







Languages
Pages
Legal


Bioinformatique: analyse des génomes
Céline Brochier-ArmanetUniversité Claude Bernard, Lyon 1
Laboratoire de Biométrie et Biologie évolutive (UMR 5558)[email protected]
Génomes procaryotes
0
10
20
30
40
50
60
70
80
0 1 2 3 4 5 6 7 8 9 10 11 12 13
Genome size (Mpb)
C+C content of genomes
Pathogens/Symbionts
Free living
Carsonellaruddii
Sorangiumcellulosum
Ignicoccushospitalis
(Brochier 2010 Oxford Press)
Ressources : génomes plantes(http://data.kew.org/cvalues/)
Ressources : génomes animaux(http://www.genomesize.com)

Taille des génomes cellulaires
Champignons
Autres eucaryotes(protistes)
Bactéries
Archées
105 106 107 108 109 1010 1011 1012
Log (taille du génome) (pb)
Amoeba Dubia
Eukaryotic genome size databases (2007)
Encephalitozoon cuniculi
AnimauxDrosophile ChimpanzéPratylenchus
(nématode)Necturus lewisi
(amphibien)
Plantes, algues
RizOstreococcus tauri(algue unicellulaire)
Fritillaria (famille des Liliacées)
Blé
Scutellospora castanea
Guillardia theta Paramecium tetraurelia
Nanoarchaeum equitans
Candidatus carsonella Sorangium
cellulosum
Methanosarcina acetivorans
Parasites (ou symbiontes) associés à des cellules
Le paradoxe de la c-value (1)
X 200
Paradoxe de la c-value (2)
• Définition – Contenu en DNA haploïde d’un génome
• « Comparing the largest and one of the smallest examples amongvertebrates, one finds that the cell of an amphiuma contains 70 times asmuch DNA as is found in a cell of the domestic, a far more highlydevelopped animal. It seems most unlikely that amphiuma contains 70times as many different genes as does the fowl or that a gene of amphiumacontains 70 times as much DNA as does one in the fowl » (Mirsky & Ris,1951)
⇒ Il n’y a pas de corrélation entre complexité apparente d’un organisme ou d’une cellule et la quantité d’ADN qu’elle contient
