
WYDZIAŁ ELEKTROTECHNIKI, AUTOMATYKI, INFORMATYKI I ...home.agh.edu.pl/~horzyk/pracedyplom/2017...
57
WYDZIAŁ ELEKTROTECHNIKI, AUTOMATYKI, INFORMATYKI I INŻYNIERII BIOMEDYCZNEJ KATEDRA AUTOMATYKI I INŻYNIERII BIOMEDYCZNEJ Praca dyplomowa magisterska Sztuczny system skojarzeniowy zastosowany do semi-automatycznej kontekstowej korekty tekstów napisanych w języku polskim. Artificial associative system used to semi -automatic contextual text correction for Polish language Autor: Mateusz Kaproń Kierunek studiów: Automatyka i robotyka Opiekun pracy: dr hab. Adrian Horzyk Kraków, 2017
Transcript of WYDZIAŁ ELEKTROTECHNIKI, AUTOMATYKI, INFORMATYKI I ...home.agh.edu.pl/~horzyk/pracedyplom/2017...

WYDZIAŁ ELEKTROTECHNIKI, AUTOMATYKI, INFORMATYKI I INŻYNIERII
BIOMEDYCZNEJ
KATEDRA AUTOMATYKI I INŻYNIERII BIOMEDYCZNEJ
Praca dyplomowa magisterska
Sztuczny system skojarzeniowy zastosowany
do semi-automatycznej kontekstowej korekty tekstów
napisanych w języku polskim.
Artificial associative system used to semi-automatic contextual text
correction for Polish language
Autor: Mateusz Kaproń
Kierunek studiów: Automatyka i robotyka
Opiekun pracy: dr hab. Adrian Horzyk
Kraków, 2017

Uprzedzony o odpowiedzialności karnej na podstawie art. 115 ust. 1 i 2 ustawy z
dnia 4 lutego 1994 r. o prawie autorskim i prawach pokrewnych (t.j. Dz.U. z
2006 r. Nr 90, poz. 631 z późn. zm.): „ Kto przywłaszcza sobie autorstwo albo
wprowadza w błąd co do autorstwa całości lub części cudzego utworu albo
artystycznego wykonania, podlega grzywnie, karze ograniczenia wolności albo
pozbawienia wolności do lat 3. Tej samej karze podlega, kto rozpowszechnia bez
podania nazwiska lub pseudonimu twórcy cudzy utwór w wersji oryginalnej albo
w postaci opracowania, artystyczne wykonanie albo publicznie zniekształca taki
utwór, artystyczne wykonanie, fonogram, wideogram lub nadanie.”, a także
uprzedzony o odpowiedzialności dyscyplinarnej na podstawie art. 211 ust. 1
ustawy z dnia 27 lipca 2005 r. Prawo o szkolnictwie wyższym (t.j. Dz. U. z 2012
r. poz. 572, z późn. zm.) „Za naruszenie przepisów obowiązujących w uczelni
oraz za czyny uchybiające godności studenta student ponosi odpowiedzialność
dyscyplinarną przed komisją dyscyplinarną albo przed sądem koleżeńskim
samorządu studenckiego, zwanym dalej „sądem koleżeńskim”, oświadczam, że
niniejszą pracę dyplomową wykonałem(-am) osobiście i samodzielnie i że nie
korzystałem(-am) ze źródeł innych niż wymienione w pracy.
…………………………………..

3
Spis treści
1. Wstęp .................................................................................................................................................. 5
2. Sieci neuronowe ................................................................................................................................. 7
2.1. Historia sieci neuronowych. ......................................................................................................... 7
2.2. Budowa neuronu. ......................................................................................................................... 8
2.3. Rodzaje sieci neuronowych. ....................................................................................................... 10
2.4. Zastosowania .............................................................................................................................. 10
3. Metody korygowania tekstu ........................................................................................................... 13
3.1. Odległość Levenshteina ............................................................................................................. 13
3.1.1. Reprezentacja tablicowa odległości edycyjnej .................................................................... 14
3.1.2. Odległość Damerau-Levenstheina ...................................................................................... 16
3.2. Odległość Jaro ............................................................................................................................ 16
3.3. N-gram ....................................................................................................................................... 16
3.4. Prawo Zipfa ................................................................................................................................ 17
4. Aktywne asocjacyjne grafy wiedzy ................................................................................................ 21
5. Kontekstowy korektor tekstu bazujący na ANAKG .................................................................... 25
5.1. Budowa i możliwości ................................................................................................................. 25
5.2. Działanie aplikacji ...................................................................................................................... 27
5.3. Dane wejściowe - korpusy tekstu ............................................................................................... 29
6. Porównanie stworzonego korektora z wybranymi narzędziami służącymi do korygowania
tekstu dla języka polskiego ................................................................................................................. 31
6.1. Korektory wykorzystywane przez wyszukiwarki internetowe ................................................... 32
6.1.1. Wyszukiwarka Google ........................................................................................................ 33
6.1.2. Wyszukiwarka Bing ............................................................................................................ 34
6.1.3. Wyszukiwarka Ask ............................................................................................................. 36
6.1.4. Wyszukiwarka Yandex ....................................................................................................... 37
6.1.5. Wyszukiwarka Nekst ........................................................................................................... 38
6.2. Korektory wykorzystywane przez edytory tekstu ...................................................................... 39
6.2.1. Edytor tekstu Microsoft Word ............................................................................................. 39
6.2.2. Edytor tekstu Apache OpenOffice ...................................................................................... 41
6.3. Korektory online ........................................................................................................................ 43
6.3.1. LanguageTool...................................................................................................................... 43
6.3.2. iKorektor ............................................................................................................................. 45

4
6.4. Własny korektor tekstu ............................................................................................................... 46
6.5 Podsumowanie testu korektorów ................................................................................................. 47
7. Podsumowanie ................................................................................................................................. 49
Literatura ............................................................................................................................................. 51
Spis rysunków ...................................................................................................................................... 53
Spis tabel .............................................................................................................................................. 55
Spis załączników .................................................................................................................................. 57

5
1. Wstęp
Narzędzia służące do analizy i korekty tekstu używane są codziennie przez miliony
użytkowników. Jedne poprawiają jedynie najprostsze błędy, inne przystosowane są do bardzo
zaawansowanej korekty, analizując nie tylko poszczególne słowa, ale i całe zdania.
Celem tej pracy jest napisanie aplikacji webowej z zaimplementowanym sztucznym
systemem skojarzeniowym zastosowanym do semi-automatycznej korekty tekstów
napisanych w języku polskim. System ten ma opierać się na Aktywnych Asocjacyjnych
Neuronowych Grafach Wiedzy (ANAKG). Zadaniem powstałej aplikacji jest wykrycie
różnych błędów w zdaniach napisanych w języku polskim oraz zaproponowanie korekty
błędnych wyrazów. Aplikacja ma za zadanie poprawiać nie tylko proste błędy gramatyczne,
lecz również rozpoznawać niewłaściwe użycie słowa w danym kontekście.
W rozdziale drugim skrótowo przedstawiono historię sieci neuronowych i ich
zastosowanie.
Rozdział trzeci zawiera opis kilku znanych metod służących do analizy i korekcji
tekstu. Opisano w nim m.in. odległość Levenshteina oraz metodę N-gramu.
W kolejnym rozdziale został szczegółowo omówiony Aktywny Asocjacyjny
Neuronowy Graf Wiedzy ANAKG, na którym opiera się stworzona aplikacja.
Rozdział piąty krótko opisuje budowę aplikacji webowej, która umożliwia korektę
wprowadzanego tekstu. Przedstawione są jej funkcje, możliwości oraz algorytm korektora
tekstu. Dalsza część rozdziału skupia się na danych wejściowych, na podstawie których został
zbudowany graf ANAKG.
Rozdział szósty zawiera testy najpopularniejszych dostępnych narzędzi służących do
korygowania tekstu oraz testy przeprowadzone dla stworzonej aplikacji. Celem testów jest
porównanie istniejących narzędzi ze stworzonym korektorem.
Pracę wieńczy podsumowanie, wykaz literatury, spis tabel, spis rysunków oraz spis
załączników.

