







Languages
Pages
Legal


Data integration: an overview on
statistical methodologies and applications
Mauro Scanu
Istat
Central Unit on User Needs,
Integration and Territorial Statistics

Poznan 20 October 2010 World Statistics Day
Summary
• In what sense methods for integration are
“statistical”?
• Record linkage: definition, examples, methods,
objectives and open problems
• Statistical matching: definition, examples,
methods, objectives and open problems
• Micro integration processing: definition,
examples, methods, objectives and open problems
• Other statistical integration methods?

Poznan 20 October 2010 World Statistics Day
Methods for integration 1
Generally speaking, integration of two data sets is
understood as a single unit integration: the objective is
the detection of those records in the different data sets
that belong to the same statistical unit. This action
allows the reconstruction of a unique record of data that
contains all the unit information collected in the different
data sources on that unit.
On the contrary: let’s distinguish two different objectives -
micro and macro
Micro: the objective is the “development” of a complete
data set
Macro: the objective is the “development” of an aggregate
(for example, a contingency table)

Poznan 20 October 2010 World Statistics Day
Methods for integration 2
Further, the methods of integration can be split in automatic and statistical methods
The automatic methods take into account a priori rules for the linkage of the data records
The statistical methods include a formal estimation or test procedure that should be applied on the available data: this estimation or test procedure
1.can be chosen according to optimality criteria,

Poznan 20 October 2010 World Statistics Day
Statistical methods
Classical inference
1) There exists a data
generating model
2) The observed sample
is an image of the data
generating model
3) We estimate the model
from the observed
sample

Poznan 20 October 2010 World Statistics Day
Statistical methods of integration
If a method of
integration is
used, it is
necessary to
include an
intermediate
phase.
The final data set
is a blurred
image of the data
generating model

Poznan 20 October 2010 World Statistics Day
Statistical methods of integration
Statistical methods for integration can be organized
according to the available input
Input Output Metodo
Two data sets that observe
(partially) overlapping groups of
units
Micro Record linkage
Two independent samples Macro/micro Statistical
matching
Sets of estimates from different
surveys, that are not coherent
Macro Calibration
methods
Graphical
methods

Poznan 20 October 2010 World Statistics Day
Record linkage
Input: two data sets on overlapping sets of units.
Problem: lack of a unique and correct record identifier
Alternative: sets of variables that (jointly) are able to identify units
Attention: variables can have “problems”!
Objective: the largest number of correct links, the lowest number of wrong links

Poznan 20 October 2010 World Statistics Day
Book of life
Dunn (1946)* describes record linkage in this way:
…each person in the world creates a book of life. The book
starts with the birth and ends with the death. Its pages
are made up of all the principal events of life. Record
linkage is the name given to the process of assembling
the pages of this book into one volume. The person
retains the same identity throughout the book. Except for
advancing age, he is the same person…
*Dunn (1946) "Record Linkage". American Journal of Public Health 36
(12): 1412–1416.

Poznan 20 October 2010 World Statistics Day
When there is the lack of
a unique identifier If a record identifier is missing or cannot be used, it is
necessary to use the common variables in the two files.
The problem is that these variables can be “unstable”:
1. Time changes (age, address, educational level)
2. Errors in data entry and coding
3. Correct answers but different codification (e.g. address)
4. Missing items

Poznan 20 October 2010 World Statistics Day
Main motivations for record linkage
According to Fellegi (1997)*, the development of tools for
integration is due to the intersection of these facts:
• occasion: construction of big data bases
• tool: computer
• need: new informative needs
*Fellegi (1997) “Record Linkage and Public Policy: A
Dynamic Evolution”. In Alvey, Jamerson (eds) Record
Linkage Techniques, Proceedings of an international
workshop and exposition, Arlington (USA) 20-21 March
1997.

Poznan 20 October 2010 World Statistics Day
Why record linkage? Some examples
1. To have joint information on two or more variables
observed in distinct data sources
2. To “enumerate” a population
3. To substitute (parts of) surveys with archives
4. To create a “list” of a population
5. Other official statistics objectives (imputation and editing
/ to enhance micro data quality; to study the risk of
identification of the released micro data)

Poznan 20 October 2010 World Statistics Day
Example 1 – analysis of mortality
Problem: to analyze jointly the “risk factors” with the event
“death”.
A) The risk factors are observed on ad hoc surveys (e.g.
those on nutrition habits, work conditions, etc.)
B) The event “death” (after some months the survey is
conducted) can be taken from administrative archives
These two sources (survey on the risk factors and death
archive) should be “fused” so that each unit observed in
the risk factor survey can be associated with a new
dichotomous variable (equal to 1 if the person is dead
and zero otherwise).

Poznan 20 October 2010 World Statistics Day
Example 2 – to enumerate a population
Problem: what is the number of residents in Italy?
Often the number of residents is found in two steps, by means of a procedure known as “capture-recapture”. This method is usually applied to determine the size of animal populations.
A) Population census
B) Post enumeration survey (some months after the census) to evaluate Census quality and give an accurate estimate of the population size
USA - in 1990 Post Enumeration Survey, in 2000 Accuracy and Coverage Evaluation
Italy - in 2001 “Indagine di Copertura del Censimento”

Poznan 20 October 2010 World Statistics Day
Example 2 – to enumerate a population
The result of the comparison between Census and post
enumeration survey is a 2 2 table:
Obs. Post Non obs Post
Obs. Cens.
noo non
Non obs Cens
nno ??

