







Languages
Pages
Legal


Apache CarbonData: An indexed columnar file format for interactive query with Spark SQL
Jihong MA, Jacky LIHUAWEI

data
Report & Dashboard OLAP & Ad-hoc Batch processing Machine learningReal Time Analytics

Challenge
• Wide Spectrum of Query Analysis• OLAP Vs Detailed Query• Full scan Vs Small scan• Point queries
Small Scan QueryBig Scan Query
Multi-dimensional OLAP Query

How to choose storage engine to facilitate query execution?

Available Options1. NoSQL Database
• Key-Value store: low latency, <5ms• No Standard SQL support
2. MPP relational Database •Shared-nothing enables fast query execution•Poor scalability: < 100 cluster size, no fault-tolerance
3. Search Engine •Advanced indexing technique for fast search•3~4X data expansion in size, no SQL support
4. SQL on Hadoop•Modern distributed architecture and high scalability•Slow on point queries

Motivation for A New File Format
CarbonData: Unified File Format
Small Scan QueryBig Scan Query
Multi-dimensional OLAP Query
A single copy of databalanced to fit all data access

Apache
• Apache Incubator Project since June, 2016
• Apache releases
• 4 stable releases
• Latest 1.0.0, Jan 28, 2017
• Contributors:
• In Production:
Compute
Storage

Introducing CarbonData
CarbonData Integration with Spark
CarbonData Table
CarbonData FileWhat is CarbonData file format?
What forms a CarbonData table on disk?
What it takes to deeply integrate withdistributed processing engine like Spark?
1
2
3

CarbonData:
An Indexed Columnar File Format

CarbonData File Structure
§ Built-in Columnar & Index § Multi-dimensional Index (B+ Tree)§ Min/Max index§ Inverted index
§ Encoding:§ RLE, Delta, Global Dictionary§ Snappy for compression§ Adaptive Data Type Compression
§ Data Type:§ Primitive type and nested type

CarbonData File Layout
• Blocklet: A set of rows in columnar format•Data are sorted along MDK (multi-dimensional keys)•Clustered data enabling efficient filtering and scan
•Column chunk: Data for one column in a Blocklet
•Footer: Metadata information•File level metadata & statistics •Schema •Blocklet Index
Carbon Data File
Blocklet 1
Column 1 Chunk
Column 2 Chunk
…Column n Chunk
Blocklet N
File Footer
…
File Metadata
Schema
Blocklet Index

File Level Blocklet Index
Blocklet 11 1 1 1 1 1 120001 1 1 2 1 2 50001 1 2 1 1 1 120001 1 2 2 1 2 50001 1 3 1 1 1 120001 1 3 2 1 2 5000
Blocklet 21 2 1 3 2 3 110001 2 2 3 2 3 110001 2 3 3 2 3 110001 3 1 4 3 4 20001 3 1 5 3 4 10001 3 2 4 3 4 2000
Blocklet 31 3 2 5 3 4 10001 3 3 4 3 4 20001 3 3 5 3 4 10001 4 1 4 1 1 200001 4 2 4 1 1 200001 4 3 4 1 1 20000
Blocklet 42 1 1 1 1 1 120002 1 1 2 1 2 50002 1 2 1 1 1 120002 1 2 2 1 2 50002 1 3 1 1 1 120002 1 3 2 1 2 5000
Blocklet IndexBlocklet1
Start Key1End Key1 Start Key1
End Key4
Start Key1End Key2
Start Key3End Key4
Start Key1End Key1
Start Key2End Key2
Start Key3End Key3
Start Key4End Key4
File FooterBlocklet• Build in-memory file level MDK index tree for filtering• Major optimization for efficient scan
C1(Min, Max)….
C7(Min, Max)
Blocklet4Start Key4End Key4
C1(Min, Max)….
C7(Min, Max)
C1(Min,Max)
…
C7(Min,Max)
C1(Min,Max)
…
C7(Min,Max)
C1(Min,Max)
…
C7(Min,Max)
C1(Min,Max)
…
C7(Min,Max)

Rich Multi-Level Index Support
Spark Driver
Executor
Carbon FileData
Footer
Carbon FileData
Footer
Carbon FileData
Footer
File Level Index & Scanner
Table Level Index
Executor
File Level Index & Scanner
Catalyst
InvertedIndex
•Using the index info in footer, twolevel B+ tree index can be built:
•File level index: local B+ tree, efficient blocklet level filtering
•Table level index: global B+ tree, efficient file level filtering
•Column chunk inverted index:efficient column chunk scan

