







Languages
Pages
Legal


Bayesian regularization of learning
Sergey Shumsky NeurOK Software LLC

Scientific methods
InductionF.Bacon
Machine
Models
Data
Deduction R.Descartes
Math. modeling

Outline Learning as ill-posed problem General problem: data generalization General remedy: model regularization
Bayesian regularization. Theory Hypothesis comparison Model comparison Free Energy & EM algorithm
Bayesian regularization. Practice Hypothesis testing Function approximation Data clustering

Outline Learning as ill-posed problem
General problem: data generalization General remedy: model regularization
Bayesian regularization. Theory Hypothesis comparison Model comparison Free Energy & EM algorithm
Bayesian regularization. Practice Hypothesis testing Function approximation Data clustering

Problem statement
Learning is inverse, ill-posed problem Model Data
Learning paradoxes Infinite predictions Finite data? How to optimize future predictions? How to select regular from casual in
data?
Regularization of learning Optimal model complexity

Well-posed problem
Solution is unique Solution is stable Hadamard (1900-s)
Tikhonoff (1960-s)
:h H h D
1 2
1 1
1 2
2 2
limD D
H h Dh h
H h D
lim limi ii i
H h H h h h

Learning from examples
Problem: Find hypothesis h, generating
observed data D in model H
Well defined if not sensitive to: noise in data (Hadamard) learning procedure (Tikhonoff)
:h H h D

Learning is ill-posed problem
Example: Function approximation
Sensitive tonoise in data
Sensitive tolearning procedure
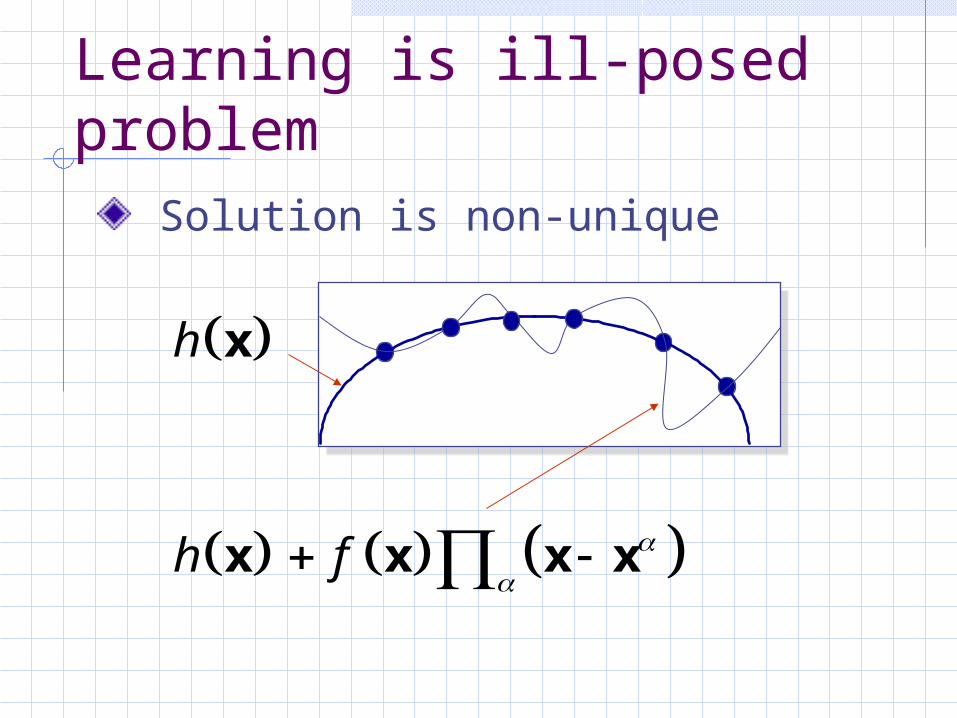
Learning is ill-posed problem
Solution is non-unique
h x
h f
x x x x

Outline Learning as ill-posed problem
General problem: data generalization General remedy: model regularization
Bayesian regularization. Theory Hypothesis comparison Model comparison Free Energy & EM algorithm
Bayesian regularization. Practice Hypothesis testing Function approximation Data clustering

