







Languages
Pages
Legal


Procédures standard d’opération pour la collecte de données
Collecte de Données
Version 9 Avril 2018
Historique de versions
Version 9 Avril 2018, 01 Version initiale
Contents 1 Avant tout ............................................................................................................................................. 1
2 Préparation des échantillons ................................................................................................................ 2
3 Préparation de l’information sur QGIS ................................................................................................. 3
3.1 Couches SPOT ............................................................................................................................... 7
3.2 Composites 2000 et 2015 de Hansen ......................................................................................... 12
3.3 Couches de couverture de canopée de l’UMD ........................................................................... 18
3.4 Modèles numériques d’élévation ............................................................................................... 18
3.4.1 ASPECT.TIF........................................................................................................................... 18
3.4.2 ALTITUDE.TIF ....................................................................................................................... 20
3.5 Carte de végétation..................................................................................................................... 23
4 Collecte de données ............................................................................................................................ 23
5 Control Qualité .................................................................................................................................... 25
6 Garder les résultats ............................................................................................................................. 25
7 Nettoyer la base de données .............................................................................................................. 26
1 Avant tout Dans le premier jour de collecte de données (seulement le premier jour), on va nettoyer les bases de
données.

1. En CE, cliquer sur Outils > Open Data Folder. On verra le dossier avec les données de CE.
a. CollectEarthDatabase.db : La base de données ou on a toutes les données collectées
jusqu’au moment.
b. Earth.properties : Proprietés du projet ouvert
c. Earth.error.log : Logfile avec les erreurs.
d. BackupSqlite : Les backup des bases de données collectées.
e. Projects : Sont les projects qu’on a ouvert
2. On va suprimer CollectEarthDatabase.db, earth.properties, earth.error.log.
On fait cela seulement pour le premier jour car cette fois on veut avoir un seul CSV avec tous les
données.
Important : Une fois commencé le travail, si un operateur va importer des données d’autres personnes
pour faire le QA, on vous recommande de prendre tous ces fichiers et les garder dans un autre endroit.
Une fois finalisé le QA, on peut supprimer les nouvelles fichiers crées et les remplacer par les fichiers
anciennes avec la base de données consolidée.
2 Préparation des échantillons 1. Le chef technique du laboratoire va fournir les suivantes fichiers issues de la préparation du plan
d’échantillonnage :
a. Test_plots.CSV : Fichier avec les points d’échantillonnage.
b. Points_echantillonnage.rar : Fichier avec les points d’échantillonnage en SHP

c. Fichier .cep : Fichier Collect Earth
2. Maintenant il faut répartir les fichiers entre plusieurs opérateurs. Pour cela il faut aller à Outils >
Utilities > Divide large CSV plot files. Vous devez choisir le fichier .csv avec les échantillons et
insérer le nombre d’interprétateurs. La sortie sont plusieurs fichiers, un part interprétateur.
3. Les groupes vont travailler chacun avec son fichier. Le chef du laboratoire doit organiser la façon
d’organiser le travail.
4. Afficher le fichier du projet de CollectEarth, aller sur Outils > Proprietés > Points
d’échantillonnage > Parcourir et afficher le fichier CSV qui correspond au groupe.
5. Une fois affiché, Google Earth se mettra à jour et montrera les placettes qui correspondent au
fichier CSV.
6. On est prêts pour commencer la collecte de données !
3 Préparation de l’information sur QGIS 1. Afficher QGIS
2. D’abord il faut sélectionner le système de coordonnées WGS84 GSC (EPSG 4326) et permettre la
visualisation qui ne sont pas dans ce système de coordonnées. On devrait voir une phrase qui
commence par EPSG dans la partie base à droite. Alors : 1) Cliquez sur EPSG ; 2) Cliquez sur
¨permettre transformation CRS¨ et 3) sélectionner le système EPSG 4326.