CarbonData Table:
Data Segment + Metadata

CarbonData Table
Carbon File
Metadata:Appendable Dictionary, Schema
Index:Separated Index per Segment
Data:Immutable Data File
Datasource
Load in batch
Segment
CarbonData TableRead
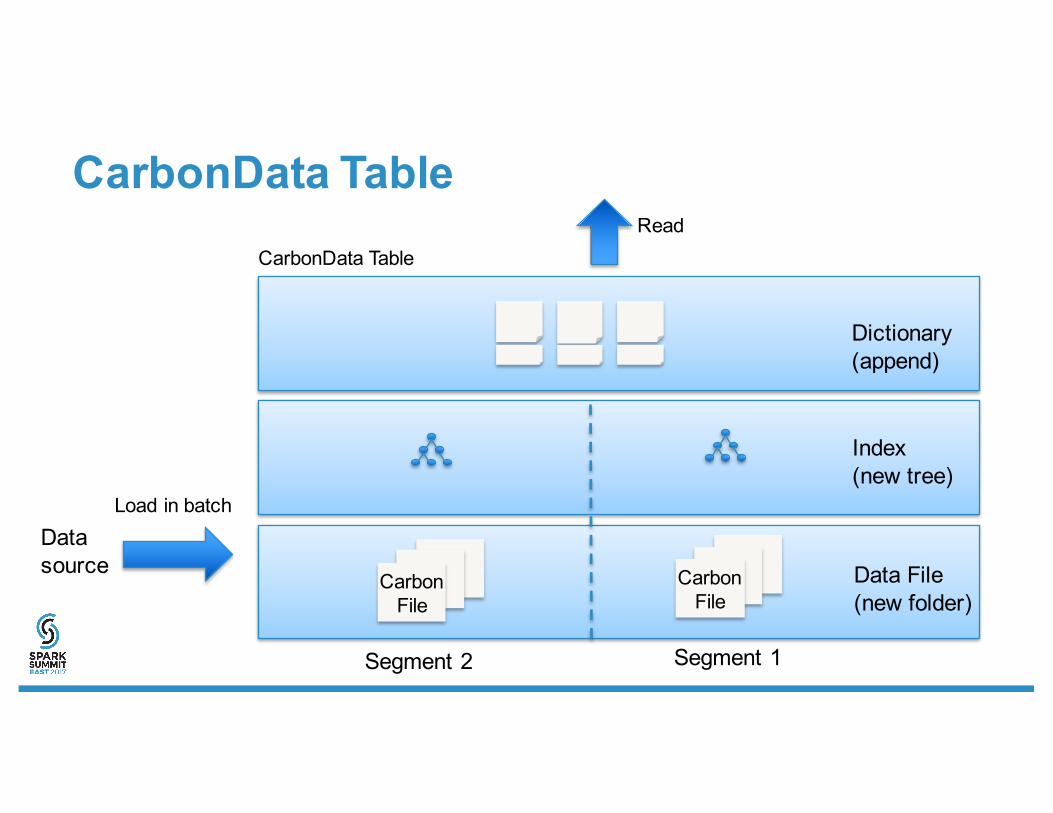
CarbonData Table
Carbon File
Carbon File
Dictionary(append)
Index(new tree)
Data File(new folder)
Datasource
Load in batch
Segment 2 Segment 1
CarbonData TableRead

CarbonData Table Layout
Carbon File
DataFooter
Carbon File
DataFooter
Carbon File
DataFooter
Carbon File
DataFooter
Dictionary File
Dictionary Map
Spark Driver
Table Level Index
Index File
All Footer
Schema File
Latest Schema
/table_name/fact/segment_id /table_name/metaHDFS
Spark

Mutation: DeleteDelete
BaseFile
Segment
CarbonData Table
DeleteDelta
Bitmap file that markdeleted rows
No changein index
No changein dictionary

Mutation: UpdateUpdate
BaseFile
Segment
CarbonData Table
DeleteDelta
InsertDelta
Bitmap file for deletedelta and regular datafile for inserted delta
New index added forinserted delta
Dictionary append

