







Languages
Pages
Legal


Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 2017Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 20171
Lecture 4:Backpropagation and
Neural Networks

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 2017
Administrative
Assignment 1 due Thursday April 20, 11:59pm on Canvas
2

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 3 - April 11, 2017
Administrative
Project: TA specialities and some project ideas are posted on Piazza
3

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 2017
Administrative
Google Cloud: All registered students will receive an email this week with instructions on how to redeem $100 in credits
4

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 20175
want
scores function
SVM loss
data loss + regularization
Where we are...

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 20176
Optimization
Landscape image is CC0 1.0 public domainWalking man image is CC0 1.0 public domain

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 20177
Numerical gradient: slow :(, approximate :(, easy to write :)Analytic gradient: fast :), exact :), error-prone :(
In practice: Derive analytic gradient, check your implementation with numerical gradient
Gradient descent
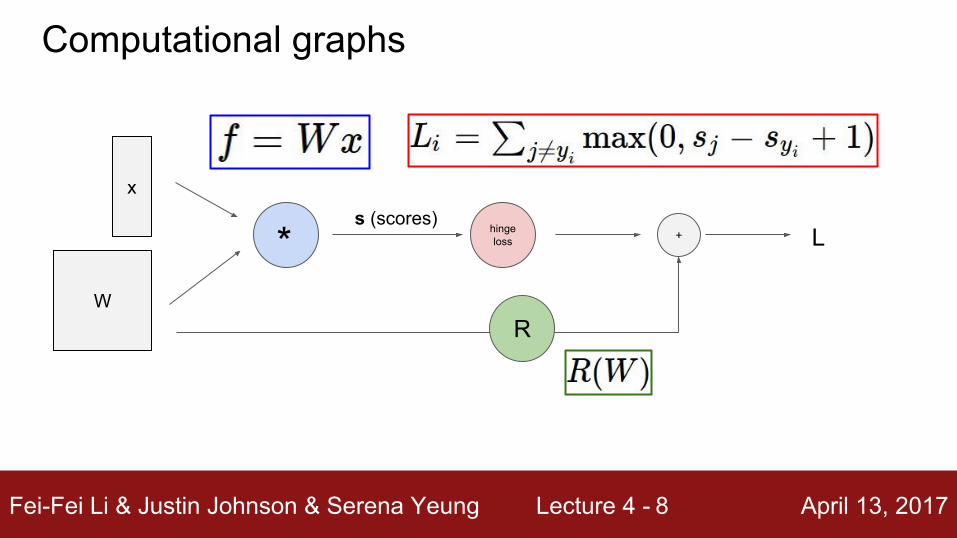
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 20178
x
W
hinge loss
R
+ Ls (scores)
Computational graphs
*
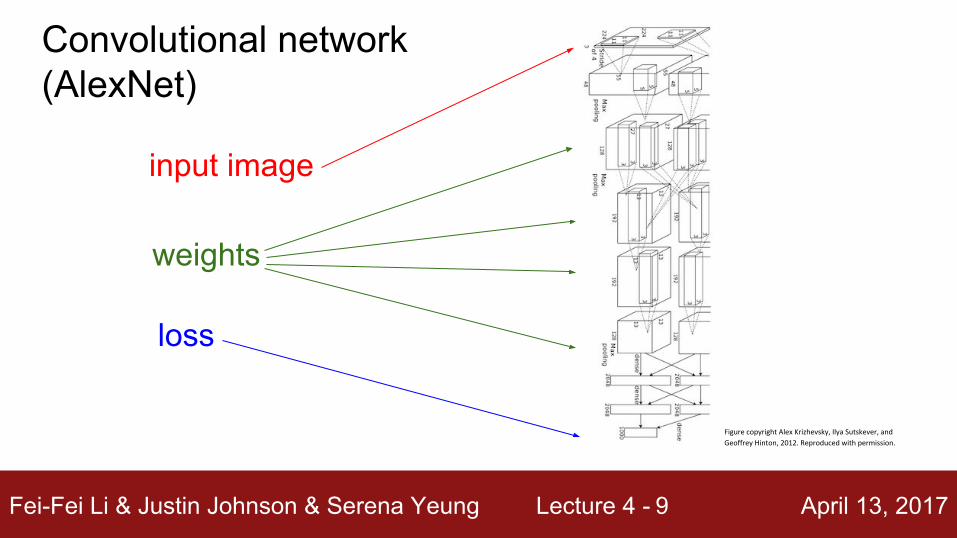
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 20179
input image
loss
weights
Convolutional network(AlexNet)
Figure copyright Alex Krizhevsky, Ilya Sutskever, and
Geoffrey Hinton, 2012. Reproduced with permission.
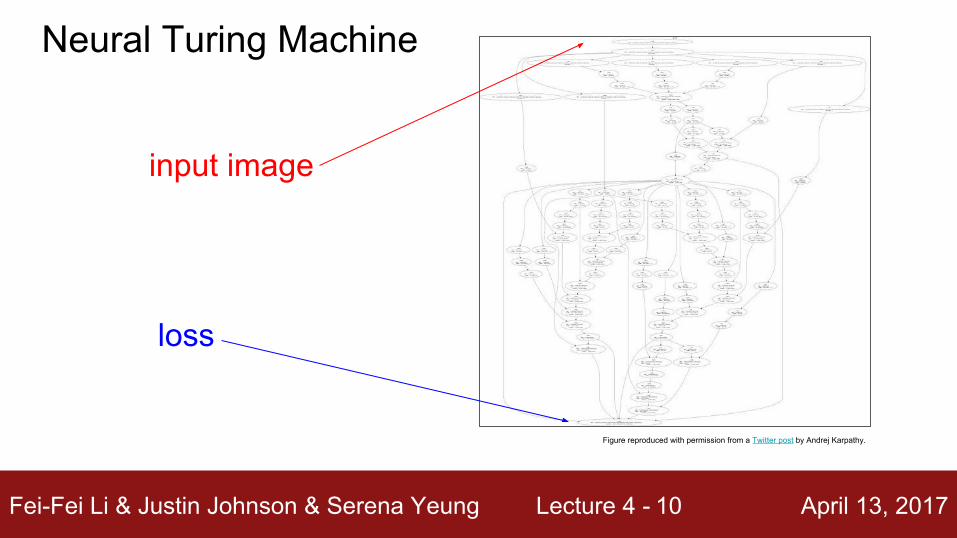
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201710
Neural Turing Machine
Figure reproduced with permission from a Twitter post by Andrej Karpathy.
input image
loss