Poznan 20 October 2010 World Statistics Day
Example 2 - to enumerate a population
For short, for any distinct unit it is necessary to understand
if it was observed
1) both in the census and in the PES
2) only in the census
3) only in the PES
These three values allow to estimate (with an appropriate
model) the fourth value.

Poznan 20 October 2010 World Statistics Day
Example 3 – surveys and archives
Problem: is it possible to use jointly administrative archives
and sample surveys?
At the micro level this means: to modify the questionnaire
of a survey dropping those questions that are already
available on some administrative archives (reduction of
the response burden)
E.g., for enterprises:
Social security archives, chambers of commerce, …

Poznan 20 October 2010 World Statistics Day
Example 4 – Creation of a list
Problem: what is the set of the active enterprises in Italy?
In Istat, ASIA (Archivio Statistico delle Imprese Attive) is the
most important example of a creation of a list of units
(the active enterprises in a time instant) “fusing” different
archives.
It is necessary to pay attention to:
• Enterprises which are present in more than one archives
(deduplication)
• Non active enterprises
• New born enterprises
• transformations (that can lead to a new enterprise or to a
continuation of the previous one)

Poznan 20 October 2010 World Statistics Day
Example 5 – Imputation and editing
Problem: to enhance microdata quality
Micro Integration in the Netherlands (virtual census, social
statistical data base)
It will be seen later, when dealing with micro integration
processing

Poznan 20 October 2010 World Statistics Day
Example 6 - Privacy
Problem: does it exist a “measure” of the degree of
identification of the released microdata?
In order to evaluate if a method for the protection of data
disclosure is good, it is possible to compare two datasets
(the true and the protected ones) and detect how many
modified records are “easily” linked to the true ones.

Poznan 20 October 2010 World Statistics Day Tiziana Tuoto, FCSM 2007, Arlington, November 6 2007
The record linkage techniques are a multidisciplinary set of
methods and practices
RECORD LINKAGE
SEARCH SPACE REDUCTION
• Sorted Neighbourhood Method
• Blocking
• Hierarchical Grouping
• …
DECISION MODEL CHOICE
• Fellegi & Sunter
• exact
• Knowledge – based
• Mixed
• …
COMPARISON FUNCTION
CHOICE
• Edit distance
• Smith-Waterman
• Q-grams
• Jaro string comparator
• Soundex code
• TF-IDF
• …
...... ......
......
PRE-PROCESSING
• Conversion of upper/lower cases
• Replacement of null strings
• Standardization
• Parsing
•…
Record linkage steps

Poznan 20 October 2010 World Statistics Day
Example (Fortini, 2008)*
Census is sometimes associated with a post enumeration
surveys, in order to detect the actual census coverage.
To this purpose, a “capture-recapture” approach is
generally considered.
It is necessary to find out how many individuals have been
observed:
• in both the census and the PES
• Only in the census
• Only in the PES
These figures allow to estimate how many individuals have
NOT been observed in both the census and the PES * In ESSnet Statistical Methodology Project on Integration of Survey and Administrative
Data “Report of WP2. Recommendations on the use of methodologies for the
integration of surveys and administrative data”, 2008

Poznan 20 October 2010 World Statistics Day
Step 1
Step 2
Step 3.b Step 3.a
Matched
households
Unmatched
households
Matched
households
Unmatched
households
Matched
people
Unmatched
people Unmatched
people
Step 4.a Step 4.b
Matched
people
Unmatched
people
Matched
people
Unmatched
people
Step 5 Matched
people Unmatched
people
CENSUS PES
Record linkage
workflow for Census -
PES
Matched
people

Poznan 20 October 2010 World Statistics Day
Problem: Lack of identifiers
Difference between step 1 and step 2 is that:
Step 1 identifies all those households that coincide for all
these variables:
• Name, surname and date of birth of the household head
• Address
• Number of male and female components
Step 2 uses the same keys, but admits the possibility of
differences of the variable states for modifications of
errors

Poznan 20 October 2010 World Statistics Day
Probabilistic record linkage
For every pairs of records from the two data sets, it is
necessary to estimate
• The probability that the differences between what
observed on the two records is due to chance, because
the two records belong to the same unit
• The probability that the two records belong to different
units
These probabilities are compared: this comparison is the
basis for the decision whether a pair of records is a
match or not
Estimate of this probability is the “statistical step” in the
probabilistic record linkage method

Poznan 20 October 2010 World Statistics Day
Statistical step
Data set A with na units.
Data set B with nb units.
K key variables (they jointly
make an identifier)
Key variables
a X1 X2 … Xk
1 Ax11 Ax12 … A
kx1 XA1
2 Ax21 Ax22 … A
kx2 XA2
… … … … … …
nA A
nax 1 A
nax 2 … A
nakx XAk
Key variables
b X1 X2 … Xk
1 Bx11 Bx12 … B
kx1 XB1
2 Bx21 Bx22 … B
kx2 XB2
… … … … … …
nb B
nbx 1 B
nbx 2 … B
nbkx XBk