Problem regularization Main idea: restrict solutions –
sacrifice precision to stability
: P hh H h D
arg minh H h D P h
How to choose?
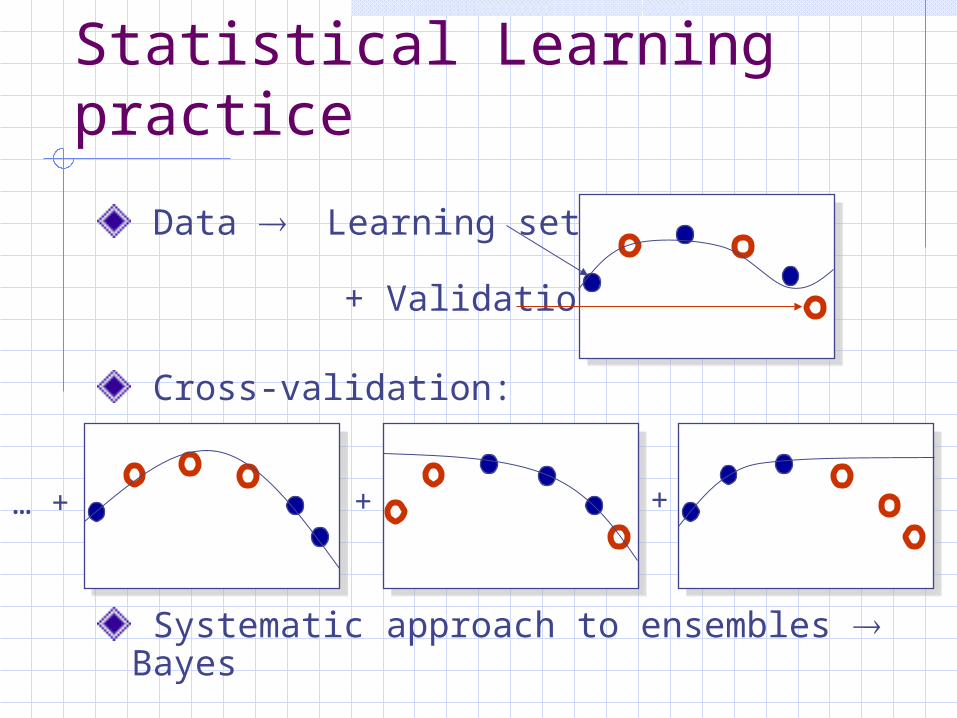
Statistical Learning practice
Data Learning set
+ Validation set
Cross-validation:
Systematic approach to ensembles Bayes
+ +… +

Outline Learning as ill-posed problem
General problem: data generalization General remedy: model regularization
Bayesian regularization. Theory Hypothesis comparison Model comparison Free Energy & EM algorithm
Bayesian regularization. Practice Hypothesis testing Function approximation Data clustering

Statistical Learning theory
Learning as inverse Probability Probability theory. H: h D
Learning theory. H: h D
, 1 hhN NN
h
NP D h H h h
N
,
,P D h H P h H
P h D HP D H
HBernoulli (1713)
Bayes (~ 1750)

Bayesian learning
D
h
,P h D H
,
,
,
P D h H P h H
P h D
P D
D
h
H
H
H P
P h H
P D HEvidence
Prior
Posterior

Coin tossing gameH
1P h
11, ,
2MP MPh h
MP
h hN Nh h h
N N N
,h h
P D h P h DP h D D P h N N N N
P D D
1 ,h
P D h P hP h D N P D h P h N N
P D

0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
2
4
6
8
10
12
14
16
18
20
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
1
2
3
4
5
6
Monte Carlo simulations
100N
P h N t
10N

Bayesian regularization
Most Probable hypothesis
arg max log ,
arg min log , log
MPh P h D H
P D h H P h H
Learning error
212
2
η
ηlog ,
2η e
y hP D h H y h
P
x
x
Example: Function approximation
Regularization

Minimal Description Length
Most Probable hypothesis
2logL x P x
Code length for:
arg max log ,
arg min log , log
MPh P h D H
P D h H P h H
Data hypothesis
Example: Optimal prefix code
1
21
4 18
18
0 1
1110
110 111
P x
Rissanen (1978)

Data Complexity
Complexity K(D |H) = min L(h,D|
H)Code length L(h,D)= coded data L(D|h) + decoding program L(h)
Data D
Decoding:H h D
Kolmogoroff (1965)

Complex = Unpredictable
Prediction error ~ L(h,D)/L(D) Random data is uncompressible Compression = predictability
Program h: length L(h,D)
Data D
Decoding:H h D
Example: block coding
Solomonoff (1978)

Universal Prior All 2L programs with
length L are equiprobable
Data complexity
,
,2, , 2
L h D HL h D H
hP h D H P D H
P D H
Solomonoff (1960) Bayes (~1750)
logK D H L D H P D H
L(h,D)
D
H

Statistical ensemble Shorter description length
Proof:
Corollary: Ensemble predictions are superior to most probable prediction
,log 2 ,L h D H
MPhL D H L h D H
, ,log 2 log 2 ,MPL h D H L h D H
MPhL h D H

