







Languages
Pages
Legal


An Introduction to Apache Spark
Amir H. [email protected]
SICS Swedish ICT
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 1 / 67

Big Data
small data big data
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 2 / 67

Big Data
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 3 / 67

How To Store and ProcessBig Data?
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 4 / 67

Scale Up vs. Scale Out
I Scale up or scale vertically
I Scale out or scale horizontally
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 5 / 67

Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 6 / 67
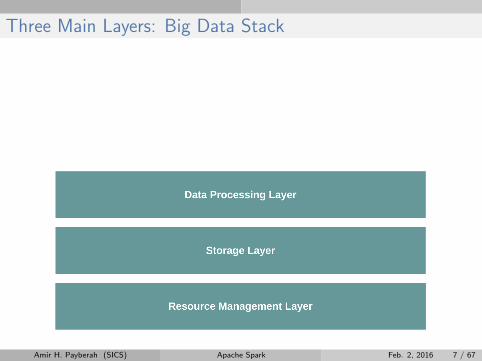
Three Main Layers: Big Data Stack
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 7 / 67
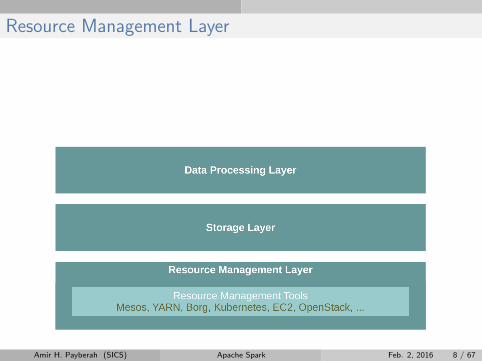
Resource Management Layer
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 8 / 67

Storage Layer
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 9 / 67
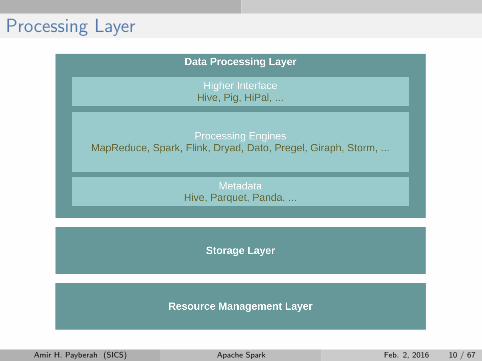
Processing Layer
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 10 / 67
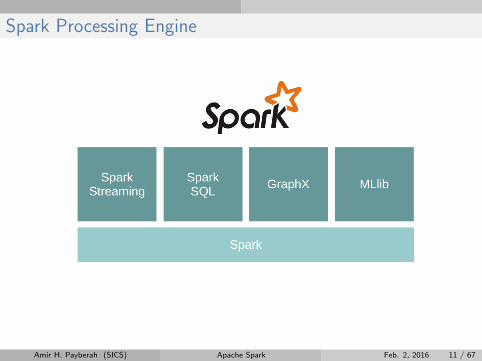
Spark Processing Engine
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 11 / 67

