







Languages
Pages
Legal


GELE5340
Circuits ITGÉ (VLSI)
Chapitre 7: Circuits arithmétiques

GELE5340 – Gabriel Cormier, Université de Moncton 2
Contenu du chapitre
• On verra dans ce chapitres les éléments de
base des circuits de traitement mathématique
des microprocesseurs:
○ Additionneurs
○ Multiplicateurs
○ Déphaseurs

GELE5340 – Gabriel Cormier, Université de Moncton 3
Organisation d’un microprocesseur
• Le microprocesseur est composé de 4
composantes principales:
○ Mémoire
○ Bloc de contrôle
○ Unité arithmétique
○ Bloc entrée / sortie
• L’unité arithmétique est la composante où les
calculs mathématiques ont lieu. C’est cette
composante qui nous intéresse.
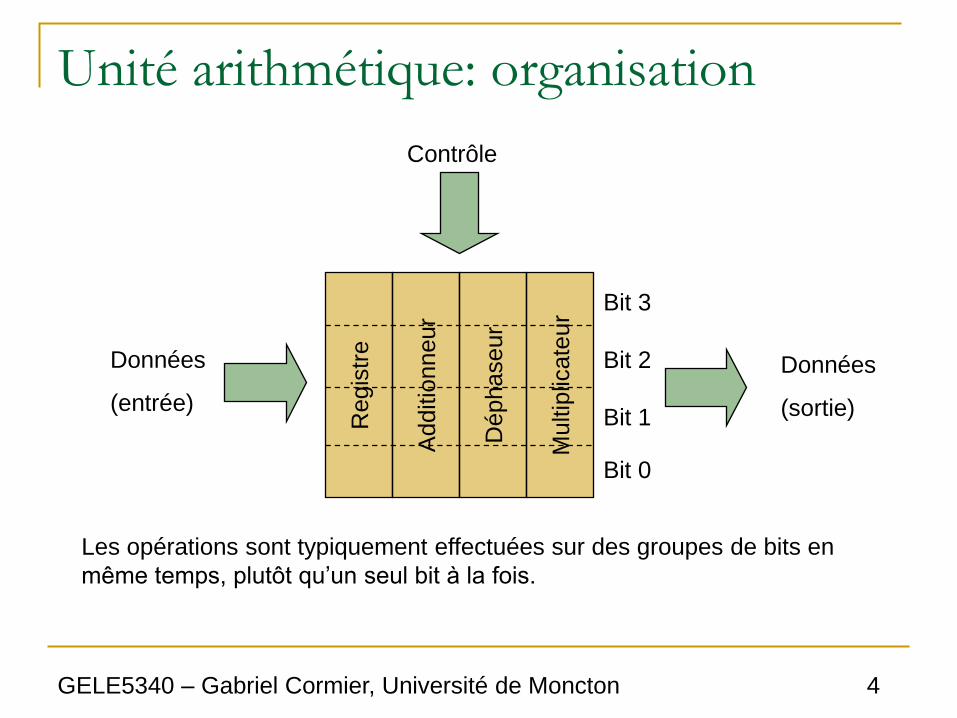
GELE5340 – Gabriel Cormier, Université de Moncton 4
Unité arithmétique: organisation
Regis
tre
Additio
nneur
Déphaseur
Multip
licate
ur
Données
(entrée)
Données
(sortie)
Contrôle
Bit 3
Bit 2
Bit 1
Bit 0
Les opérations sont typiquement effectuées sur des groupes de bits en
même temps, plutôt qu’un seul bit à la fois.

GELE5340 – Gabriel Cormier, Université de Moncton 5
Unité arithmétique
• Dans la figure précédente, les opérations
sont effectuées sur des blocs de 4 bits à la
fois.
○ Si on voudrait un microprocesseur à 24 bits, on
utiliserait 6 blocs semblables.
○ On a donc seulement besoin de faire le design
d’un bloc de 4 bits, et les 5 autres blocs sont des
copies.

L’additionneur

GELE5340 – Gabriel Cormier, Université de Moncton 7
Additionneurs
• L’addition est l’opération la plus commune. C’est
aussi l’opération la plus lente, typiquement, et donc
il faut bien optimiser le design de l’additionneur.
• Comme dans les circuits vus auparavant, il y a deux
méthodes pour optimiser la performance:
○ Optimisation au niveau logique: On réarrange les équations
pour obtenir un circuit plus petit ou plus rapide.
○ Optimisation au niveau électronique: On redimensionne ou
repositionne les transistors pour obtenir un circuit plus
rapide.

GELE5340 – Gabriel Cormier, Université de Moncton 8
L’additionneur complet à 1 bit
Additionneur
1 bit
A
B
Ci
Co
S
A B Ci Co S Report
0 0 0 0 0 delete
0 0 1 0 1 delete
0 1 0 0 1 propagate
0 1 1 1 0 propagate
1 0 0 0 1 propagate
1 0 1 1 0 propagate
1 1 0 1 0 generate
1 1 1 1 1 generate
A et B sont les entrées. Ci est le report (carry) d’entrée.
S est la somme. Co est le report de sortie.
La somme dépend de A et B (évidemment) et aussi du report d’entrée.
inCBAS iio CACBBAC

GELE5340 – Gabriel Cormier, Université de Moncton 9
L’additionneur complet à 1 bit
Additionneur
1 bit
A
B
Ci
Co
S
A B Ci Co S Report
0 0 0 0 0 delete
0 0 1 0 1 delete
0 1 0 0 1 propagate
0 1 1 1 0 propagate
1 0 0 0 1 propagate
1 0 1 1 0 propagate
1 1 0 1 0 generate
1 1 1 1 1 generate inCBAS
iio CACBBAC
Le report fonctionne selon
les 3 équations suivantes,
indépendantes de Ci:
BAD
BAP
BAG
Delete: C0 = 0.
Propagate: C0 = Cin.
Generate: C0 = 1.
GELE5340 – Gabriel Cormier, Université de Moncton 10
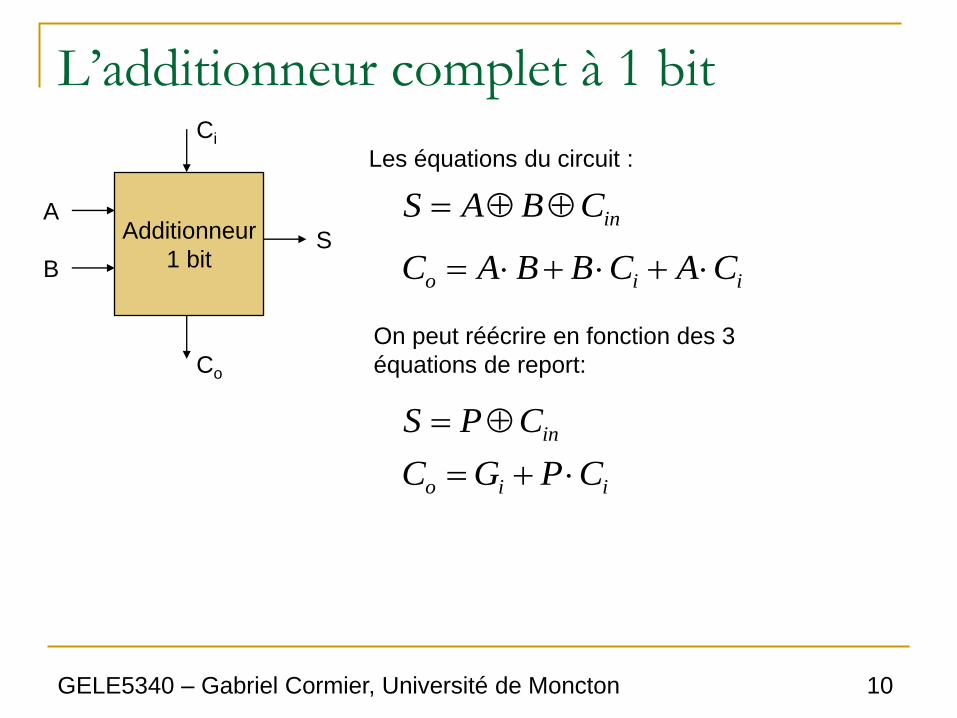
L’additionneur complet à 1 bit
Additionneur
1 bit
A
B
Ci
Co
S inCBAS
iio CACBBAC
Les équations du circuit :
On peut réécrire en fonction des 3
équations de report:
inCPS
iio CPGC

GELE5340 – Gabriel Cormier, Université de Moncton 11
Réalisation d’un additionneur
• Il existe plusieurs méthodes pour implanter un additionneur à plusieurs bits.
○ Additionneur à propagation de report Additionneur statique (CMOS complémentaire)
Additionneur miroir
Additionneur à base de portes de transmission
Chaîne de report Manchester
○ Additionneur à dérivation de report
○ Additionneur à sélection de report Linéaire
Racine carrée

GELE5340 – Gabriel Cormier, Université de Moncton 12
L’additionneur à report propagé
• L’additionneur à report propagé (carry-ripple)
est le type d’additionneur de base.
• On construit un additionneur à report propagé
à N bits en mettant en cascade N
additionneurs complets.
• Dans ce cas-ci, le report d’entrée du premier
bit doit se propager jusqu’à la sortie pour
obtenir la valeur correcte de la somme.

GELE5340 – Gabriel Cormier, Université de Moncton 13
L’additionneur à report propagé
FA
A0 B0
Ci,0
S0
FA
A1 B1
S1
FA
A2 B2
S2
FA
A3 B3
S3
Co,0
(Ci,1)
Co,3 Co,2
(Ci,3)
Co,1
(Ci,2)
Le pire délai est fonction du nombre de bits.
sumreportd ttNt )1(
Où treport = délai pour que le report d’entrée se propage au report de
sortie, et tsum = délai pour que le report se propage à la somme.
L’objectif est donc de rendre la génération du report le plus rapide possible.
treport
tsum

GELE5340 – Gabriel Cormier, Université de Moncton 14
L’additionneur à report propagé
• Selon l’équation du pire délai:
• On peut conclure que:
○ Le délai de propagation dans cette configuration
est linéaire par rapport au nombre de bits. Ceci
est important lorsqu’on design des circuits à
plusieurs bits (N = 32, 64, 128, …)
○ Pour améliorer la vitesse, il est plus important
d’optimiser treport que tsum.
sumreportd ttNt )1(

GELE5340 – Gabriel Cormier, Université de Moncton 15
Additionneur RP: CMOS complémentaire
VDD
A
VDD
Co
B
A
A
A B
B
B Ci
Ci
VDD
VDD
S
A
A
A A
B
B
B
B
Ci
Ci
Ci
Ci
28 transistors

GELE5340 – Gabriel Cormier, Université de Moncton 16
Additionneur RP: CMOS complémentaire
• L’additionneur précédent, en plus d’être gros, est
lent:
○ Il y a des PMOS en série (les PMOS ont environ 2.5x la
résistance d’un NMOS) dans le calcul de Co et S.
○ La capacitance d’entrée de Ci est grande (6 capacitances
de grille et 2 capacitances de drain).
• Cependant, quelques astuces sont présentes:
○ Ci est placé le plus près possible de la sortie; c’est un
chemin critique.
○ Effort logique de Ci = 2 (dans le parcours pour générer Co).