6

7
2. Sieci neuronowe
Dzięki niezwykłym własnościom takim jak zdolność uczenia się, równoległe
przetwarzanie informacji czy też zdolność do adaptacji i samoorganizacji sieci neuronowe
przez ostatnie dziesięciolecia stały się niezwykle popularne w środowisku naukowym.
Każda sieć neuronowa jest uproszczonym modelem ludzkiego mózgu, który składa się
on z 1010 komórek nerwowych oraz z 1015 połączeń pomiędzy nimi [6]. Przetwarzają one
impulsy o częstotliwości 1-100 Hz. Oszacowana prędkość pracy mózgu wynosi więc około
1018 operacji na sekundę. Sieć neuronowa składa się z elementów, których zadaniem jest
przetwarzanie informacji. Zwane są one neuronami.
2.1. Historia sieci neuronowych.
W roku 1943 Warren McCulloch i Walter Pitts jako pierwsi przedstawili
matematyczny model komórki nerwowej [15]. Wskazali również na możliwość przetwarzania
danych przy wykorzystaniu zaproponowanego przez nich modelu. Moment ten często
uznawany jest za początek intensywnych badań nad sieciami neuronowymi.
Pierwsza szeroko znana działająca sieć neuronowa zwana perceptronem, została
stworzona przez Franka Rosenblatta oraz Charlesa Wightmana w 1957 r. [15]. Był to układ
elektromechaniczno-elektroniczny, którego zadaniem było rozpoznawanie znaków
alfanumerycznych. Tradycyjna metoda programowania została zastąpiona procesem uczenia.
Sieć neuronowa składała się z 8 komórek nerwowych oraz 512 połączeń. Działanie układu nie
było jednak zadowalające, nie potrafił on rozpoznawać złożonych znaków oraz nie radził
sobie z rozpoznaniem po operacji przesunięcia bądź obrotu znaku.
Rys. 2.1. Schemat perceptronu jednowarstwowego
Źródło: Opracowanie własne na podstawie [6]

8
Rozwój badań nad sieciami neuronowymi gwałtownie zahamował w roku 1969 za
sprawą książki „Perceptrons: an introduction to computational geometry” autorstwa Marvina
Minsky'ego i Seymoura Paperta [15]. Udowodnili oni, że zastosowanie jednowarstwowych
sieci neuronowych jest bardzo ograniczone. Dopiero w połowie lat 80-tych udowodniono, że
wielowarstwowe, nieliniowe sieci neuronowe nie posiadają ograniczeń przedstawionych
przez Minsky'ego i Paperta. Odkrycie to przyczyniło się do ponownego wzrostu
zainteresowania sieciami neuronowymi. Druga połowa lat 80-tych uznawana jest za bardzo
intensywny okres prac nad neurokomputerami.
Tabela 2.1. Rozwój neurokomputerów w drugiej połowie lat 80
Nazwa
neurokomputera
Rok
opracowania
Liczba
elementów
Liczba
połączeń
Szybkość (ilość
przełączeń na
sekundę)
Twórca
Mark III 1985 8 ∗ 103 4 ∗ 105 3 ∗ 105 R. Hercht-Nielsen,
TRW
Neural emulator
Processor
1985 4 ∗ 103 1,6 ∗ 104 4,9 ∗ 105 C. Cruz,
IBM
Mark IV 1986 2,5 ∗ 105 5 ∗ 106 5 ∗ 106 R. Hercht-Nielsen,
TRW
Odyssey 1986 8 ∗ 103 2,5 ∗ 105 2 ∗ 106 A. Penz,
Tex. Inst. CRL
Crossbar chip 1986 256 6,4 ∗ 104 6 ∗ 109 L. JAckel,
AT&T Bell L.
Anza 1987 3 ∗ 104 5 ∗ 105 1,4 ∗ 105 R. Hercht-Nielsen,
Neurocomp. Corp.
Parallon 1987 9,1 ∗ 104 3 ∗ 105 3 ∗ 104 S. Bogoch,
Human Dev.
Anza plus 1988 106 1,5 ∗ 106 6 ∗ 106 R. Hercht-Nielsen,
Neurocomp. Corp.
Źródło: [15]
2.2. Budowa neuronu
Podstawowym elementem każdej sieci neuronowej jest neuron. Poniżej zostały
przedstawione grafiki, dzięki którym można porównać budowę prawdziwego neuronu z jego
sztucznym odpowiednikiem przedstawionym w postaci ogólnego modelu oraz z neuronem
zrealizowanym sprzętowo.

9
Rys. 2.2. Schemat budowy prawdziwego neuronu
Źródło: [6]
Rys. 2.3. Schemat budowy sztucznego neuronu
Źródło: [6]
Rys. 2.4. Schemat budowy układu elektronicznego symulującego neuron
Źródło: [9]

10
2.3. Rodzaje sieci neuronowych
Sieci neuronowe można konstruować na wiele różnych sposobów. Główną różnicą
między różnymi typami sieci jest sposób połączenia poszczególnych neuronów. W pracy [6]
dokonano następującego podziału sieci neuronowych:
sieci jednokierunkowe:
jednowarstwowe,
wielowarstwowe,
sieci rekurencyjne,
sieci komórkowe.
Sieć jednokierunkowa – najczęściej spotykany typ sieci neuronowych. Sieci te składają się
z jednej lub więcej warstw, a przepływ informacji odbywa się w jednym od wejścia do
wyjścia przez wszystkie warstwy sieci.
Sieć rekurencyjna – wykorzystuje pętle sprzężenia zwrotnego, a więc sygnał wyjściowy sieci
zależy od aktualnego sygnału wejściowego, oraz od poprzednich sygnałów wejściowych
przetworzonych przez sieć.
Sieć komórkowa – sieć, w której sprzężenia wzajemne pomiędzy neuronami dotyczą tylko
najbliższego sąsiedztwa. Przykładem sieci komórkowej jest sieć Kohonena.
2.4. Zastosowania
Sieci neuronowe mają bardzo szerokie zastosowania, m.in. takie jak:
rozpoznawanie i klasyfikacja wzorców,
regresja i aproksymacja,
prognozy giełdowe,
prognozy cen,
analiza spektralna,
diagnostyka układów elektronicznych,
dobór pracowników,
optymalizacja utylizacji odpadów,
prognozowanie sprzedaży,

11
W pracy [15] określono najważniejsze kierunki zastosowań sieci neuronowych:
predykcja,
klasyfikacja i rozpoznawanie podmiotów gospodarczych,
kojarzenie danych,
analiza danych,
filtracja sygnałów,
optymalizacja.
Jednym z przykładów zastosowania sieci neuronowych jest praca [4], w której autor pokazuje
możliwości ich zastosowania w ekonomii. Wykorzystuje je jako narzędzie do generowania
sygnałów kupna/sprzedaży na Giełdzie Papierów Wartościowych.

12

13
3. Metody korygowania tekstu
Przez ostatnie dziesięciolecia ludzie próbowali stworzyć algorytmy, które będą
w stanie analizować wprowadzany tekst i proponować jego korektę, jeżeli wykryją
nieprawidłowości. Prawidłowa korekta tekstu jest tematem bardzo istotnym w dzisiejszym
świecie. Narzędzia stworzone do analizy tekstu często są niezbędne przy pracy wielu
użytkowników każdego dnia.
Algorytmów do analizy tekstu powstała ogromna ilość. W rozdziale zostały
przedstawione najpopularniejsze metody korekty tekstu.
3.1. Odległość Levenshteina
Jedną z najbardziej popularnych metod służących do analizy i korekty tekstu jest
metoda odległości Levenshteina [12]. Jest to uogólniona metoda odległości Hamminga.
Została przedstawiona w 1966 r. przez rosyjskiego naukowca Vladimira Iosifovicha
Levenshteina. Metoda ta zdobyła ogromną popularność dzięki swej prostocie oraz dużej
skuteczności.
Odległość Levenshteina (znana również pod nazwą odległości edycyjnej) służy do
wyznaczenia odległości pomiędzy dwoma skończonymi ciągami znaków z dowolnego
alfabetu. Metoda ta jest wykorzystywana między innymi w systemach antyplagiatowych.
Odległość Levenshteina została zdefiniowana, jako miara odmienności dwóch tekstów.
Z punktu formalnego jest to metryka, dla której zostały zdefiniowanie następujące działania
proste:
zamiana znaku na inny znak,
usunięcie znaku,
dodanie znaku.
Obliczenie odległości Levenshteina polega na obliczeniu ilości wyżej wymienionych działań
prostych potrzebnych, aby przekształcić jeden ciąg znaków w drugi. Przy obliczaniu
odległości każde działanie posiada taką samą wagę.