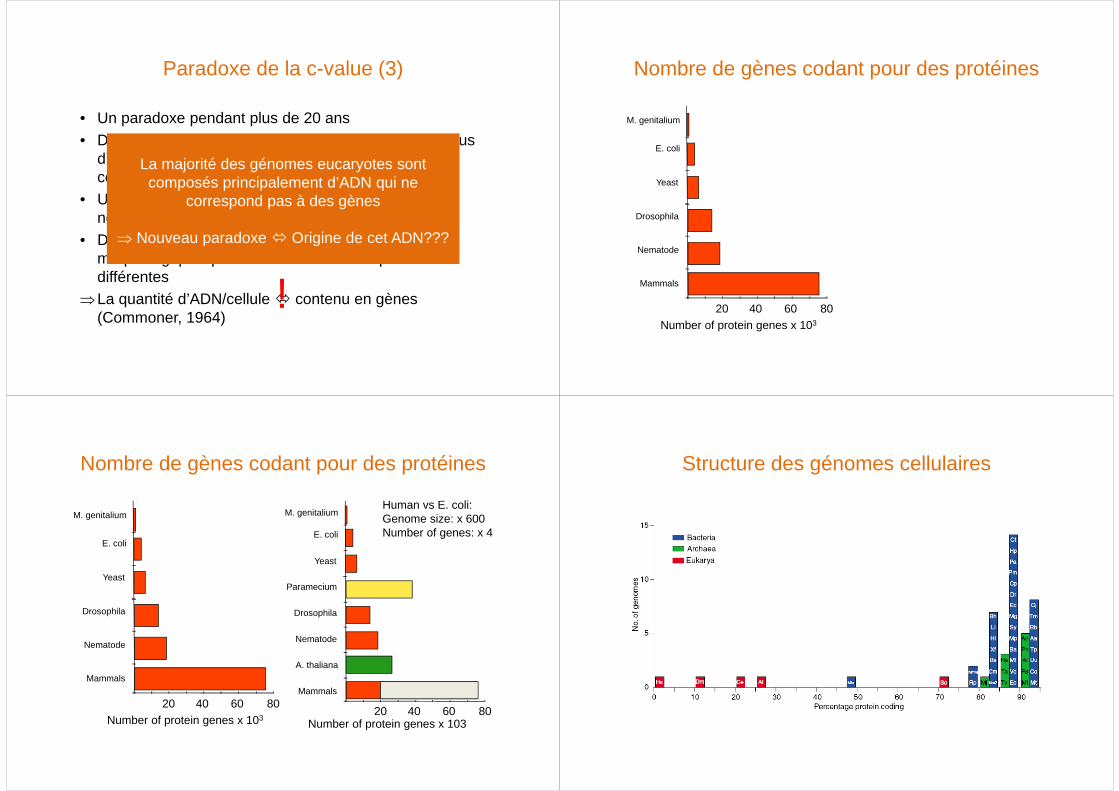
Paradoxe de la c-value (3)
• Un paradoxe pendant plus de 20 ans• Des cellules « d’organismes simples » contiennent plus
d’ADN que des cellules « d’organismes plus complexes »
• Un génome donnée semble contenir plus d’ADN que nécessaire par rapport au nombre de gènes prédits
• Des organismes présentant de fortes ressemblances morphologiques présentent des c-values parfois très différentes
⇒La quantité d’ADN/cellule � contenu en gènes (Commoner, 1964)
!
Paradoxe de la c-value (3)
• Un paradoxe pendant plus de 20 ans• Des cellules « d’organismes simples » contiennent plus
d’ADN que des cellules « d’organismes plus complexes »
• Un génome donnée semble contenir plus d’ADN que nécessaire par rapport au nombre de gènes prédits
• Des organismes présentant de fortes ressemblances morphologiques présentent des c-values parfois très différentes
⇒La quantité d’ADN/cellule � contenu en gènes (Commoner, 1964)
!
La majorité des génomes eucaryotes sont composés principalement d’ADN qui ne
correspond pas à des gènes
⇒ Nouveau paradoxe � Origine de cet ADN???
Nombre de gènes codant pour des protéines
Number of protein genes x 103
E. coli
Drosophila
Nematode
M. genitalium
Mammals
6020 40 80
Yeast
Nombre de gènes codant pour des protéines
Human vs E. coli:Genome size: x 600Number of genes: x 4
Number of protein genes x 103
E. coli
Paramecium
Drosophila
Nematode
A. thaliana
M. genitalium
Mammals
6020 40 80
Yeast
Number of protein genes x 103
E. coli
Drosophila
Nematode
M. genitalium
Mammals
6020 40 80
Yeast
Structure des génomes cellulaires

Combien y a-t-il de gènes dans le génome humain?
Technique/Source Gene estimate Comments/assumptions
Text book (1990) 100,000 if average size = 30 kb
Genomic sequencing (1994) 71,000 biased toward gene-rich region?