GELE5340 – Gabriel Cormier, Université de Moncton 17
Propriété: inversion
FA
A B
Ci
S
Co
On peut prendre avantage de la propriété d’inversion de
l’additionneur pour réduire le nombre d’inverseurs dans le circuit.
FA
A B
Ci
S
Co
),,(),,(
),,(),,(
ioio
ii
CBACCBAC
CBASCBAS
GELE5340 – Gabriel Cormier, Université de Moncton 18
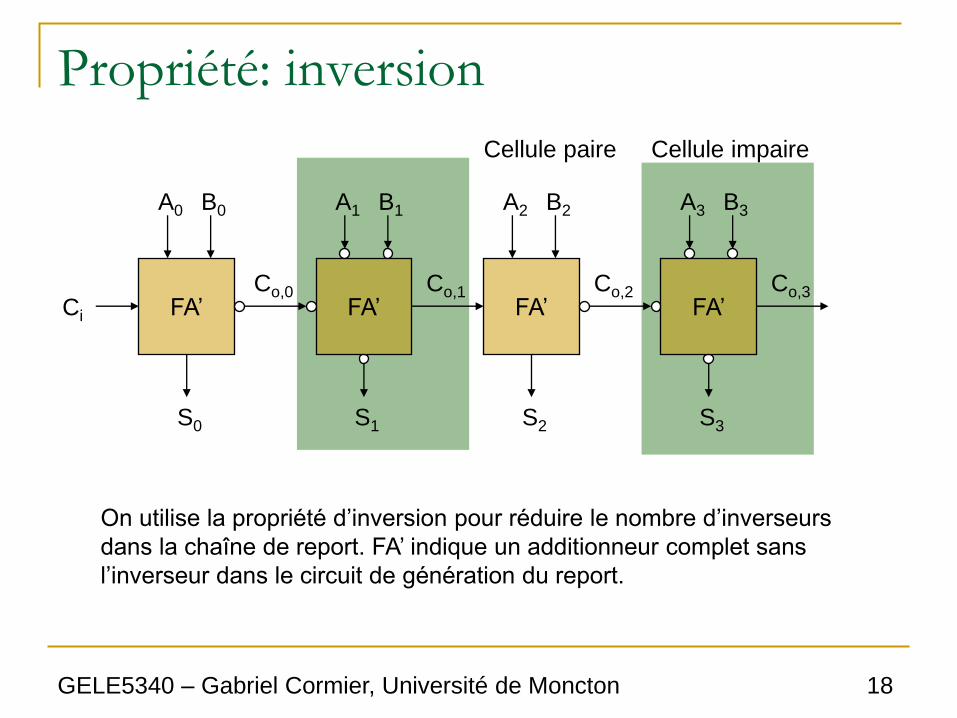
Propriété: inversion
FA’
A0 B0
Ci
S0
Co,0 FA’
A1 B1
S1
Co,1 FA’
A2 B2
S2
Co,2 FA’
A3 B3
S3
Co,3
Cellule impaire Cellule paire
On utilise la propriété d’inversion pour réduire le nombre d’inverseurs
dans la chaîne de report. FA’ indique un additionneur complet sans
l’inverseur dans le circuit de génération du report.

GELE5340 – Gabriel Cormier, Université de Moncton 19
Additionneur miroir
• L’additionneur miroir est basé sur les
équations de S et Co en fonction de P et G.
• L’additionneur miroir permet de réduire le
nombre de transistors utilisés.

GELE5340 – Gabriel Cormier, Université de Moncton 20
Additionneur miroir
VDD
A
A
A
A
B
B B
B
Ci
B Ci A
A B Ci
VDD
Co
VDD
A
A
B
B
Ci
Ci
S
24 transistors

GELE5340 – Gabriel Cormier, Université de Moncton 21
Additionneur miroir
• Avantages:
○ Il faut seulement 24 transistors (plutôt que 28).
○ Un maximum de 2 transistors sont en série dans
le circuit pour générer Co.
○ Les transistors branchés à Ci sont placés le plus
près de la sortie.
○ Seuls les transistors du circuit pour générer Co ont
besoin d’être dimensionnés pour la vitesse. Les
autres peuvent être de dimension minimale.

GELE5340 – Gabriel Cormier, Université de Moncton 22
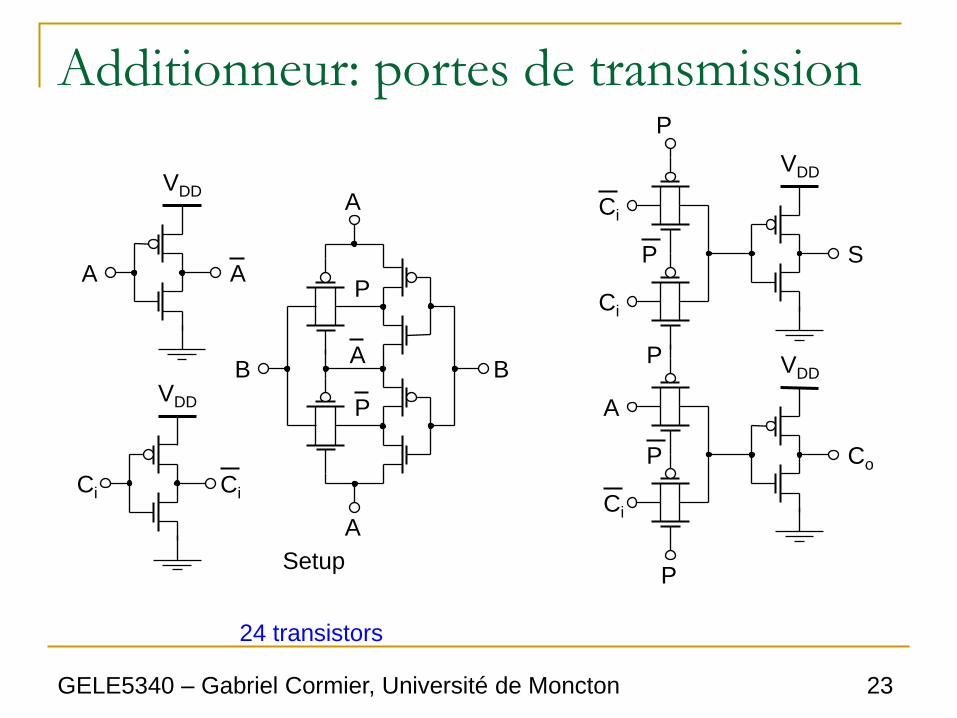
Additionneur: portes de transmission
• On peut faire un additionneur complet avec
des portes de transmission.
• Dans ce cas-ci, on utilise les équations de G
et P pour obtenir les circuits.
• Les circuits internes de l’additionneur sont
des portes XOR et des multiplexeurs.
GELE5340 – Gabriel Cormier, Université de Moncton 23
Additionneur: portes de transmission
VDD
A A
B
24 transistors
VDD
Ci Ci
A B
A
A
VDD
S
VDD
Co
A
Ci
Ci
Ci
P
P
P
P
P Setup
P
P

