







Languages
Pages
Legal


N d’ordre : 2009-ISAL-0100 Annee 2009
THESE
presentee devant
L’INSTITUT NATIONAL DES SCIENCES APPLIQUEES DE LYON
pour obtenir
LE GRADE DE DOCTEUR
ECOLE DOCTORALE : INFORMATIQUE ET MATHEMATIQUES
SPECIALITE : INFORMATIQUE
par
Ovidiu VASUTIU
Ingenieur en Informatique
GESTION DES CONNAISSANCES POUR LA
MAITRISE DE LA RELATION ENTRE
PATRIMOINE DOCUMENTAIRE ET
SYSTEME D’INFORMATION
Soutenue le : 3 decembre 2009 devant la Commission d’examen
Composition du jury :
Rapporteurs : Eric Gaussier (Professeur)
Ioan Roxin (Professeur)
Examinateurs : Youssef Amghar (Professeur)
David Jouve (Encadrant Cnedi de Lyon)
Pierre Maret (Professeur)
Jean-Marie Pinon (Professeur)
Invite : Jacques Faveeuw (Ancien Directeur Cnedi de Lyon)

Mise en page avec la classe thloria.

Remerciements
Je remercie M. Alain Folliet, Directeur du Systeme d’Information, pour m’avoir
accueilli a la Caisse Nationale des Allocations Familiales afin de participer aux projets de
la Direction du Systeme d’Information.
J’exprime ici toute ma reconnaissance a M. Jacques Faveeuw, ancien Directeur du
Centre National d’Etudes et de Developpement Informatique - Cnedi Rhone-Alpes, pour
avoir lance, encourage et soutenu pendant des nombreuses annees cet ambitieux projet de
recherche auquel cette quatrieme these apporte sa contribution.
Qu’il trouve ici l’expression de ma sincere gratitude pour ses conseils precieux et
pour son accompagnement jusqu’au bout en relisant mon manuscrit et en participant au
jury de la soutenance. Je le remercie aussi pour avoir su me transmettre cette passion et
cette fierte de travailler pour la Branche famille de la Securite Sociale.
Je remercie aussi M. Bertrand Hurel, Directeur du Centre National d’Etudes
et de Developpement Informatique - Rhone-Alpes, et M. Cyrille Broilliard, Responsable
du Secteur Informationnel, pour m’avoir offert la possibilite de realiser mes travaux de
recherche au sein du Cnedi Rhone-Alpes et pour avoir tout mis en oeuvre afin de creer
les conditions necessaires a la reussite de cette these et a la concretisation de mon projet
professionnel. Je leur adresse mes remerciements pour tous nos echanges et pour leurs
remarques et leurs observations interessantes.
Je remercie egalement M. Guy Audibert, Directeur du Centre Regional de Trai-
tement de l’Information Rhone Alpes et Auvergne, pour toute l’attention et tout l’interet
qu’il a porte a mes travaux de recherche.
Je remercie vivement M. Ioan Roxin et M. Eric Gaussier pour l’honneur qu’ils
m’ont fait en acceptant d’etre rapporteurs de cette these et pour toutes les remarques
constructives qu’ils ont formulees sur mon manuscrit.
Je presente mes remerciements a M. Pierre Maret pour avoir accepte de presider
le jury de cette these. Je suis tres honore de l’interet qu’il porte a ce travail.
Je remercie M. Bertrand Chabbat et M. David Jouve pour m’avoir accueilli dans
le cadre du projet Systeme d’Information Documentaire. Je leur remercie pour leur enca-
drement, pour leurs conseils et pour m’avoir associe a cette grande aventure institutionnelle
qu’est le projet SIDoc.
Je tiens a remercier tout particulierement M. Jean-Marie Pinon et M. Youssef
Amghar pour avoir accepte de diriger mes recherches, pour leur encadrement, et pour leur
engagement dans cette these. Merci a eux d’avoir su me faire decouvrir et aimer le metier
de chercheur et d’enseignant. Merci aussi pour leur patience et pour leurs encouragements
dans les moments moins faciles.
i

Je remercie egalement l’ensemble des personnes du Cnedi Rhone-Alpes et du
Liris, avec qui j’ai pu lier des liens d’amitie, pour leur accueil chaleureux et pour tous les
moments sympathiques que nous avons vecus pendant ces annees.
Un grand Merci a Maud et Sabine, les « arbitres des chiffres, des lettres et des
virgules » qui ont eu la patience extraordinaire de relire et de corriger ce manuscrit. Ainsi,
grace a elles, sa qualite s’est amelioree.
Enfin, je tiens a profiter de l’importance de ce manuscrit dans la vie d’un cher-
cheur, pour exprimer mon immense gratitude a tous ceux, famille, amis, collegues, qui
m’ont aide, accompagne et encourage, avec beaucoup de patience et de comprehension,
tout au long de ces longues annees. Les citer ici serait trop long ; ils se reconnaıtront.
Leur presence a mes cote et leur affection est un precieux cadeau de la vie et cette
reussite est aussi la leur. Du fond du coeur, un grand Merci ! Multumesc !
ii

Ce n’est pas parce que les choses
sont difficiles que nous n’osons pas,
c’est parce que nous n’osons pas
qu’elles sont difficiles.
Seneque
iii

iv

Table des matieres
Introduction generale 1
Partie I Contexte et problematique 5
Introduction 7
Chapitre 1 Maıtrise d’un patrimoine des connaissances metier 9
1.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.2 La Branche famille de la Securite Sociale . . . . . . . . . . . . . . . . . 10
1.2.1 La Securite Sociale . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.2.2 Mission de protection sociale de la Branche famille . . . . . . . . 11
1.2.3 Mission de mise en application de la legislation . . . . . . . . . . 11
1.3 Composante documentaire . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.3.1 Production et gestion de la composante documentaire . . . . . . 14
1.3.2 Caracteristiques de la composante documentaire . . . . . . . . . 17
1.3.3 Problematiques et enjeux de la maıtrise de la composante docu-
mentaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
1.4 Composante logicielle - le Systeme de gestion des prestations legales . . 21
1.4.1 Production de la composante logicielle . . . . . . . . . . . . . . . 21
1.4.2 Caracteristiques de la composante logicielle . . . . . . . . . . . . 25
v

Table des matieres
1.4.3 Problematiques et enjeux de la maıtrise de la composante logicielle 27
1.5 Services attendus pour la maıtrise du patrimoine des connaissances metier 30
Chapitre 2 Etat des lieux dans la Branche famille 33
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.2 Demarche generale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.2.2 Maıtrise des connaissances metier - projet SIDoc/KM . . . . . . 34
2.3 Le referentiel de production et de gestion documentaire . . . . . . . . . 36
2.3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.3.2 Architecture logique . . . . . . . . . . . . . . . . . . . . . . . . . 38
2.3.3 Fonctions de base . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2.3.4 Fonctionnalites de gestion et de production documentaire . . . . 46
2.3.5 Architecture technique . . . . . . . . . . . . . . . . . . . . . . . 47
2.3.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
Conclusions 53
Partie II Etat de l’art 55
Introduction 57
Chapitre 3 Structuration de la documentation 59
3.1 Notion de document . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
3.2 Structure documentaire . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
3.3 Langages de structuration documentaire . . . . . . . . . . . . . . . . . 63
3.4 Modelisation documentaire . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.5 Langages d’echanges documentaires . . . . . . . . . . . . . . . . . . . . 66
3.6 Synthese . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
vi

Chapitre 4 Gestion des Systemes d’Information 69
4.1 Concepts de base . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.1.1 Les cycles de developpement . . . . . . . . . . . . . . . . . . . . 71
4.1.2 Les methodologies de conception et de developpement . . . . . . 71
4.1.3 Formalisation des developpements . . . . . . . . . . . . . . . . . 72
4.1.4 Maıtrise et amelioration de la qualite . . . . . . . . . . . . . . . 73
4.1.5 Programmation des processus . . . . . . . . . . . . . . . . . . . 73
4.2 Modelisation des Systemes d’Information . . . . . . . . . . . . . . . . . 74
4.2.1 Formalismes de modelisation . . . . . . . . . . . . . . . . . . . . 75
4.2.2 Choix du formalisme de modelisation des Systemes d’Information 78
4.2.3 Maıtrise des modeles . . . . . . . . . . . . . . . . . . . . . . . . 79
4.3 Gestion des connaissances et maıtrise des Systemes d’Information . . . 80
4.4 Synthese . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
Chapitre 5 Analyse des dependances 83
5.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
5.2 Tracabilite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5.3 Analyse des dependances - livrables de conception et de developpement 86
5.4 Analyse des dependances - code source des applications . . . . . . . . . 87
5.4.1 Graphe de dependances . . . . . . . . . . . . . . . . . . . . . . . 87
5.4.2 Decoupage des programmes – Program slicing . . . . . . . . . . 88
5.5 Analyse des dependances - exigences des utilisateurs . . . . . . . . . . . 89
5.6 Analyse des dependances - execution des programmes . . . . . . . . . . 90
5.7 Synthese . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
Conclusion 93
Partie III Propositions pour l’etude d’impact 95
Introduction 97
vii

Table des matieres
Chapitre 6 Cadre pour l’etude d’impact 99
6.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
6.2 Modele d’etude d’impact – Niveaux d’abstraction . . . . . . . . . . . . 101
6.2.1 Niveau d’abstraction N 0 – le monde reel et les connaissances
du domaine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
6.2.2 Niveau d’abstraction N 1 – la representation du monde reel . . . 103
6.2.3 Niveau d’abstraction N 2 – le modele de representation . . . . . 104
6.2.4 Niveau d’abstraction N 3 – le modele d’etude d’impact . . . . . 104
6.2.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
6.3 Modele d’etude d’impact - Niveau d’abstraction N3 . . . . . . . . . . . 105
6.3.1 Connaissances d’un domaine . . . . . . . . . . . . . . . . . . . . 105
6.3.2 Structure statique du meta-modele . . . . . . . . . . . . . . . . 107
6.3.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
6.3.4 Specialisation du meta-modele - Niveau d’abstraction N2 . . . . 110
6.3.5 Representation des dependances – Niveau d’abstraction N1 . . 111
6.3.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
Chapitre 7 Application du modele generique d’etude d’impact 117
7.1 Modele d’etude d’impact associe aux modeles UML – niveauN2 . . . . 117
7.1.1 Typologie des elements - Concept UML elementaire . . . . . . . 117
7.1.2 Typologie des relations elementaires dans les modeles UML . . . 119
7.1.3 Modele de graphe specifique a UML . . . . . . . . . . . . . . . . 120
7.1.4 Graphe canonique des dependances et etude d’impact – N1 . . . 121
7.2 Modele d’etude d’impact associe aux documents – niveau N2 . . . . . 123
7.2.1 Typologie des elements - Concept documentaire elementaire . . 124
7.2.2 Typologie des relations elementaires documentaire . . . . . . . . 124
7.2.3 Graphe canonique des dependances – etude d’impact – N1 . . . 126
Chapitre 8 Integration du Modele d’etude d’impact 129
8.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
8.2 Extension du Referentiel SIDoc a la gestion des modeles UML du SI . . 131
8.2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
8.2.2 Gestion des modeles UML du SI . . . . . . . . . . . . . . . . . . 132
8.2.3 Presentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
8.2.4 Utilisation des fonctionnalites du referentiel . . . . . . . . . . . . 139
viii

8.2.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
8.3 Integration du modele d’analyse des dependances et d’etude d’impact . 142
8.3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
8.3.2 Representation des dependances – graphe d’analyse des depen-
dances . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
8.3.3 Algorithme de parcours de graphe . . . . . . . . . . . . . . . . . 147
8.3.4 Integration dans la couche service . . . . . . . . . . . . . . . . . 148
8.3.5 Integration dans la couche presentation . . . . . . . . . . . . . . 149
8.3.6 Bilan de l’integration des modeles UML dans le referentiel SIDoc 152
Conclusion 155
Partie IV Evaluation 157
Chapitre 9 Evaluation et discussions 159
9.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
9.2 Rappel des enjeux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
9.3 Modele d’etude d’impact . . . . . . . . . . . . . . . . . . . . . . . . . . 161
9.3.1 Rappel de la problematique . . . . . . . . . . . . . . . . . . . . . 161
9.3.2 Rappel de la proposition . . . . . . . . . . . . . . . . . . . . . . 161
9.3.3 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
9.3.4 L’experience de l’utilisateur . . . . . . . . . . . . . . . . . . . . . 165
9.4 Integration dans le referentiel SIDoc . . . . . . . . . . . . . . . . . . . . 166
9.4.1 Rappel de la problematique . . . . . . . . . . . . . . . . . . . . . 166
9.4.2 Rappel de la proposition . . . . . . . . . . . . . . . . . . . . . . 166
9.4.3 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
9.4.4 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
Conclusion generale 173
ix

Table des matieres
Annexe A Liste des publications 175
Annexe B Schema XSD de la recommandation XML-Schema 177
Annexe C Exemple d’un docflow 179
Annexe D Recettage fonctionnel de l’application SIDoc - Extraits 181
D.1 Recettage fonctionnel . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181
Annexe E Le systeme G-Frames 183
E.1 Les G-Frames . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
Glossaire 185
Bibliographie 189
x

Introduction generale
Pour les organisations qui ont pour mission la mise en application de la legisla-
tion, les textes reglementaires constituent, a l’image de toute entreprise produisant des
biens de consommation, une matiere premiere specifique : leur activite est fondee sur
l’analyse et le traitement de cette matiere. Mais les textes reglementaires constituent aussi
le vecteur privilegie de la communication et de la diffusion des connaissances juridiques
dans l’ensemble des ramifications de ces organisations. Ces connaissances sont exprimees
au travers de nombreuses ressources critiques pour l’entreprise : documents de reference,
supports de formation, documentation metier, documentation de conception du Systeme
d’Information, etc. Elles sont utilisees au quotidien par les personnes travaillant dans ces
organisations et chargees de mettre en application la legislation. On designe par « patri-
moine documentaire » l’ensemble de ces ressources documentaires.
Par ailleurs, au vu de la quantite massive d’information traitee au sein de l’en-
treprise, le travail depasse tres largement les capacites humaines, l’amenant a solliciter
l’assistance du Systeme d’Information qui met en oeuvre les exigences exprimees par les
textes reglementaires. Celui-ci doit accompagner au quotidien les activites et servir les
objectifs de l’organisation.
Dans le domaine juridique, une des principales caracteristiques des textes regle-
mentaires est que ceux-ci sont en evolution permanente. A chaque evolution reglementaire,
l’ensemble des documents reglementaires doit etre passe en revue et, si necessaire, mis a
jour. Mais l’impact lie a une evolution reglementaire ne se cantonne pas aux seuls docu-
ments reglementaires : il affecte egalement le Systeme d’Information. Assurer la coherence
et la conformite tout au long du processus de mise en application du droit, face aux evo-
lutions reglementaires, devient une problematique strategique et engendre alors un cout
humain et financier important.
Il devient donc necessaire de pouvoir identifier et mesurer les consequences d’une
evolution reglementaire a la fois sur le patrimoine documentaire et sur le Systeme d’Infor-
mation.
Ainsi notre problematique s’exprime sur deux plans :
– mettre en relation le patrimoine documentaire et le Systeme d’Information,
– mesurer les consequences d’une evolution reglementaire : identifier les res-
1

Introduction generale
sources qui sont susceptibles d’etre impactees (au sein du patrimoine docu-
mentaire et du Systeme d’Information) et evaluer l’importance de l’impact
subit.
Repondre a cette problematique permettra une meilleure maıtrise de l’ensemble
des ressources documentaires et du Systeme d’Information, necessaire pour accroıtre la
capacite a reagir aux changements de legislation ce qui constituera un atout strategique
pour l’organisation. On parlera alors de maıtrise du « patrimoine reglementaire » ou du
« patrimoine des connaissances metier ».
Cette problematique puise ses origines dans le contexte de la Branche Famille de
la Securite Sociale. C’est ainsi que la Caisse Nationale des Allocations Familiales (Cnaf)
a servi de cadre aux differents travaux de recherche presentes au cours de cette these.
La Cnaf est en charge de l’une des legislations les plus complexes du droit francais. Les
connaissances juridiques explicitees dans des documents reglementaires et encodees dans le
Systeme d’Information doivent etre parfaitement maıtrisees tout au long de l’elaboration
du produit fini que sont les prestations specifiques.
Ce contexte a ete particulierement utile pour comprendre et analyser les nom-
breuses difficultes liees a la gestion de la matiere reglementaire et a la maıtrise du Systeme
d’Information auxquelles peuvent etre quotidiennement confrontees des entreprises pu-
bliques ou privees. Ces problemes n’ont toutefois pas ete traites uniquement en fonction
du contexte specifique de travail (Cnaf ), mais bien en les considerant comme revelateurs
d’une problematique plus large concernant de maniere generale la gestion documentaire
et la gestion des systemes d’information.
Dans le contexte particulier de ce travail, plusieurs travaux de recherche et de de-
veloppement ont permis de construire un systeme pour la maıtrise des diverses ressources
documentaires de l’organisation : notamment ceux de Bertrand Chabbat [Chabbat 97],
sur la modelisation multiparadigme des textes reglementaires, ceux de Cecile Nicolle
[Nicolle 01] sur l’acces a des bases de donnees heterogenes et ceux de David Jouve [Jouve 03a],
qui s’est interesse a la modelisation semantique de la reglementation. A l’heure actuelle, la
Cnaf souhaite prolonger cette demarche et ce processus de gestion aux composants de son
Systeme d’Information. Ainsi, l’objectif de ce travail de recherche est de proposer les outils
manquants pour une gestion unifiee des deux types de ressources encodant les connais-
sances metier d’une entreprise : les ressources documentaires et les ressources logicielles.
Ces propositions ont ete validees lors de leur integration dans le Systeme d’Information de
[Chabbat 97] Chabbat Bertrand. Modelisation multiparadigme de textes reglementaires. These :
Institut National des Sciences Appliquees de Lyon, Lyon, France, decembre 1997. 389 p.
[Nicolle 01] Nicolle Cecile. Systeme d’acces a des Bases de Donnees Heterogenes reparties en vue
d’une aide a la decision (SABaDH). These : Institut National des Sciences Appliquees de
Lyon, decembre 2001. 125 p.
[Jouve 03a] Jouve David. Modelisation semantique de la reglementation. These : Institut National
des Sciences Appliquees de Lyon, novembre 2003. 270 p.
2

la Cnaf mais leur champ d’application peut-etre elargi a d’autres domaines.
La presente these est decoupee en quatre parties, s’interessant chacune a un aspect
particulier de notre travail de recherche.
Au cours de la premiere partie, Contexte et problematique, nous procedons a
une etude approfondie des differentes caracteristiques du patrimoine documentaire et du
Systeme d’Information de la Cnaf. Nous analysons leur perimetre et le role crucial qu’ils
sont amenes a jouer au cœur de l’activite d’une organisation et plus particulierement au
cœur des processus de mise en application du droit. Nous presentons egalement les diverses
questions que suscitent d’une part la gestion des textes reglementaires et d’autre part celle
du Systeme d’Information.
La conclusion a laquelle nous conduit l’expose de cette problematique est qu’une
maıtrise globale des connaissances metier passe par la mise en relation et par une maı-
trise commune de la composante documentaire et du Systeme d’Information. L’effet de
l’evolution d’une connaissance legislative doit pouvoir etre identifie dans l’ensemble du pa-
trimoine des connaissances metier. Nous devons donc etudier comment representer, mettre
en relation et analyser les dependances entre ces deux ressources complementaires que sont
les documents et le Systeme d’Information.
On poursuit dans la deuxieme partie, consacree a l’Etat de l’art, en etudiant
plus precisement les travaux de recherche et de developpement realises autour de cette
problematique. Nous nous interessons plus particulierement a la gestion et modelisation
documentaire, a la gestion et modelisation des systemes d’information ainsi qu’aux meca-
nismes de representation et d’analyse des dependances.
Dans la troisieme partie de cette these, Propositions pour l’etude d’impact, nous
introduisons, en nous basant sur des principes de la gestion des connaissances, un modele de
representation des dependances que les differentes composantes documentaires et logicielles
entretiennent. Ce modele commun nous permet de mettre en relation les deux composantes
du patrimoine des connaissances metier et de realiser des etudes d’impact. Le modele
propose et son adaptation pour les documents et pour les modeles UML du Systeme
d’Information ont ete implementes dans l’infrastructure du Referentiel de production et
de gestion documentaire de la Cnaf. Au travers de cette phase d’implementation, nous
avons bati une application de gestion capable de repondre aux enjeux de la maıtrise de
la matiere reglementaire, patrimoine documentaire et Systeme d’Information. Par ailleurs
nous avons mis en evidence la pertinence, la fiabilite et la coherence de notre contribution,
tout en verifiant que le modele propose reste realiste et operationnel.
Enfin, la quatrieme et derniere partie, Evaluation, presente une methode d’evalua-
tion ainsi que les resultats obtenus avec nos propositions. Nous presentons une evaluation
de notre modele d’etude d’impact ainsi que les retours des utilisateurs. La discussion,
presente a la fin de ce dernier chapitre, conclue la these en tracant quelques perspectives
academiques et applicatives aux travaux de recherche presentes.
3

Introduction generale
4

Premiere partie
Contexte et problematique
5


Introduction
La partie « Contexte et problematique » de ce manuscrit s’articule autour de
deux chapitres.
Dans le premier chapitre, nous presentons le metier et les missions de la Branche
famille de la Securite Sociale geree par la Caisse Nationale des Allocations Familiales
(Cnaf).
C’est dans ce cadre que nous mettons en evidence l’importance de la matiere
reglementaire et ses caracteristiques sur les deux volets : documentaire et logiciel. Ainsi,
nous analysons les specificites des textes reglementaires, « le patrimoine documentaire »,
en nous interessant d’une part aux flux de textes reglementaires externes et internes (de
l’Assemblee Nationale aux Caisses d’allocations familiales) et d’autre part aux differentes
fonctionnalites de maıtrise des connaissances requises par l’entreprise (consultation de
textes par differents utilisateurs, redaction de textes, recherche d’information, tracabilite
des interventions, etc.). Ce chapitre s’interesse egalement au Systeme d’Information, a sa
structure, aux problematiques de conception, de la composante logicielle, supportant le
metier des organisations telles que la Cnaf. Nous analysons les specificites du Systeme
d’Information et les fonctionnalites necessaires a la conception, au developpement et a la
maintenance des composantes du Systeme d’Information.
Enfin, dans le deuxieme chapitre de cette partie nous presentons la demarche
adoptee au sein de la Branche famille pour apprehender cette problematique complexe
ainsi que l’etat des lieux et le contexte sur lequel se base notre travail.
7

Introduction
8

Chapitre 1
Maıtrise d’un patrimoine des
connaissances metier
Sommaire
1.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.2 La Branche famille de la Securite Sociale . . . . . . . . . . . 10
1.2.1 La Securite Sociale . . . . . . . . . . . . . . . . . . . . . . . 10
1.2.2 Mission de protection sociale de la Branche famille . . . . . 11
1.2.3 Mission de mise en application de la legislation . . . . . . . 11
1.3 Composante documentaire . . . . . . . . . . . . . . . . . . . 14
1.3.1 Production et gestion de la composante documentaire . . . . 14
1.3.2 Caracteristiques de la composante documentaire . . . . . . . 17
1.3.3 Problematiques et enjeux de la maıtrise de la composante
documentaire . . . . . . . . . . . . . . . . . . . . . . . . . . 19
1.4 Composante logicielle - le Systeme de gestion des presta-
tions legales . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
1.4.1 Production de la composante logicielle . . . . . . . . . . . . 21
1.4.2 Caracteristiques de la composante logicielle . . . . . . . . . 25
1.4.3 Problematiques et enjeux de la maıtrise de la composante
logicielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
1.5 Services attendus pour la maıtrise du patrimoine des connais-
sances metier . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
1.1 Introduction
Nous presentons dans ce premier chapitre le metier et les missions de la Branche
famille de la Securite Sociale geree par la Caisse Nationale des Allocations Familiales
(Cnaf). Ce chapitre nous permet d’identifier et de comprendre l’importance des textes
9

Chapitre 1. Maıtrise d’un patrimoine des connaissances metier
reglementaires et du Systeme d’Information dans l’exercice metier des institutions telles
que la Cnaf ayant comme mission la mise en application du droit.
Nous analyserons les caracteristiques et les problematiques liees a la gestion des
textes reglementaires et a la gestion du Systeme d’Information.
1.2 La Branche famille de la Securite Sociale
1.2.1 La Securite Sociale
Le systeme francais de protection sociale, institue en 1945, a vocation, des ses de-
buts, a proteger la population francaise, en la couvrant des risques lies aux evenements et
aux situations de la vie. Appele plus communement « la Securite Sociale », le regime general
est forme d’un ensemble d’institutions organisees selon 4 branches [CodeSecuriteSociale 01] :
1. la Branche maladie, maternite, invalidite et deces,
2. la Branche accidents du travail et maladies professionnelles,
3. la Branche vieillesse et veuvage : geree par la Caisse nationale d’assurance vieillesse
des travailleurs salaries (Cnav).
4. la Branche famille : geree par Caisse nationale des allocations familiales(Cnaf).
Les deux premieres branches sont gerees par la Caisse nationale de l’assurance
maladie (Cnam).
Les ressources financieres du regime general sont collectees, centralisees et gerees
par les organismes charges du recouvrement : l’Agence centrale des organismes de secu-
rite sociale (ACOSS) et ses organismes locaux les Urssaf - Union de recouvrement des
cotisations de securite sociale et d’allocations familiales.
Pour mener a bien sa mission, chacune de ces branches est composee de divers
organismes repartis sur tout le territoire francais. Ces organismes materialisent la Securite
Sociale et participent a la mise en œuvre quotidienne de la politique de protection sociale
au plus pres des citoyens.
A titre d’exemple, la Branche famille, geree par la Caisse nationale des allocations
familiales, est formee d’un reseau de 123 Caisses d’allocations familiales (Caf).
Les services de la Direction du Systeme d’Information qui a servi de cadre aux
presents travaux de recherche participent au support de l’activite de la Branche famille.
[CodeSecuriteSociale 01] Secretariat General du Gouvernement, Hotel de Matignon, 57 rue de Varenne, 75007
PARIS. Code de la Securite Sociale – Livre 2 : Organisation du regime general,
action de prevention, action sanitaire et sociale des caisses, 2001. Disponible sur :
http ://www.legifrance.gouv.fr (consulte le 07.07.2008).
10

1.2. La Branche famille de la Securite Sociale
1.2.2 Mission de protection sociale de la Branche famille
La famille est la cellule de base de notre societe et occupe une place preponderante
parmi les preoccupations des Francais. Les transformations de la societe actuelle ainsi que
les nouveaux styles de vie et de travail engendrent diverses difficultes pour les familles
dans les domaines de l’education, du logement, des ressources. Prenant en compte les
aspirations des individus et les besoins de la societe, chaque pays a mis en place des aides
a destination des familles.
En France, depuis plus de 60 ans, dans le cadre d’une forme originale de protection
sociale et de solidarite nationale, la Branche famille de la Securite Sociale, accompagne
les familles dans leur vie quotidienne en les couvrant contre les risques et charges de toute
nature qui menacent leur securite economique et sociale.
La Branche famille, pilotee par la Cnaf, est un reseau de 123 Caisses d’Allocations
familiales presentes sur tout le territoire. Chaque Caisse d’allocations familiales prend en
charge l’attribution des prestations legales et le developpement de l’action sociale sur son
territoire. Elle peut ainsi, dans le cadre legal defini par la Cnaf, mener une politique sociale
mieux adaptee aux besoins locaux et specifiques des populations de sa region.
L’ensemble de l’Institution est mobilise au service des citoyens et des familles et a
pour but d’aider ses allocataires tout au long de leur vie. Par le biais de prestations legales
et d’actions specifiques, elle facilite les differentes etapes de la vie des allocataires : etudes,
installation, accueil d’un nouvel enfant, education des enfants, logement, lutte contre l’ex-
clusion. Ses politiques ont un impact sur plusieurs axes : la natalite, la conciliation de la
vie familiale et vie professionnelle, l’habitat et le logement, l’emploi, la sante, la precarite
et la redistribution des richesses.
Pour parvenir a ces objectifs, des prestations legales adaptees a chaque situa-
tion ont ete mises en place. Actuellement, l’Institution denombre plus de 30 allocations
differentes. Tous les ans, de nouvelles prestations viennent enrichir l’offre globale et des
prestations existantes sont modifiees. Le developpement des prestations familiales s’ac-
compagne donc d’une forte proliferation normative.
Par ailleurs, etant donne le grand nombre d’allocataires (plus de 13 millions,
soit 30 millions de personnes concernees representant 6,5 millions familles et 12 millions
d’enfants), il est nul besoin de souligner l’importance acquise de l’action de la Branche
famille au cœur de la societe francaise.
1.2.3 Mission de mise en application de la legislation
La Caisse Nationale des Allocations Familiales est en charge de l’une des le-
gislations les plus complexes du droit francais et a la delicate mission de la mettre en
application.
11

Chapitre 1. Maıtrise d’un patrimoine des connaissances metier
1.2.3.1 Metaphore industrielle
La reglementation, et par extension l’ensemble des documents qui contribue a
son expression, est frequemment percue par les nombreuses composantes de la societe –
les personnes physiques ou morales – comme une somme de contraintes comportemen-
tales auxquelles il faut se conformer. Mais, pour certaines entreprises ou organisations, les
documents reglementaires peuvent etre apprehendes d’une toute autre maniere.
En particulier, pour des organisations telles que la Branche famille dont la mis-
sion est la mise en application de la legislation, les textes reglementaires, support de la
connaissance legislative du domaine, jouent un role essentiel au cœur de leur metier et
constituent, a l’image de toute entreprise produisant des biens de consommation, une
matiere premiere essentielle [Jouve 03a].
C’est ainsi que dans une vision macroscopique, l’activite de la Branche famille
repose sur la manipulation et l’analyse de matieres premieres de deux types : les textes
reglementaires externes et les donnees factuelles (appelees donnees allocataires) 1. A partir
de la transformation et de la confrontation de ces deux types de matieres premieres, la
Branche famille est chargee de determiner les prestations specifiques que percevra l’allo-
cataire. La figure1.1 presente schematiquement le fonctionnement de la Branche famille.
Textes Réglementaires(externes) Données Allocataires
CNAF
CAF
Prestations Spécifiques
Textes Réglementaires(internes)
BRANCHE FAMILLE
Figure 1.1 – Metier de la Branche famille.
Les textes reglementaires constituent egalement le vecteur privilegie de la commu-
nication et de la diffusion de ces connaissances juridiques dans l’ensemble des ramifications
de l’organisation. Ces textes reglementaires supportent l’exercice metier des agents de la
Branche famille pour remplir les missions de l’Institution.
1. Ensemble des donnees relatives a la situation des allocataires ou allocataires potentiels (nom,prenom, age, adresse, ressources,...).
[Jouve 03a] Voir reference [Jouve 03a] definie page 2.
12

1.2. La Branche famille de la Securite Sociale
Cependant, la matiere reglementaire fournie en entree se revele etre de trop haut
niveau pour etre reellement applicable par des personnes non-juristes. Pour repondre aux
besoins de chaque profil metier, le processus de creation du droit est prolonge au cœur
meme de l’organisation : la matiere reglementaire est ainsi affinee, enrichie par l’ajout de
nouveaux documents (les textes reglementaires internes). La matiere originale est trans-
formee, distillee pour la rendre plus operationnelle 2 jusqu’aux documents directement
applicables encodant les regles de gestion.
Par ailleurs, le nombre de dossiers d’allocataires etant tres important, il est
evident que le traitement de cette information depasse largement les capacites humaines.
L’Institution s’est donc dotee d’un systeme de gestion des prestations pour l’assister dans
la mission de mise en application du droit. Ce systeme de gestion des prestations accom-
pagne les activites operationnelles de l’organisation. Celui-ci a ete developpe en prenant
en compte les exigences exprimees par les textes reglementaires et a, par consequent,
l’obligation d’assurer un traitement en conformite avec la legislation du domaine.
La metaphore industrielle peut etre parfaitement appliquee a la realite du metier
de la Branche famille. Celle-ci peut en effet etre percue comme une entreprise produisant
des biens de consommation. La matiere premiere (constituee par les textes reglementaires
externes et par les donnees allocataires) est transformee tout au long du processus de crea-
tion des « produits finis », que sont les prestations specifiques. Le Systeme d’Information,
qui vient accompagner les activites operationnelles de l’organisation, aide a automatiser
les taches et les traitements presents dans le processus de production du « produit fini ».
Ainsi, il a l’obligation d’assurer un traitement en conformite avec la legislation du domaine.
1.2.3.2 Patrimoine des connaissances metier
L’activite de l’organisation repose sur l’utilisation des textes reglementaires et des
donnees d’allocataires. Elle est accompagnee au quotidien par le Systeme d’Information.
L’ensemble des textes reglementaires, principal support des connaissances juri-
diques, ainsi que leur implementation dans le Systeme d’Information jouent un role prepon-
derant au cœur du metier des Caf et represente ainsi une veritable richesse : le patrimoine
que nous appelons « patrimoine des connaissances metier ».
Le patrimoine des connaissances metier est forme de deux composantes :
– composante documentaire : ensemble des ressources documentaires supportant
le metier de l’organisation (textes reglementaires, documentation operation-
nelle, etc.),
– composante logicielle : ensemble de ressources logicielles liees au metier de
l’organisation (applications de gestion des prestations, applications de gestion
financiere, etc.).
2. Ce mecanisme est a correler avec la hierarchisation du corpus reglementaire cf. la section 1.3.2.1
13

Chapitre 1. Maıtrise d’un patrimoine des connaissances metier
Nous allons decrire, pour chaque composante, les principales caracteristiques, les
problematiques et les enjeux auxquels l’organisation doit faire face pour mener a bien sa
mission.
1.3 Composante documentaire
Par definition, la legislation est l’ensemble des lois d’un pays ou relatives a un
domaine particulier. Dans les gouvernements constitutionnels, la legislation n’appartient
qu’au Parlement. La loi fixe les grandes lignes du plan legislatif et delegue a une autorite
dite « autorite reglementante » (le Premier Ministre, un ministere, un organisme publique.)
la tache d’en regler les details d’application generale en emettant des « reglements ». La
reglementation est formee par l’ensemble de ces reglements et est frequemment percue
comme une somme de contraintes comportementales auxquelles il faut se conformer. Mais,
pour certaines entreprises ou organisations, les documents reglementaires representent un
support essentiel de leur activite pour les accompagner dans leur mission.
1.3.1 Production et gestion de la composante documentaire
Tel que nous l’avons deja vu, les textes reglementaires, internes et externes, consti-
tuent le vecteur privilegie de la communication et de la diffusion de ces connaissances
juridiques dans l’ensemble des ramifications de l’organisation.
1.3.1.1 Textes reglementaires - matiere premiere
Les agents comme le personnel des Caisses d’allocations familiales vont s’y ap-
puyer au quotidien pour traiter des dossiers et conseiller les allocataires. D’autres, comme
les concepteurs du Systeme d’Information, vont encoder les exigences exprimees dans ces
textes reglementaires au niveau des applications du Systeme d’Information. Cependant en
ce qui concerne le niveau d’interpretation, les besoins ne sont pas les memes. Par exemple,
la conception d’une application informatique necessite une interpretation et une compre-
hension plus detaillee du texte que la reponse a une simple interrogation.
Les textes reglementaires doivent donc etre manies pour fournir a chaque compo-
sante de l’organisation l’ensemble de documents reglementaires dont elle a besoin, adaptes
a son profil metier, a ses fonctions et a ses competences.
A l’origine, les textes reglementaires recus proviennent de l’Assemblee Nationale
et des ministeres de tutelle (pour la Cnaf, il s’agit du Ministere du travail, des relations
sociales et de la solidarite).
Chaque composante de l’organisation s’approprie, utilise et transforme a sa ma-
niere une partie du corpus reglementaire en fonction de ses besoins. C’est ainsi que ces
briques organisationnelles produisent a leur tour de nouveaux textes reglementaires utilises
14

1.3. Composante documentaire
pour des objectifs divers tels que : l’implementation dans les systemes experts, la communi-
cation externe, l’elaboration d’autres documents internes, les application de consultation,
l’aide a la decision, les applications de formation et d’apprentissage en ligne, etc.
La qualite du service rendu depend de la bonne maıtrise du processus de produc-
tion et de gestion des textes que l’Institution produit et utilise.
Bertrand Chabbat [Chabbat 97] analyse les circuits des textes reglementaires. La
figure 1.2 montre de maniere globale le cheminement des textes de l’Assemblee Nationale
jusqu’aux applications de consultation ou aux systemes experts de l’organisation (ici, la
Cnaf ) en passant par les differentes briques organisationnelles appelees fonctions.
Assemblée Nationale Ministères
Organisation (Cnaf)
Documents de référence internes
Acquisition 1
Acquisition 2 Acquisition 3
Acquisition 4
Textes législatifsDécrets
Circulaires
Elaboration des règles SI
Communication externe
Documentation technique
Aide à la décision
FormationEnseignement assisté
par ordinateur
Acquisition d’information
Texte réglementaireActeur Fonction
Figure 1.2 – Flux des objets reglementaires au sein de la Cnaf.[Chabbat 97]
1.3.1.2 Ressources de la composante documentaire
Les textes reglementaires sont des objets documentaires specifiques a un domaine
qui entretiennent de nombreux liens.
Nous avons vu que la matiere reglementaire est constituee de differents types
d’objets produits ou manipules par une organisation dans le cadre de sa mission. On
appelle objet reglementaire tout document ou regle (de gestion ou de systeme expert) qui
exprime d’une maniere specifique une legislation ou une reglementation.
Il convient d’etablir une nette distinction entre les documents externes et les
objets internes. Les premiers sont recus par l’organisation qui n’a pas le pouvoir de les
modifier, tandis que les seconds sont produits et geres par l’organisation pour son propre
[Chabbat 97] Voir reference [Chabbat 97] definie page 2.
15

Chapitre 1. Maıtrise d’un patrimoine des connaissances metier
usage ou pour sa communication [Chabbat 97]. L’ensemble forme par les textes externes
et les objets internes constitue le corpus reglementaire ou le fonds documentaire reglemen-
taire.
Texte reglementaire externe – Les textes externes comprennent l’ensemble des docu-
ments juridiques applicables par l’organisation tels que le Journal Officiel, les lois,
les decrets, la jurisprudence, etc. Des textes complementaires, tels que les proces
verbaux de l’Assemblee Nationale, qui tendent a prescrire la maniere d’interpreter
la loi, doivent egalement etre pris en consideration.
Objet reglementaire interne – Les objets reglementaires internes comprennent les do-
cuments et les regles produits par les diverses couches de l’organisation. Dans le
contexte de la Branche famille, differentes categories d’objets reglementaires sont
couramment distinguees. A chacune, l’organisation attribue une valeur juridique,
generalement inversement proportionnelle a leur degre d’applicabilite (facilite de la
mise en œuvre) :
– les documents de reference internes sont constitues des circulaires produites par la
Cnaf, appelees circulaires Cnaf, et des Suivis Legislatifs. Ces derniers reprennent
le contenu des textes applicables en le traduisant de maniere a le rendre plus
comprehensible pour des utilisateurs qui ne sont pas specialistes du droit.
– a partir des documents de reference internes, chaque brique de l’organisation de
l’Institution peut etre amenee a produire ses propres objets reglementaires adaptes
a un public specifique. Ces documents ont egalement une vocation reglementaire.
– les regles de gestion sont dotees d’un degre d’applicabilite maximal. Elles sont
egalement utilisees comme base pour la conception et l’implementation de la re-
glementation. Nous detaillerons les problematiques specifiques a la conception du
Systeme d’Information dans la section 1.4 du present chapitre.
Dans le present manuscrit nous employons la notion de textes reglementaires
pour les textes qui expriment une reglementation liee a la legislation, independamment
de leur valeur juridique. Ces documents ont certaines caracteristiques qui les distinguent
des autres types de documents que l’on a pour habitude d’analyser et de gerer dans le
domaine de l’ingenierie documentaire. La matiere reglementaire ne peut etre correctement
maıtrisee qu’en prenant pleinement conscience de ses specificites [Chabbat 97][Jouve 01].
[Chabbat 97] Voir reference [Chabbat 97] definie page 2.
[Jouve 01] Jouve David, Chabbat Bertrand, Amghar Youssef et Pinon Jean-Marie. Structu-
ration semantique de la reglementation. Proc. of the XIXeme Congres INFormatique des
ORganisations et Systemes d’Information et de Decision (INFORSID’2001). Martigny,
Suisse. INFORDSID Editions, 2001, p 5–26.
16

1.3. Composante documentaire
1.3.2 Caracteristiques de la composante documentaire
David Jouve [Jouve 03a] presente en detail les specificites de la matiere regle-
mentaire. Nous nous contenterons, dans les sections suivantes de ce chapitre, de resumer
les caracteristiques de la matiere reglementaire qui interviennent dans la maıtrise du pa-
trimoine reglementaire et qui jouent un role important dans la gestion des composantes
logicielle et documentaire.
1.3.2.1 Structure hierarchisee
La matiere reglementaire est organisee en une structure pyramidale, comme pre-
sente dans la figure 1.3. Les differents niveaux de cette pyramide correspondent aux niveaux
des droits et determinent ainsi la valeur juridique des textes et leur degre d’applicabilite.
Generalement, le degre d’applicabilite est inversement proportionnel a la valeur juridique.
Les lois fondamentales, les plus importantes, sont souvent tres generales. Elles enoncent
des principes difficiles a appliquer en situation de traitement. En France, par exemple,
cette hierarchie presente au sommet : la Constitution suivie de lois parlementaires, des
circulaires ministerielles, des decrets etc.
Une organisation qui a comme mission l’application du droit, peut prolonger
cette pyramide, par des documents internes. A l’origine, les textes reglementaires recus
proviennent de l’Assemblee Nationale et des autorites concernees telles que le Gouver-
nement ou les ministeres de tutelle . Ces textes viennent ensuite alimenter les circuits de
production internes a l’organisation pour affiner et enrichir les textes de lois en fonction de
ses propres problematiques. Nous avons vu que chaque brique fonctionnelle de l’Institution
utilise et transforme ainsi les textes de reference a sa maniere. Les nouveaux documents
produits par l’organisation constituent les trois niveaux inferieurs de la pyramide regle-
mentaire representee dans la figure 1.3. Le niveau le plus bas, le niveau « Organisation
niv. 3 », presente les documents caracterises par un degre d’applicabilite maximal. En
effet, ces derniers sont extremement proches du Systeme d’Information, puisqu’il s’agit
des documents de specification et de conception des regles de gestion implantees dans le
systeme de gestion des prestations de la Cnaf.
Le processus de production des textes et de regles internes est ainsi essentiellement
vertical mais respecte une obligation de conformite : un document present a un certain
niveau doit avoir un contenu conforme aux documents en amont dans la pyramide.
1.3.2.2 Forte redondance
Le processus de creation du droit et de transformation de la matiere reglementaire
introduit une forte redondance dans l’ensemble des textes reglementaires. Comme decrit
[Jouve 03a] Voir reference [Jouve 03a] definie page 2.
17

Chapitre 1. Maıtrise d’un patrimoine des connaissances metier
Valeur Légale Type de document Origine
ParlementAssemblée Nationale Conseil des MinistresMinistère Organisation niv. 1Organisation niv. 2Organisation niv. 3
Constitution
DécretCirculaire MinistérielleTexte de Référence Int.Instructions Techniques
Loi
Règles de Gestion
Figure 1.3 – Pyramide des ressources reglementaires. [Jouve 03b]
precedemment, de nouveaux documents sont produits en affinant la matiere reglementaire
pour presenter un potentiel operationnel plus fort. Ils doivent cependant preserver un
statut de conformite vis-a-vis des documents originaux. La matiere reglementaire est ainsi
affinee sans en alterer le sens.
Au niveau de la pyramide reglementaire (voir figure 1.3), cet affinage se manifeste
par le fait que chaque document dispose generalement d’un contenu qui vient preciser ceux
des documents de niveau superieur dans la hierarchie juridique. Ainsi, une meme norme
peut faire l’objet de multiples formulations, parfois partielles et complementaires, au sein
du corpus reglementaire et se retrouve ainsi exprimee au travers de plusieurs fragments
documentaires.
Cette caracteristique est qualifiee d’heritage semantique multiple par Bertrand
Chabbat [Chabbat 97]. Son analyse met en evidence la presence de liens de partage d’in-
formation non explicites entre les differents fragments du corpus reglementaire.
1.3.2.3 Forte interconnexion
Au sein d’un ensemble documentaire de nombreux liens sont presents entre les
documents. Ces liens peuvent etre de simples liens de navigations ou porteurs d’une seman-
tique particuliere, par exemple : liens specifiant l’origine d’un document, liens precisant
les impacts d’impact, liens d’equivalence, etc... Par ailleurs lors du processus de produc-
tion documentaire il faut privilegier la reutilisation des contenus (des documents ou de
fragments de documents). Les elements d’un ensemble documentaire sont ainsi fortement
interconnectes.
1.3.2.4 Contenu dynamique
La matiere reglementaire est dynamique. Les textes doivent etre consideres comme
etant issus d’un flux constant, en perpetuelle evolution.
[Chabbat 97] Voir reference [Chabbat 97] definie page 2.
18

1.3. Composante documentaire
L’analyse de David Jouve [Jouve 03a] se focalise sur le fait que les changements
de reglementation constituent l’une des plus importantes barrieres a l’utilisation cou-
rante des techniques de base de connaissances pour les applications de droit pratique
[Bench-Capon 90][Bench-Capon 94]. Sur le plan documentaire, ce phenomene induit des
modes de gestion specifiques, offrant aux utilisateurs la possibilite d’acceder aux differentes
versions d’un texte, aux textes en cours d’application, aux dernieres mises a jour, etc.
La maıtrise de la matiere reglementaire, et notamment celle de sa coherence,
repose essentiellement sur la capacite de l’organisation a gerer correctement cette specificite
notamment en lien avec la redondance semantique.
1.3.3 Problematiques et enjeux de la maıtrise de la composante docu-
mentaire
Les caracteristiques des documents reglementaires, presentees precedemment au
cours de ce chapitre, engendrent un certain nombre de problematiques auxquelles se heurte
la gestion des objets reglementaires. Nous verrons que la matiere reglementaire ne peut
etre veritablement maıtrisee qu’au travers de la prise en compte de ses caracteristiques
intrinseques dans la maniere de representer et de gerer l’information reglementaire.
1.3.3.1 Problematiques de gestion et de production documentaire
Les problematiques de gestion et de production documentaire sont essentiellement
liees a la conception et a la maintenance des objets documentaires.
Conception et production des objets reglementaires
Nous avons vu que les organisations qui fondent leur action sur la matiere regle-
mentaire sont souvent amenees a enrichir le fonds documentaire en redigeant de nouveaux
documents, plus precis, plus lisibles et plus operationnels, a destination du personnel non
juriste. Les contenus alors elabores rassemblent une grande quantite d’informations deja
exprimees au sein des documents originaux.
Le processus d’elaboration des objets reglementaires se manifeste dans le temps
par de nombreux ajouts ou suppressions de portions documentaires.
Maintenance des objets reglementaires
[Jouve 03a] Voir reference [Jouve 03a] definie page 2.
[Bench-Capon 90] Bench-Capon Trevor et Coenen Frans. Practical Application of KBS to Law : the
Crucial Role of Maintenance. Legal Knowledge Based Systems, JURIX’90 : Aims for
Research and Development. Edited by Schmidt A.H.J. et Winkels R.G.F. Lelystad.
Koninklijke Vermande, 1990, p 1–17.
[Bench-Capon 94] Bench-Capon Trevor et Coenen Frans. The Maintenance of Legal Knowledge Based
Systems. Computers and Law. Edited by Carr I. et Williams K., p 129–172. Intellect
Books, 1994.
19

Chapitre 1. Maıtrise d’un patrimoine des connaissances metier
Les textes reglementaires sont fortement redondants ce qui augmente le risque
d’apparition d’incoherences. Ce risque est amplifie par le caractere changeant de la regle-
mentation.
A chaque modification de reglementation, meme minime, l’ensemble des textes
internes a l’organisation doit potentiellement etre mis a jour de maniere a conserver une
documentation de travail toujours en conformite vis-a-vis de la legislation.
En effet, lorsqu’une modification intervient a un certain niveau de la pyramide,
chacune des ressources en aval peut etre impactee :
– tous les textes de references internes,
– la documentation technique,
– l’ensemble des textes propres a chaque bloc fonctionnel de l’organisation (par
exemple : supports de formation, contenu des portails internet, plaquettes d’in-
formation, documents de travail, etc.).
L’impact a un niveau donne est repercute en cascade, affectant toute la pyramide
jusqu’au niveau inferieur qui est represente par les regles de gestion internes a l’orga-
nisation, impactant ainsi indirectement un certain nombre de composants du Systeme
d’Information lies a la reglementation.
Pour arriver a maıtriser la matiere reglementaire et eliminer tout risque de contra-
diction et d’incoherence, il est necessaire de prendre en compte cette specificite. Par
exemple, dans le contexte de la Cnaf, on observe une moyenne de deux evolutions par
semaine.
Dans ces conditions, les efforts deployes quotidiennement, pour maintenir la ma-
tiere reglementaire a jour et pour produire les nouvelles ressources necessaires a l’exercice
du metier, sont considerables.
1.3.3.2 Enjeux de la maıtrise de la composante documentaire
Pour une organisation qui utilise le droit, la maıtrise de la matiere reglementaire
est accompagnee de divers enjeux : tracabilite et argumentation, maıtrise de la coherence,
decisionnel et statistiques et reactivite.
Tracabilite et argumentation – Lors du processus d’elaboration des prestations spe-
cifiques a chacun des allocataires, les donnees de fait sont analysees au regard de
la legislation en vigueur. Chaque decision presente ou anterieure doit pouvoir etre
justifiee a l’appui d’un texte reglementaire.
Maıtrise de la coherence – Les textes reglementaires constituent le cœur d’un systeme
juridique, ils doivent etre imperativement geres en maıtrisant la coherence des regles
qu’ils expriment.
Decisionnel et statistiques – La reglementation ainsi que son evolution sont etudiees,
des statistiques sont elaborees afin d’alimenter les processus d’aide a la decision et
20

