







Languages
Pages
Legal


CSE 574 – Artificial Intelligence II
Statistical Relational Learning
Instructor:
Pedro Domingos

Logistics
• Instructor: Pedro DomingosEmail: [email protected]: 648 Allen CenterOffice hours: Wednesdays 4:30-5:30
• TA: Stanley KokEmail: [email protected]: 216 Allen CenterOffice hours: Mondays 4:30-5:30
• Web: www.cs.washington.edu/574• Mailing list: cse574

Evaluation
• Seminar (Pass/Fail)
• Project (100% of grade)– Proposals due April 8– Progress report due May 6– Presentation in class– Final report due June 3

Materials
• L. Getoor & B. Taskar (eds.), Statistical Relational Learning, MIT Press (to appear).– Draft chapters– Feedback for authors
• Papers

Topics
• Background
• SRL approaches
• SRL problems and applications

Background
• Statistical learning
• Inductive logic programming
• Sequential and spatial models

SRL Approaches
• Probabilistic relational models
• Stochastic logic programs
• Bayesian logic programs
• Relational Markov networks
• Markov logic networks
• Etc.

SRL Problems and Applications
• Aggregation
• Autocorrelation
• Information extraction and NLP
• Biology and medicine
• Relational reinforcement learning
• Etc.

Today: Introduction
• Motivation– The AI view– The data mining view– The statistical view– The computer science view
• Applications
• Major problem types
• A map of the field
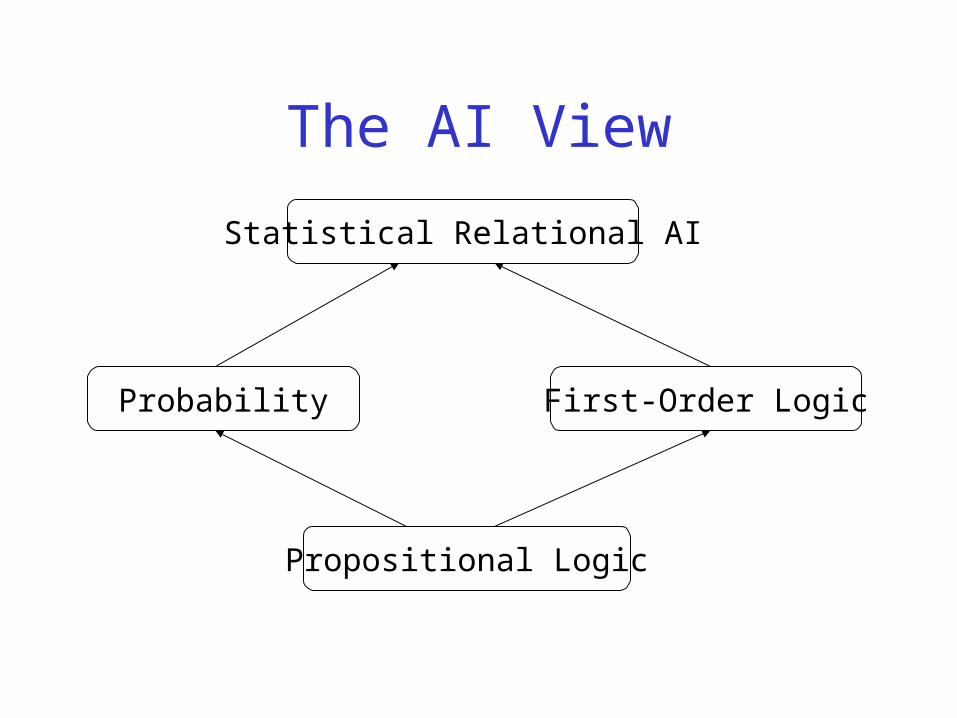
The AI View
Propositional Logic
Probability First-Order Logic
Statistical Relational AI

The Data Mining View
• Most databases contain multiple tables
• Data mining algorithms assume one table
• Manual conversion: slow, costly bottleneck
• Important patterns may be missed
• Solution: Multi-relational data mining

The Statistical View
• Most statistical models assume i.i.d. data(independent and identically distributed)
• A few assume simple regular dependence (e.g., Markov chain)
• This is a huge restriction – Let’s remove it!– Allow dependencies between samples– Allow samples with different distributions

The Computer Science View
• CS faces a complexity bottleneck– Cost of hand-coding– Brittleness
• Machine learning and probability overcome this
• But they mostly apply only to attribute vectors
• Let’s extend them to handle structured objects, class hierarchies, relational databases, etc.

Applications
• Bottom line: Using statistical and relational information gives better results– Web search (Brin & Page, WWW-98)
– Text classification (Chakrabarti et al, SIGMOD-98)
– Marketing (Domingos & Richardson, KDD-01)
– Record linkage (Pasula et al, NIPS-02)
– Gene expression (Segal et al, UAI-03)
– Information extraction (McCallum & Wellner, NIPS-04)
– Etc.

Major Problem Types
• Collective classification• Link discovery• Link-based search• Link-based clustering• Social network analysis• Object identification• Transfer learning• Etc.

A Map of the Field
• There are many approaches(“Alphabet soup”)
• Every year new ones are proposed(and for good reason)
• Key is to understand the major dimensions along which approaches can differ

Major Dimensions
• Probabilistic language
• Logical language
• Type of learning
• Type of inference
• Aggregation

Probabilistic Language
• Bayesian networks
• Markov networks (aka Markov random fields)
• Restrictions of these (e.g., logistic regression)
• Probabilistic context-free grammars

Logical Language
• Prolog / Horn clauses
• Frame systems / Description logics
• Conjunctive database queries
• Full first-order logic

Type of Learning
• Generative vs. discriminative
• Structure vs. parameters
• Knowledge-poor vs. knowledge-rich

Type of Inference
• Marginal/conditional vs. MAP– Marg./cond.: MCMC, belief propagation, etc.– MAP: Graph cuts, weighted satisfiability, etc.
• Full grounding vs. KBMC

Aggregation
• Quantifiers• SQL-like aggregators
(MAX, AVG, SUM, COUNT, MODE, etc.)
• Noisy-OR
• Logistic regression

Examples
• Probabilistic relational models(Friedman et al, IJCAI-99)
• Stochastic logic programs(Muggleton, SRL-00)
• Bayesian logic programs(Kersting & De Raedt, ILP-01)
• Relational Markov networks(Taskar et al, UAI-02)
• Markov logic networks(Richardson & Domingos, SRL-04)
Top Related