14
Matematyczną reprezentacje odległości Levenshteina opisuje wzór:
𝑑(𝑎,𝑏)(𝑖, 𝑗) =
{
max(𝑖, 𝑗) 𝑑𝑙𝑎 min(𝑖, 𝑗) = 0
𝑚𝑖𝑛 {
𝑑(𝑎,𝑏)(𝑖 − 1, 𝑗) + 1
𝑑(𝑎,𝑏)(𝑖, 𝑗 − 1) + 1
𝑑(𝑎,𝑏)(𝑖 − 1, 𝑗 − 1) + 1(𝑎𝑖≠𝑏𝑗)
𝑑𝑙𝑎 min(𝑖, 𝑗) ≠ 0 (3.1)
gdzie:
1(𝑎𝑖≠𝑏𝑗) = 0 jeśli 𝑎𝑖 = 𝑏𝑗, w przeciwnym wypadku równy 1,
𝑑(𝑎,𝑏)(𝑖, 𝑗) - odległość pomiędzy i-tym znakiem ciągu a i j-tym znakiem ciągu b.
Tabela 3.1. Odległość Levenshteina dla przykładowych ciągów znaków
Lp. Ciąg znaków nr.1 Ciąg znaków nr.2 Odległość Levenshteina
1 XYZ XYZZ 1
2 pies pies 0
3 dom łom 1
4 interesujący interesować 5
Odległość Levnstheina nie jest algorytmem idealnym dla języka polskiego. Przykładowo, jeśli
w słowie użytkownik popełnił błąd ortograficzny i zamiast „ż” użył „rz” to odległość
edycyjna będzie wynosiła 2 a nie 1. Może to skutkować tym, że algorytm zamiast
zaproponować poprawną korektę, zaproponuje całkiem inne słowo, które będzie posiadało
literę „ż” a jego odległość edycyjna będzie wynosiła 1.
3.1.1. Reprezentacja tablicowa odległości edycyjnej
Odległość Levenshteina można zobrazować w łatwy sposób za pomocą reprezentacji
tablicowej [14]. Polega ona na stworzeniu tablicy dwuwymiarowej o wymiarach n+1 oraz
m+1, gdzie n i m oznaczają długości badanych ciągów znaków.
Budowanie tablicy należy zacząć od wpisania liczb w pierwszy wiersz (liczby od 0
do n) oraz wpisania liczb w pierwszą kolumnę (liczby od 0 do m). Kolejnym krokiem jest
porównanie kolejno znaków z pierwszego wiersza, z wartością znajdująca się w pierwszej
kolumnie. Znaki porównujemy w ten sposób, że jeśli są identyczne, to wartość kosztu wynosi

15
0, jeśli natomiast znaki są różne, wartość kosztu wynosi 1. Wartość, jaką należy wpisać do
pustej komórki wyznaczamy szukając wartość minimalną spośród trzech wartości:
wartość komórki znajdującej się powyżej zwiększona o 1,
wartość komórki znajdującej się na lewo zwiększona o 1,
wartość komórki stykającej się z lewym górnym rogiem.
Następnie należy porównać znaki dla wszystkich kolumn i wierszy tak, aby każdy znak
z ciągu pierwszego został porównany z każdym znakiem ciągu drugiego. Liczba, która
znajdzie się w dolnym prawym rogu oznacza wartość odległości Levenshteina.
Tabela 3.2. Pierwszy etap konstrukcji tablicy
d o m
0 1 2 3
ł 1
o 2
m 3
Tabela 3.3. Drugi etap konstrukcji tablicy i wyznaczenie odległości edycyjnej
d o m
0 1 2 3
ł 1 1 2 3
o 2 2 1 2
m 3 3 2 1

16
3.1.2. Odległość Damerau-Levenstheina
W roku 1964r. Frederick J. Damerau opublikował pracę [2], w której przedstawił
metodą bardzo podobną do metody odległości Levenshteina. Jedyną różnica jest dodanie
nowego działania prostego. Damarau przyjął za działanie proste zamianę miejscami dwóch
sąsiednich znaków. Z jego badań wynika, że 80% błędów można naprawić za pomocą
zaproponowanych przez niego czterech działań prostych.
3.2. Odległość Jaro
Kolejną metodą służącą do korekty tekstu jest metoda odległości Jaro [1]. Podobnie
jak metoda odległości Levenstheina, służy ona do wyznaczenia odległości pomiędzy dwoma
skończonymi ciągami znaków z dowolnego alfabetu.
Odległość Jaro można wyznaczyć korzystając ze wzoru:
𝑑𝑗 = {0 𝑑𝑙𝑎 𝑚 = 0
1
3(𝑚
|𝑠1|+
𝑚
|𝑠2|+𝑚−𝑡
𝑚) 𝑑𝑙𝑎 𝑚 ≠ 0 (3.2)
gdzie:
𝑠1 oraz 𝑠2 oznaczają dwa ciągi znaków,
m oznacza ilość identycznych liter,
t oznacza ilość dopasowań po transpozycji drugiego ciągu znaków podzielona przez dwa.
3.3. N-gram
Metoda n-gram oparta jest na statystyce, dlatego do jej zastosowania potrzebny jest
ogromny zbiór danych wejściowych (np. zbiór słów w przypadku, gdy metoda ta
wykorzystywana jest do korekcji tekstu) [10]. Określa ona podobieństwa między dwoma
ciągami znaków na podstawie ilości wspólnych podciągów.
Podobieństwo ciągów można wyznaczyć ze wzoru:
𝑠𝑖𝑚𝑛(𝑠1, 𝑠2) =1
𝑁−𝑛+1∑ ℎ(𝑖)𝑁−𝑛+1𝑖=1 (3.3)
gdzie:
𝑠1 i 𝑠2 oznaczają ciągi znaków,

17
ℎ(𝑖) = 1 jeśli n-elementowy podciąg, który zaczyna się od i-tej pozycji w pierwszym ciągu,
występuje chociaż raz w drugim ciągu. W innym wypadku ℎ(𝑖) = 0,
𝑁 − 𝑛 + 1 – ilość możliwych podciągów o n elementach w pierwszym ciągu znaków.
Najczęściej spotykane są dwie odmiany tej metody, różniące się ilością poprzedzających
elementów wykorzystywanych do przewidzenie kolejnego elementu:
metoda bigramów – analiza dwóch poprzednich elementów,
metoda trigramów – analiza trzech poprzednich elementów.
Przykładowo, podobieństwo słów 𝑠1 = INTERESUJĄCY i 𝑠2 = INTERESOWAĆ przy
wykorzystaniu metody trigramów wynosi:
𝑠𝑖𝑚3(𝑠1, 𝑠2) = 0,5 (3.4)
Dla dwóch badanych słów istnieje 5 trigramów: INT, NTE, TER, ERE, RES.
3.4. Prawo Zipfa
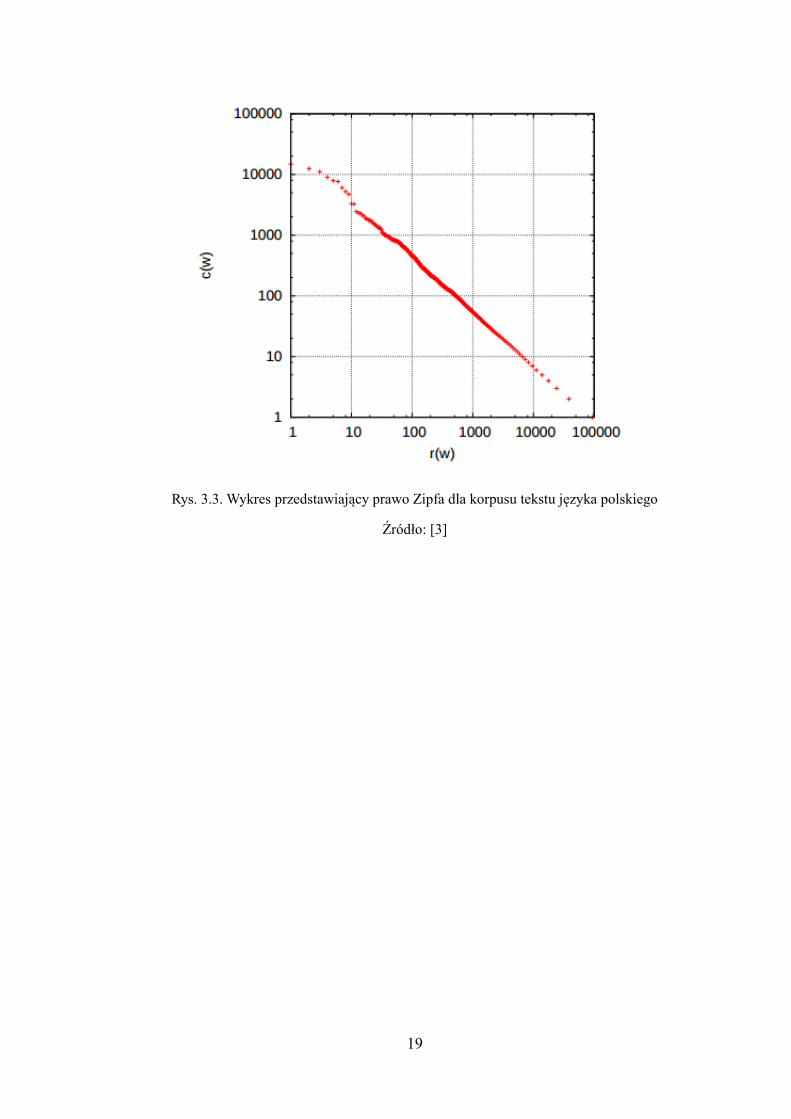
Kolejna metoda służącą do korekty tekstu również wykorzystuje statystykę. Prawo
Zipfa mówi o częstotliwości użycia słowa w danym języku [3]. Zipf zauważył, że pozycja
słowa w rankingu najczęściej używanych słów w danym korpusie tekstu jest odwrotnie
proporcjonalna do częstości wystąpienia tego słowa. Zależność tą można opisać równaniem:
𝑓 ∗ 𝑝 = 𝑘 (3.5)
gdzie:
f – częstość słowa w danym zbiorze,
p – pozycja słowa w ranking.
Poniżej zostały przedstawione tabele z pracy [3] zawierająca najczęściej występujące słowa
dla języka polskiego oraz wykres zaczerpnięty z tej samej pracy przedstawiający prawo Zipfa.