Data Compaction
Carbon File
Carbon File
Carbon File
Dictionary
Index
Data File
Segment 2 Segment 1 Segment 1.1
CarbonData TableRead
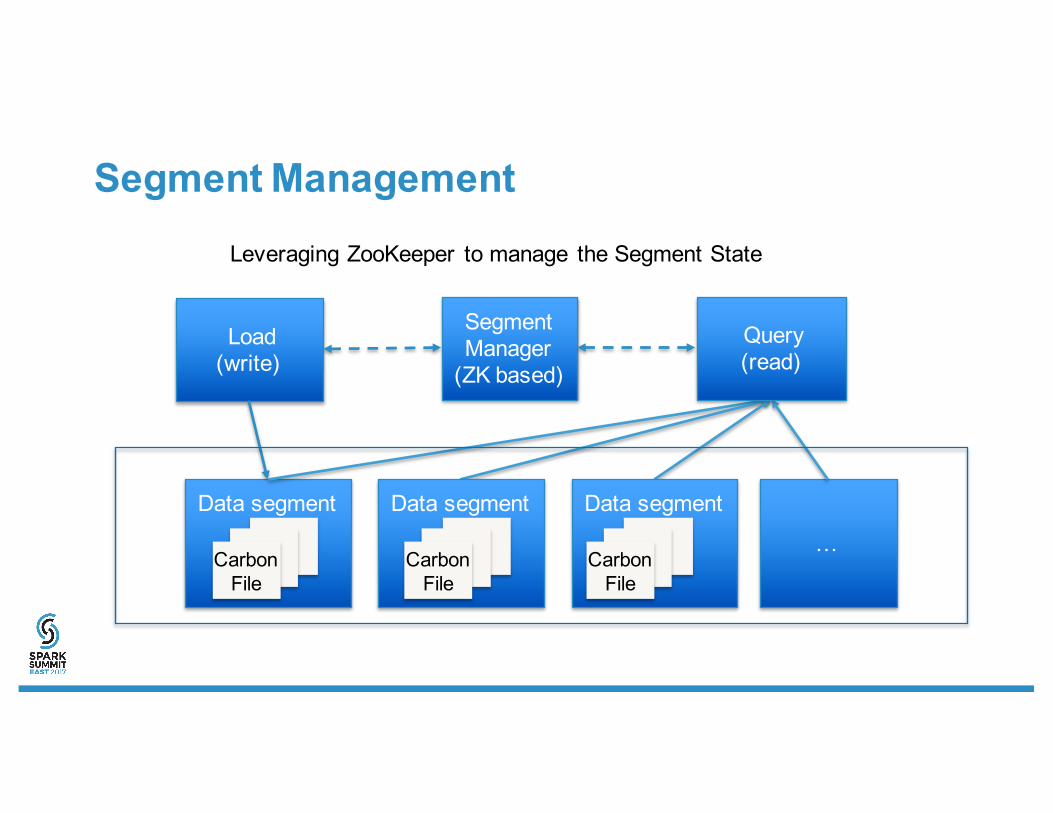
Segment Management
Data segment
…
Load(write)
Leveraging ZooKeeper to manage the Segment State
Segment Manager
(ZK based)
Carbon File
Data segment
Carbon File
Data segment
Carbon File
Query(read)

SparkSQL + CarbonData:
Enables fast interactive data analysis

Carbon-Spark Integration
• Built-in Spark integration• Spark 1.5, 1.6, 2.1
• Interface• SQL• DataFrame API
• Operation:• Load, Query (with optimization)• Update, Delete, Compaction, etc
Reader/Writer
Data Management
Query Optimization
Carbon File Carbon File Carbon File

Integration through File Format
Carbon File
Carbon File
Carbon File
HDFS
Segment 3 Segment 2 Segment 1
InputFormat/OutputFormat