Poznan 20 October 2010 World Statistics Day
Statistical procedure
The key variables of the two records in a
pair (a,b) is compared:
yab=f(xAa,xBb)
The function f(.) should register how
much the key variables observed in
the two units are different.
For instance, y can be a vector with k
components, composed of 0s
(inequalities) or 1s (equalities)
The final result is a data set of na x nb
comparisons
(a,b) comparisons
(1,1) f(XA1,XB1)= y11
(1,2) f(XA1,XB2)= y12
… … …
… … …
… … …
(na,nb) f(XAna,Xb1)= ynanb

Poznan 20 October 2010 World Statistics Day
Statistical procedure
The na x nb pairs are split in two sets:
M: the pairs that are a match
U: the unmatched pairs
Likely, the comparisons y will follow this situation:
• Low levels of diversity for the pairs that are match,
(a,b) M
• High levels of diversity for the pairs that are non-match,
(a,b) U
For instance: if y=(sum of the equalities for the k key
variables), y tends to assume large values for the pairs
in M with respect to those in U
Poznan 20 October 2010 World Statistics Day
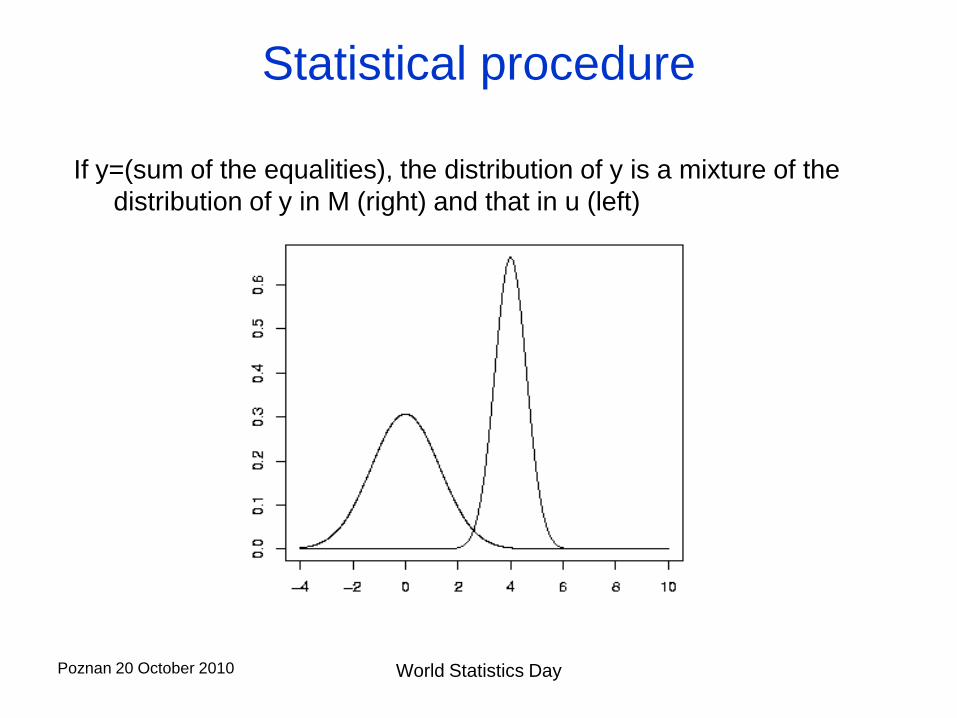
Statistical procedure
If y=(sum of the equalities), the distribution of y is a mixture of the
distribution of y in M (right) and that in u (left)

Poznan 20 October 2010 World Statistics Day
Statistical procedure
Inclusion of a pair (a,b) in M or U is a missing value (latent variable).
Let C denote the status of a pair (C=1 if (a,b) in M; C=0 if (a,b) in U)
Likelihood is the product on the na x nb pairs of
P(Y=y, C=c) = [p m(y)]c [(1-p) u(y)](1-c)
Estimation method: maximum likelihood on a partially observed data
set (EM algorithm – Expectation Maximization)
Parameters data
p: fraction of matches among the
na x nb pairs
Y: observed
m(y): distribution of y in M C: missing (latent)
u(y): distribution of y in U

Poznan 20 October 2010 World Statistics Day
Statistical procedure
A pair is assigned to M or U in the
following way
1) For every comparison y assign a
“weight”:
t(y)=m(y)/u(y)
where m and u are estimated;
2) Assign the pairs with a large weight to
M and the pairs with a small weight
to U.
3) There can be a class of weights t
where it is better to avoid definitive
decisions (m and u are similar)

Poznan 20 October 2010 World Statistics Day
Statistical procedure
The procedure
is the
following.
Note that,
generally,
probabilities of
mismatching
are still not
considered

Poznan 20 October 2010 World Statistics Day
Open problems Different probabilistic record linkage aspects should still be
better investigated. Two of them are related to record linkage quality
a) What model should be considered
– a1) on the pairs relationship (Copas and Hilton, 1990)
– a2) on the key variables relationship (Thibaudeau, 1993)
b) How probabilities of mismatching can be used for a statistical analysis of a linked data file? (Scheuren and Winkler, 1993, 1997)
Copas J.R., Hilton F.J. (1990). “Record linkage: statistical models for matching computer records”.
Journal of the Royal Statistical Society, Series A, 153, 287-320.
Thibaudeau Y. (1993). “The discrimination power of dependency structures in record linkage”. Survey Methodology, 19, 31-38.
Scheuren F., Winkler W.E. (1993). “Regression analysis of data files that are computer matched”. Survey Methodology, 19, 39-58
Scheuren F., Winkler W.E. (1997). “Regression analysis of data files that are computer matched - part II”. Survey Methodology, 23, 157-165.