3. Maintenant, cliquez sur , allez sur le fichier Shapefile qui a été envoyé avec les points et les
placettes en SHP.
4. Maintenant, cliquez avec le bouton droit du souri sur la couche avec les placettes, sélectionnez
proprietés > Style et cliquez sur Remplissage Simple. Après cliquez sur style de remplissage et
sélectionnez sans remplissage.
1
2
3
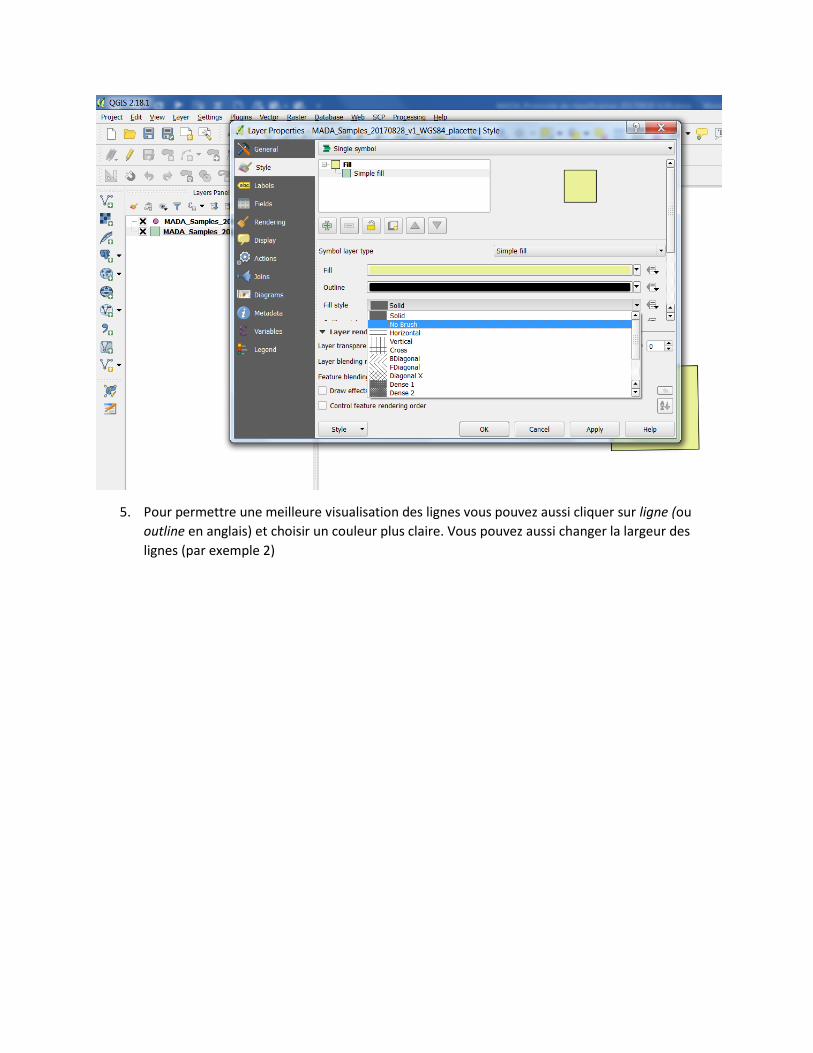
5. Pour permettre une meilleure visualisation des lignes vous pouvez aussi cliquer sur ligne (ou
outline en anglais) et choisir un couleur plus claire. Vous pouvez aussi changer la largeur des
lignes (par exemple 2)
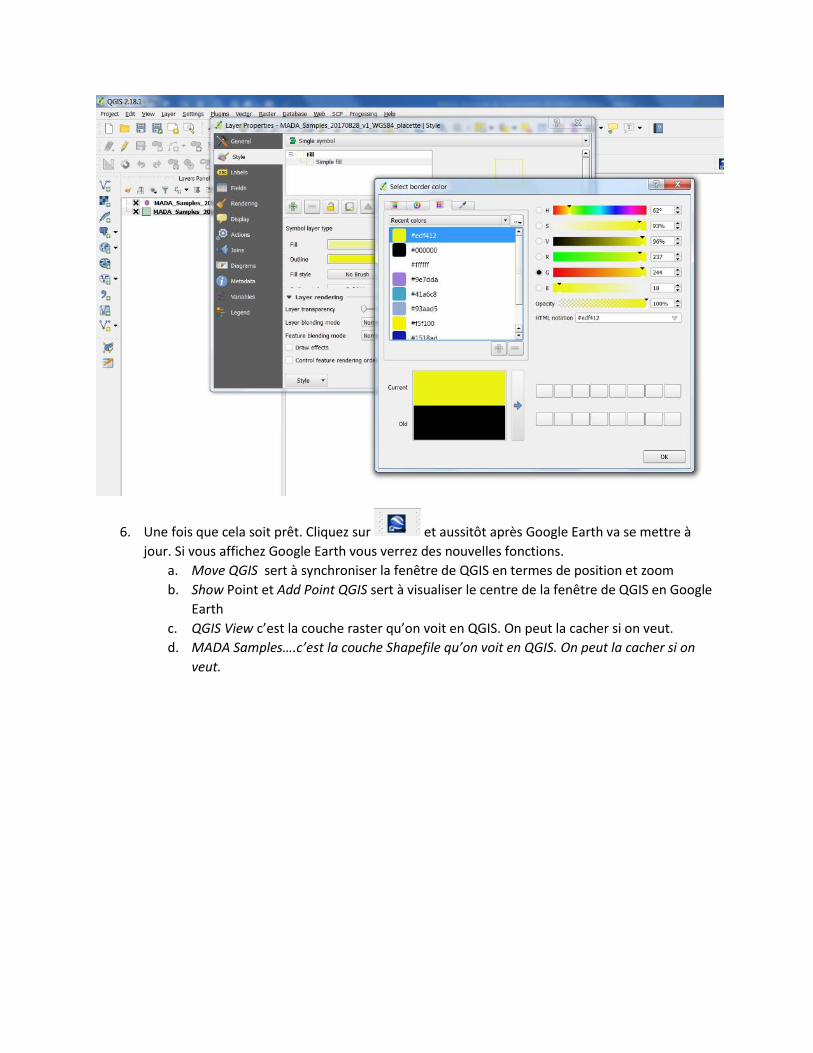
6. Une fois que cela soit prêt. Cliquez sur et aussitôt après Google Earth va se mettre à
jour. Si vous affichez Google Earth vous verrez des nouvelles fonctions.
a. Move QGIS sert à synchroniser la fenêtre de QGIS en termes de position et zoom
b. Show Point et Add Point QGIS sert à visualiser le centre de la fenêtre de QGIS en Google
Earth
c. QGIS View c’est la couche raster qu’on voit en QGIS. On peut la cacher si on veut.
d. MADA Samples….c’est la couche Shapefile qu’on voit en QGIS. On peut la cacher si on
veut.
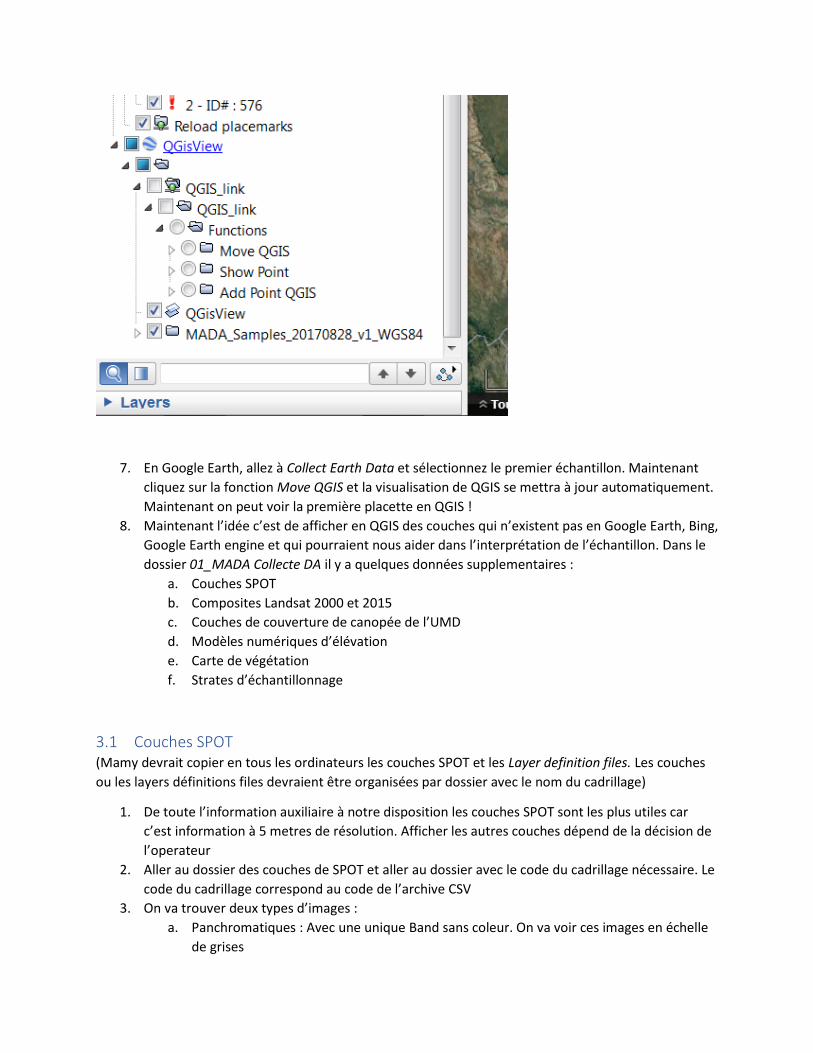
7. En Google Earth, allez à Collect Earth Data et sélectionnez le premier échantillon. Maintenant