1.4. Composante logicielle - le Systeme de gestion des prestations legales
de nourrir la reflexion legislative. En effet, les statistiques et les indicateurs generes a
l’aide des outils decisionnels permettent de donner une meilleure vision au legislateur
sur les phenomenes de societe, de mieux comprendre les effets des mesures legislatives
passees afin de mieux adapter celles futures.
Reactivite – La capacite de l’organisation a reagir est un facteur strategique. Par exemple,
l’Etat entretient une etroite relation avec la Branche famille notamment lors de l’ela-
boration d’un projet legislatif. Il est difficilement admissible que l’application d’une
nouvelle disposition reglementaire soit entravee par une indisponibilite de l’infra-
structure necessaire a sa mise en application. A chaque evolution de la reglemen-
tation, l’activite de l’organisation doit etre mise a jour pour garder la conformite
avec la legislation. Chaque evolution a ainsi un impact, parfois considerable, sur les
documents internes constituant la composante documentaire du patrimoine regle-
mentaire.
1.4 Composante logicielle - le Systeme de gestion des pres-
tations legales
La Branche famille est en charge de l’une des legislations les plus complexes du
droit francais. Le nombre de dossiers d’allocataires dont elle a la charge depasse la dizaine
de millions. Chaque situation individuelle doit etre analysee conformement au droit afin
de calculer et d’attribuer les Prestations Familiales. La quantite massive de traitement
que requiert une telle activite depasse tres largement les capacites humaines, amenant
l’organisation a solliciter l’assistance de l’ordinateur en se dotant d’un systeme de gestion
des prestations : le systeme CRISTAL developpe et maintenu par la Cnaf.
Nous appelons implementation calculatoire de la reglementation cette composante
du Systeme d’Information batie afin de soutenir une tache de mise en application du droit.
1.4.1 Production de la composante logicielle
Comme nous l’avons deja presente, les textes reglementaires sont une matiere
premiere pour la mission de l’Institution. Ils sont affines, detailles pour obtenir des docu-
ments plus precis, d’un plus bas niveau en importance juridique mais d’un plus haut degre
d’applicabilite - represente par les regles de gestion, le plus bas niveau de la pyramide
reglementaire (le niveau « Organisation – niveau 3 »).
1.4.1.1 Regles de gestion, une matiere premiere
Les regles de gestion, dotees d’un degre d’applicabilite maximal, sont utilisees
comme support pour la conception et l’implementation de la reglementation. Elles re-
21

Chapitre 1. Maıtrise d’un patrimoine des connaissances metier
presentent ainsi, a leur tour, une matiere premiere pour la conception de la composante
logicielle du patrimoine reglementaire.
Les regles de gestion embarquees au sein du systeme sont determinees au cours
d’une phase d’analyse de l’ensemble du corpus reglementaire. Elles sont detaillees, la
connaissance exprimee est affinee, interpretee et traduite dans un langage informatique
lors des differentes etapes de conception et de developpement du Systeme d’Information,
en creant ainsi des composants applicatifs. Le processus de creation de droit est ainsi
prolonge par la production de ces nouveaux objets reglementaires.
1.4.1.2 Conception du Systeme d’Information
Les organisations sont de plus en plus dependantes de leur Systeme d’Information.
Actuellement, au sein des organisations, le perimetre couvert par les Systemes d’Informa-
tion est de plus en plus large, les technologies sont de plus en plus complexes ainsi que les
outils et les modeles d’architecture. Dans ce contexte riche, des methodologies de concep-
tion et de developpement des systemes d’information sont employees. Nous ne cherchons
pas a realiser une description detaillee de ces methodologies mais souhaitons juste pointer
quelques unes de leurs caracteristiques communes. Ce travail nous permet d’analyser les
problematiques auxquelles se confrontent les organisations, quelque soit la methodologie
choisie pour la mise en place de leur Systeme d’Information.
La plupart de ces methodologies telles que « RUP - Rational Unified Process » [RUP09 09],
« MSF - Microsoft Solutions Framework » [Turner 06] ou « eXtreme Programming » [Beck 99]
ont ete developpees pour supporter les differentes phases du processus de conception et de
developpement des systemes d’information.
Chacune de ces phases font intervenir nombreux acteurs de l’organisation, chacun
apportant un point de vue different et une connaissance specifique au systeme :
– les utilisateurs et la maıtrise d’ouvrage formulent une exigence des besoins
fonctionnels,
– les concepteurs concoivent et specifient les briques applicatives,
– les architectes techniques et logiciels elaborent l’architecture du systeme,
– les developpeurs realisent l’implementation en suivant les specifications de-
taillees.
Au cours de chacune de ces phases, les acteurs vont s’appuyer sur des ressources
fournies en entree pour produire des livrables specifiques, des documents d’analyse, des
[RUP09 09] IBM Coorporation. Rational Unified Process, 2009. Disponible sur : http ://www-
01.ibm.com/software/awdtools/rup/ (consulte le 24.03.2009).
[Turner 06] Turner Michael S. V. Microsoft Solutions Framework Essentials. Microsoft Press, 2006.
336 p.
[Beck 99] Beck Kent. Extreme Programming Explained : Embrace Change. Addison-Wesley Pro-
fessional, 1999. 224 p.
22

1.4. Composante logicielle - le Systeme de gestion des prestations legales
documents de conception, de specification generale, de specification detaillee, des modeles
d’applications et du Systeme d’Information, des plan de tests, etc..
Par exemple, RUP est une methode iterative et incrementale, guidee par les
besoins des utilisateurs et centree sur l’architecture logicielle. Elle propose un processus et
un cycle de vie pour un projet informatique contenant quatre phases :
– la phase de demarrage (etude des besoins) produit des cas d’utilisation metier
de haut niveau, les principales fonctionnalites, les exigences du systeme ou de
l’application, la planification du projet et les previsions financieres.
– la phase d’elaboration traduit les besoins des utilisateurs en specifications de-
taillees des applications, en s’appuyant sur les documents de la phase prece-
dente et en creant une nouvelle connaissance sur le systeme et de nouveaux
livrables tels que : des cas d’utilisation detailles, des diagrammes de classes,
des definitions des plans de developpement, des prototypes techniques, etc.,
– la phase de construction produit la premiere livraison externe de l’application.
Elle detaille les modeles « UML - Unified Modeling Language » [OMG 07a] de
l’application pour les rendre tres proches du code developpe.
– la phase de transition clot l’activite de developpement et livre l’application
aux utilisateurs en analysant l’impact humain et organisationnel du nouveau
produit logiciel. Les formateurs vont produire la documentation d’utilisation.
Du fait de la complexite des systemes a developper, toutes ces phases peuvent etre ite-
ratives. Par ailleurs, les exigences des utilisateurs et les besoins metier des organisations
evoluent, rendant le cycle entier de ce processus iteratif lui-meme.
Tout au long de ce processus, presente dans la figure 1.4, les documents de
conception, les modeles UML, les documents projet et toutes les autres ressources sont
interconnectees et expriment la meme connaissance mais de points de vue differents. La
connaissance du systeme est ainsi construite toute au long du cycle de conception et de
developpement. Nous pouvons distinguer une hierarchie entre ces ressources de conception
en fonction de la phase ou elles sont produites. Quand les exigences et les besoins des
utilisateurs evoluent, la mise a jour du SI a potentiellement des repercussions sur chacun
des documents de conception et de developpement, y compris sur le code de l’application.
Ces methodologies offrent des regles a suivre et conseillent les meilleures pratiques
a adopter. Neanmoins, elles ne traitent pas la problematique du maintien de la coherence
entre les differents livrables (documents, modeles, code, etc.) et les differentes phases du
processus. Des solutions techniques sont presentes pour la gestion de la documentation,
pour le travail collaboratif et meme pour la gestion des exigences. Mais, comme nous le
verrons dans le chapitre 4, tres peu de solutions s’interessent a la gestion de la coherence
[OMG 07a] Object Management Group (OMG). Unified Modeling Language Specification, Ver-
sion 2.1.2, 2007. Disponible sur : http ://www.omg.org/spec/UML/2.1.2/ (consulte le
04.08.2008).
23

Chapitre 1. Maıtrise d’un patrimoine des connaissances metier
Elaboration
Démarrage
Construction
Transition
Allocation
PrestationSoc Montant
PrestationFam
Version de l’application
Condition
Revenus
Quotient
Phases du projet
Livrables
Documents Modèles & autres livrables
nouvelle itération
nouvelle itération
nouvelle itération
nouvelle itération
nouvelle itération
Figure 1.4 – Processus iteratif de conception et developpement d’un SI.
entre les differentes types de ressources, tout au long du processus et a la mise en conformite
avec les exigences des utilisateurs.
Le processus de conception du Systeme d’Information est generique a toute or-
ganisation. Dans le cadre du systeme de gestion des prestations de la Branche famille, le
point de depart de ce processus est represente, comme nous l’avons deja mentionne, par
les regles de gestion.
1.4.1.3 Ressources de la composante logicielle
« Le logiciel » est le terme generique qui designe un ensemble de ressources
ayant trait a la programmation des appareils informatiques. La description detaillee d’un
logiciel et de ses composantes est tres complexe. Nous nous contenterons ici de presenter
brievement les principales ressources qui forment le logiciel.
L’application – Le programme informatique (appele plus communement « l’executable »)
qui peut etre execute directement par l’ordinateur.
Le code source – Le code (generalement sous forme de texte) respectant les regles d’ecri-
ture d’un langage de programmation. L’executable est genere a partir du code source
par un processus de compilation et de construction (dans le cas des langages inter-
pretes, le code source est execute a la lecture).
La documentation d’analyse, de conception et de specification – l’ensemble des
24

1.4. Composante logicielle - le Systeme de gestion des prestations legales
documents issus des activites d’analyse, de specification, de conception et de deve-
loppement, realisees tout au long du processus de creation du logiciel.
Les modeles applicatifs – Ensemble des modeles decrivant le logiciel (cf. les 13 modeles
UML).
La documentation utilisateur, la documentation d’exploitation – l’ensemble des
documents decrivant le fonctionnement du logiciel, offrant de l’aide aux utilisateurs
ou precisant les exigences d’exploitation.
Diverses ressources – D’autres ressources necessaires au bon fonctionnement du logiciel
(fichiers de donnees, ressources graphiques, etc.).
1.4.2 Caracteristiques de la composante logicielle
Par ailleurs, toutes ces ressources de la composante logicielle, bien que de nature
differente, ont des caracteristiques en commun.
1.4.2.1 Structure hierarchisee
Les documents d’analyse, de specification, de conception, les modeles UML, et
toutes les autres ressources, produits tout au long du processus presente dans la figure 1.4,
sont interconnectes et expriment la meme connaissance mais de points de vue differents.
La connaissance du systeme est ainsi construite tout au long du cycle de conception et de
developpement. En fonction des phases ou ces ressources sont produites, nous pouvons les
organiser dans une structure hierarchique, similaire a la pyramide des objets reglementaires
de la figure 1.3.
Dans cette representation hierarchique, les differents niveaux determinent le degre
d’exploitation de la ressource par la machine. Nous retrouvons au niveau le plus haut les
documents d’analyse des besoins et d’expression des exigences qui s’affranchissent des
specificites techniques (systeme d’exploitation, composant de bases de donnees, langage
de programmation), mais qui ne sont pas exploitables par la machine. Ces ressources de
haut niveau sont ensuite detaillees, affinees et traduites dans des langages de plus en plus
exploitables par les appareils informatiques. Ainsi dans une presentation tres schematique,
nous pouvons considerer que les documents d’analyse sont traduits dans des specifications.
Ces dernieres seront affinees pour creer des specifications detaillees qui serviront a la
creation des modeles de l’application. Les modeles vont etre traduits dans du code source
qui, a son tour, sera interprete pour construire des executables. Le niveau le plus bas sera
donc represente par le code executable par la machine (soit le code en langage machine
resultant d’une etape de compilation « langage compile », soit le code source d’un « langage
interprete »).
Les documents d’analyse, le plus haut niveau de cette hierarchie, sont determines
au cours d’une phase d’analyse de l’ensemble du corpus reglementaire. Leur developpement
25

Chapitre 1. Maıtrise d’un patrimoine des connaissances metier
vient repondre aux exigences reglementaires. Ainsi, toutes les ressources representant le
systeme de gestion des prestations sont directement dependantes de la legislation et doivent
etre percues comme le fruit du prolongement du processus de creation du droit. Lorsque
les exigences et les besoins des utilisateurs evoluent, la mise a jour a des repercussions sur
l’ensemble des ressources de cette hierarchie, jusqu’au niveau le plus bas represente par le
code de l’application.
1.4.2.2 Forte redondance
Dans le processus de production de la composante logicielle, en vue d’un emploi
distinct, de nombreuses ressources viennent preciser la meme connaissance sur une exigence
ou sur un besoin utilisateur. A chaque etape du processus de conception et de developpe-
ment, les documents sont enrichis, modifies pour devenir de plus en plus exploitables tout
en preservant la coherence avec les exigences initiales.
1.4.2.3 Forte interconnexion
Par nature les applications informatiques sont fortement interconnectees. La reuti-
lisation, l’heritage des fragments applicatifs, le partage des services, des briques applica-
tives font partie des principes de base dans le developpement des Systemes d’Information.
Ainsi, les ressources de conception et de developpement au meme niveau ou a des niveaux
differents de la hierarchie presentee precedemment, entretiennent des nombreux liens : de
reutilisations, d’extensions, de referencements, etc..
1.4.2.4 Contenu dynamique
Les ressources logicielles sont une prolongation du processus de production du
droit et sont donc, par extension, des objets reglementaires qui doivent suivre rigoureu-
sement les evolutions de la legislation. Ainsi, lorsqu’un changement intervient au sein de
la reglementation, il est imperatif que celui-ci leur soit repercute afin de les conformer au
droit. Les processus de conception et de developpement etant iteratifs, l’ensemble de la
hierarchie des ressources logicielles doit etre revu pour integrer les nouvelles exigences ou
l’evolution des besoins des utilisateurs.
Evaluer l’impact d’une modification reglementaire sur des systemes d’information
est un probleme qui prend toute son ampleur lorsque l’on considere le nombre de regles
generalement implantees. A titre d’illustration, le systeme de gestion des prestations Cristal
mis a disposition des Caf 3 integre plus de 15000 regles.
3. Caf – Caisse d’allocations familiales. La Branche famille, pilotee par la Cnaf – Caisse nationaledes allocations familiales, est un reseau de 123 Caf presentes sur tout le territoire.
26

1.4. Composante logicielle - le Systeme de gestion des prestations legales
1.4.2.5 Composante du Systeme d’Information
La composante logicielle du patrimoine des connaissances met en oeuvre les textes
reglementaires (pour la Caf il s’agit du systeme de gestion des prestations Cristal). Elle
represente seulement une partie de tout le Systeme d’information de l’organisation. L’eten-
due de l’impact que peut avoir un changement de reglementation ne se limite generalement
pas au seul composant de gestion des prestations.
Generalement, le chaınage des impacts ne se cantonne pas a ces composants fron-
tieres avec le domaine legislatif. Comme le montre la figure 1.5, le Systeme d’Information
des Caf integre de nombreux autres composants et se caracterise par un tres haut niveau
d’interoperabilite. Eux memes peuvent aussi etre lies, au moyen de relations de depen-
dances, a d’autres composants, induisant ainsi une reaction en chaıne qu’il est necessaire
de maıtriser.
Par exemple, un changement dans les conditions d’attribution d’une allocation
va avoir un impact sur l’ensemble de la composante documentaire, sur le systeme de
gestion des prestations mais aussi sur d’autres composants du SI comme l’application de
gestion des flux comptables, les outils de simulation et de tests ou bien le site internet de
l’Institution.
Niveau hiérarchique Type de texte
Constitution
Loi
Décret
Circulaire ministérielle
Textes de ref. interne
Spécification des règles de gestion
Origine
Parlement
Assemblée nationale
Conseil des ministres
Ministère
Organisation niv. 1
Organisation niv. 2
Implémentation calculatoire de la réglementation
Documents et modèles conception
Dossiers analyse fonctionnelle
Réalisation et développements
Documentation applicative
Comp. SI 1
… … … …
Comp. SI 3 Comp. SI 2
… … … …
… … … …
Comp. SI 4
… … … …
Comp. SI 5
… … … …
Figure 1.5 – Pyramide reglemantaire et impact sur le SI.
1.4.3 Problematiques et enjeux de la maıtrise de la composante logicielle
La gestion de la composante logicielle se heurte a certain nombre de problema-
tiques de production et de gestion.
27

Chapitre 1. Maıtrise d’un patrimoine des connaissances metier
1.4.3.1 Problematiques de gestion et de production logicielle
De la meme maniere que pour la composante documentaire, les problematiques de
gestion et de production logicielle sont notamment liees a la conception et a la maintenance
de la composante logicielle.
Conception et production des ressources logicielles
Les ressources logicielles sont concues et developpees en fonction de deux types
d’exigences :
– exigences metier - il s’agit ici des exigences exprimees par les utilisateurs et qui
concernent le fonctionnement de l’application, l’interface utilisateur, la maniere
de l’utiliser, etc. .
– exigences reglementaires - il s’agit dans ce cas des exigences exprimees par
les textes reglementaires et qui visent la mise en conformite des applications
informatiques – la composante logicielle – avec les textes reglementaires. Cela
se traduit par le fait d’encoder en langage informatique les regles de gestion
definies par les textes reglementaire.
Quelque soit les exigences, le processus de prise en compte, de conception et de
developpement presente precedemment est respecte. En revanche, le temps necessaire a
chaque phase depend de la complexite de la demande. A chaque modification, meme mi-
nime, l’ensemble de ressources doit etre verifie afin de conserver un systeme de gestion
toujours conforme avec la legislation. Ainsi la prise en compte d’une evolution reglemen-
taire au niveau du Systeme d’Information peut etre tres couteuse.
Face a la frequence de l’identification des potentiels nouveaux besoins (en moyenne
deux modifications legislatives auxquelles s’ajoutent les nouveaux besoins fonctionnels
d’application metier), il devient indispensable de « fluidifier » le processus de conception.
Ainsi l’organisation mise en place permet de mener simultanement plusieurs chantiers de
conception et de developpement en utilisant les memes ressources logicielles.
Maintenance des ressources logicielles
Puisque les ressources logicielles sont concues et developpees pour repondre aux
exigences exprimees dans les textes reglementaires, elles peuvent etre percues comme le
fruit du prolongement du processus de creation du droit. Les regles, ainsi que la documen-
tation qui leur est associee, sont des objets qui doivent suivre rigoureusement les evolutions
de la legislation. Ainsi, lorsqu’un changement intervient au sein de la reglementation, il
est imperatif que celui-ci soit repercute sur les ressources logicielles afin de les conformer
au droit. Le processus de maintenance des objets reglementaires est semblable a celui de
creation. En effet, compte tenu de la complexite du systeme, le processus de conception
et de developpement est iteratif. La composante logicielle est continuellement enrichie,
amelioree pour repondre aux mieux aux exigences soit emanant des utilisateurs soit des
28

1.4. Composante logicielle - le Systeme de gestion des prestations legales
textes reglementaires. Le travail d’analyse et de maintenance conduit autour d’un tel sys-
teme est d’autant plus important que la reglementation du domaine est particulierement
changeante.
En outre, l’etendue de l’impact que peut avoir un changement de reglementation
ne se limite generalement pas au seul composant de gestion des prestations. Le Systeme
d’Information des CAF integre de nombreux autres composants et se caracterise par un
tres haut niveau d’interoperabilite. Il peut etre percu comme un maillage complexe de com-
posants logiciels dependant les uns des autres, et organises autour du composant central
qu’est le systeme de gestion des prestations. Le corollaire est que lorsque survient un chan-
gement reglementaire, fonctionnel ou technique, l’impact peut s’etendre sur l’ensemble du
Systeme d’Information et concerner des composants aussi divers que : les echanges avec
l’exterieur, les dispositifs d’acces aux donnees, les portails metiers ou public, les chaınes
editiques, la gestion des ressources humaines, la gestion des ressources financieres, la ges-
tion des partenaires, les referentiels des personnes, les applicatifs de gestion de l’action
sociale . . .
1.4.3.2 Enjeux de la maıtrise de la composante logicielle
L’analyse presentee dans cette section nous montre que les caracteristiques de
la composante logicielle et les problematiques de gestion associees sont similaires a celles
de la composante documentaire. Les enjeux associees a sa maıtrise sont par consequent
egalement comparables : tracabilite, maıtrise de la coherence et reactivite.
Tracabilite – Les prestations specifiques a chacun des allocataires sont calculees par
des applications informatiques qui analysent les donnees factuelles de l’allocataire
au regard de regles qui sont codees. Chaque attribution d’une decision presente ou
passee calculee par le systeme de gestion des prestations doit pouvoir etre justifiee a
l’appui du texte reglementaire en vigueur servant de base au calcul. Ainsi, tout code
executable doit pouvoir etre trace jusqu’au texte reglementaire exprimant l’exigence
reglementaire.
Maıtrise de la coherence – Le Systeme d’Information accompagne l’exercice metier de
l’organisation. Son fonctionnement doit etre coherent avec la legislation en vigueur.
Les regles, ainsi que la documentation qui leur est associee, sont des objets qui
doivent suivre rigoureusement les evolutions de la legislation. Lorsqu’un changement
intervient au sein de la reglementation, il est imperatif que celui-ci leur soit repercute
afin de les conformer au droit. L’evaluation de l’impact d’une modification reglemen-
taire sur un tel Systeme d’Information est un probleme qui prend toute son ampleur
lorsque l’on considere le grand nombre de regles implantees (e.g. le systeme de gestion
des prestations Cristal integre plus de 15 000 regles).
Reactivite – La capacite de l’organisation a reagir aux changements de la legislation est
29

Chapitre 1. Maıtrise d’un patrimoine des connaissances metier
un facteur determinant. Il est difficilement admissible que l’application d’une nou-
velle disposition reglementaire soit entravee par une indisponibilite de l’infrastructure
informatique necessaire a sa mise en application. Les evolutions de la reglementation
ont un impact parfois considerable sur le Systeme d’Information interne, et le pro-
cessus de mise en conformite de ce dernier n’est pas instantane. Pour ameliorer la
reactivite, il faut etre en capacite d’evaluer l’etendue des impacts afin de fournir une
estimation du temps necessaire a l’administration pour reagir face aux modifications,
et ce, des l’origine du projet legislatif ou reglementaire. Cette evaluation est menee
a partir de l’ensemble des textes reglementaires passes, presents et futurs, depuis les
documents les plus generiques jusqu’aux plus specifiques aux systemes d’information.
Par ailleurs, pour ameliorer le temps necessaire a la prise en compte des evolutions
reglementaires au niveau du Systeme d’Information, il faut etre capable de paralle-
liser les chantiers de conception et de developpement. Maintenir la coherence entre
les differents chantiers est donc une necessite.
Ainsi nous pouvons definir les services attendus pour repondre a l’ensemble des
problematiques de gestion concernant a la fois la composante documentaire et la compo-
sante logicielle.
1.5 Services attendus pour la maıtrise du patrimoine des
connaissances metier
Au cours de ce chapitre, nous avons analyse le role et la place que peut avoir la
matiere reglementaire au coeur d’organisations ou d’entreprises telles que la Cnaf.
La meme connaissance legislative se retrouve exprimee au travers de nombreuses
ressources a differents niveaux de l’entreprise : documents de reference, supports de forma-
tion, documentation metier, regles de gestion, composants du Systeme d’Information, etc.
Toutes ces ressources, qui encodent la connaissance necessaire pour que l’Institution mene
a bien sa mission, representent une reelle richesse pour l’organisation, un vrai patrimoine,
que l’on appelle : « patrimoine des connaissances metier ».
Les deux composantes (composante documentaire et composante logicielle) du
patrimoine des connaissances metier sont en apparence tres differentes. Bien qu’hetero-
genes dans la forme elles ont pourtant des proprietes equivalentes. En effet elles encodent
des connaissances du domaine, en l’occurrence des connaissances legislatives. Par ailleurs
elles sont formees par un ensemble structure et hierarchise de ressources fortement in-
terconnectees. De plus, elles doivent repondre a des problematiques de production et de
gestion semblables.
Apres cette analyse, la solution qui se distingue est de realiser l’unification des
ces deux composantes : composante logicielle et documentaire.
30

1.5. Services attendus pour la maıtrise du patrimoine des connaissances metier
Cette unification des composantes logicielle et documentaire peut etre realisee en
proposant d’une part des mecanismes de mise en relation de certains elements les compo-
sant et d’autre part en proposant des principes de production et de gestion communs.
Nous pouvons ainsi structurer le patrimoine des connaissances metier en un veri-
table referentiel de connaissances de l’organisation et le doter des principes de production
et de gestion capables de repondre aux enjeux institutionnels.
Pour assurer la coherence globale des connaissances exprimees dans l’ensemble des
ressources heterogenes du patrimoine reglementaire, il faut repondre aux problematiques
suivantes :
– la gestion de sa composante documentaire,
– la gestion de sa composante logicielle (l’implementation calculatoire de la re-
glementation),
– la tracabilite des connaissances exprimees tant au niveau documentaire qu’au
niveau logiciel : la meme connaissance se retrouve encodee dans plusieurs res-
sources avec plusieurs niveaux de details, pour plusieurs destinations,
– la maıtrise du lien qu’entretient le reste du Systeme d’Information (autre que
le systeme de gestion des prestations) avec le patrimoine reglementaire,
– identification et evaluation des impacts lies a une evolution reglementaire.
Par ailleurs les phenomenes observes depuis ce contexte particulier ne sont pas
propres au seul domaine des Prestations Familiales. Un grand nombre de ces constatations
peuvent etre generalisees a d’autres entreprises qui fondent leur action sur l’utilisation du
droit.
31

Chapitre 1. Maıtrise d’un patrimoine des connaissances metier
32

Chapitre 2
Etat des lieux dans la Branche
famille
Sommaire
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
2.2 Demarche generale . . . . . . . . . . . . . . . . . . . . . . . . 34
2.2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
2.2.2 Maıtrise des connaissances metier - projet SIDoc/KM . . . . 34
2.3 Le referentiel de production et de gestion documentaire . 36
2.3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.3.2 Architecture logique . . . . . . . . . . . . . . . . . . . . . . . 38
2.3.3 Fonctions de base . . . . . . . . . . . . . . . . . . . . . . . . 39
2.3.4 Fonctionnalites de gestion et de production documentaire . . 46
2.3.5 Architecture technique . . . . . . . . . . . . . . . . . . . . . 47
2.3.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
2.1 Introduction
Dans ce chapitre, nous dressons un etat des lieux de la Branche famille en presen-
tant la demarche adoptee pour apprehender la problematique complexe liee a la maıtrise
de son patrimoine des connaissances metier. Nous detaillons egalement le contexte de
realisation de nos travaux de recherche.
Etant donne le caractere strategique des enjeux auxquels doit repondre la maıtrise
du patrimoine des connaissances metier (documentaire et logiciel) de la Branche famille,
la Cnaf mene un vaste projet de recherche et de developpement visant la gestion des
connaissances pour leur capitalisation et leur partage. Ce projet a abouti a la mise en
place d’un Referentiel de gestion et de production documentaire qui sera decrit en detail
dans la section 2.3 du present manuscrit.
33

Chapitre 2. Etat des lieux dans la Branche famille
2.2 Demarche generale
2.2.1 Introduction
La problematique exprimee ici puise ses origines dans le contexte de la Branche
famille. Elle constitue la principale motivation de notre travail ; la demarche generale
adoptee par les projets de recherche a la Cnaf est presentee dans la figure 2.1.
Suite a une analyse approfondie, cette problematique specifique a notre Institu-
tion se revele egalement appropriee a d’autres organisations ayant la meme mission de
mise en application de la legislation voire plus generalement a tout type de structure. La
generalisation de notre problematique nous permet de nous affranchir des specificites de
notre organisation dans notre travail de recherche.
L’etat de l’art du domaine est analyse pour identifier les travaux susceptibles
d’apporter leur contribution a la consolidation d’une solution. Si l’etat de l’art et les
travaux connexes en cours ne repondent pas completement a notre problematique, une
etape de recherche est engagee.
Les resultats de cette etape de recherche seront formalises dans le cadre d’une
contribution scientifique et valides lors de differentes communications en lien avec la com-
munaute scientifique.
Les principes proposes issus de l’etape de recherche font systematiquement l’objet
d’une validation a l’aide d’un prototype. Celui-ci nous permet de tester la faisabilite de
l’implementation dans le cadre de l’organisation. Le prototype est egalement l’occasion
d’adapter la proposition scientifique generique au cas specifique de notre organisation afin
d’apporter une reponse concrete a la problematique soulevee initialement.
Le prototype est ainsi le support d’une evaluation operationnelle par les futurs
utilisateurs. La proposition ainsi validee donnera suite a un projet institutionnel qui visera
a fournir a l’organisation les services manquants dont elle a besoin.
2.2.2 Maıtrise des connaissances metier - projet SIDoc/KM
Dans ce contexte, plusieurs theses ont ete engagees en partenariat avec l’Association
Nationale de la Recherche Technique - ANRT dans le cadre d’un dispositif contrat CIFRE 4
et avec le laboratoire LIRIS 5.
Comme presente dans la figure 2.2, la Cnaf a applique la demarche dans plusieurs
projets de recherche traitant diverses problematiques :
1. Gestion logique des documents – Les travaux de Bertrand Chabbat portent sur la mo-
delisation multiparadigme des textes reglementaires. Ils proposent une structuration
4. Convention Industrielle de Formation par la Recherche5. Laboratoire d’InfoRmatique en Images et Systemes d’Information (Lyon)
34

2.2. Demarche generale
Analyse de l’état de l’art
Proposition scientifique
Prototype pilote
Contexte de l’organisation
Généralisation de la problématique
Problématique spécifique
Projet institutionnel
Niveau générique
Niveau spécifique
Figure 2.1 – Demarche de recherche a la Cnaf.
des textes reglementaires en utilisant des langages de balisage [ISO 86]. Ces travaux
ont fait l’objet d’une these de doctorat CIFRE soutenue en 1997 [Chabbat 97].
2. Gestion des connaissances et de la composante documentaire – Dans ses travaux sur
la modelisation semantique de la reglementation, David Jouve [Jouve 03a] propose
un systeme base sur la representation des connaissances pour garantir la coherence
des textes reglementaires entre les differents niveaux de la pyramide reglementaire. Il
complete ainsi la maıtrise logique proposee par les travaux de Bertrand Chabbat avec
des mecanismes de maıtrise des connaissances dans la composante documentaire. Ces
travaux ont fait l’objet d’une these de doctorat soutenue en 2003.
3. Maıtrise de la composante logicielle et de la relation avec le patrimoine documen-
taire – Cette problematique a ete traitee par le projet de recherche decrit dans ce
manuscrit. Il ambitionne d’etendre la maıtrise de la composante documentaire, ob-
tenue grace aux precedents travaux, a la composante logicielle, permettant ainsi une
maıtrise globale du patrimoine reglementaire.
Par ailleurs, cette maıtrise des ressources documentaires et du Systeme d’Infor-
mation est necessaire pour accroıtre la capacite de la DSI 6 a reagir aux changements
de legislation et ainsi assurer la coherence globale tout au long du processus de mise en
application de la legislation.
Les resultats des deux premiers travaux de recherche, valides par des prototypes
respectifs, ont donne suite a un projet institutionnel appele SIDoc/KM – Systeme d’In-
6. Direction du Systeme d’Information
[ISO 86] International Organization for Standardization. Standard Generalized Markup Language
(SGML). International Standard ISO 8879 :1986(E), Octobre 1986. 155 p.
[Chabbat 97] Voir reference [Chabbat 97] definie page 2.
[Jouve 03a] Voir reference [Jouve 03a] definie page 2.
35

Chapitre 2. Etat des lieux dans la Branche famille
Modélisation sémantique de la réglementation
Modélisation multiparadigme des textes réglementaires
Travail actuel
1997 2000 2003 2005
Démarche projet Pilote Déploiement institutionnel
Démarche projet
Pilote Déploiement institutionnel
Recherche
Recherche Démarche projet
Pilote
Recherche
Déploiement institutionnel
2008 Travaux de recherche
Aujourd’hui
Maîtrise des connaissances et de la composante documentaire
Maîtrise logique
Maîtrise de la composante logicielle et de la relation avec le patrimoine documentaire
Problématique 2009
Figure 2.2 – Projets de recherche a la Cnaf.
formation Documentaire - Knowledge Management. Ce projet vise a la mise en place du
Referentiel de production et de gestion documentaire decrit brievement dans la section 2.3
de ce chapitre. Ce referentiel offre les services necessaires a la maıtrise et a la capitalisation
des connaissances encodees dans des ressources documentaires (composante documentaire
du patrimoine reglementaire). Il adresse des fonctionnalites telles que la gestion de cycle
de vie, la gestion des modes d’acces, la recherche d’information, etc..
L’actuel projet de recherche se deroule en parallele du projet de developpement
institutionnel et participe a son effort de conception. Cette collaboration nous permet de
proposer une demarche coherente du point de vue logique mais egalement technique et
conceptuel entre le projet d’entreprise et le projet de recherche.
Le projet SIDoc/KM repond a une partie de la problematique enoncee precedem-
ment. L’actuel projet de recherche et de prototypage a pour but de preparer les idees et les
principes a mettre en oeuvre pour etendre l’offre de services et pour offrir une couverture
fonctionnelle totale dont l’Institution a besoin :
– etendre la gestion a la composante logicielle du patrimoine reglementaire,
– maıtriser la coherence globale du patrimoine reglementaire et du Systeme d’In-
formation,
– etudier l’impact et estimer les evolutions necessaires.
2.3 Le referentiel de production et de gestion documentaire
Nous avons vu precedemment que les textes reglementaires externes representent
une matiere premiere pour la Branche famille. Une production documentaire interne a
l’Institution vient enrichir l’ensemble des textes reglementaires externes, avec des docu-
ments qui affinent et traduisent ces connaissances juridiques dans un langage metier plus
operationnel. Ces documents explicitent la connaissance metier de l’organisation.
Dans cette section, nous allons presenter le referentiel de production et de gestion
documentaire, infrastructure pour la capitalisation des connaissances.
36

2.3. Le referentiel de production et de gestion documentaire
2.3.1 Introduction
Le processus institutionnel de management des connaissances (dont ce referentiel
est un outil important) vise a maıtriser les risques lies a :
– la complexification des legislations (prestations, action sociale, comptabilite,
etc.) et aux contentieux possibles ;
– la multiplication des vecteurs de diffusion de la connaissance (internet / extra-
net / intranet) ;
– l’evolution rapide de la pyramide des ages presente dans toutes les organisa-
tions ;
– les transformations organisationnelles ou territoriales (mutualisation, externa-
lisation, etc.).
Ainsi, ce referentiel doit pouvoir accueillir l’ensemble des ressources qui ont une
valeur de reference, c’est-a-dire toutes les ressources qui seront par la suite reutilisees et
dont la capitalisation est strategique. De meme, ce referentiel doit offrir les services ne-
cessaires au travail collaboratif de production documentaire. Il doit se positionner comme
un catalyseur pour la transformation de la connaissance tacite en connaissance explicite
(lors du processus de creation de contenu) d’une part, et de la connaissance explicite en
connaissance tacite(lors de la consultation du contenu pour appropriation par des em-
ployes) d’autre part.
Il est dote d’un ensemble de fonctions et de fonctionnalites supportant :
– l’acces a la connaissance ;
– le processus de production collaborative et d’enrichissement des connaissances ;
– les mecanismes pour la maıtrise de la coherence du referentiel.
Dans ce chapitre, nous allons presenter l’architecture du Systeme d’Information
Documentaire – le referentiel de production et de gestion des connaissances metier. Nous
attacherons beaucoup d’importance a la partie structuration des ressources pour pouvoir
integrer le referentiel en detaillant le cas des ressources documentaires textuelles et celui
des ressources de modelisation, modeles UML du Systeme d’Information.
Ce chapitre a pour vocation de presenter un resume synthetique de la demarche
employee et des principales fonctionnalites offertes aux utilisateurs ; nous ne souhaitons pas
etablir une documentation de specification et conception ou une documentation utilisateur
des services et composants du referentiel. Pour une description detaillee de l’implementa-
tion, nous vous proposons de consulter la documentation projet [CNEDI 07a].
[CNEDI 07a] Centre National d’Etudes et du Developpement Informatique Rhone-Alpes, 128 rue ser-
vient, 69003 Lyon. Documentation du projet SIDoc, 2007.
37

Chapitre 2. Etat des lieux dans la Branche famille
2.3.2 Architecture logique
La maıtrise des connaissances hebergees par le referentiel passe par une maı-
trise de la structuration des ressources qui les encodent. Le referentiel de gestion et de
production des connaissances contient ainsi un ensemble de « collections documentaires ».
Definition 2.3.1. Collection documentaire du referentiel de production et de gestion des
connaissances – Une collection documentaire du referentiel SIDoc est definie de la facon
suivante :
– c’est une composante du referentiel de production et de gestion documentaire,
– est formee par un ensemble de contenus non redondant et maintenu en cohe-
rence avec celui des autres collections,
– a une thematique et un perimetre clairement determines,
– s’adresse a un public(s) cible(s) avec une ligne editoriale definie en fonction
d’un usage cible.
La maıtrise du referentiel est egalement assuree par la maıtrise de la production
des connaissances qui y sont deposees. Pour chaque collection du referentiel, en fonction
de son contenu, de sa thematique et du public cible, il faut clairement definir une res-
ponsabilite editoriale et une unite d’organisation. Il s’agit donc d’assurer une production
documentaire respectant la thematique et le perimetre traites ainsi que la ligne editoriale
fixee.
Nous nous inscrivons ainsi dans une tendance de plus en plus presente, notamment
avec la mouvance Web 2.0, qui se caracterise par une facilitation des echanges, du partage
des connaissances et du travail collaboratif. Mais contrairement aux tendances Web 2.0,
une responsabilite redactionnelle forte est necessaire pour chaque contenu afin de garantir
la coherence globale du patrimoine des connaissances et sa diffusion. Le controle de la
communaute des utilisateurs ne suffit pas a lui seul pour satisfaire les contraintes de
conformite liees a un environnement dedie a la mise en application de la legislation.
2.3.2.1 Description d’une collection
Chaque collection, composee d’un ensemble de ressources, est structuree par les
definitions suivantes :
Categories de ressources – Les ressources peuvent appartenir a plusieurs categories.
Elles peuvent etre soit des ressources documentaires, soit des ressources binaires,
soit des ressources applicatives (des services associes a la collection).
Types de ressources – Chaque categorie de ressources a plusieurs types. Pour la cate-
gorie de ressources documentaires, le type de ressources designe le type de document.
Le type d’un document definit a la fois sa structure, son cycle de vie, les fonctions
38

2.3. Le referentiel de production et de gestion documentaire
disponibles et la maniere dont il est accessible (positionnement par defaut dans le
plan de classement, habilitations des utilisateurs).
Types de references – Nous avons vu precedemment que les relations existant entre les
elements composants du referentiel (un document, un fragment de document) sont
variees. La definition de la typologie des liens de reference nous permet d’expliciter
les specificites et les actions particulieres associees a une reference.
Description des taxonomies – L’acces au contenu est facilite par l’utilisation de taxo-
nomies. Elles sont definies au niveau de chaque collection, leur classement s’effectu-
rant par la suite au moment de l’edition de l’objet.
Description des docflows – Les docflows (workflow documentaire) decrivent le cycle de
vie des objets et gerent les fonctions disponibles selon les etats du document.
Description des fonctions – Chaque collection dispose d’un ensemble de fonctions de
gestion et de production documentaire.
Description des modules – Chaque collection dispose d’un ensemble de modules offrant
des fonctionnalites supplementaires de gestion (recherche d’information, tableaux de
bord, tableaux de suivi).
Definition des habilitations – Pour chaque collection, l’acces des utilisateurs et leur
role dans le processus de gestion et de production des connaissances sont definis a
l’aide des habilitations.
La figure 2.3 presente la structure de definition d’une collection.
2.3.3 Fonctions de base
2.3.3.1 Gestion de la persistance
Pour eviter la redondance caracteristique du domaine legislatif, deux structures
sont utilisees : une structure de representation et une structure de presentation des docu-
ments.
La structure de representation d’un document – la maniere dont celui-ci est mo-
delise et stocke par le systeme de gestion documentaire. Cette representation est
importante pour l’archivage, l’indexation et la recherche d’information.
la structure de presentation d’un document – la maniere dont celui-ci est presente
a l’utilisateur. Dans notre cas, les documents presentes aux utilisateurs contiennent
une information plus riche et plus detaillee que celle stockee par le systeme de ges-
tion documentaire. Pour eliminer la redondance, l’information est distribuee dans
le referentiel et des liens de references de plusieurs types sont utilises. La presen-
tation d’un document est donc une agregation des informations issues de plusieurs
representations persistantes.
39

Chapitre 2. Etat des lieux dans la Branche famille
Collection
Type d’objet Module Type de lien Taxonomie
Docflow Groupe de fonction
Règle d’habilitation
Fonction
Association
Agrégation
Légende
Figure 2.3 – Modele logique d’une collection du referentiel de gestion et de productiondes connaissances metiers.
2.3.3.2 Structure de base de stockage des documents
Les documents d’une collection sont types. Neanmoins ils respectent tous, inde-
pendamment de leur type, la meme structure de base decrite par le schema XSD [W3C 01e]
des objets du referentiel. Une forme graphique de ce schema est presentee dans la figure
2.4. Un exemple d’instanciation, pour un objet documentaire du referentiel, de ce schema
XSD est presente dans la figure 2.5.
Pour illustrer nos exemples, nous avons essaye plusieurs produits, mais un seul,
XML Spy, est pleinement exploite dans le present manuscrit. XML Spy [Altova 09] est un
produit evolue et fonctionnellement riche, qui permet d’editer des DTD et des schemas
XML ainsi que des instances XML. Il contient des convertisseurs, notamment en repre-
sentations graphiques et des generateurs automatiques d’instances et de modeles, qui se
revelent pratiques en phase d’etude.
Cet exemple nous permet de presenter les elements les plus importants retrouves
au niveau de la structure de stockage du document.
L’identifiant du document et son type sont specifies par les deux attributs de
plus haut niveau : object-id et type. L’element meta est identique pour tous les documents.
Il contient des informations concernant l’identifiant de version, le numero de revision et
[Altova 09] Voir reference [Altova 09] definie page 40.
40
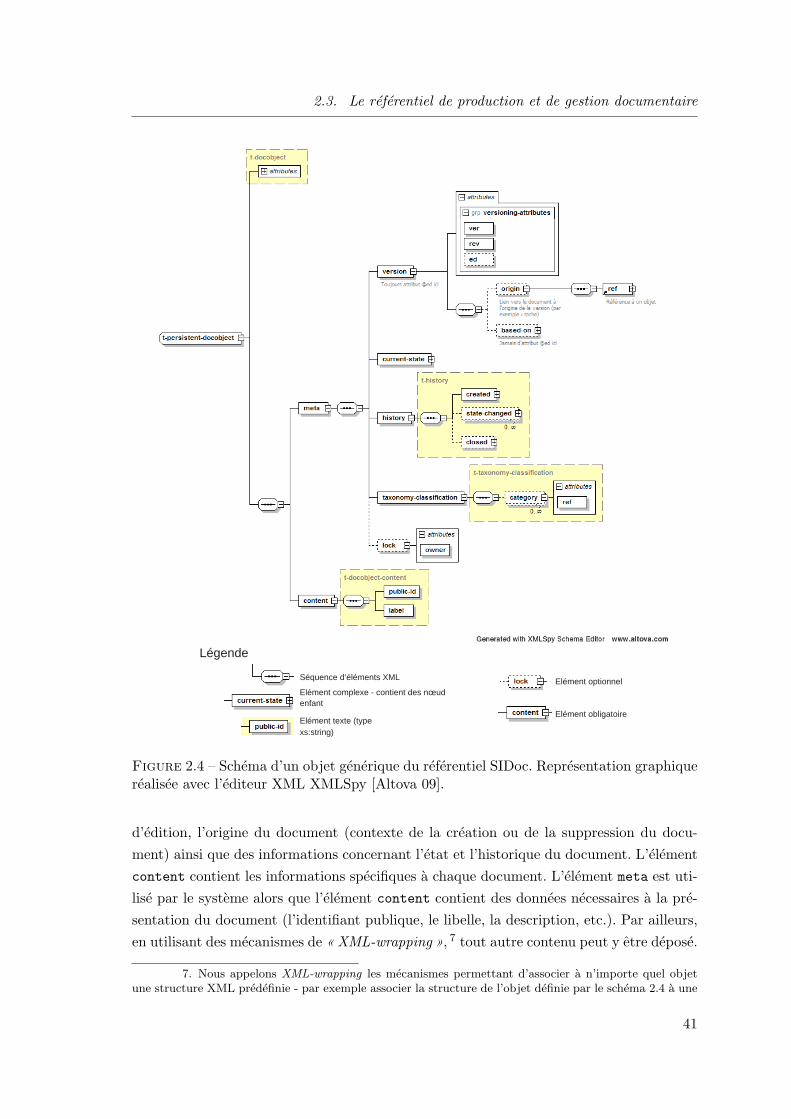
2.3. Le referentiel de production et de gestion documentaire
Légende
Séquence d’éléments XML
Elément complexe - contient des nœud enfant
Elément texte (type xs:string)
Elément optionnel
Elément obligatoire
Figure 2.4 – Schema d’un objet generique du referentiel SIDoc. Representation graphiquerealisee avec l’editeur XML XMLSpy [Altova 09].
d’edition, l’origine du document (contexte de la creation ou de la suppression du docu-
ment) ainsi que des informations concernant l’etat et l’historique du document. L’element
content contient les informations specifiques a chaque document. L’element meta est uti-
lise par le systeme alors que l’element content contient des donnees necessaires a la pre-
sentation du document (l’identifiant publique, le libelle, la description, etc.). Par ailleurs,
en utilisant des mecanismes de « XML-wrapping », 7 tout autre contenu peut y etre depose.
7. Nous appelons XML-wrapping les mecanismes permettant d’associer a n’importe quel objetune structure XML predefinie - par exemple associer la structure de l’objet definie par le schema 2.4 a une
41

Chapitre 2. Etat des lieux dans la Branche famille
<object object-id="00001221" type="donnee">
<meta>
<version ver="REF" rev="0001" ed="0001" />
<origin>
<creation>
<ref col="sair-daf" kind="docobject" type="tache"
res="00000003" ref-type="originContent"/>
<reason>Reprise de l’existant</reason>
</creation>
</origin>
<current-state uri="integre-reference"/>
<history>
<created user="Administrator" date-time="2006-10-11T16:46:20"/>
</history>
</meta>
<content>
<public-id>C10LN001</public-id>
<label>AS code nature prestation</label>
<autres-elements-specifiques>
. . .
</autres-elements-specifiques >.
.....
</content>
</object>
Figure 2.5 – Exemple d’un objet documentaire de l’infrastructure SIDoc .
Cette structure de base est adaptee en fonction de la categorie et du type de la ressource.
Nous travaillons ainsi avec un ensemble de schemas XML.
2.3.3.3 Gestion des revisions et des versions
Un espace de reference contient l’ensemble de la documentation disponible dans
un etat stable et valide, appele « version de reference ». Pour repondre a chaque evolution
de la documentation, un nouvel espace de travail est cree a partir de la version de reference,
contenant les documents qui doivent etre ajoutes, supprimes ou mis a jour (voir la figure
2.6). Plusieurs demandes d’evolution peuvent etre traitees en meme temps, en creant
plusieurs espaces de travail en parallele. Au sein de chaque espace de travail, les redacteurs
ont acces aux fonctions et fonctionnalites du systeme. Les versions de travail des documents
suivent leur cycle de vie, produisant de multiples revisions successives. A tout moment,
les redacteurs peuvent synchroniser leur version de travail avec la version de reference.
Une fois que la version de travail est validee, toutes les modifications vont etre
integrees dans l’espace de reference. Les autres espaces de travail peuvent alors se synchro-
niser pour beneficier des dernieres contributions.
image dont le code sera stocke sous la balise <content>
42