Ensemble prediction
MPh
1h
2h P h H
1h
MPh
P h H2h

Outline Learning as ill-posed problem
General problem: data generalization General remedy: model regularization
Bayesian regularization. Theory Hypothesis comparison Model comparison Free Energy & EM algorithm
Bayesian regularization. Practice Hypothesis testing Function approximation Data clustering

Model comparison
D
h
,P h D H
, iP D h H
P D HEvidence
Posterior

Statistics: Bayes vs. Fisher
Fisher: max Likelihood
Bayes: max Evidence
arg max log ,
arg max log , log
MP
ML
h P h D H
P D h H P h H h
arg max log ,
arg max log , log
MP
ML
H P H D
P D H P H H
H
H H
arg max log , logMPh P D h H P h H

Historical outlook
20 – 60s of ХХ century Parametric statistics Asymptotic N
60 - 80s of ХХ century Non-Parametric statistics Regularization of ill-posed problems Non-asymptotic learning Algorithmic complexity Statistical physics of disordered systems
h
Fisher (1912)
Chentsoff (1962)
Tikhonoff (1963)
Vapnik (1968)
Kolmogoroff (1965)
h
Gardner (1988)

Outline Learning as ill-posed problem
General problem: data generalization General remedy: model regularization
Bayesian regularization. Theory Hypothesis comparison Model comparison Free Energy & EM algorithm
Bayesian regularization. Practice Hypothesis testing Function approximation Data clustering

Statistical physics
Probability of hypothesis - microstate
Optimal model - macrostate
,
,
1, L h D H
L h D H
h
P h D H eZ
Z D H e
arg min logMLH L D H Z D H

Free energy
F = - log Z: Log of Sum
F = E – TS:
Sum of logs P = P{L}
, , log ,h
L D H P h D H L h D H P h D H
,log L h D H
hL D H e

EM algorithm. Main idea
Introduce independent P:
Iterations E-step:
М-step:
, log
log,
h
h
F h L h D H h
hL D H h L D H
P h D H
P P
PP
arg min ,
arg min ,
t t
t t
H
F H
H F H
P
P P
P

EM algorithm
Е-step Estimate Posterior for given Model
М-step Update Model for given Posterior
,t t th P D h H P D HP
arg min ,t
t
HH L D h H
P

Outline Learning as ill-posed problem
General problem: data generalization General remedy: model regularization
Bayesian regularization. Theory Hypothesis comparison Model comparison Free Energy & EM algorithm
Bayesian regularization. Practice Hypothesis testing Function approximation Data clustering

Bayesian regularization: Examples
Hypothesis testing
Function approximation
Data clustering
yh
y
h(x) x
P(x|H)
x

Outline Learning as ill-posed problem
General problem: data generalization General remedy: model regularization
Bayesian regularization. Theory Hypothesis comparison Model comparison Free Energy & EM algorithm
Bayesian regularization. Practice Hypothesis testing Function approximation Data clustering

Hypothesis testing Problem Noisy observations: y
Is theoretical value h0 true?
Model H:
2
2
0
2 exp2
2 exp2
y h
P
h hP h
Gaussian noise
Gaussian prior
yh0
00.2
0.40.6
0.8
1
0
2
4
6
8
107.5
8
8.5
9
9.5
10
10.5
11
11.5
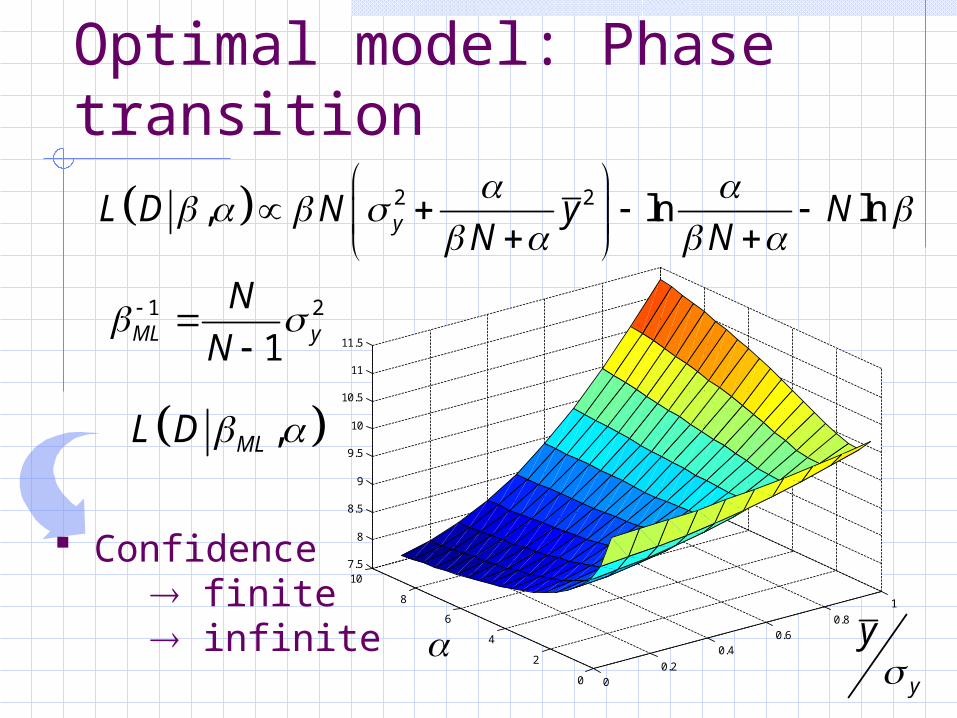
Optimal model: Phase transition
1 2
1ML y
N
N
2 2, ln lnyL D N y NN N
,MLL D
y
y
Confidence finite infinite