18
Rys. 3.1. Fragment ranking najczęściej występujących słów przedstawiający trzy pierwsze rekordy
Źródło: [3]
Rys. 3.2. Fragment ranking najczęściej występujących słów przedstawiający rekordy od czwartego do
trzynastego
Źródło: [3]
19
Rys. 3.3. Wykres przedstawiający prawo Zipfa dla korpusu tekstu języka polskiego
Źródło: [3]

20

21
4. Aktywne asocjacyjne grafy wiedzy
Odpowiednie skonstruowanie sieci neuronowej jest kluczowe do jej prawidłowego
działania. W pracy [8] dr hab. Adrian Horzyk zaproponował konstrukcje Aktywnych
Asocjacyjnych Neuronowych Grafów Wiedzy (ang. Active Neural Associative Knowledge
Graphs – ANAKG).
Grafy ANAKG pozwalają formować wiedzę, aby następnie w szybki sposób
wykorzystywać tą wiedzę w różnych celach. W porównaniu z tabelarycznym modelem do
przechowywania danych grafy ANAKG cechują się lepszą wydajnością. Jedną z ich
największych zalet w stosunku do tabel jest eliminacja czasochłonnych pętli obliczeniowych.
Grafy ANAKG mogą zostać wykorzystane do:
klasyfikacji,
sortowaniu,
agregacji,
wyszukiwania danych,
tłumaczenia tekstów,
budowy chatbotów,
korekty tekstów.
Rys. 4.1. Graf ANAKG zbudowany z kilku zdań języka angielskiego.

22
W grafie ANAKG pomiędzy poszczególnymi węzłami oblicza się dwa rodzaje
współczynników. Współczynnik skuteczności połączeń, jest zależny od „odległości”, jaka
wystąpiła między danymi słowami w zdaniu.
𝛿𝑆𝑁,𝑆�̂�𝑎𝑐𝑡 = ∑
1
𝜏{↝𝐴𝐶𝑂𝑁𝜏∶ 𝑆𝑁↝⋯↝𝑆�̂�𝜖𝐴𝐴𝑇} (4.1)
gdzie:
𝜏 – odległość pomiędzy dwoma słowami w zdaniu (dla sąsiadujących słów 𝜏 = 1).
Współczynniki wag synaptycznych definiują natomiast, jak mocno powiązane są ze sobą
neurony w grafie:
𝑤𝑆𝑁,𝑆�̂�𝐴𝐶𝑂𝑁 =
2∙𝛿𝑆𝑁,𝑆�̂�𝑎𝑐𝑡
𝜂𝑆𝑁𝑎𝑐𝑡+𝛿
𝑆𝑁,𝑆�̂�𝑎𝑐𝑡 (4.2)
gdzie:
𝜂𝑆𝑁𝑎𝑐𝑡 – ilość aktywacji neuronu 𝑆𝑁 dla określonego zbioru sekwencji uczących,
𝛿𝑆𝑁,𝑆�̂�𝑎𝑐𝑡 – współczynnik skuteczności połączenia synaptycznego 𝑆𝑁 ↝ 𝑆�̂�, określony przez
sumę ważoną ilości skutecznych aktywacji neuronu postsynaptycznego 𝑆�̂� przez neuron
presynaptyczny 𝑆𝑁.
Poniżej zostały przedstawione dwie grafiki, na których widać, jaki wpływ na współczynniki
mają wprowadzane powtarzające się ciągi znaków:
Rys. 4.2. Obliczone współczynniki wag synaptycznych oraz współczynniki skuteczności dla zbioru
wejściowego „A B C D”.

23
Rys. 4.3. Obliczone współczynniki wag synaptycznych oraz współczynniki skuteczności dla zbioru
wejściowego składającego się ze zbiorów „A B C D” oraz „A B D”.
Rysunek 4.2. przedstawia graf zbudowany z ciągu znaków „A B C D”. Współczynniki
połączeń pomiędzy kolejnymi znakami są największe i w tym przypadku wynoszą 1.
Najmniejsze współczynniki występują dla połączenia pomiędzy znakami A i D, ponieważ
znaki te są najbardziej oddalone od siebie we wprowadzonym ciągu.
Na rysunku 4.3. został przedstawiony graf powstały po dodaniu ciągu znaków „A B
D” do ciągu pierwszego. Dodanie drugiego ciągu znaków spowodowało wzmocnienie
połączeń pomiędzy znakami A i B, B i D oraz A i D. Osłabione zostały połączenia pomiędzy
znakami A i C oraz B i C, ponieważ takie połączenia znaków nie występowały w drugim
ciągu. Drugi ciąg nie zawiera również znaku C, dlatego współczynniki pomiędzy znakami C
i D nie uległy zmianie.

24

25
5. Kontekstowy korektor tekstu bazujący na
ANAKG
W celu zbadania skuteczności wykorzystania grafu ANAKG dla potrzeb kontekstowej
korekty tekstu została napisana aplikacja webowa. Stworzona została z wykorzystaniem
języka Java w wersji 8 oraz języka JavaScript. Oparta została o wzorzec MVC (Model-View-
Controller). Do jej budowy użyte wykorzystane następujące technologie:
Spring – framework języka Java, szkielet aplikacji. Oprócz głównego modułu zostały
wykorzystane również Spring Data, Spring MVC oraz Spring Boot;
Hibernate – framework języka Java, służący do komunikacji pomiędzy aplikacją
a bazą danych (warstwa dostępu do danych);
MySQL – baza danych, w której przechowywane są zdania wykorzystane do budowy
grafu;
AngularJS – framework języka JavaScript, umożliwia budowanie aplikacji webowych
na pojedynczej stronie.
d3.js – biblioteka graficzna umożliwiająca tworzenie animacji, wykresów, grafów.
Docker – oprogramowanie umożliwiające uruchomienie procesu w odrębnym
środowisku. Zostało wykorzystane do przechowywania bazy MySQL.
5.1. Budowa i możliwości
Aplikacja składa się z pojedynczej strony, która została podzielona na 4 części:
pole do wprowadzania tekstu, który będzie poddany działaniu korektora,
pole do wyświetlenia informacji zwrotnej na temat wykonanej analizy przez korektor,
pasek opcji,
okno, w którym wyświetlany jest interaktywny graf najbardziej popularnych słów
w danym kontekście.

26
Rys. 5.1. Widok aplikacji wraz z opisem.
Rys. 5.2. Widok aplikacji z rozwiniętym menu.
Stworzona aplikacja umożliwia:
tworzenie oraz rozbudowywanie grafu ANAKG (dodawanie nowych zdań),
analizę i kontekstową korektę wprowadzonego tekstu,
podgląd najczęściej występujących kolejnych słów dla danego kontekstu,
podpowiadanie kolejnego słowa na podstawie wprowadzonych pierwszych liter.

27
Rys. 5.3. Widok aplikacji z wykorzystaną funkcją podpowiadania kolejnego słowa.
W przypadku wykrycia nieprawidłowego kontekstu w tekście, słowo zmienia kolor na
pomarańczowy. Poniżej zostają wyświetlone proponowane słowa korygujące treść oraz
prawdopodobieństwo ich wystąpienia w takim kontekście w nawiasach.
Rys. 5.4. Widok aplikacji przedstawiający wynik pracy korektora.
5.2. Działanie aplikacji
Algorytm służący do kontekstowej korekty tekstu opiera się na wykorzystaniu
współczynników wag synaptycznych utworzonego grafu ANAKG. Współczynnik ten jest tym
wyższy im bardziej słowo pasuje do badanego kontekstu zdania. Poniżej został przedstawiony
wpływ kontekstu na obliczony współczynnik dla słowa „lubił”. W przypadku, gdy zostało
podane całe zdanie, współczynnik jest wyraźnie większy.
Rys. 5.5. Widok aplikacji przedstawiający wyliczony współczynnik dla części zdania.

