








Languages
Pages
Legal


Lightning-fast cluster computing

Solve the same problem

Hadoop issues
- Difficult to maintain / install
- Slow due to replication & disk storage
- Need integration for differents tools (machine learning, stream processing)
- "Spending more time learning processing data tool than processing data"

Hadoop / Spark comparison
10xfaster
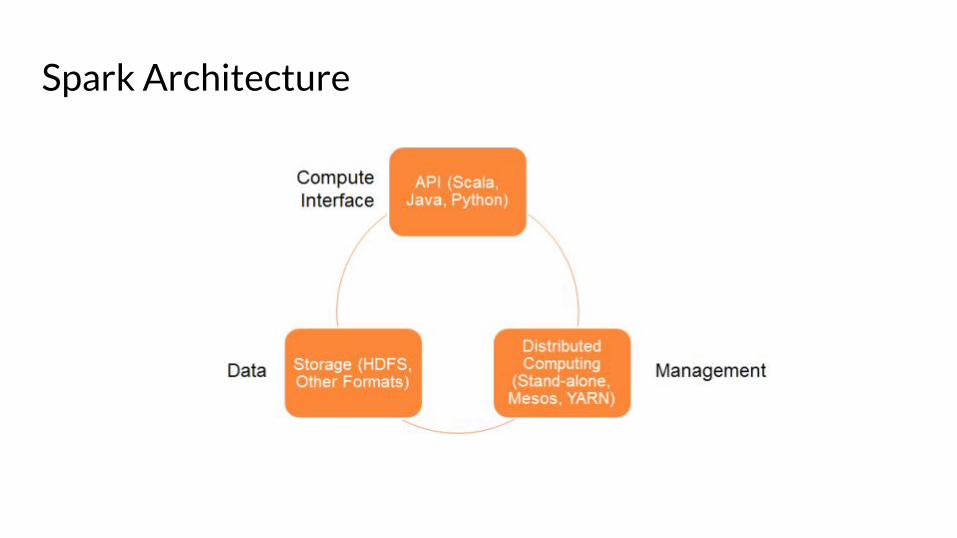
Spark Architecture

Cluster
● Standalone● Apache Mesos● Hadoop YARN (2.0)
agnostic to the underlying cluster manager

Which one should I choose ?
Standalone - simulation / repl
YARN / Mesos - run Spark alongside with other applications / use the richer resource scheduling capabilities
YARN - Resource manager / node managerMESOS - Mesos master / mesos agent
YARN - will likely be preinstalled in many Hadoop distributions.
In all cases - it is best to run Spark on the same nodes as HDFS for fast access to storage. You can install Mesos or the standalone cluster manager on the same nodes manually, or most Hadoop distributions already install YARN and HDFS together.

RDD - Resilient Distributed DatasetCluster
Error, ts, msg1, warn, ts,
msg2, Error
info, ts, msg8, info, ts, msg3,
info
Error, ts, msg5, ts, info
Error, ts, info, msg9, ts, info,
Error
RDD / 4 partitions (2-4 partition for CPU in your cluster)
Worker Worker Worker

RDD - Resilient Distributed DatasetParallelized Collections
JavaSparkContext’s parallelize method
(distData) can be operated on in parallel