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 2017
Neural Turing Machine
Figure reproduced with permission from a Twitter post by Andrej Karpathy.
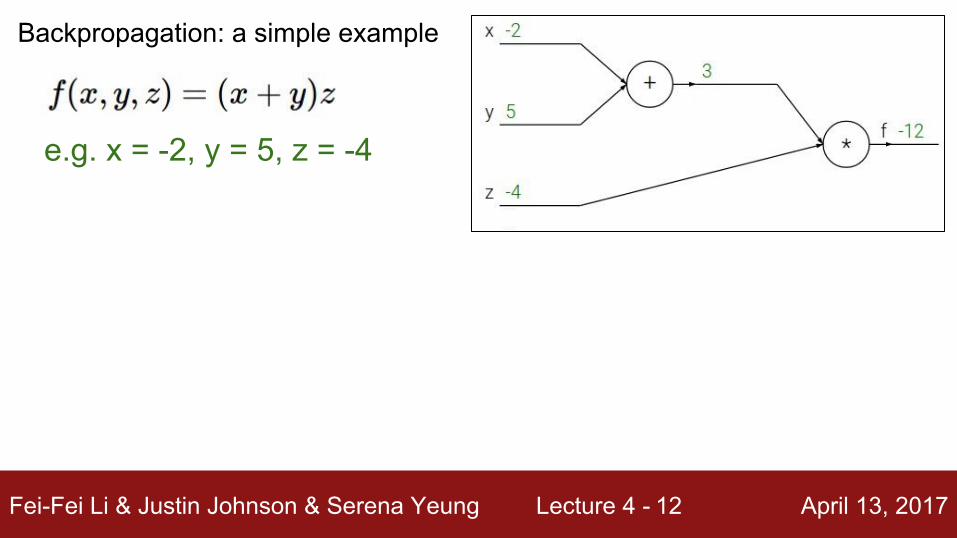
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201712
e.g. x = -2, y = 5, z = -4
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201713
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201714
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201715
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201716
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201717
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201718
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201719
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201720
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example
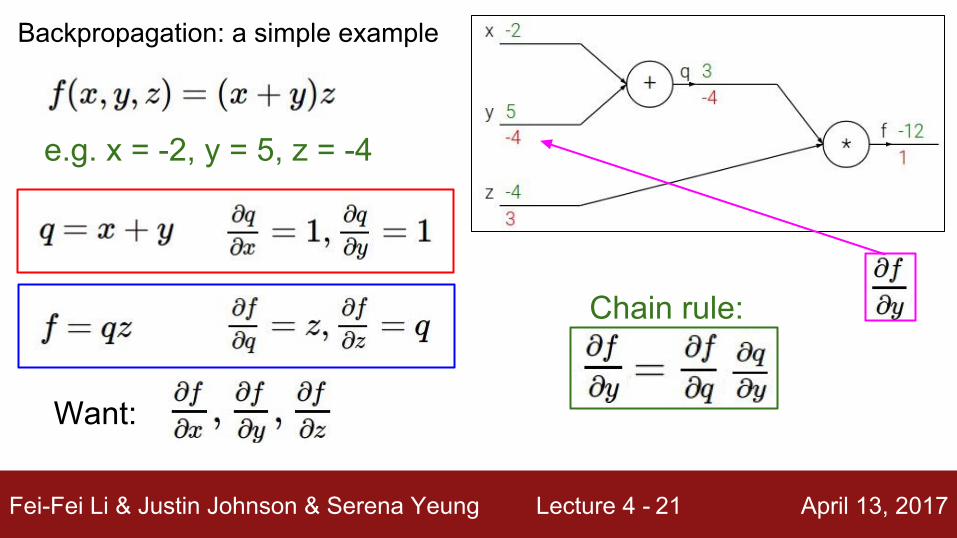
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201721
Chain rule:
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example
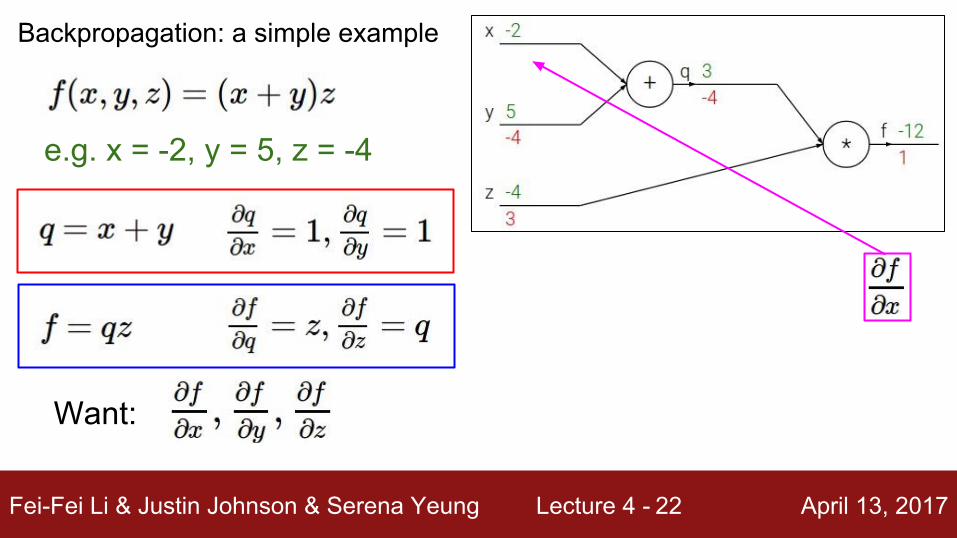
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201722
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201723
Chain rule:
e.g. x = -2, y = 5, z = -4
Want:
Backpropagation: a simple example
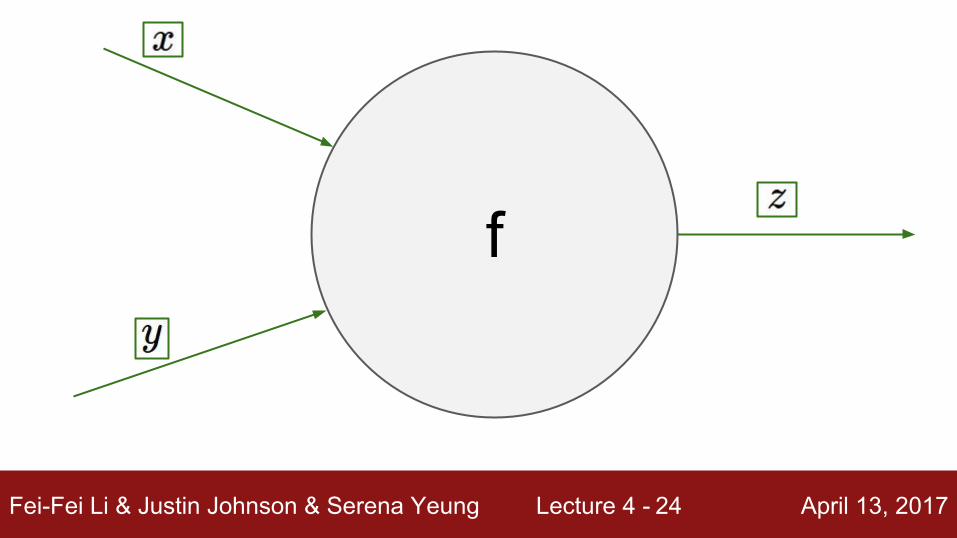
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201724
f
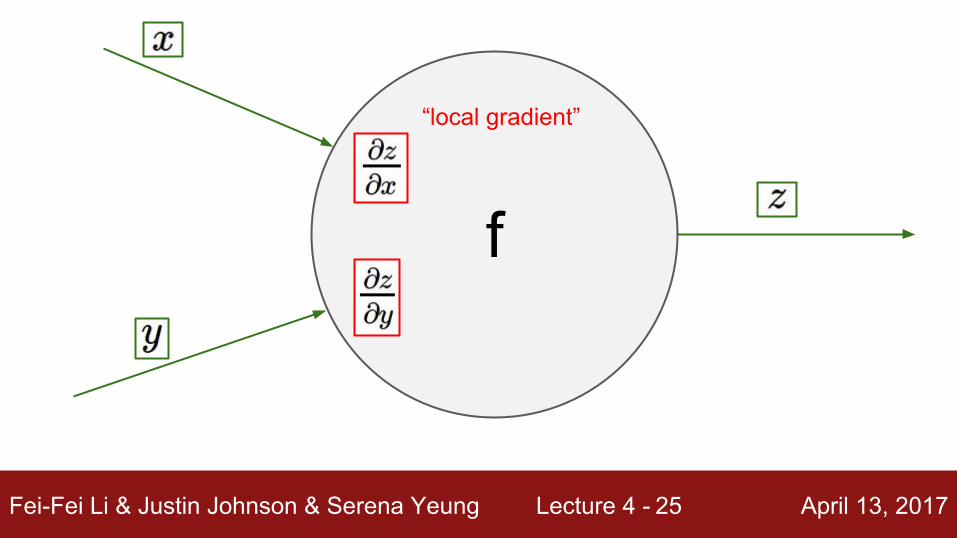
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201725
f
“local gradient”
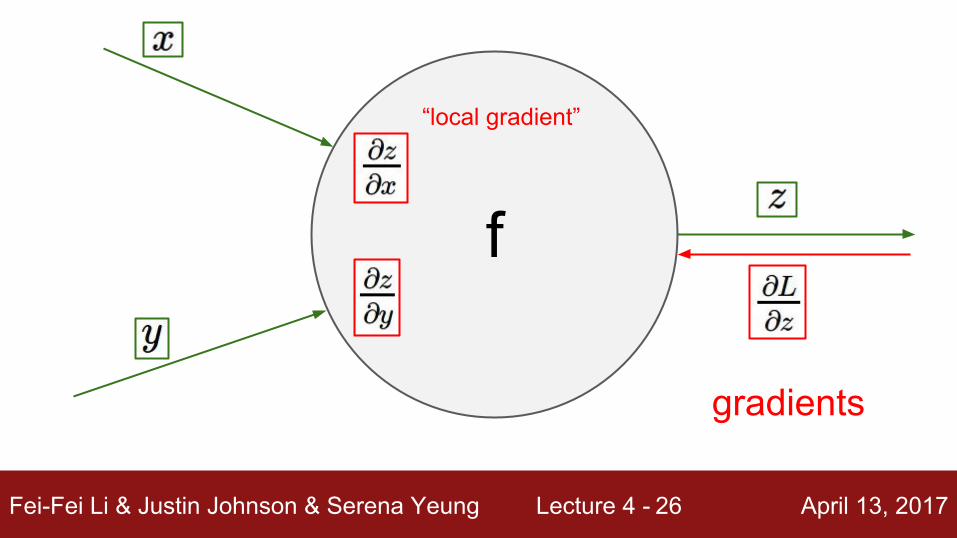
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201726
f
“local gradient”
gradients
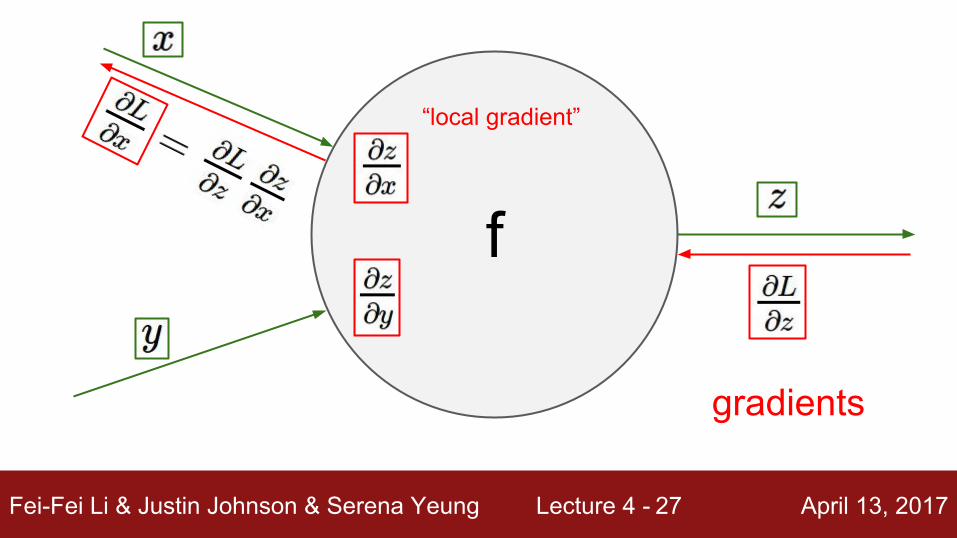
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201727
f
“local gradient”
gradients
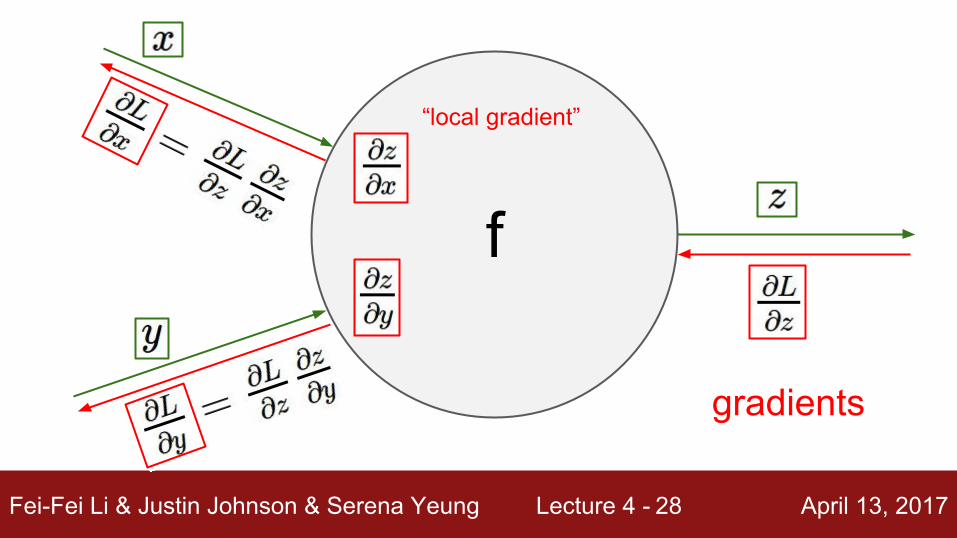
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201728
f
“local gradient”
gradients
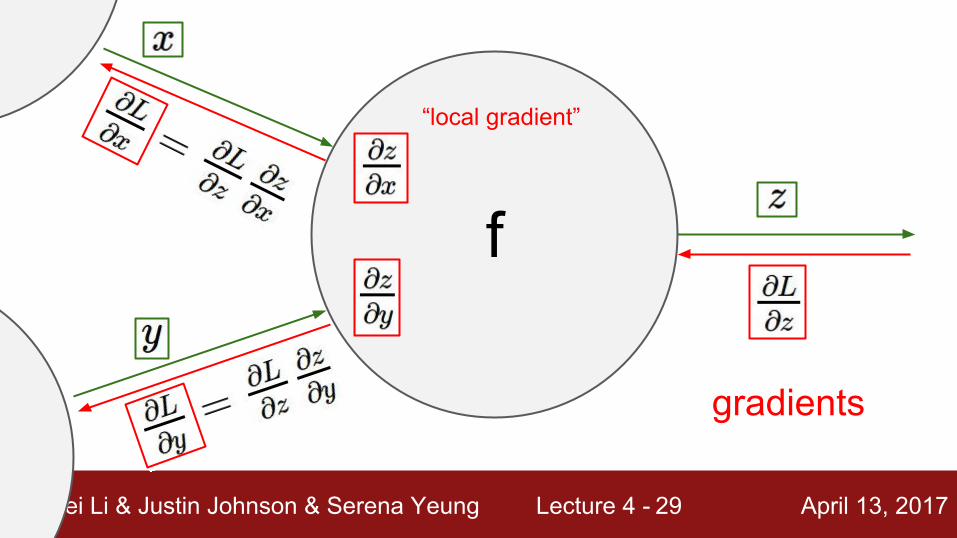
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201729
f
“local gradient”
gradients
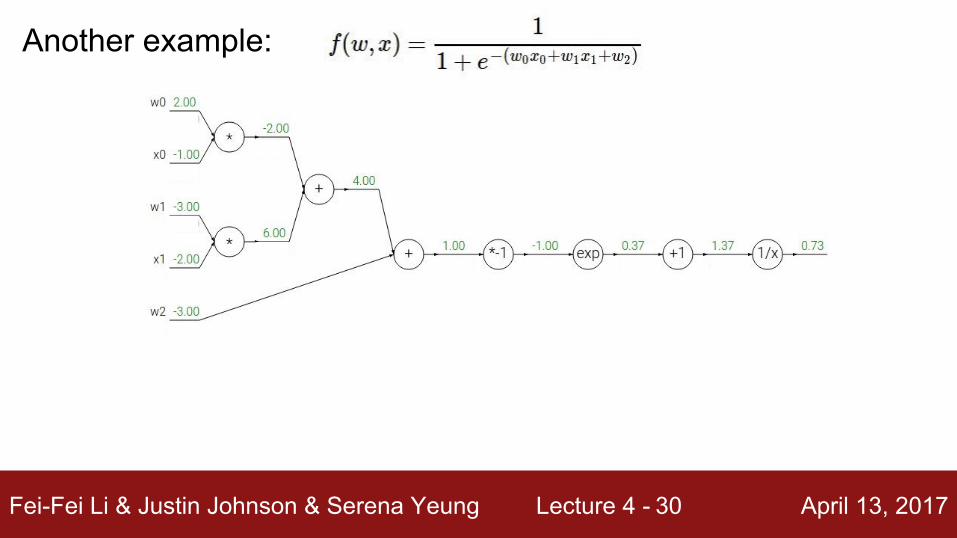
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201730
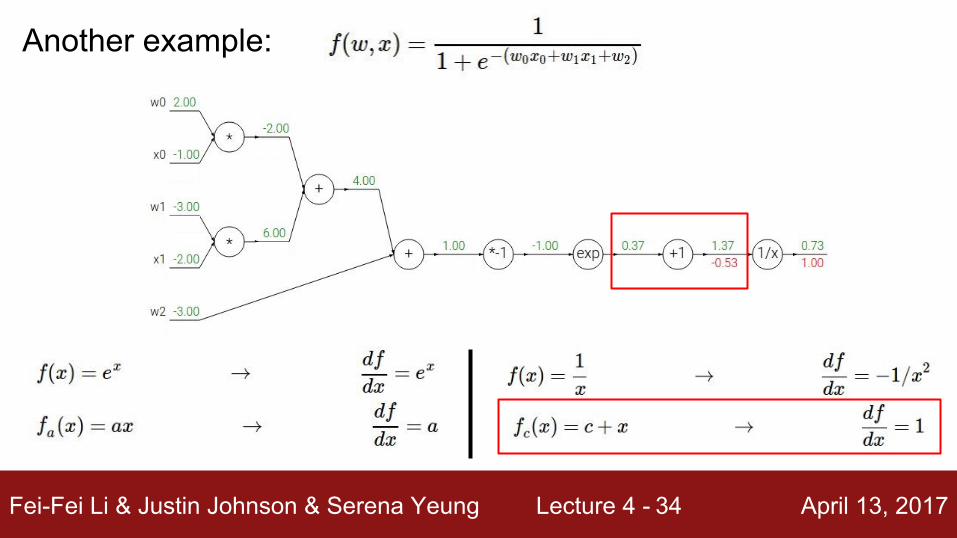