2.3. Le referentiel de production et de gestion documentaire
Figure 2.6 – Gestion en parallele des espaces de travail et des versions multiples.
2.3.3.4 Identification des ressources
Le referentiel SIDoc propose des mecanismes pour l’identification des documents
et son adressage.
Identification Dans un environnement multi-revisions et multi-versions, il est primor-
dial d’identifier precisement un document. L’identification doit pouvoir :
– identifier de maniere unique un document, une version ou une revision,
– etre independante de l’emplacement physique du document sur le support de
stockage,
– etre independante des informations modifiables dans le document.
Pour ce faire, une solution est l’utilisation des URN Universal Resource Name. Une
revision d’un document est identifiee par un unique URN constitue comme suit :
URN := collection-uri : resource-kind : resource-type : resource-id
[ : version : revision]
ou :
– collection-uri : represente l’identifiant URI Universal Resource Identifier de
la collection ;
– resource-kind : represente la categorie de ressource (e.g. un document, un
service, une resource binaire) ;
– resource-type : chaque categorie de ressources peut avoir plusieurs types de
ressources (e.g. les documents peuvent etre des documents de suivi legislatif,
des documents decrivant une donnee, une classe logicielle) ;
43

Chapitre 2. Etat des lieux dans la Branche famille
– resource-id : chaque ressource est identifiee a l’aide d’un identifiant unique.
Celui-ci est fixe a la creation de la ressource par le systeme afin d’assurer son
unicite. Ce champ de l’URN est renseigne avec la valeur de l’attribut object-id
de chaque document ;
– version : represente l’identifiant de la version de l’objet. Il correspond egale-
ment a l’identifiant de l’espace de travail ou de reference dans lequel se trouve
l’objet documentaire ;
– revision : represente le numero de revision. Une nouvelle revision est creee a
chaque evolution consideree comme importante du document (apres une etape
de validation).
Resolution des URN Considerant le grand nombre de documents, il est essentiel d’as-
surer l’integrite du referentiel. Ce mecanisme d’identification des ressources nous permet
de disposer d’un modele ou chaque ressource est identifiee de maniere unique et ou un
objet peut etre deplace sans affecter son identification et les objets qui le referencent.
La resolution des URN va permettre d’identifier le document physique associe en
prenant en compte l’identifiant unique mais egalement les identifiants de la version et de
la revision demandees.
Une revision precise est identifiee par l’identifiant de la ressource, par sa version,
et par sa revision. Si aucun identifiant de revision n’est specifie, la derniere revision active
est alors selectionnee. Si aucun identifiant de version n’est specifie, le document est alors
choisi dans la version courante ou, a defaut, dans la version de reference.
L’avantage de ce systeme d’interpretation des URNs est la flexibilite d’adressage
des documents. Nous pouvons toujours adresser la derniere revision d’un document, meme
si celui-ci evolue. De la meme maniere, nous pouvons toujours specifier une revision pre-
cise, meme si celle-ci devient obsolete. Ainsi, des documents dans des espaces d’editions
paralleles peuvent etre references sans interference.
2.3.3.5 Gestion des references
Les documents contenus dans le referentiel des connaissances ont une forte valeur
de reference. Leur contenu ne doit pas etre redondant, il faut reutiliser au maximum des
fragments de documents. Ainsi la gestion des liens et des references est un probleme crucial.
Toute l’information concernant un document est stockee avec celui-ci. Toute mise
a jour est alors disponible. Le libelle des liens est recupere au moment de la resolution de
ces liens.
Implementation Une reference est encodee sous forme d’un nœud XML contenant un
ensemble d’attributs dont les valeurs sont liees a l’URN de la ressource cible, presente dans
la figure 2.7.
44

2.3. Le referentiel de production et de gestion documentaire
<ref col="sair-daf" kind="docobject" type="tache" res="00000003"
[ver="REF" rev="0001" nodes="id1 id2" ref-type="originContent"]/>
Figure 2.7 – Exemple d’element XML representant une reference.
Les attributs col, kind, type, res definissent l’URN de la ressource referencee.
L’attribut optionnel nodes nous permet d’adresser un sous-fragment specifique d’un do-
cument.
Resolution des references Le libelle du document reference ainsi que sa description
et son type sont recuperes au moment de la resolution des liens. Si l’attribut nodes est
present, les sous-fragments identifies dans le document cible sont egalement recuperes au
moment de la resolution.
L’attribut ref-type decrit le type de lien de reference et eventuellement les ac-
tions a mener au moment de la restitution de ce lien. Un contenu supplementaire peut
etre recupere et ajoute a la forme de presentation du document appelant.
Types de references :
– references simples : une ressource faisant appel a une autre ressource, lien de
reference de base ;
– reference specialisee : l’attribut ref-type est present et il definit la semantique
de la reference. En fonction de la definition de cette semantique, le systeme va
operer les transformations necessaires pendant la phase de construction de la
forme de presentation du document appelant.
2.3.3.6 Docflow – workflow documentaire
Chaque type de document est caracterise par un cycle de vie. Chaque document
est associe a un moment donne a un etat dans son cycle de vie. Ce-dernier definit les
fonctions dont dispose l’utilisateur selon ses habilitations.
Le moteur docflow ecoute les evenements externes (fonctions actives, appel des
services, etc..) ou internes (envoyes par d’autres ressources suite a des transitions ou des
actions executees). Ces evenements peuvent, si toutes les conditions sont remplies, activer
des transitions vers un autre etat. Des actions peuvent etre executees sur une transition, a
la sortie ou a l’entree, dans un nouvel etat avec eventuellement des impacts sur l’evolution
du docflow des documents connexes. La figure C.1 de l’annexe C presente le docflow de
production d’un document de la collection Dossier d’analyse fonctionnelle. Le cycle de vie
est compose d’une succession d’etats (ex : planifie, En cours, A consolider, Consolide, etc.)
et de transitions entre ces etats. Les etats ainsi que les modalites de transition (declen-
chees par une action de l’utilisateur, par des conditions specifiques ou par des evenements
exterieurs) sont definis apres une analyse fonctionnelle approfondie des besoins en matiere
45

Chapitre 2. Etat des lieux dans la Branche famille
de production documentaire et de travail collaboratif.
2.3.3.7 Indexation et Recherche d’information
La recherche d’information est tres flexible et permet aux utilisateurs d’affiner
l’expression recherchee par un ou plusieurs mots-cles ou phrases. L’utilisateur peut spe-
cifier davantage sa recherche en precisant des informations signaletiques de la ressource :
identifiant, type de document, etat en cours, date de modification, etc.
2.3.3.8 Gestion de l’integrite et des acces
Le systeme doit assurer l’integrite des ressources et reglementer l’acces a celles-ci
en fonction des habilitations definies pour chaque role des utilisateurs.
2.3.3.9 Aide a l’utilisateur
Dans tout systeme de gestion, nous avons besoin d’une gestion de connaissances
sur les taches de l’utilisateur afin de lui faciliter l’appropriation de l’outil.
2.3.4 Fonctionnalites de gestion et de production documentaire
2.3.4.1 Referentiel unique
Le referentiel SIDoc est l’endroit unique pour la production et la gestion do-
cumentaire. De ce fait les connaissances sont gerees a un seul endroit et les differentes
applications puisent dans ce referentiel pour creer un contenu adapte a chaque besoin.
L’information presente dans le referentiel peut eventuellement etre adaptee en fonction du
canal de diffusion (intranet, extranet, internet) ou du profil de l’utilisateur.
Le referentiel introduit alors une nette distinction entre la production documen-
taire et la diffusion. Il offre un environnement de production dote des fonctions et fonc-
tionnalites enrichies visant a ameliorer la capitalisation des connaissances.
Par ailleurs, les fonctions de base d’identification, de referencement et les algo-
rithmes de resolution de liens nous permet de reduire la redondance (tres frequente dans
le cadre des ressources legislatives), sans diminuer les performances globales du systeme.
Un lien peut referencer soit la derniere revision du document, soit une revision
precise meme si celle-ci est obsolete. Le lien peut egalement, en utilisant l’attribut node, ne
referencer qu’une sous-partie d’un document. L’utilisation du type de reference (attribut
ref-type) nous permet d’associer une semantique particuliere a chaque lien (par exemple :
lien de reference vers l’origine du document, lien de dependance dans le processus de
production, lien de similarite, etc. ) et ainsi definir la maniere donc celui-ci est resolu au
moment de la presentation de la ressource (recuperation du contenu supplementaire, etc.).
46

2.3. Le referentiel de production et de gestion documentaire
2.3.4.2 Gestion du processus de production documentaire
Pour garantir la coherence du referentiel, les responsabilites doivent etre claire-
ment definies tout au long du processus de production et de gestion documentaire. Les
fonctions de docflow nous permettent de preciser l’automatisation du processus de produc-
tion, les roles de chaque participant, le flux de documents, de ressources et d’information
d’un etat a un autre.
Pour chaque collection documentaire, les roles de chaque intervenant ainsi que
les circuits de production sont precisement definis. Par exemple nous pouvons avoir des
contributeurs aux documents, des personnes en charge de la relecture, d’autres en charge
de la validation des documents qui vont intervenir tout au long du cycle de vie des objets
(le docflow de l’objet).
2.3.4.3 Tracabilite de l’information et des connaissances
La gestion des liens et de leur semantique nous permet de tracer (en suivant les
liens types) l’utilisation qui est faite d’une connaissance dans tout le referentiel. L’his-
torique des metadonnees nous permettent de tracer l’evolution de ces connaissances, les
mises a jour des ressources ainsi que les differentes contributions des utilisateurs.
Le patrimoine des connaissances est constamment mis a jour pour ameliorer l’exis-
tant ou pour repondre a de nouveaux besoins. L’historique de chaque ressource nous four-
nit les informations necessaires afin de tracer toutes les interventions effectuees sur une
ressource, et de les lier aux expressions d’exigences formulees.
Par exemple, l’application SIDoc permet de saisir les liens de dependances entre
les documents (raison de la creation ou de la modification d’un document, impacts d’un
document sur d’autres documents existants, etc.) Ces liens seront ensuite exploites pour
l’etude d’impact.
2.3.4.4 Analyse des dependances, etude d’impact et estimations des charges
associees aux evolutions
La structuration des ressources et les liens de reference definis entre les elements
du referentiel (inter et intra collections) servent de base pour l’instanciation d’un graphe
d’analyse des dependances et d’etude d’impact. Les mecanismes de raisonnement associes
a ce graphe sont presentes en detail dans [Vasutiu 06] ; ils realisent l’etude d’impact et une
estimation des charges associees aux evolutions.
2.3.5 Architecture technique
Le referentiel de production et de gestion des connaissances a ete developpe selon
une architecture n-tier presentee par la figure 2.8 dont une presentation succincte des
47

Chapitre 2. Etat des lieux dans la Branche famille
differentes couches sera faite dans la suite de ce paragraphe.
Figure 2.8 – Architecture technique n-tier SIDoc.
2.3.5.1 Couche persistance et acces aux donnees
La couche persistance assure la gestion du stockage des ressources et de leur
integrite en vue d’archivage, mise a jour, recherche d’information ou suppression. Suite
aux arguments presentes dans l’etat de l’art, nous avons fait le choix d’une base native
XML 8 accompagnee d’une definition des modeles en utilisant les schemas XSD [W3C 01e].
Les couches superieures de l’application utilisent la couche specialisee d’acces aux
donnees DAO (Data Access Objects) qui realise une abstraction du choix technologique
en matiere de persistance. Cette couche a ete definie lors des phases de conception de
l’architecture de l’application SIDoc (voir figure 2.8).
8. Les bases natives XML se basent sur un modele logique du document pouvant ainsi stockerdirectement tout type de contenu XML [Suciu 01].
48

2.3. Le referentiel de production et de gestion documentaire
2.3.5.2 Couche service
La couche service contient tous les services necessaires a la production et gestion
du referentiel. En plus des services de base comme le chargement et l’enregistrement des
objets, un ensemble de ressources a ete mis en place visant a repondre aux besoins de
gestion plus avances. Ces services correspondent aux implementations des fonctions definies
au paragraphe 2.3.3 : taxonomie, gestion des revisions, docflow, gestion des habilitations,
index et recherche d’information, acces aux ressources.
2.3.5.3 Couche controle et presentation
La couche controle interprete les actions des utilisateurs identifiees au niveau de
la couche presentation et les redirige vers le service approprie.
La couche presentation est composee de differents types de clients, comme par
exemple :
– le client leger - au sens logiciel, il est represente par le navigateur ; il depend
entierement du serveur pour toute la logique applicative et pour toutes les
donnees,
– le client lourd - logiciel qui dispose de toutes les fonctionnalites necessaires ; il
ne depend du serveur que pour l’echange des donnees,
– le client riche - il apporte une plus grande richesse dans les interfaces des clients
legers, le rapprochant du niveau de fonctionnalites des clients lourds,
– les applications externes - d’autres applications du SI qui s’interfacent avec le
serveur de l’application.
La plupart des ressources gerees par le referentiel utilisent actuellement une inter-
face utilisateur de gestion et de production sous forme de client riche. Il s’agit d’un client
web enrichi des fonctionnalites grace aux nouvelles approches telles qu’AJAX – Asynchro-
nous JavaScript and XML. La couche service fournit a la couche presentation le contenu
des objets en format XML. L’ensemble des processeurs de rendu transforme la structure
XML en une forme comprehensible par le client utilisateur. Dans le cadre des navigateurs
Internet, la plupart des interfaces utilisateurs de presentation des ressources du referen-
tiel sont definies a l’aide du langage XForms [W3C 07a]. Des processeurs de rendu tels
que Chiba [Chiba 08] permettent de generer le code source HTML a envoyer aux naviga-
teurs. D’autres clients peuvent eventuellement travailler directement a partir des flux XML
fournis par les services de chargement, par exemple les editeurs XML « client lourd ».
L’image 2.9 montre une copie d’ecran de l’application SIDoc dans un navigateur
Web.
L’ecran de l’application est divise en trois grandes zones :
1. zone de menu - zone en haut, cette zone permet l’acces aux fonctionnalites de l’ap-
plication : choix de la collection documentaire, lancement des outils de suivi de la
49

Chapitre 2. Etat des lieux dans la Branche famille
production documentaire, acces aux fonctions disponibles sur le document courant
(edition, sauvegarde, publication, etc.),
2. plan de classement - zone a gauche, plusieurs taxonomies peuvent etre definies,
permettant de proposer une classification des objets selon des categories definies par
l’utilisateur,
3. zone de visualisation du document - zone centrale, zone dans laquelle le formulaire
du document est affiche soit en consultation soit en edition.
2.3.6 Conclusion
Nous avons presente dans cette section le « Referentiel de gestion et de production
documentaire – SIDoc » de l’Institution. Les fonctionnalites proposees par ce referentiel
permettent de fournir les premiers services necessaires a la gestion et la production du
patrimoine documentaire. En revanche il ne dispose pas des fonctionnalites necessaires
pour l’identification et l’evaluation des impacts liees a une evolution reglementaire. Aussi, il
ne permet pas de fournir les services necessaires pour la gestion du Systeme d’Information.
Dans la partie problematique, nous avons vu que les services necessaires a la gestion du
Systeme d’Information sont similaires a ceux necessaire pour la gestion du patrimoine
documentaire.
50

2.3. Le referentiel de production et de gestion documentaire
Zon
e de
vi
sual
isat
ion
/ éd
ition
du
doc
umen
t
Pla
n de
cla
ssem
ent
Zon
e de
men
u
Figure 2.9 – Capture d’un ecran du referentiel SIDoc.
51

Chapitre 2. Etat des lieux dans la Branche famille
52

Conclusions
Au cours de cette partie, nous avons mis en evidence les caracteristiques de la
matiere reglementaire sur les deux volets : documentaire et logiciel.
Ainsi nous avons identifie les similarites entre ces deux ressources heterogenes
mais comparables du point de vue de leur role joue dans la gestion des connaissances.
Cette analyse nous permet, par la suite lors de la construction de notre proposition, d’ap-
prehender de la meme maniere les deux composantes du patrimoine des connaissances
metier.
Ensuite, le deuxieme chapitre de cette partie a presente un etat des lieux de
la Branche famille en precisant la demarche adoptee pour apprehender cette problema-
tique complexe, les projets engages ainsi que le contexte servant de cadre a notre travail.
Nous avons egalement presente le « Referentiel de gestion et de production documentaire
– SIDoc », l’outil de gestion de la composante documentaire.
La conclusion a laquelle nous a conduit cet expose est qu’une veritable maıtrise
de la matiere reglementaire, pour faire face aux changements recurrents de la legislation,
doit prendre en compte de maniere globale les deux volets : documentaire et logiciel.
Nous devons ensuite etudier comment integrer au sein du referentiel SIDoc les res-
sources du Systeme d’information (les modeles applicatifs, la documentation de conception,
le code source, etc. ) et comment les mettre en relation avec le patrimoine documentaire.
Pour cela il faut pouvoir repondre aux questions suivantes :
– comment representer les ressources du Systeme d’Information afin de les inte-
grer au sein du referentiel SIDoc qui se base sur la norme XML? Comment
trouver une structure commune a ces deux types de ressources ?
– comment unifier les deux composantes (identifier le lien entre les documents et
les composants du SI) ?
– comment identifier les impacts d’une evolution fonctionnelle ou legislative au
sein du referentiel couvrant a la fois la composante documentaire et la compo-
sante logicielle ?
– comment estimer l’etendue d’un impact et des charges associees a une evolu-
tion ?
Nos propositions pour l’etude d’impact, presentees dans la troisieme partie du
53

Conclusions
manuscrit, tentent d’apporter les reponses necessaires a ces interrogations.
54

Deuxieme partie
Etat de l’art
55


Introduction
La problematique exprimee dans la premiere partie de ce manuscrit se situe au
carrefour de plusieurs grands domaines de recherche : la gestion des connaissances, l’in-
genierie documentaire et la conception des Systemes d’Information. Les recherches biblio-
graphiques nous ont permis de couvrir certaines parties de ces domaines.
Nous presentons dans les trois chapitres de cette deuxieme partie une analyse des
travaux de recherche dans ces trois domaines.
Tout d’abord, nous nous interessons au domaine de l’ingenierie documentaire.
Nous presentons les travaux realises pour la structuration documentaire.
Le deuxieme chapitre de cette partie detaille les travaux en cours sur la maıtrise
des Systemes d’Information en analysant les differentes methodologies de conception et
de developpement, les differents formalismes de modelisation et les outils qui leur sont
associes.
Enfin, dans le dernier chapitre, nous passons en revue les principes d’analyse des
dependances entre des ressources differentes telles que les livrables de conception, le code
source des applications, les exigences, etc.
57

Introduction
58

Chapitre 3
Structuration de la documentation
Sommaire
3.1 Notion de document . . . . . . . . . . . . . . . . . . . . . . . 59
3.2 Structure documentaire . . . . . . . . . . . . . . . . . . . . . 62
3.3 Langages de structuration documentaire . . . . . . . . . . 63
3.4 Modelisation documentaire . . . . . . . . . . . . . . . . . . . 64
3.5 Langages d’echanges documentaires . . . . . . . . . . . . . 66
3.6 Synthese . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
3.1 Notion de document
Le terme « document » constitue le plus petit denominateur commun trouve pour
classer dans une meme famille des objets aussi varies qu’un courrier, un email, une note, un
texte de loi, une documentation technique, un dossier medical, un dictionnaire, une video,
un passeport, un ouvrage litteraire, un contrat juridique, un manuscrit ancien, un rapport,
une revue, etc. [Jouve 03a]. Le document peut donc etre percu comme le support de la
communication humaine. Il a ete cree pour etre diffuse et interprete par d’autres personnes
que son ou ses auteurs. Il represente ainsi une trace de l’activite humaine. Il est vrai que
l’ensemble de ces objets peut sembler relativement heterogene et disparate. Cependant,
tous ont pour point commun de rassembler une information en un objet unique, de per-
mettre son transport et d’en faciliter si besoin l’identification et le classement [Stern 97].
D’apres Bachimont[Bachimont 99], un document est un contenu exprime sur un
[Jouve 03a] Voir reference [Jouve 03a] definie page 2.
[Stern 97] Stern Yves. Les quatre dimensions des documents electroniques. Document Numerique,
1997, vol 1, n 1, p 55–60.
[Bachimont 99] Bachimont B. Bibliotheques numeriques audiovisuelles : des enjeux scientifiques et tech-
niques. Document Numerique, numero special Les bibliotheques numeriques, 1999, vol 2,
n 3-4, p 219–242.
59

Chapitre 3. Structuration de la documentation
support materiel, support d’inscription. Le contenu s’exprime sous une forme interpretable
et comprehensible pour un public donne. Ensuite, un certain nombre de contraintes de-
coulent du support d’inscription et de la forme d’interpretation choisie, contraignant ainsi
l’expression du contenu et ses conditions de reception et d’interpretation. Plusieurs types
de structures emergent traditionnellement dans le domaine de l’ingenierie documentaire
[Bachimont 99] :
– une structure logique qui impose un ordonnancement, une hierarchisation, une
mise en ensemble d’elements de contenus exprimes selon un mode d’expres-
sion donne. Par exemple, un document va etre constitue d’un titre, d’une ou
plusieurs parties, elles-memes composees d’un titre et de sous-parties, etc. Les
structures logiques se formalisent partiellement par les definitions des types de
documents – DTD 9 – que l’on peut rencontrer dans des formalismes comme
SGML, XML.
– une structure materielle ou physique imposant une presentation, une mise en
forme du document. Il s’agit d’une mise en forme de ces elements conformement
a l’ordonnancement prescrit. C’est le choix par exemple d’une typographie,
d’une mise en pages donnee, etc. Celle-ci depend du support de restitution, par
exemple s’il s’agit d’une representation dite « papier », la structure physique
indiquera le format de la feuille (A3, A4, A5,. . .) ainsi que l’organisation des
differentes entites logiques du document en vue de sa presentation (une ou deux
colonnes, etc.).
– une structure semantique qui s’attache a l’explicitation de la signification des
informations vehiculees par le document. A ces fins, des travaux s’interessent
a l’utilisation des ontologies [Erdmann 99] ou a la representations de connais-
sances [Jouve 03a] [Nanard 96].
Generalement, la structure materielle ou physique est calculee automatiquement a partir
de la structure logique par application d’une feuille de style – par exemple les feuilles
9. DTD – Document Type Definition [W3C 08]
[Erdmann 99] Erdmann Michael et Studer Rudi. Ontologies as Conceptual Models for XML Do-
cuments. Twelfth Workshop on Knowledge Acquisition, Modeling and Management
(KAW’99). Alberta, Canada. 1999.
[Jouve 03a] Voir reference [Jouve 03a] definie page 2.
[Nanard 96] Nanard Marc, Nanard Jocelyne, Massotte Anne Marie, Chauche Jacques, Jou-
bert Alain et Betaille Henri. Acquisition et ingenierie des connaissances, tendances
actuelles, chapitre La metaphore du generaliste : Acquisition et utilisation de la connais-
sance macroscopique sur une base de documents techniques, p 285–306. Cepadues editions,
1996.
60

3.1. Notion de document
CSS [W3C 99a, W3C 98], XSL [W3C 99b][W3C 01a] pour XML[W3C 08]. La structure
logique est habituellement stockee avec le document, tandis que la structure physique est
obtenue dynamiquement, lors de l’affichage du document a partir de la structure logique.
Bachimont identifie egalement deux contextes de manipulation des documents :
– un contexte de production, ou les differentes structures internes au document
sont mises en place en fonction d’une pratique donnee (par exemple le domaine
legislatif). Ce travail peut donner plusieurs types de documents definissant ainsi
les structures logiques utilisees.
– un contexte de reception, qui determine quant a lui la maniere dont les struc-
tures du document seront utilisees et interpretees.
Un document numerique est encode et enregistre selon un format bien definit. Il
sera presente a l’utilisateur sur un support d’appropriation (ecran, haut-parleur, papier) et
dans une forme lisible ou intelligible pour l’utilisateur (par exemple : le texte, les images
ou les sons). La consultation est realisee apres un mecanisme permettant de passer du
support d’enregistrement au support d’appropriation. Une telle operation est qualifiee de
projection dans [Champin 02].
Le document numerique, considere sur le support d’enregistrement, n’est pas un
document final mais une ressource a partir de laquelle peuvent etre calcules autant de
documents, c’est-a-dire d’instances sur un support d’appropriation. Par exemple, le for-
mat d’enregistrement interne d’un document Word [MSOffice 08] est incomprehensible par
l’utilisateur tandis que le document affiche dans l’interface du logiciel Word est parfaite-
ment comprehensible.
Definir clairement l’unite du document numerique [Bachimont 99, Bargeron 99]
devient difficile et des notions telles que celles de fragment documentaire, de document ou
de corpus tendent a s’estomper. Par exemple, un site Web compose exclusivement de pages
[W3C 99a] World Wide Web Consortium. Cascading Style Sheets, Level 1 (revised 11 Jan 1999),
W3C Recommendation, 1999. Disponible sur : http ://www.w3.org/TR/REC-CSS1
(consulte le 07.08.2009).
[W3C 98] World Wide Web Consortium. Cascading Style Sheets Level 2 Specification, W3C Re-
commendation, 1998. Disponible sur : http ://www.w3.org/TR/REC-CSS2 (consulte le
07.08.2009).
[W3C 99b] World Wide Web Consortium. Transformations XSL (XSLT) Version 1.0, W3C Recom-
mendation, 1999. Disponible sur : http ://www.w3.org/TR/xslt (consulte le 07.08.2009).
[W3C 01a] World Wide Web Consortium. Transformations XSL (XSLT) Version 1.1, W3C Working
Draft, 2001. Disponible sur : http ://www.w3.org/TR/xslt11 (consulte le 07.08.2009).
[Champin 02] Champin Pierre-Antoine. Modeliser l’experience pour en assister la reutilisation : De la
conception assistee par ordinateur au web semantique. These : Universite Claude Bernard
– Lyon 1, Lyon, France, Decembre 2002. 138 p.
[MSOffice 08] Microsoft Coorporation. Microsoft Office, 2008. Disponible sur :
http ://www.microsoft.com/france/office (consulte le 07.08.2009).
[Bargeron 99] Bargeron D., Gupta A., Grudin J., Sanocki E. et Mendelzon A. Annotations for
Streaming Video on the Web : System Design and Usage Studies. Computer Networks,
1999, vol 31, n 11-16, p 1139–1153.
61

Chapitre 3. Structuration de la documentation
HTML peut etre tantot percu comme un seul et meme document, tantot comme un en-
semble de documents plus elementaires. Un document numerique peut etre textuel, sonore,
audiovisuel, mono-media, multimedia, etc. Les supports d’enregistrement et d’appropria-
tion ainsi que les modalites de consultations sont tellement diversifies qu’il devient difficile
de cerner la notion de document. Il est donc essentiel de se munir d’une structuration qui
puisse nous aider a apprehender cette notion de document.
3.2 Structure documentaire
La problematique de la structuration multiple du document a ete abordee dans
le cadre d’un groupe de travail compose de differentes organisations (LIRIS 10, SIMMO 11,
SICOMOR 12, CNAF, etc.). Ces recherches collectives ont ete menees au sein de l’Institut
des Sciences du Document Numerique 13 (ISDN) et ont ete financees par la region Rhone-
Alpes.
David Jouve [Jouve 03a] restitue les travaux menes par ce groupe de travail qui
ont abouti notamment a la definition d’une structure documentaire.
Definition 3.2.1. Structure documentaire – Une structure documentaire est la description
d’un document par un ensemble d’elements en relation les uns avec les autres, au cours
ou en vue d’un usage. Les relations etablies entre les differents elements de structure sont
restreintes aux relations binaires. Une structure documentaire S est un graphe etiquete
connexe Sdoc = (N, R, A, LN , LA, etiq) ou :
– N est l’ensemble d’elements de structure,
– R est l’application definissant la relation binaire entre les membres de l’en-
semble N :
R : N → N, ∀x, y ∈ N, xRy,
– A est un ensemble d’arcs,
– LN est l’ensemble des etiquettes associees aux elements de structure,
– LA est l’ensemble des etiquettes associees aux arcs,
– etiq est une application qui :
1. a tout element de structure, x ∈ N, associe une etiquette dans LN ,
2. a tout arc, a ∈ A, associe une etiquette dans LA.
10. Laboratoire d’InfoRmatique en Image et Systemes d’information, voir http ://liris.cnrs.fr.11. Centre Sciences de l’Informatique, des Mathematiques, du Management et des Organisations
de l’Ecole Nationale Superieure des Mines de Saint-Etienne.
12. Equipe de Recherche sur les Systemes d’Informations et de la Communication des Organisa-tions de l’Universite Jean Moulin Lyon 3, voir http ://iae.univ-lyon3.fr/la-recherche-a-l-iae-de-lyon/centre-de-recherche-magellan/sicomor-recherche-en-systeme-d-information/.
13. Voir, http ://isdn.enssib.fr/institut/institut.html.
[Jouve 03a] Voir reference [Jouve 03a] definie page 2.
62

3.3. Langages de structuration documentaire
La notion de structure proposee par cette definition est caracterisee par un haut
degre d’abstraction et de genericite (elle est applicable a tout type de document). Cette
structure a ete elaboree de maniere a etre independante du type de media considere (e.g.
son, image, video, texte) et du type de corpus vise (e.g. documents archeologiques, do-
cuments reglementaires), des usages specifiques (e.g. stockage, recherche d’information,
consultation, navigation, restitutions multiples, edition). Cette structure est ainsi reutili-
sable mais l’abstraction reduit son caractere directement applicable. Le modele propose
doit donc prealablement etre specialise en fonction de divers parametres, tels que le media
utilise, le type de document considere ainsi que son utilisation attendue.
Dans la section suivante nous presentons quelques langages de structuration do-
cumentaire qui respectent les principes generiques enonces par la definition 3.2.1.
3.3 Langages de structuration documentaire
Le Standard Generalized Markup Language – SGML [ISO 86] et l’eXtensible Mar-
kup Language – XML [W3C 08] sont des metalangages de description de documents struc-
tures. SGML est une norme ISO internationale, tandis que XML est une recommandation
du World Wide Web Consortium 14. La norme SGML, anterieure a la specification de
XML, a ete developpee originellement pour l’echange de documents structures et a ete
utilisee notamment dans l’industrie de l’edition. Elle s’est revelee d’une grand complexite,
decourageant son adaptation a d’autres contextes industriels. SGML impose que tout do-
cument soit conforme a une structure de document type, parfaitement specifiee et validee.
SGML n’offre pas en lui-meme de mecanismes de liens bien adaptes a la creation d’un
hypertexte ouvert associant de nombreux documents. Ces liens existent dans une norme
complementaire, nommee HyTime [ISO 92]. Cette derniere, tres complete, mais complexe,
induit a son tour de grandes difficultes d’implementation. Neanmoins, SGML a demontre
que le principe fondamental visant a strictement separer description structurelle du do-
cument et description de sa realisation physique, apporte l’independance maximale entre
la representation informatique du document et les technologies particulieres (materielles
ou logicielles) necessaires a son traitement. C’est ainsi que XML et ses nombreux stan-
dards associes, sont nes de la volonte de capitaliser les acquis de SGML tout en facilitant
son implementation et son usage. Nous concentrons la suite de notre analyse sur le lan-
gage XML. Pour une comparaison plus detaillee entre SGML et XML, nous conseillons
14. World Wide Web Consortium ou W3C est une organisation ou cooperent un grand nombred’entreprises et de chercheurs partenaires.
[ISO 86] Voir reference [ISO 86] definie page 35.
[W3C 08] Voir reference [W3C 08] definie page 60.
[ISO 92] International Organization for Standardization. Hypermedia/Time-based Structuring Lan-
guage (HyTime). International Standard ISO 10744 :1992(E), Decembre 1992. 184 p.
63

Chapitre 3. Structuration de la documentation
[ben Lagha 99].
Le langage XML est fonde sur le meme principe que SGML : decrire la structure
logique des documents, principalement textuels, a l’aide d’un systeme de balises permettant
de marquer les elements qui en composent la structure, ainsi que les relations entre ces
elements. Le concept de balisage structurel consiste a admettre que tout document textuel
est construit selon une structure. Cette derniere est reconnue par les lecteurs humains
grace a des marques typographiques, des conventions de mise en page [Michard 01]. Cette
structure est rendue explicite grace a l’utilisation de balises indiquant le debut et la fin de
chacun des elements qui la composent. Un element est denote par la presence d’une balise
ouvrante – eg. <UnElement> – appariee a une balise fermante – eg. </UnElement>. Un
element peut etre vide, rassembler une portion de texte terminale ou etre compose de divers
autres elements. Les regles syntaxiques qui regissent la composition des balises imposent
aux structures specifiques une organisation arborescente. Pour qu’un document XML soit
qualifie de bien forme il est necessaire qu’il satisfasse a des contraintes syntaxiques (e.g.
balises fermees, noms en majuscule, un seul element racine).
Un exemple de source XML bien forme est fourni dans la figure 3.1. Le document
modelise est une lettre dont la structure fait apparaıtre differents elements consideres
comme constitutifs de cette classe d’objets documentaires. Une lettre est envoyee par un
EXPEDITEUR a l’attention d’un DESTINATAIRE. Elle est datee et possede un champ OBJET
ainsi qu’un CORPS. L’ensemble des elements specifiques identifies par la presence des balises
dans la source XML definit une structure arborescente.
Le langage XML peut etre utilise dans plusieurs intentions : afin de construire
une representation de l’information utile, afin d’expliciter l’interpretation des contenus
documentaires ou de retablir les relations entre les informations modelisees.
3.4 Modelisation documentaire
XML est un metalangage permettant de decrire la structure de tous les docu-
ments d’un meme type a l’aide d’un Document Type Definition ou de schemas. Les DTD
sont pour XML l’un des aspects importants directement herites de SGML. Dans le but
d’obtenir une expressivite plus forte par rapport aux DTD, la norme XML introduit des
mecanismes propres, les schemas, definis au travers de la recommandation XML-Schemas
[ben Lagha 99] b Lagha S., Sadfi W. et b Ahmed M. Une comparaison SGML-XML. Cahiers GUTen-
berg : Actes de la journee XML au Congres GUT99. Lyon, France. mai 1999, p 127–154.
[Michard 01] Michard Alain. XML Langage et Applications. Editions Eyrolles, Paris, 2001. 499 p.
64

3.4. Modelisation documentaire
<LETTRE>
<EXPEDITEUR>
<NOM>Eugene Ionesco</NOM>
<ADRESSE>
<NUMERO>5</NUMERO>
<RUE>rue du Theatre</RUE>
<VILLE>PARIS</VILLE>
</ADRESSE>
</EXPEDITEUR>
<DESTINATAIRE>
<NOM>Constantin Brancusi</NOM>
<ADRESSE>
<NUMERO>6</NUMERO>
<RUE>rue des arts</RUE>
<VILLE>PARIS</VILLE>
</ADRESSE>
</DESTINATAIRE>
<DATE>12-07-1953</DATE>
<OBJET>Journal de bord d’un voyage</OBJET>
<CORPS>
<PARAGRAPHE>Ceci est le premier paragraphe.</PARAGRAPHE>
<PARAGRAPHE>Ceci est le deuxieme paragraphe.</PARAGRAPHE>
<PARAGRAPHE>Ceci est le dernier paragraphe.</PARAGRAPHE>
</CORPS>
<SALUTATIONS>Cordialement.</SALUTATIONS>
</LETTRE>
Figure 3.1 – Document XML ou SGML : exemple d’une lettre.
[W3C 01b][W3C 01c][W3C 01d]. Les schemas sont eux-memes decrits en XML. La defi-
nition de modeles de document au travers des DTD ou des schemas est le mecanisme
par lequel les structures types predefinies, auxquelles les documents valides obeissent, sont
specifiees. Plus precisement, un document bien forme est dit valide lorsqu’il se conforme a
un modele explicitement defini. DTD et schemas rassemblent l’ensemble de toutes les de-
clarations relatives aux elements generiques, aux attributs, aux notations et aux entites qui
seront utilises lors de l’instanciation des documents specifiques. Ils permettent tous deux
la validation de documents XML au moyen d’analyseurs syntaxiques, grammaticaux, ou
autres, qui verifient que le document considere respecte la syntaxe du langage, la structure
de la DTD ou du schema, et que tous les liens faisant reference a des entites peuvent etre
resolus.
Par ailleurs, d’autres langages de description de schemas des documents XML
[W3C 01b] World Wide Web Consortium. XML Schema Part 0 : Primer, W3C Recommendation,
2001. Disponible sur : http ://www.w3.org/TR/xmlschema-0 (consulte le 04.08.2009).
[W3C 01c] World Wide Web Consortium. XML Schema Part 1 : Structures, W3C Recommendation,
2001. Disponible sur : http ://www.w3.org/TR/xmlschema-1 (consulte le 04.08.2009).
[W3C 01d] World Wide Web Consortium. XML Schema Part 2 : Datatypes, W3C Recommendation,
2001. Disponible sur : http ://www.w3.org/TR/xmlschema-2 (consulte le 04.08.2009).
65

Chapitre 3. Structuration de la documentation
ont egalement ete proposes [Lee 00], par exemple : Schematron [Rick 00][ISO 06] et DSD
[Klarlund 02].
La recommandation XML-Schemas peut etre modelisee, a l’aide d’un schema XSD
presente, sous forme graphique, dans l’annexe B.
3.5 Langages d’echanges documentaires
Un autre aspect de XML est a envisager : les documents XML representent une
solution d’echange de donnees tres plebiscitee. En effet, un des buts de XML est de per-
mettre un echange de donnees plus facile et plus transparent qu’avec les moyens existants.
Les efforts d’Object Management Group – OMG ont abouti a la proposition d’XML Me-
tadata Interchange – XMI [OMG 07b].
XMI s’appuie sur un procede de serialisation sous forme XML des objets MOF –
Meta Object Facility, un autre standard de OMG [OMG 05][OMG 06a]. Bien que l’exemple
d’usage le plus commun soit l’echange de modeles UML, l’XMI peut etre employe dans
l’echange de toutes les metadonnees dont le modele peut etre exprime en MOF.
XMI specifie ainsi un modele d’echange d’information ouvert qui est destine a
fournir les capacites d’echanger des donnees d’une facon standardisee.
3.6 Synthese
Le tableau 3.1 presente une synthese des notions presentees dans ce chapitre en
mettant en evidence les avantages et les inconvenients de chaque proposition.
[Lee 00] Lee D. et Chu W.W. Comparative analysis of six xml schema languages. SIGMOD
Record, 2000, vol 29, n 3, p 76 – 87.
[Rick 00] Rick Jellife. The Schematron – An XML Structure Validation Language using Patterns
in Trees, 2000. Disponible sur : http ://xml.ascc.net/resource/schematron/ (consulte le
04.08.2009).
[ISO 06] International Organization for Standardization. Document Schema Definition Language
(DSDL) – Rule-based validation – Schematron. International Standard ISO/IEC 19757-
3 :2006, 2006. 38 p.
[Klarlund 02] Klarlund N., Moller A. et Schwatzbach M. I. Dsd : a schema language for xml.
Automated Software Engineering, 2002, vol 9, n 3, p 285–319.
[OMG 07b] OMG – Object Management Group. XML Metadata Interchange (XMI), v2.1.1, Decem-
ber 2007. Disponible sur : http ://www.omg.org/technology/documents/formal/xmi.htm
(consulte le 03.09.2008).
[OMG 05] Internation Standardisation Organisation (ISO). Meta Object Facility Specification,
Version 1.4.1, 2005. Disponible sur : http ://www.omg.org/docs/formal/05-05-05.pdf
(consulte le 04.08.2008).
[OMG 06a] Object Management Group (OMG). Meta Object Facility Specification, Version 2.0, 2006.
Disponible sur : http ://www.omg.org/spec/MOF/2.0/ (consulte le 04.08.2008).
66

3.6
.Syn
these
Technologie Avantages Inconvenients
Structure documentaire
Definition 3.2.1(groupe de travail) haut degre d’abstraction et de genericite, appli-cable a tout type de document
la forte abstraction reduit son caractere directe-ment applicable
Langages de structuration documentaire(Section 3.3)
SGML [ISO 86] separation du modele et de l’instance complexite de la mise en oeuvre
XML [W3C 08] facilite de mise en œuvre, nombreux standardsassocies, tres repondu dans le milieu industriel
separation incomplete entre modele et le contenu
Modelisation et echanges documentaire (Section 3.4)
DTD - Document Type Definition[Michard 01]
structure precise, assure la validite des docu-ments
complexite de la mise en œuvre
XSD - XML-Schemas [W3C 01b] expressivite plus forte que le DTD, tres repandu
Schematron [ISO 06] validation en utilisant de patterns tres peu d’outils, mise en œuvre difficile
DSD [Klarlund 02] tres peu d’outils, mise en œuvre difficile
XMI [OMG 07b] format ouvert tres volumineux
Table 3.1 – Tableau de synthese des propositions67

Chapitre 3. Structuration de la documentation
68

Chapitre 4
Gestion des Systemes
d’Information
Sommaire
4.1 Concepts de base . . . . . . . . . . . . . . . . . . . . . . . . . 69
4.1.1 Les cycles de developpement . . . . . . . . . . . . . . . . . . 71
4.1.2 Les methodologies de conception et de developpement . . . 71
4.1.3 Formalisation des developpements . . . . . . . . . . . . . . . 72
4.1.4 Maıtrise et amelioration de la qualite . . . . . . . . . . . . . 73
4.1.5 Programmation des processus . . . . . . . . . . . . . . . . . 73
4.2 Modelisation des Systemes d’Information . . . . . . . . . . 74
4.2.1 Formalismes de modelisation . . . . . . . . . . . . . . . . . . 75
4.2.2 Choix du formalisme de modelisation des Systemes d’Infor-
mation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
4.2.3 Maıtrise des modeles . . . . . . . . . . . . . . . . . . . . . . 79
4.3 Gestion des connaissances et maıtrise des Systemes d’In-
formation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
4.4 Synthese . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
4.1 Concepts de base
La societe depend de plus en plus de fonctionnalites et de services offerts par des
systemes automatises par l’ordinateur. Des « fragments » de logiciels sont embarques
ou exploites par la plupart des produits modernes, a l’image des ordinateurs de bord
dans les voitures, de l’automatisation des transports, etc. Dans le futur proche, la place
occupee par le logiciel dans notre quotidien sera de plus en plus importante, rendant ainsi
69

Chapitre 4. Gestion des Systemes d’Information
l’informatique omnipresente (les fonctionnalites internet sont d’ores et deja presentes dans
l’electromenager et dans d’autres appareils domestiques).
Malheureusement, les logiciels sont des produits tres complexes, difficiles a de-
velopper et a tester. Souvent, ils se manifestent de maniere inattendue ou non souhaitee.
Chaque nouvelle edition de la newsletter ACM Software Engineering Notes publiee par
ACM SIGSOFT presente, dans une section dediee, quelques exemples d’accidents pro-
voques par les erreurs dans les logiciels. Pour toutes ces raisons, les chercheurs et les
industriels s’interessent tout particulierement a l’amelioration de la qualite des logiciels
developpes. Cet objectif peut etre atteint par plusieurs approches et techniques. Une des
priorites est l’amelioration des processus de conception et de developpement des logiciels :
le « software process »15. L’interet est prouve egalement par la standardisation internatio-
nale dont elle a fait l’objet : les normes ISO 12207 Processus du cycle de vie du logiciel et
ISO 15504 SPICE – Software Process Improvement and Capability dEtermination[ISO 04].
Alfonso Fuggetta propose dans [Fuggetta 00] quelques pistes pour l’amelioration
des processus de developpement logiciel, notamment en prenant en compte l’experience
d’autres domaines et en revisitant les langages de modelisation pour une meilleure coor-
dination des acteurs.
Les processus sont essentiels dans l’industrie car ils assurent un fonctionnement
uniforme des differents projets permettant ainsi d’augmenter la productivite, d’ameliorer
le temps necessaire a l’elaboration du produit et de reduire les couts engendres par son
developpement. Mais les processus sont importants surtout parce que l’experience a montre
qu’en controlant le processus, nous avons un meilleur controle sur la qualite du produit
[Gianpaolo 98].
Plusieurs approches ont ete proposees pour repondre aux problematiques presen-
tees precedemment. Il est difficile de presenter d’une maniere exhaustive les recherches
passees et en cours autour de ce sujet qui passionne depuis de nombreuses annees la com-
munaute scientifique en informatique.
Cependant, il nous semble interessant de dresser une liste des approches propo-
sees. En realite, ces approches ont existe et existent encore sous de nombreuses formes et
variantes. L’experience des annees de developpement logiciel a prouve qu’il n’y a pas de
« solution miracle ». Ainsi, les editeurs logiciels, les industriels choisissent les elements qui
leur semblent utiles n’hesitant pas a faire des « melanges ».
15. Software process - processus logiciel - terme anglais consacre dans la litterature dans les annees1980.
[ISO 04] International Organization for Standardization. ISO/IEC 15504 – SPICE (Software Pro-
cess Improvement and Capability dEtermination, 2004.
[Fuggetta 00] Fuggetta Alfonso. Software process : A roadmap. Proceedings of the 22nd Int. Conf.
on Software Engineering (ICSE’2000) – Future of Software Engineering Track. 2000.
[Gianpaolo 98] Gianpaolo Cugola et Carlo Guezzi. Software processes : a retrospective and a path to
the future. Software Process Improvement and Practice, 1998, vol 4, n 3, p 101–123.
70

4.1. Concepts de base
4.1.1 Les cycles de developpement
Le cycle de developpement logiciel definit une vie standard du logiciel, de sa
conception initiale a la maintenance en passant par le developpement. Le processus est
decompose dans une liste predefinie de phases, chacune etant structuree dans une serie
d’activites. Chaque phase recoit en entree un ensemble de livrables provenant de la phase
precedente et cree des livrables necessaires a la phase suivante.
Le « cycle en cascade » presente au debut des annees 70 [Royce 70] est present sous
differentes formes dans l’industrie. Il se base sur le postulat que l’ensemble des exigences
des utilisateurs sont connues au debut du processus. Il est percu comme une boıte noire
jusqu’a la fin quand il fournit le produit fini. Or, le plus souvent, l’utilisateur n’arrive pas
a bien exprimer ses besoins. Par ailleurs, le processus d’ingenierie logicielle contient des
etapes creatives qui ne peuvent pas etre apprehendees de la meme maniere que les etapes
manufacturieres. Ainsi, le developpement logiciel a besoin de cycles de vie plus flexibles et
adaptables.
La linearite de tels processus est un facteur qui augmente les couts associes aux
evolutions, qu’elles soient correctives (elles corrigent un defaut), adaptatives (elles adaptent
le logiciel a un changement d’environnement) ou perfectionnantes (elles ameliorent les
fonctionnalites existantes ou integrent de nouvelles idees et nouveaux besoins utilisateurs)
[Ghezzi 03].
4.1.2 Les methodologies de conception et de developpement
Une autre approche populaire a ete la definition de methodologies de conception
et de developpement. Les methodologies s’inscrivent dans des approches en s’appuyant sur
les differents cycles de developpement. Ces methodologies offrent des conseils experts et
indiquent les meilleures pratiques pour les processus de conception et de developpement.
Elles sont issues des developpements precedents couronnes de succes et peuvent etre per-
cues comme le fruit d’une distillation des meilleures experiences acquises au cours de la
conception et du developpement. Malgre l’enthousiasme affiche par les createurs de ces
methodologies, elles essuient quelques critiques et doivent faire face a des problemes tels
que [Pfleeger 06] :
– une methodologie est souvent appliquee dans un contexte different de celui
dont elle est issue. Par exemple, la meme methodologie peut etre appliquee
[Royce 70] Royce Winston. Managing the development of large software systems : Concepts and
techniques. In Proceedings of WesCon Conference, August 25-28 1970.
[Ghezzi 03] Ghezzi Carlo, Jazayeri Mehdi et Mandrioli Dino. Fudamentals of Software Enginee-
ring. Prentice Hall, 2003. 624 p.
[Pfleeger 06] Pfleeger Shari Lawrence et Atlee Joanne M. Software Engineering : Theory and
Practice, third edition. Prentice Hall, 2006. 736 p.
71

Chapitre 4. Gestion des Systemes d’Information
pour le developpement d’une application de gestion comme pour celui d’une
application industrielle,
– les developpeurs, en se deresponsabilisant, ont considere les methodologies
comme des « recettes » plutot que comme des conseils generiques,
– les methodologies necessitent beaucoup d’organisation, produisent de nom-
breux documents mais peu d’outils accompagnent efficacement les acteurs dans
ce travail,
– les methodologies sont souvent basees sur des notations non formelles : l’absence
d’une semantique precise a rendu les descriptions ambigues et la verification
de la coherence difficile. Dans d’autres cas, quand des notations formelles sont
utilisees, leur mise en œuvre est tres couteuse.
4.1.3 Formalisation des developpements
Contrastant avec le manque de formalisme des approches precedentes, un autre
axe de recherche a vu le jour a la fin des annees 1960. Il essaie de developper les fonde-
ments d’une approche du developpement logiciel en se basant sur les mathematiques. Ces
approches se basent sur le constat que les programmes sont des elements mathematiques
qui peuvent etre specifies d’une maniere formelle, validee. Les programmes peuvent ensuite
etre developpes correctement a travers une serie de raffinements bien definis [Dijkstra 76]
[Wirth 71] [Dahl 72] [Bauer 89].
Cette approche n’a pas pu trouver sa place comme solution generique au probleme
logiciel. Tout d’abord parce qu’elle suppose qu’une specification formelle des fonctionnalites
requises du logiciel soit disponible des le depart. Or, nous avons vu precedemment que cette
hypothese n’est pas toujours vraie. A cette premiere contrainte s’ajoute le probleme de
la « scalabilite ». En effet, bien que les methodes proposees pour le developpement des
programmes corrects obtenaient de bons resultats avec des programmes de petite taille,
elles etaient difficilement applicables au developpement de systemes complexes. Enfin, ces
methodes ne prennent pas suffisamment en compte les exigences non-fonctionnelles qui
representent une partie fondamentale de toute application complexe.
[Dijkstra 76] Dijkstra Edsger Wybe. A Discipline of Programming. Series in Automatic Computa-
tion. Prentice Hall, 1976. 240 p.
[Wirth 71] Wirth Niklaus. Program development by stepwise refinement. Communications of the
ACM, 1971, vol 14, n 4, p 221–227.
[Dahl 72] Dahl O. J., Dijkstra E. W. et Hoare C. A. R. Structured Programming. Academic
Press, 1972. 234 p.
[Bauer 89] Bauer Friedrich Ludwig, Moller Bernhard, Partsch Helmut et Pepper Peter.
Formal program construction by transformations-computer-aided, intuition-guided pro-
gramming. IEEE Trans. Softw. Eng., 1989, vol 15, n 2, p 165–180.
72