RDD - Resilient Distributed DatasetExternal Datasets

Error, ts, msg1, warn, ts,
msg2, Error
info, ts, msg8, info, ts, msg3,
info
Error, ts, msg5, ts, info
Error, ts, info, msg9, ts, info,
Error
Error, ts, msg1, ts, Error
Error, ts, msg3, ts
Error, ts, msg9, ts, Error
logLines RDD (inputBase RDD)
filter(fx) transformation
errorsRDD
RDD in action
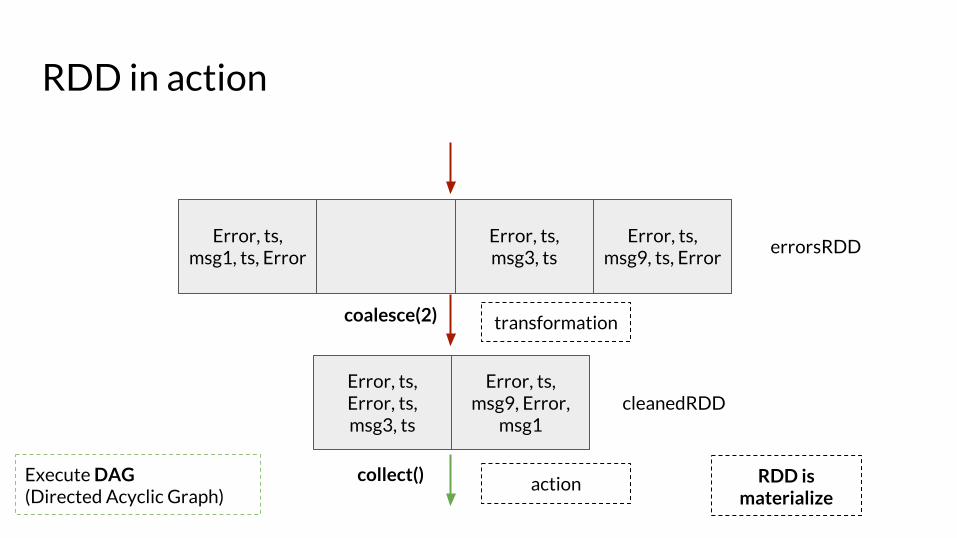
RDD in action
Error, ts, msg1, ts, Error
Error, ts, msg3, ts
Error, ts, msg9, ts, Error
Error, ts, Error, ts, msg3, ts
Error, ts, msg9, Error,
msg1
errorsRDD
coalesce(2) transformation
cleanedRDD
collect() action RDD is materialize
Execute DAG (Directed Acyclic Graph)

logLinesRDD
cleanedRDD
collect()
errosRDD
Error, ts, msg1, ts, msg3, ts
Error, ts, msg4, ts, msg1
Error, ts, msg1, ts Error, ts, ts, msg1
filter(fx)
errorMsg1RDD
count()
saveToCassandra()
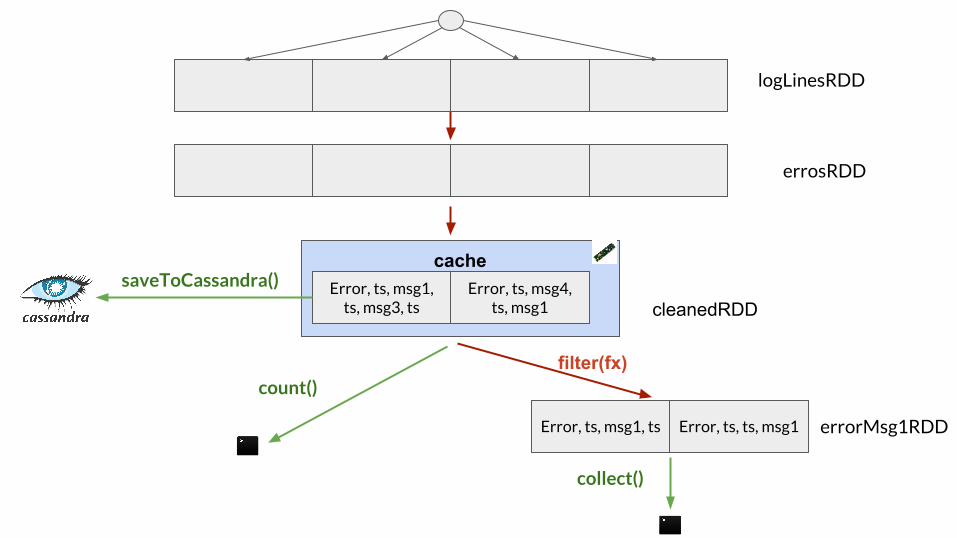
cache
logLinesRDD
cleanedRDD
collect()
errosRDD
Error, ts, msg1, ts, msg3, ts
Error, ts, msg4, ts, msg1
Error, ts, msg1, ts Error, ts, ts, msg1
filter(fx)
errorMsg1RDD
count()
saveToCassandra()

