
![[@NaukriEngineering] Apache Spark](https://static.fdocuments.net/doc/165x107/588304451a28abe70d8b6157/naukriengineering-apache-spark.jpg)






Languages
Pages
Legal


Intro to Apache Spark
Marius SoutierFreelance Software Engineer
@mariussoutier
Clustered In-Memory Computation

Motivation
• Classical data architectures break down
• RDMBS can’t handle large amounts of data well
• Most RDMBS can’t handle multiple input formats
• Most NoSQLs don’t offer analytics
Problem Running computations on BigData®

The 3 Vs of Big DataVolume
100s of GB, TB, PB
Variety Structured, Unstructured,
Semi-Structured
Velocity Sensors, Realtime
“Fast Data”

Hadoop (1)
• De-facto standard for running computations on large amounts of different data is Hadoop
• Hadoop consists of
• HDFS distributed, fault-tolerant file system
• Map/Reduce parallelizable computations pioneered by Google
• Hadoop is typically run on a (large) cluster of non-virtualized commodity hardware

Hadoop (2)
• However, Map/Reduce are batch jobs with high latency
• Not suitable for interactive queries, real-time analytics, or Machine Learning
• Pure Map/Reduce is hard to develop and maintain

Enter Spark
Spark is a framework for
clustered in-memory
data processing

• Developed at UC Berkeley, released in 2010
• Apache Top-Level Project Since February 2014, current version is 1.2.1 / 1.3.0
• USP: Uses cluster-wide available memory to speed up computations
• Very active community
Apache Spark (1)

• Written in Scala (& Akka), APIs for Java and Python
• Programming model is a collection pipeline* instead of Map/Reduce
• Supports batch, streaming, interactive, or all combined using unified API
Apache Spark (2)
* http://martinfowler.com/articles/collection-pipeline/
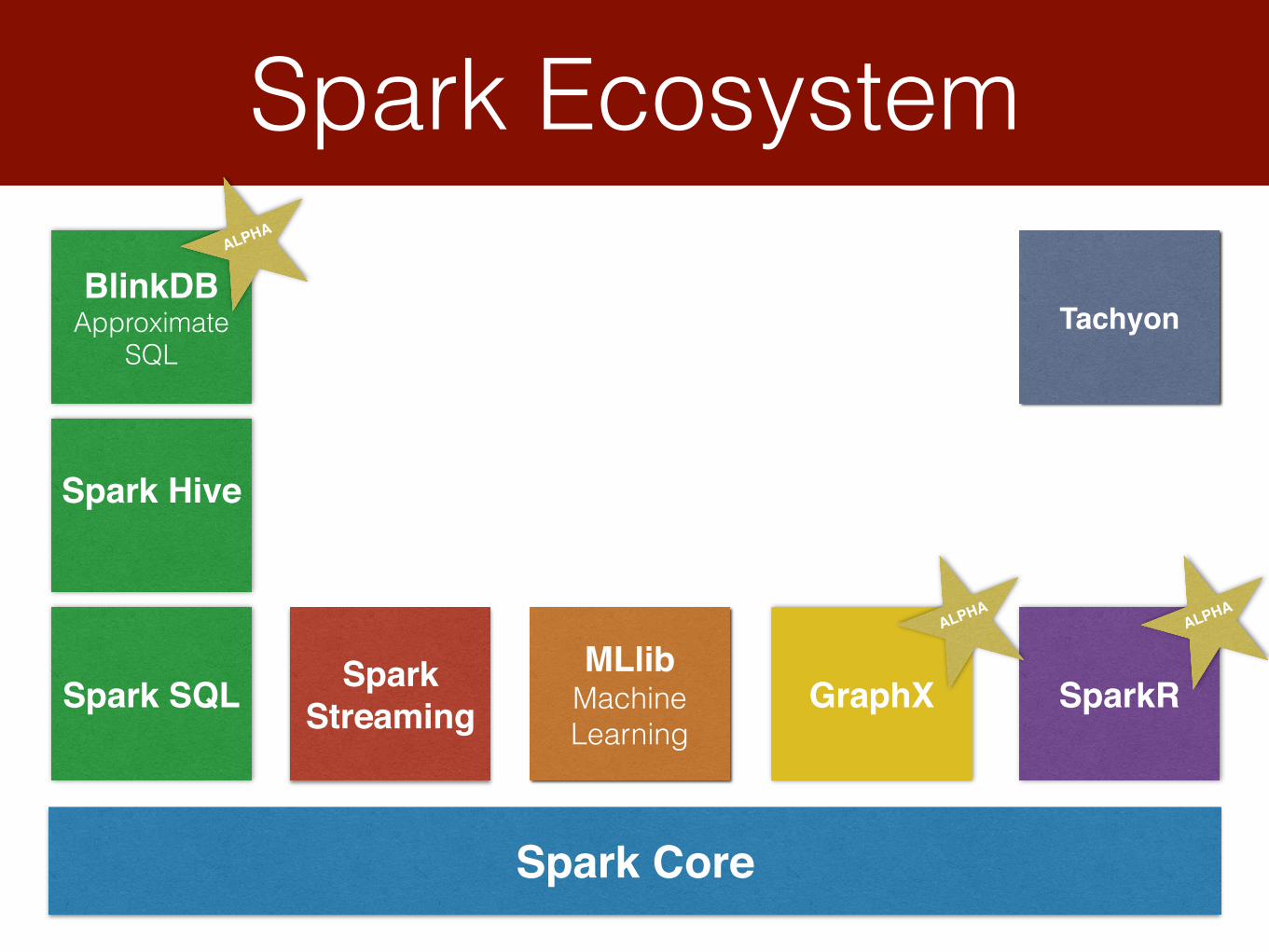
Spark Ecosystem
Spark Core
Spark SQL
Spark Hive
BlinkDBApproximate
SQL
SparkStreaming
MLlibMachine Learning
GraphX SparkR
ALPHAALPHA
ALPHA
Tachyon