Threshold effect
Student coefficient
Hypothesis h0 is true
Corrections to h0
22
2 1y
Nt y N
y
P(h)1Nt
yh
1Nt P(h)2
2
1NMP
N
th y
t
0P h h h

Outline Learning as ill-posed problem
General problem: data generalization General remedy: model regularization
Bayesian regularization. Theory Hypothesis comparison Model comparison Free Energy & EM algorithm
Bayesian regularization. Practice Hypothesis testing Function approximation Data clustering

Function approximation
Problem Noisy data: y (x ) Find approximation h(x)
Model:
Noise
Prior
1
1
,
exp
exp W
y h
P Z E
P Z E
x w
w w
y
h(x)x

Optimal model
Free energy minimization
,
,
, ln ln ln
exp
x
e
e p
xp
D
W
W
D
Z d E E
L D Z Z Z
Z d E
Z dD E
w w
w w
w
w
,n nD n
E E y h w x w

Saddle point approximation
Function of best hypothesis
,ln exp
1ln
2
D W
W MP D MP
D MP W MP
Z d E E
E E
E E
w w w
w w
w w
MPw

ЕМ learning
Е-step. Optimal hypothesis
М-step. Optimal regularization
arg minMP ML W ML DE E w w w
, arg min , ,ML ML MPL D w

Laplace Prior
Pruned weights
Equisensitive weights
1
W
W iiE w
w
sgnD W DE E Et
w
w w w w
0D i iE w w
0i D iw E w

Outline Learning as ill-posed problem
General problem: data generalization General remedy: model regularization
Bayesian regularization. Theory Hypothesis comparison Model comparison Free Energy & EM algorithm
Bayesian regularization. Practice Hypothesis testing Function approximation Data clustering

Clustering
Problem Noisy data: x
Find prototypes (mixture density approximation)
How many clusters?
Модель:
Noise
1
exp
M
m
m
P H P m P m
P m E
x x
x x h
P(x|H)
x

Optimal model
Free energy minimization
Iterations E-step:
М-step:
min ln ,n
n mL D H P m x
,min ln ln ,n
m nF m n m n P m P P x
arg min ,
arg min ,
t t
t t
H
F H
H F H
P
P P
P

ЕМ algorithm
Е-step:
М-step:
exp
exp
nm
n
nmm
P m EP m
P m E
x hx
x h
1
n n
n
m n
n
n
n
P m
P m
P m P mN
x xh
x
x

