







Languages
Pages
Legal


IntroductionRégression linéaire
IllustrationCurse of dimensionality
Introduction au machine learning
Mines Fontainebleau of doom
27 janvier 2016
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Définition ?
Conception et étude d’algorithmes qui peuvent apprendre et fairedes prédictions sur des données.Essentiellement deux types de machine learning :
l’apprentissage non supervisé (quelle est la structure de mesdonnées ? Est-ce que je peux les regrouper en classes ? Est-ce que jepeux simplifier sans perdre (trop) d’information ?)l’apprentissage supervisé : étant donné un "grand nombre" dedonnées Xi et leurs étiquettes respectives Yi , est-ce que je peuxtrouver une fonction f telle que f (Xi ) ≈ Yi ? Et est-ce que pour unenouvelle observation (X ,Y ) j’aurai bien f (X ) ≈ Y ?
Il n’est pas interdit de combiner les deux ...
Introduction au machine learning
IntroductionRégression linéaire
IllustrationCurse of dimensionality
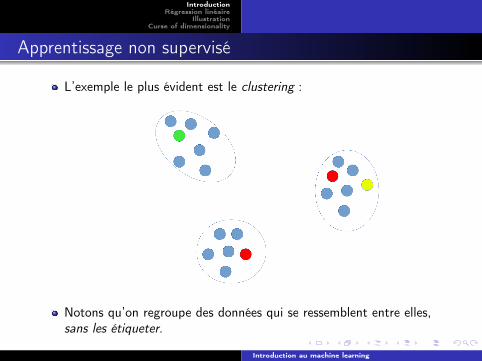
Apprentissage non supervisé
L’exemple le plus évident est le clustering :
Notons qu’on regroupe des données qui se ressemblent entre elles,sans les étiqueter.
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Apprentissage supervisé
Cas général : on dispose d’une base de données (Xi )i∈[1;N] et desannotations (ou "étiquettes", "labels", "ground truth" ...)correspondantes Yi ; on cherche une fonction f telle que pour tout i :f (Xi ) ≈ Yi .On distingue deux approches a priori différentes selon le domaine desvaleurs de Y :
Lorsque Y est un scalaire (Y prend ses valeurs dans R voire C), onparle de régression.Lorsque Y prend ses valeurs dans un ensemble non ordonné, parexemple {bleu, rouge, vert} ou {sain, malade}, on parle plutôt declassification.
Notons que pour faire de la classification binaire (deux classes) on peutsouvent se ramener à un problème de régression et fixer un seuil ; c’esttypiquement le cas de la régression logistique.
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Exemples d’apprentissage supervisé
Classification :X (prédicteurs) Y
données patient (âge, poids, taille ...) {sain, malade}son {guitare, piano, violon, ...}
image {photo, dessin, ...}e-mail {spam, ham}
Régression :X (prédicteurs) Y
robot (données capteurs) angle" vitesse
infos trafic probabilité d’embouteillageprix au cours des derniers jours prix le lendemain
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Fonction d’erreur
Qu’est-ce qu’on entend par f (Xi ) ≈ Yi ?
Typiquement, on se donne une fonction d’erreur err(f (Xi ),Yi )
On cherche alors à minimiser :
1N
N∑i=1
err(f (Xi ),Yi )
... ou pas.On cherche en fait à minimiser E [err(f (X ),Y )]
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Fonction d’erreur
Qu’est-ce qu’on entend par f (Xi ) ≈ Yi ?
Typiquement, on se donne une fonction d’erreur err(f (Xi ),Yi )
On cherche alors à minimiser :
1N
N∑i=1
err(f (Xi ),Yi )
... ou pas.On cherche en fait à minimiser E [err(f (X ),Y )]
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Formalisation
On se place dans le cas où les Xi ∈ Rp et Y ∈ R.On cherche la fonction f sous la forme fθ(x) = θ0 + θT x
Autrement dit, si on écrit Xi = (X (1)i ,X (2)
i , ...X (p)i )T , on cherche fθ de
manière à ce que :
fθ(x) = θ0 + θ1x (1) + θ2x (2) + ...+ θpx (p)
On choisit de plus err(f (x), y) = (f (x)− y)2
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Solution analytique
Si on veut minimiser l’erreur empirique :
1N
N∑i=1
(fθ(Xi )− Yi )2
la solution est donnée par :
θ̂ = (XTX)−1XTY
où X est la matrice dont la i-ième ligne est (1,X (1)i ,X (2)
i ...X (p)i )
... mais est-ce qu’on a intérêt à minimiser l’erreur empirique ?
Introduction au machine learning
IntroductionRégression linéaire
IllustrationCurse of dimensionality
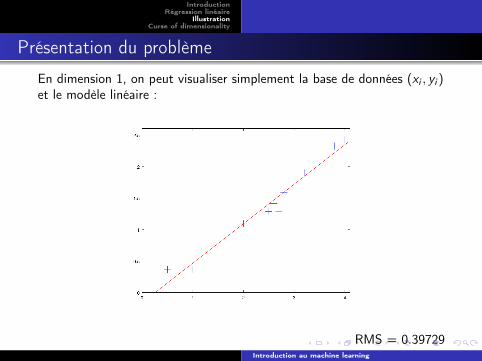
Présentation du problème
En dimension 1, on peut visualiser simplement la base de données (xi , yi )et le modèle linéaire :
RMS = 0.39729Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Régression polynômiale
Si on cherche f comme un polynôme de degré (au plus) d :
fd(x) = θ0 + θ1x + θ2x2 + ...+ θdxd
On peut en fait se ramener au cas de la régression linéaire endimension d par la transformation :