4.1. Concepts de base
4.1.4 Maıtrise et amelioration de la qualite
Dans les annees 1980, le milieu industriel est devenu de plus en plus soucieux de
la qualite. Le chef de file a ete l’industrie japonaise qui a ete tres attentive au processus de
production industrielle pour garantir la qualite des produits. Des standards internationaux
tels que la serie ISO 9000 [ISO 97], elabores pour certifier les organisations, etaient percus
comme une assurance indirecte de la qualite des produits delivres. Ces standards de qualite
se basent sur des procedures de management qui assurent un flux d’activites previsible et
ordonne. Ils ne s’interessent pas a comprendre la performance du processus metier des
organisations. C’est le but des modeles tels que Capability Maturity Model (CMM) de
definir une serie de niveaux de maturite qui caracterise une organisation de developpement
logiciel [Humphrey 89].
Les standards industriels et CMM sont tres utiles car ils prennent en compte le
point de vue de management du processus de developpement. Cependant, dans certains cas,
ceux qui les ont utilises ont pu observer qu’ils ne produisent pas une meilleure organisation
mais, au contraire, augmentent la « bureaucratie ». Les interrogations persistent donc pour
determiner s’ils sont plutot adaptes aux organisations complexes qu’aux organisations
dynamiques, flexibles et innovantes. Leur application ne se traduit pas automatiquement
par la qualite de leur produit : chaque organisation doit les considerer comme un vivier
de bonnes pratiques.
4.1.5 Programmation des processus
Leaon Osterweil a soutenu en 1987 l’idee que le processus de developpement de
logiciel est egalement un logiciel : « Software processes are software too » [Osterweil 87].
Toutes les organisations sont differentes et meme au sein d’une organisation, les divers
projets presentent des caracteristiques specifiques. Le processus doit donc etre adapte en
fonction du probleme a resoudre ; il doit prendre en compte les specificites des acteurs, du
projet et de l’organisation. Ainsi, Osterweil conclut au besoin de langages de description
des processus, de methodes de test et d’execution de ces processus, plus exactement de
definition du modele de processus. Ces langages sont appeles Process Modeling Language
[ISO 97] International Organization for Standardization. ISO 9000-3 task force, Quality mana-
gement and quality assurance standards - Part 3 : guidelines for the application of ISO
9000 to the development, supply and maintenance of software, 1997.
[Humphrey 89] Humphrey Watts S. Managing the Software Process. SEI Series in Software Engineering.
Addison-Wesley, 1989. 512 p.
[Osterweil 87] Osterweil Leaon. Software processes are software too. ICSE ’87 : Proceedings of the
9th international conference on Software Engineering. Los Alamitos, CA, USA. IEEE
Computer Society Press, 1987, p 2–13.
73

Chapitre 4. Gestion des Systemes d’Information
(PML) [Finkelstein 94]. Cette approche est consideree comme une pierre angulaire dans
la recherche moderne sur les processus de conception et de developpement et a donne
suite a la definition des Process-centered Software Engineering Environments (PSEEs)
[Arbaoui 02]. Le PSEE assiste les utilisateurs tout au long d’un processus explicite et
specifique utilise pour concevoir, specifier, developper et maintenir les produits logiciels.
4.2 Modelisation des Systemes d’Information
Les recherches bibliographiques conduites nous ont permis de denombrer deux
grands types d’approches dans la conception des Systemes d’Information :
– L’approche basee sur des langages formels decrivant le systeme a l’aide d’une
semantique parfaitement definie, par exemple : le langage B [Abrial 96], le
langage Z [Z 08], le Z++ [Lano 90], le Object Z [Smith 99], etc.
– L’approche fondee sur des langages moins formels et plus adaptes a l’homme.
Nous pouvons ici citer le standard UML – Unified Modeling Language[OMG 01][OMG 07a]
ou l’approche Merise. Ces langages semi-formels sont souvent enrichis a l’aide
de notations plus formelles, par exemple le langage OCL – Object Constraint
Language[OMG 06b] pour UML.
Notre analyse porte sur deux directions :
– comment modeliser le Systeme d’Information de l’entreprise ?
– comment estimer la capacite de ce modele a realiser des etudes d’impact
[Finkelstein 94] Finkelstein Anthony, Kramer Jeff et Nuseibeh Bashar. Software Process Modelling
and Technology. Research Studies Press Limited (J. Wiley), Taunton, UK, UK, 1994. 362
p.
[Arbaoui 02] Arbaoui Selma, Derniame Jean-Claude, Oquendo Flavio et Verjus Herve. A com-
parative review of process-centered software engineering environments. Annals of Software
Engineering, 2002, vol 14, n 1-4, p 311–340.
[Abrial 96] Abrial Jean-Raymond. The B-book : assigning programs to meanings. Cambridge Uni-
versity Press, New York, NY, USA, 1996. 779 p.
[Z 08] Programming Research Group (PRG), Oxford University. The Z notation, 2008. Dispo-
nible sur : http ://www.comlab.ox.ac.uk/archive/z.html (consulte le 07.08.2009).
[Lano 90] Lano Kevin. Z++ – an object-orientated extension to z. Z User Workshop. Workshops
in Computing, Springer-Verlag, 1990, p 151–172.
[Smith 99] Smith Graeme. The Object-Z Specification Language. Kluwer Academic Publishers,
Norwell, MA, USA, 1999. 160p.
[OMG 01] Object Management Group (OMG). Unified Modeling Language Specification, Version
1.4, septembre 2001. Disponible sur : http ://www.omg.org/spec/UML/1.4/ (consulte le
05.08.2008).
[OMG 07a] Voir reference [OMG 07a] definie page 23.
[OMG 06b] Object Management Group (OMG). Object Constraint Lan-
guage Specification, version 2.0, mai 2006. Disponible
sur :http ://www.omg.org/technology/documents/formal/ocl.htm (consulte le
08.08.2008).
74

4.2. Modelisation des Systemes d’Information
Le modele est une representation du monde reel que l’on simplifie pour mieux l’ap-
prehender dans sa globalite. En consequence, nous pouvons considerer un modele comme
la representation d’un systeme avec un formalisme donne, dans un ensemble de notations
donne.
4.2.1 Formalismes de modelisation
Pour creer le modele du systeme, il faut identifier et choisir un formalisme de
modelisation approprie. La popularite des methodes de conception orientee objet, Object
Oriented Methods (OOMs), a encourage le developpement de nombreux formalismes de
modelisation. Plusieurs langages sont donc utilises pour la modelisation des Systemes
d’Information. Chaque langage a ses points forts et ses points faibles. Les paragraphes
suivants presentent une analyse de plusieurs formalismes afin de choisir celui qui correspond
le mieux a notre problematique.
Pour nous aider a choisir la methode et le formalisme le plus adequat, nous avons
identifie quelques criteres dans un ordre decroissant d’importance :
– capacite de modelisation d’un Systeme d’Information (base sur des technologies
objet),
– appropriation du langage et adoption dans l’entreprise,
– operationnalisation, facilite de mise en œuvre dans un contexte industriel,
– possibilite de mener des etudes d’impact,
– extensibilite et specialisation.
4.2.1.1 Langage Z
Le langage Z [Z 08] a ete cree au debut des annees 1980 par le Programming
Research Group-PRG de l’Universite d’Oxford pour decrire et modeliser des Systemes
d’Information. Il s’agit d’un langage mathematique formel base sur la logique de premier
ordre et sur la theorie des ensembles.
Il a ete enrichi avec des concepts objets et des concepts plus formels : Object-Z
[Duke 00] et Z++[Lano 90].
Le langage Z a ete utilise dans certains projets industriels. Les modeles crees avec
ces notations ne sont pas faciles a lire, a comprendre et a modifier, a cause des differences
entre le concept reel et sa representation dans un langage trop formel. Les charges associees
a la realisation, la maintenance et l’exploitation d’un tel modele sont tres elevees, ce qui
represente un frein a son appropriation par les entreprises.
[Duke 00] Duke Roger et Rose Gordon. Formal Object-Oriented Specification Using Object-Z.
Palgrave Macmillan, 2000. 240 p.
[Lano 90] Voir reference [Lano 90] definie page 74.
75

Chapitre 4. Gestion des Systemes d’Information
La figure 4.1 presente un exemple de la specification en langage Z d’une fonc-
tion permettant d’ajouter une nouvelle entree dans la liste d’anniversaires des personnes
connues. Si la personne est deja connue le resultat est already know sinon, le nouvel anni-
versaire est ajoute a la liste d’anniversaires. La fonction utilise les operateurs ∨ et ∧ pour
realiser une union et respectivement une intersection des resultats des deux predicats.
Figure 4.1 – Exemple de la notation Z [Z 08].
4.2.1.2 Langage B
La methode basee sur le langage B[Abrial 96] est une methode formelle qui s’ap-
plique a toutes les phases de developpement logiciel, de la specification jusqu’a l’implemen-
tation. Elle permet d’exprimer des proprietes sous la forme de predicats de la logique de
premier ordre. Les operateurs utilises par la notation B sont egalement ceux de la theorie
des ensembles. Elle ressemble ainsi a la notation Z. Les proprietes d’un systeme a prouver
en B sont essentiellement des proprietes d’invariance. Contrairement a UML, la notation B
n’est pas orientee objet. De meme, le langage B n’a pas un formalisme graphique, il decrit
le systeme a l’aide des automates abstraits : AMN – AbstractMachine Notation.
La figure 4.2 presente un exemple d’utilisation de la notation AMN. L’exemple
definit une machine avec deux proprietes AA et nbMax : un ensemble de depart et un
intervalle 5..10 pour le nombre maximum. La machine va calculer dans la variable var,
initialement vide, tous les sous-ensemble de AA dont la cardinalite est plus petite que le
nombre maximum. L’exemple utilise la notation ASCII de B (« : » pour l’appartenance
ensembliste, « < : » pour l’inclusion, etc.).
Le langage B peut se voir adresser les memes reproches que le langage Z. Des
travaux sont en cours pour faire evoluer les deux langages qui ont du mal a s’imposer dans
les contextes operationnels des entreprises.
[Abrial 96] Voir reference [Abrial 96] definie page 74.
76

4.2. Modelisation des Systemes d’Information
MACHINE
machineExemple(AA, nbMax)
/* machine parametree par un SET et un nombre scalaire */
CONSTRAINTS
nbMax : 5..10 &
card(AA) >nbMax
VARIABLES
var
INVARIANT
var <: AA &
card(var) < nbMax +1
INITIALISATION
var := {}
OPERATIONS
operationExemple =
ANY ens WHERE ens <: AA & card(ens) < nbMax+ 1 THEN
var := ens
END
END
Figure 4.2 – Representation en langage formel utilise par B
4.2.1.3 Syntropy
Dans Syntropy [Cook 94], les modeles orientes objets sont completes par des an-
notations avec des expressions mathematiques, en utilisant le langage Z. Ces annotations
avec des expressions formelles participent a la realisation de modeles reduisant les ambiguı-
tes et favorisant la precision. Cependant, dans Syntropy, nous beneficions d’un formalisme
graphique pour la partie statique uniquement. La methode se base sur les premiers travaux
de Grady Booch car on y retrouve une demarche proche de certains diagrammes UML. La
methode a ete utilisee dans l’industrie puis remplacee par UML qui fournit une vue plus
complete sur le systeme.
4.2.1.4 MERISE
La methode MERISE est basee sur la separation des donnees et des traitements
a effectuer en plusieurs modeles conceptuels et physiques. La separation des donnees et
des traitements assure une longevite au modele.
Elle fait suite a une consultation nationale lancee en 1977 par le ministere de
l’Industrie dans le but de choisir des societes de conseil en informatique afin de definir une
methode de conception de Systemes d’Information. Les deux principales societes ayant mis
au point cette methode sont le CTI (Centre Technique d’Informatique) charge de gerer le
projet, et le CETE (Centre d’Etudes Techniques de l’Equipement).
[Cook 94] Cook Steve et Daniels John. Designing Object Systems : Object-Oriented Modelling
with Syntropy. Prentice Hall, 1994. 388 p.
77

Chapitre 4. Gestion des Systemes d’Information
Merise est surtout une methode d’analyse qui permet d’aboutir separement aux
modeles conceptuels :
– vue statique des donnees (MCD – Modele Conceptuel de Donnees) = Modele
Entite-Relations (ou Modele Entite-Association),
– vue dynamique des traitements MCT – Modele Conceptuel de Traitements.
Les deux vues, MCD et MCT, sont independantes de toute implementation.
Merise est une methode tres utilisee dans le milieu industriel en France. Nean-
moins, il s’agit d’une methode semi-formelle avec peu de possibilites d’extension.
4.2.1.5 UML – Unified Modeling Language
Le langage UML [OMG 01] [OMG 07a] est constitue des notations semi-formelles :
diagrammes de classes, diagrammes d’etat-transition, diagrammes de cas d’utilisation,
etc... Ces notations combinent une structure a base de graphismes avec des contraintes
OCL [OMG 06b] et des annotations en langue naturelle sous forme de commentaires. La
rapidite de conception, la facilite de lecture et la clarte architecturale des modeles UML
en font une methode populaire tres utilisee. Une des difficultes liee a la conception de
modeles UML fiables reside dans le manque d’outils de validation mathematique des pro-
prietes modelisees.
Par ailleurs, UML est supporte par la plupart des outils de conception et des
Ateliers de Genie Logiciel du marche. Notre reflexion donne priorite a l’etude de la base
commune aux diverses versions du langage UML.
D’autres langages de modelisation existent. Ce sont des langages qui accordent
beaucoup plus d’importance a une semantique tres precise et utilisent souvent des For-
mal Specification Techniques (FSTs). Les langages decrits ci-dessus sont representatifs des
possibilites existantes pour la conception et modelisation des Systemes d’Information.
4.2.2 Choix du formalisme de modelisation des Systemes d’Information
Suite a notre etat de l’art, nous avons identifie deux approches pour la modeli-
sation de Systemes d’Information : les approches formelles et les approches plus proches
du langage humain, approches souvent orientees objet. Les premieres approches, formelles,
sont principalement utilisees a des fins calculatoires (modeles comprehensibles et traitables
par l’ordinateur).
Nous nous interessons plus particulierement au partage de l’information et a la
collaboration des individus pour l’analyse et la conception. Par ailleurs, le but de nos
[OMG 01] Voir reference [OMG 01] definie page 74.
[OMG 07a] Voir reference [OMG 07a] definie page 23.
[OMG 06b] Voir reference [OMG 06b] definie page 75.
78

4.2. Modelisation des Systemes d’Information
travaux est de proposer des mecanismes pour la gestion des Systemes d’Information com-
plexes. Pour cela, nous avons besoin d’un langage qui soit employe tout au long du cycle
de vie du Systeme d’Information. Dans ce contexte, notre choix s’oriente donc plus vers
les langages de la deuxieme categorie.
Par rapport a notre problematique, UML offre tous les avantages et les fonctions
qui sont necessaires pour la modelisation du Systeme d’Information. Ce langage est par
ailleurs un standard de facto dans le milieu des entreprises. UML est par consequent
un bon compromis car il est suffisamment souple pour s’adapter dans le contexte tres
operationnel d’une entreprise tout en permettant d’etre enrichi du point de vue semantique
(avec le langage OCL - Object Constraint Langage [OMG 06b]) et syntaxique (par des
mecanismes tels que les profils, les stereotypes, etc.). Nous considerons aussi ses avantages
lies a la facilite a deployer, tant au niveau materiel (produits logiciel, documentation) qu’au
niveau humain (comprehension facile par les informaticiens ou les non-informaticiens).
4.2.3 Maıtrise des modeles
Au-dela de la conception des Systemes d’Information, plusieurs travaux se sont
interesses au maintien de la coherence, a leur optimisation ou a la retro-conception.
Les editeurs des Ateliers de developpement (Eclipse [Eclipse 08], IBM Rational
Rose [Rose 08]) ont des outils UML integres. Ces outils generent a partir des modeles du
code tres etroitement lie. Les modifications apportees a une partie du code ou du modele
sont tout de suite repercutees sur les elements en relation. Cette fonctionnalite est appelee
re-engineering : elle se base en grande partie sur l’etroite liaison entre le code et le modele
(les changements se propagent par une voie textuelle) [Enss 04] [Ekman 04].
D’autres travaux en cours s’attaquent a des problematiques de refonte des mo-
deles. Ces problematiques sont devenues d’actualite suite a l’interet croissant pour le deve-
loppement par des patterns et pour l’architecture orientee modeles (Model Driven Archi-
tecture - MDA). L’action s’appelle refactoring et elle reste tres compliquee a automatiser
[Eclipse 08] Eclipse Foundation. Eclipse - an open development platform, 2008. Disponible
sur : http ://www-01.ibm.com/software/awdtools/developer/rose/index.html (consulte le
04.08.2009).
[Rose 08] IBM Coorporation. Rational Rose, 2008. Disponible sur : http ://www.eclipse.org/
(consulte le 04.08.2009).
[Enss 04] Enss Raphael. Refactoring in Eclipse. Eclipse Departement of Computer Science Uni-
versity of Manitoba, 2004. Disponible sur : http ://www.cs.umanitoba.ca/ eclipse/13-
Refactoring.pdf (consulte le 04.08.2009).
[Ekman 04] Ekman Torbjorn et Asklund Ulf. Refactoring-aware versioning in eclipse. Proceedings
of the Second Eclipse Technology Exchange : eTX and the Eclipse Phenomenon (eTX
2004). Electronic Notes in Theoretical Computer Science, 2004, p 57–69.
79

Chapitre 4. Gestion des Systemes d’Information
[Opdyke 92] [Roberts 99].
D’autres travaux scientifiques se sont interesses a la verification de la coherence
des modeles UML (consistency of UML models). Chaque diagramme UML represente une
vue sur le systeme et apportant un complement d’information. Le modele est forme de
plusieurs diagrammes, chacun representant une vue differente. Les informations deduites
de ces diagrammes doivent etre coherentes [Sourrouille 02] [Engels 01] [Krishnan 00].
Neanmoins, la problematique de la gestion des changements et des etudes d’im-
pact sur ces modeles nous semble etre peu abordee dans la litterature scientifique.
4.3 Gestion des connaissances et maıtrise des Systemes d’In-
formation
Le developpement des Systemes d’Information est une activite complexe et cou-
teuse. Elle implique la resolution de plusieurs problemes souvent contradictoires concernant
la maıtrise des echeances, la maıtrise des couts, la diminution des risques d’erreurs, la per-
formance etc. La difficulte de repondre a ces problematiques est augmentee par la nature
changeante des exigences et des besoins utilisateurs, par la dynamique interne des equipes
projet et par le changement de personnel. Afin d’ameliorer les activites et le processus de
developpement des Systemes d’Information, des travaux de recherche proposent comme
solution cle le partage des connaissances et la capitalisation de l’experience [Aurum 03].
Par ailleurs, le developpement et la maintenance des Systemes d’Information est
considere comme un effort collectif. Les personnes impliquees partagent, echangent des
informations, apprennent les unes des autres. Des communautes sont ainsi creees ou chaque
membre coopere en partagant ses connaissances autour d’un sujet commun, generant ainsi
[Opdyke 92] Opdyke William F. Refactoring Object-Oriented Frameworks. These :
University of Illinois at Urbana-Champaign, 1992. Disponible sur :
http ://www.laputan.org/pub/papers/opdyke-thesis.pdf (consulte le 04.11.2009).
[Roberts 99] Roberts Donald Bradley. Practical analysis for refactoring. These : University of
Illinois at Urbana-Champaign, Champaign, IL, USA, 1999. Adviser-Ralph Johnson.
[Sourrouille 02] Sourrouille Jean Louis et Caplat Guy. Constraint checking in uml modeling. SEKE
’02 : Proceedings of the 14th international conference on Software engineering and know-
ledge engineering. New York, NY, USA. ACM, 2002, p 217–224.
[Engels 01] Engels Gregor, Kuster Jochem M., Heckel Reiko et Groenewegen Luuk. A me-
thodology for specifying and analyzing consistency of object-oriented behavioral models.
ESEC/FSE-9 : Proceedings of the 8th European software engineering conference held
jointly with 9th ACM SIGSOFT international symposium on Foundations of software
engineering. New York, NY, USA. ACM, 2001, p 186–195.
[Krishnan 00] Krishnan P. Consistency checks for uml. APSEC ’00 : Proceedings of the Seventh
Asia-Pacific Software Engineering Conference. Washington, DC, USA. IEEE Computer
Society, December 2000, p 162–169.
[Aurum 03] Aurum Aybuke, Jeffery Ross, Wohlin Claes et Handzic Meliha. Managing Software
Engineering Knowledge. Springer, 2003. 380 p.
80

4.4. Synthese
un veritable flux de connaissances [Rodrıguez 04b].
Differentes approches ont ete proposees pour le partage et la maıtrise du flux de
connaissances. La plus courante est la mise en place de systemes de gestion de connais-
sances bases sur des « agents » [Rodrıguez 04a].
La maintenance et l’exploitation des Systemes d’Information 16 est egalement une
tache complexe et difficile. Pour une correction, amelioration ou evolution d’une donnee,
il faut savoir quelles modifications apporter au Systeme d’Information, a quel niveau, a
quel module, et comprendre comment ces modifications vont affecter les autres modules du
Systeme d’Information. Souvent, les ingenieurs n’ont pas suffisamment de connaissances
sur le Systeme d’Information pour prendre la decision la plus adaptee. Pour ce faire, ils
ont besoin de connaissances dans de nombreux domaines tels que l’application, l’architec-
ture systeme, les algorithmes utilises, les exigences anciennes et nouvelles, les langages de
programmation et les environnements de developpement, etc. Des recherches ont montre
que 40% a 60% de l’effort necessaire pour la maintenance des Systemes d’Information sont
depenses pour la comprehension du systeme [Pfleeger 06].
4.4 Synthese
Le tableau 4.1 presente une synthese des notions presentees dans ce chapitre en
mettant en evidence les avantages et les inconvenients de chaque proposition.
16. Nous utilisons le terme de maintenance des Systemes d’Information pour designer la phaseposterieure a la mise en exploitation des Systemes d’Information
[Rodrıguez 04b] Rodrıguez Oscar M., Martınez Ana I., Vizcaıno Aurora, Favela Jesus et Piattini
Mario. Identifying knowledge managment needs in software maintenance groups : a qua-
litative approach. Proceedings of the 5th Internationa Conference on Computer Science
(ENC’ 2004). IEEE Computer Society Press, 2004, p 72–79.
[Rodrıguez 04a] Rodrıguez Oscar M., Martınez Ana I., Favela Jesus et Vizcaıno Aurora. Understan-
ding and supporting knowledge flows in a community of software developers. International
Workshop on Groupware (CRIWG’04). 2004, p 56–66.
[Pfleeger 06] Voir reference [Pfleeger 06] definie page 72.
81

Chapitre
4.
Ges
tion
des
Sys
tem
esd’Info
rmation
Technologie Avantages Inconvenients
Conception et developpement du SI
Les cycles linaires de developpement Parfaite maıtrise de chaque etape de conceptionet developpement
Les exigences doivent etre identifiees au debutdu cycle, tres peu flexible et adaptable, n’encou-rage pas la creativite
Formalisation des developpements Developpement valide selon des formules mathe-matiques, diminution des erreurs
Les exigences doivent etre parfaitement identi-fiees des le depart, tres difficile a appliquer pourles applications complexes, ne prennent pas encompte les exigences non-fonctionnelles
Modelisation des Systemes d’information
Langage Z Langage mathematique formel base sur la lo-gique de premier ordre
Charges associees a la realisation, la mainte-nance et l’exploitation d’un tel modele sont treselevees
Langage B Langage formel utile dans certains projets in-dustriels, notation tres precise, pas d’ambiguıte
Langage sans formalisme graphique, difficile amettre en oeuvre
Syntropy Annotations avec des expressions formelles per-mettant de reduire les ambiguıtes et d’une plusgrande precision
La methode a ete utilisee dans l’industrie puiselle a ete remplacee par UML qui fournit unevue plus complete sur le systeme
Merise (MCD et MCT) a Les deux modeles, MCD et MCT, sont indepen-dants de toute implementation.
Methode semi-formelle avec peu de possibilitesd’extension
UML Standard de-facto de l’industrie, supporte parla plupart des outils de conception, rapidite deconception, facilite
Langage semi-formel
Table 4.1 – Tableau de synthese des propositions
a. Merise est une methode d’analyse qui permet d’aboutir separement aux modeles conceptuels : le (MCD – Modele Conceptuel de Donnees) = ModeleEntite-Relations (ou Modele Entite-Association) apportant une vue statique des donnees et le MCT – Modele Conceptuel de Traitements apportant une vuedynamique des traitements.
82

Chapitre 5
Analyse des dependances
Sommaire
5.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
5.2 Tracabilite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84
5.3 Analyse des dependances - livrables de conception et de
developpement . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
5.4 Analyse des dependances - code source des applications . . 87
5.4.1 Graphe de dependances . . . . . . . . . . . . . . . . . . . . . 87
5.4.2 Decoupage des programmes – Program slicing . . . . . . . . 88
5.5 Analyse des dependances - exigences des utilisateurs . . . 89
5.6 Analyse des dependances - execution des programmes . . 90
5.7 Synthese . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 90
5.1 Introduction
Les changements dans une application logicielle sont produits par des causes va-
riees comme la correction d’une anomalie, l’ajout d’une fonctionnalite ou l’amelioration de
l’architecture et de la conception. Independamment de leur cause, les changements ne se
cantonnent generalement pas a un seul composant du Systeme d’Information. Un change-
ment peut avoir des effets de bord sur d’autres composants et/ou contredire les conditions
initiales. Par ailleurs, les methodologies d’estimation des changements des logiciels sont
tres importantes dans la maintenance des Systemes d’Information car elles permettent a
chaque evolution de diminuer les charges associees aux modifications.
Les differentes approches sont caracterisees par leur degre d’expressivite et leur
degre d’efficience. Le degre d’expressivite est defini comme la granularite des livrables
logiciels (par exemple : un fichier, une classe, une fonction). Ces derniers sont pris en
83

Chapitre 5. Analyse des dependances
compte dans l’analyse des dependances ainsi que le contexte du changement (par exemple :
un parametre ajoute a une fonction, une variable supprimee d’une classe) ou l’estimation
de l’impact est realisee. Tout comme dans le domaine de la Recherche d’Information,
l’efficience d’une methodologie depend de la precision de l’estimation realisee et du taux
de rappel en prenant en compte le cout calculatoire [Kagdi 07].
Plusieurs approches ont ete developpees pour l’analyse des dependances et l’etude
d’impact en se basant sur la tracabilite ainsi que sur les relations entre les composants
du Systeme d’Information a differents niveaux d’abstraction (executables, code source,
ressources de modelisation, documentation de conception, documentation d’analyse, etc).
5.2 Tracabilite
Les livrables du processus de developpement des applications informatiques (ex-
pression d’une exigence, code source, tests, modeles, rapports, documents de planification,
etc.) sont egalement appeles artefacts. La tracabilite represente la capacite de decrire et
de suivre leur vie dans les deux directions : en allant de l’expression des exigences jus-
qu’au modules de l’architecture logicielle et au code source de l’application et vice-versa
[Gotel 94].
La tracabilite peut nous fournir des renseignements importants pour l’evolution
du Systeme d’Information et nous aider dans sa comprehension top-down ou bottom-up.
Elle fournit egalement des informations sur les relations existantes entre les exigences,
la conception et l’implementation des logiciels etant ainsi un support propice a l’etude
d’impact.
Les outils actuels n’assurent pas de maniere satisfaisante la tracabilite. Cette
inadequation constitue une des causes les plus importantes dans le depassement des delais
et/ou l’echec des projets logiciels [Domges 98].
Quelques outils presents dans le milieu academique ou commercial sont dispo-
nibles pour la gestion de la tracabilite entre les differents livrables des projets de develop-
pement.
[Kagdi 07] Kagdi Huzefa et Maletic Jonathan I. Combining single-version and evolutionary de-
pendencies for software-change prediction. MSR ’07 : Proceedings of the Fourth Interna-
tional Workshop on Mining Software Repositories. Washington, DC, USA. IEEE Com-
puter Society, 2007, p 17.
[Gotel 94] Gotel O. et Finkelstein A. An analysis of the requirements traceability problem. In Pro-
ceedings of 1st International Conference on Requirements Engineering (Colorado Springs,
CO). Los Alamitos, CA,. IEEE Computer Society Press, 1994, p 94–101.
[Domges 98] Domges Ralf et Pohl Klaus. Adapting traceability environments to project-specific
needs. Commun. ACM, 1998, vol 41, n 12, p 54–62.
84

5.2. Tracabilite
DOORS [Doors 08], Rational RequisitePro [Requisite 08] et RDD-100 [RDD 08]
sont des outils commerciaux qui fournissent des fonctionnalites d’enregistrement, d’affi-
chage et de verification de la completude des livrables projets. Ils utilisent des moyens
graphiques pour afficher la maniere avec laquelle chaque donnee est connectee aux autres
et a sa source.
TOOR (Traceability of Object-Oriented Requirements) [Pinheiro 96] est un outil
de recherche qui prend en compte une vision plus large des exigences en y incluant les
facteurs sociaux en plus de ceux techniques ou fonctionnels. Cet outil permet de positionner
entre les livrables des liens personnalisables par les utilisateurs entre deux memes objets
afin de traduire differents types de relations.
La tracabilite entre les artefacts a egalement ete abordee par [Maletic 01] et
[Settimi 04] qui proposent une mise en relation du code source et des elements des modeles
UML en utilisant une representation XML[W3C 08] de ces deux ressources.
Le point faible de tous ces outils est le fait qu’ils ne supportent pas la maintenance
automatique ou semi-automatique des liens de tracabilite et ne prennent pas en compte
les nouvelles versions des artefacts [Alexander 02]. Ainsi, la detection et la maintenance
des liens de tracabilite doivent etre operees de maniere manuelle, engendrant des couts
importants. L’investissement est d’autant plus lourd si nous prenons en consideration la
nature iterative des processus de developpement [Cleland-Huang 03].
Le probleme de l’identification et de la reconstitution des liens de tracabilite a
[Doors 08] Telelogic AB, Telelogic AB, PO Box 4128, Kungsgatan 6, SE-203
12 Malmo, Sweden. Telelogic DOORS, 2008. Disponible sur :
http ://www.telelogic.com/products/doors/index.cfm (consulte le 07.08.2009).
[Requisite 08] IBM Corporation. Rational RequisitePro, 2008. Disponible sur : http ://www-
01.ibm.com/software/awdtools/reqpro/ (consulte le 07.08.2009).
[RDD 08] Holagent Coorporation. RDD-100, 2008. Disponible sur :
http ://www.holagent.com/products/ (consulte le 07.08.2009).
[Pinheiro 96] Pinheiro Francisco A. C. et Goguen Joseph A. An object-oriented tool for tracing
requirements. IEEE Softw., 1996, vol 13, n 2, p 52–64.
[Maletic 01] Maletic Jonathan et Marcus Andrian. Supporting program comprehension using se-
mantic and structural information. ICSE ’01 : Proceedings of the 23rd International
Conference on Software Engineering. Washington, DC, USA. IEEE Computer Society,
2001, p 103–112.
[Settimi 04] Settimi Raffaella, Cleland-Huang Jane, Khadra Oussama Ben, Mody Jigar, Lu-
kasik Wiktor et DePalma Chris. Supporting software evolution through dynamically
retrieving traces to uml artifacts. IWPSE ’04 : Proceedings of the Principles of Software
Evolution, 7th International Workshop. Washington, DC, USA. IEEE Computer Society,
2004, p 49–54.
[W3C 08] Voir reference [W3C 08] definie page 60.
[Alexander 02] Alexander Ian. Towards automatic traceability in industrial practice. Proceedings of
1st International Workshop on Traceability in Emerging Forms of Software Engineering.
2002, p 26–31.
[Cleland-Huang 03] Cleland-Huang Jane, Chang Carl K. et Christensen Mark. Event-based traceability
for managing evolutionary change. IEEE Trans. Softw. Eng., 2003, vol 29, n 9, p 796–810.
85

Chapitre 5. Analyse des dependances
souvent ete aborde dans la litterature specialisee sous l’angle de la relation entre le code
source et les elements de conception associes, en particulier des elements des diagrammes
UML. [Briand 03] utilise des regles de modification specifiees en langage OCL ; [Egyed 02]
recupere les liens de tracabilite en analysant les classes Java employees au moment de
l’execution d’un scenario ; [Richardson 04] s’interesse aux liens de tracabilite dans le cadre
des programmes generes automatiquement a partir de specifications formelles ; [Lucia 07]
emploie des techniques de recherche d’information pour la reconstitution des liens de tra-
cabilite.
5.3 Analyse des dependances - livrables de conception et de
developpement
La plupart des mecanismes d’etude d’impact se situent au niveau du code. Nous
en detaillerons quelques principes dans les sections suivantes de ce chapitre.
Quelques mecanismes d’etude d’impact ont ete proposes au niveau des livrables de
conception, tels que les modeles UML [Briand 03]. Ceux-ci se basent sur des specifications
formelles des regles d’impact, decrites en langage OCL [OMG 06b], entre les elements du
modele.
Des chercheurs se sont interesses a l’analyse des dependances en amont de l’evo-
lution du code (au moment de l’expression des exigences utilisateur) et, en aval, entre les
composants deployes. Le premier cas est detaille dans le paragraphe suivant, 5.4 de ce
chapitre, alors que le second cas ne sera pas traite dans ce manuscrit. Il est presente en
detail dans [Belguidoum 06].
Dans la litterature de specialite, de nombreux travaux s’orientent prioritairement
sur l’estimation des changements au niveau du code source. Neanmoins, l’estimation des
[Briand 03] Briand L. C., Labiche Y. et O’Sullivan L. Impact analysis and change management
of uml models. ICSM ’03 : Proceedings of the International Conference on Software
Maintenance. Washington, DC, USA. IEEE Computer Society, 2003, p 256.
[Egyed 02] Egyed Alexander et Grunbacher Paul. Automating requirements traceability : Beyond
the record & replay paradigm. ASE ’02 : Proceedings of the 17th IEEE international
conference on Automated software engineering. Washington, DC, USA. IEEE Computer
Society, 2002, p 163.
[Richardson 04] Richardson Julian et Green Jeff. Automating traceability for generated software ar-
tifacts. ASE ’04 : Proceedings of the 19th IEEE international conference on Automated
software engineering. Washington, DC, USA. IEEE Computer Society, 2004, p 24–33.
[Lucia 07] Lucia Andrea De, Fasano Fausto, Oliveto Rocco et Tortora Genoveffa. Recove-
ring traceability links in software artifact management systems using information retrieval
methods. ACM Trans. Softw. Eng. Methodol., 2007, vol 16, n 4, p 13.
[OMG 06b] Voir reference [OMG 06b] definie page 75.
[Belguidoum 06] Belguidoum Meriem et Dagnat Fabien. Analysis of deployment dependencies in software
components. SAC ’06 : Proceedings of the 2006 ACM symposium on Applied computing.
New York, NY, USA. ACM, 2006, p 735–736.
86

5.4. Analyse des dependances - code source des applications
impacts sur l’ensemble des livrables du cycle de developpement logiciel reste un axe de
recherche important.
5.4 Analyse des dependances - code source des applications
Deux approches orthogonales se remarquent : celle classee dans le domaine de
recherche Software-Change Impact Analysis (IA) [Bohner 96] et celle du domaine de re-
cherche Mining Software Repositories (MSR) [Gall 03][German 04].
L’approche IA definit des principes d’analyse de dependance entre les artefacts
logiciels au meme niveau d’abstraction (de code source a code source, entre livrables de
conception, etc). Cette analyse de dependance se base sur les relations qu’entretiennent
les livrables ou les elements d’un livrable au meme niveau d’abstraction. Cette approche
utilise generalement une seule version des livrables.
L’approche basee sur MSR prend en compte exclusivement le code source des pro-
grammes. L’avantage de cette approche est que la methodologie prend en compte plusieurs
versions du logiciel. L’analyse d’un ensemble de versions permet de definir des patterns
de modifications qui sont prises en compte pour predire de futurs changements dans les
versions ulterieures. Un autre mecanisme, base sur MSR, analyse des mises a jour reali-
sees de l’entrepot pour identifier des dependances a l’aide des changements concomitants.
[Zimmermann 04].
Kagdi [Kagdi 07] propose de combiner les deux methodes pour ameliorer les per-
formances globales.
5.4.1 Graphe de dependances
Une representation interessante des programmes peut etre realisee a travers le
graphe de dependance du programme, traduction du terme anglais Program Dependence
[Bohner 96] Bohner Shawn et Arnold Robert. Software Change Impact Analysis. Wiley, 1996. 392
p.
[Gall 03] Gall Harald, Jazayeri Mehdi et Krajewski Jacek. Cvs release history data for de-
tecting logical couplings. IWPSE ’03 : Proceedings of the 6th International Workshop on
Principles of Software Evolution. Washington, DC, USA. IEEE Computer Society, 2003,
p 13.
[German 04] German Daniel M. An empirical study of fine-grained software modifications. ICSM
’04 : Proceedings of the 20th IEEE International Conference on Software Maintenance.
Washington, DC, USA. IEEE Computer Society, 2004, p 316–325.
[Zimmermann 04] Zimmermann Thomas, Weisgerber Peter, Diehl Stephan et Zeller Andreas. Mining
version histories to guide software changes. ICSE ’04 : Proceedings of the 26th Internatio-
nal Conference on Software Engineering. Washington, DC, USA. IEEE Computer Society,
2004, p 563–572.
[Kagdi 07] Voir reference [Kagdi 07] definie page 84.
87

Chapitre 5. Analyse des dependances
Graph – PDG introduit dans [Ferrante 87] et [Ottenstein 84]. Le PDG explicite les de-
pendances entre les donnees mais aussi entre les structures de controle. Les dependances
exprimees dans le PDG connectent des parties du programme d’un point de vue calcula-
toire. Il est ainsi plus facile d’identifier des ameliorations possibles au niveau du code telles
que la vectorisation, la reorganisation du code pour eliminer les boucles, pour dedoubler
l’execution des passages, etc... Le PDG est donc largement utilise dans l’optimisation des
compilateurs pour des machines vectorielles ou paralleles.
Le PDG, qui considerait le programme d’une maniere monolithique, a ete etendu
pour prendre en compte les collections de procedures dans le cadre du System Dependence
Graphs – SDG [Binkley 91]. Le SDG, faisant l’objet d’un US-Pattent, utilise dans l’algo-
rithme de construction le contexte d’appel d’une procedure, ameliorant ainsi les techniques
de decoupage des programmes [Horwitz 04].
5.4.2 Decoupage des programmes – Program slicing
Le decoupage des programmes (traduction du terme anglais program slicing) est
une technique qui vise a extraire des parties d’un programme en respectant des regles spe-
cifiques. Depuis que Weiser a propose la notion de program slicing [Weiser 84] [Weiser 81],
de nombreuses variantes de decoupage et d’algorithmes ont ete etudiees. Celles-ci varient
de la notion statique preservant la syntaxe proposee par Weiser a une notion plus amorphe
qui ne preserve pas la syntaxe. Les algorithmes se basent sur des flux de donnees, relations
dans le flux d’information ou des graphes de dependance. L’ensemble de ces algorithmes se
base sur l’analyse du code source des programmes. En partant d’un point p de l’application
et d’une variable x, une decoupe est formee par l’ensemble des declarations et assertions
(statements) qui affectent potentiellement la valeur de x au point p de l’application. Le
programme ainsi reduit a une forme minimale (la decoupe) produit le meme effet.
Ces methodes de decoupage des programmes ont ete developpees pour aider le
debogage des applications. Neanmoins, il s’avere utile dans d’autres aspects du cycle de
developpement tels que le test des applications, la comprehension des applications, leur
[Ferrante 87] Ferrante Jeanne, Ottenstein Karl J. et Warren Joe D. The program dependence
graph and its use in optimization. ACM Trans. Program. Lang. Syst., 1987, vol 9, n 3, p
319–349.
[Ottenstein 84] Ottenstein Karl J. et Ottenstein Linda M. The program dependence graph in a
software development environment. SIGPLAN Not., 1984, vol 19, n 5, p 177–184.
[Binkley 91] Binkley David. Multi-Procedure Program Integration. These : Univ. of Wisconsin, Ma-
dison, WI, August 1991.
[Horwitz 04] Horwitz Susan, Reps Thomas et Binkley David. Interprocedural slicing using depen-
dence graphs. SIGPLAN Not., 2004, vol 39, n 4, p 229–243.
[Weiser 84] Weiser Mark. Program slicing. IEEE Transactions on Software Engineering, July 1984,
vol 10, n 4, p 352–357.
[Weiser 81] Weiser Mark. Program slicing. ICSE ’81 : Proceedings of the 5th international confe-
rence on Software engineering. Piscataway, NJ, USA. IEEE Press, 1981, p 439–449.
88

5.5. Analyse des dependances - exigences des utilisateurs
parallelisation ou leur maintenance. Des methodes (algorithmes et outils facilitant le decou-
page des programmes) ont ete developpees pour une variete de langages de programmation
tels que C [Wisconsin00 00], Java [Hatcliff 99], Oberon-2 [Oberon 08], Ada [Sward 04].
5.5 Analyse des dependances - exigences des utilisateurs
L’ingenierie des exigences (requirements engineering) [Pohl 87] a comme objec-
tif l’amelioration de la conception des systemes, en analysant et comprenant le plus tot
possible les aspects critiques d’un systeme avant meme de le construire. Comme Brooks
[Brooks 87] l’observe, la definition des besoins et des exigences est l’etape du projet la plus
difficile mais egalement celle qui a le plus d’influence negative si elle n’est pas bien realisee.
Parmi les problematiques traitees dans la gestion des exigences, celle de l’analyse
et de la maıtrise des dependances entre les differentes exigences exprimees est essentielle.
Un systeme a de nombreux composants, chacun repondant a une serie d’exigences in-
teragissant avec d’autres exigences ou avec l’environnement. Ainsi, la satisfaction d’une
exigence peut aider ou empecher la satisfaction d’une autre [van Lamsweerde 00].
En effet, les dependances mal gerees peuvent avoir des consequences sur le bon
fonctionnement des applications informatiques et peuvent provoquer le mecontentement
des utilisateurs [Feather 00].
La gestion des interactions fonctionnelles Requirements Interaction Management
[Wisconsin00 00] University of Wisconsin-Madison. The Wisconsin Program-Slicing Tool, Version 1.1,
2000. Disponible sur : http ://www.cs.wisc.edu/wpis/slicing tool/ (consulte le 07.08.2009).
[Hatcliff 99] Hatcliff John, Corbett James, Dwyer Matthew, Sokolowski Stefan et Zheng
Hongjun. A formal study of slicing for multi-threaded programs with jvm concurrency
primitives. Proceedings of the 6th International Static Analysis Symposium (SAS’99).
Springer-Verlag, 1999, p 1–18.
[Oberon 08] Institut fur Systemsoftware, Johannes Kepler Universitat, Institut fur Systemsoft-
ware, Altenbergerstr. 69, A-4040 Linz. Oberon Slicing Tool, 2008. Disponible
sur : http ://www.ssw.uni-linz.ac.at/Research/Projects/ProgramSlicing/ (consulte le
07.08.2009).
[Sward 04] Sward Ricky E. et Chamillard A.T. Adaslicer : an ada program slicer. Ada Lett., 2004,
vol XXIV, n 1, p 10–16.
[Pohl 87] Pohl Klaus. Requirements engineering : An overview. In Encyclopedia of Computer
Science and Technology, 1987, vol 36, n 21.
[Brooks 87] Brooks Frederic. No silver bullet : Essence and accidents of software engineering. Com-
puter, 1987, vol 20, n 4, p 10–19.
[van Lamsweerde 00] v Lamsweerde Axel et Letier Emmanuel. Handling obstacles in goal-oriented requi-
rements engineering. IEEE Transactions on Software Engineering, 2000, vol 26, n 10, p
978–1005.
[Feather 00] Feather Martin, Cornford Steven et Gibbel Mark. Scalable mechanisms for re-
quirements interaction management. Proceedings of the 4th International Conference on
Requirements Engineering –(Schaumburg, Illinois June 2000). IEEE Computer Society
Press, 2000, p 119–129.
89

Chapitre 5. Analyse des dependances
(RIM), proposee par [Robinson 03], est une methode d’analyse et de management des
dependances entre les exigences utilisateurs. Cette analyse est definie plus formellement
comme un ensemble d’activites ayant comme but l’identification et le management des
relations critiques parmi un ensemble d’exigences. L’emploi des ces methodes d’analyse
vise l’amelioration de la satisfaction globale des utilisateurs.
5.6 Analyse des dependances - execution des programmes
L’analyse des dependances telle que decrite precedemment est une technique
d’analyse pour identifier et determiner des types varies de dependances dans le code source
des applications. Elle est utilisee dans les activites de test, de correction, de reverse engi-
neering et de maintenance. Si cette analyse statique des dependances au niveau du code
est relativement bien maıtrisee, l’analyse dynamique des dependances de programmes au
moment de l’execution est bien plus difficile dans la mesure ou l’execution de leurs com-
posantes reste imprevisible. Plusieurs methodes ont ete proposees dans la litterature spe-
cialisee pour l’analyse de ces dependances en fonction des environnements, des langages
de programmation et de la complexite des programmes sequentiels ou concurrents. Une
etude comparative de ces techniques et methodes est proposee dans [Chen 02].
5.7 Synthese
Actuellement, aucune methode n’offre veritablement une analyse des dependances
et une etude d’impact globale prenant en compte les differents niveaux d’abstraction, en
allant de l’expression des exigences jusqu’au code source de l’application et en passant par
les differents phases du processus de developpement.
[Robinson 03] Robinson William N., Pawlowski Suzanne D. et Volkov Vecheslav. Requirements
interaction management. ACM Computing Surveys, 2003, vol 35, n 2, p 132–190.
[Chen 02] Chen Zhenqiang, Xu Baowen et Zhao Jianjun. An overview of methods for dependence
analysis of concurrent programs. SIGPLAN Not., 2002, vol 37, n 8, p 45–52.
90

5.7
.Syn
these
Technologie Avantages Inconvenients
Tracabilite
DOORS [Doors 08], Rational Re-quisitePro [Requisite 08], RDD-100[RDD 08]
Outils commerciaux qui fournissent des fonc-tionnalites d’enregistrement, d’affichage et deverification de la completude des livrables pro-jets.
Ces outils se limitent a la gestion des livrables duprojet en dressant leur liste et leur contenu. Leniveau de detail n’est pas suffisamment precis.Ils ne fournissent pas une gestion des versionsde la documentation de conception.
TOOR (Traceability of Object-Oriented Requirements)[Pinheiro 96]
Outil de recherche des exigences, prend encompte des facteurs sociaux, techniques et fonc-tionnels
Tres peu employe.
Analyse des dependances
Livrables de conception et de deve-loppement 5.3
Plusieurs approches proposees en utilisant delangages formelles tels que OCL[OMG 06b].
Les charges associees a la realisation, la mainte-nance et l’exploitation d’un tel modele sont treselevees.
Code source des applications 5.4 Deux approches proposees Software-Change Im-pact Analysis (IA) et Mining Software Reposi-tories (MSR) pour analyser le code source desapplication et en deduire des dependances.
L’analyse est tres couteuse du point de vue cal-culatoire mais permet de deduire des depen-dances liees a l’architecture des applications :reutilisation du code source, heritage, delega-tion, etc.
Program slicing - Decoupage desprogrammes 5.4.2
Ces methodes permettent d’optimiser le decou-page des applications afin d’harmoniser et opti-miser les flux des donnees ; tres utile dans unedemarche de refonte des applications.
Elles sont moins utiles pour l’analyse des depen-dances.
Execution des programmes 5.6 Analyse dynamique des dependances de pro-grammes au moment de l’execution est tres plusdifficile car l’execution de leurs composantesreste imprevisible .
Champ de recherche encore en exploration.
Table 5.1 – Tableau de synthese des propositions
91

Chapitre 5. Analyse des dependances
92

Conclusion
L’etat de l’art presente dans cette partie nous permet de couvrir une partie de
la problematique exprimee au debut de ce manuscrit, pouvoir repondre aux questions
suivantes :
1. Comment maıtriser la composante documentaire ? Comment modeliser la reglemen-
tation ?
2. Comment maıtriser la composante logicielle ? Comment modeliser les composants du
Systeme d’Information ?
3. Comment unifier les deux composantes de la matiere reglementaire (lien entre les
documents et les composants du SI) ?
4. Comment tracer l’utilisation des connaissances dans l’ensemble de la matiere regle-
mentaire ?
5. Comment analyser les impacts d’une evolution fonctionnelle ou legislative ?
6. Comment estimer l’etendue d’un impact et des charges associees a une evolution ?
1. Comment maıtriser la composante documentaire ? Comment modeliser la re-
glementation ?
En nous interessant au domaine de l’ingenierie documentaire, nous avons pu iden-
tifier une structure documentaire suffisamment generique nous permettant de representer
tout type de document. L’analyse des divers langages de modelisation nous a permis d’iden-
tifier l’opportunite d’utiliser XML pour la structuration des documents et les schemas XSD
pour leur modelisation. Par ailleurs, nous avons identifie d’autres travaux qui se sont in-
teresses a la modelisation de la reglementation.
2. Comment maıtriser la composante logicielle ? Comment modeliser les compo-
sants du Systeme d’Information ?
Cette meme analyse a ete realisee pour le Systeme d’Information. Suite a notre
analyse, UML s’est avere le choix le plus adapte pour la modelisation du Systeme d’In-
formation. Par ailleurs, UML nous permet d’exporter les modeles realises dans un format
XML en utilisant la norme XMI.
93