cliquez sur la fonction Move QGIS et la visualisation de QGIS se mettra à jour automatiquement.
Maintenant on peut voir la première placette en QGIS !
8. Maintenant l’idée c’est de afficher en QGIS des couches qui n’existent pas en Google Earth, Bing,
Google Earth engine et qui pourraient nous aider dans l’interprétation de l’échantillon. Dans le
dossier 01_MADA Collecte DA il y a quelques données supplementaires :
a. Couches SPOT
b. Composites Landsat 2000 et 2015
c. Couches de couverture de canopée de l’UMD
d. Modèles numériques d’élévation
e. Carte de végétation
f. Strates d’échantillonnage
3.1 Couches SPOT (Mamy devrait copier en tous les ordinateurs les couches SPOT et les Layer definition files. Les couches
ou les layers définitions files devraient être organisées par dossier avec le nom du cadrillage)
1. De toute l’information auxiliaire à notre disposition les couches SPOT sont les plus utiles car
c’est information à 5 metres de résolution. Afficher les autres couches dépend de la décision de
l’operateur
2. Aller au dossier des couches de SPOT et aller au dossier avec le code du cadrillage nécessaire. Le
code du cadrillage correspond au code de l’archive CSV
3. On va trouver deux types d’images :
a. Panchromatiques : Avec une unique Band sans coleur. On va voir ces images en échelle
de grises