28
Rys. 5.6. Widok aplikacji przedstawiający wyliczony współczynnik dla całego zdania.
Algorytm zaimplementowanego korektora tekstu można opisać w kilku krokach.
1. Sprawdzenie poprawności pojedynczych słów.
Każde słowo z wprowadzonego zdania zostaje wyszukane w zbudowanym grafie
ANAKG. Słowo, które nie zostanie znalezione lub zostanie znalezione, ale ilość
wystąpień tego słowa w korpusach tekstu była poniżej określonego progu, jest
uznawane jako błędne. Mała ilość wystąpień słowa może świadczyć, że zdanie,
w którym występowało, zawiera błędy.
2. Sprawdzenie poprawności użycia danego słowa w kontekście.
Każde słowo, które zostało uznane za poprawne w kroku pierwszym, zostaje
sprawdzone pod względem wystąpienia w danym kontekście. Jeśli węzeł ze słowem
poprzedzającym słowo badane nie posiada bezpośredniego połączenia z węzłem
badanego słowa, to znaczy, że słowo to nie wystąpiło w danym kontekście
w wejściowych korpusach tekstów wykorzystanych do budowy grafu ANAKG. Jego
użycie uznawane jest więc jako błędne.
3. Wyznaczenie zbioru słów mogących zastąpić błędne słowo.
a) Zostaje wyznaczony zbiór słów, które są następnikami poprzedniego słowa.
b) Każdemu słowu z poprzednio wyznaczonego zbioru zostaje przypisana suma
wag synaptycznych, które pochodzą od wszystkich poprawnych słów
w badanym zdaniu (zarówno poprzedników błędnego słowa jak i jego
następników).
c) Dla każdego słowa ze zbioru zostaje wyznaczona odległość Levenshteina od
błędnego słowa. Słowa posiadające odległość edycyjną 3 lub większą zostają
odrzucone.
d) Pięć słów z powstałego zbioru, które posiadają największą sumę wag
synaptycznych tworzy zbiór słów proponowanych do skorygowania słowa
błędnego.

29
5.3. Dane wejściowe - korpusy tekstu
Do budowy grafu ANAKG zostało wykorzystane 400 000 zdań napisanych w języku
polskim. Korpusy tekstu, które zostały wykorzystane do budowy grafu zostały pobrane
z dwóch źródeł.
Pierwsze źródło, z którego pochodzi około 20% wszystkich zgromadzony zdań to
polska wersja strony Wikiźródła [24]. Jest to portal, który gromadzi wcześniej opublikowane
teksty, które zostały udostępnione na wolnej licencji. W pracy zostały wykorzystane m.in.
takie pozycje jak:
20.000 mil podmorskiej żeglugi - Juljusz Verne,
Mendel Gdański - Maria Konopnicka,
Nowy Tarzan. Opowiadania wesołe i niewesołe - Antoni Lange,
Opowieść Wigilijna – Charles Dickens,
Pies Baskerville’ów - Arthur Conan Doyle,
Przypadki Robinsona Kruzoe - Daniel Defoe,
W pustyni i w puszczy – Henryk Sienkiewicz.
Pozycje te są przepisywane bez poprawy znalezionych błędów. Zostały one jednak
wyszczególnione dla każdej pozycji. Odsetek błędnych zdań jest jednak niewielki, dlatego
można założyć, że korpusy tekstu są poprawne i nadają się do wykorzystania.
Drugie źródło to niemiecki portal Leipzig Corpora Collection [5]. Zgromadzone są
tam korpusy tekstu dla ponad 100 języków. Udostępnione zdania napisane w języku polskim
pochodzą z 3 źródeł, a ich łączna ilość wynosi ponad 10 milionów. Do budowy grafu
ANAKG został użyty zbiór z kategorii ”Newscrawl”, a więc zdania pochodzące z polskich
portali informacyjnych. W przeciwieństwie jednak do książek, artykuły umieszczane na
portalach informacyjnych często są pisane w pośpiechu, co przyczynia się do popełniania
wielu błędów przez osoby je tworzące. Zbiór zdań zawiera również zdania, które zostały
napisane prze zwykłych użytkowników pod artykułem. Wypowiedzi te często zawierają wiele
błędów. Poniżej zostały przedstawione błędne zdania występujące w wykorzystywanym
zbiorze.
1. Brak znaków interpunkcyjnych:
P.Bąk powinien bezapelacyjnie zostać starostą zdyskwalifikował wynikami wszystkich.
2. Dwa zdania nieoddzielone kropką:
"Gra na czas" i "finansowe sztuczki" w sprawie Grecji "Decyzje istotne dla Polski
zapadają poza kontrolą" Co tam Tusk.

30
Wysłany: Pon, 17 Paź 2011, 21:14 nadchodzi czas pękania balonowych funduszy
Kiedy inwestorzy odkryją kolejne piramidy WGI?
Tysiące gospodarstw bez prądu Na tropie pogodynki.
3. Brak niektórych polskich znaków:
Jak się srodkiem drogi idzie to policja powinna wziąc się za tego idącego a nie szukać
wiatru w polu.
Dzieki ludziom dobrej woli, w tym także naszym Czytelnikom, wyjechała leczyć się do
Chin.
Na dzien dzisiejszy Rzeszów to większa metropolia niż Lublin,350 tysięczny moloch,
który skazany jest na upadek.
4. Inne błędne przykładowe zdania, które mogę wprowadzać zakłamanie do działania
korektora:
Jeszcze żyła dodano: 20 września 2011, 10:55 tagi:śmierć policja Rzeszów tragedia
(fot.
Konkurs na „Nojpiykniyjsy gminny moj” ogłosiło też Gminne Centrum Kultury,
Sportu i Turystyki w Lipnicy Wielkiej.
Ekwador, nogi, biało, reprezentacja Polacy wezmą rewanż za mundial?
Odsłony: 1550 Więcej… Dodaj komentarz Czwartek, 22 Kwietnia 2010 13:09
Wyeliminowanie wszystkich błędnych zdań z tak dużego zbioru danych jest niemożliwe,
dlatego zbudowany graf ANAKG zawiera również zdania błędne. Aplikacja wykorzystuje
jednak fakt, że konkretne błędy nie powtarzają się często. Został więc wprowadzony próg
poprawności, który określa, ile razy dane słowo musi wystąpić, aby było uznane za słowo
poprawne.

31
6. Porównanie stworzonego korektora
z wybranymi narzędziami służącymi do
korygowania tekstu dla języka polskiego
Rozwój technologii pozwolił na powstanie wielu narzędzi służących do korygowania tekstu.
W rozdziale tym zostały przedstawione i przetestowane najbardziej rozbudowane narzędzia,
za pomocą których możliwe jest korygowanie tekstu napisanego w języku polskim.
Omawiane narzędzia można podzielić na trzy grupy:
a) Korektory wykorzystywane przez wyszukiwarki internetowe:
Google,
Bing,
Ask,
Yandex,
Nekst.
b) Korektory wykorzystywane przeze edytory tekstu:
Microsoft Word,
Apache OpenOffice.
c) Korektory online:
LanguageTool,
iKorektor.
Wymienione narzędzia posiadają różne funkcjonalności. Jedne korygują jedynie błędy
ortograficzne, inne pozwalają na kompleksową analizę zdania i wykrycie dużo bardziej
skomplikowanych błędów językowych. W dalszej części rozdziału zostaną szczegółowo
omówione i przetestowane wyżej wymienione narzędzia w trzech różnych wyróżnionych
kategoriach. Działanie każdego narzędzia zostanie przetestowane na zdaniach:
1. Dziś jest pęikny i słoneczny dzien.
2. Ona lubił bardzo swojego kotta.
3. To była bardz interesująca ksiąrzka.

32
Zdania te pozwoliły na zbadanie 6 podstawowych błędów:
„pęikny” – przestawienie liter w wyrazie,
„dzien” – brak polskiej litery „ń”,
„ona lubił” – niepoprawna odmiana czasownika „lubić”,
„kotta” - jedna litera zdublowana przypadkowo,
„bardz” – brakuje litery „o”,
„ksiąrzka” – błąd ortograficzny.
W ostatnim podrozdziale zostały przedstawione rezultaty otrzymane przez stworzony
korektor tekstu.
6.1. Korektory wykorzystywane przez wyszukiwarki
internetowe
Wyszukiwarki internetowe obsługują dziennie ogromną liczbę wyszukiwań ([11] średnia ilość
wyszukiwań w najpopularniejszej wyszukiwarce Google w grudniu 2016 roku wynosiła
2.3 miliona wyszukiwań na sekundę). Część z nich, wykorzystuje ogromną liczbę
użytkowników do tworzenia coraz to lepszego systemu do analizy i korekty tekstu.
Douglas Merrill (Chief Information Officer firmy Google) opisuje, jak łatwo działa korekcja
tekstu w wyszukiwarce Google. Cały proces składa się z czterech kroków:
1. Użytkownik wpisuje zapytanie z błędnym słowem.
2. Użytkownik nie znajduje informacji, których szuka.
3. Użytkownik orientuje się, że popełnił błąd przy wpisywaniu zapytania, więc poprawia
zapytanie.
4. Użytkownik klika w jeden z pierwszych linków podesłanych przez wyszukiwarkę.
Te 4 proste kroki powtarzane miliony razy pozwoliły na nauczenie systemu odpowiedzialnego
za korektę tekstu, jakie błędy są najczęściej popełniane przez użytkowników.
Inne wyszukiwarki działają w podobny sposób jak ten przedstawiony powyżej.
Wysoka trafność podpowiedzi wyszukiwarek internetowych oparta jest na ogromniej liczbie
użytkowników, którzy (zazwyczaj nieświadomie) każdego dnia pomagają w tworzeniu coraz
lepszego korektora tekstu.