CpG islands 80,000 assumes 66% human genes have CpG islands
EST analysis (1994) 64,000 matching with GenBank; 50% EST redundancy
Chromosome 22 (1999) 45,000 correction for high gene density on chrom. 22
Exofish (2000) 28,000-34,000 Comparison human/fish
EST (2000) 35,000 Number of genes
EST (2000) 120,000 Number of transcripts
First genome draft (2001) 30,000-40,000 Known genes + predictions
Comparison / mouse (2002) 30,000 Known genes + predictions
Finished genome (2004) 20,000-25,000 Known genes + predictions
Finished genome (2007) 20,000 Improved gene annotation
17%0.5%
Drosophila
85%2%
13%
E. coli
70%2%
28%
Yeast
1.2%
0.05%
98%
Human
28%
0.5%71%
Nematode
0.05%
0.01%
Lungfish
(dipnoi)Coding (protein)RNANon-coding
82%
99.5%
Eléments fonctionnels des génomes
Annotation des génomes complets
• H. influenzae => 1709 gènes
• Saccharomyces cerevisiae => ~ 5600 gènes
• Drosophila melanogatser => ~13000 gènes
• C. elegans => ~19000 gènes
• Arabidopsis thaliana => ~24000 gènes
• Homo sapiens => ~30000 gènes
Bioinformatique et annotation des génomes
• Organisation de l’information le long des séquences génomique
⇒ Approches expérimentales trop coûteuses (en temps et argent) pour être appliquées de manière systématique aux projets de séquençage des génomes
⇒ Prédictions (in silico)
⇒ Tests expérimentaux

Principe de l’annotation des génomes
• Annotation structurale: Inventaire et analyse des éléments présents dans un génome– Identification des régions codantes, sites promoteurs, de
terminaison de la transcription et de la traduction, d’épissage, introns, exons…
– Séquences répétées…– Origine et terminaison de la réplication
• Annotation fonctionnelle– Fonction des gènes– Signaux de régulation…
Structure d’un gène procaryote
Structure d’un gène eucaryoteComment identifier les gènes dans un
génome procaryote ?
• Délimitation des Open Reading Frame (ORF)
• Composition en codons de la région codante– Table d’usage des codons
• Recherche de signaux caractéristiques au niveau de l’ADN – Promoteurs– Sites de terminaison de la transcription– RBS– codons START et STOP
• Recherche de similitudes avec des séquences présentes dans les banques

Comment identifier les gènes dans un génome procaryote ?
• Délimitation des Open Reading Frame (ORF)
• Composition en codons de la région codante– Table d’usage des codons
• Recherche de signaux caractéristiques au niveau de l’ADN – Promoteurs– Sites de terminaison de la transcription– RBS– codons START et STOP
• Recherche de similitudes avec des séquences présentes dans les banques
Recherche des ORFs dans des séquences aléatoires
• Il existe 3 codons START et 3 codons STOP parmi les 64 codons possibles• Séquences aléatoires
– Après un START P(codon suivant = STOP) = 3/64
– Probabilité d’occurrence d’un STOP suit une loi de PoissonPSTOP( X=n ) = e-λL x (λL)n / n! avec λ = 3/64
– Probabilité d’observer une séquencede longueur L sans codon stop
PSTOP(X=0) = e-λL
L= longueur ORFn = nb de stop dans un segment de longueur L.
ATG ? ? ? ? ? ? ?
Longeur des CDSs dans des séquences générées aléatoirement
00,10,20,30,40,50,60,70,80,9
1
0 20 40 60 80 100 120 140 160 180 200
Longueur (nb de codons)
Pro
port
ion
Longeur des CDSs dans des séquences générées aléatoirement
00,10,20,30,40,50,60,70,80,9
1
0 20 40 60 80 100 120 140 160 180 200
Longueur (nb de codons)
Pro
port
ion
Taille des CDSs dans des séquences réelles (génome d’E. coli)
Usage des codons START et STOP chez les procaryotes
L’usage du codon STOP varie plus considérablement que celui du codon START chez les procaryotes

Usage des codons START et STOP chez les procaryotes
Faible corrélation entre le choix du codon START et le contenu en G+C
du génome
Forte corrélation pour UAA et UGA Indépendante pour UAG
Comment identifier les gènes dans un génome procaryote ?
• Délimitation des Open Reading Frame (ORF)
• Composition en codons de la région codante– Table d’usage des codons
• Recherche de signaux caractéristiques au niveau de l’ADN – Promoteurs– Sites de terminaison de la transcription– RBS– codons START et STOP
• Recherche de similitudes avec des séquences présentes dans les banques
Code génétique Biais d’usage des codons
• Tous les codons ne sont pas utilisés avec la même fréquence- Certains codons sont surreprésentés- Certains codons sont sous-représentés
⇒ Biais d’usage des codons par rapport à leur fréquence d’usage théorique

Biais d’usage du code
Ces biais sont spécifiques des organismes considérés
Utiliser les biais d’usage du code pour l’annotation
Comment identifier les gènes dans un génome procaryote ?