b. Multiespectrales : Avec 4 bandes : a) Bande 1 est la bande B2 du rouge ; b) Bande 2 est
la bande B1 du vert ; c) Bande 3 est la bande B0 du bleu ; d) Bande 4 est la bande B3 du
Infra Rouge proche. La combinaison par défaut est 1,2,3 ou B2,B1,B0, donc coleur
naturelle.
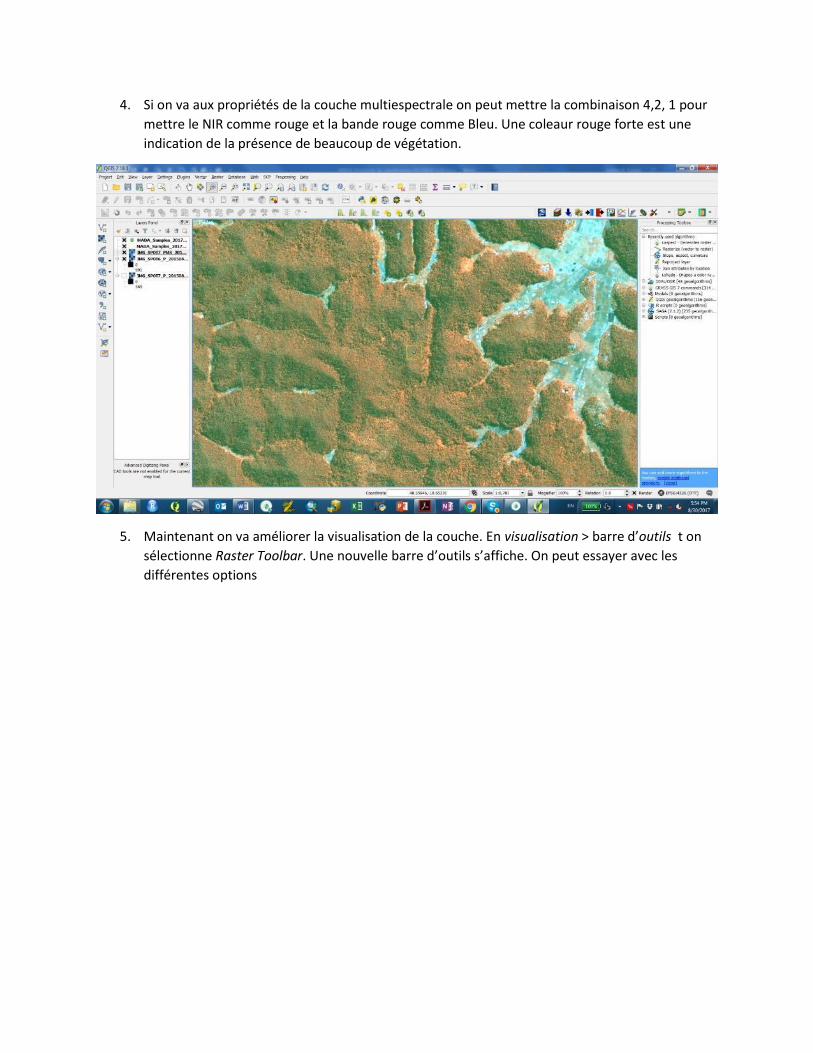
4. Si on va aux propriétés de la couche multiespectrale on peut mettre la combinaison 4,2, 1 pour
mettre le NIR comme rouge et la bande rouge comme Bleu. Une coleaur rouge forte est une
indication de la présence de beaucoup de végétation.
5. Maintenant on va améliorer la visualisation de la couche. En visualisation > barre d’outils t on
sélectionne Raster Toolbar. Une nouvelle barre d’outils s’affiche. On peut essayer avec les
différentes options
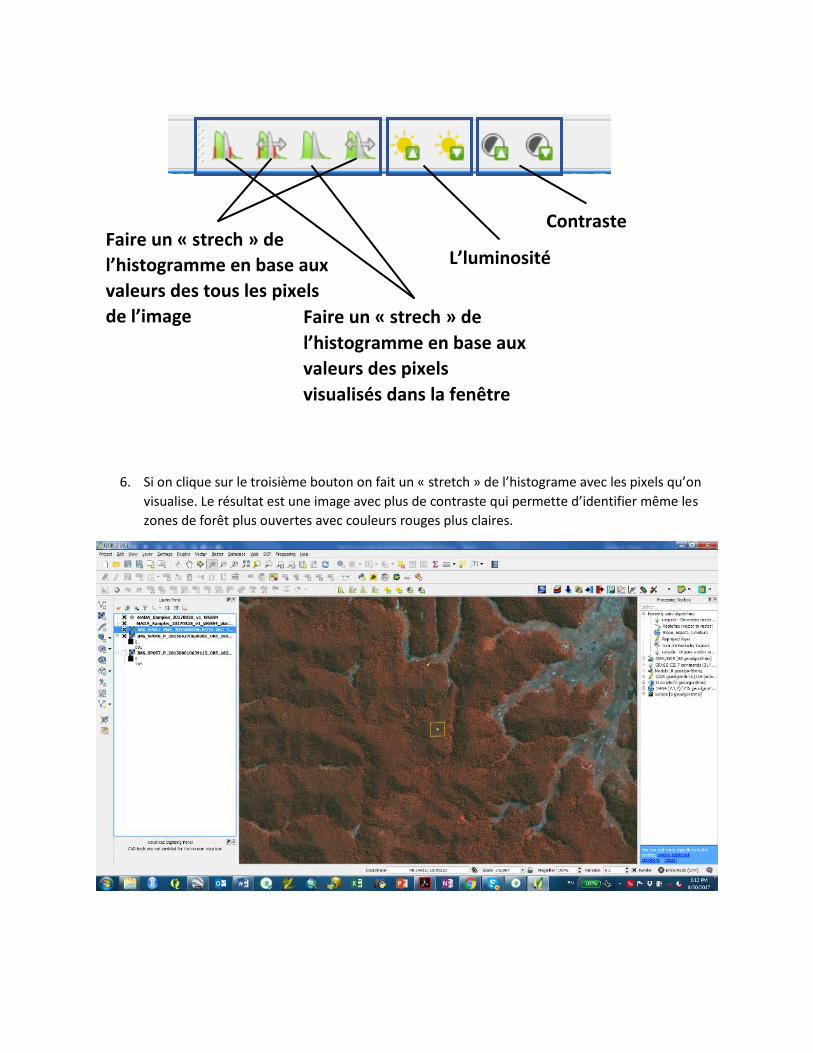
6. Si on clique sur le troisième bouton on fait un « stretch » de l’histograme avec les pixels qu’on
visualise. Le résultat est une image avec plus de contraste qui permette d’identifier même les
zones de forêt plus ouvertes avec couleurs rouges plus claires.
Contraste
L’luminosité
Faire un « strech » de
l’histogramme en base aux
valeurs des pixels
visualisés dans la fenêtre
Faire un « strech » de
l’histogramme en base aux
valeurs des tous les pixels
de l’image