GELE5340 – Gabriel Cormier, Université de Moncton 24
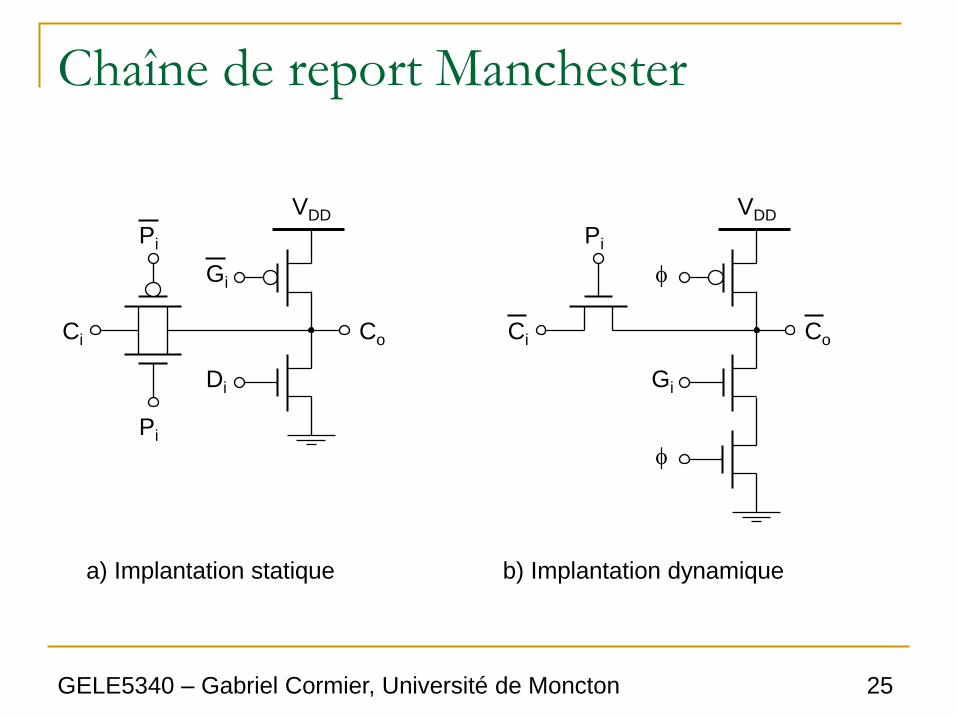
Chaîne de report Manchester
• On peut simplifier le circuit précédent de
génération du report si on utilise les signaux
generate et delete.
• L’implantation peut se faire de deux
méthodes:
○ Statique, avec des portes de transmission
○ Dynamique
GELE5340 – Gabriel Cormier, Université de Moncton 25
Chaîne de report Manchester
VDD
Ci Co
Pi
Pi
Di
Gi
VDD
Ci Co
Pi
Gi
a) Implantation statique b) Implantation dynamique
GELE5340 – Gabriel Cormier, Université de Moncton 26
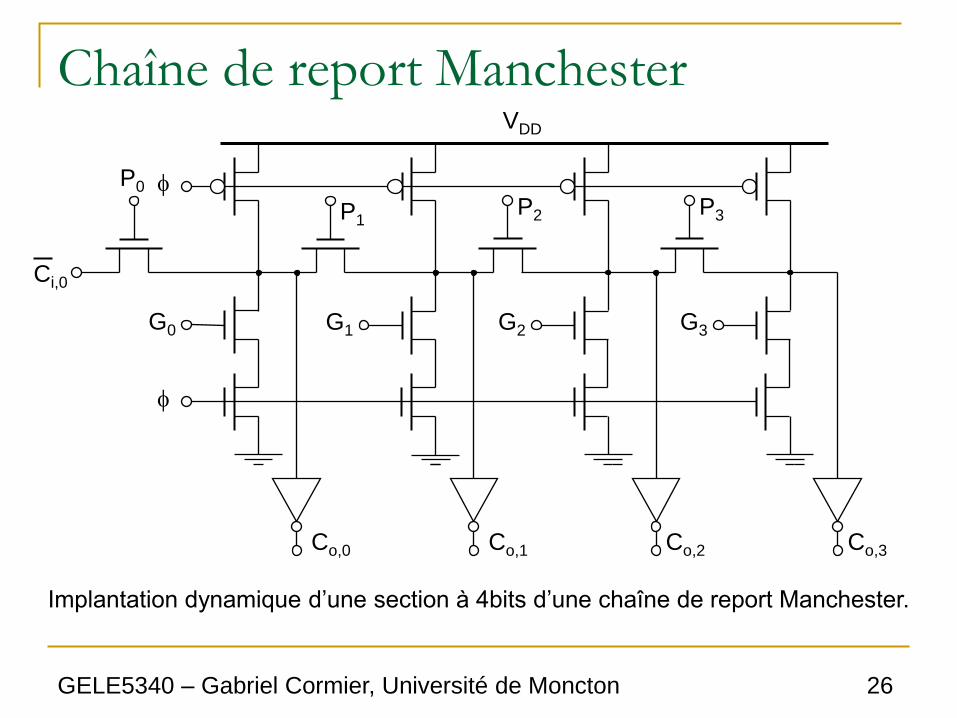
Chaîne de report Manchester
Ci,0
P0
G0
P1
G1
VDD
P2
G2
P3
G3
Co,0 Co,1 Co,2 Co,3
Implantation dynamique d’une section à 4bits d’une chaîne de report Manchester.

GELE5340 – Gabriel Cormier, Université de Moncton 27
Délai: chaîne de report Manchester
• Le délai d’une chaîne de report Manchester
peut être évalué avec le délai Elmore:
si tous les transistors ont la même dimension.
• Il y a donc une relation quadratique avec le
nombre d’étages.
RCNN
t p2
)1(69.0

GELE5340 – Gabriel Cormier, Université de Moncton 28
Additionneurs: considérations logiques
• On cherche maintenant à optimiser la vitesse
des additionneurs en manipulant les
équations logiques.
• Les additionneurs à propagation de report
fonctionnent bien pour des microprocesseurs
à peu de bits, mais pour des applications à
beaucoup de bits (ex: 64bits dans les
serveurs, 128bits dans le PlayStation3), ils
sont trop lents.

GELE5340 – Gabriel Cormier, Université de Moncton 29
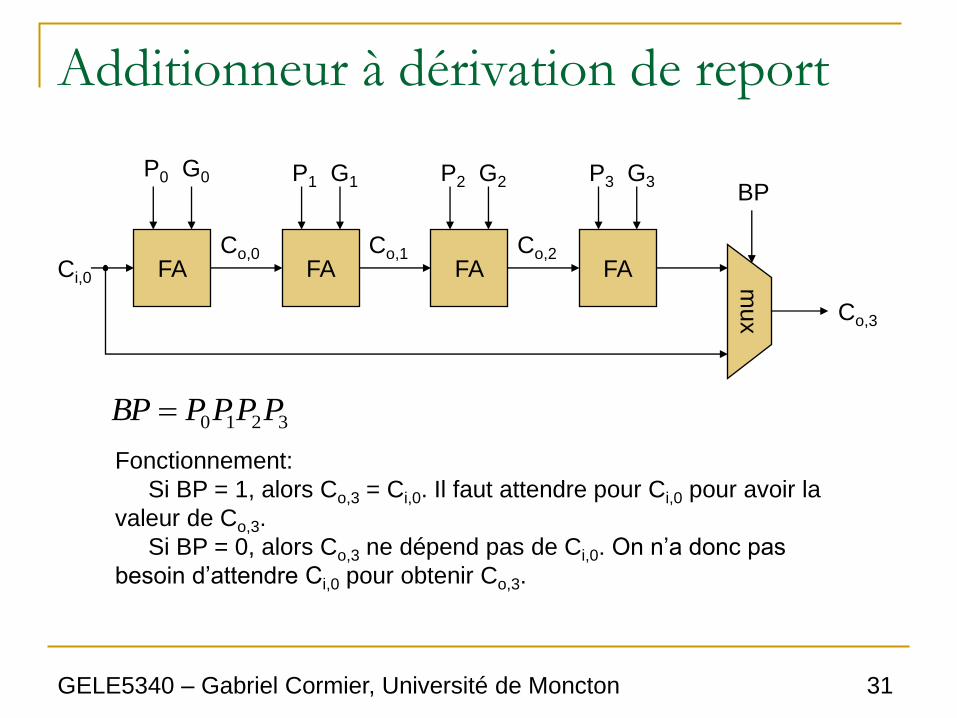
Additionneur à dérivation de report
• L’additionneur à dérivation de report (carry-
bypass) se sert des équations de P et G pour
accélérer l’additionneur.
• Rappel:
• On cherche à savoir si on a besoin du Ci, ou
sinon, on n’a pas besoin d’attendre et on peut
continuer les calculs.
iio CPGC

GELE5340 – Gabriel Cormier, Université de Moncton 30
Additionneur à dérivation de report
FA
P0 G0
Ci,0 FA
P1 G1
FA
P2 G2
FA
P3 G3
Co,0 Co,3 Co,2 Co,1
Le seul cas où Ci,0 se propage à la sortie est quand tous les P (P0, P1, P2, P3)
sont 1. Pour chaque bit, si P = 0, alors Co = G.
iio CPGC
GELE5340 – Gabriel Cormier, Université de Moncton 31
Additionneur à dérivation de report
FA
P0 G0
Ci,0
P1 G1 P2 G2 P3 G3
Co,0
Co,3
Co,2 Co,1 FA FA FA
mux
BP
3210 PPPPBP
Fonctionnement:
Si BP = 1, alors Co,3 = Ci,0. Il faut attendre pour Ci,0 pour avoir la
valeur de Co,3.
Si BP = 0, alors Co,3 ne dépend pas de Ci,0. On n’a donc pas
besoin d’attendre Ci,0 pour obtenir Co,3.
GELE5340 – Gabriel Cormier, Université de Moncton 32
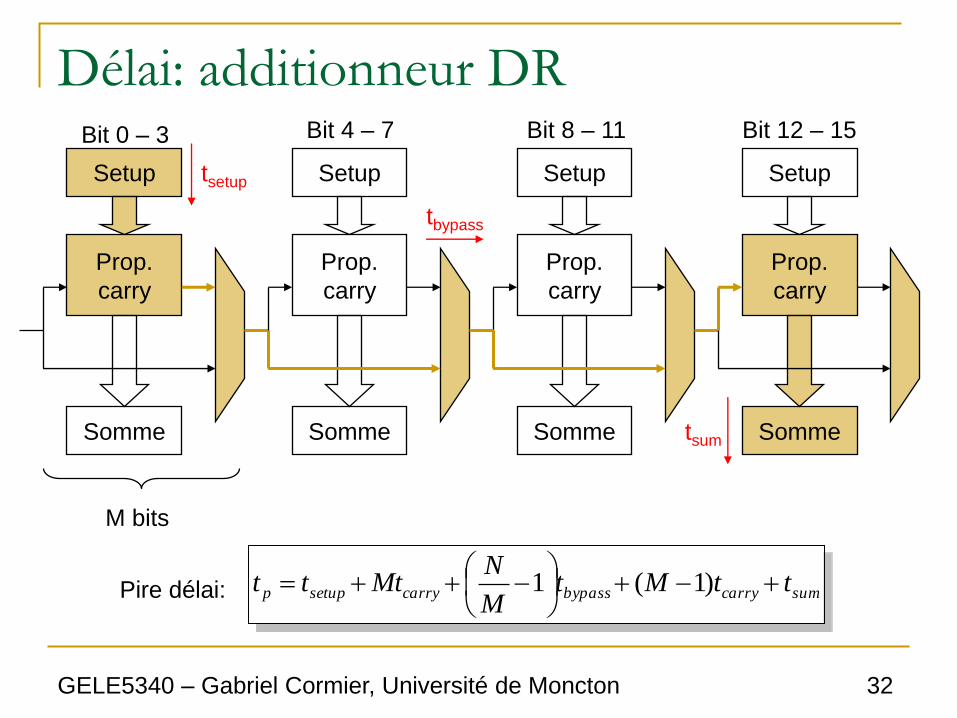
Délai: additionneur DR
Setup
Prop.
carry
Somme
Setup
Prop.
carry
Somme
Setup
Prop.
carry
Somme
Setup
Prop.
carry
Somme
Bit 0 – 3 Bit 4 – 7 Bit 8 – 11 Bit 12 – 15
M bits
sumcarrybypasscarrysetupp ttMtM
NMttt
)1(1Pire délai:
tsetup
tbypass
tsum

GELE5340 – Gabriel Cormier, Université de Moncton 33
Délai: additionneur DR
N
tp
Additionneur
DR
Additionneur
PR
4…8
Pour des additionneurs à plus de 8
bits, l’additionneur à dérivation de
report est plus rapide.
Cependant, la dépendance du délai
sur le nombre de bits est quand
même linéaire.
L’additionneur à dérivation de report occupe cependant un peu plus de
superficie (10% - 20%) que l’additionneur à propagation de report.