• Délimitation des Open Reading Frame (ORF)
• Composition en codons de la région codante– Table d’usage des codons
• Recherche de signaux caractéristiques au niveau de l’ADN – Promoteurs– Sites de terminaison de la transcription– RBS
• Recherche de similitudes avec des séquences présentes dans les banques

Recherche de promoteurs
• Régions situées juste en amont du site d’initiation de la transcription⇒ Reconnues par la sous-unité σ de l’ARN polymérase
• Séquence consensus reconnu par σ70
-- TTGACA------…---- TATAAT-------CAT-35 -10 +1
Boite de Pribnow boite TATA
Recherche de signaux caractéristiques(l’exemple des RBS; B. subtilis)
Détermination de séquences consensus
1 2 3 4 5 6
Séquence 1 G G A G G T
Séquence 2 C G A G G T
Séquence 3 G C A G C T
Séquence 4 G G T G C A
Consensus G G A G [GC] T
Niveau d’information faible
Etablissement de matrices poids/position
1 2 3 4 5 6
G 3 3 0 4 2 0
A 0 0 3 0 0 1
T 0 0 1 0 0 3
C 1 1 0 0 2 0
1) Construction d’une matrice de comptage
1 2 3 4 5 6
Séquence 1 G G A G G T
Séquence 2 C G A G G T
Séquence 3 G C A G C T
Séquence 4 G G T G C A

Etablissement de matrices poids/position
1 2 3 4 5 6
G 3 3 0 4 2 0
A 0 0 3 0 0 1
T 0 0 1 0 0 3
C 1 1 0 0 2 0
1 2 3 4 5 6
G 0.75 0.75 0 1 0.5 0
A 0 0 0.75 0 0 0.25
T 0 0 0.25 0 0 0.75
C 0.25 0.25 0 0 0.5 0
2) Construction d’une matrice de fréquences/probabilités
Etablissement de matrices poids/position
1 2 3 4 5 6
G 3 3 0 4 2 0
A 0 0 3 0 0 1
T 0 0 1 0 0 3
C 1 1 0 0 2 0
1 2 3 4 5 6
G 0.75 0.75 0 1 0.5 0
A 0 0 0.75 0 0 0.25
T 0 0 0.25 0 0 0.75
C 0.25 0.25 0 0 0.5 0
f6,Cf5,Cf4,Cf3,Cf2,Cf1,CC
f6,Tf5,Tf4,Tf3,Tf2,Tf1,TT
f6,Af5,Af4,Af3,Af2,Af1,AA
f6,Gf5,Gf4,Gf3,Gf2,Gf1,GG
654321
f6,Cf5,Cf4,Cf3,Cf2,Cf1,CC
f6,Tf5,Tf4,Tf3,Tf2,Tf1,TT
f6,Af5,Af4,Af3,Af2,Af1,AA
f6,Gf5,Gf4,Gf3,Gf2,Gf1,GG
654321
2) Construction d’une matrice de fréquences/probabilités
Etablissement de matrices poids/position
f6,Cf5,Cf4,Cf3,Cf2,Cf1,CC
f6,Tf5,Tf4,Tf3,Tf2,Tf1,TT
f6,Af5,Af4,Af3,Af2,Af1,AA
f6,Gf5,Gf4,Gf3,Gf2,Gf1,GG
654321
f6,Cf5,Cf4,Cf3,Cf2,Cf1,CC
f6,Tf5,Tf4,Tf3,Tf2,Tf1,TT
f6,Af5,Af4,Af3,Af2,Af1,AA
f6,Gf5,Gf4,Gf3,Gf2,Gf1,GG
654321
f6,C/fCf5,C/fCf4,C/fCf3,C/fCf2,C/fCf1,C/fCC
f6,T/fTf5,T/fTf4,T/fTf3,T/fTf2,T/fTf1,T/fTT
f6,A/fAf5,A/fAf4,A/fAf3,A/fAf2,A/fAf1,A/fAA