7. La date spécifique de l’image SPOT se trouve dans le nom. Par exemple, l’image
IMG_SPOT7_PMS_201508010639115_ORT_1859813101_R1C1 a une date de 01-08-2015, donc
le premier jour d’Aout de 2015. Toutes les images sont de 2015 ou 2014
8. Après, vous cliquez sur et vous verrez l’image SPOT en Google Earth, ce qui est útile
pour compléter les images de Google Earth et aussi apprendre à interpréter les images de SPOT.
3.2 Composites 2000 et 2015 de Hansen 1. Dans le dossier 02_Landsat composites 2000 2015 vous allez trouver les composites des années
2000 et 2015 de Hansen (Université de Maryland). Bien que on aurait ces mèmes informations
en Google Earth engine, ces couches sont normalement de mieux qualité et il est plus simple de
changer la visualisation des couches comme on va voir.
2. Cliquez sur pour afficher des RASTERS. Allez à 01_MADA Collecte DA\02_Landsat
composites 2000 2015 et vous trouverez quatre couches .TIF :
a. Hansen_GFC-2015-v1.3_first_10S_040E.TIF: Composite de 2000 de la zone 10S 40E
b. Hansen_GFC-2015-v1.3_first_10S_050E.TIF: Composite de 2000 de la zone 10s 50E
c. Hansen_GFC-2015-v1.3_last_10S_040E.TIF: Composite 2015 de la zone 10s 40E
d. Hansen_GFC-2015-v1.3_last_10S_050E.TIF: Composite 2015 de la zone 10s 50E
3. Si vous affichez ces couches vous ne verrez rien. La problème est la configuration par défaut de
la visualisation. On va changer la configuration.
4. Si vous choisissez un des rasters et vous cliquez sur propriétés > Style on peut constater que la
combinaison 1,2,3 a été choisisse. Vous verrez qu’Il y a quatre bandes qui correspondent aux
différentes bandes Landsat
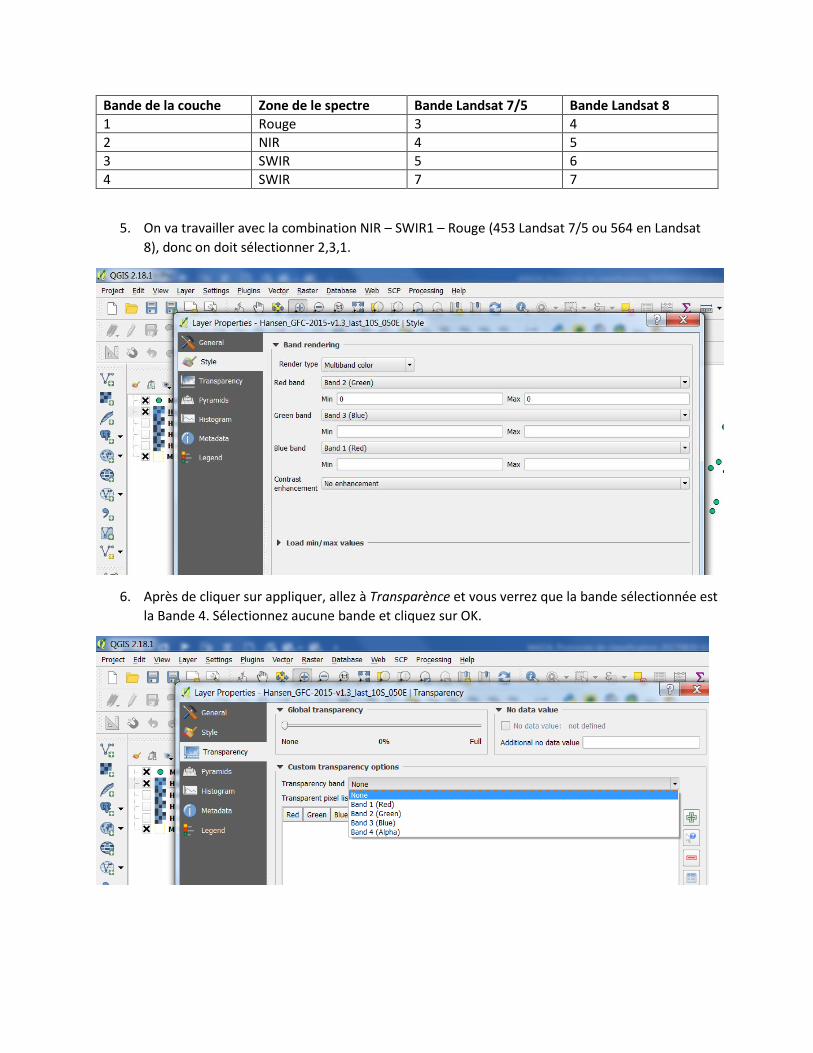
Bande de la couche Zone de le spectre Bande Landsat 7/5 Bande Landsat 8
1 Rouge 3 4
2 NIR 4 5
3 SWIR 5 6
4 SWIR 7 7
5. On va travailler avec la combination NIR – SWIR1 – Rouge (453 Landsat 7/5 ou 564 en Landsat
8), donc on doit sélectionner 2,3,1.
6. Après de cliquer sur appliquer, allez à Transparènce et vous verrez que la bande sélectionnée est
la Bande 4. Sélectionnez aucune bande et cliquez sur OK.