GELE5340 – Gabriel Cormier, Université de Moncton 34
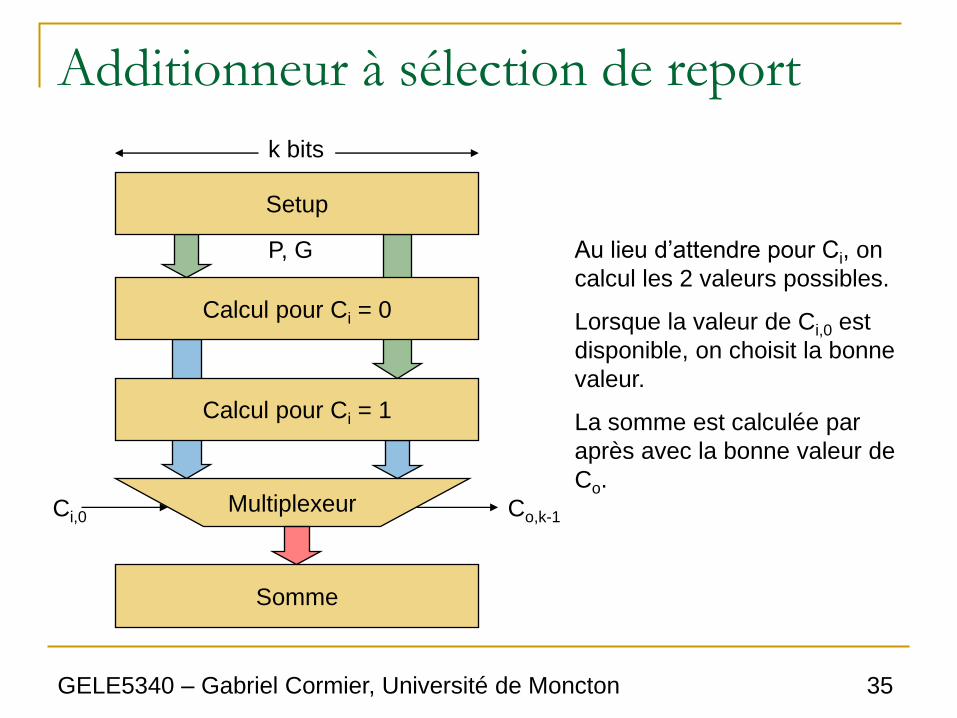
Additionneur à sélection de report
• Dans l’additionneur à propagation de report, il faut
attendre le calcul du report de l’étape précédente
avant de faire le calcul du report de sortie.
• On peut accélérer le processus en faisant le calcul
pour les deux valeurs possibles du report d’entrée (0
ou 1) et en choisissant la bonne valeur lorsque le
report d’entrée arrive.
• On calcul donc deux valeurs de Co, une pour Ci = 0
et l’autre pour Ci = 1. Un multiplexeur choisi la
valeur correcte, selon la valeur réelle de Ci.
GELE5340 – Gabriel Cormier, Université de Moncton 35
Additionneur à sélection de report
Multiplexeur
Somme
Setup
P, G
Calcul pour Ci = 1
Calcul pour Ci = 0
Ci,0 Co,k-1
k bits
Au lieu d’attendre pour Ci, on
calcul les 2 valeurs possibles.
Lorsque la valeur de Ci,0 est
disponible, on choisit la bonne
valeur.
La somme est calculée par
après avec la bonne valeur de
Co.
GELE5340 – Gabriel Cormier, Université de Moncton 36
Additionneur à sélection de report
Mux
Setup
Somme
Bit 0 – 3
0: Report
1: Report
Mux
Setup
Somme
Bit 4 – 7
0: Report
1: Report
Mux
Setup
Somme
Bit 8 – 11
0: Report
1: Report
Mux
Setup
Somme
Bit 12 – 15
0: Report
1: Report
S0-3 S4-7 S8-11 S12-15
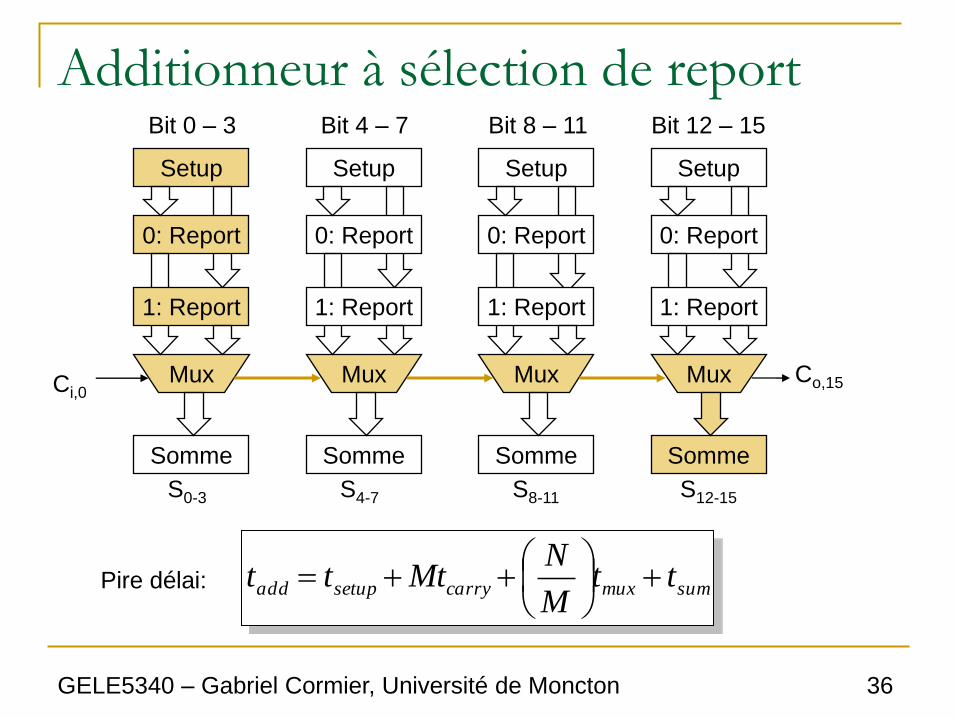
summuxcarrysetupadd ttM
NMttt
Ci,0 Co,15
Pire délai:
GELE5340 – Gabriel Cormier, Université de Moncton 37
Sélection de report: délai
Mux
Setup
Somme
Bit 0 – 3
0: Report
1: Report
Mux
Setup
Somme
Bit 4 – 7
0: Report
1: Report
Mux
Setup
Somme
Bit 8 – 11
0: Report
1: Report
Mux
Setup
Somme
Bit 12 – 15
0: Report
1: Report
S0-3 S4-7 S8-11 S12-15
Ci,0 Co,15
(1)
(1)
(5) (5)
(6) (7) (8) (9)
(10)
(5) (5) (5)
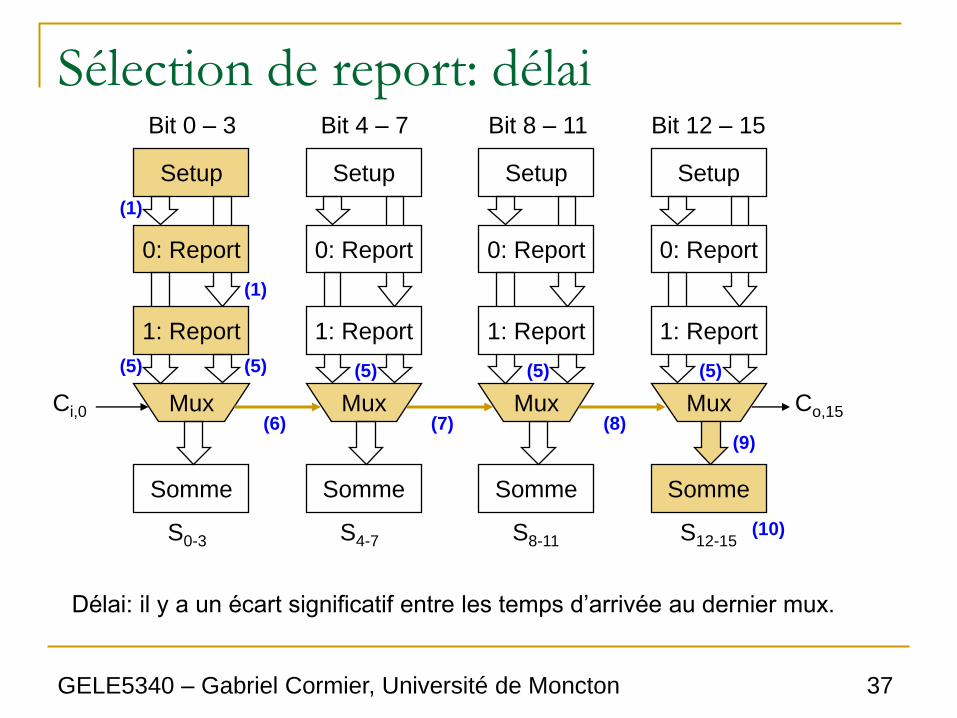
Délai: il y a un écart significatif entre les temps d’arrivée au dernier mux.

GELE5340 – Gabriel Cormier, Université de Moncton 38
Sélection de report: délai
• Pour réduire cet écart entre les temps
d’arrivée, on essaie d’égaliser les délais entre
les chemins.
• On réalise ceci en ajoutant de plus en plus de
bits aux étages supérieurs.
○ Ex: le premier étage peut ajouter 2 bits, le 2e
étage 3 bits, le 3e étage 4bits, etc…
• La dépendance est maintenant sous-linéaire.

GELE5340 – Gabriel Cormier, Université de Moncton 39
Sélection de report: racine carrée
Mux
Setup
Somme
Bit 0 – 1
0: Report
1: Report
Mux
Setup
Somme
Bit 2 – 4
0: Report
1: Report
Mux
Setup
Somme
Bit 5 – 8
0: Report
1: Report
Mux
Setup
Somme
Bit 9 – 13
0: Report
1: Report
S0-1 S2-4 S5-8 S9-13
Ci,0
(1)
(1)
(3) (3)
(4) (5) (6) (7)
(8)
(4) (5) (6)
Mux
Setup
Somme
0: Report
1: Report
S14-19
(8)
(9)
(7)
Bit 14 – 19
Dans ce cas-ci, les bits arrivent tous aux multiplexeurs en même temps.