f6,G/fGf5,G/fGf4,G/fGf3,G/fGf2,G/fGf1,G/fGG
654321
f6,C/fCf5,C/fCf4,C/fCf3,C/fCf2,C/fCf1,C/fCC
f6,T/fTf5,T/fTf4,T/fTf3,T/fTf2,T/fTf1,T/fTT
f6,A/fAf5,A/fAf4,A/fAf3,A/fAf2,A/fAf1,A/fAA
f6,G/fGf5,G/fGf4,G/fGf3,G/fGf2,G/fGf1,G/fGG
654321
f1,G = fréq. G à la position 1du motif étudié
fG = fréq. G dans le génomede l’organisme étudié
f1,G/fG = fréq. de G à la position 1 du motif étudié par rapport à la fréq. attendue de G (i.e. fréq. de G dans le génome étudié)
3) Construction d’une matrice de fréquences/probabilités relatives (odds)
Etablissement de matrices poids/position
4062-10C
0-110-11T
5-21831A
555058G
654321
4062-10C
0-110-11T
5-21831A
555058G
654321
4) Construction d’une matrice de Log Odds
f6,C/fCf5,C/fCf4,C/fCf3,C/fCf2,C/fCf1,C/fCC
f6,T/fTf5,T/fTf4,T/fTf3,T/fTf2,T/fTf1,T/fTT
f6,A/fAf5,A/fAf4,A/fAf3,A/fAf2,A/fAf1,A/fAA
f6,G/fGf5,G/fGf4,G/fGf3,G/fGf2,G/fGf1,G/fGG
654321
f6,C/fCf5,C/fCf4,C/fCf3,C/fCf2,C/fCf1,C/fCC
f6,T/fTf5,T/fTf4,T/fTf3,T/fTf2,T/fTf1,T/fTT
f6,A/fAf5,A/fAf4,A/fAf3,A/fAf2,A/fAf1,A/fAA
f6,G/fGf5,G/fGf4,G/fGf3,G/fGf2,G/fGf1,G/fGG
654321

SéquenceATCTAGAGGGTATTAATA
Est-ce que cette séquence contient une séquence de Shine-Dalgarno ?
PRINCIPE DE L’ANALYSE⇒ Regarder tous les motifs de 6 nucléotides contenus dans la séquence
⇒ Calcul d’un score pour chaque motif grâce à la matrice des Log-odds⇒ Si score > seuil => on a une séquence de Shine-Dalgarno possible à la position considérée⇒ Si score < seuil => pas de séquence de Shine-Dalgarno à la position considérée
⇒ On décale la séquence de 1 et on recommence
Principe de la recherche de signaux Application
4062-10C
0-110-11T
5-21831A
555058G
654321
4062-10C
0-110-11T
5-21831A
555058G
654321
Matrice des log-odds (Bacillus subtilis)
SéquenceATCTAGAGGGTATTAATA
ATCTAG :1-1+2+1-2+5 = 6
Application
4062-10C
0-110-11T
5-21831A
555058G
654321
4062-10C
0-110-11T
5-21831A
555058G
654321
SéquenceATCTAGAGGGTATTAATA
ATCTAG :1-1+2+1-2+5 = 6TCTAGA :1-1+0+1+5+5 = 11CTAGAG :0-1+8+5-2+5 = 15TAGAGG :1+3+0+1+5+5 = 15AGAGGG :1+5+8+5+5+5 = 29GAGGGT :8+3+0+5+5+0 = 21AGGGTA :1+5+0+5-1+5 = 15GGGTAT :8+5+0+1-2+0 = 12GGTATT :8+5+0+1-1+0 = 13GTATTA :8-1+8+1-1+5 = 20TATTAA :1+3+0+1-2+5 = 8ATTAAT :1-1+0+1-2+0 = -1TTAATA :1-1+8+1-1+5 = 13
Smax
Autres « bons »Score ?