Spark is a framework for clustered in-memory data processing
Spark is a platform for data driven products.

• Base abstraction Resilient Distributed Dataset (RDD)
• Essentially a distributed collection of objects
• Can be cached in memory or on disk
RDD

RDD Word Countval sc = new SparkContext()val input: RDD[String] = sc.textFile("/tmp/word.txt")
val words: RDD[(String, Long)] = input .flatMap(line => line.toLowerCase.split("\\s+")) .map(word => word -> 1L) .cache()
val wordCountsRdd: RDD[(String, Long)] = words .reduceByKey(_ + _) .sortByKey() val wordCounts: Array[(String, Long)] = wordCountsRdd.collect()
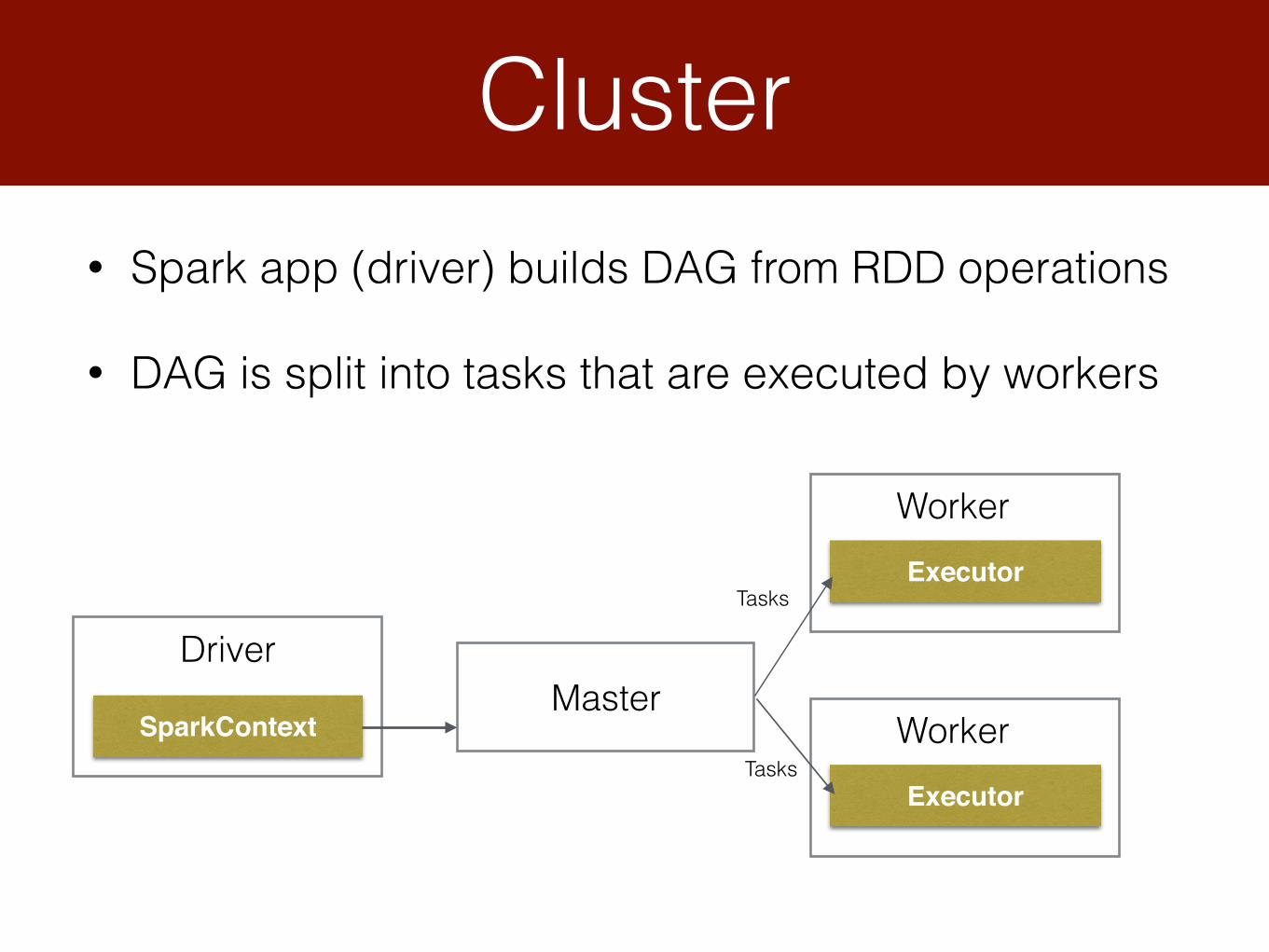
Cluster
Driver
SparkContextMaster
WorkerExecutor
WorkerExecutor
Tasks
Tasks
• Spark app (driver) builds DAG from RDD operations
• DAG is split into tasks that are executed by workers
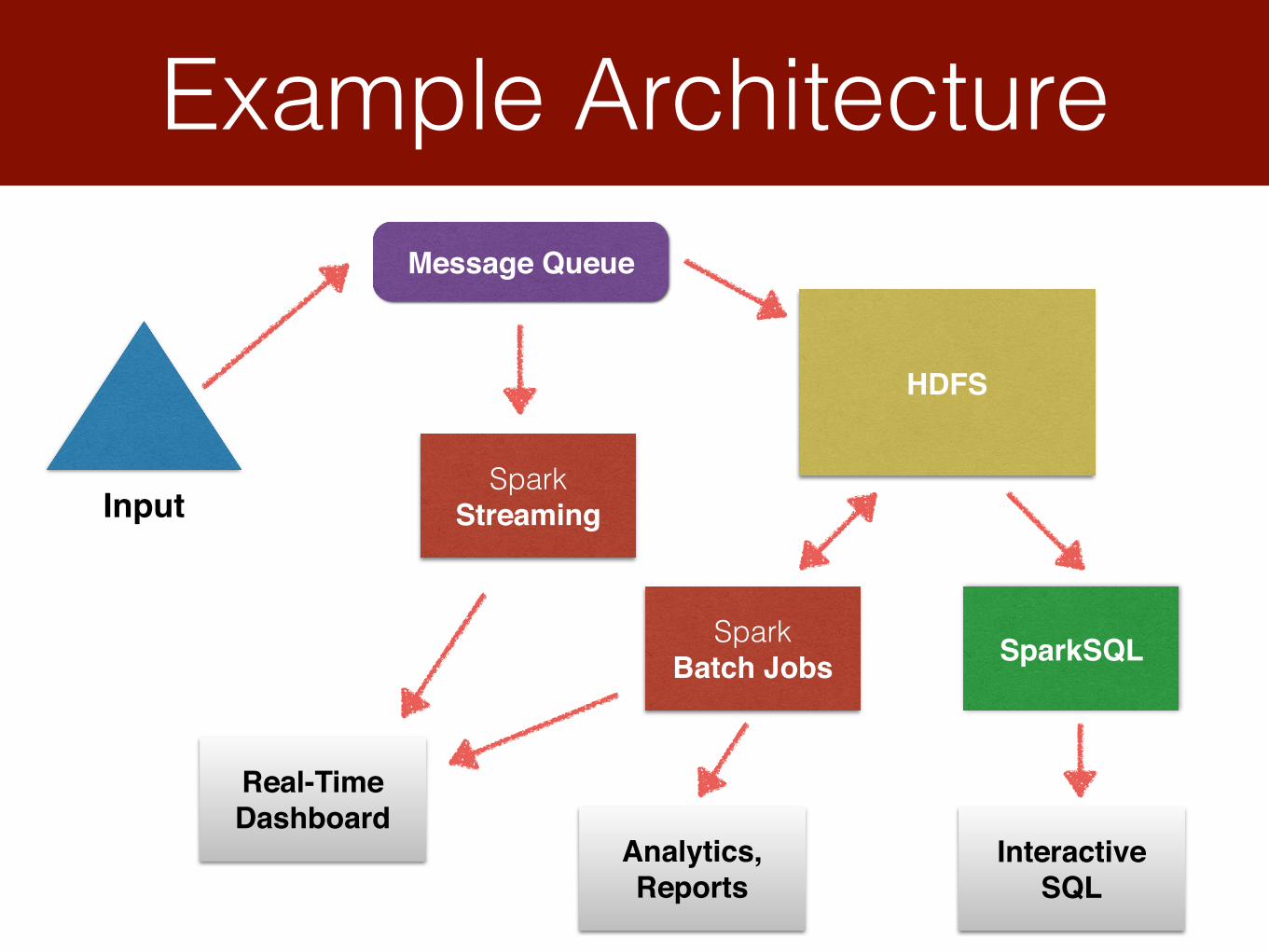
Example Architecture
Input
HDFS
Message Queue
Spark Streaming
Spark Batch Jobs SparkSQL
Real-TimeDashboard
InteractiveSQL
Analytics,Reports

Demo
Questions?
Top Related