GELE5340 – Gabriel Cormier, Université de Moncton 40
Sélection de report: racine carrée
• Pour calculer le délai, on suppose: ○ N est le nombre total de bits
○ M est le nombre de bits du premier étage
○ P est le nombre d’étages
• Si M << N, on peut simplifier à:
2
1
22
)1(
)1()3()2()1(
2
MPPPP
MP
PMMMMMN
2/2PN ou NP 2

GELE5340 – Gabriel Cormier, Université de Moncton 41
Sélection de report: racine carrée
• Le délai de l’additionneur à sélection de
report peut donc être exprimé par l’équation
suivante:
• On voit bien la dépendance « racine carrée »
du délai sur le nombre de bits.
summuxcarrysetupadd ttNMttt 2
GELE5340 – Gabriel Cormier, Université de Moncton 42
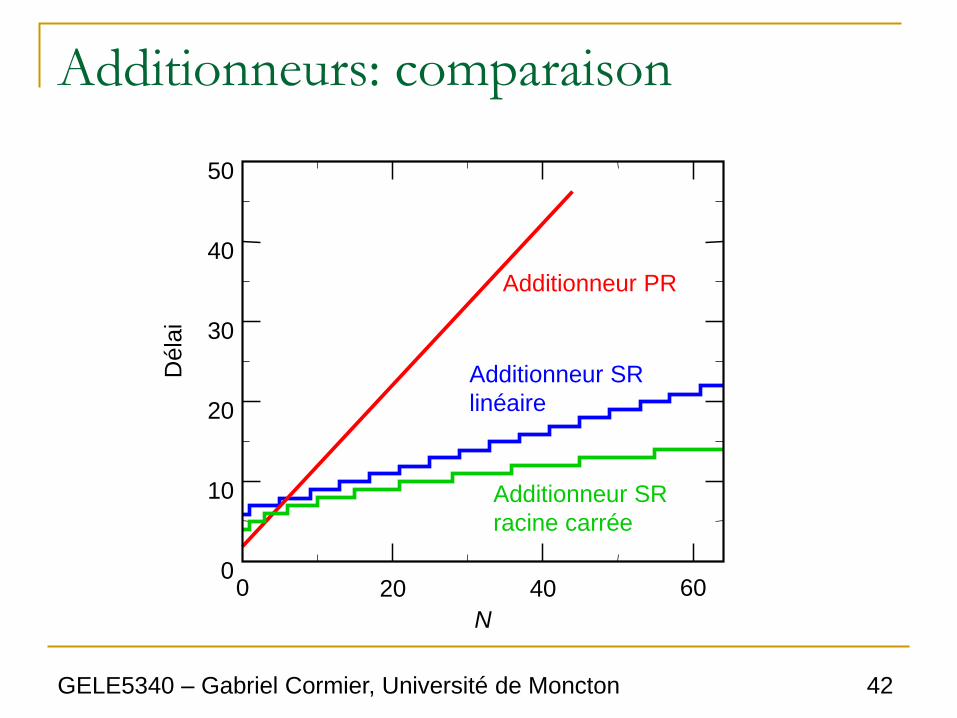
Additionneurs: comparaison
20 40 N
60 0
10
0
20
30
40
50
Additionneur PR
Additionneur SR
linéaire
Additionneur SR
racine carrée
Déla
i

Multiplicateurs

GELE5340 – Gabriel Cormier, Université de Moncton 44
Multiplicateurs
• La multiplication est un processus lent. La performance de plusieurs problèmes est souvent limitée par la multiplication.
• La multiplication est, en fait, une série d’additions.
○ Les analyses des additionneurs sont en grande partie applicables aux multiplicateurs.
• On verra un peu comment la multiplication est effectuée, et comment optimiser les circuits.

GELE5340 – Gabriel Cormier, Université de Moncton 45
Multiplication binaire
Soit deux chiffres binaires, X et Y:
1
0
2M
i
i
iXX
1
0
2N
j
j
jYY
La multiplication des deux chiffres donne:
1
0
1
0
1
0
1
0
1
0
222
2
M
i
N
j
ji
ji
N
j
j
j
M
i
i
i
NM
k
k
k
YXYX
ZYXZ

GELE5340 – Gabriel Cormier, Université de Moncton 46
Multiplication binaire
• La méthode la plus simple de faire une
multiplication binaire est de faire une série
d’additions.
• Pour des entrées de M bits et N bits, la
multiplication prend M cycles en utilisant un
additionneur à N bits.
○ On additionne M produits partiels.
○ La multiplication est essentiellement une série
d’opérations AND.

GELE5340 – Gabriel Cormier, Université de Moncton 47
Multiplication binaire
x
Produits partiels
Multiplicande
Multiplicateur
Résultat
1 0 1 0 1 0
1 0 1 0 1 0
1 0 1 0 1 0
1 1 1 0 0 1 1 1 0
0 0 0 0 0 0
1 0 1 0 1 0
1 0 1 1
N bits
M bits
On a M additions de N bits. Le résultat a (M + N – 1) bits.

GELE5340 – Gabriel Cormier, Université de Moncton 48
Produits partiels
A B A×B
0 0 0
0 1 0
1 0 0
1 1 1
La multiplication de deux chiffres est équivalent à l’opération AND.
Pour créer les produits partiels, on a besoin que de portes AND.
a
b a×b
GELE5340 – Gabriel Cormier, Université de Moncton 49
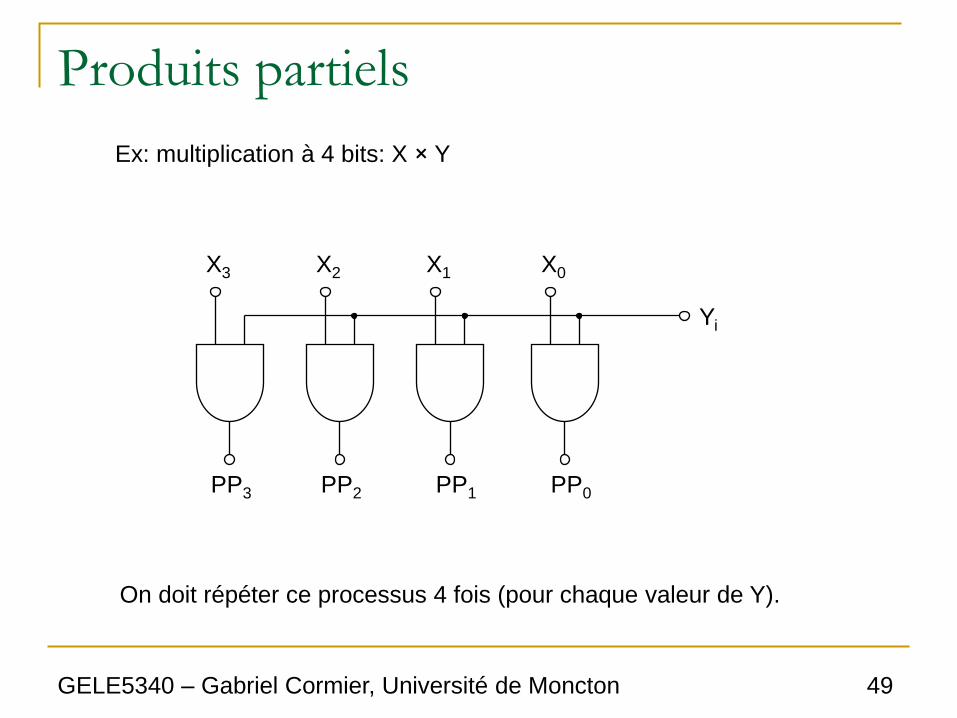
Produits partiels
Ex: multiplication à 4 bits: X × Y
X3 X2 X1 X0
Yi
PP3 PP2 PP1 PP0
On doit répéter ce processus 4 fois (pour chaque valeur de Y).