4062-10C
0-110-11T
5-21831A
555058G
654321
4062-10C
0-110-11T
5-21831A
555058G
654321
SéquenceATCTAGAGGGTATTAATA
ATCTAG :1-1+2+1-2+5 = 6TCTAGA :1-1+0+1+5+5 = 11CTAGAG :0-1+8+5-2+5 = 15TAGAGG :1+3+0+1+5+5 = 15AGAGGG :1+5+8+5+5+5 = 29GAGGGT :8+3+0+5+5+0 = 21AGGGTA :1+5+0+5-1+5 = 15GGGTAT :8+5+0+1-2+0 = 12GGTATT :8+5+0+1-1+0 = 13GTATTA :8-1+8+1-1+5 = 20TATTAA :1+3+0+1-2+5 = 8ATTAAT :1-1+0+1-2+0 = -1TTAATA :1-1+8+1-1+5 = 13

Score = f(position)
-5
0
5
10
15
20
25
30
35
40
0 1 2 3 4 5 6 7 8 9 10 11 12
Position
Sco
re
Score max théo = 37*
Smax
Smax obs = 29* *
4062-10C
0-110-11T
5-21831A
555058G
654321
4062-10C
0-110-11T
5-21831A
555058G
654321
SéquenceATCTAGAGGGTATTAATA
ATCTAG :1-1+2+1-2+5 = 6TCTAGA :1-1+0+1+5+5 = 11CTAGAG :0-1+8+5-2+5 = 15TAGAGG :1+3+0+1+5+5 = 15AGAGGG :1+5+8+5+5+5 = 29GAGGGT :8+3+0+5+5+0 = 21AGGGTA :1+5+0+5-1+5 = 15GGGTAT :8+5+0+1-2+0 = 12GGTATT :8+5+0+1-1+0 = 13GTATTA :8-1+8+1-1+5 = 20TATTAA :1+3+0+1-2+5 = 8ATTAAT :1-1+0+1-2+0 = -1TTAATA :1-1+8+1-1+5 = 13
Autres « bons »Score ?
Seuil de significativité
• Smax � plus fort score observé⇒ Est-il significatif ou peut-il la conséquence du au hasard?⇒ Quelle est la probabilité d’obtenir Smax avec une séquence
aléatoire de même composition ?
• Méthode simple d’estimation statistique du score: calcul d’une p-value⇒ Générer N (~1000) séquences aléatoires de même composition que la
séquence étudiée⇒ Compter n = Nb de fois où Smax aléatoire > Smax obs
• Obtention d’une p-value = n/N (� probabilité que le résultat observé soit du au hasard)⇒ 0 ≤ p-value ≤ 1
⇒ Acceptation de l’observation si p-value ≤ 0.05 ⇒ Risque d’erreur dans 1 cas sur 20
Intérêts/Limites de ces approches
• Séquences nucléiques souvent peu conservées• Présence de séquences conservées en amont des gènes• Importance biologique (promoteur, site d’initiation, de terminaison,
de régulation…)• Identifier les caractéristiques communes de ces séquences et qui
sont absentes des séquences qui ne sont pas des promoteurs
• Signaux brefs et dégradés⇒ Grand nombre de faux positifs• Caractéristiques variables d’une organisme à l’autre• Pas de séquences uniques