Poznan 20 October 2010 World Statistics Day
Statistical matching
What kind of integration should be considered if the
analysis involves two variables observed in two
independent sample surveys?
• Let A and B be two samples of size nA and nB
respectively, drawn from the same population.
• Some variables X are observed in both samples
• Variables Y are observed only in A
• Variables Z are observed only in B.
Statistical matching aims at determining information on
(X;Y;Z), or at least on the pairs of variables which are not
observed jointly (Y;Z)

Poznan 20 October 2010 World Statistics Day
Statistical matching
It is very improbable that the two samples observe the
same units, hence record linkage is useless.

Poznan 20 October 2010 World Statistics Day
Some statistical matching applications 1 The objective of the integration of the Time Use Survey (TUS) and of the
Labour Force Survey (LFS) is to create at a micro level, a synthetic file of
both surveys that allows the study of the relationships between variables
measured in each specific survey.
By using together the data relative to the specific variables of both surveys,
one would be able to analyse the characteristics of employment and the
time balances at the same time.
Information on labour force units and the organisation of her/his life
times will help enhance the analyses of the labour market
The analyses of the working condition characteristics that result from
the labour force survey will integrate the TUS more general analysis of
the quality of life

Poznan 20 October 2010 World Statistics Day
Some statistical matching applications 1
The possibilities for a reciprocal enrichment have been largely recognised
(see the 17th International Conference of Labour Statistics in 2003 and the
2003 and 2004 works of the Paris group). The emphasis was indeed put on
how the integration of the two surveys could contribute to analysing the
different participation modalities in the labour market determined by hour
and contract flexibility.
Among the issues raised by researchers on time use, we list the following
two:
the usefulness and limitations involved in using and combining various
sources, such as labour force and time-use surveys, for improving data
quality
Time-use surveys are useful, especially for measuring hours worked of
workers in the informal economy, in home-based work, and by the
hidden or undeclared workforce, as well as to measure absence from
work

Poznan 20 October 2010 World Statistics Day
Some statistical matching applications 1
Specific variables in the TUS (Y ): it enables to estimate the
time
dedicated to daily work and to study its level of
"fragmentation" (number of intervals/interruptions),
flexibility (exact start and end of working hours) and intra-
relations with the other life times
Specific variables in the LFS (Z): The vastness of the
information gathered allow us to examine the peculiar
aspects of the Italian participation in the labour market:
professional condition, economic activity sector, type of
working hours, job duration, profession carried out, etc.
Moreover, it is also possible to investigate dimensions
relative to the quality of the job

Poznan 20 October 2010 World Statistics Day
Some statistical matching applications 2
The Social Policy Simulation Database and Model (SPSD/M)
is a micro computer-based product designed to assist those
interested in analyzing the financial interactions of
governments and individuals in Canada (see
http://www.statcan.ca/english/spsd/spsdm.htm).
It can help one to assess the cost implications or income
redistributive effects of changes in the personal taxation and
cash transfer system.
The SPSD is a non-confidential, statistically representative
database of individuals in their family context, with enough
information on each individual to compute taxes paid to and
cash transfers received from government.

Poznan 20 October 2010 World Statistics Day
Some statistical matching applications 2
The SPSM is a static accounting model which processes
each individual and family on the SPSD, calculates taxes
and transfers using legislated or proposed programs and
algorithms, and reports on the results.
It gives the user a high degree of control over the inputs
and outputs to the model and can allow the user to modify
existing tax/transfer programs or test proposals for entirely
new programs. The model can be run using a visual
interface and it comes with full documentation.

Poznan 20 October 2010 World Statistics Day
Some statistical matching applications 2
In order to apply the algorithms for microsimulation of tax–transfer
benefits policies, it is necessary to have a data set representative of the
Canadian population. This data set should contain information on
structural (age, sex,...), economic (income, house ownership, car
ownership, ...), health–related (permanent illnesses, child care,...)
social (elder assistance, cultural–educational benefits,...) variables
(among the others).
• It does not exist a unique data set that contains all the variables that
can influence the fiscal policy of a state
• In Canada 4 samples are integrated (Survey of consumers finances,
Tax return data, Unemployment insurance claim histories, Family
expenditure survey)
• Common variables: some socio-demographic variables
• Interest is on the relation between the distinct variables in the different
samples

Poznan 20 October 2010 World Statistics Day
Example (Coli et al, 2006*)
The new European System of the Accounts (ESA95) is a
detailed source of information on all the economic
agents, as households and enterprises. The social
accounting matrix (SAM) has a relevant role.
Module on households: it includes the amount of
expenditures and income, per typology of household
Coli A., Tartamella F., Sacco G., Faiella I., D’Orazio M., Di Zio M.,
Scanu M., Siciliani I., Colombini S., Masi A. (2006). “La costruzione
di un Archivio di microdati sulle famiglie italiane ottenuto integrando
l’indagine ISTAT sui consumi delle famiglie italiane e l’Indagine
Banca d’Italia sui bilanci delle famiglie italiane”, Documenti ISTAT,
n.12/2006.