Cluster Programming Model
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 12 / 67
Warm-up Task (1/2)
I We have a huge text document.
I Count the number of times each distinct word appears in the file
I Application: analyze web server logs to find popular URLs.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 13 / 67
Warm-up Task (2/2)
I File is too large for memory, but all 〈word, count〉 pairs fit in mem-ory.
I words(doc.txt) | sort | uniq -c
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 14 / 67
Warm-up Task in MapReduce
I words(doc.txt) | sort | uniq -c
I Sequentially read a lot of data.
I Map: extract something you care about.
I Group by key: sort and shuffle.
I Reduce: aggregate, summarize, filter or transform.
I Write the result.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 15 / 67
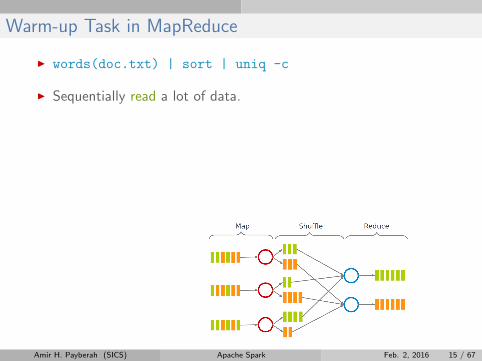
Warm-up Task in MapReduce
I words(doc.txt) | sort | uniq -c
I Sequentially read a lot of data.
I Map: extract something you care about.
I Group by key: sort and shuffle.
I Reduce: aggregate, summarize, filter or transform.
I Write the result.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 15 / 67
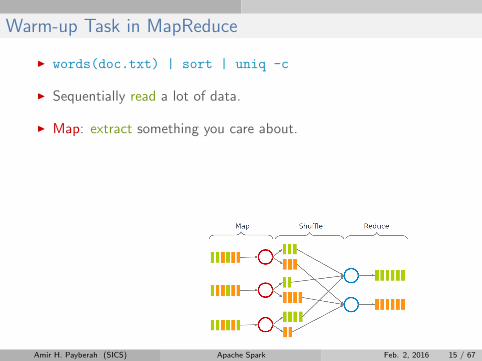
Warm-up Task in MapReduce
I words(doc.txt) | sort | uniq -c
I Sequentially read a lot of data.
I Map: extract something you care about.
I Group by key: sort and shuffle.
I Reduce: aggregate, summarize, filter or transform.
I Write the result.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 15 / 67
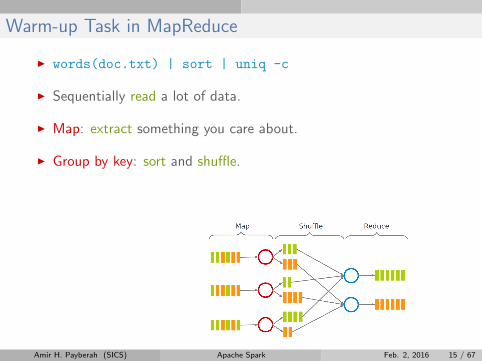
Warm-up Task in MapReduce
I words(doc.txt) | sort | uniq -c
I Sequentially read a lot of data.
I Map: extract something you care about.
I Group by key: sort and shuffle.
I Reduce: aggregate, summarize, filter or transform.
I Write the result.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 15 / 67
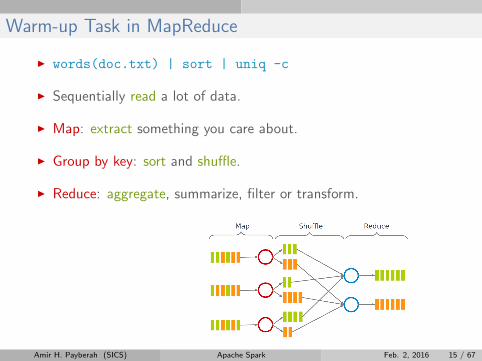
Warm-up Task in MapReduce
I words(doc.txt) | sort | uniq -c
I Sequentially read a lot of data.
I Map: extract something you care about.
I Group by key: sort and shuffle.
I Reduce: aggregate, summarize, filter or transform.
I Write the result.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 15 / 67
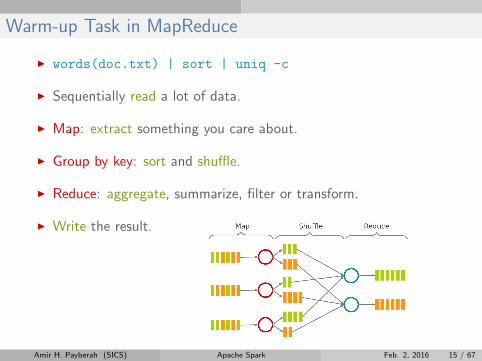
Warm-up Task in MapReduce
I words(doc.txt) | sort | uniq -c
I Sequentially read a lot of data.
I Map: extract something you care about.
I Group by key: sort and shuffle.
I Reduce: aggregate, summarize, filter or transform.
I Write the result.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 15 / 67
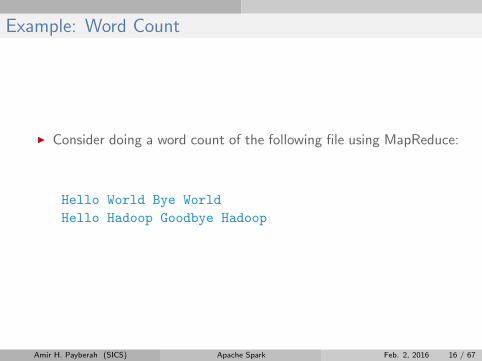
Example: Word Count
I Consider doing a word count of the following file using MapReduce:
Hello World Bye World
Hello Hadoop Goodbye Hadoop
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 16 / 67
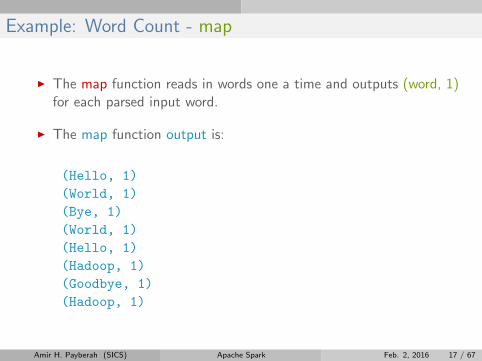
Example: Word Count - map
I The map function reads in words one a time and outputs (word, 1)for each parsed input word.
I The map function output is:
(Hello, 1)
(World, 1)
(Bye, 1)
(World, 1)
(Hello, 1)
(Hadoop, 1)
(Goodbye, 1)
(Hadoop, 1)
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 17 / 67
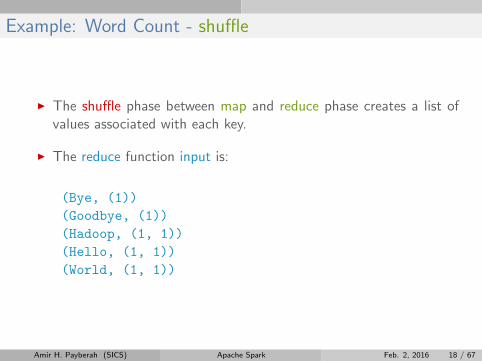
Example: Word Count - shuffle