Conclusion
3. Comment unifier les deux composantes de la matiere reglementaire (lien entre
les documents et les composants du SI) ?
Nous avons identifie differentes manieres de modeliser la composante documen-
taire et la composante logicielle tout en utilisant le meme langage de representation : le
langage XML. Celui-ci represente la base technique de leur mise en relation. En revanche,
il faut identifier les elements a mettre en relation entre les deux composantes. Le chapitre
6 va detailler les mecanismes que nous proposons pour cette mise en relation.
4. Comment tracer l’utilisation des connaissances dans l’ensemble de la matiere
reglementaire ?
5. Comment analyser les impacts d’une evolution fonctionnelle ou legislative ?
6. Comment estimer l’etendue d’un impact et des charges associees a une evolu-
tion ?
Ces questions n’ont trouve que des reponses partielles dans l’etat de l’art.
Pour repondre a cette problematique, nous detaillons dans la partie suivante
nos propositions pour l’etude d’impact. En nous appuyant sur l’etat de l’art en matiere
d’analyse de dependances entre les livrables de conception et entre les exigences des utilisa-
teurs, nous proposons une analyse globale des dependances en considerant simultanement
les differents niveaux d’abstraction : l’expression des exigences, la documentation de spe-
cification, la documentation de conception.
Par ailleurs, les travaux de recherche sur l’analyse des dependances, d’une part,
au sein du code source des applications et, d’autre part au moment de l’execution des
programmes viendront enrichir les perspectives scientifiques de notre travail.
94

Troisieme partie
Propositions pour l’etude d’impact
95


Introduction
Ayn Rand definit la connaissance comme la comprehension mentale d’un fait de
realite, obtenue soit par l’observation perceptuelle directe, soit par un processus de la raison
fonde par l’observation perceptuelle [Rand 79]. La connaissance est une notion abstraite
qui peut englober des informations complexes telles que : les processus, les actions, la
causalite, le temps, les motivations, les hypotheses, les objectifs, etc. Par ailleurs, on peut
considerer comme « connaissance » tout ce qui est connu par un individu ou par une
societe.
Il convient de distinguer : la connaissance, sa formulation et sa representation.
La representation de connaissance est un substitut pour la connaissance elle-meme. Les
personnes ou les applications ont besoin d’utiliser de telles representations lors de l’expres-
sion des connaissances, de leur communication ou d’un raisonnement qui leur est associe.
David Jouve [Jouve 03a] realise une nette distinction entre ces deux formes resultantes :
– la formulation des connaissances est leur representation en langage naturel.
Formuler les connaissances est le moyen le plus employe par les humains dans
la communication. Par exemple, les documents reglementaires sont des objets
offrant une base pour la formulation de certaines connaissances juridiques.
– la representation des connaissances est leur transcription dans un langage for-
mel ou semi-formel. Par exemple, l’expression des normes juridiques entrepo-
sees au sein d’une base de connaissances est une forme de representation des
connaissances.
L’hypothese dans ce travail de recherche se fonde sur la constatation suivante :
des ressources de nature differente et heterogenes (documents reglementaires, Systeme
d’Information, ressources de conception du Systeme d’Information, modeles du Systeme
d’Information) sont des representations variees pour encoder la meme connaissance du
domaine. Dans certains cas, nous sommes en presence d’une formulation de connaissances
et dans d’autre cas, d’une representation plus ou mois formelle. Pour chaque categorie,
plusieurs formalismes sont disponibles.
[Rand 79] Rand Ayn. Introduction to Objectivist Epistemology. New American Library, New York,
USA, 1979. 314 p.
[Jouve 03a] Voir reference [Jouve 03a] definie page 2.
97

Introduction
Nous avons montre dans le chapitre « Problematique » qu’un des enjeux majeurs,
auxquels les institutions telles que la Cnaf doivent faire face, est constitue par la nature
changeante de leur patrimoine des connaissances metier. Chaque evolution reglementaire,
fonctionnelle ou corrective a une consequence, directe ou indirecte, sur un ensemble de
ressources du patrimoine reglementaire.
Nous avons presente dans la partie consacree a l’etat de l’art que des recherches
ont abouti a des mecanismes qui offrent des reponses a des problematiques de modelisation
du patrimoine reglementaire. Des formalismes, tels qu’UML, nous permettent de modeliser
le Systeme d’Information (composante logicielle de ce patrimoine reglementaire). D’autres
formalismes ont ete proposes pour la modelisation des documents.
En revanche, nous ne disposons pas des mecanismes pour la definition d’un modele
commun assurant la coherence globale entre les connaissances explicitees soit dans les docu-
ments reglementaires soit dans les composantes du Systeme d’Information (respectivement
la composante documentaire et la composante logicielle d’un patrimoine reglementaire).
Bien que les divers modeles de formulation ou de representation des connaissances
ne soient pas strictement isomorphiques, ils peuvent neanmoins etre mis en relation. Leur
mise en relation et leur maıtrise conjointe passent par la maıtrise des connaissances expri-
mees dans leurs diverses representations.
Dans cette partie, nous proposons un modele generique pour la representation des
relations de dependances, commun a la fois a la composante documentaire et a la compo-
sante logicielle. Ce modele generique est ensuite enrichi avec des mecanismes d’etude d’im-
pact qui, en s’affranchissant des specificites de chacune de ces composantes, nous permet
d’assurer la coherence globale du patrimoine reglementaire et du Systeme d’Information.
La mise en relation des differentes composantes de ce patrimoine (composante
documentaire, composante logicielle) nous permettra :
– de conserver une trace de la provenance des informations a l’origine des even-
tuelles modifications,
– de pouvoir conduire de raisonnements,
– de faciliter la maintenance et d’assurer la coherence des ressources heterogenes,
– d’exploiter les diverses representations pour une meilleure gestion des ressources
documentaires, des ressources de conception d’une organisation,
– d’exploiter les liens entretenus afin d’etablir des etudes d’impact globales.
98

Chapitre 6
Cadre pour l’etude d’impact
Sommaire
6.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99
6.2 Modele d’etude d’impact – Niveaux d’abstraction . . . . . 101
6.2.1 Niveau d’abstraction N 0 – le monde reel et les connaissances
du domaine . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
6.2.2 Niveau d’abstraction N 1 – la representation du monde reel 103
6.2.3 Niveau d’abstraction N 2 – le modele de representation . . . 104
6.2.4 Niveau d’abstraction N 3 – le modele d’etude d’impact . . . 104
6.2.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
6.3 Modele d’etude d’impact - Niveau d’abstraction N3 . . . 105
6.3.1 Connaissances d’un domaine . . . . . . . . . . . . . . . . . . 105
6.3.2 Structure statique du meta-modele . . . . . . . . . . . . . . 107
6.3.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
6.3.4 Specialisation du meta-modele - Niveau d’abstraction N2 . 110
6.3.5 Representation des dependances – Niveau d’abstraction N1 111
6.3.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
6.1 Introduction
Un modele est une representation abstraite du monde reel offrant une vision
schematique d’un certain nombre d’elements qui nous interessent. Le modele nous aide
ainsi a mieux comprendre le monde reel en n’y retenant qu’un ensemble de concepts qui
representent mieux la realite selon un point de vue precis.
Par exemple, dans le domaine de l’urbanisme, pour la construction d’un batiment
on va utiliser le meme modele du batiment, le monde reel, mais avec des vues differentes
selon les divers corps de metier. Sur chaque vue on n’y represente que les elements qui
99

Chapitre 6. Cadre pour l’etude d’impact
sont necessaires a un corps metier et en faisant abstraction des autres details. Les electri-
ciens vont utiliser une vue sur le modele du batiment qui represente les murs, les circuits
electriques, les caracteristiques des cables electriques a utiliser tandis que les peintres se-
ront plutot interesses par la nature des murs, les types de peinture a utiliser, etc. Afin de
faciliter les taches de ces deux corps de metiers, ces deux vues (representant pourtant le
meme modele de la meme realite) sont differentes : elles n’emploient pas le meme ensemble
d’elements, ni le meme formalisme.
Par ailleurs, « un dessin vaut mieux qu’un long discours » a-t-on coutume de
dire. Un modele peut egalement servir d’interface commune pour communiquer et pour
echanger des points de vue afin d’avoir une comprehension commune et precise d’un meme
probleme.
Une evolution du monde reel doit etre reportee sur l’ensemble des modeles le
decrivant. Dans l’exemple precedant, une evolution dans la consistance d’un mur affecte le
travail de l’electricien mais pas celui du peintre alors que la position de la fenetre affecte
le travail des deux metiers. Une evolution peut demander a un corps de metier de faire
des choix qui impactent le travail des autres.
Pour avoir une vision claire des effets d’une possible modification nous devons
donc prendre soin de mettre en relation les deux modeles et de raisonner de maniere
globale.
Le cas decrit ci-dessus est revelateur de la problematique plus generale presente
au sein de la Branche Famille, liee a la gestion du patrimoine reglementaire.
Contrairement au domaine de la construction, nous ne disposons pas d’un meme
modele pour representer, meme avec de vues differentes, a la fois la composante logicielle
et la composante documentaire.
Nous avons presente dans la partie « Etat de l’art » que nous disposons de mo-
deles differents pour la representation du Systeme d’Information, pour la modelisation des
documents et pour la representation des connaissances.
Mais la maıtrise du patrimoine reglementaire passe par :
– la mise en relation des deux composantes (logicielle et documentaire) ;
– l’etude d’impact globale, sur les ressources heterogenes presentes dans ces deux
composantes.
Pour pouvoir mettre en relation les deux composantes logicielle et documentaire,
il faut pouvoir s’affranchir des specificites de chaque domaine et des concepts specifiques
employes par les differents modeles et les differentes representations. Cela passe par la
maıtrise des connaissances partagees.
Ainsi, pour une bonne maıtrise du patrimoine reglementaire il faut utiliser un seul
modele commun a toutes ces representations. Chacune de ces representations sera une vue
differente du meme modele. Lors de la definition de ce modele commun nous ne retiendrons
100

6.2. Modele d’etude d’impact – Niveaux d’abstraction
que les concepts de base, elementaires, communs a ces differentes representations et les
relations elementaires qu’ils entretiennent.
Par ailleurs, pour realiser des etudes d’impact sur ce modele commun nous nous
interesserons a la constitution de ces composantes, a leurs sous-ensembles et leurs ele-
ments, et a la maniere dont ceux-ci sont interconnectes. En partant d’une evolution d’un
composant systeme, notre mecanisme doit pouvoir evaluer l’effet qu’elle a sur les autres
constituants du SI.
Nous proposerons un modele generique representant les dependances entre des
concepts du domaine modelise. Nous allons egalement doter ce modele des mecanismes de
raisonnement pour realiser les estimations des effets qu’une modification peut avoir sur
l’ensemble des composants du systeme. L’exploitation des instances de ce modele nous
conduira ainsi a des etudes d’impact.
Les chapitres suivants presenteront l’application de ce modele et son integration
dans le Systeme d’Information et proposera l’application de ce modele a la fois au domaine
logiciel et au corpus documentaire.
6.2 Modele d’etude d’impact – Niveaux d’abstraction
Pour mettre en relation des ressources heterogenes, il faut pouvoir s’affranchir des
modeles qui portent ces ressources en raisonnant sur une structure plus generique com-
mune. Nous proposons le modele d’etude d’impact. Le modele d’etude d’impact jouera
donc le role d’un meta-modele commun pour plusieurs modeles de representation speci-
fiques.
Ainsi, a l’image du domaine de la construction, l’ensemble de ces ressources (les
documents reglementaires, les documents de conception, les composantes du Systeme d’In-
formation) representent des vues de ce meme modele commun d’etude d’impact.
Nous proposons une architecture, en quatre niveaux d’abstraction (voir la figure
6.1). Ensuite nous fournissons les bases pour la mise en relation et l’etude d’impact.
Cette architecture detaillee ci-dessous propose un graphe comme mode de repre-
sentation des connaissances en s’interessant aux dependances. Ce graphe sera le support
de l’analyse des dependances et de l’etude d’impact. Ce mode de representation est definit
par un modele commun aux differentes representations.
6.2.1 Niveau d’abstraction N 0 – le monde reel et les connaissances du
domaine
Dans le niveau d’abstraction le plus bas de cette architecture on retrouve le monde
reel et les connaissances du domaine concerne.
Le metier de la Branche Famille de la Securite Sociale consiste a calculer les
101

Chapitre 6. Cadre pour l’etude d’impact
Modèle d’étude d’impact
Connaissances du domaine N 0
Représentation des dépendances / Graphe canonique d’étude d’impact
Modèle de la représentation A
des connaissances
Modèle d’étude d’impact / Méta-modèle des représentations A, B, C
Modèle de la représentation B
des connaissances
Modèle de la représentation C
des connaissances
N 3
N 2
N 1
Représentation A des connaissances
Représentation B des connaissances
Représentation C des connaissances
Relation « instance de… »
Relation de traduction
Figure 6.1 – Cadre pour l’etude d’impact - Architecture en 4 niveaux d’abstraction.
prestations specifiques a chaque allocataire en fonction de la connaissance de la situation
de l’allocataire et de la connaissance legislative du domaine de la Securite Sociale. Ces
connaissances forment le premier niveau.
Par exemple a ce niveau d’abstraction, pour un allocataire, on connaıt son nom,
son prenom, sa civilite, ses revenus et ses charges. Les connaissances legislatives nous
indiquent dans quelles conditions l’allocataire a le droit a l’Aide personnalisee au logement.
A ce meme niveau, on retrouve le Systeme d’Information qui, a l’aide de l’ap-
plication de gestion des prestations Cristal et en fonction de la legislation, calcule le
montant exact de l’aide attribuee a chaque allocataire. Le Systeme d’Information est ainsi
dependant de la connaissance legislative du domaine des prestations legales. Ces liens de
dependance font egalement partie de la connaissance du domaine.
Ces connaissances du monde reel sont tacites, appartenant aux individus. Face
a la complexite de la realite et face aux besoins de communication, d’echanges et de
traitement informatise, differentes representations ont ete introduites. Ces representations
sont au niveau N1 d’abstraction.
102

6.2. Modele d’etude d’impact – Niveaux d’abstraction
6.2.2 Niveau d’abstraction N 1 – la representation du monde reel
Un « modele » , ou une representation, est une description d’une realite concue de
telle maniere qu’il soit possible de simuler formellement le fonctionnement de celle-ci. En
fonction des objectifs, differents modeles de representation du monde reel sont proposes.
6.2.2.1 Representation des connaissances legislatives
Comme nous avons deja evoque dans le domaine legislatif nous nous retrouvons
face a l’emploi du langage naturel dans le cadre d’une formulation des connaissances pour
une meilleure communication entre humains. La connaissance legislative est ainsi explicitee
dans des textes reglementaires.
Les connaissances legislatives sont explicitees et communiquees sous forme de
documents reglementaires. Par exemple, les conditions d’attribution de l’Aide personnalise
au logement sont explicitees dans un document de reference de l’Institution [CNAF 08]
dont voici un extrait :
Qualite
Toute personne physique :
– personne seule,
– menage (l’un ou l’autre des deux conjoints ou concubins), quel que soit celui
qui est titulaire du bail ou du contrat de pret.
Remarque :Les partenaires d’un Pacs sont assimiles aux concubins dans toute la
suite du document.
Charges de logement Assumer le paiement d’un loyer prevu par un bail conforme
a la convention ou le remboursement d’emprunts (Cf. paragraphe 42). Exception : La prise
en charge du paiement du loyer par l’aide sociale ne fait pas obstacle au paiement de l’APL.
Les informations concernant l’etat civil d’un allocataire ont une representation
sous forme d’enregistrement dans une base de donnees.
6.2.2.2 Representation des connaissances de la composante logicielle
Les applications du Systeme d’Information telles que le systeme de gestion des
prestations Cristal peuvent disposer d’une representation sous forme de modele UML.
6.2.2.3 Representation des connaissances liees aux dependances
Le Systeme d’Information est dependant de la legislation. Des representations
existent pour expliciter les connaissances legislatives ou les connaissances du Systeme
[CNAF 08] Caisse Nationale des Allocations Familiales, 32, avenue de la Sibelle, 75685 PARIS CEDEX
14. Aide personnalisee au logement - Suivi legislatif, 2008.
103

Chapitre 6. Cadre pour l’etude d’impact
d’Information. Nous ne disposons pas d’une representation commune pour representer les
dependances entre ces connaissances.
Pour des besoins specifiques lies a l’etude d’impact, nous avons besoin d’une
representation des dependances que les connaissances du domaine entretiennent les unes
avec les autres. Une representation sous forme de graphe serait la plus appropriee a ces
besoins car elle nous permet d’appliquer les principes et les algorithmes de parcours de
graphes pour identifier les impacts. Puisqu’un tel graphe represente les elements de base
du domaine modelise, ainsi que les relations qu’ils entretiennent, il sera appele graphe
canonique des dependances ou graphe canonique d’etude d’impact.
Les representations des connaissances specifiques aux differents domaines (e.g.
documentaire, Systeme d’Information) sont traduites dans un graphe de dependances. La
structure de ce graphe, les modalites de creation ainsi que les principes de parcours sont
decrits dans la section suivante.
6.2.3 Niveau d’abstraction N 2 – le modele de representation
L’abstraction realisee en proposant une modelisation de la realite par des forma-
lismes de representation de connaissances peut etre etendue a une abstraction de ceux-ci.
Chaque structure de representation de connaissances du niveau d’abstraction N 1 est, a
son tour, decrite par un modele dans le niveau d’abstraction N 2.
Par exemple, un document legislatif peut etre modelise a l’aide d’un schema
documentaire. Dans la partie Etat de l’art nous avons presente plusieurs langages de mo-
delisation de documents tels que les DTD Document Type Definition et les XML schemas.
Par ailleurs les representations sous forme de modele UML sont definies par le
modele du langage UML, plus communement appele le meta-modele UML [OMG 01].
6.2.4 Niveau d’abstraction N 3 – le modele d’etude d’impact
Le meta-modele est une structure generique a l’aide de laquelle tous les autres
modeles du niveau d’abstraction N 2 peuvent etre derives. L’avantage de l’utilisation de ce
meta-modele est de rendre les definitions des modeles et des representations independantes
des domaines d’application et de fournir ainsi un ensemble de concepts precis et concis
pour la definition de nouveaux modeles. Cette definition nous permet de mettre en relation
des concepts specifiques aux differents domaines presents au niveau N1.
Ce meta-modele d’etude d’impact est en effet le modele d’etude d’impact. L’en-
semble des modeles de representation du monde reel peut etre traduit dans une instance
de ce modele en produisant le graphe canonique des dependances.
La section 6.3.5.2 decrit comment on obtient un modele de graphe canonique
d’etude d’impact a partir d’une analyse du domaine.
[OMG 01] Voir reference [OMG 01] definie page 74.
104

6.3. Modele d’etude d’impact - Niveau d’abstraction N3
Ce meta-modele est commun a toutes les instances de niveau N2. Il definit ainsi
les elements communs a la fois aux differents modeles de representation de connaissances et
au modele de graphe canonique d’etude d’impact. Ainsi ces concepts et les relations qu’ils
emploient nous serviront dans la mise en place des mecanismes et des principes d’etude
d’impact.
6.2.5 Conclusion
L’architecture a quatre niveaux d’abstraction presentee dans la figure 6.1 illustre
comment le principe d’abstraction peut etre etendu a des niveaux superieurs. Tout comme
l’abstraction des langages de programmation facilite l’interoperabilite entre des Systemes
d’Information developpes en utilisant des langages de programmation differents, l’abstrac-
tion des modeles facilite l’interaction entre differents modeles et leur mise en relation.
De la meme maniere qu’UML est specifie en utilisant le formalisme UML (meta-
modele) et que le meta-modele est lui-meme specifie en utilisant les concepts du Meta
Object Facility [OMG 06a], nous allons employer le langage UML pour la description des
differents modeles pour les 3 niveaux d’abstraction (description du graphe, du modele de
graphe ainsi que les modeles specifiques a chaque representation).
La suite de ce chapitre detaillera la structure du meta-modele pour l’etude d’im-
pact (niveau N3 ), la specialisation de ce meta-modele pour la description des modeles
de representation et enfin la structure et la dynamique du modele d’etude d’impact au
niveau N1. Nous presenterons egalement comme exemple l’analyse et la mise en place de
la structure de deux modeles specifiques, l’un propre au domaine documentaire et l’autre
au domaine logiciel (Niveau N2 ).
6.3 Modele d’etude d’impact - Niveau d’abstraction N3
6.3.1 Connaissances d’un domaine
Democrite (460-370 av. J.-C.), philosophe materialiste, a promu la theorie ato-
miste considerant que l’Univers est construit d’atomes et de vide. L’atome, qui en grecque
signifie « indivisible », represente ces blocs de base. Les futures recherches en physique ont
montre que les atomes etaient eux-memes composes de plus petits constituants : l’electron,
le proton, le neutron qui, a leur tour, pouvaient etre percus comme un assemblage d’autres
objets encore plus petits, appeles particules elementaires.
Ainsi, nous avons l’habitude de considerer le monde qui nous entoure, plus genera-
lement l’Univers et plus particulierement chaque objet, comme un assemblage de quelques
uns de ces blocs fondamentaux de base que l’on peut appeler particules.
[OMG 06a] Voir reference [OMG 06a] definie page 67.
105

Chapitre 6. Cadre pour l’etude d’impact
Par ailleurs, une des principales lignes de recherche adoptees dans le cadre de
la representation des connaissances se fonde sur l’idee que les connaissances doivent etre
structurees en caracterisant les classes d’objets et les relations qui les unissent [Jouve 03a].
Ce rapprochement nous permet de considerer, dans la suite de nos travaux, que les
connaissances d’un domaines sont en effet un « assemblage » de connaissances elementaires
qui entretiennent des liens entre elles. Nous proposons ainsi les definitions suivantes.
6.3.1.1 Particules de connaissance
Definition 6.3.1. Particule de connaissances – Pour un domaine D nous considerons que
ses connaissances peuvent etre exprimees par des particules de connaissances. Tout chose
elementaire connue ou sue est particule de connaissance qui apporte sa participation a un
assemblage constituant la connaissance du domaine.
Definition 6.3.2. Ensemble des particules de connaissances – Pour un domaine D nous
considerons que toute la connaissance du domaine est encodee par les elements d’un en-
semble de particules de connaissances, note PCD. Cet ensemble peut etre definit en ex-
tension par la liste de tous ses elements, enumeration des connaissances du domaine :
PCD = {pc1, pc2, pc3, pc4, pc5, ..., pcn} ou pci, i = 1..n represente les particules de connais-
sance du domaine. Nous considerons que, par definition, cet ensemble est toujours denom-
brable.
Par exemple, les connaissances legislatives concernant les prestations legales sont
composees de connaissances specifiques a chaque prestations : aide personnalisee au lo-
gement, aide au parent isole, aide pour l’accueil d’un jeune enfant, etc. A leur tour,
les connaissances sur une prestation legale peuvent etre decomposees dans les connais-
sances reglementaire concernant les conditions d’attribution, les organismes debiteurs, les
montant des aides, etc. Les conditions d’attributions peuvent concerner l’allocataire, le
conjoint, les enfants, les revenus et ainsi de suite.
6.3.1.2 Relations elementaires
Lorsque l’on modelise un ensemble, comme une collection d’elements, on doit
rendre compte d’une correspondance entre ses elements.
Une connaissance est acquise et devient fonctionnelle quand elle fait appel a
d’autres connaissances pour raisonner, resoudre un probleme ou en deduire des nouvelles
connaissances [Vergnaud 90]. Donc lier ou relier les connaissances signifie plus que les
[Jouve 03a] Voir reference [Jouve 03a] definie page 2.
[Vergnaud 90] Vergnaud Gilles. La theorie des champs conceptuels. Recherches en didactique des
mathematiques, 1990, vol 10, p 133 – 170.
106

6.3. Modele d’etude d’impact - Niveau d’abstraction N3
mettre ensemble : c’est mettre en reseau des connaissances qui prennent ainsi du sens les
unes par rapport aux autres [Morin 99]. Les relations qu’entretiennent les particules de
connaissances peuvent donc etre tres variees.
Definition 6.3.3. Relation elementaire – Nous appelons une relation elementaire notee
R(x,y), ou x R y, une relation interne a l’ensemble de particules de connaissance PCD
induisant une forme de relation entre deux particules de connaissances x et y. Cette relation
structure notre ensemble du point de vue de la relation entre les particules de connaissances.
R : PCD → PCD , R = {(x, y) ∈ PCD × PCD |x EstEnRelationAvec y }
Proprietes de la relation R(x,y) :
– binaire : la relation elementaire intervient toujours entre deux particules de
connaissances. Donc R : PCD → PCD est par definition une relation binaire
car R ⊆ PCD × PCD . Par la suite, on notera xRy, ou R(x,y) pour signifier
que le couple (x,y) satisfait la relation R,
– interne : la relation elementaire intervient seulement entre les elements de
l’ensemble des particules de connaissances. Donc R : PCD → PCD car PCD ≡
PCD,
– non-reflexive : par convention nous considerons qu’aucune particule de connais-
sances n’est en relation avec elle-meme.
∀x ∈ PCD x¬Rx
La propriete de reflexivite/non-reflexivite est arbitraire car elle est definie par
convention en fonction de l’analyse du domaine. Puisque cette relation sera
notamment utilisee lors de l’analyse des dependances, afin de faciliter l’ex-
ploitation du modele, nous considerons que la relation elementaire n’est pas
reflexive.
– transitive : lorsqu’un premier element de PCD est en relation avec un deuxieme
element lui-meme en relation avec un troisieme, le premier element est aussi en
relation avec le troisieme
∀x, y, z ∈ PCD xRy ∧ yRz → xRz
6.3.2 Structure statique du meta-modele
Les connaissances d’un domaine evoluent. De par leur relation de dependances,
une evolution sur une connaissance a des impacts sur les autres.
[Morin 99] Morin Edgar. Relier les connaissances – Le defi du XXIe siecle. Seuil, 1999. 478 p.
107

Chapitre 6. Cadre pour l’etude d’impact
6.3.2.1 Elements impactables
Definition 6.3.4. Element impactable – Particule de connaissance susceptible d’evoluer
et donc d’etre marquee comme « impactee ». Chaque particule de connaissance peut evo-
luer. Ainsi, pour un domaine donne, l’ensemble des elements impactables est constitue par
l’ensemble des occurrences des particules de connaissance du domaine.
Definition 6.3.5. Element impacte – Un element impacte est un « element impactable »
qui a subit un impact. L’element est ainsi marque de l’etiquette « impacte ». Un element
impacte subit un impact avec un degre et une conviction d’impact superieurs a zero (voir
les definitions 6.3.8 et 6.3.9).
Definition 6.3.6. Evenement impactant – Evenement E ayant pour cible directe un ele-
ment impactable et dont la consequence est de marquer ce dernier de l’etiquette « impacte ».
Les evenements impactants se propagent sur les relations elementaires pour se repercuter
sur d’autres elements impactables (cibles indirectes). Un evenement impactant utilise la
propriete de transitivite de la relation elementaire.
Definition 6.3.7. Impact – designe la consequence de l’occurrence d’un evenement impac-
tant sur l’ensemble PCD des particules de connaissances. Ainsi, l’impact d’un evenement
impactant E sur un domaine correspond a l’ensemble des particules de connaissance du
PCD marques de l’etiquette « impacte» suite a l’occurrence de E.
Definition 6.3.8. Degre d’impact elementaire – represente, sur une echelle de 0 a 100, la
couverture estimee de l’impact sur un element impactable. Le degre d’impact elementaire
permet d’etablir une mesure estimative de l’effort necessaire pour mettre a jour l’element
afin de prendre en compte cet impact. Par exemple, cet effort peut etre traduit en nombre
de jours de travail (redaction ou developpement) necessaires pour la mise a jour du fond
documentaire ou des composants du SI.
Definition 6.3.9. Conviction d’impact elementaire – represente sur une echelle de 0 a
100 la precision avec laquelle nous pouvons affirmer la presence d’un impact elementaire.
La conviction d’impact elementaire permet de prendre en compte les cas ou les
impacts ne peuvent pas etre identifies avec certitude. La valeur 0 correspond au cas ou nous
ne pouvons pas determiner s’il existe un impact. C’est-a-dire que nous n’avons, au vu des
donnees fournies sur le systeme, aucune conviction qu’il n’y ait un impact. La valeur 100
correspond quant a elle au cas ou un impact a ete identifie a l’aide des donnees fournies. Les
valeurs intermediaires peuvent nuancer cette conviction en fonction de notre connaissance
du domaine : 75 montre plus de conviction que 50. Par analogie avec la logique floue
nous essayons ainsi de mesurer avec des heuristiques la certitude qu’un impact ait lieu
ou non. Par exemple, si les conditions d’attributions evoluent, la conviction d’impact sur
108

6.3. Modele d’etude d’impact - Niveau d’abstraction N3
la situation de l’allocataire est proche de 100 alors que sur l’organisme debiteur elle est
nulle. En revanche, nous ne pouvons pas estimer avec certitude l’impact que cela aura sur
le Systeme d’Information car cela dependra de la nature de l’evolution. En effet, s’il s’agit
juste d’une modification de types de revenus pris en compte, l’impact sera nul ; alors que
s’il s’agit de la prise en compte d’une nouvelle information, l’impact sera de 100. Ainsi,
les valeurs intermediaires nous permettent de nuancer la conviction d’impact dans des
situations ambigues.
Les particules de connaissance sont ainsi caracterisees par deux proprietes : le
degre d’impact et la conviction d’impact.
6.3.2.2 Interpretation de la relation elementaire
Du point de vue de la gestion des connaissances, les relations peuvent etre : soit
des relations de mise en commun (constitution de l’ensemble des particules de connais-
sance du domaine), soit des relations de mise en reseau pour en deduire des nouvelles
connaissances.
Du point de vue de l’etude d’impact, la signification de la relation qui lie deux
elements impactables a un role important dans la maniere de propager l’impact d’un
element impactable a un autre.
Definition 6.3.10. Coefficient de propagation – est un indice de 0 a 100, porte par toute
relation elementaire du modele, qui permet d’attenuer l’impact lors de sa propagation de
la particule A vers la particule B.
Ce coefficient depend d’un certain nombre de parametres etablis en fonction du
contexte du domaine, du type et de la signification associes a chaque relation. Dans cer-
tains cas, nous sommes surs que l’impact sera transmis a l’element correspondant, donc le
coefficient de propagation sera egal a 100 alors que, dans d’autres cas, meme s’il y a une
relation, celle-ci ne jouera aucun role dans la propagation de l’impact (coefficient egal a
0). Les valeurs intermediaires nous permettent de nuancer et repondre a des situations ou
la semantique du modele sur lequel porte l’etude n’est pas assez precise pour savoir s’il y
aura ou non une propagation de l’impact.
6.3.3 Conclusion
Les notions de particule de connaissance, « d’element impactable » et de relation
elementaire permettent d’elaborer la statique du meta-modele de representation des de-
pendances presente dans la figure 6.2. L’instanciation de ce meta-modele permet d’obtenir
un modele de graphe de dependances specifique a un domaine donne. Par la suite, une
instance de ce modele est representee par un graphe canonique des dependances qui peut
servir de support pour les etudes d’impacts.
109

Chapitre 6. Cadre pour l’etude d’impact
-degréImpact -convictionImpact
ElementImpactable
-coefficientPropagation
RelationElementaire
EvénementImpactant -degréImpact -convictionImpact
Impact
élémentOrigine
1
relation
relation
élémentCible
élémentImpacté 1
événement impacts
1
impact
0..*
0..*
0..*
0..*
ParticuleElementaire Est une
I m p
a c t
e
S u
b i t
Produit
Participe
Participe
Figure 6.2 – Meta-modele d’etude d’impact, modele du graphe de representation desdependances.
6.3.4 Specialisation du meta-modele - Niveau d’abstraction N2
En fonction du domaine represente (niveau N0 ) et de l’usage souhaite, differents
formalismes pour la representation des connaissances (niveau N1 ) peuvent etre employes.
Le meta-modele (niveau N3 ) definit une structure generique commune aux differents mo-
deles de representation de connaissances. Une instance de ce meta-modele sera alors utilisee
pour la modelisation de la representation ou formulation des connaissances.
Une representation specialisee des connaissances est le graphe canonique des de-
pendances (niveau N1 ). Celui-ci est definit par un modele de graphe definit par la meme
structure generique de niveau N2, le modele generique.
Afin de decrire plus precisement le domaine, une typologie des elements et une
typologie des relations seront definies. Les instances des meta-classes ElementImpactable
et RelationElementaire peuvent ainsi etre specialisees a leur tour en plusieurs types d’ele-
ments et de relations.
Par exemple, dans le domaine de la modelisation documentaire, les elements im-
pactables pourraient etre : le chapitre, la section, le paragraphe et les relations elementaires
(e.g. la composition, l’encapsulation, le referencement).
Les typologies precises d’elements et de relations correspondantes aux domaines
documentaire et logiciel seront definies dans les sections suivantes.
La meme structure est utilisee pour definir tous les modeles de graphe de depen-
dance associes aux differentes representations.
Definition 6.3.11. Type d’element – Pour un domaine D on notera Telem l’ensemble des
types d’elements constituant le domaine. Cet ensemble est decrit lors de la definition du
110

6.3. Modele d’etude d’impact - Niveau d’abstraction N3
modele de graphe de dependances associe au domaine.
Definition 6.3.12. Type de dependance – Pour un domaine D on notera Tdep l’ensemble
des types de dependances entre ses elements. Chaque type de dependance est caracterise
par un coefficient de propagation (voir definition 6.3.10). Cet ensemble est decrit lors de
la definition du modele de graphe de dependances associe au domaine.
Ce niveau N2 nous permet de disposer des elements necessaires pour determiner
le graphe de dependances associe (niveau N1 ), presente dans la section 6.2.2 de ce chapitre.
Les concepts du monde reel caracterises par leur type d’element deviennent des
nœuds de ce graphe. Et les relations qui les unissent, caracterisees par le type de depen-
dance, deviennent des arcs de ce graphe de dependance. Les informations sur le type de
nœud et le type d’arc seront utilisees lors des procedures de raisonnement dans l’evaluation
de la propagation de l’impact.
Les deux dernieres sections presentent quelques exemples de specialisation du
modele generique d’etude d’impacts pour deux formalismes differents et heterogenes :
d’une part, des representations UML du Systeme d’Information, composante logicielle
du patrimoine reglementaire et d’autre part les documents reglementaires, composante
documentaire de ce meme patrimoine.
Pour chaque representation nous nous livrons d’abord a une etude de son modele
definissant sa structure, afin d’y identifier la typologie d’elements elementaires et la ty-
pologie de relations elementaires. Pour la representation a l’aide des modeles UML, cette
etude sera realisee au niveau du meta-modele UML. Pour les documents et les collections
de documents, cet exercice est plus delicat car les documents ont des structures differentes.
6.3.5 Representation des dependances – Niveau d’abstraction N1
6.3.5.1 Introduction
Nous avons presente precedemment que les connaissances d’un domaine peuvent
etre formulees ou representees en utilisant differents formalismes ou langages de formu-
lation ou representation. Le choix du formalisme de representation des connaissances se
fait en fonction du besoin identifie. Pour une interpretation calculatoire nous avons besoin
d’une representation des connaissances avec un degre de formalisation tres eleve alors que
pour supporter la communication humaine, une formulation en langage naturel suffit.
Pour supporter des etudes d’impact nous nous interessons plutot aux liens que
les differentes particules de connaissances entretiennent entre elles. Nous souhaitons ainsi
identifier les dependances entre les differents objets.
« Devant un grand nombre de situations, une vieille habitude pousse l’homme
a tracer sur le papier des points representant des individus, des localites, des corps chi-
111

Chapitre 6. Cadre pour l’etude d’impact
miques, etc., joints entre eux par des lignes ou des fleches symbolisant une certaine rela-
tion. »[Wulf 58].
Ainsi pour mieux apprehender la complexite, nous optons pour une representation
sous forme de graphe. Pour un domaine D donne, l’analyse des particules de connaissances
et des relations elementaires permet d’elaborer un graphe representant les elements et les
relations qu’ils entretiennent.
Ce graphe sera une instance du modele definit au niveau superieur, niveau N2,
de l’architecture multi-niveaux presentee au paragraphe 6.2.
6.3.5.2 Graphe canonique des dependances
Le graphe canonique consolide les informations extraites du domaine et constitue
ainsi un support pour l’etude d’impact et le calcul des degres d’impact et des convictions
d’impact au sein du modele, suite a l’occurence d’un evenement impactant.
Definition 6.3.13. Ensemble des occurrences – Soit un domaine D, nous notons ED
l’ensemble des occurrences des elements impactables apparaissant dans D.
Definition 6.3.14. Graphe canonique – Nous appelons Graphe Canonique des depen-
dances un graphe GCD = (ED, R, I, ϕ) tel que :
– EDest l’ensemble des occurrences considere comme un ensemble de points (ou
sommets du graphe) ;
– R est une application R : ED → ED associant a chaque point de EDcomme ori-
gine, un sous-ensemble eventuellement vide de ED comme image. R represente
ainsi l’ensemble des fleches ou arcs de GCD ;
– I = [0..100] est sous ensemble de valeurs possibles pour la definition des carac-
teristiques des Elements impactables et des Relations elementaires ;
– ϕ est une application ϕ : ED × ED → [0 : 100] telle que ∀x, y ∈ ED :
– x¬Ry → ϕ (R(x, y)) = 0 ;
– xRy → ϕ (R(x, y)) = α ou α est le coefficient de propagation associe a la
relation entre x et y R(x,y) avec αin (0 : 100].
6.3.5.3 Modele generique du graphe canonique des dependances
La definition du graphe canonique des dependances nous permet de definir son
modele generique. L’instanciation des differents modeles definis au niveau N2 se traduit
par un graphe respectant le modele presente dans la figure 6.3.
[Wulf 58] Wulf William A., Shaw Mary, Hilfinger Paul N. et Flon Lawrence. Theorie des
graphes et ses applications. Dunod, 1958.
112

6.3. Modele d’etude d’impact - Niveau d’abstraction N3
-degréImpact -convictionImpact
Noeud
-coefficientPropagation
RelationElementaire
0..*
relation
noeudOrigine
1
relation 0..*
noeudCible
1
Figure 6.3 – Modele generique du graphe des dependances.
6.3.5.4 Chemin de propagation
Traduire les relations qu’entretiennent les elements de connaissance d’un domaine
dans un graphe canonique nous permet d’appliquer les notions et les principes lies a la
theorie des graphes (notamment des mecanismes de parcours de graphes). Chaque arc a
un sens donne par la relation elementaire entre les deux elements adjacents representes
par ses extremites, la propagation des impacts se fait en sens inverse de l’arc. Ainsi un arc
represente une dependance directe.
Definition 6.3.15. Chemin de propagation – Soit le graphe canonique GCD = (ED, R, I, ϕ) ,
on appelle chemin de propagation toute succession d’elements impactes suite a une mo-
dification du domaine, x0, x1, x2, x3, ....., xntelle que chaque couple (xi, xi+1) soit un arc
de R ,c’est-a-dire xiRxi+1. Alors par definition le coefficient de propagation de l’impact
α = ϕ (xi, xi+1) > 0.
6.3.5.5 Recherche de chemins dans un graphe
L’etude d’impact consiste a rechercher les chemins allant d’un sommet x donne a
tout autre sommet y : en partant d’un element impacte donne, represente par le sommet x,
nous construisons tous les chemins possibles vers tout autre sommet y accessible. Toutes
les dependances directes ou indirectes doit etre prise en compte.
Puisque le graphe est susceptible de contenir des boucles, afin d’eviter des chemins
de propagation infinis, l’algorithme de parcours de graphe verifiera a chaque etape si le
nœud a deja ete « visite » dans le chemin de propagation en cours.
6.3.5.6 Inference – Calcul des impacts
Une connaissance fait appel a d’autres connaissances pour raisonner, ou resoudre
un probleme ou en deduire des nouvelles connaissances. Les connaissances sont mises en
reseau et prennent sens les unes par rapport aux autres. Les concepts presentes ci-dessus
113

Chapitre 6. Cadre pour l’etude d’impact
definissent la statique de notre modele d’etude d’impacts. Au cours de cette section, nous
proposons une procedure de raisonnement en exploitant cette structure.
Les regles definies par les relations elementaires et les coefficients de propagation
seront utilisees pour manipuler les connaissances sur un ou plusieurs elements du reseau
(concernant le degre et de la conviction d’impact) et pour realiser une deduction logique
de nouvelles connaissances : l’impact subi par d’autres elements, le degre et la conviction
d’impact.
A la fin de notre procedure de raisonnement, a partir de l’information d’une
evolution d’une particule de connaissance, nous allons obtenir une mesure estimative de sa
portee sur l’ensemble des elements, c’est-a-dire l’ensemble des particules de connaissance
du domaine.
Definition 6.3.16. Etude d’impact – L’etude d’impact suite a la survenue d’un evene-
ment impactant, est le calcul du degre d’impact et de la conviction d’impact pour tous les
elements impactables du modele.
6.3.5.7 Degre elementaire et conviction elementaire de l’impact
Chaque element impactable, xi+1 ∈ ED, du chemin de propagation est caracterise
par le degre elementaire et la conviction elementaire de l’impact, calcules en fonction de
son predecesseur xi ∈ ED, dans le chemin de propagation.
Le degre d’impact elementaire de xi−1 sur xi, note degElem(xi,xi−1), se definit
comme :
degElem (xi, xi−1) =degElem (xi−1, xi−2)
|Exi|
ou :
– xi−2, xi−1, xi sont trois nœuds consecutifs appartenant au meme chemin de
propagation ;
– xi−1 est le predecesseur de xi dans ce chemin de propagation et xi−2 est le
predecesseur de xi−1 dans ce chemin de propagation ;
– Exiest le sous-ensemble contenant les elements de ED dont xi depend, c’est-
a-dire qu’il y a une relation elementaire entre ses elements et xi :
Exi= {∀y ∈ ED |yRxi }
– |Exi| represente la cardinalite de ce sous-ensemble.
Un element peut subir plusieurs impacts provenant des differents chemins de
propagation. L’importance d’un impact subit a partir d’un chemin de propagation est re-
lativisee en fonction de nombre de chemins auxquels participe le noeud (nombre d’elements
114

6.3. Modele d’etude d’impact - Niveau d’abstraction N3
avec lesquels il est en relation). Le degre d’impact est plus important quand l’element n’a
pas beaucoup de « predecesseurs ». De plus si le predecesseur xi−2 de xi−1 n’existe pas, cela
signifie que xi−1 est la source initiale de l’impact, donc convictionElem(xi−1,xi−2) = 100.
De la meme maniere la conviction d’impact elementaire de xi−1 sur xi note
convictionElem(xi,xi−1), se definit comme :
convictionElem (xi, xi−1) =convictionElem (xi−1, xi−2)
|Exi|
Ou :
– xi−2, xi−1, xi sont trois nœuds consecutifs appartenant au meme chemin de
propagation,
– xi−1 etant le predecesseur de xi dans ce chemin de propagation et xi−2 etant
le predecesseur de xi−1 dans ce chemin de propagation,
– Exiest le sous-ensemble contenant les elements de ED dont xi depend, c’est-a-
dire qu’il y a une relation elementaire entre ses elements et xi :
Exi= {∀y ∈ ED |yRxi }
– |Exi| represente la cardinalite de ce sous-ensemble.
6.3.5.8 Consolidation des impacts
Des que le modele contient de multiples elements lies deux a deux par des rela-
tions elementaires, la propagation des impacts devient complexe et induit la creation de
nombreux chemins de propagation. Un meme element peut etre ainsi membre de plusieurs
chemins de propagation et donc etre touche par divers impacts elementaires. Il devient
alors necessaire de consolider les impacts.
Definition 6.3.17. Degre consolide d’impact – Le degre consolide d’impact d’un element
xi appartenant a l’ensemble des elements du domaine ED, note degre(xi), represente, sur
une echelle de 0 a 100, la somme de ses degres d’impact elementaires subis dans les divers
chemins de propagation.
degre(xi) =
∑
xi−1∈Exi
degreElem(xi, xi−1)
|ED|
Definition 6.3.18. Conviction consolidee d’impact – La conviction consolidee d’impact
d’un element xi appartenant a l’ensemble des elements du domaine ED, note conviction(xi),
represente, sur une echelle de 0 a 100, la somme de ses convictions d’impact elementaires.
conviction(xi) =
∑
xi−1∈Exi
conviction(xi, xi−1)
|ED|
115

Chapitre 6. Cadre pour l’etude d’impact
6.3.6 Conclusion
Le cadre pour l’etude d’impact que nous avons presente dans la figure 6.1 se base
sur une architecture a quatre niveaux d’abstraction. Le cadre pour l’etude d’impact utilise
l’abstraction des modeles pour faciliter leur interaction et leur mise en relation.
Nous avons definit un meta-modele commun aux differents modeles de represen-
tation des connaissances en nous interessant en particulier a l’explicitation des elements
constituant le domaine (les particules de connaissances) et des relations de dependances
qu’ils entretiennent. En s’appuyant sur ces meta-modele communs nous avons defini le mo-
dele d’etude d’impact commun a plusieurs modeles de representation des connaissances.
Pour un domaine, une instance de ce modele d’impact est le graphe canonique de repre-
sentation des dependances.
Le chapitre suivant va detailler l’instanciation de ce meta-modele pour d’une part
les modeles UML du Systeme d’Information et d’autre part les modeles des ressources do-
cumentaires de l’Institution. Cette instanciation nous permet de retenir des deux modeles
les seuls concepts communs (definis par le meta-modele) et de les traduire ainsi dans la
meme representation : le graphe canonique des dependances. Ce dernier nous permet ainsi
de mettre en relation les deux composantes (documentaire et logicielle) et de realiser des
etudes d’impact.
116

Chapitre 7
Application du modele generique
d’etude d’impact
Sommaire
7.1 Modele d’etude d’impact associe aux modeles UML – ni-
veauN2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
7.1.1 Typologie des elements - Concept UML elementaire . . . . . 117
7.1.2 Typologie des relations elementaires dans les modeles UML 119
7.1.3 Modele de graphe specifique a UML . . . . . . . . . . . . . . 120
7.1.4 Graphe canonique des dependances et etude d’impact – N1 . 121
7.2 Modele d’etude d’impact associe aux documents – niveau
N2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
7.2.1 Typologie des elements - Concept documentaire elementaire 124
7.2.2 Typologie des relations elementaires documentaire . . . . . . 124
7.2.3 Graphe canonique des dependances – etude d’impact – N1 . 126
7.1 Modele d’etude d’impact associe aux modeles UML –
niveauN2
L’etude du meta-modele UML nous permet d’identifier les concepts presents dans
le langage UML, leurs proprietes et les relations qu’ils entretiennent.
7.1.1 Typologie des elements - Concept UML elementaire
Suite a l’analyse du meta-modele du langage UML, nous remarquons qu’un mo-
dele UML est compose de plusieurs elements de base tels que les classes, interfaces, types
de donnees, attributs, operations, tous heritant du meme concept ModelElement. Chaque
117

Chapitre 7. Application du modele generique d’etude d’impact
element de base dispose d’un certain nombre de proprietes : name, visibility, multiplicity,
largeScope, initialValue, concurency, kind, defaulValue, etc.
Definition 7.1.1. Concept UML – Nous appelons concept UML tout element present dans
le formalisme UML : les diagrammes, les classes, les attributs, les roles, les operations ainsi
que leurs proprietes telles que le nom, le type, la visibilite, etc.
Dans l’usage des concepts UML on remarque que parfois le meme aspect d’un
modele peut etre represente de manieres differentes avec des concepts UML differents.
L’exemple suivant presente le concept d’attribut et celui de role : d’une part, la figure 7.1a
montre une classe ClasseA avec un attribut de type ClasseB, et d’autre part, la figure 7.1b
montre une association entre deux classes, ClasseA et ClasseB, basee sur un role.
+uneMethode() : void
-unAttribut : ClasseB
ClasseA
+uneMethode() : void
ClasseA ClasseB -unAttribut
0..1
(a) (b)
Figure 7.1 – Relation entre les classes et leurs attributs.
Definition 7.1.2. Concept UML elementaire – L’ensemble de concepts elementaires CE
est un sous-ensemble de concepts UML, compose de telle maniere qu’aucune relation
d’equivalence semantique ne puisse etre definie entre deux de ses elements (c’est-a-dire
qu’il n’existe aucun moyen de representer la meme connaissance avec deux concepts ele-
mentaires differents).
La strategie de construction de cet ensemble de concepts elementaires consiste
a ne conserver, entre deux elements semantiquement equivalents, que l’element le plus
expressif. Par exemple : le concept d’attribut de la partie a de la figure 7.1 peut se rapporter
au concept de role, la partie b de la meme figure. Celui-ci est plus representatif puisqu’il
fait apparaıtre la notion de cardinalite (0..1, ou 1..1). C’est ainsi que le concept UML
d’attribut n’est pas considere comme un concept elementaire a l’inverse du concept UML
de role.
Ces definitions nous permettent de definir en extension l’ensemble EUML d’ins-
tances des concepts ElementsImpactables (voir la figure 6.2). Pour les etudes d’impact nous
nous limitons a cet ensemble de concepts du langage UML. D’autres elements peuvent y
etre ajoutes si le perimetre d’etude est elargi.
Definition 7.1.3. Elements impactables du formalisme UML – L’ensemble des elements
impactables du formalisme UML, pris en compte dans l’etude d’impact, est definit en
118