33
6.1.1. Wyszukiwarka Google
Jako pierwsza została przetestowana aktualnie najbardziej popularna wyszukiwarka
internetowa na świecie. Google zdominował rynek wyszukiwarek internetowych, dzięki
czemu posiada ogromne grono użytkowników, którzy codziennie pomagają w ulepszaniu jego
korekta tekstu.
Rys. 6.1. Korekta zdania nr. 1 przy użyciu wyszukiwarki Google
Korektor tekstu wykrył pierwszy napotkany błąd w słowie „pęikny” i poprawnie zasugerował
poprawę na słowo „piękny”. Nie zostało jednak wykryte błędne słowo „dzien”.
Rys. 6.2. Korekta zdania nr. 2 przy użyciu wyszukiwarki Google
W drugim testowym zdaniu korektor prawidłowo wykrył dwa błędne słowa i zasugerował
prawidłową poprawę zdania.

34
Rys. 6.3. Korekta zdania nr. 3 przy użyciu wyszukiwarki Google
Z ostatnim zdaniem korektor również poradził sobie prawidłowo i proponowana poprawa jest
trafna.
Korektor tekstu wyszukiwarki Google okazał się niezwykle skuteczny. Poprawił 5 z 6
występujących błędów. Nie poradził sobie jedynie ze słowem „dzien”. Dokładniejsza analiza
potwierdziła, że korektor ten nie wykrywa błędów związanych z polskimi znakami.
6.1.2. Wyszukiwarka Bing
Jednym z największych konkurentów dla wyszukiwarki Google jest Bing. Wyszukiwarka
stworzona została przez amerykańską firmę Microsoft.
Rys. 6.4. Korekta zdania nr. 1 przy użyciu wyszukiwarki Bing
Podobnie jak w przypadku wyszukiwarki Google, słowo „pęikny” zostało wykryte
i zaproponowana została poprawna korekta, natomiast słowo „dzien” nie zostało
sklasyfikowane jako błędne.

35
Rys. 6.5. Korekta zdania nr. 2 przy użyciu wyszukiwarki Bing
Drugie zdanie zostało poprawione tylko częściowo. Słowo „lubił” nie zostało oznaczone jako
błędne.
Rys. 6.6. Korekta zdania nr. 3 przy użyciu wyszukiwarki Bing
Trzecie zdanie zostało poprawione tylko częściowo. Bing nie poradził sobie z wykryciem
błędu w słowie „ksiąrzka”.
Korektor wyszukiwarki Bing okazał się mniej skuteczny od korektora wyszukiwarki Google.
Obie wyszukiwarki nie poradziły sobie z poprawieniem słowa „dzien”. Bing nie wykrył
również złej odmiany czasownika „lubić” w drugim zdaniu oraz błędu ortograficznego
w słowie „ksiąrzka”.

36
6.1.3. Wyszukiwarka Ask
Kolejny badany korektor tekstu wykorzystywany jest przez wyszukiwarkę Ask. Jest to dużo
mniej popularna wyszukiwarka od dwóch poprzednich, a więc można przewidywać, że
poradzi sobie gorzej od poprzedników.
Rys. 6.7. Korekta zdania nr. 1 przy użyciu wyszukiwarki Ask
Słowo „pęikny” zostało wykryte i poprawnie zastąpione. Korektor tekstu wyszukiwarki Ask
nie poradził sobie jednak ze słowem „dzien”.
Rys. 6.8. Korekta zdania nr. 2 przy użyciu wyszukiwarki Ask
Wszystkie błędy zostały wykryte w drugim zdaniu i proponowana korekta jest prawidłowa.
Rys. 6.9. Korekta zdania nr. 3 przy użyciu wyszukiwarki Ask
Korektor wyszukiwarki Ask poradził sobie również z ostatnim zdaniem i trafnie
zaproponował korektę tekstu.
Ask okazał się równie dobry co wyszukiwarka Google. Obydwie wyszukiwarki nie poradziły
sobie jedynie z wykryciem błędnego słowa „dzien”.

37
6.1.4. Wyszukiwarka Yandex
Yandex jest największa rosyjską wyszukiwarką internetową. Wyszukiwarka przez długi czas
rozwijana była jedynie jako narzędzie przystosowane do języka rosyjskiego, jednak od kilku
lat rozwija się również międzynarodowa wersja tej przeglądarki.
Rys. 6.10. Korekta zdania nr. 1 przy użyciu wyszukiwarki Yandex
Pierwsze zdanie zostało poprawione identycznie jak w przypadku poprzednich wyszukiwarek.
Yandex nie wykrył błędnego słowa „dzien”.
Rys. 6.11. Korekta zdania nr. 2 przy użyciu wyszukiwarki Yandex
Słowo „kotta” zostało wykryte jednak proponowana poprawa nie pasuje do kontekstu zdania.
Słowo „lubił” nie zostało wykryte.
Rys. 6.12. Korekta zdania nr. 3 przy użyciu wyszukiwarki Yandex
Trzecie zdanie zostało trafnie poprawione.
38
Korektor wyszukiwarki Yandex wypadł nieco słabiej od swoich poprzedników. Wykrył 5 z 6
błędów, jednak tylko 4 błędy zostały trafnie poprawione.
6.1.5. Wyszukiwarka Nekst
Ostatnią badaną wyszukiwarką jest Nekst. Jest to polska wyszukiwarka, którą rozwijają
naukowcy z Instytutu Podstaw Informatyki PAN w Warszawie oraz Politechniki
Wrocławskiej.
Rys. 6.13. Korekta zdania nr. 1 przy użyciu wyszukiwarki Nekst
Korektor poprawnie wykrył błędy w dwóch słowach, lecz tylko pierwsze słowo zostało
poprawione trafnie.
Rys. 6.14. Korekta zdania nr. 2 przy użyciu wyszukiwarki Nekst
W drugim zdaniu wyszukiwarka nie wykryła błędnego słowa „kotta” oraz słowa „lubił”.
Rys. 6.15. Korekta zdania nr. 3 przy użyciu wyszukiwarki Nekst

39
Błędne słowo „ksiąrzka” zostało wykryte i poprawione prawidłowo. Nekst nie poradził sobie
jednak ze słowem „bardz”.
Nekst jest jedyną z badanych wyszukiwarek, która poradziła sobie z wykryciem błędu
w słowie „dzien”. Niestety korektora nie potrafił zaproponować poprawnej korekty.
W przypadku pozostałych błędów wyszukiwarka nie poradziła sobie dobrze i wypada
najgorzej spośród badanych wyszukiwarek.
6.2. Korektory wykorzystywane przez edytory tekstu
Kolejną grupą narzędzi są aplikacje służące jako edytory tekstu. W dzisiejszych
czasach od edytora tekstu wymaga się znacznie więcej niż jeszcze kilkanaście lat temu.
Korektor tekstu w tego rodzaju aplikacjach jest jednym z wielu podstawowych
funkcjonalności, które mogą wpłynąć bardzo pozytywnie na jakość produktu oraz jego
popularność. Poprawnie działający korektor tekstu może zwiększyć efektywność pracy oraz
jakość tekstu wprowadzonego przez użytkownika.
6.2.1. Edytor tekstu Microsoft Word
Najpopularniejszym edytorem tekstu używanym na świecie jest Microsoft Word
z pakietu Microsoft Office. Jest to niezwykle rozbudowane narzędzie, które posiada
specjalistyczny korektor tekstu.
Rys. 6.16. Korekta zdania nr.1 przy użyciu edytora Microsoft Word
Pierwsze błędne słowo zostało poprawnie wykryte i poprawione. W przypadku słowa „dzień”
korektor nie zaproponował poprawy, lecz samoistnie poprawił słowo na prawidłowe, uznając
ze 100% pewnością, że możliwa poprawa jest tylko jedna.

40
Rys. 6.17. Korekta zdania nr.2 przy użyciu edytora Microsoft Word
Słowo „lubił” nie zostało poprawione, słowo „kotta” zostało wykryte i prawidłowa poprawa
została zaproponowana jako druga możliwość.
Rys. 6.18. Korekta pierwszego słowa w zdaniu nr.3 przy użyciu edytora Microsoft Word
Rys. 6.19. Korekta drugiego słowa w zdaniu nr.3 przy użyciu edytora Microsoft Word
Obydwa słowa w zdaniu trzecim zostały poprawione w sposób prawidłowy.
Korektor tekstu będący częścią aplikacji Microsoft Word okazał się skuteczny prawie we
wszystkich przypadkach. Zaskakujące jest jednak, że nie poradził sobie z wykryciem
nieprawidłowej odmiany słowa „lubił” w zdaniu drugim.