Deep Integration with SparkSQL
Carbon File
Carbon File
Carbon File
IntegrateSparkSQLOptimizer
HDFS
Segment 3 Segment 2 Segment 1
CarbonData Table Read/Write/Update/Delete
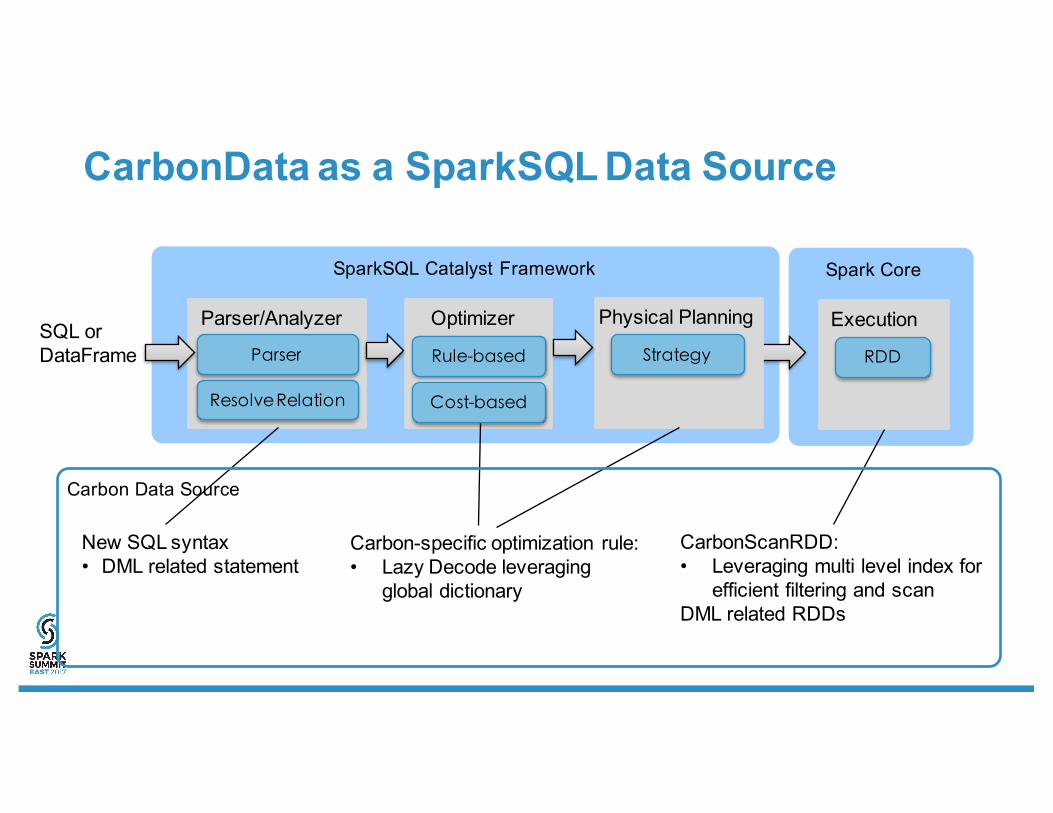
CarbonData as a SparkSQL Data Source
Parser/Analyzer Optimizer ExecutionSQL orDataFrame
Resolve Relation
Carbon-specific optimization rule:• Lazy Decode leveraging
global dictionary
Rule-based
New SQL syntax• DML related statement
RDD
CarbonScanRDD:• Leveraging multi level index for
efficient filtering and scanDML related RDDs
Parser
SparkSQL Catalyst Framework
Cost-based
Physical Planning
Strategy
Carbon Data Source
Spark Core
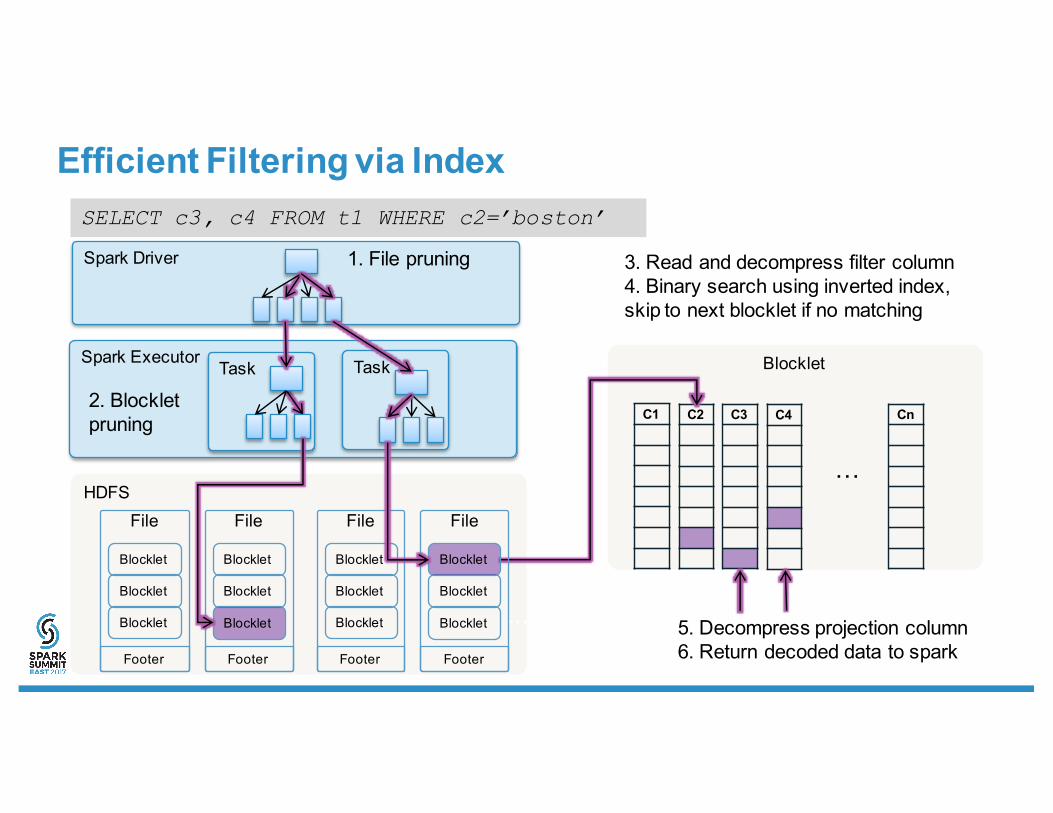
Spark Executor
Spark Driver
Blocklet
Efficient Filtering via Index
HDFSFile
Footer
Blocklet
Blocklet
……
C1 C2 C3 C4 Cn
1. File pruning
File
Blocklet
Blocklet
Footer
File
Footer
Blocklet
Blocklet
File
Blocklet
Blocklet
Footer
Blocklet Blocklet Blocklet Blocklet
Task Task
2. Blockletpruning
3. Read and decompress filter column4. Binary search using inverted index,skip to next blocklet if no matching
…
5. Decompress projection column6. Return decoded data to spark
SELECT c3, c4 FROM t1 WHERE c2=’boston’