How many clusters?
Number of clusters M()
Optimal number of clusters
h(m)
1/
min ln ,m mmL D d P D h h
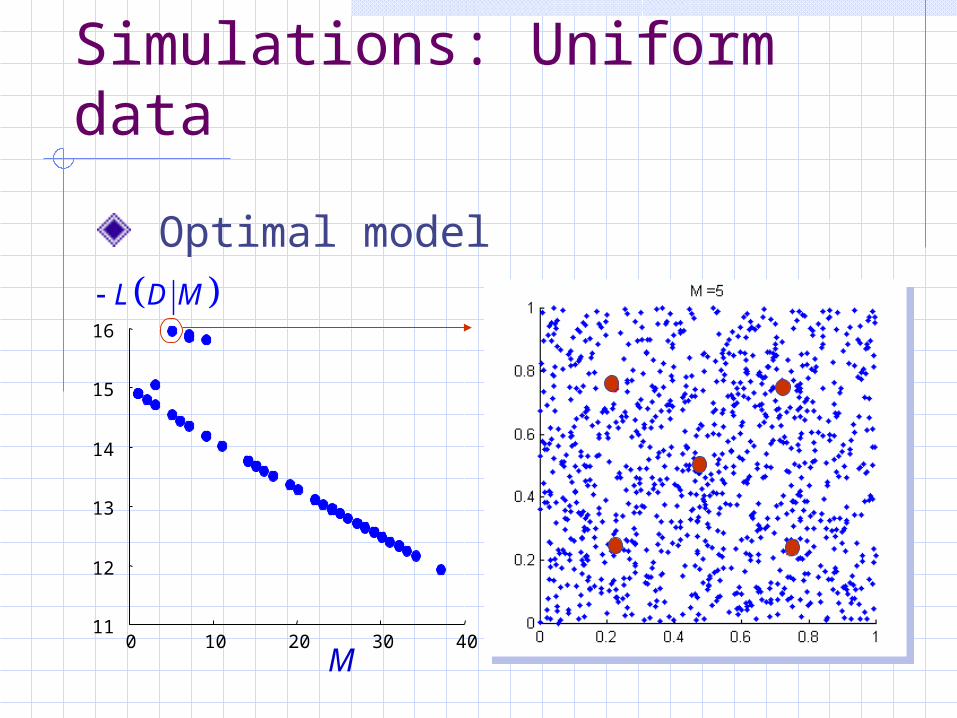
Simulations: Uniform data
Optimal model
0 10 20 30 4011
12
13
14
15
16
M
L D M

Simulations: Gaussian data
Optimal model
M0 10 20 30 40 50
-12.5
-12
-11.5
-11
-10.5
-10
-9.5 L D M
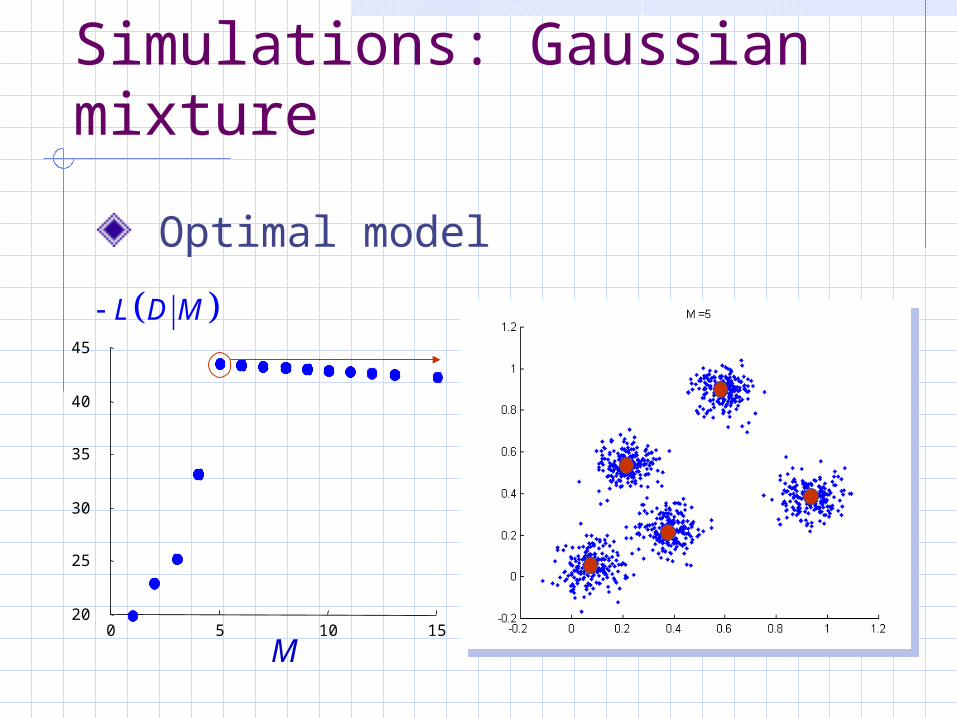
0 5 10 1520
25
30
35
40
45
Simulations: Gaussian mixture
Optimal model
M
L D M

Outline Learning as ill-posed problem
General problem: data generalization General remedy: model regularization
Bayesian regularization. Theory Hypothesis comparison Model comparison Free Energy & EM algorithm
Bayesian regularization. Practice Hypothesis testing Function approximation Data clustering

Summary
Learning Ill-posed problem Remedy: regularization
Bayesian learning Built-in regularization (model assumptions) Optimal model = minimal Description Length
= minimal Free Energy
Practical issues Learning algorithms with built-in optimal
regularization - from first principles (opposite to cross validation)
Top Related