I The shuffle phase between map and reduce phase creates a list ofvalues associated with each key.
I The reduce function input is:
(Bye, (1))
(Goodbye, (1))
(Hadoop, (1, 1))
(Hello, (1, 1))
(World, (1, 1))
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 18 / 67
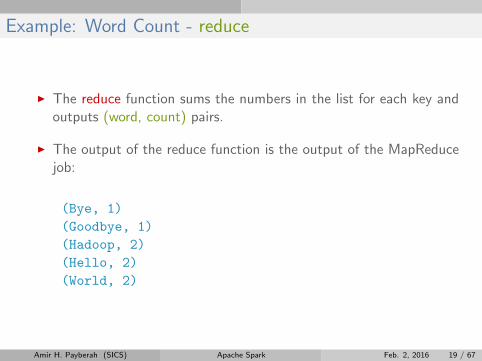
Example: Word Count - reduce
I The reduce function sums the numbers in the list for each key andoutputs (word, count) pairs.
I The output of the reduce function is the output of the MapReducejob:
(Bye, 1)
(Goodbye, 1)
(Hadoop, 2)
(Hello, 2)
(World, 2)
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 19 / 67
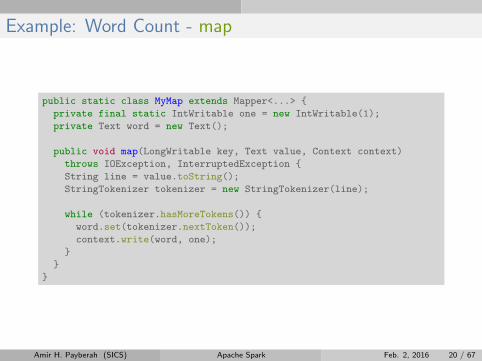
Example: Word Count - map
public static class MyMap extends Mapper<...> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 20 / 67
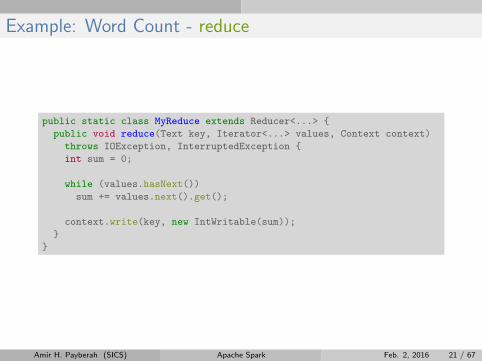
Example: Word Count - reduce
public static class MyReduce extends Reducer<...> {
public void reduce(Text key, Iterator<...> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
while (values.hasNext())
sum += values.next().get();
context.write(key, new IntWritable(sum));
}
}
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 21 / 67
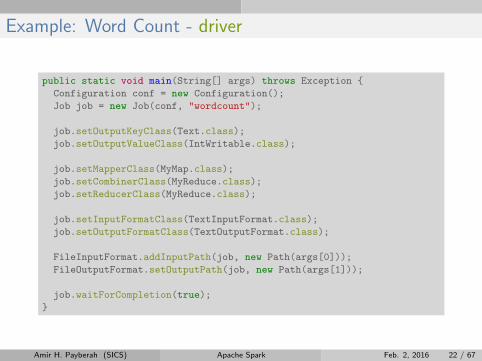
Example: Word Count - driver
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(MyMap.class);
job.setCombinerClass(MyReduce.class);
job.setReducerClass(MyReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 22 / 67
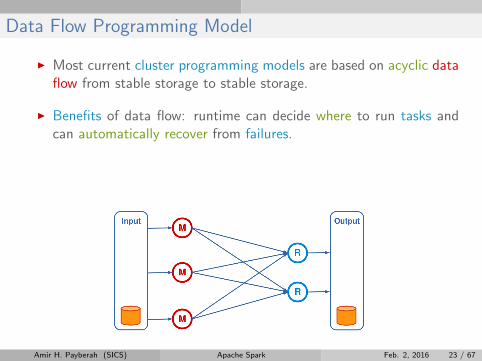
Data Flow Programming Model
I Most current cluster programming models are based on acyclic dataflow from stable storage to stable storage.
I Benefits of data flow: runtime can decide where to run tasks andcan automatically recover from failures.
I MapReduce greatly simplified big data analysis on large unreliableclusters.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 23 / 67
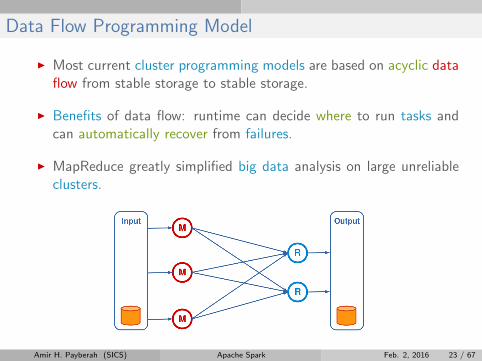
Data Flow Programming Model
I Most current cluster programming models are based on acyclic dataflow from stable storage to stable storage.
I Benefits of data flow: runtime can decide where to run tasks andcan automatically recover from failures.
I MapReduce greatly simplified big data analysis on large unreliableclusters.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 23 / 67
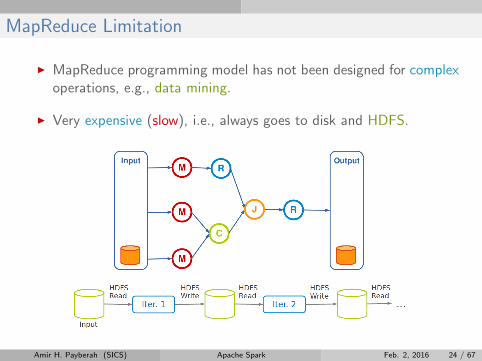
MapReduce Limitation
I MapReduce programming model has not been designed for complexoperations, e.g., data mining.
I Very expensive (slow), i.e., always goes to disk and HDFS.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 24 / 67
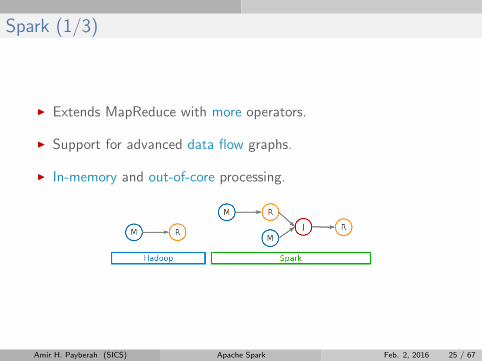
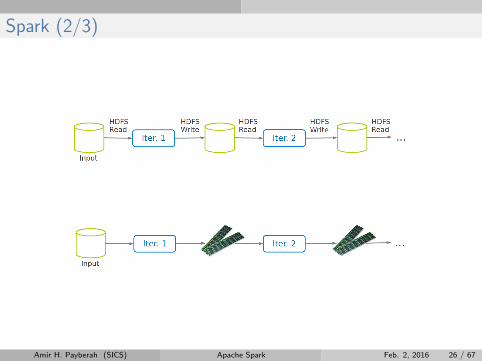
Spark (1/3)
I Extends MapReduce with more operators.
I Support for advanced data flow graphs.
I In-memory and out-of-core processing.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 25 / 67
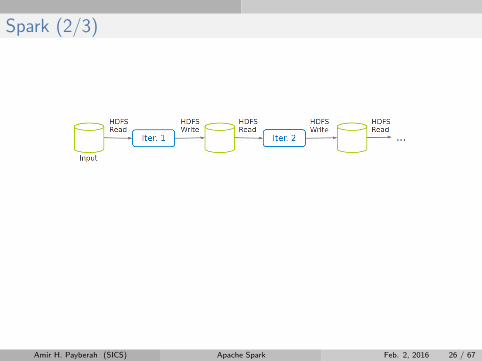
Spark (2/3)
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 26 / 67
Spark (2/3)
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 26 / 67
Spark (3/3)
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 27 / 67
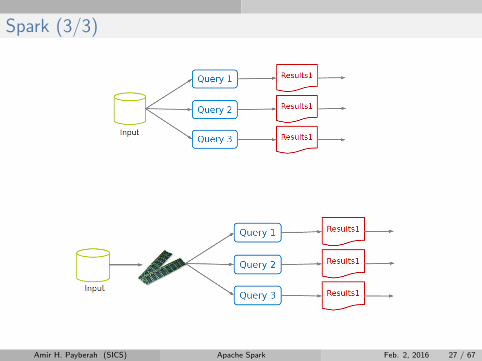
Spark (3/3)
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 27 / 67