Stage 2
Stage 1
Stage 2
Stage 1
Lazy Decoding by Leveraging Global Dictionary
Final Aggregation
Partial Aggregation
Scan with Filter(decode c1, c2, c3)
Final Aggregation
Partial Aggregation
Scan with Filter(decode c1, c2 only)
Dictionary Decode
Before applying Lazy Decode After applying Lazy Decode
SELECT c3, sum(c2) FROM t1 WHERE c1>10 GROUP BY c3
Aggregate onencodedvalue of c3
Decode c3 tostring type

Usage: Write
• Using SQL
• Using Dataframe
df.write.format(“carbondata").options("tableName“, “t1")).mode(SaveMode.Overwrite).save()
CREATE TABLE tablename (name String, PhoneNumber String) STORED BY “carbondata”
LOAD DATA [LOCAL] INPATH 'folder path' [OVERWRITE] INTO TABLE tablenameOPTIONS(property_name=property_value, ...)
INSERT INTO TABLE tablennme select_statement1 FROM table1;

Usage: Read
• Using SQL
• Using Dataframe
SELECT project_list FROM t1WHERE cond_listGROUP BY columnsORDER BY columns
df = sparkSession.read.format(“carbondata”).option(“tableName”, “t1”).load(“path_to_carbon_file”)
df.select(…).show

Usage: Update and Delete
UPDATE table1 ASET (A.PRODUCT, A.REVENUE) =
(SELECT PRODUCT, REVENUEFROM table2 BWHERE B.CITY = A.CITY AND B.BROKER = A.BROKER
)WHERE A.DATE BETWEEN ‘2017-01-01’ AND ‘2017-01-31’
table1 table2
UPDATE table1 ASET A.REVENUE = A.REVENUE - 10WHERE A.PRODUCT = ‘phone’
DELETE FROM table1 AWHERE A.CUSTOMERID = ‘123’
123,abc456, jkd
phone, 70 60car,100
phone, 30 20
Modify one column in table1
Modify two columns in table1 with values from table2
Delete records in table1

Performance Result

Test1. TPC-H benchmark (500GB)2. Test on Production Data Set (Billions of rows)3. Test on Large Data Set for Scalability (1000B rows, 103TB)
• Storage– Parquet:
• Partitioned by time column (c1)– CarbonData:
• Multi-dimensional Index by c1~c10
• Compute– Spark 2.1