Poznan 20 October 2010 World Statistics Day
Example
Problem:
1) Income are observed on a Bank of Italy survey
2) Expenditures are observed on an Istat survey
3) The two samples are composed of different households,
hence record linkage is useless

Poznan 20 October 2010 World Statistics Day
Adopted solutions 1
The first statistical matching solution was imputation of missing data.
Usually, “distance hot deck” was used.
In pratice, this method “mimics” record linkage: instead of matching
records of the same unit, this approach “matches” records of similar
units, where similarity is in terms of the common variables in the two
files.
The procedure is
1) Compute the distances between the matching variables for every
pair of records
2) Every record in A is associated to that record in B with minimum
distance
Poznan 20 October 2010 World Statistics Day
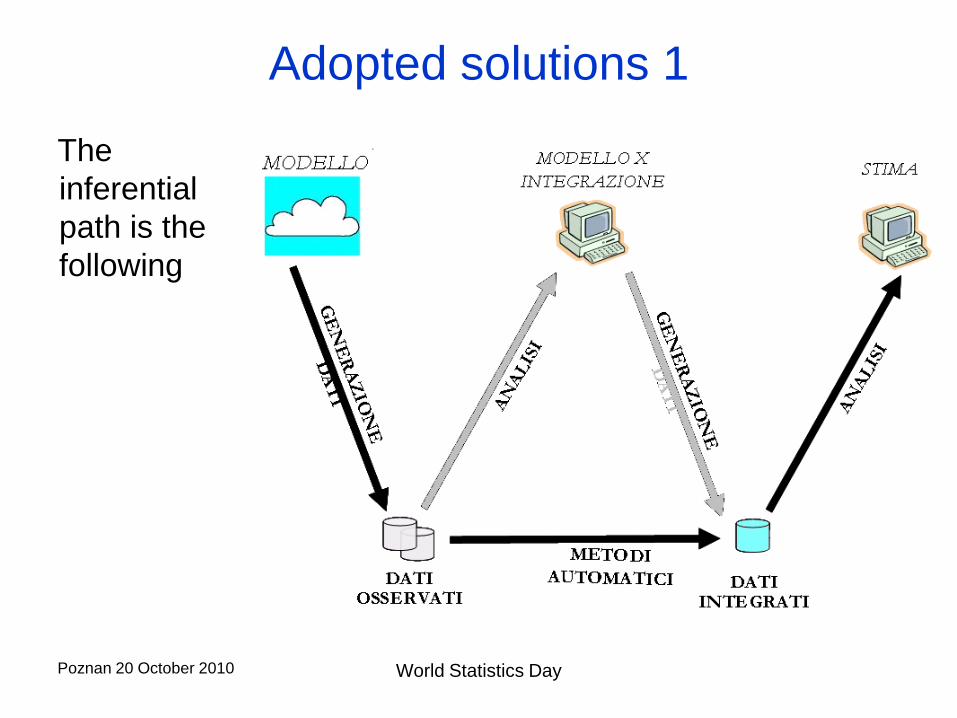
Adopted solutions 1
The
inferential
path is the
following

Poznan 20 October 2010 World Statistics Day
Adopted solutions 2
It is applied an estimate procedure under specific models
that considers the presence of missing items. The easiest
model is: conditional independence of the never jointly
observed variables (e.g., income and expenditures) given
the matching variables.
Example:
Y = income, Z = expenditures, X = house surface
(X,Y,Z) is distributed as a multivariate normal with
parameters:
Mean vector =
Variance matrix =

Poznan 20 October 2010 World Statistics Day
Adopted solutions 2
1) Estimate the regression equation on A: Y= + X
2) Impute Y in B: Yb= + Xb , b=1,…,nB
3) Estimate the regression equation in B: Z= + X
4) Impute Z in A: Za= + Xa , a=1,…,nA

Poznan 20 October 2010 World Statistics Day
Adopted solutions 2
The inferential
mechanism
assumes that
Y and Z are
independent
given X
(there is not
the regression
coefficient of Z
on Y
given X)

Poznan 20 October 2010 World Statistics Day
Adopted solutions 2
This method
can be
applied also
with this
inferential
scheme: the
problem is
what
hypotheses
are before
the analysis
phase

Poznan 20 October 2010 World Statistics Day
Adopted solutions 3
We do not hypothesize any model. It is estimated a set of
values, one for every plausible model given the
observed data
Example
When matching two sample surveys on farms (Rica-Rea -
FADN and SPA - FSS), it was asked the following
contingency table for farms
Y = presence of cattle (FSS)
Z = class of intermediate consumption (from FADN)
Using the common variables
X1 = Utilized Agricultural Area (UAA) ,
X2 = Livestock Size Unit (LSU)
X3 = geographical characteristics

Poznan 20 October 2010 World Statistics Day
Example
We consider all the models that we cam estimate from the
observed data in the two surveys
In practice, the available data allow to say that the estimate
of the number of farms with at least one cow (Y=1) in the
lowest class of intermediate consumption (Z=1) is
between 2,9% and 4,9%

Poznan 20 October 2010 World Statistics Day
Inferential machine
The inferential machine
does not use any specific
model
It is possible to simulate data including uncertainty on the data generation model (e.g. by multiple imputation)