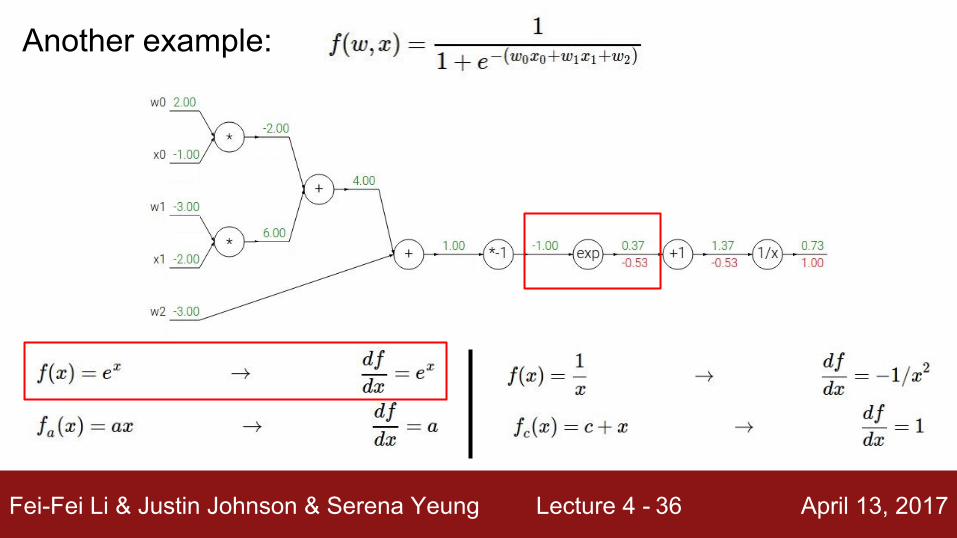
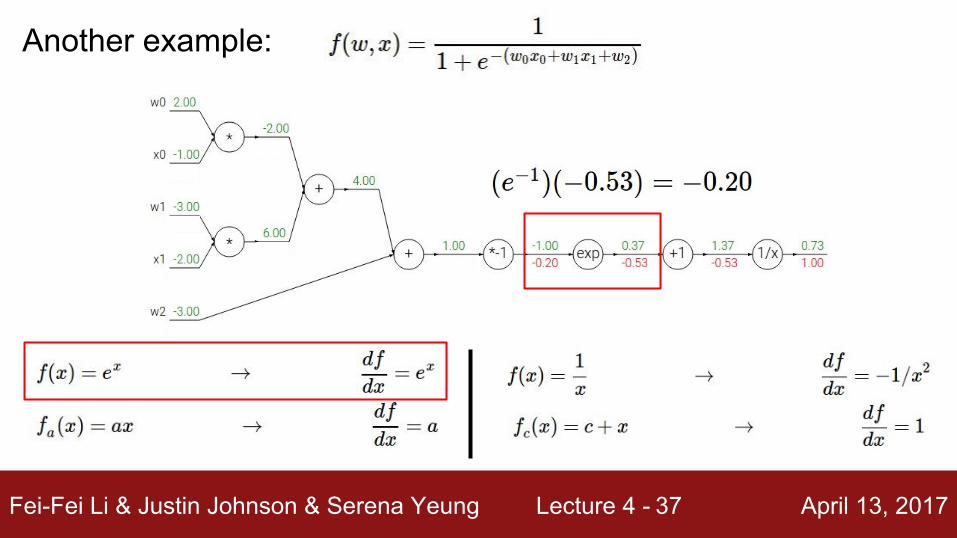
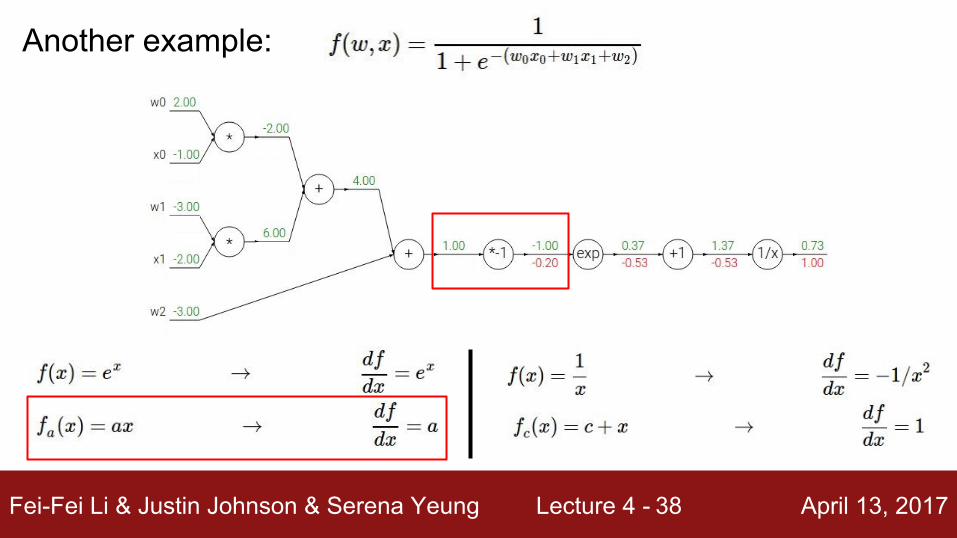
Another example:
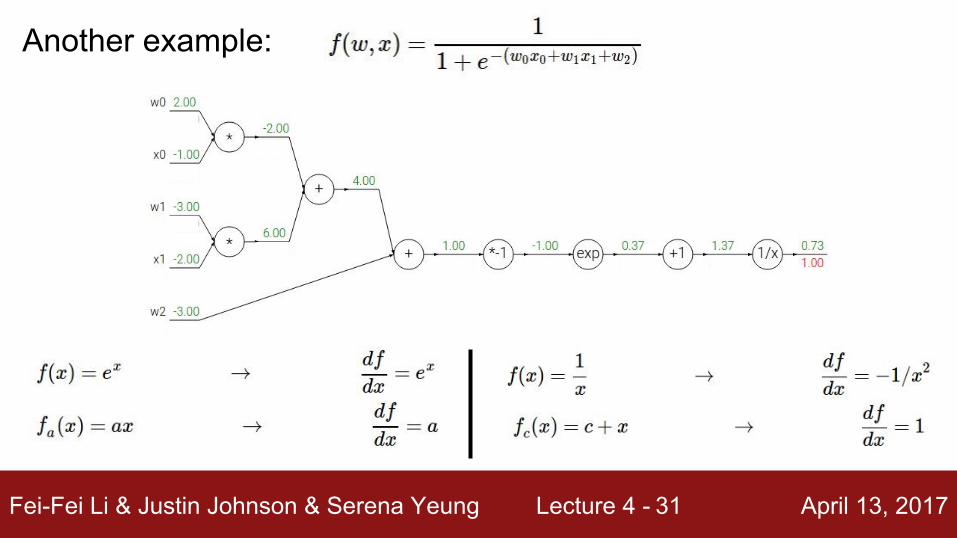
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201731
Another example:
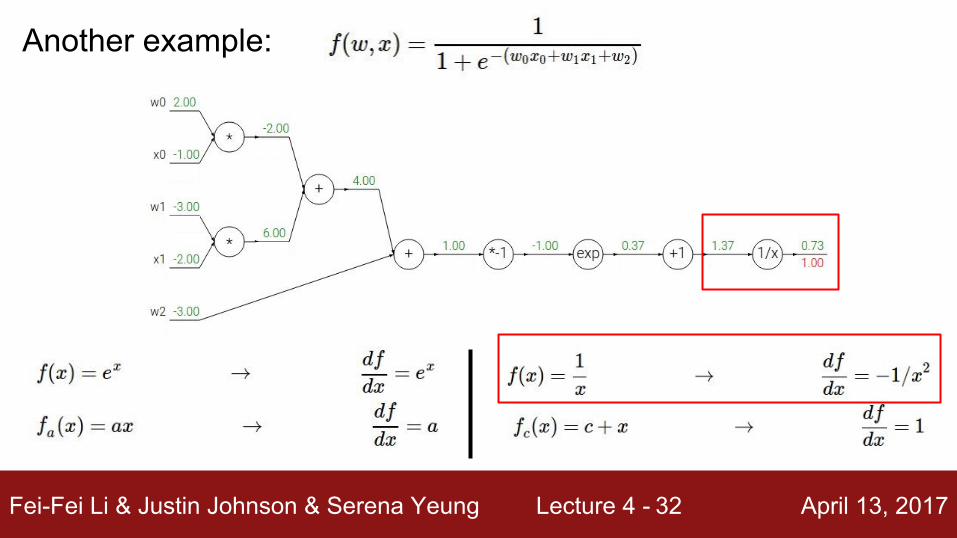
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201732
Another example:
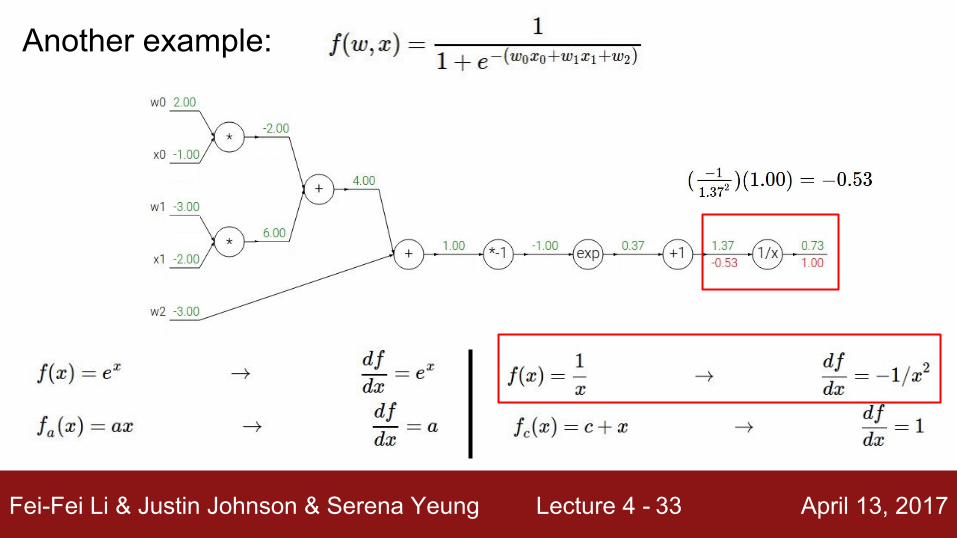
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201733
Another example:
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201734
Another example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201735
Another example:
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201736
Another example:
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201737
Another example:
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201738
Another example:
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201739
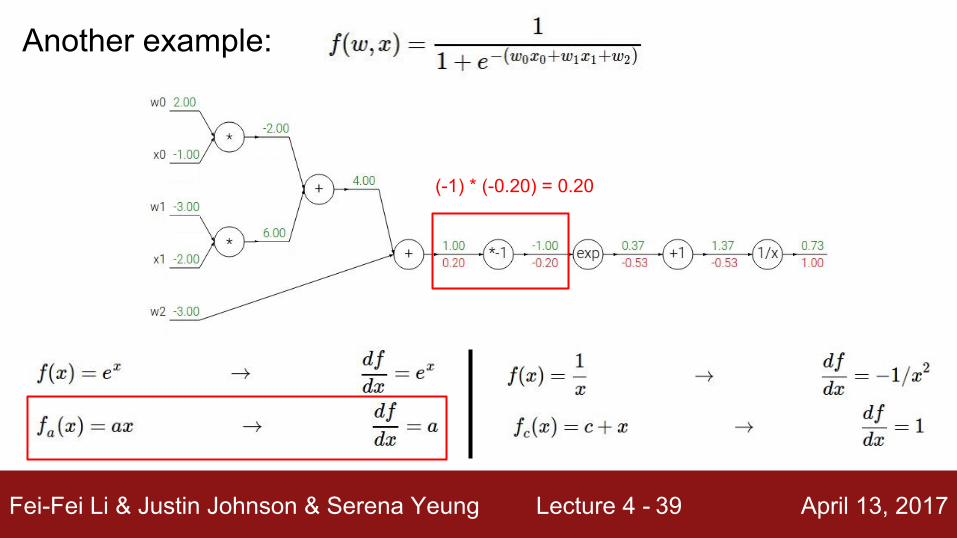
Another example:
(-1) * (-0.20) = 0.20
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201740
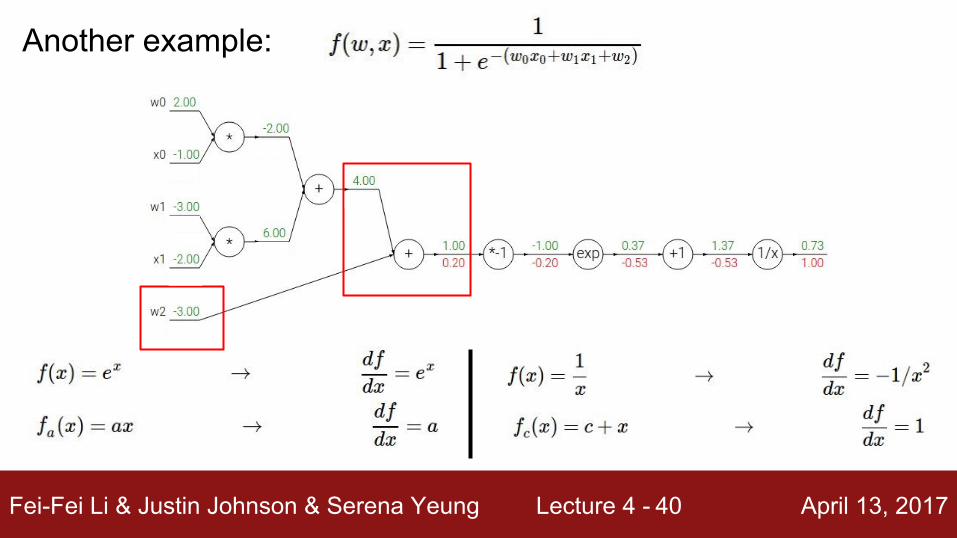
Another example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201741
Another example:
[local gradient] x [upstream gradient][1] x [0.2] = 0.2[1] x [0.2] = 0.2 (both inputs!)
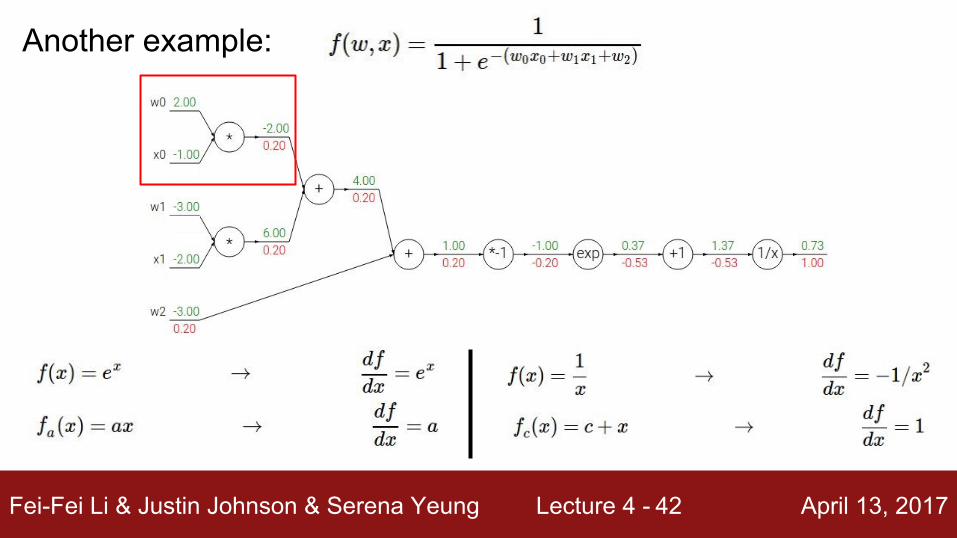
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201742
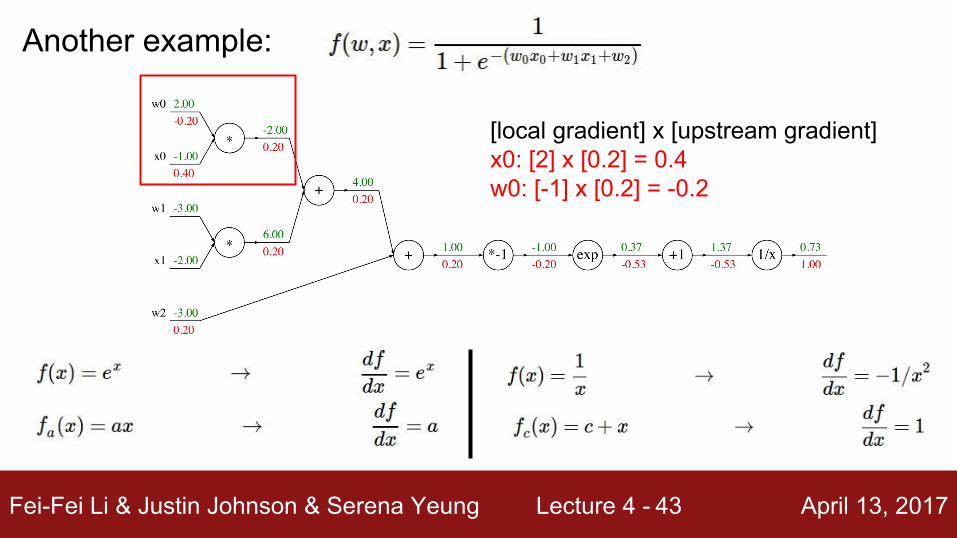
Another example:
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201743
Another example:
[local gradient] x [upstream gradient]x0: [2] x [0.2] = 0.4w0: [-1] x [0.2] = -0.2
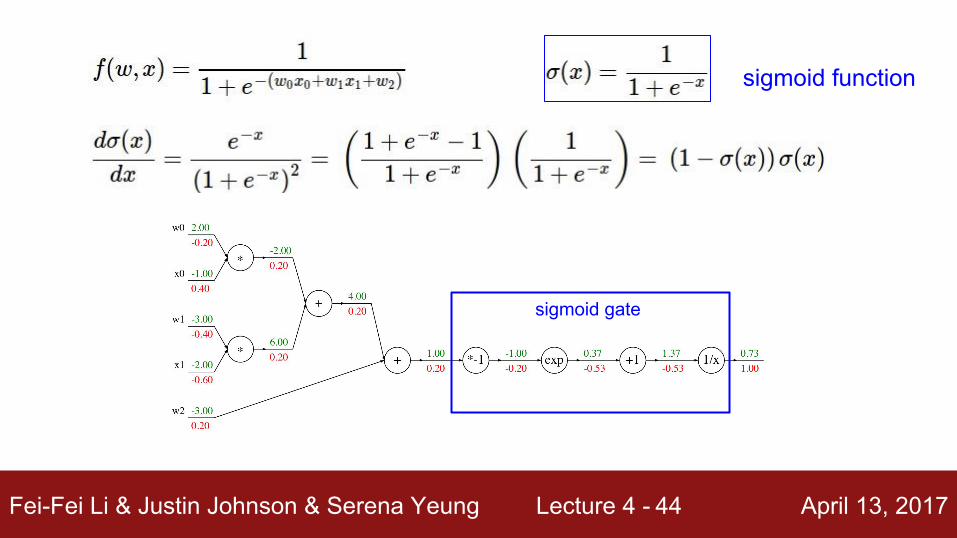
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201744
sigmoid function
sigmoid gate
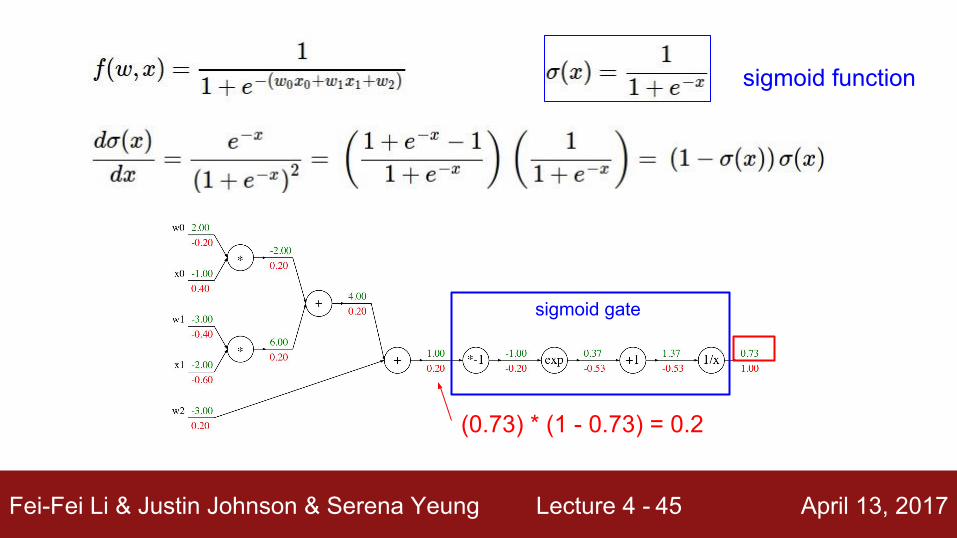
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 2017
sigmoid gate
45
sigmoid function
(0.73) * (1 - 0.73) = 0.2
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201746
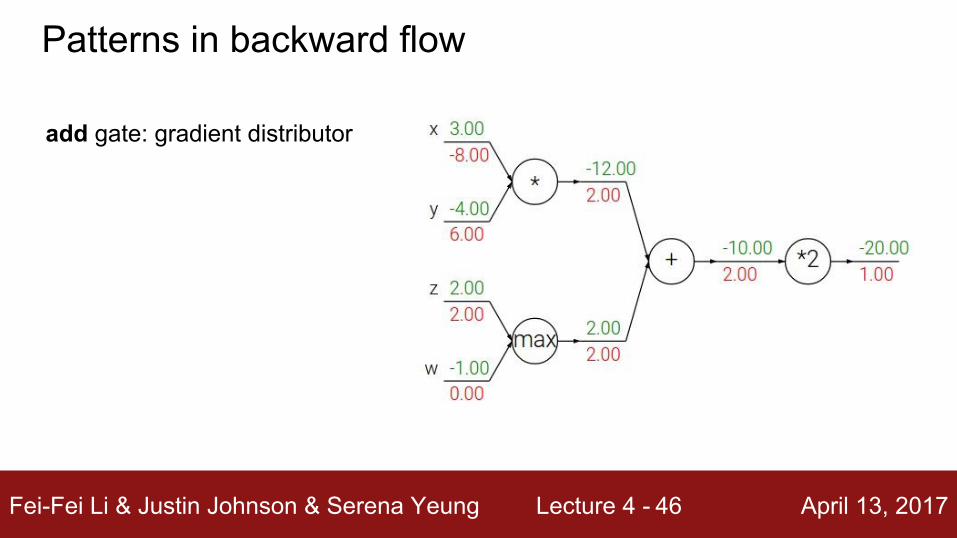
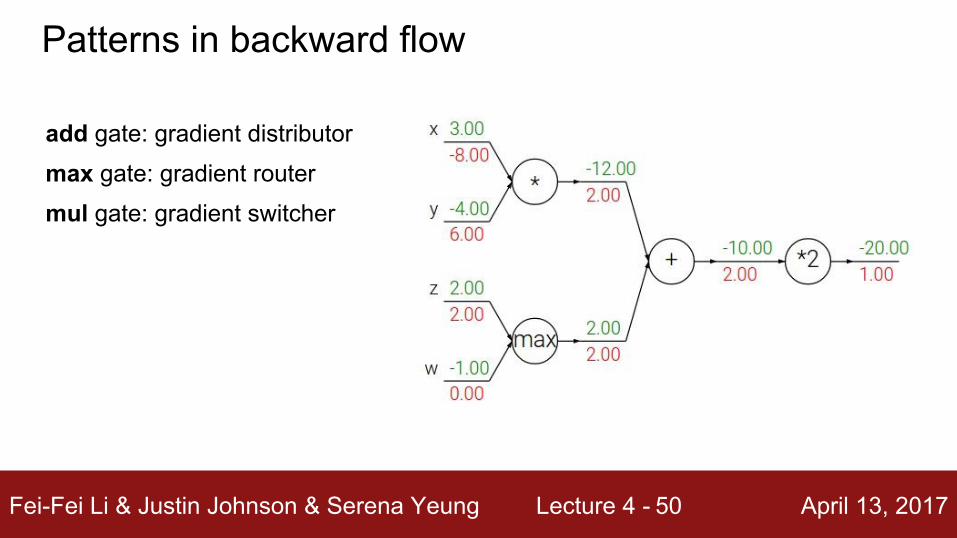
add gate: gradient distributor
Patterns in backward flow