TPC-H: Query
For big scan queries, similar performance,±20%
0
100
200
300
400
500
600
700
800
Response Time (sec)
Parquet
CarbonData
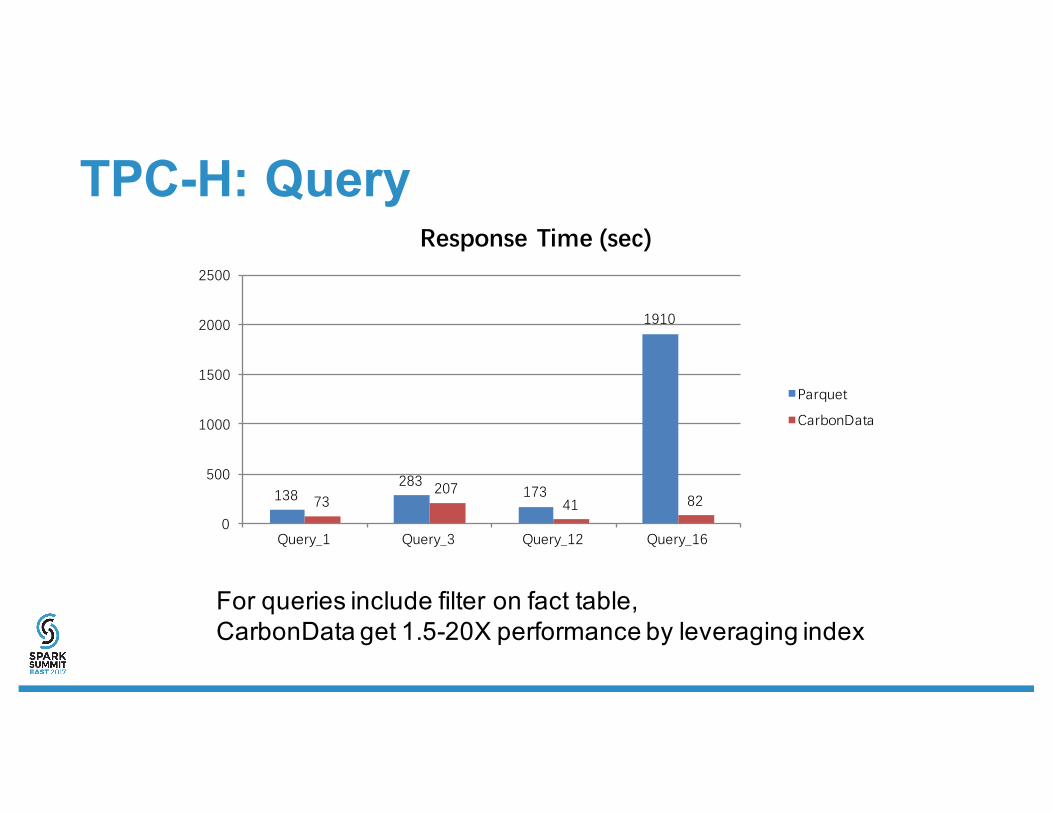
TPC-H: Query
138283
173
1910
73207
41 82
0
500
1000
1500
2000
2500
Query_1 Query_3 Query_12 Query_16
Response Time (sec)
Parquet
CarbonData
For queries include filter on fact table,CarbonData get 1.5-20X performance by leveraging index

TPC-H: Loading and Compression
83.27
44.30
0.00 10.00 20.00 30.00 40.00 50.00 60.00 70.00 80.00 90.00
Parquet CarbonData
loading throughput (MB/sec/node)
2.96 2.74
0.00
0.50
1.00
1.50
2.00
2.50
3.00
3.50
Parquet CarbonData
compression ratio