>Genomic scaffold, whole genome shotgun sequenceACCCCTCTGATCATCTGGATAGTGGATTACATTAAAAAAAGAGAAAAACATTTCACAATTACCTCATATA TAATTTCATTGATTTTCCTTGTAATGATGGGCAGCATGCTAGATGCCTTACTTTTTTATTATATTAGTAA CAAATCATTTTTTAGTGCAATTATAGCATTAAATATAGTCATGGATCCAACAACTTTAGTTTTGTTCTAC GCCTTTATAAAAATAGCAAAATCAAAATCCGTAAAATTTTCATCGAAAACAATTATTAATACCACTGCCC TAATTACATGGTCTGAAATTTCGATGGCCTTATTTCTAAAATCACTTGCATTGAATGGGATATTTAATCA TAATTTAATAATAAATTATTTTTCATATTTTGGTGCTTCGATTACGTATATTCTATTTTTAATCCCAATG GTAACGGAAATGATTTTTTTTATCATTACAAACCTTAATGGCACTGAACGTTTTATTGGTTTACTCTTGC TTATTATGCAGGTGGCAGATCCAGCCATGCTCAGTGGTTATATGGAAATTCCATTACTTGTTGCTTATTC AGTAATAATGTTTTTAGTTCTGTATAGCCTGGTACGCTATGTTTACACACATAGGAAGAGTTTAACAGAG AAAAACAGAAGATTAATATCATATACGGGGGTTGTTATCGCTATATCAACTGCCAGCATAATTGAACCAT TTATTATATTTCGTCCATTTGGCTTCTCATGGTTTGTACTTGCATTAGGCATGGTTGTATCAATGTTTTT ATATTTTCAGATAGTTTTAGGTTACTATGAATAAAATATTCTCCTGATCAATACTAACTTTTTGTGCAAC ATAGGGAATGTATACACGTTTTATATATACTATGGGGAAGATTACCATTAATGGTATTCAGTATAGGCTG GTAGAGATTAACAGCATCCCCGGCAAAAAATATGGCCGGAACATCCTAAGAAGGGATGAGGGAATAGATG …TCTTATACAGAATATTTTAGGCAGAGAACTAGATGGCTGCGTGGGTATCACCAGGTATTTCTCCATTCAA AGAAAAAATTTAGCAAACTTACTGATTTTGATGCACTTATGATCGTTCTTGCGCCTACGTTTTCAGGTAT ACTTTTCTTCGGATGGCTCTATATATCACTCCTAAATTTTTATAATCCTTTTGTTCACTCAATGAGAACC TATTTCATTTCCTTAATCCTGATATCACTGATAATTTATGCTGTCGCCCTTATACTGGTTCTGATAAAGA AACGGCAAAATCTGATTTACTTACCATTGATATACATATATTTAACATTGAATTCACTGATTTCAATATA CACGCTGTTTCTGGAAGTTACAGGTGCAAAGCGTGTATGGCATAAGGTAAAGAAAACGGGCAAGACAACA CTTTAATAATTACTTTTTTATATACAACCATGGTACTGGACTCATACAGGAAAAATGCAGACAAATTCTT AAATCCCATTACAGAAAAATTCTCTGGAATAAACCCCAACACTGTTTCTGTACTATCACTAGCCTTTGCC GCTCTGGGTGGTATATTCTACTATCTCAGCCATTCTTTTCTCCTGCTCGCCTTTGTGTTTATTATTTTAT CTGCCCTGTTCGATGCACTTGACGGGAAAATTGCCAGGTTAAAGAATATTTCTTCCAAAAAGGGTGATAT GCTGGACCATGTATTTGACCGGTACTCGGATATCTTTATCGTACTTGGGATGGCATTTTCAATTTATGGT AATGTATACCTTGGATTATTTGCCATTATCGGAATCCTACTTACAAGTTATATGGGCACACAGTCACAGG CACTTGGATTAAAAAGAAATTATTCGGGAATTGCCGGAAGGGCTGACAGACTCGTTCTGATCATAATATT
ORF finder(http://www.ncbi.nlm.nih.gov/gorf/orfig.cgi)
Recherche les phases ouvertes de lecture (ORF)Commencent par un START Finissent par un STOPTaille en nucléotides = multiple de 3
Recherche d’homologues