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201747
add gate: gradient distributor
Patterns in backward flow
Q: What is a max gate?
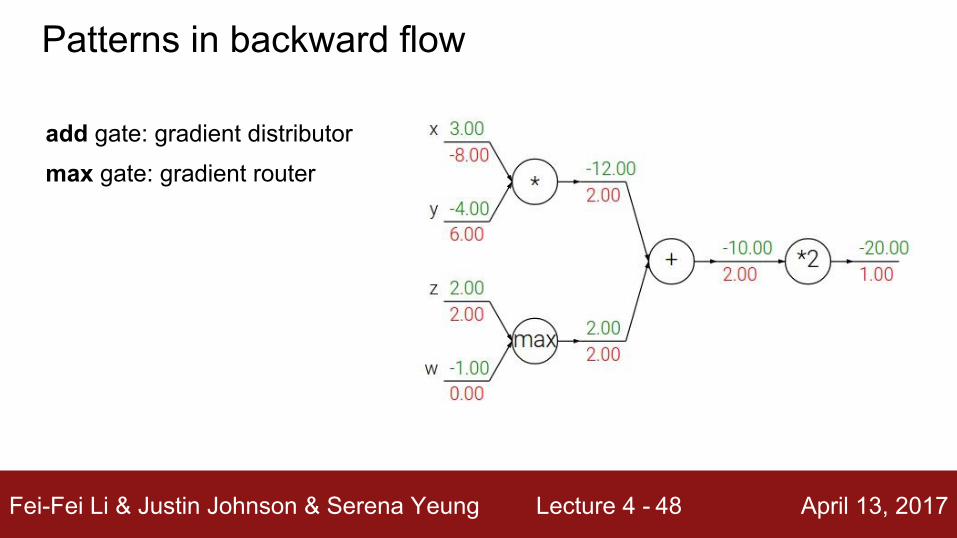
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201748
add gate: gradient distributor
Patterns in backward flow
max gate: gradient router