7. Après de cliquer sur appliquer, allez à Transparènce et vous verrez que la bande sélectionnée est
la Bande 4. Sélectionnez aucune bande et cliquez sur OK. Vous verrez maintenant l’image mais
elle n’est pas très claire.
8. Pour ne devoir faire ces changements tout le temps, on vous suggère de cliquer sur la couche et
la sauver comme un fichier de définition de la couche ou Layer définition file. Si dans l’avenir on
veut afficher ce couche une autre fois, on peut directement afficher ce fichier avec une
extension .QLR.

9.
10. Si vous cliquez sur vous faites un « stretch » local de l’histogramme et le résultat et une
constraste plus forte. Maintenant on peut bien distinguer entre les zones avec moins végétation
et distinguer les zones avec sol nu. IMPORTANT : Chaque fois que vous changez de visualization
le stretching n’est pas fait automatiquement.
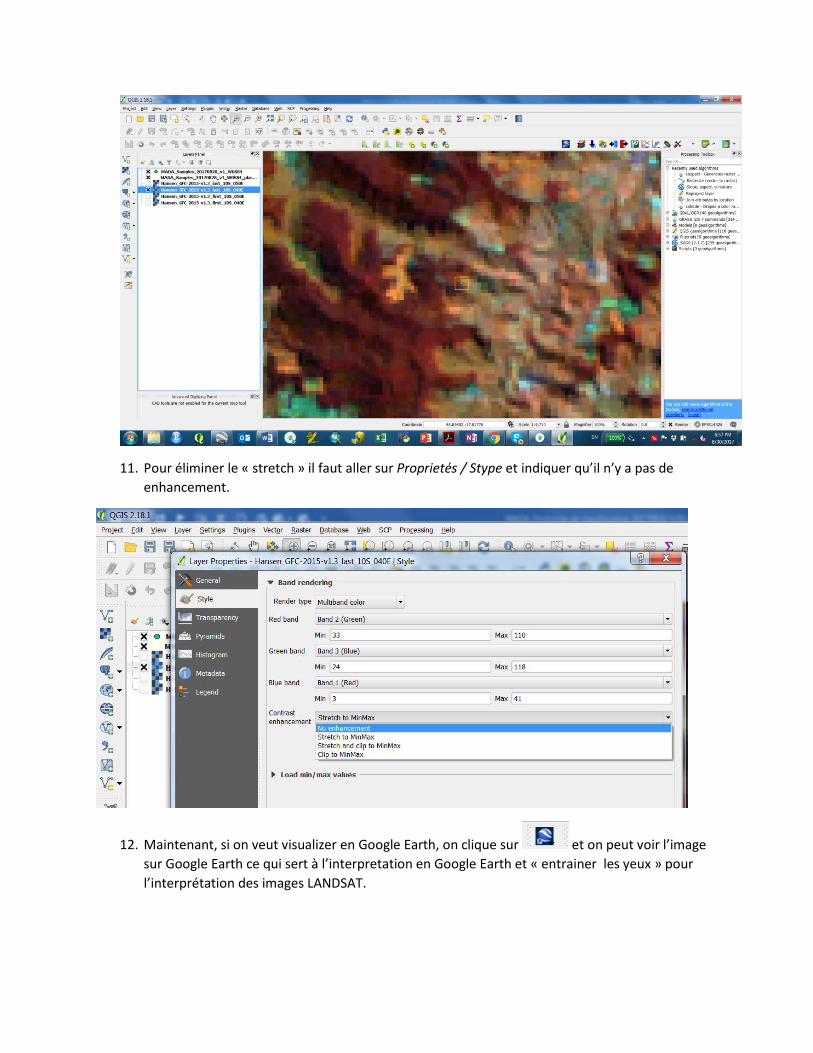
11. Pour éliminer le « stretch » il faut aller sur Proprietés / Stype et indiquer qu’il n’y a pas de
enhancement.
12. Maintenant, si on veut visualizer en Google Earth, on clique sur et on peut voir l’image
sur Google Earth ce qui sert à l’interpretation en Google Earth et « entrainer les yeux » pour
l’interprétation des images LANDSAT.