Poznan 20 October 2010 World Statistics Day
Quotation (Manski, 1995*)
…”The pressure to produce answers, without qualifications, seems particularly intense in the environs of Washington, D.C. A perhaps apocryphal, but quite believable, story circulates about an economist’s attempt to describe his uncertainty about a forecast to President Lyndon Johnson. The economist presented his forecast as a likely range of values for the quantity under discussion. Johnson is said to have replied, “Ranges are for cattle. Give me a number”
*Manski, C. F. (1995) Identification problems in the Social Sciences, Harvard University Press.
Manski and other authors show that in a wide range of applied areas (econometrics, sociology, psychometrics) there is a problem of identifiability of the models of interest, usually caused by the presence of missing data. The statistical matching problem is an
example of this.

Poznan 20 October 2010 World Statistics Day
Why statistical matching?
Applications in Istat
SAM
Joint analysis FADN / FSS
Joint use of Time Use / Labour force
Objectives
Estimates of parameters of not jointly observed parameters
Creation of synthetic data (e.g. data set for
microsimulation)

Poznan 20 October 2010 World Statistics Day
Open problems 1) Uncertainty estimate (D’Orazio et al, 2006)
2) Variability of uncertainty (Imbens e Manski, 2004)
3) Use of sample drawn according to complex survey designs (Rubin, 1986; Renssen, 1998)
4) Use of nonparametric methods (Marella et al, 2008; Conti et al 2008)
Conti P.L., Marella D., Scanu M. (2008). “Evaluation of matching noise for imputation techniques based on the local linear regression estimator”. Computational Statistics and Data Analysis, 53, 354-365.
D’Orazio M., Di Zio M., Scanu M. (2006). “Statistical Matching for Categorical Data: Displaying Uncertainty and Using Logical Constraints”, Journal of Official Statistics, 22, 137-157.
Imbens, G.W, Manski, C. F. (2004). "Confidence intervals for partially identified parameters". Econometrica, Vol. 72, No. 6 (November, 2004), 1845–1857
Marella D., Scanu M., Conti P.L. (2008). “On the matching noise of some nonparametric imputation procedures”, Statistics and Probability Letters, 78, 1593-1600.
Renssen, R.H. (1998) Use of statistical matching techniques in calibration estimation. Survey Methodology 24, 171–183.
Rubin, D.B. (1986) Statistical matching using file concatenation with adjusted weights and multiple imputations. Journal of Business and Economic Statistics 4, 87–94.

Poznan 20 October 2010 World Statistics Day
Micro integration processing
It can be applied every time it is produced a complete data
set (micro level) by any kind of method. Up to now,
applied after exact record linkage
Micro integration processing consists of putting in place all
the necessary actions aimed to ensure better quality of
the matched results as quality and timeliness of the
matched files. It includes
• defining checks,
• editing procedures to get better estimates,
• imputation procedures to get better estimates.

Poznan 20 October 2010 World Statistics Day
Micro integration processing
It should be kept in mind that some sources are more
reliable than others.
Some sources have a better coverage than others, and
there may even be conflicting information between
sources.
So, it is important to recognize the strong and weak points
of all the data sources used.

Poznan 20 October 2010 World Statistics Day
Micro integration processing
Since there are differences between sources, a micro integration
process is needed to check data and adjust incorrect data. It is
believed that integrated data will provide far more reliable results,
because they are based on an optimal amount of information. Also
the coverage of (sub) populations will be better, because when data
are missing in one source, another source can be used. Another
advantage of integration is that users of statistical information will
get one figure on each social phenomenon, instead of a confusing
number of different figures depending on which source has been
used.

Poznan 20 October 2010 World Statistics Day
Micro integration processing
During the micro integration of the data sources the following steps
have to be taken (Van der Laan, 2000):
a. harmonisation of statistical units;
b. harmonisation of reference periods;
c. completion of populations (coverage);
d. harmonisation of variables, in case of differences in definition;
e. harmonisation of classifications;
f. adjustment for measurement errors, when corresponding variables
still do not have the same value after harmonisation for differences
in definitions;
g. imputations in the case of item nonresponse;
h. derivation of (new) variables; creation of variables out of different
data sources;
i. checks for overall consistency.
All steps are controlled by a set of integration rules and fully automated.

Poznan 20 October 2010 World Statistics Day
Example: Micro integration processing
From Schulte Nordholt, Linder (2007) Statistical Journal of the IAOS 24,163–171
Suppose that someone becomes unemployed at the end of November and gets unemployment benefits from the beginning of December. The jobs register may indicate that this person has lost the job at the end of the year, perhaps due to administrative delay or because of payments after job termination. The registration of benefits is believed to be more accurate. When confronting these facts the ’integrator’ could decide to change the date of termination of the job to the end of November, because it is unlikely that the person simultaneously had a job and benefits in December. Such decisions are made with the utmost care. As soon as there are convincing counter indications of other jobs register variables, indicating that the job was still there in December, the termination date will, in general, not be adjusted.