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201749
add gate: gradient distributor
Patterns in backward flow
max gate: gradient router
Q: What is a mul gate?
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201750
add gate: gradient distributor
Patterns in backward flow
max gate: gradient router
mul gate: gradient switcher
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201751
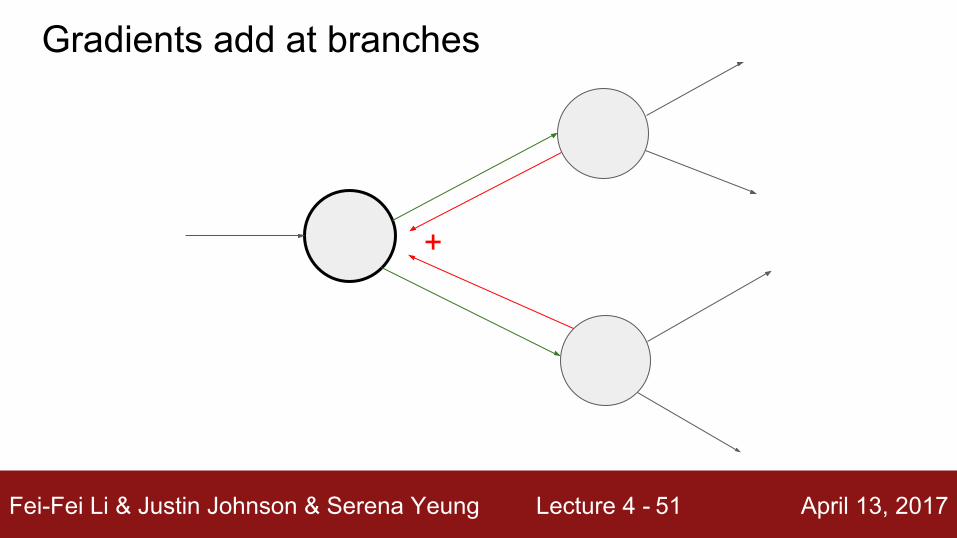
+
Gradients add at branches
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201752
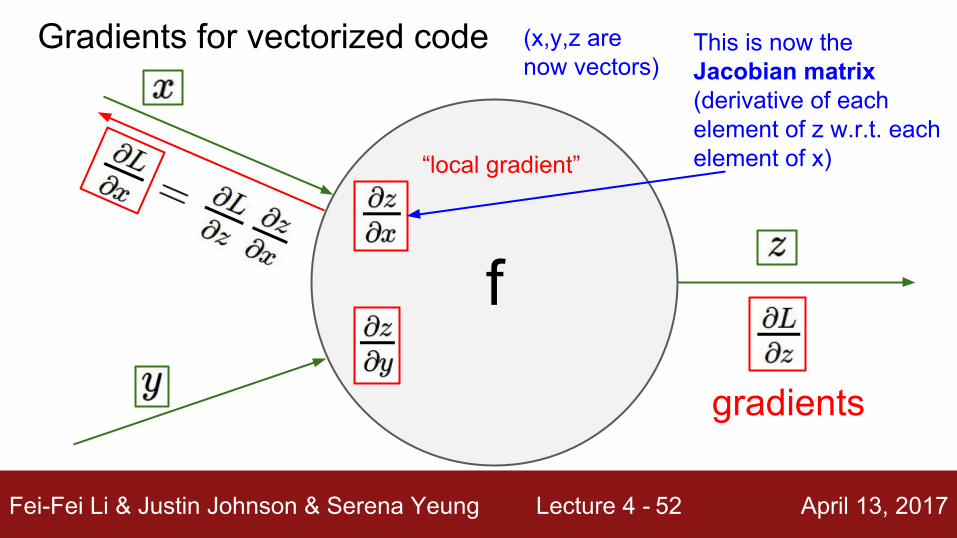
f
“local gradient”
This is now the Jacobian matrix (derivative of each element of z w.r.t. each element of x)
(x,y,z are now vectors)
gradients
Gradients for vectorized code
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201753
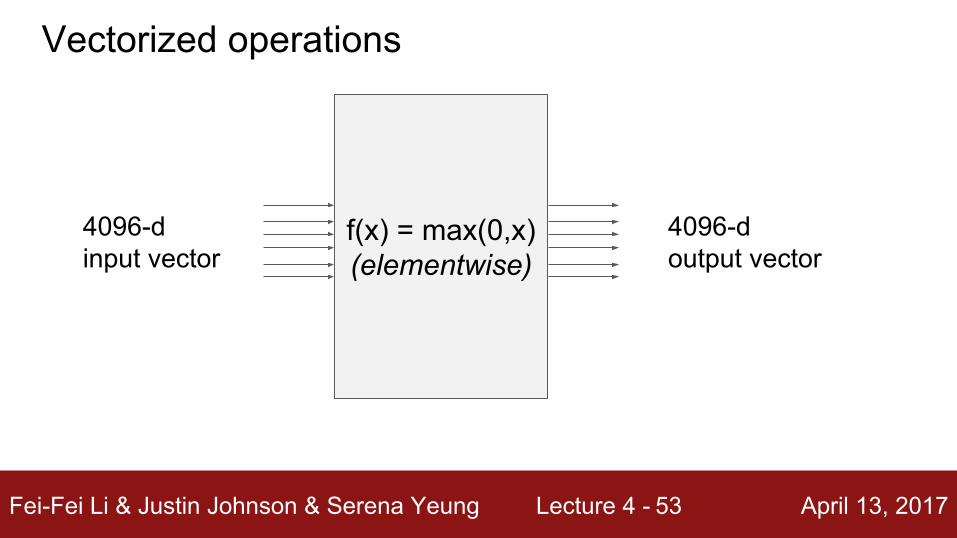
f(x) = max(0,x)(elementwise)
4096-d input vector
4096-d output vector
Vectorized operations
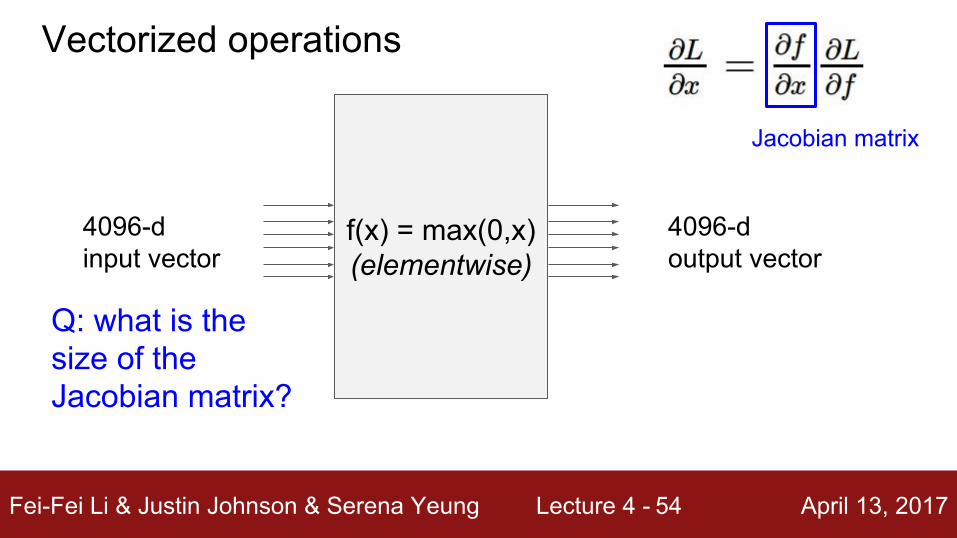
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201754
Jacobian matrix
f(x) = max(0,x)(elementwise)
4096-d input vector
4096-d output vector
Vectorized operations
Q: what is the size of the Jacobian matrix?
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201755
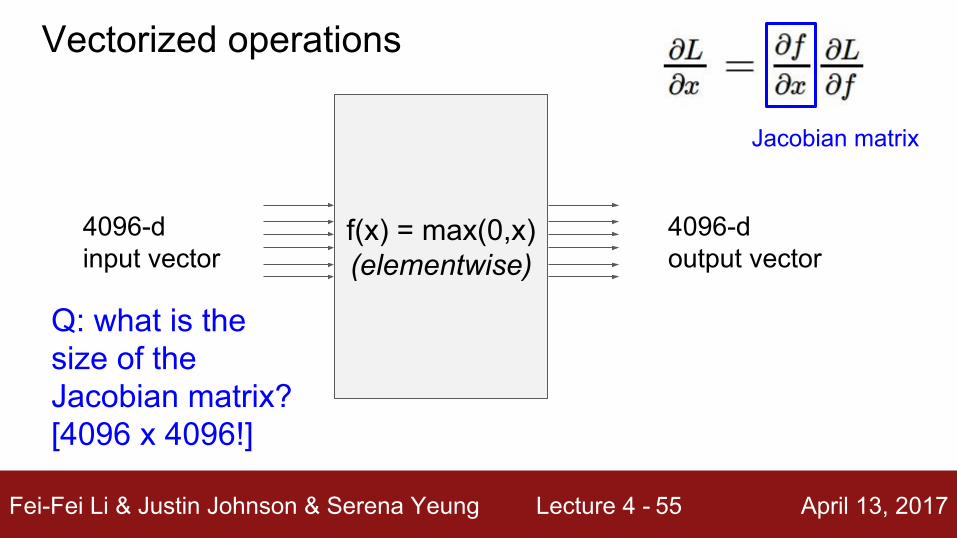
Jacobian matrix
f(x) = max(0,x)(elementwise)
4096-d input vector
4096-d output vector
Vectorized operations
Q: what is the size of the Jacobian matrix?[4096 x 4096!]