>Genomic scaffold, whole genome shotgun sequenceACCCCTCTGATCATCTGGATAGTGGATTACATTAAAAAAAGAGAAAAACATTTCACAATTACCTCATATA TAATTTCATTGATTTTCCTTGTAATGATGGGCAGCATGCTAGATGCCTTACTTTTTTATTATATTAGTAA CAAATCATTTTTTAGTGCAATTATAGCATTAAATATAGTCATGGATCCAACAACTTTAGTTTTGTTCTAC GCCTTTATAAAAATAGCAAAATCAAAATCCGTAAAATTTTCATCGAAAACAATTATTAATACCACTGCCC TAATTACATGGTCTGAAATTTCGATGGCCTTATTTCTAAAATCACTTGCATTGAATGGGATATTTAATCA TAATTTAATAATAAATTATTTTTCATATTTTGGTGCTTCGATTACGTATATTCTATTTTTAATCCCAATG GTAACGGAAATGATTTTTTTTATCATTACAAACCTTAATGGCACTGAACGTTTTATTGGTTTACTCTTGC TTATTATGCAGGTGGCAGATCCAGCCATGCTCAGTGGTTATATGGAAATTCCATTACTTGTTGCTTATTC AGTAATAATGTTTTTAGTTCTGTATAGCCTGGTACGCTATGTTTACACACATAGGAAGAGTTTAACAGAG AAAAACAGAAGATTAATATCATATACGGGGGTTGTTATCGCTATATCAACTGCCAGCATAATTGAACCAT TTATTATATTTCGTCCATTTGGCTTCTCATGGTTTGTACTTGCATTAGGCATGGTTGTATCAATGTTTTT ATATTTTCAGATAGTTTTAGGTTACTATGAATAAAATATTCTCCTGATCAATACTAACTTTTTGTGCAAC ATAGGGAATGTATACACGTTTTATATATACTATGGGGAAGATTACCATTAATGGTATTCAGTATAGGCTG GTAGAGATTAACAGCATCCCCGGCAAAAAATATGGCCGGAACATCCTAAGAAGGGATGAGGGAATAGATG …TCTTATACAGAATATTTTAGGCAGAGAACTAGATGGCTGCGTGGGTATCACCAGGTATTTCTCCATTCAA AGAAAAAATTTAGCAAACTTACTGATTTTGATGCACTTATGATCGTTCTTGCGCCTACGTTTTCAGGTAT ACTTTTCTTCGGATGGCTCTATATATCACTCCTAAATTTTTATAATCCTTTTGTTCACTCAATGAGAACC TATTTCATTTCCTTAATCCTGATATCACTGATAATTTATGCTGTCGCCCTTATACTGGTTCTGATAAAGA AACGGCAAAATCTGATTTACTTACCATTGATATACATATATTTAACATTGAATTCACTGATTTCAATATA CACGCTGTTTCTGGAAGTTACAGGTGCAAAGCGTGTATGGCATAAGGTAAAGAAAACGGGCAAGACAACA CTTTAATAATTACTTTTTTATATACAACCATGGTACTGGACTCATACAGGAAAAATGCAGACAAATTCTT AAATCCCATTACAGAAAAATTCTCTGGAATAAACCCCAACACTGTTTCTGTACTATCACTAGCCTTTGCC GCTCTGGGTGGTATATTCTACTATCTCAGCCATTCTTTTCTCCTGCTCGCCTTTGTGTTTATTATTTTAT CTGCCCTGTTCGATGCACTTGACGGGAAAATTGCCAGGTTAAAGAATATTTCTTCCAAAAAGGGTGATAT GCTGGACCATGTATTTGACCGGTACTCGGATATCTTTATCGTACTTGGGATGGCATTTTCAATTTATGGT AATGTATACCTTGGATTATTTGCCATTATCGGAATCCTACTTACAAGTTATATGGGCACACAGTCACAGG CACTTGGATTAAAAAGAAATTATTCGGGAATTGCCGGAAGGGCTGACAGACTCGTTCTGATCATAATATT
ORF finder(http://www.ncbi.nlm.nih.gov/gorf/orfig.cgi)
Recherche les phases ouvertes de lecture (ORF)Commencent par un START Finissent par un STOPTaille en nucléotides = multiple de 3
Recherche d’homologues
ORF finder(http://www.ncbi.nlm.nih.gov/gorf/orfig.cgi)
Recherche d’homologues

Recherche de
similitudes avec des
séquences déjà connues
Top Related