3.3 Couches de couverture de canopée de l’UMD Dans les dossiers il y a aussi des couches de couverture de canopée dans les années 2000, 2005, 2010,
2015. On pourrait les utiliser pour nous donner information contextuelle, mais il faut se rappeler que ces
couches ne sont pas les informations originelles et qu’ils ont des erreurs.
Pour l’instant on ne va pas travailler avec ces couches.
3.4 Modèles numériques d’élévation 1. Dans le dossier 04_Model numerique de elevation Il y a deux couches :
a. Aspect.TIF : C’est une couche avec les orientations. Les valeurs vont de 0 a 365. Une
orientation de 90 c’est NORD et une orientation de 270 est SUD.
b. Altitude.TIF.
2. Ces couches pourraient servir pour donner un peu de contexte à l’opérateur, surtout la couche
des orientations. Les images satellitales peuvent avoir des ombres ou des différentes tonalités à
cause de l’orientation du sol.
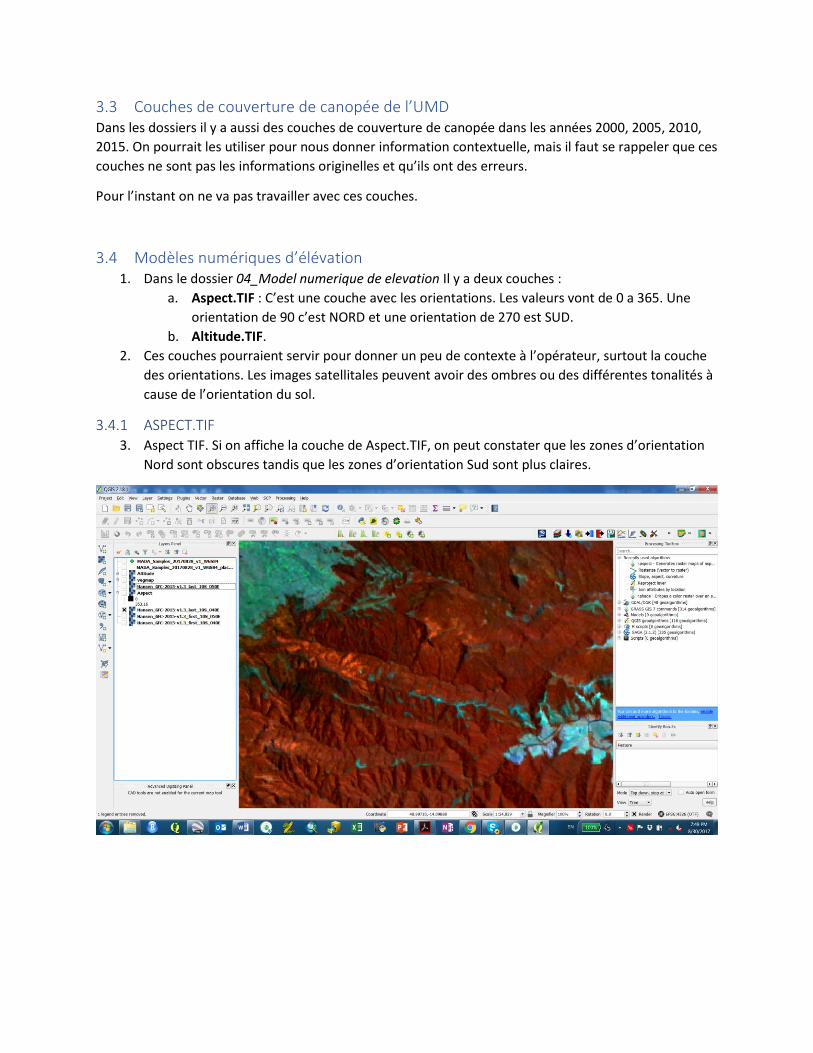
3.4.1 ASPECT.TIF 3. Aspect TIF. Si on affiche la couche de Aspect.TIF, on peut constater que les zones d’orientation
Nord sont obscures tandis que les zones d’orientation Sud sont plus claires.

4. Cette visualisation pourrait être bizarre pour certains interprétateurs qui sont habitués à voir les
zones avec plus d’insolation au Nord. Pour le changer, il faut aller aux Proprietés / Style et
changer le gradient de couleur de Noir à Blanche à Blanche à Noire.
5. Maintenant l’orientation est plus réaliste.

6. Pour garder la configuration, vous pouvez créer un layer definition file qu’on peut afficher après
7. Il faut se rappeler que ce couche n’a pas une bonne précision de position donc il pourraient
avoir des problèmes de co-registrement avec autres couches.
3.4.2 ALTITUDE.TIF 1. Si vous affichez la couche de Altitude.tif vous pouvez constater qu’il y a une visualisation par
défaut montrant en bleu les zones de altitude plus élevée et en jeune les zones moins élevées.

2. Maintenant si vous allez à Proprietés / Style et vous changez l’option à une seule band pseudo
couleur (singleband pseudocolor) et cliquez sur Classifier vous pouvez constater que maintenant
nous avons une classification discrète en 5 classes. Si on clique on appliquer on voit une
changement

3. Si on change le mode the Continuous à Intervalle égale on peut constater qu’on peut changer le
nombre de classes. Si on change le nombre de classes a 20 on aura 20 classes. Vous pouvez voir
quelle serait la meilleure visualisation.
4. Un autre possiblité est de combiner les orientations avec les altitudes. On fait cela en Proprietés
/ Transparènce et en changeant la transparence globale à 25%.
5. Maintenant si on active la couche des orientations et on la mette après altitude dans l’ordre de
visualization on peut voir tous les deux couches ensemble, ce qui nous donne beaucoup plus de
contexte

3.5 Carte de végétation Vu que dans la zone du programme de réduction d’émissions il n’y a que deux types de forêt (Humide et
forêt littorale) on ne va pas travailler avec ces couches.
4 Collecte de données Maintenant tout est prêt pour commencer à relever les données. On a les informations de Collect Earth
et les informations additionnelles de QGIS. Dans les SOPs d’Interpretation on peut trouver plus
d’informations.
Il faut se rappeler des suivantes règles générales :
• Une forêt primaire ou une forêt perturbée ne peut que se dégrader : Si à la fin de la période on
voit une forêt dense primaire ou perturbée, il est sûr que la forêt était primaire ou perturbée
dans le début de la période d’analyse. En principe ces forêts ne peuvent pas gagner mais perdre
couverture.
• NORMALEMENT, le processus de déforestation d’une forêt primaire est liée à un avancement
de la lisière de la forêt. En 2005 on peut avoir le doute de si une forêt et secondaire ou
primaire/perturbé. Il ne faut pas que voir la dynamique régionale. Le défrichement avance et les
forêts primaires commencent à être plus accessibles ce qui cause perturbations. Les forêt
secondaires normalement sont une étape ultérieure de dégradation du paysage.
• Une forêt secondaire résulte d’un défrichement total de la végétation.