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 2017
i.e. Jacobian would technically be a[409,600 x 409,600] matrix :\
f(x) = max(0,x)(elementwise)
4096-d input vector
4096-d output vector
Vectorized operations
Q: what is the size of the Jacobian matrix?[4096 x 4096!]
in practice we process an entire minibatch (e.g. 100) of examples at one time:
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 2017
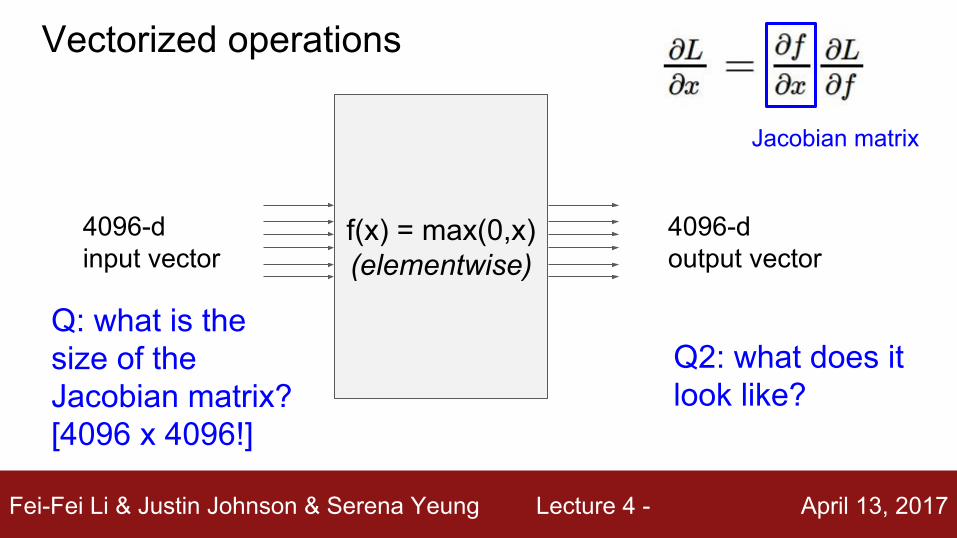
Q: what is the size of the Jacobian matrix?[4096 x 4096!]
Q2: what does it look like?
f(x) = max(0,x)(elementwise)
4096-d input vector
4096-d output vector
Vectorized operations
Jacobian matrix