41
6.2.2. Edytor tekstu Apache OpenOffice
Początkowo rozwijana przez firmę Oracle, a następnie przekazana Apache Software
Fundation, aplikacja OpenOffice jest doskonałą darmową alternatywą dla produktu firmy
Microsoft.
Rys. 6.20. Korekta pierwsza słowa w zdaniu nr.1 przy użyciu edytora OpenOffice
Rys. 6.21. Korekta drugiego słowa w zdaniu nr.1 przy użyciu edytora OpenOffice
Aplikacja doskonale poradziła sobie z pierwszym zdaniem.

42
Rys. 6.22. Korekta zdania nr.2 przy użyciu edytora OpenOffice
Słowo „lubił” nie został wykryte. Trafna korekta słowa „kotta” została zaproponowana
dopiero na 4 miejscu.
Rys. 6.23. Korekta pierwsza słowa w zdaniu nr.3 przy użyciu edytora OpenOffice
Rys. 6.24. Korekta drugiego słowa w zdaniu nr.3 przy użyciu edytora OpenOffice
Poprawna korekta słowa „bardz” została zaproponowana dopiero na 3 miejscu. Drugie błędne
słowo zostało trafnie poprawione.

43
6.3. Korektory online
Ostatnią badaną grupą korektorów są aplikacje webowe służące jedynie do analizy
i korekty tekstu.
6.3.1. LanguageTool
Narzędzie korektorskie, które obsługuje ponad 25 języków, w tym język polski.
Może służyć jako wtyczka do najpopularniejszych przeglądarek internetowych (Google
Chrome, Firefox) oraz jak dodatek do oprogramowania LibreOffice lub OpenOffice.
Rys. 6.25. Korekta pierwsza słowa w zdaniu nr.1 przy użyciu korektora LanguageTool
Rys. 6.26. Korekta drugiego słowa w zdaniu nr.1 przy użyciu korektora LanguageTool
Aplikacja wykryła błędne słowa i w obydwu przypadkach zaproponowała poprawna korektę.

44
Rys. 6.27. Korekta zdania nr.2 przy użyciu korektora LanguageTool
W zdaniu drugim korektor wykrył tylko drugie błędne słowa. Nie potrafił jednak
zaproponować poprawnej korekty.
Rys. 6.28. Korekta pierwsza słowa w zdaniu nr.3 przy użyciu korektora LanguageTool
Rys. 6.29. Korekta drugiego słowa w zdaniu nr.3 przy użyciu korektora LanguageTool
Trzecie zdanie zostało poprawione poprawnie.
LanguageTool poradził sobie z poprawą zdania nr.1 i nr.3. Aplikacja nie zdołała jednak
poprawić błędów w zdaniu drugim. Jest to kolejne narzędzie, które nie wykryło błędnej
odmiany czasownika „lubić”.

45
6.3.2. iKorektor
Kolejną aplikacją webową, która umożliwia analizę tekstu jest aplikacja iKorektor.
Aplikacja przystosowana jest jedynie do analizy i poprawy tekstu napisanego w języku
polskim.
Rys. 6.30. Korekta zdania nr.1 przy użyciu korektora iKokorektor
Pierwsze zdanie zostało trafnie poprawione w całości.
Rys. 6.31. Korekta zdania zdaniu nr.2 przy użyciu korektora iKokorektor
iKorektor nie poradził sobie ze zdaniem drugim. Nie wykrył żadnego błędu.
Rys. 6.32. Korekta zdania nr.3 przy użyciu korektora iKokorektor
Obydwa słowa w trzecim zdaniu korektor poprawił prawidłowo.
iKorektor poprawił jedynie 4 z 6 występujących błędów. Największym zaskoczeniem jest
fakt, że aplikacja nie wykryła błędnego słowa „kotta” w drugim zdaniu.

46
6.4. Własny korektor tekstu
Ostatnią badaną aplikacją jest własny korektor tekstu wykorzystujący graf ANAKG.
Rys. 6.33. Korekta zdania nr.1 przy użyciu własnego korektora tekstu
Pierwsze zdanie zostało poprawione prawidłowo. Aplikacja poradziła sobie z dwoma
występującymi błędami.
Rys. 6.34. Korekta zdania nr.2 przy użyciu własnego korektora tekstu

47
Korektor wykrył również błędy w zdaniu drugim. Proponowana korekta jest prawidłowa.
W przypadku słowa „kotta” aplikacja zasugerowała poprawnie słowo „kota”, jednak podała
jeszcze kilka innych alternatyw.
Rys. 6.35. Korekta zdania nr.3 przy użyciu własnego korektora tekstu
Trzecie zdanie zostało poprawione prawidłowo.
Własny korektor okazał się skuteczny w przypadku badanych zdań. Wszystkie błędne słowa
zostały wykryte oraz prawidłowo poprawione.
6.5 Podsumowanie testu korektorów
Przeprowadzona analiza pozwala stwierdzić, że używane na codzień narzędzia służące
do korygowania tekstu nie są idealne. Spośród 10 przebadanych korektorów, tylko własny
korektor oparty na ANAKG wykrył i poprawił prawidłowo wszystkie błędy. Część badanych
korektorów nie poradziła sobie tylko z jednym błędem. Fakt, że błędy te nie były identyczne
dla różnych narzędzi świadczyć może o zastosowaniu innych algorytmów do analizy
i korekty tekstu.

48

49
7. Podsumowanie
Analizując poprzedni rozdział można wywnioskować, że stworzony korektor tekstu
działał prawidłowo dla losowo wybranych trzech zdań z języka polskiego. Jego skuteczność
okazała się lepsza od niektórych przebadanych narzędzi, również komercyjnych. Po bardziej
wnikliwej analizie, okazuje się jednak, że korektor czasem nie działa w sposób prawidłowy.
Głównym czynnikiem, który ma na to wpływ jest ograniczona ilość tekstu wykorzystana do
budowy grafu ANAKG. Pomimo wykorzystania 400 000 zdań do budowy grafu, nadal
występują słowa języka polskiego, które nie znajdują się w grafie. Często też słowa, które są
częścią grafu, nie zostały użyte w kontekście, w jakim zostały wykorzystane w zdaniu
poddanym korekcie.
Niewielkie korpus tekstu nie jest jednak przeszkodą dla prawidłowego działania
aplikacji. Korektor wykorzystujący graf ANAKG w wielu przypadkach będzie działał
prawidłowo, ponieważ do korekty tekstu wykorzystuje kontekst słowny, który wcześniej
został użyty przy budowie grafu oraz adaptacji wag. Cecha ta sprawia, że korektor nie
potrzebuje ogromnego korpusu tekstu, aby działać prawidłowo i móc konkurować z innymi
narzędziami służącymi do korekty tekstu dla języka polskiego.
Graf wykorzystywany w aplikacji został stworzony na komputerze przenośnym
posiadającym dwurdzeniowy procesor Intel Core i7-5500u. Częstotliwość pracy jednego
rdzenia tego procesora wynosi 2,4 GHz. Niskie taktowanie procesora miało widoczny wpływ
na małą prędkość budowy grafu. Sporym ograniczeniem była również ilość pamięci RAM.
Komputer, na którym przeprowadzane były testy posiadał 8 GB pamięci RAM. Było to
główne ograniczenie, które nie pozwalało na budowę większego grafu. Wykorzystanie
komputera o lepszych podzespołach pozwoliłoby na stworzenie większego grafu, co
przełożyłoby się na zwiększenie efektywności działania aplikacji.
Innym czynnikiem, który ma negatywny wpływ na działanie korektora, jest użyty
korpus tekstu. Część zdań z tego zbioru posiada błędy. Wyeliminowanie nieprawidłowych
zdań wejściowych wpłynęłoby pozytywnie na działanie korektora, ale jest to zadanie bardzo
czasochłonne.