7.1. Modele d’etude d’impact associe aux modeles UML – niveauN2
extension :
EUML =
ElementClasse,
ElementInterface
ElementRole,
ElementOperation,
ElementParametre,
ElementDataType,
ElementPropriete
∀x ∈ EUML → x :: ElementImpactable
Chaque element impactable du formalisme UML est une instance de la meta-
classe ElementImpactable definie dans le meta-modele d’etude d’impact.
7.1.2 Typologie des relations elementaires dans les modeles UML
Suite a l’analyse du meta-modele du langage UML nous identifions les types de
relations presentes entre les elements d’un modele UML.
A partir du sous-ensemble UML manipule a travers les diagrammes de classe et
de sequence, nous identifions six types de relations elementaires induisant une forme de
dependance entre deux concepts UML elementaires x et y :
– association : association UML entre deux classes,
– generalisation : relation UML de generalisation/specialisation entre deux classes,
– implementation : relation UML d’implementation entre une classe et une de
ses interfaces fournissant une vue totale ou partielle d’un ensemble de services
offerts,
– agregation par valeur, par reference : relation UML de composition de deux
classes,
– dependance : relation UML de dependance entre deux classes,
– relation structurelle d’encapsulation : relation entre une classe et ses membres
(operations, roles, etc.) et entre un membre et ses proprietes (nom, visibilite,
cardinalite, etc.),
– relation d’acces a un membre : relation deduite des diagrammes de sequence
qui offrent une autre perspective sur le modele : une methode invoque une autre
methode, une methode utilise un role, etc.,
– relation de reference : un element du modele reference une cible externe du
modele : soit un autre element d’un autre modele, soit un document ou un
fragment d’un document. Cette relation est employee notamment pour la mise
en relation de la documentation de conception avec les modeles UML.
119

Chapitre 7. Application du modele generique d’etude d’impact
Remarque 7.1.1. Pour des raisons de concision, nous nous sommes limites a l’etude
des diagrammes de classe et de sequence, mais l’ensemble de concepts elementaires et de
relations elementaires peut etre elargi aux autres diagrammes du formalisme UML 1.4.2
(OMG, 2003).
Cette analyse nous permet de definir en extension l’ensemble RUML d’instances
de la meta-classe RelationElementaire.
Definition 7.1.4. Relation elementaire du formalisme UML – L’ensemble des types de
relation elementaires du formalisme UML, pris en compte dans l’etude d’impact, est definit
en extension :
RUML =
RelationAssociation,
RelationAgregationValeur
RelationAgregationReference,
RelationGeneralisation,
RelationImplemantation
RelationDependance,
RelationEncapsulation,
RelationUtilisation
RelationReference
∀y ∈ RUML → y :: RelationElementaire
Chaque relation elementaire presente entre les elements du formalisme UML est
une instance de la meta-classe RelationElementaire definie dans le meta-modele d’etude
d’impact. Pour les etudes d’impact nous nous limitons a cet ensemble de relations pre-
sentes entre les elements du langage UML. D’autres relations peuvent y etre ajoutees si le
perimetre d’etude est elargi.
Chaque instance de la relation entre les elements du formalisme UML est carac-
terisee par la propriete coefficientPropagation. La definition n’est pas munie d’une seman-
tique forte, elle depend d’un certain nombre de parametres etablis en fonction du contexte
du domaine, du systeme represente, des technologies employees, du type et de la signi-
fication associes a chaque relation (par exemple : une relation de composition aura un
coefficient de propagation different d’une relation d’association).
7.1.3 Modele de graphe specifique a UML
L’analyse du formalisme UML et les notions de concept UML elementaire et de
relation UML elementaire, definies ci-dessus, permettent d’elaborer un modele de graphe
de dependance en utilisant le meta-modele decrit dans le chapitre 6. L’instanciation de ce
modele permet d’obtenir un graphe servant de support pour des analyses des dependances
et des etudes d’impacts.
120

7.1. Modele d’etude d’impact associe aux modeles UML – niveauN2
L’instanciation du meta-modele du graphe de dependances pour des modeles
UML nous permet de definir un modele pour les graphes de dependances au sein des mo-
deles UML du Systeme d’Information. Les concepts UML elementaires sont des instances
du concept ElementImpactable du meta-modele d’analyse des dependances. Les relations
UML elementaires sont, quant a elles, des instances du concept RelationElementaire du
meta-modele.
ElémentClasse
ElémentAttribut
ElémentOpération
ElémentParamétre ElémentDataType ElémentPropriété
-degréImpact -convictionImpact
ElémentUML::ElémentImpactable
-coefficientPropagation
RelationUML::RélationElémentaire
RelationAssociation
RelationAgrégation
RelationGénéralisation
RelationDépendance
RelationEncapsulation RelationUtilisation
ElémentRôle
noeudOrigine
1 noeudCible
1 relation
relation
*
*
Figure 7.2 – Modele du graphe d’analyse des dependances et etude d’impact specifiquea l’UML.
7.1.4 Graphe canonique des dependances et etude d’impact – N1
En utilisant les concepts du meta-modele definis au niveau N3 un modele UML
peut ainsi etre traduit dans un graphe de dependances. Les concepts du monde reel repre-
sentes par des elements UML deviennent des nœuds de ce graphe, et les relations qui les
unissent deviennent des arcs de ce graphe de dependances.
En consequence nous pouvons appliquer les procedures de raisonnement associees
au graphe canonique des dependances.
7.1.4.1 Instanciation du graphe canonique
Le type d’element definit les proprietes du nœud du graphe, le type de relation
celles des arcs a utiliser lors des l’etude d’impact.
Pour les modeles UML, nous ne ferons pas de distinction entre les differents types
d’elements et, par consequent, entre les differents nœuds du graphe d’etude d’impact. En
revanche, le type de relation UML sera utilise pour definir les coefficients de propagation
associes a chaque arc du graphe d’etude d’impact.
121

Chapitre 7. Application du modele generique d’etude d’impact
Ce coefficient depend d’un certain nombre de parametres etablis en fonction du
contexte du domaine, du systeme represente, des technologies employees, du type et de la
signification associes a chaque relation (e.g. une relation de composition aura un coefficient
de propagation different d’une relation d’association). Dans la pratique, pour un modele
d’application precis et un domaine specifique, ces parametres peuvent etre ajustes et affines
apres des experimentations afin de s’approcher au mieux de l’impact reel.
7.1.4.2 Exemple d’instanciation
Nous partons d’un exemple UML simple mais representatif pour illustrer notre
proposition (figure 7.3).
Personne Enfant
-asc 2..2 -desc *
Figure 7.3 – Exemple d’un extrait d’un diagramme UML de classe.
Nous en deduisons le graphe canonique associe presente dans la figure 7.1.4.2.
Nous observons que tous les elements UML qu’ils soient une classe, un attribut et une
propriete de l’attribut (e.g. nom, type, etc.) sont representes au meme niveau sur le meme
graphe. Differentes relations sont presentes entre ces elements. Tous ces elements sont en
effet des concepts UML elementaires unis par des relations elementaires. Pour faciliter
la comprehension de la presentation, dans la figure 7.4 nous avons associe des elements
graphiques differents pour chaque type d’element ou de relation represente.
Dans l’exemple de la figure 7.1.4.2, l’occurrence Personne du concept elementaire
Classe est une generalisation de l’occurrence Enfant du meme concept elementaire ce qui
induit que la relation elementaire : R(Enfant, Personne) = α ou α est le coefficient de
propagation associe a la relation de generalisation (un impact de la classe parent risque de
se propager a la classe fils). Par contre, R(Personne, Enfant) = 0 puisqu’une modification
de la classe fils n’affecte pas le parent (la relation elementaire de generalisation n’est pas
symetrique).
La traduction de ce modele UML dans le graphe de dependances est presente
dans la figure 7.1.4.2.
Ainsi en analysant notre graphe nous observons qu’en partant d’un noeud (par
exemple la propriete Name de l’attribut Nom) nous pouvons suivre les differentes relations
de dependances (en suivant les fleches a l’inverse) pour atteindre tous les autres noeuds
du graphe susceptibles d’etre impacte. Ainsi modifier la propriete Name de l’attribut Nom
aura d’abord un impact direct sur l’attribut Nom. Un impact sur l’attribut Nom aura
122

7.2. Modele d’etude d’impact associe aux documents – niveau N2
Figure 7.4 – Exemple d’instanciation du graphe canonique des dependances associe audiagramme precedent.
un impact sur la classe Personne et sur la methode eppelerNom, qui a leur tour vont
propager cet impact vers les autres noeuds dependant. C’est ainsi que la classe Enfant
sera impactee deux fois : par les modifications de la classe Personne dont elle herite et par
les modifications de sa methode eppelerNom.
7.2 Modele d’etude d’impact associe aux documents – ni-
veau N2
Nous avons presente en details, dans la partie Etat de l’art, la definition 3.2.1
d’une structure documentaire.
Nous rappellerons que la notion de structure proposee par cette definition est
caracterisee par un haut degre d’abstraction et de genericite. Cette structure a ete elaboree
de maniere a etre independante du type de media considere, du type de corpus vise, des
usages specifiques.
Pour les documents textuels, cette structure generique se retrouve dans d’autres
modeles qui se sont imposes de facto comme standards.
Par exemple, les schemas XML[W3C 01b], Schematron [ISO 06] , DSD[Klarlund 02],
presentes dans la partie Etat de l’art, proposent une structuration des documents XML
(W3C) qui sont largement utilises dans les Systemes d’Information. Pour mieux decrire la
[W3C 01b] Voir reference [W3C 01b] definie page 65.
[ISO 06] Voir reference [ISO 06] definie page 66.
[Klarlund 02] Voir reference [Klarlund 02] definie page 66.
123

Chapitre 7. Application du modele generique d’etude d’impact
structure et le contenu des documents XML ces langages de schema proposent une serie
de concepts, d’elements documentaires.
On peut donc considerer le document comme une composition de concepts ele-
mentaires, la plus petite structure indivisible du document.
L’analyse de la recommandation des schemas XSD nous permet de definir :
– la typologie d’elements presents dans un document
– la typologie des relations que les elements documentaires entretiennent
7.2.1 Typologie des elements - Concept documentaire elementaire
L’analyse du schema des documents presentes dans la partie Etat de l’art nous
permet de definir, pour les documents textuels, les concepts generiques presents au niveau
du meta-modele de documents ou modele des schemas de documents et ensuite de definir en
extension l’ensemble d’instances d’elements ElementsImpactables (EDoc). Pour les etudes
d’impact nous nous limitons a cet ensemble de concepts de modelisation documentaire.
D’autres concepts peuvent y etre ajoutes si le perimetre d’etude est elargi.
Definition 7.2.1. Concept documentaire elementaire – Nous appelons concept documen-
taire elementaire tout element faisant partie d’une structure de document (e.g. les elements,
les attributs, les annotations, les proprietes des elements).
EDoc =
ElementDocumentaire
ElementAttribute
ElementContenu
ElementPropriete
∀x ∈ EDoc → x :: ElementImpactable du meta-modele
7.2.2 Typologie des relations elementaires documentaire
L’analyse du schema des documents presentes dans la partie Etat de l’art, pour
les documents textuels, nous permet de definir les types de relations presentes entre les
elements constituant des documents textuels.
Deux grandes categories de relations elementaires peuvent etre identifiees indui-
sant une forme de dependance entre deux concepts documentaires : relations logiques et
relations semantiques.
Les relations logiques sont des relations liees a la structure documentaire :
– Relations d’encapsulation : relation entre un element documentaire et ses pro-
prietes (e.g. nom, type, commentaire) ;
124

7.2. Modele d’etude d’impact associe aux documents – niveau N2
– Relations de reference : un element documentaire (document ou fragment de
document) peut faire reference a un autre element documentaire ;
– Relations de composition : un element documentaire est compose d’autres ele-
ments documentaires (e.g. une section d’un document est composee de plusieurs
fragments).
Les relations semantiques sont des relations liees a l’expression des connaissances
dans les documents :
– Relations d’implementation des exigences : relation qui permet de tracer l’ori-
gine de la mise en place d’un element documentaire. Dans le domaine des textes
juridiques, pour modifier un texte existant, il est imperatif de promulguer un
nouveau texte. Ainsi, on garde le lien d’implementation des exigences ce qui
nous permet de retrouver le texte demandant la creation ou la mise a jour.
– Relations de partage d’information : un texte peut clarifier le contenu d’un
autre texte (specificite egalement presente dans le domaine juridique). Donc,
deux elements documentaires expriment differemment la meme connaissance
[Chabbat 97].
Cette analyse nous permet de definir en extension l’ensemble d’instances d’ele-
ments RelationElementaire (RDoc). Pour les etudes d’impact nous nous limitons a cet
ensemble de types de relations entre les elements de modelisation documentaire. D’autres
types de relation peuvent y etre ajoutes si le perimetre d’etude est elargi.
Definition 7.2.2. Relation elementaire documentaire – Nous definissons ainsi l’ensemble
de relations elementaires documentaires
RDoc =
RelationEncapsulation,
RelationReference,
RelationComposition,
RelationExigences,
RelationPartageInfo
∀y ∈ RDoc → y :: RelationElementaire
Chaque relation elementaire presente entre les elements documentaires est une
instance de la meta-classe RelationElementaire definie dans le meta-modele d’etude d’im-
pact.
Chaque instance de la meta-classe RelationElementaire (voir figure 6.2) est ca-
racterisee par la propriete coefficientPropagation. La definition n’est pas munie d’une se-
mantique forte ; elle depend d’un certain nombre de parametres etablis en fonction du
contexte du domaine, du type de document, du type de contenu et de la signification as-
[Chabbat 97] Voir reference [Chabbat 97] definie page 2.
125

Chapitre 7. Application du modele generique d’etude d’impact
socies a chaque relation (par exemple : une relation de composition aura un coefficient de
propagation different d’une relation de reference).
7.2.2.1 Modele de graphe specifique aux documents
L’analyse du modele generique des documents et les elements decrits ci-dessous
nous permettent de realiser le modele de graphe d’analyse des dependances et etude d’im-
pact specifique a un ensemble de documents.
L’instanciation de ce modele, definit a l’aide du meta-modele du niveau N3, nous
permet d’obtenir un graphe servant de support pour des analyses des dependances et des
etudes d’impact dans un ensemble de documents.
ElémentDocumentaire
ElémenetAttribut
ElémentContenu
ElémenetPropriété
-degréImpact -convictionImpact
ElémentDoc::ElémentImpactable
-coefficientPropagation
RelationDoc::RelationElémentaire
-élémentOrigine
*
*
*
-élémentCible *
RelationEncapsulation
RelationRéférence
RelationComposition
RelationExigences
RelationPartageInfo
Figure 7.5 – Modele de graphe d’analyse des dependances et d’etude d’impact specifiqueaux documents
7.2.3 Graphe canonique des dependances – etude d’impact – N1
En utilisant les concepts du meta-modele definis au niveau N3 un document peut
ainsi etre traduit dans un graphe de dependances. Les concepts du monde reel representes
par des elements constituant le document deviennent des nœuds de ce graphe, et les
relations qui les unissent deviennent des arcs de ce graphe de dependance.
Ainsi nous pouvons appliquer les procedures de raisonnement associees au graphe
canonique des dependances.
7.2.3.1 Instanciation du graphe canonique
De la meme maniere que pour les modeles UML, le type d’element definit les pro-
prietes du nœud du graphe et le type de relation celles de l’arc associe. Cette instanciation
est utilisee lors des procedures d’etude d’impact.
126

7.2. Modele d’etude d’impact associe aux documents – niveau N2
Pour les etudes au sein de collections documentaires nous ne ferons pas de distinc-
tion entre les differents types d’elements ainsi il n’y a pas de difference entre les nœuds du
graphe d’etude d’impact. Nous utiliseront les types de relation elementaire presente entre
les concepts documentaires pour definir les coefficients de propagation associes a chaque
arc du graphe d’etude d’impact.
Ce coefficient depend d’un certain nombre de parametres etablis en fonction du
contexte du domaine, du type de document et du type de contenu et de la signification
associes a chaque relation (par exemple : une relation de composition aura un coefficient
de propagation different d’une relation d’association). Dans la pratique, pour un modele
documentaire precis, un domaine specifique et des regles de redaction bien etablies, ces
parametres peuvent etre ajustes et affines apres des experimentations afin de mieux s’ap-
procher de la realite.
127

Chapitre 7. Application du modele generique d’etude d’impact
128

Chapitre 8
Integration du Modele generique
d’etude d’impact dans le
Referentiel de production et de
gestion des connaissances de la
Cnaf
Sommaire
8.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
8.2 Extension du Referentiel SIDoc a la gestion des modeles
UML du SI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
8.2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
8.2.2 Gestion des modeles UML du SI . . . . . . . . . . . . . . . . 132
8.2.3 Presentation . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
8.2.4 Utilisation des fonctionnalites du referentiel . . . . . . . . . 139
8.2.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
8.3 Integration du modele d’analyse des dependances et d’etude
d’impact . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
8.3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
8.3.2 Representation des dependances – graphe d’analyse des de-
pendances . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
8.3.3 Algorithme de parcours de graphe . . . . . . . . . . . . . . . 147
8.3.4 Integration dans la couche service . . . . . . . . . . . . . . . 148
8.3.5 Integration dans la couche presentation . . . . . . . . . . . . 149
8.3.6 Bilan de l’integration des modeles UML dans le referentiel
SIDoc . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
129

Chapitre 8. Integration du Modele d’etude d’impact
8.1 Introduction
Nous avons presente dans la partie Problematique les enjeux auxquels un Systeme
d’Information doit repondre afin d’assurer la maıtrise du patrimoine reglementaire.
L’evolution legislative ne se cantonne pas aux seules connaissances presentes dans
les documents reglementaires, elles ont le plus souvent un impact direct sur le Systeme
d’Information, outil d’application du droit. Il devient necessaire d’avoir une maıtrise glo-
bale des ressources documentaires et du Systeme d’Information pour accroıtre la capacite
de la DSI 17 a reagir aux changements de legislation et ainsi assurer la coherence tout au
long du processus d’application du droit.
C’est ainsi que le systeme de gestion et de production des connaissances doit gerer
l’ensemble de ces ressources heterogenes.
La section 2.3 de la partie Problematique presente le Referentiel de production et
de gestion des connaissances SIDoc. Ce referentiel est dote d’un ensemble de fonctionnalites
pour la gestion et la production des documents textuels. Les fonctionnalites offertes par
le referentiel SIDoc permettent d’assurer une maıtrise de la composante documentaire :
gestion des revisions et de versions, gestion des cycles de vie, recherche d’information,
tracabilite de l’information, etc.
Pour repondre a cette problematique nous apporterons deux contributions : etendre
les services de gestion offerts par le referentiel SIDoc a la composante logicielle et enri-
chir ces services avec des fonctionnalites permettant d’assurer la maıtrise commune de ses
ressources.
D’abord, nous souhaitons etendre les services de gestion offerts par le referentiel
SIDoc a la composante logicielle de maniere similaire aux services qu’il offre pour la com-
posante documentaire. La maıtrise de la composante logicielle passe par la maıtrise des
ressources de conception : documents d’analyse, documents de specifications, modeles de
conception, etc. Si les premieres categories de ressources s’apparentent a des documents
textuels et sont donc integrees naturellement dans les services de gestion SIDoc, c’est
moins le cas des modeles UML.
Nous allons nous interesser plus precisement dans ce chapitre a la maniere dont
nous integrons les modeles UML dans l’infrastructure de gestion et de production des
connaissances de l’Institution.
L’integration des modeles du Systeme d’Information nous permet egalement d’etendre
le perimetre couvert par le referentiel et d’offrir ainsi le cadre necessaire pour une mise en
relation des ces ressources heterogenes.
17. DSI : Direction du Systeme d’Information
130

8.2. Extension du Referentiel SIDoc a la gestion des modeles UML du SI
Ensuite, nous souhaitons enrichir les services de gestion du referentiel avec des
fonctionnalites permettant d’assurer la maıtrise commune de ses ressources face aux diffe-
rentes evolutions.
Notre contribution, presentee dans ce chapitre, se situe donc sur deux volets :
– integrer les modeles UML du Systeme d’Information au referentiel de gestion
et de production des connaissances,
– mettre en place le modele d’analyse des dependances et d’etude d’impact ca-
pable d’identifier et d’evaluer les impacts.
Cette double contribution nous permettra d’offrir aux modeles UML l’acces aux
outils de gestion du referentiel SIDoc ainsi que l’integration dans l’architecture du re-
ferentiel SIDoc des principaux composants lies a l’analyse des dependances et a l’etude
d’impact.
Nous tenons a preciser que ce chapitre n’a pas pour vocation d’etablir une docu-
mentation de specification et conception ou une documentation utilisateur des nouveaux
services et composants du referentiel mais plutot de presenter un resume synthetique de
la demarche employee et des principales nouvelles fonctionnalites offertes aux utilisateurs.
Pour une description detaillee de l’implementation et de l’utilisation des evolutions pro-
posees ainsi que de l’ensemble du referentiel SIDoc, nous vous proposons de consulter la
documentation du projet [CNEDI 07a].
8.2 Extension du Referentiel SIDoc a la gestion des modeles
UML du SI
8.2.1 Introduction
L’ensemble des modeles UML represente un des livrables le plus important dans
le processus de conception du Systeme d’Information. Il permet de modeliser le systeme
d’une facon standard d’un point de vue informatique.
Les modeles UML representent ainsi une vue sur le systeme et ont, par conse-
quent, une vocation de reference. Par ailleurs, ils entretiennent des liens etroits avec des
documents d’expression de besoins, d’analyse et de conception. Enfin, ils n’introduisent
pas de redondance avec d’autres elements du referentiel. Les modeles UML font donc par-
tie des documents de reference et ont, par consequent, vocation a integrer le Referentiel
de gestion et de production des connaissances de l’Institution.
Nous presentons dans les paragraphes suivants les elements mis en place pour
mener a bien cette integration. Nous allons nous interesser a la representation des modeles
UML dans un format compatible avec l’infrastructure du referentiel, aux mecanismes de
[CNEDI 07a] Voir reference [CNEDI 07a] definie page 37.
131

Chapitre 8. Integration du Modele d’etude d’impact
mise en relation avec les autres composants du referentiel ainsi qu’aux evolutions apportees
a l’interface utilisateur pour une restitution conviviale, ergonomique adaptee aux besoins
de l’utilisateur.
8.2.2 Gestion des modeles UML du SI
8.2.2.1 Representation XML des modeles UML
Afin de pouvoir integrer les modeles UML du SI dans le referentiel SIDoc et
beneficier des fonctions proposees par celui-ci, nous avons besoin de representer ces modeles
UML dans un format comprehensible par l’infrastructure SIDoc. Cette representation nous
permettra une gestion avancee des connaissances representees au sein meme de ces modeles.
Nous avons decrit dans le paragraphe 2.3 l’infrastructure du referentiel SIDoc basee sur
une representation en langage XML de ces ressources . Par ailleurs, la norme XMI – XML
Metadata Interchange [OMG 07b] definit, en utilisant le langage XML, la serialisation
des objets MOF [OMG 05][OMG 06a] et donc, entre autres, des modeles UML. Nombreux
ateliers de genie logiciel et outils de modelisation disposent de fonctionnalites pour l’export
des modeles UML en utilisant une representation XMI.
Le contenu XMI ainsi cree est forme de deux grandes partie :
– un element <UML:Model> contenant la description des elements du modele,
des types de donnees et des associations. Cet element incarne ainsi toutes les
connaissances apportees par la modelisation UML du systeme.
– une serie d’elements <UML:Diagram> contenant la description des differentes dia-
grammes associes dans la modelisation, chacun representant une vue differente
sur le modele.
L’element <UML:Model> contient toutes les informations necessaires pour la gestion du mo-
dele et pour les etudes d’impact. Cependant, nous gardons egalement l’element <UML:Model>
qui offre les informations graphiques sur chaque diagramme, interessantes au moment de
la restitution a l’utilisateur.
La representation des modeles UML en utilisant la norme XMI genere une tra-
duction du modele UML dans le langage XML rendant ainsi possible son integration dans
le referentiel SIDoc.
8.2.2.2 Integration dans le referentiel SIDoc
La representation XMI d’un modele UML est une traduction dans un format XML
du contenu du modele. Pour beneficier des services de gestion SIDoc, il est necessaire de
[OMG 07b] Voir reference [OMG 07b] definie page 66.
[OMG 05] Voir reference [OMG 05] definie page 66.
[OMG 06a] Voir reference [OMG 06a] definie page 67.
132
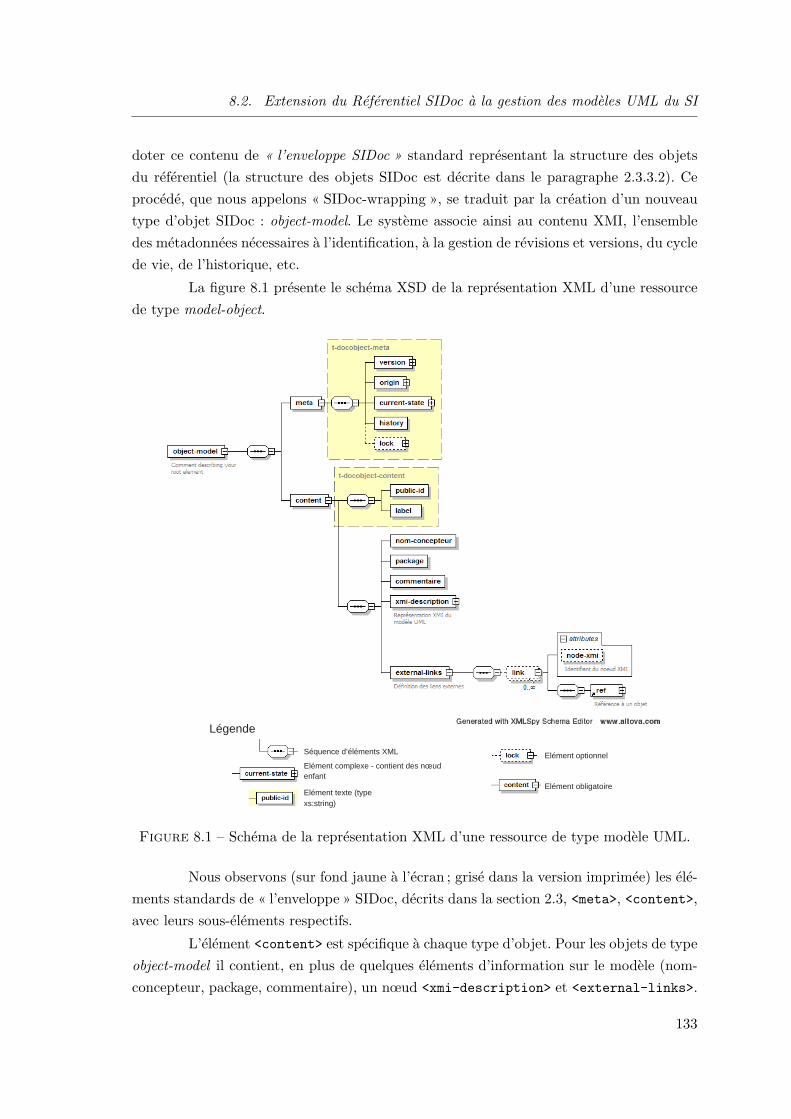
8.2. Extension du Referentiel SIDoc a la gestion des modeles UML du SI
doter ce contenu de « l’enveloppe SIDoc » standard representant la structure des objets
du referentiel (la structure des objets SIDoc est decrite dans le paragraphe 2.3.3.2). Ce
procede, que nous appelons « SIDoc-wrapping », se traduit par la creation d’un nouveau
type d’objet SIDoc : object-model. Le systeme associe ainsi au contenu XMI, l’ensemble
des metadonnees necessaires a l’identification, a la gestion de revisions et versions, du cycle
de vie, de l’historique, etc.
La figure 8.1 presente le schema XSD de la representation XML d’une ressource
de type model-object.
Légende
Séquence d’éléments XML
Elément complexe - contient des nœud enfant
Elément texte (type xs:string)
Elément optionnel
Elément obligatoire
Figure 8.1 – Schema de la representation XML d’une ressource de type modele UML.
Nous observons (sur fond jaune a l’ecran ; grise dans la version imprimee) les ele-
ments standards de « l’enveloppe » SIDoc, decrits dans la section 2.3, <meta>, <content>,
avec leurs sous-elements respectifs.
L’element <content> est specifique a chaque type d’objet. Pour les objets de type
object-model il contient, en plus de quelques elements d’information sur le modele (nom-
concepteur, package, commentaire), un nœud <xmi-description> et <external-links>.
133

Chapitre 8. Integration du Modele d’etude d’impact
Nous ne nous attarderons pas ici en detaillant la structure du nœud <xmi-
description> car celui-ci contient la description XMI du modele, exportee par l’outil
de modelisation. Cette description, respectant la norme OMG, a ete presentee dans la
partie Etat de l’art, paragraphe 3.5.
En revanche, la structure du nœud <external-links>, contenant la definition
des liens que les elements du modele entretiennent avec les autres ressources du referentiel,
sera detaillee dans la section suivante.
8.2.2.3 Representation des liens
L’integration des modeles UML dans le referentiel nous permet de mettre en
relation (en positionnant des liens) les elements du modele UML et les autres ressources
du referentiel (par exemple : documents ou fragments de documents).
Ne voulant pas denaturer la representation normalisee XMI des modeles UML
avec des elements specifiques a notre infrastructure, les definitions des liens seront sau-
vegardees dans un element specifique <external-links>. Ce mecanisme nous permet de
preserver dans l’element <xmi-description>, un contenu XML normalise qui peut etre
exporte et reutilise par les outils de modelisation.
La figure 8.2 realise un zoom sur la figure precedente, montre le schema XSD de
l’objet model-object, et presente en detail la structure de l’element <external-links>.
L’element <external-links> est une sequence vide ou non-limitee d’elements
<link>. Chaque element <link> possede un attribut optionnel node-xmi renseigne avec
la valeur de l’identifiant du nœud XMI, l’attribut xmi.id, correspondant a l’element du
modele porteur du lien. Cet element du modele porteur du lien est defini dans le corps de
la description XMI du modele, element <xmi-description> presente precedemment. Si
l’attribut node-xmi n’est pas present, cela signifie que le modele entier est le porteur du
lien.
L’element <link> contient un et seulement un nœud <ref>, element standard de
l’infrastructure SIDoc defini dans la section 2.3.3.5. Ainsi notre modele beneficie de tous
les mecanismes de resolution de liens proposes par l’infrastructure SIDoc.
L’exemple d’instance d’un element <external-links>, presente dans la figure
8.3, met en evidence trois instances differentes de liens :
1. un lien entre un element du modele (identifie par l’attribut node-xmi) et un autre
element d’un autre modele UML (modele identifie par l’attribut res et element
identifie par l’attribut nodes),
2. un lien entre un element du modele (identifie par l’attribut node-xmi) et un docu-
ment de type type=’donnee’ (document identifie par l’attribut res),
3. un lien entre le modele (attribut node-xmi absent) et un autre document de type
type=’parametre’ (document identifie par l’attribut res).
134

8.2. Extension du Referentiel SIDoc a la gestion des modeles UML du SI
Légende
Séquence d’éléments XML
Elément complexe - contient des nœud enfant
Elément texte (type xs:string)
Elément optionnel
Elément obligatoire
Figure 8.2 – Schema XSD de l’element <external-links> definisant les liens entre ele-ments du modele et elements du referentiel.
8.2.3 Presentation
Dans le cadre d’une exploitation courante, les outils de gestion sont caracterises
par une interface conviviale et ergonomique pour la communication homme/machine. Nous
presentons dans les deux sections suivantes, deux formes de presentation des modeles UML
au sein de l’interface utilisateur du referentiel SIDoc : une presentation sous forme de
formulaire et une presentation graphique sous forme de diagrammes.
Notons toutefois que l’infrastructure du referentiel SIDoc a ete concue dans un
souci d’evolutivite et de modularite permettant de facilement l’enrichir avec des nouveaux
composants aux differentes couches applicatives sans aucun impact sur l’existant du sys-
teme. Ainsi, des nouveaux modes de presentation pourront y etre integres.
135

Chapitre 8. Integration du Modele d’etude d’impact
<external-links>
<link node-xmi="63--112-2-71--32bad2ff:1134d518fcb:-8000:000000000000077C">
<ref col="uml-doc" kind="docobject" type="modele-uml" res="00000003"
nodes="I88ee03m104d161ab3bmm7f2b"/>
</link>
<link node-xmi ="63--112-2-71--32bad2ff:1134d518fcb:-8000:0000000000000781">
<ref col="sair" kind="docobject" type="donnee" res="00002703"/>
</link>
<link>
<ref col="sair" kind="docobject" type="parametre" res="00002801"/>
</link>
</external-links>
Figure 8.3 – Exemple de l’element XML <external-links>.
8.2.3.1 Presentation sous forme de formulaire
Nous avons montre dans le chapitre 2 que les ressources du referentiel SIDoc
disposaient de differentes formes de presentation. Compte tenu de la structuration des
objets en format XML, la presentation plus communement utilisee est celle definie a l’aide
des formulaires XForms [W3C 07a].
Le langage XForms nous permet de specifier l’interface utilisateur associe a un
modele de donnees. Les services de presentation de l’infrastructure SIDoc generent le
formulaire correspondant a partir d’une instance de donnees representant un modele UML
et en fonction de la definition de l’interface utilisateur en XForms. Ce formulaire est
disponible en deux etats : consultation et edition.
Le but de l’infrastructure SIDoc n’est pas l’edition des modeles UML, les outils
disponibles sur le marche offrent des fonctionnalites tres avancees dans ce sens. Cependant,
il s’avere utile de disposer d’une interface de mise a jour fournie a l’aide de l’etat en edition
du formulaire XForms.
La figure 8.4, presente une capture d’ecran d’une presentation sous forme de
formulaire d’un modele UML.
La presentation XForms nous permet d’avoir une integration homogene et har-
monieuse dans l’interface utilisateur globale du referentiel SIDoc.
8.2.3.2 Presentation sous forme de diagramme
Le modele UML est constitue des diagrammes, chacun representant une vue dif-
ferente sur le systeme. Les connaissances (e.g. elements, associations, types de donnees,
proprietes) definies dans chaque diagramme viennent enrichir le meme modele.
Bien que l’infrastructure SIDoc ait pour vocation de recenser les connaissances
faisant partie du referentiel, perspective dans laquelle une presentation sous forme de
[W3C 07a] World Wide Web Consortium. XForms 1.0 (Third Edition), October 2007. Disponible
sur : http ://www.w3.org/TR/xforms (consulte le 10.08.2009).
136

8.2. Extension du Referentiel SIDoc a la gestion des modeles UML du SI
Figure 8.4 – Formulaire en consultation presentant un modele UML.
137

Chapitre 8. Integration du Modele d’etude d’impact
formulaire suffit, il est egalement opportun de retrouver la presentation familiere d’un
modele UML sous forme d’un ou plusieurs diagrammes pour faciliter la communication
avec les utilisateurs.
Considerant la nature changeante du domaine et des ressources le representant,
y compris des modeles UML, une presentation dynamique s’imposait a la place des pre-
sentations sous forme des images issues des exports graphiques a partir des outils de
modelisation.
La recommandation SVG – Scalable Vector Graphics [W3C 03] specifie un lan-
gage XML de definition des dessins vectoriels. Les diagrammes UML sont facilement pre-
sentables sous forme d’un dessin vectoriel et la norme XMI leur fournit une definition en
XML.
Nous avons ainsi developpe et integre dans l’infrastructure SIDoc un processeur de
presentation (voir section 2.3.5.3) supportant le dessin vectoriel SVG des diagrammes defi-
nis dans les modeles UML. Pour cela, l’outil met en œuvre un ensemble de transformations
XSLT [W3C 99b] et XPath [W3C 99c] afin d’enrichir le document XMI et d’en obtenir
une presentation graphique : notation UML encodee en SVG. Ce procede est transparent
pour l’utilisateur qui aura acces aux diagrammes definis par un nœud <UML :Diagram> de
la representation XMI des modeles UML.
Les diagrammes peuvent ainsi etre visualises dans n’importe quel navigateur web.
La plupart des navigateurs internet [Mozilla 08][Microsoft 06][Microsoft 07] interpretent
soit nativement soit a l’aide d’un plugin, le contenu SVG de la page. Ils offrent des fonc-
tionnalites de agrandissement, de navigation et d’impression.
Le nouveau processeur de presentation nous permet d’offrir une vue sur le modele
UML sous forme de diagramme tel que presente par la copie d’ecran de la figure 8.5.
Cette presentation est similaire a celle offerte par les outils de modelisation. Ce-
pendant, quelques differences peuvent apparaıtre concernant notamment les elements gra-
phiques (e.g. icones, format des polices et des traits) employes par chaque outil pour les
elements d’un modele UML.
[W3C 03] World Wide Web Consortium. Scalable Vector Graphics (SVG) 1.0. Specification, January
2003. Disponible sur : http ://www.w3.org/TR/svg (consulte le 10.08.2009).
[W3C 99b] Voir reference [W3C 99b] definie page 61.
[W3C 99c] World Wide Web Consortium. XML Path Language (XPath), Version 1.0, W3C Recom-
mendation, 1999. Disponible sur : http ://www.w3.org/TR/xpath (consulte le 07.08.2009).
[Mozilla 08] Fondation Mozilla. Le projet Firefox de la fondation Mozilla, 2008. Disponible sur :
http ://www.mozilla-europe.org/fr/firefox/ (consulte le 07.08.2009).
[Microsoft 06] Microsoft Coorporation. Le navigateur Microsoft Internet Explorer, version 6, 2006.
Disponible sur : http ://www.microsoft.com/windows/ie/ie6/default.mspx (consulte le
07.08.2009).
[Microsoft 07] Microsoft Coorporation. Le navigateur Microsoft Internet Explorer, version 7, 2007.
Disponible sur : http ://www.microsoft.com/windows/internet-explorer/ie7/ (consulte le
07.08.2009).
138

8.2. Extension du Referentiel SIDoc a la gestion des modeles UML du SI
Cette presentation sous forme de diagramme, en utilisant un langage de dessin
vectoriel, ne dispose pas de fonctionnalites d’edition.
La presentation SVG nous permet de retrouver une visualisation des diagrammes
integree de maniere homogene dans l’interface utilisateur globale du referentiel SIDoc.
8.2.4 Utilisation des fonctionnalites du referentiel
Nous avons presente au cours des premieres sections de ce chapitre que l’integra-
tion des modeles UML dans le referentiel de production et de gestion des connaissances
vient enrichir le referentiel avec les connaissances issues des modeles UML et permet la
mise en relation des documents avec des modeles.
Nous avons montre dans la partie Etat de l’art que la plupart des outils de mo-
delisation offrent des fonctionnalites de modelisation tres riches et avancees. En revanche,
ils ne disposent pas toujours de fonctionnalites de referentiel :
– de gestion du cycle de vie,
– de management des revisions et des versions,
– de gestion de la tracabilite,
– d’analyse des dependances et de gestion de la coherence avec la documentation
associee.
Ainsi, ce travail ne vise pas a remplacer les outils de modelisation mais seulement a integrer
les modeles UML dans le referentiel des connaissances pour beneficier de ses fonctionnalites
de gestion. L’utilisation de la norme XMI assure une independance vis-a-vis de l’outil
de modelisation. Des fonctions d’import/export du referentiel manipulant la norme XMI
permettent de realiser l’interface entre les outils employes dans les phases de modelisation
et le referentiel SIDoc.
L’integration des modeles UML nous permet egalement de beneficier des fonc-
tionnalites de gestion offertes par l’infrastructure SIDoc.
8.2.4.1 Referentiel unique
Les modeles UML sont stockes dans un seul endroit accessible par tous, evitant
ainsi le risque de doublures et d’incoherences. Cette fonctionnalite regle egalement le pro-
bleme de la concurrence d’acces dans un environnement multi-utilisateurs.
8.2.4.2 Gestion du processus de production de connaissance
La responsabilite dans le processus de production et de gestion des modeles est
partagee entre plusieurs acteurs. Les fonctions de docflow 18 nous permettent de definir
l’automatisation du processus de production et les roles de chaque participant.
18. Par convention, nous appelons docflow un workflow de gestion documentaire
139

Chapitre 8. Integration du Modele d’etude d’impact
Figure 8.5 – Presentation a l’aide des images SVG des diagrammes UML.
140

8.2. Extension du Referentiel SIDoc a la gestion des modeles UML du SI
Les fonctions de docflow identifient et de gerent les etapes de validation des mo-
deles, envoient des messages aux autres objets et declenchent des actions pour automatiser
la gestion du referentiel.
La gestion des revisions et des versions multiples d’une meme ressource du referen-
tiel SIDoc appliquee aux modeles UML permet a tout moment de disposer d’une revision
en particulier et de l’associer, a travers les mecanismes de tracabilite, a l’expression des
exigences associees. Par ailleurs, la gestion des versions et les fonctions de synchronisa-
tion entre les differentes versions offre la possibilite de lancer en parallele des chantiers de
modelisation, portant sur les memes composants. Cette fonctionnalite offre la possibilite
d’anticiper les futures evolutions du Systeme d’Information et d’obtenir ainsi un gain de
temps pendant la phase de modelisation.
8.2.4.3 Tracabilite de l’information et des connaissances
La gestion des liens et de leur semantique nous permet de tracer (en suivant
les liens types) l’utilisation qui est faite d’une connaissance dans tout le referentiel. Les
meta-donnees sont utilisees pour retrouver les documents a l’origine de cette evolution.
Par ailleurs, l’historique de chaque ressource modele nous fournit les informations
necessaires pour tracer toutes les interventions effectuees et les acteurs qui sont intervenus.
8.2.4.4 Analyse des dependances, etude d’impact et estimations des charges
associees aux evolutions
L’integration des modeles UML dans le referentiel SIDoc en lien avec les docu-
ments de conception sert de base a l’instanciation d’un graphe d’analyse des dependances
et d’etude d’impact. La section suivante decrit plus en detail cette fonctionnalite.
8.2.5 Conclusion
Au cours de cette section nous avons presente l’integration des modeles UML au
referentiel SIDoc. Nous avons associe aux modeles UML une representation en utilisant un
langage et une structure homogene avec le reste du referentiel : « l’enveloppe SIDoc » et le
langage XML. Cette integration permet de definir des liens entre les elements du referentiel
et mettre ainsi en lien la composante documentaire avec celle logicielle. Cette nouvelle
structure est la base de notre modele d’etude d’impact decrit dans la section suivante.
141

Chapitre 8. Integration du Modele d’etude d’impact
8.3 Integration du modele d’analyse des dependances et
d’etude d’impact
8.3.1 Introduction
Nous allons presenter d’abord les principes d’instanciation du modele de graphe
des dependances pour les differents types de ressources du referentiel. Nous poursui-
vrons par la presentation de l’algorithme d’etude d’impact et son implementation dans
les couches persistance et service de l’application. Enfin, nous presenterons l’interface uti-
lisateur enrichie pour mettre en evidence les resultats de l’etude d’impact.
8.3.2 Representation des dependances – graphe d’analyse des depen-
dances
Nous identifions les references en analysant les objets presents dans la base.
La premiere etape est l’identification des elements impactables, structures de base
de chaque ressource. Les sections suivantes de ce chapitre montrent les mecanismes mis
en place pour chaque type de ressource. Pour les documents textuels, nous allons prendre
en compte des unites de base comme le document ou le fragment de document. Pour des
ressources telles que les modeles UML, ces unites seront plutot les concepts du formalisme
UML.
La deuxieme etape, l’identification des dependances est realisee en deux phases :
– l’analyse de la structure : pour identifier les dependances internes specifiques
a chaque ressource et celles liees a la construction des elements du referentiel
(e.g. un document est compose de plusieurs fragments, une classe possede des
operations) ;
– l’analyse des liens de reference : en suivant les elements <ref> qui representent
un lien entre des objets du referentiel, induisant une forme de dependance.
Puisque les dependances sont representees dans la base, l’analyse du referentiel
est realisee en utilisant une procedure implementee en langage XQuery – XML Query Lan-
guage [W3C 07b] et XPath – XML Path Language [W3C 99c] dans la couche persistance.
L’exploitation de cette structure nous permet de construire une representation du graphe
d’analyse des dependances.
[W3C 07b] World Wide Web Consortium. XML Query Language (XQuery), Version 1.0, W3C Re-
commendation, January 2007. Disponible sur : http ://www.w3.org/TR/xquery (consulte
le 07.08.2009).
[W3C 99c] Voir reference [W3C 99c] definie page 138.
142

8.3. Integration du modele d’analyse des dependances et d’etude d’impact
8.3.2.1 Instanciation pour les modeles UML
Le modele de graphe presente dans le chapitre 6 sera instancie pour chaque modele
UML en analysant ses elements.
La representation XMI contenue a l’interieur de l’objet SIDoc est analysee en
identifiant les nœuds correspondant aux types d’ElementImpactable definis par le meta-
modele (chapitre 6). Pour chaque element de l’ensemble EUML de concepts UML, le tableau
8.1 presente l’element de representation XMI correspondant.
Element Impactable Instance de representation
ElementClasse Element : <UML:Class>ElementRole Elements : <UML:AssociationEnd>, <UML:Attribute>ElementOperation Element : <UML:Operation>ElementParametre Element : <UML:Parameter>ElementDataType Element : <UML:DataType>ElementPropriete Par exemple pour un attribut : la visibilite, le nom, et l’ele-
ment <UML:Multiplicity>
Table 8.1 – Table de correspondance entre les concepts UML et les elements de represen-tation XMI
Nous appliquons la meme demarche pour l’identification des relations de depen-
dance entre les concepts UML elementaires. Pour chaque element de l’ensemble RUML de
relations definies pour les modeles UML, le tableau 8.2 presente l’element de representation
correspondant.
Relation elementaire Instance de representation
RelationAssociation Element : <UML:Association> avec l’attributaggregation=”none”
RelationGeneralisation Element : <UML:Generalization>RelationAgregationValeur Element : <UML:Association> avec l’attribut
aggregation= ”composite”RelationAgregationReference Element : <UML:Association> avec l’attribut
aggregation=”aggregate”RelationDependance Element : <UML:Dependency>RelationEncapsulation Hierarchie des nœuds et attributs dans XMIRelationUtilisation Element : <UML:Interaction> dans les diagrammes de se-
quenceRelationReference Elements <content>/<external-links> des objets SIDoc.
Table 8.2 – Table de correspondance entre les relations UML et les elements de represen-tation XMI
Pour les modeles UML nous ne ferons pas de distinction entre les differents types
143

Chapitre 8. Integration du Modele d’etude d’impact
d’elements et, par consequent, entre les differents nœuds du graphe d’etude d’impact. En
revanche, le type de relation UML sera utilise pour definir les coefficients de propagation
associes a chaque arc du graphe d’etude d’impact.
Parametrage des coefficients de propagation
Dans nos experimentations realisees sur un modele UML correspondant au mo-
dele de gestion des prestations familiales de la Cnaf, nous avons defini les coefficients de
propagation presentes dans le tableau 8.3.
Relation elem. Coeff. Relation elem. Coeff.
Association 100 Dependance 50Generalisation 75 Relation structurelle 100Agregation par valeur 100 Relation d’utilisation 100Agregation par reference 100
Table 8.3 – Table de parametrage des coefficients de propagation employes pour unmodele UML
Dans la pratique, pour un modele d’application precis et un domaine specifique,
ces parametres peuvent etre encore ajustes et affines apres des experimentations de plus
longue duree afin de mieux s’approcher de la realite.
8.3.2.2 Instanciation pour les documents
De la meme maniere que pour les modeles UML, l’analyse des ressources docu-
mentaires au regard des principes definis par le modele de graphe associe aux documents
(voir chapitre 6) definit les modalites d’instanciation du graphe d’analyse des dependances
associe aux documents.
Le schema XML decrit le modele des documents XML : il definit le vocabulaire
employe dans les documents XML permettant de decrire leur structure. En consequence le
vocabulaire definit par un schema XML ne peut etre mis en œuvre qu’en suivant des regles
rigoureuses d’agencement de ses elements. Pour un document XML precis, le schema XML
edicte ces regles en respectant la recommandation definie dans « XML Schema ».
L’enveloppe SIDoc presentee dans la section 2.3.3.2 definit les elements communs
a tous les documents XML du referentiel tels que l’element <meta>. Le contenu de l’ele-
ment <content> est, quant a lui, defini par une structure(vocabulaire et agencement des
elements) specifique a chaque type de document. Le referentiel dispose ainsi d’un ensemble
de schemas de documents XML et d’une application qui associe un document a un schema
donne.
L’element <content> encode les connaissances de la ressource du referentiel. Nous
nous y referons donc en vue de l’instanciation du graphe des dependances . Les nœuds
144