o Si on a le doute de si une forêt est secondaire, on peut toujours voir s’il y a eu un
défrichement total de la végétation dans le passé. Dans le cas de 2005 on peut regarder
Landsat 7 et Landsat 5 et voir s’il y a eu des défrichements avant. Dans le cas de 2016,
on peut faire le même avec d’autres capteurs.
o La végétation secondaire devient forêt après 10-20 ans. Si on a le doute de si une
végétation est forêt, il faut regarder quand est-ce que le dernier défrichement a eu lieu.
• La perte de forêt peut être instantanée tandis que le gain prend du temps.
Les étapes à suivre pour la collecte de données :
1. Google Earth : La première chose à faire est de regarder les données de Google Earth pour avoir
un aperçu de la végétation que nous avons prêt de 2016 et les dynamiques de couverture s’il y a
plus des images.
2. Bing : On observe Bing pour voir s’il y a des images complémentaires qui peuvent nous donner
un aperçu sur l’état actuelle et le changement.
3. Google Earth Engine : En Google Earth Engine on a acces à tous les images Sentinel à 10 m de
résolution disponibles. Ces images nous donne une information importante jusqu’au fin 2016
4. Couverture 2016 :
a. Avec l’information de Google et de Bing on remplisse la première feuille de Collect
Earth.
b. IMPORTANT ! Il faut toujours confirmer en Google Earth Engine Explorer et
Playground la couverture de 2016. Il faut noter que les images de 2016 sont faites avec
les pixels plus vertes, donc s’il y a eu de déboisement en 2016 il es probable qu’il ne
apparaissent pas.
c. IMPORTANT : Utilisez toutes les outils disponibles pour confirmer quel était l’état le
31 Décembre 2016
5. Source des données 2016 : Si les images sont trop distantes, il faut inclure dans les
commentaires quelle est l’autre source de données utilisée pour confirmer l’état en 2016.
6. Couverture 2005 : Pour la couverture 2005 il faut utiliser toutes les images disponibles et tout
l’information temporelle pour nous permettre comprendre quelle est la couverture plus
probable
a. Google Earth et Bing : Si en Google earth nous avons des images qui permettent la
détermination de l’état le 1 Janvier 2005.
b. Google earth engine explorer et Playground : En sachant la classe de 2016, commencer
avec 2016 et commencer à observer les images vers 2000 afin de comprendre les
dynamiques de changement du sol. Voir en GEE Explorer les images avant 2000 si
nécessaire.
c. Classifier la couverture 2005 : En base à toutes les données recueillies, classifier la
couverture de 2005.
7. Source de données 2005 : S’il y a des images THR pour 2 ans avant ou après, il faut indiquer que
THR a été utilisée et inclure dans les commentaires quelle est l’autre source de données utilisée
pour confirmer l’état en 2005. Si les images THR sont trop distantes, il faut indiquer quelle est la
source utilisée.

8. Changement de couverture : En base à toutes ces informations on serait capables de classifier le
changement de couverture. Pour déterminer l’année exacte, vous pouvez utiliser les images
Landsat 5/7/8 de GEE Explorer de 32-day ou les images Sentinel 2 de GEE.
Possibles produits de GEE Explorer :
• Landsat 8 Annual Greenest Pixel TOA reflectance composite
• Landsat 7 Annual Greenest Pixel TOA reflectance composite
• Landsat 5 Annual Greenest Pixel TOA reflectance composite
• Landsat 8 32-day TOA reflectance composite
• Landsat 7 32-day TOA reflectance composite
• Landsat 5 32-day TOA reflectance composite
Vous pouvez aussi observer les Landsat 5, 7, 8 TOA reflectance individuelles.
5 Control Qualité Une fois qu’on remplisse une placette, il faut faire le check sur l’information inclus. Surtout si c’est
logique le changement de couvert attribué et les classes de 2005 et 2016. Il faut avoir correspondance.
6 Garder les résultats Une fois qu’on complète toutes les placettes d’un fichier CSV il faut l’exporter et le garder. Il faut les
exporter en deux fichiers différents :
CSV
1. Aller sur Collect Earth à Outils > Importer/Exporter les données > Exporter les données en CSV
2. Appeler le ficher en suivant le code suivant : CodeGroupe_Date
3. Garder le fichier dans un dossier qui s’appelle Résultats et envoyer le fichier à Roger Luc et
Andres.
4. Le fichier est un fichier CSV avec toutes les informations collectées.

XML zippé
Il faut aussi exporter les données dans un archive XML zippé à fin de permettre la mise en œuvre de la
procédure d’assurance de la qualité :
1. Aller sur Collect Earth à Outils > Importer/Exporter les données > Exporter les données en XML
> Exporter les données en XML
2. Appeler le ficher en suivant le code suivant : CodeGroupe_Date
3. Garder le fichier dans un dossier qui s’appelle Résultats et envoyer le fichier à Roger Luc et
Andres.
4. Le fichier est un fichier ZIP avec toutes les informations collectées. Ce fichier, au contraire que le
CSV, peut être afficher en Collect Earth.
7 Nettoyer la base de données Il ne faut pas nettoyer la base de données.
Important : Une fois commencé le travail, si un operateur va importer des données d’autres personnes
pour faire le QA, on vous recommande de prendre tous ces fichiers et les garder dans un autre endroit.
Une fois finalisé le QA, on peut supprimer les nouvelles fichiers crées et les remplacer par les fichiers
anciennes avec la base de données consolidée.
Top Related