50

51
Literatura
[1]. Cohen W. W., Ravikumar P., Fienberg S. E., Comparison of String Metrics for Matching
Names and Records, Carnegie Mellon University, 2003.
[2]. Damerau F. J., A technique for computer detection and correction of spelling errors,
Communications of the ACM, vol. 7, nr. 3, 1964, pp. 171–176.
[3]. Dębowski Ł., Prawo Zipfa - próby objaśnień, Instytut Podstaw Informatyki PAN, 2005.
[4]. Domaradzki R., Zastosowanie sieci neuronowych do wspomagania decyzji
inwestycyjnych, http://bossa.pl/analizy/techniczna/elementarz/sieci_neuronowe/
[5] Goldhahn D., Eckart T., Quasthoff U., Building Large Monolingual Dictionaries at the
Leipzig Corpora Collection: From 100 to 200 Languages, Proceedings of the 8th
International Language Ressources and Evaluation (LREC'12), 2012.
[6]. Gołda A., Wstęp do sieci neuronowych, http://galaxy.uci.agh.edu.pl/~vlsi/AI/wstep/
[7]. Horzyk A., Metody inżynierii wiedzy, http://home.agh.edu.pl/~horzyk/ahdydaktyka.php
[8]. Horzyk A., Sztuczne systemy skojarzeniowe i asocjacyjna sztuczna inteligencja,
Akademicka Oficyna Wydawnicza EXIT, Warszawa, 2013.
[9]. Klaus Rafał, Budowa neuronu, Instytut Informatyki Politechniki Poznańskiej,
http://www.cs.put.poznan.pl/rklaus/assn/neuron.htm
[10]. Niewiadomski A., Materiały, przykłady i ćwiczenia do przedmiotu Komputerowe
Systemy Rozpoznawania, Instytut Informatyki Politechniki Łódzkiej, 2009.
[11]. Google Search Statistics, http://expandedramblings.com/index.php/by-the-numbers-a-
gigantic-list-of-google-stats-and-facts/
[12]. Levenshtein V. I., Binary codes capable of correcting deletions, insertions, and
reversals, Soviet Physics Doklady, vol 10, nr. 8, 1966, pp. 707–710.
[13]. Merrill D., Search 101, https://www.youtube.com/watch?v=syKY8CrHkck#t=22m03s

52
[14]. Świetlicki R., Odległość Levenshteina (odległość edycyjna), http://www.algorytm.org/
przetwarzanie-tekstu/odleglosc-levenshteina-odleglosc-edycyjna.html
[15]. Tadeusiewicz R., Sieci Neuronowe, Akademicka Oficyna Wydawnicza RM, 1993.
[16] Ziółko B., Skurzok D., Michalska M., Polish n-grams and their correction process,
Proceedings of The 4th International Conference on Multimedia and Ubiquitous Engineering
(MUE 2010), Cebu, Filipiny, 2010.
[15]. Apache OpenOffice https://www.openoffice.org/
[16]. d3js, https://d3js.org/
[17]. Hibernate, http://hibernate.org/
[18]. iKorektor, http://ikorektor.pl/
[19]. Java, https://docs.oracle.com
[20]. LanguageTool, https://www.languagetool.org/
[21]. Microsoft Office, https://support.office.com
[22]. Projekt Gutenberg, http://www.gutenberg.org/
[23]. Spring, https://spring.io/
[24]. Wikiźródła, https://pl.wikisource.org/

53
Spis rysunków
Rys. 2.1. Schemat perceptronu jednowarstwowego……………………………………………7
Rys. 2.2. Schemat budowy prawdziwego neuronu ………………………………..…………..9
Rys. 2.3. Schemat budowy sztucznego neuronu …………………………………………..…..9
Rys. 2.4. Schemat budowy układu elektronicznego symulującego neuron…………..………..9
Rys. 3.1. Fragment ranking najczęściej występujących słów przedstawiający trzy pierwsze
rekordy………………………………………………………………………………………..18
Rys. 3.2. Fragment ranking najczęściej występujących słów przedstawiający rekordy od
czwartego do trzynastego…………………………………………………………………..…18
Rys. 3.3. Wykres przedstawiający prawo Zipfa dla korpusu tekstu języka polskiego……….19
Rys. 4.1. Graf ANAKG zbudowany z kilku zdań języka angielskiego………………………21
Rys. 4.2. Obliczone współczynniki wag synaptycznych oraz współczynniki skuteczności dla
zbioru wejściowego „A B C D”……………………………………………………………....22
Rys. 4.3. Obliczone współczynniki wag synaptycznych oraz współczynniki skuteczności dla
zbioru wejściowego „A B C D A B D”…………………………………………………….....23
Rys. 5.1. Widok aplikacji wraz z opisem………………………………………………….….26
Rys. 5.2. Widok aplikacji z rozwiniętym menu……………………………………………....26
Rys. 5.3. Widok aplikacji z wykorzystaną funkcją podpowiadania kolejnego słowa.……….27
Rys. 5.4. Widok aplikacji przedstawiający wynik pracy korektora…………………………..27
Rys. 5.5. Widok aplikacji przedstawiający wyliczony współczynnik dla części zdania……..27
Rys. 5.6. Widok aplikacji przedstawiający wyliczony współczynnik dla całego zdania…….28
Rys. 6.1. Korekta zdania nr.1 przy użyciu wyszukiwarki Google……………………………33
Rys. 6.2. Korekta zdania nr.2 przy użyciu wyszukiwarki Google……………………………33
Rys. 6.3. Korekta zdania nr.3 przy użyciu wyszukiwarki Google……………………………34
Rys. 6.4. Korekta zdania nr.1 przy użyciu wyszukiwarki Bing………………………………34
Rys. 6.5. Korekta zdania nr.2 przy użyciu wyszukiwarki Bing………………………………35
Rys. 6.6. Korekta zdania nr.3 przy użyciu wyszukiwarki Bing………………………………35
Rys. 6.7. Korekta zdania nr.1 przy użyciu wyszukiwarki Ask……………………………….36
Rys. 6.8. Korekta zdania nr.2 przy użyciu wyszukiwarki Ask……………………………….36
Rys. 6.9. Korekta zdania nr.3 przy użyciu wyszukiwarki Ask………………………………..36
Rys. 6.10. Korekta zdania nr.1 przy użyciu wyszukiwarki Yandex…………………………..37
Rys. 6.11. Korekta zdania nr.2 przy użyciu wyszukiwarki Yandex…………………………..37
Rys. 6.12. Korekta zdania nr.3 przy użyciu wyszukiwarki Yandex…………………………..37
Rys. 6.13. Korekta zdania nr.1 przy użyciu wyszukiwarki Nekst…………………………….38
Rys. 6.14. Korekta zdania nr.2 przy użyciu wyszukiwarki Nekst…………………………….38
Rys. 6.15. Korekta zdania nr.3 przy użyciu wyszukiwarki Nekst…………………………….38

54
Rys. 6.16. Korekta zdania nr.1 przy użyciu edytora Microsoft Word………………………...39
Rys. 6.17. Korekta zdania nr.2 przy użyciu edytora Microsoft Word………………………...40
Rys. 6.18. Korekta pierwszego słowa w zdaniu nr.3 przy użyciu edytora Microsoft
Word…………………………………………………………………………………………..40
Rys. 6.19. Korekta drugiego słowa w zdaniu nr.3 przy użyciu edytora Microsoft Word…….40
Rys. 6.20. Korekta pierwsza słowa w zdaniu nr.1 przy użyciu edytora OpenOffice…………41
Rys. 6.21. Korekta drugiego słowa w zdaniu nr.1 przy użyciu edytora OpenOffice…………41
Rys. 6.22. Korekta zdania nr.2 przy użyciu edytora OpenOffice……………………………..42
Rys. 6.23. Korekta pierwsza słowa w zdaniu nr.3 przy użyciu edytora OpenOffice…………42
Rys. 6.24. Korekta drugiego słowa w zdaniu nr.3 przy użyciu edytora OpenOffice…………42
Rys. 6.25. Korekta pierwsza słowa w zdaniu nr.1 przy użyciu korektora LanguageTool……43
Rys. 6.26. Korekta drugiego słowa w zdaniu nr.1 przy użyciu korektora LanguageTool……43
Rys. 6.27. Korekta zdania nr.2 przy użyciu korektora LanguageTool………………………..44
Rys. 6.28. Korekta pierwsza słowa w zdaniu nr.3 przy użyciu korektora LanguageTool……44
Rys. 6.29. Korekta drugiego słowa w zdaniu nr.3 przy użyciu korektora LanguageTool……44
Rys. 6.30. Korekta zdania nr.1 przy użyciu korektora iKokorektor…………………………..45
Rys. 6.31. Korekta zdania zdaniu nr.2 przy użyciu korektora iKokorektor…………………..45
Rys. 6.32. Korekta zdania nr.3 przy użyciu korektora iKokorektor…………………………..45
Rys. 6.33. Korekta zdania nr.1 przy użyciu własnego korektora tekstu……………………...46
Rys. 6.34. Korekta zdania nr.2 przy użyciu własnego korektora tekstu……………………...46
Rys. 6.35. Korekta zdania nr.3 przy użyciu własnego korektora tekstu……………………...47

55
Spis tabel
Tabela 2.1. Rozwój neurokomputerów w drugiej połowie lat 80……………………………...8
Tabela 3.1. Odległość Levenshteina dla przykładowych ciągów znaków……………………14
Tabela 3.2. Pierwszy etap konstrukcji tablicy………………………………………………...15
Tabela 3.3. Drugi etap konstrukcji tablicy i wyznaczenie odległości edycyjnej……………..15

56

57
Spis załączników
Załącznik 1. Płyta CD zawierająca:
kod aplikacji;
pełny tekst pracy dyplomowej w formacie PDF.


















