online data
HADOOP
archive data
Flushed dataMR
Bach proc. result

Filesystem = HDFS ?

HBase
key timestamp cf dane cf adres
80071223097 t3 miasto=Warszawa
80071223097 t2 miasto=Gdańsk
80071223097 t1 imie=Jan
86121267222 t2 ulica=Długa
86121267222 t1 imie=Maria miasto=Poznań

HTable table = new HTable("osoby");Put event = new Put(Bytes.toBytes("80071223097") .add(Bytes.toBytes("dane"), Bytes.toBytes("imie"), Bytes.toBytes("Jan")) .add(Bytes.toBytes("adres"), Bytes.toBytes("miasto"), Bytes.toBytes("Warszawa")) ;table.put(event);
// https://github.com/nearinfinity/hbase-dslHTable table = new HTable("osoby");hBase.save(table).row("80071223097").
family("dane").col("imie", "Jan").family("adres").col("miasto", "Warszawa");
# http://happybase.readthedocs.org/table = connection.table('osoby')table.put('80071223097’,
{'dane:imie': 'Jan', 'adres:miasto': 'Warszawa'})

# Count rows in a tabledef _count_internal(interval = 1000, caching_rows = 10) # We can safely set scanner cachingwith the first key only filter scan = org.apache.hadoop.hbase.client.Scan.new scan.cache_blocks = false scan.caching = caching_rows scan.setFilter(org.apache.hadoop.hbase.filter.FirstKeyOnlyFilter.new)
# Run the scanner scanner = @table.getScanner(scan) count = 0 iter = scanner.iterator
# Iterate results while iter.hasNext row = iter.next count += 1 next unless (block_given? && count % interval == 0) # Allow command modules to visualize counting process yield(count, String.from_java_bytes(row.getRow)) end
# Return the counter return countend
HBase Shell

Koszmar pakietowy
org.apache.hadoop.mapred
Wszystko_mający Status: legacy Chain_mr Operacja JOIN na MR
org.apache.hadoop.mapreduce
Przyjazne API Klasy bazowe Konteksty Wsparcie dla CLI i CoC
Smaczki z Maven Repo:
Przepakietowana GUAVAZależności do commons-loggingDystrybucje tylko w 3rd party repoHBASE z zależnościami do: jetty i servlet-api

Bałagan z wersjami

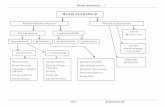
Przykładowa architektura systemu
Bazy danych nadal nadają sens aplikacji
MR = Batch

Hadoop + SOLR = SOLR Cloud

Nie każdy problem jest dość duży…
FACEBOOK CLUSTER2k maszyn12 TB per maszyna30 PB całkowitej pojemności1200 maszyn x 8 core800 maszyn X 16 core

Zastosowania• Indeksowanie dokumentów
• Analiza wykorzystania serwisów internetowych
• Logi serwerów, firewalli
• Repozytoria obrazów, filmów
• Metryki parametrów systemów
• Systemy rekomendacji

More info …
http://hortonworks.com/blog/
http://www.cloudera.com/blog/
http://hadoopblog.blogspot.com/
http://www.larsgeorge.com/
http://natishalom.typepad.com/nati_shaloms_blog/
http://developer.yahoo.com/blogs/ydn/categories/hadoop/
http://bradhedlund.com/topics/big-data/
Top Related