Poznan 20 October 2010 World Statistics Day
Example: Micro integration processing
Method: definition of rules for the creation of a usable
complete data set after the linkage process.
If these approaches are not applied, the integrated data set
can contain conflicting information at the micro level.
These approaches are still strictly based on quality of data
sets knowledge.
Proposition for a possible next ESSnet on integration: study
the links between imputation and editing activities and

Poznan 20 October 2010 World Statistics Day
Other supporting slides

Poznan 20 October 2010 World Statistics Day
Macro integration: coherence of
estimates Sometimes it is useful to integrate aggregate data, where
aggregates are computed from different sample surveys.
For instance: to include a set of tables in an information
system
A problem is the coherence of information in different
tables.
The adopted solution is at the estimate level: for instance,
with calibration procedures (e.g.: the Virtual census in
the Netherlands)

Poznan 20 October 2010 World Statistics Day
Project
The objective of a project is to gather the developments in
two distinct areas
Probabilistic expert systems: these are graphical models,
characterized by the presence of an easy updating
system of the joint distribution of a set of variables, once
one of them is updated. These models have been used
for a class of estimators that includes poststratification
estimators
Statistical information systems: SIS for the production of
statistical output (Istar) with the objective to integrate
and manage statistical data given and validated by the
Istat production areas, in order to produce purposeful
output for the end users

Poznan 20 October 2010 World Statistics Day
Objectives and open problems
Objectives To develop a statistical information system for agriculture
data, managing tables from FADN. FSS, and lists used
for sampling (containing census and archive data)
To manage coherence bewteen different tables
To update information on data from the most recent survey
and to visualize what changes happen to the other
tables
To allow simulations (for policy making)
Problems
Use of graphical models for complex survey data
To link the selection of tables to the updating algorithm
To update more than one table at the same time

Poznan 20 October 2010 World Statistics Day
Some practical aspects for integration:
Software There exist different software tools for record linkage
record linkage and statistical matching
Relais:
http://www.istat.it/strumenti/metodi/software/analisi_dati/
relais/
R package for statistical matching:
http://cran.r-project.org/index.html
Look for Statmatch
Probabilistic expert systems: Hugin (it does not work with
complex survey data)

Poznan 20 October 2010 World Statistics Day
Bibliography
Batini C, Scannapieco M (2006) Data Quality, Springer
Verlag, Heidelberg.
Scanu M (2003) Metodi statistici per il record linkage,
collana Metodi e Norme n. 16, Istat.
D’Orazio M., Di Zio M., Scanu M. (2006) Statistical
matching: theory and practice, J. Wiley & Sons,
Chichester.
Ballin M., De Francisci S., Scanu M., Tininini L., Vicard P.
(2009) Integrated statistical systems: an approach to
preserve coherence between a set of surveys based on
the use of probabilistic expert systems, NTTS 2009,
Bruxelles.