8.3. Integration du modele d’analyse des dependances et d’etude d’impact
encodant une connaissance du referentiel sont identifies par un attribut « id ».
Pour l’exemple specifique des nœuds contenant des extraits des textes legislatifs,
nous proposons le schema de la figure 8.6.
Légende
Séquence d’éléments XML
Elément complexe - contient des nœud enfant
Elément texte (type xs:string)
Elément optionnel
Elément obligatoire
Figure 8.6 – Schema d’une section de texte reglementaire.
Le but du schema presente dans la figure 8.6 est de definir le vocabulaire a
employer pour structurer une narration legislative afin de pouvoir identifier les parties
importantes du texte dans le cadre de l’analyse des dependances, tout en gardant une
maıtrise de sa structure et de sa mise en forme.
Ces elements sont les nœuds <section> et <bloc-element> munis d’un identi-
fiant. Ainsi les mecanismes de referencement du referentiel SIDoc pourront etre utilises.
L’element <section> correspond aux sections d’un document legislatif alors que l’element
<bloc-element> correspond a des elements de structure (e.g. le paragraphe, item d’une
liste a puces, cellule, ligne ou colonne d’un tableau). L’element <inline-element> permet
de disposer d’informations concernant la forme de la narration(la definition des styles) qui
importe dans le processus d’appropriation des connaissances.
De la meme maniere que pour les representations UML, la representation des don-
nees textuelles est analysee en identifiant les nœuds correspondant aux types d’ElementImpactable
145

Chapitre 8. Integration du Modele d’etude d’impact
definis pour les documents par le meta-modele d’etude d’impact (chapitre 6). Pour chaque
element de l’ensemble EDoc des elements documentaires, le tableau 8.4 presente l’element
de representation XML correspondant.
Element Impactable Instance de representation
ElementDocumentaire Toutes les elements du nœud <content>
(munis d’un attribut ’id’ ) : instances de xs:ElementExemple : <section> ou <block-element>
ElementContenu Le contenu texte d’un nœud XMLElementAttribut Les attributs des nœuds XMLElementPropriete Le nom des elements
Table 8.4 – Table de correspondance entre les objets documentaires et les elements derepresentation XML
Nous appliquons la meme demarche pour l’identification des relations de depen-
dance entre les elements documentaires. Pour chaque element de l’ensemble RDoc de re-
lations definies pour les documents, le tableau 8.5 presente l’element de representation
correspondant.
Relation elementaire Instance de representation
RelationEncapsulation Relation entre nœuds XML et ses attributsRelationComposition Relation de composition entre le document,
les sections, sous sections <section> etles blocs d’elements <block-element>
RelationReference Presence d’un element <ref> simpleRelationExigences Presence de l’element <ref> type dans les elements utilises
pour la tracabilite (par exemple : element <meta>/<origin>)RelationPartageInfo Presence de l’element <ref> avec le ref-type=’partage-info’
Table 8.5 – Table de correspondance entre les relations documentaires et les elements derepresentation XML
Comme pour les modeles UML, dans cette premiere version de l’analyse nous ne
ferons pas de distinction entre les differents types d’elements constituant les documents
et, par consequent, entre les differents nœuds du graphe d’etude d’impact. En revanche,
le type de relation entre les elements du document sera utilise pour definir les coefficients
de propagation associes a chaque arc du graphe d’etude d’impact.
Parametrage des coefficients de propagation
Dans nos experimentations realisees sur une collection documentaire representant
la documentation de conception du modele de gestion des prestations familiales de la Cnaf,
nous avons defini d’une maniere empirique les coefficients de propagation presentes dans
146

8.3. Integration du modele d’analyse des dependances et d’etude d’impact
le tableau 8.6.
Relation elem. Coeff. Relation elem. Coeff.
RelationEncapsulation 75 RelationExigences 100RelationComposition 100 RelationPartageInfo 100RelationReference 50
Table 8.6 – Table de parametrage des coefficients de propagation employes pour un corpus
Dans la pratique, pour un modele de document precis, pour un domaine specifique
et pour un style de redaction particulier, ces parametres peuvent etre ajustes et affines
apres des experimentations afin de mieux s’approcher de la realite.
8.3.2.3 Instanciation pour les objets binaires
Comme decrit dans le paragrape 2.2.2, les objets binaires representent une autre
categorie de ressources du referentiel SIDoc. Ils constituent des ressources diverses, ayant
une valeur pour le referentiel, telles que des ressources binaires, images, documents issus
des outils de bureautiques classiques, etc. Ils sont integres dans le referentiel a l’aide d’une
enveloppe SIDoc specifique et beneficient ainsi de tous les outils et principes de gestion
globale de celui-ci. Ils peuvent ainsi participer aux liens de reference qui se tissent au sein
du referentiel.
La gestion des objets binaires se fait d’une maniere globale, ainsi, aucune specia-
lisation du modele de graphe de dependances n’est prevue pour ce domaine. Leur instan-
ciation utilise le modele generique :
– nœuds du graphe : les objets binaires sont instancies dans le graphe d’analyse
des dependances en tant qu’instances du concept generique ElementImpactable,
– arcs du graphe : l’analyse des liens de reference entre les elements du referentiel
et les ressources binaires instancient les arcs du graphe avec un coefficient de
propagation fixe a 75% pour notre domaine.
8.3.3 Algorithme de parcours de graphe
Le graphe de dependances ainsi cree (regroupant les instances issues de l’analyse
des ressources UML, des ressources documentaires et des objet binaires) constitue la base
de l’etude d’impact. Cette section decrit l’algorithme d’etude d’impact et de calcul du
degre et de la conviction d’impact pour chaque element du referentiel.
Au niveau algorithmique, le graphe etant susceptible de contenir des cycles et
afin d’eviter des chemins de propagation infinis, nous verifions a chaque etape si le nœud
a ete deja visite dans le chemin de propagation en cours.
147

Chapitre 8. Integration du Modele d’etude d’impact
Algorithme general de propagation est presente dans la figure 8.7. La fonction
calculImpact permet de calculer de maniere recursive a partir d’un element impacte initial
unElement tous les degres et toutes les convictions d’impact (calcules a l’aide des fonctions
caculDegreImpact et calculConvictionImpact) de tous ses successeurs et d’en deduire tous
les chemins de propagation. En effet, lorsqu’un element a plusieurs successeurs, l’impact
va prendre plusieurs chemins de propagation (methode bifurquer(chemin)). Le parcours
du graphe produit ainsi une liste de chemins de propagation qui seront consolides par des
algorithmes de consolidation.
Pour des raisons de performance l’algorithme decrit dans cette section est imple-
mente en utilisant les langages XQuery et XPath et il est execute par le serveur de gestion
de la base de donnees.
Fonction calculImpact(unElement, unCheminPropagation)
Pour chaque p, successeur d’unElement
Si p n’a pas ete visite dans ce chemin alors
calculDegreImpact(p, unElement)
calculConvictionImpact(p, unElement)
ajouter p dans unCheminPropagation
calculImpact(p, unCheminPropagation)
si unElement a un autre successeur : p’ alors
//on cree un autre chemin de propagation
nouveauChemin=bifurquer(unCheminPropagation)
calculImpact(p’, nouveauChemin)
fin si
fin si
fin pour
fin fonction
Figure 8.7 – Algorithme general de propagation.
8.3.4 Integration dans la couche service
8.3.4.1 Appel du service
Le service d’analyse des dependances est implemente en tant que service web. A
partir d’une requete recue precisant le point de depart (identification du nœud de depart
et de l’impact subi), il demande a la couche d’acces aux donnees de creer, en analysant les
contenus du referentiel, les objets metier representant les ressources impactees.
Le flux XML entrant est une instance du schema presente dans la figure 8.8.
8.3.4.2 Resultat de l’analyse
Les resultats de l’analyse des dependances enrichis avec les resultats de l’etude
d’impact sont renvoyes comme reponse a l’invocation du service d’analyse des dependances
et d’etude d’impact.
148

8.3. Integration du modele d’analyse des dependances et d’etude d’impact
Légende
Séquence d’éléments XML
Elément complexe - contient des nœud enfant
Elément texte (type xs:string)
Elément optionnel
Elément obligatoire
Figure 8.8 – Schema du flux entrant du service d’analyse des dependances et d’etuded’impact, developpe pour le referentiel SIDoc .
Le flux XML sortant est une instance du schema presente dans la figure 8.9.
8.3.5 Integration dans la couche presentation
Les connaissances deduites de l’etude d’impact seront restituees a l’utilisateur
dans la couche presentation, de maniere harmonieuse avec la charte graphique de toute
l’application.
8.3.5.1 Le module d’etude d’impact
Le point d’acces a l’outil d’etude d’impact et d’analyse des dependances est le
Module d’analyse des dependances. L’interface utilisateur du module d’analyse des depen-
dances, presentee dans la figure 8.10, est constituee de quatre zones importantes : zone
de recherche, zone d’identification de l’origine, zone d’identification du fragment, zone de
resultats.
Zone de recherche – permet de rechercher la ressource qui subit l’impact d’origine et
de saisir un ensemble de criteres pour faciliter l’acces a cette ressource.
Zone d’identification de l’origine – identifie la ressource choisie comme origine de
l’impact.
Zone d’identification du fragment – offre la possibilite, a partir de la ressource choi-
sie, d’identifier de maniere plus precise l’origine de l’impact. Par exemple : une sec-
tion, paragraphe d’un document, un element d’un modele UML, etc.
149

Chapitre 8. Integration du Modele d’etude d’impact
Légende
Séquence d’éléments XML
Elément complexe - contient des nœud enfant
Elément texte (type xs:string)
Elément optionnel
Elément obligatoire
Figure 8.9 – Schema du flux sortant du service d’analyse des dependances et d’etuded’impact, developpe pour le referentiel SIDoc .
Zone de resultats – presente les resultats de l’impact sous forme d’un tableau. Celui-ci
presente les ressources du referentiel impactees (e.g. liste de documents, de modeles).
Pour avoir des details sur les sous-elements, des presentations des impacts objet par
objet sont proposees, comme celle pour les modeles UML (voir la section suivante).
8.3.5.2 Detail de la presentation des impacts sur les modeles UML
Certains types de ressources beneficient des representations specifiques. Nous
avons vu que dans le cas d’UML, le systeme permet une presentation XForms mais egale-
ment une presentation sous forme de diagramme UML.
Les resultats sont reportes sur les memes diagrammes UML fournis en entree grace
a un mecanisme d’annotation visuelle (e.g. jeu de couleurs, info-bulles) comme presente
dans la figure 8.11.
Nous souhaitons faciliter ainsi l’utilisation de l’outil et eviter l’appropriation d’un
nouveau formalisme de presentation tel que le graphe canonique.
150

8.3
.In
tegratio
ndu
mod
eled’a
nalyse
des
depen
dances
etd’etu
de
d’im
pact
Identification de la ressource origine de l’impact
Identification du fragment origine de l’impact
Résultat de l’étude d’impact
Zone de recherche
Fig
ure
8.10–
Le
module
d’an
alyse
des
dep
endan
ceset
presen
tationdes
resultats.151

Chapitre 8. Integration du Modele d’etude d’impact
8.3.6 Bilan de l’integration des modeles UML dans le referentiel SIDoc
Le referentiel de production et de gestion des connaissances gere d’ores et deja
une partie des documents a vocation de reference de l’Institution. Des nombreux chantiers
sont en perspective pour l’integration dans le referentiel d’autres ressources.
Notre contribution liee au travail de recherche s’inscrit directement au cœur de
ce projet institutionnel. Elle a ete initiee dans l’intention de repondre a deux principaux
enjeux :
– completer l’infrastructure du referentiel SIDoc par des mecanismes manquants
pour la rendre capable de repondre aux enjeux d’une maıtrise globale du pa-
trimoine reglementaire
– valider par l’experimentation les diverses propositions emises dans le cadre de
la presente these.
Nous avons presente au cours de cette section la maniere dont les modeles UML
d’une part et le modele d’etude d’impact d’autre part, ont ete integres au referentiel de
production et de gestion des connaissances SIDoc developpe au sein de la Branche famille
de la Securite Sociale.
Pour integrer les modeles UML, nous avons utilise des representations conformes
a la norme XMI et mis en place une structure XML respectant le modele du referentiel
qui enveloppe cette representation. Une telle integration a un double benefice :
– elle nous permet d’enrichir le referentiel avec les connaissances issues des mo-
deles UML et de realiser ainsi des references entre celles-ci et les autres elements
du referentiel,
– elle nous permet de beneficier, au niveau des modeles UML, de l’ensemble des
services de gestion qu’offre le referentiel SIDoc : gestion du travail collaboratif,
du cycle de vie, de revisions et versions, et de la tracabilite.
Nous avons egalement presente dans ce chapitre les principes d’instanciation du
graphe d’analyse des dependances, en presentant la maniere d’explorer des ressources
documentaires, des modeles UML et des ressources binaires. Nous avons egalement presente
l’implementation de l’etude d’impact ainsi que son integration dans la couche services
(section 8.3.4) et dans la couche presentation (section 8.3.5) de l’application.
152

8.3. Integration du modele d’analyse des dependances et d’etude d’impact
Figure 8.11 – Enrichissement de la presentation d’un diagramme UML avec les resultatsdes etudes d’impact.
153

Chapitre 8. Integration du Modele d’etude d’impact
154

Conclusion
La problematique des etudes d’impact est tres simple dans les cas minimalistes
mais elle peut s’averer tres difficile dans les cas plus compliques. Des lors que nous sommes
en presence de plusieurs elements lies par plusieurs relations, la propagation des im-
pacts devient complexe et surtout definie par des nombreux chemins de propagation. La
consolidation de ces resultats est tres difficile. Face a cette problematique le modele gene-
rique d’etude d’impacts devient necessaire pour automatiser cette etude et nous permettre
d’identifier l’ampleur de l’impact.
Par ailleurs, la notion de probabilite est tres importante et repond au manque de
semantique precise dans les modeles UML. Ainsi, une etude d’impact, realisee a l’aide de
notre modele, peut predire les nombreux impacts mais avec des probabilites tres differentes.
Le modele generique peut ensuite etre specialise avec des profiles specifiques a un
domaine et a l’aide des coefficients de propagation probabiliste associes a chaque type de
relation. Ces moyens de specialisation nous permettent de realiser une etude d’impact plus
proche de la realite.
Le meta-modele d’etude d’impact a ete concu de telle maniere qu’il puisse integrer
dans le graphe d’analyse des dependances des instances issues de futurs types de ressources.
Un modele de graphe specifique au niveau N2 nous permettra de definir les modalites
d’instanciation de ce graphe (e.g. typologie d’elements, typologie de relations).
Une premiere piste d’integration serait la prise en compte du code source pre-
sent dans des applications, code source qui lui-meme represente une autre vue sur les
connaissances du Systeme d’Information.
Par ailleurs, au niveau des documents reglementaire nous utilisons les liens po-
sitionnes au niveau des documents pour l’identification des dependances. Le systeme G-
Frames propose une representation des connaissances dotee de mecanismes d’inference.
Une integration des representations G-Frames nous permettra d’atteindre un niveau supe-
rieur dans la maıtrise des connaissances et du corpus reglementaire. L’annexe E presente
le systeme de G-Frames.
155

Conclusion
156

Quatrieme partie
Evaluation
157


Chapitre 9
Evaluation et discussions
Sommaire
9.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
9.2 Rappel des enjeux . . . . . . . . . . . . . . . . . . . . . . . . 159
9.3 Modele d’etude d’impact . . . . . . . . . . . . . . . . . . . . 161
9.3.1 Rappel de la problematique . . . . . . . . . . . . . . . . . . 161
9.3.2 Rappel de la proposition . . . . . . . . . . . . . . . . . . . . 161
9.3.3 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
9.3.4 L’experience de l’utilisateur . . . . . . . . . . . . . . . . . . 165
9.4 Integration dans le referentiel SIDoc . . . . . . . . . . . . . 166
9.4.1 Rappel de la problematique . . . . . . . . . . . . . . . . . . 166
9.4.2 Rappel de la proposition . . . . . . . . . . . . . . . . . . . . 166
9.4.3 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 166
9.4.4 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . 169
9.1 Introduction
Cette derniere partie a pour but d’effectuer une synthese et une evaluation de
differentes propositions que nous avons faites au cours de cette these. Nous evaluons chaque
proposition au regard des besoins initialement exprimes dans la partie problematique de
ce manuscrit.
9.2 Rappel des enjeux
La meme connaissance legislative se retrouve exprimee au travers de nombreuses
ressources a des niveaux differents de l’entreprise : documents de reference, supports de
formation, documentation metier, regles de gestion, composants du Systeme d’Information,
159

Chapitre 9. Evaluation et discussions
etc. Toutes ces ressources (e.g. textes reglementaires, les objets du Systeme d’Information)
qui encodent la connaissance necessaire pour que l’Institution mene a bien sa mission
representent une vraie richesse pour l’organisation, un vrai patrimoine, que l’on a appele
patrimoine des connaissances metier.
Ce patrimoine des connaissances metier doit toujours etre conforme a la legisla-
tion. La nature changeante de la legislation rend la maintenance d’un tel dispositif parti-
culierement difficile.
La composante documentaire ainsi que la composante logicielle doivent suivre
rigoureusement les evolutions de la legislation. Ainsi, lorsqu’un changement intervient au
sein de la reglementation, il est imperatif que celui-ci leur soit repercute afin que ces deux
composantes restent conformes au droit.
Comme presente dans la partie Problematique, afin d’assurer cette coherence glo-
bale des connaissances exprimees dans l’ensemble des ressources heterogenes du patrimoine
reglementaire, nous avons propose d’apporter une reponse aux problematiques suivantes :
– la tracabilite des connaissances exprimee tant au niveau documentaire qu’au
niveau logiciel : la meme connaissance se retrouve encodee dans plusieurs res-
sources avec plusieurs niveaux de details pour plusieurs destinations,
– la maıtrise de la coherence de sa composante documentaire,
– la maıtrise de la coherence de sa composante logicielle (l’implementation cal-
culatoire de la reglementation),
– l’identification le lien qu’entretient le reste du Systeme d’Information avec le
patrimoine reglementaire.
Notre proposition s’est articulee en trois temps.
Tout d’abord, nous avons analyse les caracteristiques des deux composantes du
patrimoine des connaissances metier (composante documentaire et composante logicielle).
Bien qu’en apparence differentes et heterogenes, ces deux composantes ont des proprietes
equivalentes. Toutes les deux encodent les connaissances metier de l’entreprise. Par la suite
nous avons vu que ces deux composantes peuvent etre apprehendees comme des ensembles
de ressources structures, hierarchises et fortement interconnectes. Par ailleurs, ces deux
composantes doivent repondre a des problematiques de production et de gestion semblables
visant a capitaliser les connaissances metier qu’elles encodent.
C’est dans cet esprit que, dans un deuxieme temps, nous avons propose et mis
en place les mecanismes pour une gestion unifiee de la composante logicielle et de la
composante documentaire. Nous avons propose une structure specifique de representation
des modeles UML a l’aide du langage XML, en utilisant la norme XMI, nous permettant de
les integrer dans le referentiel SIDoc de production et gestion documentaire de l’Institution.
Enfin, dans un troisieme temps, nous avons propose un meta-modele d’etude
d’impact visant a fournir les concepts et les mecanismes necessaires pour les etudes d’im-
pact dans un ensemble de particules de connaissances. Ce meta-modele peut etre specialise
160

9.3. Modele d’etude d’impact
pour differents domaines. Deux specialisations de ce meta-modele ont ete decrites en de-
tail. L’une s’interesse au domaine documentaire et l’autre au domaine des modeles UML
des Systemes d’Information. Le meta-modele propose nous permet de nous affranchir des
specificites de chaque type de ressource pour realiser des analyses de dependances et des
etudes d’impact a travers des ensembles de ressources heterogenes.
Dans les sections suivantes de ce chapitre nous allons evaluer en detail ces pro-
positions.
9.3 Modele d’etude d’impact
9.3.1 Rappel de la problematique
Lorsqu’une modification intervient a un certain niveau de la pyramide reglemen-
taire, l’ensemble des ressources en aval peut etre impacte. L’impact a un niveau donne est
repercute en cascade affectant toute la pyramide jusqu’au niveau de base qui est represente
par les regles de gestion, internes a l’organisation impactant ainsi directement un certain
nombre de composants du Systeme d’Information lies a la reglementation. L’impact peut
ensuite etre propage a d’autres composants du SI induisant ainsi une reaction en chaıne
qu’il est necessaire de maıtriser.
Par exemple, un changement dans les conditions d’attribution d’une allocation
va avoir un impact sur l’ensemble de la composante documentaire, sur le systeme de
gestion des prestations mais aussi sur d’autres composants du SI comme l’application de
gestion des flux comptables, les outils de simulation et de tests ou bien le site internet de
l’Institution.
9.3.2 Rappel de la proposition
Documents legislatifs, documents de conception, documents de specification, di-
vers livrables du cycle de conception et de developpement, tous sont des ressources qui
encodent la connaissance metier autour du Systeme d’Information. La proposition d’un
meta-modele definissant pour chaque type de ressource un modele de representation des
elements elementaires encodant des connaissances metier et des relations que ces elements
elementaires entretiennent, nous permet d’apprehender de la meme maniere ces ressources,
bien qu’elles soient differentes et heterogenes.
Leur mise en relation nous permet de garantir la tracabilite de l’utilisation qui est
faite des connaissances a travers l’ensemble des ressources de l’organisation qu’elles soient
documentaires ou logicielles. En se basant sur la representation des dependances issues de
cette tracabilite, l’etude d’impact nous renseigne sur l’effet qu’une evolution d’un element
du referentiel (par exemple une connaissance legislative) aura sur l’ensemble du referentiel.
161

Chapitre 9. Evaluation et discussions
Nos travaux proposent un mecanisme generique pour l’etude d’impact au sein
d’un modele d’un Systeme d’Information nous permettant d’identifier l’ensemble des com-
posants impactes a partir d’une modification survenue. Notre contribution a permis d’eta-
blir un support essentiel et necessaire pour l’instauration d’un controle de la coherence et
de la conformite de la composante logicielle du patrimoine reglementaire.
C’est ainsi que, suite a une analyse de la structure des modeles UML, dans la
section 7.1 nous avons introduit la notion de concept UML elementaire et de relation UML
elementaire. Nous avons egalement propose les mecanismes d’instanciation du meta-modele
d’etude d’impact pour les modeles UML. Nous avons aussi detaille la maniere d’analyser
les modeles pour l’instanciation du graphe canonique des dependances associe. Le travail
equivalent a ete fait pour les collections documentaires, dans la section 7.2 en proposant les
notions de concept documentaire elementaire et relation documentaire elementaire. Nous
avons egalement propose les modalites d’instanciation du meta-modele d’etude d’impact
pour les documents reglementaires.
9.3.3 Evaluation
9.3.3.1 Demarche
L’etude d’impact est basee sur l’analyse des dependances dans les graphes ca-
noniques de dependances, instances du niveau N1 du modele d’etude d’impact. Chacune
de ces representations est une instance du niveau superieur N2. Nous avons presente les
modeles d’etude d’impact associes a UML, dans la section 7.1 et aux documents, dans
la section 7.2. La granularite la plus fine utilisee pour l’etude d’impact est celle prise en
compte dans les modeles d’etude d’impact N1.
9.3.3.2 Methode d’evaluation
En partant d’un element impacte nous utilisons notre implementation afin de
calculer, pour chaque element du referentiel SIDoc, son degre 19 et sa conviction d’im-
pact 20. Nous considerons un element comme impacte a partir du moment ou sa conviction
d’impact a une valeur superieure a zero.
Cette estimation a ete realisee en trois phases :
– une estimation sur l’ensemble documentaire seul : le Dossier d’analyse fonction-
nelle specifiant les exigences de l’application de gestion des prestations Cristal,
– une estimation sur un modele UML seul,
19. Le degre d’impact represente la couverture estimee de l’impact sur un element impactable. Voirla definition 6.3.8.
20. La conviction d’impact represente la precision avec laquelle nous pouvons affirmer la presenced’un impact elementaire. Voir la definition 6.3.9.
162

9.3. Modele d’etude d’impact
– une estimation sur un ensemble de documents de conception associes au modele
UML.
Pour mesurer les resultats de l’etude d’impact, nous utilisons la methode proposee
dans [Kagdi 07]. Il s’agit de comparer les evolutions realisees par l’utilisateur pour palier
un impact (les documents ou les modeles UML modifies) avec les resultats de l’etude
d’impact.
A chaque fois, les resultats estimes ont ete proposes aux utilisateurs en charge
de la maintenance des ressources, afin qu’ils soient confrontes a leur propre perception :
un groupe de redacteurs dans la premiere phase, les concepteurs et developpeurs dans les
deux dernieres pases.
9.3.3.3 Mesures d’evaluation
Deux mesures largement utilisees, issues du domaine de la Recherche d’Informa-
tion, le taux de precision et le taux de rappel, seront employees dans la mesure de l’efficacite
des mecanismes d’etude d’impact. En effet, notre etude d’impact peut etre apprehendee
comme une recherche d’information qui, a la place des mots-cles et de l’indexation, utilise
l’algorithme de calcul d’impacts presente dans cette these.
En partant d’un impact identifie nous definissons :
– l’ensemble Ei des impacts estimes par notre mecanisme d’etude d’impact. Nous
considerons un element impacte a partir du moment ou la confiance de l’impact
est superieure a un certain seuil ǫ positif,
– l’ensemble Ci des impacts reels, concretement identifies par une analyse ma-
nuelle des ressources.
– l’ensemble Pi des impacts pertinents, c’est a dire le nombre d’impacts identifies
par notre etude d’impact qui sont egalement des impacts reels. Il s’agit de
l’intersection des deux ensembles Ei et Ci.
Pour chaque evaluation, le taux de precision et le taux de rappel sont definis de
la maniere suivante :
Definition 9.3.1. Taux de precision – Rapport du nombre d’elements pertinents identifies
au nombre total d’elements trouves.
P =1
n
n∑
i=1
card(Pi)
card(Ei)=
1
n
n∑
i=1
card(Ei
⋂
Ci)
card(Ei)
Definition 9.3.2. Taux de rappel – Rapport du nombre de documents pertinents trouves
au nombre total de documents pertinents.
[Kagdi 07] Voir reference [Kagdi 07] definie page 84.
163

Chapitre 9. Evaluation et discussions
P =1
n
n∑
i=1
card(Pi)
card(Ci)=
1
n
n∑
i=1
card(Ei
⋂
Ci)
card(Ci)
D’une maniere plus intuitive nous pouvons considerer que le taux de precision
represente la pertinence du systeme et le taux de rappel represente sa couverture.
Dans certaines applications, le taux de rappel est beaucoup plus important que le
taux de precision. Par exemple, lorsqu’il s’agit de trouver les courriels qui ne sont pas des
pourriels, il est tres important de trouver tous les courriels qui ne sont pas des pourriels ;
il est cependant moins grave que certains pourriels survivent au filtrage.
Par ailleurs, le contraire peut etre egalement vrai : quand la precision est plus
importante que le taux de rappel. Supposons qu’on doive attribuer a des documents des
mots-cles pour faciliter la recherche. Si les mots cles ne sont pas suffisamment precis le bruit
est trop important et l’information utile risque d’etre noyee dans de nombreux resultats.
Par exemple, une recherche sur le mot-cle « avocat » peut trouver des reponses lies aussi
bien au domaine juridique qu’aux recettes de cuisine de la belle saison.
Nous pouvons jouer sur la valeur de la confiance d’impact pour faire varier les
taux de precision et les taux de rappel. En choisissant d’ignorer les impacts deceles avec
une confiance tres faible, nous prenons le risque de passer a cote d’impacts pertinents ; le
taux de precision est plus eleve au risque de voir diminuer celui de rappel. En revanche,
en acceptant tous les impacts deceles, y compris ceux dont la confiance est tres faible, le
taux de rappel est tres bon, le systeme est certain d’avoir identifie le maximum d’impacts
pertinents mais la precision diminue et l’utilisateur est confronte a une multitude d’impact
potentiels dont seule une partie est pertinente.
9.3.3.4 Resultats
Cette estimation a ete realisee en trois scenarios :
1. une estimation sur l’ensemble documentaire forme de plus de 7000 elements docu-
mentaires de conception du systeme de gestion des prestations Cristal 21
2. une estimation sur un modele UML contenant plus de 340 elements (e.g. classes,
attributs, methodes)
3. une estimation sur l’ensemble de documents de conception et des modeles UML
associes ; soit un total de 7340 elements.
Chaque scenario est repete plusieurs fois avec des evenements impactants diffe-
rents. Les resultats sont synthetises dans le tableau 9.1 disponible a la fin du chapitre.
Nous observons que, dans la composante documentaire, nous disposons de re-
lations dont la conviction d’impact est plus importante (relations de composition, de
21. Ces documents font partie du Dossier d’Analyse Fonctionnelle de Cristal
164

9.3. Modele d’etude d’impact
reutilisation ou meme d’interpretation), donc la precision est toujours tres importante.
Les impacts remontes sont pertinents mais le risque est d’en oublier certains : le taux de
rappel est diminue par rapport a la valeur maximale.
En revanche, au niveau des modeles UML, la presence de relations dont le coef-
ficient de propagation est plus petit (telles que la relation d’association, de generalisation
ou de dependance) fait que la precision est plus petite. Le systeme a tendance a remonter
beaucoup plus d’impact qu’en realite. Le taux de rappel est maximal car tous les ele-
ments du modele UML pertinents sont trouves meme si des resultats non-pertinents sont
egalement presentes.
Les resultats sur un ensemble combinant a la fois les modeles UML et les docu-
ments de specification sont largement influences par les caracteristiques de la composante
documentaire (une tres bonne valeur de la precision).
9.3.3.5 Observations
Cette experimentation s’est basee sur les coefficients de propagation, associes aux
differents types de relations entre les elements, definis dans le tableau 8.3 pour la compo-
sante logicielle et dans le tableau 8.6 pour la composante documentaire. L’experimentation
montre que ces coefficients sont importants dans l’evolution du taux de precision et de
rappel du modele decrit. Les valeurs de ces coefficients doivent etre affinees en fonction
d’une analyse plus approfondie des habitudes de modelisation documentaire et logicielle
correlee avec des experimentations enrichies et en utilisant des principes statistiques de
determination d’echantillons representatifs.
Ceci constitue une perspective a court terme de nos travaux de recherche.
Par ailleurs, la qualite des resultats de l’etude d’impact depend beaucoup des liens
de dependance positionnes par les utilisateurs dans les modeles documentaire et logiciel.
Ceux-ci seront ensuite traduits en tant que relations au sein du modele d’etude d’impact.
Ainsi, pour de meilleurs resultats, les utilisateurs doivent etre sensibilises a l’importance
d’expliciter le plus grand nombre de liens de dependances entre les elements du referentiel
des connaissances metier.
9.3.4 L’experience de l’utilisateur
Malgre la complexite de ces mesures, il n’est pas certain qu’elles refletent l’ef-
ficacite du systeme du point de vue de l’utilisateur. En fait, il a ete demontre que les
differentes tentatives faites pour apprecier l’experience de l’utilisateur avec des mesures
mathematiques echouent [Turpin 06]. Seule une mesure qualitative de l’experience des
[Turpin 06] Turpin Andrew et Scholer Falk. User performance versus precision measures for simple
search tasks. SIGIR ’06 : Proceedings of the 29th annual international ACM SIGIR
conference on Research and development in information retrieval. New York, NY, USA.
ACM, 2006, p 11–18.
165

Chapitre 9. Evaluation et discussions
utilisateurs peut etre revelatrice de l’appropriation de l’outil propose.
L’appropriation de l’outil par les utilisateurs a ete evaluee en meme temps que
l’integration dans le referentiel SIDoc et est presentee dans la section suivante.
9.4 Integration dans le referentiel SIDoc
9.4.1 Rappel de la problematique
Le referentiel de production et de gestion des connaissances gere d’ores et deja
une partie des documents de reference de l’Institution. De nombreux chantiers sont en
perspective pour l’integration d’autres ressources.
La maıtrise du Systeme d’Information est strategique pour les organisations ayant
comme mission la mise en application de la legislation. Le processus de conception et
de developpement est tres complexe et fortement collaboratif. Un des plus importants
projets d’integration dans le referentiel de production et de gestion des connaissances est
l’integration des ressources d’analyse et de conception du Systeme d’Information.
9.4.2 Rappel de la proposition
L’integration des modeles UML dans le referentiel SIDoc nous a permis de faire
beneficier les modeles UML des fonctionnalites de gestion et production offertes par le
referentiel SIDoc.
Par ailleurs, la structuration XML et la gestion des references specifiques au
referentiel SIDoc nous ont permis la mise en relation des elements des deux composantes
du patrimoine reglementaire et la maıtrise de la tracabilite entre eux.
9.4.3 Evaluation
L’efficacite d’une application de gestion est difficile a mesurer et a quantifier.
Nous devons nous fier au ressenti des utilisateurs.
Le ressenti des utilisateurs a ete analyse a l’aide des fiches d’evaluation lors de la
phase de recette fonctionnelle de l’application SIDoc. Nous reproduisons ici les conclusions
concernant le module d’analyse des dependances. Pour plus de details, veuillez consulter
les dossiers de recette technique et fonctionnelle du projet [CNEDI 07b][CNEDI 07c].
[CNEDI 07b] Centre National d’Etudes et du Developpement Informatique Rhone-Alpes, 128 rue ser-
vient, 69003 Lyon. SIDoc - Systeme d’Aide a l’Implementation de la Reglementation -
Recettage fonctionnel de la V0, 2007.
[CNEDI 07c] Centre National d’Etudes et du Developpement Informatique Rhone-Alpes, 128 rue ser-
vient, 69003 Lyon. SIDoc - Systeme d’Aide a l’Implementation de la Reglementation -
Recettage technique de la V0, 2007.
166

9.4. Integration dans le referentiel SIDoc
9.4.3.1 Retour sur l’experimentation avec les utilisateurs
Dans ce contexte nous avons souhaite proceder a une evaluation par l’experimen-
tation de cette contribution afin d’identifier et de valider :
– les difficultes d’appropriation du nouveau mode de gestion des ressources,
– l’interface utilisateur proposee,
– l’acuite des analyses des dependances et des etudes d’impact,
– l’importance et l’utilite de ces etudes dans le processus de maıtrise du patri-
moine des connaissances.
Constitution de l’equipe d’evaluation
Les avis ont ete recueillis aupres d’un groupe d’utilisateurs forme de personnes
ayant differents profils (developpeurs, concepteurs et responsables d’equipe). N’ayant pas
toujours la possibilite de definir des mesures quantifiables, leurs avis sont recueillis sous
forme de sondage.
Le groupe realisant la validation fonctionnelle est composee de 12 personnes avec
les profils suivants :
– responsable d’equipe de conception ou de developpement, responsable du suivi
et de la coordination (3 personnes)
– personne exercant une activite principale d’analyse fonctionnelle (2 personnes)
– personne exercant une activite principale de conception (4 personnes)
– personne exercant une activite principale de developpement (3 personnes)
Leurs appreciations, consolidees a la fin du chapitre dans le tableau 9.2, sont
detaillees dans les sections suivantes. Quelques extraits de la synthese des evaluation sont
presentes dans l’annexe D.
La validation des principes mis en œuvre par le referentiel SIDoc permet d’envi-
sager sereinement son extension a d’autres ressources strategiques de l’organisation, nous
assurant l’adhesion future de l’ensemble des utilisateurs.
9.4.3.2 Nouveau mode de gestion des modeles UML
La phase de modelisation est toujours realisee par les outils de modelisation tres
avances en fonctionnalites de modelisation, seule la gestion est confiee au referentiel SIDoc.
Les fonctions d’import/export faisant le lien entre les deux environnements intro-
duisent une etape supplementaire dans le processus de gestion. Une meilleure integration
des outils de modelisation et du referentiel serait un plus. Par exemple : l’utilisation directe
a partir de l’outil de modelisation, des services de chargement et de sauvegarde des objets
du referentiel sans passer par des fichiers d’export/import.
La gestion mise en place au niveau des representations XMI issues des outils
de modelisation permet de supporter certaines specificites. Malgre cela nous souhaitons
167

Chapitre 9. Evaluation et discussions
introduire le respect de la norme XMI afin d’assurer la prise en compte de toutes les
connaissances issues de la phase de modelisation.
Dans un environnement multi-utilisateurs avec des equipes nombreuses, les utili-
sateurs apprecient particulierement de pouvoir disposer d’un seul endroit de stockage des
modeles UML et d’autres ressources et livrables produits tout au long du processus de
conception et developpement.
Toujours dans ce contexte riche, ils apprecient de disposer d’un referentiel ras-
semblant l’ensemble des ressources et des connaissances produites a partir de l’expression
des besoins, des documents d’analyse jusqu’a la documentation utilisateur en passant par
la conception et le developpement.
Les fonctionnalites phares qui reviennent souvent dans les reponses des utili-
sateurs sont liees a la gestion des cycles de vie, de la concurrence d’acces et des revi-
sions/versions, fonctionnalites qui leur permettent de mieux apprehender la complexite
des applications a developper.
En effet, la gestion des revisions et des versions multiples d’une meme ressource
du referentiel SIDoc appliquee aux modeles UML permet de disposer a tout moment
d’une revision en particulier et de l’associer, a travers les mecanismes de tracabilite, a
l’expression des exigences associees. Par ailleurs, la gestion des versions et les fonctions de
synchronisation entre differentes versions, permet de lancer en parallele des chantiers de
modelisation, portant sur les memes composants. Cette fonctionnalite offre la possibilite
d’anticiper les futures evolutions du Systeme d’Information et d’obtenir ainsi un gain de
temps pendant la phase de modelisation.
9.4.3.3 Interface utilisateur
L’integration dans le referentiel a donne la possibilite aux utilisateurs de beneficier
des services SIDoc. Ainsi, ils apprecient les services de recherche d’information, la facilite
d’acces par le plan de classement, les modules et les tableaux de bord de suivi de la
production de contenu du referentiel.
Les nouvelles technologies employees dans les approches telles qu’AJAX 22 per-
mettent de creer des interfaces utilisateurs plus riches et plus reactives.
La presentation sous forme d’XForms des modeles UML a connu un bon accueil,
les utilisateurs appreciant la vue globale, depourvue de tout artifice visuel, qu’elle offre
sur l’ensemble des elements du modele. Cependant, la vue sous forme de diagramme a ete
preferee car elle permet de retrouver la presentation familiere de l’outil de modelisation.
Les utilisateurs estiment que la presentation des impacts reportee sur la version
SVG 23 des diagrammes UML par un mecanisme d’annotation visuelle (jeu de couleurs,
22. AJAX – Asynchronous JavaScript and XML permet d’enrichir les fonctionnalites d’un clientweb
23. SVG – Langage XML de definition des dessins vectoriels [W3C 03].
168

9.4. Integration dans le referentiel SIDoc
info-bulles) donne un bon apercu de l’etendu de l’impact. Mais ils preferent la presentation
sous forme de tableau de bord qui synthetise les resultats de cette etude en fournissant
une estimation des charges associees.
La norme XMI etant particulierement verbeuse, les temps de reponse necessaires a
la creation du dessin vectoriel SVG associe a chaque diagramme ne respectent pas toujours
les principes d’ergonomie definis dans l’Institution (a savoir le temps de chargement d’une
page qui peut etre trop important).
9.4.3.4 Analyse des dependances et etude d’impact
Par ailleurs, les resultats de l’etude d’impact estimes ont ete proposes a un groupe
de developpeurs en charge de l’application afin qu’ils soient confrontes a leur propre per-
ception. Les resultats ont ete juges assez proches de la realite (de ceux obtenus par une
estimation manuelle). Neanmoins, une limite a ete identifiee : le systeme dans sa ver-
sion actuelle ne permet pas de moduler l’estimation du nombre ou l’etendu de l’impact
en fonction du respect des bonnes regles de developpement (comme l’encapsulation). Ces
regles permettent de reduire les impacts reels par rapport aux impacts estimes seulement
en regardant le modele UML. Par consequent, le modele d’estimation est qualifie comme
pessimiste ; dans la situation actuelle, il detecte plus d’impacts que dans la realite.
L’ajustement des coefficients de propagation associes a chaque type de depen-
dance present dans les modeles UML (cf. 7.1.4.2), nous permet d’approcher l’interpretation
donnee a la realite par notre procedure d’etude d’impact.
Ce service nous permet d’ouvrir des pistes pour la mise en place d’autre fonc-
tionnalites telles que l’estimation des charges associees aux evolutions du referentiel et du
Systeme d’Information [Vasutiu 08].
9.4.4 Conclusions
La validation des nos contributions par les utilisateurs nous permet d’integrer les
nouveaux services dans le referentiel SIDoc enrichissant ainsi son offre de service a l’aube
de son extension, nous assurant l’adhesion future de l’ensemble des utilisateurs.
La problematique des etudes d’impact est tres simple dans les cas minimalistes
mais elle peut s’averer tres difficile dans des cas plus compliques. Des lors que nous sommes
en presence de plusieurs elements lies par plusieurs relations, la propagation des impacts
devient tres compliquee et surtout est definie par des nombreux chemins de propagation.
La consolidation de ces resultats est tres difficile. Face a cette problematique le modele
[Vasutiu 08] Vasutiu Ovidiu, Jouve David, Amghar Youssef et Pinon Jean-Marie. Knowledge ma-
nagement in information system design and delivery process. Proc. of the Xth Internation
Congres On Enterprise Information Systems (ICEIS’2008). Barcelona, Spain. INSTICC,
2008, p 5–26.
169

Chapitre 9. Evaluation et discussions
generique d’etude d’impacts devient necessaire pour automatiser cette etude et nous per-
mettre d’identifier l’ampleur de l’impact.
Par ailleurs, la notion de probabilite est tres importante et repond au manque de
semantique precise dans les modeles UML. Ainsi, une etude d’impact realisee a l’aide de
notre modele peut predire des nombreux impacts mais avec des probabilites tres differentes.
Le modele generique peut ensuite etre specialise avec des profils specifiques a un
domaine et a l’aide des coefficients de propagation probabilistes associes a chaque type
de relation. Ces moyens de specialisation nous permettent de realiser une etude d’impact
plus proche de la realite.
Le meta-modele d’etude d’impact a ete concu de maniere qu’il puisse integrer dans
le graphe d’analyse des dependances des instances issues de futurs types de ressources. Un
modele de graphe specifique au niveau N2 (modele de graphe d’analyse des dependances)
nous permettra de definir les modalites d’instanciation de ce graphe (typologie d’elements,
typologie de relations).
Une premiere piste d’integration serait la prise en compte du code source present
dans les applications, code source qui lui-meme represente une autre vue sur les connais-
sances du Systeme d’Information.
170
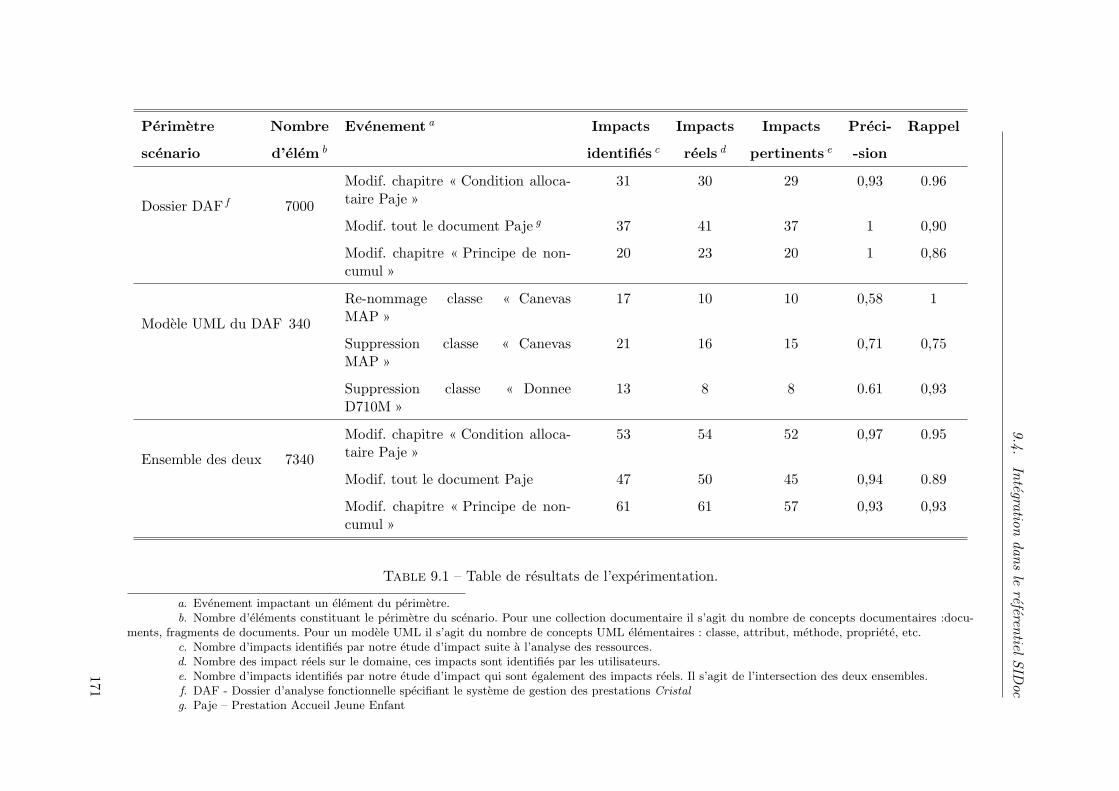
9.4
.In
tegratio
ndans
lereferen
tielSID
oc
Perimetre Nombre Evenement a Impacts Impacts Impacts Preci- Rappel
scenario d’elem b identifies c reels d pertinents e -sion
Dossier DAF f 7000
Modif. chapitre « Condition alloca-taire Paje »
31 30 29 0,93 0.96
Modif. tout le document Paje g 37 41 37 1 0,90
Modif. chapitre « Principe de non-cumul »
20 23 20 1 0,86
Modele UML du DAF 340
Re-nommage classe « CanevasMAP »
17 10 10 0,58 1
Suppression classe « CanevasMAP »
21 16 15 0,71 0,75
Suppression classe « DonneeD710M »
13 8 8 0.61 0,93
Ensemble des deux 7340
Modif. chapitre « Condition alloca-taire Paje »
53 54 52 0,97 0.95
Modif. tout le document Paje 47 50 45 0,94 0.89
Modif. chapitre « Principe de non-cumul »
61 61 57 0,93 0,93
Table 9.1 – Table de resultats de l’experimentation.
a. Evenement impactant un element du perimetre.b. Nombre d’elements constituant le perimetre du scenario. Pour une collection documentaire il s’agit du nombre de concepts documentaires :docu-
ments, fragments de documents. Pour un modele UML il s’agit du nombre de concepts UML elementaires : classe, attribut, methode, propriete, etc.c. Nombre d’impacts identifies par notre etude d’impact suite a l’analyse des ressources.d. Nombre des impact reels sur le domaine, ces impacts sont identifies par les utilisateurs.e. Nombre d’impacts identifies par notre etude d’impact qui sont egalement des impacts reels. Il s’agit de l’intersection des deux ensembles.f. DAF - Dossier d’analyse fonctionnelle specifiant le systeme de gestion des prestations Cristalg. Paje – Prestation Accueil Jeune Enfant
171

Chapitre 9. Evaluation et discussions
Fonctionnalite Appreciation Commentaire
(min 0 - max 5)
Gestion des modelesUML
4 Une meilleure integration avec les outilsde modelisation est necessaire. Voir la dis-cussion dans le paragraphe 9.4.3.2
Interface utilisateur 3 La presentation des impacts sous formede jeu de couleurs est tres appreciee. Lestemps de reponse sont tres longs et lesdiagrammes complexes ne sont pas tres li-sibles dans le navigateur. Voir la discus-sion dans le paragraphe 9.4.3.3
Etude d’impact 4 Les resultats de l’analyse sont pertinents.Il faut ameliorer la presentation des resul-tats nombreux ; les regrouper en fonctiondes chantiers. Voir la discussion dans leparagraphe 9.4.3.4
Table 9.2 – Tableau validation fonctionnelle.
172

Conclusion generale
Les travaux de recherche exposes au cours de la presente these ont ete menes
autour d’une problematique qui trouve son origine dans le contexte de la Branche Famille
de la Securite Sociale. C’est ainsi que la Caisse Nationale des Allocations Familiales a
servi de cadre pour l’elaboration de nos propositions. Ce contexte a ete particulierement
utile pour comprendre et analyser les nombreuses difficultes liees a la gestion de la matiere
reglementaire et a la maıtrise du Systeme d’Information, auxquelles peuvent etre quoti-
diennement confrontees des entreprises publiques ou privees. Ces problemes n’ont toutefois
pas ete traites uniquement en fonction du contexte specifique de travail (Cnaf), mais bien
en les considerant comme revelateurs d’une problematique plus large concernant la ges-
tion documentaire et la gestion des Systemes d’Information. Ainsi, notre modele generique
a ete illustre et teste dans le cadre specifique de la Cnaf mais son champ d’application
peut-etre elargi a d’autres domaines.
Apres avoir procede a une etude approfondie des differentes caracteristiques du
patrimoine documentaire, du Systeme d’Information et du role crucial que ces deux com-
posantes sont amenees a jouer au cœur de l’activite d’une organisation et, plus particuliere-
ment, au cœur des processus de mise en application du droit, nous nous sommes interesses
aux diverses problematiques et enjeux que suscitent la gestion des textes reglementaires
d’une part et celle du Systeme d’Information d’autre part.
Afin d’assurer la maıtrise du patrimoine des connaissances face aux evolutions
liees a la legislation, nous proposons d’utiliser une representation des dependances et des
methodes d’analyse et d’etude d’impact communs a la composante documentaire et logi-
cielle. C’est ainsi que, afin de constituer un modele adapte, tout en aspirant a la genericite,
nous introduisons le « modele d’etude d’impact » et « le graphe canonique de depen-
dances ». Ce modele nous permet de representer de la meme maniere les dependances
qu’entretiennent les elements de la composante documentaire et ceux de la composante
logicielle ainsi que de les mettre en relation.
Le modele propose a donc ete adapte pour les documents et pour les modeles
UML du Systeme d’Information. Il a ete implemente dans l’infrastructure du referentiel de
production et de gestion documentaire de la Cnaf. A travers cette phase d’implementation,
nous avons bati une infrastructure de gestion capable de repondre aux enjeux de la maıtrise
173