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201758
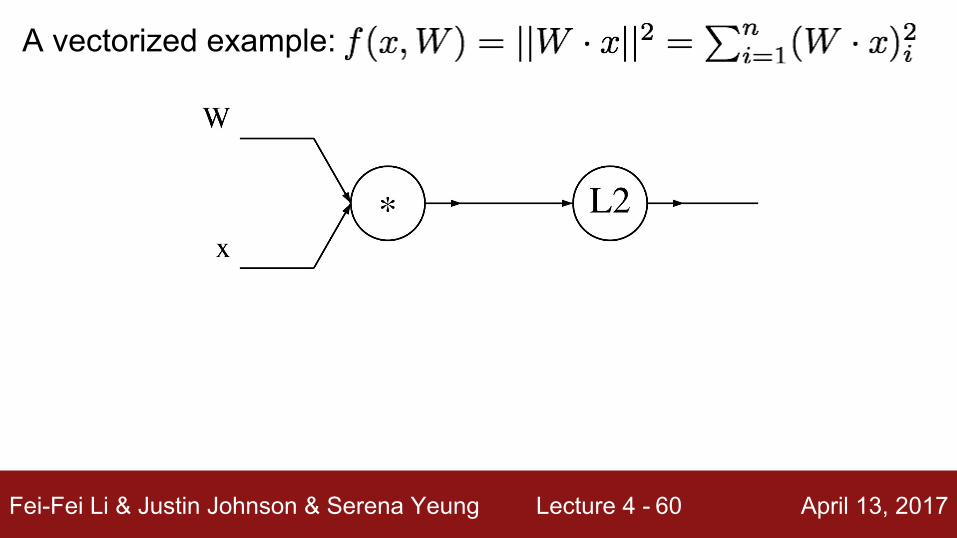
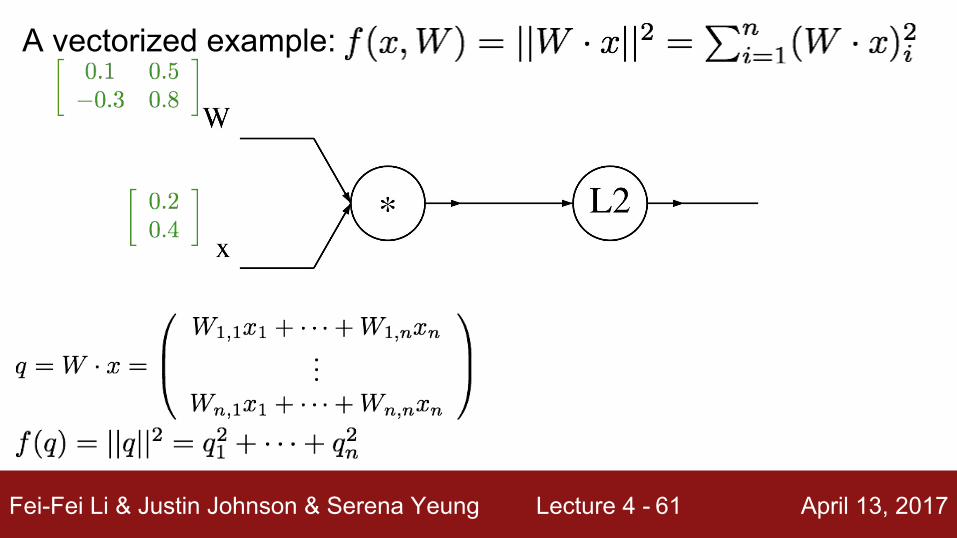
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201759
A vectorized example:
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201760
A vectorized example:
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201761
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201762
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201763
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201764
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201765
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201766
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201767
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201768
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201769
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201770
A vectorized example:
Always check: The gradient with respect to a variable should have the same shape as the variable

