







Languages
Pages
Legal


Gearing for Exabyte Storagewith Hadoop Distributed Filesystem
Edward Bortnikov, Amir Langer, Artyom Sharov

LADIS workshop, 2014 2
Scale, Scale, Scale HDFS storage growing all the time
Anticipating 1 XB Hadoop grids ~30K of dense (36 TB) nodes
Harsh reality is … Single system of 5K nodes hard to build 10K impossible to build

LADIS workshop, 2014 3
Why is Scaling So Hard?
Look into architectural bottlenecks Are they hard to dissolve?
Example: Job Scheduling Centralized in Hadoop’s early days Distributed since Hadoop 2.0 (YARN)
This talk: the HDFS Namenode bottleneck

LADIS workshop, 2014 4
How HDFS Works
B1
B2
B3
Namenode (NN)
Datanodes (DN’s)
FS API (metadata)
FS API (data)
Client
Bottleneck!
Memory-speedFS Tree Block Map Edit Log
Block report
B4

LADIS workshop, 2014 5
Quick Math Typical setting for MR I/O parallelism
Small files (file:block ratio = 1:1) Small blocks (block size = 64MB = 226 B)
1XB = 260 bytes 234 blocks, 234 files Inode data = 188 B, block data = 136 B Overall, 5+ TB metadata in RAM
Requires super-high-end hardware Unimaginable for 64-bit JVM (GC explodes)

LADIS workshop, 2014 6
Optimizing the Centralized NN
Reduce the use of Java references (HDFS-6658) Save 20% of block data
Off-heap data storage (HDFS-7244) Most of the block data outside the JVM Off-heap data management via a slab allocator Negligible penalty for accessing non-Java memory
Exploit entropy in file and directory names Huge redundancy in text

LADIS workshop, 2014 7
One Process, Two Services Filesystem vs Block Management
Compete for the RAM and the CPU Filesystem vs Block metadata Filesystem calls vs {Block reports, Replication}
Grossly varying access patterns Filesystem data has huge locality Block data is accessed uniformly (reports)

LADIS workshop, 2014 8
We Can Gain from a Split Scalability
Easier to scale the services independently, on separate hardware
Usability Standalone block management API attractive for
applications (e.g., object store - HDFS-7240)

LADIS workshop, 2014 9
The Pros
Block Management Easy to infinitely scale horizontally (flat space) Can be physically co-located with datanodes
Filesystem Management Easy to scale vertically (cold storage - HDFS-5389) De-facto, infinite scalability Almost always memory speed

LADIS workshop, 2014 10
The Cons Extra Latency
Backward compatibility of API requires an extra network hop (can be optimized)
Management Complexity Separate service lifecycles New failure/recovery scenarios (can be mitigated)

LADIS workshop, 2014 11
(Re-)Design Principles
Correctness, Scalability, Performance
API and Protocol Compatibility
Simple Recovery
Complete design in HDFS-5477

LADIS workshop, 2014 12
Block Management as a ServiceFS Manager
DN1 DN2 DN3 DN4 DN5 DN6 DN7 DN8 DN9 DN10
Block Manager
FS API (metadata)
Block report
NN
/BM
API
FS API (data)
External API/protocol
Internal API/protocol
Workers
Workers
Replication

LADIS workshop, 2014 13
Splitting the StateFS Manager
DN1 DN2 DN3 DN4 DN5 DN6 DN7 DN8 DN9 DN10
Block Manager
FS API (metadata)
Block report
Edit Log
NN
/BM
API
FS API (data)
External API/protocol
Internal API/protocol

LADIS workshop, 2014 14
Scaling Out the Block ManagementFS Manager
BM1 BM2 BM4 BM5
DN1 DN2 DN3 DN4 DN5 DN6 DN7 DN8 DN9 DN10
PartitionedBlock
Manager
Block Pool
BM3
Edit Log
Block Collection

LADIS workshop, 2014 15
Consistency of Global State State = inode data + block data
Multiple scenarios modify both
Big Central Lock in good old times Impossible to maintain: cripples performance when
spanning RPC’s
Fine-grained distributed locks? Only the path to the modified inode is locked All top-level directories in shared mode

LADIS workshop, 2014 16
Fine-Grained Locks Scale
0 500 1000 1500 2000 2500 3000 3500 40000
20
40
60
80
100
120
140
160
180
200
Late
ncy,
mse
c
Throughput, transactions/sec
Mixed workload
3 reads (getBlockLocations()): 1 write (createFile())
FL, writes
FL, reads
GL, writes
GL, reads

LADIS workshop, 2014 17
Fine-Grained Locks - Challenges Impede progress upon spurious delays Might lead to deadlocks (flows starting
concurrently at the FSM and the BM) Problematic to maintain upon failures
Do we really need them?