Test on Production Data Set
Filter Response Time (sec) Number of TaskQuery c1 c2 c3 c4 c5 c6 … c10 Parquet CarbonData Parquet CarbonData
Q1 6.4 1.3 55 5
Q2 65 1.3 804 5
Q3 71 5.2 804 9
Q5 64 4.7 804 9
Q4 67 2.7 804 161
Q6 62 3.7 804 161
Q7 63 21.85 804 588
Q8 69 11.2 804 645
Filter Query
Observation:Less scan task (resource) is needed because of more efficient filtering by leveraging multi-levelindex
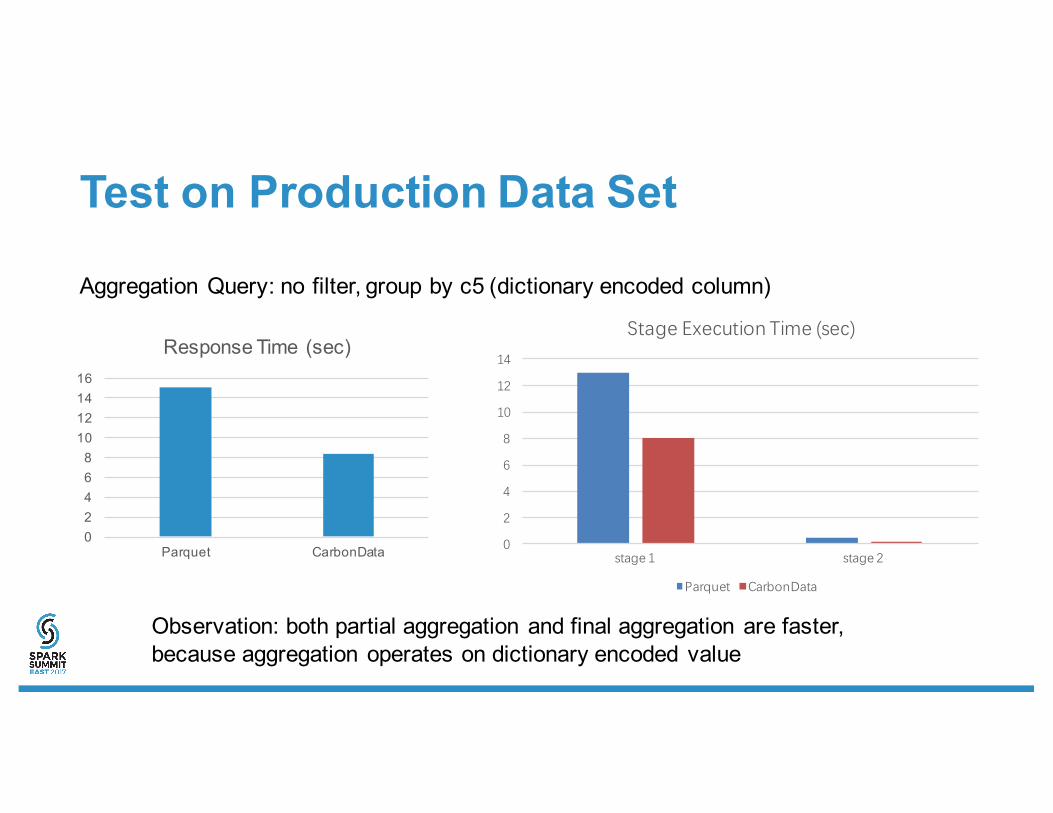
Test on Production Data Set
Aggregation Query: no filter, group by c5 (dictionary encoded column)
02468
10121416
Parquet CarbonData
Response Time (sec)
0
2
4
6
8
10
12
14
stage 1 stage 2
Stage Execution Time (sec)
Parquet CarbonData
Observation: both partial aggregation and final aggregation are faster,because aggregation operates on dictionary encoded value

Test on large data set
Observation
When data increase:l Index is efficient to reduce response time for IO bound query: Q1, Q2l Spark can scale linearly for CPU bound query: Q3
Data: 200 to 1000 Billion Rows (half year oftelecom data in one china province)
Cluster: 70 nodes, 1120 cores
Query:Q1: filter (c1~c4), select *Q2: filter (c10), select *Q3: full scan aggregate
0.00%
100.00%
200.00%
300.00%
400.00%
500.00%
200B 400B 600B 800B 1000B
Response Time (% of 200B)
Q1 Q2 Q3

What’s Coming Next

What’s coming next
l Enhancement on data loading & compression
l Streaming Ingest:
• Introduce row-based format for fast ingestion
• Gradually compact row-based to column-based for analytic workload
• Optimization for time series data
l Broader Integration across big data ecosystem: Beam, Flink, Kafka, Kylin

Apache
• Love feedbacks, try out, any kind of contribution!• Code: https://github.com/apache/incubator-carbondata
• JIRA: https://issues.apache.org/jira/browse/CARBONDATA• dev mailing list: [email protected]
• Website: http://http://carbondata.incubator.apache.org
• Current Contributor: 64
• Monthly resolved JIRA issue: 100+

Thank [email protected]@huawei.com
Top Related