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201771
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201772
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201773
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201774
A vectorized example:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201775
Modularized implementation: forward / backward API
Graph (or Net) object (rough psuedo code)

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201776
(x,y,z are scalars)
x
y
z*
Modularized implementation: forward / backward API

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201777
(x,y,z are scalars)
x
y
z*
Modularized implementation: forward / backward API
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201778
Example: Caffe layers
Caffe is licensed under BSD 2-Clause

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201779
* top_diff (chain rule)
Caffe is licensed under BSD 2-Clause
Caffe Sigmoid Layer

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201780
Stage your forward/backward computation!E.g. for the SVM:
margins
In Assignment 1: Writing SVM / Softmax

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201781
● neural nets will be very large: impractical to write down gradient formula by hand for all parameters
● backpropagation = recursive application of the chain rule along a computational graph to compute the gradients of all inputs/parameters/intermediates
● implementations maintain a graph structure, where the nodes implement the forward() / backward() API
● forward: compute result of an operation and save any intermediates needed for gradient computation in memory
● backward: apply the chain rule to compute the gradient of the loss function with respect to the inputs
Summary so far...

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201782
Next: Neural Networks

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201783
Neural networks: without the brain stuff
(Before) Linear score function:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201784
(Before) Linear score function:
(Now) 2-layer Neural Network
Neural networks: without the brain stuff

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201785
(Before) Linear score function:
(Now) 2-layer Neural Network
Neural networks: without the brain stuff
x hW1 sW2
3072 100 10

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201786
(Before) Linear score function:
(Now) 2-layer Neural Network
Neural networks: without the brain stuff
x hW1 sW2
3072 100 10

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201787
Neural networks: without the brain stuff
(Before) Linear score function:
(Now) 2-layer Neural Network or 3-layer Neural Network

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201788
Full implementation of training a 2-layer Neural Network needs ~20 lines:

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201789
In Assignment 2: Writing a 2-layer net

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201790
This image by Fotis Bobolas is licensed under CC-BY 2.0
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201791
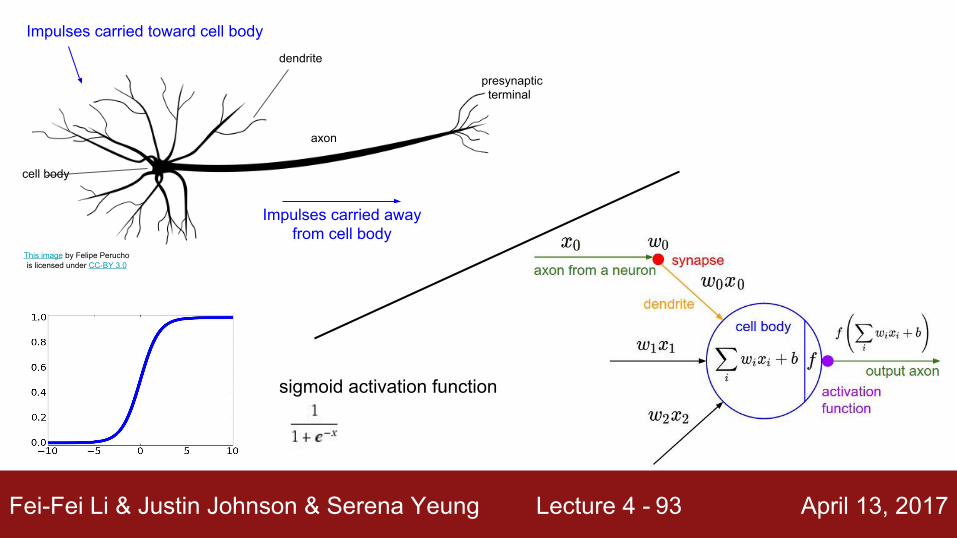
Impulses carried toward cell body
Impulses carried away from cell body
This image by Felipe Peruchois licensed under CC-BY 3.0
dendrite
cell body
axon
presynaptic terminal
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201792
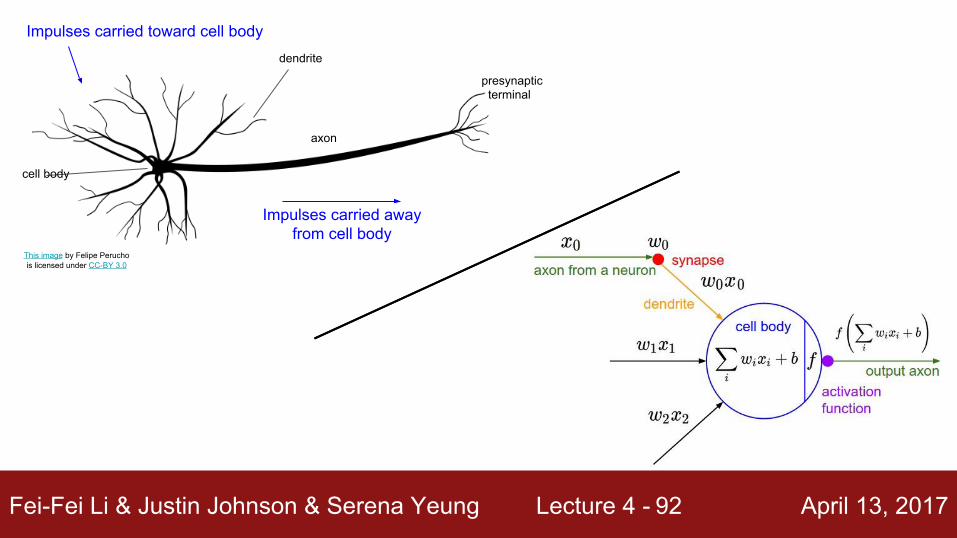
Impulses carried toward cell body
Impulses carried away from cell body
This image by Felipe Peruchois licensed under CC-BY 3.0
dendrite
cell body
axon
presynaptic terminal
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201793
sigmoid activation function
Impulses carried toward cell body
Impulses carried away from cell body
This image by Felipe Peruchois licensed under CC-BY 3.0
dendrite
cell body
axon
presynaptic terminal
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 20179494
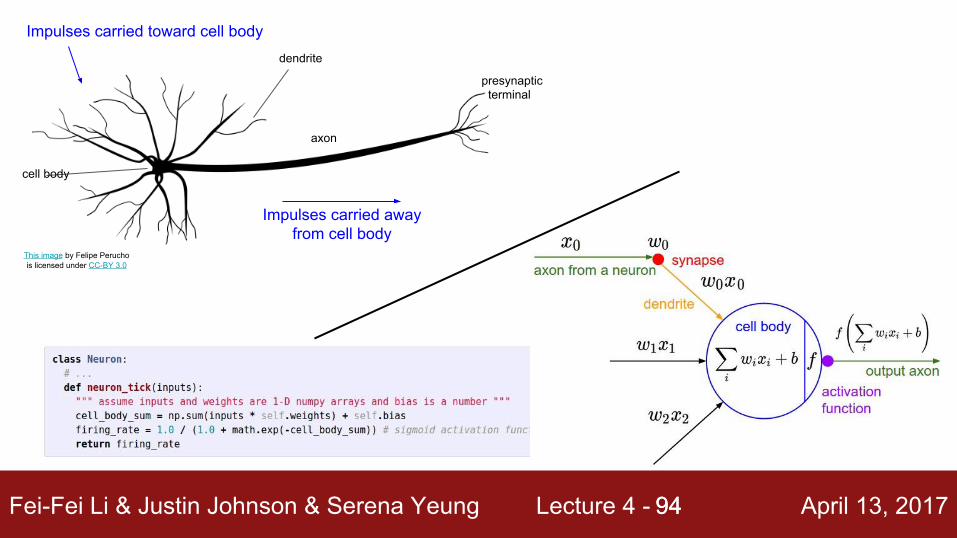
Impulses carried toward cell body
Impulses carried away from cell body
This image by Felipe Peruchois licensed under CC-BY 3.0
dendrite
cell body
axon
presynaptic terminal

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201795
Biological Neurons:● Many different types● Dendrites can perform complex non-linear computations● Synapses are not a single weight but a complex non-linear dynamical
system● Rate code may not be adequate
[Dendritic Computation. London and Hausser]
Be very careful with your brain analogies!

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201796
Sigmoid
tanh
ReLU
Leaky ReLU
Maxout
ELU
Activation functions
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201797
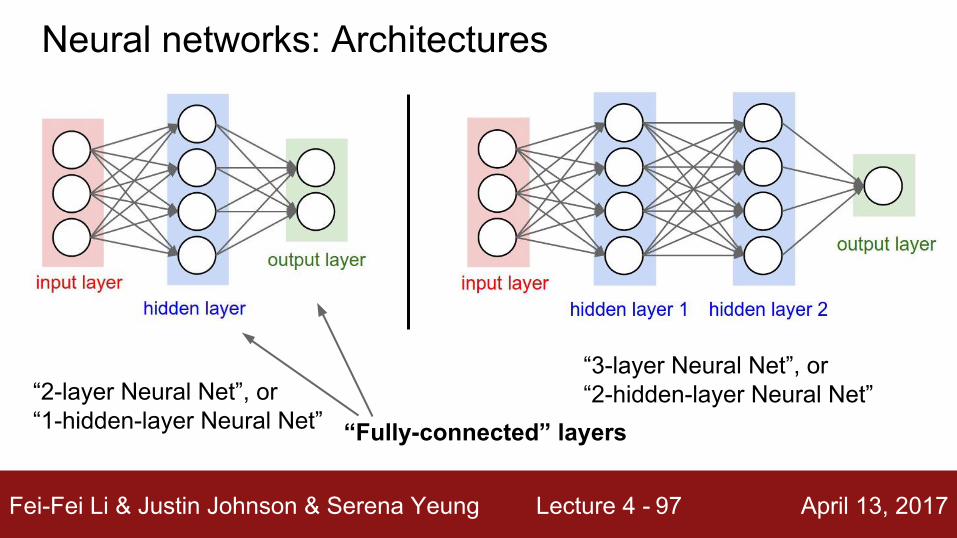
“Fully-connected” layers“2-layer Neural Net”, or“1-hidden-layer Neural Net”
“3-layer Neural Net”, or“2-hidden-layer Neural Net”
Neural networks: Architectures

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201798
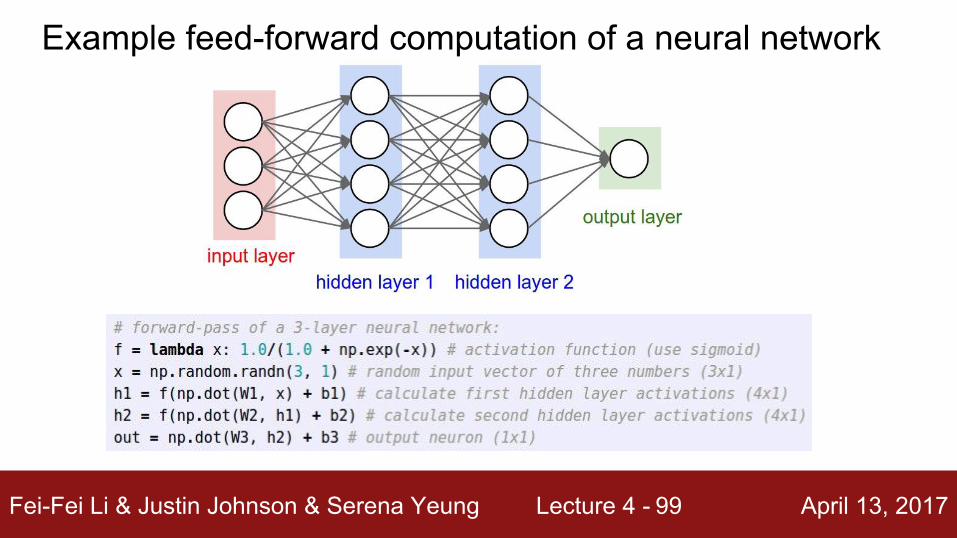
We can efficiently evaluate an entire layer of neurons.
Example feed-forward computation of a neural network
Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 201799
Example feed-forward computation of a neural network

Fei-Fei Li & Justin Johnson & Serena Yeung Lecture 4 - April 13, 2017100
Summary
- We arrange neurons into fully-connected layers- The abstraction of a layer has the nice property that it
allows us to use efficient vectorized code (e.g. matrix multiplies)
- Neural networks are not really neural- Next time: Convolutional Neural Networks
Top Related