LADIS workshop, 2014 18
Pushing the Envelope
Actually, we don’t really need atomicity!
Some transient state discrepancies can be tolerated for a while Example: orphaned blocks can emerge upon
partially complete API’s No worries – no data loss! Can be collected lazily in the background

LADIS workshop, 2014 19
Distributed Locks Eliminated No locks held across RPCs
Guaranteeing serializability All updates start at the BM side Generation timestamps break ties
Temporary state gaps resolved in background Timestamps used to reconcile
More details in HDFS-5477

LADIS workshop, 2014 20
Beyond the Scope …
Scaling the network connections
Asynchronous dataflow architecture versus lock-based concurrency control
Multi-tier bootstrap and recovery

LADIS workshop, 2014 21
Summary HDFS namenode is a major scalability hurdle
Many low-hanging optimizations – but centralized architecture inherently limited
Distributed block-management-as-a-service key for future scalability
Prototype implementation at Yahoo

LADIS workshop, 2014 22
Backup

LADIS workshop, 2014 23
Bootstrap and Recovery The common log simplifies things One peer (the FSM or the BM) enters read-
only mode when the other is not available HA similar to bootstrap but failover is faster
Drawback The BM not designed to operate in the FSM’s absence
LADIS workshop, 2014 24
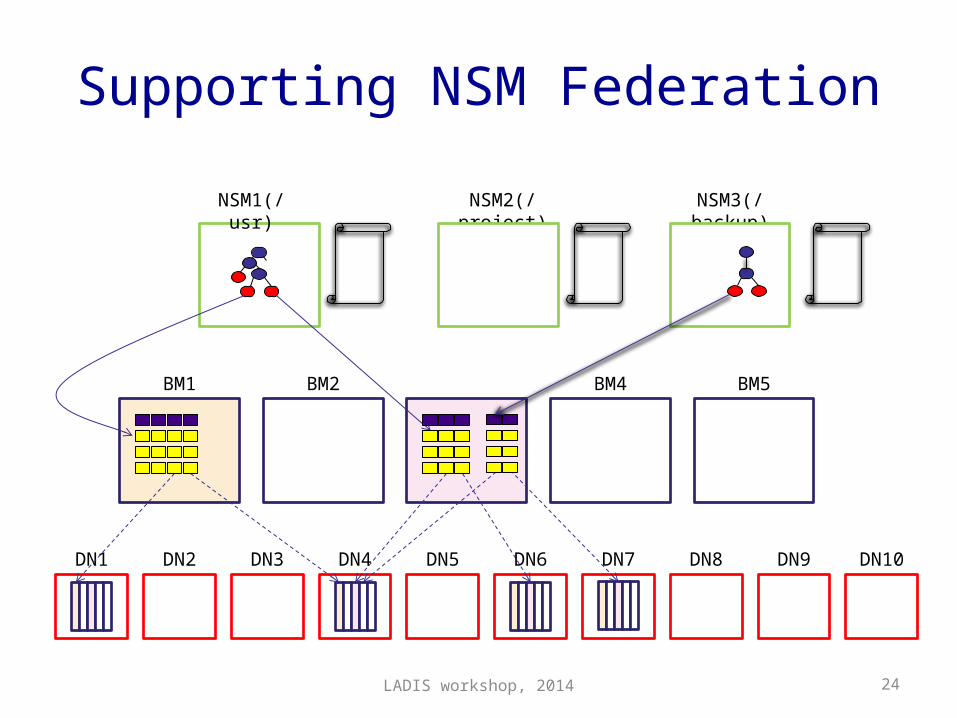
Supporting NSM FederationNSM1(/usr) NSM2(/project) NSM3(/backup)
BM1 BM2 BM4 BM5
DN1 DN2 DN3 DN4 DN5 DN6 DN7 DN8 DN9 DN10
Top Related