GELE5340 – Gabriel Cormier, Université de Moncton 50
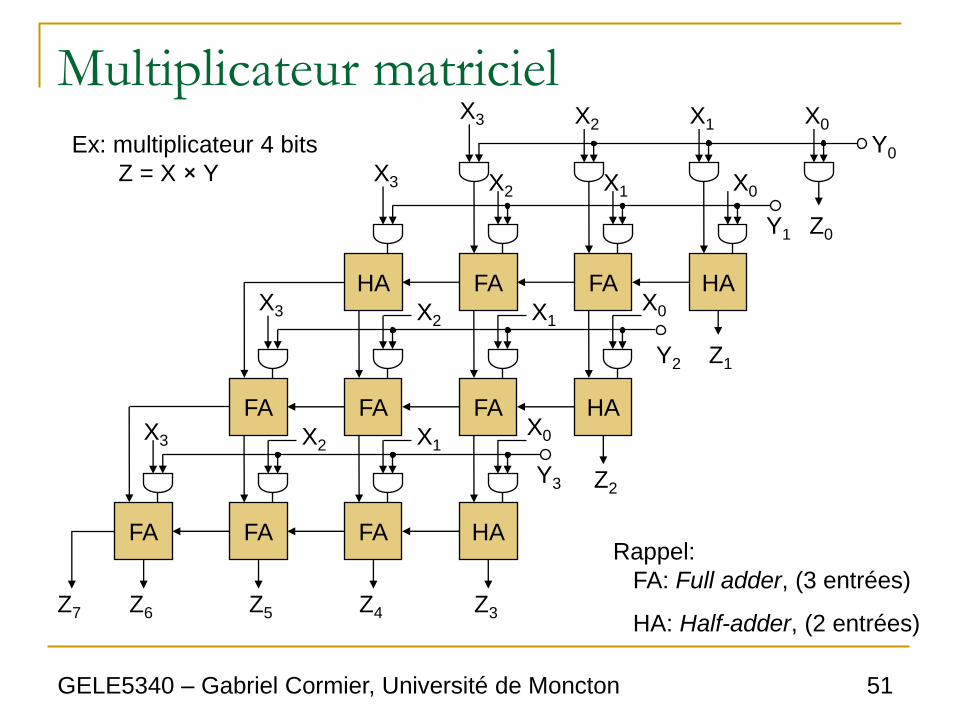
Multiplicateur matriciel
• Le multiplicateur matriciel est le multiplicateur
de base.
• C’est une implantation directe de la
multiplication manuelle (voir diapo #47).
○ On a N×M portes AND.
○ Pour additionner les produits partiels, il faut N – 1
additionneurs de M bits.
GELE5340 – Gabriel Cormier, Université de Moncton 51
Multiplicateur matriciel
FA FA FA HA
FA FA FA HA
HA FA FA HA
Z6 Z7 Z5 Z4 Z3
Z0
Z1
Z2
Y0
Y1
Y2
Y3
Ex: multiplicateur 4 bits
Z = X × Y
X0
X0
X3
X3
X3
X3 X2 X1
X1 X2
Rappel:
FA: Full adder, (3 entrées)
HA: Half-adder, (2 entrées)
X0 X2 X1
X2 X1 X0
GELE5340 – Gabriel Cormier, Université de Moncton 52
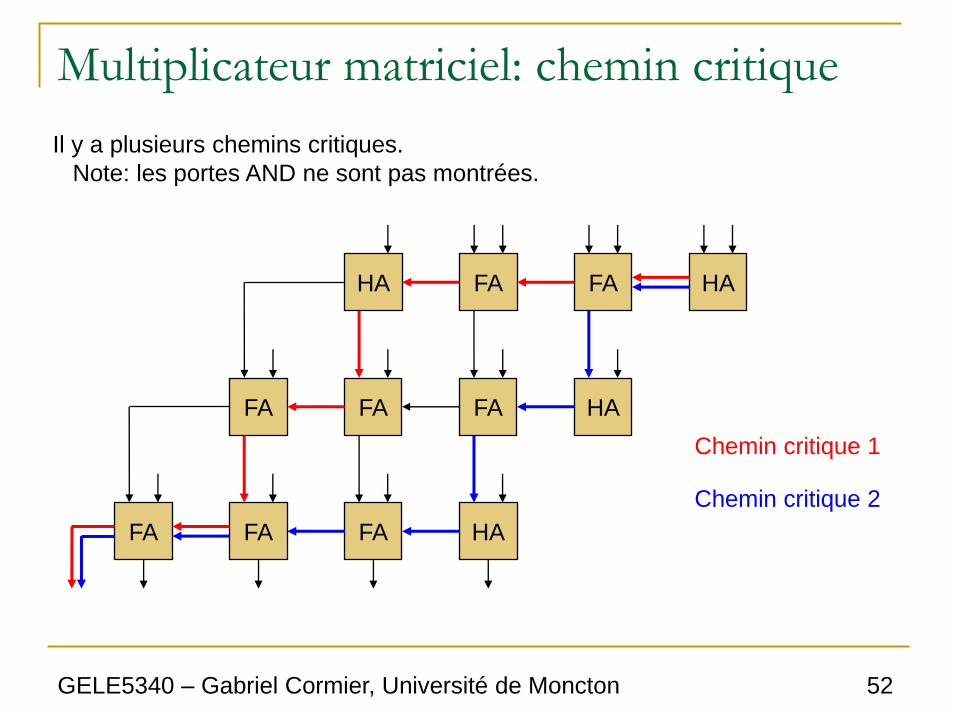
Multiplicateur matriciel: chemin critique
FA FA FA HA
FA FA FA HA
HA FA FA HA
Il y a plusieurs chemins critiques.
Note: les portes AND ne sont pas montrées.
Chemin critique 1
Chemin critique 2

GELE5340 – Gabriel Cormier, Université de Moncton 53
Multiplicateur matriciel: chemin critique
• Il existe plusieurs chemins de même délai
dans ce multiplicateur.
• En observant les chemins critiques de la
figure précédente, on peut approximer le
délai de ce multiplicateur par l’équation
suivante:
andsumcarrymult ttNtNMt 121

GELE5340 – Gabriel Cormier, Université de Moncton 54
Multiplicateur à sauvegarde de report
• Parce qu’il y a plusieurs chemins critiques dans le
multiplicateur matriciel, il y aura peu d’amélioration à
la performance si on dimensionne les transistors.
• Cependant, on peut réorganiser le multiplicateur
lorsqu’on remarque que le résultat de la
multiplication ne change pas si le report est passé
de façon diagonale à l’étage suivant.
○ Cependant, on doit ajouter un nouvel étage d’addition.
GELE5340 – Gabriel Cormier, Université de Moncton 55
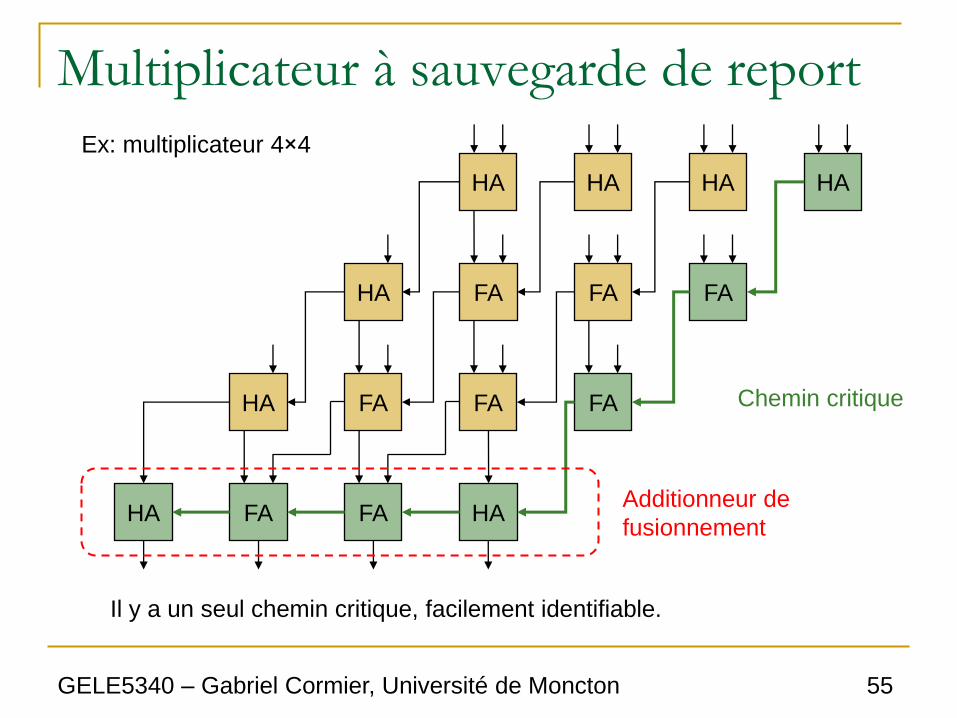
Multiplicateur à sauvegarde de report
HA FA FA HA
HA FA FA FA
HA FA FA FA
HA HA HA HA
Chemin critique
Additionneur de
fusionnement
Ex: multiplicateur 4×4
Il y a un seul chemin critique, facilement identifiable.

GELE5340 – Gabriel Cormier, Université de Moncton 56
Multiplicateur à sauvegarde de report
• Dans ce cas-ci, le chemin critique est facilement identifiable et on peut donc écrire une équation pour le délai:
• Le délai tmerge représente le délai dans le bloc de fusionnement. Il s’agit d’un additionneur à propagation de report, et donc les techniques vues auparavant pour accélérer ce genre d’additionneur sont applicables.
mergecarryandmult ttNtt 1
GELE5340 – Gabriel Cormier, Université de Moncton 57
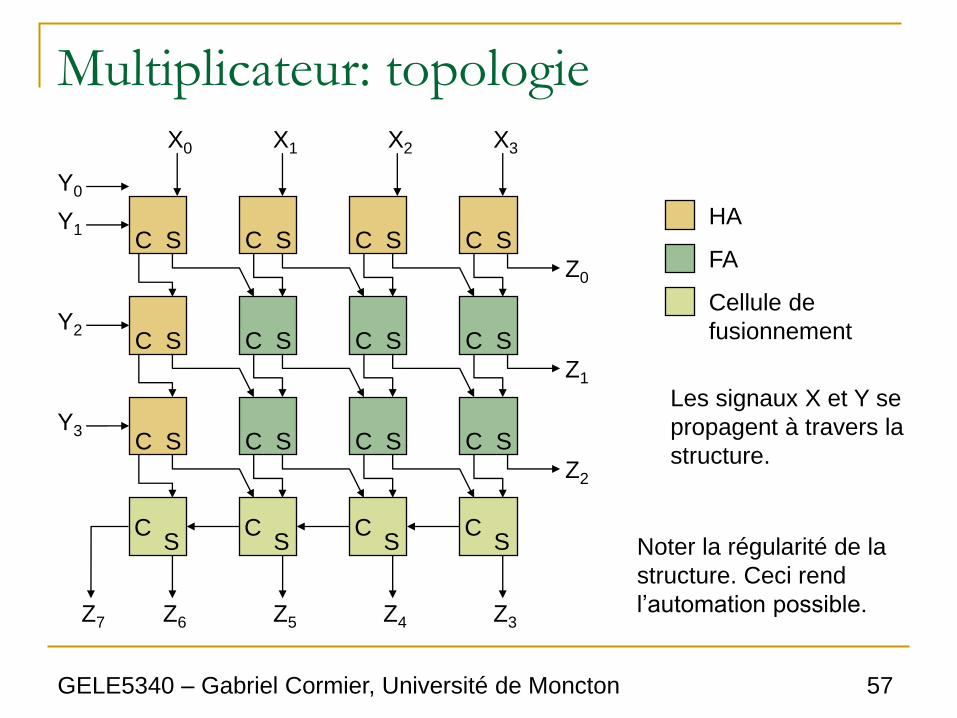
Multiplicateur: topologie
C S
C S
C S
C S
C S
C S
C S
C S
C S
C S
C S
C S
S
S
S
S C C C C
X0 X1 X2 X3
Y0
Y1
Y2
Y3
Z0
Z1
Z2
Z3 Z4 Z5 Z6 Z7
HA
FA
Cellule de
fusionnement
Les signaux X et Y se
propagent à travers la
structure.
Noter la régularité de la
structure. Ceci rend
l’automation possible.

GELE5340 – Gabriel Cormier, Université de Moncton 58
Multiplicateur Wallace-Tree
• On peut réarranger les produits partiels de
sorte qu’ils forment un arbre.
• Cette structure peut ensuite être utilisée pour
réduire le nombre de produits partiels.
• On appelle ce type de multiplicateur le
Wallace-Tree Mulitiplier.