Resilient Distributed Datasets (RDD) (1/2)
I A distributed memory abstraction.
I Immutable collections of objects spread across a cluster.• Like a LinkedList <MyObjects>
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 28 / 67

Resilient Distributed Datasets (RDD) (2/2)
I An RDD is divided into a number of partitions, which are atomicpieces of information.
I Partitions of an RDD can be stored on different nodes of a cluster.
I Built through coarse grained transformations, e.g., map, filter,join.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 29 / 67

Resilient Distributed Datasets (RDD) (2/2)
I An RDD is divided into a number of partitions, which are atomicpieces of information.
I Partitions of an RDD can be stored on different nodes of a cluster.
I Built through coarse grained transformations, e.g., map, filter,join.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 29 / 67
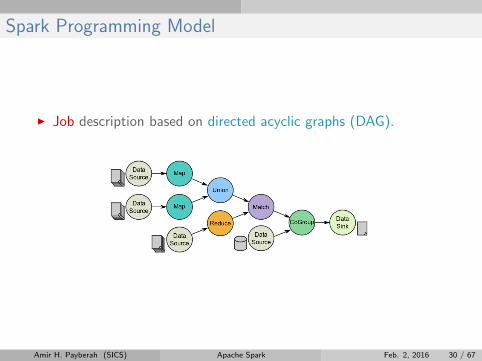
Spark Programming Model
I Job description based on directed acyclic graphs (DAG).
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 30 / 67
Creating RDDs
I Turn a collection into an RDD.
val a = sc.parallelize(Array(1, 2, 3))
I Load text file from local FS, HDFS, or S3.
val a = sc.textFile("file.txt")
val b = sc.textFile("directory/*.txt")
val c = sc.textFile("hdfs://namenode:9000/path/file")
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 31 / 67
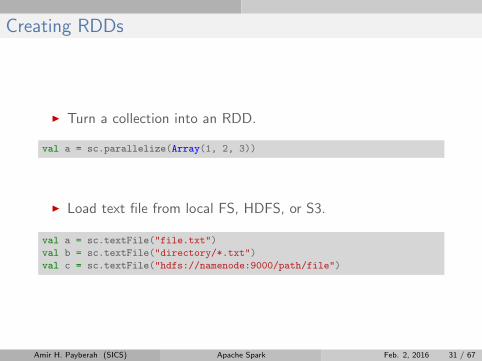
Creating RDDs
I Turn a collection into an RDD.
val a = sc.parallelize(Array(1, 2, 3))
I Load text file from local FS, HDFS, or S3.
val a = sc.textFile("file.txt")
val b = sc.textFile("directory/*.txt")
val c = sc.textFile("hdfs://namenode:9000/path/file")
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 31 / 67

RDD Higher-Order Functions
I Higher-order functions: RDDs operators.
I There are two types of RDD operators: transformations and actions.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 32 / 67
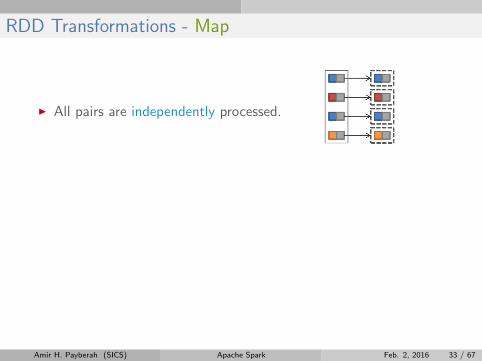
RDD Transformations - Map
I All pairs are independently processed.
// passing each element through a function.
val nums = sc.parallelize(Array(1, 2, 3))
val squares = nums.map(x => x * x) // {1, 4, 9}
// selecting those elements that func returns true.
val even = squares.filter(x => x % 2 == 0) // {4}
// mapping each element to zero or more others.
nums.flatMap(x => Range(0, x, 1)) // {0, 0, 1, 0, 1, 2}
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 33 / 67