Poznan 20 October 2010 World Statistics Day
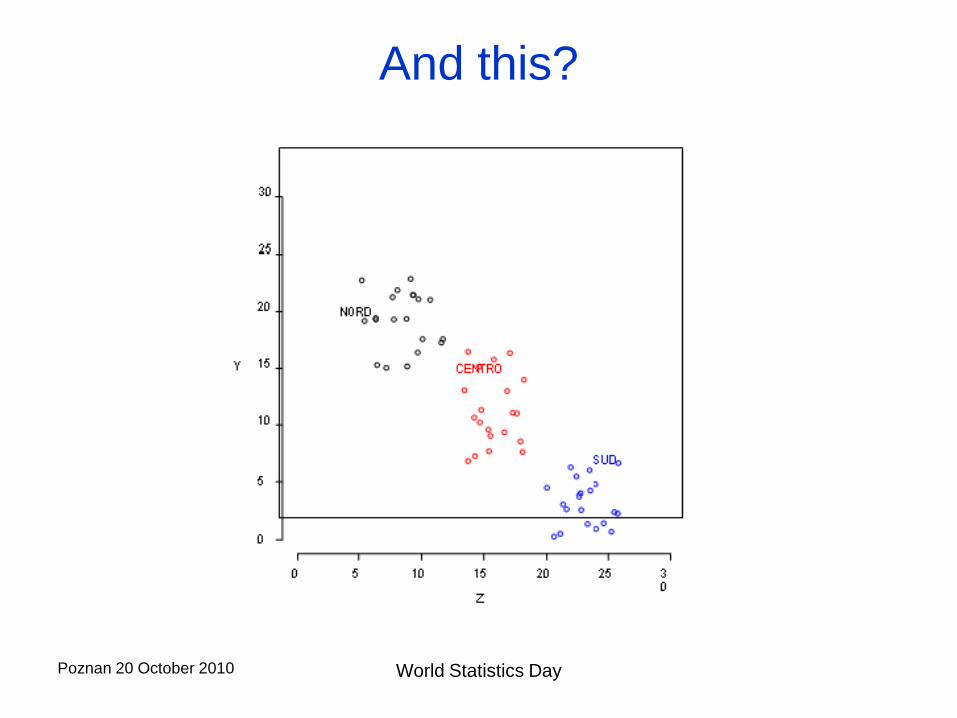
Is this conditional independence?
Poznan 20 October 2010 World Statistics Day
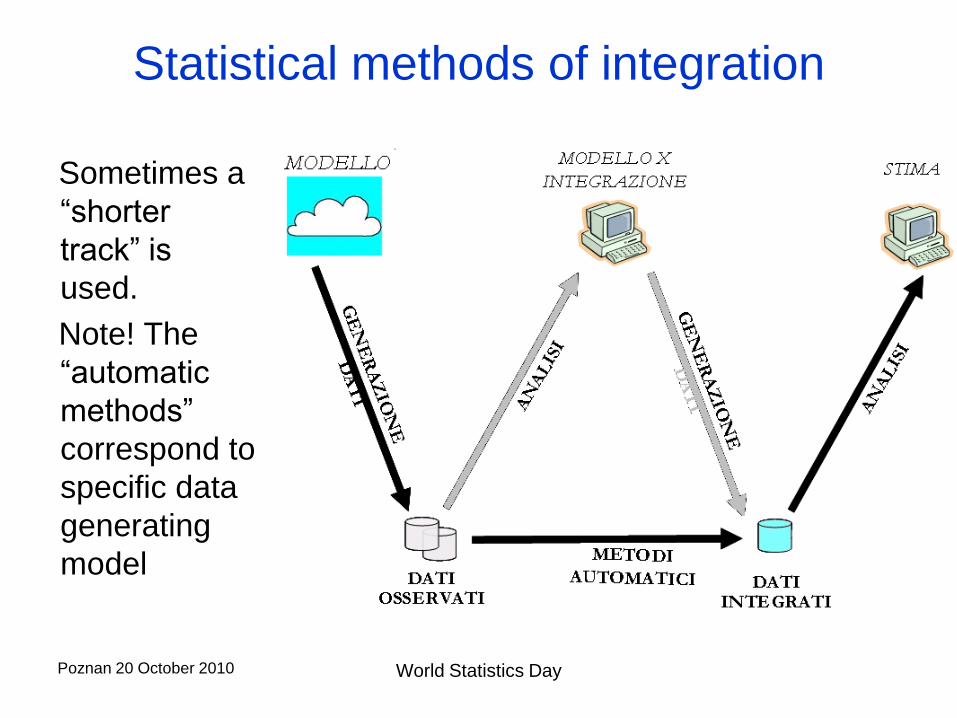
And this?
Poznan 20 October 2010 World Statistics Day
Statistical methods of integration
Sometimes a
“shorter
track” is
used.
Note! The
“automatic
methods”
correspond to
specific data
generating
model
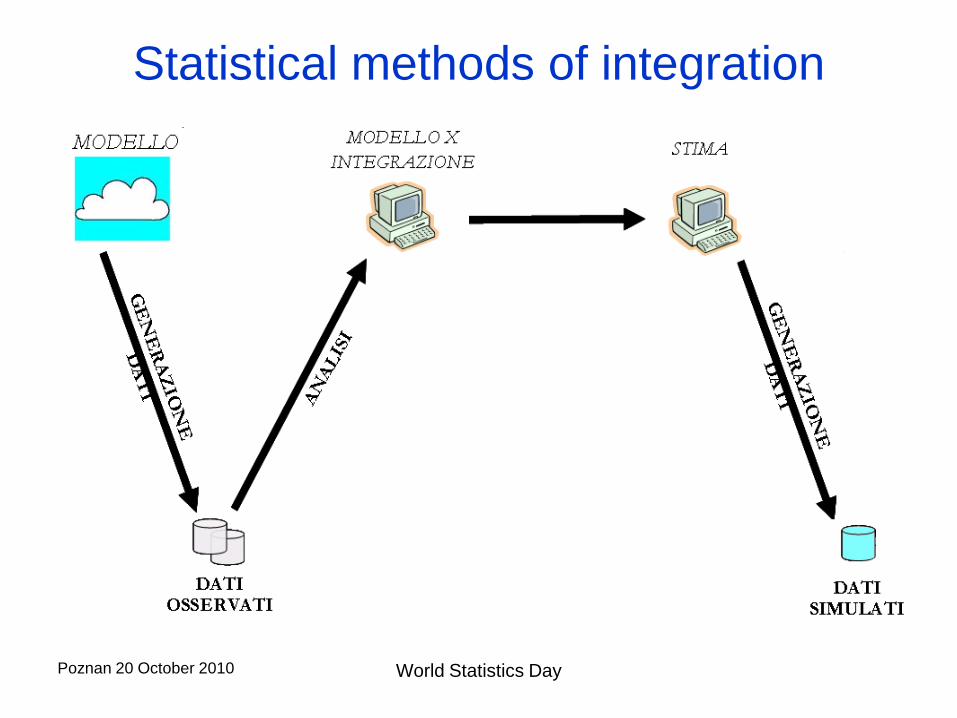
Poznan 20 October 2010 World Statistics Day
Statistical methods of integration

Poznan 20 October 2010 World Statistics Day
Statistical methods of integration
The last approach is very appealing:
1) Estimate a data generating model from the two data samples at
hand
2) Use this estimate for the estimation of aggregate data (e.g.
contingency tables on non jointly observed variables)
3) If necessary, develop a complete data set by simulation from the
estimated model: the integrated data generating mechanism is the
“nearest” to the data generating model, according to the optimality
properties of the model estimator
Attention! Issue 1 includes hypothesis that cannot be tested on the
available data (this is true for record linkage and, more
“dramatically”, for statistical matching)

Mauro Scanu
Data integration: an overview on
statistical methodologies
and applications
Top Related