Conclusion generale
de la matiere reglementaire, patrimoine documentaire et Systeme d’Information. Nous
avons mis en evidence la pertinence, la fiabilite et la coherence de notre contribution, tout
en verifiant que le modele propose est realiste et operationnalisable.
Enfin, dans la derniere partie de la these nous avons presente une evaluation des
resultats de nos propositions, plus particulierement une evaluation des resultats de notre
modele d’etude d’impact et les retours des utilisateurs. La discussion qui clot le present
manuscrit est l’occasion de tracer quelques perspectives applicatives et scientifiques suite
aux travaux de recherche presentes.
Perspectives
Perspectives applicatives
La maıtrise du Systeme d’Information passe par la maıtrise des ressources de
conception : documents d’analyse, documents de specifications, modeles de conception,
code source des applications, etc. Nous avons propose les modalites necessaires pour inte-
grer les modeles UML dans l’infrastructure de gestion et de production des connaissances
de l’Institution.
Une autre piste d’integration serait la prise en compte du code source des applica-
tions du SI, representant une autre vue sur le Systeme d’Information. Ainsi l’integration des
modeles et du code des applications du Systeme d’Information nous permettra d’etendre
le perimetre couvert par le referentiel et d’offrir ainsi le cadre necessaire pour la maıtrise
des evolutions de l’ensemble des ressources de l’Institution.
Enfin, un travail de parametrage des coefficients de propagation pour le modele
documentaire et le modele logiciel est necessaire pour accorder au mieux les resultats des
estimations des impacts avec le domaine modelise et les habitudes de modelisation des
utilisateurs.
Perspectives scientifiques
Le systeme G-Frames [Jouve 03a] propose une modelisation semantique de la re-
glementation et une representation des connaissances dotee de mecanismes d’inference.
Une integration des representations G-Frames nous permettra d’atteindre un niveau su-
perieur dans la maıtrise du patrimoine des connaissances et du corpus reglementaire.
Lors de l’extension des services d’analyse des dependances et d’etude d’impact a
d’autres ressources institutionnelles, un nouveau terrain de recherche qui doit etre explore
consiste a adapter notre modele aux difficultes d’analyse d’un referentiel tres volumineux.
[Jouve 03a] Voir reference [Jouve 03a] definie page 2.
174

Annexe A
Liste des publications
1. Vasutiu O., Amghar Y., Jouve D., « Gestion des changements et etude d’impact
dans un systeme d’information reglementaire». Actes du XXIVeme Congres INFor-
matique des Organisations et Systemes d’Information et de Decision (INFORSID
2006), p. 1007-1022.
2. Vasutiu O., Vasutiu F., « Database Design Patterns for multi-language support in
software applications». Conference of PhD Students in Computer Science (CSCS
2006), p. 99-100.
3. Vasutiu O., Jouve D., Amghar Y., Pinon J.-M. «XML based Legal Document Draf-
ting Environement», Workshop on Legislative XML, 20th Aniversary Annual JURIX
Conference, 12-15 December 2007, CityplaceLeiden, Netherland
4. Vasutiu O., Jouve D., Amghar Y., Pinon J.-M. «Knowledge Management in In-
formation System Design and Delivery Process», 10th International Conference on
CityEnterprise Information Systems, 12-16 June 2008, CityplaceBarcelona, country-
regionSpain
175

Annexe A. Liste des publications
176

Annexe B
Schema XSD de la
recommandation XML-Schema
La recommandation XML-Schemas peut etre modelisee, a l’aide d’un schema XSD
presente, sous forme graphique par la figure B.1
Remarque : Pour illustrer nos exemples, nous avons essaye quelques produits,
mais un seul, XML Spy, est pleinement exploite dans le present manuscrit. XML Spy
[Altova 09] est un produit evolue et fonctionnellement riche, qui permet d’editer des DTD
et des schemas XML ainsi que des instances XML. Il contient des convertisseurs, notam-
ment en representations graphiques et des generateurs automatiques d’instances et de
modeles, qui se revelent pratiques en phase d’etude.
[Altova 09] Voir reference [Altova 09] definie page 40.
177
Annexe B. Schema XSD de la recommandation XML-Schema
Figure B.1 – Schema de la recommandation XML-Schemas. Representation graphiquerealisee par l’editeur de schemas XML XMLSpy [Altova 09].
178

Annexe C
Exemple d’un docflow
179
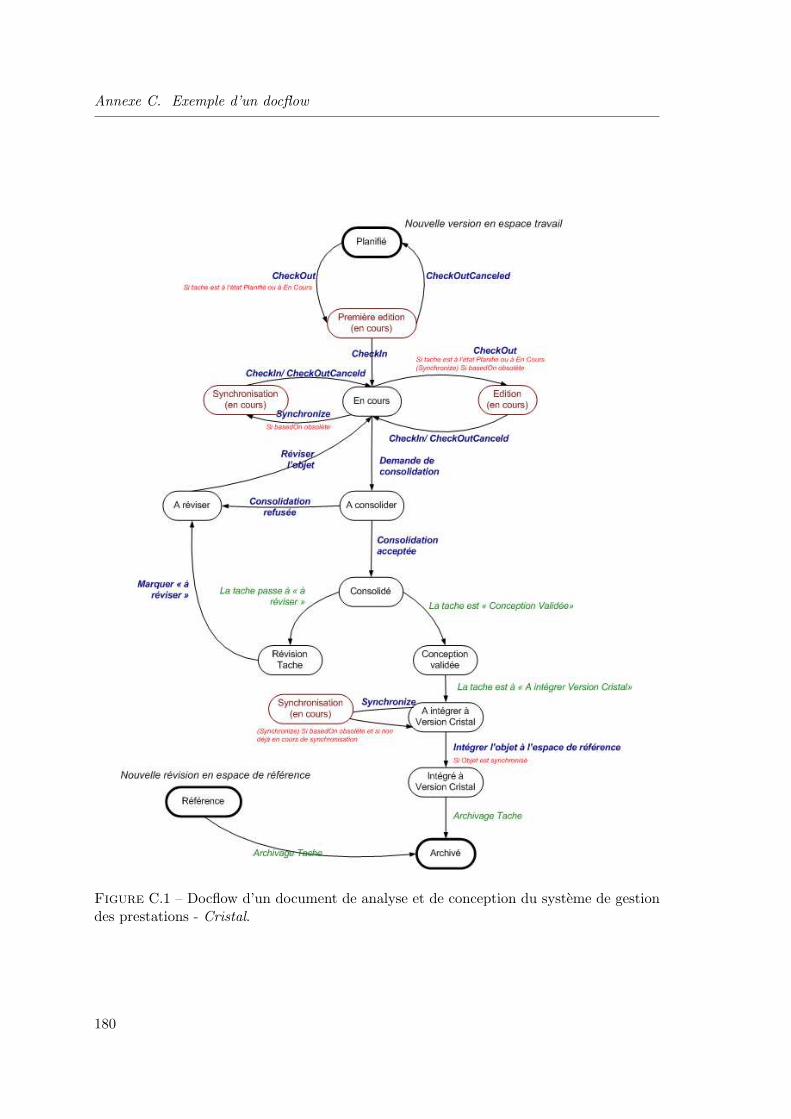
Annexe C. Exemple d’un docflow
Figure C.1 – Docflow d’un document de analyse et de conception du systeme de gestiondes prestations - Cristal.
180

Annexe D
Recettage fonctionnel de
l’application SIDoc - Extraits
D.1 Recettage fonctionnel
L’objet de cette demarche a ete de dresser un bilan fonctionnel des composants
mis a disposition dans le cadre de la premiere version du Referentiel de production et de
gestion documentaire au vu des criteres suivants :
– reponse au besoin,
– ergonomie,
– performances.
Parmi les differentes fonctionnalites proposees, l’analyse des dependances et l’etude
d’impact ont egalement ete evaluees. Les tableaux suivants presentent quelques extraits
de la synthese des evaluations des utilisateurs. Pour plus de details veuillez consulter le
compte-rendu des journees de recette fonctionnelle [CNEDI 07b].
[CNEDI 07b] Voir reference [CNEDI 07b] definie page 166.
181

Annexe D. Recettage fonctionnel de l’application SIDoc - Extraits
1.1. P érimètre de la V0
Fonctionnalités
Cah
ier
des
ch
arge
s
initi
al
Mis
en
pl
ace
en V
0
Observations / Appréciation (min 0 - max 5)
Accès possible à de multiples collections documentaires
Oui Oui 5
Consultation des objets documentaires /UML Oui Oui 4 – formulair es très riches
Consultation sous forme graphique Non Oui 3 - temps de réponse
Navigation dans la documentation viens des liens hypertexte Oui Oui 4
Edition des objets documentaires Oui Oui 5
Edition des objets UML Non Oui 3 – édition formulaire très difficile. Prévoir l’interfaçage avec des AGL UML
Gestion du multi - fenêtrage pour la consultation et l’édition des objets documentaires
Non Oui 5
Affichage d’une table des matières pour les documents volumineux
Non Oui 5
Plans de classement multiples ( consultation) Oui Oui 5
….. .... ….. ……
1.2. Gestion de la traçabilité
Fonctionnalités
Cah
ier
des
ch
arge
s
initi
al
Mis
en
plac
e
en V
0
Observations / Appréciation (min 0 - max 5)
Mise en corrélation des documents du DAF et des documents de la DPF Oui Oui
4 - P ermettre une mise en relation élémentaire d’une planification de révision/création/suppression avec un ou plusieurs paragraphes des documents associés à la Demande de modification Mise en corrélation des documents du
DAF et des documents UML N on Oui 4 – G ranularité suffisamment fine.
…. …. … ……
1.3. Gestion des impacts
Fonctionnalités
Cah
ier
des
ch
arge
s
initi
al
Mis
en
plac
e
en V
0
Observations / Appréciation (min 0 - max 5)
Etude d’impact Oui Oui 4 – Résultats pertinents. La liste des résultats devra faire a pparaître des regroupement de références par Tache.
Etude d’impact – forme graphique Non Oui 3 – chargement difficile de l’interface utilisateur.
…….. …… ……. ………
Figure D.1 – Extrait de la synthese d’evaluation
182

Annexe E
Le systeme G-Frames
E.1 Les G-Frames
David Jouve [Jouve 03a] realise un couplage du formalisme des frames et du
formalisme des graphes conceptuels, base sur la logique du 1er ordre, pour composer le
systeme primitif des G-Frames. Ainsi il beneficie des avantages de chacune de ces deux
structures : l’expressivite des langages de frames et la semantique forte des graphes concep-
tuels. La figure E.1 nous montre un exemple de traduction d’un acte juridique a l’aide de
G-Frame.
David Jouve definit egalement l’operation fondamentale de raisonnement du do-
maine, la projection G-Projection qui permet de calcul de la relation de specialisation/generalisation
sur les G-Frames. Le modele de G-Frames ainsi que les mecanismes de raisonnements at-
taches repondent dans le domaine juridique a des problematiques liees a la representation
de la legislation et a la detection des incoherences et des conflits au sein d’une base de
normes reglementaires.
[Jouve 03a] Voir reference [Jouve 03a] definie page 2.
183

Annexe E. Le systeme G-Frames
Livre 5: Prestations Familiales et prestations assimilées
Titre I: Champ d’application - Généralités...
Chapitre II: Champ d’application
art. L. 512-1 Toute personne française ou étrangère résidant en France, ayant à sa chargeun ou plusieurs enfants...
Code de la Sécurité Sociale... Suivi Législatif : CEE
I - Allocataire
I.1 Conditions généralesI.1.a Personne
I.1.c Résidence
...
I.1.d Enfants à charge...
Allocataire
Paramétre
Condition derésidence
Condition d’activité
Personne Physique : *x
Type
Activité
France réside
exerce France loc
Enfant
Union Européenne
résideaChargeCondition de charge d’enfant
I.1.b Activité...
Champ Prestations Familiales
......
... réside en ...
FS SNN
Personne Physique : ?x
Personne Physique : ?x
Personne Physique : ?x
Figure E.1 – Exemple de G-Frames. Extrait de [Jouve 03a].
184

Glossaire
AJAX : Asynchronous JavaScript and XML - approche permettant d’enrichir les fonc-
tionnalites des clients Web
CAF : Caisse d’Allocation Familiales.
CNAF : Caisse Nationale des Allocations Familiales.
CNEDI : Centre National d’Etudes et de Developpements Informatiques.
Collection documentaire : Composante du referentiel de production et de gestion docu-
mentaire qui est formee par un ensemble de contenus non redondant et maintenu
en coherence avec celui des autres collections. Voir definition 2.3.1
Consistance (modeles UML) : Propriete des modeles UML qui disposent d’un ensemble
de diagrammes coherent explicitant des proprietes du domaine correctes les unes
avec les autres.
Contexte de production : Il s’agit du contexte dans lequel les differentes structures
internes au document sont mises en place en fonction d’une pratique donnee (par
exemple le domaine legislatif). Les acteurs intervenant dans le contexte de pro-
duction sont les redacteurs (producteurs de contenu) des documents
Contexte de reception : Le contexte de reception determine la maniere dont les struc-
tures du document seront utilisees et interpretees par les lecteurs.
Conviction : Propriete d’un impact, represente sur une echelle de 0 a 100 la precision
avec laquelle nous pouvons affirmer la presence d’un impact elementaire.
CRISTAL : Systeme dedie a la gestion des prestations pour la Branche Famille de la
Securite Sociale.
Degre : Propriete d’un impact, represente, sur une echelle de 0 a 100, la couverture estimee
de l’impact sur un element impactable.
Docflow : Cycle de vie du document dans le cadre d’un processus de production docu-
mentaire.
Document multistructure : Voir Document polystructure.
Document polystructure : Document caracterise par la presence de plusieurs structures
concurrentes correspondant a des usages varies du document.
185

Glossaire
DSI : Direction du Systeme d’Information.
DTD : Document Type Definition – definit la structure d’un document.
Frame : Structure de donnees pour la representation d’une situation stereotypee.
G-Frame : Primitive fournie par le systeme des G-Frames afin d’exprimer des connais-
sances de nature assertionnelle.
HyTime : Hypermedia/Time-based Structuring Language.
ISDN : Institut des Sciences du Document Numerique.
Livrable logiciel : Livrable issus d’une des etapes d’un des processus de conception et
de developpement logiciel.
OCL : Object Constraint Language.
Ontologie : Dans le domaine de l’intelligence artificielle, une ontologie est frequemment
consideree comme la specification explicite d’une conceptualisation.
Organisation : Entreprise publique, entreprise privee ou institution publique (ministere,
tribunal, etc.).
PF : Prestation(s) Familiale(s).
Projection : Mecanisme permettant de passer du support d’enregistrement au support
d’appropriation
Raisonnement : Processus permettant, a partir de connaissances encodees de facon expli-
cite, de mettre en lumiere des connaissances qui n’etaient alors qu’implicitement
connues.
RDF : Resource Description Framework.
SGML : Standard Generalized Markup Language.
SI : Systeme d’Information.
SIDoc : Systeme d’Information Documentaire - le projet informatique qui a cree le Refe-
rentiel de gestion et de production documentaire.
Structure generique : Un document generique correspond a une classe de document.
Des langages de structuration documentaire tels que XML associent a cette notion
celle de DTD ou de schema.
Structure materielle : Structure imposant une presentation, une mise en forme du
document conformement a l’ordonnancement prescrit. Par exemple : un choix des
polices, de mise en page, etc.
Structure physique : Voir structure materielle
Structure semantique : Structure qui s’attache a l’explicitation de la signification des
informations vehiculees par le document
186

Structure specifique : Un document specifique est une instance d’un document ge-
nerique. Des langages tels que XML font correspondre a cette notion celle de
document valide. Un document valide est un document specifique conforme aux
contraintes structurelles imposees par le document generique dont il est l’exem-
plification.
Support d’appropriation : Support sur lequel le document est presente a l’utilisateur
lecteur.
Support d’enregistrement : Support sur lequel le document numerique est enregistre
selon un format de codage predefinit.
SVG : Langage XML de definition des dessins vectoriels.
Systeme Primitif des G-Frames : Systeme des G-Frames denue de toute extension
ontologique.
Taux de precision : Rapport du nombre d’elements pertinents identifies au nombre total
d’elements trouves. En anglais precision.
Taux de rappel : Rapport du nombre de documents pertinents trouves au nombre total
de documents pertinents. En anglais recall.
XML : eXtensible Markup Language.
XSD : Schema XML d’un document – tout comme les DTD definit la structure d’un
document. Les schemas sont eux-memes decrits en XML
187

Glossaire
188

Bibliographie
[Abrial 96] Abrial Jean-Raymond. The B-book : assigning programs to
meanings. Cambridge University Press, New York, NY, USA,
1996. 779 p.
[Alexander 02] Alexander Ian. Towards automatic traceability in industrial
practice. Proceedings of 1st International Workshop on Traceabi-
lity in Emerging Forms of Software Engineering. 2002, p 26–31.
[Altova 09] Altova, Rudolfsplatz 13a/9, A-1010 Wien, Austria. Al-
tova XMLSpy Schema Editor, 2009. Disponible sur :
http ://www.altova.com (consulte le 07.08.2009).
[Arbaoui 02] Arbaoui Selma, Derniame Jean-Claude, Oquendo Fla-
vio et Verjus Herve. A comparative review of process-
centered software engineering environments. Annals of Software
Engineering, 2002, vol 14, n 1-4, p 311–340.
[Aurum 03] Aurum Aybuke, Jeffery Ross, Wohlin Claes et Handzic
Meliha. Managing Software Engineering Knowledge. Springer,
2003. 380 p.
[Bachimont 99] Bachimont B. Bibliotheques numeriques audiovisuelles : des
enjeux scientifiques et techniques. Document Numerique, nu-
mero special Les bibliotheques numeriques, 1999, vol 2, n 3-4, p
219–242.
[Bargeron 99] Bargeron D., Gupta A., Grudin J., Sanocki E. et Men-
delzon A. Annotations for Streaming Video on the Web :
System Design and Usage Studies. Computer Networks, 1999,
vol 31, n 11-16, p 1139–1153.
[Bauer 89] Bauer Friedrich Ludwig, Moller Bernhard, Partsch
Helmut et Pepper Peter. Formal program construction by
transformations-computer-aided, intuition-guided programming.
IEEE Trans. Softw. Eng., 1989, vol 15, n 2, p 165–180.
189

Bibliographie
[Beck 99] Beck Kent. Extreme Programming Explained : Embrace
Change. Addison-Wesley Professional, 1999. 224 p.
[Belguidoum 06] Belguidoum Meriem et Dagnat Fabien. Analysis of deploy-
ment dependencies in software components. SAC ’06 : Procee-
dings of the 2006 ACM symposium on Applied computing. New
York, NY, USA. ACM, 2006, p 735–736.
[ben Lagha 99] b Lagha S., Sadfi W. et b Ahmed M. Une comparaison
SGML-XML. Cahiers GUTenberg : Actes de la journee XML au
Congres GUT99. Lyon, France. mai 1999, p 127–154.
[Bench-Capon 90] Bench-Capon Trevor et Coenen Frans. Practical Appli-
cation of KBS to Law : the Crucial Role of Maintenance. Legal
Knowledge Based Systems, JURIX’90 : Aims for Research and
Development. Edited by Schmidt A.H.J. et Winkels R.G.F.
Lelystad. Koninklijke Vermande, 1990, p 1–17.
[Bench-Capon 94] Bench-Capon Trevor et Coenen Frans. The Maintenance
of Legal Knowledge Based Systems. Computers and Law. Edited
by Carr I. et Williams K., p 129–172. Intellect Books, 1994.
[Binkley 91] Binkley David. Multi-Procedure Program Integration. These :
Univ. of Wisconsin, Madison, WI, August 1991.
[Bohner 96] Bohner Shawn et Arnold Robert. Software Change Impact
Analysis. Wiley, 1996. 392 p.
[Briand 03] Briand L. C., Labiche Y. et O’Sullivan L. Impact analysis
and change management of uml models. ICSM ’03 : Procee-
dings of the International Conference on Software Maintenance.
Washington, DC, USA. IEEE Computer Society, 2003, p 256.
[Brooks 87] Brooks Frederic. No silver bullet : Essence and accidents of
software engineering. Computer, 1987, vol 20, n 4, p 10–19.
[Chabbat 97] Chabbat Bertrand. Modelisation multiparadigme de textes
reglementaires. These : Institut National des Sciences Appliquees
de Lyon, Lyon, France, decembre 1997. 389 p.
[Champin 02] Champin Pierre-Antoine. Modeliser l’experience pour en as-
sister la reutilisation : De la conception assistee par ordinateur
au web semantique. These : Universite Claude Bernard – Lyon
1, Lyon, France, Decembre 2002. 138 p.
[Chen 02] Chen Zhenqiang, Xu Baowen et Zhao Jianjun. An over-
view of methods for dependence analysis of concurrent programs.
SIGPLAN Not., 2002, vol 37, n 8, p 45–52.
190

[Chiba 08] Chiba project. Chiba, 2008. Disponible sur :
http ://chiba.sourceforge.net/ (consulte le 10.09.2008).
[Cleland-Huang 03] Cleland-Huang Jane, Chang Carl K. et Christensen
Mark. Event-based traceability for managing evolutionary
change. IEEE Trans. Softw. Eng., 2003, vol 29, n 9, p 796–810.
[CNAF 08] Caisse Nationale des Allocations Familiales, 32, avenue de la Si-
belle, 75685 PARIS CEDEX 14. Aide personnalisee au logement
- Suivi legislatif, 2008.
[CNEDI 07a] Centre National d’Etudes et du Developpement Informatique
Rhone-Alpes, 128 rue servient, 69003 Lyon. Documentation du
projet SIDoc, 2007.
[CNEDI 07b] Centre National d’Etudes et du Developpement Informatique
Rhone-Alpes, 128 rue servient, 69003 Lyon. SIDoc - Systeme
d’Aide a l’Implementation de la Reglementation - Recettage
fonctionnel de la V0, 2007.
[CNEDI 07c] Centre National d’Etudes et du Developpement Informatique
Rhone-Alpes, 128 rue servient, 69003 Lyon. SIDoc - Systeme
d’Aide a l’Implementation de la Reglementation - Recettage tech-
nique de la V0, 2007.
[CodeSecuriteSociale 01] Secretariat General du Gouvernement, Hotel de Matignon, 57
rue de Varenne, 75007 PARIS. Code de la Securite Sociale –
Livre 2 : Organisation du regime general, action de prevention,
action sanitaire et sociale des caisses, 2001. Disponible sur :
http ://www.legifrance.gouv.fr (consulte le 07.07.2008).
[Cook 94] Cook Steve et Daniels John. Designing Object Systems :
Object-Oriented Modelling with Syntropy. Prentice Hall, 1994.
388 p.
[Dahl 72] Dahl O. J., Dijkstra E. W. et Hoare C. A. R. Structured
Programming. Academic Press, 1972. 234 p.
[Dijkstra 76] Dijkstra Edsger Wybe. A Discipline of Programming. Series
in Automatic Computation. Prentice Hall, 1976. 240 p.
[Domges 98] Domges Ralf et Pohl Klaus. Adapting traceability environ-
ments to project-specific needs. Commun. ACM, 1998, vol 41,
n 12, p 54–62.
[Doors 08] Telelogic AB, Telelogic AB, PO Box 4128, Kungsgatan 6, SE-203
12 Malmo, Sweden. Telelogic DOORS, 2008. Disponible sur :
191

Bibliographie
http ://www.telelogic.com/products/doors/index.cfm (consulte
le 07.08.2009).
[Duke 00] Duke Roger et Rose Gordon. Formal Object-Oriented Spe-
cification Using Object-Z. Palgrave Macmillan, 2000. 240 p.
[Eclipse 08] Eclipse Foundation. Eclipse - an open develop-
ment platform, 2008. Disponible sur : http ://www-
01.ibm.com/software/awdtools/developer/rose/index.html
(consulte le 04.08.2009).
[Egyed 02] Egyed Alexander et Grunbacher Paul. Automating re-
quirements traceability : Beyond the record & replay paradigm.
ASE ’02 : Proceedings of the 17th IEEE international conference
on Automated software engineering. Washington, DC, USA.
IEEE Computer Society, 2002, p 163.
[Ekman 04] Ekman Torbjorn et Asklund Ulf. Refactoring-aware ver-
sioning in eclipse. Proceedings of the Second Eclipse Technology
Exchange : eTX and the Eclipse Phenomenon (eTX 2004). Elec-
tronic Notes in Theoretical Computer Science, 2004, p 57–69.
[Engels 01] Engels Gregor, Kuster Jochem M., Heckel Reiko et
Groenewegen Luuk. A methodology for specifying and
analyzing consistency of object-oriented behavioral models.
ESEC/FSE-9 : Proceedings of the 8th European software engi-
neering conference held jointly with 9th ACM SIGSOFT interna-
tional symposium on Foundations of software engineering. New
York, NY, USA. ACM, 2001, p 186–195.
[Enss 04] Enss Raphael. Refactoring in Eclipse. Eclipse Departement
of Computer Science University of Manitoba, 2004. Disponible
sur : http ://www.cs.umanitoba.ca/ eclipse/13-Refactoring.pdf
(consulte le 04.08.2009).
[Erdmann 99] Erdmann Michael et Studer Rudi. Ontologies as Concep-
tual Models for XML Documents. Twelfth Workshop on Know-
ledge Acquisition, Modeling and Management (KAW’99). Al-
berta, Canada. 1999.
[Feather 00] Feather Martin, Cornford Steven et Gibbel Mark.
Scalable mechanisms for requirements interaction management.
Proceedings of the 4th International Conference on Requirements
Engineering –(Schaumburg, Illinois June 2000). IEEE Compu-
ter Society Press, 2000, p 119–129.
192

[Ferrante 87] Ferrante Jeanne, Ottenstein Karl J. et Warren Joe D.
The program dependence graph and its use in optimization.
ACM Trans. Program. Lang. Syst., 1987, vol 9, n 3, p 319–349.
[Finkelstein 94] Finkelstein Anthony, Kramer Jeff et Nuseibeh Bashar.
Software Process Modelling and Technology. Research Studies
Press Limited (J. Wiley), Taunton, UK, UK, 1994. 362 p.
[Fuggetta 00] Fuggetta Alfonso. Software process : A roadmap. Pro-
ceedings of the 22nd Int. Conf. on Software Engineering (IC-
SE’2000) – Future of Software Engineering Track. 2000.
[Gall 03] Gall Harald, Jazayeri Mehdi et Krajewski Jacek. Cvs
release history data for detecting logical couplings. IWPSE ’03 :
Proceedings of the 6th International Workshop on Principles of
Software Evolution. Washington, DC, USA. IEEE Computer
Society, 2003, p 13.
[German 04] German Daniel M. An empirical study of fine-grained soft-
ware modifications. ICSM ’04 : Proceedings of the 20th IEEE
International Conference on Software Maintenance. Washing-
ton, DC, USA. IEEE Computer Society, 2004, p 316–325.
[Ghezzi 03] Ghezzi Carlo, Jazayeri Mehdi et Mandrioli Dino. Fu-
damentals of Software Engineering. Prentice Hall, 2003. 624
p.
[Gianpaolo 98] Gianpaolo Cugola et Carlo Guezzi. Software processes : a
retrospective and a path to the future. Software Process Impro-
vement and Practice, 1998, vol 4, n 3, p 101–123.
[Gotel 94] Gotel O. et Finkelstein A. An analysis of the requirements
traceability problem. In Proceedings of 1st International Confe-
rence on Requirements Engineering (Colorado Springs, CO). Los
Alamitos, CA,. IEEE Computer Society Press, 1994, p 94–101.
[Hatcliff 99] Hatcliff John, Corbett James, Dwyer Matthew, Soko-
lowski Stefan et Zheng Hongjun. A formal study of slicing
for multi-threaded programs with jvm concurrency primitives.
Proceedings of the 6th International Static Analysis Symposium
(SAS’99). Springer-Verlag, 1999, p 1–18.
[Horwitz 04] Horwitz Susan, Reps Thomas et Binkley David. Interpro-
cedural slicing using dependence graphs. SIGPLAN Not., 2004,
vol 39, n 4, p 229–243.
193

Bibliographie
[Humphrey 89] Humphrey Watts S. Managing the Software Process. SEI
Series in Software Engineering. Addison-Wesley, 1989. 512 p.
[ISO 86] International Organization for Standardization. Standard Gene-
ralized Markup Language (SGML). International Standard ISO
8879 :1986(E), Octobre 1986. 155 p.
[ISO 92] International Organization for Standardization.
Hypermedia/Time-based Structuring Language (HyTime).
International Standard ISO 10744 :1992(E), Decembre 1992.
184 p.
[ISO 97] International Organization for Standardization. ISO 9000-3 task
force, Quality management and quality assurance standards -
Part 3 : guidelines for the application of ISO 9000 to the de-
velopment, supply and maintenance of software, 1997.
[ISO 04] International Organization for Standardization. ISO/IEC 15504
– SPICE (Software Process Improvement and Capability dEter-
mination, 2004.
[ISO 06] International Organization for Standardization. Document
Schema Definition Language (DSDL) – Rule-based validation
– Schematron. International Standard ISO/IEC 19757-3 :2006,
2006. 38 p.
[Jouve 01] Jouve David, Chabbat Bertrand, Amghar Youssef et Pi-
non Jean-Marie. Structuration semantique de la reglemen-
tation. Proc. of the XIXeme Congres INFormatique des OR-
ganisations et Systemes d’Information et de Decision (INFOR-
SID’2001). Martigny, Suisse. INFORDSID Editions, 2001, p 5–
26.
[Jouve 03a] Jouve David. Modelisation semantique de la reglementation.
These : Institut National des Sciences Appliquees de Lyon, no-
vembre 2003. 270 p.
[Jouve 03b] Jouve David, Amghar Youssef, Chabbat Bertrand et Pi-
non Jean-Marie. Conceptual Framework for Document Se-
mantic Modelling : an Application to Document and Knowledge
Management in the Legal Domain. Data & Knowledge Enginee-
ring, 2003, vol 46, n 3, p 345 – 375.
[Kagdi 07] Kagdi Huzefa et Maletic Jonathan I. Combining single-
version and evolutionary dependencies for software-change pre-
diction. MSR ’07 : Proceedings of the Fourth International
194

Workshop on Mining Software Repositories. Washington, DC,
USA. IEEE Computer Society, 2007, p 17.
[Klarlund 02] Klarlund N., Moller A. et Schwatzbach M. I. Dsd :
a schema language for xml. Automated Software Engineering,
2002, vol 9, n 3, p 285–319.
[Krishnan 00] Krishnan P. Consistency checks for uml. APSEC ’00 : Procee-
dings of the Seventh Asia-Pacific Software Engineering Confe-
rence. Washington, DC, USA. IEEE Computer Society, Decem-
ber 2000, p 162–169.
[Lano 90] Lano Kevin. Z++ – an object-orientated extension to z. Z User
Workshop. Workshops in Computing, Springer-Verlag, 1990, p
151–172.
[Lee 00] Lee D. et Chu W.W. Comparative analysis of six xml schema
languages. SIGMOD Record, 2000, vol 29, n 3, p 76 – 87.
[Lucia 07] Lucia Andrea De, Fasano Fausto, Oliveto Rocco et
Tortora Genoveffa. Recovering traceability links in soft-
ware artifact management systems using information retrieval
methods. ACM Trans. Softw. Eng. Methodol., 2007, vol 16, n 4,
p 13.
[Maletic 01] Maletic Jonathan et Marcus Andrian. Supporting pro-
gram comprehension using semantic and structural information.
ICSE ’01 : Proceedings of the 23rd International Conference on
Software Engineering. Washington, DC, USA. IEEE Computer
Society, 2001, p 103–112.
[Michard 01] Michard Alain. XML Langage et Applications. Editions Ey-
rolles, Paris, 2001. 499 p.
[Microsoft 06] Microsoft Coorporation. Le navigateur Microsoft In-
ternet Explorer, version 6, 2006. Disponible sur :
http ://www.microsoft.com/windows/ie/ie6/default.mspx
(consulte le 07.08.2009).
[Microsoft 07] Microsoft Coorporation. Le navigateur Microsoft In-
ternet Explorer, version 7, 2007. Disponible sur :
http ://www.microsoft.com/windows/internet-explorer/ie7/
(consulte le 07.08.2009).
[Morin 99] Morin Edgar. Relier les connaissances – Le defi du XXIe
siecle. Seuil, 1999. 478 p.
195

Bibliographie
[Mozilla 08] Fondation Mozilla. Le projet Firefox de la fondation
Mozilla, 2008. Disponible sur : http ://www.mozilla-
europe.org/fr/firefox/ (consulte le 07.08.2009).
[MSOffice 08] Microsoft Coorporation. Microsoft Office, 2008. Dispo-
nible sur : http ://www.microsoft.com/france/office (consulte le
07.08.2009).
[Nanard 96] Nanard Marc, Nanard Jocelyne, Massotte Anne Ma-
rie, Chauche Jacques, Joubert Alain et Betaille Henri.
Acquisition et ingenierie des connaissances, tendances actuelles,
chapitre La metaphore du generaliste : Acquisition et utilisation
de la connaissance macroscopique sur une base de documents
techniques, p 285–306. Cepadues editions, 1996.
[Nicolle 01] Nicolle Cecile. Systeme d’acces a des Bases de Donnees He-
terogenes reparties en vue d’une aide a la decision (SABaDH).
These : Institut National des Sciences Appliquees de Lyon, de-
cembre 2001. 125 p.
[Oberon 08] Institut fur Systemsoftware, Johannes Kepler Universitat, Insti-
tut fur Systemsoftware, Altenbergerstr. 69, A-4040 Linz. Oberon
Slicing Tool, 2008. Disponible sur : http ://www.ssw.uni-
linz.ac.at/Research/Projects/ProgramSlicing/ (consulte le
07.08.2009).
[OMG 01] Object Management Group (OMG). Unified Modeling Language
Specification, Version 1.4, septembre 2001. Disponible sur :
http ://www.omg.org/spec/UML/1.4/ (consulte le 05.08.2008).
[OMG 05] Internation Standardisation Organisation (ISO). Meta Ob-
ject Facility Specification, Version 1.4.1, 2005. Disponible
sur : http ://www.omg.org/docs/formal/05-05-05.pdf (consulte
le 04.08.2008).
[OMG 06a] Object Management Group (OMG). Meta Object Faci-
lity Specification, Version 2.0, 2006. Disponible sur :
http ://www.omg.org/spec/MOF/2.0/ (consulte le 04.08.2008).
[OMG 06b] Object Management Group (OMG). Object Constraint
Language Specification, version 2.0, mai 2006. Disponible
sur :http ://www.omg.org/technology/documents/formal/ocl.htm
(consulte le 08.08.2008).
[OMG 07a] Object Management Group (OMG). Unified Modeling
Language Specification, Version 2.1.2, 2007. Disponible
196

sur : http ://www.omg.org/spec/UML/2.1.2/ (consulte le
04.08.2008).
[OMG 07b] OMG – Object Management Group. XML Metadata In-
terchange (XMI), v2.1.1, December 2007. Disponible sur :
http ://www.omg.org/technology/documents/formal/xmi.htm
(consulte le 03.09.2008).
[Opdyke 92] Opdyke William F. Refactoring Object-Oriented Frame-
works. These : University of Illinois at Urbana-Champaign, 1992.
Disponible sur : http ://www.laputan.org/pub/papers/opdyke-
thesis.pdf (consulte le 04.11.2009).
[Osterweil 87] Osterweil Leaon. Software processes are software too. ICSE
’87 : Proceedings of the 9th international conference on Software
Engineering. Los Alamitos, CA, USA. IEEE Computer Society
Press, 1987, p 2–13.
[Ottenstein 84] Ottenstein Karl J. et Ottenstein Linda M. The program
dependence graph in a software development environment. SIG-
PLAN Not., 1984, vol 19, n 5, p 177–184.
[Pfleeger 06] Pfleeger Shari Lawrence et Atlee Joanne M. Software
Engineering : Theory and Practice, third edition. Prentice Hall,
2006. 736 p.
[Pinheiro 96] Pinheiro Francisco A. C. et Goguen Joseph A. An object-
oriented tool for tracing requirements. IEEE Softw., 1996, vol 13,
n 2, p 52–64.
[Pohl 87] Pohl Klaus. Requirements engineering : An overview. In En-
cyclopedia of Computer Science and Technology, 1987, vol 36,
n 21.
[Rand 79] Rand Ayn. Introduction to Objectivist Epistemology. New Ame-
rican Library, New York, USA, 1979. 314 p.
[RDD 08] Holagent Coorporation. RDD-100, 2008. Disponible sur :
http ://www.holagent.com/products/ (consulte le 07.08.2009).
[Requisite 08] IBM Corporation. Rational RequisitePro, 2008. Disponible sur :
http ://www-01.ibm.com/software/awdtools/reqpro/ (consulte
le 07.08.2009).
[Richardson 04] Richardson Julian et Green Jeff. Automating traceabi-
lity for generated software artifacts. ASE ’04 : Proceedings of
the 19th IEEE international conference on Automated software
197

Bibliographie
engineering. Washington, DC, USA. IEEE Computer Society,
2004, p 24–33.
[Rick 00] Rick Jellife. The Schematron – An XML Structure Va-
lidation Language using Patterns in Trees, 2000. Disponible
sur : http ://xml.ascc.net/resource/schematron/ (consulte le
04.08.2009).
[Roberts 99] Roberts Donald Bradley. Practical analysis for refactoring.
These : University of Illinois at Urbana-Champaign, Champaign,
IL, USA, 1999. Adviser-Ralph Johnson.
[Robinson 03] Robinson William N., Pawlowski Suzanne D. et Vol-
kov Vecheslav. Requirements interaction management. ACM
Computing Surveys, 2003, vol 35, n 2, p 132–190.
[Rodrıguez 04a] Rodrıguez Oscar M., Martınez Ana I., Favela Jesus
et Vizcaıno Aurora. Understanding and supporting know-
ledge flows in a community of software developers. International
Workshop on Groupware (CRIWG’04). 2004, p 56–66.
[Rodrıguez 04b] Rodrıguez Oscar M., Martınez Ana I., Vizcaıno Au-
rora, Favela Jesus et Piattini Mario. Identifying know-
ledge managment needs in software maintenance groups : a quali-
tative approach. Proceedings of the 5th Internationa Conference
on Computer Science (ENC’ 2004). IEEE Computer Society
Press, 2004, p 72–79.
[Rose 08] IBM Coorporation. Rational Rose, 2008. Disponible sur :
http ://www.eclipse.org/ (consulte le 04.08.2009).
[Royce 70] Royce Winston. Managing the development of large software
systems : Concepts and techniques. In Proceedings of WesCon
Conference, August 25-28 1970.
[RUP09 09] IBM Coorporation. Rational Unified Process, 2009. Dispo-
nible sur : http ://www-01.ibm.com/software/awdtools/rup/
(consulte le 24.03.2009).
[Settimi 04] Settimi Raffaella, Cleland-Huang Jane, Khadra Ous-
sama Ben, Mody Jigar, Lukasik Wiktor et DePalma
Chris. Supporting software evolution through dynamically re-
trieving traces to uml artifacts. IWPSE ’04 : Proceedings of the
Principles of Software Evolution, 7th International Workshop.
Washington, DC, USA. IEEE Computer Society, 2004, p 49–54.
198

[Smith 99] Smith Graeme. The Object-Z Specification Language. Kluwer
Academic Publishers, Norwell, MA, USA, 1999. 160p.
[Sourrouille 02] Sourrouille Jean Louis et Caplat Guy. Constraint che-
cking in uml modeling. SEKE ’02 : Proceedings of the 14th in-
ternational conference on Software engineering and knowledge
engineering. New York, NY, USA. ACM, 2002, p 217–224.
[Stern 97] Stern Yves. Les quatre dimensions des documents electro-
niques. Document Numerique, 1997, vol 1, n 1, p 55–60.
[Suciu 01] Suciu Dan. On database theory and xml. SIGMOD Rec., 2001,
vol 30, n 3, p 39–45.
[Sward 04] Sward Ricky E. et Chamillard A.T. Adaslicer : an ada
program slicer. Ada Lett., 2004, vol XXIV, n 1, p 10–16.
[Turner 06] Turner Michael S. V. Microsoft Solutions Framework Es-
sentials. Microsoft Press, 2006. 336 p.
[Turpin 06] Turpin Andrew et Scholer Falk. User performance versus
precision measures for simple search tasks. SIGIR ’06 : Procee-
dings of the 29th annual international ACM SIGIR conference
on Research and development in information retrieval. New
York, NY, USA. ACM, 2006, p 11–18.
[van Lamsweerde 00] v Lamsweerde Axel et Letier Emmanuel. Handling obs-
tacles in goal-oriented requirements engineering. IEEE Transac-
tions on Software Engineering, 2000, vol 26, n 10, p 978–1005.
[Vasutiu 06] Vasutiu Ovidiu, Jouve David et Amghar Youssef. Gestion
des changements et etude d’impact dans un Systeme d’Informa-
tion reglementaire. INFORSID’2006 - Informatique des ORga-
nisations et Systemes d’Information et de Decision 2006. Edited
by Inforsid . Actes du XXIVeme Congres. Association Inforsid,
juin 2006, p 1007–1022.
[Vasutiu 08] Vasutiu Ovidiu, Jouve David, Amghar Youssef et Pinon
Jean-Marie. Knowledge management in information system
design and delivery process. Proc. of the Xth Internation Congres
On Enterprise Information Systems (ICEIS’2008). Barcelona,
Spain. INSTICC, 2008, p 5–26.
[Vergnaud 90] Vergnaud Gilles. La theorie des champs conceptuels. Re-
cherches en didactique des mathematiques, 1990, vol 10, p 133 –
170.
199

Bibliographie
[W3C 98] World Wide Web Consortium. Cascading Style Sheets Level
2 Specification, W3C Recommendation, 1998. Disponible sur :
http ://www.w3.org/TR/REC-CSS2 (consulte le 07.08.2009).
[W3C 99a] World Wide Web Consortium. Cascading Style Sheets, Level
1 (revised 11 Jan 1999), W3C Recommendation, 1999. Dis-
ponible sur : http ://www.w3.org/TR/REC-CSS1 (consulte le
07.08.2009).
[W3C 99b] World Wide Web Consortium. Transformations XSL (XSLT)
Version 1.0, W3C Recommendation, 1999. Disponible sur :
http ://www.w3.org/TR/xslt (consulte le 07.08.2009).
[W3C 99c] World Wide Web Consortium. XML Path Language (XPath),
Version 1.0, W3C Recommendation, 1999. Disponible sur :
http ://www.w3.org/TR/xpath (consulte le 07.08.2009).
[W3C 01a] World Wide Web Consortium. Transformations XSL (XSLT)
Version 1.1, W3C Working Draft, 2001. Disponible sur :
http ://www.w3.org/TR/xslt11 (consulte le 07.08.2009).
[W3C 01b] World Wide Web Consortium. XML Schema Part 0 :
Primer, W3C Recommendation, 2001. Disponible sur :
http ://www.w3.org/TR/xmlschema-0 (consulte le 04.08.2009).
[W3C 01c] World Wide Web Consortium. XML Schema Part 1 :
Structures, W3C Recommendation, 2001. Disponible sur :
http ://www.w3.org/TR/xmlschema-1 (consulte le 04.08.2009).
[W3C 01d] World Wide Web Consortium. XML Schema Part 2 :
Datatypes, W3C Recommendation, 2001. Disponible sur :
http ://www.w3.org/TR/xmlschema-2 (consulte le 04.08.2009).
[W3C 01e] World Wide Web Consortium. XML Schema,
W3C Recommendation, 2001. Disponible sur :
http ://www.w3.org/XML/Schema (consulte le 04.08.2009).
[W3C 03] World Wide Web Consortium. Scalable Vector Graphics
(SVG) 1.0. Specification, January 2003. Disponible sur :
http ://www.w3.org/TR/svg (consulte le 10.08.2009).
[W3C 07a] World Wide Web Consortium. XForms 1.0 (Third Edition), Oc-
tober 2007. Disponible sur : http ://www.w3.org/TR/xforms
(consulte le 10.08.2009).
[W3C 07b] World Wide Web Consortium. XML Query Language (XQuery),
Version 1.0, W3C Recommendation, January 2007. Disponible
sur : http ://www.w3.org/TR/xquery (consulte le 07.08.2009).
200

[W3C 08] World Wide Web Consortium. Extensible Markup Language
(XML) 1.0 (Fifth Edition), W3C Recommendation, August
2008. Disponible sur : http ://www.w3.org/TR/REC-XML
(consulte le 11.08.2009).
[Weiser 81] Weiser Mark. Program slicing. ICSE ’81 : Proceedings of the
5th international conference on Software engineering. Piscata-
way, NJ, USA. IEEE Press, 1981, p 439–449.
[Weiser 84] Weiser Mark. Program slicing. IEEE Transactions on Soft-
ware Engineering, July 1984, vol 10, n 4, p 352–357.
[Wirth 71] Wirth Niklaus. Program development by stepwise refinement.
Communications of the ACM, 1971, vol 14, n 4, p 221–227.
[Wisconsin00 00] University of Wisconsin-Madison. The Wisconsin Program-
Slicing Tool, Version 1.1, 2000. Disponible sur :
http ://www.cs.wisc.edu/wpis/slicing tool/ (consulte le
07.08.2009).
[Wulf 58] Wulf William A., Shaw Mary, Hilfinger Paul N. et Flon
Lawrence. Theorie des graphes et ses applications. Dunod,
1958.
[Z 08] Programming Research Group (PRG), Oxford Uni-
versity. The Z notation, 2008. Disponible sur :
http ://www.comlab.ox.ac.uk/archive/z.html (consulte le
07.08.2009).
[Zimmermann 04] Zimmermann Thomas, Weisgerber Peter, Diehl Stephan
et Zeller Andreas. Mining version histories to guide software
changes. ICSE ’04 : Proceedings of the 26th International Confe-
rence on Software Engineering. Washington, DC, USA. IEEE
Computer Society, 2004, p 563–572.
201

Bibliographie
202

Resume
L’activite des organisations qui ont pour mission la mise en application de la le-
gislation est fondee sur l’analyse et la manipulation des textes reglementaires. Par ailleurs,
au vu de la quantite massive d’information traitee au sein de ces organisations, le travail
depasse tres largement les capacites humaines, les amenant a solliciter l’assistance du Sys-
teme d’Information. Une des principales caracteristiques des textes reglementaires est que
ceux-ci sont en perpetuelle evolution. Leur mise en œuvre au sein du Systeme d’Informa-
tion doit etre reexaminee a chacune de ces evolutions afin d’en assurer la coherence et la
conformite. Pour cela nous proposons un modele commun pour la mise en relation des
textes reglementaires et des composants du Systeme d’Information. Ce modele commun
est ensuite enrichi des mecanismes d’analyse des dependances et d’etude d’impact per-
mettant d’identifier et d’evaluer les consequences d’une modification reglementaire sur les
textes reglementaires et sur le Systeme d’Information. Ces problemes, issus du contexte
de la Caisse Nationale des Allocations Familiales (Cnaf), n’ont toutefois pas ete traites
uniquement en fonction du contexte specifique de travail, mais bien en les considerant
comme revelateurs d’une problematique plus large concernant de maniere generale la ges-
tion documentaire et la gestion des Systemes d’Information. Ainsi ces propositions ont ete
validees lors de leur integration dans le Systeme d’Information Documentaire de la Cnaf
mais leur champ d’application peut-etre elargi a d’autres domaines.
Mots-cles: Mesure d’impact, Analyse des dependances, Gestion des connaissances, Sys-
teme d’Information, Document Reglementaire, XML, UML.
Abstract
The activity of organization whose mission is the application of the legislation is
based on analyzing and treatment of legal documents. Considering the enormous quantity
of information that has to be processed by theses organizations, their work overwhelms
human’s capacities making them use the assistance of an Information System. One of the
most important properties of the legal documents is that they are constantly evolving.
Their implementation within the Information System must be updated with each one of
the legal evolution. Therefore our objective is to propose un common model to be used to
manage the relation between legal documents and Information System components. This
model will be enriched by procedures to analyze dependencies and impact studies in order
203

to identify and evaluate all the impacts that a legal update has on the organization : on the
legal documents and on the Information System. This issues initially originated at the Cnaf
– French National Family Benefits Office but were be treated as more general problems
concerning document management and Information System management. Therefore our
proposition was tested while being integrated in the Information System of the Cnaf but
their application field can be enlarged to other organizations.
Keywords: Knoledge Management, Impact study, Collaborative work, Legal document,
Web 2.0, XML, UML
204