RDD Transformations - Map
I All pairs are independently processed.
// passing each element through a function.
val nums = sc.parallelize(Array(1, 2, 3))
val squares = nums.map(x => x * x) // {1, 4, 9}
// selecting those elements that func returns true.
val even = squares.filter(x => x % 2 == 0) // {4}
// mapping each element to zero or more others.
nums.flatMap(x => Range(0, x, 1)) // {0, 0, 1, 0, 1, 2}
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 33 / 67
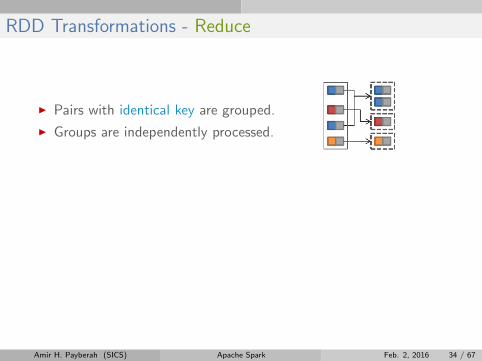
RDD Transformations - Reduce
I Pairs with identical key are grouped.
I Groups are independently processed.
val pets = sc.parallelize(Seq(("cat", 1), ("dog", 1), ("cat", 2)))
pets.reduceByKey((x, y) => x + y)
// {(cat, 3), (dog, 1)}
pets.groupByKey()
// {(cat, (1, 2)), (dog, (1))}
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 34 / 67
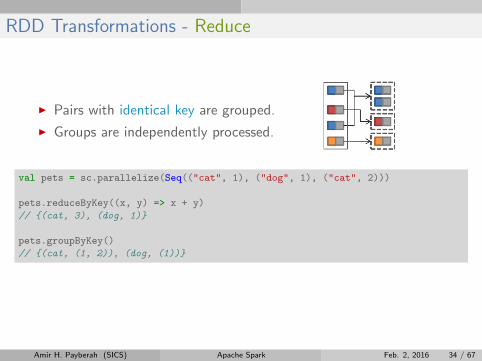
RDD Transformations - Reduce
I Pairs with identical key are grouped.
I Groups are independently processed.
val pets = sc.parallelize(Seq(("cat", 1), ("dog", 1), ("cat", 2)))
pets.reduceByKey((x, y) => x + y)
// {(cat, 3), (dog, 1)}
pets.groupByKey()
// {(cat, (1, 2)), (dog, (1))}
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 34 / 67
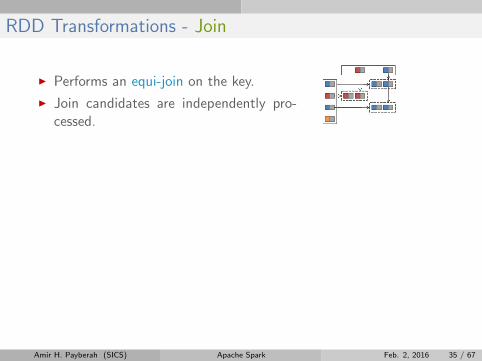
RDD Transformations - Join
I Performs an equi-join on the key.
I Join candidates are independently pro-cessed.
val visits = sc.parallelize(Seq(("index.html", "1.2.3.4"),
("about.html", "3.4.5.6"),
("index.html", "1.3.3.1")))
val pageNames = sc.parallelize(Seq(("index.html", "Home"),
("about.html", "About")))
visits.join(pageNames)
// ("index.html", ("1.2.3.4", "Home"))
// ("index.html", ("1.3.3.1", "Home"))
// ("about.html", ("3.4.5.6", "About"))
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 35 / 67
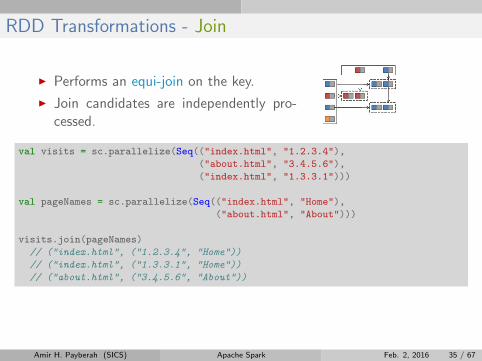
RDD Transformations - Join
I Performs an equi-join on the key.
I Join candidates are independently pro-cessed.
val visits = sc.parallelize(Seq(("index.html", "1.2.3.4"),
("about.html", "3.4.5.6"),
("index.html", "1.3.3.1")))
val pageNames = sc.parallelize(Seq(("index.html", "Home"),
("about.html", "About")))
visits.join(pageNames)
// ("index.html", ("1.2.3.4", "Home"))
// ("index.html", ("1.3.3.1", "Home"))
// ("about.html", ("3.4.5.6", "About"))
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 35 / 67
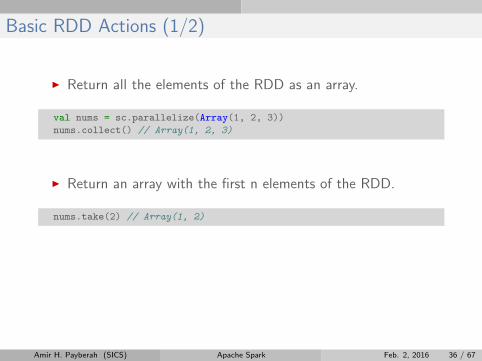
Basic RDD Actions (1/2)
I Return all the elements of the RDD as an array.
val nums = sc.parallelize(Array(1, 2, 3))
nums.collect() // Array(1, 2, 3)
I Return an array with the first n elements of the RDD.
nums.take(2) // Array(1, 2)
I Return the number of elements in the RDD.
nums.count() // 3
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 36 / 67
Basic RDD Actions (1/2)
I Return all the elements of the RDD as an array.
val nums = sc.parallelize(Array(1, 2, 3))
nums.collect() // Array(1, 2, 3)
I Return an array with the first n elements of the RDD.
nums.take(2) // Array(1, 2)
I Return the number of elements in the RDD.
nums.count() // 3
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 36 / 67

Basic RDD Actions (1/2)
I Return all the elements of the RDD as an array.
val nums = sc.parallelize(Array(1, 2, 3))
nums.collect() // Array(1, 2, 3)
I Return an array with the first n elements of the RDD.
nums.take(2) // Array(1, 2)
I Return the number of elements in the RDD.
nums.count() // 3
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 36 / 67
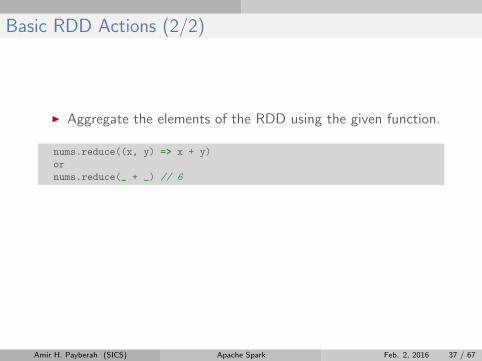
Basic RDD Actions (2/2)
I Aggregate the elements of the RDD using the given function.
nums.reduce((x, y) => x + y)
or
nums.reduce(_ + _) // 6
I Write the elements of the RDD as a text file.
nums.saveAsTextFile("hdfs://file.txt")
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 37 / 67

Basic RDD Actions (2/2)
I Aggregate the elements of the RDD using the given function.
nums.reduce((x, y) => x + y)
or
nums.reduce(_ + _) // 6
I Write the elements of the RDD as a text file.
nums.saveAsTextFile("hdfs://file.txt")
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 37 / 67