GELE5340 – Gabriel Cormier, Université de Moncton 59
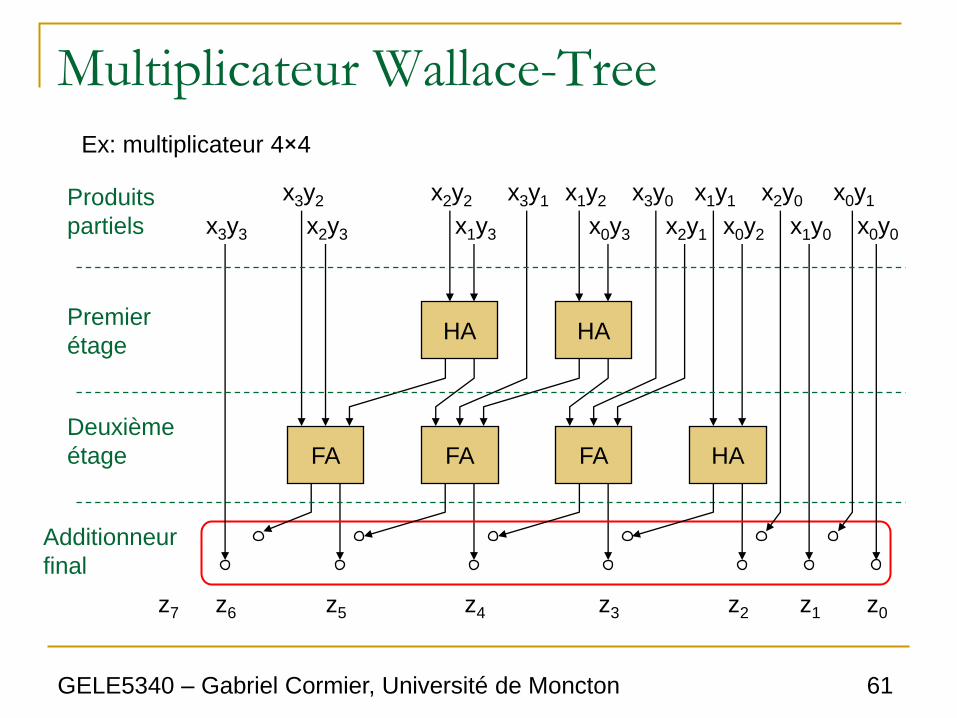
Multiplicateur Wallace-Tree
0 1 2 3 4 5 6
Produits partiels Position du bit
0 1 2 3 4 5 6 On modifie
pour faire un
arbre
HA
0 1 2 3 4 5 6
FA
0 1 2 3 4 5 6
Résultat final

GELE5340 – Gabriel Cormier, Université de Moncton 60
Multiplicateur Wallace-Tree
0 1 2 3 4 5 6
HA
0 1 2 3 4 5 6
FA
Un HA prend deux bits comme entrées, et produit 2 bits de sortie: le premier à
la même position (la somme), et le second dans la position d’après (report).
Le FA prend trois bits comme entrées, et produits 2 bits de sortie de la même
façon que le HA.
Comment fonctionne cette réduction?
i i+1 i i+1 i i+1 i i+1
GELE5340 – Gabriel Cormier, Université de Moncton 61
Multiplicateur Wallace-Tree
FA
HA
FA FA HA
HA
Ex: multiplicateur 4×4
x0y3
x1y2 x2y2 x3y1 x3y0
x2y1 x0y2 x1y0 x0y0
x0y1 x2y0 x1y1
x1y3 x2y3
x3y2
x3y3
Produits
partiels
Premier
étage
Deuxième
étage
Additionneur
final
z0 z1 z2 z3 z4 z5 z6 z7

GELE5340 – Gabriel Cormier, Université de Moncton 62
Multiplicateur Wallace-Tree
• Si on compare avec le multiplicateur à sauvegarde
de report:
○ Sauvegarde de report: 6 HA, 6 FA, 1 additionneur
○ Wallace-Tree: 3 HA, 3 FA, 1 additionneur
• L’additionneur final est un simple additionneur. On
peut utiliser n’importe quel type d’additionneur, mais
l’additionneur à dérivation est un choix populaire.
• Cependant, la topologie du multiplicateur Wallace-
Tree est très irrégulière, et rend son implantation
pratique plus difficile.

GELE5340 – Gabriel Cormier, Université de Moncton 63
Multiplicateurs: sommaire
• Buts différents de l’additionneur
○ Dans certaines structures, délai carry = délai somme
○ Analyse plus difficile: chemins critiques multiples
• D’autre techniques possibles
○ Encodage de Booth (très populaire)
○ Pipelining
• Exemple de performance:
○ Multiplicateur 54 bits × 54 bits, délai: 1.58ns, 0.18m

Déphaseur

GELE5340 – Gabriel Cormier, Université de Moncton 65
Déphaseur
• L’opération de déphasage (« shift ») est une autre
composante importante d’une unité arithmétique.
• On s’en sert dans les unités à virgule flottante
(« floating-point unit »), ou la multiplication par une
constante.
• L’implantation d’un déphaseur qui déphase d’un
montant constant est facile, mais un déphaseur
programmable est plus complexe.
• À la base, un déphaseur est un multiplexeur
complexe.
GELE5340 – Gabriel Cormier, Université de Moncton 66
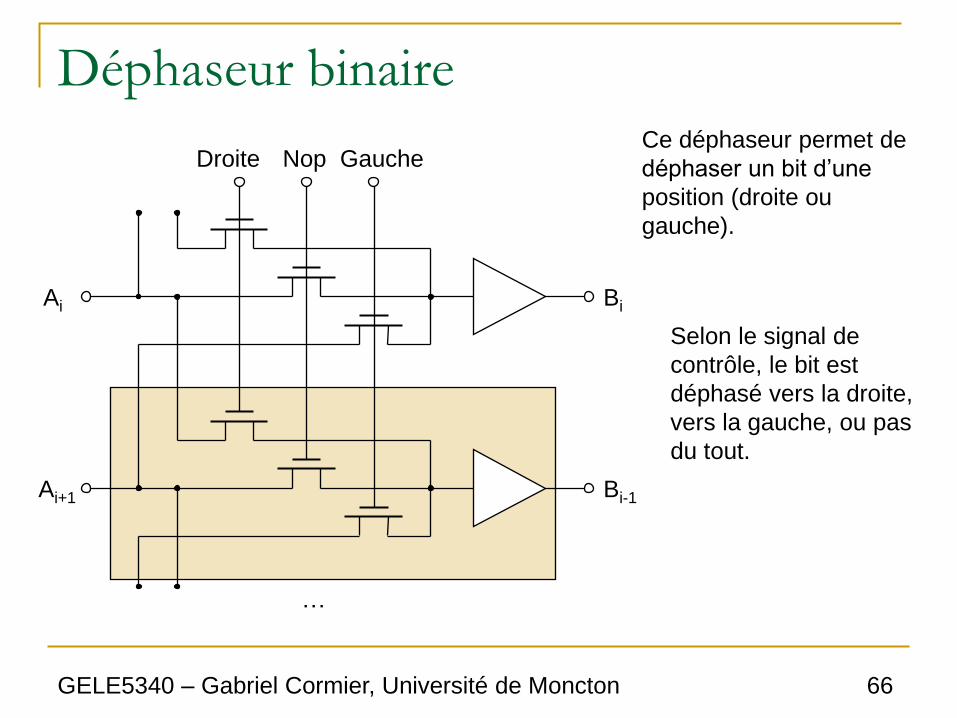
Déphaseur binaire
Bi
Bi-1
Ai
Ai+1
Droite Nop Gauche
…
Ce déphaseur permet de
déphaser un bit d’une
position (droite ou
gauche).
Selon le signal de
contrôle, le bit est
déphasé vers la droite,
vers la gauche, ou pas
du tout.
GELE5340 – Gabriel Cormier, Université de Moncton 67
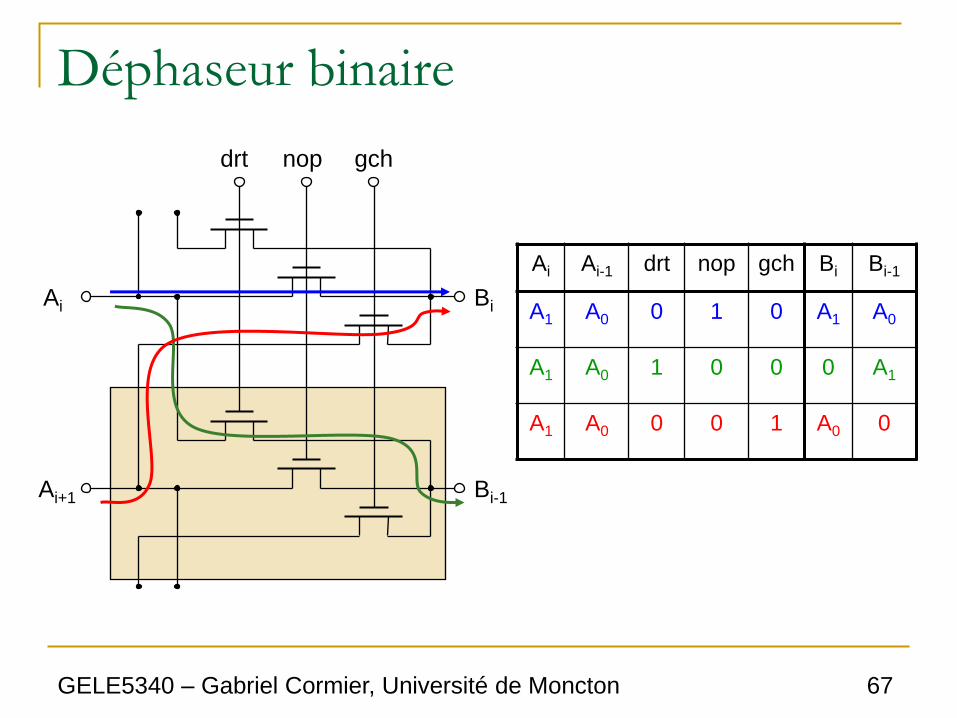
Déphaseur binaire
Bi
Bi-1
Ai
Ai+1
drt nop gch
Ai Ai-1 drt nop gch Bi Bi-1
A1 A0 0 1 0 A1 A0
A1 A0 1 0 0 0 A1
A1 A0 0 0 1 A0 0