RDD - Resilient Distributed DatasetRDD Persistence
persist() ->
MEMORY_ONLY, MEMORY_AND_DISK, MEMORY_ONLY_SER (Java and Scala),
MEMORY_AND_DISK_SER (Java and Scala), DISK_ONLY
cache() -> default (StorageLevel.MEMORY_ONLY)

RDD - Resilient Distributed DatasetWhich Storage Level to Choose
MEMORY_ONLY -> MEMORY_ONLY_SER -> DISK_ONLY

RDD - Resilient Distributed DatasetRemoving data
- LRU (least-recently-used)- RDD.unpersist() method.

Lifecycle of a Spark program
1) Create some input RDD from external data
2) Lazily transform them (filter(), map())
3) Ask Spark to cache() RDDs that need to be reuse
4) Launch actions (count(), reduce()) to kick off parallel computation

Example job

Dependency types

Scheduling Process
Spark SQL
DataFrames can be created from different data sources such as:
- Existing RDDs- Structured data files- JSON datasets- Hive tables- External databases
SQLContext
HiveContext(HiveQL)
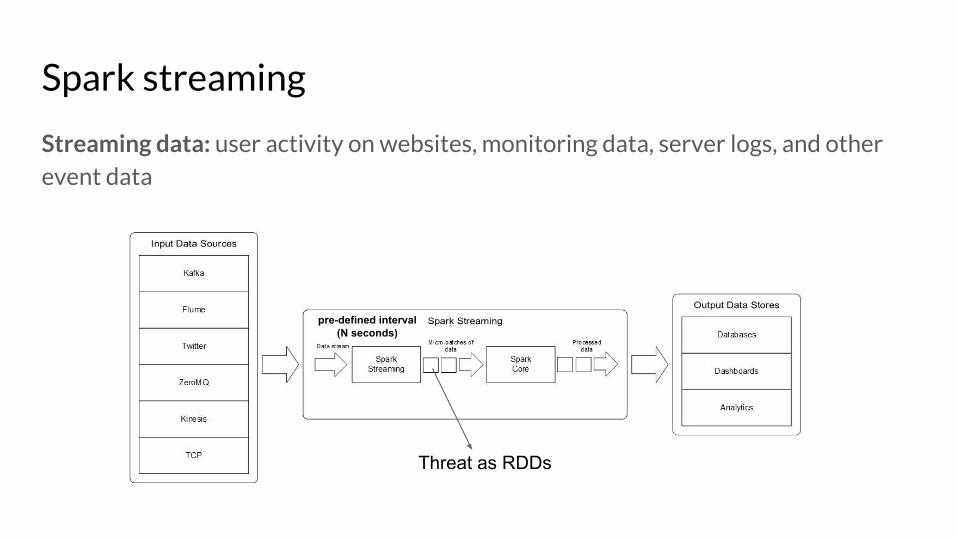
Spark streaming
Streaming data: user activity on websites, monitoring data, server logs, and other event data
Threat as RDDs
pre-defined interval (N seconds)

Other Spark libraries
- MLib (Machine learning)
- Spark Streaming (Streaming)
- GraphX (distributed graph processing)
- Third party projects
(https://cwiki.apache.org/confluence/display/SPARK/Third+Party+Projects)

Monitoring
- Web interface
- Rest API
- JMX

Security
Authentication via a shared secret
- YARN: spark.authenticate to true / automatically handle generation and distribution of shared secret
- OTHERS: spark.authenticate.secret for each node
WebUI - java servlet filters (spark.ui.filters)

References
http://spark.apache.org/docs/latest/cluster-overview.html
https://www.youtube.com/watch?v=PFK6gsnlV5E
https://www.youtube.com/watch?v=49Hr5xZyTEA
Top Related