SparkContext
I Main entry point to Spark functionality.
I Available in shell as variable sc.
I In standalone programs, you should make your own.
val sc = new SparkContext(master, appName, [sparkHome], [jars])
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 38 / 67
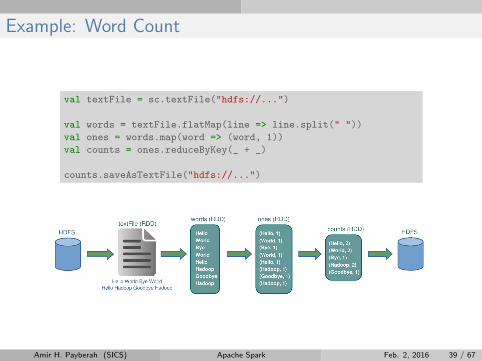
Example: Word Count
val textFile = sc.textFile("hdfs://...")
val words = textFile.flatMap(line => line.split(" "))
val ones = words.map(word => (word, 1))
val counts = ones.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 39 / 67
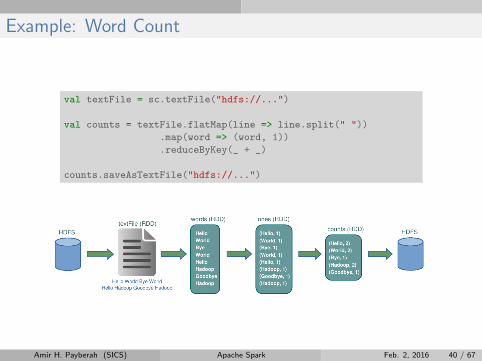
Example: Word Count
val textFile = sc.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 40 / 67
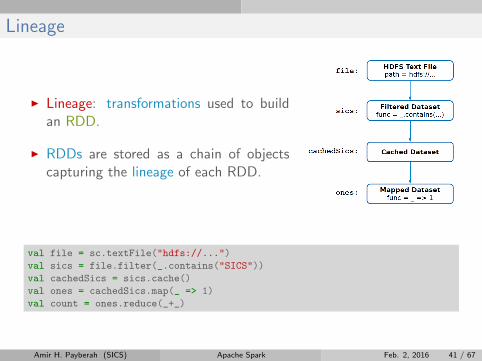
Lineage
I Lineage: transformations used to buildan RDD.
I RDDs are stored as a chain of objectscapturing the lineage of each RDD.
val file = sc.textFile("hdfs://...")
val sics = file.filter(_.contains("SICS"))
val cachedSics = sics.cache()
val ones = cachedSics.map(_ => 1)
val count = ones.reduce(_+_)
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 41 / 67
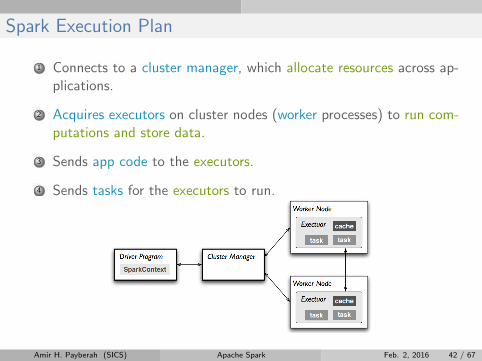
Spark Execution Plan
1 Connects to a cluster manager, which allocate resources across ap-plications.
2 Acquires executors on cluster nodes (worker processes) to run com-putations and store data.
3 Sends app code to the executors.
4 Sends tasks for the executors to run.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 42 / 67