GELE5340 – Gabriel Cormier, Université de Moncton 68
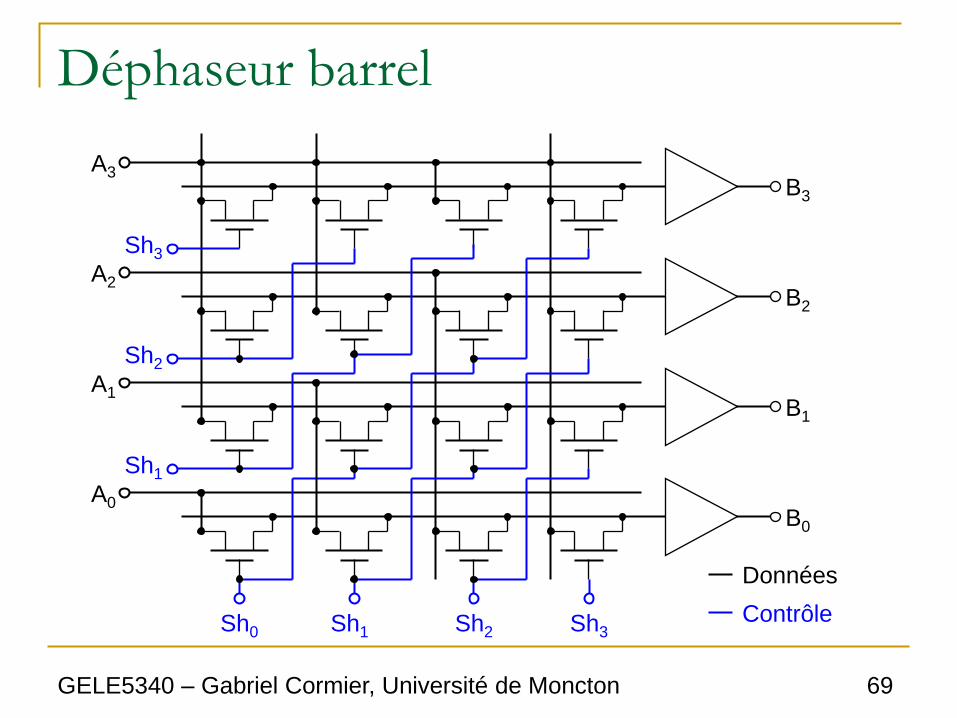
Déphaseur binaire
• Le déphaseur binaire est simple d’opération, mais il
ne permet de déphaser que d’un seul bit.
• Pour construire des déphaseurs multi-bit, on peut
mettre plusieurs déphaseurs binaires en cascade.
• Cependant, ceci implique que le circuit devient
rapidement complexe, et aussi très lent pour être
utile.
• On doit donc avoir des circuits plus structurés:
○ Déphaseur barrel
○ Déphaseur logarithmique
GELE5340 – Gabriel Cormier, Université de Moncton 69
Déphaseur barrel
A3
A2
A1
A0
Sh0 Sh1 Sh2 Sh3
Sh1
Sh2
Sh3
B3
B2
B1
B0
Données
Contrôle
GELE5340 – Gabriel Cormier, Université de Moncton 70
Déphaseur barrel
A3
A2
A1
A0
Sh0 Sh1 Sh2 Sh3
Sh1
Sh2
Sh3
B3
B2
B1
B0
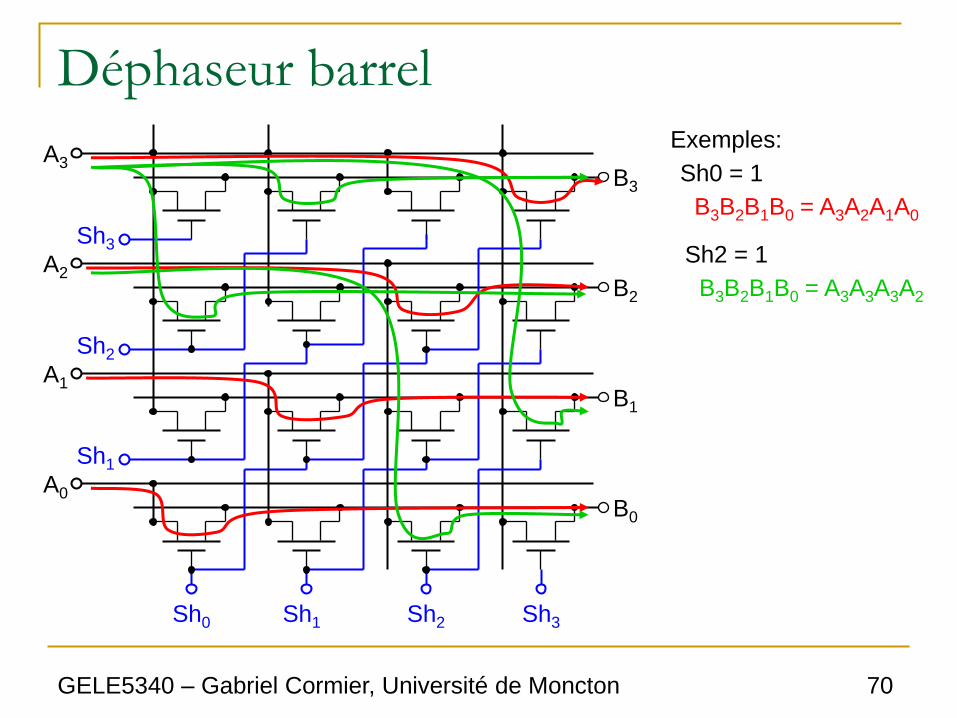
Exemples:
Sh0 = 1
B3B2B1B0 = A3A2A1A0
Sh2 = 1
B3B2B1B0 = A3A3A3A2

GELE5340 – Gabriel Cormier, Université de Moncton 71
Déphaseur barrel
Exemple de topologie: déphaseur 4x4
Buffer Sh3 Sh2 Sh1 Sh0
A 3
A 2
A 1
A 0

GELE5340 – Gabriel Cormier, Université de Moncton 72
Déphaseur barrel
• La topologie du déphaseur barrel n’est pas
dominée par les transistors, mais plutôt par
les fils.
○ La densité de la topologie est limitée par la
distance minimale entre les fils.
• Le déphaseur barrel est relativement rapide,
puisque les signaux ont seulement besoin de
passer à travers un seul transistor passant.

GELE5340 – Gabriel Cormier, Université de Moncton 73
Déphaseur logarithmique
• Le déphaseur logarithmique utilise des
étages pour réaliser le déphasage. La valeur
totale du déphasage est répartie sur des
signaux ayant une puissance de 2.
○ Pour un déphasage maximum de M – 1, il faut
log2M étages.
Ex: pour un déphaseur de 7 bits, il faut 3 étages.
On aurait donc 3 signaux de contrôle.

GELE5340 – Gabriel Cormier, Université de Moncton 74
Déphaseur logarithmique Sh1 Sh1 Sh2 Sh2 Sh4 Sh4
B3
B2
B1
B0
A3
A2
A1
A0
GELE5340 – Gabriel Cormier, Université de Moncton 75
Déphaseur logarithmique: exemple
Sh1 Sh1 Sh2 Sh2 Sh4 Sh4
B3
B2
B1
B0
A3
A2
A1
A0
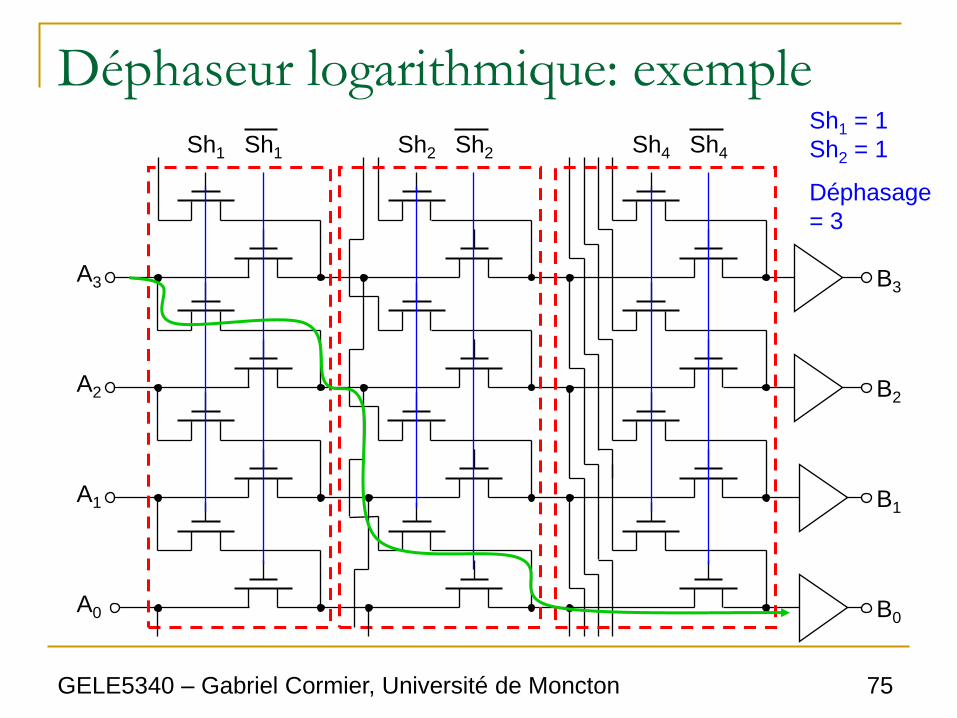
Sh1 = 1
Sh2 = 1
Déphasage
= 3

GELE5340 – Gabriel Cormier, Université de Moncton 76
Déphaseur logarithmique
A3
A2
A1
A0
B3
B2
B1
B0
Déphaseur 0 – 7 bits.

GELE5340 – Gabriel Cormier, Université de Moncton 77
Déphaseur logarithmique
• La vitesse du déphaseur logarithmique
dépend de la quantité de déphasage; plus on
déphase, plus c’est lent.
• Le déphaseur barrel est meilleur pour de
petits déphasages, tandis que le déphaseur
logarithmique est meilleur pour de grand
déphasages (il est meilleur en termes de
superficie et de vitesse).

GELE5340 – Gabriel Cormier, Université de Moncton 78
Conclusion
• On a vu les circuits pour réaliser les
opérations mathématiques de base:
○ Addition: il existe plusieurs types de circuits pour
implanter des additionneurs.
○ Multiplication: la multiplication est une série
d’additions.
○ Déphasage.
Top Related