x → (x , x2, ..., xd)
La régression polynômiale peut donc en fait être vue comme unerégression linéaire (en dimension supérieure).
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Régression polynômiale
Si on cherche f comme un polynôme de degré (au plus) d :
fd(x) = θ0 + θ1x + θ2x2 + ...+ θdxd
On peut en fait se ramener au cas de la régression linéaire endimension d par la transformation :
x → (x , x2, ..., xd)
La régression polynômiale peut donc en fait être vue comme unerégression linéaire (en dimension supérieure).
Introduction au machine learning
IntroductionRégression linéaire
IllustrationCurse of dimensionality
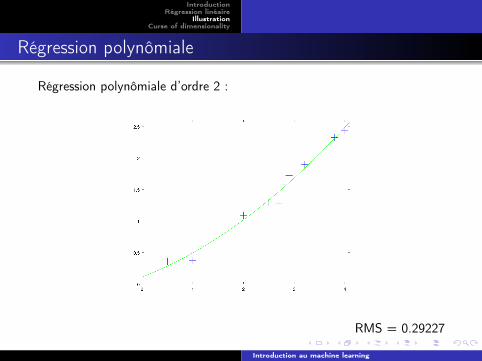
Régression polynômiale
Régression polynômiale d’ordre 2 :
RMS = 0.29227
Introduction au machine learning
IntroductionRégression linéaire
IllustrationCurse of dimensionality
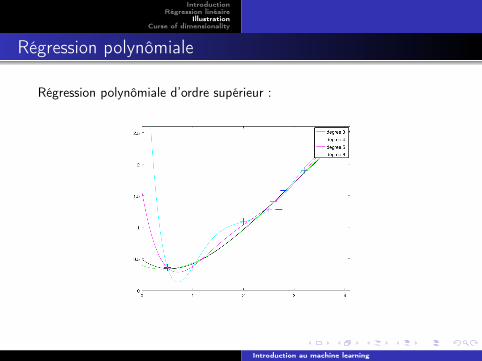
Régression polynômiale
Régression polynômiale d’ordre supérieur :
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Régression polynômiale
Régression polynômiale d’ordre supérieur :
Introduction au machine learning
IntroductionRégression linéaire
IllustrationCurse of dimensionality
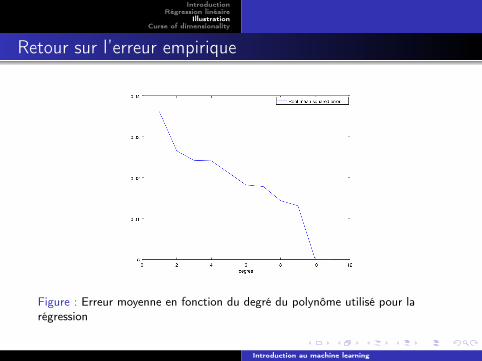
Retour sur l’erreur empirique
Figure : Erreur moyenne en fonction du degré du polynôme utilisé pour larégression
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Bias/variance tradeoff
Si on suppose qu’il existe une fonction fopt telle que Y = fopt(X ) + ε où εest une variable aléatoire de moyenne nulle et de variance σ2, et qu’onnote f̂ la fonction apprise sur une première base de données, l’erreurattendue sur une nouvelle base Xval peut s’écrire :
E[(Y − f̂ (X ))2
]= Bias2 + Var + σ2
avec :Bias = E
[f̂ (X )
]− f (X )
Var = E[f̂ (X )− E
[f̂ (X )
]2]
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Bias/variance tradeoff
Le biais Bias est d’autant plus petit que le modèle "colle" à la based’apprentissage (quitte à apprendre du bruit et à prédire n’importequoi en dehors des points de la base).La variance est une sorte de mesure de stabilité du modèle ; ellemesure à quel point deux modèles appris sur des bases similaires(mais distinctes) sont proches en moyenne.
! ! ! Se méfier donc des articles qui annoncent un taux de bonneclassification de 98% ou une erreur moyenne ridiculement petite ; ça nesert à rien de minimiser le biais si la variance est élevée.Ce phénomène s’appelle le surapprentissage ou overfit, et constitue unedes erreurs les plus courantes en machine learning.
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Nearest neighbors
1-nearest neighbor :1-NN : on attribue à un point le label de son plus proche voisin.k-NN : on attribue le label majoritaire parmi les k plus prochesvoisins.
Introduction au machine learning
IntroductionRégression linéaire
IllustrationCurse of dimensionality
Où est le plus proche voisin ?
Si les données d’entrée sont réparties uniformément dans le cube[−1; 1]p, où est le point le plus proche de l’origine ?
Plus précisément, quelle est la probabilité d’avoir un point à unedistance de moins de 1 de l’origine ?Réponse : Vp
2p
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Où est le plus proche voisin ?
Si les données d’entrée sont réparties uniformément dans le cube[−1; 1]p, où est le point le plus proche de l’origine ?Plus précisément, quelle est la probabilité d’avoir un point à unedistance de moins de 1 de l’origine ?
Réponse : Vp2p
Introduction au machine learning
IntroductionRégression linéaire
IllustrationCurse of dimensionality
Où est le plus proche voisin ?
Si les données d’entrée sont réparties uniformément dans le cube[−1; 1]p, où est le point le plus proche de l’origine ?Plus précisément, quelle est la probabilité d’avoir un point à unedistance de moins de 1 de l’origine ?Réponse : Vp
2p
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
Volume de la boule unité
On démontre facilement que :
V2k =πk
k!
V2k+1 =2k+1πk
(2k + 1)!!
Introduction au machine learning

IntroductionRégression linéaire
IllustrationCurse of dimensionality
So alone
La probabilité d’avoir un voisin à une distance de moins de 1 est donc :
p2k = (π
4)k
1k!
p2k+1 =πk
2k(2k + 1)!!
Introduction au machine learning