Spark SQL
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 43 / 67

Spark SQL
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 44 / 67

DataFrame
I A DataFrame is a distributed collection of rows with a homogeneousschema.
I It is equivalent to a table in a relational database.
I It can also be manipulated in similar ways to RDDs.
I DataFrames are lazy.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 45 / 67
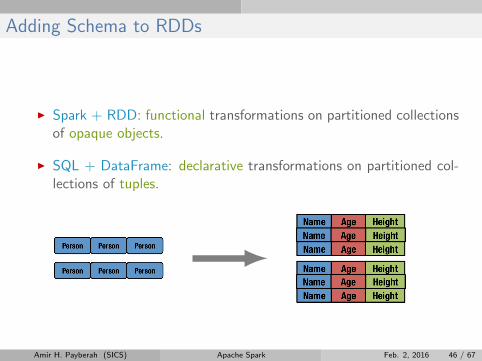
Adding Schema to RDDs
I Spark + RDD: functional transformations on partitioned collectionsof opaque objects.
I SQL + DataFrame: declarative transformations on partitioned col-lections of tuples.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 46 / 67
Creating DataFrames
I The entry point into all functionality in Spark SQL is theSQLContext.
val sc: SparkContext // An existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val df = sqlContext.read.json(...)
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 47 / 67
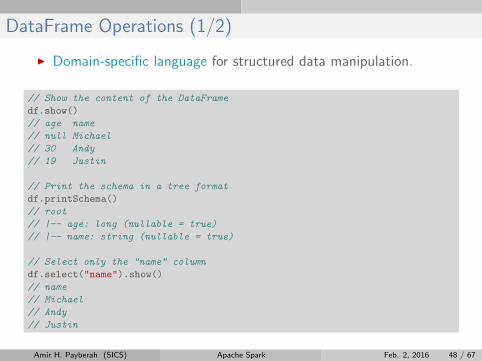
DataFrame Operations (1/2)
I Domain-specific language for structured data manipulation.
// Show the content of the DataFrame
df.show()
// age name
// null Michael
// 30 Andy
// 19 Justin
// Print the schema in a tree format
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Select only the "name" column
df.select("name").show()
// name
// Michael
// Andy
// Justin
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 48 / 67
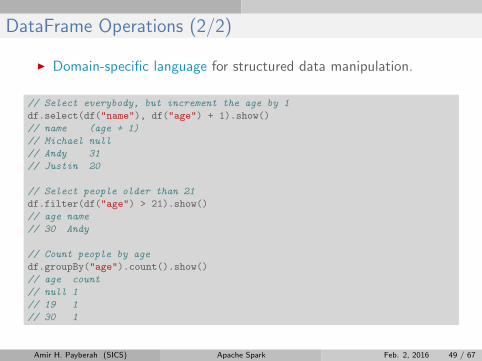
DataFrame Operations (2/2)
I Domain-specific language for structured data manipulation.
// Select everybody, but increment the age by 1
df.select(df("name"), df("age") + 1).show()
// name (age + 1)
// Michael null
// Andy 31
// Justin 20
// Select people older than 21
df.filter(df("age") > 21).show()
// age name
// 30 Andy
// Count people by age
df.groupBy("age").count().show()
// age count
// null 1
// 19 1
// 30 1
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 49 / 67
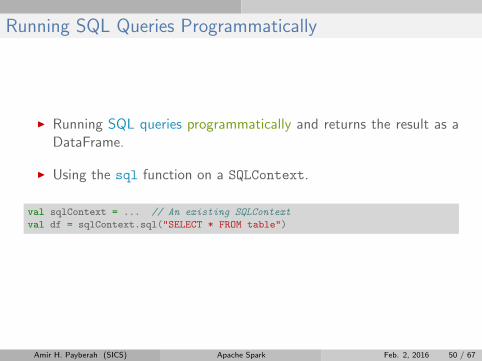
Running SQL Queries Programmatically
I Running SQL queries programmatically and returns the result as aDataFrame.
I Using the sql function on a SQLContext.
val sqlContext = ... // An existing SQLContext
val df = sqlContext.sql("SELECT * FROM table")
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 50 / 67
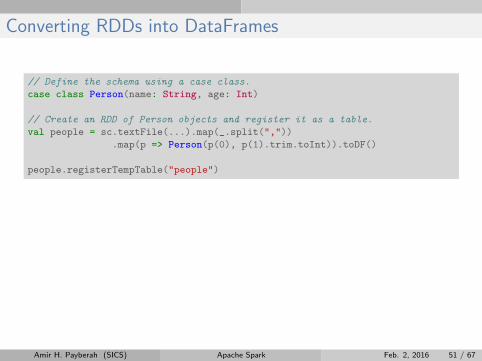
Converting RDDs into DataFrames
// Define the schema using a case class.
case class Person(name: String, age: Int)
// Create an RDD of Person objects and register it as a table.
val people = sc.textFile(...).map(_.split(","))
.map(p => Person(p(0), p(1).trim.toInt)).toDF()
people.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.
val teenagers = sqlContext
.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
// The results of SQL queries are DataFrames.
teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
teenagers.map(t => "Name: " + t.getAs[String]("name")).collect()
.foreach(println)
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 51 / 67
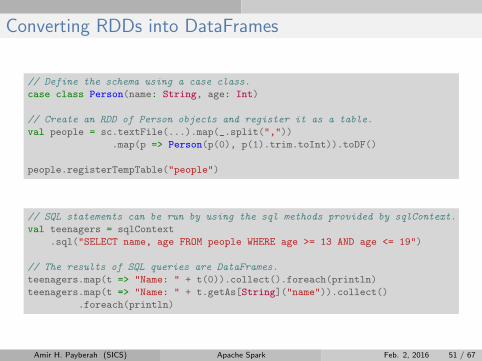
Converting RDDs into DataFrames
// Define the schema using a case class.
case class Person(name: String, age: Int)
// Create an RDD of Person objects and register it as a table.
val people = sc.textFile(...).map(_.split(","))
.map(p => Person(p(0), p(1).trim.toInt)).toDF()
people.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.
val teenagers = sqlContext
.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
// The results of SQL queries are DataFrames.
teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
teenagers.map(t => "Name: " + t.getAs[String]("name")).collect()
.foreach(println)
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 51 / 67

Spark Streaming
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 52 / 67
Data Streaming
I Many applications must process large streams of live data and pro-vide results in real-time.
• Wireless sensor networks
• Traffic management applications
• Stock marketing
• Environmental monitoring applications
• Fraud detection tools
• ...
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 53 / 67
Stream Processing Systems
I Stream Processing Systems (SPS): data-in-motion analytics• Processing information as it flows, without storing them persistently.
I Database Management Systems (DBMS): data-at-rest analytics• Store and index data before processing it.• Process data only when explicitly asked by the users.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 54 / 67
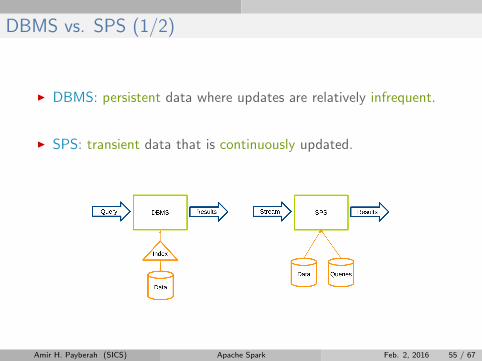
DBMS vs. SPS (1/2)
I DBMS: persistent data where updates are relatively infrequent.
I SPS: transient data that is continuously updated.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 55 / 67
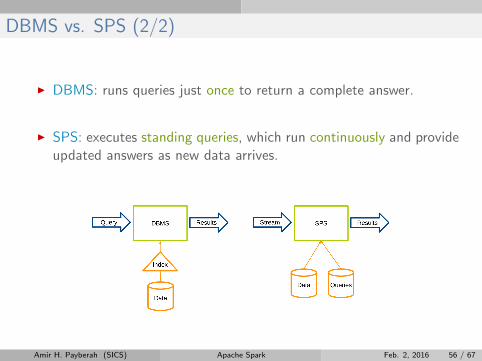
DBMS vs. SPS (2/2)
I DBMS: runs queries just once to return a complete answer.
I SPS: executes standing queries, which run continuously and provideupdated answers as new data arrives.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 56 / 67
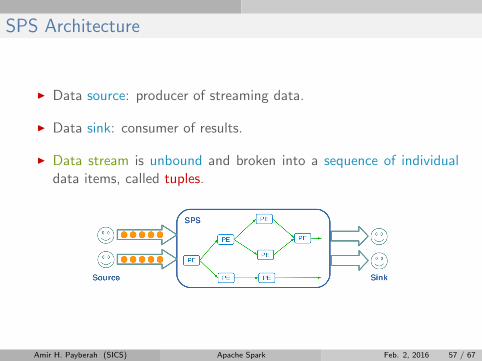
SPS Architecture
I Data source: producer of streaming data.
I Data sink: consumer of results.
I Data stream is unbound and broken into a sequence of individualdata items, called tuples.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 57 / 67

Spark Streaming
I Run a streaming computation as a series of very small, deterministicbatch jobs.
• Chop up the live stream into batches of X seconds.
• Treats each batch of data as RDDs and processes them using RDDoperations.
• Finally, the processed results of the RDD operations are returned inbatches.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 58 / 67
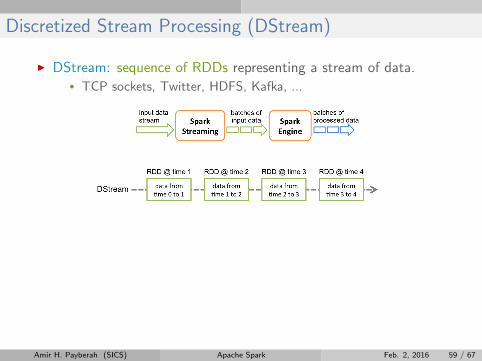
Discretized Stream Processing (DStream)
I DStream: sequence of RDDs representing a stream of data.• TCP sockets, Twitter, HDFS, Kafka, ...
I Initializing Spark streaming
val scc = new StreamingContext(master, appName, batchDuration,
[sparkHome], [jars])
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 59 / 67

Discretized Stream Processing (DStream)
I DStream: sequence of RDDs representing a stream of data.• TCP sockets, Twitter, HDFS, Kafka, ...
I Initializing Spark streaming
val scc = new StreamingContext(master, appName, batchDuration,
[sparkHome], [jars])
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 59 / 67

DStream API
I Transformations: modify data from on DStream to a new DStream.• Standard RDD operations: map, join, ...
• Window operations: group all the records from a sliding window of thepast time intervals into one RDD: window, reduceByAndWindow, ...
Window length: the duration of the window.Slide interval: the interval at which the operation is performed.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 60 / 67

DStream API
I Transformations: modify data from on DStream to a new DStream.• Standard RDD operations: map, join, ...
• Window operations: group all the records from a sliding window of thepast time intervals into one RDD: window, reduceByAndWindow, ...
Window length: the duration of the window.Slide interval: the interval at which the operation is performed.
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 60 / 67
Example 1 (1/3)
I Get hash-tags from Twitter.
val ssc = new StreamingContext("local[2]", "test", Seconds(1))
val tweets = ssc.twitterStream(<username>, <password>)
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 61 / 67
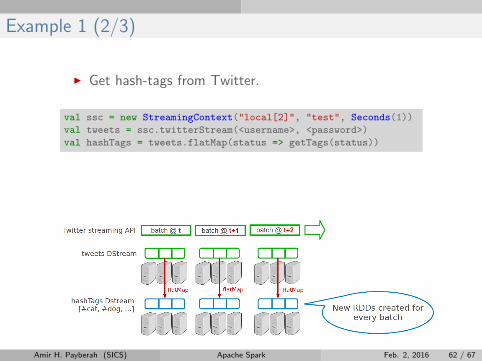
Example 1 (2/3)
I Get hash-tags from Twitter.
val ssc = new StreamingContext("local[2]", "test", Seconds(1))
val tweets = ssc.twitterStream(<username>, <password>)
val hashTags = tweets.flatMap(status => getTags(status))
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 62 / 67
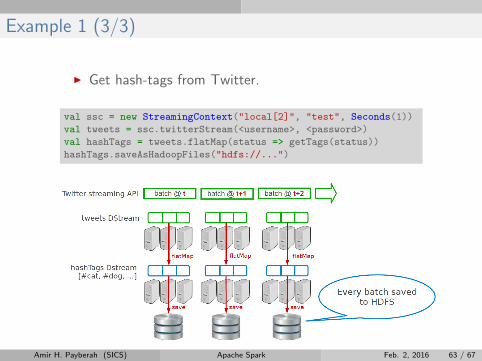
Example 1 (3/3)
I Get hash-tags from Twitter.
val ssc = new StreamingContext("local[2]", "test", Seconds(1))
val tweets = ssc.twitterStream(<username>, <password>)
val hashTags = tweets.flatMap(status => getTags(status))
hashTags.saveAsHadoopFiles("hdfs://...")
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 63 / 67
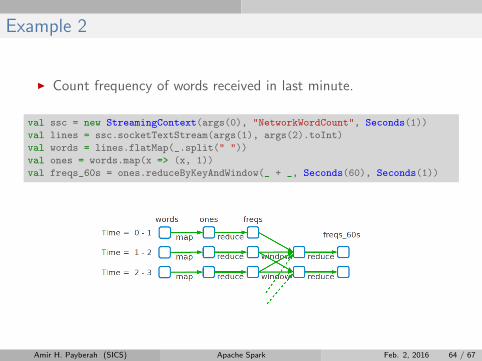
Example 2
I Count frequency of words received in last minute.
val ssc = new StreamingContext(args(0), "NetworkWordCount", Seconds(1))
val lines = ssc.socketTextStream(args(1), args(2).toInt)
val words = lines.flatMap(_.split(" "))
val ones = words.map(x => (x, 1))
val freqs_60s = ones.reduceByKeyAndWindow(_ + _, Seconds(60), Seconds(1))
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 64 / 67

Summary
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 65 / 67

Summary
I How to store and process big data? scale up vs. scalue out
I Cluster programming model: dataflow
I Spark: RDD (transformations and actions)
I Spark SQL: DataFrame (RDD + schema)
I Spark Streaming: DStream (sequence of RDDs)
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 66 / 67

Questions?
Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 67 / 67
Top Related